
Abstract
Bayesian methods to infer model dimensionality in factor analysis generally assume a lower triangular structure for the factor loadings matrix. Consequently, the ordering of the outcomes influences the results. Therefore, we propose a method to infer model dimensionality without imposing any prior restriction on the loadings matrix. Our approach considers a relatively large number of factors and includes auxiliary multiplicative parameters, which may render null the unnecessary columns in the loadings matrix. The underlying dimensionality is then inferred based on the number of nonnull columns in the factor loadings matrix, and the model parameters are estimated with a postprocessing scheme. The advantages of the method in selecting the correct dimensionality are illustrated via simulations and using real data sets.
Introduction
Factor analytic models are widely used in fields such as behavioral science, medical research, and financial studies. The main purpose of factor analysis is to describe the dependence among a set of outcomes in terms of a lower number of latent factors. Compared with the frequentist setting, Bayesian factor analysis provides more flexibility to fit models across different scenarios (Lee & Song, 2002). In the frequentist setting, exploratory factor analysis is carried out as a multistep approach when the number of factors is unclear. First, model dimensionality is selected, and then, factor rotation is conducted to obtain model simplicity and interpretability. This multistep approach is theoretically suboptimal due to the possible loss of information between steps, especially taking into account the variety of methods for factor extraction and factor rotation, each with its own pros and cons (Chen, 2021).
In contrast, Bayesian methods can simultaneously conduct model selection and parameter estimation in factor analysis (e.g., Carvalho et al., 2008; Conti et al., 2014; Mavridis & Ntzoufras, 2014). However, these Bayesian approaches generally assume a lower triangular structure for the factor loadings matrix in order to ensure identifiability of the models. As discussed in Carvalho et al. (2008), when using this restriction for model identification, the order of the variables introduces unintended prior information, which may influence the results when inferring model dimensionality. Chen (2021) proposed a Bayesian regularized approach to exploratory factor analysis (BREFA) without assuming a lower triangular structure for the factor loadings matrix. In this method, the constraints for model identifiability are imposed on the factor covariance matrix. Alternatively, to overcome the dependence on the order of the outcomes, Man and Culpepper (2022) introduced a permuted positive lower triangular restriction to address rotational invariance. The authors introduced a Bayesian sampling algorithm that explores the multimodal posterior surface of the factor loadings matrix. Nonetheless, this approach does not perform automatic selection of the number of factors.
We propose a method to select model dimensionality in factor analysis without imposing the lower triangular condition for model identifiability. Our approach considers a model with a relatively large number of factors and includes auxiliary multiplicative parameters, which may render null the unnecessary columns in the factor loadings matrix. We introduce a peaked and heavy-tailed prior that induces sparsity on the auxiliary parameters. Hence, the underlying dimensionality is inferred based on the number of nonnull columns in the factor loadings matrix. The specification of this proposal permits its easy implementation in Bayesian packages. We solve rotational indeterminacy to estimate the model parameters using the postprocessing scheme in Papastamoulis and Ntzoufras (2022).
To decide which columns are nonnull in the factor loadings matrix, we make use of the spike-slab prior, which is a popular tool in Bayesian model selection. Mitchell and Beauchamp (1988) introduced the spike-slab distribution in Bayesian variable selection as the mixture of a point mass at zero and a uniform distribution, in order to determine which regression coefficients are null in linear regression models. George and McCulloch (1993) proposed a modification, which simplifies Gibbs sampling by taking as prior a mixture of two normal distributions with different variances. Alternatively, Kuo and Mallick (1998) suggested a mixture of a point mass at zero and a normal distribution to avoid the need of choosing the variance of the normal component corresponding to the spike in George and McCulloch (1993).
Mavridis and Ntzoufras (2014) developed a Markov chain Monte Carlo (MCMC) algorithm based on the prior of George and McCulloch (1993) for estimating the factor model and identifying promising subsets of manifest variables. Pan et al. (2021) extended this methodology to investigate latent risk factors of mixed type of outcomes. On the other hand, proposals such as Lucas et al. (2006), Carvalho et al. (2008), Conti et al. (2014), Ročková and George (2016), Frühwirth-Schnatter and Lopes (2018), and the Indian buffet process in Ghahramani and Griffiths (2005) carry out Bayesian factor analysis using sparsity mixture priors based on Kuo and Mallick (1998). This avoids choosing the variance of the normal component for the spike in George and McCulloch (1993), but sampling from the posteriors is more involved due to the point mass at zero component.
We use the spike-slab prior of George and McCulloch (1993) to decide which elements are nonnull in the factor loadings matrix, similarly as in Mavridis and Ntzoufras (2014) and Pan et al. (2021). This leads to a simple MCMC estimation procedure because the conditional posteriors for Gibbs sampling correspond to closed-form distributions. In addition, Bayesian methods for exploratory factor analysis in the literature assign a spike-slab prior to each factor loading in order to determine which elements are null in the factor loadings matrix (see, e.g., Lucas et al., 2006; Carvalho et al., 2008; Conti et al., 2014; Ročková & George, 2016; Chen, 2021). In contrast, our approach assigns a spike-slab prior to a parameter that multiplies each column in the factor loadings matrix. As we illustrate, this may lead to more power for inferring the number of factors since it is not necessary to determine whether each single factor loading is non-null. Instead, our approach uses the information of the full column of factor loadings to determine whether the full column is null or not.
The outline of this article is as follows. First, we discuss the general factor analytic model and a sparse representation for overfitted models. Then, the proposed prior is introduced and the Gibbs procedure to infer the number of factors is discussed together with the identifiability of the model. Finally, we demonstrate the advantages of our proposal via simulations and illustrate the method using real data sets.
Factor Model Specification
The factor analytic model assumes that each p-dimensional observation

where
The marginal distribution of
Geweke and Singleton (1980) proved that when the factor loadings matrix is not of full rank, that is, the true number of factors is

for any
Sparse Model Representation
Instead of considering the lack of identifiability in Equation 2 as a difficulty in factor analysis, we use it as a tool in our approach to determine model dimensionality. For this, we show that if the true number of factors is
It is well known that for any
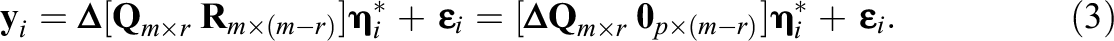
This result is intuitive. For overfitted models, there must exist a rotated solution in which, for the unnecessary factors, the columns of the factor loadings matrix are null. We introduce auxiliary parameters
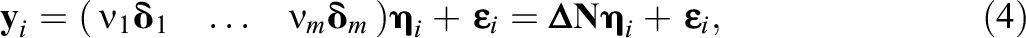
with factor loadings matrix
From Equation 3, we know that if the number of factors is
The value of m can be selected based on the previous analyses or expert knowledge. In the absence of prior information, m can be chosen as the maximum number of factors leading to an identified model. As explained later, it corresponds to the maximum value of m, such that
Prior Specification
In the IDIFA approach, we consider the “effective rank” of the factor loadings matrix, that is, the minimum number of columns that are importantly different from null. To approximate the solution in Equation 3 via MCMC methods, we use a similar strategy as in George and McCulloch (1993). Namely, each component of
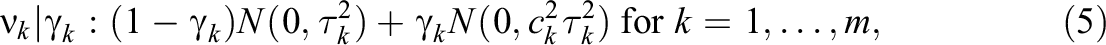
with
The elements
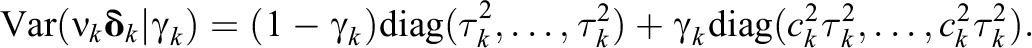
Hence, if
In the IDIFA approach, the inclusion probability
Finally, we choose an inverse gamma prior for the idiosyncratic variances, namely,
Selecting the Hyperparameters
The density in the slab component corresponds to the distribution of the product of two normal variables, that is,
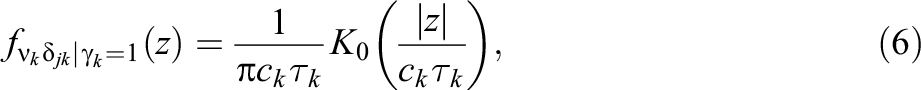
where K
0 is the modified Bessel function of the second kind and zero order. See Online Appendix A for further details on this modified Bessel function. Similarly, the density for the spike component is
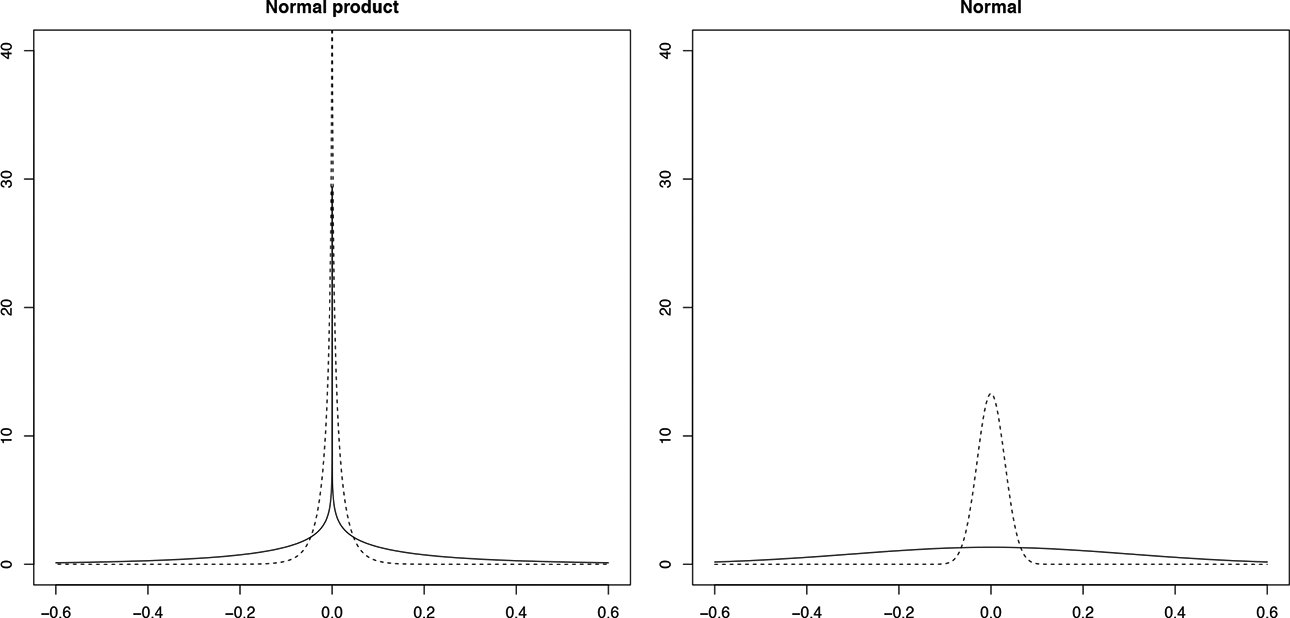
Marginal prior density for ν k δ jk assuming a normal product prior (left) and a normal prior (right). The dotted line corresponds to the spike and the solid line to the slab.
When a factor is not necessary, then
The intersection between the spike and the slab can be regarded as a threshold for declaring practical significance (George & McCulloch, 1993). Using a first-order expansion for the modified Bessel function (Abramowitz & Stegun, 1964), we find that the two densities intersect approximately at
Characteristics of the Prior
The density in Equation 6 goes to infinity as z approaches zero. Therefore, the prior in IDIFA is peaked around zero even for the slab component. This is crucial in our approach because, for important factors with
For comparison purposes, let us consider for
The peakedness around zero for the proposed prior in Equation 6 is essential for IDIFA because it reflects that several factor loadings can be null for the underlying factors. In contrast, the prior in Figure 1 (right panel) has lower density around zero for the slab component and
Finally, the prior in Equation 6 resulting from the product of two normal variables is a heavy-tailed distribution (Guo, 2017). For instance, when generating a sample of
Inferring the Number of Factors
Gibbs Sampling
In the IDIFA approach, it is not necessary to fit all models with
We take values a and b, such that the prior
Hence, we can infer the number of factors using the Gibbs sequence
Model Identifiability
Given that the model in Equation 1 is not identifiable under orthogonal rotation, traditional methods impose additional restrictions to
As discussed by Lopes and West (2004), when imposing a lower triangular structure for
Consequently, the traditional Bayesian methods for inferring dimensionality, which use the estimates from the restricted models, also depend on the ordering of the variables. This order dependence is undesirable because it introduces unintended prior information to the analysis. Moreover, it is difficult to determine in practice, which outcomes are most relevant in order to select them as founders of the factors. In contrast, the IDIFA approach does not require to ensure rotational invariance for each of the models under comparison in the MCMC approach. The number of factors is inferred based merely on the posterior distribution of
To solve the rotational indeterminacy in IDIFA, we use the postprocessing scheme in Papastamoulis and Ntzoufras (2022), which transforms all MCMC iterations toward the same solution. It is a two-stage approach that first applies a Varimax rotation to the matrix in each MCMC iteration. Then, the procedure deals with sign and column switching as an optimization problem, where all possible rotations are transformed until they are sufficiently close to the same reference value. This approach can be implemented with the function
In addition, it is necessary to ensure uniqueness of the variance decomposition as discussed in Frühwirth-Schnatter and Lopes (2018). The columns of the factor loadings matrix must have at least two nonzero factor loadings to avoid lack of identifiability. As explained above, the factor loadings with absolute value higher than
Simulation Study
We consider four simulation examples to evaluate the performance of IDIFA. First, we explore how well our methodology selects the number of factors in comparison to the Bayes factor (BF) under scenarios, where the factor loadings matrix is lower triangular and under scenarios where it is not. Then, we analyze the effect of assigning a spike-slab prior to the factor loadings
The models under comparison are fit based on three chains. We take 1,000 iterations as burn-in, followed by 5,000 additional iterations thinned by a factor of 5, which results in a final MCMC sample size of 1,000 for each chain. The convergence of the MCMC samples was assessed based on the Brooks–Gelman–Rubin (BGR) diagnostic (Brooks & Gelman, 1998). The values of BGR were lower than
Three Factor Model
The BF is defined as the ratio of two competing models represented by their marginal likelihood, which is integrated over the parameter space. BF is used to quantify the support for one model over the other and has been commonly used to select dimensionality in factor analysis (Dutta & Ghosh, 2013). A lower triangular structure is generally assumed for the factor loadings matrix when computing BF in order to have identified models. Therefore, we generate the data with the following factor loadings matrix:

and the idiosyncratic variances are specified as
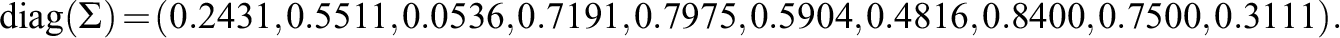
We take
We generate 100 simulated data sets and implement IDIFA taking different values a and b for which the prior π ~
Given that the MCMC procedure selects samples from the sparse model representation in Equation 3, the number of factors is equal to the number of nonnull columns in the factor loadings matrix. Therefore, we infer the number of factors as the dimensionality
Table 1 reports the posterior probability of selecting the true model after generating 100 simulated data sets for the different hyperparameter settings in IDIFA. The results are similar for different values of a, ck
, and
Posterior Probability of Selecting the True Model and the Average RMSE of the Factor Loadings for Different Settings of the Hyperparameters

Note. RMSE = root mean squared error.
Table 2 presents the bias (bias) and root mean squared error (RMSE) of the factor loadings estimates obtained by IDIFA when selecting
Bias and MSE of the Factor Loadings After Estimating the Parameters With IDIFA
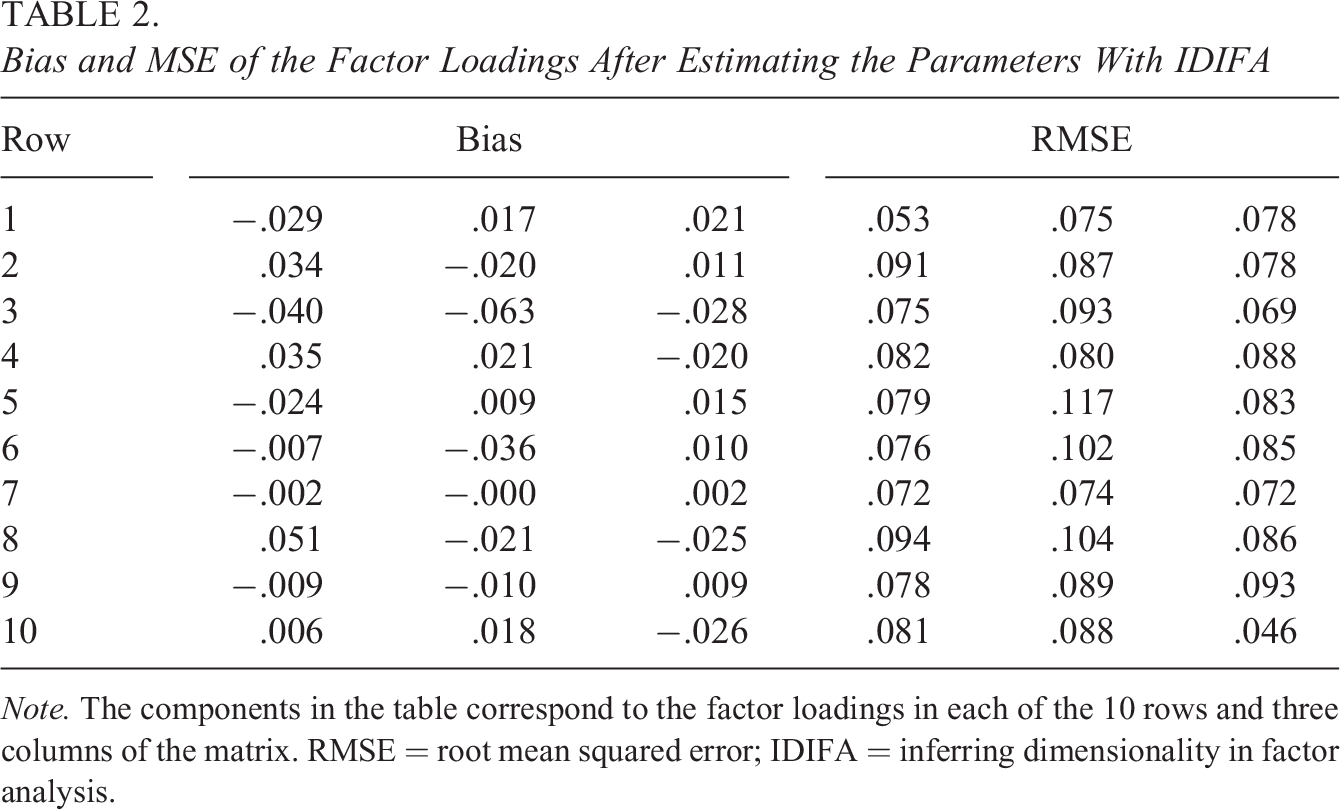
Note. The components in the table correspond to the factor loadings in each of the 10 rows and three columns of the matrix. RMSE = root mean squared error; IDIFA = inferring dimensionality in factor analysis.
BFLS selected the correct number of factors 100/100 times, as well as IDIFA with
Reshuffling the Order of the Outcomes
Many simulation studies in the literature, including the above analysis, specify the factor loadings matrix

and the idiosyncratic variances are specified as
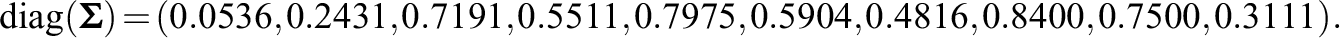
This factor loadings matrix and the idiosyncratic variances are the same as in the previous simulation setting, except that the order of the outcomes in the first four positions has changed. For example, the outcome that was in the third position is now in the first one. After this reordering of the outcomes, the first
After simulating the data, BFLS selected three factors 91/100 times, suggested two factors 3/100 times and selected four factors 7/100 times. In contrast, IDIFA selected the correct number of factors 100/100 times as in the previous simulation setting. As pointed out by one of the reviewers, BF operates as a statistical test, whereas IDIFA selects the best-fitting model, so these two methods are not strictly comparable. However, we contrast here IDIFA with BF since both alternatives can be used to select model dimensionality in practice.
IDIFA does not impose any structure on the factor loadings matrix, so it can perform better in selecting model dimensionality when identifiability cannot be guaranteed based on the positive lower triangular constraint for
As illustrated here, reshuffling the order of the variables in the original data can result in a rank-deficit submatrix in the leading m rows, which causes the positive lower triangular constraint to fail to guarantee identifiability. As a practical implication, the number of selected factors may differ depending on the ordering of the outcomes if the method assumes a lower triangular structure such as BF and most of the methods in the literature for Bayesian factor analysis. When selecting the number of factors with these methods, the choice of the first outcomes is a key modeling decision and not a simple task (Carvalho et al., 2008), but it can be avoided if IDIFA is employed.
Variable Selection on Factor Loadings Components
As discussed in the Introduction, a number of approaches have been proposed to infer model dimensionality assigning a spike-slab prior to the factor loadings
We compare the performance of IDIFA with the proposal in Conti et al. (2014), which is implemented in the
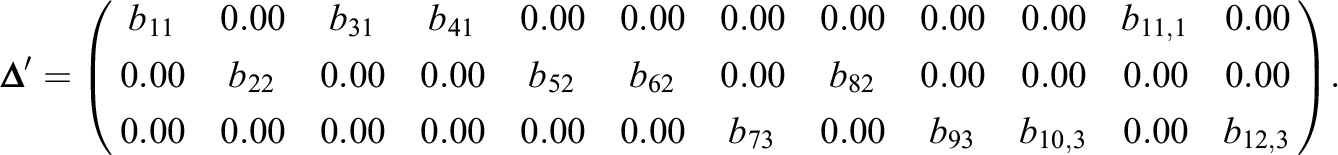
The nonzero loadings are randomly generated from a uniform distribution on
Percentage of Times That Each Number of Factors Was Selected Using 1,000 Monte Carlo Replications
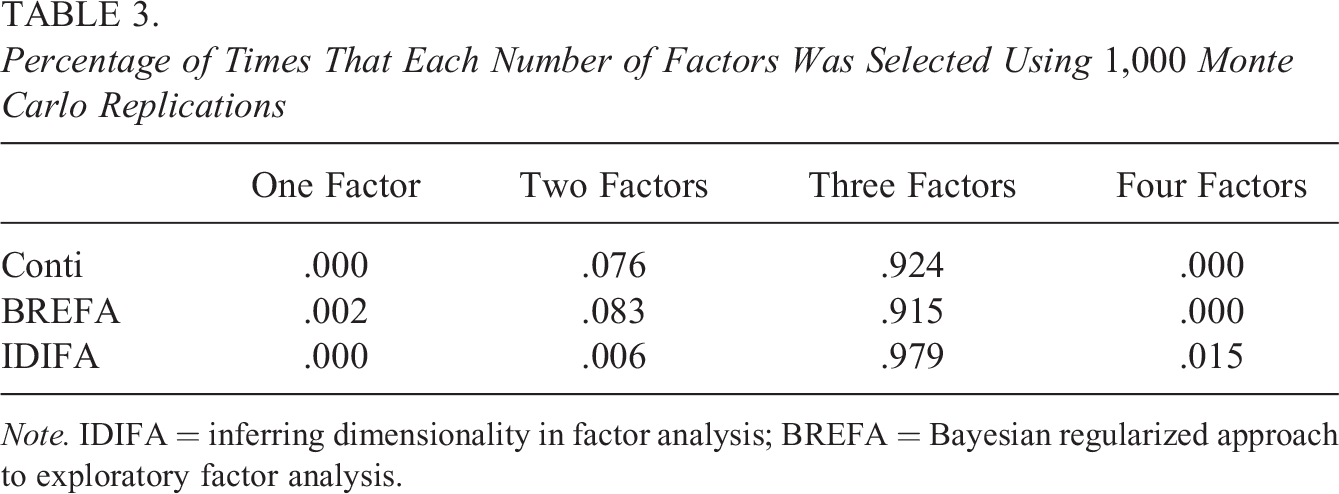
Note. IDIFA = inferring dimensionality in factor analysis; BREFA = Bayesian regularized approach to exploratory factor analysis.
In IDIFA, there is only one indicator
A Correlated Factor Model
The model in Equation 1 assumes that the factors are uncorrelated. However, any model with a finite number of factors can be rotated to an orthogonal structure. Indeed, the covariance matrix of the factors can be expressed as
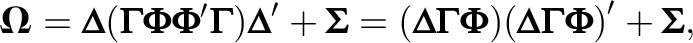
which is equivalent to a model with orthogonal factors and factor loadings matrix

The number of observations for this simulation is
Data Analysis
In the following, we apply the IDIFA approach to two real data sets. First, we use scores on nine mental ability test scores from two different schools in Chicago. In the second data set, we explore the factor structure underlying the measurement of socioeconomic status of students in Colombia. We used three chains with a burn-in of 5,000 iterations, followed by 10,000 additional iterations thinned by a factor of
The Grant-White School Data Set
In this example, we use scores on nine psychological tests of 301 students in seventh and eighth grades from two different schools (Pasteur and Grant-White) in Chicago. The data are publicly available in the
Implementing the IDIFA approach with
Estimated Posterior Means of Factor Loadings for the Three Factor Model Based on IDIFA for the Grant-White School Data Set
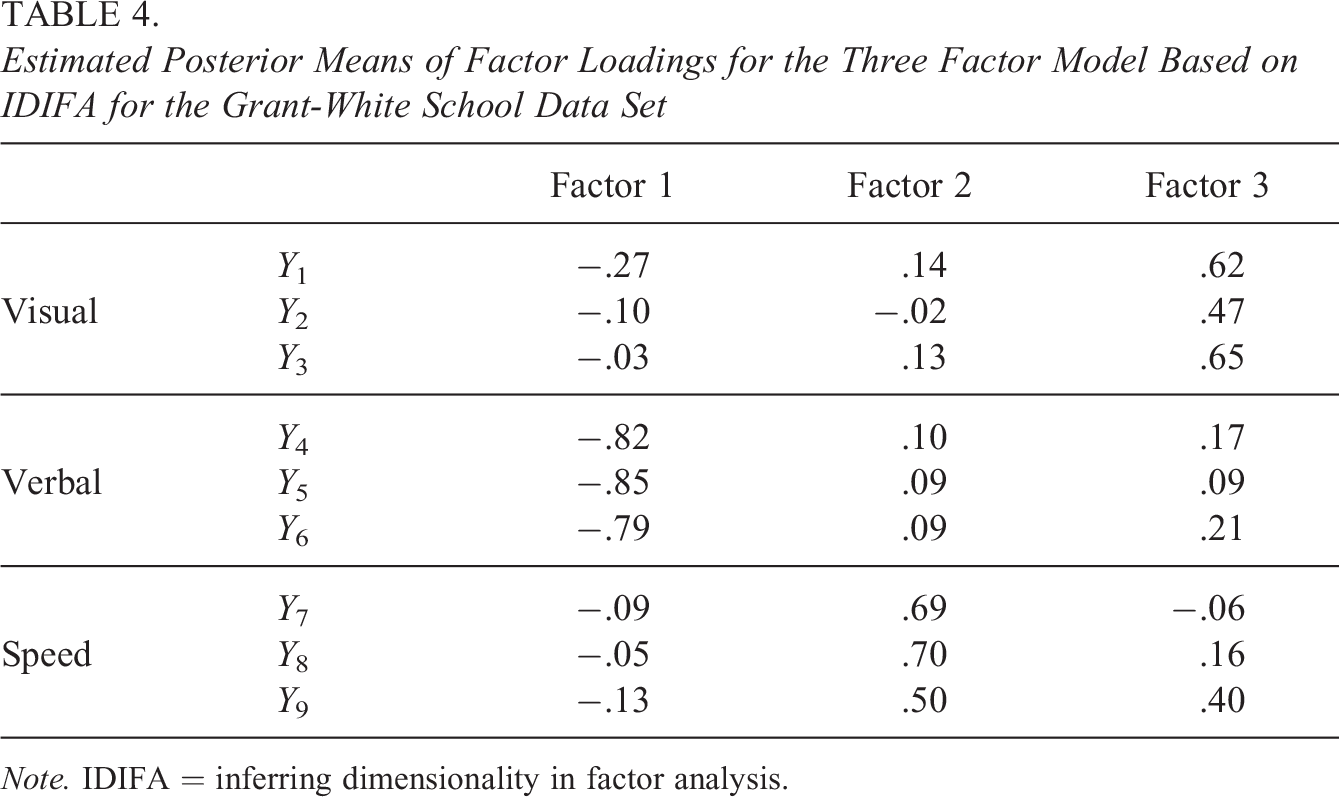
Note. IDIFA = inferring dimensionality in factor analysis.
The convergence of the factor loadings after postprocessing was verified with the BGR diagnostic, the Monte Carlo standard error (MCSE), and the effective sample size (ESS). All values of BGR were smaller than 1.1 and the MCSE was below 5% of the posterior standard deviation of each parameter, indicating convergence in the estimation process (Lesaffre & Lawson, 2012). The minimum value of ESS was
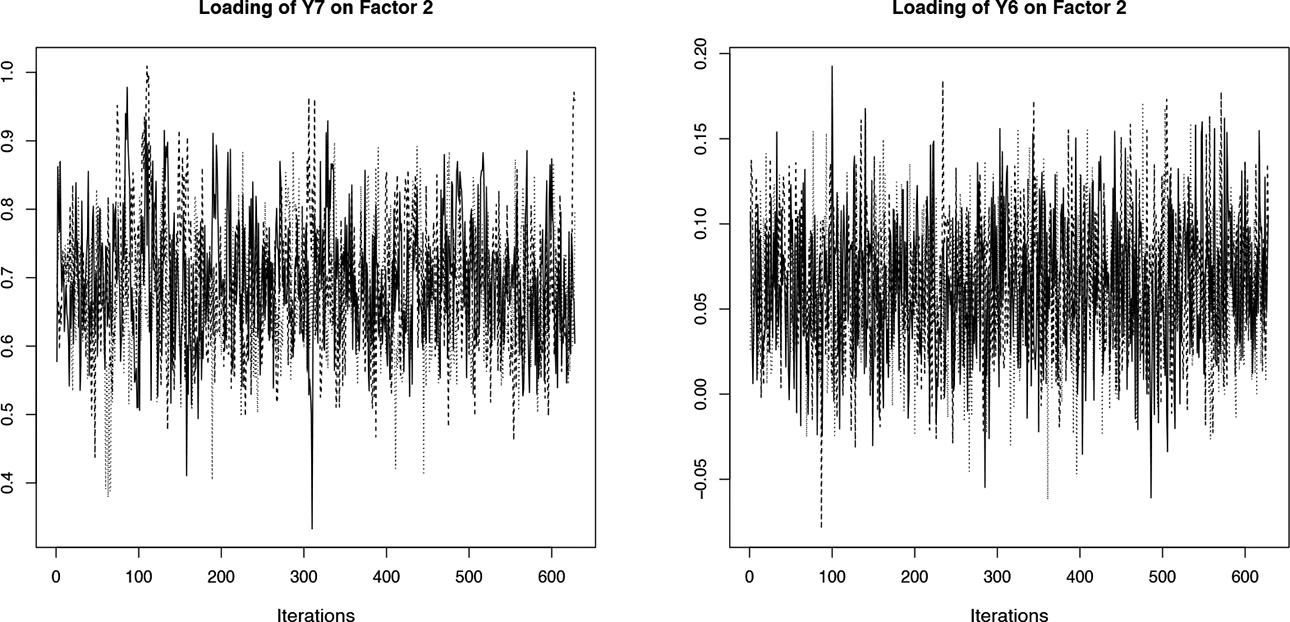
Traceplot of the factor loadings after applying the postprocessing scheme to the Markov chain Monte Carlo iterations.
Socioeconomic Status of Students in Colombia
We now explore the factor structure underlying the measurement of socioeconomic status of students in Colombia. The cognitive test Saber 11 is administered in the last year of high school. The data set consists of a sample of 235 examinees who answered the test in 2018 in the municipality “El Colegio,” which is near Bogota. A questionnaire was administered to collect eight variables (see Table 5) related to parents’ education attainment (Items 1 and 2), household possessions (Items 3–5), and food consumption at home (Items 6–8). It is of interest to determine whether there are in fact three underlying factors or whether the data could be explained by a unique factor, namely, the socioeconomic status.
Factor Structure for the Items Used in the Measurement of Socioeconomic Status of Students in Colombia Based on a Two Factor Model and a Three Factor Model
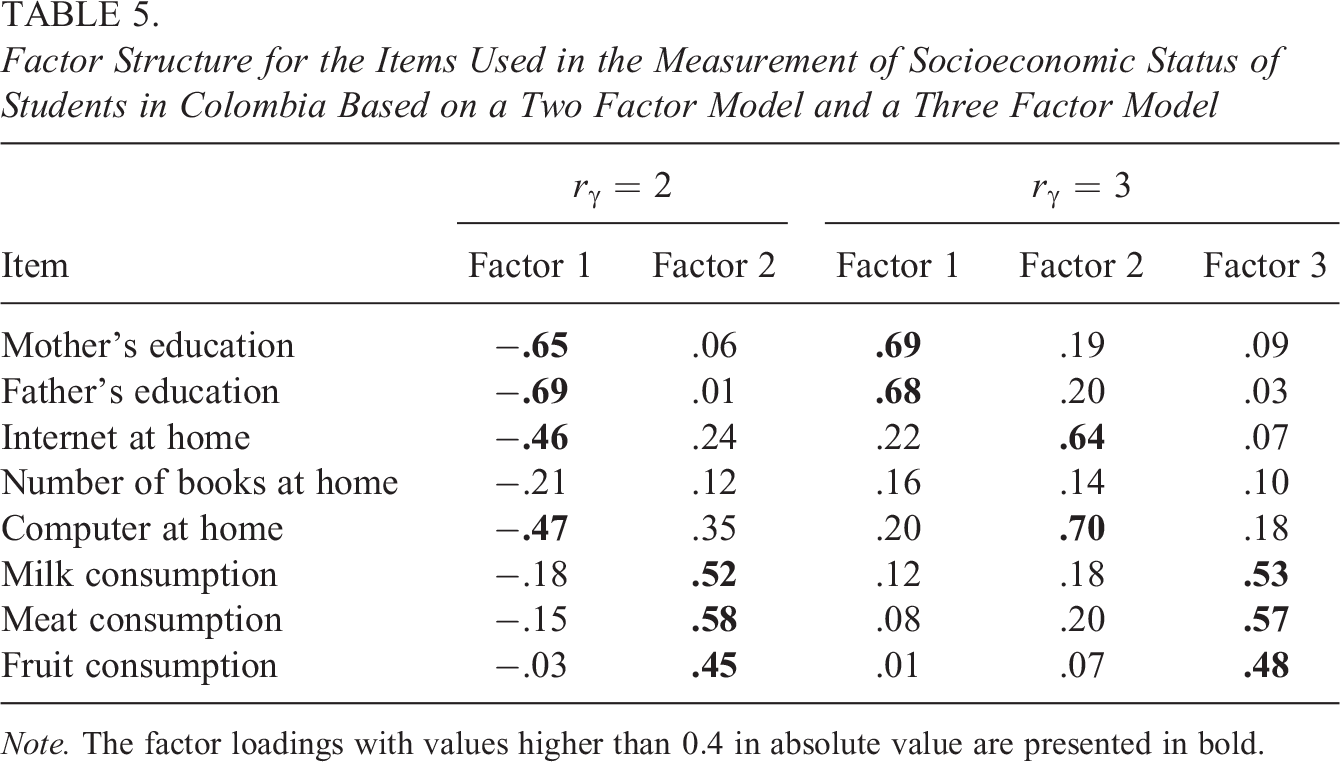
Note. The factor loadings with values higher than
The items related to parental education are ordinal with 10 options between no schooling up to postgraduate studies, while the questions internet at home and computer at home take the values yes/no. The item number of books at home is ordinal with four response options. The questions related to food consumption ask for the number of times the student consumes the item per week and there are four response options lying between almost never and almost everyday.
We implemented IDIFA with
To illustrate what occurs when the maximum number of factors m is lower than the true dimensionality, we carried out again IDIFA but taking
Discussion
Bayesian methods to infer model dimensionality in the literature generally assume a lower triangular structure for the factor loadings matrix. As discussed by Lopes and West (2004), making this assumption before model dimensionality is properly selected may cause that the ordering of the outcomes influences the results. We corroborated this in the simulation study.
In this article, we have proposed an alternative method for Bayesian exploratory factor analysis without imposing any restriction on the factor loadings matrix. In IDIFA approach, we infer model dimensionality based on the number of nonnull columns in the factor loadings matrix. The posterior probability for the selected dimensionality provides information about the certainty/uncertainty on the number of factors given the data. After selecting the number of factors, we solve rotational indeterminacy to estimate the model parameters using the postprocessing scheme in Papastamoulis and Ntzoufras (2022). With respect to the hyperparameter values, selecting
The Bayesian methods for exploratory factor analysis in the literature base the inference for each column k of the factor loadings matrix on multiple indicators, taking one
Fitting our model is simple via Gibbs sampling, whereas implementation of the methods in the literature is rather involved in general. This permits that IDIFA can be easily implemented in Bayesian packages. Our proposal assumes that the factors are uncorrelated but may perform well for correlated factor models, since any m-factor model can be rotated to an orthogonal structure.
The model in Equation 4 may be easily extended to analyze hierarchical data by including random effects. Moreover, in cases where one desires to select what outcomes to include in the analysis such as in Kaufmann and Schumacher (2017), a modification of the model in Equation 4 can be implemented. Namely,
Supplemental Material
Supplemental Material, sj-docx-1-jeb-10.3102_10769986231176023 - Bayesian Exploratory Factor Analysis via Gibbs Sampling
Supplemental Material, sj-docx-1-jeb-10.3102_10769986231176023 for Bayesian Exploratory Factor Analysis via Gibbs Sampling by Adrian Quintero, Emmanuel Lesaffre and Geert Verbeke in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research and/or authorship of this article: This work was supported by Icfes—Colombian Institute for Educational Evaluation.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.