
Abstract
To objectively compare groups on any latent trait using tests, the absence of differential item functioning (DIF) is crucial. While the importance of DIF has been well-established in research, the question of how to identify DIF-free items is still largely open. The fact that item difficulty is not identified from observations may explain this. Recently, DIF tests utilizing the differences between item difficulties across groups, which are identified, were proposed for the Rasch and 2-parameter logistic models. The current paper aims to extend these approaches to the polytomous case using the partial credit model. Performance of the new approach is assessed using a simulation study, and practical recommendations are made.
Keywords
To objectively compare differences in latent variables between groups, it is essential that items function the same way across these groups. In item response theory (IRT), an item functions the same way across groups if the item parameters are identical across groups. A lack of identical item parameters across groups is often referred to as differential item functioning (DIF). In the factor analytic and structural equation modeling frameworks, the same phenomenon is frequently described as measurement non-invariance (Byrne & Watkins, 2003; Van De Schoot et al., 2015).
When DIF occurs, participants of different groups with the same latent trait scores will have different probabilities of answering an item a certain way. Participants with identical latent trait scores having unequal answer probabilities are undesirable and inconvenient at best. At worst, it opens up issues of systemic discrimination against certain groups by certain tests. As an example, one could think of an aptitude test used in school placements that unfairly discriminates against participants with a migration background.
As unfair discrimination with potentially life-altering consequences is naturally not intended when constructing tests, many methods have been proposed to detect DIF in an item. IRT-based methods provide a natural way of separating between-group differences in ability from item-level DIF. For this reason, a plethora of IRT methods for testing DIF have been developed.
The most popular of these are Lord’s chi-square test (Lord, 1980), area-based methods (Kim & Cohen, 1991, 1995; Millsap & Everson, 1993), and the likelihood-ratio test (Cohen et al., 1996; Kim & Cohen, 1998; W.-C. Wang & Yeh, 2003). Unfortunately, these methods often do not achieve their stated aim of identifying which items have unequal item parameters across groups regardless of group differences in ability. The reason for this is simple. When analyzing DIF using IRT models, it is necessary to establish a common scale for the item parameters. This requires an arbitrary identification constraint to be made, such as constraining at least one item to have equal item parameters across groups or constraining the average item difficulty to be the same across groups (Bechger & Maris, 2015; Kopf et al., 2015b, 2015a). While the choice of constraint imposed is arbitrary, the results of DIF testing procedures are influenced by which constraint is chosen (Bechger & Maris, 2015).
In the approaches listed above, DIF is usually thought of as being a property of an item. However, the difficulty of an item in isolation is not an empirically identifiable property. As a consequence, the question whether a particular item shows DIF or not is not an empirical matter, as explained in detail by Bechger and Maris (2015). Essentially, this means that it is not possible to empirically establish whether any single item shows DIF or not without making additional assumptions about anchor items, such as the majority of items being DIF-free. As a consequence of this, thinking of DIF as an item property may lead to conceptually and practically problematic methods of DIF detection.
To resolve this problem, Bechger and Maris (2015) propose to focus on differential item pair functioning rather than DIF. In the approach proposed by Bechger and Maris (2015) and further developed by Pohl et al. (2017, 2020), Pohl and Schulze (2021), the differences in difficulties of item pairs, which are identifiable properties, are utilized. First, they test whether the difference between item difficulties is the same across groups for each item pair. Second, they cluster the items such that those items that have similar differences in difficulties across groups are placed in the same cluster and those that do not are placed in different clusters.
The approach by Bechger and Maris (2015) has several advantages over traditional IRT DIF testing methods. First of all, it explicitly acknowledges the non-identifiability of DIF in single items, which makes the method more theoretically sound and forces researchers to acknowledge this problem. Second, the method results in clusters of items with the task of choosing the right “DIF-free” cluster left to the researcher. Importantly, this makes researchers explicitly state their criteria for which cluster to choose. This is a desirable property, as some requirements for current DIF testing methods (e.g., at least half of all items are DIF-free and DIF does not favor one group more than the other) to function well may be less known, especially to less method-inclined researchers. This could easily lead to these methods being applied without being aware of these requirements and corresponding limitations. In addition, making researchers state their assumptions leaves other researchers free to question these assumptions and also easily see what results might have been if different clusters were designated as DIF-free. Third, the assumptions about the nature of DIF (e.g., at least half the items are DIF-free, the DIF is balanced) are moved to a later stage of the DIF testing process. While the proposed DIF methods still require assumptions about the nature of the DIF to be made, these are made when choosing a cluster that is “DIF-free.” Importantly, the process of constructing the clusters themselves does not require any assumptions about the nature of DIF. This alleviates the circularity of DIF testing (to see what kind of DIF is present, a researcher already needs to make assumptions about what kind of DIF is present, which then limits what kind of DIF can be found, which may then influence future ideas about the nature of DIF as the existing literature is affected by assumptions of current DIF testing methods). Fourth, the cluster approach results in clusters of items that function similarly, rather than DIF items and non-DIF items. This may encourage researchers to think more about why certain items function similarly, and others do not, rather than merely discarding all DIF items from the test.
While the advantages of the cluster approach are clear, as of yet, no method extending this approach to the polytomous case has been developed. Polytomous items potentially function similarly or differently on any item threshold, rather than the single difficulty parameter provided by the Rasch model or 2PL model. It is not yet clear how the presence of multiple item thresholds can best be dealt with. The current paper thus aims to develop a new cluster approach to DIF in the polytomous case utilizing the partial credit model (PCM; Masters, 1982).
The rest of the paper proceeds as follows: First, the “Cluster Approach to DIF in the Dichotomous Case” section describes the methods developed by Bechger and Maris (2015) and Pohl et al. (2021) in more detail. Second, the “DIF in Polytomous Items Under the Partial Credit Model” section describes the proposed approach to detecting DIF in polytomous items. Third, the “Simulation Study” section describes conditions and outcomes of a simulation study testing the new approach. Finally, the “Discussion” section discusses the results and provides recommendations for practical use of the method proposed in this paper.
The Cluster Approach to DIF in the Dichotomous Case
To illustrate the Bechger and Maris (2015) approach to uniform DIF in the Rasch model, we provide an example below. In Table 1, the difficulties of four hypothetical Rasch model items (i.e., items with a slope parameter set to 1) in two groups with the mean ability of both groups constrained to zero are provided.
Example Matrix of Item Difficulties

Note.
Rather than directly comparing the difficulties of items across groups that are not identifiable, we instead assess the differences in difficulties of items across groups that are identifiable. Matrices of pairwise differences between item parameters per group can be constructed utilizing Equation 1:

where
While the approach by Bechger and Maris (2015) is promising, several problems may occur. The first problem lies in the use of the statistical testing approach to forming item clusters. After all, it is possible for item 1 to not function differentially from item 2, and item 2 to not function differentially from item 3, while items 1 and 3 do function differentially. It is unclear what the clusters should be in this situation. The second potential problem is the visual approach to detecting the clusters Bechger and Maris (2015) advocate if there are no a priori expectations about the clusters. This visual approach may be difficult to implement in practice if there are many items and is difficult to test in simulation studies (Pohl et al., 2021).
For the aforementioned reasons, Pohl et al. (2021) utilize k-means clustering rather than a statistical test or utilizing visual approaches. As k-means clustering is based on the differences between the
DIF in Polytomous Items Under the PCM
Equations 2 and 3 present the PCM for an item with
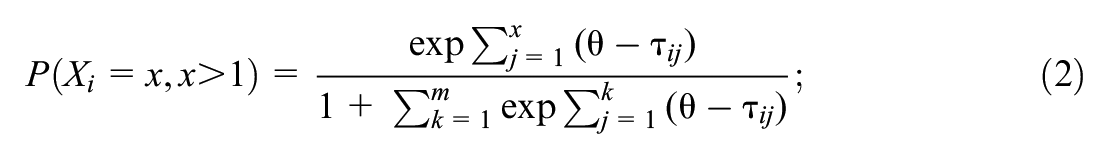
where
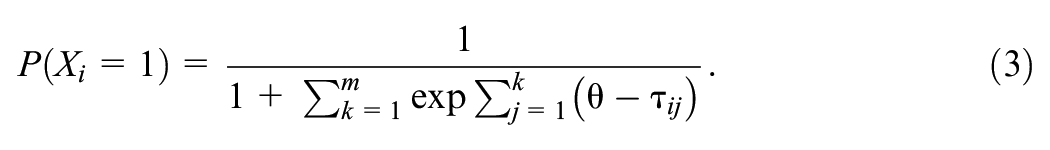
As the PCM has
Stage One: Equidistant Thresholds Test
To illustrate the approach in this paper, we utilize a four-category PCM item with three-item thresholds. The approach can be generalized to items with a different number of categories and generalized partial credit items, which we discuss in the discussion section. In the first stage of the approach, we are interested in establishing whether the distances between the item thresholds of a single item are the same across groups. A violation of this property would mean that a specific item has DIF. Note that while for dichotomous items DIF of a single item is not an identifiable property, the violation of equidistant thresholds is. To test for equidistant thresholds in a four-category item with three-item thresholds, the means of groups 1 and 2 are constrained to zero. We can test for equidistant thresholds by testing whether
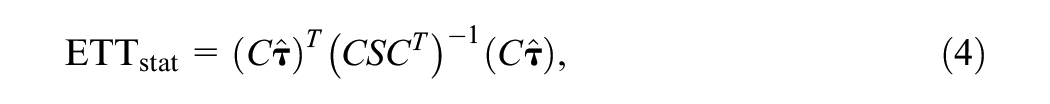
where
Stage Two: Forming Item Clusters
To establish whether items that pass the ETT function similarly to other items or not, we extend the cluster approach from Pohl et al. (2021). First, we fit the model with all items that passed the ETT having the distances between item thresholds constrained to be equal across groups and the means of groups 1 and 2 constrained to zero.
1
Note that imposing these constraints induces positive covariances between the item parameters of different groups, which reduces the standard error of the
The clustering described above could be accomplished using various methods. In this paper, following Pohl et al. (2021), we chose to cluster items by conducting k-means clustering on an arbitrary row/column of the
As a final step in the clustering process, one of the clusters that form needs to be designated as the DIF-free cluster. While several approaches to this problem are possible, all of these do again involve bringing in some outside information or assumptions about the items, same as the traditional DIF-testing methods. In fact, designating the cluster with most items as the DIF-free cluster would make this method similar to traditional DIF testing methods (Pohl et al., 2021). Nevertheless, we believe the conceptual and practical advantages of this method described earlier, including its flexibility in which clusters are designated as DIF-free, still make this method a worthwhile development over traditional methods. Alternative methods of choosing a cluster are described in the discussion.
Empirical Example
To illustrate how an application of the approach to real data would proceed, an empirical example is provided. We utilize a multigroup dataset with four-category items obtained from the Program for International Student Assessment (PISA), a well-known and publicly accessible source for multigroup data (OECD, 2000). We used the reading attitude scale from PISA 2009 (OECD, 2010). The scale has eleven four-category items, for example, “I read only if I have to” (reverse coded) and “I like talking about books with other people.” The response options were “Strongly disagree,”“Disagree,”“Agree,” and “Strongly agree,” with higher scores indicating higher levels of reading enthusiasm once the reverse-coded items are considered. All code utilized in this example is available in online Supplemental Materials (available in the online version of the journal) and on https://osf.io/mfqkg/, and the data is freely accessible on the PISA website.
For the purposes of this example, we chose to examine Latvia (N = 4,502) and Serbia (N = 5,523). These groups were preferred over other countries for several reasons. First of all, the countries did not eliminate too many items in the ETT stage of the item similarity test. Second, the countries showed an interesting pattern in the clustering stage of the item similarity test, with multiple clusters of different sizes forming. It is important to note here that we chose this specific example to illustrate the approach best; we do not make any claims about its generalizability.
As a first step in the analysis, we estimated the PCM model with the means of the latent variable in both groups fixed to 0 for identification purposes. With these constraints, the average item thresholds were [−1.88, −0.30, 2.00], indicating somewhat balanced item thresholds. The values for the ETT statistics calculated using Equation 4 can be found in Table 2. Items exceeding the critical value of 5.99 based on a chi-square distribution with two degrees of freedom and a type I error rate of 0.05 are marked in bold. In addition to the ETT statistic, the difference in distances across groups is contained in the table.
Results of the ETT
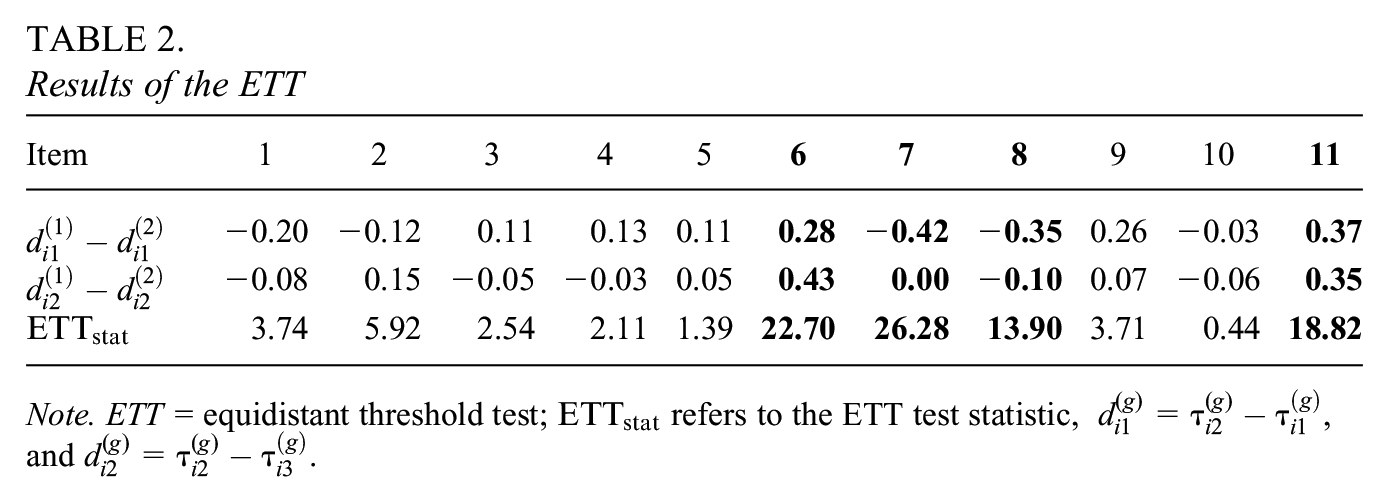
Note. ETT = equidistant threshold test;
As can be seen in Table 2, items 6, 7, 8, and 11 are found to have non-eq5 thresholds. After determining items 6, 7, 8, and 11 items do not pass the ETT, we run the reparametrized PCM model with the latent trait means of both groups fixed to zero. The distance parameters of the items that did not fail the ETT are constrained to be equal across groups.
To illustrate the 0.2 threshold range approach (Pohl et al., 2021) using the Ckmeans.1d.dp package, all

As can be seen in Table 3, items 1, 2, 4, and 10 function similarly, items 3 and 9 function similarly, and item 5 does not function similarly to any other item. As a final step in the analysis, a researcher must choose a cluster of items to be designated as DIF-free or utilize model averaging. The choice of cluster can be based on various criteria. Most current DIF testing methods utilize the principle that the largest cluster is the DIF-free cluster, but a researcher may also base their conclusion on content expertise or other grounds. The items in the designated DIF-free cluster are used as anchor items and have their item thresholds constrained to be equal across groups.
To illustrate the impact of utilizing different clusters as DIF-free on the latent trait means of the groups, we discuss the various conclusions depending on which cluster is designated as DIF-free. Note that the mean of Serbia (
Simulation Study
To best assess the performance of the proposed method, we first examine the performance of both stages separately. Second, we evaluate the performance of the two stages combined. All code is available in Supplemental Material (available in the online version of the journal) and on https://osf.io/mfqkg/.
Conditions and Outcomes for the Equidistant Thresholds Test
All data in this simulation study were generated using R 4.2.2 (R Core Team, 2022), and all conditions were replicated 500 times. First, data were generated for two groups, where both groups had a latent trait distributed
In the generated data, the proportion of items with equidistant thresholds was kept constant at 0.5 to ensure that we have the same number of DIF and non-DIF observations to base our outcome estimates on. Non-eq6 thresholds were induced by adding a value
As outcome measures, the type I error (
Results for the Equidistant Thresholds Test
As can be seen in Table 4, the power to detect non-equidistant thresholds is generally quite high. Only when the sample size per group is 1,000 and the
Results for the
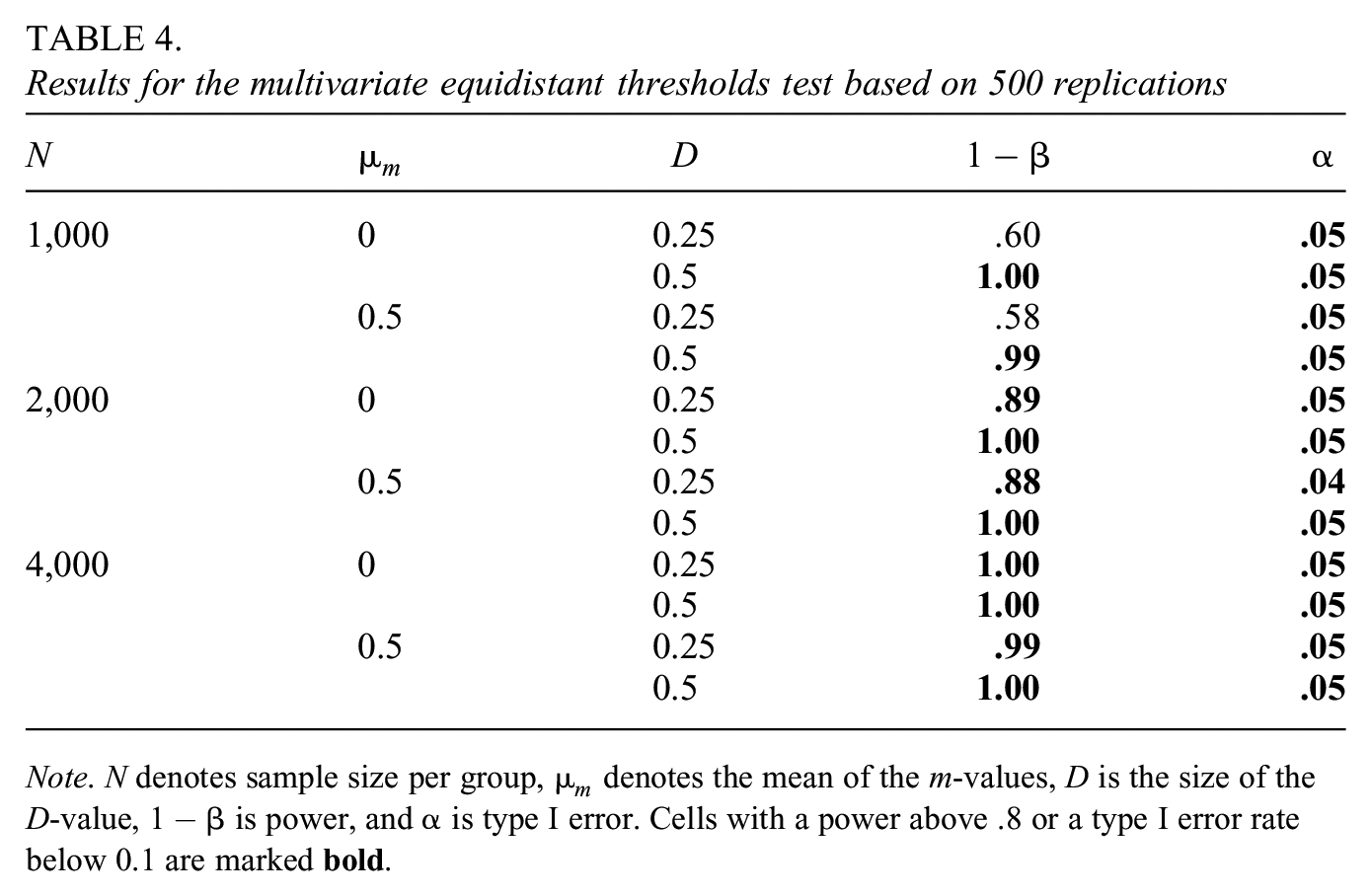
Note. N denotes sample size per group,
Conditions and Outcomes for the Forming of Item Clusters
Conditions for the clustering simulation largely follow the conditions for the ETT simulation. Item thresholds, sample sizes, and identification constraints were identical to the ETT study. Three major changes were made to the simulation design. First, we now drop the
Concerning the outcome measures of the cluster approach, we were most interested in how well the DIF-free cluster was recovered. We thus chose to label the cluster with the most DIF-free items as the focal cluster, similar to Pohl et al. (2021), and examine outcomes related to this cluster. We chose the false positive rate (FPR, the rate of items that do belong in the focal cluster but are not placed there by the clustering) and true positive rate (TPR, the rate of items that do not belong in the focal cluster and are not placed there) as outcomes. In addition, we were interested in two further outcomes. First, the number of clusters formed was of vital importance. If the number of clusters formed is too high, the eventual step of designating a cluster as a non-DIF cluster that has to be made by the researcher would become needlessly complex and prone to error. Finally, we considered the specificity (the proportion of items in the focal cluster that are DIF-free/similar items) to be of interest. Specificity is relevant here for two reasons. First of all, the focal cluster should contain as few DIF items as possible to prevent misestimation of the latent trait. Second, a researcher may wish to apply traditional DIF techniques to their selected non-DIF cluster. In order for these techniques to be effective, a specificity above 0.5 may be required (Woods, 2009).
Results for the Forming of Item Clusters
Note that several approaches for selecting the number of clusters were considered. As the 0.2 threshold range approach showed high TPR rates even in lower sample size conditions, we display results based on this criterion in Table 5. Results for threshold range approaches of 0.4 or 0.6 and the BIC for selecting a number of clusters can be found in Supplemental Material A (available in the online version of the journal).
Clustering Results for the Threshold Range Criterion of 0.2 Based on 500 Replications
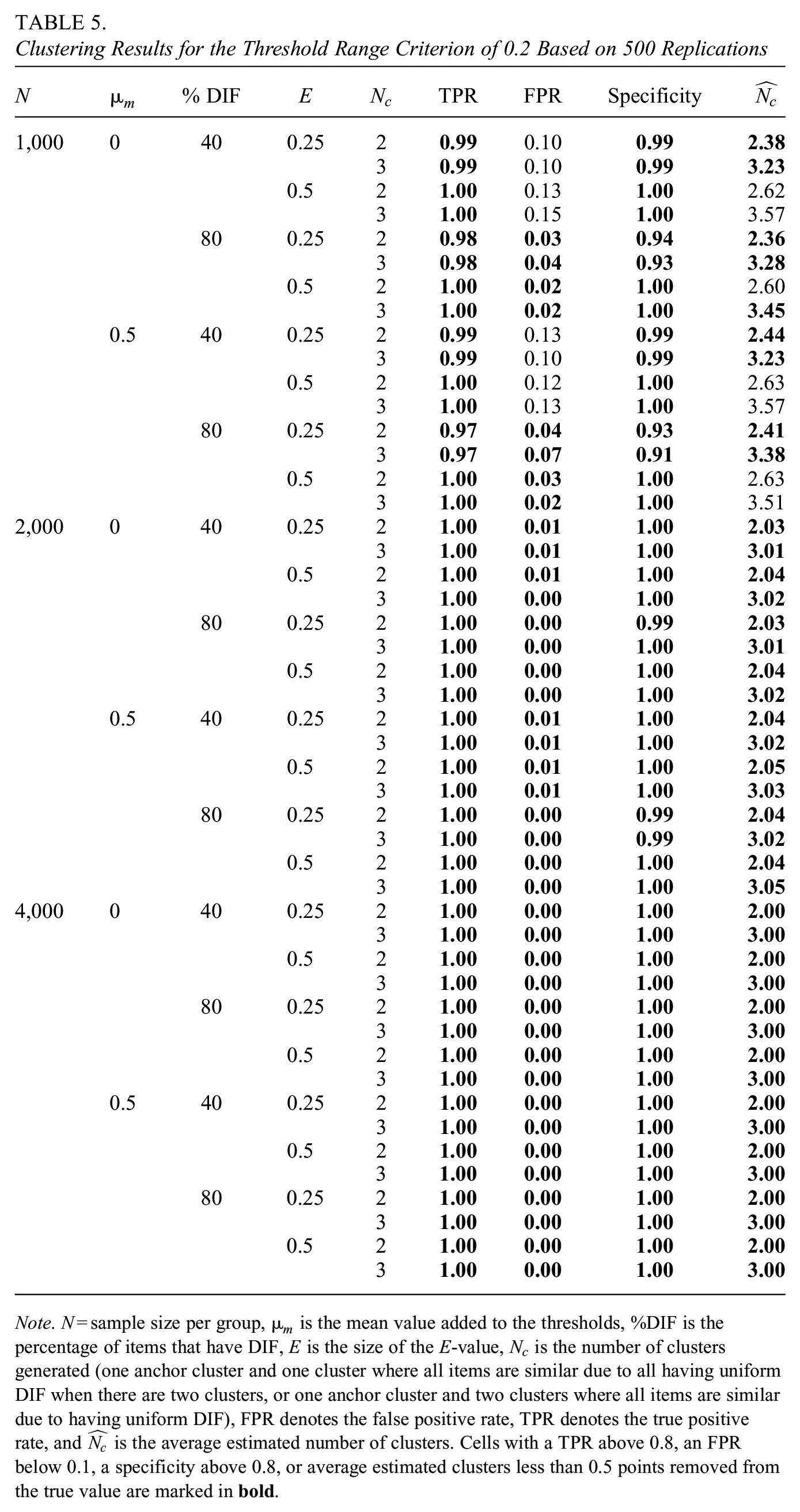
Note. N = sample size per group,
As can be seen in Table 5, the threshold range criterion of 0.2 generally has a high TPR in all conditions. Since the TPR is always near 1, the effect of factors is difficult to distinguish here.
The high power at lower sample sizes does come at the cost of an inflated FPR when the sample size is 1,000 participants per group. This inflated FPR is particularly pronounced when the percentage of DIF items is low. This seemingly contradictory behavior can be explained by the fact that as the number of anchor items increases, it becomes more and more likely that the most extreme anchor items are not within a
Due to the high power, the specificity of the focal cluster is often close to 1 and remains above 0.9 in all conditions. Smaller
In terms of the average number of estimated clusters (
Conditions and Outcomes for the Combined Approach
Finally, we were also interested in showcasing a combination of the ETT and cluster methods, as would be done in practice. As a full factorial design here would lead to a very high number of conditions and an inaccessibly large set of results, we chose to instead showcase some specific conditions as an illustration.
First of all, conditions where there is no DIF present were considered to evaluate the FPR rate of the proposed full approach. Item thresholds and sample sizes were generated identically to previous conditions. No
Second, the performance of the ETT and clustering combined was evaluated in the presence of both types of DIF. As the performance of the ETT and cluster approaches separately is already examined in the previous conditions, we were particularly interested in conditions where the ETT does not perform optimally. This enabled us to observe whether a less successful ETT adversely affects the subsequent clustering. We thus chose three conditions where the ETT did not perform well in terms of power: A sample size of 1,000 with a mean
When examining the performance of the combined approach, it is important to keep in mind that eliminating items due to failing the ETT will reduce the effective sample size of the cluster stage (i.e., the number of items that can be clustered). We thus wanted to ensure that any potentially observed reduction in clustering performance was due to “contaminated” non-ET items making it into the cluster stage rather than a reduction in the effective clustering sample size. We, therefore, added two extra conditions where the ETT performed well: A sample size of 1,000 with a mean
As all five aforementioned ETT results concern conditions where half of the items had non-eq7 thresholds, we chose to again induce non-equidistant thresholds in half of the items. In addition, 12 of the items were designated as dissimilar by subtracting (and adding in the case of multiple dissimilar item clusters) an
Concerning the outcome measures of the combined approach, we distinguish between the conditions where no DIF is present and the conditions where DIF is present. In the no DIF conditions, we were interested in the FPR and the number of clusters formed.
In the DIF conditions, we were again most interested in how well the DIF-free cluster was recovered. We thus chose the FPR, TPR, number of clusters formed, and the specificity as the first outcomes. TPR is again calculated as the proportion of dissimilar items in the focal cluster (the cluster with most similarly functioning items). Note that an item is labeled as dissimilar if it has either non-equidistant thresholds or if an
Results for the Combination of the ETT and the Clustering of Items When No Item Dissimilarity Is Present Using a Threshold Range Value of 0.2 Based on 500 Replications
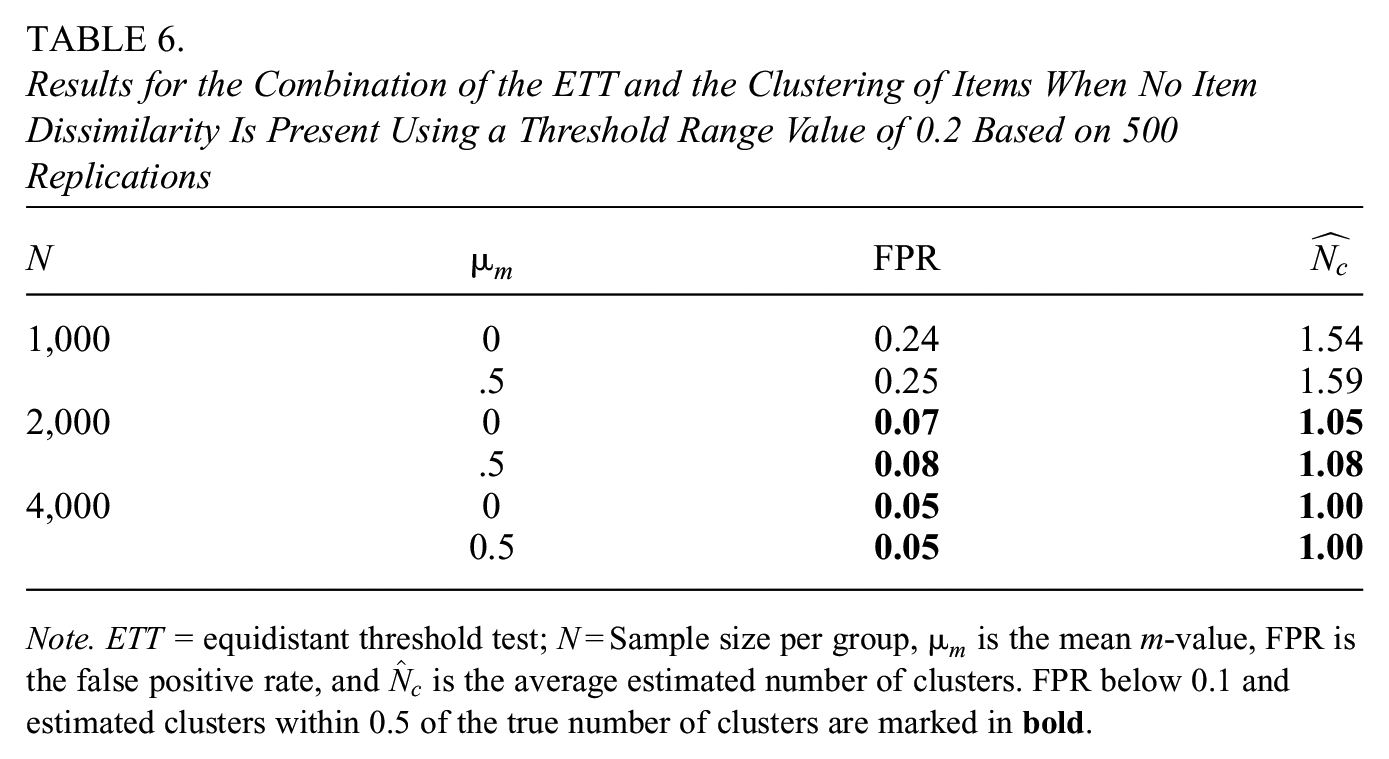
Note. ETT = equidistant threshold test; N = Sample size per group,
Results for the Combined Approach
Conditions Without DIF
As can be seen in Table 6, the FPR of the approach remains below 0.1 as long as the sample size is at least 2,000 for each group. The FPR can be inflated at lower sample sizes due to the higher standard errors of the
Concerning the number of clusters formed, higher sample sizes lead to an
Results for the Combination of the ETT and the Clustering of Items When Item Dissimilarity Is Present Using a Threshold Range Value of 0.2 Based on 500 Replications
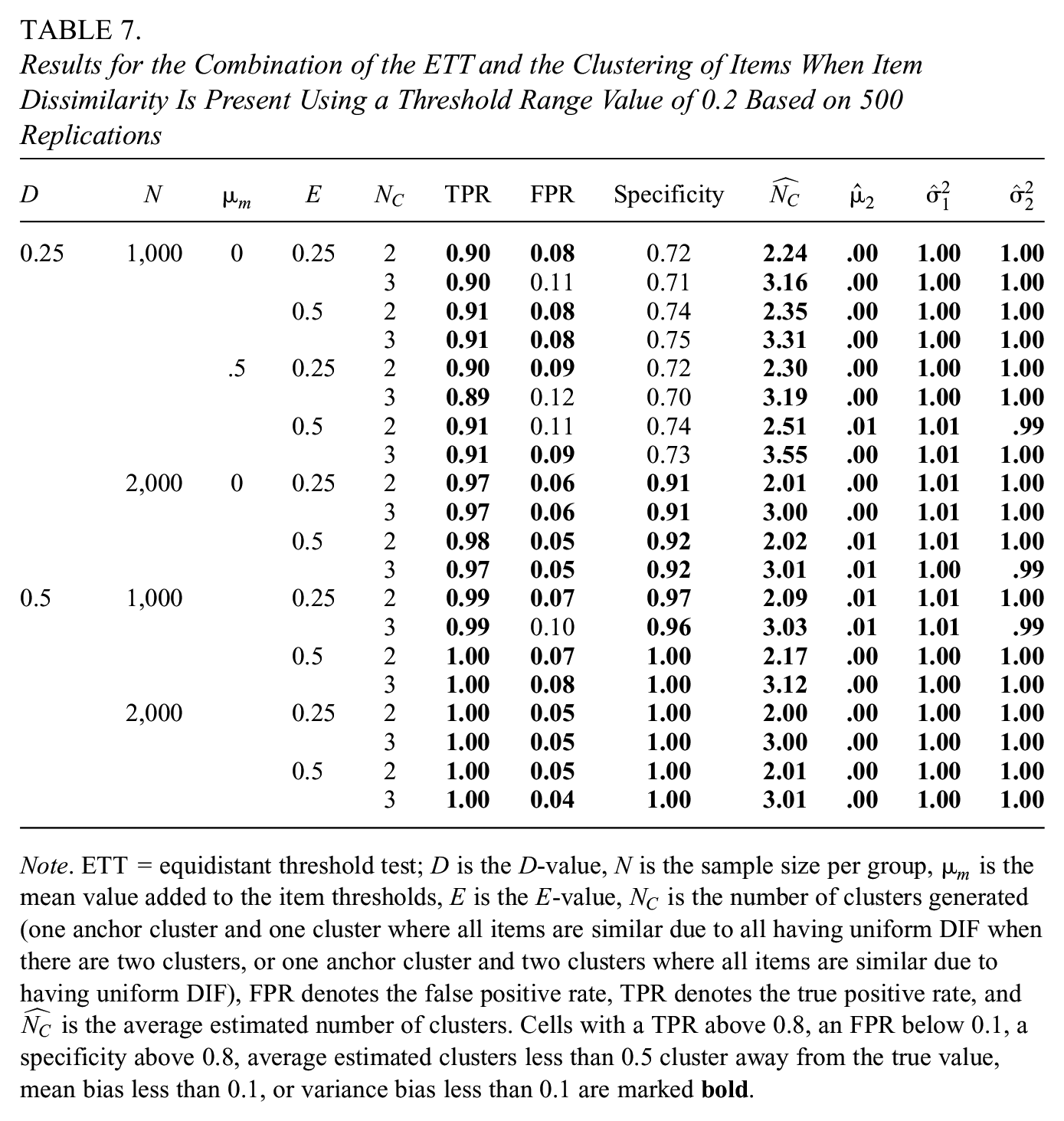
Note. ETT = equidistant threshold test;
Conditions With DIF
As can be seen in Table 7, the TPR is at least 0.9 across all conditions, again showcasing the high TPR of the 0.2 threshold range approach. An underpowered ETT thus does not seem to adversely affect clustering performance. Note that the decrease in TPR from near 1 to 0.9 (and consequent decrease in specificity) is driven by the lower power of the ETT when sample sizes are below 2,000. In essence, we see that the ETT stage of the approach is somewhat more conservative (i.e., retains more items) than the clustering stage. Increasing the sample size or increasing the
When considering the FPR, we again see that lower sample sizes can lead to an FPR above 0.1. This is especially the case when multiple DIF clusters are present, and the
The specificity of the clusters formed mostly seems to be determined by the performance of the ETT. Perhaps not surprisingly, an underpowered ETT leads to a lower specificity of the focal cluster, as items with non-eq8 thresholds are admitted to the focal cluster. The specificity is thus lower for lower sample sizes and lower
Regarding the number of estimated clusters, we mostly see a repetition of earlier findings. When
Finally, there appears to be little bias in any of the latent trait parameters as long as the focal cluster is used to anchor the scale. This is likely due to the high power of the 0.2 threshold range approach eliminating almost all items with uniform DIF. In addition, the specificity of the focal cluster does stay somewhat high in all conditions, with at least 69% of all items in the cluster being anchor items. It thus seems that as long as most items are anchor items and all uniform DIF items are eliminated, little bias in latent trait parameters occurs.
Discussion
The present study set out to highlight an alternative and empirically identified approach to DIF testing utilizing item (dis)similarity and extended the proposed approaches for dichotomous items to the polytomous case utilizing the PCM. As a first stage in the approach, it is assessed whether items have equidistant thresholds across groups. As the second stage, the items with equidistant thresholds are clustered on all thresholds to reveal clusters of similarly functioning items. The two stages were first evaluated on their individual performance separately and finally on their combined performance. The results will be discussed in this order.
The ETT performed well in most simulated conditions, with the type I error of the approach remaining at the 0.05 level for all conditions. In terms of power, we recommend a sample size of at least 2,000 participants per group if a researcher is interested in detecting the smaller levels of non-equidistant thresholds at a type I error rate of 0.05.
When evaluating the second stage of the approach, a threshold range criterion of 0.2 was considered in the main paper. This approach led to a higher TPR but, in turn, showed a higher FPR than the BIC approach detailed in Supplemental Material A, especially when sample size was below 2,000 participants per group. Researchers aiming to utilize the threshold range approach when the sample sizes per group are below 2,000 could consider increasing the number of items to ensure that after completing this stage, one can expect enough items to remain to construct a valid test. Alternatively, the cluster approach could be combined with traditional DIF testing methods, such as the likelihood-ratio test with the designated DIF-free cluster as an anchor cluster to add more items to the DIF-free cluster.
To assess the performance of the combined approaches, several conditions were considered. First, several conditions where no DIF was present in any item were analyzed. Again, lower sample sizes lead to an inflated FPR when utilizing the 0.2 threshold range approach. It must be noted that the FPR of the combined approach was often somewhat higher than the FPR of the separate approaches. The advice to increase the number of items when dealing with DIF-analysis utilizing a sample size below 1,000 thus holds even stronger for the combined condition. Second, several DIF conditions were considered. In the conditions with DIF present, we were mostly interested in whether an underpowered ETT would adversely affect the performance of the clustering. Fortunately, this did not seem to be the case in the observed conditions. The results of the combined conditions did, however, again emphasize the need for a sample size above 1,000 participants per group or a high number of items to combat the FPR. Notably, no bias in the latent trait occurred in any condition as long as the focal cluster was used as an anchoring cluster.
A final aspect of the approach that must be discussed is how a researcher would designate a cluster as DIF-free in practice. Several approaches to this problem have been proposed previously. First of all, it is possible to designate the cluster with most items as DIF-free (Pohl et al., 2017). Opponents of this approach may call the assumption that most items are DIF-free “wishful thinking” and point to the fact various group-level differences in response style are frequently found (Chun et al., 1974; Clarke, 2001; Marin et al., 1992; Zhang & Wang, 2020). Truly DIF-free items may thus be rare. In addition, it is very well possible the cluster approach results in multiple clusters of the same size.
A second approach to designating the DIF-free cluster is to select the cluster with the lowest variance (Pohl et al., 2017). The logic behind this approach is that the
Finally, one could involve content experts in designating the cluster they believe to be DIF-free. An advantage of this approach is the opportunity to involve substantive expertise in the cluster decision. As a disadvantage, it may prove difficult to isolate the decision process from preexisting biases by the experts and the researcher.
While the proposed approach performs adequately as long as sample sizes are not too small, the current study has limitations, and several avenues for future research remain open. As a first limitation, the current study was a simulation study, where not all conditions may be generalizable to real-life conditions. For example, items were answered with no missing data, the DIF induced in the items was quite uniform in its strength, and only four-category PCM items were examined. Future research should examine the performance of this approach when conditions such as these are varied.
Second, the approach should be extended to different IRT models. Note that while the approach presented here was illustrated using four-category items, extensions to items with more categories can be achieved by simply increasing the number of distances tested in the ETT. While several operationalizations of these distances are possible, it may be simplest to conceive of the distances as the space between two neighboring thresholds. In addition, the approach described here could be generalized to the GPCM by starting with an additional clustering step on the log slopes as described in Pohl et al. (2021) and implementing the approach described in this paper conditional on items being in the same slope cluster. While the extension of the approach described here to the GPCM may be theoretically straightforward, several practical questions remain. First of all, it is not yet clear how clustering on slopes rather than thresholds will influence the sample size required for the method to function adequately. Second, increasing the number of clustering stages, as proposed by Pohl et al. (2021), may adversely affect the FP rate of the approach. Further research is needed in these areas. In addition to the GPCM, the approach could be extended in a similar way to the graded response model (Samejima, 1969). Again, further research is needed when evaluating the efficacy of the approach for this model.
As a third limitation, it is not yet clear which method of clustering items will perform best under which conditions. While the current paper considered k-means clustering on an arbitrary row of the
Fourth, the current paper proposes a Wald test when establishing whether items have equidistant thresholds or not. While the approach performs reasonably in the simulated conditions, other approaches, such as bootstrap tests or Bayesian methods, are possible and may show superior performance. Alternative approaches to the first step may also relax the assumption of completely equidistant thresholds across items, for example, in favor of approximately equidistant thresholds. Future research should evaluate the performance of these approaches.
Fifth, the current paper limits its scope to situations where only two clearly defined groups are present. Future research would do well to extend the method to situations where groups are not clearly defined (e.g., latent classes are present in the data). Additionally, scenarios with more than two groups present should be examined. When many groups are present, one may consider mixture-multigroup factor analysis methods to reduce inflated type I error rates resulting from many pairwise comparisons (De Roover, 2021; De Roover et al., 2022).
Finally, the current paper aims to detect items that are fully measurement invariant. To identify the model, technically, only a single threshold of a single item needs to be set to be equivalent across groups. While it is naturally preferred for items to achieve full rather than partial invariance, future research could examine the performance of the approach if some aspects of the invariance were relaxed.
From this paper, several practical recommendations can be made. First of all, researchers should consider their conceptualization of DIF. As DIF is not empirically identifiable, they may wish to think in terms of similar/dissimilar item functioning instead. This approach to DIF has several conceptual advantages, such as being rooted in empiricism and forcing researchers to explicate their assumptions about DIF when designating a DIF-free cluster.
Second, researchers should assess what their beliefs about DIF are when designating a DIF-free cluster. A central point of contention here will be if the assumption that most items are DIF-free is realistic or not. We encourage researchers to explicate their beliefs and allow other researchers to see what results would have been if different assumptions were made, which is most easily achieved by utilizing the cluster-based approach to DIF.
Third, researchers should consider what the maximum amount of DIF they are willing to accept is. Formulating what amount of DIF is “acceptable” will aid in choosing an appropriate threshold range criterion. If the amount of DIF one accepts is too great, many items will erroneously be placed in the same cluster (this can be seen when examining the results for the 0.4 and 0.6 threshold ranges in Supplemental Material A). If the amount of DIF one accepts is too small, many items will be wrongly placed in different clusters. To inform the size of the threshold, one may refer to benchmarks of DIF in large-scale assessments, as suggested by Pohl et al. (2021). Alternatively, one could consider the standard errors of the
Summarizing, the current paper extends the cluster approach to DIF to polytomous items. We advocate for a two-stage approach, where the distances between thresholds within an item across groups are compared first. Second, items that are found to have equidistant thresholds are clustered on all thresholds. The proposed approach can bring many conceptual and practical advantages to the DIF testing framework, and we encourage researchers to consider their conceptualization of and assumptions about DIF.
Supplemental Material
sj-docx-1-jeb-10.3102_10769986241256033 – Supplemental material for Extending the Cluster Approach to Differential Item Functioning in Polytomous Items
Supplemental material, sj-docx-1-jeb-10.3102_10769986241256033 for Extending the Cluster Approach to Differential Item Functioning in Polytomous Items by Martijn Schoenmakers, Jesper Tijmstra, Jeroen Vermunt and Maria Bolsinova in Journal of Educational and Behavioral Statistics
Supplemental Material
sj-zip-2-jeb-10.3102_10769986241256033 – Supplemental material for Extending the Cluster Approach to Differential Item Functioning in Polytomous Items
Supplemental material, sj-zip-2-jeb-10.3102_10769986241256033 for Extending the Cluster Approach to Differential Item Functioning in Polytomous Items by Martijn Schoenmakers, Jesper Tijmstra, Jeroen Vermunt and Maria Bolsinova in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Authors
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.