
Abstract
In this paper, we employ both narrative and systematic review methodologies to explore Running Records, a reading assessment tool designed for use with children in the early years of school. To contextualize Running Records, we describe their development over the past 50 years. We show that, as a tool designed to analyze reading errors, Running Records were used to develop and substantiate a cueing-based model of reading. Drawing on contemporary evidence-based cognitive models of reading, which controvert cueing-based models of reading, we demonstrate that the error analysis methodology rests on an incorrect assumption: that behaviors that are observed when a reader makes an error accurately represent the cognitive strategies a reader uses to read successfully. We describe robust evidence that the strategies used when a reader makes an error are compensatory behaviors peculiar to moments of reading failure. In light of this challenge to the rationale by which the use of Running Records is justified, the question is posed: What is the empirical and theoretical evidence for the valid use of Running Records to measure student progress and guide teaching? Through a systematic narrative review, we explore the peer-reviewed evidence concerning the use of Running Records to measure students’ reading progress and/or guide teaching. We conclude by proposing that alternative assessment methods are both available and necessary to more effectively support teachers of children first learning to read.
Keywords
In the late 1960s, New Zealand educator and psychologist Marie Clay (b. 1926–d. 2007) observed 100 children as they started to learn to read in their first year of school (Clay, 1966). Clay’s analytic method was limited to studying cognitive processes through observable behavior, which resulted in the development of an “error analysis” approach when assessing students’ reading. Clay recorded and analyzed observations of children’s reading errors and instances of error self-correction (Clay, 1969). From her analyses, Clay developed a theory of reading and reading acquisition (Clay, 1966, 2015a, 2015b; Doyle, 2018) and, in turn, Reading Recovery, a reading intervention approach from which many current mainstream reading instruction practices evolved (Hanford, 2022; Pinnell, 2010). Since her death in 2007, updated editions of many of Clay’s books have been published posthumously by The Marie Clay Trust (e.g., Clay, 2015a, 2015b, 2017, 2019). 1 The error analysis methodology was adapted by Clay into the Running Record assessment tool (Clay, 1979a, 2015b). Running Records remain widely used and endorsed to monitor children’s progress in early reading and to guide teaching decisions in early years literacy classrooms (Barone et al., 2020; D’Agostino et al., 2019; Stouffer, 2021).
Given their common use, in this paper, we appraise the theoretical and empirical evidence for the use of Running Records to measure student progress and guide teaching. We first describe cueing-based models of reading and the fundamental link between Clay’s cueing-based model of reading and Running Records. From there, we describe a model of reading and the process of reading acquisition, which is supported by established cognitive science research, and explore how this research contraindicates the use of an error analysis methodology to study the process of successful reading. We do not critique Clay’s work in this way to diminish her research or ideas. Indeed, an exploration of the historical context in which Running Records were developed highlights her hypotheses (and similar hypotheses of contemporaneous researchers) as forward-thinking, and the testing of cueing-based models of reading as an important chapter in reading research history. Hand and electronically searched evidence and close reading of Clay’s published works inform the narrative review that forms the first part of this paper. We then systematically review literature concerning Running Records to assess the evidence supporting their use in contemporary early years reading classrooms.
Narrative Review
Cueing-Based Models of Reading
Cueing-based models of reading, as discussed in this paper, refer to assumptions that successful reading is a “problem-solving” process of reconstructing an author’s message (e.g., Clay, 2015a; K. S. Goodman, 1965, 1979), and that reading is achieved through the strategic use of linguistic and visual information as cues in that problem-solving process (e.g., Clay, 2015a; K. S. Goodman, 1967). That is, after anticipating the meaning of a text, readers use their knowledge of language, together with visual information about the words and letters on the page, to predict the words used to convey that meaning and to successfully confirm or reject the predictions made. According to this conceptualization, reading is a verbal response to text, guided by meaning-making (Butler & Clay, 1987; Clay, 1966, 2015a, 2015b), rather than a deciphering of written text into oral language so it can then be understood. Multiple theoretical descriptions of reading as a problem-solving task achieved through the strategic use of linguistic and visual information as cues have been described. These include “the three-cueing method” (Stouffer, 2021), “the searchlights model” (see Rose, 2006), “the hypothesis testing model” (see Stanovich, 1984), “the psycholinguistic model” (Pearson, 1976), an “interactive model of reading” (Rumelhart, 1994, in Clay, 2015b, pp. 108–111), “the meaning construction model” (K. S. Goodman, 1997), and “the Goodman Model of Reading” (Cambourne, 1976). However, we have confined our discussion to the work of Clay and US researcher Kenneth Goodman (b. 1927–d. 2020), who worked closely with Yetta Goodman and other colleagues. Goodman’s research journey had marked similarities to Clay’s. Goodman also observed children who were learning to read and analyzed errors they made while reading aloud (e.g., K. S. Goodman & Burke, 1968). Like Clay, Goodman described linguistic connections between words in the text and words that children said in error while reading. Goodman also later built on these findings to develop influential theories of reading and pedagogical advice (K. S. Goodman, 2014).
When discussing cueing-based models of reading, Clay (1966, 2015a, 2015b) and K. S. Goodman (1967, 1969) posited that readers arrive at the meaning of the author’s message from the context of the written text, without having to convert each written word into sounds. K. S. Goodman (1967) and Clay (1966, 2015a, 2015b) asserted that readers sample “some selected features of the forms of words” (Clay, 2015a, p. 8) to check that the meaning they draw from the text and the words they predict to convey that meaning match the author’s choice of words. In sampling, the reader’s “guesses, or tentative choices if you prefer” (K. S. Goodman, 1967, p. 4), about the words on the page are “confirmed, rejected or refined” (K. S. Goodman, 1967, p. 2). The process of sampling text, therefore, provides the reader with just enough information, or cues, 2 to efficiently determine and confirm the meaning of the text and predictions about the language likely to be used to express that meaning. Sampling was proposed as a way to reduce the amount of print the reader needed to process, which, in turn, would increase the efficiency of reading (Clay, 1993a, 2015a; K. S. Goodman, 1967, 1969, 1979, 1997). Clay drew an analogy comparing the sampling of a text with rock climbing, where climbers do not need to survey every part of a cliff’s surface but only need to find the particular hand- and footholds necessary to form a path (Clay, 1991, 2015a). Clay suggested that for proficient readers, the primary source of cues in a text was not the letters on the page but “the main sweep of structure and meaning” of the text (Clay, 2015a, p. 296). Similarly, Goodman described a reader using predicting and sampling as looking at a page and seeing “partly what he [the reader] sees but largely what he expects to see” (K. S. Goodman, 1973, p. 9) with the words on the page acting as a corrective guide to ensure the reader has understood the author’s thoughts and reconstructed the words used by the author to convey those thoughts correctly. Clay and Goodman both described three key categories of cues used for reading (Clay, 1966, 2019; K. S. Goodman, 1969, 1997; K. S. Goodman & Burke, 1968): cues from linguistic meaning (meaning or sematic cues); cues from grammatical structures (structure or syntactic cues); and cues from visual information the reader accesses when looking at text, including words and the letters within them (visual or graphophonic cues, where grapho refers to letters and phon refers to the sounds in words). Clay (1993a) proposed that illustrations in a text also provide meaning cues (rather than visual cues) as they support a reader’s understanding of the meaning of a text. This contrasts with Goodman, who stated that pictures were “external” cues that were not part of the reading process (K. S. Goodman, 1964).
Clay argued that in cueing-based models of reading, when a reader becomes aware of a dissonance between their predictions and the information gained from meaning, structure, and/or visual cues, they are prompted to revise their predictions until they have resolved the difference (Butler & Clay, 1987; Clay, 1966, 1976, 2015b). She posited that the process of sampling allows the reader to limit the number of graphophonic cues they need to draw on. For example, if a reader can confirm a prediction based on meaning and structure cues using only the first letter of a word, they need not, and would not, expend additional energy processing the other letters in the word (Clay, 2015a). From here, she argued that depending too much on letters was a habit of poor readers (Clay, 1976), as when children learn to read, they must learn to direct their attention to all linguistic cues, not just letters (Clay, 2015a, 2015b). For example, she described five-year-old Marlene, who “actually read” only one word out of six on a page but still managed to “repeat the precise message” through the use of picture cues and memory (2015a, p. 164). Clay reported that Marlene was in the “top 25 percent for reading progress” a year later at age six (Clay, 2015a, p. 164).
Clay maintained that guiding children to emulate the progression of successful beginning readers (like Marlene described previously) was the key to ensuring a successful reading trajectory for all children (Clay, 1966, 2015b; Doyle, 2018; Pinnell & Fountas, 2006). Despite similarities to Goodman’s descriptions of cueing-based models of reading, Clay argued that her position on reading acquisition differed from Goodman’s (Clay, 2015b). She contended that Goodman considered reading to be achieved via a static set of skills that were learned in childhood and used throughout the lifetime. In contrast, she posited that readers’ skills change, expand, and become more complex over time (Clay, 1993b, 2015b). Clay asserted that, wherever possible, teachers should support struggling readers to follow a description of “optimum functioning in beginning reading behaviour” (Clay, 1966, p. 129). She first described this optimum functioning in beginning reading behavior in her doctoral dissertation (Clay, 1966) and frequently drew on this description over her career (for example, Clay, 1969, 2015a, 2015b). Clay developed “the ‘literacy processing’ view of progress during literacy acquisition” (Clay, 2015b, p. 42) from these descriptions.
The Literacy Processing View of Progress During Literacy Acquisition
Clay stressed that her description of reading acquisition was not of clear “stages” but rather of potential “changes” (Clay, 2015b, p.77) from simple to complex processing of text. She acknowledged that “we have enough data to consider a theoretical description of change over time to be feasible, but we have insufficient detailed research to construct more than a skeleton built up from fragments” (Clay, 2015b, p.77). Clay described reading as a set of skills that evolve and expand in complexity through interaction with texts and teaching (Clay, 1966, 2015a, 2015b). When interacting with texts, each time a child identifies and corrects an error they make as they read, they add to their repertoire of reading skills and improve as readers (Clay, 1969, 1982, 2015a, 2015b). In this way, Clay maintained that children’s self-correction and problem-solving act as a means of learning and reinforcement while reading (Doyle, 2018). She hypothesized that by repeating the words in a book from memory, children construct the understanding that those memorized words are represented by the written words on the page. In her dissertation, Clay described a hypothetical child who had just started school, experiencing this process: Before long he is given a picture book with marks on it and he finds he is expected to say something as the teacher turns the pages. He may take this book home and say these things to his parents. When the teacher is very pleased with his talking she puts him in a group of children, and they talk about a book together. Slowly he becomes aware that the book contains specific messages which match the pictures. As he looks and talks, he locates some of the marks he has become familiar with in his printing. These seem to signal special words. (Clay, 1966, p. 54)
Clay argued that recognizing that spoken words match the text on the page leads to children’s initial attempts to actively match their speech to the written text by breaking both their speech and the text into words. From there, she reasoned that children start to notice if and when the text and their words do not match. That is, they make a spoken response to the words in a book and then check “whether the print could have said this” (Clay, 1966, p. 79). Recognizing mismatches between their words and the text, Clay maintained, allowed the novice reader to construct another key understanding: that reading involves actively ensuring that what they say matches both the meaning of the text and the visual cues of the text. She proposed that when children could ensure that the words they used to share the meaning of the text matched the written words of the text, they could then use further reading experiences to practice and expand the range of linguistic cues at their disposal to predict and check the text. Clay cautioned that for beginner readers, the cues available to them will be largely meaning and structure cues, as the child will bring these to reading from their oral language knowledge. However, visual cues are increasingly utilized as the reader becomes more proficient. It followed that a beginning reader’s use of visual cues could be increased through access to texts that could be largely “read” using meaning and structure cues but which provided enough difficulty to compel the reader to “problem solve” through visual cues as well (Clay, 2015a). Clay stated that, by using context to problem solve a given word in text several times, a child will “come gradually to attribute a particular identity to that word standing alone” and thus the word will be added to the child’s “reading vocabulary” (Clay, 1979b, p. 159).
Clay’s and Goodman’s Research
Although Clay and Goodman never formally collaborated, their research trajectories were remarkably similar. First, both started with error analysis studies, which they used as empirical validation of cueing-based models of reading. Clay and Goodman then both developed assessment tools that aligned with their error analysis approaches and, from there, developed instructional approaches for early years reading. We will discuss Clay’s work in greater detail while also considering Goodman’s work.
Clay: Research and Running Records
Clay spearheaded her development of a cueing-based model of reading with research for her doctoral thesis at the University of Auckland (Clay, 1966), which she subsequently described in peer-reviewed articles (e.g., Clay, 1968, 1969) and in authored books (e.g., Clay, 2015a, 2015b). For her doctoral research, Clay observed 100 children weekly over the course of a school year. They were being taught to read using a recently revised New Zealand national curriculum, which used a standard series of 12 simple books (e.g., School Publications Branch, 1963). Four out of five of the schools included in Clay’s study also provided children with “caption books,” which had pictures with matching text in captions that was generally repetitious across pages and could be memorized by most children (Clay, 1966). The revised curriculum, implemented just prior to Clay’s doctoral research, actively rejected letter-sound teaching and whole-word memorization approaches to teaching early reading. Instead, it emphasized the importance of children thinking about the meaning of the text and problem-solving the words in the text. Teachers using the new curriculum were advised that “teaching should not precede reading” (Clay, 1966, p. 3) but rather, they should focus their instruction on children’s responses to errors children made while reading texts (Clay, 1966, 1968, 1976, 1982). This method of teaching placed New Zealand’s early reading instruction “outside the bounds of promulgated methods in the reading literature” (Clay, 1976, p. 8) at the time. Following her doctoral studies, Clay reported the benefits of this approach (Clay, 1966) and went on to promote it throughout her career (e.g., Clay, 2015a, 2015b).
For her doctoral research, Clay observed children before and after they were able to read books from the series of 12 books used in the new curriculum. After children started reading from the series, Clay observed them with the book (from the series) that they had most recently focused on in class for at least a week prior to the observation. As they read, she recorded correctly read words along with words read with errors, word repetitions, and self-corrections. Most of her participants were first given books from the series by their teacher between 9 and 36 weeks after starting school, meaning the number of observations Clay made of each child reading was varied (Clay, 1966, 1982). Throughout the year, the children’s success in reading the 12 books in the series varied substantially, ranging from strong to poor. Clay posited that a child who read less than 90% of words in a book correctly could not meaningfully read that book (Clay, 1966), possibly based on studies from the 1940s (e.g., Betts, 1946 in Halladay, 2012), which found readers’ comprehension decreased and frustration increased proportionately to their rate of errors. By this criterion, 61 of the 100 children could successfully read multiple books in the series by the end of the year, with 14 completing the entire series. Seventeen of the 100 children were able to read the first book in the series but failed to reach 90% accuracy reading any other book; 11 children attempted this first book but could not read it with 90% word accuracy by the end of the year. Three children were not able to attempt the first book in the series by the end of the year (Clay, 1966). This first book contained 18 unique, repeated words in the text, with a total of 60 words of text for children to read (School Publications Branch, 1963). Overall, 18 children read less than 120 words in total during Clay’s observations (Clay, 1969).
After a year, the same 100 children all completed two word recognition tests: the Schonell R.1 Test of Word Recognition (Linfoot, 1967) examining children’s ability to read 45 words, and the Word Perception Test (Clay, 1966) examining children’s ability to read 15 words that were commonly used in the series of 12 books. Clay found that neither test individually gave a desirable spread of scores across the cohort (only 8% of the children she tested when they had turned six had a reading score of age six or above on the Schonell R.1 Test of Word Recognition). She combined the results from both tests by aggregating students’ T-scaled scores (standard scores with a mean of 50 and standard deviation of 10) of each test and finding a T-scaled score for the new, combined score (Clay, 1966). Clay used the new scores as the criterion for the categorization of children into one of four quartile groups. She then considered the cumulative number of errors and self-corrections the children made while reading from the series of 12 books across the year, considering these quartile groups. The “high readers” in the top quartile on the word reading test at the end of the year had, on average, made errors on less than 5% of the words and had a high self-correction-to-error ratio by Clay’s calculations. Clay interpreted this pattern as the children showing “efficient” (Clay, 1969, p. 51) use of cues when reading, which allowed them to use self-correction and problem-solving to improve their reading skills each time they read. Children in the second quartile, who Clay referred to as “high-middle readers,” had lower word reading accuracy in texts but a high self-correction ratio. Clay interpreted this pattern as showing that these children were processing cues while reading (as evidenced by their ability to identify errors and correct them), but they were doing so inefficiently (as shown by the relatively large number of errors). She maintained that children reading at this level were well-placed to improve their processing of contextual cues through teacher support. Children in the bottom two quartiles read with low accuracy and low self-correction ratios. Clay argued that these children could not process sufficient cues from the texts to gain a sense of meaning, limiting their opportunities to learn or practice self-correction and problem-solving, and hence could not improve their overall reading skills with these texts. For these children, Clay believed that the text should be changed to one in which a higher accuracy score (i.e., over 90% accuracy) could be achieved. Books containing predictable text with simple but accurate syntax and familiar words were suggested by Clay to allow weaker readers to make progress. This form of predictable book reading remains a mainstay of many English-speaking early years classroom instruction today (Cunningham et al., 2005; Fitzgerald et al., 2016; Hanford, 2022; Hiebert & Tortorelli, 2022; S. Schwartz, 2019).
Importantly, in Clay’s interpretation of the accuracy ratios of children in each quartile (e.g., Clay, 1966, 1969, 2015b), she asserted that high levels of accuracy were not caused by a child’s reading proficiency but were, in fact, the drivers of the child’s reading proficiency. That is, because the children she observed who read books with above 90% accuracy also scored in the top two quartiles of a word reading test, she concluded that reading texts at above 90% accuracy had led to improvement in these children’s reading skills. Clay theorized that the process of self-correction leads to improved reading proficiency because children with a higher proportion of self-corrected errors also scored higher on the word reading test. From this hypothesis, Clay argued that creating opportunities for children to read with above 90% accuracy (either independently or with teacher support) with occasion to self-correct errors would allow them to increase their reading proficiency (Clay, 2015a)—that is, their reading would be “successful enough to free attention to pick up new information at the point of problem-solving” (Clay, 2015a, p. 329).
Running Records: Inextricably Linked to Cueing-Based Models of Reading
Across her career, Clay contended that she had built her understanding of reading and reading acquisition by observing children through an “unusual lens”: Running Records (Clay, 2015b, p. 46). She developed protocols for Running Records to allow teachers to observe their students’ reading in the same way that she had observed her study participants, as described previously (Clay, 2015a, 2017). Clay asserted that “you cannot get closer to the valid measure of oral reading than being able to say the child can read the book you want him to be reading at this or that level with this or that processing behaviour” (Clay, 1993a, p. 7). She maintained that the standardized procedures she developed for taking Running Records and a gradient of difficulty in texts used for teaching reading ensured that the statements made about levels and processing behaviors of children reading could be made based on reliable data (Clay, 1979a). The codified processes of identification and analysis of errors and self-corrections in Running Records provided teachers with the information they needed to understand the individual reading acquisition journey of any child, just as she described herself doing when using the “lens” of Running Records in her research (Clay, 2015b). Clay wrote that she held a “firm conviction that similar educational procedures will produce different effects in different children” (Clay, 1966, p. 89) and maintained that the ability to observe children closely was more helpful to teachers than receiving instructional advice from her or other researchers (Clay, 2015a). She argued that observations from a Running Record would provide teachers with sufficient information to develop their own instructional practices relevant to the needs of each child (Clark, 1992; Clay, 2015a). She further argued that errors and self-corrections analyzed on a Running Record provided insights into the otherwise hidden cues a child was using when reading and that these insights could be used to guide teaching (Clay, 2015a, 2015b). Clay also maintained that using Running Records would help teachers to focus attention on the errors and self-corrections of their students, which in turn, would lead to a professional understanding of reading as a cueing-based activity (Clay, 1976, 2015a, 2015b) just as she had done in her own research (Clay, 1982). Today, multiple commercial programs and assessment systems use Running Records or assessments based on Running Records (Barone et al., 2020; Harmey & Kabuto, 2018).
The process for taking and analyzing Running Records has remained remarkably stable over the half-century since Clay’s first descriptions. Procedures for administering Running Records were first published in 1972 (Clay, 2019). In 1993, Clay authored An Observation Survey of Early Literacy Achievement (OSELA), a suite of assessment tools that included a more formalized administration process for Running Records as well as assessment tasks for letter identification, word reading, writing vocabulary, and hearing and recording sounds in words (Clay, 1993a, 2019). In 2000, she authored a stand-alone manual for administering Running Records, largely based on excerpts from the OSELA. Three editions of the OSELA that include contributions from unnamed international teachers and researchers have been published posthumously by the Marie Clay Literacy Trust (MCLT) in Clay’s name (Clay, 2019). A second edition of the Running Records manual was also published posthumously by the MCLT (Clay, 2017); in the most recent edition of the OSELA, it is confirmed that the descriptions across the Running Records manual and the OSELA manual match (Clay, 2019). Normative data for the use of the Running Records component of the OSELA were calculated posthumously in 2012 (Clay, 2019) and are provided in the OSELA manual. The norms describe children’s progress over 30 text levels, but no detail is provided in the manual about the texts or text levels used. In describing the norming of the OSELA, D’Agostino et al. (2018) reported that specific texts, leveled using “the RR [Reading Recovery] system” (p. 53), were used but did not provide the titles of the texts. While administration of Running Records for the normative data is not described in the OSELA manual (Clay, 2019), D’Agostino et al. (2018) stated that the procedures used to develop the norms differed from the procedures used for other Running Records, as the norms were developed using specified, unseen text and short scripted text introductions.
To conduct a Running Record, a teacher first selects a text. Clay recommended using texts that are familiar to the child, as this ensures “the child understands the meaning of the text and meaningfulness will guide the reading” (Clay, 1993a, p. 23), although more recent manuals (e.g., Clay, 2019) do not include this statement. The teacher listens to a child reading between 100 and 200 words of the text. As the child reads, the teacher uses a separate page to mark each word read successfully and uses codified notations to mark errors, including incorrectly read words, repetitions, non-responses, appeals to the teacher for support, and children’s own self-corrections. The total number of errors and self-corrections is tallied, and the proportions of errors to total words in the text and errors to self-corrections are calculated to determine the appropriateness of the text to the learner’s need (Clay, 2019). Clay described three levels of reading difficulty derived from accuracy ratings (Clay, 1979a, 2019), which aligned with the results of the four quartiles of students in her dissertation research (Clay, 1966). “Easy” texts were read with an accuracy rate of more than 95%. “Instructional” texts were read with an accuracy of 90% to 94%. Finally, “Hard” texts were read with an accuracy rate between 80% and 89%. Importantly, the labels Easy, Instructional, and Hard relate to a child’s experience of a text at the point of testing, not to the innate difficulty of the text itself (Clay, 2019).
According to Clay (2017, 2019), Running Records are used for two purposes. Firstly, the tool is used to guide teaching by providing insight into “what the reader already knows, what he attended to, and what he overlooked” (Clay, 2017, p. 7) to determine helpful next steps in teaching, and secondly, to capture a child’s progress reading texts of increasing difficulty. In describing Running Records, Clay argued that this assessment tool was not designed to assess children’s reading in the typical way of most standardized assessments (Clay, 2015b). That is, she did not see Running Records as a means to measure a child’s forward progress in reading along a predetermined path or set of stages. Instead, she stated that each child makes idiosyncratic “changes” as their reading skills develop, and some of these changes were worthy of investigation and observation due to their prevalence in her observations of children (Clay, 2015b). She claimed, however, that book levels could be a valid proxy for children’s successful management of cues in increasingly complex ways (Clay, 1979a, 2019). Accordingly, specific series of leveled books are found in her original research (Clay, 1966) and in the Reading Recovery Program (Clay, 1979b; D’Agostino et al., 2018). Graduated reading resources were assumed to be used by teachers administering the OSELA in early editions of the manual (Clay, 1993a), though the current edition cautions users to consider whether publishers of leveled texts trialed their system, and if so, which children it was trialed on (Clay, 2019).
Meaning, Structure, and Visual Analysis
After calculating accuracy scores in a Running Record, the assessor considers each error and postulates which contextual cues the child may have used (in line with Clay’s cueing-based model of reading) when they made the error (Clay, 2017, 2019). To support this analysis, meaning, structure, and visual cues are linked to question prompts, which are often summarized as: “Does it make sense?”; “Does it sound right?”; and “Does it look right?” respectively (Clay, 1979a; Griffith & Ruan, 2006; Pratt & Urbanowski, 2016). Clay (2019) cautioned that in an MSV analysis, V “stands for the stimulus information on the page irrespective of whether processing is through a phonological system or a visual system,” so teachers identifying a child’s use of visual cues might “differ in their understanding of what a reader is doing” (p. 75). Clay (2019) gave the following example of an MSV analysis involving two children, Peter and John, reading a text about a bicycle with the line “the boy got on.” Both children read the word “boy” incorrectly: John replaced “boy” with “man,” and Peter replaced “boy” with “box.” Clay reported that John, who read “the man got on,” was using a meaning cue and a structure cue when reading, as his error was semantically consistent with the meaning of the text (it made sense) and syntactically plausible (it sounded right). However, the word “man” is not visually consistent with the word “boy” in the text (it does not look right), which implies John was not using visual cues to confirm his prediction. Peter read, “the box got on” instead of “the boy got on.” He did use visual cues to predict the word, Clay argued, as “box” and “boy” share letters. Clay described Peter as also using structure cues, as “box” and “boy” are both nouns that can follow “the.” She reports, however, that Peter did not recognize the meaning cue that would have alerted him to his misunderstanding of the author’s meaning: the nonsensical nature of a box riding a bicycle. Clay reported that, to emulate competent readers, average and low-progress readers’ skills using structure, meaning, and visual cues should be developed and strengthened “in that order” (Clay, 2015a, p. 309).
Goodman: Miscue Analysis
Similar to Clay, Goodman supported his cueing-based model of reading with findings from his own error analysis research (K. S. Goodman, 1969; K. S. Goodman & Burke, 1968). In 1967, he described his ideas about cueing-based models of reading in a now well-known and heavily cited paper, “Reading: A psycholinguistic guessing game” (K. S. Goodman, 1967). Goodman asserted that “miscue” was a more appropriate word than error because miscues were “produced in response to the same cues which produce expected responses” (Burke & Goodman, 1970, p. 121) and efficient reading has miscues in it (K. S. Goodman, 1969, 1973). Based on his observations, Goodman developed a taxonomy of cues and miscues in reading (K. S. Goodman, 1969). In 1971, Yetta Goodman and Carolyn Burke published a classroom assessment of reading based on Goodman’s analysis of miscues, the Reading Miscue Inventory (see K. S. Goodman, 2015). Kenneth Goodman also developed teaching practices for reading, which came to be known as the “whole language” approach (K. S. Goodman, 2014).
Language and Language Acquisition Research in the Late 1960s
In the 1960s, linguistics was seen as the way forward to the most important insights into reading and reading instruction (Central Advisory Council for Education (England), 1967; Chall, 1968; Wardhaugh, 1968); linguistics was “in” in education research (Wardhaugh, 1968, p. 1). Inspired by the work of Chomsky (e.g., Chomsky, 1959, 1965), new ideas were emerging about how children acquired language. From an expanding understanding of syntactic and phonological elements of language, Chomsky (1965) proposed that children had an innate ability to build and then use implicit knowledge of language rules to generate novel sentences to express their thoughts and ideas. In this sense, children were not seen as “blank slates” in language acquisition but as active participants who would acquire language if provided with linguistic input. Both Clay and Goodman argued that research findings on oral language acquisition were analogous to, and therefore directly applicable to, reading acquisition (Clay, 1998, 2015a, 2015b; K. S. Goodman, 1967, 1973): just as children learn to speak language through hearing language, they reasoned that children learn to read text through seeing text (Butler & Clay, 1987; Clay, 2015a; K. S. Goodman, 2014). Indeed, Clay maintained that the concept of literacy “emerging” through experience was so central to early reading that she coined the term “emergent literacy” to describe it (Clay, 2015a, Pinnell et al., 1994). However, the heuristic of an analogous relationship between oral language development and reading acquisition has subsequently been found to be flawed (Dehaene, 2011).
It is understandable that Clay and Goodman studied reading and reading acquisition through the lens of contemporaneous ideas about language and language acquisition emanating from linguistics and psycholinguistics. Their initial postulations can and should be seen as an important step toward insights into reading. However, there have been well-established concerns of many reading researchers (e.g., Chapman & Tunmer, 2019; Chapman et al., 2001; Seidenberg, 2017) about the educational outcomes, over a number of decades, of students taught using instructional approaches derived from cueing-based models of reading. These concerns were highlighted in 2019 and 2022 podcasts by US journalist Emily Hanford (Hanford, 2019, 2022), which have received substantial interest from stakeholders around the English-speaking world. We will now explore evidence that controverts cueing-based models of reading and the use of the error analysis methodology.
A Cognitive Science Model: The Simple View of Reading
In the decades following Clay and Goodman’s development of cueing-based models of reading, models and descriptions of reading emerged from the discipline of cognitive psychology, which differed markedly from cueing-based models of reading. In this paper, we focus on the Simple View of Reading (SVR) (Gough & Tunmer, 1986). The Simple View of Reading has been validated by an extensive body of rigorous research using a range of methodologies (Catts, 2018; Catts et al., 2006; García & Cain, 2014; Language and Reading Research Consortium (LARRC) & Chiu, 2018; Lonigan et al., 2018), including reviews of research in instructional practices aligned to the model (Adams & Osborn, 1990; Buckingham et al., 2019; National Reading Panel, 2000; Rose, 2006; Rowe, 2005). Through the SVR, Gough and Tunmer posited that the ability to comprehend literal and inferred meaning in written texts (reading comprehension) is the product (not the sum) of two cognitive capacities (Hoover & Tunmer, 2018): decoding, or word recognition, 3 and language comprehension, also referred to as listening comprehension or linguistic comprehension (LARRC & Chiu, 2018). In the SVR model, word recognition refers to the ability to rapidly and accurately recover the pronunciation and meaning of a word from the sequence of letters that comprise the written word (Stuart & Stainthorp, 2015). Language comprehension is the ability to comprehend literal and inferred meaning in language (Hoover & Tunmer, 2018) and has been described as how well the reader could understand a text if it were read aloud to them (LARRC & Chiu, 2018). Because reading comprehension is the product of word recognition and language comprehension skills in the SVR, both word recognition and language comprehension are considered necessary for reading comprehension, but neither is sufficient on its own, nor can strength in one mitigate weakness in the other. Despite its name, the SVR “does not deny the complexity of reading but asserts that such complexities are restricted to either of the two components [word recognition and language comprehension]” (Hoover & Gough, 1990, p. 150).
In both cueing-based models of reading and the SVR, the importance of the reader ultimately extracting meaning from written text is emphasized. However, Clay argued that the role of meaning is “a facilitator of reading not merely a product of it” (Clay, 2015a, p. 290). Both Clay and Goodman defined reading as involving continuous texts that are read for meaning (e.g., Clay, 2015a, 2015b; K. S. Goodman, 1965, 2014). Under this definition, “a theory of text reading cannot be studied in experiments with single letters or words” as tasks involving words in isolation, including naming individually presented words “are skills but they are not reading” (Clay, 2015a, p. 262). These differing conceptions of reading have distinct implications for instruction, assessment, and intervention practices. We will now describe current understandings of word recognition skills and acquisition in more detail to explore those implications.
Word Recognition
Knowledge of the cognitive processes underlying word recognition has increased substantially over recent decades (Castles & Nation, 2022; Castles et al., 2018; Dehaene, 2011; Ehri, 2020, 2023) supported by models of word reading, including the dual route cascaded model (Coltheart, 2005) and connectionist models such as the triangle model (Seidenberg et al., 2022). Word recognition relies on three linked mental representations of a word (Stuart & Stainthorp, 2015): the stored spelling of a word is the orthographic representation; its stored sound pattern is the phonological representation; and the stored meaning of the word is the semantic representation. For proficient readers, word recognition is thought to occur through the connection of these three representations via one of two important cognitive processes (Castles et al., 2018; Coltheart, 2005; Dehaene, 2010; Perfetti & Helder, 2022; Seidenberg, 2017). The first allows familiar words to be translated from the orthographic representation simultaneously into both the semantic representation and the phonological representation. The second allows novel or less familiar words to be translated first from the orthographic representation to the phonological representation through the cognitive conversion of letters to sounds and then from the phonological representation to the semantic representation. Language comprehension occurs concurrently with either of these cognitive processes during reading (Perfetti & Helder, 2022). This understanding of the process of word recognition has been supported by reviews of research in methodologies unavailable to Clay and Goodman in the 1960s: neuroscience and medical imaging (Dehaene, 2010, 2020) as well as computational models (Castles et al., 2018; Seidenberg, 2017).
While the SVR was first published in 1986, extensive research since the 1960s has informed descriptions of the process of a child progressing from a novice to a reader who can quickly and easily recognize words (Castles & Nation, 2022; Castles et al., 2018; Chall, 1976; Ehri, 1994, 2005, 2020). As English is an orthographically “deep” language with a high proportion of words with uncommon phoneme-grapheme correspondences (Lee et al., 2022), beginning readers can benefit from learning a small number of so-called irregular or tricky words (i.e., high-frequency words that contain phoneme-grapheme correspondences that might be classified as more irregular than regular, such as was, one, eye, or here) as single units (Castles et al., 2018). However, the development of fluent word recognition for the sizable majority of English words relies on children acquiring the two cognitive processes described previously, through repeated exposure and practice (see Castles et al., 2018, for a comprehensive summary of the process of learning efficient word recognition). To learn to efficiently recognize words, children must first understand the alphabetic principle: that words are made up of sounds and that letters are used to represent those sounds, either alone or in combination with each other (Castles et al., 2018). After they have grasped the alphabetic principle, a child can learn to sequentially translate the letters or letter patterns of an orthographic representation of a word into sounds and then blend those sounds to form a phonological representation of the word. If they are aware of the meaning linked to that phonological representation, the child will also then access the semantic representation from the phonological representation and understand the word they have sounded out (Castles et al., 2018; Ehri, 2020). This process is initially effortful on the part of the child. Over time, children start to complete this process more efficiently, deciphering and blending each sound in the word simultaneously rather than sequentially. With these increased skills, children begin to translate orthographic representations of words into phonological representations (and from there the semantic representation) in a rapid and seemingly effortless manner. As the novice links orthographic representations of words with their phonological and semantic representations multiple times, lasting connections between the representations are built. This connection-forming process, also referred to as orthographic mapping, results in efficient and automatic recognition of previously encountered words (Ehri, 2023). At this point, the child can access both cognitive processes described previously. While they are still in the early stages of their journey to skilled reading, within the smaller domain of word recognition, the child can be seen to have transitioned from novice to expert (Castles et al., 2018).
As children build banks of known phoneme-grapheme correspondences and orthographically mapped words, they can use statistical learning (Elleman et al., 2019; Lee et al., 2022) to detect and internalize patterns in orthographic-phonological relationships (Elleman et al., 2019). They can then use those patterns as a basis for probabilistic reasoning to decipher novel words they encounter (Castles & Nation, 2022; Tunmer & Chapman, 2012). When children encounter a word with novel phoneme-grapheme correspondences, they are often able to decipher the word by considering an initial close phonological approximation (formed using the phoneme-grapheme correspondences they do know) in light of the meaning of the word (assumed by its context) and their existing vocabulary (Share, 2008). When successful, this process allows children to both add new words to their bank of stored (orthographically mapped) words and to add new phoneme-grapheme correspondences to their long-term memory for future probabilistic reasoning. Share described this process as the “self-teaching hypothesis.” Self-teaching leads to a rapid increase in children’s reading vocabulary, allowing it to grow closer to their spoken vocabulary (Perfetti & Helder, 2022; Share, 1995), which in turn promotes reading fluency and comprehension (Ehri, 2020).
Share’s (1995, 1999) self-teaching hypothesis, described previously, and Clay’s description of reading acquisition both culminate in a “self-extending” system that relies on a child’s active problem-solving of words in text. However, according to the self-teaching hypothesis, a self-extending system can develop only after a child learns to analyze all letters and letter combinations to successfully recognize words (Castles & Nation, 2022; Castles et al., 2018; Tunmer & Chapman, 2012). Word recognition research positions learning letter-sound correspondences (i.e., acquiring phonics knowledge) as the critical first step to fluent word recognition and current evidence supports explicit teaching of the requisite foundational skills (Castles et al., 2018; Dehaene & Dehaene-Lambertz, 2016) through which novice readers can learn and apply the alphabetic principle. By contrast, Clay argued that using knowledge of visual information, such as letters, is just one of many strategies that are built through reading experiences (Clay, 2015a, 2015b) and that it does not require explicit phonics teaching (Clay, 2015a). Clay cautioned that teachers should try “not to dismember the reading task” (Clay, 2015b, p. 222) by teaching letters and words in isolation. Across her career, Clay argued that while knowing the links between letters and sounds in written words was important for proficient readers, that knowledge “cannot play a major role in the child’s decisions about text in the first year” (Clay, 2015a, p. 256). Rather, children could build an understanding of letter-sound correspondences themselves through words they had successfully read (through any means, not just sounding out) that were then available to them in their reading vocabulary for “closer analysis” (Clay, 2015a, p. 291). She stated that once children “have learned a few letters, they usually have a procedure for learning letters and they can learn the remainder while writing and reading” (Clay, 2015a, p. 263). Clay maintained that a self-extending system developed when children had access to the meaning of a text so that they could use problem-solving and self-correction to construct an individualized pattern of cognitive control over the reading process (Clay, 2015a, 2015b).
Despite the divergence between cueing-based models of reading and models of reading based on cognitive science, Clay and Goodman consistently reported that their cueing-based models had sound empirical foundations. To illustrate why those empirical foundations provided apparent, but ultimately flawed, evidence for cueing-based models of reading, we will now discuss the error analysis methodology used by Clay and Goodman in more detail.
Error Analysis
Both Clay and Goodman posited that readers use the same cognitive processes when they read successfully as when they make an error and, as such, reading errors are observable behaviors from which unobservable cognitive operations can be inferred; a rare “window” into readers’ otherwise hidden, mental reading processes (Clay, 1966, 2015a, 2015b; K. S. Goodman, 1973, 2014). This “window” must be true for the findings of error analysis studies to be relevant to models of successful reading (and hence reading instruction) (Leu, 1982). However, there is a lack of empirical evidence to support this posited link between reading errors and successful reading (Blaiklock, 2004; Leu, 1982; Wixson, 1979).
By 1993, when Clay published protocols for Running Records in the OSELA, the finding that the word recognition processes of a skilled reader were “so rapid and automatic that they did not need to rely on contextual information” (Stanovich, 1993, p. 282) was well replicated and consistent enough to be considered scientifically uncontroversial (Adams & Bruck, 1993; Stanovich, 1993). Following West and Stanovich (1978) reporting that skilled readers took no longer to read a target word in an incongruous context (“the girl sat on the cat”) than a congruous one (“the dog ran after the cat”), Stanovich (1984) listed available evidence from studies of oral reading errors, timed text reading, text disruption manipulations, single word priming, and paragraph priming, which converged to show that the use of context cues for word recognition when reading was not an indicator of proficient reading. These findings, together with a deepening understanding of the process of word-recognition development (Castles et al., 2018), highlight that the use of context is an adjunct to the primary use of graphic information to recognize words in text. In 2006, in a significant systematic review commissioned by the UK government due to escalating concerns about school children’s reading abilities, Rose stated that to read, “skilled readers do not use context: they are simply subject to it” (Rose, 2006, p. 83). Readers may consider semantic or syntactic context as an auxiliary support to help disambiguate homographs (where the two words are written the same way but pronounced differently, such as invalid [noun] and invalid [adjective]) or, importantly, when fluent word recognition fails (Rose, 2006). As novice and/or poor readers are likely to experience word recognition failure more often, they are more likely to need to use semantic and syntactic context as an alternative when that failure occurs (Adams & Bruck, 1993; Hempenstall, 2003; Juel, 1995; Rose, 2006; Seidenberg, 2017). In addition, predictions based on semantic and syntactic context are, more often than not, unsuccessful (Adams & Bruck, 1993; Share, 1995; Snow et al., 1999). After all, words that could be highly predictable from context—I sat down on a chair—are the most likely to be left out: “there is simply no need to state the obvious” (Share, 1995, p. 154). In summary, successful reading relies on rapid word recognition. The use of context cues is an additional process that can be used to support comprehension by, for example, disambiguating homographs. However, when rapid word recognition fails and a reader cannot recognize a word, they are forced to use alternative cognitive processes to determine what the text may say. Commonly, these alternative processes involve the use of context cues to help problem-solve the unrecognized word. However, as the use of context cues to problem-solve a word is highly fallible, it often leads to errors, even for skilled readers. Ergo, the error analyses in Clay’s and Goodman’s studies do accurately identify a connection between context cues and error responses when reading, but this connection is not relevant to successful reading.
It is not a coincidence that Clay and Goodman independently developed similar cueing-based models of reading. They both sought to understand the reading process by exploring readers’ errors based on an assumption that the cognitive processes behind making reading errors mirror the cognitive processes of successful reading. Ironically, their models are accurate descriptions of unsuccessful reading. It is when readers cannot recognize a word that they are obliged to problem solve using context, a portion of the relevant phoneme-grapheme correspondences, or other sources of information they have available, particularly if they have not been taught how to systematically recognize words (Chapman et al., 2001; Seidenberg, 2017). Ultimately, the observable behavior of a child making an error when reading no more describes successful reading behavior than a description of a person falling off a bicycle describes effective cycling.
Systematic Narrative Review of the Evidence Describing the Valid Use of Running Records to Measure Student Progress and Guide Teaching
Running Records are purported to measure student progress and guide teaching in early years literacy classrooms (Clay, 2017, 2019). Our narrative review has highlighted methodological concerns regarding the use of error analysis to assess reading and theoretical concerns with the cueing-based model of reading underpinning the interpretation of Running Records. Despite the concerns raised previously, Running Records remain a popular assessment tool in early years classrooms (Barone et al., 2020; D’Agostino et al., 2019; Stouffer, 2021). We therefore performed a systematic narrative review (Turnbull et al., 2023) of peer-reviewed evidence regarding the use of Running Records to reliably and validly measure student progress and/or guide teaching in early years English-speaking classrooms.
Establishing the validity of a test for a specific purpose is “a process of constructing and evaluating arguments for and against the intended interpretation of test scores and their relevance to the proposed use” (AERA et al., 2014, p. 11). Valid assessment tools accurately measure what they set out to measure in a reliable way (Sullivan, 2011). In this systematic narrative review, we aimed to build an overview of peer-reviewed evidence that supported and/or refuted the utility of Running Records as a tool to measure progress in early reading and/or guide teaching in early reading. To do this, we critically analyzed a broad corpus of peer-reviewed sources that provided primary or secondary evidence regarding the interpretation of Running Records and the relevance of these interpretations to student progress and teacher instruction in beginning reading.
Our research questions for the systematic narrative review were:
What is the evidence that Running Records validly and reliably measure the progress of children learning to read?
What is the evidence that Running Records usefully inform the teaching of children learning to read?
Methodology
Search Strategy
The search terms “running record” OR “running records” OR “reading record” OR “reading records” were included in searches of The Education Database (Proquest), ERIC, PsychInfo, A+ Education, and Web of Science databases, yielding a total of 285 unique records.
Source Selection
Source selection was based on inclusion and exclusion criteria (Table 1).
Inclusion and exclusion criteria
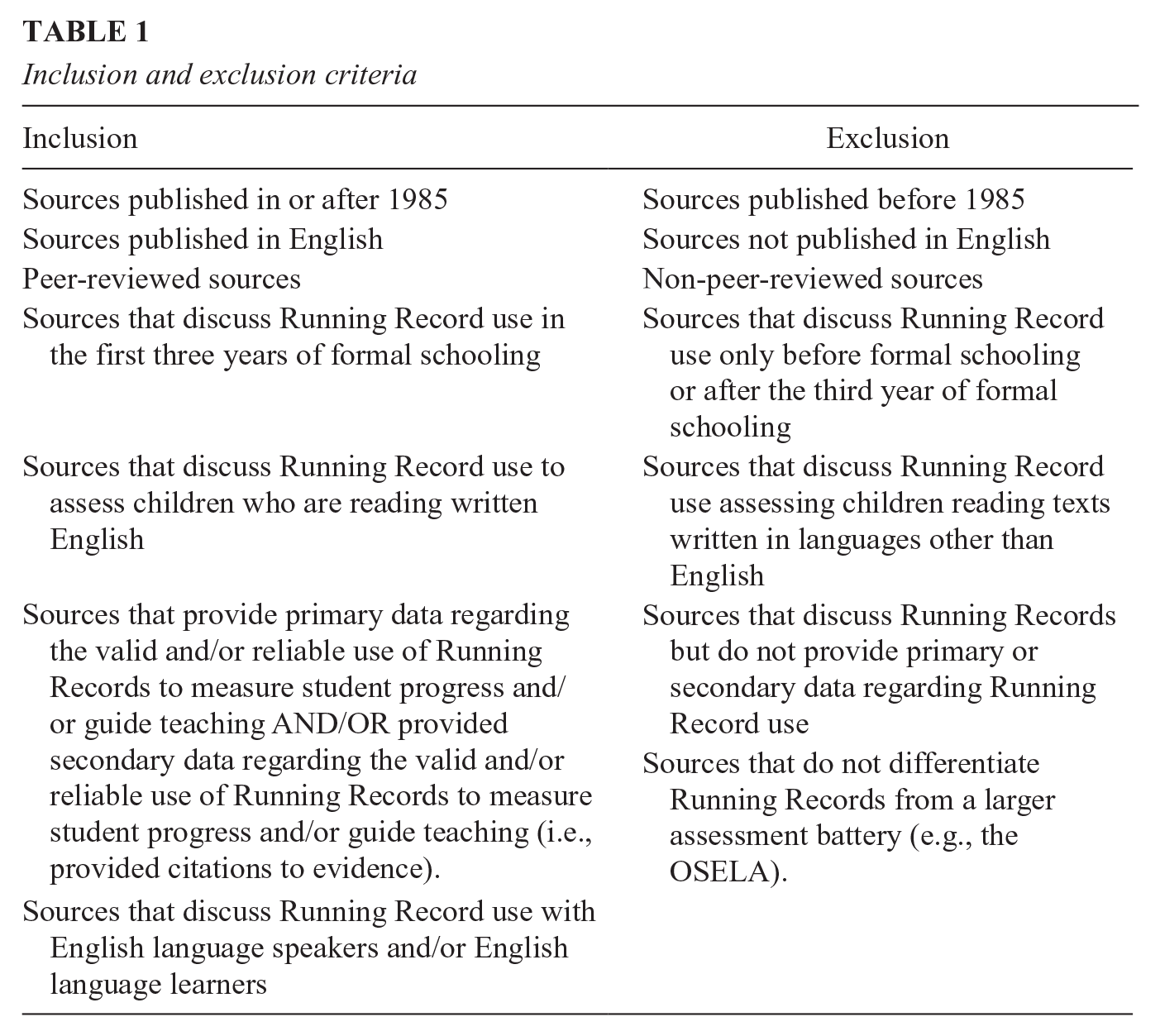
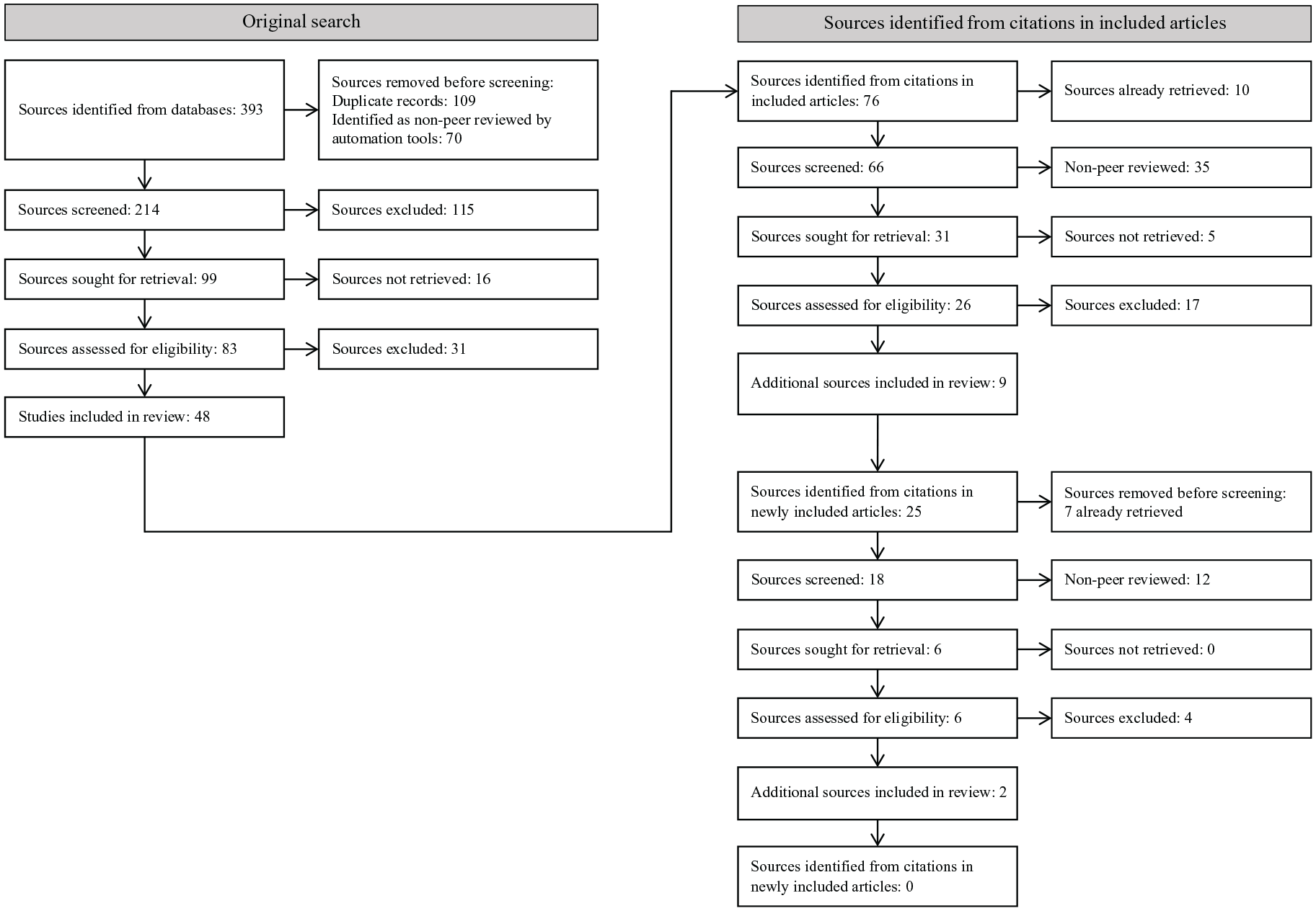
Figure 1 shows the phases of source review and selection. Screening by title and abstract by the first author resulted in the retrieval of 83 sources for full text analysis. After a full text reading by the first author, 48 sources were considered eligible based on the inclusion and exclusion criteria. During the full read, all citations to secondary data regarding the valid and/or reliable use of Running Records to measure student progress and/or guide teaching were extracted and collated. Non-peer-reviewed and already-reviewed sources were removed from the collated citations, and the remaining citations were retrieved and assessed for eligibility. This process was repeated iteratively until no new citations to secondary data were identified. In total, 11 additional eligible sources were identified through citations to secondary data. All included, and 43 excluded, articles were reviewed by the fourth author to assess eligibility. All discrepancies were resolved through discussion between both authors. In total, 57 sources were included in this review (see Online Supplementary Table 1); for exemplar excluded articles, see Online Supplementary Table 2.
Systematic search procedure.
Following the first read of all sources, recurring themes were identified. All sources were then analyzed for each theme. For each article that contained a discussion of a theme, a relevant summary was written. This information was then synthesized, and commonalities and differences were identified. Results were compiled in narrative format.
Systematic Narrative Review: Results
The findings from the included sources in this review confirm the use of Running Records for two distinct purposes: measuring student progress and guiding teaching. Themes impacting the utility of Running Records were found for both uses. We identified four themes impacting the reliability and validity of Running Records to measure student progress: firstly, the use of Running Records within larger assessment batteries; secondly, the use of accuracy scores in Running Records over a gradient of text difficulty to describe reading progress; thirdly, the generalizability of Running Record scores across text levels; and finally, the interrater reliability of Running Records when used to measure student progress. We identified four themes impacting the reliability and validity of Running Records to guide teaching: firstly, the provision of data from Running Records to justify the use of Running Records; secondly, the evidence provided to support the use of error analysis to gain insight into children’s cognitive processes; thirdly, the interrater reliability of the MSV analysis portion of Running Records; and fourthly, empirical evidence for the consequential validity of Running Records to positively guide teaching. These themes will be considered here.
The Use of Running Records to Measure Student Progress
Running Records as Part of Larger Assessments
Running Records were reported to be frequently included as part of larger assessment batteries (Fountas & Pinnell, 2012; Paris, 2002), including Informal Reading Inventories (IRIs) and the OSELA. Burgin and Hughes (2009) described an IRI assessment and Running Records as “essentially two different tests with similar procedures and the same objective” (p. 33). Ascenzi-Moreno (2016) described differences between Running Records and IRIs while also acknowledging that the teachers in her study typically referred to assessments in IRIs as Running Records, even when the IRI assessment contained additional tasks or components. Some sources differentiated Running Records used as part of the OSELA from other Running Records explicitly (D’Agostino et al., 2018) or implicitly (Pinnell et al., 1994). Compton et al. (2010) considered the use of Running Records using a predetermined set of leveled books as part of a screening battery in Year 1 with the aim of identifying measures that may reduce the number of children incorrectly identified as needing reading intervention. They found that Running Records did little to eliminate false positives within the samples studied, though they cautioned that the Running Records were collected without fidelity data, and findings must be evaluated with this in mind.
Text Levels and Reading Levels
Running Records (individually or as part of larger assessments) were commonly used to measure a student’s progress in reading proficiency. Progress was monitored by using a specified set of leveled texts and monitoring a child’s ability to read texts of increasing difficulty within the set with specified degrees of accuracy (e.g., Bennet & Lancaster, 2012; Jinkins, 2001; Jones, 2011; Pinnell et al., 1994). For clarity, the level of difficulty of a text (i.e., Easy, Instructional, or Hard) as determined by the accuracy with which a child can read that text will be referred to here as a child’s functional level of reading (FL); the ordinal level assigned to a text in a specified series will be referred to as a text level (TL); and the highest TL at which the child is assessed as receiving an Instructional FL will be referred to as their instructional reading level (IRL). Several studies in this review used Running Records (either individually or as part of a wider test battery) to measure children’s IRLs over time (e.g., Burgin & Hughes, 2009; Pinnell et al., 1994; Schirmer & Schaffer, 2010; Weber, 2018). Comparisons between this use of Running Records and other reading assessments suggested a broad association between IRL progress and other measures of reading progress (e.g., Denton et al., 2006; Goetze & Burkett, 2010; Pinnell et al., 1994), potentially supporting their use in long-term progress monitoring in this way.
Some authors cautioned that comparisons between Running Records rely on the assumptions that any texts used are accurately graded for difficulty (Blaiklock, 2004; Paris, 2002; Schirmer & Schaffer, 2010). That is, the validity of Running Records to determine (and measure progress in) a child’s IRL rests on the degree to which each leveled book being used for those Running Records can be reliably shown to be easier than books in higher TLs, harder than books in lower TLs, and equally difficult to other books in the same TL. Discussion of how TLs within a given leveling system were differentiated was sparse. Some studies provided references to the leveling system used (e.g., Goetze & Burkett, 2010; Jones, 2011; Kaye, 2006). Fountas and Pinnell (2012) and Alowais (2021) provided theoretical explanations of differences between TLs with a leveling system, and Schmitt (2001) described differences between four TLs used in their study. D’Agostino et al. (2019) found the average book level read and average words read by 140 students over 3814 Running Records correlated at .95, concluding that total words was a sufficient proxy for text difficulty. Authors cautioned against tracking student progress over IRLs for research or project evaluation, as TLs in a leveling system are arranged on an ordinal scale rather than an interval scale (Denton et al., 2006; Paris, 2002). That is, within a set of leveled books, each TL is considered differentiated from other TLs, but the extent to which any two TLs are separated by equal levels of difficulty cannot be assumed to be consistent. D’Agostino et al. (2018) tested a total score combining all subtests for the OSELA, using a “defined, standard testing packet” (p. 67) of texts in which TLs were calibrated to match TLs used in Reading Recovery lessons, but they did not provide information about the texts in that packet. They found that the relationship between IRL scores and OSELA total scores suggested that the TLs measured appeared to fall on a roughly equal scale, except for the tails (TLs below around level 8 and above around level 25).
Generalizability of Running Records Over Texts at a Single TL
The generalizability of student performance on Running Records across multiple texts at a single TL (in a text-leveling system used in the Reading Recovery program) was studied using generalizability theory (D’Agostino et al., 2021; Fawson et al., 2006). Fawson et al. found that absolute decisions (i.e., determining whether Reading Recovery Level 14 was a child’s IRL) required an assessor to average scores on Running Records for three or more texts from the same TL. By comparison, D’Agostino et al. (2021) found that at least nine or ten reads would be required to confidently determine a child’s FL for a particular TL (though more would be required if the student’s average score across these reads was not clearly within the Instructional range). The reason for the low level of generalizability in both studies was unknown; however, potential unreliability of text-leveling techniques was considered (D’Agostino et al., 2021; Fawson et al., 2006).
Interrater Reliability of Running Records When Used to Measure Student Progress
Interrater reliability describes the likelihood that, in a given context, multiple raters using a tool will obtain similar results, acknowledging that each step of test administration can be a source of potential error in scoring (Sullivan, 2011). Sources in this review studied the reliability of multiple trained raters identifying the total number of errors observed, calculating an error ratio or an accuracy score, identifying children’s FL on a specific text, and identifying children’s IRLs. Clay’s reliability data from her PhD thesis was frequently cited by sources in this review (e.g., D’Agostino et al., 2021; Denton et al., 2006; Rodgers et al., 2021). Clay audio-recorded 46 children as they read with her. She reported no significant difference between error identification on 12 of the Running Records she made in person and Running Records made by five trained students and a stenographer listening to the audio recording. Clay reported high intrarater reliability (the likelihood one rater will obtain the same results across two occasions) coefficient between her live scores and scores she made two years later from the audio tapes. In the current review, interrater reliability coefficients over .80 4 were reported for error identification (D’Agostino et al., 2019), accuracy calculations (D’Agostino et al., 2021; Fawson et al., 2006), and IRL calculations (Denton et al., 2006; Goetze & Burkett, 2010; Pinnell et al., 1994). By contrast, Harmey and Kabuto (2018) reported interrater reliability coefficients below .80 for error identification, accuracy calculation, and FL calculation. Rodgers et al. (2021) and Harmey and Kabuto (2018) demonstrated that calculations of children’s FL and IRL can achieve comparatively high interrater agreement, even when there is low interrater agreement for the number of errors identified. This is not an unexpected outcome given that each difficulty level (Easy, Instructional, Hard) encompasses a range of possible scores and therefore a range of possible total errors.
Rodgers et al. (2021) asked 114 teachers who had recently completed training in Running Record administration to quantify and interpret a pre-coded Running Record. Fewer than half (45.6%) of the teachers correctly counted the number of errors. Rodgers et al. (2021) determined that the central cause of this low accuracy stemmed from the scoring of proper nouns, where multiple different incorrect attempts are counted only as a single error for the purposes of the accuracy score. Rodgers et al. (2021) reported that only 4% of raters calculated the error ratio correctly. Concerns about the algorithm used for this calculation were voiced by Blaiklock (2004). Rodgers et al. (2021) described the rules and algorithm for the error ratio calculation as unnecessarily complex and easily confused, impacting inter-rater reliability for no discernible benefit.
The Use of Running Records to Guide Teaching
In this systematic narrative review, we found that Running Records are used to guide teaching through the MSV analysis of errors and self-corrections, which was seen to inform teachers about what word-solving strategies a child is or is not using while reading (e.g., Aitken et al., 2018; D’Agostino et al., 2021; Fawson et al., 2006; Fitzharris et al., 2008; Jones, 2011; McGee et al., 2015; Murphy, 2009). The MSV analysis was referred to as a “miscue analysis” in several sources (e.g., Goetze & Burkett, 2010; Jones, 2011; Kragler & Martin, 2009), though Harmey and Kabuto (2018) highlighted differences between the MSV analysis and a miscue analysis. The MSV analysis was often stated to be the most valuable aspect of a Running Record (e.g., Barone et al., 2020; Fried, 2013; Gillett & Ellingson, 2017; Stouffer, 2021; Wilson & Dash, 1999). Concerns were raised about Running Records being used primarily as an accuracy calculation tool for measuring children’s progress through TLs rather than being used to guide teaching (e.g., Barone et al., 2020; Fried, 2013; Outred, 2006).
The provision of data from Running Records to justify the use of Running Records
Across the sources, the majority of evidence provided to endorse the use of Running Records to guide teaching came from examples of MSV analyses, which were used to form hypotheses about children’s cognitive processes during reading. Multiple sources used Running Records in case studies to demonstrate how the tool could be used to guide teaching (e.g., Barone et al., 2020; Fried, 2013; Rubin, 2011; Stouffer, 2021) or described this use theoretically (see Stouffer, 2021, for extensive discussion). Several sources described the potential use and modification of Running Records in linguistically diverse settings (Ascenzi-Moreno, 2016; Briceño & Klein, 2018, 2019; Jones, 2011) or specific cultural contexts (Bennet & Lancaster, 2012; Jones, 2011). Other sources described approaches to analyzing reading errors identified in Running Records beyond techniques codified by Clay to demonstrate how Running Records could be used to glean additional information about students’ cognitive processes during reading to inform teaching (Fried, 2013; Kaye, 2006; McGee et al., 2015; Schmitt, 2001).
Evidence for the Use of the Error Analysis Methodology
Multiple sources included statements supporting the use of error analysis to understand children’s successful reading (e.g., Gillett & Ellingson, 2017; Jones, 2011; Kaye, 2006; Kragler & Martin, 2009; Murphy, 2009; Pinnell & Fountas, 2006; Schmitt, 2001; R. M. Schwartz, 2005; Stouffer, 2021). Evidence for the use of error analysis was implicitly derived from on the alignment of interpretations of MSV analyses to descriptions of reading framed by the theories of Clay (e.g., Fried, 2013; Harmey & Kabuto, 2018; R. M. Schwartz, 2005; Stouffer, 2021), Goodman (e.g., Fitzharris et al., 2008), Rumelhart (Harmey & Kabuto, 2018; Kaye, 2006; Stouffer, 2021), and Singer (Harmey & Kabuto, 2018; Kaye, 2006). Three sources explicitly critiqued the error analysis methodology. McGee et al. (2015) provided a literature review of the validity of the error analysis methodology and used error analysis on Running Records to study children’s strategic use of information at points of difficulty in reading. They reviewed historical error analysis studies informed by three theoretical perspectives (linguistic theory, metacognitive theory, and overlapping waves theories of learning) and highlighted a critical review of error analysis research by Leu (1982) (not included in this review). However, they did not respond to Leu’s concern that claims made about the reading process or instructional practices from error analysis studies rested on the assumption that “a portion of reading behavior (the errors readers make) is used to infer the nature of oral reading processing” (p. 431) and that evidence was needed to prove this assumption before any such claims should be accepted. Kaye (2006) also provided a discussion of historical error analysis studies and concluded that “analyzing records of students’ reading on continuous text is recommended to help teachers get insight into the processes children use as they read” (p. 72) with two peer-reviewed sources: Leu’s review described previously, and a review of miscue analysis by Wixson (1979) (not included in this review). Like Leu, Wixson asserted that, at the time of their review, the relationship between miscue analyses and successful reading was unclear and, as such, the “use of miscue analysis procedures as a basis for evaluation and planning in both research and instruction appears at best to be premature” (p. 172). Blaiklock (2004) provided a literature review highlighting the “erroneous interpretation of the meaning of oral reading errors” (p. 250) in Running Records.
Sources included in this systematic narrative review describe a paucity of research discussing the utility of analyzing self-corrections in order to guide teaching (D’Agostino et al., 2019; McGee et al., 2015). D’Agostino et al. (2019) used Running Records to explore the role of self-correction in the reading progress of first-grade students, using the average number of self-corrections per Running Record per student in their calculations rather than the self-correction ratio. Their findings suggested a correlation between the presence of self-corrections and reading progress within the Reading Recovery context, with further research required to determine potential implications on teaching. Kragler and Martin (2009) and Kragler et al. (2015) used Running Records in studies of young children’s metacognitive behavior (including self-corrections) while reading. They compared data from Running Records to other assessments of children’s metacognition during reading, including interviews, on the assumption that the MSV analysis of the Running Records and anecdotal notes could be analyzed to “determine the metacognitive strategies [participants] used while reading” (Kragler & Martin, 2009, p. 519) though the specific construct being measured by Running Records was unclear. Discrepancies between Running Records and other assessment measures were found.
Inter-Rater Reliability of MSV Analysis
Inter-rater reliability evidence for the MSV analysis was mixed. Sources reported both high agreement between raters (Freppon, 1991; Schmitt, 2001) and low agreement (Harmey & Kabuto, 2018). Raters’ understanding and use of MSV analysis varied, even after specific training (Bennet & Lancaster, 2012; Fitzharris et al., 2008; Rodgers et al., 2021). Rodgers et al. (2021) highlighted the paucity of research examining the reliability of raters completing MSV analyses on Running Records. They reported that agreement between 114 teachers’ analyses and their own analysis for specific errors and self-correction of errors on a pre-coded Running Record ranged between 6.1% and 81.5%. They found that the analysis of visual information used was the least reliable. Rodgers et al. (2021) acknowledge the threat this low level of agreement posed to the Running Records and their usefulness in guiding teaching, while also arguing that the MSV analysis was optional. Harmey and Kabuto (2018) calculated 78% agreement for identification of self-corrections between two raters, and D’Agostino et al. (2021) reported high inter-rater reliability (.90) for self-corrections (self-correction identification and self-correction ratio calculation).
Consequential validity of the MSV analysis
Consequential validity refers to the degree to which claims about the purported consequence of completing an assessment are supported by evidence. The use of Running Records to guide teaching implies a consequential chain: firstly, teachers will be able to tailor their teaching practices to an assessed child following a Running Record, and secondly, those tailored teaching practices will result in positive learning outcomes for that child. In this review, anecdotal accounts linked Running Records to teacher behavior (Lyons, 1993) and student reading improvement (Bennet & Lancaster, 2012; Jinkins, 2001; Stouffer, 2021), and Pressley et al. (2001) reported that five teachers who had been identified as “outstanding in promoting student literacy achievement” (p. 39) used Running Records. Cox and Hopkins (2006), however, acknowledged that “there is little, if any, research directly focused on the relationship between teachers’ use of RR [Reading Recovery]’s observation and assessment tools [i.e., Running Records], their resulting teaching decisions, and the effectiveness of those decisions” (p. 263). Rodgers et al. (2021) stated that, “If it is the case that teacher knowledge about sources of information used or neglected matters to student progress (Fitzharris et al., 2008; Rodgers et al., 2016), then it is essential that we are careful when quantifying and interpreting a Running Record” (p. 28). Of the sources they cited, Rodgers et al. (2016) (not included in this review) provided initial findings around the relationship between teacher knowledge about sources of information used/not used and student progress, confirming the complexity of the relationship and lack of research in the area. Fitzharris et al. (2008) (included in this review) described varying levels of understanding and competency in completing MSV analyses in interviewed teachers. Ross (2004) found that, from a sample of 75 schools, those in which teachers received training to complete Running Records had higher literacy outcomes than schools in which teachers received professional development aligned to a self-selected school goal. He argued that this implied that Running Records are likely to positively guide teaching.
Systematic Narrative Review: Discussion
What Is the Evidence That Running Records Validly and Reliably Measure Progress of Children Learning to Read?
The results of this systematic narrative review suggest that it is likely that Running Records scored by trained assessors provide a reliable measure of a child’s overall accuracy on a given text (that is, the proportion of words they can read correctly in the text) with two important caveats. Firstly, the error ratio calculation specified in a Running Record is unnecessarily complex and likely to pose a significant risk to the inter-rater reliability of the tool to measure accuracy of text reading. Secondly, the marking protocol for proper nouns, wherein only the first error on a proper noun is counted in the total number of errors (even if a different error is made each time the proper noun is repeated), is also likely to pose a significant risk to the validity and reliability of the tool. No clear rationale for this calculation approach to proper nouns was provided in the review, nor by Clay when describing the protocol (e.g., Clay, 2017, 2019). In light of these caveats, the protocols for taking a Running Record may, in fact, reduce the reliability (and hence validity) with which a teacher can measure a child’s accuracy when reading a text.
Running Records are commonly used to assess children’s accuracy when reading leveled texts, with advancement of their IRL across TLs considered an indicator of their progress. In a small number of studies, this progression over a set of texts was seen to correlate to other standardized indicators of reading progress. However, this must be qualified by the finding that at least nine or ten Running Records need to be taken at a given Reading Recovery TL to confidently determine the child’s FL. The time taken to complete this would be untenable in a typical early years reading classroom, especially when other psychometrically robust and brief progress monitoring tools are available. The use of specified texts to measure progress appears to overcome this hurdle and was the approach used when norming the Running Record component of the OSELA. However, there is a concerning lack of clarity regarding this process in the OSELA manual, and tensions exist between this approach and the protocols described in the same manual. Users of Running Records must be acutely aware that the validity of Running Records to measure student progress is dependent on (and limited by) the texts selected for the child to read, and how well those texts can be shown to represent reading progress.
It was not our direct aim to explore specific leveling systems in this review. However, given the considerable interconnection between leveling systems and Running Records when measuring student progress, the lack of consideration in sources in this review of the evidence (or lack thereof) supporting the texts used to measure student progress was striking. Understanding the evidence underpinning any leveling system must move to the front of mind for every user of Running Records. Providing that evidence must move to the front of mind for every researcher using or discussing the use of Running Records to measure progress.
What Is the Evidence That Running Records Usefully Inform the Teaching of Children First Learning to Read?
This review confirmed that information from Running Records is commonly assumed to provide teachers with insights into the cognitive operations of children learning to read, with the MSV analysis and self-correction ratio typically considered central to this purpose. While the inter-rater reliability of MSV analyses is currently not established, a large body of evidence in this review demonstrated that assessors reported a perceived ability to identify consistent patterns of responses in children’s errors. These patterns include children replacing words in a text with alternative responses that aligned with the text’s meaning, linguistic structure, and/or visual representation, and children identifying and self-correcting when an error had been made. We also found that users of Running Records assumed that these patterns mirrored strategies that children use during successful reading. However, sources in this review provided limited evidence to support this assumption. Evidence provided to support the link between MSV analyses and successful reading rested heavily on evidence of congruity between interpretations of MSV analyses and theoretical descriptions of reading. Notably, the theoretical descriptions of reading described were, by and large, cueing-based models of reading that were developed from the results of error analyses similar to or identical to MSV analyses. As such, the accuracy of those cueing-based models of reading relies on the assumed utility of error analysis to describe successful reading. However, the same cueing-based models of reading are also being used to justify the utility of error analyses to describe successful reading. This is circular reasoning. Additional evidence validating the link between MSV analyses and successful reading using different methodologies is required but has not been provided.
The review provided evidence that self-correction ratios may be calculated with adequate reliability on Running Records. Evidence of the role self-correction plays in reading ability and reading acquisition is currently sparse, precluding valid inferences about teaching practices being formed from self-correction data. As such, there is not sufficient theoretical or empirical evidence to support the claim that self-correction data in a Running Record provide early years teachers with valid information for guiding their teaching. Indeed, current Running Record protocols suggest self-correction ratios be calculated, but no details of how this data should be interpreted or used are provided (Clay, 2017, 2019), and Clay (2015b) states that assessors should not “engage in quantitative analyses of these ratios” (p. 194). The time taken to calculate a self-correction ratio is not trivial; the expectation of this time being used for no benefit appears perverse and counterproductive.
Concerns around error analysis and self-correction data collection described previously do not negate the possibility that Running Records may nonetheless usefully inform teaching through an alternative mechanism. Overall, however, there was limited empirical evidence identified to confirm this possibility. Reported evidence rested on speculative associations between student outcomes and Running Record use, and a single study that found that reading outcomes in schools that received training in Running Record use were better than in schools in which teachers received alternative training. This is an interesting finding, but it is not robust enough to endorse Running Records’ use in classrooms.
Systematic Narrative Review: Limitations
In this review, we sought to build an overview of evidence that supported and/or refuted the utility of Running Records as a tool to measure progress in early reading and/or guide teaching in early reading. As only published, peer-reviewed sources were included in this review, the findings may have been impacted by publication bias. Eligibility of sources in the review was confirmed by a second author for a portion, but not all, of the excluded sources, which is acknowledged as a threat to the reliability of the review process. To achieve a comprehensive overview of evidence, we used broad inclusion criteria and a process of retrieving additional sources through relevant citations. We chose to include the articles that provided these citations to support transparency of the search process. However, this led to the inclusion of sources that added little to the synthesis and analysis of the review beyond describing the utility of Running Records and providing a citation (e.g., Akrofi et al., 2010; Compton-Lilly, 2006). The broad inclusion criteria also led to the inclusion of a large total number of sources in this review. The large number of sources necessitated a less extensive analysis of each. For example, study design was not critiqued, but it obviously makes an important contribution to study quality.
We aimed to isolate discussion of Running Records from other, related constructs in this review, in particular text leveling systems and IRIs. However, this was not achievable. Discussions of Running Records and text leveling systems were highly intertwined within and across sources and, at times, conflated. Our discussion on text leveling cannot be seen as a systematic or comprehensive review of text leveling. Rather, it is a discussion of text leveling only as it relates to the valid and reliable use of Running Records to measure student progress. Similarly, when exploring the evidence for the error analysis methodology, we considered only that evidence directly related to Running Records. Evidence supporting the error analysis methodology as it is used in Running Records to guide teaching may be available in sources that were not included in this review. However, given that this evidence is fundamental to the validity of Running Records to guide teaching, the limited engagement with this question in the peer-reviewed literature is notable.
Conclusion
Running Records are a reading assessment tool that directs a teacher’s attention to a student’s errors while reading aloud (McNaughton, 2014). Clay’s position was that by observing and analyzing students’ errors, she had developed an accurate, cueing-based model of early reading. She designed Running Records to provide teachers with the same “view” into their students’ minds. However, there is now robust evidence to show that the analysis of errors does not provide the insight into effective reading that Clay claimed. Rather, Running Records provide insight into reading errors. By diverting teachers’ attention away from markers of proficient word recognition and toward markers of word recognition failure, Running Records risk encouraging teachers to develop and sustain misconceptions about the processes of reading and reading acquisition. In Running Records, Clay claimed to have created a tool that codified the task of listening to children read and provided clear, valid, and reliable information for the teacher to use to measure student progress and guide their teaching. Teachers listening to students reading in early years classrooms is a helpful, relevant, and, ideally, enjoyable task. When listening to children read, within or outside of a standardized assessment protocol, teachers can hear the child’s fluency and prosody and observe how well they are applying their word recognition skills. Teachers can compare the number of words the child reads correctly and incorrectly using simple percentage calculations and can compare these results to earlier or later readings of the same text. They can discuss the text read with the student. They can provide the learner with praise and encouragement, building joy and motivation on that child’s journey to learning to read. However, a Running Record is not needed to do these things.
Like Running Records, normed tests of oral reading fluency (ORF) provide teachers with an opportunity to listen to children read and a means of quantitatively analyzing that reading against standardized norms. ORF measures involve a child reading an unfamiliar passage for one minute while the assessor monitors accuracy. The number of words read correctly is then calculated and compared to established norms (e.g., Hasbrouck & Tindal, 2017). ORF measures can be used as a proximal indicator of children’s overall reading competency (Fuchs et al., 2001; Hasbrouck & Tindal, 2006). ORF measures are a type of curriculum-based measurement (CBM). CBM is a framework for monitoring student progress through standardized and researched-based assessments of academic skills (Hasbrouck & Tindal, 2006), which supports teacher decision-making. January and Klingbeil (2020) completed a systematic review and meta-analysis of several early reading CBM and found a medium to large relationship between early reading CBM tools and reading achievement but cautioned that additional research is needed to investigate their use in identifying students at risk in reading.
Scientific progress follows a jagged path rather than a smooth, upward trajectory (Shavelson & Towne, 2002). The most promising hypotheses, based on the culmination of best evidence in any given moment of time, can ultimately be unsupported. In the late 1960s, Clay and Goodman made forward-thinking hypotheses about cueing-based models of reading based on available linguistic knowledge. These hypotheses, while ultimately unsubstantiated, were important milestones on the path toward our understanding of what proficient reading is and what it is not. However, it is now clear that there is a lack of empirical support for cueing-based models of reading and, hence, for the use of Running Records which are inextricably linked to cueing-based models of reading.
We have presented a cautionary tale of adopting practices at scale without rigorous evidence to support them. In education, we must be cautious not just of failing to adopt evidence-based practices but also of failing to monitor and critically appraise the evidence supporting practices we do adopt. We must be willing to identify and test assumptions built into our research practice and policies and be prepared to change our minds when it is clear that insufficient evidence exists for a preferred approach and/or when a body of new evidence is amassed.
Supplemental Material
sj-docx-1-rer-10.3102_00346543251348258 – Supplemental material for The Road to Running Records: A Narrative Review of Their History and a Systematic Narrative Review of the Evidence for Their Use
Supplemental material, sj-docx-1-rer-10.3102_00346543251348258 for The Road to Running Records: A Narrative Review of Their History and a Systematic Narrative Review of the Evidence for Their Use by Annie Unger, Tanya Serry, Pamela C. Snow and Tessa Weadman in Review of Educational Research
Footnotes
Notes
Authors
ANNIE UNGER is a PhD candidate at La Trobe University, School of Education, La Trobe University, Bundoora, 3083; email:
TANYA SERRY is a professor at La Trobe University, School of Education, La Trobe University, Bundoora, 3083; email:
PAMELA C. SNOW is a professor at La Trobe University, School of Education, La Trobe University, Bundoora, 3083; email:
TESSA WEADMAN is a lecturer at La Trobe University, School of Education, La Trobe University, Bundoora, 3083; email:
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.