
Abstract
The notion of similarity has been studied in many areas of Computer Science; in a general sense, this concept is defined to provide a measure of the semantic equivalence between two pieces of knowledge, expressing how “close” their meaning can be regarded. In this work, we study similarity as a tool useful to improve the representation of arguments, the interpretation of the relations between arguments, and the semantic evaluation associated with the arguments in the argumentative process. In this direction, we present a novel mechanism to determine the similarity between two arguments based on descriptors representing particular aspects associated with these arguments. This mechanism involves a comparison process influenced by the context in which the process develops, where this context provides the relevant aspects that need to be analyzed in the application domain. Then, we use this similarity measure as a quantity to compute the result of attacks and supports in the argumentation process. These valuations, applied to a Bipolar Argumentation Frameworks, allowed us to refine the argument relations, providing the tools to establish a family of new argumentation semantics that considers the similarity between arguments as a crucial part for the argumentation process.
Introduction
Human commonsense reasoning involves in many occasions a process of analysis over a set of (potentially contradictory) alternatives and the evaluation of their support. The study of such cognitive process has led to the development of several formalisms that were introduced in an attempt to provide a formal model for this mechanism. In this direction, argumentation has become a topic of significant impact in the field of Artificial Intelligence (AI). The basic idea is to identify arguments in favor and against an affirmation and then select which arguments are acceptable among them, with the goal of resolving whether the reasoner can accept the assertion. Thus, Argumentation Theory provides reasoning mechanisms able to handle contradictory information concerning specific issues.
In the course of the research on the argumentation field, several argument-based formalisms have emerged to study the various possible relations among arguments. In [32], Dung proposes Abstract Argumentation Frameworks (AF) to model real-world situations by representing attack relations between abstract entities called arguments, providing different acceptability semantics for determining which sets of arguments are acceptable. Subsequently, Cayrol and Lagasquie-Schiex in [22] extended Dung’s framework [32] taking into account two independent types of interaction between arguments by adding the relation of support to the original relation of attack in abstract argumentation frameworks. The resulting Bipolar Argumentation Frameworks (BAFs) allow to model situations in which an argument can, for instance, reinforce another argument providing more reasons to believe in it; moreover, they adapt Dung’s acceptability semantics adding the consideration of the support relationship. Also, there exist some argumentative formalisms that represent the attributes associated to arguments providing more information to determine arguments acceptability [15,19,20,23], while others consider relations between the arguments to calculate the acceptability and safety of a given set of arguments [10].
Leaving aside the advances in argumentation frameworks [15,20,23], several representational aspects of the argumentation process still require further study. For example, a very natural tool for argument-based reasoning is the notion of similarity among arguments: during an argumentation process we sometimes tend to group arguments according to their shared characteristics or to the topics to which they refer. It can be argued that any comparison process requires the definition of a context in which such comparison can be meaningful [25,43,73]. The same applies to arguments: two arguments may be similar in a given context, but they may be entirely unrelated (or even incomparable) under different circumstances of analysis. Argumentative reasoning that gives importance to the similarities between pieces of knowledge represents a natural form of everyday human reasoning [76,77,79]. As computational argumentation aims to the definition of useful systems based on common sense, it seems reasonable, and desirable, to formalize the notion of similarity between arguments. As it happens with the similarity analysis in other settings where entities are compared provided they have some essential aspects in common, similarities between arguments also require the consideration of the context where they are issued identifying the aspects that are relevant in the comparison and the assessment of their importance in the similarity analysis. Notwithstanding the usefulness of exploring these problems concerning the argumentation process, similarity relations between arguments have not been deeply explored in the argumentation literature.
As a running example that we will develop over this work, consider the following situation where a user wants to decide about which activities to perform considering the weather conditions. The user has the following set of arguments which wants to use to decide whether going out for a walk or staying at home.
On rainy days we should eat chocolate since chocolate lifts the mood and makes us happy.
If we are happy, we want to go out for a walk.
In rainy days we are happy and in a good mood, therefore, we go out shopping.
Rainy days may be depressing. Since today is raining, I prefer to stay to keep the house.
Sunny days are optimal for outdoor activities, in that way help to release endorphins.
It is not a good idea to go for a walk to relax, because we can hurt our feet; thus, it is better to watch a movie instead.
If we go shopping, we take a walk and burn calories; therefore, it is a good plan.
Keeping the house is stressful since it is a job that requires several days, therefore, it is better to hire somebody else to do it.
This example illustrates how the knowledge used to decide can be naturally structured as arguments; to reach a decision it is necessary to consider the relationships between these arguments, and how strong, or weak, those connections are. In particular, this scenario shows a support relation between arguments A, B, and C. However, it would be necessary to analyze how strong the ties in this set are, i.e., how cohesive the set is, to have a measure of the strength of the support among the arguments in it; similarly, it is possible to examine how controversial a set of conflicting arguments is. For instance, regarding the conflict relation between arguments C, D, and H, we can analyze the (dis)similarity between these arguments given a context that will depend on the application domain; furthermore, the comparison process must be performed under the expressed user’s preferences.
Notice that the similarity between a pair of arguments can be judged differently by each user, and consequently, the argumentation process where the relations between arguments are analyzed should reflect this important aspect. Although the perceived similarity among arguments is not the only tool that can be used to define the strength of the relations of support and attack it provides a natural alternative that can help to weight the relationships based on the (dis)similarity of the different situations in which the arguments are issued.
We will propose a Similarity-based Bipolar Argumentation Framework, which provides mechanisms for considering the context of the comparison between arguments, based on a set of descriptors that are common to the arguments which are being analyzed. Thus, we can represent and determine similarities between arguments introducing means to enrich the representation of the relationships between them and to be able to distinguish among arguments that are weakly related from those whose relationship is stronger. In this direction, we use an arguments’ similarity degree, computed from the descriptors that arguments have in common, combined with the weight those descriptors have in the process comparison. Thus, we determine a cohesion value between supporting arguments and a controversy value between conflicting arguments. Based on this analysis, we can refine the acceptability process provided by a BAF to obtain a new family of argumentation semantics. It is important to remark that the descriptors attached to arguments are additional knowledge representation devices added by this proposal. The basic assignment of the particular values to the descriptors is a task that can be performed in different ways. On the one hand, this can be performed by hand by a knowledge engineer; on the other hand, several tools have been introduced in the computational argumentation field by the research of argument mining techniques for which we will provide references below since the topic is outside the reach of this work.
The presentation will be structured as follows. We begin with an introduction to the BAFs is presented in Section 2. In Section 3 a brief, general description of the similarity concept will be addressed. The development of the tools for similarity comparison between arguments in the argumentation domains is presented in Section 4. Then, Section 5 contains the proposed argumentation formalism, the Similarity-based Bipolar Argumentation Framework, where an interpretation of supporting and attacking arguments is given based on the notion of similarity, also studying how this interpretation affects the acceptability process. In Section 6, we offer a case study by using an example in the food and nutrition domain. Finally, in Section 7 and 8, we present related works and offer conclusions, respectively.
When using arguments to reason, different types of relationships between them can be considered. One possible view is that arguments exhibit a “bipolar” behavior since reasons in favor of an affirmation can be considered as being positive while reasons against it can be viewed as negative. This approach was taken in the presentation of Bipolar Argumentation Frameworks (BAFs) that was proposed by Cayrol and Lagasquie-Schiex in [22], extending Dung’s notion of acceptability by distinguishing two independent forms of interaction between arguments: support and attack. We will assume that the reader is familiar with the formalism of Abstract Argumentation Frameworks [32].
(Bipolar Argumentation Framework (BAF)).
A Bipolar Argumentation Framework is a 3-tuple
To provide a graphical representation of BAFs, Cayrol and Lagasquie-Schiex also extended argumentation graphs presented by Dung in [32] by adding the representation of the support relation between arguments. This argumentation model introduced a starting point to analyze human reasoning adding the consideration of the bipolar aspect that naturally occurs in any debate to our modeling toolbox. Furthermore, they introduced the notions of supported and secondary attack that combine a sequence of supports with a direct attack considering the interaction between supporting and attacking arguments. These relations are defined as follows:
(Attacks in BAF).
Let There is a direct attack from There is a supported attack from There is a secondary attack from
Cayrol and Lagasquie-Schiex argued in [22] that a set of arguments must keep in some sense a minimum of coherence to be able to model one side of any reasonable dispute adequately. They propose that the coherence of an acceptable set of arguments can be kept internally by requiring the set not to contain an argument that attacks another in the same set, and externally by requiring the set not to include both a supporter and an attacker of the same argument. Internal coherence can be obtained by extending the definition of conflict free set proposed in [32] and external coherence can be captured by the notion of a safe set.
(Conflict-freeness and safety properties in BAF).
Let
The notion of conflict-freeness requires taking in consideration the direct, supported, and secondary attacks. Additionally, Cayrol and Lagasquie-Schiex show that the notion of safe set is powerful enough to encompass the concept of conflict-freeness, i.e., if a set is safe, it is also conflict-free. The closure under
(Closure property in BAF).
Let
Using these ideas, Cayrol and Lagasquie-Schiex in [22] extended the notions of defense for an argument with respect to a given set, where they take into account the relations of support and conflict.
(Defense from a set of arguments
to a single argument
in BAF).
Let
The authors proposed three different definitions of admissibility which reflect three different levels of generality. The most general, called d-admissibility, is based on Dung’s admissibility capturing the internal coherence requirement through the conflict-free property. Then, the authors refine d-admissibility in two directions: one that captures the external coherence notion through the safe property, called s-admissibility; and the other, that considers the closure property over a conflict-free set, called c-admissibility. Formally:
(Admissibility notions in BAF).
Let
Note that, a c-admissible extension is a set of arguments that is conflict-free and closed under support. Naturally, this extension is also a d-admissible extension since it is conflict-free and defends all its elements. Furthermore, the arguments that belong to the extension cannot attack an argument that they support, because this action violates the conflict-freeness property. Thus, this extension satisfies the external coherence property obtaining that a c-admissible extension is also a s-admissible extension. On the other hand, the s-admissible extension satisfies the conflict-freeness property, since a safe set of arguments is a conflict-free set that satisfies the external coherence. Roughly speaking, we can note that a d-admissible extension is refined to consider: external coherence in a s-admissible set, and closure under support condition in a c-admissible set.
Cayrol and Lagasquie-Schiex in [22] proposed different semantics for computing acceptability. These semantics consider the previous admissibility notions, redefining the classical ones proposed in [32] by Dung.
(Stable extension in BAF).
Let
(Preferred extensions in BAF).
Let
Our running example can be represented by a BAF, characterized by
Representation of attack and support relations in BAF.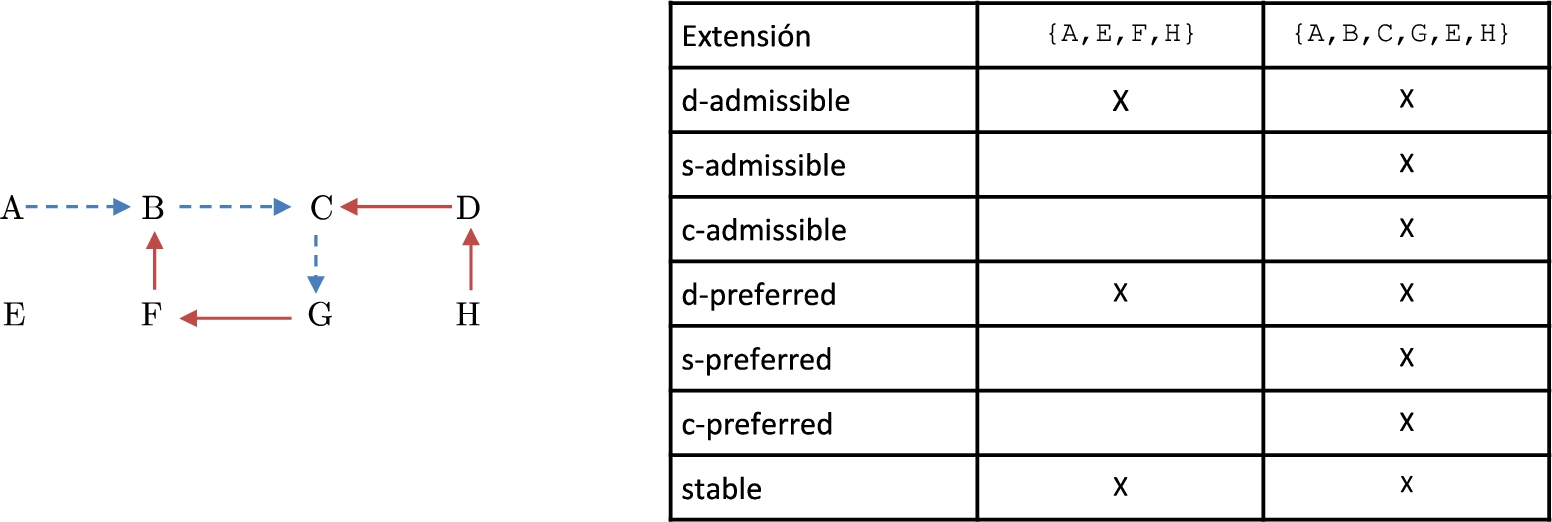
Figure 1 represents the attack and support relation between arguments, using solid arrows and dashed arrows, respectively. Observe that there is a supported attack from
On another hand, the set
A bipolar argumentation framework obtains an acceptable set of arguments based on a specific analysis that considers the support and conflict relations between the arguments involved in a dispute. However, this formalism does not provide with tools to adequately analyze how cohesive or controversial are the arguments in a discussion. In the following sections, we extend the basic BAF to refine the argumentation analysis in this sense.
The concept of similarity has been studied in many areas of Computer Science, in general sense, that is considering the similarity between two pieces of text. Thus, the textual semantic similarity is a measure of the equivalence of meaning between these two texts, which expresses the similarity or resemblance between them [1]. However, similarity can refer to syntactical or semantical aspects, and therefore the concept has been studied by various areas of AI such as natural language processing and argumentation. From the perspective of natural language processing, there exists, for example, several well-known techniques for disambiguation of words [2,28,57] or induction of word meaning [3,27,72]. From the field of argumentation, numerous advances have occurred in the area of argumentation mining such as the development of techniques linked to the processing of natural language [41,56,64]. However, the use of a measurement of similarity between arguments for reasoning that involves uncertain or potentially contradictory information is an area where, to the best of our knowledge, no previous work addresses the issue in depth.
Lin et al. in [54] present an independent definition of similarity, which compares the information included in the description of two objects A and B definitions, based on the information Theory, comparing the amount of information contained in the definition of the two objects. They argue that it is also essential to establish a measure of the difference between the objects to be compared because the more differences there are between the objects, the less similar they are. In that work, the authors propose that the similarity between two objects A and B be calculated from the relationship between the average of the information held in the description of the objects and the average of the information referring to their common aspects. Formally:
On the other hand, numerous studies have put the focus on finding a measure of similarity between objects, according to the domain of application to which these objects belong. One of the best-known measures is the cosine similarity [44] from the representation of the entities in the Bag-Of-Words (BOW) format [50]. The BOW format consists of finding a set of words that describe an entity, e.g., those that are present in a text, and each word has associated a weight representing the importance of the word in that text. This format allows to calculate the similarity between two entities using the measure of cosine similarity, and it is especially useful for information retrieval [44]. More clearly, in each text, it is possible to identify the words that will be part of the BOW and the weight assigned to each word may be the frequency of its appearance in the text; so, the terms that appear most frequently in the text are those that will have a higher weight.
In [74] the authors suggest a practical use of the BOW format to compare two entities using an ontology and to determine the semantic similarity between these entities. In this specific case, the process is carried out to find the semantic similarity between domains, using two sets of words obtained from the application of web mining techniques in search and recommendation systems. From the ontology, it is feasible to find concepts related to the entities under consideration by applying a spreading process.
In a similar direction, Rusu et al. [71] presents a summary of different possible metrics to determine the similarity between concepts in an ontology, highlighting the theoretical models proposed by cognitive psychology. Among them are mentioned: measures based on definitions like Lesk algorithm [53]; measures based on structures, for example distance Rada [69], the Leacock and Chodorow Similarity [51] and the Wu and Palmer Similarity [80]; and measures based on the information content, such as Resnik Measure [70] or Jiang Distance [48]. These measurements have their origin in a geometric model [26], or in the coincidence of features or characteristics models [75]. The first represents the concepts and relationships between them, stored in a computer memory that simulates human memory, using three hierarchical levels of storage: the concept, its category, and its properties. The second one mentions the comparison between objects of any nature to find similarities and dissimilarities between them, beyond the distance between points, by comparing characteristic features [75]. The proposal of Rusu et al. in [71] is also based on the distance between concepts defined on an ontology, but concepts and relationships are weighted; then, the similarity between the concepts according to the weight of the shortest path between them. Finally, Amgoud et al. in [11] explore several similarity measures between logical arguments and define a very general function denoted as a similarity measure. Then, they define a set of basic principles that a similarity measure should satisfy, such as syntax independence, maximality, symmetry, substitution, monotony, and dominance. While in [12], the authors work with logical entities representing the structures of the arguments and propose a mechanism to calculate similarity measures using concise refinements of arguments based on the arguments that only contain useful information in their premises to infer the conclusion. Furthermore, in [8], the authors use the similarity between arguments as the means to analyze an individual argument and its attackers and the concept to introduce a new semantics. Also, they present properties that this semantics should satisfy. This brief description summarizes some of the results that can be found in the literature on the subject, and which are the basis for the approach taken in our proposal.
Introducing similarity measures for arguments
A crucial component in the determination of the similarity between arguments is the definition of the conditions under which such comparison is performed [77]. In [54], D. Lin states that the main problem with existent similarity measures is that they assume a particular domain model, i.e., the conditions over which the similarity is calculated are considered preexistent. Although the similarity is related to the properties shared between the two entities being compared, the comparison of two arguments largely depends on an agent’s perception which can be influenced by the mental status of the agent, e.g., her beliefs, goals, or by external, possible unknown external variables. All these factors are part of a context that affects the assessment of the similarities between two arguments. The intuition that we have just presented is essential to define a similarity measure between arguments.
In this section, we present a method that allows us to determine the similarity between arguments, according to a given context. In general, this method consists of the following three stages: (i) the specification of argument’s descriptors; (ii) the setting of the context based on argument’s descriptors; and (iii) the computation of the similarity degree among the arguments being compared. In what follows, we present and develop these three stages.
Specification of argument’s descriptors
As suggested above, a descriptor is a word, a tag, or a label that describes an aspect to which the argument is in some way connected [21]. In this sense, the set of descriptors associated with each argument involved in a debate should be representative of the domain of such discussion. Finding the particular set of descriptors associated with an argument can be done by an analyst (knowledge engineer) or can involve the use of argumentation mining techniques, which is currently an important topic in the area of computational argumentation; however, this task is complex and exceeds the scope of this paper, we refer the reader to the comprehensive work in [49,55,66] for further details. We assume this information is available and that an argument comes with a set of descriptors and a mapping from these descriptors to values in a corresponding application domain; still, as it is usual in abstract argumentation frameworks, no reference to the underlying structure of the argument will be made, here we are interested in giving significance to what this argument refers to, without delving into its the logical details.
As a prelude to the next definitions, we introduce a few notational conventions. We denote as
(Enriched argument).
Given a set of arguments
Intuitively, an enriched argument
(Arguments from a set of enriched arguments).
Let
Next, we analyze the example presented in the introduction in order to identify the descriptors associated to each argument, and the values of these descriptors according to the information provided by the arguments.
Continuing with Example 1 presented in the introduction, we can instantiate the universe of descriptors for this specific domain as the set:
As several descriptors can be associated with an argument, it is necessary to establish contexts in which to conduct the comparisons and the means of prioritizing the descriptors in such comparisons as well. We borrow the formal elements of the mechanism for computing similarities among arguments from work proposed in [21]; however, in that framework, there is no way of judging the importance of the descriptors in the comparison. Next, we extend the mechanism to establish a comparison based on context, in which each descriptor has a weight or degree of importance associated.
The descriptors of the arguments may refer to different topics, a fact that makes more complicated the comparison process. For that reason, as part of the knowledge representation task, it would be essential to correctly establish the context to evaluate the similarities and differences between the arguments. Following this idea, the definition of a context defines a set of restrictions over the comparison process. As an initial requirement, two arguments can only be compared if they have in common at least one descriptor. In [21], a simple notion of context is proposed where essentially a context corresponds to a set of descriptors. A natural extension of this approach is acknowledging that comparisons among arguments require that different descriptors have a different impact on the similarity analysis, conveying the meaning that some aspects of the arguments are more (or less) relevant for the comparison than others. In this proposal, in the definition of a context, we incorporate to descriptors a relevance weight to achieve this goal, and thus increase the representation capabilities of the argumentative framework.
(Context).
Let
To exemplify the definition above we continue developing the last example.
Returning to Example 3 we have the following domain:
The context could be instantiated in different ways, perhaps as:
In order to keep the definition as general as possible, no conditions are established to set the weight associated with the elements of the context. However, as a broad guide, we will discuss some ideas explored in the literature to carry out such valuations in different domains. In one way, we can analyze the valuations of descriptors from the same point of view as that of social voting in the valued-based argumentation frameworks [9,15,63], where the appraisals mainly depend on the user or the audience participating in the discussion. Thus, we embed the user’s, or audience’s, preferences in the framework, but no semantic analysis on descriptors is performed. On the other hand, we can say that the descriptors associated with the arguments are not isolated, and they could be related to each other, leading to a semantic network of concepts. Thus, we can propose a mathematical representation where nodes are topics, and the connection between the nodes (arcs) is the semantic connection between them. Then, an initial assessment can be achieved, according to the number of times which are used those descriptors in the discussion. A possible improvement of this idea is to apply a “page rank” technique in the descriptor ontology. Thus, the initial valuation can be strengthened by the semantic linkage between the descriptors through the application of the page ranking algorithm [31].
With the elements defined so far, we can compute the similarity between arguments as formalized below.
Some recent works have studied the problem of similarity between arguments. In [62], the authors propose to find similar arguments, or argument facets, by detecting propositions paraphrased or labels that refer to a particular aspect of an argument, limiting to political and social dialogues. Rather than providing a mechanism to decide whether two arguments are similar or not, we propose to evaluate the values of argument’s descriptors in a given context
In the following, given an enriched argument
(Similarity coefficient for a descriptor).
Let
(Similarity degree between arguments).
Let
(Similarity coefficient for a descriptor).
The coefficient function operates considering the number of descriptors specified in the context. For this reason, the lower bound of the function is zero, while the upper bound is not possible to determine a priori but is finite and positive.
(Similarity degree between arguments).
The similarity function is operated under a t-norm or c-norm, satisfying the commutative and associative properties. For this reason, the order in which the descriptors in the set
Note that
Let
Positivity:
Symmetry:
Maximality:
In our running example, we focus on the value that each of the descriptors takes for every argument, according to the following context:
Similarity degrees for the set of enriched arguments from Example 3.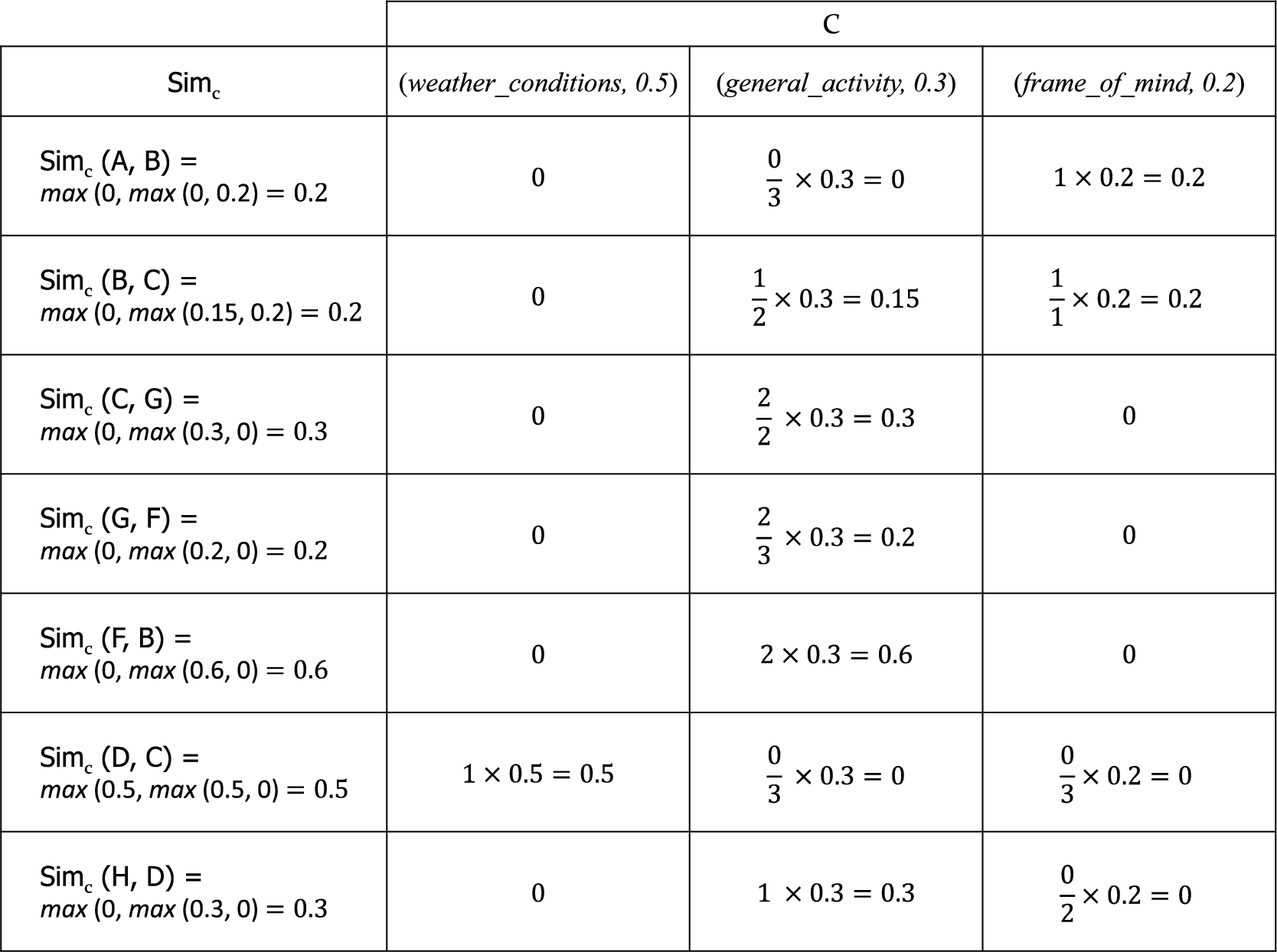
In this case, based on the argument descriptors established in the Example 3, an optimistic instantiation of the similarity function, i.e., a maximum t-conorm is used to define
Finally, we instantiate the similarity function with the maximum t-conorm as follows:
In the next section, we analyze how this similarity function can be applied to characterize the conflict and support relations in a BAF. In particular, we instantiate the similarity function to present an optimistic (or pessimistic) posture in the interpretation process that we perform over a BAF.
From the elements presented in this section, we address in the following section a mechanism to interpret the support and attack relationships in a BAF. Our leading purpose is to determine the cohesion of a set of supporting arguments and the controversy associated with a set of attacking arguments.
We are now ready to extend the notions of support and attack from abstract argumentation frameworks to enriched arguments. Thus, two enriched arguments
(Support and attacks between enriched arguments).
Let The attack relation between enriched arguments, denoted as the support relation between enriched arguments, denoted as
Note that, these notions provide an extension associated with an underlying BAF Θ. Consequently, we use the bipolar argumentation graph associated to Θ to represent the enriched arguments and the relations between them.
In [21], the authors introduce a formalism to compute the similarity between two arguments, as long as they possess descriptors in common. The idea behind this proposal is that to determine the similarity degree between entities it is necessary that these entities have common and comparable aspects in the context where the comparison is made. However, it is possible to use the similarity between arguments to analyze the relations between them more effectively, by specifying a controversy evaluation of an attack relation, and a cohesiveness assessment of a support relation, respectively providing a measure of the strength of conflicts and supports. That is to say that the controversy or cohesion values associated with two arguments which are in an attack or support relationship should be high when these arguments both refer to the same aspect of the debate, in a specific sense. Following these intuitions, we examine these issues in the context of a BAF, introducing similarities between arguments as a device to enrich the argumentation analysis needed to distinguish those entities weakly related from those whose relationship is stronger.
(Cohesion and controversial operators).
Let The cohesion operator of The controversy operator of
As with the similarity function
In a given context, cohesiveness and controversy values are two distinct outcomes arising from the similarity function. They can be interpreted independently or jointly, depending on the domain in which they are applied. In this paper, cohesiveness represents the degree of support that an argument receives from a set of supporting arguments, while controversy expresses how much a particular set of arguments resists an argument according to pre-established comparison conditions. Thus, in a bipolar analysis, these notions are used, for example, to examine supported attacks where the support and conflict relations play a role together (see Fig. 5). Furthermore, when internal and external coherency is analyzed, we will use both concepts to identify the cohesion and controversy level associated with the argument set (see Fig. 7). Besides, the information provided by the enriched arguments is fundamental in the examination of the argumentative process.
We now define a S-BAF, which extends a BAF [10], incorporating the tools to interpret the relationship between the arguments in the argumentation process under a different light. In particular, this framework provides the means to compute the similarity between related arguments to decide which attacks (supports) must be considered in the discussion, given their degree of controversy (cohesion, respectively).
(Similarity-based Bipolar Argumentation Framework).
Given a bipolar argumentation framework
The definition of a S-BAF is quite general so that we can use, in theory, different similarity functions for the comparisons among arguments. This proposal is based on the use of
It is important to note that, in the argumentation framework, once we determine (or fix) the similarity function that is to be used to compute the similarity between related arguments, we can affirm that the similarity values associated to these relations do not change even if the discussion is extended. That is, if the number of arguments that participate in the discussion increases, the computed similarity values calculated for the original set of arguments do not change giving a fixed similarity function. We formalize this idea in the next proposition.
Let
The result in Proposition 1 states that we can analyze an argumentation framework once, and if in the future we want to consider an expansion of it there will not be necessary to recompute all similarity values between the arguments in the previously existent relationships, i.e., as long as the similarity function does not change, it will suffice to compute the new ones. This result potentially gives us a way to work in the argumentation process dynamically and incrementally when necessary.
Under this new framework, we analyze how the attacks between the arguments must be considered in a Enriched BAF taking into account the similarity function defined in the previous section. Next, we discuss a possible way to classify attacks based on similarity, controversy, and cohesion. Informally at first, we use notions such as “high” and “weak” to refer to these degrees but we formally establish their proper meaning later on this section.
Direct attack: An attack between two arguments A and B is evaluated considering the similarity measure associated with them. Thus, if the similarity between them is high (weak), then we can assume that the controversy between these arguments is high (weak) because they refer to related (unrelated) issues (see Fig. 3).
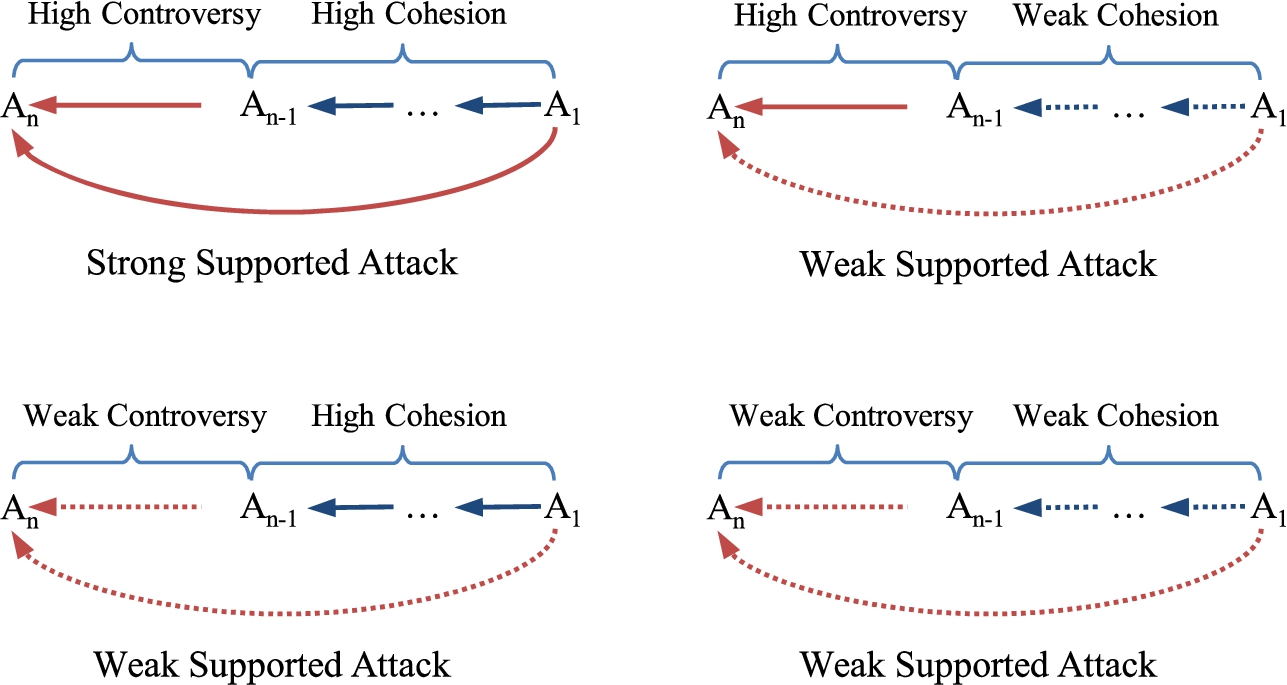
Analysis of direct attacks under a similarity measure. Supported attack: Let
Analysis of supported attacks under a similarity measure. Secondary attack: Let
Analysis of secondary attacks under a similarity measure.
In the analysis presented, we refer to a high or weak cohesion and controversial values. To this end, we can set a threshold that determines the minimal cohesion or controversial values associated with the arguments involved. Formally: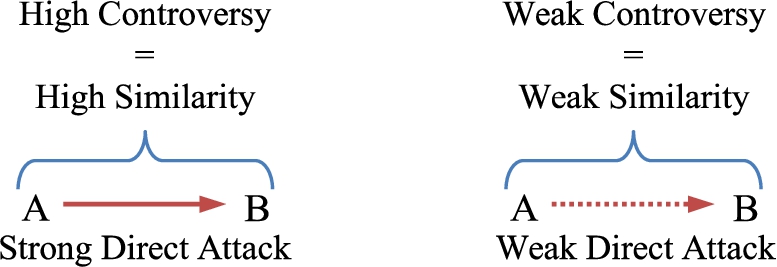
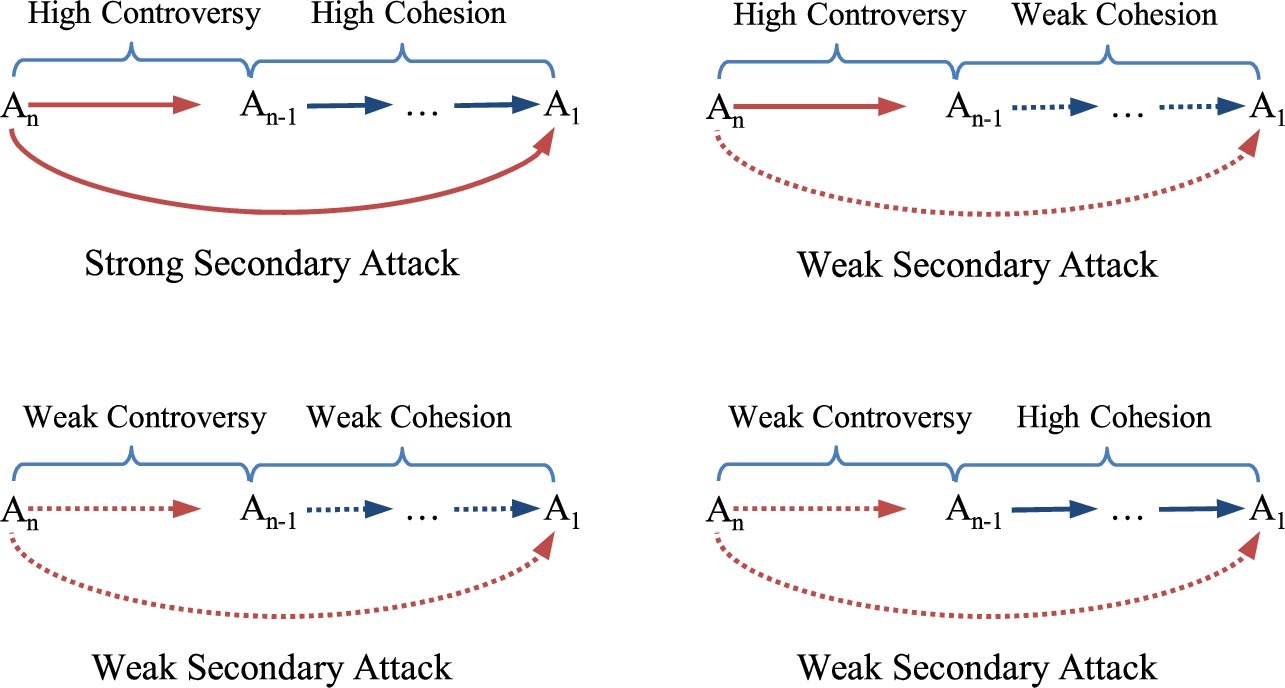
Let There is a strong support from A to B if There is a weak support from A to B if There is a strong direct attack from A to B if There is a weak direct attack from A to B if There is a strong supported attack from A to B if there exists a sequence There is a weak supported attack A to B if there exists a sequence There is a strong secondary attack A to B if there exists a sequence There is a weak secondary attack A to B if there exists a sequence
Once the attacks are appropriately evaluated, we analyze the coherence of an enriched argument set. As in [10], the internal coherence is captured by the definition of conflict free set, and external coherence is captured with the notion of safe set. In our case, the classical conflict-free notion can be weakened by the existence of weak attacks, which allows a certain degree of tolerance to inconsistent information (see Fig. 6). So, we can specify a strong-conflict-free set (a set with no conflict), a τ-conflict-free set (only admitting weak-conflicts whereas the controversy value associated with this set does not exceed the limit τ), and a weak-conflict-free set (the more general set, since it is possible to admit any weak attacks in the domain). Furthermore, the classical notion of safety can also be weakened considering weak attacks and supports to an external argument. Note that, in Fig. 7,
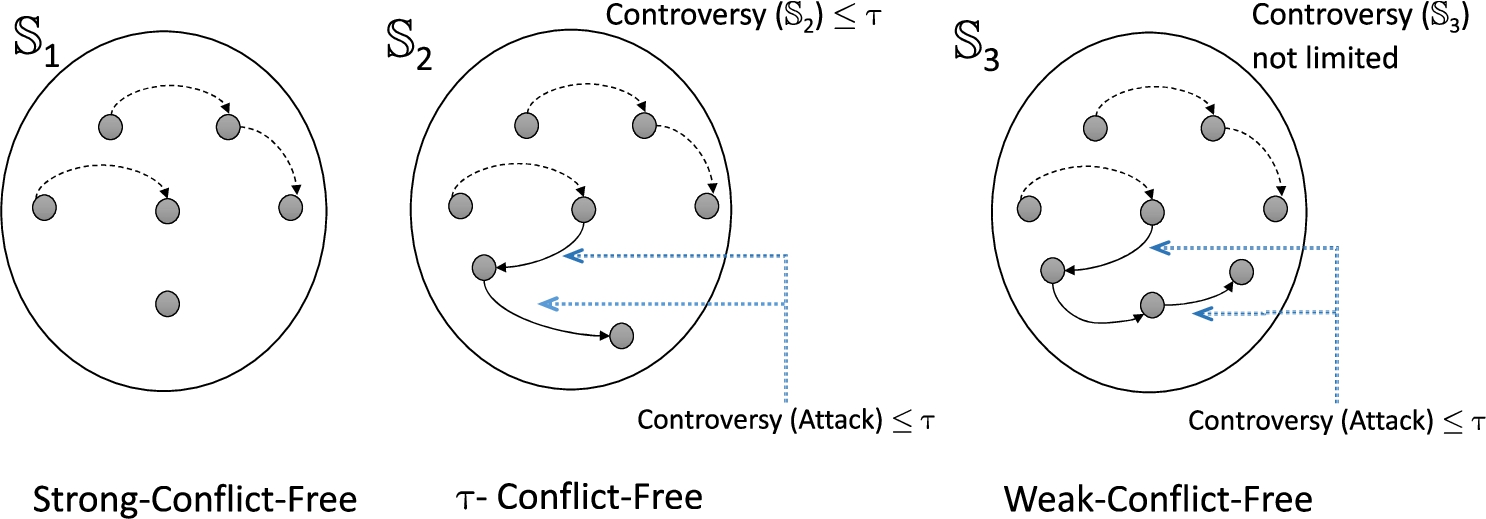
Interpretation of conflict-free set (conflict-free strength).
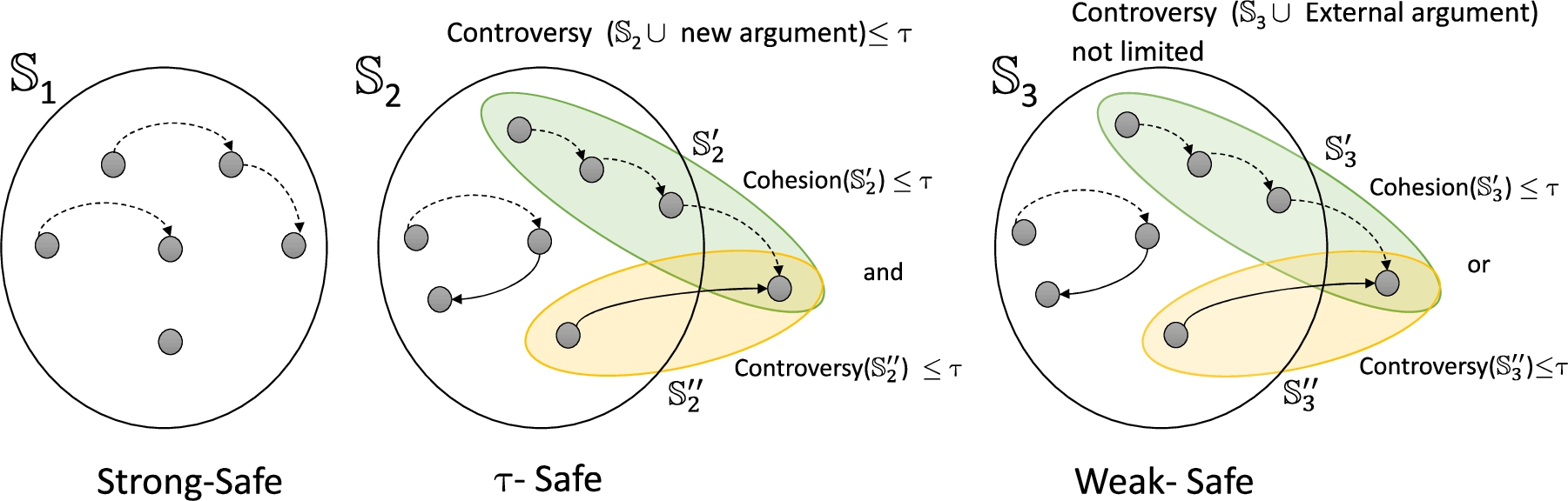
Interpretation of safe set (safe strength).
Given a S-BAF
Next, in Proposition 2, we show the relationships between the strong conflict-freeness and safety versions and the classical ones, while Proposition 3, shows the connection between the safety, conflict-freeness, and closure (under
Let if if
where
Let
if
if
if
if
if
if
Note that, conflict-freeness and safety sets are expanded from a classical one to be more “flexible” sets. In this sense, we can introduce weak attackers into the argument sets; consequently, these new arguments can be strong attackers of the previous ones (see Fig. 8). Thus, there is no strict inclusion relationship between the different types of conflict-free sets. The intuition is that, if we raise the tolerance to attack up to a threshold τ big enough, strong attackers may appear and eliminate arguments that are weakly defended.
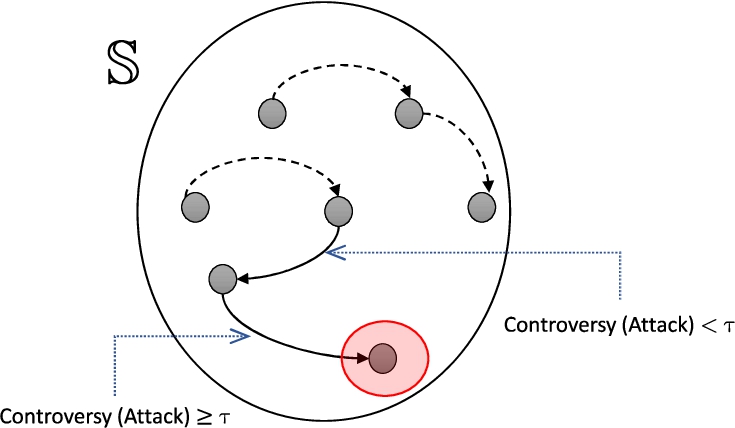
Reinstatement of arguments with strong attacks in τ and weak-conflict-free sets.
Next, we present an example that will make clear the intuitions of this approach.
Continuing with the Example 3 which is represented in Fig. 9, where the similarity between the involved arguments are computed in the Example 5 considering the context
To facilitate the practical interpretation of the enunciated concepts, Fig. 9 will be useful:
Representation of attack and support relations in S-BAF.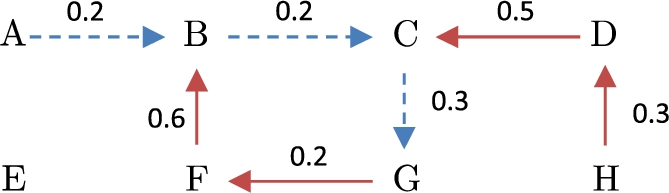
Thus, for this example and considering a setting where a threshold H is a weak direct attacker for D, since G is a weak direct attacker for F, since D is a strong direct attacker for C, since C is a weak supported attacker for F, since F is a strong direct attacker for B, since B is a weak supported attacker for F, since A is a weak supported attacker for F, since D is a weak supported attacker for G, since F is a weak secondary attacker for C, since F is a strong secondary attacker for G, since
Next, we examine the different conflict-free sets that are possible to obtain analyzing the presented framework: The set
On the other hand, analyzing the external coherence of the sets, we have that:
Next, we extend the notions of defense for an argument with respect to a set of arguments, where we consider the attack relations introduced in Definition 17 instead.
Let
We present different definitions for admissibility, from the most general and strong to the most specific and weak. The most general is based on the classical notion of admissibility where only the attack relations are considered (both the strong and the weak ones). Then, we extended this notion taking into account external coherence considering the different attack and support degrees among arguments. Finally, external coherence is strengthened by requiring the closure of the
Let
In this manner, admissibility becomes a characteristic of a set of arguments that can be evaluated from different perspectives. The most restrictive admissible sets are those that do not admit conflicts and that defend all their elements with values of controversy greater than the given threshold. A more flexible admissibility property is one in which a certain level of controversy associated with the set, limited by a threshold, is acceptable. In this case, the defense related to the arguments can oscillate between strong and weak. Finally, the most flexible set is one that allows the incorporation of conflicts where the controversy associated with them is strictly less than the threshold; i.e., the controversy is analyzed in each conflict between arguments. Note that, in the two last cases, the defense related to the arguments can oscillate between strong and weak.
Next, in Proposition 4, we show the relationships between the strong versions of admissibility and the classical ones. Furthermore, in Proposition 5, we identify how the conflict-freeness, safety, and closure property are related in the admissibility notion.
Let if if if
where
Let
if
if
if
if
if
if
From the notions of coherence (internal and external) and admissibility, it is possible to introduce different acceptability semantics. First, we define strong-stable, τ-stable, and weak-stable extensions. The strong-stable extension asks for a strong-conflict-free set and the existence of a strong attack for every element that does not belong to the extension. Meanwhile a weak-stable extension would a be maximal weak-conflict-free set, and the attack produced from the extension to each element that does not belong to it must be strong (direct, supported, or secondary attack) or, alternatively, be a strong-conflict-free set for which there must exist at least one element that does not belong to the set and it is only weak attacked (direct, supported, or secondary attack) by the set. In other words, a strong-stable extension guarantees inconsistency with all external arguments. A τ-stable extension is reasonably destabilized since it allows some degree of inconsistency as long as it does not exceed the determined threshold.
Let
In general, an extension will be stable when it can ensure its internal and external coherence and the defense of its elements; this may have different implications as we explain in what follows. First, it is clear that the strong-stable extension is equivalent to a BAF’s stable extension. Since the controversy of the set cannot exceed the τ-value, in the τ-stable extension, it may be null (when the value of τ is very close to zero, or it is zero). If this is the case, there must be at least a weak attack over each external element. Being the conditions more flexible, it is possible that there exist no internal attacks in the weak-stable extension, in which case the set must weakly attack each external element. However, if the extension has internal attacks, where these individual attacks do not exceed the τ-value, it is sufficient that the set strongly attacks each external element. Next, in Proposition 6, we show the relationships between the strong versions of stable extension and the classical one. Furthermore, in Proposition 8 we establish the case in which a stable extension combined with a safety property results in a set that is closed under support, and the circumstances in which a stable extension combined with a closed under support condition result in a safety set.
Let
Next, in Proposition 7, we present the property of uniqueness associated to the strong-stable extensions as presented by Cayrol and Lagasquie-Schiex [22] for BAF.
Let
Let
if
if
if
In the following we propose a more fine-grained definition of preferred extensions.
Let
Next, in Proposition 9, we show the relationships between the strong versions of preferred extensions and the classical ones, while in Corollay 1 we identify the conditions under which the strong-preferred extensions are equal to the classical preferred extensions. This result is relevant given that represents a bridge between both formalisms.
Let
Note that, to ensure that there is an equivalence between a strong-preferred extension and a classical preferred extension, the relationships between the arguments in S-BAF must all be higher than the threshold. This condition is imposed mainly by the characterization of the notion of defense in S-BAF. That is, suppose that in BAF, there is a conflict-free set that defends all its arguments; in this scenario, we cannot differentiate the class of defenders that the same ones possess, while in S-BAF a strong defense is required.
Let
In Proposition 10, we identify how the conflict-freeness, safety, and closure property are related to the preferred extensions.
Let
if
if
if
if
if
if
Next, in Proposition 11 , we identify the relation between the preferred and stable extensions in S-BAF.
Let
if
if
if
Continuing with Example 5, we now analyze the extension that characterize the bipolar argumentation framework. Hence, considering the set
On the other hand,
About the set
We have introduced a Similarity-based Bipolar Argumentation Framework, considering the context of the comparison between arguments, based on a set of descriptors that are common to the arguments which are being analyzed. In this way, we use a tool to enrich the representation of the relationships between the arguments, being able to determine and represent similarities between them, distinguishing among arguments weakly related from those whose relationship is stronger. In this direction, we determined a cohesion value between supporting arguments and a controversy value between conflicting arguments, as measures of the arguments relationships quality. Based on this analysis, we improve the acceptability process considering a threshold that specifies how permissive are we about the quality of relationships among arguments. More specifically, we can specify how cohesive the supporting arguments must be and how much controversy it is possible to admit in the accepted arguments set. In the argumentation domain, we are looking for those sets of arguments that possess a strong cohesive and a low controversy position. In this work, the notions of cohesion and controversy associated with an acceptable set of arguments are considered independently, despite working jointly. Indeed, only a threshold is taken into account to refine the argument relations and to perform the acceptability process. However, the study of the relation between these two concepts in our acceptability semantics is an interesting aspect that we will study in future works. Thus, we can refine the family of semantics introduced in this paper characterizing the acceptable arguments in the following way: acceptable arguments possess a higher degree of cohesiveness than of controversy, and on the other end of the spectrum, those arguments that possess a lower degree of cohesiveness than controversy are rejected. In the following section, we present a concrete example applying our formalism.
Now, let us examine the following scenario, in which Stephanie, concerned about the effects on health, wants to investigate the possible benefits coming from ingesting antioxidants supplements. Naturally, it is a simplified view of the problem but with enough elements as to show the use of the framework. Quoting from MedlinePlus (see footnote below):
“Antioxidants are human-made or natural substances that may prevent or delay some types of cell damage. Antioxidants are found in many foods, including fruits and vegetables. They are also available as dietary supplements.”
For instance:
Antioxidants may protect cells from free radical damage, improving the immune system. So, they are a healthy choice to incorporate to a diet.
The dietary antioxidants can be damaging to your health if they are consumed for long periods, and may interact negatively with certain medications.
If you incorporate antioxidants to your diet, you lower the risk of infections. Especially, vitamin ‘A’ which is important to improve the immune system.
Increasing antioxidant intake is essential for optimum health, especially in today’s polluted world because the body cannot keep up with antioxidant production. It is recommendable to consume frozen vegetables.
As functional foods, dietary antioxidants help in the control of human diseases, protecting cells from free radical damage and reducing oxidative stress.
Vitamin ‘A’ intake might increase cholesterol and raise the chance of vitamin ‘A’ poisoning. Therefore, this vitamin can affect the general immune system.
Dietary antioxidants have been claimed to be the magic bullets for keeping a healthy living mostly without interfering with any medication. These physio-chemicals are found extensively in fruits and vegetables, particularly brightly colored varieties.

Bipolar Argumentation model.
Thus, for instance, to calculate
Then, by successively computing the probabilistic sum between the three values obtained, we have
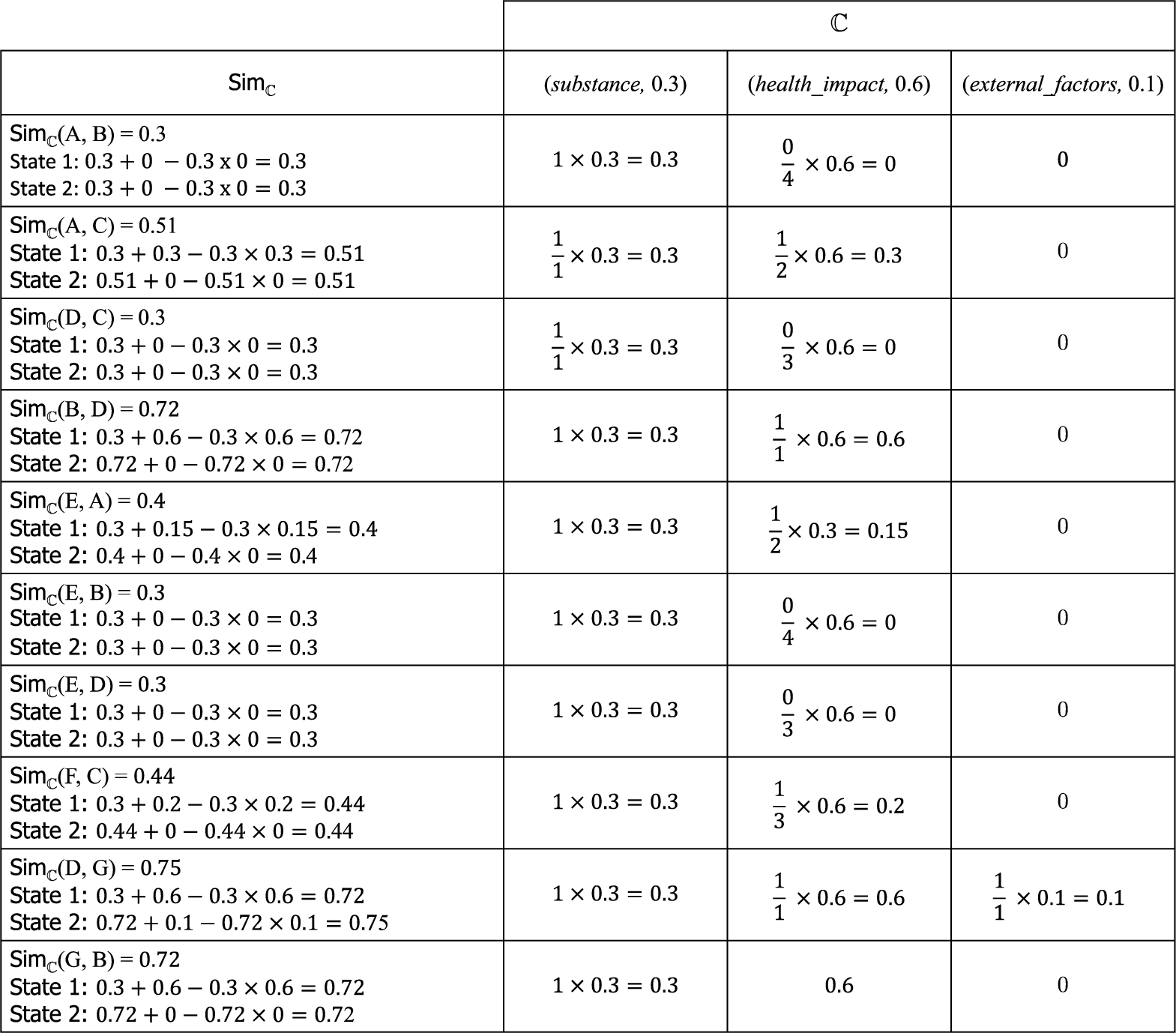
Similarity degrees between considered arguments.
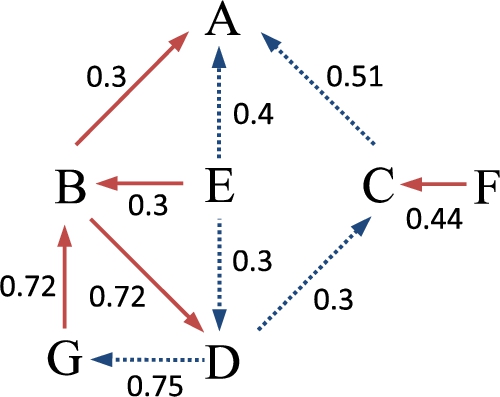
S-BAF argumentation model.
Thus, for this example, we identify the following relations considering the threshold
B is a weak direct attack for A, since
B is a strong direct attack for D, since
E is a weak direct attack for B, since
F is a weak direct attack for C, since
G is a strong direct attack for B, since
F is a weak secondary attack for A, since
B is a strong secondary attack for G, since
D is a strong supported attack for B, since
E is a weak supported attack for B, since
Next, we will describe how the acceptability process over a bipolar argumentative framework can be improved incorporating the extra knowledge obtained so far. To do that, we will analyze the maximal sets with respect to the inclusion operator, then we will consider the following sets:
Regarding admissibility notion and considering the characteristics previously analyzed of each set, we have that:
Analyzing the acceptability notions and considering the characteristics previously analyzed of each set we have that:
Note that this simple example illustrates the usefulness of a mechanism that allows introducing a degree of flexibility when analyzing the admissibility of arguments. Using the measure of similarity to express the support cohesion, the controversy of an attack, and the behavior of both measures combined in indirect attacks, it is possible to consider in the decision process those arguments that would have been discarded from the perspective of a classical BAF.
Several meaningful research efforts have motivated the ideas put together in the research introduced here. We have already described some of the works that are closely related to ours in Section 3, but there is additional literature that should be mentioned. Below, we will analyze this corpus divided into three main categories: the notion of similarity, the degradation or strengthening of the relationships between arguments, and the admission of inconsistency in the semantics of acceptable arguments.
Similarity in argumentation
The notion of similarity has been widely studied in terms of its meaning and usage [29,38,39,43,68]. The pioneering works address the treatment of the similarity as mathematical proportions to represent common behaviors and experimental effects in scientific models, to obtain patterns of causal relations in the phenomenal observed [43]. In [73], Sowa used an estimation function using and conceptual graphs, to find the differences between the arguments. On the other hand, in a refinement of Hesse’s idea, Walton [78] points out that it is not easy to clearly define the comparison between arguments as this requires interpreting the similarities and differences between them at various levels. Cecchi et al. in [25] used a binary relation to characterize and formalize the behavior of a preference criterion among arguments; as an approximation of the similarity between them. In [74] the authors proposed a process for comparing two sets of words or entities to find semantic similarities between them using ontologies. The process of comparison is based on BOW (Bag-Of-Word) format, and used the cosine similarity measures to represent each entity by a set of weighted terms that describes it. In a similar direction, in [71], the authors presented a summary of the different metrics that can be used to determine the similarity between concepts over ontologies; for example, the authors mention definitions-based measures such as Lesk Algorithm, which compares two concepts according to the number of common words in their definitions. They use structure-based measures as Rada Distance based on ontology’s graph representation, where the metric used to estimate the similarity between two concepts is the minimum number of edges connecting them.
More recently, in [61,62] the authors studied the use of paraphrased phrases in the summaries that provide websites, based on labels that represent essential aspects of arguments or argument facet. The authors used a regression model in machine learning to introduce the arguments and predict the similarity between them using a scalar value. Although the term argument facet is equivalent to the context in our work, the focus on [61,62] is different from our propose, since our principal contribution is at the conceptual level, regardless of the various techniques that can be used. Furthermore, both postures are complementary: in [42] the authors presented a review over different techniques to evaluate the similar textual semantic and proposed a Align-and-Penalize Approach, where two sentences are compared and the penalization is applied over syntactic contradictions or terms not aligned. In [37], the authors used techniques based on the manipulation of distances in graphs, to determine the similarity between text documents in the biomedical domain. It is a practical approach where the values of the descriptors or concepts needed to measure the semantic similarity, correspond to a vocabulary included in Systematized Nomenclature of Medicine-Clinical Terminology (SNOMED CT); Medical Subject Headings (MeSH); and the Unified Medical Language System (UMLS, [4]). This work demonstrates the importance of considering the similarity between arguments in specific domains. However, it is a restricted example based on specific biomedical concepts. In [11], the authors explore several similarity measures between logical arguments and define a very general function as a similarity measure; then, the authors define a set of principles that a similarity measure should satisfy. In this case, the arguments are expressed as logical entities denoted by pairs (support, conclusion), where the syntactic similarity between two arguments is calculated using an extension of the traditional Jaccard measure [47], comparing the elements of their correspondent pairs. This novel approach expressed arguments as logical entities, in a different form as the arguments considered in our proposal, which make, for instance, postulates not being directly translatable for our similarity functions.
Relation refinement in argumentation
Following a related idea that expands the representational capabilities of abstract argumentation frameworks, Martinez et al. [59,60] and later Dunne et al. in [34] proposed various refinements of the attack relation assigning weight to each attack indicating the relative force of this attack. In [24], Cayrol et al. convincingly held that argumentation is based on the exchange of interacting arguments and their valuation, leading to the adoption of the most acceptable ones and proposing the concept of “graduality” in the selection process of the best arguments to render progressive levels of acceptability. Furthermore, in a series of works [5–7,13], Amgoud et al. introduce a closely related line of research, where the authors define principles that a particular semantics should satisfy in a bipolar setting. Such principles are useful for defining reasonable semantics, for a better understanding of the design choices or foundations of each semantics, and for comparing pairs of semantics. Furthermore, the authors propose the definition of new gradual semantics for the subclass of non-maximal acyclic bipolar graphs, showing that it satisfies a set of principles. In [67], Potyka proposes a continuous dynamical system as a well-suited tool to analyze cyclic and acyclic bipolar argumentation frameworks, arriving at a convergence state. Towards this end, the author gives the conditions under successive procedures that can be transformed into well-defined dynamical systems; furthermore, the model satisfies a set of axiomatic properties that complement the existing approaches. In contrast with our work, this approach includes the possibility of treating cyclic bipolar argumentation frameworks; however, the author proposed a special and unique propagating function, where the valuations given by this function may not always represent real-world behavior. On another work, Hunter in [45] argues that when constructing an argument graph from informal arguments, where arguments are described in free text, it is often evident that there is uncertainty about whether some of the attacks hold. This situation might be produced because there is some expressed doubt that an attack holds or because there is some imprecision in the language used in the arguments. In this direction, Hunter assigns an uncertainty measure to the attacks in the argumentation framework; to do this assignment, the set of the spanning subgraphs of an argument graph is analyzed as a sample space, where a spanning subgraph contains all the arguments and a subset of the attacks of the argument graph. Finally, using the probability distribution over subgraphs, the probability that a set of arguments be admissible can be determined.
Our formalism shares the same goal, with particular attention over a well-defined notion of similarity defined between arguments that participate in an argumentative discussion. These similarity functions can be instantiated in different ways, and each one of them embodying a specific viewpoint, shifting the model from one perspective to another. Furthermore, we improve the argumentation framework analyzing the effectiveness of the support and conflict relations, considering the similarity measure associated with the participating arguments. Additionally, we present a new family of semantics refining the classic ones.
Tolerance to inconsistency in argumentation
An interesting investigation is presented by Bertossi et al. in [16], where the authors highlighted the need for inconsistency tolerance in order to create more robust and more intelligent computing systems. Inconsistency tolerance is being introduced on foundational technologies for identifying and analyzing inconsistency in information, for representing and reasoning with inconsistent information, for resolving inconsistencies in information, and for merging inconsistent information. In this direction, Dunne et al. in [33,34] propose a natural extension of Dung’s well-known model of argument systems in which attacks are associated with a weight, indicating the relative strength of the attack. An important point of the system is the use of an inconsistency tolerance threshold, which allowed attacks to be discarded when the threshold was not exceeded. In this way, it was possible to perform a more refined scan of the framework giving useful solutions when conventional (unweighted) argument systems have none. Furthermore, Hunter and Konieczny in [46] present a review of the measures of information and contradiction, studying some potential practical applications. Specifically, they analyze two ideas: the importance of the conflict is reflected by the number of formulae in the knowledge base involved in deriving the contradiction (the more formulae needed, the less important the conflict), and the importance of the conflict is described by the number of atoms on which we have contradictory information. Thus, the notion of weights presented by Dunne et al. in [33,34] can be interpreted considering these intuitions. Additionally, Arieli in [14] presents a new kind of semantics for abstract argumentation frameworks, in which conflicting arguments can be accepted. The rationality behind such semantics is that, in real-world applications, there are situations in which contradictory arguments coexist in the same theory; moreover, the author correctly argues that the removal of contradictory indications in such theories may imply a loss of information and may lead to erroneous conclusions. Thus, in their framework they propose to: introduce self-referring argumentation and avoid information loss that may be caused by the conflict-freeness requirement (then, for instance, it may be better to accept extensions with a small fragment of conflicting arguments than, say, obtaining the empty extension), and refine the undecided case in standard labeling systems. The last point reflects (at least) two totally different situations: one case is that the reasoner abstains from having an opinion about an argument because there are no indications whether this argument should be accepted or rejected; another case that may cause a neutral opinion is that there are simultaneous considerations for and against accepting a specific argument. These two cases should be distinguishable since their outcomes may be different. Our research shares the same intuitions, relaxing the conditions imposed by classic formalisms to consider a certain tolerance to conflicting arguments to obtain resolutions to particular problematics, despite containing certain inconsistency levels. In our case, the support and conflict relation are analyzed, impacting on the notions of internal and external coherence associated with a set of arguments.
Conclusions and future works
In this work, we presented a novel mechanism for determining the similarity between arguments, based on labels or descriptors which represent aspects that an argument refers to. This mechanism involves a comparison process guided by a context, which determines the set of descriptors and a relevance relation among them. With these elements, we proposed a similarity function between arguments, which we later use to measure the controversy of attacks and the cohesion of supports in Bipolar Argumentation Frameworks. These valuations, applied to abstract argumentation frameworks allowed us to define different notions of argument sets acceptability, which is useful in determining how strong the support is for an attacking argument; this is relevant in domains where it is necessary to consider arguments that have weak opinions against but may be dismissed under existing argumentative approaches. Our proposal allows for a more fine-grained analysis among arguments relationships. It is important to note that Natural Language Processing techniques are beyond the scope of this research, but future advances in the state of the art of the subject will help generate more robust implementations of frameworks similar to the one presented.
Future work presents different possibilities, such as the development of an implementation of S-BAFsby using the existing DeLP [35,36,52] system as a basis.2
See