
Abstract
Embedding models turn words/documents into real-number vectors via co-occurrence data from unrelated texts. Crafting domain-specific embeddings from general corpora with limited domain vocabulary is challenging. Existing solutions retrain models on small domain datasets, overlooking potential of gathering rich in-domain texts. We exploit Named Entity Recognition and Doc2Vec for autonomous in-domain corpus creation. Our experiments compare models from general and in-domain corpora, highlighting that domain-specific training attains the best outcome.
Introduction
The learning of word embeddings has gained momentum in many Natural Language Processing (NLP) applications, ranging from text document summarisation (Mohd et al., 2020), fake news detection (Faustini and Covões, 2017; Silva et al., 2020), and term similarity measure (Lastra et al., 2019; Gali et al., 2019) to sentiment classification (Rezaeinia et al., 2019; Giatsoglou et al., 2017; Park et al., 2021), edutainment (Blanco et al., 2020), Named Entity Recognition (Turian et al., 2010; Gutiérrez-Batista et al., 2018), classification tasks (Jung et al., 2022) and personalization systems (Valcarce et al., 2019), just to name a few. Most popular methods consider a large corpus of texts and represent each word with a real-valued dense vector, which captures its meaning assuming that words sharing common contexts in the input corpus are semantically related to each other (and consequently their respective word vectors are close in the vector space) (Mikolov et al., 2013b). Drawing inspiration from such word representations, in last years document embeddings have emerged as a natural extension of word embeddings, by mapping variable-length documents (sentences, paragraphs or full documents) to vector representations. Their effectiveness has been remarkable in a wide diversity of tasks, such as text classification and sentiment analysis (Fu et al., 2018; Le and Mikolov, 2014; Bansal and Srivastava, 2019), multi-document summarisation (Lamsiyah et al., 2021; Rani and Lobiyal, 2022), forum question duplication (Lau and Baldwin, 2016), document similarity (Dai et al., 2020), sentence pair similarity (Chen et al., 2019), and even semantic relatedness and paraphrase detection (Logeswaran and Lee, 2018).
Mostly-adopted approaches to word and document embeddings leverage unsupervised learning methods from large collections of unlabelled documents that serve as training corpora in considering word-word co-occurrences. In the literature, commonly-used corpora compile a huge number of unrelated texts, such as a full collection of English Wikipedia, the Associated Press English news articles released from 2009 to 2015,1 or a dataset of high quality English paragraphs containing over three billion words (Han et al., 2013). Such collections lead to learning general-domain embedding models that do not perform well when working in a very specific domain (for example, on a particular historical event or a concrete medical discipline), whose common vocabulary is unlikely to be included in a generic corpus. As stated in Nooralahzadeh et al. (2018), “domain-specific terms are challenging for general domain embeddings since there are few statistical clues in the underlying corpora for these items”. This idea was also previously stemmed from the results attained in Bollegala et al. (2015), Pilehvar and Collier (2016).
Bearing this limitation in mind, many researchers leveraged the findings of fields such as multi-task learning and transfer learning (Axelrod et al., 2011) and adopted a mixed-domain training in two phases: First, a general domain corpus is used to train an embedding model, which is next trained incrementally with specialised documents that are related to the particular domain. Thanks to this continual training, the general knowledge of the first phase can be transfered to the second one in order to be exploited along with the lexical and semantic specificities in that domain (Liu et al., 2015; Xu et al., 2019). However, there also exist works that concluded that, in domains with abundant unlabelled texts, the domain-specific training is not improved with the transfer from general domains. As a running example in biomedicine, the authors of Gu et al. (2021) showed that “domain-specific training from scratch substantially outperforms continual pretraining of generic language models, thus demonstrating that the prevailing assumption in support of mixed-domain pretraining is not always applicable”.
The benefits of resorting to only a domain-specific training from scratch have also been confirmed in other works (Nooralahzadeh et al., 2018; Kim et al., 2018; Lau and Baldwin, 2016). In particular, the authors of Nooralahzadeh et al. (2018) concluded that models learned from ad hoc corpora provide “better results than general domain models for a domain-specific benchmark”, demonstrating besides that “constructing domain-specific word embeddings is beneficial even with limited input data”. Actually, these approaches rely on small-sized ad hoc corpora, whose documents are gathered by hand and indiscriminately from publicly-available sources in the Internet (Chiu et al., 2016; Nooralahzadeh et al., 2018; Gu et al., 2021; Cano and Morisio, 2017). Specifically, to the best of the authors’ knowledge, existing approaches do not consider the relevance of a document (in the particular domain) when deciding whether or not that text should be included in the ad hoc corpus. This process is obviously costly and clearly unfeasible without automatic assistance, in view of the myriad of possible domains/topics (and the huge amount of available documents on each of them). However, according to the results achieved in Chiu et al. (2016), the relevance of the specialised texts chosen as training documents is a critical parameter in learning of embedding models. Specifically, these researchers handled two ad hoc corpora including each one a different number of in-domain documents about biomedicine. Their results confirmed that the highest quality embedding models were learned from the smallest ad hoc corpus, proving that “bigger corpora do not necessarily produce better biomedical domain word embeddings”. In other words, disregarding the suitability of the considered documents in the particular domain may distort the training.
Taking into account the above conditions, the interest and main contributions of the proposed approach can be summarised as follows:
Ad hoc corpora enable learning successful embedding models in very specific domains (e.g. medicine, history or chemical engineering, to name a few), where the huge public generic datasets that are usually adopted fail to accurately model the peculiarities (and the particular vocabulary) of these specialised domains.
The approach described in the paper automatically builds such corpora retrieving large amounts of candidate training texts from Internet sources and incorporating only those that are relevant in the context under consideration. For that purpose, NER facilities (to identify named entities in the input text) and Doc2Vec models (to assess the relationship between the input text and each of the retrieved candidate documents) are exploited.
The only input required in the approach is a fragment of text representative of the context, making human assistance during the creation of the ad hoc corpus unnecessary and allowing to deal with any topic or domain, however specific they may be.
The automatic procedure for building the resulting corpus greatly simplifies the hard work associated with traditional manual collection procedures, while providing more and better domain-specific documents.
This paper is organized as follows: Section 2 explores relevant works within the context of our approach to automatic custom training corpus creation. Section 3 focuses on the procedure devised to gather a set of in-domain candidate texts from the Internet, using a particular history event (the Battle of Thermopylae between Greeks and Persians in 480 BC) to illustrate the approach. The mechanism to validate the selection of relevant candidates to be incorporated into the automatically-built tailor-made corpus is detailed in Section 4. In this section, we also describe the tests conducted to evaluate the consistency of several Doc2Vec models, including a model trained on a general-domain corpus sourced from news articles of the Associated Press (AP), as well as in-domain models learned from ad hoc corpora. Finally, Section 5 concludes the paper and highlights further research directions.
Our literature review is organized into three main sections. In Section 2.1, the focus is on prominent embedding models that lay the foundation for our research, whose learning in specialised scopes requires domain-specific training documents. Since our research contributes to the automatic generation of such kind of ad hoc corpora, Section 2.2 describes relevant related approaches for constructing custom datasets, emphasizing the key distinctions from our procedure. Our algorithm for selecting in-domain training documents starts by identifying named entities in the input text that contextualizes the specific theme for building the ad hoc dataset. Since named entities can have multiple possible interpretations, accurately distinguishing the associated meaning for each entity is crucial in this process. To achieve this, the commonly-adopted approaches to named entity disambiguation will be thoroughly reviewed in Section 2.3.
Embedding Models
The germ of learning language representations using models pre-trained on large collections of unlabelled texts springs from word embeddings such as Word2Vec (Mikolov et al., 2013b) and GloVe (Pennington et al., 2014). Word2Vec trains a model on the context of each word such that similar words have similar vector representations. Considering word-word co-occurrences, these embeddings capture semantics and meaning-related relationships (enabling, for instance, to detect that two words are similar or opposite, or that the pair of words Spain and Madrid have an analogous relation to Canada and Ottawa), along with syntax and grammar-related relationships (have and had are at same level as are and were). Word2Vec is a feed-forward neural network that learns vectors to improve its predictive ability, offering two different models: CBOW (where the goal is to predict a word based on the words in its context) and Skip-Gram (where the aim is to predict surrounding words given an input word) (Khatua et al., 2019). This model suffers from two main weaknesses which, briefly, are mainly related to the impossibility of (i) dealing with words that do not appear in the training corpus, and (ii) considering different meanings for the same word.
Regarding the first limitation, these kind of approaches are not able to embed Out-Of- Vocabulary (OOV) words unseen in the training corpus, which makes it impossible to deal with rare/unusual terms and misspelling. The embedding model FastText circumvents the OOV problem by working at character-n-gram level (Armand et al., 2017).
On the other hand, more sophisticated models have emerged in the literature which capture the contextualized meaning of words. In particular, models like ELMo (Petters et al., 2018), GPT (Radford et al., 2019) and BERT (Devlin et al., 2019) enable to learn contextual relationships among words. For instance, in the sentences “I have hit my head” and “The Head of school sent a message to the students” the meaning of the word head depends on its left context in the first sentence (I have hit my) and on the right context in the second one (of school sent a message to the students). Bearing this motivation example in mind, some approaches moved from fixed word embeddings to contextualized models that consider both the sense of the next and previous words.
The main differences between the most popular contextualized embeddings (BERT, ELMo and GPT) are related to architectural internals: While ELMo relies on a Long Short-Term Memory (LSTM) model, GPT, BERT and its variants resort to a Transformer-based architecture (Reimers and Gurevych, 2019; Wang and Jay-Kuo, 2020). Details of both architectures, out of the scope of this paper, can be found in (Ethayarajh, 2019). Before the irruption of the latest BERT-based document embedding models, the commonly adopted approach was Paragraph Vector (also called Doc2Vec), the natural extension of Word2Vec for learning vector representations for pieces of variable-length texts (sentences, paragraphs and documents) (Le and Mikolov, 2014; Lau and Baldwin, 2016; Kim et al., 2018; Bhattacharya et al., 2022). Similar to Word2Vec, Doc2Vec works with two different models: Distributed Memory version of Paragraph Vector (PV-DM) and Distributed Bag Of Words version of Paragraph Vector (PV-DBOW). In both models the training enables to learn a vector for the initial text (called paragraph vector in Le and Mikolov, 2014), considering or not the Word2Vec embeddings of the single words depending on the approach, replicating such procedure in the prediction phase to provide a vector representing the paragraph/document.
The results described in Kim et al. (2018) highlighted that Doc2Vec outperformed previous sentence embeddings methods, ranging from simple approaches that use a weighted average of all the words in the document (Grefenstette et al., 2013; Mikolov et al., 2013a) to more sophisticated models like Skip-Thought (Kiros et al., 2015) and Quick-Thoughts (Kiros et al., 2018) that have attained good performance on diverse NLP tasks, such as semantic relatedness, paraphrase detection, image-sentence ranking and question-type classification (Kiros et al., 2018). The main features of the above models are summarised in Table 1.
Embedding models defined in the literature and their main features.
As noted in Section 1, many existing embedding models enable to fine-tune the training process on a new in-domain dataset for a concrete NLP task. However, as far as the authors of this paper know, there are no relevant approaches in the literature that automatically assemble such a dataset as a custom-built training corpus containing a large amount of relevant documents to capture meaningful domain-specific information. This would lead to more accurate embedding representations, which could improve the performance of existing (word-level and document- level) models. In this regard, it should be noted that this paper is not about using an ad hoc corpus to train existing models with an ad hoc corpus in order to compare their respective performances and assess their strengths. Instead, the goal of this research is to devise a semantics-driven mechanism to automatically collect an in-domain dataset and verify that can lead to models with better performance that the ones trained with a generic corpus. To do so, the presented research considers a particular model (in this case, Doc2Vec) and a very specific application domain (a historical event like the Battle of the Thermopylae, as will be described in the validation scenario presented in Section 4).
Having tested this hypothesis with a Doc2Vec model, the viability and utility of the proposed semantics-driven mechanism are confirmed, and the door is open for its application in different scenarios involving other more sophisticated Transformer-based embeddings defined in the literature. This further goal is beyond the scope of the experimental validation presented in this paper, where the focus is on assessing the quality of a tailor-made training corpus rather than on quantifying the performance of the multiple models that could be learned from it.
The web has long been considered a mega corpus with the potential to uncover new information across diverse fields (Crystal, 2011; Gatto, 2014). Consequently, numerous works in the literature focus on processing web-based corpora to find, extract, or transform information. This trend has intensified with the explosive growth of NLP research over the past decade, leading to extensive efforts in gathering both labelled and raw text corpora for discovering linguistic regularities, generating embeddings, and performing downstream tasks like classification, sentiment analysis, summarisation, or Q&A. Despite this importance, relevant results regarding automating the generation of such corpora remain scarce; there is hardly any research work related to automatic corpus creation.
The corpus construction approaches from the web that can be found in the literature primarily aim to support research and professional training in linguistic and translation fields. Typically, their objective is to create corpora for gaining an overview of a given language. Thus, these approaches mainly involve exploring the web to study pages based on their language rather than their content, resulting in general corpora rather than specialised ones. The most prevalent approach in these initiatives is the BootCat tool (Baroni and Bernardini, 2004), followed by successive refinements known as the WebBootCat web application (Baroni et al., 2006) later marketed as SketchEngine (Kilgarriff et al., 2014), relies on issuing a general set of search-engine queries involving domain-specific keywords to obtain focused collections of documents. This approach requires users to provide initial seeds (keywords) to begin the search. Subsequently, a large number of queries combining these seeds are issued against search engines like Google, Yahoo, or Bing, and the more relevant results are recovered to form the corpus.
However, these approaches primarily rely on web crawling followed by some linguistic processing to filter inadequate results. They work with literal keywords, querying for documents (web pages) containing those keywords, and repeat the process with the links contained in each page. They do not explore categories to classify the pages nor similarities among documents to establish their relevance for inclusion in the corpus or to trigger new searching processes or URL selection beyond those explicitly contained in the recovered documents. The text gathering procedure is somewhat coarse, and manual refinement is often necessary to guide these tools in the search for appropriate texts for the corpus to achieve a quality output. As a result, these projects lead to relatively small corpora, suitable for studying a language in a teaching environment but insufficient for training neural networks.
Similar approaches are used in projects creating corpora for linguistic and translation purposes, such as specialised health corpora (Symseridou, 2018) for instructing translation professionals in required abilities like locating terms, studying collocations, grammar, and syntax. The same approach is followed in Castagnoli (2015) to build corpora for health, law, and cell phone scenarios, and in Lynn et al. (2015), aimed at constructing linguistic corpora for less commonly used languages (e.g. Irish). In all these cases, the core algorithm is based on web crawling, with language being the main driving constraint for selecting pages to add or continue searching.
The evolution of these approaches has been significantly influenced by the explosive growth of the web and subsequent restrictions imposed by search engines regarding massive querying of the web (Barbaresi, 2013a). This led to the exploration of alternative ways to discover documents for the corpus, such as exploring social networks and blogging platforms (Barbaresi, 2013b), the Open Directory Project and Wikipedia (Barbaresi, 2014), or the Common Crawl platform, a free Internet crawling initiative (Smith et al., 2013).
There are also automatic corpus-construction experiences centred not on the whole web but on closed repositories, aimed at filtering relevant documents for specific queries. These projects typically involve structured and well-known repositories, where the goal is to create information corpora restricted to characteristics specified by users, resembling more of a database query than web exploration. Their objectives focus on information analysis to guarantee compliance with restrictions rather than finding more similar texts from the current one. An example is Primpeli et al. (2019), which focuses on recovering text resources about e-commerce items from the WDC Product Data Corpus, extracted from the Common Crawl data repository. The compiled data, originally attached to product pages by e-commerce companies, forms an automatically created corpus used to group similar products in clusters. The quality of this corpus is confirmed by Peeters et al. (2020), Peeters and Bizer (2021), where embedding models were trained using such corpora. Zhang and Song (2022) utilizes information extracted from the same sources to feed various processes in the field of NLP, such as embedding generation or model training. Both scenarios share some similarities with ours as a corpus is created for training Machine Learning models. However, the documents collected in their research are located in a specific source, originating from an already available corpus containing semantic annotations, with no relevance to the subject being measured for such documents, and no new text is discovered from the analysed ones.
Numerous other research works claim automatic corpus creation in Machine Learning settings. For example, Zhang et al. (2021) creates a new corpus from the Amazon product dataset to train a new BERT model; Abacha and Dina (2016) automatically creates a corpus of equivalent pairs of questions (Textual Entailments) from the National Library of Medicine’s database of questions (USA); Zanzotto and Pennacchiotti (2010) extracts pairs of entailments from Wikipedia by studying the successive historic revisions of some articles; and Zhou et al. (2022) builds a new corpus of Paraphrase Detection by refining existing corpora like the Stanford Natural Language Inference corpus (SNLI) and the Multi-Genre Natural Language Inference corpus (MNLI). However, to our knowledge, all these approaches focus on processing closed repositories to obtain a new corpus, with no exploration of the web (or large repositories like Wikipedia) to search for new unknown documents. Moreover, no examples exist of studying the relevance of documents for a given subject openly specified by the user; the working theme is already fixed at the creation of the project. In the first group, new documents are discovered simply by crawling (with the language constraint), while no new previously unknown document is discovered in the second group.
In summary, the literature includes several works on the automatic creation of corpora. On the one hand, there is an older research line centred on linguistic and translation fields, where approaches are relatively simple, exploring the web from user-provided seeds, and generally involving simple web crawlers primarily driven by the language of pages. On the other hand, more elaborate approaches are found in specific fields like health or e-commerce, as well as a significant number of cases also centered on Machine Learning model training. However, to our knowledge, all these approaches are focused on processing closed repositories to create a new corpus, with no exploration of the web (or large repositories like Wikipedia) to search for new unknown documents. In neither approach do examples exist of studying the relevance of documents for a given subject openly specified by the user, and no new documents are discovered beyond the initial corpus.
Named Entity Disambiguation
In the literature, named entity disambiguation (NED) is commonly defined as the process of determining the precise meaning or sense of a named entity within a given context. These named entities can be identified by well-known named entity recognition tools like DBpedia-Spotlight (Mendes et al., 2011). More specifically, the goal of NED is to resolve ambiguity by associating the named entity with a specific concept within a semantic knowledge base. Previous studies have addressed the challenge of entity disambiguation through the utilization of statistical methods and rule-based approaches. These works take into account the contextual words surrounding the target named entity during the disambiguation process. However, they often neglect the semantic nuances of words and lack generalizability since the rules are typically specific to certain domains (An et al., 2020; Songa et al., 2019).
Subsequently, more advanced mechanisms emerged, such as the methods based on entity features. In these approaches, when an entity possesses multiple interpretations, inconsistent entities are filtered out by assessing their semantic similarity. The disambiguation process considers the semantic attributes of the entity, the contextual information surrounding the entity, and even its frequency of occurrence in the processed text. Notably, these methods leverage contextual embedding models, which assign different vector representations to entities with the same spelling based on their specific meanings within each context. To achieve this, entity features-based disambiguation methods typically obtain the contextual embedding vector of the target entity. They then calculate the semantic distance between this vector and the embedding vectors of each candidate entity to effectively disambiguate and remove any ambiguous entities (Barrena et al., 2015; Zwicklbauer et al., 2016). However, despite the efficacy of this approach, it disregards the structural characteristics of the knowledge base in which the target entity is situated, such as the interconnections between entities. Consequently, it fails to capture the global semantic features of each entity (Adjali et al., 2020). Additionally, this disambiguation method requires large training corpus to learn an embedding model.
To address this challenge, recent studies have turned to deep neural networks for entity disambiguation. Specifically, neural network-based approaches have gained popularity by incorporating the subgraph structure features of knowledge bases. These features are utilized as inputs to graph neural networks, enabling the disambiguation of entities within the knowledge base (Ma et al., 2021). Various methods have been explored, including convolutional and recurrent neural networks, as well as LSTM networks, to disambiguate entities based on extracted associations among them (Geng et al., 2021; Phan et al., 2017).
Transformer-based language models have also demonstrated significant promising in capturing complex linguistic knowledge, leading researchers to employ attention mechanisms to obtain contextual embedding vectors for each entity and consider coherence between entities for joint disambiguation (Ganea and Hofmann, 2017). Furthermore, graph neural networks have been trained to acquire entity graph embeddings that encode global semantic features, subsequently transferred to statistical models to address entity ambiguity. While these approaches demonstrate potential in achieving human-level performance in entity disambiguation, they often require substantial amounts of training data and computational resources (Hu et al., 2020). Therefore, challenges persist in optimizing these models and reducing their reliance on in-domain training datasets, which may not always be readily available, especially in highly specific or specialised domains like those handled in our ad hoc corpus generation approach. In simple terms, these models are not suitable for our purposes because they require training with ad hoc corpora, which is precisely what our work seeks to achieve, that is, automatically gathering collections of in-domain texts that were previously absent in the literature.
While we acknowledge the positive outcomes achieved by existing approaches in entity disambiguation within recent literature, their complexity and requirements, such as domain-specific training datasets and high computational demands, surpass the needs of our ad hoc corpus generation algorithm. In contrast, we employ a simpler yet effective mechanism, as evidenced by the obtained results, to identify the right entities in the given initial text. Details will be given in Section 3.2.
How to Build a Domain-Specific Training Corpus
The candidate documents to be incorporated into the automatically-built ad hoc corpus (for training the embedding models) are gathered from the Internet by a procedure that has been implemented in Python and made freely available in a GitHub repository (
First, the NER facilities provided by the DBpedia Spotlight tool are exploited to identify DBpedia named entities present in the input text (denoted as DB-SL entities). In addition, the approach searches for other semantically related entities that share some common features with these DB-SL entities (e.g. semantic topics and categories or wikicats). This step is addressed in Sections 3.1, 3.2 and 3.3.
Next, the goal is to retrieve (and preprocess to remove irrelevant information) Wikipedia articles in which the previously identified entities are mentioned, as described in Sections 3.4 and 3.5.
Finally, the retrieved texts that are actually relevant (according to the relatedness measured between each of them and the input text) are incorporated into the ad hoc corpus. As detailed in Section 3.6, this stage of the algorithm is driven by a semantic similarity metric based on a Doc2Vec embedding model.
Before delving into each phase of our algorithm, it is essential to justify the usage of Wikipedia in our research. Specifically, we prioritize retrieving texts from this source due to several compelling advantages: (i) Wikipedia serves as an extensive repository encompassing information about any subject, and it includes entries for relevant individuals, places, or events; (ii) DBpedia provides a wealth of semantic information about these entries, enhancing the depth and context of our analysis; and (iii) there is a well-established and reliable mechanism to follow links between these repositories, and even connect them to others, which facilitates the discovery and retrieval of new documents.
While our approach to constructing ad hoc corpora is equally effective for texts from Wikipedia or any other source, there are additional remarkable features of this information repository that make it particularly suitable: documents cover a wide range of topics and disciplines; these articles are written and reviewed by a committed community of volunteer contributors; and it is constantly updated, reflecting recent advances in different fields of knowledge. Further evidence supporting the quality, representativeness, and significance of the texts within this online encyclopedia is demonstrated by the use of large corpora of articles extracted from Wikipedia in Transformer architectures. These architectures have garnered remarkable achievements in the field of NLP by employing such corpora for pre-training their base models, enabling them to acquire extensive language knowledge and a broad contextual understanding. This initial pre-training phase primes the models before they are fine-tuned for specific NLP tasks, underscoring the significance and value of the texts extracted from Wikipedia in fostering the advancement of sophisticated language models.
As the aim is to build an ad hoc corpus, it is necessary to define some way of characterising the topic on which this tailor-made dataset should be based (i.e. a seed describing the context of interest). For that purpose, a short initial text is used, representative of the thematic to which all the document in the corpus should be more or less related. In other words, the goal is to search the Internet for documents with some kind of relationship to this initial text.
All along this document, the following initial text will be used.

This 1926 character-long text (hereafter denoted as
The approach conducted in this paper to discover documents leverages the Semantic Web and the Linked Open Data (LOD) (Oliveira et al., 2017) initiatives, which form a global repository of interrelated knowledge with a multitude of structured data to study their relationships and obtain new information from the available one. Thus, the core of the procedure is based on identifying relevant entities in the initial text (e.g. people, locations, events…), discovering categories in which these entities are classified and, finally, gathering other entities also classified in those categories. For each entity discovered, its description can be retrieved from the LOD repositories, becoming a new candidate text to be included in the domain-specific corpus.
To delimit this work, the initial source of the data considered is Wikipedia and its structured counterpart, the DBpedia (Lehmann et al., 2012). Given the vast amount of information available in these repositories, we leverage the existing capability to freely query them through well-known endpoints by SPARQL (SPARQL Protocol And RDF Query Language) queries. In particular, SPARQL is a language explicitly designed for retrieving data stored in RDF format through queries to repositories like DBpedia. DBpedia is not an isolated information repository but allows establishing links to other well-known datasets to enhance query results, such as YAGO (Pellissier et al., 2020) and WikiData (Ismayilov et al., 2015) that are extensively used in this work.2 In sum, SPARQL plays a crucial role in the Semantic Web and Linked Open Data (LOD) initiatives due to its remarkable capabilities in pattern searching and result filtering based on specified conditions, enabling efficient access to information within semantic repositories.
Regarding the categories in which to classify the DB-SL entities identified in
On the one hand, the
On the other one, through the
As will be described in the next sections, both properties are exploited in the paper as they are significant sources of information on the subject of a document, thus helping to discover new data and to assess its relevance.
The identification of the relevant entities present in the initial text
To this aim, DB-SL provides both a web application interface available online and a well-known endpoint running an API to programmatically access the service remotely.3 This last option is the most interesting one since the aim of this work is develop an automatic service that should be as autonomous as possible. However, this official service rejects bulk queries as it is only provided for testing purposes, so to speed up the execution it is advisable to install a local copy of DBpedia-Spotlight using a Docker image, for instance, provided by its creators.4
So, the text
In this example,
Sometimes, DB-SL is not able to properly disambiguate candidates and provides some wrong entity associations in the results. In the example, for instance, the
In spite of the notable performance achieved by the existing approaches in named entity disambiguation described in Section 2.3, their complexity and requirements, such as the necessity of domain-specific training datasets that are hard to find and high computational demands, go beyond the needs of our ad hoc corpus generation algorithm. Depending on such custom in-domain datasets for disambiguating named entities in a work like ours, which specifically aims to construct tailor-made ad hoc corpora that are missing in the literature, would be impractical. In these circumstances, we have opted to employ a simpler yet effective mechanism to identify the correct entities in the initial text
In particular, our mechanism leverages the semantic attributes, such as wikicats and subjects, associated with each entity in DBpedia and other linked repositories. Indeed, our approach specifically targets the identification of overlaps between the attributes of the target entity and those of other entities within
Applying this procedure, some entities are discarded, such as
This approach has proven to be sufficient as any errors in the disambiguation process only have a limited impact on our algorithm. As explained throughout the paper, if we fail to identify any entity, we consider tangentially related documents to
With the goal of finding new documents that are significantly related to the initial text,
To carry out this characterisation process, it is necessary to analyse the property
This

Simple wikicats consisting of a single word are eliminated – e.g.
Next, the set
In the example,
Sometimes, depending on the entities found by DB-SL, a large number of wikicats are collected in this phase. In order not to disperse the search, at this time the user has the possibility to discard some of those wikicats (see Fig. 1) if they are not meaningful in the target context, keeping only the selected set of wikicats for the following steps.7
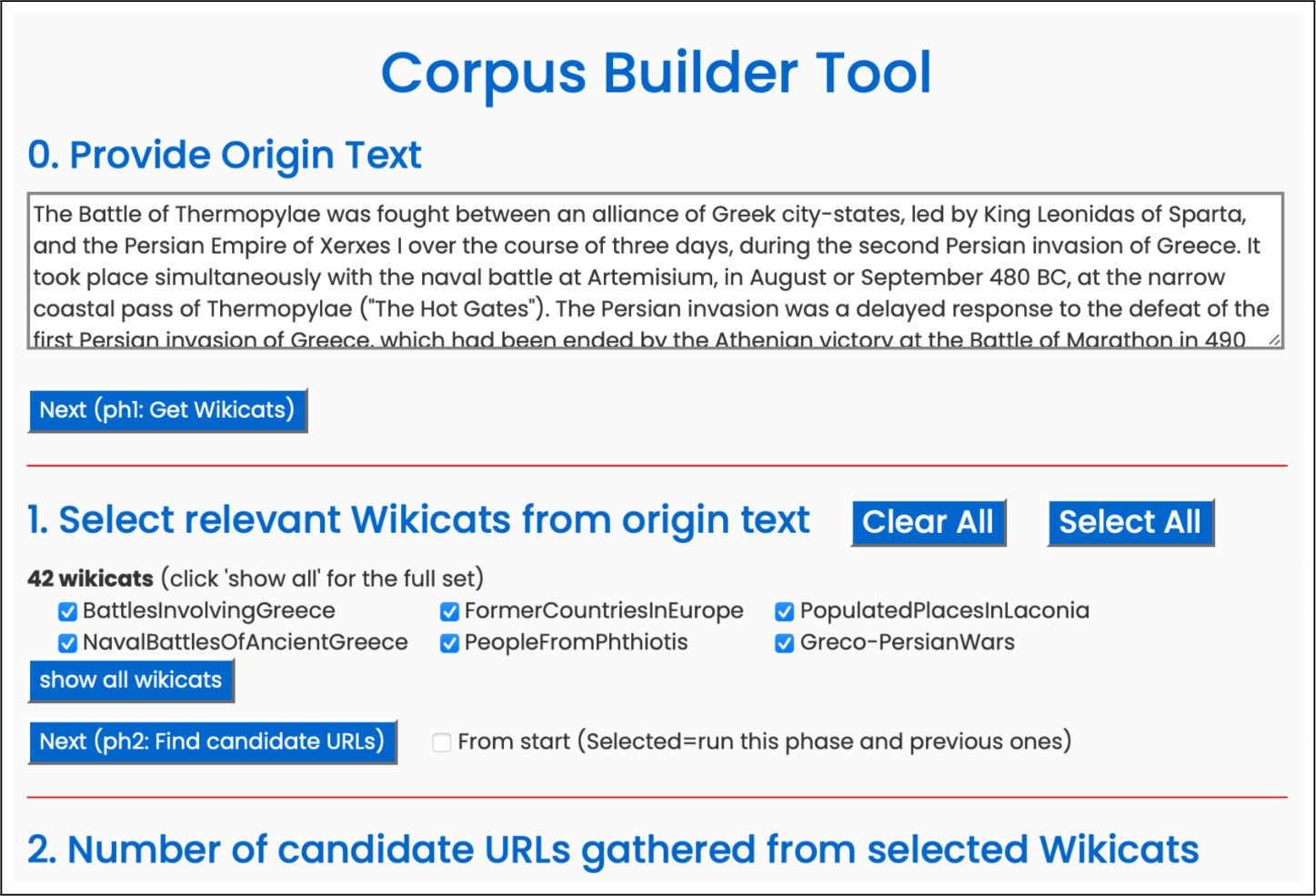
Snapshot of the corpus builder tool developed to explore and identify wikicats that are relevant in the context of the initial text
So far, a number of entities have been identified in
First, for each wikicat in
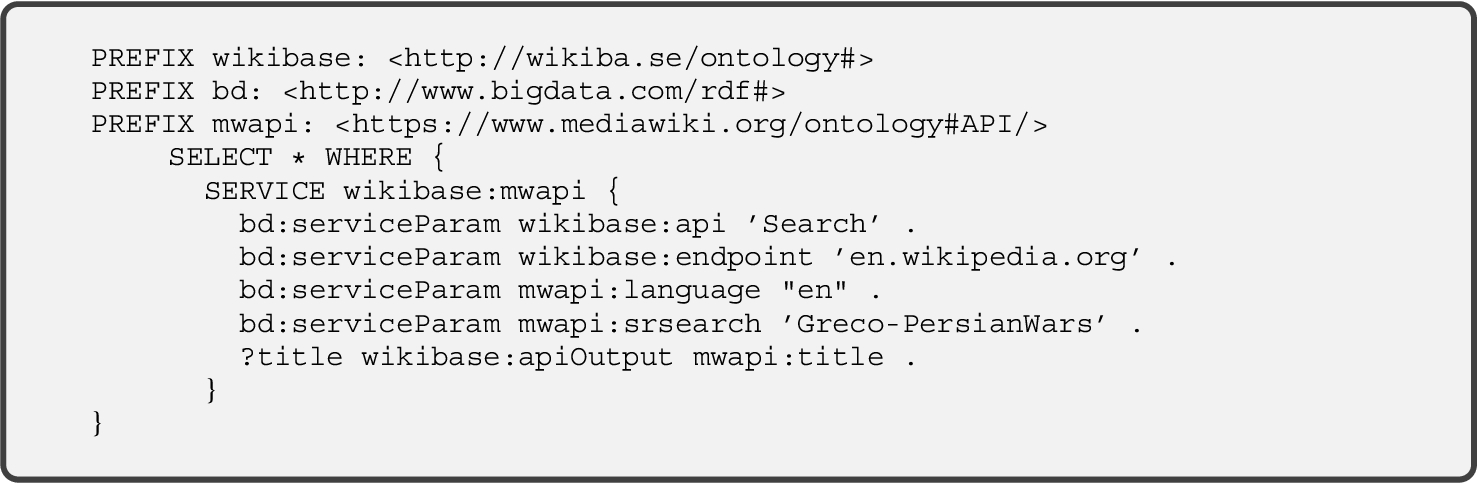
To fetch this set of URLs, the following SPARQL query is sent to the well-known DBpedia endpoint8 (being

The approach considers the
In addition, Wikidata (Vrandeĉić and Krötzsch, 2014; Yoo and Jeong, 2020) is also queried to gather all the Wikipedia pages related to the components of the wikicat name. Wikidata is the central repository of structured information for all the projects of the Wikimedia Foundation, storing more than 92 million data items (text, images, dates, …) accessible by SPARQL queries. Same as Wikipedia, Wikidata is aimed at a crowdsourced data acquisition, being freely editable by people or programs, not only regarding contents, but also data structure. To fetch this second set of URLs, the following SPARQL query is made to the Wikidata well-known access endpoint9 (being this time
This query provides a second set of URLs (denoted as
The second query permits to collect some interesting documents tightly related to the application scenario that, by any reason, have not been tagged by users with the set of characterising wikicats (may be even they are tagged with some similar wikicat that has not been retrieved in the first phase, e.g.
Finally, both sets of URLs (represented in Eqs. (6) and (7)) are joined (removing duplicates) resulting in Eq. (8):
At this point,
In the example,
Every URL
Of course, a large number of these documents might have a tangential relationship to the initial text (e.g. a battle involving Athens corresponding to a different historical stage). It is therefore necessary to measure their similarity to the particular context, order them according to that metric, and discard the irrelevant ones.
By simple visual inspection, it is easy to notice that a significant amount of the documents obtained in the previous phase do not have a strong-enough relationship to the proposed domain, and for that reason they should not be incorporated into a domain-specific corpus. Of course, the wikicats retrieved could be quite specific (e.g.
To detect and discard these uninteresting documents, the similarity between the initial text
The different similarity metrics that have been taken into account to detect the relationship between each of the candidate texts and
When it comes to detecting resemblance between each candidate text and the input one (
This metric measures the similarity between the initial text
This metric is similar to the previous one but using common subjects between
The computation of similarity values by means of this metric is driven by spaCy,11 a Python package for natural language processing. As usual in similar packages, it provides functions for tokenizing texts, removing stopwords and punctuation, classifying words according grammatical categories… In addition, it also implements mechanisms to assign a vector to each word. For this task, it uses algorithms like Glove or Word2Vec (a variant of this by default) to assign a word embeddings vector to each word of the vocabulary.12 And, naturally, it provides functions to measure similarity between words, comparing vectors through the traditional cosine-based similarity. Directly derived from this, spaCy also provides a simple mechanism to measure similarity between texts, generating a vector for each text (the average of the corresponding vectors for each word of the text) and computing cosine-based similarity between the text vectors.
Some works in the literature have shown that Doc2Vec performs robustly in measuring document similarity when trained using large external corpora (Lau and Baldwin, 2016; Dai et al., 2020). Bearing these results in mind, this embedding model has been explored to select the most similar candidate documents to the initial text Using this model and the Gensim implementation of the Doc2Vec algorithm, the approach obtained the characteristic vector for both each candidate text
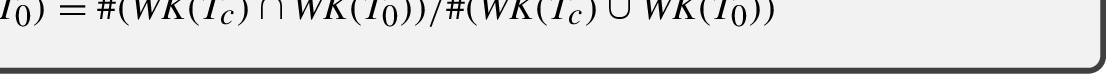
In order to decide which of the four metrics described in the previous section (
First, the similarity between the initial text and each candidate text will be computed using each one of the similarity metrics. This allows the set of candidate texts in
Each entity
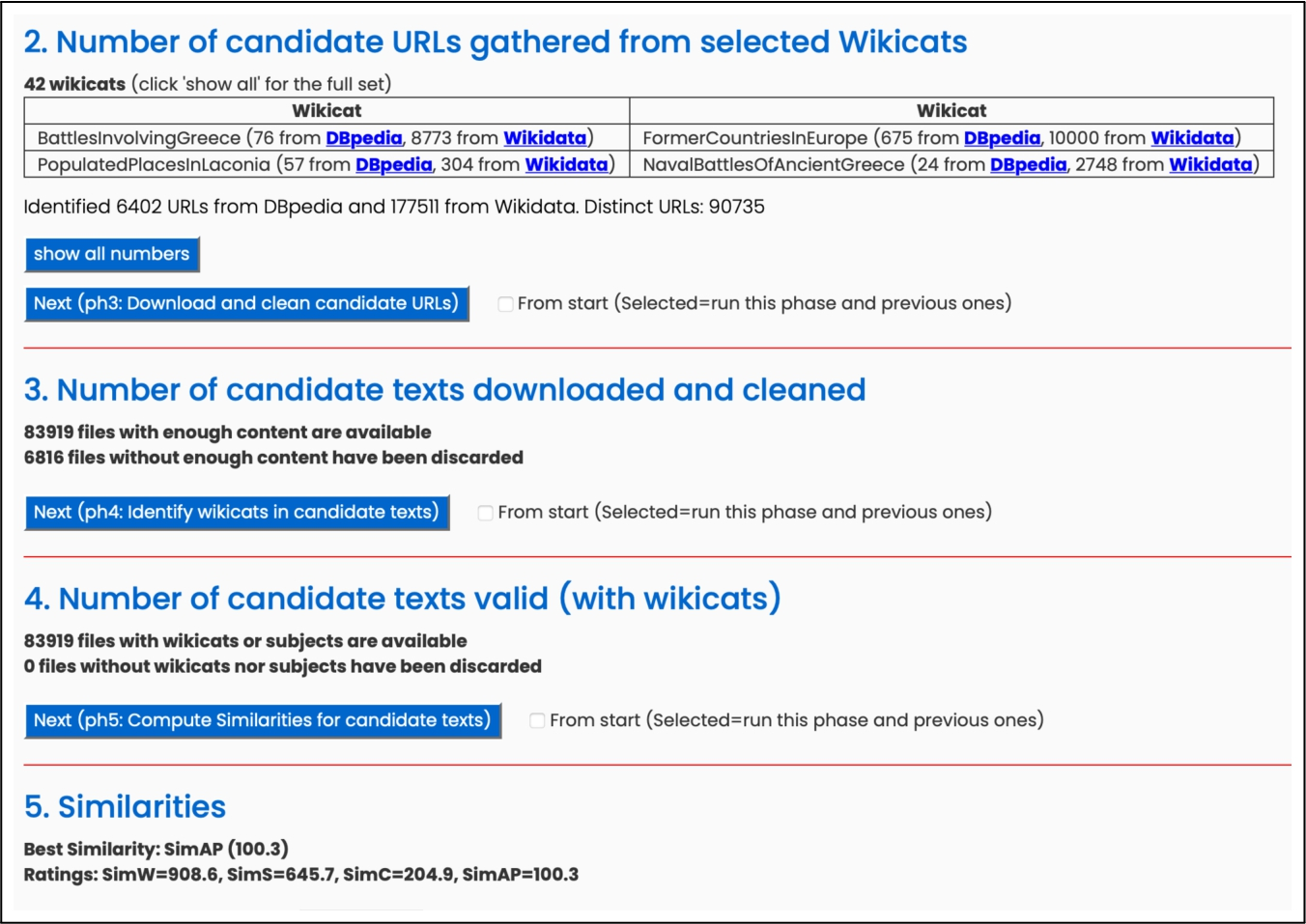
Interface of the corpus builder tool developed by the authors of the paper, which aims to evaluate the similarity between the initial text
Returning to the example illustrated throughout this section, Table 2 shows the positions occupied by the 10 DB-SL entities (discovered in
Positions occupied by the 10 DB-SL entities (discovered in the initial text
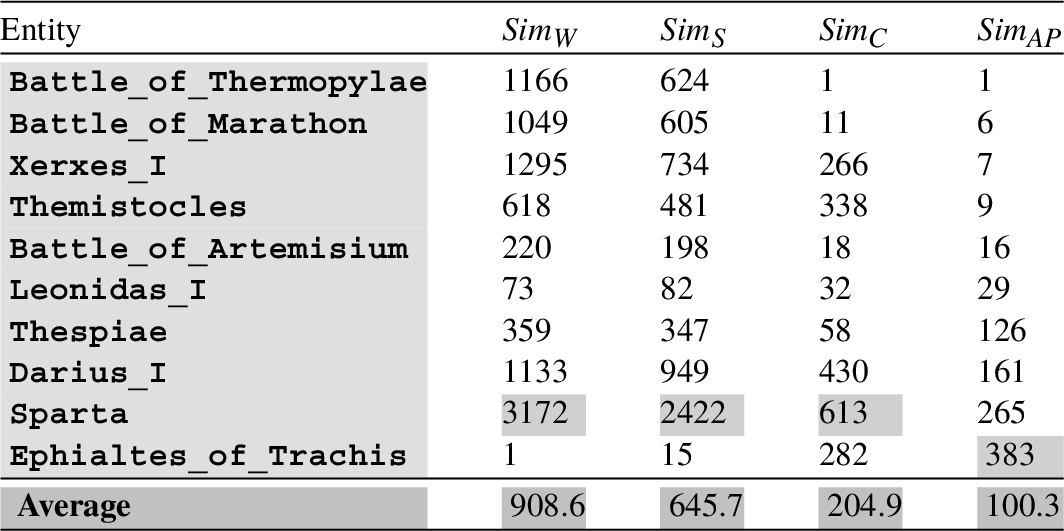
These data are not deterministic for the Doc2Vec-based similarity
To solve that issue, and compare Doc2Vec with the other similarity metrics, the proposed algorithm (which is outlined in Algorithm 1) computes the results for 5 different executions, and uses the average for every entity. As depicted in Table 2, the Doc2Vec-driven metric was found to be the best one according to the defined criterion (the average is 100.3). In light of the results, the Doc2Vec similarity metric (denoted by

As depicted in above sketched algorithm, a subset of the candidate documents that occupy the top positions in
But one thing that can be done is to analyse different scenarios and study their results according to a common criterion. This allows to assess the performance of the models obtained by training on different subsets of the
The starting point is the collection of candidate documents that have been gathered from Wikipedia and ordered according to their similarity to
This comparison should serve to answer a relevant outstanding question: “are any of these ad hoc models better than the generic AP model?’ Note that this is the cornerstone of the research described in the paper, which aims to devise a procedure to build an ad hoc corpus (composed of documents significantly related to a given application scenario), as there are several references in the literature stating that the model derived from such a corpus should be better than a model trained on a generic corpus of documents (not particularly related to the scenario under consideration). Therefore, evidences in this respect should be provided.
Consistency Tests for Evaluating Embedding Models Learned from Ad Hoc Corpora
One simple consistency test to check the resulting models is to compute the self-rank of each training document when searching for similar documents. That is, for each one of the training files, the model is asked for the N most similar documents to it, as if such file were new and not already in the model. Obviously, the model should select the same file as the most similar to itself (1-rank), that is, the first in the list of most similar docs.18 But sometimes, the model makes a mistake and finds other document that is even more similar. The less mistakes, the better the model.
Table 3 depicts the results for the 10 Doc2Vec models (which have been trained on the 10 ad hoc corpora), where the
1-rank results obtained for 10 ad hoc Doc2Vec models generated in the approach (
to
). The results confirm that, given a training document, these models were almost always correct in identifying that document as the most similar to itself (on average, this was true for 98.5% of the training documents).
1-rank results obtained for 10 ad hoc Doc2Vec models generated in the approach (
Another simple consistency check for the models consists of observing how well they discriminate between similar and dissimilar documents. To this aim, a simple experiment was made where two lists of documents in
Each of these 200 documents was divided into two parts of equal size, and several similarity values were computed for each one of the 10 ad hoc Doc2Vec models:
The average of the similarities
Similarity values that our 10 Doc2Vec models have measured between documents that are related to
The previous tests showed that the models generated in this approach work well, but they did not confirm which one is the best or if they are better than the generic Doc2Vec AP model. To try to shed light on such issue, the performance of the models when they are used in some scenario has to be evaluated. The methodology adopted in the validation and the discussion on results obtained are detailed in Section 4.2.1 and Section 4.2.2, respectively.
Experimental Methodology
The proposed validation scenario is inspired by the procedure that was adopted to select the similarity metric based on the Doc2Vec AP model (
First, the
Next, the focus was put on the positions of the
Set of 18 DB-SL entities considered in the experimental validation in the context of the Battle of Thermopylae.
For a more robust comparison in the application scenario linked to the Battle of Thermopylae, the list of 10 DB-SL entities initially discovered was extended with new entities that were actually significant in the context of the second Persian invasion of Greece (but were not mentioned in the initial text
Lastly, the positions of those 18 DBpedia entities were searched in the sets
Positions occupied by the 18 DB-SL entities of
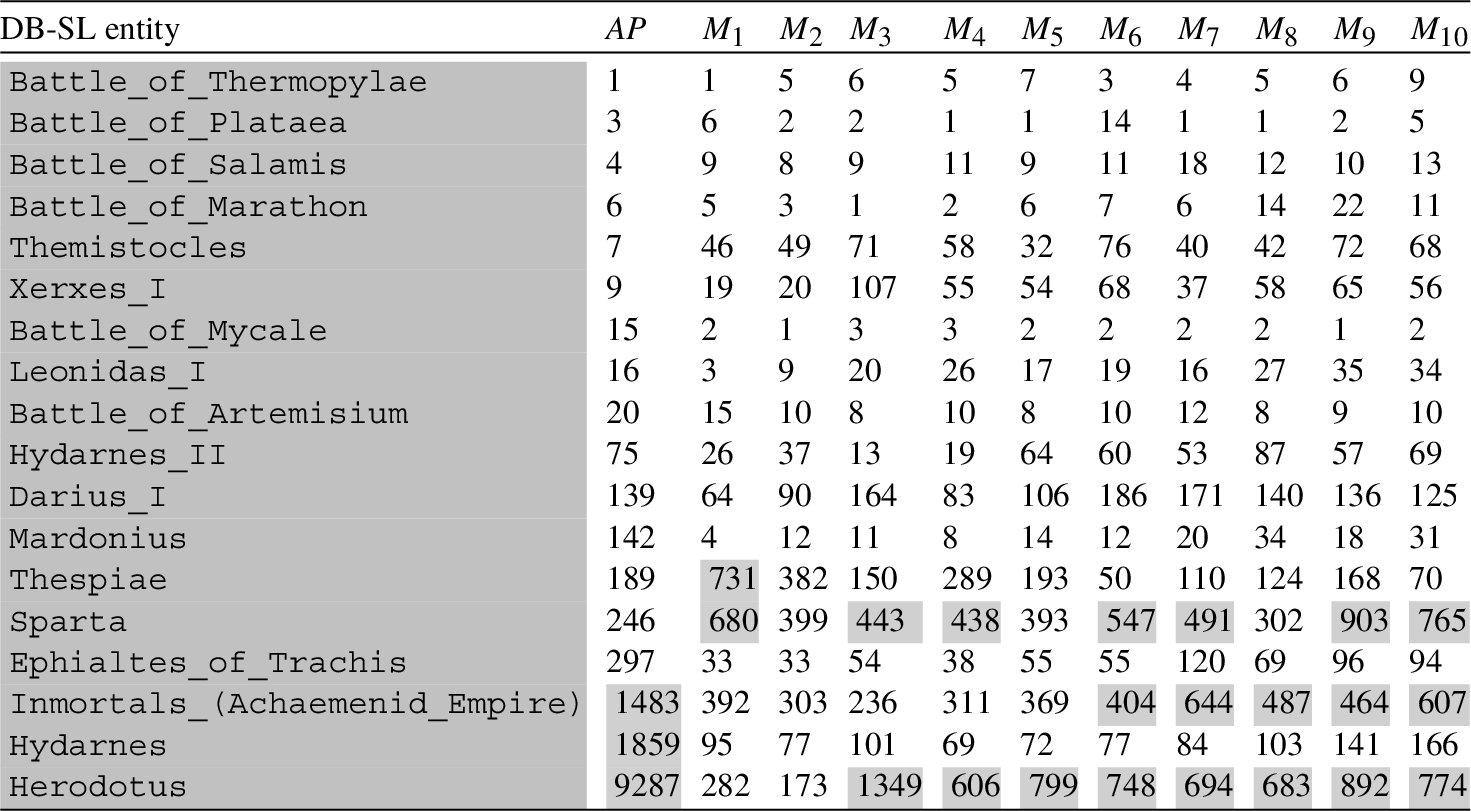
As shown in Table 6, most of the entities occupy relevant positions in all of the studied orderings. This happened to be always true, even though the actual numbers change among different trainings of the same subset of candidates. As mentioned before, the Doc2Vec training algorithm involves some randomness in its steps (for instance, some data is randomly discarded to accelerate the convergence without having significant influence in the final results). This is not important for calculating a given similarity, as the fact that this value is 0.865 or 0.863 should not make any difference. But when ordering 83919 documents, these little differences can lead to all entities slightly changing their positions up or down. For instance, the
In addition, some discordant values have been highlighted with background gray color in Table 6. They are clearly outliers that have to be taken into account to conduct a more appropriate analysis. In this regard, note that word embeddings are machine learning techniques that can be influenced by many factors that lead sometimes to unexpected results. For example, it may happen that a key figure of the historical event under consideration is described in the candidate text (retrieved from Wikipedia) in a way that is not rich enough for these methods to lead to the expected similarity values. This is the case for the candidate text of the entity
For the above reasons, it is natural that outliers appear. These are documents that should have been rated high, but are not. This happens both with small ad hoc corpora and with the huge generic AP corpus. But, as shown in Table 6, these outliers are not the same in all cases (although they are quite similar in the ad hoc corpora). Because of this, in order to appropriately compare ad hoc models among them and with AP model, it is convenient to remove such outliers, as the overall quality of a model should be assessed by the most of its results, and not influenced by a small number of irregular items.
This way, the Z-score (Jiang et al., 2009; Aggarwal, 2017) and the IQR (Tukey, 1977; Sunitha et al., 2014) methods were adopted to identify outliers. Both methods confirmed the highlighted values as discordant with the previous ones. Only values over position 400 were analysed as it is clear that low values may be discordant from a mathematical point of view but still significative regarding similarity.20
When removing discordant outliers, it should be borne in mind that averages are being compared and therefore it is necessary to include the same number of elements in the calculation. This is due to the fact that outliers occupy the highest positions in any ranking and simply discarding them in their individual rankings would lead to results that are not directly comparable. Thus, the different rankings were studied to find the one with the highest number of outliers (3 in AP), and this amount was removed from all models. Thus, the 15 entities ranked in the lowest positions were considered for all models. It is worth noting that this is the best case scenario for the AP model (the 3 highest entities were removed from that ordering, thus reducing its mean and giving more value to any other model that outperforms AP).
The results obtained with the 10 ad hoc models learned by taking as training datasets different percentages (from 1% to 10%) of the candidate texts in
Average positions occupied by the 15 best ranked entities, considering both the AP model and 20 Doc2Vec in-domain models learned by taking between 1% and 20% of the initially-selected candidate documents. The results confirm that the
model obtains the best outcome as it allows finding the 15 entities in the candidate documents that have been selected as the most similar to the input text (i.e. those occupying the lowest positions in the set
).
Average positions occupied by the 15 best ranked entities, considering both the AP model and 20 Doc2Vec in-domain models learned by taking between 1% and 20% of the initially-selected candidate documents. The results confirm that the
Based on the results, when compared to the 78-score21 of the
To examine the evolution of the consistency across a larger number of models derived from different percentages of
Based on Table 7, it can be observed that models trained with high percentages (17% to 20%) of candidate documents perform less effectively than the generic model
To sum up, the results presented in Table 7 confirm that the initial ad hoc models significantly outperform the generic AP model. For the domain studied in this paper, a corpus containing only 5% of the candidate texts yielded the best results with an average position of 43, as opposed to the AP model’s 78-score. This implies that, based on the criteria employed in this study, such ad hoc models (which have been constructed fully automatically, without requiring human contributions except for optimizing corpus creation) are more effective than the generic AP model in identifying the documents most relevant to a specific context defined in the initial text
In this paper, an automatic procedure based on the Linked Open Data infrastructure has been proposed, which allows easily to obtain ad hoc corpora (from a user-specified short input text) that bring benefits for existing word-level and document-level embedding models. So far, such models have been fine-tuned on small collections of in-domain documents in order to improve the performance. These documents are often compiled manually and without assessing in any way the relevance of each text in the particular domain. In opposite, the approach described in this paper automatically gathers numerous in-domain training texts by relying on NER tools and state-of-the-art embedding models in order to guarantee a meaningful relationship between each possible training document and the initial text.
On the one hand, DBpedia-Spotlight is used to recognize DBpedia named entities in the initial text and drive the process of building an initial ad hoc corpus. On the other one, Doc2Vec models allow to identify new relevant in-domain texts (to be incorporated into the ad hoc training dataset). This way, the final tailor-made corpus brings together a large amount of meaningful and precise information sources, which lead to learning high quality domain-specific embeddings.
These dense vector representations accurately model domain peculiarities, which is especially critical for exploiting the language representation capabilities of embedding models in very particular fields (e.g. medicine, History or mechanical engineering, just to name a few). These fields are not conveniently considered in either the huge publicly available generic training datasets or the small-sized hand-collected domain datasets adopted in some existing approaches. Unlike these works, our approach is able to build, without human assistance, a training corpus on any topic and domain that can be exploited by existing models, requiring only to provide as input a variable-length piece of text.
In line with this, well-known models (like Word2Vec and GloVe) could take advantage of this approach to fight the Out-Of-Vocabulary problem, which is stemmed from the usage of generic training corpora. This limitation has been traditionally alleviated in other models (like FastText) by working at subword-level, which introduces excessive computational costs and memory requirements (Armand et al., 2017). However, this approach enables to embed in-domain words that would be rare/unusual in a publicly-available generic corpus, and therefore impossible to be learned from general-domain datasets or even from imprecise/incomplete domain-specific datasets.
Our procedure to custom corpus construction shows several advantages over the different approaches presented in the related work section that address similar objectives: the approach here described is more autonomous, less dependent on user feedback to guaranty the quality of outputs; in our work, the relevance of the documents for the given subject is measured before including them in the corpus; and the search process is based on an open large repository where new unknown documents can be discovered, analysed and included into the corpus, besides being used to trigger new searching processes, thus leading to larger custom corpora composed of thousands of documents.
As an honest limitation, the paper concentrates on evaluating the performance of the proposed method using Doc2Vec embeddings, while not considering other Transformer-based models. Despite acknowledging the potential and remarkable results achieved by sophisticated Transformer architectures like BERT, such approaches have been omitted due to certain characteristics of the available models that do not align well with the specific objectives of our validation. In particular, our experimental validation has demonstrated that the performance of the custom-built in-domain corpus, when compared to a generic training dataset, is superior within the context of the specific embedding model used (Doc2Vec in this case). To achieve this, we trained a Doc2Vec model from scratch using the tailored collection and compared it to a generic model. However, training a BERT model from scratch in the case of Transformers is not feasible for us due to its unaffordable computational requirements. Instead, it is common practice to start with a pre-trained model on a massive collection of generic information (referred to as base model) and then fine-tune it for specific NLP tasks and custom corpora.
Given that our approach aimed to compare a model trained from scratch on the ad-hoc collection against one trained on a generic collection, we found the use of Doc2Vec more suitable for the purposes of our research. This choice was driven by the need for a more equitable comparison scenario between the general and ad hoc approaches, which is made possible by comparing models trained from scratch with Doc2Vec. The proposed experimental validation has tested the research hypothesis considered in the approach and has demonstrated that the performance of the automatically-built in-domain corpus is better than that of a generic training dataset in the context of a particular embedding model (Doc2Vec in this case). In reality, replicating or even improving this behaviour with other recent and sophisticated Transformer-based embedding models (such as GPT, BERT and their multiple variants) does not invalidate the results obtained in this work with Doc2Vec. In particular, apart from the aforementioned reasons, Doc2Vec presents two additional compelling advantages. Firstly, its good performance against related document-level models (Bhattacharya et al., 2022; Kim et al., 2018; Grefenstette et al., 2013; Mikolov et al., 2013a; Kiros et al., 2015, 2018) and secondly, the existence of a mature implementation of it through GenSim (Rehürek and Sojka, 2010), which allowed to train own models from scratch and evaluate the effects of the training corpus on the quality of the resulting models (rather than being able to simply use pre-trained models that have been learned from inaccessible documents).
Regarding the further work, having experimentally validated that in-domain corpora improve generic training datasets in a very specific domain, short-term research plans to explore the performance of models that have first been learned from a generic corpus and then fine-tuned on a collection of in-domain texts (which will be automatically retrieved by the proposed algorithm). The goal of these experiments is to incorporate a diverse array of models, encompassing advanced Transformer-based approaches like BERT, along with numerous other models that are continually emerging in the literature.
Footnotes
Of course, even though other sources of information could be easily explored through the appropriate study of their URL formats, it will be shown that the components and tools involved in this research are representative enough of the potentialities of this approach.
Available at
In the following, some numbers will be provided, which are related to this default text. These numbers are continuously changing in a minor way, as Wikipedia pages are frequently added, removed, or modified, and new categories are constantly being created.
This is just an optimization to speed up the process.
Beautiful Soup Python library has been used for this purpose.
Note that several English vocabularies can be loaded at startup, from small to large ones.
The tutorial available at
Tests of keeping and removing stop-words before training showed that better results were obtained by removing them.
Currently, the approach considers only entities of types Person, Location and Event (the 10 entities identified in the example text meet this requirement).
Note that, opposite to Word2Vec vectors for words in the vocabulary, there is no vector stored in the model for the new documents, so such vector must be computed on the way, replicating the training process.
See
Actually, only documents larger than 3KB were included in each of the lists because very small documents were of little significance for testing purposes.
For example, in the series 1, 2, 3, 10 the last one would be an outlier from a pure mathematical point of view, but it is obvious that, when talking about positions within a set of 83919 elements, it is a low position that must be understood as a relevant value regarding any similarity ranking.
Recall that this score means that 78 is the average of the positions occupied by the 15 DB-SL entities in the ordered set of candidate texts. The lower the average, the better, as this means that the relevant entities have been identified by the model as very similar to the initial text.
Mathematical Notation Adopted
| Notation | Meaning | Equations |
| Set of DBpedia entities that DBpedia Spotlight identifies in the input text , which share common Wikicats and/or subjects. | (1) and (2) | |
| Set of relevant Wikicats that characterise a given entity e. | (3) and (4) | |
| Set of relevant Wikicats that characterise the input text . | (5) | |
| Set of URLs of pages dealing with entities tagged with the wikicat in DBpedia. | (6) | |
| Set of URLs of pages dealing with entities tagged with the wikicat in Wikidata. | (7) | |
| Union of the sets and . | (8) | |
| Set of URLs that are associated with some wikicat included in . | (9) | |
| Set of documents, related to in some extent, that are candidates to be incorporated into the ad hoc training corpus. | (10) | |
| Custom-built training corpus that includes only the domain-specific documents in that are significantly related to . | (11) | |
| Semantic similarity metric based on the common wikicats identified between the candidate text and the input text . | 3.6.1 and 3.6.2 | |
| Semantic similarity metric based on the common subjects identified between and t . | 3.6.1 and 3.6.2 | |
| Semantic similarity metric between and measured by the spaCy Python package. | 3.6.1 and 3.6.2 | |
| Semantic similarity metric between and measured by the existing AP Doc2Vec model (which has been trained with a generic collection of Associated Press news). | 3.6.1 and 3.6.2 | |
| Set resulting from sorting in decreasing order as per the similarity values measured (between each and ) by the metric . | 3.6.2 | |
| Set resulting from sorting in decreasing order as per the similarity values measured (between each and ) by the metric . | 3.6.2 | |
| Set resulting from sorting in decreasing order as per the similarity values measured (between each and ) by the metric . | 3.6.2 | |
| Set resulting from sorting in decreasing order as per the similarity values measured (between each and ) by the metric . | 3.6.2 | |
| with | Doc2Vec model learned from an ad hoc training corpus including i% (from 1% in to 20% in ) of the candidate documents in . | 4.1 and 4.2 |
| , | Set resulting from sorting by the Doc2Vec ad hoc model . | 4.2.1 and 4.2.2 |