
Abstract
Multiple meta-analyses have now documented small positive effects of teacher professional development (PD) on pupil test scores. However, the field lacks any validated explanatory account of what differentiates more from less effective in-service training. As a result, researchers have little in the way of advice for those tasked with designing or commissioning better PD. We set out to remedy this by developing a new theory of effective PD based on combinations of causally active components targeted at developing teachers’ insights, motivating change, developing teaching techniques, and then embedding these changes in teachers’ practice. We test two important implications of the theory using data identified through a systematic review and meta-analysis of 104 randomized controlled trials, finding qualified empirical support for the theory. The main contribution of the article is to provide a testable theory of what makes PD more effective, which can be used to guide future empirical research on this topic.
Effective teachers improve pupil achievement, help close the gaps between more and less advantaged pupils, and increase pupil earnings in later life (Chetty et al., 2014; Hamre & Pianta, 2005; Slater et al., 2012). Policymakers and educators have therefore invested considerable time and money in trying to enhance the skills of the teaching workforce. As a result, teachers now spend an average of 10.5 days per year attending courses, workshops, conferences, seminars, observation visits, or other types of in-service training (Sellen, 2016). In parallel, governments worldwide have invested billions of dollars in research intended to find out how best to design this teacher professional development (PD; Boulay et al., 2018; Dawson et al., 2018).
This investment has resulted in a marked increase in the number of rigorous studies quantifying the impact of different approaches to teacher PD on the quality of teaching, as reflected in pupil learning (Edovald & Nevill, 2021; Hedges & Schauer, 2018). In 2007, a review by Yoon et al. found just 9 such studies; in 2016, a review by Kennedy found 28 such studies; and in 2019, Lynch et al. found 95 such studies focused on science and math alone. Recent meta-analyses of this literature tend to find average effect sizes of teacher PD on standardized test scores of around .06 (Lynch et al., 2019). On average, PD has small positive effects on the quality of teaching, as reflected in pupil learning.
While much has been learned from this evaluation literature, fundamental questions remain. Most schools do not have access to the PD programs that have so far been evaluated, because they are not available on the open market, or because they are too geographically distant, or because of capacity constraints on providers. Moreover, meta-analysis suggests considerable variation in the impact of PD, depending on how the PD is designed (Basma & Savage, 2017; Didion et al., 2020; Egert et al., 2018; Kennedy, 2016; Kraft et al., 2018; Lynch et al, 2019). Policymakers and school leaders therefore need to know which characteristics of PD make it effective, so that they can design or commission the best PD available for their teachers (Hill et al., 2013).
Existing attempts to explain what differentiates more from less effective PD have not made much progress. One strand of the literature has employed narrative reviews and thematic analyses in an attempt to identify what differentiates more and less effective PD (Desimone, 2009; Timperley et al., 2007; Wei et al., 2009). Indeed, some of the researchers working in this tradition have even claimed that the field has reached a consensus on the characteristics of effective PD (e.g., Darling-Hammond et al., 2017). However, the narrative reviews on which this claim is based have two important methodological weaknesses. First, many of them include studies employing nonequivalent control groups. Second, they lack any method for differentiating the causally active from causally inactive components of the PD (Sims & Fletcher-Wood, 2021).
A second strand of research has used meta-regression to investigate the associations between different aspects of PD design and impact on pupil outcomes (Basma & Savage, 2017; Didion et al., 2020; Kraft et al., 2018; Lynch et al, 2019). However, there is presently little consensus on which specific characteristics of PD should be entered into such meta-regression models, with different papers testing different aspects of PD design (e.g., Kraft et al., 2018; Lynch et al, 2019). Previous research has provided rich ways of conceptualizing and categorizing PD (Boylan & Demack, 2018; Dall’Alba & Sandberg, 2006; Kennedy, 2016; Opfer & Pedder, 2011; Sztjan et al. 2011; Webster-Wright, 2009). However, existing theory offers few testable hypotheses about what makes PD more or less effective, which leaves researchers guessing as to how their meta-regression models should be specified and thus how the coefficients should be interpreted.
In sum, we now know about the causal impact of a wide variety of PD programs but do not have much useful to say about what differentiates more from less effective PD. In Cummins’s (2000, p. 120) words, “We are overwhelmed with things to explain, and somewhat underwhelmed by things to explain them with.” In this article, we set out to remedy this by proposing and empirically testing a new theory of effective teacher PD. Throughout the article, we define effective PD narrowly, but precisely, as the ability to improve teaching, as reflected in pupil test scores. Like all theorizing, our goal is to explain why certain PD designs result in greater impact on teaching and learning. In doing so, we hope to provide a practical theory (Berkman & Wilson, 2021) that suggests actionable steps by which policymakers and school leaders can improve PD design. Our research team, which is composed of researchers and teacher educators, reflects this goal.
In the next section of the article, we begin by theorizing about the four things that PD needs to achieve in order to secure improvements in teaching. The subsequent section then synthesizes a set of mechanisms for achieving each of these four purposes of PD. We also derive some testable implications of this theory. Next, we set out the methods by which we conducted a systematic review and meta-analysis in which we code 104 experimentally evaluated PD programs for the presence or absence of each of these mechanisms. The results section then presents the findings from a number of meta-analytic tests of hypotheses that fall out of this theory.
Theorizing How PD Fails: Insights, Motivation, Techniques, Practice
Practical theory building should begin with a review of research providing rich descriptions of the target problem (Berkman & Wilson, 2021; Scheel et al., 2021). This supports the identification of important concepts, which can then be used as the building blocks of a new theory (Hempel, 1966). We take as our central problem the difficulty of designing PD that results in sustained improvements in teaching (Copur-Gencturk & Papakonstantinou, 2016; Hanno, 2021; Hobbiss et al., 2021). In this section, we review a range of descriptive research drawing on data from surveys, longitudinal classroom observations, interviews, and diary studies that, taken together, suggest four things that PD needs to achieve in order to bring about sustained improvements in teaching.
Teachers’ knowledge serves as the foundation on which they base decisions about their practice. Teachers need multiple types of knowledge to support their work, including content knowledge, pedagogical content knowledge, and general pedagogical knowledge (Shulman, 1986). Empirical research has illuminated the many ways in which this knowledge influences their practice (Baumert et al., 2010; Campbell et al., 2014; Carpenter et al., 1989; Franke et al., 2001; Hill et al., 2008; Kersting et al., 2012; Sadler et al., 2013) and measures of teachers’ knowledge have been shown to correlate with estimates of teacher effectiveness (Hill & Chin, 2018). This suggests that one way in which PD might fail to improve teaching and learning is by failing to bring about changes in teachers’ understanding of teaching and learning. This might happen because the knowledge provided by the PD is inaccurate or irrelevant (e.g., Riener & Willingham, 2010), because teachers cannot reconcile the new knowledge with existing mental models (Gregoire, 2003), or because new learning tends to be forgotten over time (Arzi & White, 2008; Liu & Phelps, 2020). The first purpose of PD is therefore to provide insight, which we define as teachers gaining a deeper understanding of how teaching and learning occur in the classroom. We prefer the term insight to knowledge (Desimone, 2009) because it implies a deeper, more practically oriented understanding (Greeno & Berger, 1987).
Insight alone is unlikely to bring about changes in practice (Kennedy, 2016; Lord et al., 2017). For example, diary studies have found that teachers report 50% of school-based learning experiences result in changes in their knowledge and beliefs, but in only a quarter of these cases do these changes in beliefs feed through into changes in their intended practice (Bakkenes et al., 2010). Multiple reviews of the literature have therefore emphasized the importance of building teachers’ motivation to take part in PD (Dunst et al., 2015; Kennedy, 2016; Timperley et al., 2007). Quantitative studies and meta-analytic reviews of the general training literature support the claim that motivation is an important moderator of whether training results in changes in practice (Grohmann et al., 2014; Rheinhold et al., 2018). Likewise, qualitative research suggests that teachers’ motivation influences whether they adopt new practice (Emo, 2015; Foley, 2011). Hence, PD might also fail to improve teaching if it does not motivate teachers to change their practice accordingly. Building directly on previous theory development (Kennedy, 2016), the second purpose of PD is therefore to build teachers’ motivation to change. Motivation here refers to a person’s willingness to exert effort in pursuit of a goal or outcome (American Psychological Association, n.d.).
Another point at which PD might fail is around teachers enacting what they have learned in the classroom. For example, a 3-year study found that early-career science teachers espoused strong beliefs in the importance and value of student-centered teaching methods but that this was often not reflected in their classroom practice (Simmons et al., 1999). Tightly controlled laboratory studies show that knowledge of classroom management techniques and informal formative assessment practices is often insufficient to bring about changes in teachers’ practice (Cohen & Wiseman, 2019; Cohen et al., 2020). However, when similar teachers are also given feedback on, and practice with, the target skill then this results in improvements in practice (Cohen et al., 2021). PD can therefore also fail when it neglects to provide teachers with the skills necessary to put what they have learned into practice in the classroom. Our third purpose of PD is therefore developing technique, which we define as helping a teacher to utilize a new teaching practice. We prefer the term technique to skill (Desimone, 2009) because definitions of the latter tend to make reference to broadly defined capacities (e.g., a skillful driver), whereas we are interested in more granular day-to-day teaching practices (Dhand, 1990).
Descriptive research also illuminates the difficulties in embedding these changes in change. For example, Copur-Gencturk and Papakonstantinou (2016) collected detailed observations on a group of teachers over a 4-year period following a mathematics PD program. The results show how PD can bring about initial changes in practice, but this subsequently fades over time. Other studies have documented similar patterns of “fade-out.” Boston and Smith (2011) report case studies illustrating how some teachers who implemented cognitively challenging math instruction immediately after a PD program no longer did so in a follow-up observation. Similarly, Hanno (2021) uses repeated classroom observation to show how some improvements in practice dissipate quickly. The fourth and final purpose of PD in our framework is therefore embedding in practice. Following Wiliam’s research on embedding formative assessment, we define this as rooting a technique firmly within a teacher’s repertoire (Wiliam & Leahy, 2016). This fourth purpose of PD (embedding changes in practice) differs from the third (developing technique) in that the former requires persistent use in a classroom setting. For example, a PD program may incorporate rehearsal of “cold-call” questioning, thus helping teachers develop this particular technique. However, without some way of embedding this in practice, the technique may not become rooted in a teacher’s repertoire and hence fail to result in sustained changes in teaching.
In summary, we propose that PD needs to pay careful attention to four things if it is to bring about sustained improvements in teaching. First, it needs to provide insight (I) about teaching and learning. For example, a teacher might learn that working memory is composed of separate visual-spatial and phonological systems, each of which has limited capacity (Baddeley & Hitch, 1974). Second, PD should motivate (M) teachers to make changes to their practice. For example, a teacher might resolve to limit the cognitive load their exposition of a subject places on either the visual-spatial or the phonological system within working memory. Third, PD should provide techniques (T) for putting these insights to work. For example, a teacher might invite pupils to read text from the board in silence, rather than also reading out the text, in order to avoid overloading the phonological loop with both written and aural input. Fourth, PD must embed that change in practice (P). For example, a teacher might use the “read silently from the board” technique multiple times, across different classes, until it becomes a routine part of their practice.
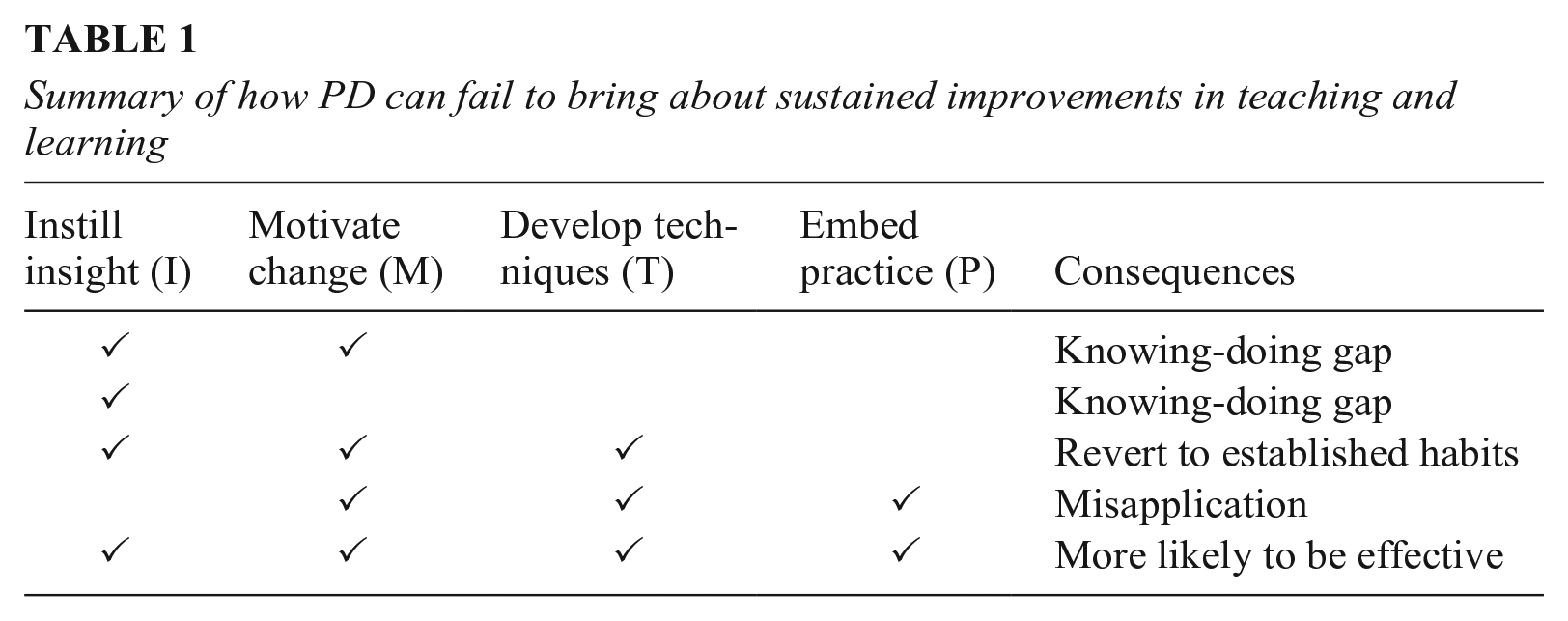
Table 1 summarizes our contentions about how PD can fail if (combinations of) these four purposes of PD are not addressed. Table 1 also serves to illustrate the potential explanatory breadth of our theory by showing that it nests within it several other theories/hypotheses in the existing literature about (in)effective PD. First, consider the case in which PD brings about the necessary changes to I and perhaps M, but not to T and P (row 2 and 3); this seems unlikely to lead to sustained improvements in practice. This claim has been made elsewhere in the literature, where it is known as the “knowing-doing gap” (Knight et al., 2013) or the “problem of enactment” (Kennedy, 1999). Second, consider the case in which PD brings about the necessary changes to I, M, and T, but not P. We argue that this is likely to result in teachers abandoning new practices and reverting to established ways of working (row 4). This reflects the extensive empirical literature on the importance of automaticity and habits in making teachers’ practice resistant to change (Feldon, 2007; Hobbiss et al., 2021). Third, consider the case in which PD brings about the necessary changes to M, T, and P, but not I (row 5). We contend that when PD fails to provide an understanding of why (and when) a particular practice is effective, this is likely to lead to misapplication of a technique in a way that renders it ineffective (Kennedy, 2016; Mokyr, 2002). This is sometimes referred to as a “lethal mutation” in the education literature (Brown & Campione, 1996, p. 259). By contrast (row 6), we theorize that when PD succeeds in addressing I, M, T, and P, it is more likely to be effective.
Summary of how PD can fail to bring about sustained improvements in teaching and learning
Theorizing How PD Succeeds: Mechanisms
Having theorized the different ways in which PD might fail, we now turn to consider how PD might successfully address all four of instilling insights, building motivation, developing techniques, and embedding these changes in practice. Which design features should PD incorporate in order to address all four of these purposes? As previously noted, an important challenge here is in differentiating the causally active from the causally inactive components of a PD design (Mackie, 1974). After all, associations between particular components of PD and the effects of that PD on pupil outcomes could be spurious. Yet a practical theory, capable of providing actionable advice for the design of better PD, requires the associations to reflect an underlying causal relationship. We refer to these causally active components of a PD program as mechanisms. Mechanisms are defined as the entities and activities that are causally responsible for bringing about the effects of some PD on teaching and learning (Illari & Williamson, 2012, p. 14). Mechanisms both bring about a causal effect and help explain how that causal effect occurred.
We would be warranted in claiming something to be a PD mechanism if we could find causal evidence that it helps achieve I, M, T, or P. Ideally, this would involve A/B tests in which the same PD program is tested with and without a single candidate mechanism included. Unfortunately, there is currently very little of this sort of evidence available within education, with A/B tests remaining extremely rare in this literature (Willingham & Daniel, 2021). The small number of A/B tests that do exist tend to test large differences in PD design, such as switching from a traditional “workshop model” to a “coaching model” (e.g., Cilliers et al., 2020; Piasta et al., 2020). These studies do not isolate individual mechanisms and, by changing many things at once, make it harder to understand how any differences in the causal effect occurred.
In developing our list of potential mechanisms, we therefore looked outside of the teacher PD literature. This type of reasoning—known as analogical abduction—is commonly used in developing explanatory theories: “If one finds a similar set of phenomena in another field that is better understood, then one can ‘borrow’ explanatory principles from that field to inform one’s own” (Borsboom et al., 2021, p.761). In line with this approach, we searched the broader literature for mechanisms that (a) have causal evidence from multiple domains outside of education and (b) provide an explanatory account of how they affect I, M, T, or P. In doing so, we ended up drawing heavily on research from cognitive science, behavioral science (Michie et al., 2013), and the literature on training medical doctors. We thus rely on the following form of (analogical) reasoning: If a mechanism x helps to achieve I, M, T, or P in multiple domains beyond teacher PD and we also observe an association between the presence of x in PD programs and the impact of that PD, then x is likely also a causally active component in teacher PD (Sims & Fletcher-Wood, 2021). In the final section of the article, we return to discuss the potential limitations of our analogical approach.
With respect to insight (I), we found two such mechanisms. The first is to manage the cognitive load for the teachers taking part in the PD. This can be achieved by focusing on a single idea or task, removing redundant information, or by providing worked examples, all of which help to prevent working memory from becoming overloaded. For causal evidence that this helps with learning new material among school students and adult medical trainees, see the reviews by Sweller et al. (2019) and Fraser et al. (2015). The second mechanism is revisit material, which can be achieved by reteaching or prompting recall of important ideas on separate occasions, both of which help to strengthen memory. Causal evidence that this aids with learning in lab settings, as well as in history, math, and language learning at school, can be found in the reviews by Adesope et al. (2017), Rohrer (2015), and Yang (2021).
As regards motivation (M), we found three putative mechanisms, all of which were taken from Michie et al. (2013). The first is to go through an explicit goal-setting process, in which teachers consciously agree on an objective around changing a specific part of their practice. This works by directing attention and energy toward the target change (Locke & Latham, 2002). Epton et al. (2017) provide a review of evidence that goal setting brings about change in sporting, health-related, and educational settings. Of course, PD programs usually have some fixed overarching goal in mind (e.g., improved use of informal formative assessment). By “goal setting,” we mean much more granular goals than the overall aim of increasing inquiry teaching. For example, more frequently use of mini whiteboards to check for pupil understanding. The second motivation mechanism is to present evidence supporting the change from a credible source, by which we mean findings from empirical research. For reviews of evidence that statistical evidence or justified arguments help change people’s minds and intentions in setting including health, crime, and education, see O’Keefe (1998) and Hornikx (2005). This supports teachers to engage in second-order reasoning about the value of using particular approaches to teaching (Chinn & Duncan, 2018). The third mechanism is reinforcement, which can be achieved through praising or restating the value of a certain teaching practice. This has been shown to increase motivation in domains including arts, games, and math (Delin & Baumeister, 1994). While we prefer to rely on causal evidence from other domains, it is worth highlighting that (noncausal) studies in the teacher PD literature have emphasized the importance of goal setting (Caena, 2011; Hawley & Valli, 1999) and integrating evidence (Antoniou et al., 2015; Cordingley et al., 2015) in PD.
With respect to technique, we found five mechanisms that met our criteria: instruction, practical social support, modelling, feedback, and rehearsal (Michie et al., 2013). Practical social support involves arranging advice on how to implement a practice from a teacher’s colleagues. Causal studies show that this supports practice change in medical training (Grierson et al., 2012) and in various health behavior settings (Dale et al., 2012; Jolly et al., 2012; Ramchand et al., 2017). Modelling involves providing an observable example of the target teaching practice, which provides a visual guide for subsequent practice (Renkl, 2014). Many experimental studies in the medical education literature have found that modelling helps with acquisition of new clinical (Cordovani & Cordovani, 2016) and surgical skills (Harris et al., 2018). Instruction is the provision of directive advice on how to implement some teaching method. Instruction works by eliminating ambiguity about what is required to successfully use a procedure and has been shown to be beneficial in science education and medical training contexts (Kirschner et al., 2006; Sweller et al., 2019). Feedback is the provision of evaluative guidance based on prior observation of the focal practice. It works by identifying and then advising on areas for improvement and has been shown to improve learning among pupils and motor-cognitive skills among dental and medical trainees (Al-Saud et al., 2017; Hatala et al., 2014; Ivers et al., 2012; Van Der Kleij et al., 2015). Finally, rehearsal refers to structured practice outside of a real classroom setting. This improves accuracy and speed of future performance. There is considerable correlational evidence for the importance of rehearsal across various domains (Macnamara et al., 2016) with causal evidence from medical education (McGaghie et al., 2011). Again, we note that (noncausal) studies in the teacher PD literature have also emphasized the importance of, for example, providing peer support (Lieberman, 2000; Wiliam, 2009) and opportunities for rehearsal and feedback (Kraft et al., 2018) in PD.
Finally, with respect to embedding practice—supporting a teacher to consistently make use of some technique—we found four potential mechanisms that met our criteria (Michie et al., 2013). Action planning involves specifying when and how a change in practice will be made in a future lesson. This creates situational cues that help trigger new practice (Webb & Sheeran, 2008) and has been shown to help change practice in health, education, and lab settings (Gollwitzer & Sheeran, 2006). Context specific repetition refers to rehearsing the target practice in a realistic classroom setting. This helps overwrite existing cue-response relationships (habits) by reassociating the classroom setting with the new practice (Hobbiss et al., 2021). Experimental studies have shown that rehearsal in realistic simulators for surgical trainees (even without feedback from an observer) leads to improved practice on a delayed posttest (Andreatta et al., 2006; Van Sickle et al., 2008). Experimental studies have also found that interventions focused on overwriting old habits can help embed health behavior change (Carels et al., 2011). Prompts/cues involve introducing environmental stimuli with the purposes of prompting the desired practice. Prompts/cues have been shown to trigger increased goal-directed behavior in experimental research on gym attendance (Calzolari & Nardotto, 2017), changing doctors’ clinical practice (Shojania et al., 2010), and in increasing appointment attendance by patients (Guy et al., 2012). Finally, self-monitoring involves establishing a method for somebody to record and then review their own practice. Causal research shows that self-monitoring helps to embed health behavior changes around weight loss, sleep hygiene, and physical activity (Burke et al., 2011; Compernolle et al., 2019; Todd & Mullan, 2014).
While we prefer to rely on the causal evidence cited above, it is again worth noting that (noncausal) evidence on teachers has also suggested integrating, for example, opportunities for lesson planning (Birman et al., 2000; Coenders & Verhoef, 2019) and classroom-embedded practice (Cavasos et al., 2018; Guskey, 2003) in PD.
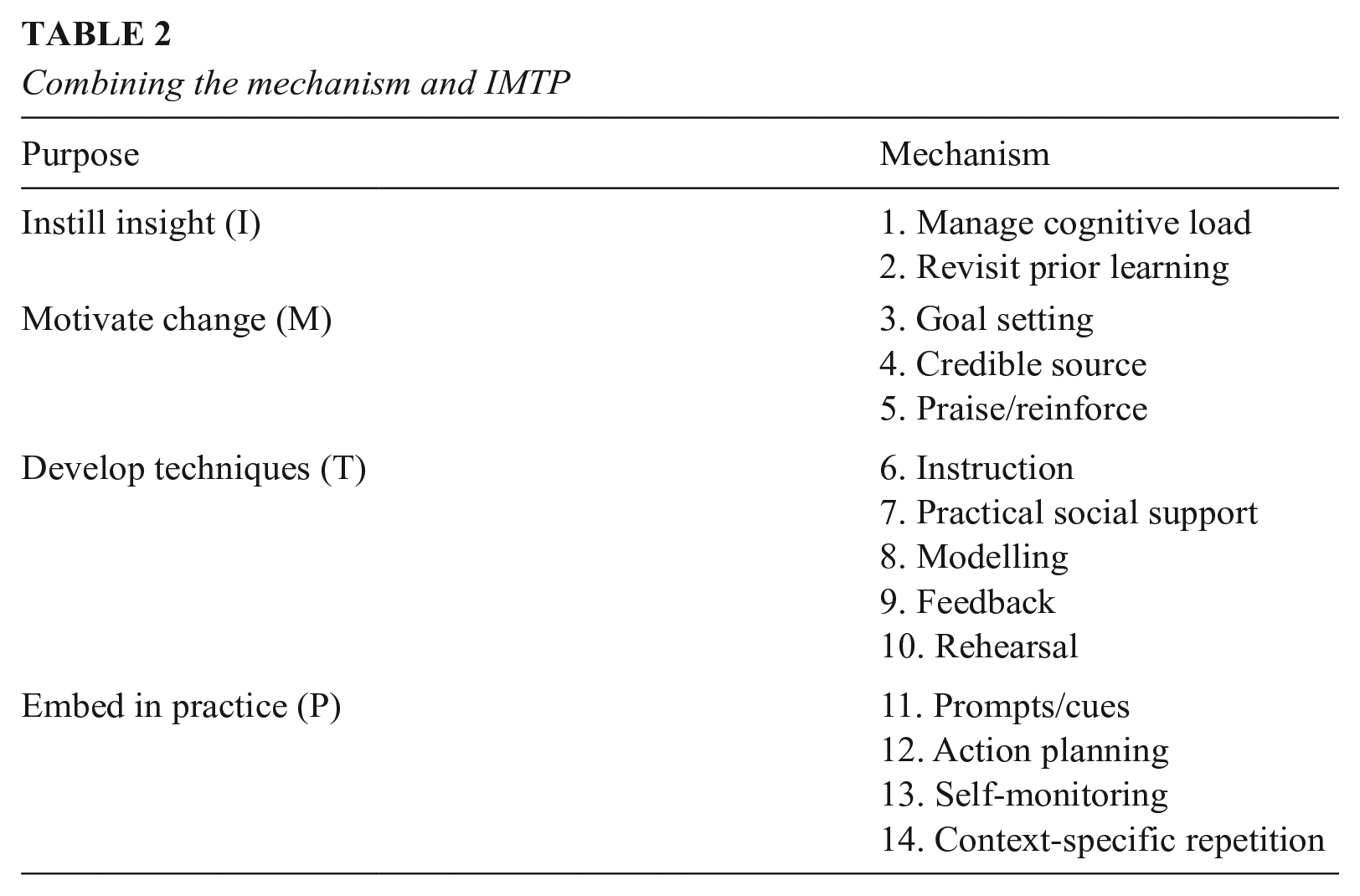
Table 2 summarizes the mechanisms across the four (IMTP) purposes of PD. We have allocated the mechanisms to the highest of the four (purposes of PD) categories to which they contribute. For example, goal setting does not help provide new insights but does help motivate change. We therefore allocated it to the motivate change category. However, this does not imply that goal setting does not help support teachers in developing new techniques, for example. Indeed, we think goal setting probably does support teachers developing new techniques, albeit in a much more distal and indirect way. In sum, mechanisms may also support the purposes of PD lower down Table 2.
Combining the mechanism and IMTP
Three further clarificatory points are in order regarding the theoretical claims set out above. First, while we have searched extensively, and have included every mechanism for which we could find sufficient supporting evidence, this list is unlikely to be complete. Indeed, future research may identify additional relevant mechanisms. Second, mechanisms are likely to have a cumulative effect. For example, combining revisiting material and worked examples (Newman & DeCaro, 2019), testing and feedback (Yang et al., 2021), and action planning and self-monitoring (Schroé et al., 2020) have previously been found to have cumulative effects. Third, we make no assumptions about the size of the effects of the different mechanisms. Our argument is only that improvements in, for example, technique are an increasing function of the number of technique mechanisms incorporated in a given PD program. This assumption is formalized in Appendix A in the online version of the journal.
Research Questions and Hypotheses
The published protocol for this review (Sims, Fletcher-Wood, O’Mara-Evers, Stansfield, et al., 2021) proposed three main research questions. For transparency, we reproduce these in full here:
Research Question 1 (RQ1): What are the characteristics of the studies and interventions in the experimental impact evaluation literature on teacher PD?
RQ2: Overall, are teacher PD interventions effective at increasing pupil achievement compared to business as usual?
Does this vary based on study characteristics (features of the evaluation not specific to the intervention itself)? Does this vary by study-level pupil disadvantage?
RQ3: Which forms of PD are associated with the greatest impact?
Which forms (clusters of mechanisms) do we observe in the literature? Are forms more likely to be effective when they incorporate mechanisms addressing all four of instill insights (I); motivate change (M); develop techniques (T); and embed practice (P)? Which forms (clusters of mechanisms) are associated with the largest effects on teacher practice and pupil achievement?
This article focuses specifically on developing and testing the theoretical account, set out in the subsections above, of what distinguishes more from less effective professional development. In this article, we therefore report results from RQ1 (which provides a descriptive account of our meta-analytic data), RQ2 and RQ2a (which quantify the variation in effectiveness of PD that our theory aims to explain), and RQ3b (which is a direct test of our theory). The other research questions (RQ2b, RQ3a, RQ3c) are not relevant to testing the theory set out above and are therefore beyond the scope of this article. For transparency, readers can find the empirical results relating to all research questions listed above in the original report (Sims, Fletcher-Wood, O’Mara-Evers, Cottingham, et al., 2021).
Since a primary objective of this article is to test theory, it is useful to explicitly state the two hypotheses that we will be testing:
Hypothesis 1 (H1): The number of mechanisms incorporated in PD programs will be positively correlated with the impact of those PD programs on pupil test scores.
This hypothesis is formalized in online Appendix A. To be clear, this hypothesis was not preregistered in our protocol. This was because we had yet to identify the mechanisms at the time data collection started and therefore did not know how many mechanisms we would identify in the literature. However, we believe this hypothesis is a natural, logical corollary of the theory we set out above. In particular, since we theorized that each of the mechanisms in Table 2 are causally active in contributing to the effects of PD, this implies that PD incorporating more mechanisms will tend to have a great impact. If PD with more mechanisms was not more effective, then there would be reason to doubt that our putative mechanisms were in fact causally active. Indeed, in the absence of evidence that the mechanisms were causally active, there would be little motivation to test whether PD incorporating mechanisms addressing each of the four purposes of PD was more effective. We therefore test H1 before moving on to test our second hypothesis.
In addition, we theorized that PD is likely to be more effective if it addresses all four purposes of PD. This was set out explicitly in Table 2 above and is formalized in online Appendix A. In line with this, we hypothesize that:
2. H2: PD programs that incorporate at least one mechanism in each of the four I/M/T/P categories (a “balanced” PD program) will have a larger impact on pupil test scores.
This hypothesis was preregistered in the protocol for this review (page 6 ).
Methods
Eligibility Criteria
We systematically searched the literature to identify primary research studies that could be used to test these hypotheses. We included studies in our meta-analysis if they met all of the following criteria:
1) Published during or after 2002. This specific start date was selected because it is the year in which the Institute of Education Sciences in the United States was established, which marked the beginning of a new era in terms of the funding and conduct of rigorous experimental evaluations of PD in education (Hedges & Schauer, 2018).
2) Written in English and excluded studies in languages other than English.
3) Reported in journal papers, working papers or institutional report formats, as well as doctoral theses that could be obtained via current UCL (University College London) subscriptions. We excluded conference papers or extended abstracts on the grounds that they do not contain enough information to assess quality or to extract sufficiently detailed information about intervention components.
4) Conducted in an Organization for Economic Cooperation and Development (OECD) country. We employed this criterion to limit the sample to countries with a broadly comparable level of economic development. We acknowledge that this limits the generalizability of findings beyond this group of countries.
5) Evaluated a teacher PD program, defined as structured, facilitated activity intended to improve their teaching ability. We excluded programs that incorporated a change in the pupil:teacher ratio (for example, training teachers in the delivery of small-group or one-to-one tuition). Our focus is on the relationship between certain characteristics of PD and the impact of that PD on pupil achievement. Small-group tuition is known to be highly effective in and of itself (Nickow et al., 2020), so including evaluations of PD that also incorporated small-group tuition would confound the relationship between the PD characteristics and the impact of the PD. In line with our definition of PD, we excluded programs that aimed only to briefly familiarize teachers with educational technology or curriculum materials.
6) Focused on qualified teachers working in formal education settings with children 3 to 18 years of age. We excluded studies in higher education (HE) settings.
7) Employed a randomized controlled trial (RCT) design, thus allowing clean causal inference.
8) Measured pupil achievement using standardized tests in any school curriculum subject. While test scores are not the only measure of pupils learning, or even the only valuable outcome of PD, this was necessary to allow comparability across a wide range of studies. Previous reviews have found very few evaluations of PD programs on non-test-score outcomes (Fletcher-Wood & Zuccollo, 2020). We excluded researcher-designed (as opposed to standardized) tests because they have been shown to display systematically larger effect sizes (Cheung & Slavin, 2016). We excluded studies that only measured achievement using observational protocols (e.g., Assessment of Scientific Argumentation in the Classroom; Sampson et al., 2012) or that used holistic teacher judgements, as opposed to quantitative aggregation of marks from multiple test items (e.g., the Early Years Foundation Stage Profile). This is justified because of various studies showing systematic bias in teacher assessments (e.g., Black & New, 2020). We included state-mandated tests (set by any branch of government, and often of a high-stakes nature) and standardized tests not mandated by the state.
9) The control group received either business as usual PD or no PD.
Search Strategy
We employed various combinations of search terms intended to capture three main concepts: (a) teachers (e.g., “teachers,” “educators”); (b) professional development (e.g., “in-service training,” “professional learning”); and (c) RCT. We used these terms to query 11 different databases and search engines during November 2020: Australian Education Index (Proquest), British Education Index (BEI), EconLit (EBSCO), Education Resources Information Center (ERIC) (EBSCO), Education Abstracts (EBSCO), Educational Administration Abstracts (EBSCO), EPPI-Centre database of education research, ProQuest Dissertations & Theses, PsycINFO (OVID), Teacher Reference Center (EBSCO), Google Scholar. A full example of our search of the ERIC database is available in online Appendix B. In addition, we searched the reference lists of 11 previous reviews (Cordingley et al., 2015; Desimone, 2009; Dunst et al., 2015; Kennedy, 2016; Kraft et al., 2018; Lynch et al., 2019; Rogers et al., 2020; Timperley et al., 2007; Walter & Briggs, 2012; Wei et al., 2009; Yoon et al., 2007). We also employed reference checking and forward citation searching (for all included studies that were available in Microsoft Academic). Finally, we also browsed eight websites containing education research repositories: Center for Coordinated Education MRDC publications, CUREE—Centre for the use of evidence and research in education, Digital Education Resource Archive, Education Endowment Foundation (EEF), EIPEE search portal, EPPICentre database of education research, Institute of Education Studies What Works Clearinghouse, Nuffield Foundation.
All records were uploaded into the EPPI Reviewer software, deduplicated, and then screened on title and abstract using prioritized screening (O’Mara-Eves et al., 2015; Thomas et al., 2011). All studies included at this stage (N = 347) were then reviewed in full. This process resulted in 121 eligible experimental studies being retained (see the PRISMA flow diagram in Figure 1 for a summary). Online Appendix C includes a tabulation of the reasons for which studies were not included after screening on full text, as well as examples of excluded studies.
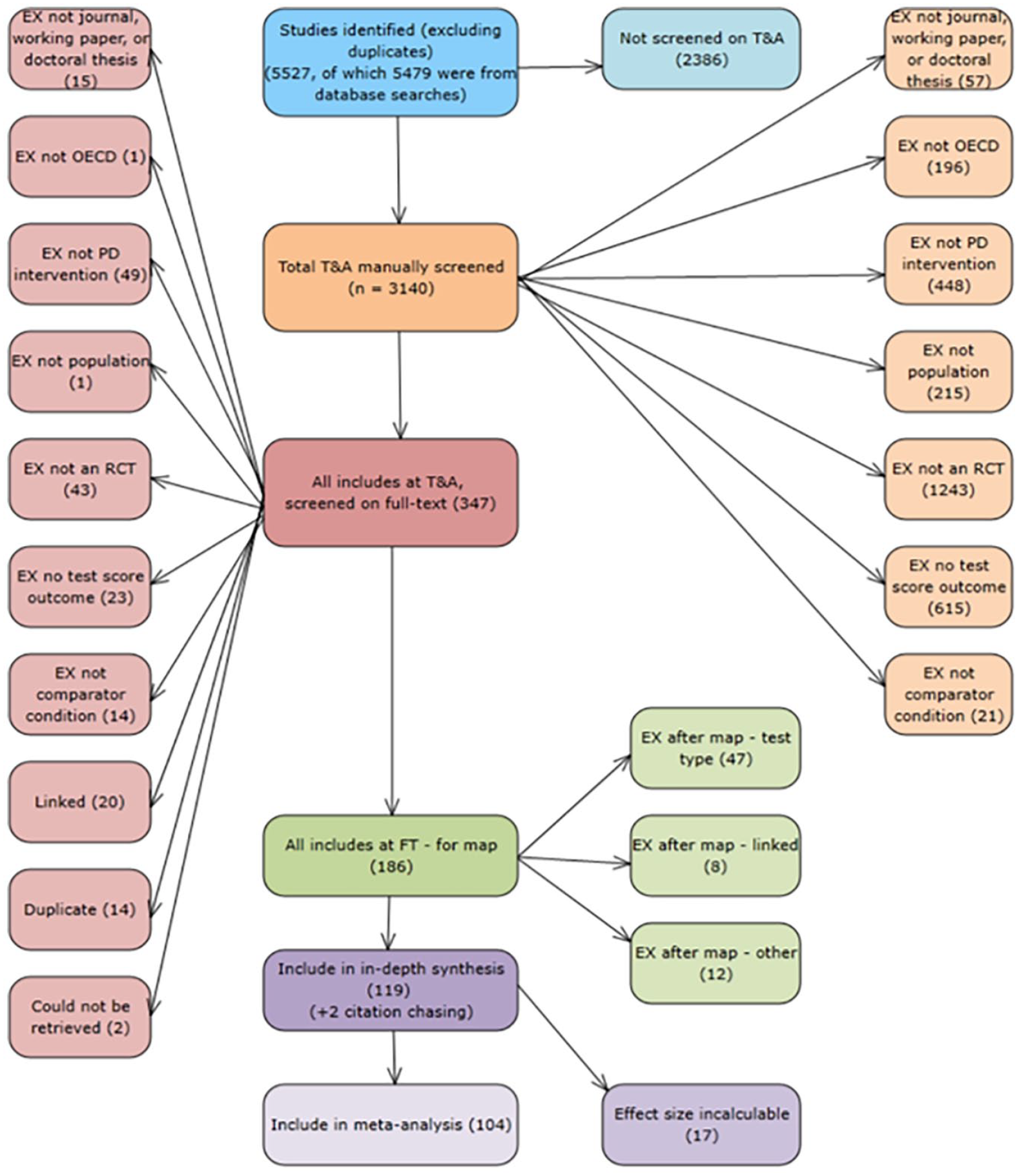
PRISMA flow diagram.
Effect Size Calculations
We extracted Cohen’s d effect sizes for each of the studies in our sample using the formulae from Lipsey and Wilson (2001). This was possible for 104 of the 121 studies. Cohen’s d is known to display small bias in small studies and can be corrected using Hedges’ g (Hedges, 1981). However, Hedges’ g could not be calculated for 2 of the 104 studies due to missing data. We therefore present all our results using Cohen’s d, on the basis that losing studies from the meta-analysis is highly undesirable. The full list of 104 studies that form out final meta-analytic sample are listed in Appendix D in the online version of the journal. In cases where eligible studies reported multiple standardized test score outcomes, we selected the primary test score outcome (if specified), or else collected all standardized test score outcomes. Contour plots, trim-and-fill, and p-curve analysis all suggested either zero or small publication bias (see Appendix E in the online version of the journal).
Study Coding (Data Extraction)
We coded the studies based on whether the PD incorporated each of the 14 mechanisms. To support this, we developed a coding frame that included guidance on how to code the mechanism, a theoretical account of how the mechanism works, an example of the mechanism from a PD program illustrating something that does qualify for the code, and a nonexample from a PD program illustrating something that does not qualify for the code. This coding frame drew on prior work by Michie et al. (2013). For example, for the “action planning” mechanism, the guidance states that this must involve “prompt[ing] detailed planning of performance of the behavior (must include at least one of context, frequency, duration and intensity).” Further to this, we explicitly included any instance of authentic lesson planning in this definition. The example included in the coding frame was “Staff teams . . . worked to develop their [lesson] plans . . . via a focus on two of the four aspects of oral language competence targeted by ICPALER” (Snow, 2014, p. 500). The nonexample was “Teachers were given time to meet in grade-level groups and as school teams to discuss how to modify the materials to meet their specific students’ needs” (Olson et al., 2017, p. 7). This did not qualify for the code due to the absence of any specific context/frequency for the planned action.
In cases where eligible studies reported evaluations of multiple versions of a PD program (n = 6 of the 104 studies in the meta-analysis), we focused on the most intensive version. Only two of these six studies explicitly stated which was the most intensive version. However, in all six cases, it was clear which was the most intensive version, since it included all the same components as the less intensive version, as well as additional components.
Two authors then double coded 46 papers using this mechanism coding frame. Raw interrater agreement was 82%. Interrater agreement as measured by Cohen’s Kappa was .61, which is conventionally interpreted as being on the border of “moderate” and “substantial” agreement. After the initial coding, the two coders then met to discuss discrepancies until consensus was reached. The coding frame was then revised to further eliminate ambiguity and to support consistent coding. The final coding frame can be found in online Appendix F. The remaining papers were then coded for mechanisms by a single author. In our empirical analysis, we will test the sensitivity of our main results to the presence of measurement error using errors-in-variables regression. We implement this using the eivreg Stata command, which adjusts the regression coefficients to account for measurement error using the method set out in StataCorp (2023).
We collected three further types of information from each study. First, we coded for the geographic location, age group, and subject focus for each experiment. Second, we coded for the “broad area of focus” of the PD, based on whether the content of the PD was largely based on cognitive science (how memory works and how humans learn), informal formative assessment (how to elicit evidence of pupil understanding and then use this evidence to adapt the next steps in instruction), inquiry learning (pedagogy that encourages students to construct knowledge for themselves via solving problems and completing authentic tasks, working with autonomy), or data-driven instruction (cyclical classwide testing to systematically collect data on pupil progress and then refocusing or differentiating instruction based on the findings). These four categories were preregistered in the protocol and are not exhaustive, meaning that some PD programs do not fall in any of these four categories. Third, we coded for four important indicators of study quality: whether the experiment was preregistered; whether the RCT met the What Works Clearinghouse “cautious” standards for acceptable attrition; whether the study randomized more than 50 units to treatment and control; and whether the study included a measure of pupil achievement taken from a state-mandated test (Cheung & Slavin, 2016). We collected these indicators of study quality to use in sensitivity analysis of our main empirical results. We chose not to exclude studies based on these study quality indicators, as that would involve throwing away the potentially valuable information that is nevertheless contained in e.g., smaller studies, or studies using low-stakes standardized test score outcomes.
Synthesis
To describe our meta-analytic sample (RQ1), we simply calculated frequencies and proportions of the different characteristics we coded for, and then tabulated and plotted the results. To quantify the overall effects of PD compared to business as usual (RQ2), we calculated meta-analytic average effect sizes, using robust variance estimation (RVE) random effect meta-analysis (Hedges et al., 2010; Tanner-Smith & Tipton, 2013). We then explored whether this varied based on study characteristics (RQ2a) using sub-group analysis.
To test whether PD incorporating more mechanisms tended to have a greater impact (H1), we plotted the impact of all 104 PD programs on test scores (expressed as an effect size) against the number of mechanisms per program. We then added a meta-regression (precision weighted) line of best fit. If we observe a positive gradient, then we cannot reject H1. If we observe a flat or negative gradient, then we would reject H1. These plots have the advantage of conveying more information about the underlying data than meta-regression tables. Since it is not possible to produce these plots using RVE, we used the primary outcome (if specified), or else one randomly chosen outcome per PD program.
To test the sensitivity of these results, we then produce a number of equivalent plots, each time stratifying the data based on the broad content area of the PD and various indicators of study quality. This holds the content of the PD broadly fixed, while varying the number of mechanisms. We also create an equivalent plot using errors-in-variables regression, which helps to account for any lack of reliability in our coding of the mechanisms incorporated in each PD program. One important caveat about all these plots is that the experimental impact estimates on the y-axis all contain random (classical) measurement error. This artificially increases the variance on the y-axis and, by extension, reduces the proportion of variance explained by the model.
To test whether PD programs that incorporate at least one mechanism in each of the four I/M/T/P categories have a greater impact (H2), we used two analytical methods.
The first was—again—RVE random effect meta-analysis, with the meta-analytic average effect sizes and 95% confidence intervals (CIs) plotted in charts. We also produce equivalent plots in which we test the sensitivity of our results to changes in our assumptions about which purposes of PD are being addressed by which mechanisms. If the average effect size is higher for “balanced” PD than other PD, then we cannot reject H2. If “balanced” PD has the same impact as other PD, then we would reject H2.
Our second analytical approach to testing H2 drew on some of the tools of crisp set qualitative comparative analysis (QCA; Thomas et al., 2014). This involved creating a truth table, in which each of the unique combinations of I, M, T and P were included as rows of the table. We then calculated the consistency (or proportion of instances) in which the study-specific effect sizes in each row exceeded a given threshold. This was implemented using the “fuzzy” command in the Stata software. As set out in our protocol (Sims, Fletcher-Wood, O’Mara-Evers, Stansfield, et al., 2021), we used d = .10 as our main threshold. We chose this value for two reasons. First, it is equivalent to average effect size from experimental research in education (Kraft, 2020). Second, because it is approximately equivalent to the additional learning that would be necessary for an average student to overtake one other pupil in a classroom of average size. However, we also report sensitivity tests for cutoff values of d = .08 and .12. If the row of the table corresponding to “balanced” PD programs exceeds this threshold more often than the other rows, this would be consistent with our H2. If other rows of the table exceeded this threshold more often than the row for balances deigns, this would contradict H2.
The mechanisms incorporated in each PD program in our sample are not themselves randomly assigned, meaning that our meta-analysis cannot estimate the causal effects of those mechanisms. So how can our study provide actionable advice to educators looking to improve the design of PD? When asked how observational studies can move beyond correlation to causation, Fisher advised researchers to “make their theories elaborate.” The rationale for this is that empirical corroboration of a complicated pattern of predictions helps rule out alternative explanations (quoted in Rosenbaum, 2005, p. 8). With respect to H1, our theory synthesizes empirical evidence that our mechanisms are causally active in a range of other domains, which makes it less plausible that an association within the domain of PD programs is spurious. H2 is also elaborate in the Fisherian sense. Why else would a PD program with at least one mechanism in each of the I/M/T/P categories be more effective than, for example, a program with at least one mechanism in three but not four of the categories?
Deviations From Protocol
We deviated from the preregistered protocol (Sims, Fletcher-Wood, O’Mara-Evers, Stansfield, et al., 2021) in the following ways:
The ERIC database search strategy was expanded upon slightly. Additional databases searched were Australian Education Index and British Education Index. We did not identify additional systematic reviews from our searches to screen their references as we had already identified a substantial number of reviews prior to screening and felt resources were better spent elsewhere.
In the protocol, we stated that we would run a sensitivity analysis on our main results by excluding studies with high levels of noncompliance (top ranked 5% of interventions on teacher nonattendance). However, we found that very few studies reported this, rendering the analysis infeasible.
In the protocol, we stated that we would run a sensitivity analysis on our main results looking at studies randomized at the individual versus cluster level and studies in dissertations versus journal articles. However, in both cases we found very few studies in the former category, rendering the analysis infeasible.
In the protocol, we stated our intention to use forest plots. However, the number of studies exceeded our expectations and the forest plots would have been prohibitively hard to display or to interpret.
In addition to the three publication bias checks that we proposed in the protocol, we also produced and reported a contour-enhanced funnel plot (Peters et al., 2008). Given the number of studies included in the review for which we could not calculate an effect size (n = 17), we felt it was helpful to consider whether any hypothetically missing studies are likely to be due to nonreporting biases related to significance levels, which is a key assumption of publication bias.
In the protocol, we planned to report heterogeneity statistics for our meta-analytic averages. However, we had not anticipated that these cannot be calculated using the robust variance estimation command in Stata.
Results
RQ1: What Are the Characteristics of the Studies and Interventions in the Experimental Impact Literature on Teacher PD?
Table 3 summarizes the characteristics of the (104) studies and PD programs in our meta-analytic sample. The vast majority of studies were conducted in the United States (70%) or UK (24%). Exactly half are based in primary schools, with around a quarter in each of early years and middle/secondary/high schools. Half (50%) focus on literacy, 29% on math, 12% on science, and a further 17% have a cross-curricular focus. Thirty-seven percent of the studies focus on one of our four preregistered areas of focus, with inquiry (15%) and formative assessment (14%) being the most common areas of focus. With respect to our indicators of study quality, 25% of the studies are preregistered, 25% have “acceptable” attrition, 62% allocated more 50 units to treatment/control, and only 28% used state-mandated standardized tests.
Descriptive statistics for the meta-analytic sample

Note. Percentages may not sum to 100 within cells, and counts may not sum to 104 within cells, due to rounding or due to subcategories not being exhaustive.
Figure 2 summarizes the frequency with which the various mechanisms occur in our meta-analytic sample. The left-hand panel shows the distribution of the number of mechanisms in each of our 104 PD programs. We observe a minimum of zero mechanisms (in just one PD program) and a maximum of 13 (again in just one PD program). The median number of mechanisms is five, and there is a long right tail of mechanism-rich programs. The right-hand panel shows the frequency with which each of the 14 mechanisms occur. All of the mechanisms occur at least once, with prompts/cues being the least common and instruction being the most common. The techniques (T) mechanisms are the most frequently occurring.
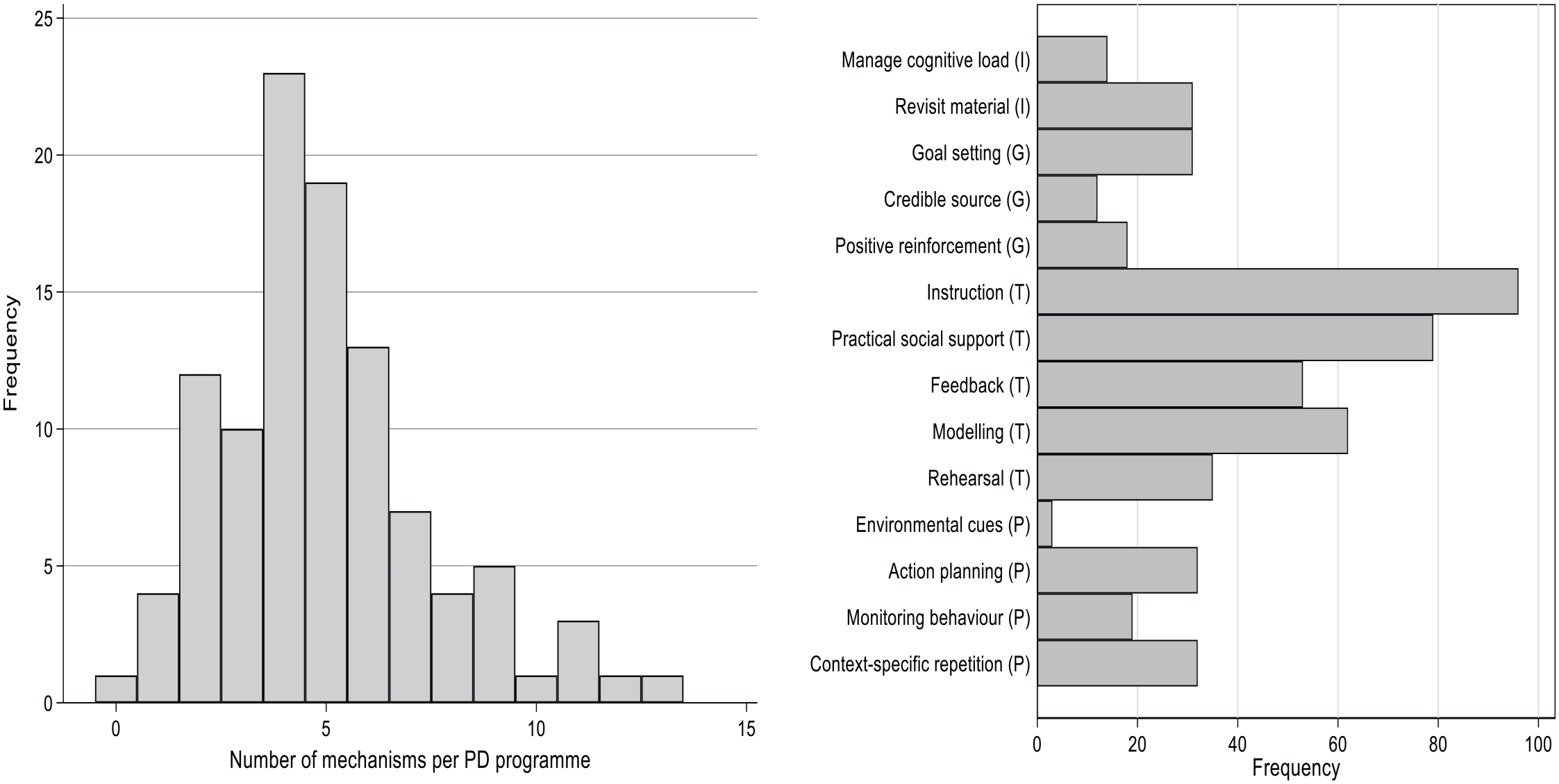
Mechanisms descriptive statistics. N = 104 PD programs.
In summary, we find a diverse set of PD programs in the experimental literature, which display substantial variation in terms of the number and types of mechanisms that they incorporate. This makes our sample suitable for testing our theoretical framework.
RQ2: Are Teacher PD Interventions Effective at Increasing Pupil Achievement?
Table 4 summarizes our overall meta-analytic results. Across our full sample, the precision-weighted average impact of PD is equal to an effect size of .05 (p < .01). Average effect sizes are approximately twice as large (.09) in early years (prekindergarten) settings as they are in school settings (.04). RQ2a further asked whether this overall finding varies based on study characteristics (features of the evaluation not specific to the intervention itself). We found variation based on some study characteristics. In particular, impact is lower for studies with “acceptable” levels of attrition (d = .02) compared to those with unacceptable attrition (d = .08), and for larger studies (those with more than 50 units randomized) (d = .04) compared to those with fewer than 50 units (d = .10). The effect of preregistered studies (d = .01) is much lower than the effect for those not preregistered (d = .07). Indeed, the meta-analytic average effect size for studies that are preregistered is not significantly different from zero (p > .05).
Overall effect of PD, including by indicators of study quality
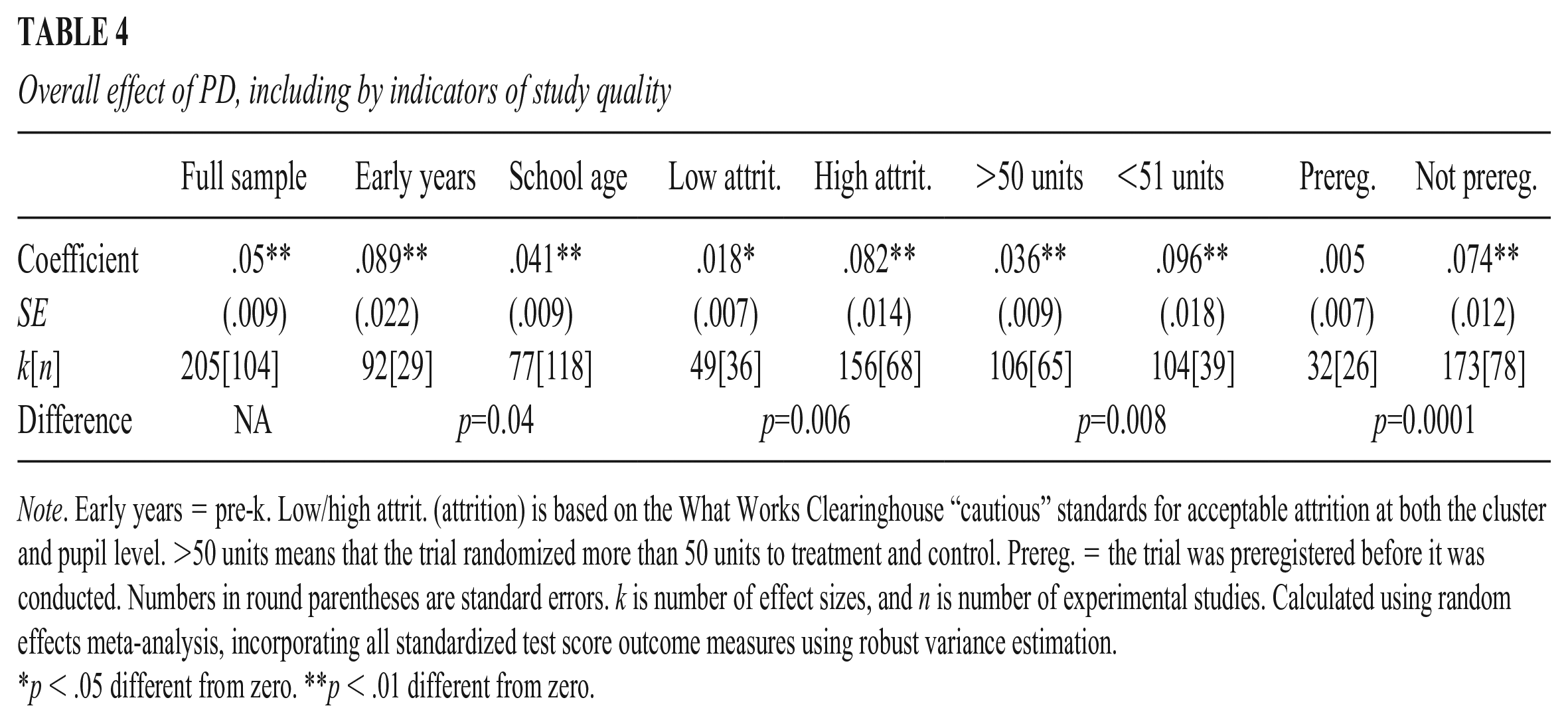
Note. Early years = pre-k. Low/high attrit. (attrition) is based on the What Works Clearinghouse “cautious” standards for acceptable attrition at both the cluster and pupil level. >50 units means that the trial randomized more than 50 units to treatment and control. Prereg. = the trial was preregistered before it was conducted. Numbers in round parentheses are standard errors. k is number of effect sizes, and n is number of experimental studies. Calculated using random effects meta-analysis, incorporating all standardized test score outcome measures using robust variance estimation.
p < .05 different from zero. **p < .01 different from zero.
In summary, we find that PD programs do appear to have a positive impact on pupil learning, albeit with the important caveat that this varies across studies, including by indicators of study quality. With this established, we now move to attempting to model differences in the effects of PD across programs.
Do PD Programs Incorporating More Mechanisms Have a Greater Impact?
Recall that H1 (which was not preregistered) states that the number of mechanisms incorporated in PD programs will be positively correlated with the impact of those PD programs on pupil test scores. Our first test of H1 can be found in Figure 3, which plots the number of mechanisms against the impact estimate (scaled as an effect size) for all 104 PD programs in our sample. Larger circles represent studies with more precise estimates, with the size being proportional to the weight they are given in the analysis. The meta-regression line of best fit is upward sloping (ß = .01, p = .02). PD interventions incorporating zero mechanisms have an expected effect size close to zero, and PD mechanisms incorporating 13 mechanisms have an expected effect size close to .15.
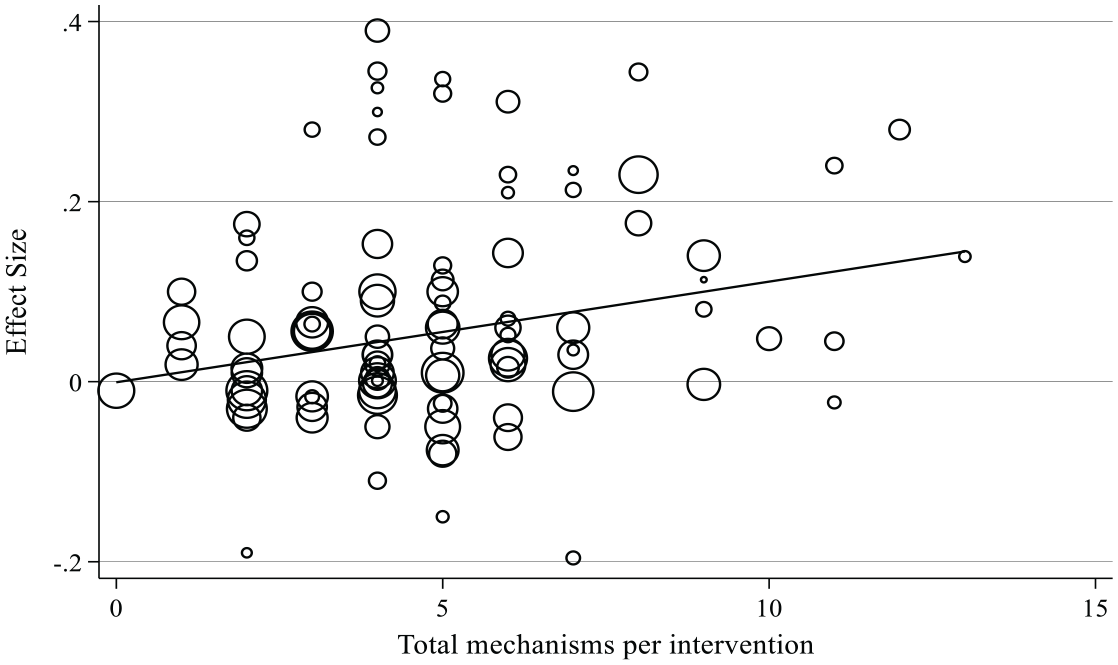
Relationship between the number of mechanisms in a PD program and impact on pupil test scores. n = 104 studies. Uses the primary outcome as specified in the study or else one randomly selected outcome per study. Effect sizes > .5 or < –.2 are used in the underlying meta-regression but are not shown in the figure to aid visual clarity.
Figure 3 suggests a considerable degree of unexplained variation. Figure 4 therefore stratifies the analysis based on the broad content area of the PD. The proportion of variance explained doubles from 16% to 36%—although both will be underestimates due to classical measurement error on the y-axis. The gradient for informal formative assessment remains positive but is no longer statistically significant at conventional levels (ß = .02, p = .09). The gradient for PD focused on data-driven instruction is neither positive nor statistically significant (ß = –.01, p = .64), albeit this is based on a sample of just seven studies. For context, the average impact of PD focused on informal formative assessment (d = .04, p = .08) and data-driven instruction are not significantly different from zero in general (d = .04, p = .08), so these two findings are perhaps not surprising. The gradient for inquiry increased to .03 (p = .046), which is statistically significant. This is consistent with the average impact of PD focused on inquiry being positive (d = .07, p = .01).
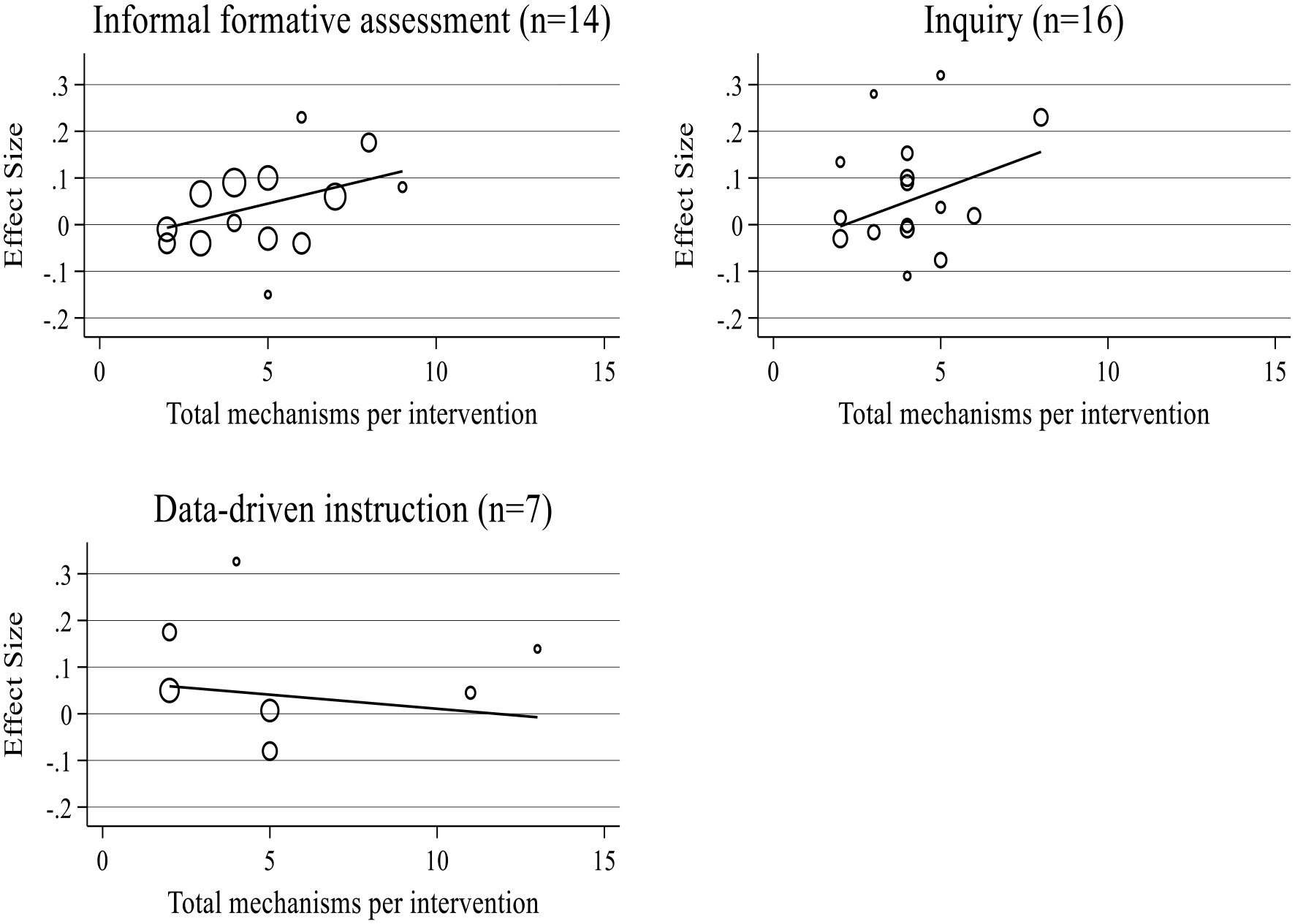
Relationship between the number of mechanisms in a PD program and impact on pupil test scores, by content area of the PD. N = number of separate experimental studies. Uses the primary outcome as specified in the study or else one randomly selected outcome per study. Effect sizes > .5 or < –.2 are used in the underlying meta-regression but are not shown in the figure to aid visual clarity. We did not include a separate graph for cognitive science because we only found one PD program that focused on this content area.
Our final analysis relating to H1 is to test the sensitivity of the hypothesized relationship to various indicators of study quality and treatment heterogeneity (Figure 5). We find a similar relationship among studies using state-mandated tests (Panel 1, ß = .01, p = .04), among large trials (Panel 3, ß = .01, p = .04), and among PD programs that do not include sets of new curriculum materials (Panel 5, ß = .01, p = .03). We also find a very similar gradient in our errors in variables regression (Panel 6, ß = .01, p = .12) and in studies with low attrition (Panel 2, ß = .01, p = .06). However, these last two results are no longer statistically significant at conventional levels.
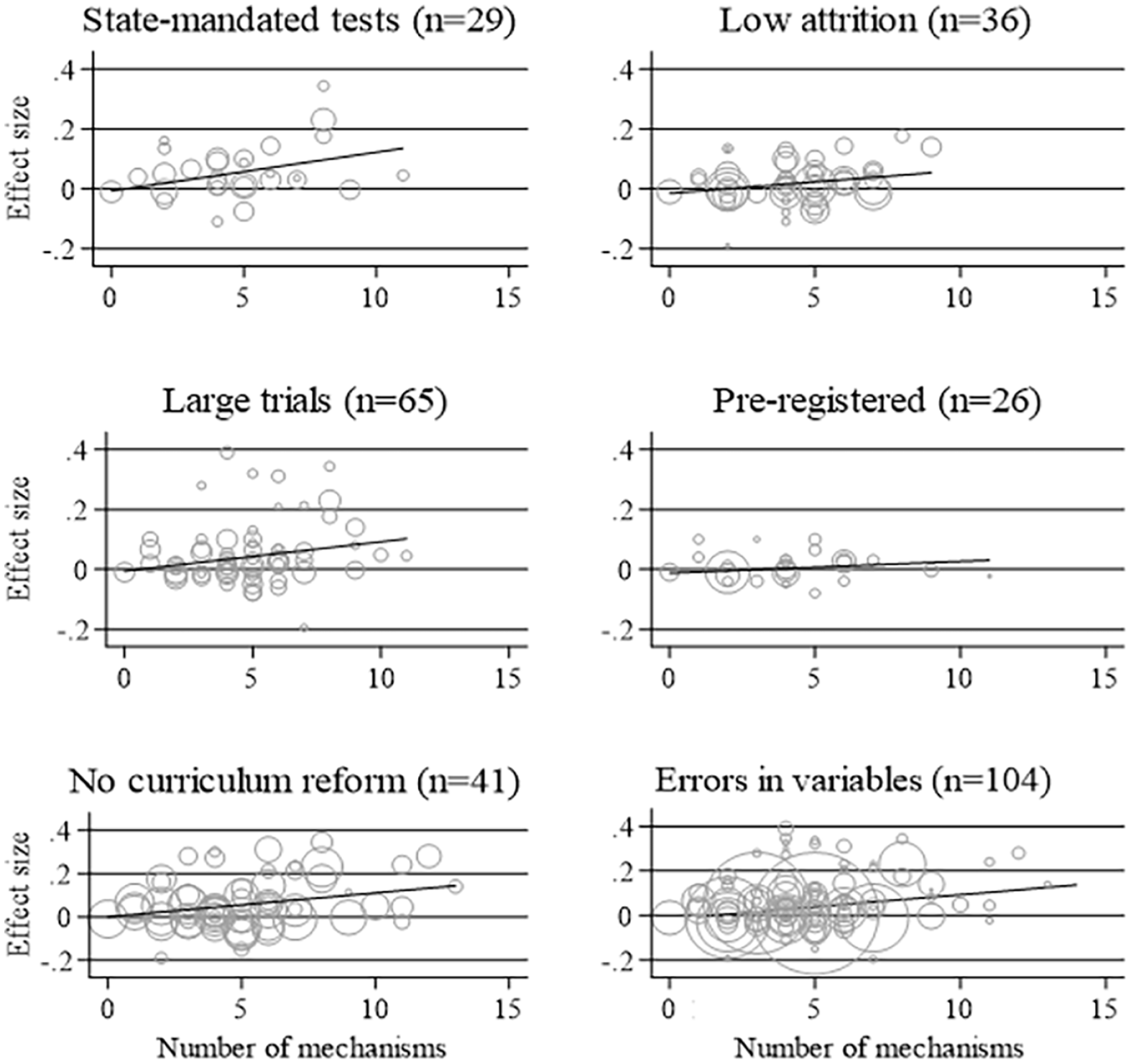
Relationship between the number of mechanisms in a PD program and impact on pupil test scores, by indicators of study quality. N = number of separate experimental studies. ‘Large trials’ involve more than 50 units randomised to treatment or control. Uses the primary outcome as specified in the study or else one randomly selected outcome per study. Effect sizes > .5 or < –.2 are used in the underlying meta-regression but not shown in the chart in order to aid visual clarity.
The most concerning part of Figure 5 is the panel for preregistered studies, in which both the gradient and p value break down (Panel 4, ß = .004, p = .32). In principle, the absence of a relationship among preregistered studies could be explained by p-hacking in trials that are not preregistered, otherwise higher methodological standards in preregistered trials, or inferior selection of PD programs by the types of funders that require preregistration. We probe these potential explanations further in online Appendix G. Our p-curve analysis does not indicate motivated p hacking in our sample (Simonsohn et al., 2014a, 2014b). Our comparison of methodological standards shows that preregistered trials are indeed more likely to use state-mandated test score outcomes and have lower attrition (indicators of higher methodological standards). We also find some evidence that preregistered PD tends to incorporate slightly fewer of our 14 mechanisms.
In summary, we find qualified support for H1. In our overall sample, the number of mechanisms incorporated in a PD program is associated with greater impact of the PD on test scores. This result holds when we restrict the sample and use variation in PD design within content areas where PD is effective on average (i.e., inquiry). However, it does not hold in other content areas. The positive association remains intact across four of our five indicators of study quality, but not among preregistered studies.
Do Balanced PD Programs Have Greater Impact?
We now turn to our empirical tests of H2, which states that PD programs that incorporate at least one mechanism in each of the four I/M/T/P categories (“balanced” PD programs) will have a larger impact on pupil test scores. Figure 6 shows the average impact of five separate groups of PD. On the left are PD programs that incorporate mechanisms addressing all four I/M/T/P purposes of PD (“balanced” PD programs). To the right of that are PD programs that incorporate mechanism(s) addressing three or fewer purposes of PD (“imbalanced” PD programs). Imbalanced PD programs have an average effect size of .05, regardless of whether they address one, two, or three purposes of PD. By contrast, balanced PD programs have an average effect size of .15 (p = .03). However, the 95% CI for balanced PD programs is wide and overlaps with the CI for all imbalanced PD programs. When we formally test for the difference between balanced PD programs and all other PD programs using meta-regression, the difference is not statistically significant at conventional levels (p = .22). There are two reasons that the CI is much wider on the balanced PD plot. First, there are fewer studies in the balanced PD (n = 9) versus imbalanced PD plots (n = 95). Second, there is more heterogeneity—captured by the standard deviation of the effect sizes (τ) among the effect sizes in the balanced PD (τ = .1) versus imbalanced PD plots (τ = .05). We return to this point in the discussion section.
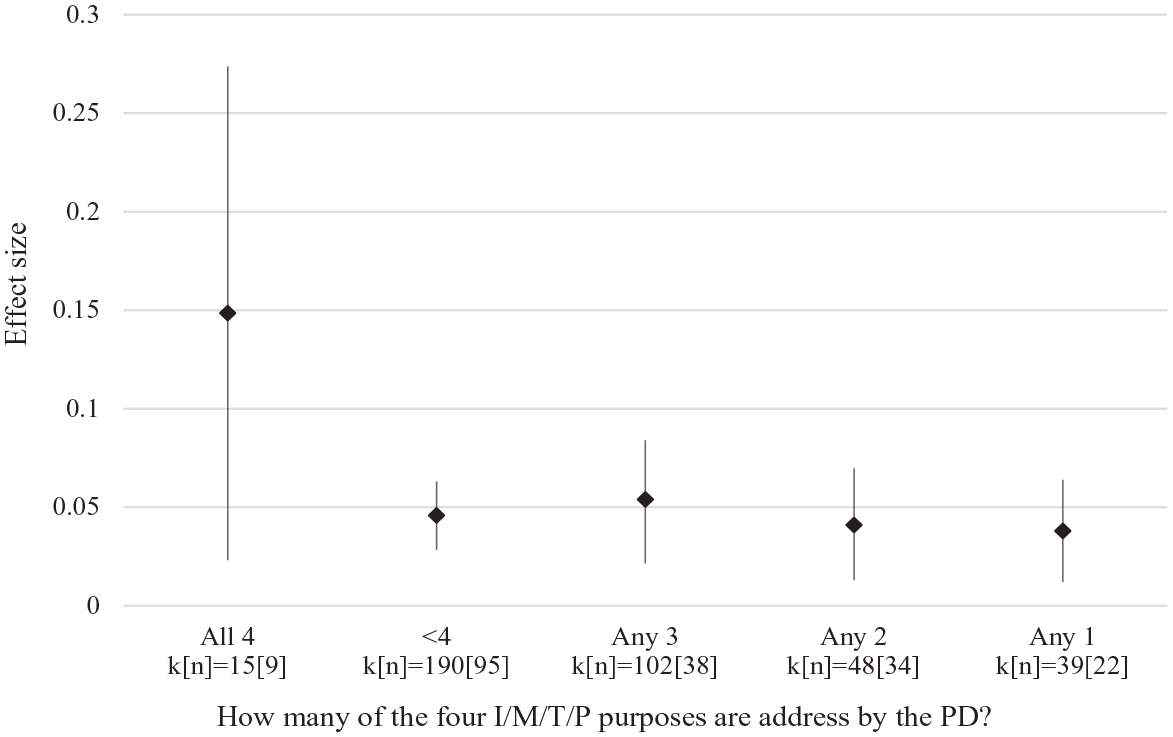
Average impact of PD on test scores, by how many of the four “purposes of PD” are addressed by the PD. k = number of effect sizes. n = number of separate experimental studies. Random effects meta-analysis, incorporating all standardized test score outcomes using robust variance estimation. Vertical lines represent 95% CIs.
Our theoretical framework encodes a set of assumptions about which mechanisms address which of the four purposes of PD. While we preregistered the overall I/M/T/P framework, and we believe the match between mechanism and purposes to be well grounded in theory, we did not preregister our list of mechanisms. Figure 7 therefore checks the sensitivity of our findings to reallocating mechanisms in four cases where our assumptions might be arguable. First, we reallocated the feedback mechanism to the insight (I) purpose. Second, we reallocated the credible source mechanisms to the insight (I) purpose. Third, we reallocated the praise/reinforce mechanism to the embed practice (P) purpose. Fourth, we reallocated the context-specific repetition mechanism to the techniques (T) purpose. The results are qualitatively similar to those in Figure 6, suggesting that our findings are not particularly sensitive to these assumptions.
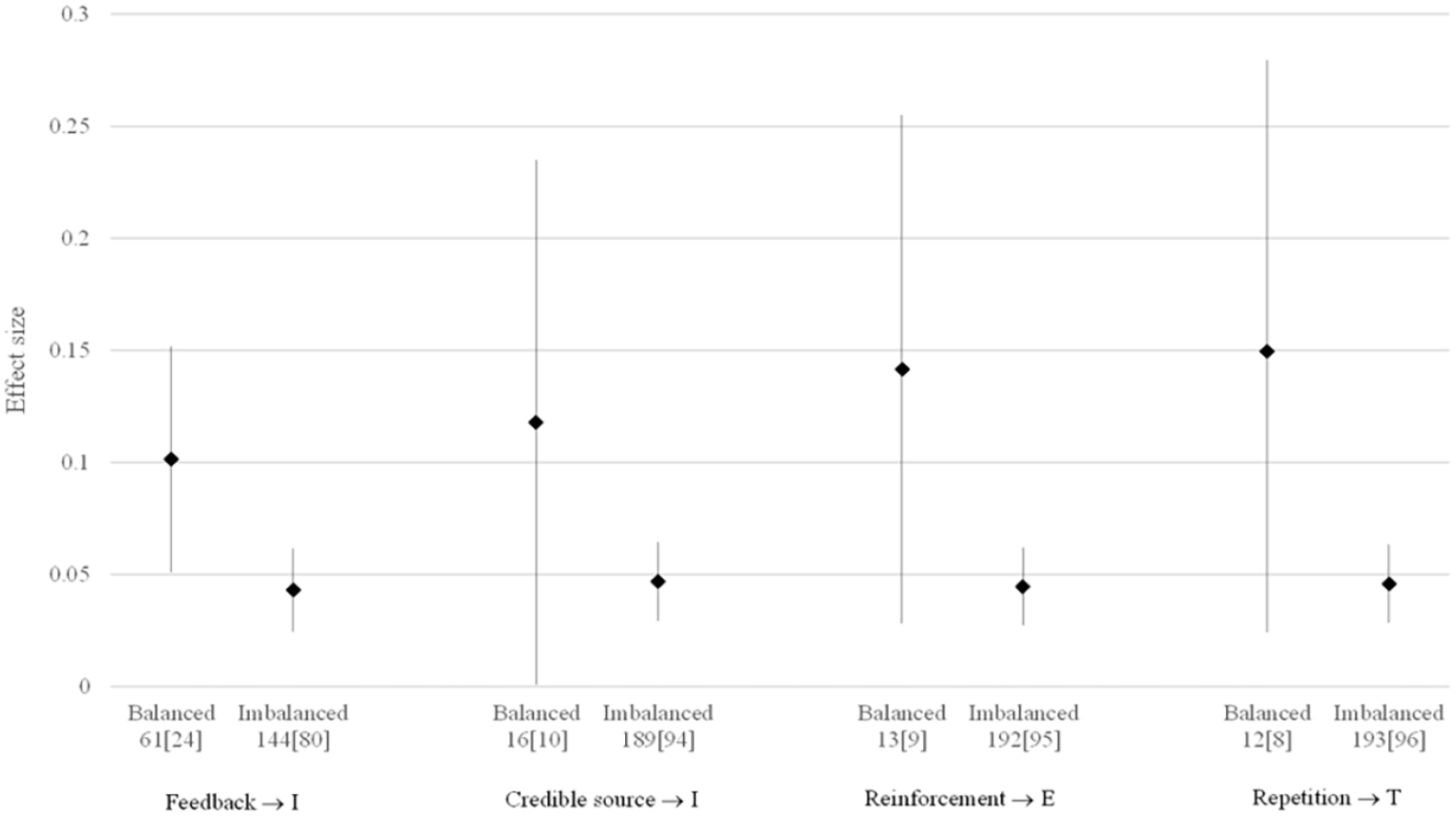
Sensitivity analysis for meta-analytic average impact of PD on test scores, by how many of the four “purposes of PD” are addressed by the PD design. k = number of effect sizes. n = number of separate experimental studies. Random effects meta-analysis, incorporating all standardized test score outcomes using robust variance estimation. Vertical lines represent 95% CIs.
Our final test of H2 is based on QCA. Table 5 shows the results. Each row represents a different combination of the IMTP purposes of PD, with lowercase letters indicating that a given purpose is not addressed by any mechanism and uppercase letters indicating that a purpose that is addressed by at least one mechanism. For example, imTP (row 3) includes all PD programs that include mechanisms addressing T and P but no mechanisms addressing i or m. Using our preferred cutoff (d ≥ .10), balanced PD programs have a consistency of 67%. To put it another way, in the final row of our table, there are nine balanced PD programs, and six of them have effect sizes higher than .10. Balanced PD programs have a higher consistency than any of the other (imbalanced) PD programs. The pattern of results is similar using the other two cut-off values (.08 and .12), with balanced PD programs always having the highest levels of consistency. Having said that, the consistency for balanced PD programs is always lower than the conventional QCA consistency criteria of 80%, which means the Quine-McCluskey algorithm cannot be used to test for causal redundancy.
Qualitative comparative analysis
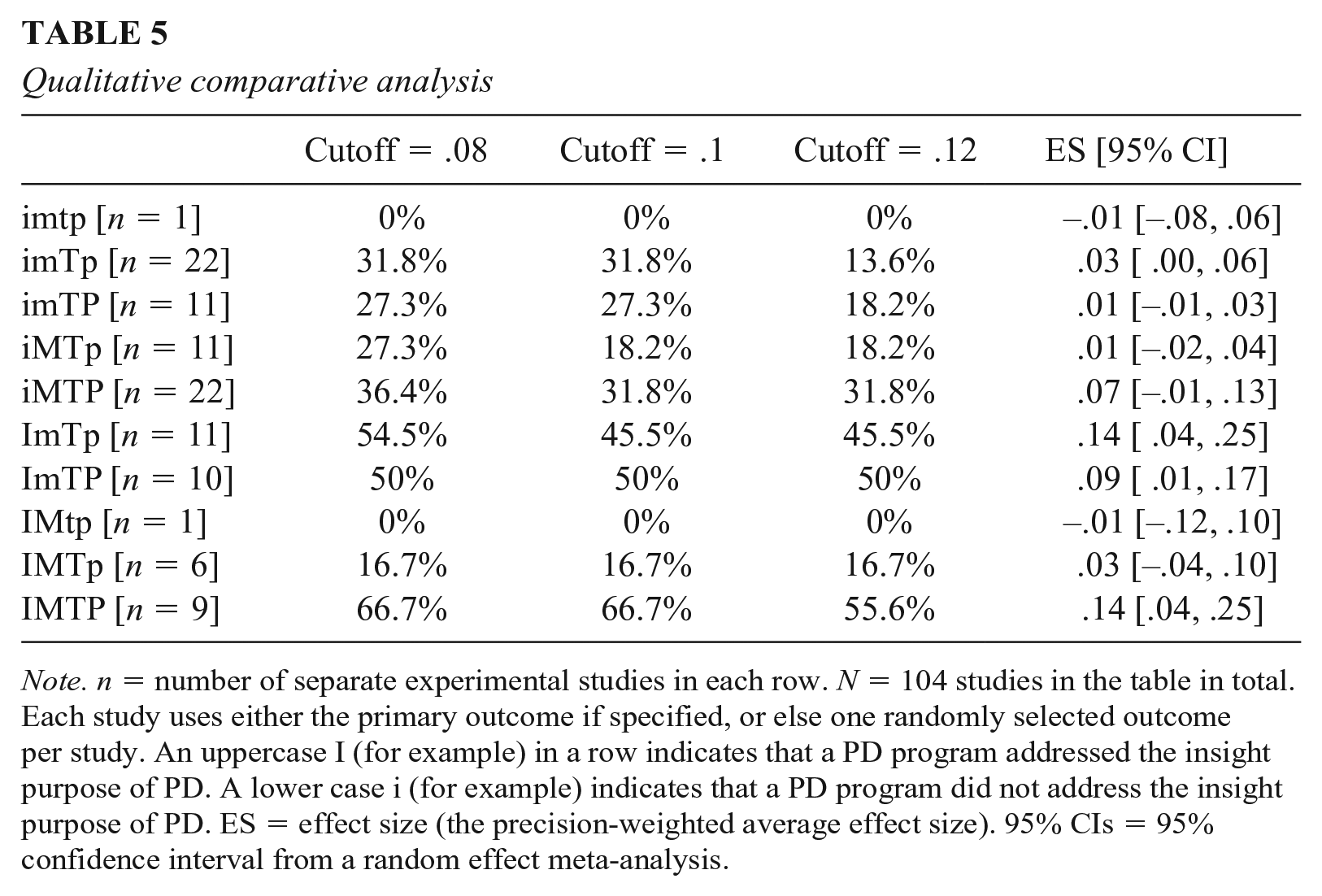
Note. n = number of separate experimental studies in each row. N = 104 studies in the table in total. Each study uses either the primary outcome if specified, or else one randomly selected outcome per study. An uppercase I (for example) in a row indicates that a PD program addressed the insight purpose of PD. A lower case i (for example) indicates that a PD program did not address the insight purpose of PD. ES = effect size (the precision-weighted average effect size). 95% CIs = 95% confidence interval from a random effect meta-analysis.
For completeness, Table 5 also includes the meta-analytic average effect sizes for each row in the table, thus disaggregating the data further than in Figure 6. Seven of the 10 rows have CIs that include zero. Of the remaining three, one is balanced PD programs with IMPT (d = .14; 95% CI [.04, .25]), another is iMPT (d = .09; 95% CI [.01, .17], and the third is ImTp (d = .14; 95% CI [.04, .25]).
In summary, we again find qualified support for H2. Balanced PD programs do have higher average effect sizes than imbalanced PD programs in general, as well as eight of the nine types of imbalanced PD programs. Having said that, the difference is not statistically significant at conventional levels. Balanced PD programs are also more consistently effective than imbalanced PD programs (based on a variety of thresholds for effectiveness), including all nine types of imbalanced PD programs. However, the consistency for balanced PD programs does not exceed conventional thresholds for consistency in QCA analysis.
Discussion
We set out to develop and test a useful theory of effective teacher PD. To do so, we developed an account of four things that PD needs to do to bring about sustained improvements in teaching and learning. Against this, we synthesized a set of mechanisms hypothesized to be causally active in addressing each of these four purposes of PD. In the remainder of the article, we discuss the strengths and limitations of the theory we have developed, first by evaluating it against standards for theory development, and then by comparing it with existing theories of effective teacher PD. We also discuss some important limitations of our empirical analysis.
Evaluating the Theory in Its Own Right
Various frameworks have been suggested for evaluating theories (Gawronski & Bodenhausen, 2015; Kuhn, 1977; Van Lange, 2015). While there are differences in emphasis and language, all of these frameworks emphasize the importance of abstraction/parsimony, plausibility/coherence, usefulness/applicability, and explanatory power. We will now assess the strength and limitations of our theoretical framework against each of these criteria.
Parsimony requires that theories abstract away from empirical detail, using the fewest assumptions or components necessary to explain the target phenomenon (Eronen & Bringmann, 2021; Gawronski & Bodenhausen, 2015). Our top-level framework involves just four components: insights, motivation, techniques, and embedding practice. As set out in Table 1, this simple setup nests within it a range of arguments and hypotheses previously made in the PD literature, including the knowing/doing gap, the importance of habits, and lethal mutations. Within each of the I/M/T/P categories, our framework includes between two and five mechanisms, which collectively allowed us to characterize and capture considerable variation in our set of 104 experimentally evaluated PD interventions. We found some instances of all 14 mechanisms and one intervention containing 13 of these 14 mechanisms, suggesting the framework is not overly elaborate relative to current PD design. We were also able to formalize several aspects of our framework (online Appendix A).
The coherence and plausibility of a theory depends on its degree of fit with existing knowledge or other, well-corroborated theory (Scheel et al., 2021). An important and distinctive feature of our framework is the requirement that each mechanism be supported by empirical causal evidence from multiple domains. A strength of our theory is that it is therefore closely integrated with empirical findings from the cognitive science, behavioral science, and medical education literatures. Having said that, the fact that our theory largely draws on knowledge from other disciplines and domains could also be construed as a weakness. However, we believe that using strong causal evidence from neighboring disciplines or domains is preferable to using the (much weaker) mechanism-level evidence currently available from within education. It is common for scientific theories to be built through this sort of analogical reasoning (Borsboom et al., 2021). Indeed, in the absence of strong empirical evidence from within education, we think this is the best way forward.
For a theory to be practical it should point towards actionable steps for solving a real-world problem (Berkman & Wilson, 2021). Our theory potentially provides a flexible framework for designers of PD to use when thinking about how to combine different components of PD in order to develop teacher insights, motivate change, develop techniques, and embed these in practice. This granular, flexible approach is more likely to be useful than black box evaluations of entire PD programs, which are likely unavailable to the majority of schools (Hill et al., 2013). The theory may also be useful for researchers in helping to express with clarity what is involved in the PD programs that they evaluate. This is important, since attempts to scale up or imitate successful interventions requires clarity on the causally active components of the PD program. While tools have been developed to aid more precise descriptions of interventions in the medical literature (Hoffmann et al., 2014), our review highlights that the education literature still has some way to go in this respect. Using our framework to describe the design of PD in evaluation reports would be a step forward in helping researchers increase the precision with which they report the likely causally active components, thus reducing ambiguity where ambiguity matters most.
Finally, a theory has explanatory power if it can provide an accurate account of how and why something occurred by citing earlier events (Cummins, 2000; Elster, 2015). Our theory achieves this in two senses. In a qualitative sense, it provides an account of how PD succeeds or fails to improve teaching via changes in I/M/T/P, brought about by the mechanisms incorporated in the PD. We were careful to provide such an account both for how different combinations of I/M/T/P affect (or not) teaching, as well as for how each individual mechanism affects I/M/T/P. In a quantitative or statistical sense, our meta-analysis showed that the number and combination of mechanisms incorporated in the PD can explain variation in effects between 0 and 0.15 standard deviations (though we acknowledge this hypothesis was not preregistered). We argue that the persuasiveness of our account derives from the combination of these two types of evidence: independent causal evidence that each of our mechanisms is causally active in various other domains, plus evidence of an association between PD incorporating those mechanisms and the impact on test scores.
Having said that, our empirical findings come with three important caveats. First, while we did find that balanced PD programs have higher average effect sizes than imbalanced PD programs in general, one of the nine specific types of imbalanced PD programs (ImTp) had an equally large average effect size. This suggests that addressing all four (IMTP) purposes may not be strictly necessary for effective PD, perhaps due to differences in participants’ prior characteristics, for example, motivation. Second, and relatedly, there was a wide confidence interval on the estimate for balanced PD programs. This is likely largely due to the smaller number of evaluations (n = 9) for balanced PD programs. Further experimental evaluations of PD are therefore needed in order to provide a more precise test of this hypothesis. The third caveat relates to the absence of a statistically significant relationship between the number of mechanisms and the impact of the PD among the subset of preregistered studies. Our additional analysis in online Appendix G suggests that this likely reflects greater use of state-mandated test scores, lower attrition, and perhaps slightly weaker PD designs among preregistered evaluations, but not p-hacking. Our theory could be further stress-tested here by conducting preregistered A/B tests in which the same PD content is delivered using low-mechanism and high-mechanism designs.
Evaluating the Theory Relative to Other Existing Theories
How does our theory compare to prior attempts at explaining what differentiates more from less effective PD? An influential early framework came from Desimone (2009), who suggested focusing on critical features of effective PD, as opposed to types of activities involved in the PD. In particular, Desimone suggested that PD is more effective if it focused on the content being taught, involved opportunities for active learning, cohered with teachers’ existing knowledge and beliefs, was sustained in duration, and involved collective participation of teachers. Desimone’s five “critical features” were not supported by subsequent empirical tests (Kennedy, 2016; Kraft et al., 2018), and the review on which the framework is based has been criticized on methodological grounds (Sims & Fletcher-Wood, 2021). The five features therefore do not feature in our framework at all. However, out list of mechanisms can be seen as an updating of the critical features approach, but this time based on stronger evidential standards: causal evidence of mechanism from other domains, as well as a correlation between the presence of these mechanisms and the impact of PD programs. Future research should test the causal effect of the different mechanisms on teacher development, perhaps using experimental classroom simulator studies (e.g., Cohen et al., 2020).
In 2016, Kennedy introduced a new framework for understanding how PD works. This was intended as a response to criticism of the “critical features” approach being somewhat atheoretical (Sztajn et al., 2011). Thus, Kennedy’s model set out to provide a more explanatory account of how PD improves teaching, using a four-part distinction between PD designed around prescription, strategies, insights, and bodies of knowledge. In the empirical analysis presented by Kennedy, this framework does not clearly differentiate more from less effective PD. However, our I/M/T/P framework builds directly on Kenndy’s call for a more explanatory account of how PD affects teaching, as well as drawing directly on Kenndy’s emphasis on insights and motivation. However, in contrast to Kennedy, we do not dismiss the idea of identifying more granular “critical features.” Instead, we combine a list of mechanisms with the I/M/T/P explanatory framework. In short, our theory combines the granularity/practicality of Desimone’s (2009) theory with the explanatory orientation of Kenndy’s framework. The I/M/T/P framework also does a slightly better job of explaining empirical variation in the impact of PD than either preceding theory.
Limitations
The findings from our meta-analysis should, of course, be interpreted in light of the limitations of this research. Four in particular stand out. First, our ability to accurately code up the mechanisms incorporated in each PD program was limited by the detail in which each program was described in the research reports. We cannot rule out the possibility that we missed some PD mechanisms because they were not mentioned in the research reports. Conversely, some mechanisms may have been mentioned in research reports but not implemented with fidelity. This would tend to bias our meta-regression coefficient estimates. Having said that, we take some reassurance about the general quality of our measurement from the moderate/substantial interrater agreement on our mechanisms coding and the very similar coefficient estimates we found in our errors-in-variables regression. Nevertheless, resource constraints meant that we were unable to double code all (104) papers, which is a limitation of our approach.
The second limitation relates to the potential for mechanisms to be missing from our coding framework in the first place. For example, it could be argued that our framework omits any knowledge-building mechanisms aimed at schema formation, which helps experts to recognize and respond to problems in the workplace (van Merriënboer & Sweller, 2010). However, at the time of writing, we did not find the causal evidence necessary to include activities aimed at schema formation as a mechanism in our framework. Similarly, it could be argued that our framework omits mechanisms based on generative or constructive/interactive methods of building knowledge (Chi & Wylie, 2014; Fiorella & Mayer, 2016). However, we did not find any examples of this sort of activity incorporated in the 104 PD programs in our sample, which suggests that this would not have changed our empirical findings. In addition, it may just be very hard to gather evidence on the causal effect of certain mechanisms. For example, it is not clear how experimental research could test whether voluntary participation in PD improves motivation. Can somebody be assigned by an experimenter to do something voluntarily? In general, future research should keep candidate mechanisms under review and amend the I/M/T/P framework accordingly.
The third limitation of our analysis is that we focus primarily on the design of the PD, as opposed to the content. Content is of course a critical consideration—poor or inaccurate PD content is very unlikely to improve teaching, regardless of how PD is designed. We attempted to check the sensitivity of our results across broad categories of PD content (Figure 4) but were inevitably constrained by the size and diversity of content represented in the existing PD evaluation literature. There may also be interactions between the content of the PD and the way it should be designed. For example, Parkhouse et al. (2019) found that PD focused on fostering inclusive and equitable classrooms may need to incorporate mechanisms addressing potential resistance to discussion around diversity and equity. As the number of evaluations of such PD grows, scholars should attempt to investigate these sorts of interactions between content and mechanisms of PD.
The fourth and final limitation relates to the inherent risks of reasoning by analogy when building theory. It is possible that, while we have evidence that the mechanisms in our framework are causally active in other domains, they may not be in the domain of teacher PD. For example, we draw on evidence showing that reducing cognitive load helps with learning among school students. However, school students are generally learning more novel material, while teachers engaged in PD are more likely to be refining or reconstructing existing knowledge, which may make cognitive load less relevant. We also draw on evidence that reducing cognitive load helps medical trainees learn, which mitigates the risk of disanalogy since medical students often have considerable background knowledge and experience, more akin to teachers. Regardless, we acknowledge that reasoning by analogy always has risks.
Conclusion
In conclusion, we submit that the I/M/T/P theory represents an advance over existing theories of effective PD in providing a parsimonious, coherent, and explanatory (Haig, 2009) account of what differentiates more and less effective teacher PD. We found qualified empirical support for the theory, with some mixed findings and important caveats around statistical precision. The main contribution of the article is therefore to provide a new theoretical framework, which can be used to guide future empirical research on this topic.
Supplemental Material
sj-docx-1-rer-10.3102_00346543231217480 – Supplemental material for Effective Teacher Professional Development: New Theory and a Meta-Analytic Test
Supplemental material, sj-docx-1-rer-10.3102_00346543231217480 for Effective Teacher Professional Development: New Theory and a Meta-Analytic Test by Sam Sims, Harry Fletcher-Wood, Alison O’Mara-Eves, Sarah Cottingham, Claire Stansfield, Josh Goodrich, Jo Van Herwegen and Jake Anders in Review of Educational Research
Footnotes
Notes
Sam Sims and Sarah Cottingham declare that they work for a charity that provides PD to teachers and schools in return for fees. Alison O’Mara-Eves, Claire Stansfield, Jo Van Herwegen, Sam Sims, and Jake Anders declare that they work for a university that also provides PD to teachers in return for fees. Josh Goodrich works for a commercial organisation, Step lab, that provides PD software to teachers in return for fees. All authors declare no other conflicts of interest. This research was supported by the Education Endowment Foundation.
Authors
SAM SIMS is a lecturer at University College London, Gower St, London, WC1E 6BT; e-mail:
HARRY FLETCHER-WOOD is an independent researcher; e-mail:
ALISON O’MARA-EVES is an associate professor at University College London, Gower St, London, WC1E 6BT; e-mail:
SARAH COTTINGHAM is an associate dean at Ambition Institute, 2, Bridge Wharf, 156 Caledonian Rd, London, N1 9UU; e-mail:
CLAIRE STANSFIELD is a senior research fellow at University College London, Gower St, London, WC1E 6BT; e-mail:
JOSH GOODRICH is chief executive at Steplab; e-mail:
JO VAN HERWEGEN is a professor at University College London, Gower St, London, WC1E 6BT; e-mail:
JAKE ANDERS is an associate professor at University College London, Gower St, London, WC1E 6BT; e-mail:
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.