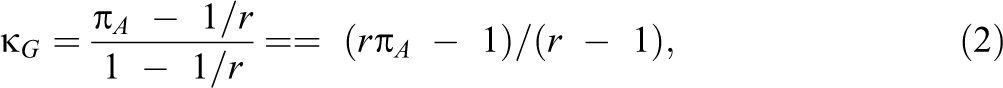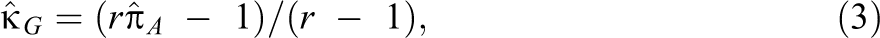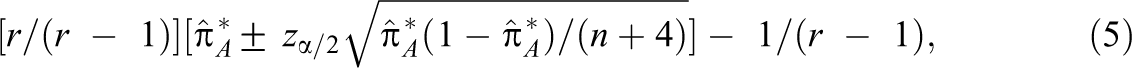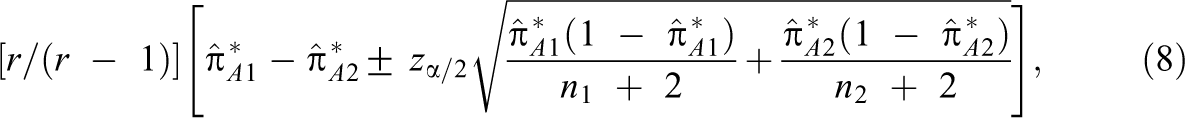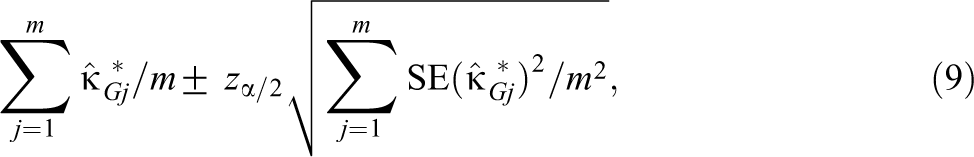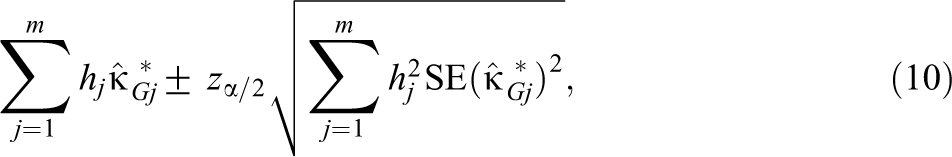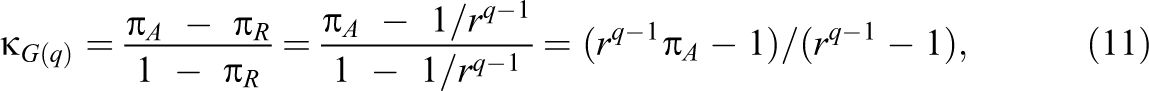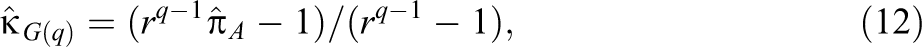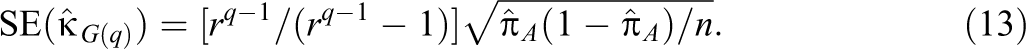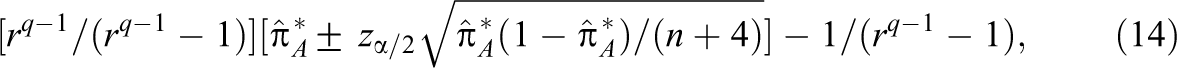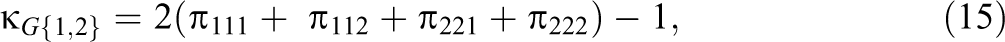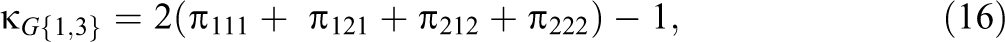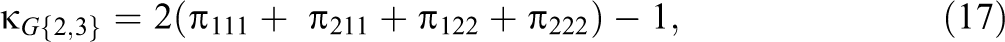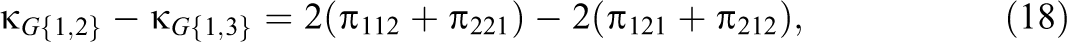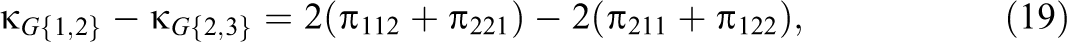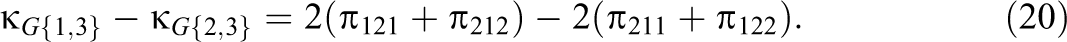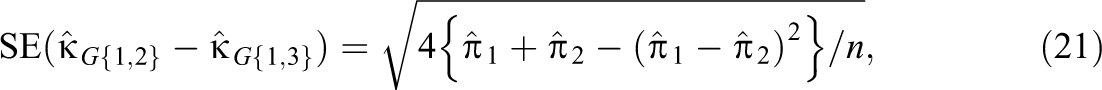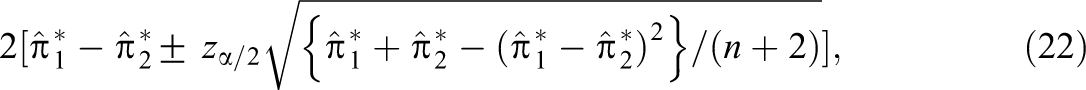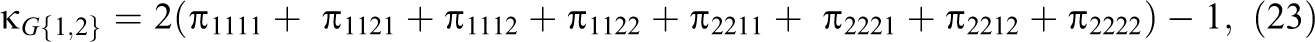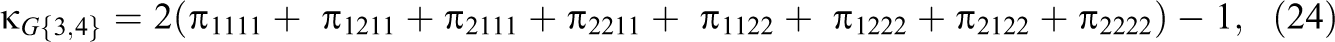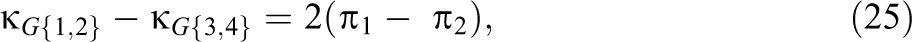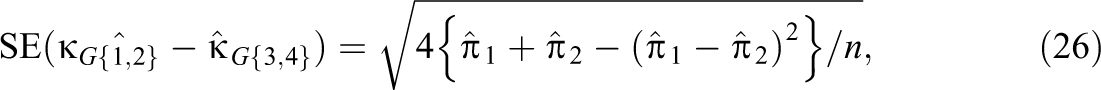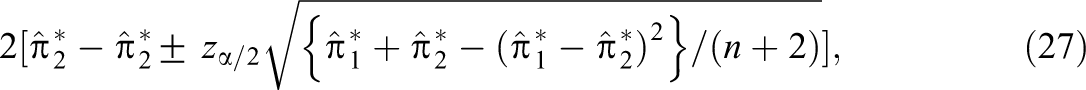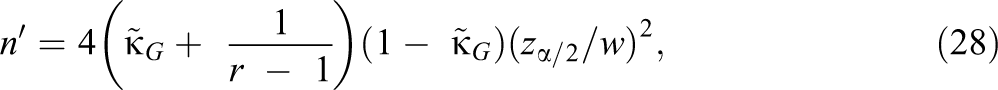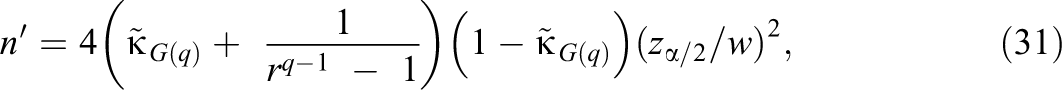The limitations of Cohen’s κ are reviewed and an alternative G-index is recommended for assessing nominal-scale agreement. Maximum likelihood estimates, standard errors, and confidence intervals for a two-rater G-index are derived for one-group and two-group designs. A new G-index of agreement for multirater designs is proposed. Statistical inference methods for some important special cases of the multirater design also are derived. G-index meta-analysis methods are proposed and can be used to combine and compare agreement across two or more populations. Closed-form sample-size formulas to achieve desired confidence interval precision are proposed for two-rater and multirater designs. R functions are given for all results.
The assignment of mutually exclusive nominal ratings to a set of objects by different raters is a very common activity in many fields of research. For example, suppose two deliberately selected raters assign every object in a population of objects to one and only one of r clearly defined nominal categories. The ratings can then be summarized in an r × r contingency table of population proportions, where is the population proportion of objects assigned to category i (i = 1 to r) by Rater 1 and category j (j = 1 to r) by Rater 2, is the population proportion of objects assigned to category i (i = 1 to r) by Rater 1, and is the population proportion of objects assigned to category i (i = 1 to r) by Rater 2.
If the population of objects is large or if the rating process is time-consuming or costly, it may be necessary to obtain a random sample of n objects from the population and have each rater classify the sample of n objects. When two raters each classify a random sample of n objects, the resulting classifications can be summarized into an r × r table of observed frequency counts, where is the number of sample objects assigned to category i (i = 1 to r) by Rater 1 and category j (j = 1 to r) by Rater 2, is the number of sample objects assigned to category i (i = 1 to r) by Rater 1, and is the number of sample objects assigned to category i (i = 1 to r) by Rater 2. The observed frequency counts can be used to estimate the population proportions in the r × r contingency table. Specifically, the maximum likelihood estimates of , , and are , , and , respectively.
In the two-rater design, one measure of agreement is the proportion of objects that are assigned to the same nominal category by both raters. This proportion is and its maximum likelihood estimate is .
2. Chance-Corrected Measures of Agreement
As a measure of agreement, exaggerates the degree of agreement between two raters because can be greater than 0 even if both raters classify the objects in a purely random manner. A general chance-corrected measure of agreement (Scott, 1955) is defined as
where is the proportion of agreements that would be expected if the two raters had assigned the classifications independently and at random. The maximum value of is 1, representing perfect agreement, and the minimum value of is .
Different definitions of define different chance-corrected measures of agreement. Scott (1955) sets , Bennett et al. (1954) set = 1/r, and Gwet (2008) sets =, where . The chance-corrected measure of agreement proposed by Krippendorff (1970) also sets but makes a small-sample adjustment to the estimate of . For r = 2, Scott’s measure of agreement is also called intraclass κ (Shoukri, 2011). The most well-known and widely used chance-corrected measure of agreement in the social sciences is Cohen’s κ (Cohen, 1960), where .
The population value of Cohen’s κ is denoted here as . A maximum likelihood estimate of , denoted as , is obtained by replacing with and replacing with in Equation 1. An approximate large-sample standard error of was derived by Fleiss et al. (1969), which can be used to construct a Wald confidence interval for .
SAS (SAS Institute, 2011) and Stata (StataCorp, 2019) software compute the Wald confidence interval for . The cohen.kappa function in the psych R package (Revelle, 2022) also computes the Wald confidence interval for . The Wald confidence interval for Cohen’s κ () is known to have poor performance characteristics (Blackman & Koval, 2000; Flack, 1987). Although several alternative confidence interval estimation methods for have been proposed (see Lee & Tu, 1994), bootstrap confidence intervals for appear to be the best option (Klar et al., 2002). Lee and Tu (1994) found that a sample of at least n = 100 objects must be rated before the Wald confidence interval for can be expected to perform properly. The simulation results of Klar et al. (2002) suggest that the bootstrap confidence interval for should not be used for n < 35.
Cohen’s κ is widely used but has several limitations. Feinstein and Cicchetti (1990) explain how can have a very low value even when is close to 1. For example, with = 97, = 0, = 2, and = 1, there is near perfect agreement between the two raters but = .492. With = 80, = 20, = 0, and = 0, there is high agreement between the two raters but = 0. Warrens (2010) shows that is paradoxically larger when . For example, = .40 with = 35, = 15, = 15, and = 35, where , but paradoxically increases to .45 with = 35, = 0, = 30, and = 35, where is unchanged but .
Cohen’s definition of is perhaps its most serious weakness as a measure of nominal agreement. This definition implies that Rater 1 would assign objects to category i with probability and Rater 2 would assign subjects to category i with probability if both raters were simply guessing. However, is estimated using sample data, where raters typically are not guessing. For example, if r = 3 and Rater 1 classifies 20% of the objects in category 1, 45% in category 2, and 35% in category 3, Cohen’s κ assumes that these exact same marginal proportions would be obtained if Rater 1 was simply guessing. Green (1981) argued that could be justified in the arguably unrealistic situation where a rater would “guess at a rate equivalent to the proportion of time they have determined the presence of a characteristic when they were not guessing.” Except for the chance-corrected measure of agreement proposed by Bennett et al. (1954), all of the other measures of agreement also use an estimate of in situations where raters are typically not guessing. Furthermore, estimating introduces another source of sampling variability into , which degrades the small-sample performance of the Wald confidence interval for .
For r = 2, Byrt et al. (1993) define prevalence as and bias as and then show that a bias adjustment to is equal to the intraclass κ. They also show that a bias adjustment combined with a prevalence adjustment to is equal to the Bennett–Alpert–Goldstein index. For r = 2, Blackman and Koval (1993) show that intraclass κ is a large-sample approximation to an intraclass reliability of a single rater from a one-way analysis of variance (ANOVA), while Cohen’s κ is a large-sample approximation to an intraclass reliability of a single rater from a two-way ANOVA. In an interrater reliability study, the intraclass reliability coefficient describes the reliability of a single rater assuming parallel measurements (McDonald, 1999). Parallel measurements are assumed to be homoscedastic, and this assumption is violated in the case of r = 2 if . Although Cohen’s κ is arguably an inappropriate measure of interrater agreement, it is an appropriate measure of interrater reliability in the special case of r = 2 and homoscedasticity. Maclure and Willett (1987) argue that should not be used with r > 2.
Some of the controversy and debate regarding interrater agreement stems from a failure to distinguish between interrater agreement and interrater reliability (Kottner & Stiener, 2011). One of the claimed limitations of is the attenuation that occurs in a 2 × 2 table when or is close to 1 or 0. Although this attenuation of is an inappropriate characteristic for a measure of interrater agreement, it is a perfectly appropriate characteristic for a measure of interrater reliability because reliability cannot be large if there is little variability in the ratings, and the variability of the dichotomous ratings will be small when or is close to 1 or 0. The problem of assessing interrater agreement rather than interrater reliability is addressed here.
3. G-index for Two Raters
As noted above, the chance-corrected measure of agreement proposed by Bennett et al. (1954) sets = 1/r. This value for assumes that two independent raters, if they were simply guessing, would select one of the r categories with probability 1/r, so that the joint probabilities in the r × r contingency table under random and independent ratings is 1/r2. The sum of the r joint agreement probabilities gives = 1/r. This definition of is a sensible assumption for random nominal-scale classifications and is consistent with signal detection theory (Wickens, 2002, p. 95) when choosing among r alternatives under a pure noise condition. Setting = 1/r is also consistent with the conceptualization of chance agreement proposed by Lawlis and Lu (1972), Maxwell (1977), and Grove et al. (1981). Hayes and Krippendorff (2007) criticize using = 1/r. They argue that any category that is unused by both raters will “inflate” the Bennet–Alpert–Goldstein coefficient but not Cohen’s κ. However, a category that is unused by both raters indicates perfect agreement for that category and it is appropriate that the Bennet–Alpert–Goldstein coefficient reflects this agreement.
and has a possible range of −1/(r – 1) to 1. The maximum likelihood estimate of is
where is the unbiased maximum likelihood estimate of . The estimator of is an unbiased maximum likelihood estimator because it is a linear function of the unbiased maximum likelihood estimator of . An approximate standard error for given below
which is a linear function of the standard error of . In the above example where = 97, = 0, = 2, and = 1, the estimate of (Equation 3) is .96 and appropriately describes the near perfect agreement between the two raters.
The following 100(1 − )% adjusted Wald confidence interval for is proposed here
where and fA = . The ci.qrater R function in the Online Supplementary Material computes Equations 3–5.
Although a point estimate of was proposed decades ago (Bennett et al., 1954), little progress has been made in terms of statistical inference for . For the special case of r = 2, a standard error of is given in Shoukri (2011) as
which can be algebraically reexpressed in the form of Equation 4. For r = 2, this standard error could be used to compute the following 100(1 − )% Wald confidence interval for
It can be shown that Equation 7 can be expressed in the form of Equation 5, where the interval estimate in brackets is the traditional Wald confidence interval for a population proportion. Agresti and Coull (1998) showed that the traditional Wald confidence interval has poor performance characteristics under realistic conditions and they proposed an adjusted Wald confidence interval. With sample sizes as small as n = 10, the 95% Agresti–Coull confidence interval had an average coverage probability close to .95 and a worst-case coverage probability no less than .92 across the entire range of possible population proportion values (Agresti & Coull, 1998). The interval estimate in brackets of Equation 7 is the Agresti–Coull confidence interval, and hence, Equation 5 inherits all of its performance characteristics because is a linear function of . The “exact” Clopper–Pearson confidence interval for also could be used in place of the Agresti–Coull confidence interval in Equation 5 (see Section 10). Note that Cohen’s κ cannot be expressed solely in terms of and hence the Agresti–Coull or Clopper–Pearson confidence intervals cannot be used to obtain a confidence interval for Cohen’s κ.
4. Comparing Agreement in Two-Group Designs
Assessing interrater agreement from two independent groups can answer a wide variety of interesting research questions. The two-group design can be experimental or nonexperimental. A two-group nonexperimental design could consist of two types of randomly sampled objects (e.g., male vs. female students) that are classified into r categories by the same two raters. In a two-group experimental design, a single sample of objects is randomly divided into two groups and each group could be rated by different types of raters (e.g., expert vs. novice) or under differing rating conditions (e.g., complete vs. incomplete case files). Methods for comparing two or more independent intraclass κ values have been proposed by Donner et al. (1996) and Donner and Zou (2002).
Let denote the population value of the G-index that will be estimated from subpopulation j in a two-group nonexperimental design or from condition j in a two-group experimental design. It is easy to show that the difference can be expressed as , where is the population proportion of agreements that will be estimated in group j. The following 100(1 − )% adjusted Wald confidence interval for is proposed here
where . Note that the confidence interval in brackets is the adjusted Wald confidence interval for a difference between two independent proportions developed by Agresti and Caffo (2000), which has been shown to have excellent small-sample properties under a wide range of conditions. With sample sizes as small as 10 per group, the 95% Agresti–Caffo confidence interval had an average coverage probability close to .95 and a worst-case coverage probability no less than .92 in the 10,000 conditions they considered (Agresti & Caffo, 2000). The ci.diff R function in the Online Supplementary Material computes Equation 8.
5. Multistudy Designs
A small sample of objects might be necessary if the ratings are costly or time-consuming. However, a confidence interval for might be uselessly wide if the sample size is too small. One way to obtain a more accurate estimate of is to statistically combine agreement estimates from two or more independent studies. Combining parameter estimates from two or more studies is called a meta-analysis, and Vacha-Haase (1998) referred to a meta-analysis of reliability estimates as reliability generalization. Bonett (2010) developed statistical methods for combining and comparing Cronbach’s α reliability coefficients from two or more studies. The logic and rationale for reliability generalization also apply to interrater agreement with the goal of obtaining a more precise and generalizable estimate of agreement and also to assess the degree to which an agreement index might vary across different types of raters, different rating conditions, or different types of rated objects.
Sun (2011) showed how the classical fixed-effect and random-effects meta-analysis methods (see Borenstein et al., 2009) can be used to obtain a confidence interval for an average of two or more population Cohen κ values. The varying-coefficient meta-analysis method (Bonett & Price, 2015) is used here to obtain a confidence interval for an average of G-index values from multiple populations. The varying-coefficient model does not require the unrealistic assumptions of the classical fixed-effect and random-effects meta-analysis methods. Unlike the traditional fixed-effect model, the varying-coefficient model does not assume effect-size homogeneity, and unlike the random-effects model, the varying-coefficient model does not assume randomly selected studies or effect size standard errors that are uncorrelated with the effect sizes (see Bonett & Price, 2015, for more details).
Let represent the population G-index value that has been estimated in study j (j = 1 to m). The following 100(1 − )% adjusted Wald confidence interval for is proposed here
where , , and . Note that , and hence, the end points of Equation 9 are linear functions of the end points of the adjusted Wald confidence interval proposed by Price and Bonett (2004) for a linear function of independent proportions. The Price–Bonett confidence interval is a generalization of the Agesti–Coull confidence interval and has been shown to have excellent small-sample properties under a wide range of conditions. In meta-analysis applications with m = 5, 15, or 30 studies and sample sizes as small as 10 per group, the 95% Price–Bonett confidence interval had an average coverage probability close to .95 and a worst-case coverage probability no less than .938 in the 13,500 conditions they considered (Price & Bonett, 2004). The ci.meta R function in the Online Supplementary Material computes Equation 9 using the sample sizes and number of agreements from each study.
Important differences in values across the m populations could be due to differences in rating conditions, rater characteristics, or characteristics of the rated objects. A linear contrast of values can be expressed as , where the hj values are specified by the researcher and = 0. For example, in a meta-analysis of m = 5 comparable interrater agreement studies where the first three studies rated the behavior of high school students and the last two studies rated the behavior of college students, the researcher might want to estimate . This linear contrast can be specified with contrast coefficients h1= 1/3, h2 = 1/3, h3 = 1/3, h4 = −1/2, and h5 = −1/2.
The following 100(1 − )% adjusted Wald confidence interval for is proposed here
where and are defined above with m set equal to the number of nonzero hj values as recommended by Price and Bonett (2004). Note that , and hence, the end points of Equation 10 are linear functions of the end points of the adjusted Wald confidence interval proposed by Price and Bonett (2004) for a linear function of independent proportions. The Price–Bonett confidence interval has been shown to have excellent performance characteristics. With sample sizes as small as 20 per group, the 95% Price–Bonett confidence interval had an average coverage probability close to .95 and a worst-case coverage probability no less than .920 across 10,000 population proportion values and several different types of linear contrasts (Price & Bonett, 2004). The ci.contrast R function in the Online Supplementary Material computes Equation 10.
6. Multirater Designs
If q different and deliberately selected raters each classify a random sample of objects into r categories, the results can be summarized in a rq contingency table. A G-index of agreement for any two raters can be computed by collapsing the rq table into an r × r table for the two raters of interest and then applying Equations 3–5.
A G-index of agreement among all q raters is defined here as
where is the probability of unanimous agreement among the q raters and is the probability of unanimous agreement among the q raters for category i. Assuming random and independent ratings, the joint probability in the rq contingency table is , so that the probability of random agreement in any of the r categories is . Note that satisfies the definition of agreement among multiple raters given by Hubert (1977).
The maximum likelihood estimate of is
where is the maximum likelihood estimate of . The approximate standard error for given below is a function of the variance of
The following 100(1 − )% adjusted Wald confidence interval for is proposed here
where and fA = . Like Equation 5, Equation 14 uses the Agresti–Coull adjusted Wald confidence interval for a single population proportion. The ci.qrater R function in the Online Supplementary Material computes Equation 14.
6.1. Three-Rater Design (r = 2)
Consider a q = 3 rater design with r = 2. The three pairwise G-indices are denoted as , , and . The average of all pairwise measures of agreement is an alternative multirater measure of agreement proposed by Hubert (1977). It can be shown for the special case of q = 3, using straightforward but tedious algebra, that .
In some applications, it will be informative to compare , , and . For example, if Raters 1 and 2 are novices and Rater 3 is an expert, confidence intervals for , , and will provide information regarding the direction and the magnitude of these pairwise differences. The three G-indices in a three-rater design with r = 2 can be expressed as
and it follows that the pairwise differences in these G-indices can be expressed as
Maximum likelihood estimates of , , and and the pairwise differences in G-indices are obtained by replacing in Equations 15–20 with the maximum likelihood estimate = .
An approximate standard error of each pairwise difference is derived by first collapsing the 23 table of multinomial proportions into three mutually exclusive categories. For example, from Equation 18, the three categories needed to assess have probabilities of , , and . Using the variances and covariances of a multinomial distribution (Bishop et al., 1975, p. 442), an approximate standard error of is
where and . An approximate standard error of is given by Equation 21 with and , and an approximate standard error of is given by Equation 21 with and .
A 100(1 − )% adjusted Wald confidence interval for is
where and . The confidence interval for is given by Equation 22 with and , and the confidence interval for is given by Equation 22 with and . The adjusted Wald confidence interval in brackets of Equation 22 was developed by Bonett and Price (2012) and was shown to have excellent small-sample properties under a wide range of conditions. With sample sizes as small as n = 15, the 95% Bonett–Price confidence interval had an average coverage probability that was slightly greater than .95 and a worst-case coverage probability no less than .910 in the 25,000 conditions they considered (Bonett & Price, 2012). The agree.3rater R function in the Online Supplementary Material computes Equation 22 for all three pairs of raters and also computes Equation 14 for .
6.2. Four-Rater Design (r = 2)
The case of q = 4 raters with r = 2 has received special attention in the literature (Banerjee et al., 1999; Donner et al., 2000; McKenzie et al., 1996; Williamson & Manatunga, 1997) because some of the research questions that can be answered using the two-group design described previously might be answered more economically using a one-group design with four raters. The four-rater design can be used to compare the agreement between two different types of raters, such as two novice raters and two expert raters or two male raters and two female raters.
A G-index for any two raters in a four-rater design can be computed by collapsing the 24 table into a 2 × 2 table for any two raters of interest and then applying Equations 3–5. The focus here will be the comparison of agreement between the first two raters () with the last two raters (). These two G-indices in a four-rater design can be expressed as
and it follows that the difference between these two G-indices can be expressed as
where = + + + and = + + + . The maximum likelihood estimate of − is obtained by replacing the population proportions in Equations 23 and 24 with their maximum likelihood estimates.
Applying the same approach used to derive Equation 22 gives the following approximate standard error of –
and the following 100(1 − )% adjusted Wald confidence interval for −
where and are the maximum-likelihood estimates, + + + and + + + . Note that the adjusted Wald confidence interval in brackets is a Bonett–Price confidence described in Equation 22. The ci.4rater R function in the Online Supplementary Material computes the maximum likelihood estimate and confidence interval for − requiring only the sample size, = + + + , and + + + as input.
The above results for q = 3 and q = 4 raters can be applied to designs with q 4 raters by collapsing a 2q table into a 23 table if the comparison involves three raters or a 24 table if the comparison involves four raters. For example, with q = 5, an estimate and confidence interval for − is computed from a 23 table for Raters 1, 3, and 4, and an estimate and confidence interval for − is computed from a 24 table for Raters 1, 3, 4, and 5.
7. Benchmark G-Index Values
When reporting the numerical results for a measure of agreement, it is common to also provide a verbal description of the strength of agreement. Altman (1991), Fleiss et al. (2003), and Landis and Koch (1977) have each suggested their own benchmark verbal descriptions for different point estimates of Cohen’s κ. Landis and Koch (1977) suggested that a Cohen κ value within one of the following six ranges < 0, 0–.20, .21–.40, .41–.60, .61–.80, or .81–1.0 represents a “poor,” “slight,” “fair,” “moderate,” “substantial,” or “almost perfect” agreement, respectively. The Landis–Koch benchmarks are frequently used to describe a point estimate of an agreement index. This practice is misleading because point estimates contain a sampling error of unknown magnitude and direction. Benchmark descriptions should be applied to an interval estimate rather than a point estimate. Although the Landis–Koch benchmark scale is appealing because of its six very specific descriptive categories, a confidence interval is likely to cover two or more of these categories unless n is large. Fleiss et al. (2003) proposed a three category scale for Cohen’s κ where values below .4 represent “poor” agreement, values between .40 and .75 represent “good” agreement, and values greater than .75 represent “excellent” agreement. Some researchers might find the Fleiss scale to be too crude for their purposes.
A four category benchmark scale is proposed here for the G-index. A G-index value within one of the four ranges < .25, .25–.50, .51–.75, and .76–1.0 could be described as “poor,” “fair,” “good,” and “excellent,” respectively. A confidence interval is less likely to include more than two descriptive categories in a four category scale than a six category scale. For example, a confidence interval of [.581, .824] would be described as “moderate, substantial, or almost perfect agreement” using the Landis–Koch scale and would be described as “good or excellent agreement” using the proposed scale.
8. Sample-Size Planning
Sample-size planning is one of the most important components in the design of an interrater agreement study. If the number of objects sampled is too small, the confidence interval for the population agreement index could be uselessly wide. Several methods to approximate the sample-size requirement when assessing Cohen’s κ have been proposed (Bujang & Baharun, 2017; Cantor, 1996; Donner & Eliasziw, 1992; Flack et al., 1988). The available sample-size methods for Cohen’s κ are of limited value because they require assumptions about the classification probabilities of each rater in addition to the value for . Closed-form sample-size formulas are derived here that approximate the required sample size to obtain confidence intervals for , and with desired precision. These closed-form formulas are particularly useful because they do not require assumptions about the classification probabilities of each rater.
Larger sample sizes give narrower confidence intervals, and it is possible to approximate the sample size that will give the desired width (w) of a confidence interval for a specified level of confidence. The sample size needed to obtain a confidence interval for (Equation 5) having a desired width (upper limit minus lower limit) equal to w is approximately
where is a planning value of . Equation 28 was derived from Equation 4, where 2SE( is the approximate width of Equation 5. Setting this width to w, solving for n, and then replacing with gives Equation 28. A planning value of is obtained from expert opinion, pilot studies, or previously published research. Setting = (r – 2)/[2(r – 1)] maximizes Equation 28 and is useful in applications where no prior information about is available.
The width of Equation 5 tends to be greater than 2SE(, especially in small samples or if is close to 0 or 1, and hence, n′ tends to understate the required sample size. Following the general approach of Bonett and Wright (2000), a more accurate sample-size approximation is
where is the width of Equation 5 computed using n = n′ and the value of implied by . The size.ci.qrater R function in the Online Supplementary Material computes Equation 28 and then adjusts the result using Equation 29.
The sample size per group needed to obtain a confidence interval for (Equation 8) in a two-group design having a desired width of w is approximately
where v = and is a planning value of . If no prior information is available, and can be set to (r − 2)/[2(r − 1)], which maximizes Equation 30. Equation 30 was derived by setting 2 equal to w, solving for n, and replacing with .
The width of Equation 8 tends to be greater than 2, especially in small samples or if either or is close to 0 or 1, and hence, tends to understate the required sample size per group. The size.ci.diff R function in the Online Supplementary Material computes Equation 30 and then adjusts the result using Equation 29.
The sample size needed to obtain a confidence interval for (Equation 14) having a desired width of w is approximately
where is a planning value of . Equation 31 was derived from Equation 13, where 2 SE( is the approximate width of Equation 14. Setting this width to w, solving for n, and then replacing with gives Equation 31. Setting = (– 2)/[2(– 1)] maximizes Equation 31 and is useful in applications where no prior information about is available.
The width of Equation 14 tends to be greater than 2SE(, especially in small samples or if is close to 0 or 1, and hence, n′ tends to understate the required sample size. The size.ci.qrater R function in the Online Supplementary Material computes Equation 31 and then adjusts the result using Equation 29.
9. Illustrative Examples
The Online Supplementary Material contains R functions that will compute confidence intervals for (1) (Equation 5), (2) in two-group designs (Equation 8), (3) in meta-analysis applications (Equation 9), (4) a general linear contrast of in multiple group designs (Equation 10), (5) in multirater designs (Equation 14), and (6) pairwise comparisons in three-rater (Equation 22) and four-rater designs (Equation 27). The Online Supplementary Material also contains R functions that will compute the sample-size requirements to (1) estimate with desired precision (Equation 28), (2) estimate with desired precision (Equation 30), and (3) estimate with desired precision (Equation 31). The following examples are adapted from the author’s statistical consulting files.
9.1. Two Raters in One-Group Design
Two research assistants classified a random sample of n = 90 open-ended questionnaire responses into r = 3 predetermined categories, and 82 of the 90 responses were classified into the same categories by both research assistants. The command ci.qrater(.05, 90, 82, 3) computes Equations 3–5 and returns a point estimate for of .867 with a 95% confidence interval of [.747, .934].
9.2. Two Raters in Two-Group Design
Two school psychologists evaluated a random sample of n1 = 75 case files for boys and a random sample of n2 = 60 case files for girls. Each psychologist rated each child as having or not having (r = 2) attention deficit hyperactivity disorder symptoms. The psychologist ratings agreed in 70 of the 75 cases for the boys and in 45 of the 60 cases for the girls. The command ci.diff(.05, 75, 70, 60, 45, 2) computes Equation 8 and returns a 95% confidence interval for the difference in agreement for boys and girls of [.112, .609]. This function also returns point estimates of .867 and .500 with 95% confidence intervals of [.697, .948] and [.252, .685] for boys and girls, respectively. In this example where the two ratings are dichotomous, Cohen’s κ and intraclass κ are questionable measures of interrater agreement, but they are valid measures of interrater reliability. To obtain point and interval estimates of Cohen’s κ and intraclass κ, the frequency counts in the two 2 × 2 contingency tables for boys and girls are required. Suppose the frequency counts for boys are = 65, = 4, = 1, and = 5. The point estimates are .631 and .630, and the 95% Wald confidence intervals are [.336, .926] and [.331, .928] for Cohen’s κ and intraclass κ, respectively. Suppose the frequency counts for girls are = 35, = 8, = 7, and = 10. The point estimates are .395 and .395, and the 95% Wald confidence intervals are [.142, .649] and [.141, .649] for Cohen’s κ and intraclass κ, respectively.
9.3. Meta-Analysis of Two-Rater Studies
Suppose two published studies used two raters to assess interrater agreement for the absence or presence (r = 2) of gender stereotype behavior in educational children’s TV shows. The first published study used a random sample of n1 = 50 episodes and reported agreement in 41 of the 50 episodes. The second published study used a random sample of n2 = 70 episodes and reported agreement in 58 of the 70 episodes. The three commands f = c(41, 58), n = c(50, 70), and ci.meta(.05, f, n, 2) computes Equation 9 and returns a point estimate for ( of .648 with a 95% confidence interval of [.488, .766].
9.4. Linear Contrast in a Three-Study Design
Suppose the above meta-analysis included a third published study that sampled episodes of noneducational children’s TV shows. The third study used a random sample of n3 = 90 episodes and reported agreement in 85 of the 90 episodes. The four commands f = c(41, 58, 85), n = c(50, 70, 90), h = c(−.5, −.5, 1), and ci.contrast(.05, f, n, h, 2) compute Equation 10 and return a point estimate for – ( of .240 with a 95% confidence interval of [.071, .412]. This result suggests that interrater agreement is greater for noneducational than educational TV shows.
9.5. Four-Rater Design
Four parole officers (q = 4) evaluated the parole application files of 100 prisoners, and there was a unanimous grant or deny (r = 2) agreement in 87 of the 100 files. The command ci.qrater(.05, 100, 87, 4, 2) computes Equations 12–14 and returns a point estimate for of .851 with a 95% confidence interval of [.758, .912].
9.6. Three-Rater Design
A school psychologist (Rater 1), a teacher (Rater 2), and a principal (Rater 3) evaluated a sample of 300 high school students with disciplinary problems and gave a suspension or a nonsuspension recommendation (r = 2) for each student. The ci.3rater function requires a vector of the eight frequency counts in the 23 contingency table (see comments in the ci.3rater function about how to order the frequencies). In this example, suppose the frequency counts are 100, 6, 4, 40, 20, 1, 9, and 120. The two commands f = c(100, 6, 4, 40, 20, 1, 9, 120) and ci.3rater(.05, f) compute Equations 21 and 22 and return 95% confidence intervals for − , − , and − of [.006, .127], [−.407, −.189], and [−.462, −.266], respectively. These results indicate that the agreement between the school psychologist and teacher is greater than the agreement between the school psychologist and principal. The results also indicate that the agreement between the teacher and the principal is greater than the agreement between the school psychologist and teacher as well as the agreement between the school psychologist and principal.
9.7. Comparison of Two-Rater Agreement in Four-Rater Design
Two graduate students (Raters 1 and 2) and two undergraduate students (Raters 3 and 4) were trained to code open-ended responses for the absence or presence (r = 2) of a particular ideological theme in newspaper articles. Suppose these four raters coded 300 articles and frequency counts of f1 = 78 and f2 = 52 are extracted from the 24 table (see Equation 27 for definition of f1 and f2). The command ci.4rater(.05, 300, 78, 52) computes Equations 26 and 27 and returns a point estimate − of .173 with a 95% confidence interval of [.024, .320].
9.8. Sample Size Requirements for Two-Rater and Three-Rater Designs
A proposed study will use two master teachers (q = 2) to provide dichotomous ratings (meets expectations or needs improvement) for a sample of student teachers based on classroom observations. Setting = .90, r = 2, = .05, and a desired confidence interval width of .25, size.qrater(.05, .9, 2, .25, 2) computes Equations 28 and 29 and returns a sample-size requirement of 71 student teachers to be rated by two master teachers. The researcher is also considering using three master teachers to rate each student. Setting = .90, r = 2, = .05, and a desired confidence interval width of .25, size.qrater(.05, .9, 2, .25, 3) computes Equations 31 and 29 and returns a sample-size requirement of 42 student teachers to be rated by three master teachers.
9.9. Sample Size Requirement for Two-Group Design
The interrater reliability for two expert raters will be compared with the interrater reliability of two novice raters. The expert raters will classify one random sample of newspaper articles regarding educational reform into three different categories. The novice raters will perform the same task using another random sample of newspaper articles. Setting = .80, = .7, r = 3, = .05, and a desired confidence interval width of .30, size.diff(.05, .8, .7, 3, .3) computes Equations 30 and 29 and returns a sample-size requirement of 107 per group. The two expert raters should evaluate one random sample of 107 newspaper articles and the two novice raters should evaluate a second random sample of 107 newspaper articles.
10. Conclusion
The G-index of agreement is an attractive alternative to Cohen’s κ for the assessment of nominal-scale agreement. The new confidence interval and sample size methods presented here parallel the methods developed for Cohen’s κ over the last 50 years. The R functions in the Online Supplementary Material can be used to apply the new methods presented here for the G-index of agreement, so that researchers will now be able to perform the same types of inferential and sample-size analyses that are currently available for Cohen’s κ.
All of the proposed confidence intervals are based on adjusted Wald confidence intervals, which have been shown to have excellent performance characteristics in terms of expected coverage probability, worst-case coverage probability, and expected confidence interval width (Agresti & Caffo, 2000; Agresti & Coull, 1998; Bonett & Price, 2012; Price & Bonett, 2004). Newcombe (2013) describes alternatives to the adjusted Wald confidence intervals that have different performance characteristics that might be more desirable in certain applications. For example, the Clopper–Pearson confidence interval for a single population proportion tends to be substantially wider than the adjusted Wald interval but it has a worst-case coverage probability that is guaranteed to be no less than 1 − . If worst-case coverage probability is the primary concern, then the adjusted Wald confidence intervals (the terms in brackets) in Equations 5 and 14 could be replaced with Clopper–Pearson confidence intervals. If any current or newly developed confidence interval for a single proportion, a difference of independent proportions, a difference of paired proportions, or a linear function of proportions is considered to be more appropriate than an adjusted Wald confidence, then that confidence interval can be used in place of the adjusted Wald intervals used here.
The results in Sections 3, 4, 5, and 6 are general for r 2, but the results in Sections 6.1 and 6.2 are limited to r = 2. Future research could extend the results in Sections 6.1 and 6.2 to the general case of r 2.
Supplemental Material
Supplemental Material, sj-docx-1-jeb-10.3102_10769986221088561 - Statistical Inference for G-indices of Agreement
Supplemental Material, sj-docx-1-jeb-10.3102_10769986221088561 for Statistical Inference for G-indices of Agreement by Douglas G. Bonett in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
1.
AgrestiA.CaffoB. (2000). Simple and effective confidence intervals for proportions and differences of proportions result from adding two successes and two failures. The American Statistician, 54, 280–288.
2.
AgrestiA.CoullB. A. (1998). Approximate is better than “exact” for interval estimation of binomial proportions. The American Statistician, 52, 119–126.
3.
AltmanD. G. (1991). Practical statistics for medical research. Chapman and Hall.
4.
BanerjeeM.CapozzoliM.McSweeneyL.SinhaD. (1999). Beyond kappa: A review of interrater agreement measures. Canadian Journal of Statistics, 27, 3–23.
5.
BennettE. M.AlpertR.GoldsteinA. C. (1954). Communications through limited response questioning. Public Opinion Quarterly, 18, 303–308.
6.
BishopY. M. M.FienbergS. E.HollandP. W. (1975). Discrete multivariate analysis: Theory and practice. MIT Press.
7.
BlackmanN. J-M.KovalJ. J. (1993). Estimating rater agreement in 2x2 tables: Correction for chance and intraclass correlation. Applied Psychological Measurement, 17, 211–223.
8.
BlackmanN. J-M.KovalJ. J. (2000). Interval estimation for Cohen’s kappa as a measure of agreement. Statistics in Medicine, 19, 723–741.
9.
BonettD. G. (2010). Varying coefficient meta-analytic methods for alpha reliability. Psychological Methods, 15, 368–385.
10.
BonettD. G.PriceR. M. (2012). Adjusted Wald interval for a difference of binomial proportions based on paired data. Journal of Educational and Behavioral Statistics, 37, 479–488.
11.
BonettD. G.PriceR. M. (2015). Varying coefficient meta-analysis methods for odds ratios and risk ratios. Psychological Methods, 20, 394–406.
12.
BonettD. G.WrightT. A. (2000). Sample size requirements for estimating Pearson, Kendall, and Spearman correlations. Psychometrika, 65, 23–28.
13.
BorensteinM.HedgesL. V.HigginsJ. P. T.RothsteinH. R. (2009). Introduction to meta-analysis. Wiley.
14.
BrennanR. L.PredigerD. J. (1981). Coefficient kappa: Some uses, misuses, and alternatives. Educational and Psychological Measurement, 41, 687–699.
15.
BujangM. A.BaharumN. (2017). Guidelines of the minimum sample size requirements for Cohen’s kappa. Biostatistics, 14, e12267 -1.
16.
ByrtT.BishopJ.CarlinJ. B. (1993). Bias, prevalence and kappa. Journal of Clinical Epidemiology, 46, 423–429.
17.
CantorA. B. (1996). Sample-size calculations for Cohen’s kappa. Psychological Methods, 1, 150–153.
18.
CohenJ. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20, 37–46.
19.
DonnerA.EliasziwM. (1992). A goodness-of-fit approach to inference procedures for the kappa statistic: Confidence interval construction, significance-testing and sample size estimation. Statistics in Medicine, 11, 1511–1519.
20.
DonnerA.EliasaziwM.KlarN. (1996). Testing the homogeneity of kappa statistics. Biometrics, 52, 176–183.
21.
DonnerA.ShoukriM. M.KlarN.BartfayE. (2000). Testing the equality of two dependent kappa statistics. Statistics in Medicine, 19, 373–387.
22.
DonnerA.ZouG. (2002). Interval estimation for a difference between intraclass kappa statistics. Biometrics, 58, 209–215.
23.
FeinsteinA. R.CicchettiD. V. (1990). High agreement but low kappa: I. The problem of two paradoxes. Journal of Clinical Epidemiology, 43, 543–549.
24.
FlackV. F. (1987). Confidence intervals for the interrater agreement measure kappa. Communications in Statistics—Theory and Methods, 16, 953–968.
25.
FlackV. F.AfifiA. ALachenbruchP. ASchoutenH. J. A. (1988). Sample size determination for the two rater kappa statistic. Psychometrika, 53, 321–325.
26.
FleissJ. L.CohenJ.EverittB. S. (1969). Large sample standard errors of kappa and weighted kappa. Psychological Bulletin, 72, 323–327.
27.
FleissJ. L.LevinB.PaikM. C. (2003). Statistical methods for rates and proportions (3rded.). Wiley.
28.
GreenS. B. (1981). A comparison of three indexes of agreement between observers: Proportion of agreement, G-index, and kappa. Educational and Psychological Measurement, 41, 1069–1072.
29.
GroveW. M.AndreasesN. C.McDonald-ScottPKellerM. B.ShapiroR. W. (1981). Reliability studies of psychiatric diagnosis. Archives of General Psychiatry, 38, 408–413.
30.
GwetK. L. (2008). Computing inter-rater reliability and its variance in the presence of high agreement. British Journal of Mathematical and Statistical Psychology, 61, 29–48.
31.
HayesA. F.KrippendorffK. (2007). Answering the call for a standard reliability measure for coding data. Communications Methods and Measures, 1, 77–89.
32.
HolleyW.GuilfordJ. P. (1964). A note on the G-index of agreement. Educational and Psychological Measurement, 24, 749–754.
KlarN.LipsitzS. R.ParzenM.LeongT. (2002). Exact confidence interval for κ in small samples. Journal of the Royal Statistical Society: Series D, 51, 467–478.
35.
KottnerJ.StreinerD. L. (2011). The difference between reliability and agreement. Journal of Clinical Epidemiology, 64, 701–707.
36.
KrippendorffK. (1970). Estimating the reliability, systematic error, and random error of interval data. Educational and Psychological Measurement, 30, 61–70.
37.
LandisJ. R.KochG. (1977). The measurement of observer agreement for categorical data. Biometrics, 33, 159–174.
38.
LawlisG. F.LuE. (1972). Judgements of counseling process: Reliability, agreement, and error. Psychological Bulletin, 78, 17–20.
39.
LeeJ. J.TuZ. N. (1994). A better confidence interval for kappa (κ) on measuring agreement between two raters with binary outcomes. Journal of Computational and Graphical Statistics, 3, 301–321.
40.
MaclureM.WillettW. C. (1987). Misinterpretation and misuse of the kappa statistic. American Journal of Epidemiology, 126, 161–169.
41.
MaxwellA. E. (1977). Coefficient of agreement between observers and their interpretations. British Journal of Psychiatry, 130, 79–83.
42.
McDonaldR. P. (1999). Test theory: A unified treatment. Lawrence Erlbaum.
43.
McKenzieD. P.MacKinnonA. J.PéladeauN.OnghenaP. C.ClarkeD. M.HarringanS.McGorryP. D. (1996). Comparing correlated Kappas by resampling: Is one level of agreement significantly different from another?Journal of Psychiatry Research, 30, 483–492.
44.
NewcombeR. G. (2013). Confidence intervals for proportions and related measures of effect size. CRC Press.
45.
PriceR. M.BonettD. G. (2004). Improved confidence interval for a linear function of binomial proportions. Computational Statistics & Data Analysis, 45, 449–456.
46.
RevelleW. (2022). Psych: Procedures for psychological, psychometric, and personality research. Northwestern University, Evanston, Illinois. R package version 2.2.3, https://CRAN.R-project.org/package=psych
47.
SAS Institute. (2011). SAS/STAT(R) 9.2 user’s guide (2nd ed.).
48.
ScottW. A. (1955). Reliability of content analysis: The case of nominal scale coding. Public Opinion Quarterly, 19, 321–325.
49.
ShoukriM. M. (2011). Measures of interobserver agreement and reliability (2nd ed.). CRC Press.
50.
StataCorp. (2019). Stata Statistical Software: Release16. StataCorp LLC.
51.
SunS. (2011). Meta-analysis of Cohen’s kappa. Health Services and Outcomes Research Methodology, 11, 145–163.
52.
Vacha-HaaseT. (1998). Reliability generalization: Exploring variance in measurement error affecting score reliability. Educational and Psychological Measurement, 58, 6–20.
53.
WarrensM. J. (2010). A formal proof of a paradox associated with Cohen’s kappa. Journal of Classification, 27, 322–332.
54.
WickensT. D. (2002). Elementary signal detection theory. Oxford University Press.
55.
WilliamsonJ. M.ManatungaA. K. (1997). The Consultant’s Forum: Assessing interrater agreement from dependent data. Biometrics, 53, 707–714.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.