
Abstract
Electroencephalogram (EEG) data depict various emotional states and reflect brain activity. There has been increasing interest in EEG emotion recognition in brain–computer interface systems (BCIs). In the World Robot Contest (WRC), the BCI Controlled Robot Contest successfully staged an emotion recognition technology competition. Three types of emotions (happy, sad, and neutral) are modeled using EEG signals. In this study, 5 methods employed by different teams are compared. The results reveal that classical machine learning approaches and deep learning methods perform similarly in offline recognition, whereas deep learning methods perform better in online cross-subject decoding.
Keywords
1 Introduction
Emotion is a vital part of humans and plays an important role in people’s daily communication [1]. Emotion recognition is the most fundamental and significant connection in emotion computing, as well as a critical research topic in the domains of brain–computer interface and human–computer interaction [2]. Traditional emotion recognition methods use auditory (speech) and visual (facial expression) attributes to predict human emotional responses, however, these external expressions cannot reliably detect emotion, especially when people subjectively hide their feelings [3]. At the moment, the acquisition of physiological reactions is gaining popularity in defining emotional states [4, 5]. Many research teams undertake emotion identification investigations using physiological signals such as breathing, body temperature, electromyography (EMG), electrocardiography (ECG), and electroencephalography (EEG). In comparison to other types of peripheral physiological signals, EEG is directly created by the human body’s central nervous system, which is intimately associated with the emotional state; hence, EEG can give deeper emotional information [6].
In recent years, emotion recognition based on scalp EEG has attracted considerable attention and has become a new direction of brain–computer interface (BCI), namely affective brain–computer interface (aBCI). EEG-based aBCI system mainly involves preprocessing, feature extraction, and classification, among which feature extraction of emotional EEG is a key factor affecting the effect of emotion recognition [7]. EEG signals have limited spatial resolution and frequency range, low signal-to-noise ratio, and are susceptible to the external environment and human activities such as respiration, ECG, and electrooculogram. How to get the most emotion-related EEG characteristics for emotional EEG is a fundamental scientific topic in the study of an aBCI system. EEG characteristics utilized for emotion identification are broadly classified into three types: time-domain characteristics, frequency-domain characteristics, and time-frequency characteristic. Time-domain features include Hjorth parameter [8], fractal dimension [9], higher-order crossing (HOC) [10], etc. Frequency domain features include differential entropy (DE) [11], differential asymmetry (DASM) [12], rational asymmetry (RASM) [13] and differential causality (DCAU) [14] in five classical frequency bands: delta (1–3 Hz), theta (4–7 Hz), alpha (8–13 Hz), beta (14–30 Hz) and gamma (31–50 Hz). Methods for extracting time-frequency features primarily include the short-time Fourier transform, wavelet transform, and others [15].
At the moment, the effective features utilized in EEG emotional recognition are mostly frequency domain features extracted from each EEG rhythm, and the DE feature has been demonstrated to be one of the most stable features with exceptional performance [16]. Meanwhile, several EEG emotion identification algorithms have been developed, with the majority of them being typical machine learning techniques. Consider the support vector machine (SVM) [17], k-nearest neighbor (KNN) [18], logistic regression (LR) [19] and random forest [20] supervised learning algorithms.
The existing EEG-based emotion recognition methods are mainly based on supervised machine learning. Wang et al. [21] compared power spectral density (PSD), wavelet, and nonlinear dynamic features with SVM. Zheng et al. [16] investigated the critical bands and channels using PSD, DE, and PSD asymmetric features, and obtained robust accuracy using a deep belief network. Significant variances in EEG signals exist between participants, limiting the generalization capabilities of the classifier learned in the single-subject classification context. This issue must yet be addressed.
BCI Controlled Robot Contest in World Robot Contest (WRC) held emotion recognition technology competition in 2021 [22]. The technological competition focused on the teams’ abilities to create and improve their algorithms, with an emphasis on the research team’s algorithms’ accuracy and reaction speed. The competition consists of a preliminary contest and a final contest. The preliminary contest was held in the cloud and the final contest was held on-site. The relevant competition data collected from the 2020 skill competition was used for the 2021 preliminaries. The 2021 finals will compete using real-time data gathered from the 2021 skill competition finals, ranking in real time based on the accuracy and efficiency of the calculation findings. Many university teams took part in the competition.
We compare the algorithms of several teams in this study. Some recommendations are made for future EEG-based emotion recognition across participants.
2 Background
2.1 Subjects and EEG recording
In the preliminary contest, 23 subjects (A1–A23) participated in the emotion recognition technology competition of WRC2021. Subjects wore the 62-channel EEG caps during the experiment while watching movie clips that might produce various emotional states, and EEG was recorded concurrently. Each experiment was recorded for about 1 h. The sampling rate of the raw EEG signals is 1000 Hz. The final contest had four individuals (F1–F4), and the EEG acquisition experimental parameters for the two phases were the same.
2.2 Emotion induction experiment
During an emotion induction experiment, subjects need to watch three categories of emotions (positive, neutral, and negative) videos. Each emotional video is a varied duration, and there is a time delay between clips for people to offer comments rest. To assure the induction impact of three types of emotions, the video clips utilized for emotion induction are rigorously analyzed and inspected (happy, sad, and neutral, the proportions are balanced). There are a total of 15 clips selected from Chinese films. There was a 5 s hint before each clip, 45 s for self-assessment. Subjects were asked to fill out a questionnaire immediately after seeing each video clip and express their emotional reactions to each video clip to collect feedback. The experimental process is shown in Fig. 1. Each subject participates in one experiment, and different subjects may watch different video clips. One video clip corresponds to one trial, one block comprises numerous trials (the number varies), and each subject’s data contains many blocks.
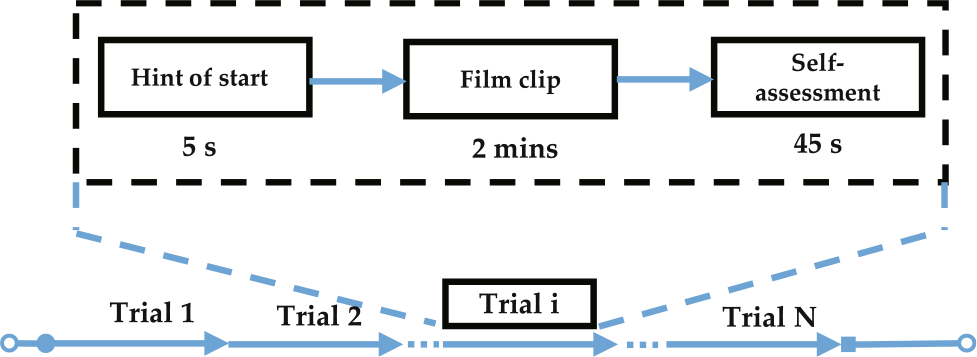
Time interval of one trial.
3 Methods
In this section, we describe the methods of preprocessing, feature extraction, and classification. The specific schemes used by different teams are detailed in Table 1. EEGNet-20, 8 [23] represents it has 20 temporal filters and 8 spatial filters. We utilized PSD as a feature and SVM with RBF kernel as a classifier as the baseline since it is simple and widely used in emotion identification tasks.
3.1 Preprocessing
Table 1 briefly presents the preprocessing setup of each method. Before our analysis, raw EEG data is passed through a 3rd- or 4th-order bandpass filter. Finally, EEG data is filtered between 0.5 and 49 or 50 Hz. The filtered continuous EEG data is segmented by extracting data segments while film clips are being shown. We downsampled the 62-channel EEG signals to 250 Hz to speed up the processing.
Comparison of different methods.

Butter_bandpass: Butterworth bandpass filter. MinMaxScaler: transform amplitude of signals by scaling each amplitude to a given range. Butter_notch: Butterworth notch filter.
3.2 Feature extraction
Three techniques have been used: PSD, DE, and Hjorth parameters.
3.2.1 Power spectral density
The power spectrum of the five aforementioned rhythms of EEG is a common feature. PSD may be computed under the premise that each state is ergodic by computing the Fourier transform of its temporal autocorrelation function. The PSD calculating procedure is as follows.
Let an EEG sample on an electrode be x(n). First, divide it into L segments, the i-th segment signal xi (n) is shown in Eq. (1).

where n = 0, 1,…, M; i = 0, 1,…, L −1. D is the translation length of the signal. Calculate the power spectral density psdi ( f ) of the i-th segment signal by periodic diagram method, as shown in Eq. (2).
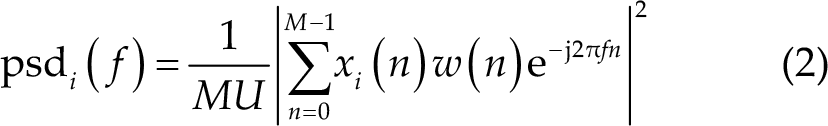
where, i = 0,1,…, L −1 , j is the imaginary unit. w(n) is the Hamming window function, which can reduce spectrum leakage, and its length is the same as that of each signal. U is the regularization coefficient of the window, which is used to reduce the influence of window function on power spectrum estimation. Its calculation method is shown in Eq. (3).
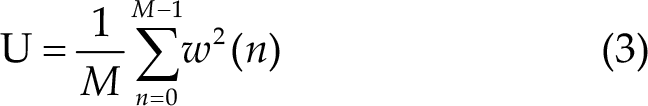
Finally, the PSD estimated by the Welch method is the average value of each segment of PSD, as shown in Eq. (4).
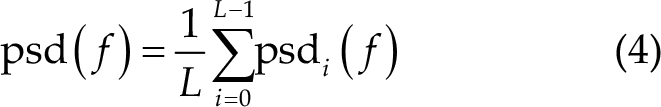
3.2.2 Differential entropy
DE is a widely used feature in EEG-based emotion recognition, and can be defined as follow:
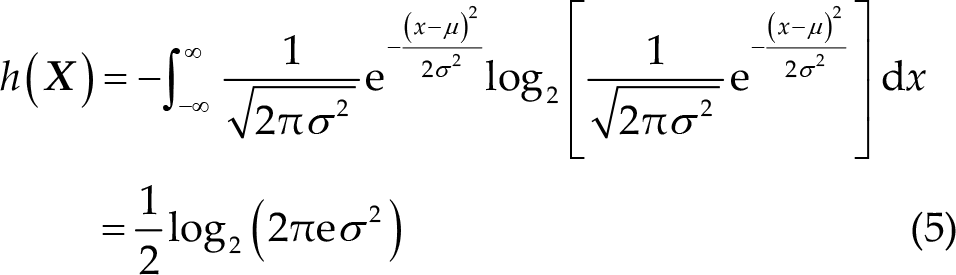
where the time series
3.2.3 Hjorth parameters
There are three statistical properties introduced by Bo Hjorth [8]. The Hjorth parameters, which assess the signal’s complexity, are as follows [24]: Activity parameter (m
0) represents the power of the signal. Mobility parameter (m
2) is the ratio of the standard deviation of the first derivative of the signal to the standard deviation of the original signal. Complexity parameter (m
4) represents the change of frequency.
The discrete formula used to calculate these parameters is based on the following derivation (Eq. (6)):
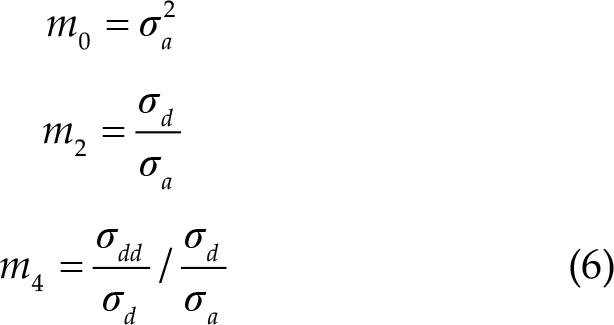
where
3.3 Feature smoothing
The majority of existing EEG-based emotion detection techniques translate EEG signals to static discrete emotional states, which may be illogical given that emotion is not a discrete psychophysiological state [25, 26]. It is necessary to smooth the features we extracted above because emotion usually varies smoothly while the features contained many rapid fluctuations.
In this research, we employed the traditional moving average (MA) approach to remove components that are not related to emotional states. Specifically, we applied MA with a window of 10 s to smooth features. We did not apply MA to M5 because it accepts raw EEG data as input. To accelerate the convergence of the model training, we further normalized the smoothed features.
4 Results & discussion
In this section, we briefly present the experimental setup and results.
For offline analysis in the preliminary contest, to evaluate the performance of each algorithm a cross-validation (CV) and a hold-out (HO) analysis were conducted. The CV analysis was conducted in a 10-fold setting, where 9 folds are used for training and the remaining 1 fold for testing. For cross-subject classification, a HO analysis is utilized. The whole data for a specific subject is utilized for testing in the HO analysis, and model training is conducted on the data for all other subjects. While in online analysis in the final contest, every team must give real-time feedback when the fire-new and consecutive emotional EEG signals were obtained. Notably, no team has access to all individuals’ EEG signals, which implies that players may only train models using data from other participants. In this scenario, the competition organizer provided a training dataset. This dataset includes four healthy volunteers (F1–F4), and the 62-channel EEG signals were originally captured at 1000 Hz, following the final contest arrangement. In this research, we train models for online analysis in the final contest utilizing this four-subjects dataset.
Table 2 presents the 10-fold CV accuracies for all subjects in the preliminary contest. M2, which only extracts DE features matched the performance of the best performing method for most subjects resulting in the best average classification accuracy. It’s worth noting that M1 and M3, which combine DE characteristics and other feature sets, perform poorly. This phenomenon is caused by serially concatenating two or more feature sets into a composite feature set. Vectors often have very large dimensions, which can place a significant strain on the emotion classification job and lead to overfitting issues [27]. In this instance, using appropriate feature fusion algorithms may be an ideal solution for minimizing side effects.
Classification accuracy (%) of different algorithms in offline EEG emotion recognition of a single subject in the preliminary contest.
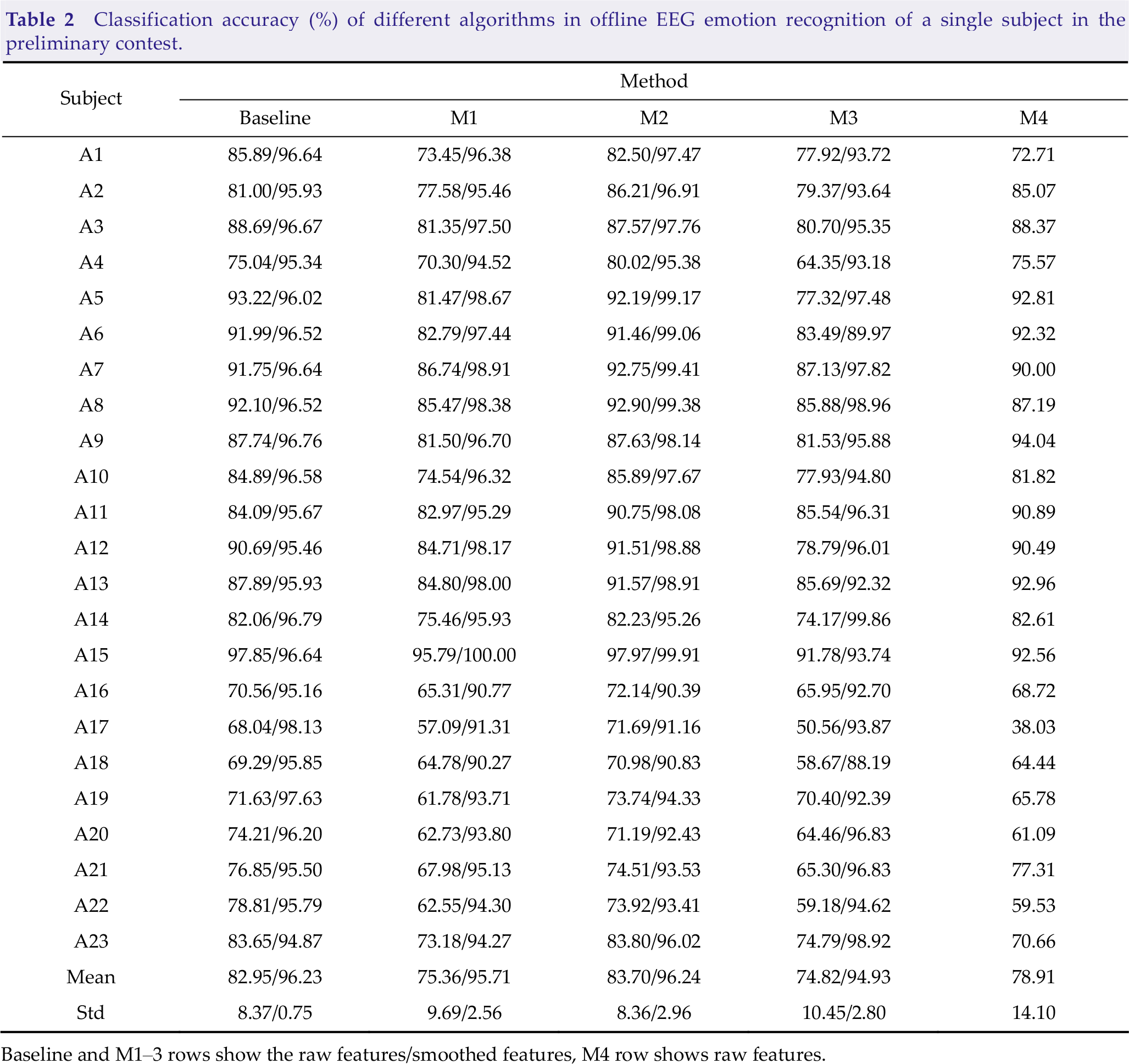
Baseline and M1–3 rows show the raw features/smoothed features, M4 row shows raw features.
The result of the HO analysis can be seen in Table 3. It is not straightforward to see that each approach has a considerable decline in performance (up to 27.8% inaccuracy), which is due to the low generalizability of the EEG characteristics in representing emotional information across people [28]. We see that all methods have a slight difference in performance ranking. M2 and baseline perform the best, whereas M1 and M3 perform the poorest. M4, the sole deep learning approach, performs poorly in both CV analysis and HO analysis.
Classification accuracy (%) of different methods in offline EEG emotion recognition across subjects in the preliminary contest.
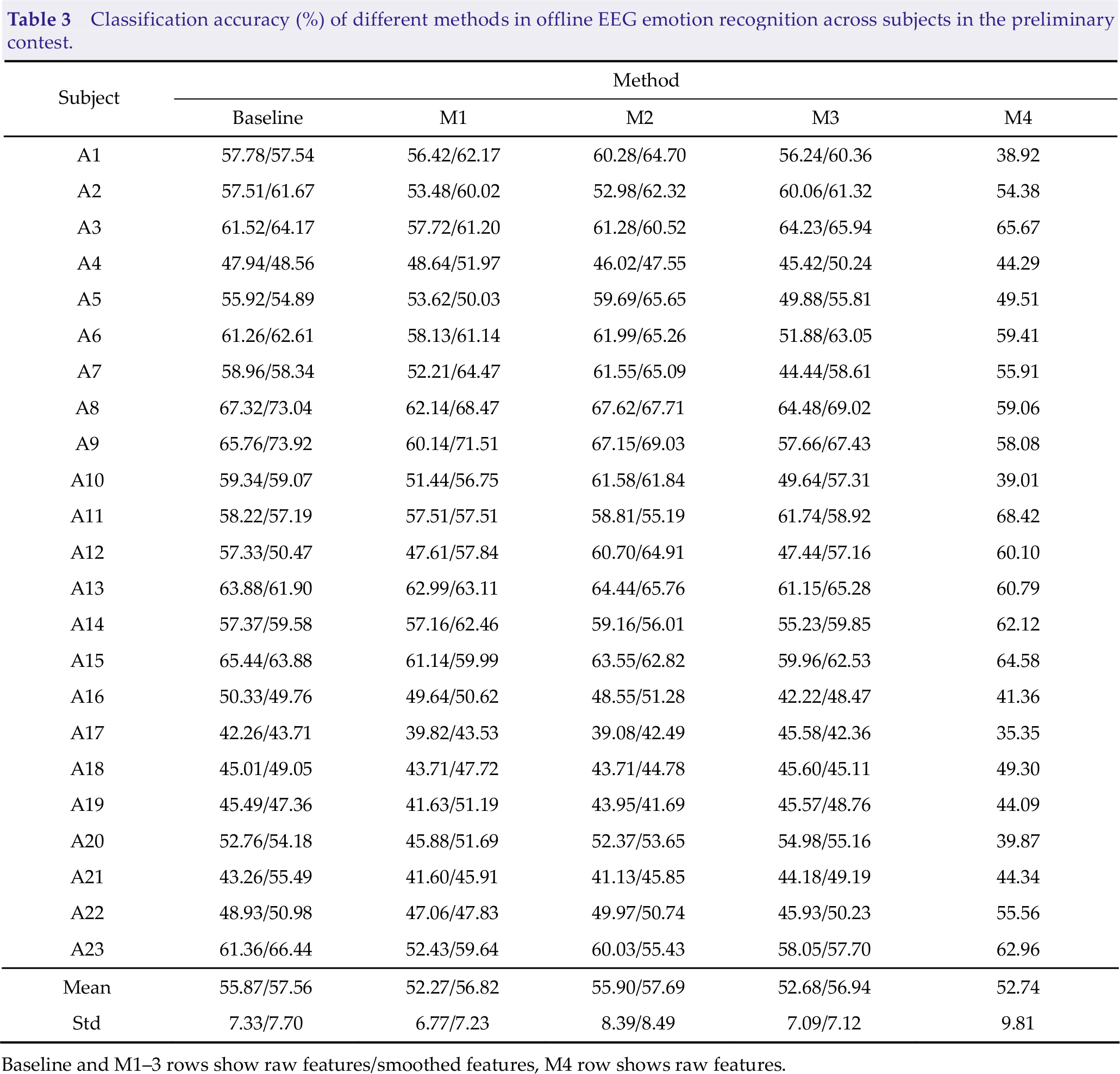
Baseline and M1–3 rows show raw features/smoothed features, M4 row shows raw features.
Classification accuracy(%) of different methods in online EEG emotion recognition across subjects in the final contest. Each session has three blocks.
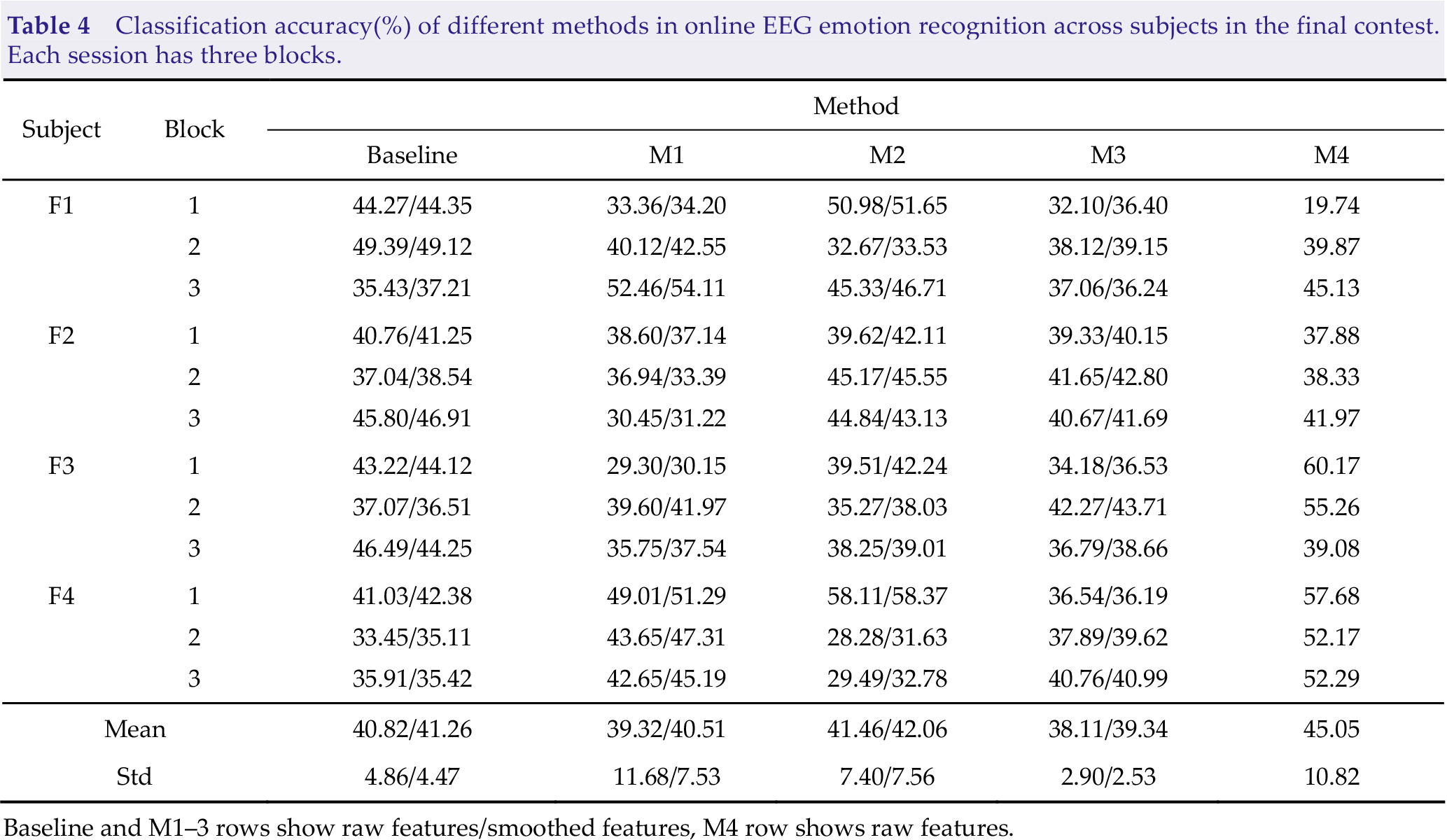
Baseline and M1–3 rows show raw features/smoothed features, M4 row shows raw features.
We also evaluate the performance of the feature smoothing algorithms. Fig. 2 presents an example of features before and after smoothing. The original features fluctuate greatly, while the smoothed features change slowly. From Tables 2–4, we find that the classification accuracy of smoothed features is better than that of original features. Especially in CV analysis in offline emotion recognition, the means of the classification accuracies of M1 in percentages achieves up to 20.35% higher after applying MA. Another intriguing occurrence is that MA has a lower capacity to enhance accuracy in HO analysis in offline emotion identification, with a maximum improvement of 4.55%, and much lower in online emotion detection, with a maximum improvement of 1.23%. This result can be attributed to the huge individual difference in EEG signals, which makes it complex to extract features with strong generalization ability and limits the upper limit of classification performance of algorithms. To summarize, feature smoothing is an essential procedure for improving classification performance.
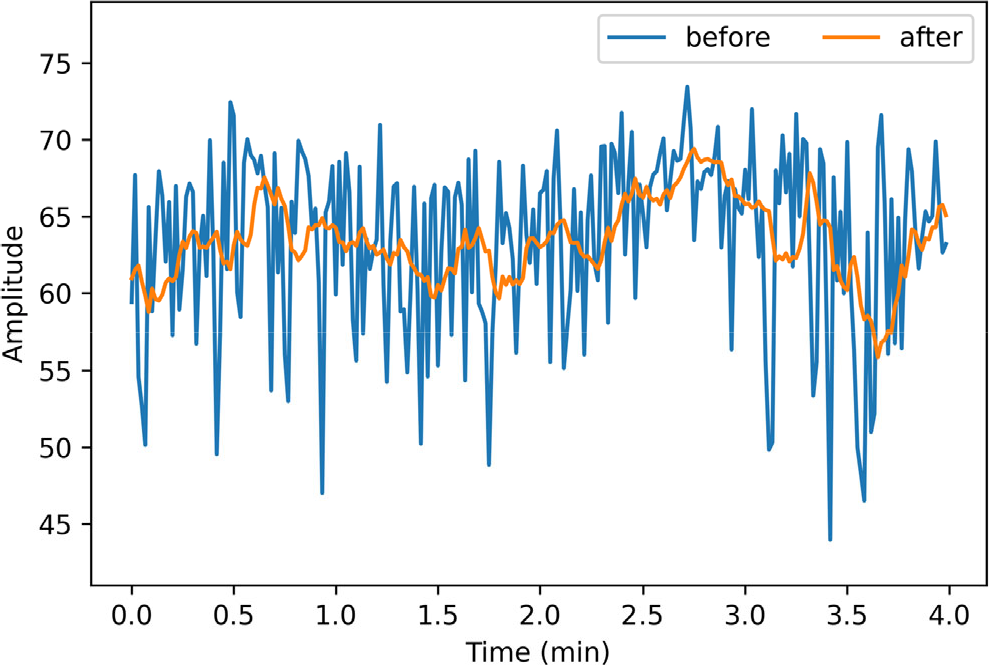
Difference between features before and after smoothing.
The time spent by the algorithm is an important metric in online emotion recognition tasks. The time required by each method for feature extraction and classification of a single sample (1-second EEG signal with 62 channels) is illustrated in Fig. 3. The baseline approach takes the shortest time, only 1.53 ms, while the rest of the methods take about the same time. M4, being a deep learning algorithm, takes the second-longest time, which is understandable given the complexity of deep learning models. M1 takes longer than M4, which might be because M1 extracts more characteristics.
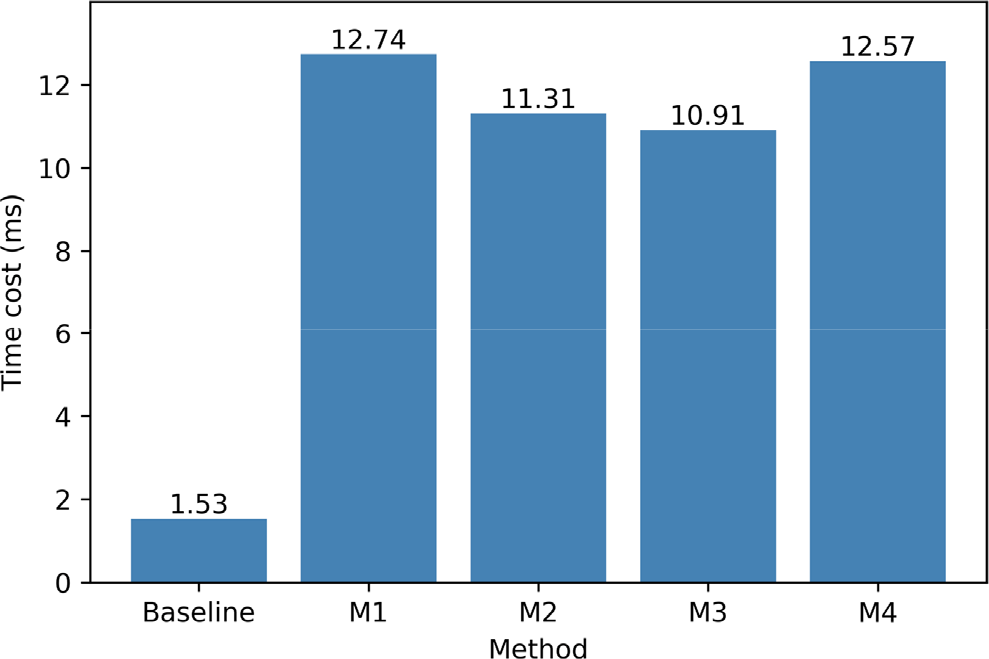
Time cost of each method in online emotion recognition.
5 Conclusion
This work systematically studies the offline and online performance of the top 5 methods in the emotion recognition technology competition of WRC2021 on the emotion recognition task. We experimentally established that EEGNet-20,8 is more suited for online emotion categorization, despite its poor performance in offline analysis. We also discover that there is no substantial performance benefit from just serially concatenating the DE feature set with other feature sets into a combined feature vector, implying that using a suitable feature process technique is critical. One possible way of dealing with this issue is to adopt suitable feature fusion techniques [29–31], which could be studied in the future.
It is worth noting that EEG signals are a kind of unsteady signals and have individual differences. In general, it is challenging to build accurate cross-subject emotion identification models using traditional machine learning methods. Transfer learning offers a possible solution to the problem of individual differences in emotion recognition models [32–34]. It is a great choice that uses transfer learning to improve higher classification accuracy in future online emotion identification tasks.
Most of the existing emotion-inducing experiments are in the laboratory environment, and the subjects induce specific emotions by watching stimulating pictures or videos. The preceding section’s results reveal that online decoding accuracy is much lower than offline decoding accuracy, which might be attributed to inadequate stimulus induction in the real scene. This discovery raises an essential question: how to rapidly collect high-quality emotional EEG data in real-world complicated scenes™ Solving this problem might be an interesting and challenging research subject.
Footnotes
Conflict of interests
All contributing authors have no conflict of interests.
Funding
This work was supported in part by the National Natural Science Foundation of China (Grant Nos. U21A20485, 61976175).
Authors’ contribution
Chao Tang: Methodology, writing-original draft. Yunhuan Li: Software, formal analysis. Badong Chen: Reviewing, editing, and supervision.