
Abstract
As a new type of brain–computer interface (BCI), the rapid serial visual presentation (RSVP) paradigm has attracted significant attention. The mechanism of RSVP is detecting the P300 component corresponding to the target image to realize fast and correct recognition. This paper proposed an improved EEGNet model to achieve good performance in offline and online data. Specifically, the data were filtered by xDAWN to enhance the signal-to-noise ratio of the electroencephalogram (EEG) signals. The focal loss function was used instead of the cross-entropy loss function to solve the classification problems of unbalanced samples. Additionally, the subject-specific data were fed to the improved EEGNet model to obtain a subject-specific model. We applied the proposed model at the BCI Controlled Robot Contest in World Robot Contest 2021 and won the second place. The average recall rate of the four participants reached 51.56% in triple classification. In the offline data benchmark dataset (64 subjects-RSVP tasks), the average recall rates of groups A and B reached 76.07% and 78.11%, respectively. We provided an alternative method to identify targets based on the RSVP paradigm.
Keywords
1 Introduction
Brain–computer interfaces (BCIs) transform brain activity into commands or information through electrical signals, realizing direct control over external devices. BCIs’ most significant technological innovation is that it changes the way humans communicate with the outside world [1]. Multiple BCI paradigms have been developed, and there are many BCI-based applications in healthcare, smart home, entertainment, and other fields. For example, the BCI system can control the cursor with electroencephalogram (EEG) signals [2]. For people with disabilities, BCI has designed a brain-driven wheelchair that can help and facilitate their movement [3, 4]. Event-related potential (ERP)-based non-invasive BCI has been widely used in different EEG signals [5]. In particular, P300, an ERP induced by external stimuli, such as visual, auditory, or tactile stimuli, is named because it corresponds to the positive waveform related to decision-making generated about 300 ms after the event. It has been widely used in the BCI system based on ERP [6]. With computer hardware and algorithm development, the BCI system is gradually applied to image recognition. The rapid serial visual presentation (RSVP) paradigm [7] can induce endogenous ERP [8] in the brain according to the visual stimulation of the target image. The target image can be recognized indirectly by detecting ERP in EEG signals. In the RSVP paradigm, images are divided into different categories, image sequences are continuously presented at a high rate, and subjects need to recognize the target image from other non-target images. The P300 component is one of the most commonly used ERP components; thus, detecting the P300 component in an EEG signal is critical for target image recognition.
Different algorithms for single RSVP EEG classification were proposed based on spatial filtering and traditional machine learning methods. Existing methods include the common spatial patterns algorithm and its derived common spatio-spectral pattern algorithm [9], common sparse spectral spatial pattern algorithm [10], common spatio-temporal pattern algorithm [11], and bilinear common spatial pattern algorithm [12], and other algorithms. Sajda et al. [13] applied hierarchical discriminant component analysis (HDCA) to linearly weighted 64 channels of recorded EEG signals first in space and then in time to achieve real-time classification and scoring image sets. Marathe et al. [14] proposed an improved sliding HDCA algorithm based on HDCA to overcome the temporal variability of neural responses. Traditional machine learning methods have also been widely used in the RSVP paradigm. Mathan et al. [15] used a support vector machine method to apply the classifier trained by one subject to other subjects, proving that the RSVP system has generalization ability among different subjects. Xiao et al. [16] proposed a feature classification method to discriminate canonical pattern matching algorithm and proved the generalization ability of the method to identify various regions of ERP.
With the development of computer hardware, deep learning has developed rapidly in the past decades. It has also comprehensively surpassed the traditional machine learning algorithm in many standard datasets and achieved the highest technical achievements representing the current technology level. Convolution neural networks (CNNs), restricted Boltzmann machines, deep belief networks, and other deep learning models have also been widely used in EEG decoding. In recognition of the P300 EEG signal, CNN [17], long and short-term memory network (LSTM) [18], and other methods are mainly used for detection. Cecotti et al. [17] used CNN to extract spatial and temporal features from P300 data to obtain good classification performance as the most representative work. Since then, EEGNet [19], BN3 [20], MACRO [21], and other network models have been derived. These methods use many training parameters and datasets to extract spatial and temporal information through a specific network structure. Therefore, to solve the need for a mass of training samples, Ma et al. [22] proposed a model based on a capsule network, which increased the interpretability and improved the detection accuracy. However, the calculation was complicated due to the increase in dimensions.
The spatial filtering method needs to manually select important features after feature extraction and then classify them. It has strong pertinence to specific factors; however, the algorithm is often complex, and its accuracy is affected by feature selection. The traditional machine learning algorithm is less complex and applicable to the classification of various feature data; it also requires a small dataset. The algorithm is highly interpretable, but the computational complexity is high. Deep learning belongs to end-to-end learning with a simple structure and can be transplanted to various tasks with high classification accuracy but high demand for sample data. Therefore, in this competition, these previous methods could not identify the target well and solve the training problems under the limited dataset and online recognition without timeouts.
This study proposed an improved EEGNet model to classify EEG data from a single RSVP task effectively. First, xDAWN filtering was performed on EEG data before feeding the data into the EEGNet model to enhance the signal-to-noise ratio (SNR) of EEG signals. Second, we used the temporal convolution layer to extract the temporal information and reduce the temporal dimension. Third, the spatial filters at specific frequencies can be efficiently extracted using spatial convolution layers. Furthermore, we used the depth separable convolution layer to reduce the number of convolution layer parameters and further extract temporal features. Next, we classified the extracted features by the full connection layer with the softmax function. Finally, we used focal loss as the loss function. Compared with cross-entropy, the focal loss can better focus on samples that are difficult to classify and better deal with multi-classification problems. We used the BCI Controlled Robot Contest in World Robot Contest 2021 (WRC2021) data as an online dataset to compare the impact of different methods, such as xDAWN+LR, CNN, DeepConvNet [23], EEGNet, and the improved EEGNet on model performance. Additionally, we also used Tsinghua University’s A benchmark dataset for RSVP-based on BCI [24] as an offline dataset to compare the performance of these models. The results showed that in recognition of target images, the improved EEGNet model could achieve a higher recall rate and better solve the classification problem of the RSVP paradigm.
2 Methods
2.1 Stimuli
The experimental paradigm and data used to evaluate the model were provided by the program committee of the BCI Controlled Robot Contest in WRC2021. The ERP paradigm is shown in Fig. 1. Specifically, there are three types of images in this experiment: two types of targets (cars and people) and one background (street scene without cars and nobody). All images are taken from the street scenes, and image sequences are presented using the RSVP paradigm to the subjects.
The paradigm for collecting data from offline datasets is similar to the competition paradigm. The difference is that this dataset has two types of images: target images with people and non-target images without people.
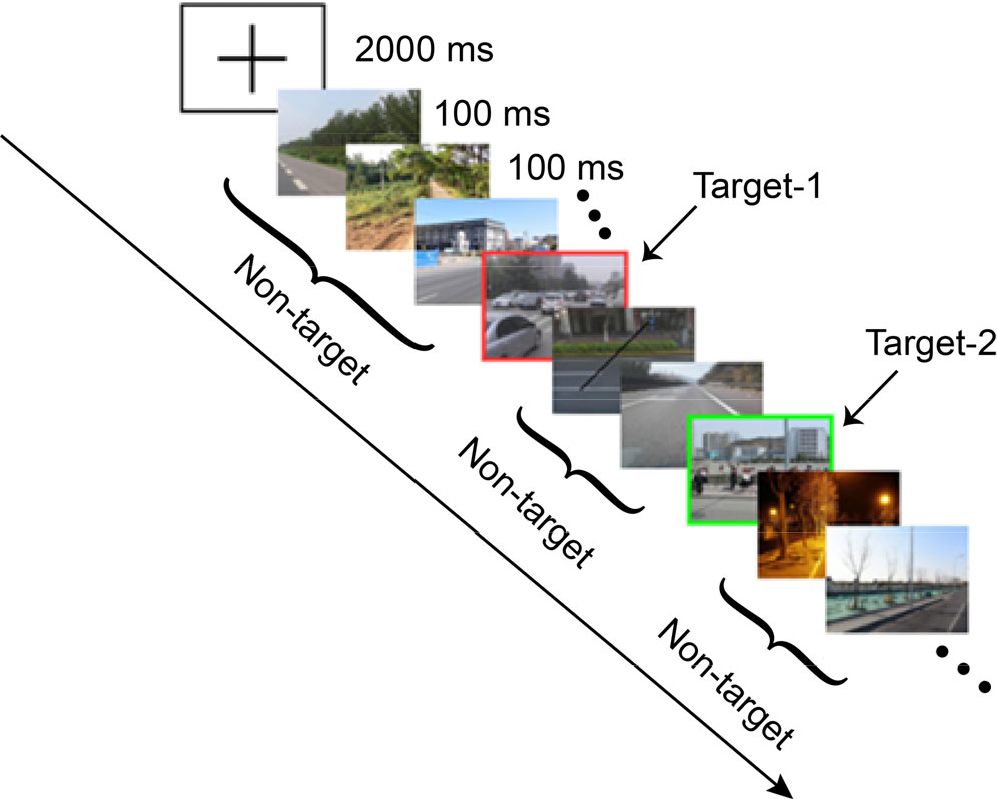
Schematic diagram of RSVP paradigm.
2.2 Data collection
Experimental data were collected using Neuracle 64-channel EEG acquisition equipment, and the 65th electrode was trigger information. The original sampling rate was 1000 Hz, and the data was sampled down to 250 Hz. The impedance of all electrodes was kept below 10 kΩ. Data from 64 electrodes were provided in the competition, and 59 electrodes (except ECG, HEOR, HEOL, VEOU, and VEOL) were selected for further processing. More details on data processing will be covered in a later section.
The device used for offline dataset acquisition was the Synamps2 system (Neuroscan, Inc.). The original sampling rate was 1000 Hz, and the data was sampled down to 250 Hz. Electrode impedance remained below 10 kΩ. Data from 64 electrodes were provided in the dataset, and we selected 62 of them (1–32, 34–42, 44–64) for further processing [24].
2.3 Evaluation index
The recall rate was used to quantitatively evaluate the effectiveness of different algorithms in this contest, which can be calculated using the following formula:
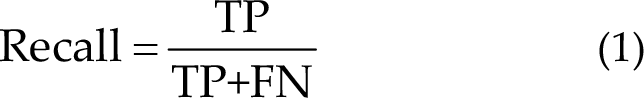
Here, TP represents the sample as the target image (target-1, target-2), and the prediction result is also the target image. FN represents that the sample is the target image, but the prediction result is the non-target image. In particular, the system calculated the recall rate in units of each trial during the context and finally averaged all blocks for scoring.
2.4 Participants
Four healthy students were randomly assigned to a real-time assessment during the competition. These four students were subjects of a subject-specific model group. The four subjects first participated in the subject-unspecific model group and then trained four models from the data. The four models were matched with the four subjects to participate in the subject-specific model group. The visual acuity of all subjects was normal or corrected to normal. Each subject had three blocks, and each block had 20 trials.
Each subject collects data in a block. In this competition, each subject collects multiple blocks. Before each block starts, there will be a hint in the center of the screen. At the beginning of each trial, there will be a cross prompt on the screen to prompt the subjects to pay attention to the center of the screen. Each trial contains 50 pictures, among which the type and number of targets are not fixed (maximum of five target images). Each image is presented in the center of the screen at the presentation rate of ten images per second. Each block contains 20 trials.
There are data for 64 subjects (32 females; aged 19–27 years, mean age of 22 years). The visual acuity of all subjects was normal or corrected to normal. The data of 64 subjects have been divided into two groups A and B, in chronological order. There are two blocks in each group. There are 40 trials in each block, and each trial contains 100 images. For each subject, the data of block 1 is used for training, and the data of block 2 is used for testing, which is used as offline data with training questions to evaluate the model’s performance.
2.5 Subject-specific algorithm
2.5.1 Signal preprocessing
There was a subject-specific group involving four subjects. After each trial, EEG data of 50 pictures were obtained. Then, the EEG data were pre-processed in the temporal and frequency domains. A fragment of 0–1000 ms was extracted after the stimulation, resulting in a matrix of 59 (electrodes) × 250 (sampling point) to extract P300 EEG data. Then, the EEG data were processed at 0.5–40 Hz with common mean reference, detrending, and bandpass filtering. Consequently, the EEG data were normalized.
For the processing of the offline dataset, a 0–1000 ms segment was extracted after the stimulation, a matrix of 62 (electrodes) × 250 (sampling points) was obtained, and the rest of the preprocessing steps were the same the above steps.
2.5.2 Spatial filtering
In the recording process of EEG signals of the subjects, the original EEG signals contain the required P300 evoked potentials. It also contains the continuous activity of the brain, muscles, and eye artifacts. Therefore, not only is the SNR very low, but it is not easy to complete the classification task [25]. The xDAWN algorithm was used to filter the raw EEG signals to enhance the P300 evoked potentials.
In this competition, a set of four spatial filters were established for each class (non-target, target-1, and target-2) to improve the SNR of evoked potentials [26]. Thus, the resulting signal consists of 3 × 4 = 12 virtual channels. In the offline dataset, since there are only two types of targets (non-target and target), the generated signal consists of 2 × 4 = 8 virtual channels. We used the xDAWN algorithm to learn spatial filters. Let
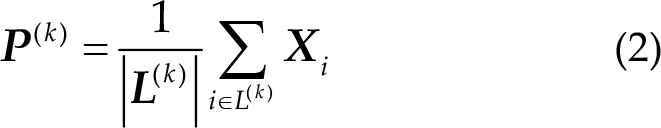
where
In this paper, the spatial filter is a vector
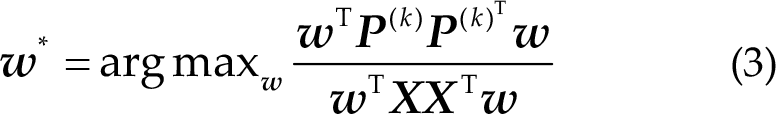
This equation is a generalized Rayleigh quotient, which can be solved by eigenvector decomposition of the matrix
Let us denote by

2.5.3 EEGNet
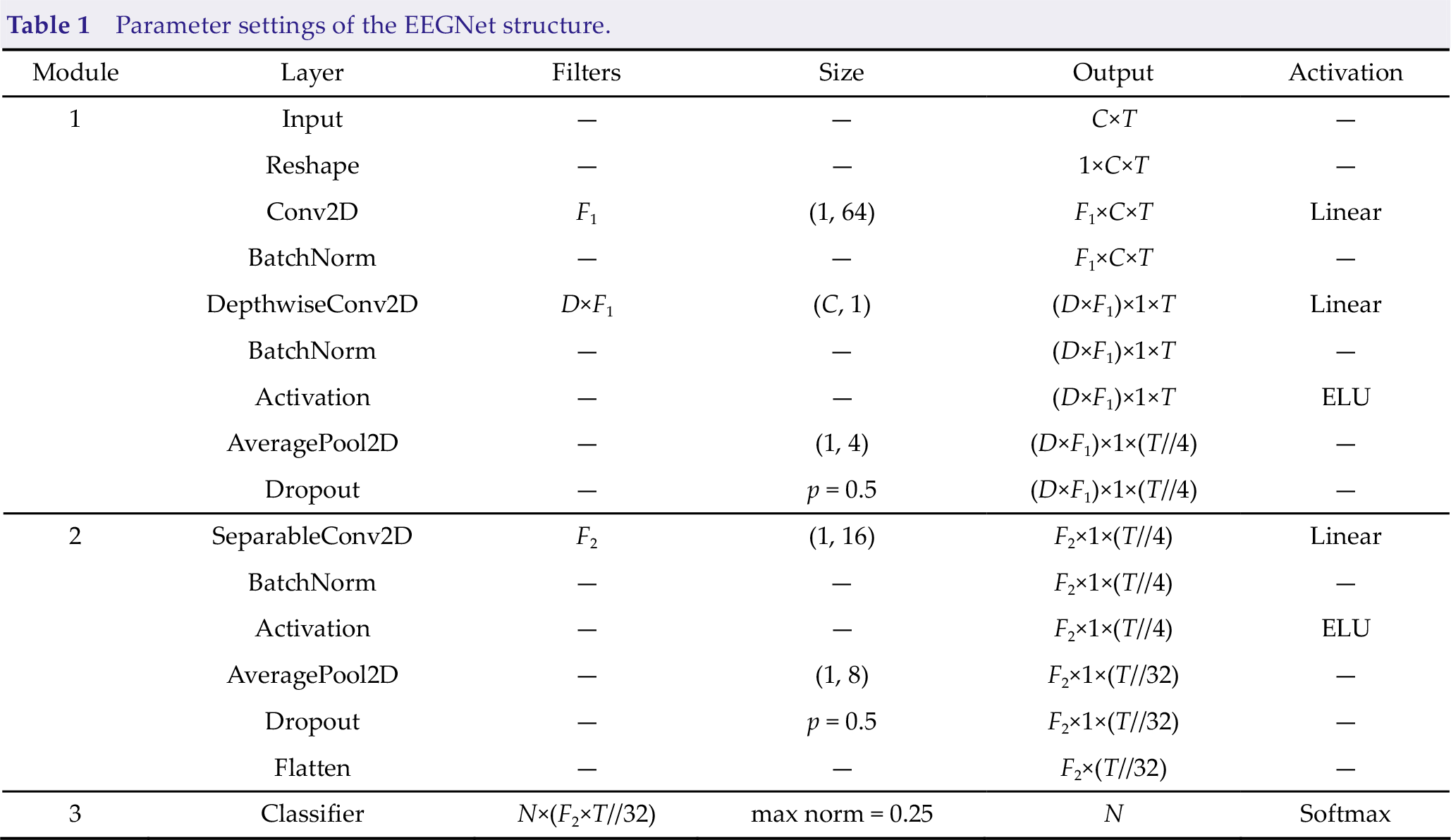
EEGNet is a compact CNN architecture that can be applied to motor imagery classification tasks and ERP, feedback error-related negativity, and steady-state visual evoked potential (SSVEP), as demonstrated by Vernon Lawhern et al. [19]. The advantage of EEGNet is that it can be trained with a limited number of datasets and can produce separable features. Additionally, the EEGNet model has good generalization. Based on the above advantages, this paper uses the EEGNet model for P300 detection to solve the three classification problems of the RSVP paradigm. Fig. 2 shows the overall structure of the improved EEGNet model. Table 1 presents the specific parameters of the improved EEGNet model. The input layer size of the model is (C, T), where C represents the number of channels, and T represents the sampling points of each channel. The EEGNet model mainly consists of three modules, and the specific structural framework of each module is defined as follows:
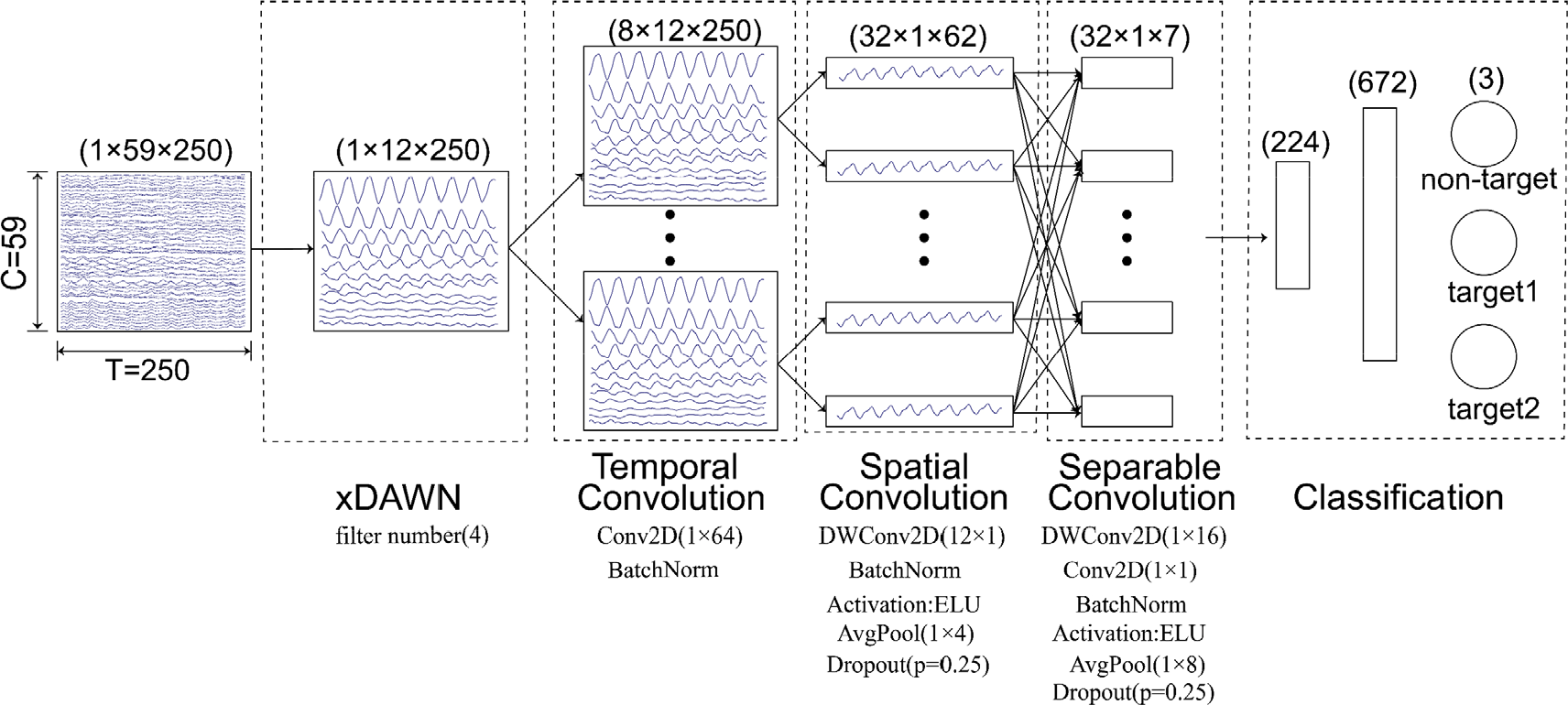
Overall visualization of the improved EEGNet structure. Lines represent the connectivity of the convolution kernel between input and output.
Parameter settings of the EEGNet structure.
Module 1 is the combination of temporal and spatial convolutions in Fig. 2. In module 1, EEG data enter the input layer after xDAWN filtering. The module consists of two convolution steps including the input layer. First, a feature map (consisting of an EEG signal with bandpass frequency) is output using a Conv2D convolution and a filter with parameter F 1, and then batch normalization is performed. Second, a depthwiseConv2D is used to learn spatial filters and then perform batch normalization. The main advantage of depthwiseConv2D is that it can reduce the number of trainable parameters to be fitted. Importantly, a combination of Conv2D and depthwiseConv2D can be used to efficiently extract spatial filters at specific frequencies for specific EEG applications. In each feature map, the number of spatial filters to be learned is controlled by D. The main idea of a two-step convolution sequence comes from the filter-bank common spatial pattern [27]. Additionally, the essence of bilinear discriminant component analysis [28] is similar to two-step convolution. Dropout technology is also introduced for regularization and modeling. Finally, an average pooling layer is adopted to reduce the number of features.
Module 2 is the separable convolution in Fig. 2. In module 2, the deeply separable convolution method is introduced, which is a depthwise convolution. It includes the depthwise convolution and pointwise convolution layers [29] with parameter F 2. The use of separable convolution has two advantages. The first advantage is that separable convolution reduces the number of parameters to be fitted. The second advantage is that separable convolution can learn feature kernels and summarize each feature map with the best combination output. When training EEG data, this combination method can distinguish between learning how to summarize individual feature graphs over time (the depthwise convolution) and optimizing combined feature graphs (the pointwise convolution). Finally, the average pooling layer is used to reduce the size.
Module 3 is the classification layer. In the classification module, the features extracted after the convolution of the previous layers are directly transferred to the softmax classification layer with N units. Here, N is the number of tasks in the data. In this paper, the value of N is 3. Dense layers are used for feature aggregation before softmax classification layers to reduce the number of parameters [30].
As presented in Table 1, the specific parameters of the EEGNet model are set as follows: C represents the number of channels, which is 12 in this model; T represents the sampling points, which is 250 in this model; F 1 represents the number of temporal filters, which is set to 8 in this model; D represents the depth multiplier, which is also the number of spatial filters, and is set to 2 in this model; F 2 represents the number of pointwise filters, which is set to 16 in this model; N represents the number of target types to be identified, and this model is set to 3. Set the mode in linear to the same. For the subject-specific model, the model sets the p in the dropout layer to 0.25 as the classification of the subject-specific model.
In this competition, the improved EEGNet model has five layers, and the specific network layer is introduced as follows: (1) (2) (3) (4) Equation (5) represents the ratio of parameter quantity. Therefore, the depthwise separable convolutions can reduce the parameters of the model. (5) Here,
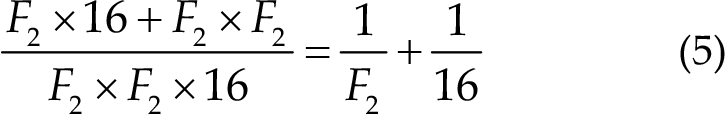
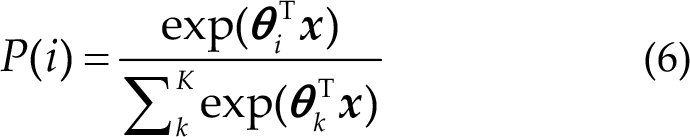
2.5.4 Loss function
In this study, we used the focal loss [32] as the loss function. This loss function is optimized based on the standard cross-entropy loss function. For the problem of unbalanced samples, the focal loss function can reduce the weight of non-target samples to make the model focus more on the classification of target samples during training [33]. The formula of the focal loss function is as follows:
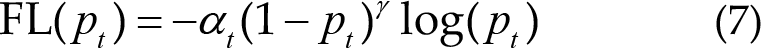
Compared with the cross-entropy loss function, focal loss first adds a factor on its basis, where γ > 0 reduces the loss of non-target samples so that more attention can be paid to the classification of target samples. Moreover, in this study, γ = 2. Additionally, focal loss adds a balancing factor αt used to balance the problem of proportional imbalance between the target- and non-target samples.
2.6 Model comparisons
To evaluate the performance of the improved EEGNet model, we compared the results with three representative models: CNN, deep ConvNet (DCN), EEGNet, and xDAWN spatial filtering + logistic regression (xDAWN + LR). xDAWN + LR is a machine algorithm that first performs xDAWN filtering and then logistic regression. CNN is a classical deep learning model. DCN is a sample code given in the finals of the BCI Controlled Robot Contest in WRC2021 to test the deep learning model of the RSVP paradigm. EEGNet model is suitable for many kinds of BCI paradigms and can achieve good results.
CNN consists of three layers: convolution layer 1, convolution layer 2, and output layer. The convolution kernel size in convolution layer 1 is (59, 1), whereas convolution layer 2 is (1, 10).
DCN consists of five layers: convolution layers 1, 2, 3, 4, and other output layers. There are two convolution kernels in convolution layer 1, with sizes of (1, 5) and (59, 1). The convolution kernel in convolution layers 2, 3, and 4 have the same size as (1, 5).
EEGNet model parameters are the same as those of the improved EEGNet model. However, the data were not filtered by xDAWN filters. The loss function of EEGNet was cross-entropy, whereas the loss function of the improved EEGNet was a focal loss.
Furthermore, xDAWN + LR data are classified by logistic regression after preprocessing and xDAWN filtering.
3 Results
3.1 ERP of RSVP experiment
Figure 3 shows the characteristics of the three types of EEG signals learned by the xDAWN filter. The features extracted by the xDAWN filter for non-target data are also shown in the figure. There was no apparent energy production in the parietal and occipital lobes of non-target EEG topography. For target-1 (person) data, there was obvious energy production in the occipital region of the EEG topography, which was significantly different from the non-target EEG topography. For target-2 (car), energy was also generated in the occipital region of the EEG topographic map; however, its energy was smaller than that of target-1, indicating that the P300 signal of target-2 was not as obvious as that of target-1. This was also reflected in the comparison of recall rates later. In other words, the recall rate of target-1 was higher than that of target-2.
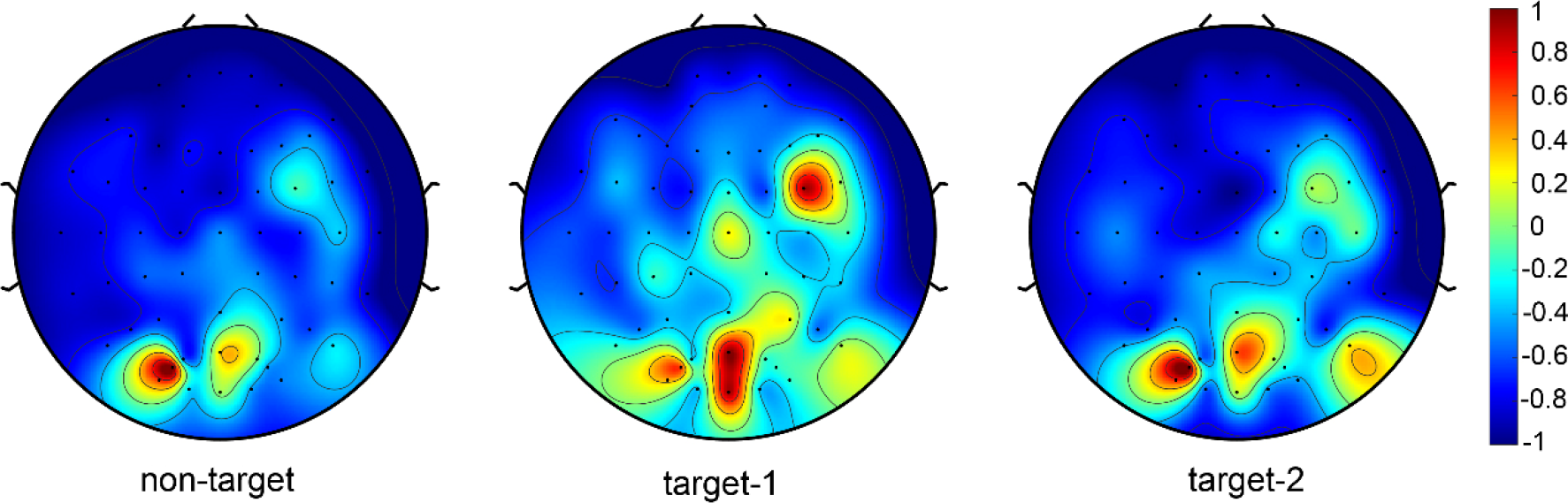
Visualization of each class weight of xDAWN filters.
For the offline dataset, we normalized the non-target and target data and then sent it into the network model for training. We draw the spatial topographic map of target and non-target data to intuitively reflect the difference between EEG signals when subjects saw the target and non-target pictures. As shown in Fig. 4, the larger weights were distributed in the parietal and central regions of the subjects when the target picture appeared, which was consistent with the spatial distribution of the P300 signal. However, when the non-target picture appeared, it was not a P300 signal that was generated.
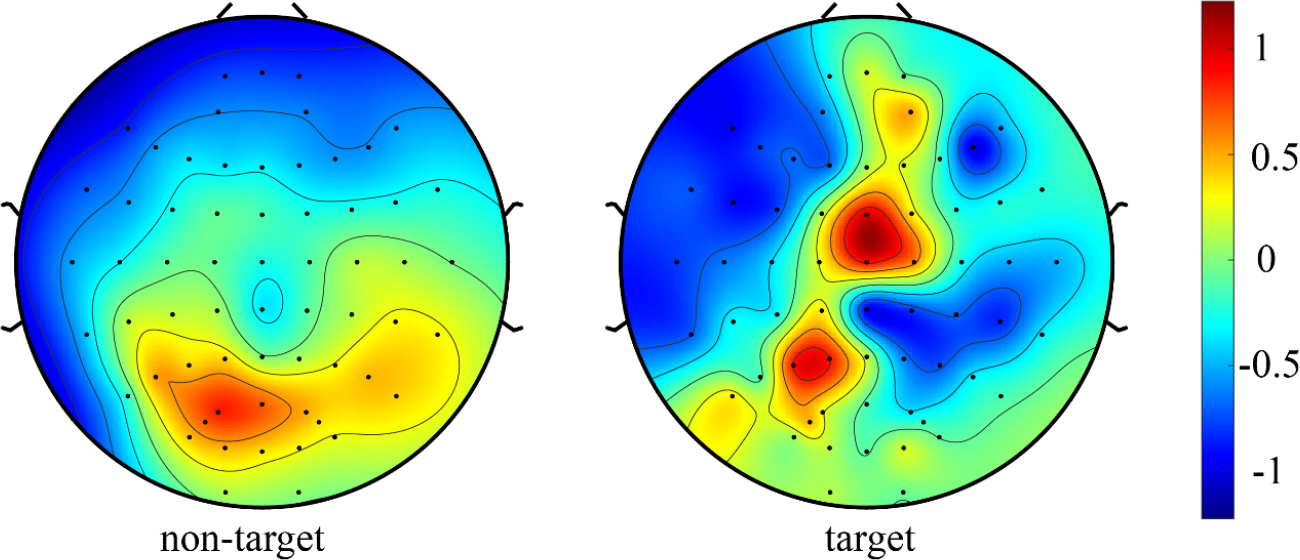
EEG topography of target and non-target normalized data.
3.2 Subject-specific results
Figure 5 shows the recall rate results and their average values for four subjects under different algorithms with their comparison. For target-1 (person), the improved EEGNet model achieves better results. The average recall rates of the four methods are 15.72%, 16.49%, 30.64%, 48.69%, and 60.77%, corresponding to xDAWN + LR, DCN, CNN, EEGNet, and an improved EEGNet, respectively. The results show that the improved EEGNet model can achieve a high recall rate for specific subjects and the average recall rate of four subjects on target-1. In other words, the improved EEGNet model can achieve good results in recognition of target-1, while the other three methods cannot accurately identify target-1.
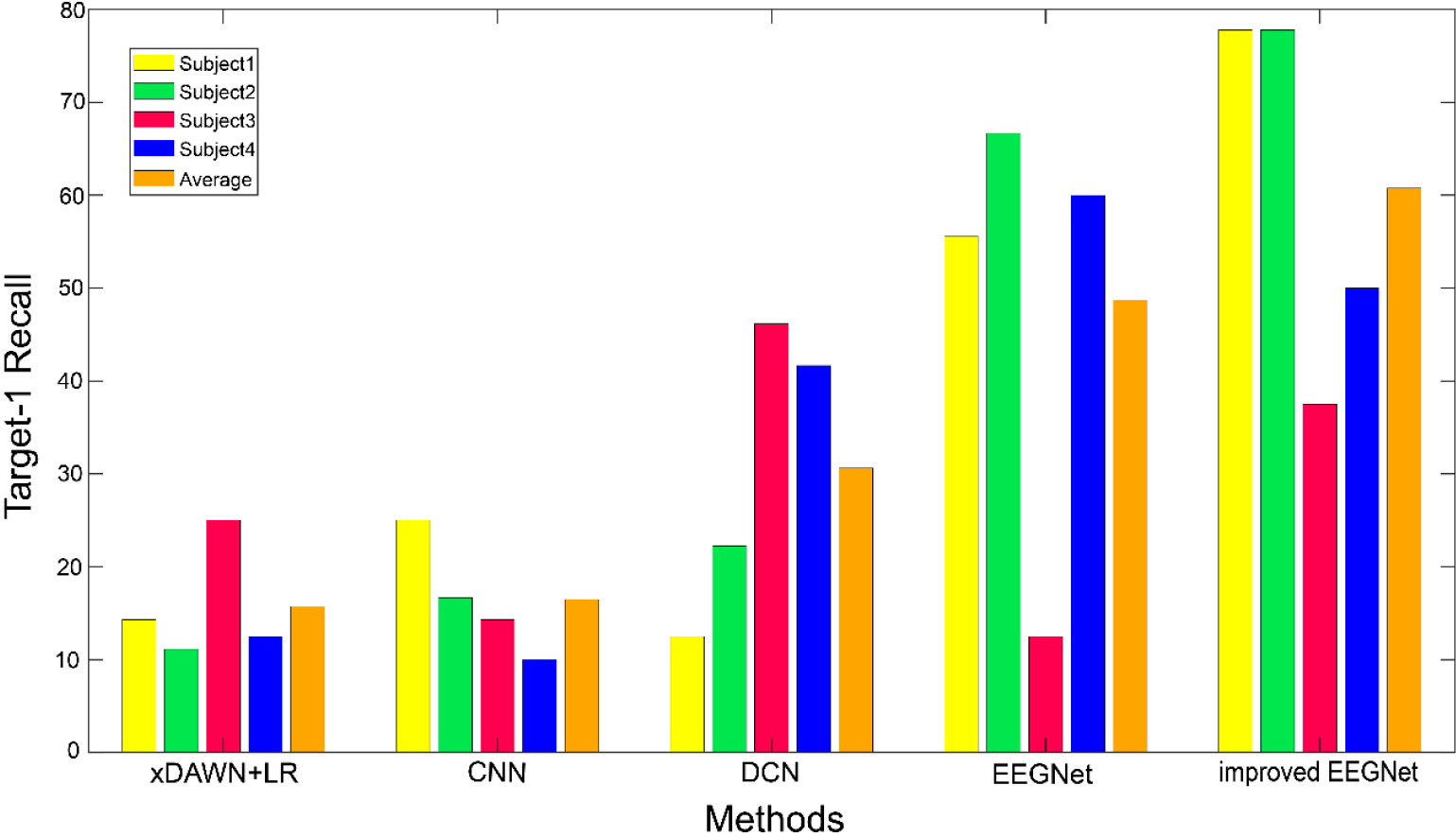
Comparison of recall rate, and the average value of target-1 recognition under different methods.
Figure 6 shows the results of the recall rate for target-2 and the average values of four subjects under different algorithms. For target-2, the average recall rates of the five methods are 35.90%, 39.68%, 31.25%, 42.74%, and 45.52% for xDAWN + LR, CNN, DCN, EEGNet, and the improved EEGNet, respectively. Additionally, DCN model had a higher recall rate for Subject1 than the improved EEGNet model. For Subject2, CNN model had a higher recall rate than the improved EEGNet model. For Subject3, xDAWN + LR model had a higher recall rate than the improved EEGNet model. The EEGNet model performed slightly better than the improved EEGNet model in the average recall rate of target-2. The result showed that compared with the recall rate of target-1, the other four methods had a certain improvement, whereas the improved EEGNet model had a certain decline; thus, indicating that the improved EEGNet could not identify target-2 as accurately as target-1.
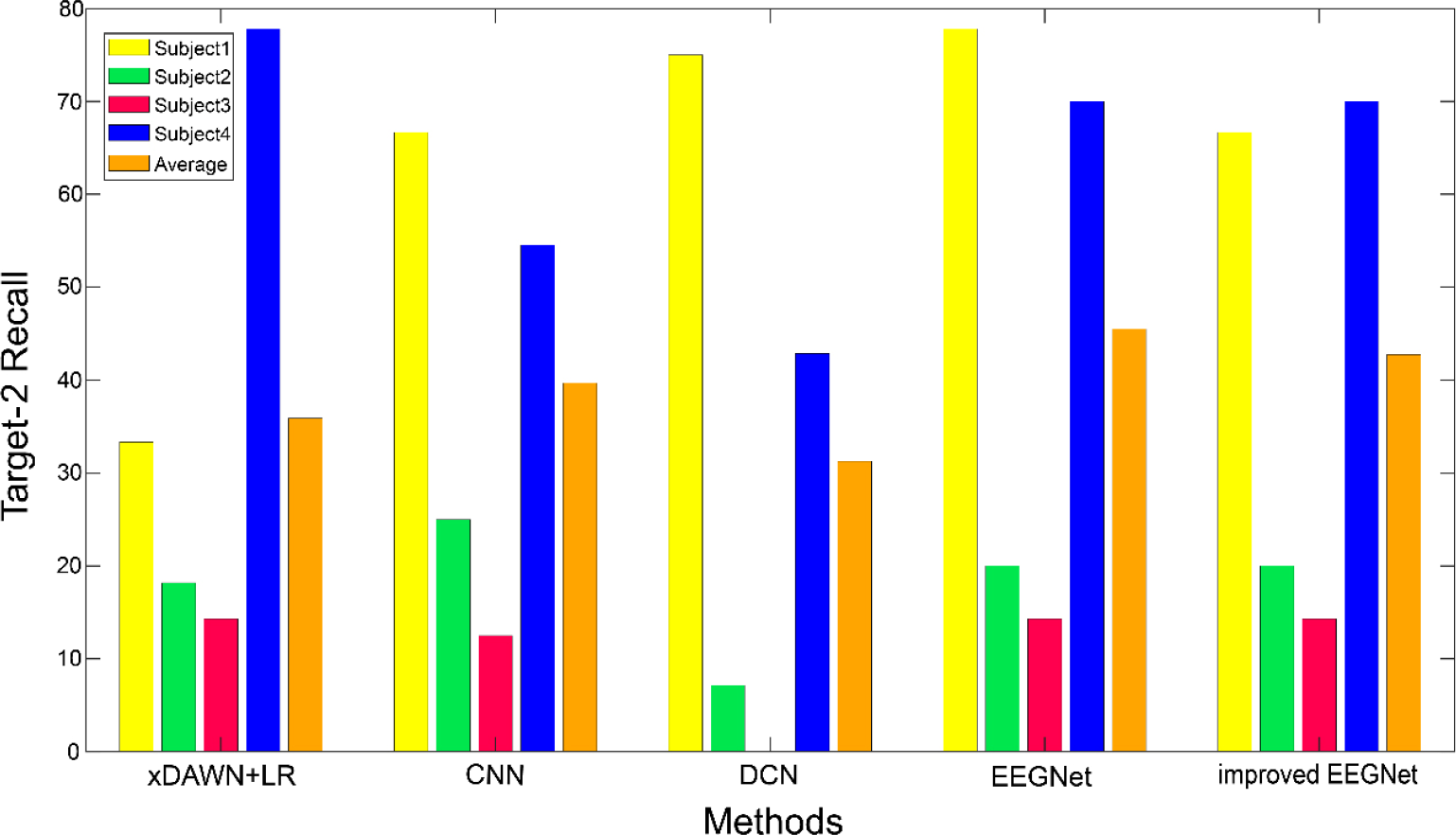
Comparison of recall rate, and the average value of target-2 recognition under different methods.
Figure 7 shows the total recall rate results and their mean values of four subjects under different algorithms. For the total recall rate (target-1 and target-2), the improved EEGNet model still achieved some advantages. The average recall rate of the four subjects was 51.56%, whereas the average recall rates of xDAWN + LR, CNN, DCN, and EEGNet algorithm were 25.81%, 28.99%, 30.07%, and 46.78%, respectively. It can be seen that the models of the other four algorithms may achieve a higher recall rate for a specific subject than the improved EEGNet. However, in terms of the total recall rate of the four subjects, the improved EEGNet model still had a higher recall rate than the other four algorithms. In other words, the improved EEGNet can effectively solve the three classification problems of these four subjects and achieve good results.
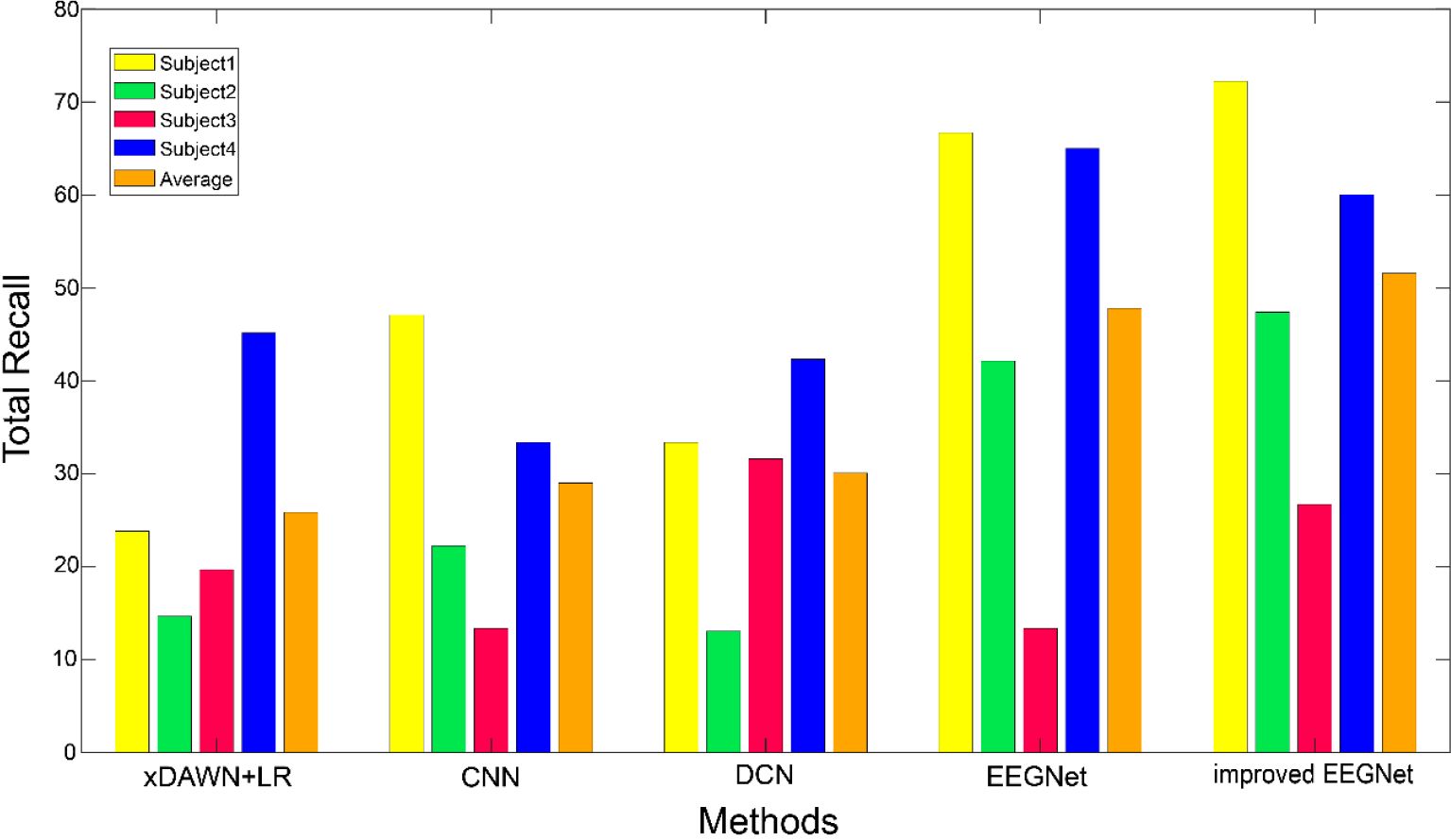
Comparison of total recall rate, and the mean value of four subjects under different methods.
Figure 8 compares recall on target images under different algorithms for 64 subjects in offline dataset Group A. For the results on Group A of offline datasets, the improved EEGNet model achieved higher recall than other models. The classification results of xDAWN + LR, CNN, DCN, EEGNet, and the improved EEGNet models were 69.85% ± 16.94%, 66.71% ± 12.68%, 66.95% ± 17.06%, 70.63% ± 15.29%, and 76.07% ± 11.07%, respectively.
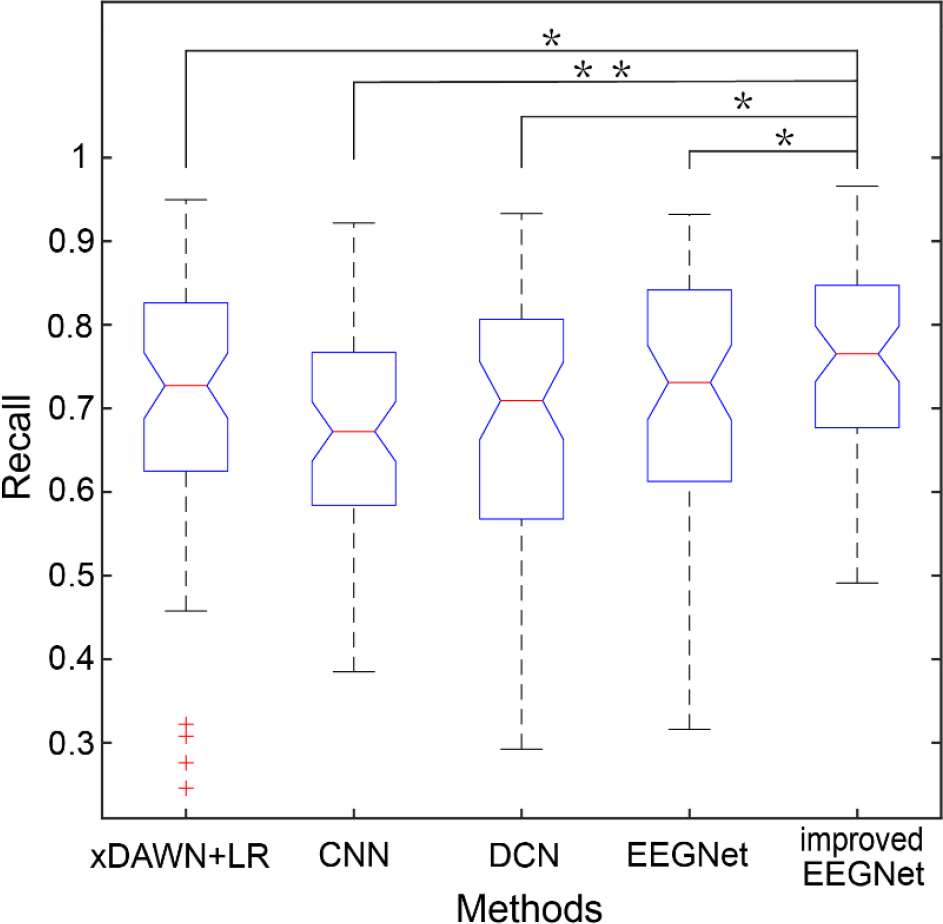
Comparison of recall rates of different methods for offline data Group A
Figure 9 compares recall on target images under different algorithms for 64 subjects in offline dataset Group B. There were more discrete values in Group B; however, the recall rates of the five models were higher than those of Group A. Among them, the improved EEGNet recall rate was 78.11% ± 11.87%. The recall rates of the xDAWN +LR, CNN, DCN, and EEGNet models were 70.35% ± 16.96%, 69.20% ± 12.28%, 68.23% ± 18.09%, 74.67% ± 14.03%, respectively.
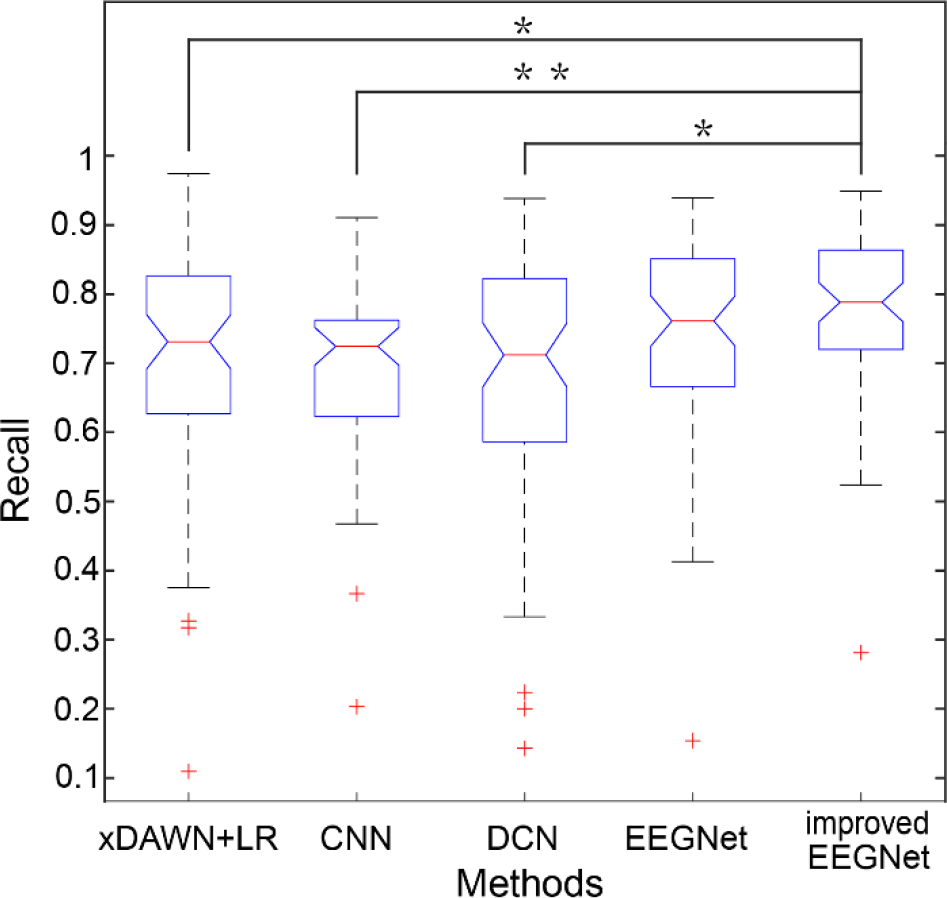
Comparison of recall rates of different methods for offline data Group B.
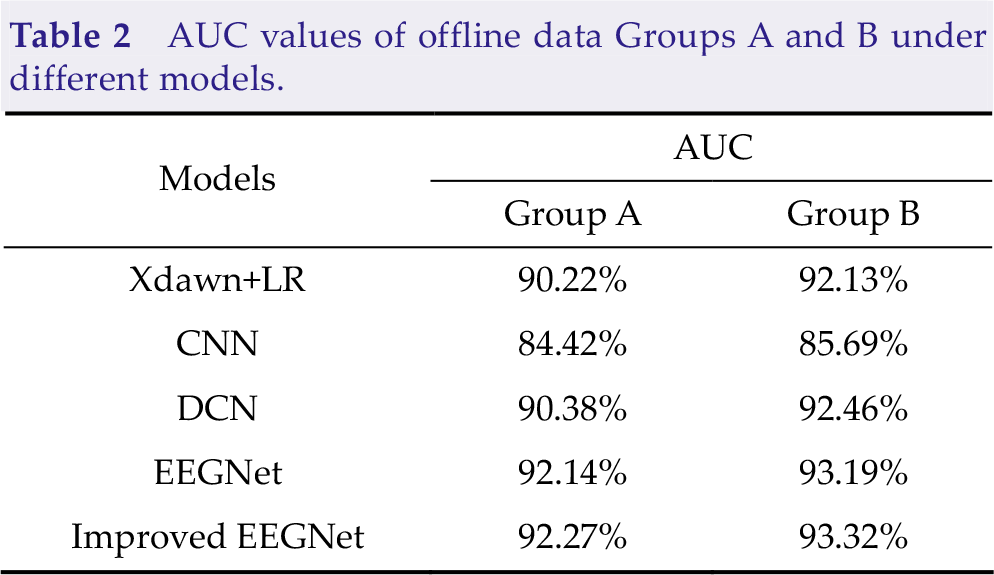
To further investigate the classification performance of the models, we calculated the AUC values of the five models in offline data. The AUC values of the five methods are presented in Table 2. For the data of groups A and B, the AUC values of the five methods were greater than 80%, indicating that the five models had certain classification performances. The improved EEGNet model still achieved the highest AUC value among these models. The above results showed that the improved EEGNet model had better model classification performance in unbalanced sample classification problems.
AUC values of offline data Groups A and B under different models.
4 Discussion
In the performance comparison with other methods, the improved EEGNet model achieved high recall in online and offline datasets. This showed that our improved model effectively learned the difference in EEG signals between target and non-target stimuli and effectively found the target pictures.
We found that our deep learning model performed better than other models. The main reasons are summarized as follows: (1) xDAWN spatial filtering can increase the SNR of ERP signal and make the signal quality of the input neural network better. (2) Focal loss function can make the neural network focus on the samples that are difficult to classify, which is a good solution to the sample imbalance problem. These two points effectively improve the model’s feature extraction ability and classification performance.
The improved EEGNet model achieved better performance than the other four models. Additionally, the improved EEGNet model achieved a higher recall rate than the other four models, and there was no timeout in the BCI Controlled Robot Contest in WRC2021. In offline datasets, the improved EEGNet model also achieved better results. Therefore, the improved EEGNet is beneficial for practical applications. In the improved EEGNet model, the xDAWN filtering was first performed on EEG signals to improve the SNR of ERP. Second, a temporal convolution was performed to learn the characteristics of EEG in the temporal domain, and a depthwise convolution was used to learn the spatial filter. Finally, the depthwise separable convolution layer could reduce the model parameters and sizes. Inspired by the focal loss function that could reduce the weight of easily classified samples, we used this loss function instead of the traditional cross-entropy loss function to solve the three classifications problems of the RSVP paradigm in this competition to effectively improve the classification performance.
In conclusion, the improved EEGNet model improved the SNR of the EEG signal. It also used the focal loss function to solve the sample imbalance problem in the deep learning model, thus achieving good results in the online and offline datasets.
Generally, our model provides a method for using deep learning to solve the binary and triple classification problems in the RSVP paradigm and efficiently recognize target images in offline and online environments. Furthermore, the improved EEGNet has better classification performance than several traditional algorithms and deep learning models.
5 Conclusion
This study proposed an improved EEGNet model to detect P300 EEG signals. The proposed model was evaluated in the subject-specific scenario in the BCI Controlled Robot Contest in WRC2021. Consequently, the proposed model achieved good results in the subject-specific group, and we won second place in the ERP subject-specific group. In a benchmark dataset for RSVP-based BCIs, good results have also been achieved. The research results of this paper may provide a valuable reference for deep learning-based EEG research and the development of BCI systems in the future.
Footnotes
Ethical approval
This work was approved by institutional review board of Tsinghua University (NO. 20210032).
Consent
All the subjects were approved by Institutional Review Board of Tsinghua University.
Conflict of interests
All contributing authors have no conflict of interests.
Funding
This work is granted by the Special Projects in Key Fields Supported by the Technology Development Project of Guangdong Province (Grant No. 2020ZDZX3018), the Special Fund for Science and Technology of Guangdong Province (Grant No. 2020182), the Wuyi University and Hong Kong & Macao Joint Research Project (Grant No. 2019WGALH16), the Guangdong Basic and Applied Basic Research Foundation (Grant No. 2020A1515111154), and the Characteristic Innovation Projects of Ordinary Universities in Guangdong Province (Grant No. 2021KTSCX136).
Authors’ contribution
Hongfei Zhang: Conceptualization, writing the original draft. Zehui Wang: Software, writing the original draft. Yinhu Yu: Software. Haojun Yin: Software. Chuangquan Chen: Validation. Hongtao Wang: Conceptualization, validation. All the authors approved the final manuscript.