
Abstract
This paper proposes a formal top-level model of explaining the outputs of machine-learning-based decision-making applications and evaluates it experimentally with three data sets. The model draws on AI & law research on argumentation with cases, which models how lawyers draw analogies to past cases and discuss their relevant similarities and differences in terms of relevant factors and dimensions in the problem domain. A case-based approach is natural since the input data of machine-learning applications can be seen as cases. While the approach is motivated by legal decision making, it also applies to other kinds of decision making, such as commercial decisions about loan applications or employee hiring, as long as the outcome is binary and the input conforms to this paper’s factor- or dimension format. The model is top-level in that it can be extended with more refined accounts of similarities and differences between cases. It is shown to overcome several limitations of similar argumentation-based explanation models, which only have binary features and do not represent the tendency of features towards particular outcomes. The results of the experimental evaluation studies indicate that the model may be feasible in practice, but that further development and experimentation is needed to confirm its usefulness as an explanation model. Main challenges here are selecting from a large number of possible explanations, reducing the number of features in the explanations and adding more meaningful information to them. It also remains to be investigated how suitable our approach is for explaining non-linear models.
Introduction
There is currently an explosion of interest in automated explanation of machine-learning applications [2,26,31]. Some explanation methods explain the entire learned model (global explanation) while other methods explain an output in a specific case (local explanation). Also, some methods assume access to the model (model-aware explanation) while other methods assume no such access (model-agnostic explanation). This paper presents a model-agnostic method for (locally) explaining outcomes of learned classification models and evaluates it experimentally with three data sets. Our model-agnostic approach is motivated by the fact that access to a learned model often is impossible (since the application is proprietary) or uninformative (since the learned model is not transparent). We will only assume access to the training data and the possibility to observe a learned model’s output given input data. There are several model-agnostic explanation methods, including example-based methods, which explain a decision for a case by comparing it to similar cases in the training set [35]. We take a similar approach, drawing on AI & law research on argumentation with cases, which models how lawyers draw analogies to past cases and discuss their relevant similarities and differences. A case-based approach is natural since the training data of machine-learning algorithms can be seen as collections of cases. The resulting explanation model does not explain how a learned model reached a decision (it cannot do so since it has no access to the learned model) but under which assumptions the decision can be justified in terms of an argumentation model. Our explanation model thus not only provides better understanding of the decision but also grounds to critique it.
Our explanation model is top-level in that it itself gives no reasons for why differences between cases matter or can be downplayed but can be extended with more refined accounts of similarities or differences between cases in which such reasons are given. The model is formally defined as an instance of Dung’s well-known theory of abstract argumentation frameworks [24]. The results of our experimental evaluation studies indicate that our model is to some extent feasible in practice, but further development and more experimental studies, especially with human users and with extensions of our top-level model, are needed to confirm its usefulness as an explanation model. While our approach is motivated by legal decision making, it also applies to other kinds of decision making, such as commercial decisions about loan applications or employee hiring, as long as the outcome is binary and the input conforms to this paper’s factor- or dimension format.
There is so far little work on argumentation for model-agnostic explanation of machine-learning algorithms but recent research suggests the feasibility of an argumentation approach. We are inspired by the work of Čyras et al. [20,21], also applied by [18,19]. They define cases as sets of binary features plus a binary outcome (in [20] also a case’s ‘stages’ are considered, but for present purposes these can be ignored). Then they explain the outcome of a ‘focus case’ in terms of a graph structure that essentially utilises an argument game for grounded semantics of abstract argumentation semantics [24,32]. We want to use the latter idea while overcoming some limitations of Čyras et al.’s approach. First, they do not consider the tendency of features to favour one side or another, while in many applications information on these tendencies will be available. Second, their features are binary, while many realistic applications will have multi-valued features. Finally, they leave the precise nature in which their graph structures explain an outcome somewhat implicit. We want to address all three limitations in terms of recent AI & law work on case-based reasoning. A more detailed comparison with [20] will be given in Section 8.
As suggested by [31], good explanations are selective, contrastive and social. That an explanation is selective means that only the most salient points relevant to an outcome are presented. That an explanation is contrastive means that it not just explains why the given outcome was reached but also why another outcome was not reached. Finally, that an explanation is social means that in the transfer of knowledge, assumptions about the user’s prior knowledge and views influence what constitutes a proper explanation. In Section 10 we will argue that our model satisfies these criteria in several respects.
This paper is organised as follows. We present preliminaries in Section 2 and outline our general approach and its underlying assumptions in Section 3. We then present a boolean-factor-based definition of case-based explanation dialogues in Section 4 and extend it to multi-valued factors or ‘dimensions’ in Section 5. In Section 6 we report on experiments with datasets to evaluate our approach and in Section 7 we briefly discuss how our top-level model can be extended with more refined accounts of similarities and differences between cases. We then discuss related research in Section 8 after which in Section 9 we discuss in a more general sense whether our method is an explanation method or something else. We conclude in Section 10. Sections 2–5 are an extended and somewhat revised version of [37] while Section 6 is adapted from [41].
Preliminaries
In this section we describe some preliminaries. After a brief overview of AI & law research on case-based reasoning, we briefly summarise the theory of abstract argumentation frameworks and outline the factor-based theory of precedential constraint. The dimension-based version of the latter theory will be discussed later in Section 5.
AI & law accounts of case-based reasoning
Many
In AI & Law research, factors are legally relevant fact patterns which tend to favour one side or the other. Factors have to be weighed or balanced in each case, unlike legal rules, of which the conditions are ordinarily sufficient for accepting their conclusion. Factors can be boolean (e.g. ‘the secret was obtained by deceiving the plaintiff’, ‘a non-disclosure agreement was signed’ or ‘the product was reverse-engineerable’) or multi-valued (e.g. the number of people to whom the plaintiff had disclosed the secret or the severity of security measures taken by the plaintiff). Multi-valued factors are often called dimensions; henceforth the term ‘factor’ will be reserved for boolean factors. In a factor-based approach, cases are defined as two sets of factors pro and con a decision (for example, there was misuse of trade secrets) plus (in case of precedents) the decision. In his CATO system, Aleven [3,4] also considers support and attack relations between less and more abstract factors (for instance, that the products are identical is a reason to believe that the information was used) and uses them to define argument moves for emphasizing or downplaying distinctions. Dimensions are not simply pro or con an outcome but are stronger or weaker for a side depending on their value in a case. Accordingly, in dimension-based approaches cases are defined as collections of value assignments to dimensions plus (for precedents) the decision.
While HYPO-style work mainly focuses on rhetoric (generating persuasive debates), other work addresses the logical question how precedents constrain decisions in new cases. An important idea here is that precedents are sources of preferences between factor sets [27,39] and that these preferences are often justified by balancing underlying legal or societal values [13,14]. This work has recently been extended to dimensions [11,28,43]. Since new cases are rarely identical to precedents, these preferences and values often do not uniquely determine a decision in a new case. Therefore the systems based on these ideas suggest alternative decisions with their arguments pro and con.
Some theory of abstract argumentation frameworks
An
Factor-based precedential constraint
For describing
Note that given the way the tendency of factors towards a particular outcome is defined, we cannot model dependency relations between factors. For example, we cannot model that one factor is pro an outcome only if another factor is present. In AI & law research on case-based reasoning with factors or dimensions there is a general assumption that factors or dimensions are independent from each other but this assumption may not always be warranted. The assumption also means that our model may be less suitable for explaining non-linear decision-making models.
We next summarise Horty’s [27] factor-based ‘result’ model of precedential constraint (the differences with his ‘reason model’ are irrelevant for present purposes, and hence not discussed here).
(Preference relation on fact situations [27]).
Let X and Y be two fact situations. Then
(Precedential constraint with factors [27]).
Let
Horty thus models a fortiori reasoning in that an outcome in a focus case is forced if a precedent with the same outcome exists such that all their differences make the focus case as least as strong for their outcome as the precedent.
A case base
As our running example we use a small part of the US trade secrets domain of the HYPO and CATO systems. We assume the following six factors along with whether they favour the outcome ‘misuse of trade secrets’ (π for ‘plaintiff’) or ‘no misuse of trade secrets’ (δ for ‘defendant’): the defendant had obtained the secret by deceiving the plaintiff (
Consider next the following fact situation:
We finally recall some ideas and results of [38] and add a new result to them. In [38] a similarity relation is defined on a case base given a focus case and a correspondence is proven with Horty’s factor-based model of precedential constraint. The similarity relation is defined in terms of the relevant differences between a precedent and the focus case. These differences are the situations in which a precedent can be distinguished in a HYPO/CATO-style approach with factors [3,5], namely, when the new case lacks some factors pro its outcome that are in the precedent or has new factors con its outcome that are not in the precedent. To define the similarity relation, it is relevant whether the two cases have the same outcome or different outcomes.
If they have the same outcome, then a factor in the precedent that lacks in the focus case is only relevant if it is pro that outcome; otherwise its absence in the focus case only makes the focus case stronger than the precedent. Likewise, an additional factor in the focus case is only relevant if it is con the outcome. If the focus case and the precedent have opposite outcomes, then this becomes different. If the precedent has an additional factor that is pro the outcome in the precedent (so con the outcome in the focus case), then its missing in the focus case makes the focus case stronger than the other case, so it is a relevant difference. However, if the additional factor in the precedent is con the outcome in that case, then its missing in the focus case as (as a factor pro its outcome) makes the focus case weaker compared to the precedent. So this is not a relevant difference. On the other hand, if the focus case has an additional factor pro its outcome, then its addition to the precedent (as a factor con its outcome) might have changed its outcome, so this is a relevant difference between the cases. Finally, if the additional factor in the focus case is con its outcome, then adding it to the precedent (as a factor pro its outcome) strengthens the precedent, so this is not a relevant difference between the cases.
Let c and f be two cases. The set If If
Figure 1 illustrates this definition.
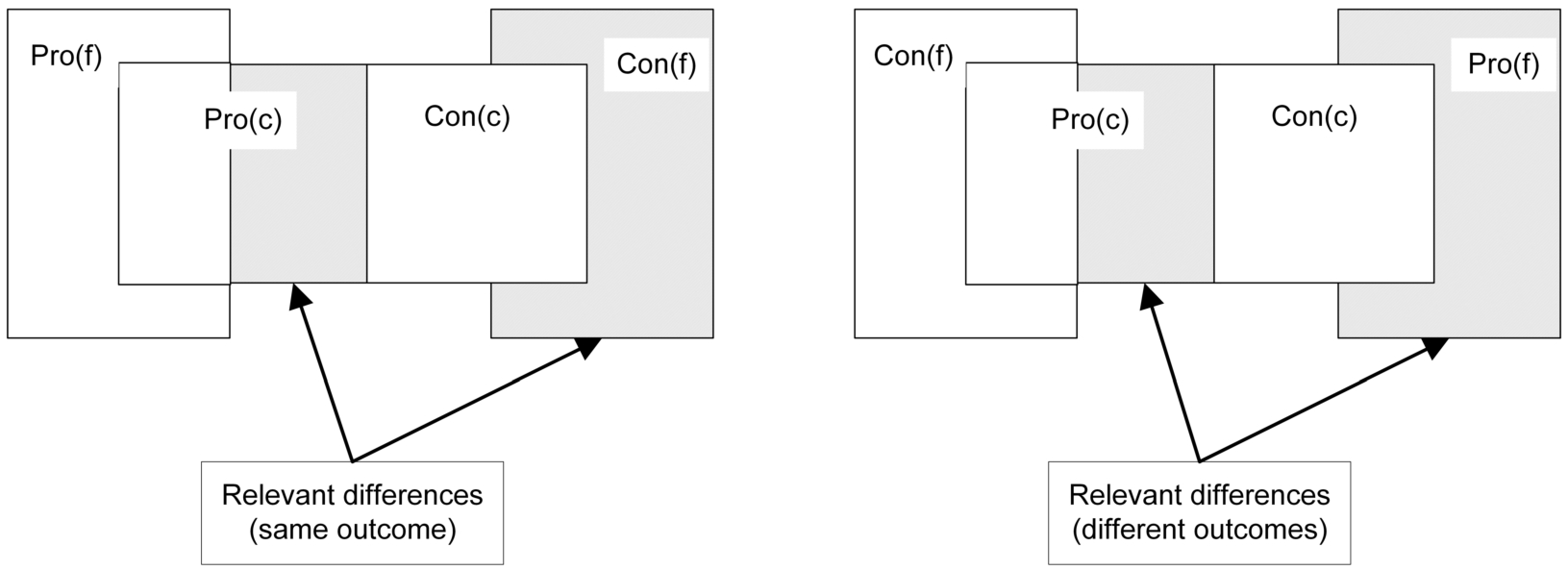
Relevant differences
Consider again our running example and consider first any focus case f with outcome π and with a fact situation that has at least the π-factors
The following result, which yields a simple syntactic criterion for determining whether a decision is forced, is proven in [38].
Let
We call a case citable given f iff it shares at least one factor pro its outcome with f and they have the same outcome [5]. Then clearly every case c such that
As a new result, it can be proven that for any two cases with opposite outcomes that both have differences with the focus case, their sets of differences with the focus case are mutually incomparable (as with
Let
We next sketch our general approach and its underlying assumptions. For a given classification model resulting from supervised learning we assume knowledge of the set of the model’s input features, i.e., factors or dimensions and a binary outcome, plus the ability to observe the output of the learned model for given input. We also assume knowledge about the tendency of the input factors or dimensions towards a specific outcome, plus access to the training set from which the classification model was learned (data plus label). We then want to generate an explanation for a specific input-output pair of the classification model (the focus case) in terms of similar cases in the training set. Later, in Section 7, we will briefly discuss a more general task where further domain specific information may be used to generate the explanation. It should be noted that there is one important difference between our approach and the ‘traditional’ case-based argumentation models described above in Section 2.1: in our approach the outcome of the case to be explained is given as input while in traditional approaches the outcome of the new case is an output of the model.
Since we have no access to the classification model, we do not know how the decision makers reasoned when deciding the cases in the training set. All we can do is generate the explanations in terms of a reasoning model that is arguably close to the domain, such as the above-described AI & law models of case-based argumentation. Accordingly, our aim is to investigate to what extent an explanation can be given in terms of these argumentation models.
There are a few important differences between our approach and more familiar model-agnostic local explanation techniques. Feature summary approaches, such as LIME [42], explain a prediction in terms of the contribution of features to the model’s decision. Our approach offers more context by explaining the decision relative to other instances (cases) in the data set. Providing this context can help answer contrastive questions, such as: ‘Why did c have outcome x rather than y?’.
A second important difference is that our model does not explain how the learned model reached its decision but how this decision can be justified in terms of another model. It may happen that the outcomes of a black-box classification model and the argumentation-based model of precedential constraint disagree for a given input in that the output given by the classification model is not forced by the argumentation model. Such a discrepancy does not imply that the argumentation model is wrong. It may also be that the learned classification model is wrong, since such models are rarely 100% accurate. If the two models disagree, it may be informative to show the user under which assumptions the outcome of the learned model is forced according to the argumentation model. The user can then decide whether to accept these assumptions. Accordingly, the information our explanations should provide is twofold: whether the focus case is forced, and if not, then what it takes to make it forced. Our explanation model can thus not only provide better understanding of the decision but also grounds to critique it. In Section 9 we will discuss these points in more detail.
Explanation with factors
We now present our top-level model for case-based explanation dialogues with factors, formalised as an application of the grounded argument game to a case-based abstract argumentation framework. The model is top-level in that it gives no reasons for why differences between cases matter or can be downplayed. In Section 7 we briefly discuss how our top-level model can be extended with more refined accounts of similarities and differences between cases in which such reasons can be given. The idea of our model is that the proponent starts a dialogue for the explanation of a given focus case f by citing a most similar precedent in the case base
Definition 5 formalises these ideas in the form of a specification of a set of arguments plus an attack relation. We first informally introduce the definition. Figure 2 informally displays the two distinguishing moves and all ways to downplay them, while Fig. 3 shows how these moves can be used in our running example. Further example explanations (with both factors and dimensions) are given in Appendix A.2.
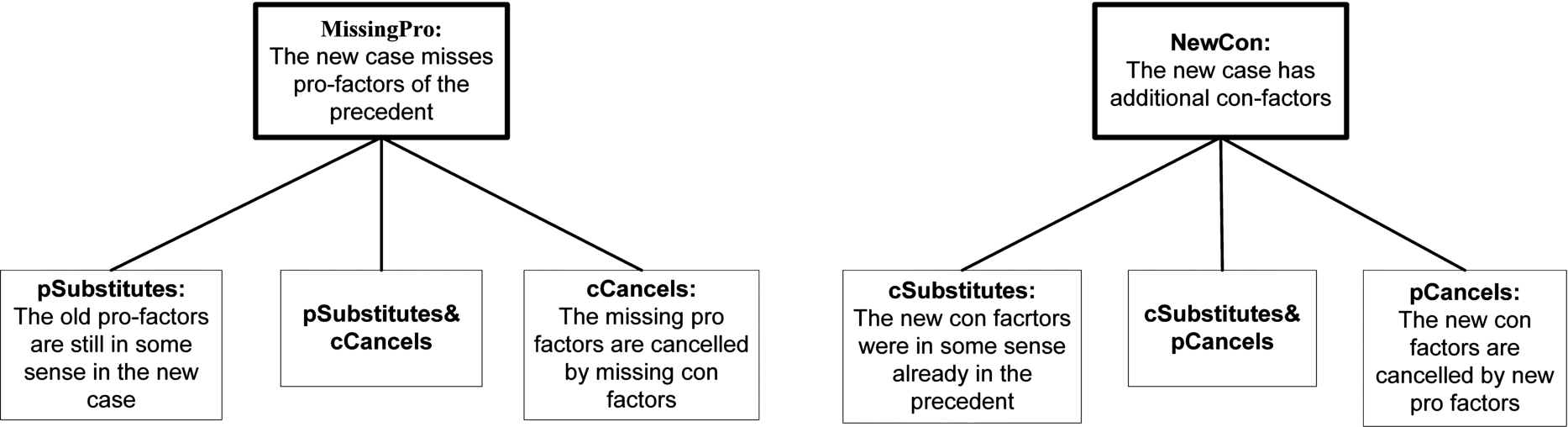
Distinguishing and downplaying distinctions.
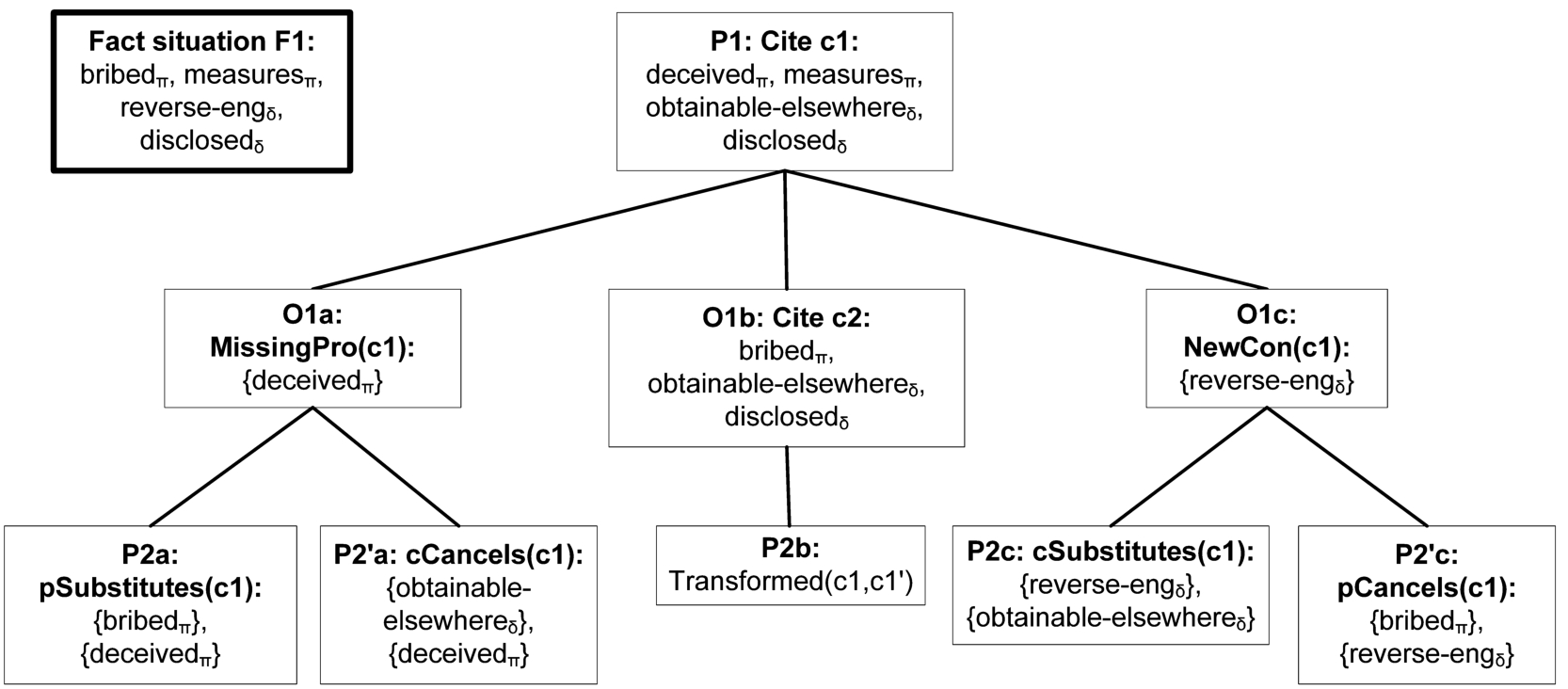
Example dialogue game tree.
The set
The next six moves are meant as replies to such distinguishing moves. They are inspired by the ‘downplaying a distinction’ moves from [3] (although that work does not contain counterparts of our
There are also two ways to downplay a NewCon distinction. The
For now all these moves will simply be formalised as statements. Later, in Section 7, we briefly discuss how full-blown arguments can be constructed with premises supporting these statements. To this end, our formal definition of the set of arguments assumes an unspecified set
A complication is how to handle that a MissingPro or NewCon argument can be attacked in different ways on different subsets of the missing pro-s or new con-s factors. For instance, two different missing pro factors may be p-substituted with two different new pro factors, or one subset of the missing pro factors can be p-substituted by new pro factors while another subset can be c-cancelled by missing con-s factors. The first situation can be accounted for in definitions in the set
The last move is meant as a reply to a counterexample. For now its underlying idea can only be outlined. It is meant to say that an initial citation of a most similar case for the outcome of f can be transformed by the downplaying moves into a case with no relevant differences with f and which can therefore attack the counterexample. A more formal explanation can only be given after Definition 8.
Given a finite case base
A attacks B iff: B is of the form A is of the form A is of the form B is of the form A is of the form A is of the form
Henceforth the arguments that attack a
(Explanation-complete case-based AFs).
An abstract argumentation framework for explanation with factors
The grounded argument game now directly applies. The idea (inspired by [20,21]) is to explain the focus case f by showing a winning strategy for the proponent in the grounded game, which guarantees that the citation of the focus case is in the grounded extension of the argumentation framework defined in Definition 5. Such a winning strategy shows how all possible attacks of the opponent on the initial citation can be counterattacked. In our approach, an explanation dialogue should start with a ‘best’ citable precedent c in
Given an abstract argumentation framework for explanation with factors if i and j are odd and if i is even, then if
If i is odd (even), we say that the player of
Recall that a strategy for a player can be displayed as a tree of dialogues which only branches after that player’s moves and which contains all attackers of this move. A strategy for a player is then winning if all dialogues in the tree end with a move by that player; cf. [32].
One idea of our approach is that all moves in an explanation receive their meaning from (or are thus justified by) the formal theory of precedential constraint. To make this formal, we now specify the following operational semantics of the downplaying arguments in
[Downplaying with factors: operational semantics] Given an
Then given
In our running example we henceforth assume that
Given an
For any abstract argumentation framework for explanation with factors
A case
Note that Lemma 3 justifies that a Transformed move attacks a citation of a counterexample, since it says that the moves in an explanation dialogue that downplay a distinction transform the initially cited case in the dialogue to a case with no relevant differences with the focus case. This means that the counterexample to the initial citation moved by the opponent loses its force, since it is not a counterexample to the transformed case. This is one illustration of the idea that an explanation dialogue identifies the assumptions that have to be accepted to justify a predicted outcome of the focus case.
One underlying reason that Proposition 4 holds is that a substituting or cancelling set can be empty, which is necessary to make the proponent win if the opposite outcome of the focus case is forced. Admittedly, such a justification of the outcome of the focus case is weak, but at least it informs a user that justifying the outcome of the focus case requires making the case base inconsistent. In all other cases where the outcome of f is not forced, the following proposition tells us that a winning strategy in fact transforms the initial precedent into a precedent that does control the focus case.
Let T be a winning strategy for the proponent in an explanation dialogue with an initial move c such that
Together, our results formally capture the sense in which an explanation according to Definition 7 explains the focus case. If the focus case is forced, then any precedent with no relevant differences explains the focus case; if neither outcome is forced, then an explanation sequence of downplaying moves derived from the winning strategy explains what has to be accepted to make the focus case forced; and if the opposite outcome is forced, then explaining the outcome boils down to explaining that justifying the outcome of f requires making the case base inconsistent.
We next adapt the above-defined factor-based explanation model to cases with dimensions. We first outline some formal preliminaries.
Dimension-based precedential constraint
We adopt from [28] the following technical ideas (again with some notational differences). A dimension is a tuple
Note that the set of value assignments of a case is unlike the set of factors of a case not partitioned into two subsets pro and con the case’s outcome. The reason is that with value assignments it is often hard to say in advance whether they are pro or con the case’s outcome. All that can often be said in advance is which side is favoured more and which side less if a value of a dimension changes, as captured by the two partial orders
Note also that, since the partial orders
In HYPO [6,44], two of the factors from our running example are actually dimensions. Security-Measures-Adopted has a linearly ordered range, below listed in simplified form (where later items increasingly favour the plaintiff so decreasingly favour the defendant):
Minimal-Measures, Access-To-Premises-Controlled, Entry-By-Visitors-Restricted, Restrictions-On-Entry-By-Employees
(For simplicity we will below assume that each case contains exactly one security measure; generalisation to multiple measures is straightforward by defining the orderings on sets of measures.). Moreover, disclosed has a range from 1 to some high number, where higher numbers increasingly favour the defendant so decreasingly favour the plaintiff. For the remaining four factors we assume that they have two values 0 and 1, where presence (absence) of a factor means that its value is 1 (0) and where for the pro-plaintiff factors we have
Accordingly, we change our running example as follows.
In Horty’s [28] dimension-based result model of precedential constraint a decision in a fact situation is forced iff there exists a precedent c for that decision such that on each dimension the fact situation is at least as favourable for that decision as the precedent. He formalises this idea with the help of the following preference relation between sets of value assignments.
(Preference relation on dimensional fact situations [28]).
Let F and
Definition 3 of (in)consistent case bases now directly applies to case bases with dimensions.
In our running example we have for any fact situation
Then adapting Definition 2 to dimensions is straightforward.
(Precedential constraint with dimensions [28]).
Let
In our running example, deciding
We next recall [38]’s adaptation of Definition 4 to dimensions. Unlike with factors, there is no need to indicate whether a value assignment favours a particular side, since we have the
(Differences between cases with dimensions [38]).
Let If If
Let c be a precedent and f a focus case. Then clause (1) says that if the outcomes of the precedent and the focus case are the same, then any value assignment in the focus case that is not at least as favourable for the outcome as in the precedent is a relevant difference. Clause (2) says that if the outcomes are different, then any value assignment in the focus case that is not at most as favourable for the outcome of the focus case as in the precedent is a relevant difference. In our running example, we have:
Let, given a set D of dimensions,
The counterpart of Proposition 2 can be proven as a new result.
Let, given a set D of dimensions,
When extending our explanation model with dimensions, we see factors simply as a special case of dimensions with just two values 0 and 1 where
This simplification overcomes a limitation of [37], in which worse values of dimensions cannot be compensated with factors.
Given a finite case base
A attacks B iff: B is of the form
In our running example, a citation of
At first sight, it would seem strange that the dimension-based set of moves is simpler than the factor-based set. However, on closer inspection we can see that the dimension-based downplaying move abstracts from things made explicit in the factor-based downplaying moves, namely, the reasons why the differences do not matter. For example, suppose that in a domain with two factors
Definition 7 now directly applies to explanation with dimensions. The operational semantics for the new downplaying move is defined as follows.
(Downplaying with dimensions: operational semantics).
Given an
In other words, on the dimensions with relevant differences, the precedent’s values are replaced with the focus case’s values. This way of downplaying dimensional differences is admittedly rather crude but more refined ways can only be defined if additional information is available (cf. Section 7 below). With this semantics for
Given an
For any abstract argumentation framework for explanation with dimensions
A case
Let T be a winning strategy for P in an explanation dialogue with an initial move c such that
In this section we report on experiments with three data sets to evaluate our approach. We in particular want to gain some initial insights into the circumstances under which our approach is feasible, and on which aspects it should be further developed or tested. We will evaluate the outcomes in terms of the nature of the generated explanations (size, comprehensibility, need for trivial explanations) and on how inconsistencies are dealt with. We first introduce the three data sets that were used for the experiments. After that, we discuss how the data instances were transformed into cases, making up the case bases. We then report on the experiments and evaluate the method based on the results. Recall that some example explanations for the three data sets are displayed in Appendix A.2.
About the data sets
For the experiments, we used three publicly available data sets: Churn [46], Mushroom [23] and Graduate Admission [1]. All data sets are tabular, consisting of several features, together with an outcome variable. The Churn data set contains information about customers of a telecom service. The outcome variable Churn represents whether a customer continued using a company’s telecom services or churned, that is, cancelled the subscription. The Mushroom set consists of descriptions of hypothetical samples corresponding to species of mushrooms in the Agaricus and Lepiota Family. All features of this set are categorical and the outcome variable represents whether the mushroom is either definitely edible or (possibly) poisonous. The Mushroom data set was also used in [18,19] to test their ANNA method. The Admission set consists of features – such as exam scores – with which a prediction can be made about whether an applicant will be admitted to a master program.
We made a heterogeneous selection of data sets in terms of consistency (recall that according to Definition 3 a case base is inconsistent if a fact situation exists for which two opposite decisions are forced). The Churn data set is of a highly statistical nature; on average, we can tell which profiles are likely to stay or churn based on the features, but there are many exceptions. In the Mushroom data set, on the other hand, the features do seem to possess enough information to consider the outcome variables some ‘truth’ in that cases with the same features must have the same outcome. The Admission data set forms a middle ground between the statistical Churn and the more consistent Mushroom data set. Further details about the data sets can be found in Table 1.
We did our experiments in two variants: one with the full data sets and one with the full Admission data set plus random selections of 500 cases from the Mushroom and Churn data sets. This allows us to observe effects of size differences on the results.
Data set statistics
Data set statistics
To prepare the data, we made several modifications. The outcome values of the Graduate Admission data set were transformed into binary values by replacing every value below 0.5 with 0, and other values with 1. We removed one feature from the Mushroom data set – ‘veil-type’ – for which all instances have the same value assignment.
We used an automatic approach to establish the tendencies of features to promote outcomes, using Pearson correlation coefficients. When a continuous feature positively (negatively) correlates with outcome s, we concluded that
Every row of data was transformed into a case. The feature values of an instance were represented as a fact situation: a list of pairs,
Consistency statistics (3 × 500)
Consistency statistics (3 × 500)
Before applying our method, we measured the consistency of the three case bases. With the 3 × 500 data sets, the Mushroom case base was nearly consistent (98.60%). This was different for the other case bases; for about 16% of the Churn cases and 20% of the Admission cases, a case that is more favorable for that outcome but received the opposite outcome could be found. This inconsistency seems caused by a small number of ‘exceptional’ cases. As Table 2 shows, removing respectively 5.6% and 3.2% of the most inconsistent cases results in consistent Churn and Admission case bases. With the full-size data sets (see Table 3), the degree of consistency of the Churn case base was reduced to less than 50%. Removing 11.4% of the most inconsistent cases resulted in a consistent case base. The consistency of the Mushroom case base barely changed when using the full-size data set.
Consistency statistics (full size)
Consistency statistics (full size)
In realistic applications data sets will often be inconsistent to some degree, for instance, due to imperfect assignment of features to cases, missed dependencies among features or incomplete information. For that reason, any explanation method has to be able to deal with inconsistency. In Section 6.3 below we will discuss how our method fares in the face of inconsistency.
In this section we present the results of the conducted computer experiments. All instances of the data sets are transformed into cases and included in the case base. For a single experiment, every case in the case base is used once as the focus case, while all remaining cases are used as candidate precedents.
Selection of precedents
In our method, the first step in explaining a focus case is to cite a best precedent. In Section 4 we defined a best precedent as a case in the case base that:
received the same outcome as the focus case has a minimal set of relevant differences with the focus case compared to other cases in the case base.
The following abstract example with factors illustrates this notion.
Consider the following case base and a focus case with predicted outcome o, where
In this experiment, we checked the average number of best precedents for focus cases. Arguably, the lower this number, the better, since with a high number a single explanation can be said to be somewhat arbitrary. Multiple cases can meet both criteria for best precedents. For the 3 × 500 case bases, Table 4 shows the average and standard deviation of the number of best precedents that can be found.
Average and standard deviation of the number of best precedents (3 × 500)
Table 5 shows the same numbers for the full-size case bases. These numbers indicate that the average number of best precedents is rather high for all three databases, especially if they are full-size. This points at the need for future research on meaningful additional selection criteria for best precedents.
Average and standard deviation of the number of best precedents (full size)
We next checked how many focus cases have a trivial winning strategy. When there are no relevant differences between the focus case and a precedent
As shown by Table 6, for all three databases a majority of the focus cases has a trivial winning strategy, and this majority increases to over 90% for the full-size case bases. This increase is to be expected, since the larger the case base, the easier it is to find precedents with opposite outcomes for a focus case which both have no relevant differences with it.
We can conclude that the larger or the more inconsistent the data sets, the less frequently the distinguishing and downplaying features of our explanation model can be used. The same may hold the fewer features a data set has (note that Admission has substantially fewer features than Mushroom and Churn). A possible remedy is that in trivial cases also some cases with the opposite outcome are shown with their relevant differences, even though this is not required by our explanation game. Also, other distance measures can be studied as alternatives to our rather coarse similarity relation between cases.
Percentages trivial winning strategies
Percentages trivial winning strategies
Finally, until now we have considered explanations of correct predictions, but it is also interesting to see what the explanation system tells us in case of an incorrect prediction. If for each focus case we switch its outcome to its opposite, then it follows from our definitions that the percentage of cases with a trivial winning strategy equals the percentage of cases for which the case base is inconsistent. Then we see that this percentage is for all case bases considerably lower, in most cases even far lower. This is as should be expected from an explanation model.
The structure of the explanation game can differ between best precedents that do have relevant differences with the focus case. A simple measure with which best precedents can be compared is whether any empty downplaying moves are needed to defend against attacks on the citation. An empty downplaying move is a way of saying that the differences between the focus case and precedent cannot be downplayed by other features, but still do not matter. This can be seen as the weakest form of attack, so the lower the percentage of cases that require empty downplaying moves, the better.
For instance, in Example 13, after the proponent begins by citing
To obtain an idea of whether there exist relevant differences between the best precedents that are selected for a focus case, we divided selections of best precedents into four outcome classes: selections of only trivial winning strategies and selections in which none, a part of or all of the precedents need empty downplaying moves. We show the results for the 3 x 500 case bases, as the appearance of non-trivial winning strategies is rare with full-size case bases (see Table 6). In Table 7 the distribution over these four groups is shown.
Number of occurrences of each outcome class for the 500 focus cases. Non-trivial winning strategies are divided in three classes: focus cases for which none, some or all of the best precedents need empty downplay (3 × 500)
Number of occurrences of each outcome class for the 500 focus cases. Non-trivial winning strategies are divided in three classes: focus cases for which none, some or all of the best precedents need empty downplay (3 × 500)
In only one case of the Churn case base was it necessary to use empty downplaying moves to defend any of the best precedents. In other cases, the system could at least defend part of the best precedents against the distinguishing moves by pointing to compensating features. We can conclude that the number of cases requiring empty downplay is rather low in both cases.
In the experiments so far, we considered the output of our method when presented with only correct or only incorrect predictions as input (since the focus cases are selected from the precedents in the case base, for which we know their outcome). By contrast, in an actual application the system would receive the predictions of another classification model as input. It is interesting to see whether the system responds differently to the specific instances that another model predicts incorrectly. In this final experiment, we will compare the percentage of focus cases for which a trivial winning strategy exists given correct and incorrect predictions of another classifier.
We first made a selection of classifiers to test which models perform best on our data sets. We selected three classifiers which are currently very popular in practical applications: DecisionTree, Support Vector Machine and Naive Bayes [22]. We also added two popular meta-algorithms used in combination with a DecisionTree, named RandomForest and AdaBoost. Finally, we added a simple white-box classifier in the form of a Logistic Regression. Decision Trees and coefficients of linear Support Vector Machines can be examined similar to Logistic Regressions and can therefore also be considered white boxes. We used built-in classifiers from the Python sklearn library. Details about the models can be found in Appendix A.3.
In order to select the best performing models for each data set, we measured the performance of the models using 5-fold cross validation. This entails that we shuffled the data sets and split them into 5 sets of equal size. Per set, a model was trained on the 80% of remaining data, after which it was tested on the set. Because of the uneven class distributions, we measured the performance of a model using the average weighted F1-score of both labels. The F1-score is calculated as:
The analysis made clear that there exist multiple models that reach 100% prediction accuracy on the Mushroom data set. We therefore only continued this experiment with the Churn and Admission data sets, doing it for the full-size case bases only. For this experiment, we again used 5-fold cross-validation on all instances of the data sets. On the Churn data set, a Logistic Regression performed best with an F1-score of 0.797. On the Admission data set, the Random Forest was most accurate, reaching a F1-score of 0.964. The performance of all models is specified in Table 8.
Mean performance, measured as the weighted F1-score, of the 5-fold cross validation on the six classifiers
Mean performance, measured as the weighted F1-score, of the 5-fold cross validation on the six classifiers
Table 9 shows the percentages of focus cases with a trivial winning strategy for correct and incorrect predictions, using the best scoring models. To obtain the model’s predictions, we split the data again into 5 sets of equal size. We then collected the predictions for each set by training it on the 4 other sets and testing it on the selected set. As we can see, on both data sets the percentage trivial winning strategies is substantially higher for correct predictions as desired, except for full-size Churn, when the difference is just over 3%. The high percentage of trivial winning strategies for incorrect outcomes using full-size Churn seems to be caused by a combination of high inconsistency and large case-base size.
Percentage of focus cases with a trivial winning strategy per data set for correct and incorrect predictions of the classifier. A logistic regression was used for the Churn predictions; a random forest for the Admission predictions
Finally, we compared the performance of the best classifier on consistent and inconsistent cases. We did this for the full-size Churn base, omitting the Mushroom case base since the best performing models reach a 100% accuracy on all cases and omitting the Admission case base because of the small absolute number of inconsistent cases. Table 10 shows the results.
We see that the difference in performance on consistent and inconsistent cases is quite large. We comment on the significance of these results in Section 6.3.
Performance (weighted F1-score) of the best performing classifier (logistic regression) on consistent and inconsistent cases
The aim of our experiments was to gain some initial insights in the circumstances under which our approach is feasible, and on which aspects it should be further developed or tested. We now discuss our findings in light of these aims.
The nature of explanations
First of all, we found that in all three data sets the number of best precedents is rather high for all three databases, especially if they are full-size. This makes the selection of a best precedent with which to explain the focus case somewhat arbitrary if there are no additional meaningful selection criteria. We identified this as a first issue for further research. Second, we found for all data sets that for a substantial part of the focus cases a trivial winning strategy existed for the correct outcome, and that this is the more so the larger the data sets are. In such cases the full power of our explanation model is left unused. We discussed a possible remedy but more research is needed at this point. On the other hand, we also found that for cases with nontrivial explanations the percentage of cases that required non-trivial downplaying is rather low, which is encouraging.
We did not do user experiments on comprehensibility of our explanations but our three example explanations shown in Appendix A.2, especially the one for the Mushroom case base with its 22 features, suggest that research is needed to look for possibilities to decrease the number of features used in the method or presented to the user. In [18,19] the use of an autoencoder neural network for this purpose is studied. As stated by Molnar [34], the interpretability of example-based methods crucially depends on the comprehensibility of a single instance in the data set.
We finally tested the intended use of our explanation model, by letting it generate explanations for predictions of several machine-learning classifiers applied to the same data sets. We found that for correct predictions of the classifiers our explanation model generated substantially more trivial explanations than for incorrect predictions. This is to be expected, since the incorrectly predicted outcome will often not be forced in terms of the theory of precedential constraint.
How to deal with inconsistencies
When transforming the data sets into case bases, we found that both the Churn- and the Admission data set were, to a considerable degree, inconsistent. This means that while using the case base, a non-negligible number of focus cases exist for which our method would find a trivial winning strategy for both outcomes. Is this a problem for our method? To start with, recall that above we observed that many realistic data sets will to some degree be inconsistent, so any explanation method has to be able to deal with inconsistency. In a data set like Churn, with data about customers of a company, a considerable degree of inconsistency is to be expected, since different customers can have widely varying preferences. In a data set like Admission a lower degree of inconsistency is more likely, since decision makers from the same or similar institutions can be expected to have more shared values and preferences. Finally, data sets like Mushroom can be expected to be highly consistent, since they reflect biological ground truths.
As shown by Table 10, the best-performing classifier performs better for consistent than for inconsistent cases. Therefore, informing a user that a focus case is (in)consistent can be useful. In addition, just as we proposed for trivial cases (of which inconsistent cases are a subclass), in case of inconsistency it can be useful to show cases with the opposite outcome that have relevant differences with the focus case, even though this is not required by our explanation game. In addition, it would be good to investigate what further useful information can be given in inconsistent cases.
A related topic for future research arises from the observation that the consistency of the databases partly depends on how we determined the tendency of features in our experiments. We did this by measuring the individual correlations with the outcome variable but this method is less suitable when there are too many dependencies between features. Using our current approach, we could, for example, find that both a large size and a purple colour of a mushroom positively correlate with being edible, while in reality a purple colour only promotes the chance of being edible when the mushroom is large. Recall that in AI & law research on case-based reasoning with factors or dimensions there is a general assumption that factors or dimensions are independent from each other but this assumption may not always be warranted. In any case, future research is needed on how to measure the tendency of features towards outcomes.
Extending the top-level model
So far we have modelled explanation dialogues that only use information from the case base, that is, from the training set of the machine-learning application. However, depending on the nature of the application, more relevant information may be available, provided in advance by a knowledge engineer or during an explanation dialogue by a user. It is for this reason that our explanation model contains a thus far undefined set
AI & law provides many insights here [10]. For example, the premises of pSubstitutes and cSubstitutes claims can be founded on a ‘factor hierarchy’ as defined for the CATO system [3,4]. We gave examples of this above. Furthermore, the pCancels and cCancels arguments can be said to express a preference for a set of pro factors over a set of con factors. In AI & law accounts have been developed of basing such preferences on underlying legal, moral or societal values, for example, by saying that deciding for a side on the basis of the presence of particular factors promotes or demotes particular legal or societal values. Arguments according to these accounts can provide the premises of arguments for the pCancels and cCancels claims. For example, move
Applying these ideas requires that arguments have a richer internal structure, where the various claims become conclusions of inferences from sets of premises. One way to achieve this is to formalise relevant argument schemes in a suitable structured formal account of argumentation [29]. In [9,12,40] this approach was followed in the context of the ASPIC+ framework [33]. To give an idea of how the approach of these papers can be applied in the present context, we now semiformally sketch a few relevant argument schemes. The first is a scheme for cancelling new con factors with new pro factors: 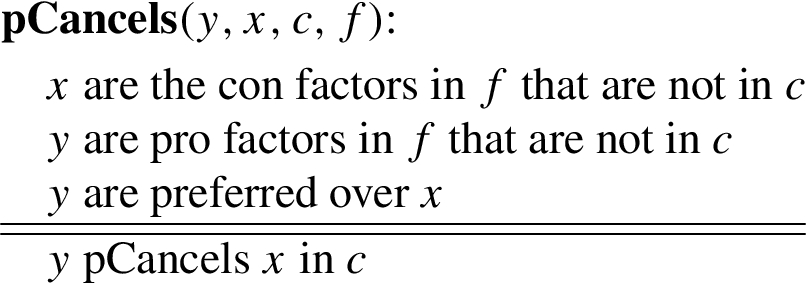 The conclusion of this scheme can be defined as an undercutter of a similar scheme with conclusion ‘f has new con factors x that are not in c’. The pCancels scheme can be combined with a further argument scheme for arguing for preferences between factor sets on the basis of preferences between the sets of values promoted by these factor sets. The conclusion of this scheme in fact expresses that y pCancels x according to
The conclusion of this scheme can be defined as an undercutter of a similar scheme with conclusion ‘f has new con factors x that are not in c’. The pCancels scheme can be combined with a further argument scheme for arguing for preferences between factor sets on the basis of preferences between the sets of values promoted by these factor sets. The conclusion of this scheme in fact expresses that y pCancels x according to  We intend to further elaborate on these ideas in future research.
We intend to further elaborate on these ideas in future research.
Related research
In this section we discuss related research on using case-based argumentation for explanation. A recent overview of AI & law models of explanation is [8]. An early suggestion to use example-based approaches for explaining machine-learning outcomes was [35]. Recently, the idea of ‘twin systems’ was proposed to explain artificial neural networks with case-based reasoning [30]. In this work a neural-network ‘black box’ model is mapped onto a more interpretable case-based reasoning system that works with the same data set as the neural net and that can be used to justify outputs of the neural net. The main focus in [30] is on methods for learning feature weights from neural networks for use in a k-nearest neighbor classifier. Similar methods could be useful for extensions of our current model with factor or dimension weights. Recent related work from AI & law is of Grabmair [25], who, adapting ideas of [17], predicts outcomes of legal cases in terms of factors and value judgements and explains these predictions with argumentation. While inspiring for our proposed research, his method relies on the use of an explicit argumentation model in the formulation of the classification problem, which he then uses for explaining the outcomes of the classifier. So his explanation method is, unlike our approach, not model agnostic. Finally, a recent empirical study suggests that a case-based style of explanation may lead to a lower degree of perceived justice than other styles [15]. We note that these experiments do not test for understandability of an explanation; it may be that the degree of perceived justice for case-based explanations is lower since they are more understandable than explanations of different kinds.
The closest to our approach and a main source of inspiration for us is Čyras et al.’s approach in [20,21]; it therefore deserves a detailed discussion and comparison. We here summarise the account of [20], where we will ignore their ‘stages’, which for present purposes are irrelevant. Cases in [20] are pairs of feature sets F and binary outcome o or
Note that if F and
Now because of the chosen attack relations (and since we ignore Čyras et al.’s stages) there will, if adding the focus case to
While this approach is very interesting, it also has some limitations. First of all, the features are binary, while many realistic applications will have multi-valued features. Furthermore, the model does not represent the tendency of features (from now on ‘factors’) to support a particular outcome. When factors can be pro or con an outcome, then cases with factors not shared by the focus case can be informative, so that the design decision to have cases attacked by the focus case can result in loss of information relevant for explaining an outcome. Suppose, for example, that a focus case has outcome o with pro-o factor
Another limitation is that since Čyras et al. do not model the tendency of features, they are forced to have a broader notion of consistency (which they call ‘coherency’) for case bases, in which a case base is only inconsistent if it contains two cases with exactly the same features but opposite outcomes. This makes that situations where one case is even better for an outcome than another case but still has the opposite outcome, go unnoticed in their model, while in our approach they make the case base inconsistent. We regard this as an advantage of our approach, since many realistic applications will have case bases that are inconsistent in our sense and, as we argued above in Section 6.3, noting such inconsistencies may give meaningful information to a user.
We finally compare the explanations generated by Čyras et al. in our running example to the explanations generated by our method. If the default outcome is π then they generate the following winning strategy:
Explaining predictions of another classifier: Explaining, justifying or comparing?
In the previous section we discussed alternative example- and argumentation-based methods for explaining black-box classifiers. Yet a more general discussion of how to deal with black-box models is in order. As we noted at the end of Section 3, it may happen that the outcomes of a black-box classification model and the argumentation-based model of precedential constraint disagree for a given input in that the output given by the classification model is not forced according to the argumentation model. We proposed that in such cases it may be informative to show the user under which assumptions the outcome of the learned model is forced according to the argumentation model. This is captured in our operational semantics of the moves in an explanation dialogue, which for a focus case with non-forced outcomes shows how a best precedent is transformed through the dialogue into a case that forces the outcome of the focus case. Our explanation model can thus provide grounds to critique a learned model. Yet this also means that our explanation model does not simply explain how the classification model made its classification for the focus case. Instead of explaining how a black-box model comes to a prediction, our method explains how a different, more interpretable model can justify the prediction made. As a result, the explanation can fully deviate from the way the prediction model works.
At first sight, this would seem to make one of Rudin’s [45] criticisms apply to our method, namely, the criticism that our explanation system must as a separate classifier be worse than the prediction model, since otherwise the explanation system would make the prediction model redundant. Rudin’s worry is that given that the explanation system is worse, the system might distract the user from following correct predictions of the black-box. Yet this is not how our explanation system works; as Propositions 4 and 10 show, our explanation method is not designed to generate separate predictions that can be compared to those of the black-box classifier but to generate justified arguments for the black-box predictions, where the dialectical proofs of why these arguments are justified reveal the assumptions under which they are justified.
Because of her worries, Rudin proposes that at least for high-stake decisions, the aim should not be to explain black-box machine learning models but to design interpretable models instead. In fact, in [18,19] the model of Čyras et al. was not applied to explain a separate prediction model but to generate predictions itself, which were then claimed to be explainable since they were in argumentation-based form (see also the approach of [25]). For example, in [18] the model was applied to the Mushroom data set after an autoencoder neural network was first used to trim down the feature space. The argumentation classifier was then shown to perform better than a neural-network and a decision-tree classifier (though as noted above in Section 6.2.4, several 100% accurate classifiers for this data set are available). Although Rudin offers very valuable insights into the pros and cons of the various approaches, in our opinion the only way to know what is the right approach is by developing, applying and testing each of them. And in this paper we have developed and tested one way of modelling the explanation approach.
Conclusion
In this paper we have presented an argumentation-based top-level model of explaining the outcomes of machine-learning applications where access to the learned model is impossible or uninformative. We investigated the model on its formal properties and we evaluated it experimentally with three data sets. The results of our experimental evaluation studies indicate that our model may be feasible in practice but that further development and experimentation, especially with human users and with extensions of our top-level model, are needed to confirm its usefulness and practical applicability as an explanation model. Main challenges here are selecting from a large number of possible explanations, reducing the amount of features in the explanations and adding more meaningful information to them. Also, it remains to be investigated how suitable our approach is for explaining non-linear models, given the independence assumptions on factors and dimensions that we inherit from the AI & law models on which we build.
The core idea of our approach was to see the training data of the machine-learning application as decided cases, to see input to the learned model as a new case and to explain the new case with techniques from case-based argumentation, embedded in the theory of abstract argumentation frameworks. Explanations of the outcome in a new case take the form of winning strategies in the argument game for grounded semantics, either showing that the outcome of the new case is justified in grounded semantics, or revealing assumptions under which it can be made justified. Thus our explanation model allows for mismatches between the machine-learning- and argumentation models due to the possibility that one or both of these models may not be fully correct. In the latter case, our explanation model may be used to critique instead of explain the outcome of the learned model. Our approach is inspired by earlier work of [20,21] but extends it to multi-valued features and to (boolean or multi-valued) features with a tendency towards a particular outcome.
As suggested by [31], good explanations are selective, contrastive and social. That an explanation is selective means that only the most salient points relevant to an outcome are presented. Our method is, to some extent, selective since in explaining outcomes it only presents those differences between a precedent and a focus case that are relevant. However, we noted that further research is needed to improve our method in this respect. That an explanation is contrastive means that it not just explains why the given outcome was reached but also why another outcome was not reached. Our explanations are indeed contrastive in this sense, as reflected in our mechanism for emphasising and downplaying a distinction, although more research is needed to avoid too many ‘trivial’ explanations. Finally, that an explanation is social means that in the transfer of knowledge, assumptions about the user’s prior knowledge and views influence what constitutes a proper explanation. The dialogical and argumentation-based form of our explanations create the prospects for truly social explanations, since users may be enabled to provide their knowledge and views (values) to the system by using argument schemes of the kind discussed in Section 7. Of course, future research should investigate to what extent it is realistic to allow users to add such relevant information during an explanation dialogue.
While our approach was motivated by legal decision making, it may also apply to other kinds of decision making, such as commercial decisions about loan applications, employee hiring or customer treatment, as long as the outcome is binary and the input conforms to this paper’s factor- or dimension format. Nevertheless, as our experiments with the Churn and Admission data sets showed, the question remains whether our model only applies to a relatively small set of cases (as is often the case in the law; cf. [8]), or whether it can also be made practically feasible with large data sets.
Throughout the paper we gave a number of specific suggestions for further research. We conclude by observing that, on the one hand, our model has several attractive features and received several encouraging experimental outcomes but that, on the other hand, the added value of our explanation method is not self-evident and needs further development and further experimentation with human test subjects. A main aim of our paper has been to lay the foundations for such further development and experiments.