
Abstract
We present a novel argumentation-based method for finding and analyzing communities in social media on the Web, where a community is regarded as a set of supported opinions that might be in conflict. Based on their stance, we identify argumentative coalitions to define them; then, we apply a similarity-based evaluation method over the set of arguments in the coalition to determine the level of cohesion inherent to each community, classifying them appropriately. Introducing conflict points and attacks between coalitions based on argumentative (dis)similarities to model the interaction between communities leads to considering a meta-argumentation framework where the set of coalitions plays the role of the set of arguments and where the attack relation between the coalitions is assigned a particular strength which is inherited from the arguments belonging to the coalition. Various semantics are introduced to consider attacks’ strength to particularize the effect of the new perspective. Finally, we analyze a case study where all the elements of the formal construction of the formalism are exercised.
Introduction
The identification of communities in social media and the detection of stances in Tweets has become increasingly important in recent times [15,18,19,26,28] as a result of the tangible effect that these platforms have on the public opinion. In this domain, identifying communities implies analyzing the position of contributing agents concerning a particular topic or their respective argumentative stance; several tools can be used for this purpose, for instance [19] describes an approximation solution based on a supervised classifier that finds stances, and classifies them, over a graph representation. Most of the explored work on identifying stances focuses on the classification of tweets as “in favor” (support), “against” (dispute), or “neutral” (comments or questions) regarding a previous tweet in a conversation [35,37]. Most of these methods focus on analyzing tweets to characterize the relationship between messages in a set.
In this work, we propose an argumentation-based method to analyze stances in a debate exchange and formally characterize the relationships between these stances using similarity, understanding the similarity as an attribute of the relationship, not just of the message. Thus, a similarity measure associated with arguments will allow us to find defined positions or communities in social media; to do that, we use argumentation to formalize the exchange of views. In a general sense, argumentation can be defined as the study of the interaction of arguments in favor and against a position or claim to determine which are acceptable. Formal Argumentation Theory provides several formalisms to model emerging behavior, creating different platforms to perform defeasible reasoning and solve several problematic situations [5–7,20,44]. In the context of our research, an argument and an argumentative stance will be considered synonyms.
In [16], Dung introduced Abstract Argumentation Frameworks (AFs), intending to create a tool for modeling situations where an agent considers arguments supporting a claim. The framework allows the representation of attack relations between abstract entities called arguments and provides different acceptability semantics that, in essence, characterize different criteria under which sets of arguments can be accepted together. Cayrol and Lagasquie-Schiex [12] extended Dung’s framework by considering two independent types of interactions between arguments: the relationships of attack and support. This formalism, called Bipolar Argumentation Frameworks (
Based on the bipolar formalism, in [11] the authors presented an approach to use a similarity degree measure between arguments to characterize the attack and support relations in a
Briefly speaking, to represent a community’s strength, first, we analyze the arguments proposed by each community. Then, we consider the context where the argumentation discussion is put into play since the opinions of a particular community may vary according to the argumentative context. Finally, we perform a comparison procedure where arguments are analyzed considering the set of descriptors (a tag or a label describing an aspect to which an argument is connected) that have in common in combination with the defined context. Thus, the closer or more similar the arguments of a particular community are, the greater the strength of the position proposed by the community is. Note that we mainly refer to discursive communities. This clarification is necessary because it will allow us to regard communities as subgroups with cohesive thinking, inspiring us to find a cohesive measure to characterize their behavior.
In this regard, it is pertinent to find a way to determine how close, or cohesive, these communities are. Precisely, the cohesion associated with a community expresses how united its members are, how integrated, how fraternal and supportive they are to each other, how much they strive to think together, and how willing they are to work together to achieve collective goals and support a specific outcome.
The following example will illustrate the ideas involved in this research.
Figure 1 shows a set of opinions extracted from the ProCon website1
See

Arguments in favor and against the possible causes of climate change.
By analyzing these well-defined general postures, we will obtain the details of the beliefs each community backs; but, by closely examining the opinions in each community, we can determine each community’s inherent strength.
We structured this presentation as follows: In Section 2, we briefly explore the notion of coalition in a
In [12], Cayrol and Lagasquie-Schiex proposed an approach to model two different forms of interaction between arguments, one of these positive, when an argument provides support to another, and the other negative, as an argument performs an attack to another argument, thus extending Dung’s abstract argumentation frameworks by adding the support relation. This approach, known as bipolar argumentation, is characterized as an Bipolar Argumentation Framework or
(Bipolar Argumentation Framework (baf )).
A Bipolar Argumentation Framework is a 3-tuple
The graph description introduced in Dung [16] is extended in
(Defeat in baf ).
Let
Considering the simplest case of defeat in any
There exist other forms of attack that are considered in other interpretations of
Following the Cayrol and Lagasquie-Schiex approach [12], in some sense, a set of arguments must keep a minimum of coherence to model one side of any reasonable dispute adequately. They propose that the coherence of an acceptable set of arguments can be kept internally by requiring the set not to contain an argument that attacks another one in the same set. Meanwhile, external coherence can be maintained by requiring that the set does not include both a supporter and an attacker of the same argument. Internal coherence can be obtained by extending the definition of conflict-free set proposed in [16], and external coherence can be captured by the notion of a safe set.
(Conflict-freeness and Safety Properties in BAF).
Let
Conflict-freeness requires considering the direct, supported, and secondary attacks. Additionally, Cayrol and Lagasquie-Schiex show that the notion of a safe set is powerful enough to encompass the concept of conflict-freeness, i.e., if a set is safe, it is also conflict-free. The closure under
(Closure Property in BAF).
Let
Succinctly, these are some salient features of this formalism:
It allows to represent relationships between arguments through a bipolar interaction graph that has two kinds of edges: one of them to represent the attack relation and the other for the support relation.
It introduces the identification of special types of attack. The notions of supported and secondary attack combine sequences of supports with a direct attack considering the interaction between supporting and attacking arguments.
It describes the notions of internal and external coherence. The set of arguments must keep a minimum of coherence to be able to model adequately one side of any reasonable dispute. This form of consistency is both internal and external when a subset of arguments is considered, and can be obtained by extending the definition of conflict free set proposed in [16] in the internal case, while the external coherence can be captured by the notion of safe set presented in [12].
It redefines conflict-free sets. As we mentioned in the previous item, the notion of conflict-freeness requires considering both supported and secondary attacks. Additionally, the notion of a safe set is powerful enough to encompass the concept of conflict-freeness, i.e., if a set is safe, it is also conflict-free. Another critical requirement to be a safe set is that it should be closed under the support relationship [12].
In this work, we will introduce the concept of a coalition as it is revealed through considering similarity to help identify argumentative stances in a conversation and characterizing the relationships between these stances.
Next, we present a
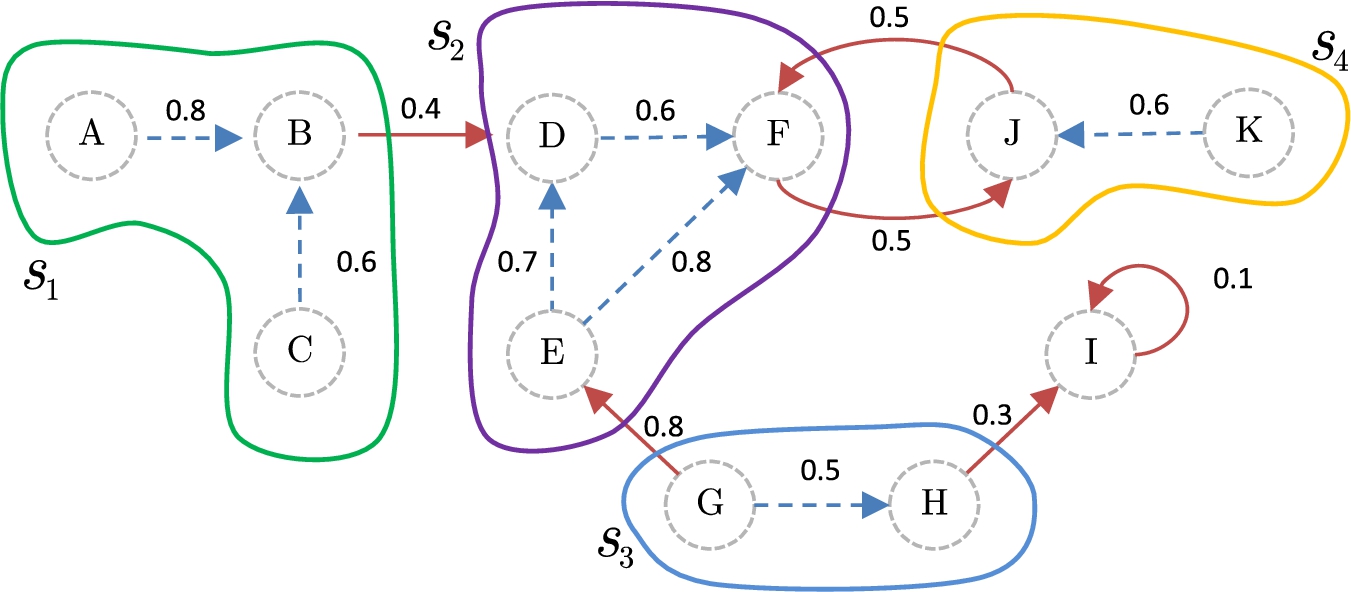
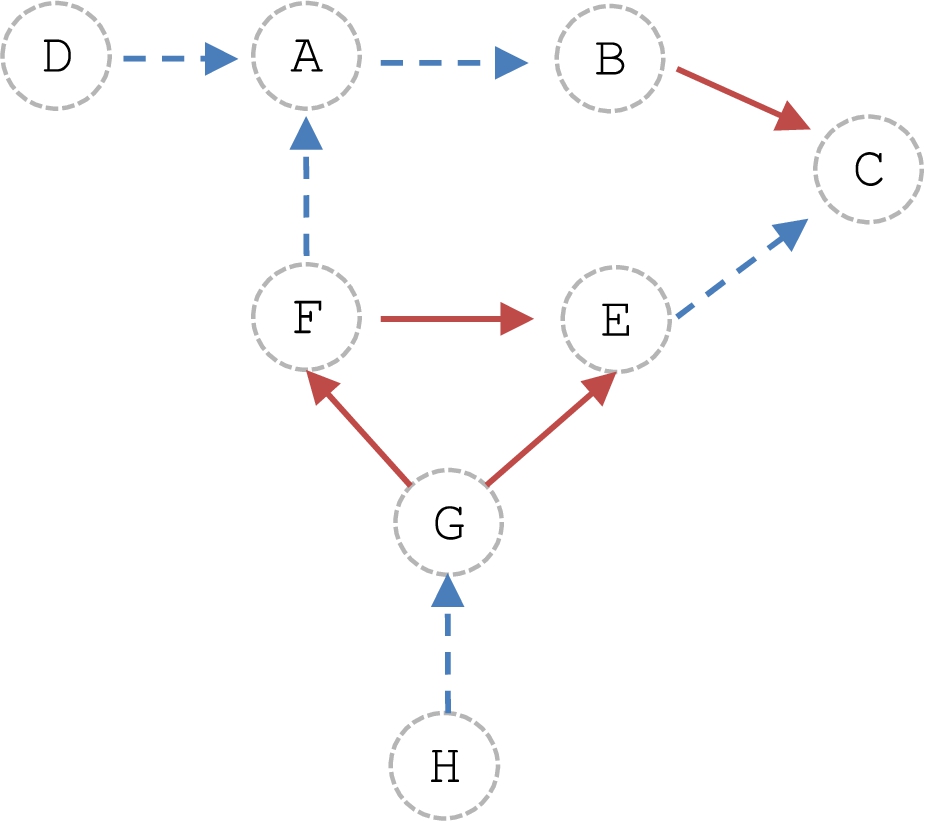
Representation of the attack and support relations in 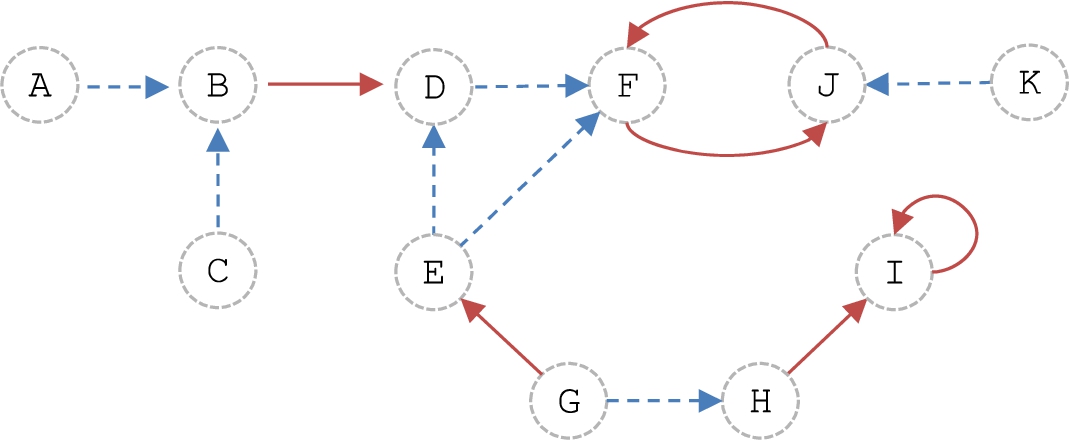
Conflict-freeness requires considering the direct, supported, and secondary attacks. Figure 2 shows the bipolar argumentation graph of this particular Representation of the secondary and supported attacks in 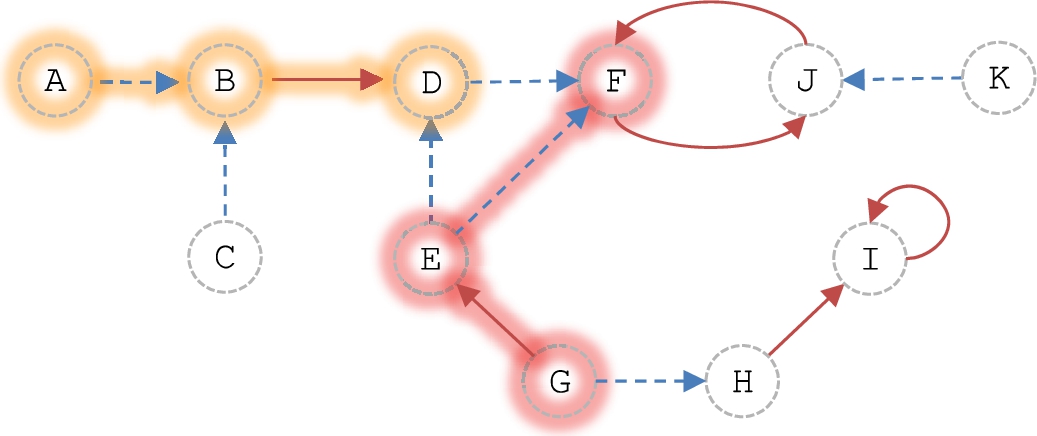
This formalism can approach a representation of how human beings think by recognizing the bipolar nature of a debate when discussing a particular topic; however, it is not feasible to clearly distinguish stances on a specific subject. For this reason, in [13], the authors proposed a notion of coalitions between supporting arguments that will be discussed next.
The capability of representing support among arguments available in Bipolar argumentation frameworks becomes relevant when it is necessary to reason with maximal and coherent sets of arguments that are collectively related through that relationship. Cayrol and Lagasquie-Schiex in [13] perform an in-depth analysis of the bipolar framework abstraction introducing the notion of coalition that aims to obtain the maximal set of coherent arguments which collaborate to justify a conclusion, i.e., arguments that do not attack each other directly or indirectly. The following definition formally introduces the notion of a coalition.
(Coalitions in a baf ).
Let
Note that if (i)
A coalition represents a relationship on the set of arguments; therefore, the notion of attack between them introduces a meta-argumentation framework that provides a higher locus where to interpret and analyze the set of supported arguments and the attacks between those sets:
(Attack between coalitions in baf ).
Let
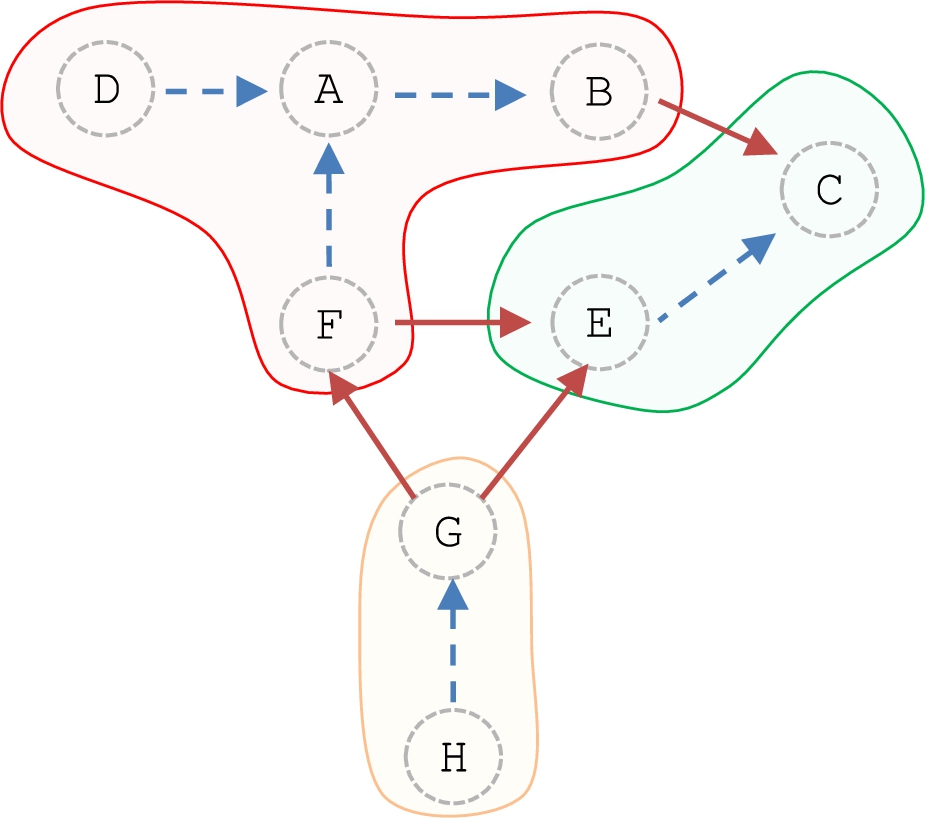
Continuing with Example 2, Fig. 4 shows the following four coalitions:
Coalitions in 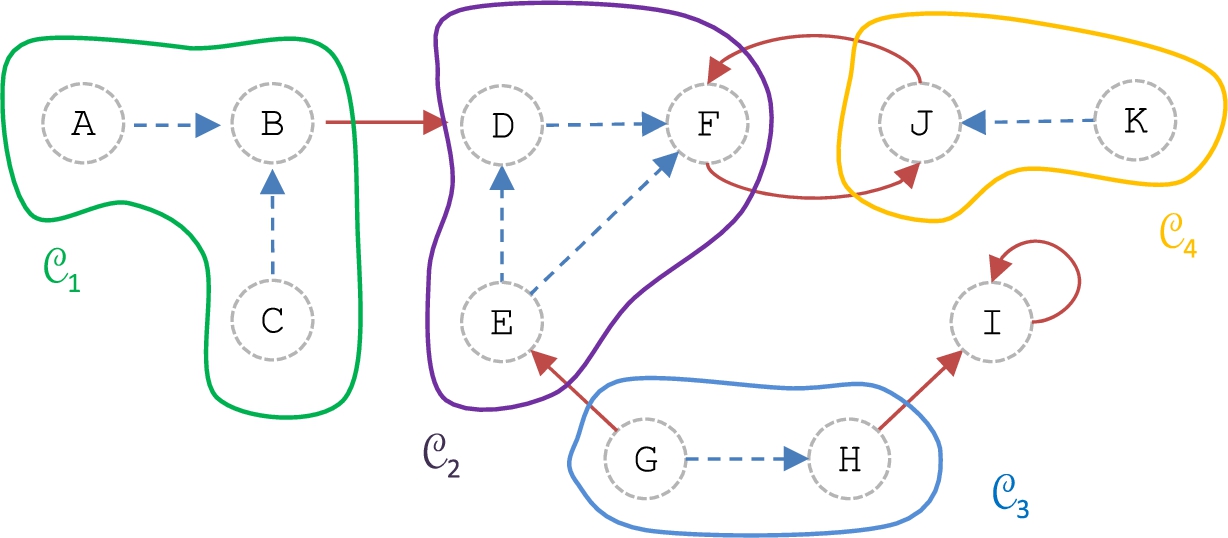
These are maximal conflict-free sets, and
The notions presented in [13] initially do not provide the tools to analyze how strong the coalitions, and the attacks between them, are. Also, note that argument
Despite the representation capacity that bipolar frameworks offer, some argument’s characteristics should be taken into account to improve the performance of their semantics. For example, a very natural tool for argument-based reasoning is the notion of similarity among arguments: during an argumentation process, we sometimes tend to group arguments according to their shared characteristics or to the topics to which they refer. It can be argued that any comparison process requires defining a context in which such comparison can be meaningful [23,48]. These intuitions can be applied to arguments as follows: two arguments may be similar in a given context but may be entirely unrelated (or even incomparable) under different circumstances. Reasoning that considers similarities between arguments represents a natural form that is used in everyday human reasoning [11].
Budán et al. introduced a Similarity-based Bipolar Argumentation Framework (or
We will make some notational conventions to facilitate the following definitions. We assume a set
(Enriched Argument).
Let
Next, we introduce the notion of context of the argumentation.
(Context).
Let
Using the additional information provided by the context, it is possible to represent and determine similarities between arguments by introducing means to enrich the analysis of the relationships between them and distinguish between arguments that are weakly related to those with stronger relationships. In this direction, it is possible to compute an argument’s similarity degree between two arguments. To do that, we consider the descriptors that arguments have in common and the weight those descriptors have in the process comparison in a specific context comparison
(Similarity coefficient for a descriptor).
Let
Intuitively, finding the similarity coefficient between two arguments for a particular descriptor requires finding the number of semantic values common to that descriptor in both arguments and dividing it by the number of semantic values for the descriptor that the arguments do not have in common, and then weighing the resulting value according to the relevance associated with the descriptor in the definition of the context considered [24,29,32].
(Similarity degree between arguments).
Let
Note that the order in which the descriptors are considered in computing
The abstract concepts presented earlier will be illustrated in the following example.
Suppose that the arguments Research published in the High School Journal indicated that “students who spent between 31 and 90 minutes each day on homework scored about 40 points higher on the SAT-Mathematics subtest than their peers, who reported spending no time on homework each day, on average.” Research by the Institute for the Study of Labor (IZA) concluded that “increased homework led to better GPAs and higher probability of college attendance for high school boys. In fact, students who attended college did more than three hours of additional homework per week in high school.”
Analyzing the arguments above, we observe that they have the following descriptors and values:
Now, suppose that the context for the arguments comparison is the following:
Per each descriptor, we have:
For the descriptor For the descriptor For the descriptor
Now, considering the bounded sum T-conorm, we have that the
The similarity value obtained reflects that the both arguments refer to a good practice for the students, but each argument gives different reasons (results) for this assertion.
The next step is to define a cohesion degree between supporting arguments and a controversy degree between conflicting arguments. In the following definition, we introduce the enriched
Let
Given that the Enriched
Now, the cohesion degree of a set of supporting enriched arguments and the controversy degree associated with a set of attacking enriched arguments can be formally introduced.
(Cohesion & Controversy degrees).
Let The cohesion degree for The controversy degree for
Both
Next, for simplicity, we present our abstract example where the similarity degree associated with each relationship (attack or support) was previously established (for more details, see [11]). Note that, in this formalism, both attacks and support are treated likewise. If an argument X attacks or supports another argument Y, the similarity measure is assigned to the relationship without differentiating the kind of relationship. Mainly it is because we want to be balanced in dealing with the positive and negative actions over a discussion.
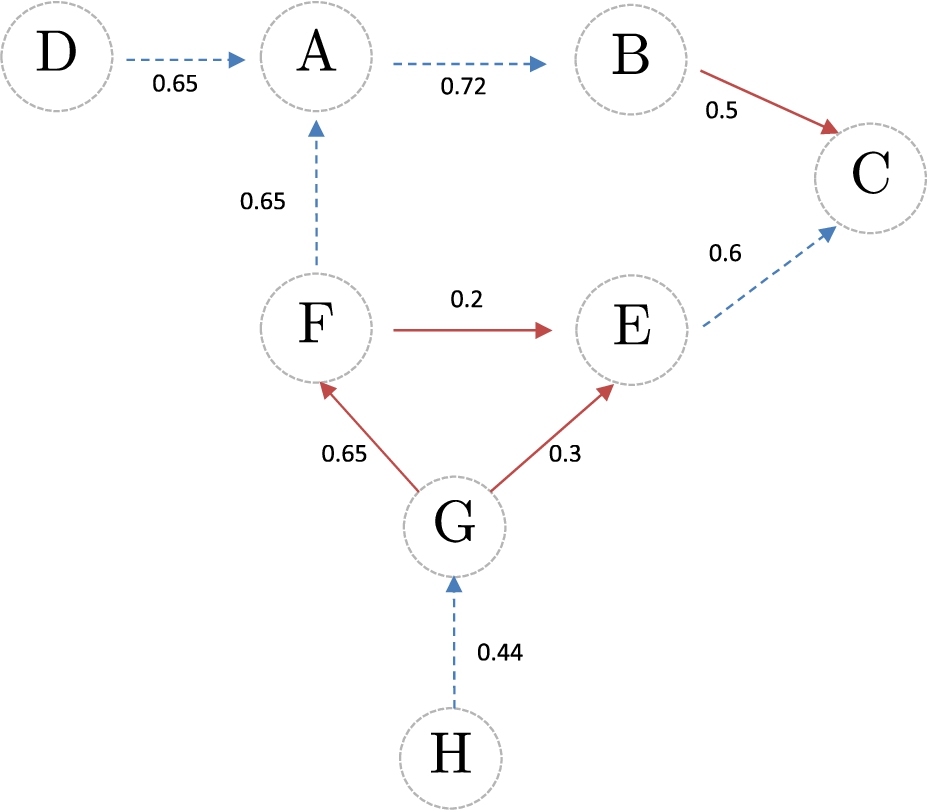
We continue with our abstract example, the graph in Fig. 5 shows the similarity degree associated with the arguments in each relation. Intuitively, we can observe that the attack between the arguments B and D is weaker than the attack between G and E. Note that the attack between F and J have the same similarity degree that the attack from J to F since the similarity relation is symmetric. Additionally, we can also differentiate the weakest support relationship existing in the whole model: the one between G and H. Based on the similarity degree obtained in each relation, we compute the cohesion coefficient associated with the set of supporting arguments (considering a product T-norm) and the controversy coefficient associated with attacking arguments (considering a max T-conorm). Thus, we have that:
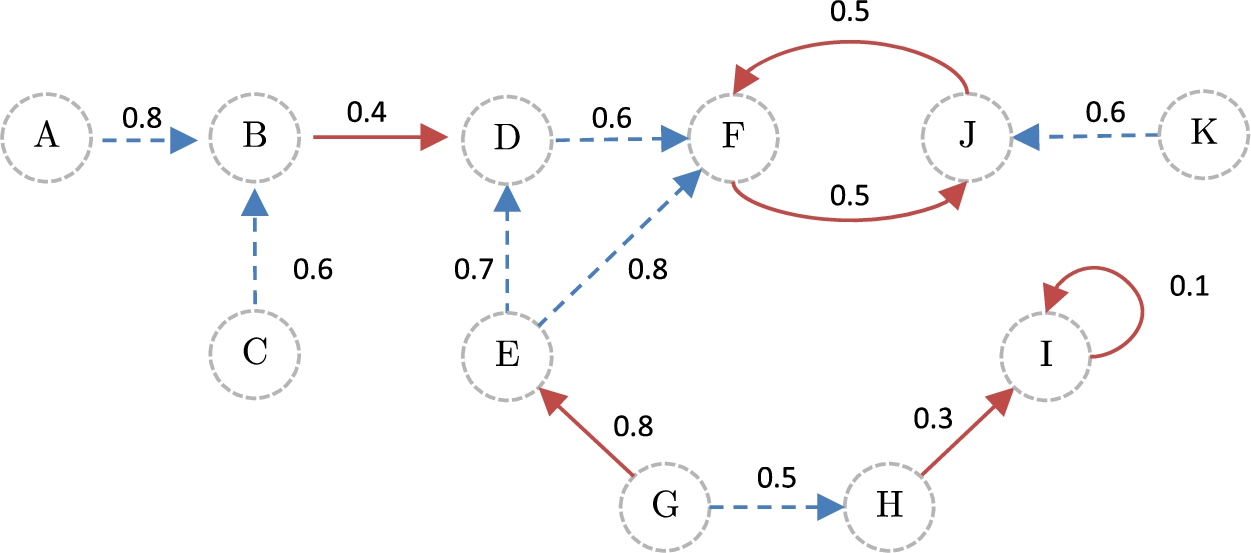
Observe that, in this particular case, the cohesion associated with the support relation is analyzed considering the support chain presented in the argumentation model (see Figure 5). At the same time, the controversy measure is obtained by analyzing the pairs of attacking arguments.
The enriched
Let
When no confusion may arise, we will avoid mentioning the
Additionally, in
Now, and considering the elements introduced above, the authors in [11] redefine the classical notions of conflict-free and safe sets in a
(Conflict-freeness and Safety properties in a s-baf ).
Let
In the following step, in [11] the authors extended the notions of defense for an argument with respect to a set of arguments. Furthermore, the paper introduces different definitions of admissibility, from the most general and strong to the most specific and weak. The most general is based on the classical notion of admissibility, where only the attack relations are considered, both the strong and the weak ones.
Let
Then, this notion is extended by considering external coherence and under different attack and support degrees among arguments. Finally, external coherence is strengthened by requiring the closure under the support relation
Let
In this manner, in [11] it is argued that admissibility becomes a characteristic of a set of arguments that can be perceived from different perspectives. The most restrictive admissible sets do not admit conflicts and defend all their elements with values of controversy greater than the given threshold. A more flexible admissibility property is when a certain level of controversy associated with the set, which is limited by the threshold, is acceptable. In this case, the arguments’ defense can oscillate between strong and weak. Finally, the most flexible set allows the existence of conflicts where the controversy associated with them is strictly less than the threshold; i.e., the controversy is analyzed individually for each pair of conflicting arguments. In the last two cases, the arguments’ defense can fluctuate between strong and weak.
From the notions of coherence (internal and external) and admissibility, it is possible to introduce different acceptability semantics. In [11], Budan et al. introduced a more fine-grained definition of preferred extensions as follows:
Let
Next, we analyze our running example to obtain the different types of acceptable argument sets, where the properties of conflict-freeness and safety are considered.
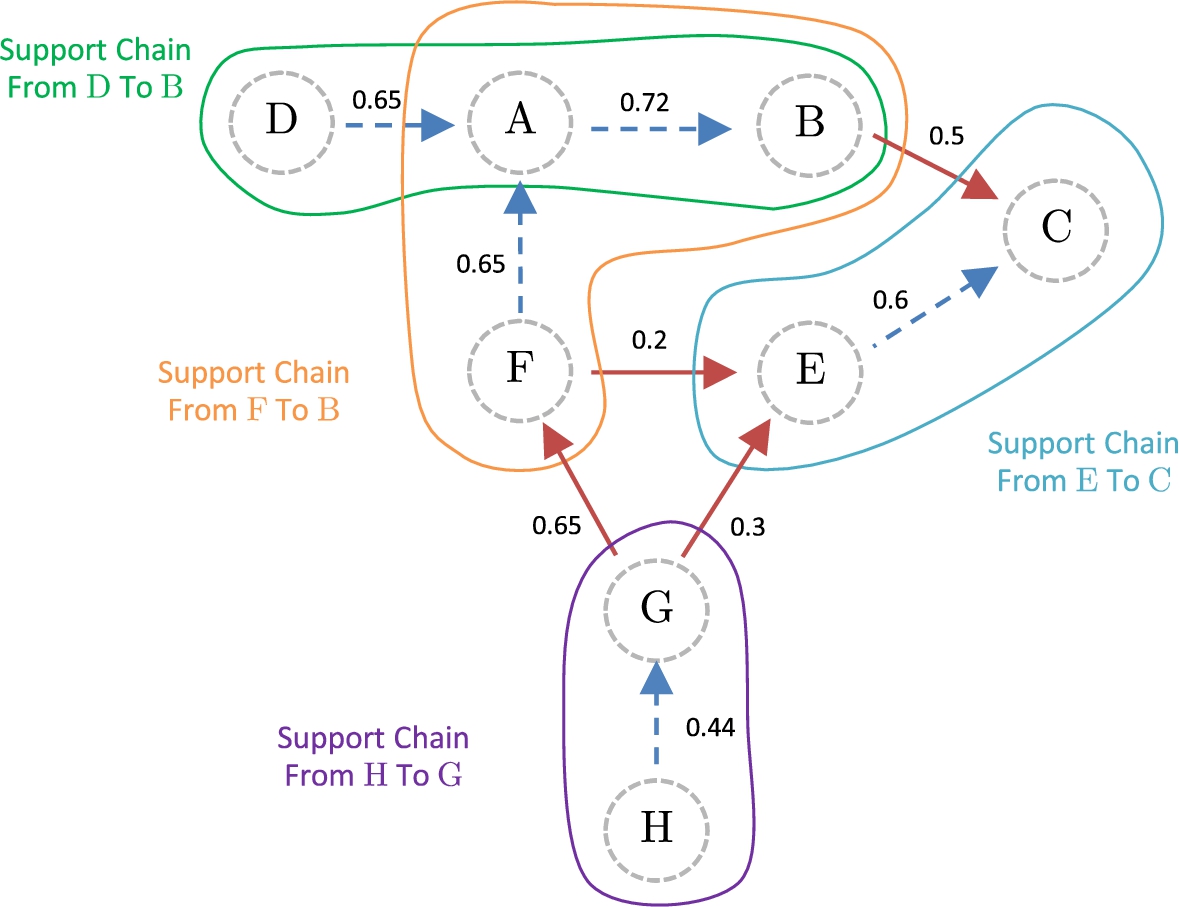
We continue analyzing the Example 5 presented in Fig. 5, introducing a threshold Weakly-direct attacks, with controversy coefficient lower than τ, are from B to D, H to I, and from I to I. Strongly-direct attacks, with a controversy coefficient greater than τ, are from F to J, J to F, and from G to E. Weakly-supported attacks are from C to D (since Strongly-supported attacks, with the controversy and cohesion coefficients greater than τ, are from E to J, and from K to F. A strongly-secondary attack, with the controversy and cohesion coefficients greater than τ, is from G to F. A weakly-secondary attack is from B to F because Analysis of admissibility in
Additionally, we have:
Preferred extensions in 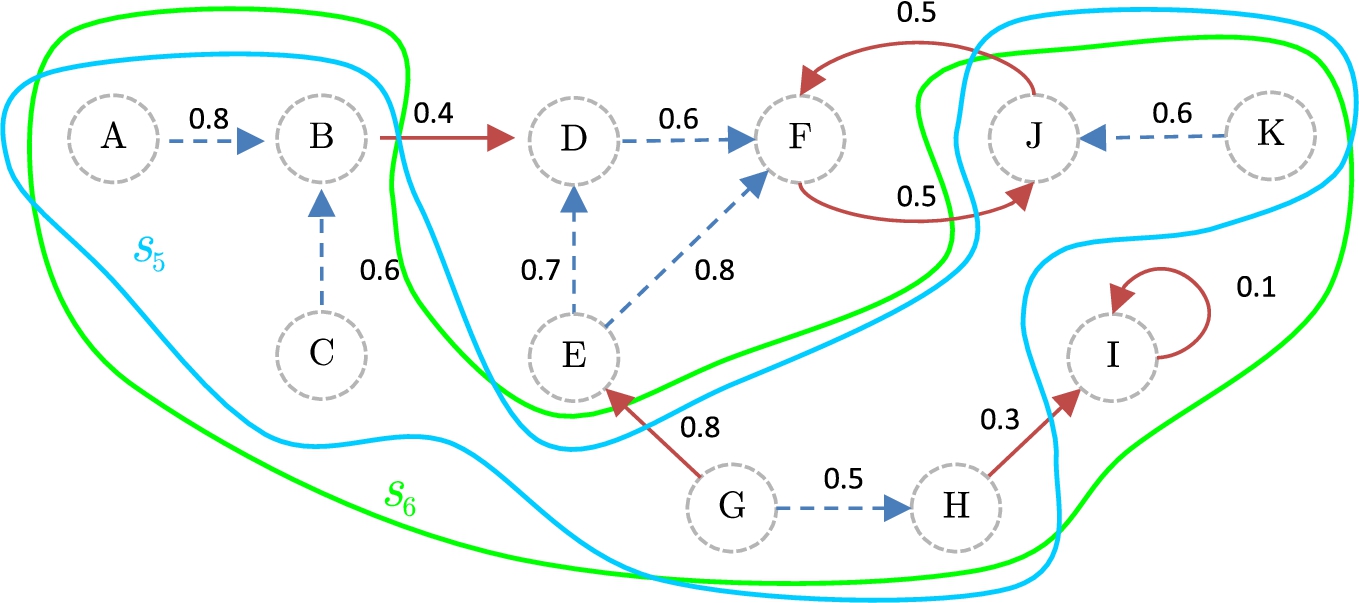
As we can see, the analysis of a
A human community is a social unit considered a discrete constituent of society with shared norms, values, customs, or identity. Communities may share a sense of being placed in a given geographical area (e.g., country, village, town, or neighborhood) or a virtual space through digital platforms, including associations expanding outside direct genealogical relations, which also define a sense of community, becoming essential to the identity, practice, and roles in the various usual social institutions such as family, workplace environment, governmental organizations, or any other social construct to which individuals consider themselves as participants [25]. As we can see, formulating a definition of the community term is a complex task that is being approached from different perspectives [9]. It is possible to find several notions about this kind of organization, like the ones that follow:
A community can be defined as a group of people that interact and have common interests. They can share or not geographical localities [9].
A community is a way to decompose a social network by clustering nodes with strong links [14]. This meaning implies a structural representation of the community as a graph.
A community is a gathering of people assembled around a topic of common interest [22]. Its members participate in the community by exchanging information, obtaining answers to personal questions or problems, improving their understanding of a subject, sharing common passions, or playing interests.
A community can be considered a network of people (possibly distributed in different locations) that share specific beliefs such as solidarity, identity, or a set of rules that govern their behavior [9].
Communities, or clusters or modules, are a group of vertices in a graph that probably share common properties or play similar roles [17].
According to a structural perspective, a community is a set of nodes strongly linked to each other and loosely linked to other nodes. However, it is also a set of nodes that share the same interests, based on a semantic position [14].
From the perspective of Social Psychology, a person is attracted to a group in which they can serve as inspiration or give an opinion according to the culture of the social organization [34]. This characteristic has a significant effect on the cohesion of a community. However, another critical concept exists when we refer to these groups: the consensual validation that represents the uniformity and conformity in the community. It is important to note that the members of the community share feelings, opinions, beliefs, priorities, or goals. In other words, the community has structural and semantic aspects [14]. From a different standpoint, Sarason in [45] argues that a psychological sense of community is the perception of being similar to others. There is an acknowledged interdependence with others, a willingness to maintain it by giving to or doing what others expect from them, including the feeling that one is part of a larger, dependable, stable structure.
Adopting a practical stance, McMillan and Chavis in [34] identify four elements of the “sense of community” involving the four aspects of membership, sense of influence, the fulfillment of needs, and a shared emotional connection: (i) the feeling of belonging to a group or, in other words, a sense of membership, (ii) the feeling of being essential to the group or having influence in this group, (iii) the members of the community are integrated into it, and they can fulfill their necessities leading to the reinforcement of that feeling, and (iv) the group members share an emotional connection represented by the belief that they have and will continue having a shared history and places, spending time together, and partaking of comparable experiences. Concerning this, a “sense of community index (SCI)” was developed by Chavis and colleagues2
See
All the observations above outline an essential characteristic of a community: its members have a shared context unique to them. The context informs all the activities inside the community and provides the background information necessary for reasoning and acting by its members.
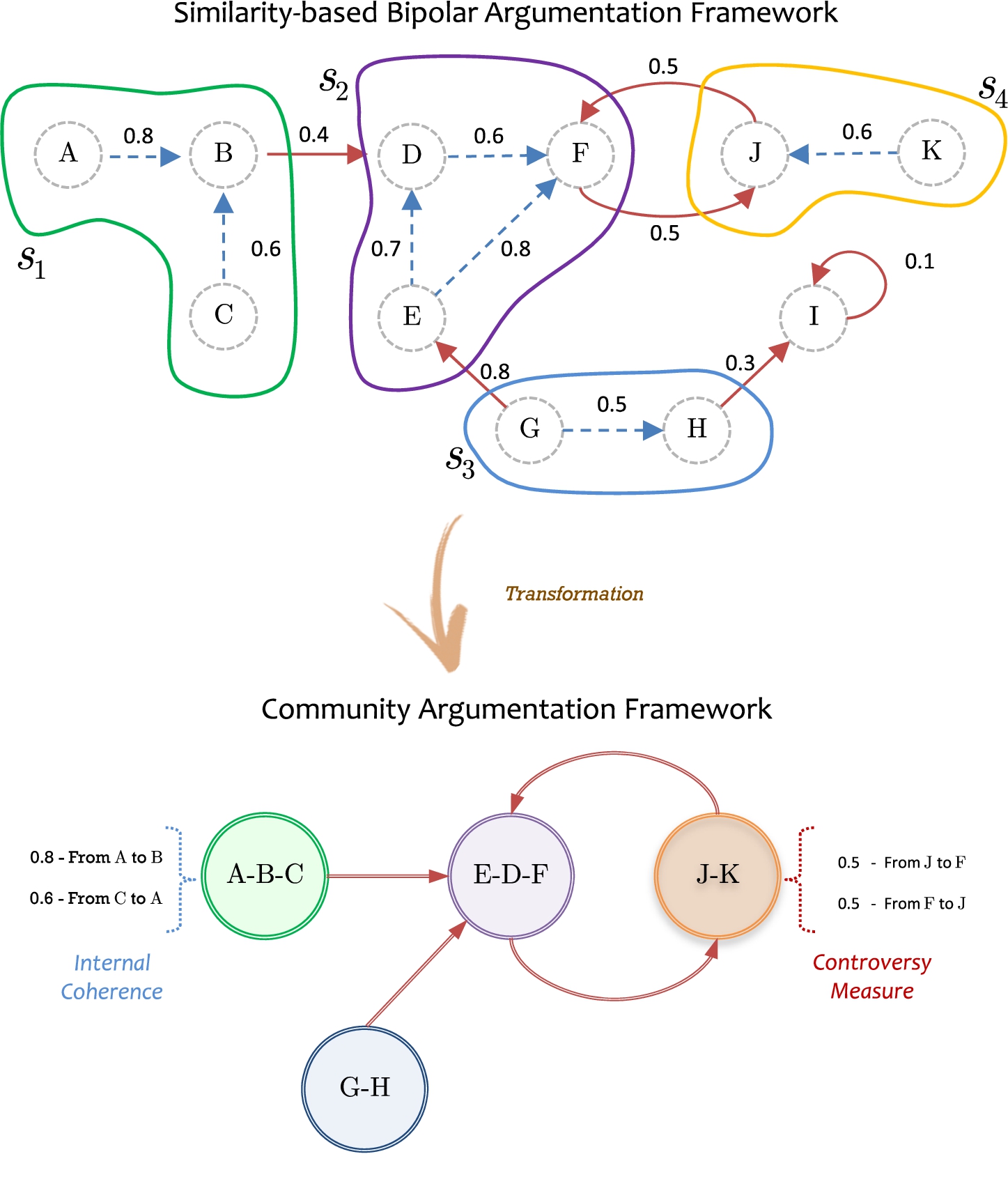
Communities in bipolar argumentation frameworks.
Now, considering our specific application domain, Porter in [40] defines a virtual community as an aggregate of individuals or business partners (in connection with one or more organic communities) that interact on a shared (or complementary) interest and in which a common language implements the interaction and eventually a possible common paralanguage, led by some protocols or shared norms. Taking as a basis this definition, Prodnik in [41] establishes a virtual community as a social construction where the language is the basis of its organization, and the technology in general and the internet, in particular, have a predominant role. Given the importance of the language in virtual communities, arguments can be helpful in detecting them, reflecting the thoughts of the organization’s members in a given discussion. Thus, arguments may have an opinion for or against a specific statement, representing communities interacting in a particular argumentative discourse.
In this work, when referring to a community, it will be understood as a group of agents presenting different postures through a set of arguments expressing supporting and conflicting positions in a setting akin to a debate (see Fig. 8). Support can be interpreted as a relationship among the group members through common opinions; consequently, coalitions in
Given a system that represents knowledge as arguments and considers the existing conflicts and supports between these arguments, a primary goal is to find sets of arguments that can be kept together by handling the conflicts appropriately while fulfilling relevant properties. It is feasible to create maximal cohesive sets of arguments by taking advantage of the mechanism proposed in [11] to collect in a set as many conflict-free and related-by-support arguments as possible, ensuring coherence of the whole set. Nevertheless, it is also interesting to include some degree of controversy by considering the addition of attacks and maintaining a coherence threshold in a dialogue or debate. Thus, it is possible in the proposed framework to find sets of arguments or stances that conform to a community, where for the present work, a community is a set of consistent stances in favor (or against) a specific topic. The threshold has two different meanings in the valuation proposed here. On the one hand, the threshold is the maximal degree of controversy that a community can admit without losing the essence that identifies it as a discursive and coherent community. On the other hand, the threshold represents the minimal level of coherence required by a set of opinions to be considered at least as a community with a moderately solid and consolidated position among its members. There might be many possible threshold settings; in each case, it is essential to determine the most appropriate one to use. This threshold setting is a methodological issue involving the semantics of the domain. The question could be tackled by devising experiments using examples where the desired conclusion is well known or by performing tests using the cognitive evaluation of human subjects to approximate their assessment of the valuations obtained after their interactions. Furthermore, according to [46], it could be challenging to find the correct value for a heuristic threshold; a complete discussion of the generality of this choice for representing uncertain information can be found in [50]. This issue exceeds the scope of our work. However, given the practical usefulness of this parameter, we plan to return to this question in future works.
When analyzing social media conversations as an exchange of arguments, it is natural to find many arguments in favor of a conclusion; generally, these arguments are similar but have some nuances in their meanings. To recognize communities, we propose considering an argumentation graph where the arguments are decorated with labels that will allow us to determine how similar the supported and attacked arguments are. Aiming at that, we introduce a bipolar argumentation graph whose arcs are labeled with a similarity degree between the related arguments, as follows:
(S-valued bipolar argumentation graph).
Given
Now, it is necessary to revisit the concept of coalitions given by Cayrol and Lagasquie-Schiex in [12] to extend it by formalizing how a similarity degree can influence the support relations. Formally:
(S-coalitions ).
Given an
Note that self-attacking arguments are disregarded in this approach according to the classic definition of a coalition where no attacks are permitted (Definition 5). In other words, an opinion that contradicts itself cannot be part of a discourse community. However, in future research, the attack might spur different coalition classes by weakening the strong-conflict-free condition by admitting certain conflicting opinions within a community.
The following result follows naturally from the definition of S-coalitions.
Let
Once the set of coalitions is obtained, we can use the internal coherence of each element in this set to characterize an s-coalition. Note that, as an s-coalition is a set of enriched arguments, we can use the cohesion function established in Definition 12 to determine a cohesion measure associated with that s-coalition.
Let
Intuitively, a strong-coalition does not admit conflict between its arguments, assuring that these pieces of knowledge refer to the same aspects of the argumentation process, i.e., the opinions allude to precisely the same values for each considered descriptor. In a τ-coalition, even though the arguments do not contradict each other, they essentially refer to the same aspects, i.e., the opinions allude to the same values for each descriptor considered but contain some descriptors whose values differ. Lastly, in a weak-coalition, although the arguments do not contradict each other, they can refer to the same aspects differently, or some of them might refer to different aspects of the issue, i.e., either the opinions mainly allude to each considered descriptor differently, or each opinion refers to different descriptors. The threshold is a sensitive value to determining what type the s-coalition is a group of supported opinions. A higher threshold value allows more flexibility in the descriptors’ values for each considered descriptor.
A coalition can be regarded as an argument at a meta-level built from argumentation stances that deal with contextual features with different degrees of strength. In an everyday discussion, even when stances do not contradict each other, the different members of the coalition do not have the same strength. So, we can associate a coalition to discourse communities. In this direction, a possible way to detect and classify these discourse communities is to find s-coalitions. Furthermore, the following criteria for distinguishing discourse communities from coalitions can be considered:
(s-discourse-communities).
Let
Those criteria are defined taking into account:
According to the characteristics of a community, an sd-robust-community represents a maximum level of consensual validation and strong support (possibly emotional) connection. In contrast, an sd-fragile-community shows a minimum level of consensus and support connection inside the organization. Next, we introduce an example to clarify the preceding ideas.
Continuing our Example 6, using a product T-norm to obtain the cohesion value, considering a Communities in bipolar argumentation frameworks.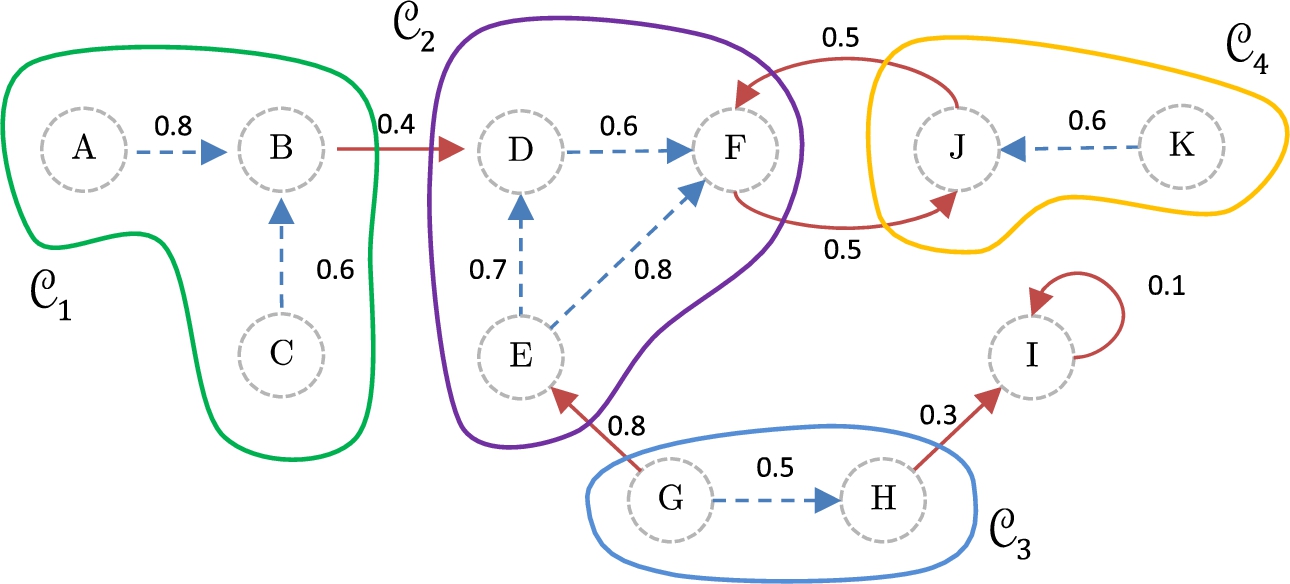
The difference between an sd-robust-community and an sd-moderate-community is a design choice. Still, we believe the intuition behind an s-coalition is that the stances (arguments) in it must be fully supported, taking into account the aspects they refer to. It is possible to follow a simple procedure to find and classify s-coalitions computationally from an s-valued bipolar argumentation graph: first, consider the paths following the support relation; then, calculate the coherence value for each path found considering the threshold τ given; and finally, determine the corresponding s-coalition type based on these coherence values.
The nature of the support relation allows us to establish some properties. For example, when we find a strong support relation inside a coalition, it is natural to think that the cohesion associated with the supported arguments would be high.
Let
Now, it is necessary to introduce an attack relationship between conflicting coalitions. The characterization of these new attacks considers the attacks between the arguments that are part of these coalitions as formalized in the following definition.
Given the
Intuitively, it is possible to say that if there is an attack between two arguments that belong to two different coalitions, then it is natural to raise this conflict to the coalition level and define now an attack between these coalitions.
(S-coalitions Attacks).
Let
Furthermore, it is interesting to study the strength of the attack from one coalition to another by considering the strength of the attacks that define the existing points of conflict. Formally:
(Strength of attack between s-coalitions).
Given an
The attack degree can be obtained by instantiating the
Once the attacks between s-coalitions are identified, and their strength is computed, we begin by using the attack degree to distinguish between strong and weak attacks. This classification can be employed to define different semantics by using different forms of acceptability; for instance, conflicting s-coalitions could be part of a set of acceptable s-coalitions when the attack degree is not strong enough to be considered a defeat.
(Classification of attacks between s-coalitions).
Given an
The previous definition formalizes the intuition that a strong attack considers two necessary elements: the strength of attack and the s-coalition internal cohesion measure applied to the set of the enriched arguments in the s-coalition. Once the s-coalitions and associated attacks are obtained from the
(Meta-argumentation framework).
Given
Note that in the new meta-argumentation framework, the set
Next, we will introduce the measure of controversy associated with a set of s-coalitions, where the different types of attacks are analyzed to specify how contradictory they are.
(Controversy degree for a s-coalition set).
Given a meta-argumentation framework
The instantiation of the controversy degree function is a design decision, i.e., users can choose what they consider more appropriate for the problem at hand. Two possible choices are the T-norms and T-conorms. This measure returns a non-negative real number in
Given the
Given that the controversy associated with a set of coalitions is the same as the controversy associated with the set of enriched arguments involved, the previous result establishes a common point between the
Now, based on the semantic analysis done in [11], we introduce the notions of conflict-free s-coalition sets in our meta-argumentation framework
Given a meta-argumentation framework
The following proposition establishes the semantic connections between the meta-argumentation framework dealing with coalitions of arguments and the subjacent similarity-based argumentation framework.
Let If If
Previous examples have examined how to obtain the coalitions associated with an
Continuing the analysis of Example 7, and recalling that the threshold set is There is a conflict point between the s-coalitions There is a conflict point between the s-coalitions There is a conflict point between the s-coalitions Attacks between coalitions in a meta argumentation framework.
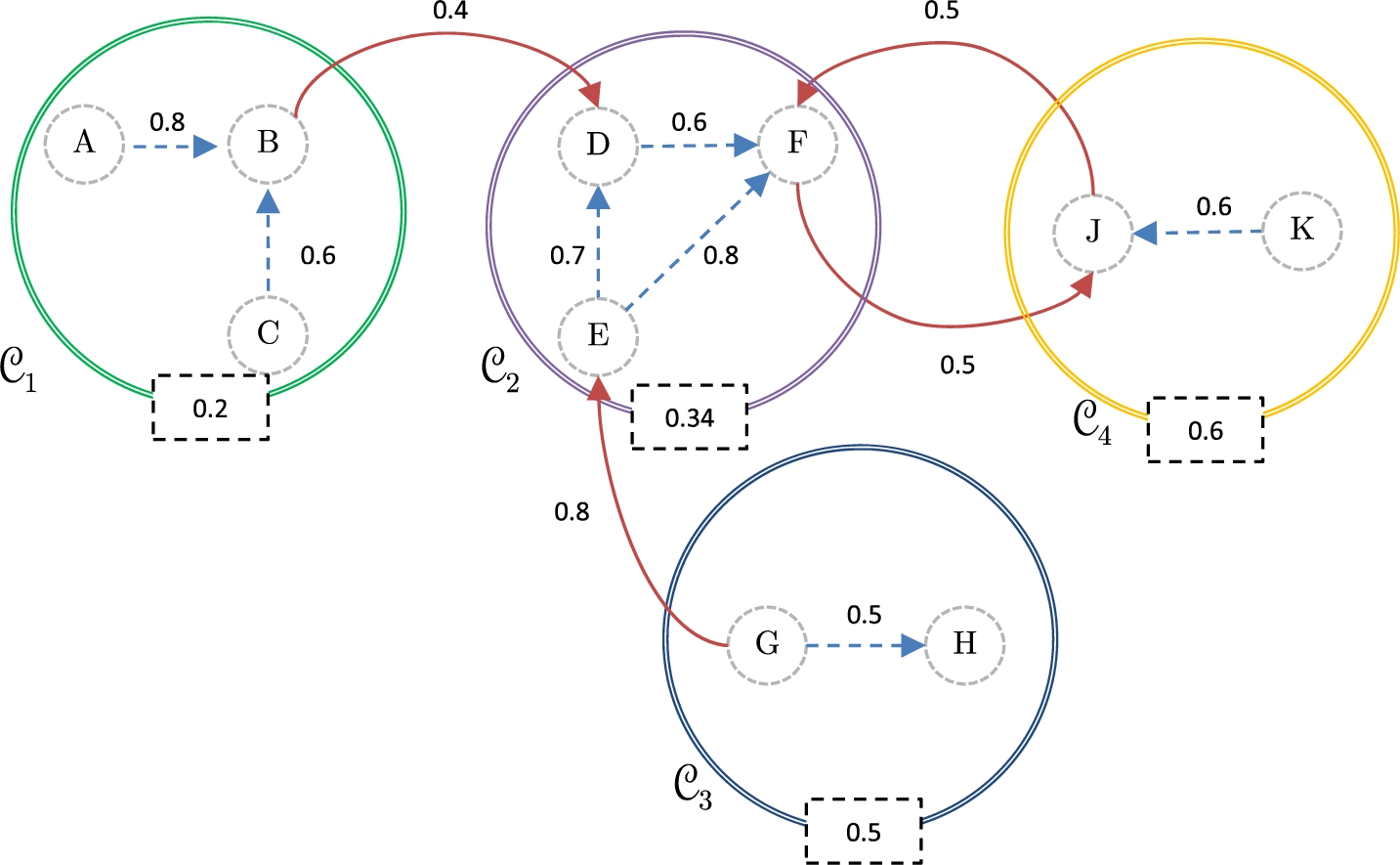
The characterization of the attack relationship between coalitions and considering the associated strength of attacks allows us to establish the following property. This result will be relevant to characterize how an s-coalition “absorbs,” or “assimilates” other s-coalitions.
Let
Now, we will introduce the notions of defense for coalitions by extrapolating from the defense relationship between the arguments gathered in the coalitions involved in the analysis. Furthermore, we present different definitions for admissibility, from the most general and strong to the most specific and weak.
Let The set The set
Once the attack and defense relationships are specified in the meta-argumentation framework, we can perform the semantic analysis over the argumentation model. The following definition establishes three levels of admissibility over the set of communities based on the level of tolerance to conflict between them and considering the quality of defense that the set provides to its elements.
Let The set The set The set
From Definition 19, the following proposition establishes that any set of admissible coalitions is also closed by the notion of support in the underlying
Let
It is possible to determine different connections between the meta-argumentation framework and the underlying similarity-based argumentation framework. This connection is essential to carry out a semantic analysis of the relations between communities.
Let If
Finally, we present the preferred extensions for the meta-argumentation framework resulting from considering coalitions, where the notions of defense and conflict-freeness are put together to establish a set of communities with particular properties important to analyzing an argumentative discussion.
Let
Naturally, Definitions 28 to 31 are extensions of those presented in Section 2.2 developed under the
The following result establishes the connection between the meta-argumentation framework and the underlying similarity-based argumentation framework.
Let If
Continuing with the running example and considering the elements provided by the Example 8, we observe that Preferred semantics in a meta argumentation framework.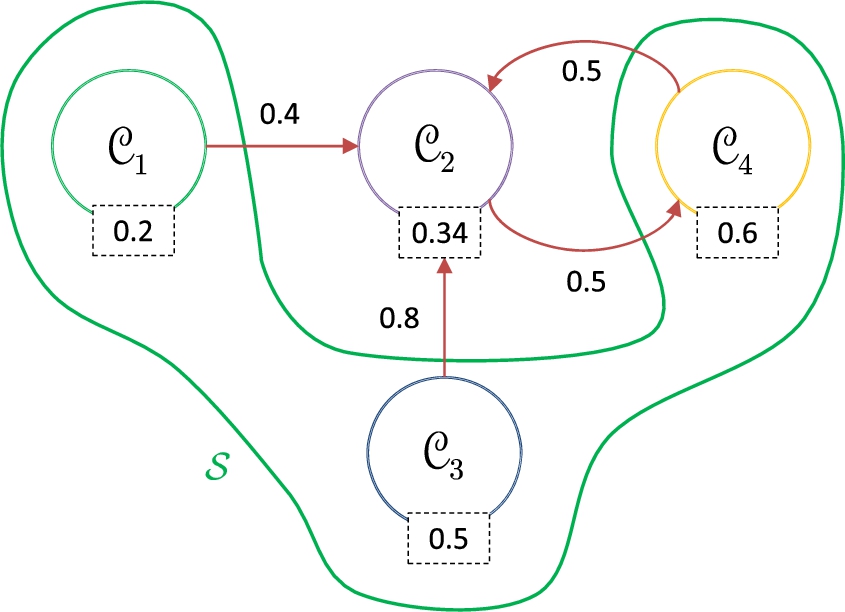
Under the classic approaches to modeling argumentative debate [3,16], even the introduction of a trivial opposing idea is treated as an attack undistinguishable from the other attacks resulting in that the attacked argument is effectively defeated or rebutted. However, following typical human behavior, it is natural to consider two coalitions that weakly attack each other as a unique set of stances, i.e., a group of arguments with slight nuances that do not truly change their aim or the foundation of the community.
Let
The definition of assimilation of s-communities comes naturally, introducing the potential of admitting a certain degree of controversy into a set of ideas or opinions. The intuition behind this tolerance is that two communities may have differences; however, these differences may become insignificant when we carefully study them in the context of a debate, so the stances supported in both sets can be considered as a single s-community with some internal, minor disagreements. In other words, a coalition coming from an assimilation is such that it has partially consistent beliefs, but the internal controversy can be tolerated. The new set of beliefs will be a possible weaker coalition but can evolve into more entrenched beliefs.
Given a meta-argumentation framework
Note that the attacks are maintained after the assimilation process, i.e., if a coalition
From another perspective, when a coalition assimilates another, the set of arguments expands by including other postures; thus, the resulting coalition has a more flexible view of the situation by admitting these alternatives. Nevertheless, the process results in a new coalition with a cohesion degree that cannot be greater than the assimilating coalition. The following proposition formalizes this result.
Given a meta-argumentation framework
Returning to Example 9, we observe that Assimilated coalitions in a meta argumentation framework. Preferred semantics of the meta argumentation framework.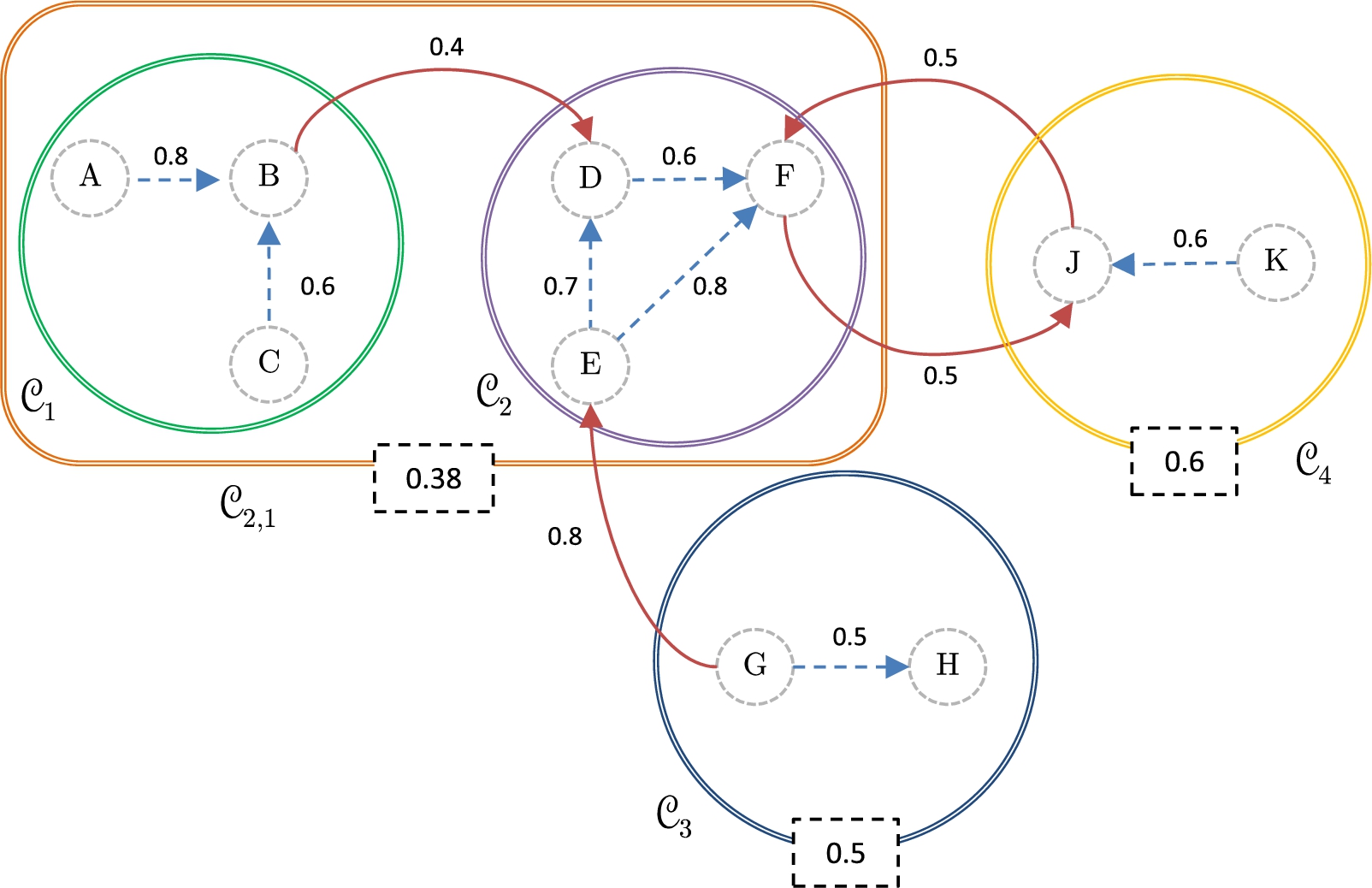
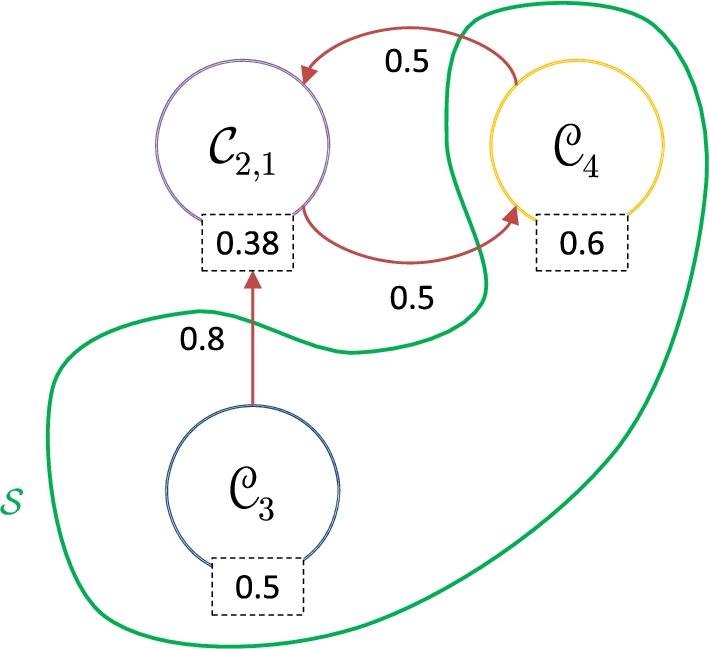
Note that, as a result of the assimilation process, the argumentation model can change. For example, when weak attacks are admitted as part of a coalition, attacks from one coalition to another can be transformed from weak to strong, among other situations. Thus, the changes in the argumentation model could impact the set of accepted arguments. In this sense, it would be reasonable to think that it will be necessary to compute the semantics again and detect the group of acceptable coalitions. However, one way to partially compute the semantics would be to detect the zones where changes occur in the argumentative framework, that is, which parts of the discussion are affected by the assimilation process, computing only the acceptability process over the coalitions affected. This issue exceeds the scope of this work, but we will explore it in future research.
Given the options now available for the preferred extensions (τ-preferred extension and weakly-preferred extension), we can ensure that it is always possible to carry out the coalition assimilation process within these extensions.
Given a meta-argumentation framework
To conclude, it is appropriate to observe that the notion of coalition introduced supports the definition of communities in the context of an argumentation-supported debate. We can also remark that the notions of conflict-freeness and safety can be replicated in this type of community, and these characteristics are especially interesting for analyzing complex debates, such as those that frequently occur in the social networks. The reason is that our expansion of formal argumentation theory provides tools to improve the analysis of a debate, like the situation when a community can assimilate another to widen the perspectives and establish a conflict characterization between disagreeing communities.
Now, let us consider the actual opinions in favor of (pro) or against (con) presented in Figure 14 about the following proposition “Is Human Activity Primarily Responsible for Global Climate Change?”.

A set of arguments concerning the possible causes of climate change.
The case study can be represented as a
Climate change argumentative process represented in a
From this set of arguments, informally, we can distinguish three general stances about climate change represented in Fig. 16: one of them (highlighted red) groups the arguments that disagree with the posture that human activity is the primary cause of climate change, another group (highlighted green) gathers the opinions that confront the previous one; the third (highlighted orange) collects the ones that adopt an intermediate posture. Now, we consider a specific context to perform a complete analysis, starting by computing the similarity between arguments, that allow us to detect how strong the relation between them are. So, we establish the following context of comparison:
Strong-direct attacks: from B to C, given that from G to F, given that Weak-direct attacks: from F to E, due to from G to E, given that Weak-supported attacks: between H and F since between H and E since Strong-secondary attacks: between G and B since between G and A since Weak-secondary attacks: between G and C since between F and C since since Strong-supported attacks: between A and C since between D and C since between F and C since
Doing an extended analysis to determine the set of acceptable arguments (see Fig. 19), we have that:
We have analyzed the relationship between the arguments of our example as a
Informal identification of stances concerning climate change.
Climate change stances represented as arguments in an
Interpretation of the cohesion and controversial measures.
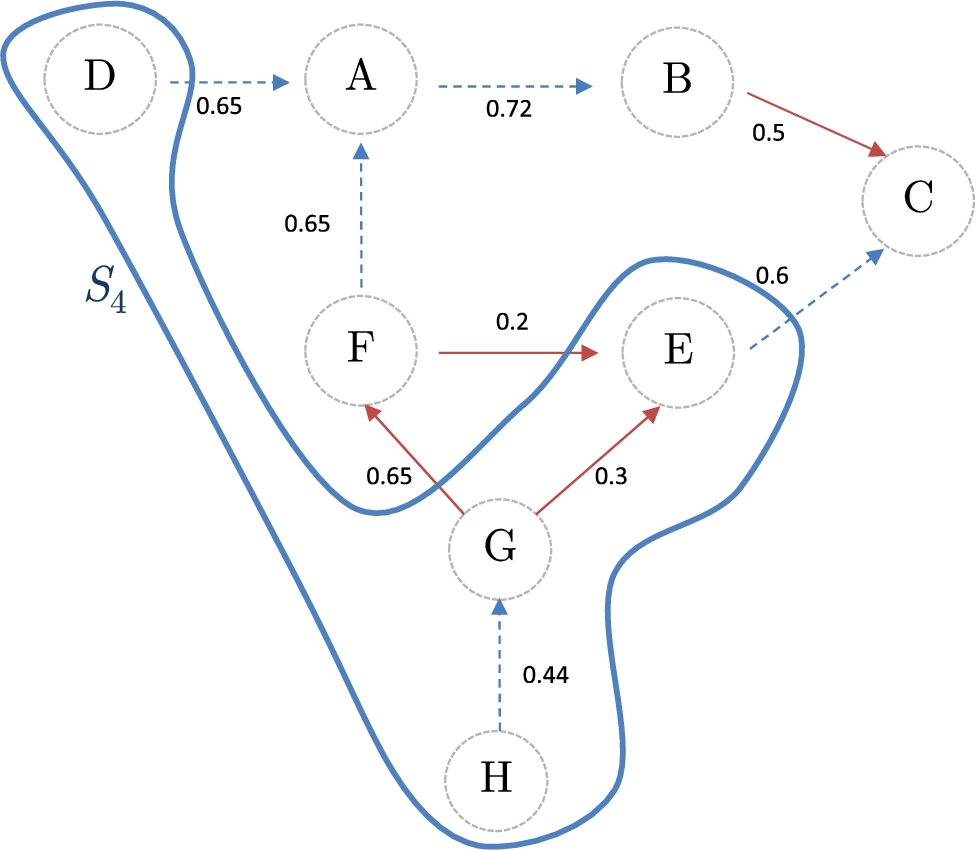
Semantic extension in
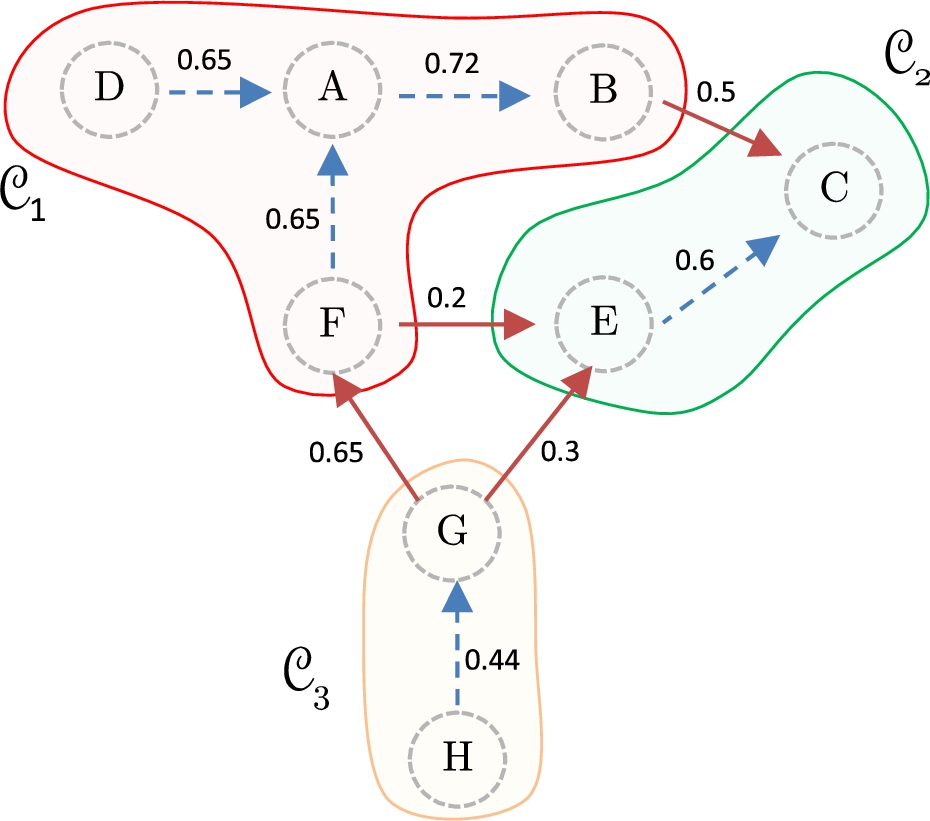
Identification of coalitions in the climate change debate.
Based on these cohesion values, we can classify the coalition as follows:
We have that, There are two conflict points between the s-coalitions The strength associated with the attack between
Analyzing the semantic level (see Fig. 21), we note that
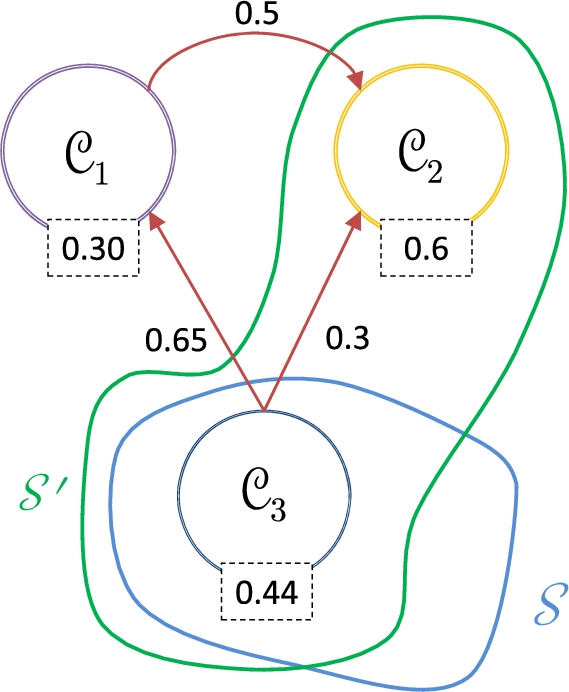
Preferred extensions for the climate change debate.
In this way, we carried out a complete analysis of the example at three levels:
Regarding the concept of “community,” although Fortunato [17] relates them with clusters, or modules, the author asserts the need to recognize that there is no accepted definition of what a community is. However, he notes that community detection is a significant issue in areas such as Biology, Sociology, and Computer Science. In that work, graphs are used as structures representing objects that coexist in order or disorder, and some valuable tools for finding clusters are mentioned, such as graph partitioning, hierarchical clustering, partitional clustering, and spectral clustering. However, no specific algorithm is provided in this regard. In our work, the objects that coexist in an argumentative discourse are the arguments supporting or attacking each other. Besides, we established the foundations to find communities (or coalitions), eliciting them from the enriched arguments and characterizing them by introducing computational models supporting our approach.
Concerning characterization of existing methods for community detection, Chochani et al. [14] present an extensive and comparative review of the detection methods of interesting communities in Online Social Networks, underlining the differences between several approaches based on specific criteria and classifying them. They assert the importance of this topic given the knowledge provided by these communities, highlighting the importance of recognizing how the groups exchange knowledge in the detection of shared interests and goals, among other elements that give the group the attribute of cohesiveness. Note that this work presents a comparative review of methods oriented to the search of communities represented with a graph structure. In addition, the authors mention a set of criteria to compare community detection approaches, like the following:
Structural features or interactions between users. Social activities o behaviors inside the social network (for instance, comments on a post). Attributes that represent information about the nodes in the graph, which are embedded as labels in these nodes. Content provided by posts or multimedia publications. Social influence allowing the spread of information.
According to these criteria, our work considers structural features represented as the relationships of attack and support, attributes as descriptors in enriched arguments, and the degree of similarity between arguments. Based on these attributes, we introduced and exploited the degrees of controversy and cohesion to find communities as attributes inherent to the relation between the nodes in our argumentative graph structure. Furthermore, the process of assimilation between coalitions will be explored in future work as a possible measure of social influence.
More specifically, referring to communities as coalitions, and despite having referred to coalitions in Section 2, it is appropriate to mention the work of Amgoud et al. [1], where the term coalition is associated with collaborative and coordinated work among agents in order to accomplish a task. The work mentioned focuses on defining the structure of the coalition, determining which tasks can be executed independently, or analyzing the best way to distribute the tasks. Several works have been developed from a similar perspective, as detailed in [33]. Coalitions are studied in the decision-making process and multi-agent systems with different purposes. For example, in [42] the authors present an experimental work where coalitions are essential for the decision-making regarding classifiers, which can work collaboratively using dispersed knowledge based on friendly relationships; however, the classifiers can also have a conflictive or neutral relationship. In [4], the coalition represents cooperative tasks in a multi-agent system, where the agents share minimal private information about the other agents’ preferences but jointly are capable of achieving their goals. In the same direction, in [8] the authors connect the abstract perspective of formal argumentation theories with the social theories of agent coalitions that offer a conceptual, less formal stance based on modeling languages that contribute more details to the representation. Coalitions are defined by “contracts” in which each agent contributes to the coalition and obtain benefits from it. For the argumentation process required for arguing about coalitions, three social viewpoints are defined with abstraction and refinement relations between them, adapting particular coalition argumentation theory to reason about the coalitions defined in the most abstract viewpoint, which is represented as a set of dynamic dependencies between agents. From an internal point of view, the agents inside a coalition can be described by viewpoints. Thus, a coalition is characterized as a set of agents with their goals and skills, as a set of agents related due to the notion of power, or as a set of dynamic dependencies. In our current approach, we have not analyzed the coalitions as a tool employed to coordinate work between agents.
Concerning the other topic inherent to our work, Furman et al. [19] present a method to find discursive communities in social media. The authors analyze small and comprehensive annotated datasets using standard tools like graphs, an algorithm for Modularity Maximization, and a supervised classifier. This approach has good practical performance when the source of the datasets is Twitter, and the topic is different from “feminism.” Briefly, the proposed method consists of (i) obtaining tweets; (ii) constructing a graph of users where each node represents a user, and the edge is a retweet between them, (iii) detecting communities using an algorithm for Modularity Maximization, (iv) using of a supervised classifier to label communities, and (v) training of the classifier. In this approach, it is necessary to make assumptions about the number and distribution of stances. Another proposal is by Pamungkas et al. [37], which presents a method to classify tweets based on affective features, developing a tool to prevent spreading rumors. In this case, the rumors are provided as data inherent to an annotated dataset obtained from Twitter. The Jaccard similarity measure is used to characterize the conversational thread, measuring the similarity between a tweet source and the rest of the tweets in the thread. Then, each tweet is classified as agree, accept, or support the rumor, reject or deny the rumor, request or questioning the rumor, and given an opinion or comment about the rumor. This contribution is important, but it is limited to effective conversations. In previous work, but on the same line of research, in [56], the authors not only classified tweets but also presented a method to determine if each message is relevant or irrelevant for the considered target. The authors used supervised and weakly supervised tasks, considering five predefined targets with labeled training data. Although our research can be used to find communities in social media, we generalized a method to characterize these communities by understanding them as coalitions. The coalitions and their features are helpful in the examination of any websites where debates are raised and analyzed, e.g., political debates. As we have described when developing our work, we have not used Modularity Maximization or any machine learning methods, although these techniques are not discarded in future work that will extend the current approach. Instead, we focus on the relationship between different pieces of knowledge and how these relationships help classify communities.
Continuing with work related to the process of identifying communities, Li [31] presents a comparison between three discovery algorithms, where a genetic algorithm is better than OCPLP (Overlapping Community Partitioning based on Label Propagation) and FSOCA (Footpad Skin Optical Clearing Agent) algorithms to find overlapping communities. An interesting point in this work is that the author does not use datasets like tweets; instead, simulated complex neural networks were used. This contribution naturally employs a very different approach from ours, not only because the AI techniques used to discover communities are different, but the work of Li [31] does not consider the coalition concept. Another interesting work in identifying communities is proposed by Puertas et al. [43] who presents an approach to detecting communities in social networks, analyzing several tweets from Colombian Universities’ accounts, and finding sociolinguistic features in them. The proposed method considers three components: an expert, computational linguistics, and AI techniques. The authors: (i) extracted profiles and conversations from the mentioned sources and processed those conversations, examining the personal information of the users, the vocabulary employed in the communication between the users, the relation between them (followers or being followed), and their shared concepts, words, and interests; (ii) used techniques such as term-frequency, inverse-document frequency, and word frequency, identifying the features of the communities; in this step, the authors proposed determining the language of the content, applying some techniques such as the extraction of noun phrases, the analysis of the dependencies in a sentence, the finding of tokens in the sentence, and the reduction of the words to their roots; and, (iii) found the relation between words and categories of an area of interest and determined the relation between the words employed by the users and those used in the social network. Finally, this approach uses these results to detect social groups through their vocabulary. One of the most critical differences between the described work and ours is that the s-coalitions detection method presented here is not focused on the user that put forward an opinion; in fact, our work only considers the relationships among the opinions introduced in a debate to find communities or coalitions and to characterize them. However, both works consider some features depending on the language, e.g., Puertas et al. use some techniques related to the frequency of the terms, and we based our method on the enriched arguments or arguments with additional information provided by a set of descriptors.
We can mention the work developed in [30] where the author presents a review of the literature concerning the research on different coalition categories: conceptual or based on mathematical models, quasi-conceptual or considering deducible empirical regularities, and extrapolative, that include experimentation with statistical models. Our work can be placed in the first category. In this direction, the proposed approach is based on
Finally, Budán et al. in [10], the authors offered the formalization of an abstract argumentation framework that considers a set of interrelated topics used to decorate arguments. One of the contributions is the examination of new argumentation semantics that consider these topics to obtain the accepted arguments. The topics are related to each other, leading to a graph structure representing that relationship; furthermore, from the graph, a notion of distance between topics is used to study proximity-based semantics. The main idea in these argumentation semantics is that an argument should be defended by arguments that are closely related to the addressed topics. In this sense, the authors explored this position by defining new elements, such as distance-bounded admissible sets and a new notion of skeptical semantics called focused extension. One of the main differences with our work is that, in our proposal, it is possible to analyze the bipolarity of human thought and model both support and attacks. Likewise, in Budán et al. proposal, only the effects of the distance between arguments are analyzed regarding notions of defense. At the same time, in our work, both attacks and supports can be dismissed or weakened according to similarity. Lastly, our work analyzes relationships to find communities that may have slightly conflicting thoughts.
Conclusion and future work
Community detection is an important research area in social networks analysis where we are concerned with discovering the network structure. The tendency of people with similar tastes, choices, and preferences to get associated in a network leads to virtual clusters or communities. Detection of these communities can benefit numerous applications, such as finding a common research area in collaboration networks, finding a set of like-minded users for marketing and recommendations, or finding protein interaction networks in biological networks. Detecting communities is essential in sociology, biology, and computer science, where often these communities are very complex, and only limited representation tools are available; in some cases, only a graph is used to represent the interchange of entities.
In a discussion, it is possible to find clusters or communities with a common point of view on a given topic or issue under discussion among debate participants. In this sense, finding these communities helps detect how many different points of view exist in a discussion, how strong they are, what relationships exist between them, and how they affect argumentative discourse.
In this sense, this work presented a novel mechanism to find meta-structures (coalitions) based on the similarity between the supported related arguments, using this measure as a sense of the coalition’s cohesion. We used the similarity between supported related arguments to obtain the coherence of the coalition; this notion allowed us to rate them and find the trends of the conversation.
Furthermore, we employed the similarity degree to characterize the attacks between coalitions, advancing a controversy measure. Additionally, computing all the attacks received by an s-coalition, we proposed a mechanism to determine the weakening level over this set of arguments. However, these mechanisms have certain drawbacks. For example, they depend on the descriptors of the arguments, and obtaining these descriptors can rely on very specialized argument mining techniques.
Future work offers different lines of research, such as developing an implementation of
Footnotes
Proofs
Coalitions algorithm
Algorithm 1, presents a procedure to obtain the s-coalitions given an s-valued bipolar argumentation graph. The algorithm is straightforward, and its computational complexity highly depends on how the nodes are visited; it can vary widely according to how the searching algorithm is implemented [36,47]. According to Niewola and Podsedkowski [36], the