
Abstract
A general framework of latent trait item response models for continuous responses is given. In contrast to classical test theory (CTT) models, which traditionally distinguish between true scores and error scores, the responses are clearly linked to latent traits. It is shown that CTT models can be derived as special cases, but the model class is much wider. It provides, in particular, appropriate modeling of responses that are restricted in some way, for example, if responses are positive or are restricted to an interval. Restrictions of this sort are easily incorporated in the modeling framework. Restriction to an interval is typically ignored in common models yielding inappropriate models, for example, when modeling Likert-type data. The model also extends common response time models, which can be treated as special cases. The properties of the model class are derived and the role of the total score is investigated, which leads to a modified total score. Several applications illustrate the use of the model including an example, in which covariates that may modify the response are taken into account.
1. Introduction
The development of item response theory (IRT) that clearly separates the observed response from the underlying latent traits has been mainly driven by the consideration of binary items, in which it is distinguished between a correct response and an incorrect one as outlined, for example, in Rasch (1960). Items with continuous response formats have been largely considered within the framework of classical test theory (CTT), which distinguishes between a true score, essentially the expected response, and an error score (Lord & Novick, 2008). Although there are some approaches to modeling continuous responses, there seems no general framework available that considers responses as generated by latent traits and item characteristics.
Continuous responses occur in particular in the form of time to complete a task and responses within a line segment (e.g., responses on a visual analogue scale). Especially, time response modeling, which has already been considered by Rasch (1960), has drawn much attention (De Boeck & Wilson, 2004; Ferrando & Lorenzo-Seva, 2007; Roskam, 1997; van der Linden, 2006). Also, Likert-type scales, which are quite common in practice, are often modeled as continuous responses despite of an ongoing discussion as to whether that is the right way to analyze this type of data. An overview concerning problems and the pros and cons have been given by Harpe (2015). The controversy focuses on the problem as to whether Likert-type categories constitute interval-level measurement or have to be treated as ordered responses. If the measurement level is only ordinal, then it is questionable if item sums should be used. Harpe (2015) distinguishes between the “ordinalist” and the “intervalist” view and concludes that “individual rating items with numerical response formats at least five categories in length may generally be treated as continuous data.” Although one has not to agree, it seems worthwhile to investigate whether there is much difference between continuous and discrete modeling, given proper latent trait models for both cases are available. One particular case which exemplifies these considerations is given by fitting normal theory-based models with robust standard errors to categorical factor analysis (FA) models (Rhemtulla et al., 2012). Although a practically feasible approach, the standard errors may become biased; however, depending on the sample size and number of categories, the effect may diminish.
When modeling responses that are restricted in some way, it is sensible to account for restrictions in a proper way. Otherwise, the models do not match the data. For illustration, let us consider an example in which data are confined to the interval
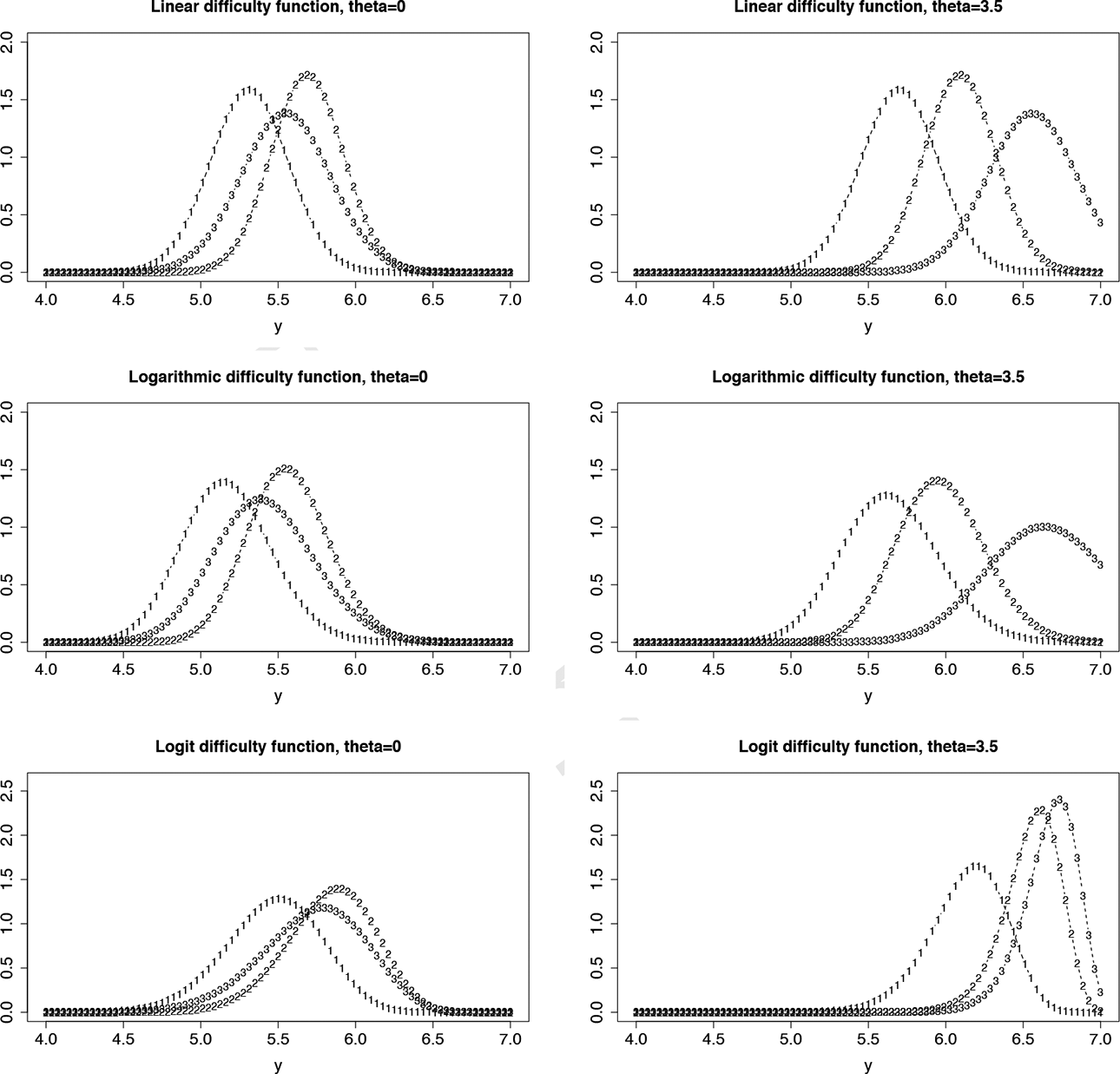
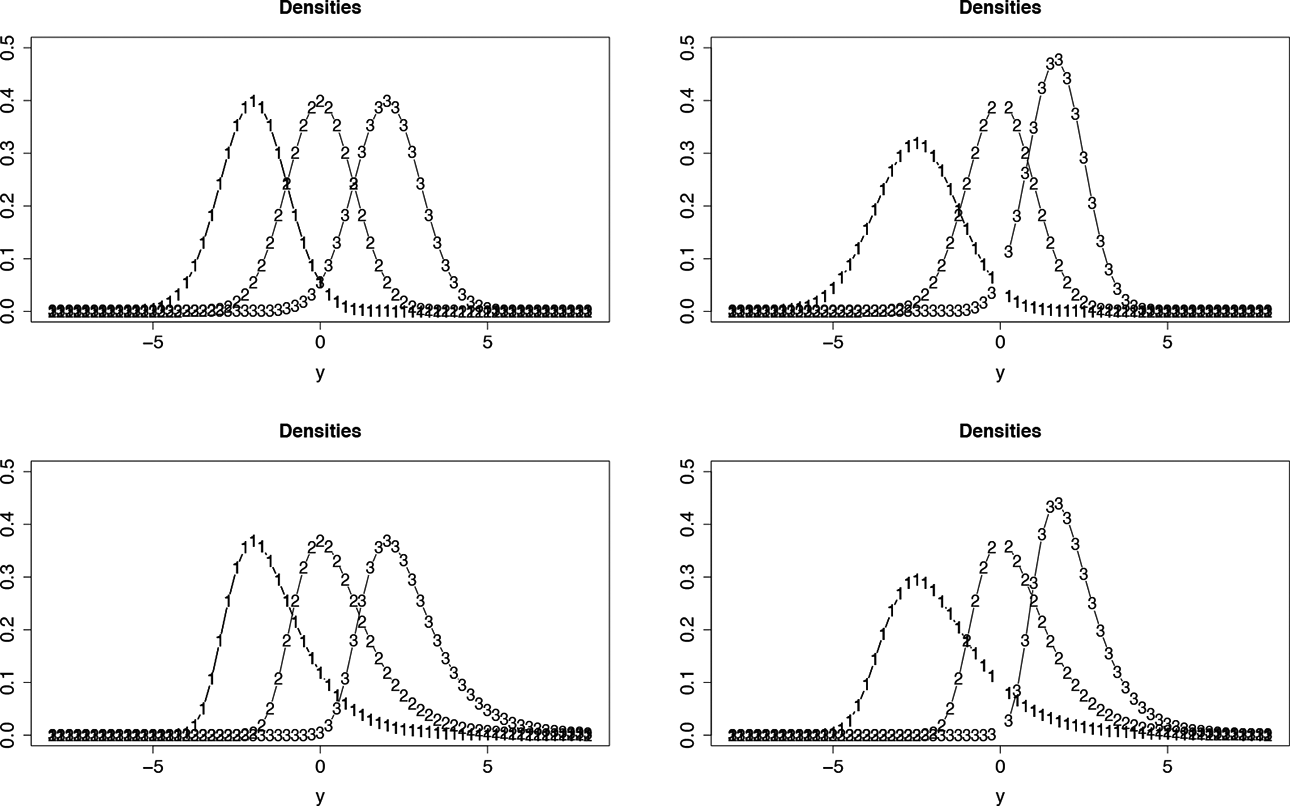
Estimated densities for self-regulation. First row: linear difficulty functions, second row: logarithmic difficulty functions, third row: logit difficulty functions, left:
The objective of the present article is to propagate genuine latent trait models for continuous responses and investigate their properties. The general framework that is used is the thresholds model framework (Tutz, 2022b). The threshold model has been proposed as a model that allows for different item formats, but continuous responses have been treated very cursorily. In the following, the focus is on continuous responses and the approach is extended in several ways. The link to various versions of the CTT model is investigated in detail, basic results are obtained by using quantile functions, which have not been considered before, and the role of total scores is examined and modified versions are proposed. Also, the embedding of response time models, the comparison of models with differing response functions, and the explicit inclusion of explanatory variables have not been investigated before. Further, referring to the potential use in a Likert-type scale setting, we emphasize the need to properly account for the support of the data and show how this can be accomplished via the general modeling framework.
The general framework for continuous item response models does not only include various models as special cases but offers new modeling strategies that allow for valid inference. For responses that are restricted to an interval, as in analogue scales, one obtains models that account for the restriction. The models yield better fits and, importantly, yield more trustworthy significance tests, which is in particular helpful if the impact of covariate effects is to be investigated. Significance test based on the assumption of a normal distribution, which implies that responses can take values far beyond the fixed interval of responses, cannot be considered as reliable if responses are restricted. Problems with significance tests may occur any time if the distribution is strongly misspecified. Thus, alternative distributions are useful beyond the improvement of fits that can be obtained. For responses in the positive domain, the framework offers alternative distributions beyond the log-normal distributions and more flexible parameterizations.
This article is structured as follows: In Section 2, the general modeling framework is presented. In Section 3, we discuss linear models and show that the model allows for a variety of response distributions. Also, the link to CTT is investigated in detail. It is shown how the CTT model can be given as a genuine latent trait model. It also covers CTT-type models with alternative response distributions. Although the basic CTT model lacks distributional assumptions, some distributional assumptions are often tacitly assumed when fitting unidimensional CTT models via FA. Interesting distributions of practical relevance are in particular obtained when using nonlinear thresholds models (Section 4). The models allow one to find distributions that account for the restriction to closed or open intervals, yielding models that are much more appropriate than distribution models that ignore these restriction as, for example, the normal distribution. Section 5 is devoted to transformed responses and the link to thresholds models is investigated. In Section 6, the modeling approach is illustrated by using several data sets with differing response formats. It includes an example with reaction time data and shows how better fitting models than classical response time models can be constructed. Within the application section, Likert-type data are also discussed. It is shown that if one uses continuous modeling of Likert-type items, which is not uncommon, one should at least account for the fact that responses are restricted to an interval; otherwise, models show distinctly inferior fit.
2. Thresholds Models: Basic Concepts
Let
where
One of the important features of the model is that
The concrete form of the thresholds model is determined by the choice of the difficulty functions
3. Linear Models
We will first consider models in which the mean of the response is a linear function of the latent ability. This can be obtained within the framework of thresholds models by assuming that the difficulty functions are linear. An important feature is that any strictly continuous response distribution can be obtained by combining a linear difficulty function with a response function that is chosen according to the assumed response.
3.1. Linking Latent Traits and Responses
Let
When investigating the distribution of responses, it is helpful to define the distribution function
That means the distribution function of the responses,
The expectation and variance of
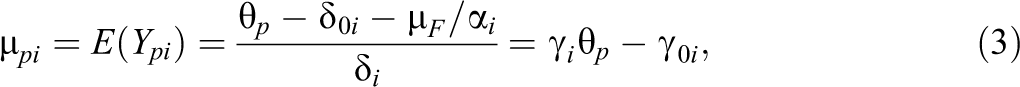

where
It is noteworthy that one can choose any fixed function
For illustration, Figure 2 shows the distributions obtained for a person with
Densities for three items with equal slopes and varying intercepts (first column) and for three items with varying slopes (second column). First row: normal response function; second row: Gumbel for
The derived results hold for all strictly continuous distribution functions
3.2. Thresholds Models and CTT
In CTT, the response usually is decomposed into the “true score” and the “error score,” typically at the population level. A similar decomposition holds for threshold models on the population level and the person level. At the person level, one has

where the noise variable
One can then define—following Novick (1966) and Holland and Hoskens (2003)—the true score random variable Ti
as the true score of a randomly selected test taker from the population and the error variable

Herein,
This representation has several consequences. Given that a threshold model holds a CTT model holds for randomly selected test takers. Thus, all CTT based quantities, like reliability coefficient, may be defined appropriately, and all of the derived results for true score prediction may be applied to the TM setting (for details, we refer to Holland and Hoskens (2003)). Hence, a plethora of already established results become applicable. Another important aspect is that the threshold model can be seen as a latent trait model underlying the CTT model. In the CTT model, expectations of item responses are simply considered as representing the true scores, but latent traits as the driving force behind the individual’s responses on items are not clearly identified. We note, however, that the unrestricted CTT model is in almost any cases fulfilled by appropriate definitions of the true and error score terms (Novick, 1966). It only imposes empirical testable restrictions when it is used in its restricted form—via submodels (which are further described in the following). These submodels are oftentimes estimated via the factor analytical approach—hence, in practical applications of CTT models, there is a close connection to normal theory-based FA models—despite the fact that the original CTT setup lacks any distributional assumptions.
Now, assuming the special case of a linear TM model, one may derive specific submodels of CTT. To this end, it is helpful to recall the following distinction (Raykov, 1997): Measurements are called congeneric if all true scores may be expressed as affine functions of a single true score, that is,
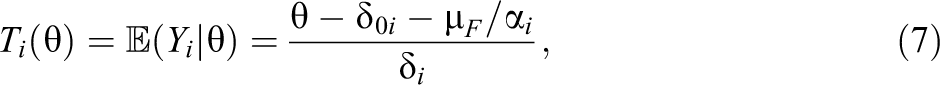
and therefore
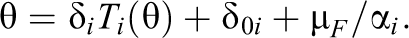
Thus, measurements are congeneric. As will be shown in the following, in nonlinear TMs,
The latter is caused solely by the fact that the CTT-based definition of unidimensionality requires linear relationships on the level of the true scores, whereas a general TM model provides a nonlinear relation, as the following argument shows. The dependency of the ith true score on
One may further subdivide the congeneric model—assuming in the following a linear TM. Measurements are called essentially tau-equivalent if
The even stricter requirement of essentially parallel measurements demands in addition to tau-equivalency the equality of the error variances. From Equation 4, one obtains
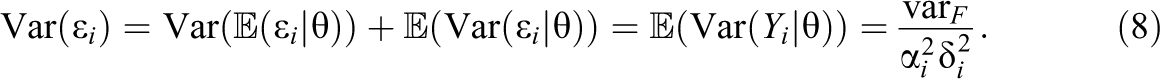
Accordingly, if
Two consequences of parallelity are worth mentioning. First, the best linear predictor of the true score weighs all item scores equally, providing further justification for the usage of simple sum scores. Second, the estimation of test reliability via the split-half approach is justified.
Taken together, these results show that
(1) on the second-order level (i.e., using only conditional expectations and variances), the general threshold model yields CTT models, and
(2) the unidimensional CTT model can be motivated by an underlying linear threshold model.
3.3. Quantile Function and Further Properties
It has already been highlighted that the mean is a linear function of the latent ability and that the variance does not depend on
The quantile function for the response
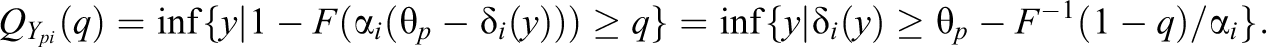
For strictly increasing difficulty functions
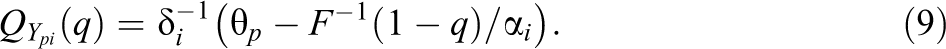
We now examine the case of linear difficulty functions more closely. Since difficulty functions are linear, one obtains
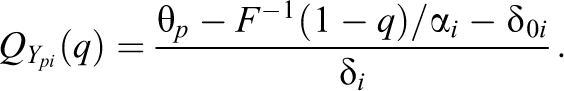
Therefore, each quantile of
The quantile function may be used to derive formulas for the moments of
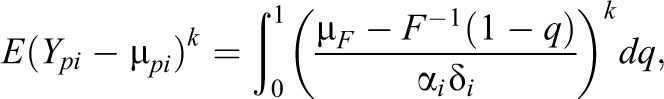
see Proposition 8.4. A consequence is that also central moments do not depend on
A simpler form of the density of responses may be obtained by rewriting (2) in centered form as
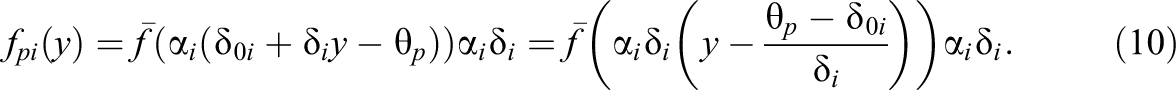
From the change of variable formula, one may deduce from Equation 10 the following:
Let X denotes a random variable with distribution function
A common measure for the performance of persons that is typically used is the total score
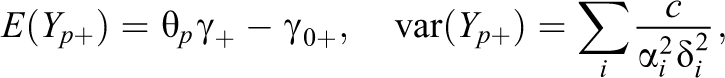
where
4. Nonlinear Models
In traditional item response models like the Rasch model or the normal-ogive model, the mean response is a nonlinear function of the person’s latent trait. This is sensible because the means in binary responses are restricted to the interval [0,1] and linear functions tend to take values outside this interval. In general, nonlinear functions are always to be expected if the response is restricted in some way. This holds also if responses are continuous but restricted, for example, to take positive values only, which is the case in many applications.
Within the framework of threshold models, restrictions on the support of responses are obtained in a natural way by specifying appropriate nonlinear difficulty functions. This leads to models, in which the mean and other characteristics of the responses are the nonlinear functions of the latent trait. In the following, we consider difficulty functions of the form
4.1. Responses in the Positive Domain
Let the response function
For illustration, Figure 3 shows the response distributions for three items if the difficulty function is the logarithmic function. The left picture shows the distribution if the response function is the normal distribution; on the right side, the Gompertz distribution has been used as a response function.
Densities for three items, logarithmic difficulty functions. Left: normal response function with intercepts and slopes given by
Expectations and variances of responses are no longer linear functions of the person parameter. For the logarithmic function, one obtains
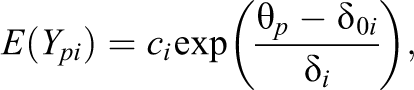
where ci
is a constant that depends on
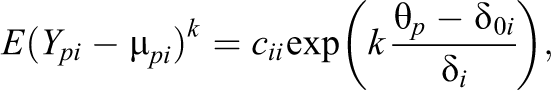
where
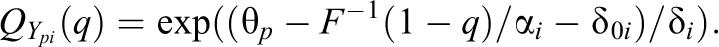
4.1.1. Decomposition
One can again try to decompose into a true score and an error score by using the representation
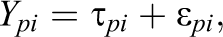
where
The form of the expectation has the consequence that the total score
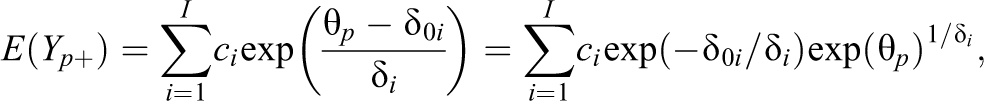
which is a weighted sum of exponential terms with the terms depending on the item (Proposition 8.4). Conditions under which the total score is an appropriate measure have been investigated in particular for categorical responses (see, e.g., Hemker et al., 1997; Hemker et al., 2001; Masters, 1982; Sijtsma & Hemker, 2000). In the present case, a condition is that items are homogeneous, that is,
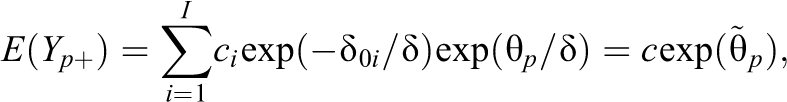
where
4.1.2. Link to classical response-time models
If one assumes for
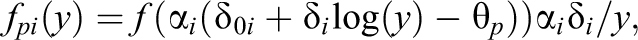
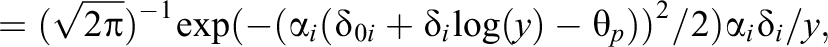
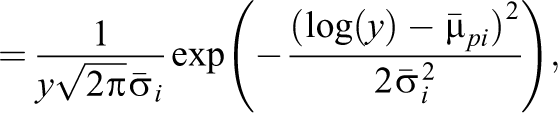
where
The threshold version of van der Linden’s model is a generalization allowing for varying slope parameters. It also offers the possibility to consider alternative response functions that replace the normal distribution and might yield better fit (see the application in Section 6.2).
4.2. Responses in an Interval
Let again the response function
For illustration, Figure 4 shows the distributions that are obtained for the interval
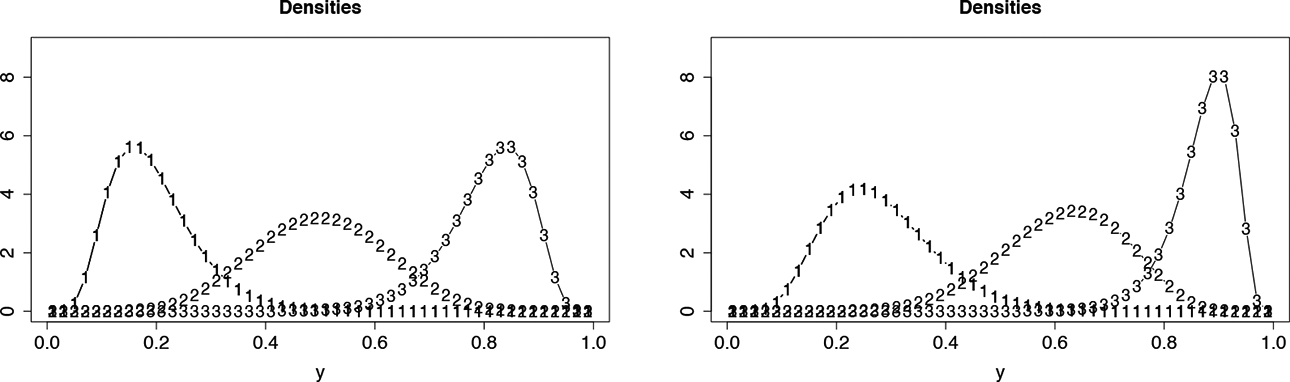
Distributions of responses for items with intercept and slope given by
Similar pictures are obtained if other difficulty functions that restrict the responses to an interval are used. To this end, all inverse distribution functions can be used. For simplicity, we focus on the logit function, that is, the inverse logistic distribution, which in the applications section is shown to outperform difficulty functions that ignore the restriction.
For the expectation and variances of responses, one obtains rather complicated formulae, which are not given. As in the case of logarithmic difficulty functions, they depend on the person’s ability
The case of responses in intervals is especially important in Likert-type items, which by definition are restricted to a fixed interval
5. Transformation of Responses and Linearity
It is interesting that at the heart of all threshold models, there is a linear relationship between abilities and expectations; however, it does not relate to the expectations of the responses itself but to transformed responses. More concise, one can derive the general result
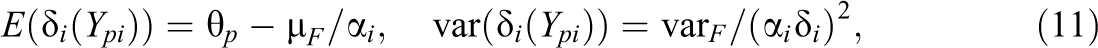
where
One can establish a simple general relationship between the TM and the chosen response function
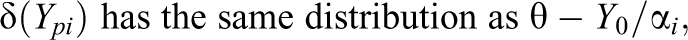
where Y
0 follows the distribution function
One consequence of (11) is that the expected transformed total score
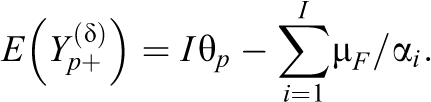
Thus,
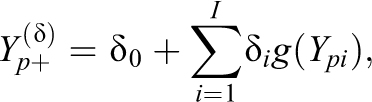
which is a weighted sum of transformed responses.
The previous considerations suggest that one could also work with the transformed responses
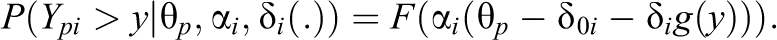
If the model holds, one obtains for the transformed responses
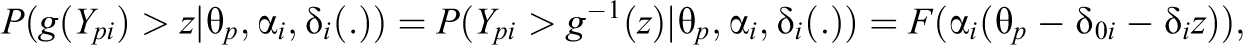
which means that
When comparing models with different specifications as, for example, different difficulty functions, one can use goodness-of-fit measures as the log-likelihood or Akaike information criterion (AIC) values of the models. However, some caution is warranted if transformed data are considered. Although the TM(F, {
The log-likelihood contribution of observation
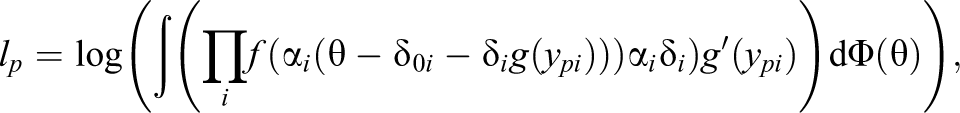
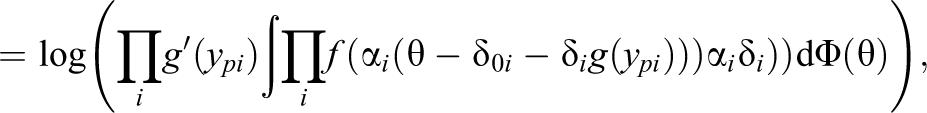
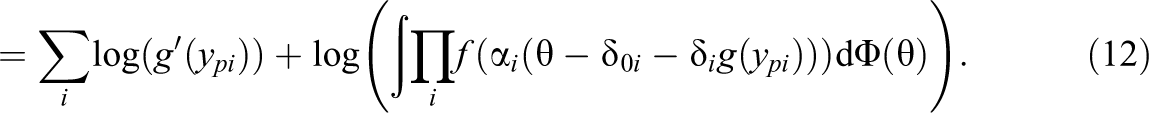
The log-likelihood contribution of the transformed observation
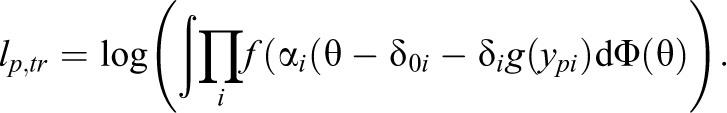
Since the term
A consequence is that the choice of difficulty functions should not be based on comparing fits of transformed data. Response transformations
As an example, we use the self-regulation data to be considered later (Section 6.1). The log-likelihood obtained when fitting a model with normal response function and logarithmic difficulty function is −654.136, and when fitting a model with linear difficulty function to the log-transformed data, one obtains −326.531. These models should definitely not be compared via goodness-of-fit measures based on their log-likelihoods although parameter estimates for both models are identical.
6. Applications
We illustrate the usage of the nonlinear TM models with three examples. Along with the modeling of properly continuous data, like response times, we will in particular focus on the practical usage of the application of these models to Likert-type scales, whereby in contrast to a direct linear, unrestricted treatment, we take care of the range of the restricted support via appropriately chosen difficulty functions.
All models are fitted using the MML-procedure and Gauss–Hermite quadrature, whereby a centered normal distribution with unknown variance
6.1. Self-Regulation
The data set Lakes from the R package MPsychoR (Mair, 2018) is a multifacet G-theory application taken from Lakes and Hoyt (2009). The authors used the response to assess children’s self-regulation in response to a physically challenging situation. The scale consists of three domains: cognitive, affective/motivational, and physical. We use the physical domain only. Each of the 194 children was rated by five raters on three items on their self-regulatory ability with ratings on a scale from 1 to 7. We use the average rating over the five raters, which yields a response that takes values in the interval
Table 1 shows log-likelihoods and estimates of
Fits for Self-Regulation Data
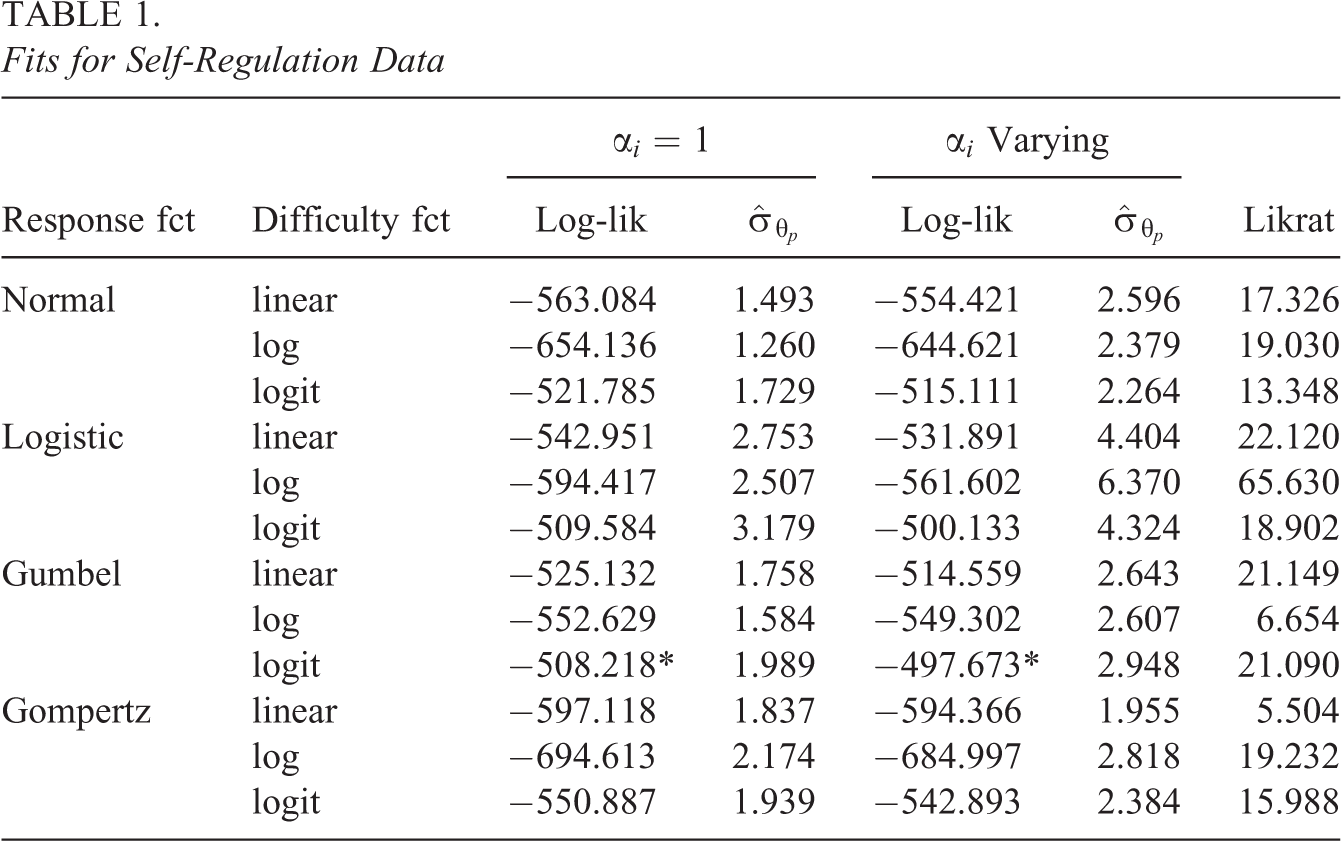
The example demonstrates that better fits are obtained when the restriction of the responses to a fixed interval is taken seriously by using logit difficulty functions. Although a skewed response function as the Gumbel function performs better when using inadequate difficulty functions as the linear function, there is not much support for preferring the Gumbel response function over the symmetric logistic function. The corresponding log-likelihoods (−497.673 and −500.133) are very close.
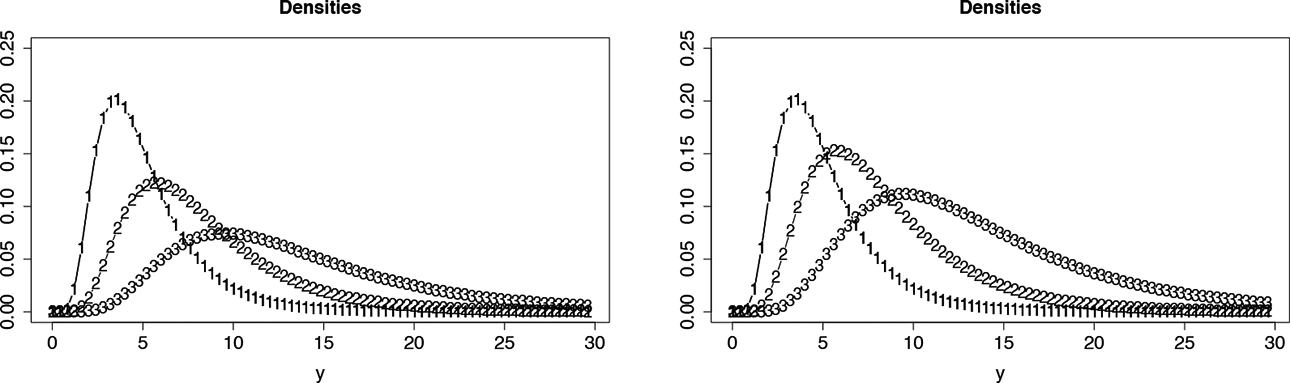
Figure 1, which has already been considered in Section 1, shows the estimated response densities for the three items with varying discrimination parameters (using as response function the normal distribution). First row shows linear difficulty functions, second row shows logarithmic difficulty functions, third row shows logit difficulty functions, left column shows responses for latent trait
To demonstrate the consequences of fitting models that ignore the restrictions on the support of responses, the posterior estimates of person parameters have been computed for the model with a normal response function and linear difficulty function (varying discrimination parameters). Figure 5 shows the predicted distributions for Item 3 that are obtained for the 20 largest estimated person parameters. It is seen that for many of them, the mode is above the threshold 7. If modes were used as estimates of the performance on the item, one would obtain values that are beyond the threshold. It demonstrates that predictions on tasks similar to Item 3 are bound to yield improper values.
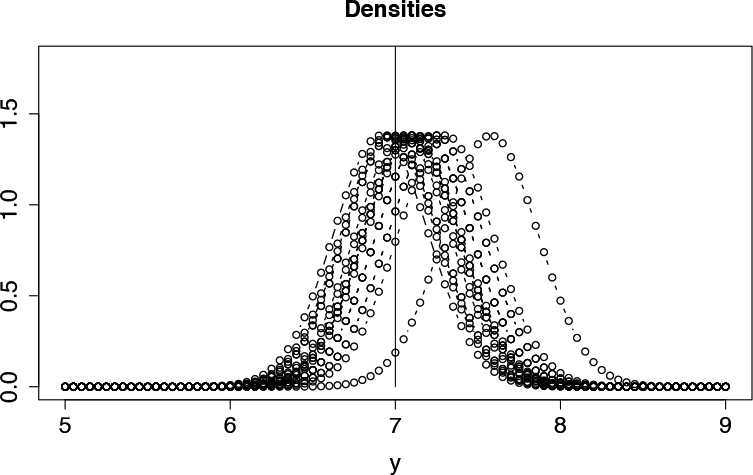
Densities of Item 3 evaluated at the 20 largest values of estimated person parameters when using the TM with a normal response function and linear difficulty function.
6.2. Rotation Response Time
The R package diffIRT contains response time data of 121 subjects to 10 mental rotation items. Each item consists of a graphical display of two three-dimensional objects. The second object was either a rotated version of the first object or a rotated version of a different object. Subjects were asked whether the second object was the same as the first object (yes/no). The degree of rotation of the second object was 50°, 100°, or 150°. Response times were recorded in seconds.
We fitted thresholds model with logarithmic difficulty function and fixed discrimination parameter. The best fit was obtained for the normal response function (loglik −1,300.378,
Parameter Estimates for Response Time Data With Varying and Constant Slopes
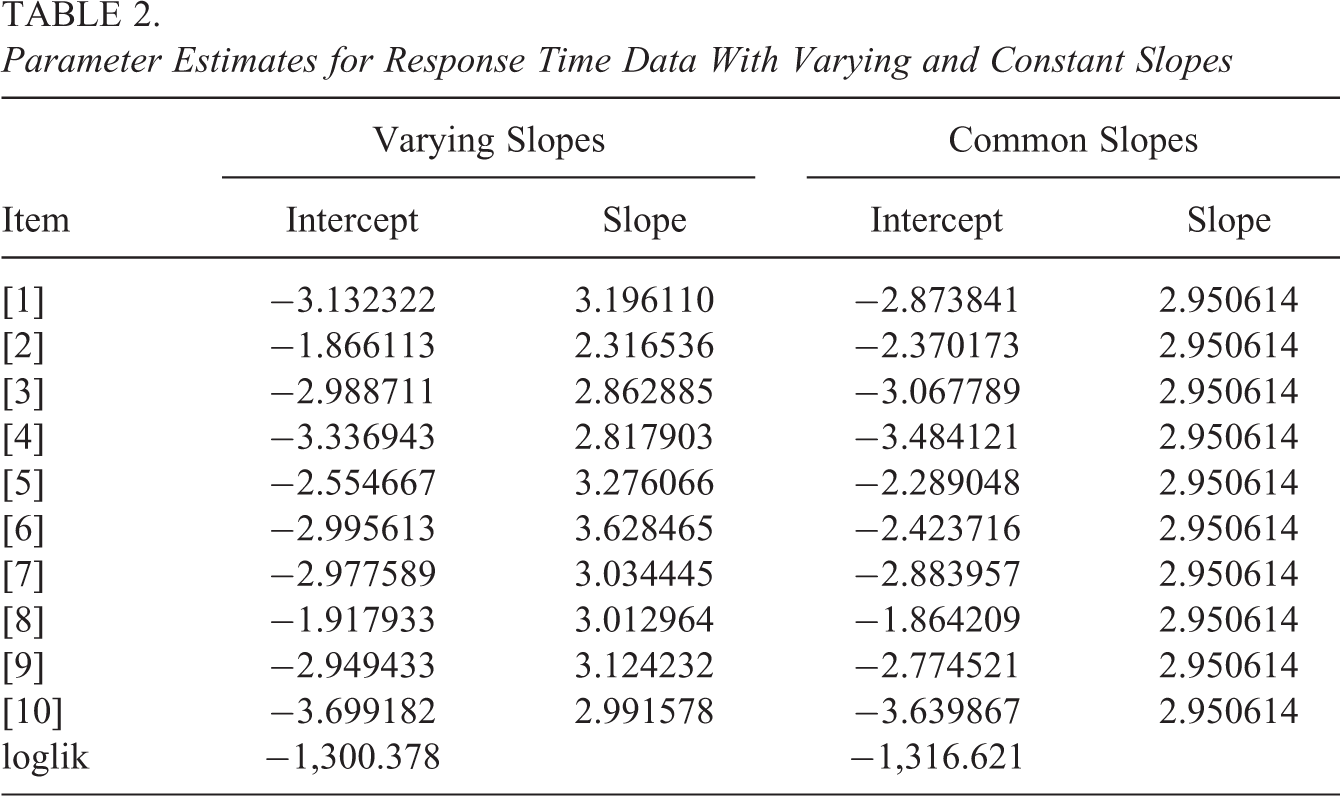
The fit of the model could additionally be improved by allowing for varying discrimination parameter. The corresponding log-likelihood was −1,296.027; however, it does not significantly improve the fit (log-likelihood test is 8.702 on 9 df). Note that picking (solely) on significance is in general not advised, as for large sample size, even smallest improvements become significant. Figure 6 shows the estimated response distributions for the first five items for
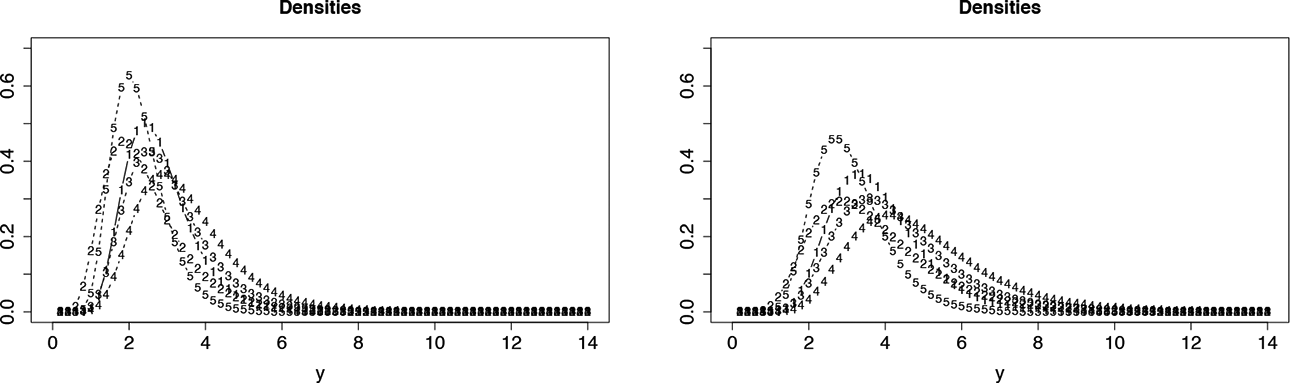
Response distributions for the first five items of the mental rotation data set for
6.3. Political Fears
In this application, Likert-type scales are considered. We use data from the German Longitudinal Election Study, which is a long-term study of the German electoral process (Rattinger et al., 2014). The data we are using originate from the pre-election survey for the German federal election in 2017 and consist of responses to various items addressing political fears. The participants were asked: “How afraid are you due to the…”—(1) refugee crisis?—(2) global climate change?—(3) international terrorism?—(4) globalization?—(5) use of nuclear energy? The answers were measured on Likert-type scales from 1 (not afraid at all) to 7 (very afraid). The model is fitted under the assumption that fear is the dominating latent trait, which is considered as unidimensional. We use 200 persons sampled randomly from the available set of observations.
Within the thresholds modeling framework, the restriction to a finite interval
Figure 7 shows the resulting distributions for alternative assumptions concerning the distribution of responses. The first row shows the fitted densities if one assumes a normal distribution, which is equivalent to a normal distribution CTT model, and the second row shows the densities for the thresholds model with logistic difficulty function. The left side shows the distributions for a low value of the person parameter, and the right side shows the distributions for a high value of the person parameter. Obviously, the normal model does not yield proper distributions since the support of the distributions is much larger than the interval
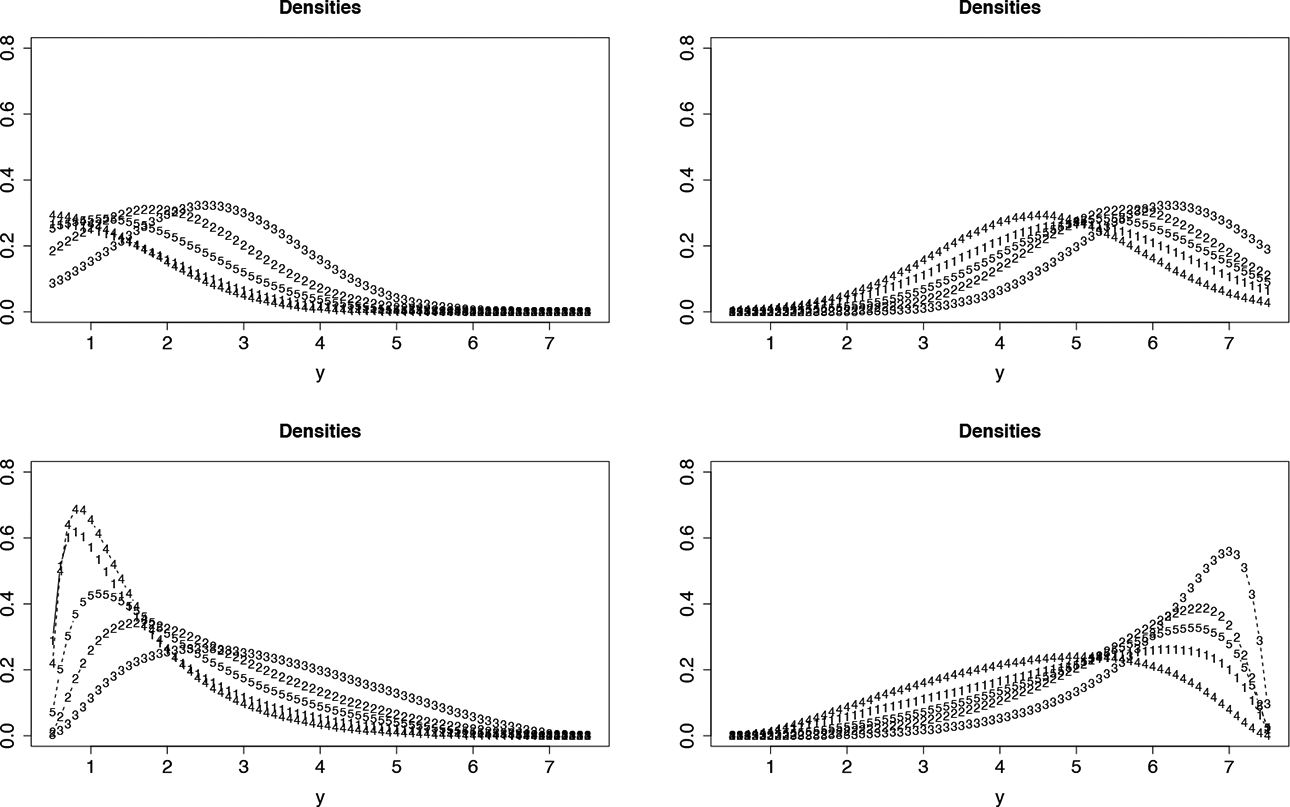
Estimated densities for fear data. Left: low person parameter, right: high person parameter, first row: normal distribution model corresponding to linear difficulty functions (
Table 3 shows the log-likelihoods, the AIC values, and estimates of
Thresholds Models for Fears Data
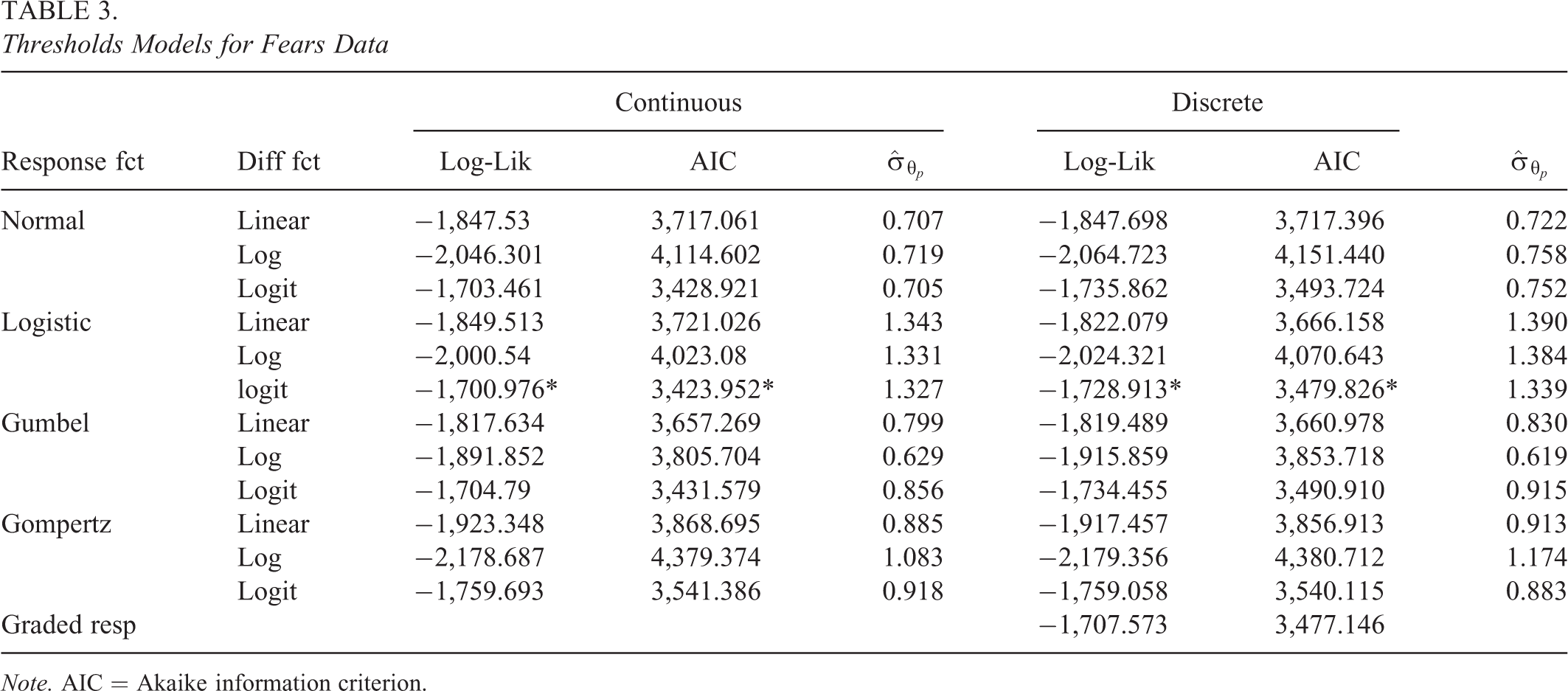
Note. AIC = Akaike information criterion.
We considered continuous and discrete fits since for Likert-type scales with at least five categories continuous models are often used (see, e.g., Harpe, 2015). Therefore, it seems sensible to investigate whether the approximation is warranted. In this application, although the fits for discrete and continuous models differ, in both cases, the same models turn out to be the best models when using the log-likelihood or AIC as criterion. For a further evaluation of the difference between continuous and discrete modeling, we computed the posterior estimates of person parameters. Figure 8 shows the estimates plotted against the transformed sum scores
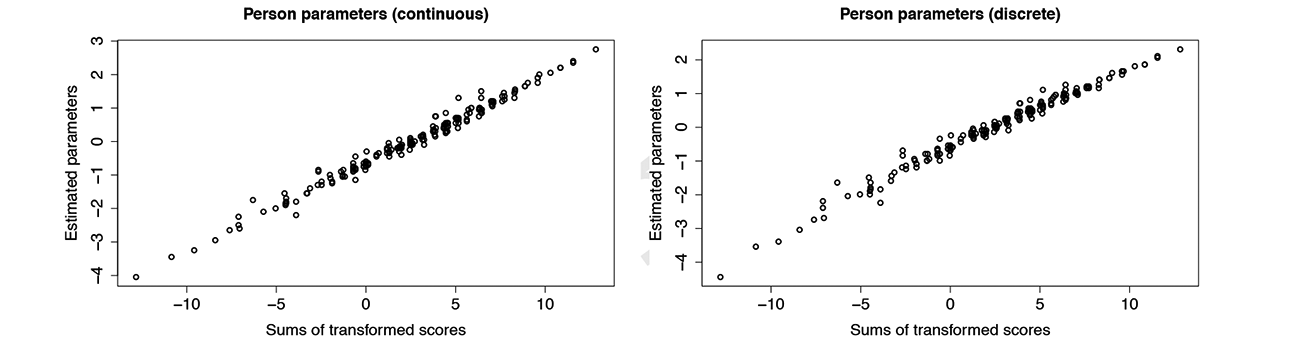
Estimated person parameters for fears data.
Nevertheless, Likert-type scales are by definition discrete, and the approximation by continuous distributions cannot in general be assumed to be sufficiently accurate. General recommendations like the one that “numerical response formats with at least five categories may generally treated as continuous data” (Harpe, 2015) should be viewed with skepticism since the accuracy of the approximation may depend on the distribution of individuals, in the case of thresholds models on the distribution of person parameters. Within the thresholds model framework, one can fit continuous as well as discrete responses and compare the resulting fits and predictions. Alternatives that explicitly account for the discreteness of the response are ordinal IRT models as the graded response model (Samejima, 2016), which can be given by
For the distribution of person parameters and for further comparisons of discrete and continuous modeling strategies, we refer the reader to the Online Appendix.
7. Extensions and Alternative Models
7.1. Including Covariates
The basic threshold model assumes that latent traits are unidimensional and not affected by covariates. If one suspects that covariates may modify the response behavior, it can be tested by including them explicitly in the explanatory term. Let
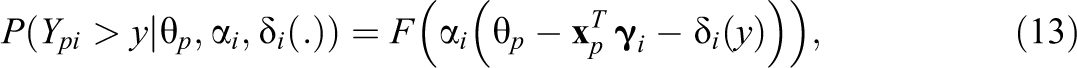
where the parameter
Within IRT, the inclusion of covariates can be seen as investigating differential item functioning (DIF), which is the well-known phenomenon that the probability of a correct response among equally able persons may differ in subgroups (see, e.g., Magis et al., 2010; Millsap & Everson, 1993; Osterlind & Everson, 2009; Rogers, 2005; Zumbo, 1999). If
Model (13) can also be seen as a rather general multivariate regression model with heterogeneity. Models of this type have been considered within the framework of explanatory item response modeling (De Boeck & Wilson, 2004, 2016). If one is primarily interested in the effects of covariates, one considers
Let us consider the fear data with covariates gender (1: female; 0: male) and age in years. Table 4 shows the estimates for the basic model without covariates and the model with covariates age and gender (discrete response,
Parameter Estimates for the Fears Data With Logit Difficulty Function, Logistic Response Function Without Covariates and With Covariates
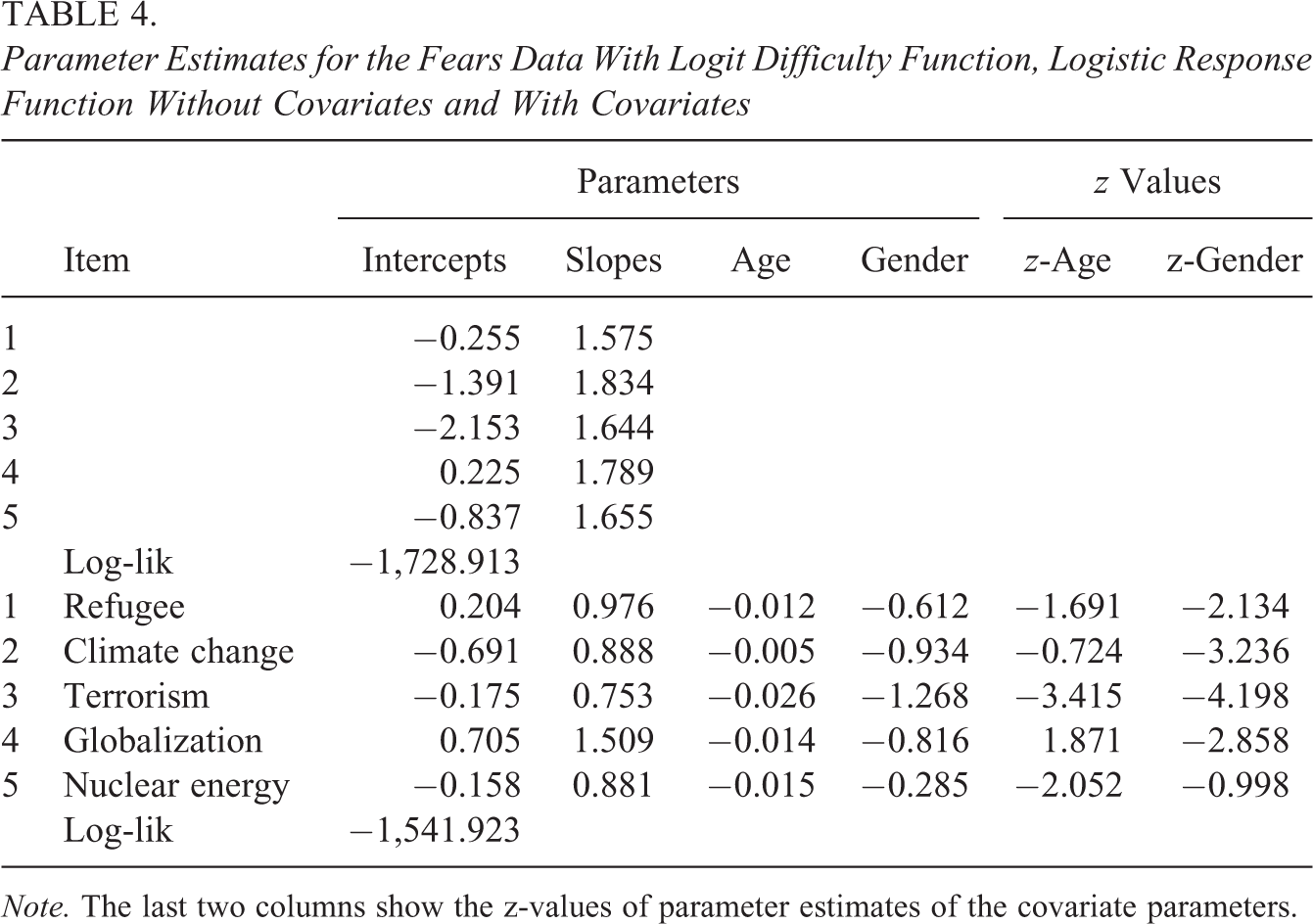
Note. The last two columns show the z-values of parameter estimates of the covariate parameters.
It is seen from Table 3 that difficulty functions that account for the restriction to an interval yield better fits when no covariates are included. If covariates are included, one is typically also interested in the significance of covariates. Then, models that ignore the restriction and therefore work with improper distributions can hardly be trusted to yield reliable results in significance tests. For example, fitting of a normal distribution model with covariates yields for covariate age the z values −2.16, 0.26, −2.94, −2.12, and −1.50 (for Items 1–5), which differ from the values given in Table 4, −1.69, −0.72, −3.41, 1.87, and −2.05. Thus, fitting of models with improper distributions might yield misleading results in significance tests.
7.2. Alternative Models
7.2.1. Generalized linear IRT (GLIRT)
Mellenbergh (1994) proposed a GLIRT and a corresponding comprehensive class of models. In essence, the model assumes that a monotone differentiable transformation g of the expected value
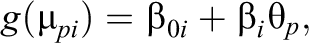
where for the sake of simplicity, we have confined the model description to a unidimensional latent variable model without covariates. In addition to this link function, a response function from an exponential family is assumed for the conditional distribution of
If responses are multinomially distributed, some modifications toward vectorized expectations are necessary to adopt the model to fit traditional polytomous IRT models. Polytomous responses are not one-dimensional; therefore, the transformation of expected responses is less simple since one has a vector of response and therefore a vector of expectations referring to the probabilities of specific categories. By appropriate modification, classical response models as the graded response model and the partial credit model can be shown to be special cases. Threshold model also contains generalized graded response models as special cases but not the partial credit model. For discrete responses with infinite support, GLIRT type models have been considered by Wang (2010), also assuming a fixed distribution, Poisson with zero inflation. Also, in this case, threshold type models are not restricted to fixed distributions (see Tutz, 2022a).
While in thresholds models, the distribution is a result of the response function and the difficulty function in GLRIT models a distribution is assumed and the link refers to the expected value. Although many models in current use can be represented as GLRIT models for continuous responses, they are less flexible. In particular, the restriction to an interval is hard to obtain. When considering Likert-type scales as approximations to continuous responses, Mellenbergh (1994) refers to the normal distribution. The strength of thresholds models is that they can adapt very flexibly to the demands of item formats without having to assume a fixed distribution for responses.
7.2.2. Factor analysis
Another approach to the modeling of continuous responses, though not commonly subsumed under the IRT framework, is given by the class of FA (or more generally: structural equation models) models. Within this approach, the evaluation metric and oftentimes also the model fitting differs from the IRT framework. More specifically, FA is mostly focused on the reproduction of the covariance matrix of the manifest variables (Mardia et al., 1979). This in turn is reflected in model fitting approaches, which may rely on minimizing a weighted least squares distance between the model implied and the observed covariance matrices (Du & Bentler, 2021). Despite these differences, there is, however, a connection between the commonly employed FA models and our TM IRT model. To highlight this connection, we assume a unidimensional FA model of the form
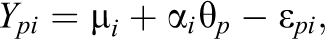
with the assumption that conditionally on the factor
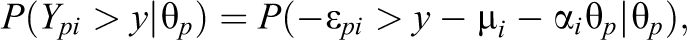
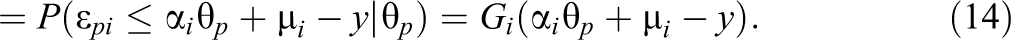
If the Gi
originates from a common location scale family, that is, if
Therefore, the FA model (with a flexible choice for the distribution of the residual term) can be subsumed under the TM family. This holds also for multifactor models, in which
Note, however, that fitting a model with the standard factor analytical framework presupposes normality of the residuals. There are methods for the corrections of standard errors in the presence of nonnormality. Nevertheless, the fitting of a TM will result in more efficient estimates due to the fact that the TM estimates are derived via maximum likelihood, whereas the FA based estimates are only maximum likelihood estimates in the presence of normality.
8. Concluding Remarks
The topic of latent trait modeling for continuous responses has been addressed within the framework of threshold models. With respect to continuous responses, the lognormal and the normal-linear model (the basic building block in the FA model) have been shown to be the members of the thresholds modeling class. Furthermore, a better approximation to the handling of Likert-type data has been suggested via the usage of appropriately chosen nonlinear difficulty functions. It has also been demonstrated that response functions other than the normal distribution can be more appropriate.
Future research could focus on multidimensional extensions of the TM class, which would ultimately provide a latent trait model for multidimensional abilities and continuous responses. Alongside these multidimensional extensions, the modeling of data for mixed measurement levels also becomes important. For instance, response times are usually recorded in conjunction with the accuracy of the response (correct/incorrect). A proper approach would need to model the joint distribution of
Supplemental Material
Supplemental Material, sj-pdf-1-jeb-10.3102_10769986231184147 - Latent Trait Item Response Models for Continuous Responses
Supplemental Material, sj-pdf-1-jeb-10.3102_10769986231184147 for Latent Trait Item Response Models for Continuous Responses by Gerhard Tutz and Pascal Jordan in Journal of Educational and Behavioral Statistics
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.