
Abstract
Anti-cancer immunotherapy dramatically changes the clinical management of many types of tumours towards less harmful and more personalized treatment plans than conventional chemotherapy or radiation. Precise analysis of the spatial distribution of immune cells in the tumourous tissue is necessary to select patients that would best respond to the treatment. Here, we introduce a deep learning-based workflow for cell nuclei segmentation and subsequent immune cell identification in routine diagnostic images. We applied our workflow on a set of hematoxylin and eosin (H&E) stained breast cancer and colorectal cancer tissue images to detect tumour-infiltrating lymphocytes. Firstly, to segment all nuclei in the tissue, we applied the multiple-image input layer architecture (Micro-Net, Dice coefficient (DC)
Introduction
A host-tumour immune conflict is a well-known process happening during the tumourigenesis. It is now clear that tumours aim to escape host immune responses by a variety of biological mechanisms (Beatty and Gladney, 2015; Zappasodi et al., 2018; Allard et al., 2018). Thus the importance of tumour-infiltrating lymphocytes (TILs) in pathology diagnosis, prognosis, and treatment increases. Quantification of the immune infiltrate along tumour margins in the tumour microenvironment has gathered researchers’ attention as a reliable prognostic measure for various cancer types (Basavanhally et al., 2010; Galon et al., 2012; Huh et al., 2012; Rasmusson et al., 2020). With the emergence of whole slide imaging (WSI) and recent Federal Drug Administration’s (FDA) approval for WSI usage in clinical practice, various techniques have been proposed to detect lymphocytes in digital pathology images focusing on the algorithms based on colour, texture, and shape feature extraction, morphological operations, region growing, and image classification.
As opposed to individual nuclei detection, models proposed in Turkki et al. (2016) and Saltz et al. (2018) have been trained to identify TIL-enriched areas rather than stand-alone lymphocytes. In a study by Saltz et al. (2018), authors have developed a convolutional neural network (CNN) classifier capable of identifying TIL-enriched areas in WSI slides from TCGA (The Cancer Genome Atlas) database. Similarly, in Turkki et al. (2016), lymphocyte-rich areas were identified by training an SVM classifier on a set of features extracted by the VGG-F neural network from CD45 IHC-guided superpixel-level annotations in digitized H&E specimen.
Such a high-level tissue segmentation approach has been widely used for cancer tissue segmentation tasks, such as stroma-epithelium tissue classification (Morkunas et al., 2018). However, lymphocyte infiltration quantification accuracy would benefit from a more granular level analysis using object segmentation models. Convolutional encoder-decoder based model architectures (convolutional autoencoders CAEs) have been established as an efficient method for medical imaging tasks. U-Net autoencoder model, proposed in Ronneberger et al. (2015), has become a golden standard model for medical areas ranging from cell nuclei segmentation to tissue analysis in computed tomography (CT) scans (Ma et al., 2019). The deep, semantic feature maps from the U-Net decoder are combined with shallow, low-level feature maps from the encoder part of the model via skip connections, thus maintaining the fine-grained features of the input image. This renders U-Net applicable in medical image segmentation, where precise detail recreation is of utmost importance. Specifically for lymphocyte detection, approaches utilizing fully convolutional neural networks on the digital H&E slides were published by Chen and Srinivas (2016) and Linder et al. (2019). Both approaches investigate convolutional autoencoders using histology sample patches with annotated lymphocyte nuclei. Detection and classification, but not segmentation of nuclei in H&E images, were done using spatially constrained CNN in Sirinukunwattana et al. (2016). Notably, the classification into four cell types (epithelial, inflammatory, fibroblast, and miscellaneous) was performed on patches centred on nuclei considering their local neighbourhood. A more recent adaptation – the Micro-Net model – incorporates an additional input image downsampling layer that circumvents the max-pooling process, thus maintaining the input features ignored by the max-pooling layer. This way, more detailed contextual information is passed into the output layer, enabling better segmentation of adjacent cell nuclei (Raza et al., 2019).
The Hover-Net model published in Graham et al. (2019) enables simultaneous cell nuclei segmentation and classification by three dedicated branches of the model – segmenting, separating, and classifying. Hover-Net was applied to two datasets and achieved 0.573 and 0.631 classification f-score. In Janowczyk and Madabhushi (2016), AlexNet was employed to identify centres of lymphocyte nuclei. The network was trained on cropped lymphocyte nuclei as a positive class, and the negative class was sampled from the most distant regions with respect to the annotated ground truth. The trained network produces the posterior class membership probabilities for every pixel in the test image; subsequently, potential centres of lymphocyte nuclei are identified by disk kernel convolution and thresholding. In Alom et al. (2019), the same dataset was utilized to evaluate different advanced neural networks for a variety of digital pathology tasks, including lymphocyte detection. The authors proposed a densely connected recurrent convolution network (DCRCNN) to directly regress the density surface with peaks corresponding to lymphocyte centres. When compared to AlexNet, the DCRCNN improves the f-score by 1%, yet it is worth mentioning that both (Janowczyk and Madabhushi, 2016; Alom et al., 2019) do not demonstrate method generalization – in the respective studies, the same dataset was used for training and testing.
Our study focuses on the customization of cell segmentation autoencoder architecture and aims to investigate a two-step cell segmentation and subsequent lymphocyte classification workflow using digital histology images of H&E stained tumour tissues. Robust separation of clumped cell nuclei is a common challenge in whole slide image analysis (Guo et al., 2018). To tackle this nuclei segmentation challenge, our cell nuclei segmentation model renders an additional active contour layer, which increases the segmentation efficiency of adjacent cell nuclei. Apart from overlapping nuclei, image magnification is another critical factor for nuclei segmentation models. Publicly available annotated nuclei datasets contain histological samples scanned at
The paper is organized as follows. In Section 2.1, we describe the datasets used in the study. In Section 2.2, we introduce the segmentation method based on autoencoder neural network architecture, followed by the classification of segmented nuclei. In Section 3, we present experimental results comparing different cell nuclei segmentation as well as lymphocyte discrimination approaches. In particular, Section 3.3 covers the evaluation of our method on the publicly available annotated data set of breast cancer H&E images. We formulate conclusions in Section 4.
Materials and Methods
The Datasets
1 WSI slide was obtained from The Cancer Genome Atlas database, tile ID: TCGA_AN_A0AM (Grossman et al., 2016), and used for both segmentation and classification testing.
Two additional public datasets were used for classification testing purposes. The CRCHistoPhenotypes dataset (CRCHP) contains colorectal adenocarcinoma cell nuclei. 1143 nuclei are annotated as inflammatory (used for lymphocyte category in our experiments), and 1040 annotated as epithelial (used for other cell type category) (Sirinukunwattana et al., 2016). The breast cancer dataset (JAN) published by Janowczyk and Madabhushi (2016) consists of 100 images (
Two datasets were used for segmentation and classification tasks. Segmentation experiments were performed on
pixel-sized image patches. Classification experiments were performed on extracted cell nuclei embedded in blank
pixel-sized placeholders.
Two datasets were used for segmentation and classification tasks. Segmentation experiments were performed on
Image augmentation techniques and parameters used for training dataset expansion.
The segmentation dataset is summarized in Table 1, and the techniques used to augment training patches are summarized in Table 2.
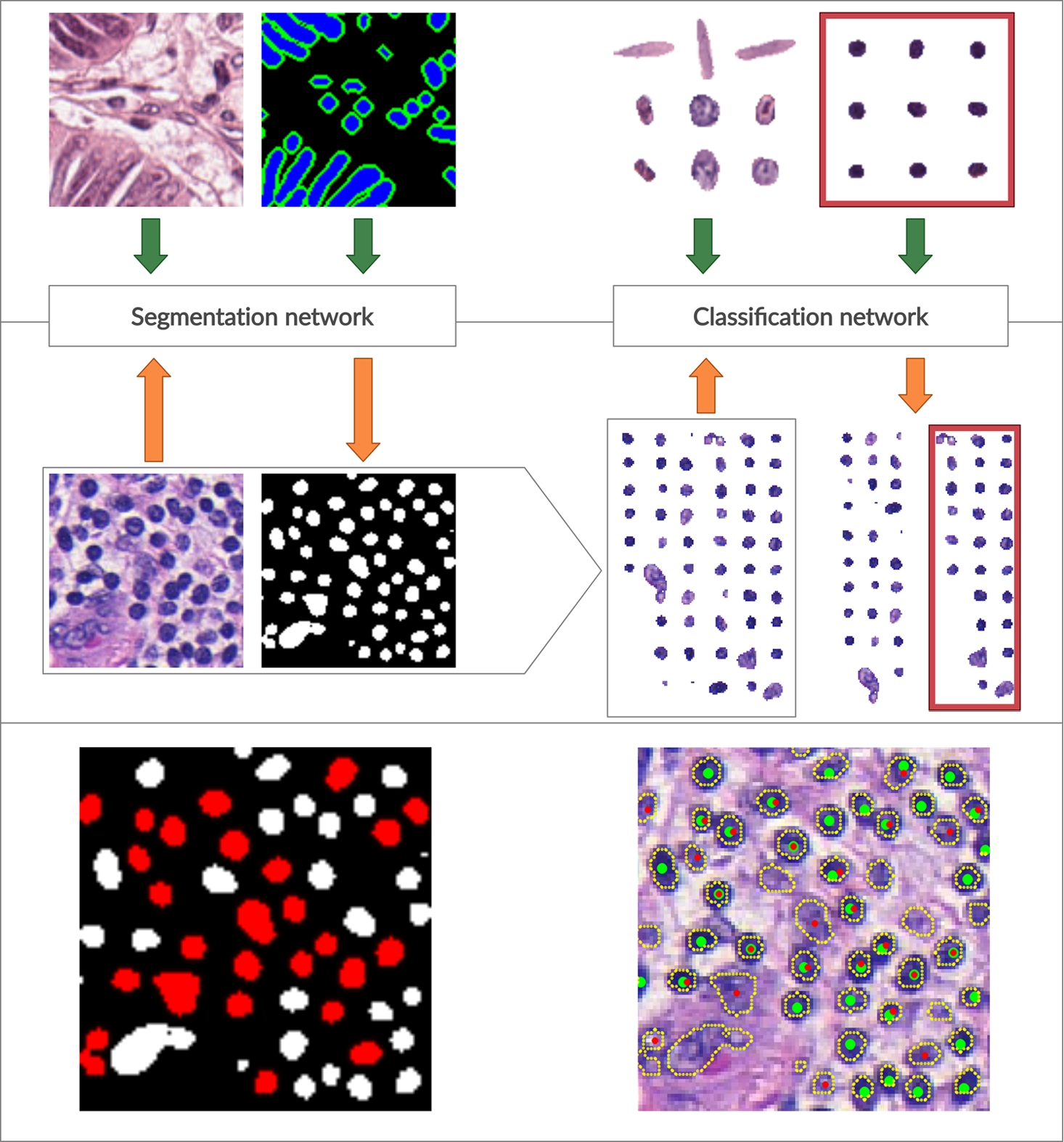
Overall schema of the proposed workflow. On top, a training phase for both segmentation and classification models is shown. The segmentation network is trained on original image patches and manually annotated ground truth images. The classification model is trained on cropped nuclei to discriminate lymphocytes (in the red box) from other nuclei. In the middle, a testing phase is shown. The trained segmentation model accepts new images and produces segmentation masks (for clarity, the active contour layer in the resulting segmentation mask is not shown). Resulting segmentation masks are used to crop out detected cell nuclei that are fed into the classifier model and sorted into lymphocytes and non-lymphocyte nuclei. In the bottom panel, on the left, we have representative segmentation results (lymphocyte nuclei are coloured in red for clarity), and on the right, we have an original image with detected nuclei contours outlined and detected lymphocyte nuclei depicted with red dots. Green dots indicate lymphocyte ground truth.
The overall schema of the proposed workflow is summarized in Fig. 1.
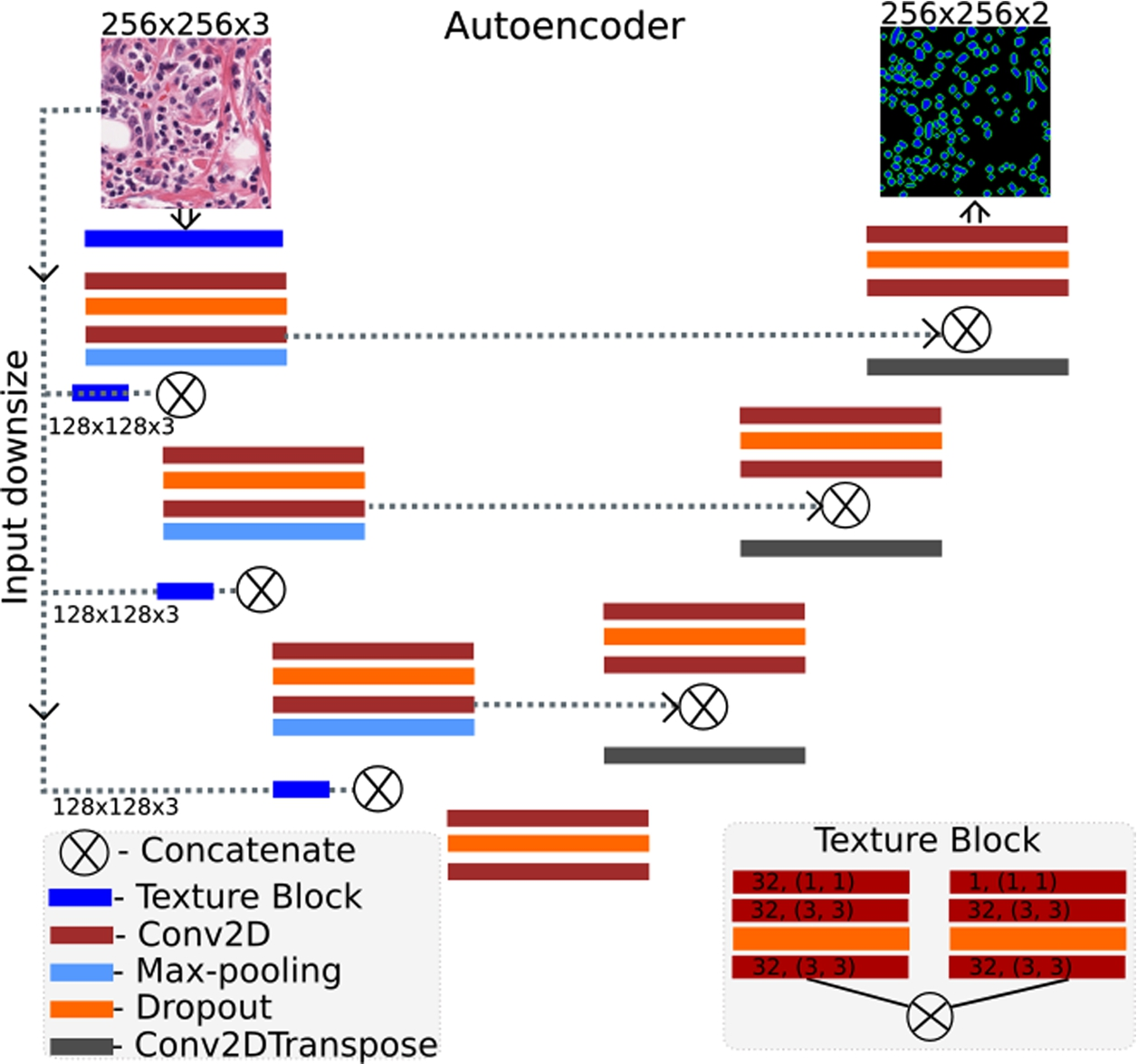
The architecture of the proposed deep learning model.
The autoencoder architecture for nuclei segmentation is shown in Fig. 2. The model consists of 3 encoder and 3 decoder blocks consisting of 2 convolution layers (
We used elu activation after each convolution layer and sigmoid activation for the output layer. Adam optimizer was used with initial learning rate
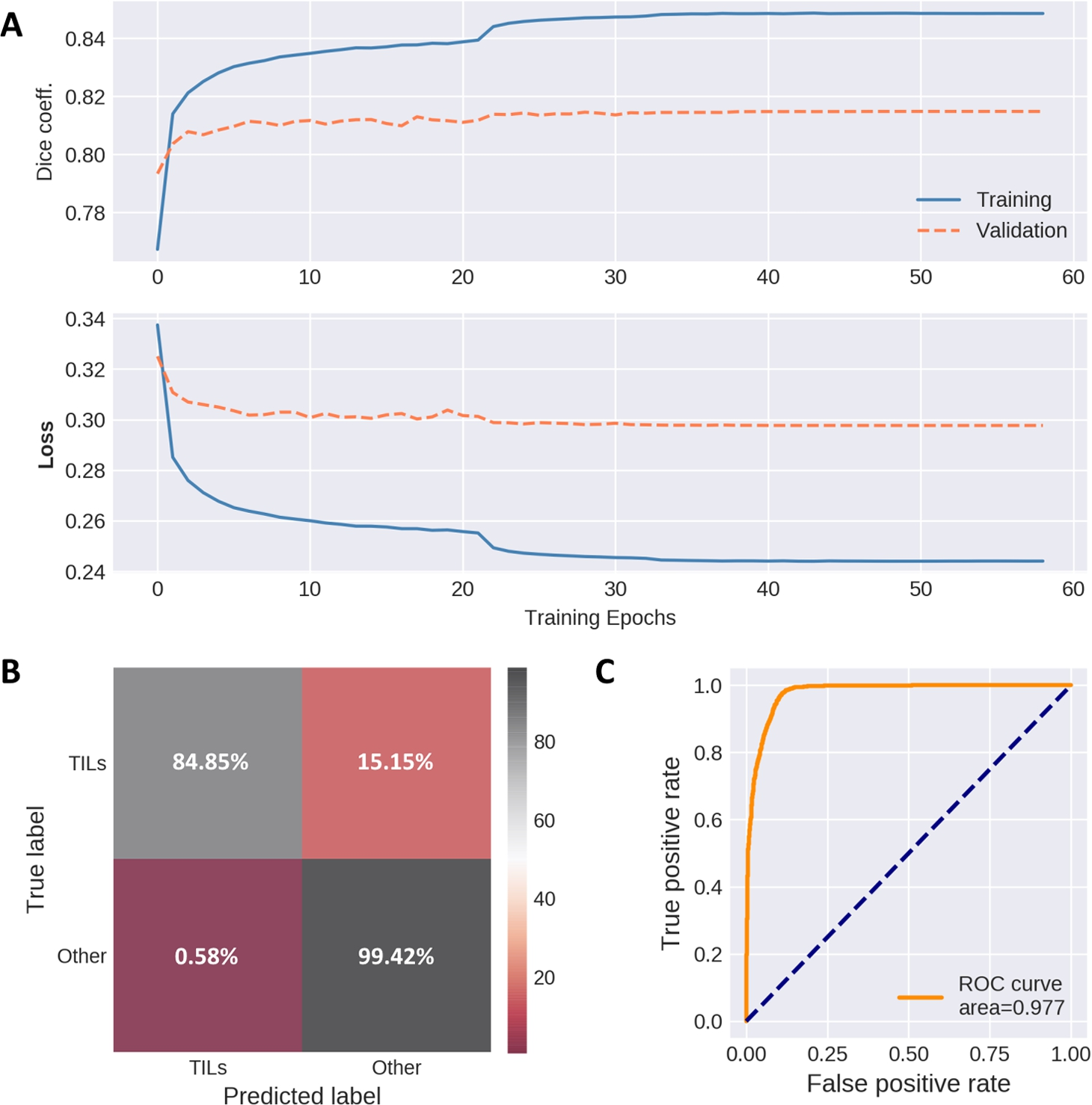
The performance metrics of segmentation and classifier models. A: training and validation metrics (top-Dice coefficient, below-loss values per epoch) of segmentation autoencoder, B: confusion matrix depicting cell nuclei classifier performance on the testing set (true positive lymphocyte predictions and true negatives marked in grey, false predictions – in red), C: ROC curve obtained from nuclei classifier testing data.
Model converged after 36 epochs (see Fig. 3A) using batch size of 1 (input image dimensions:
The multilayer perceptron model was employed to solve the binary classification problem of lymphocyte identification. Our experiment’s model consists of three dense layers (number of nodes: 4096, 2048, 1024), with softmax as the output layer activation function. For each layer, we used relu activation, followed by batch normalization. The dropout layer (dropout rate 0.4) was used in the middle layer instead of batch normalization to avoid model overfitting. We used Adam optimizer with initial learning rate
Implementation
Neural network models for nuclei segmentation and cell-type classification were trained on GeForce GTX 1050 GPU, 16 Gb RAM using Tensorflow, and Keras machine learning libraries (Abadi et al., 2016). Proposed neural model architectures are available in the GitHub repository.1
Results
Nuclei Segmentation
Hyperparameter Tuning
The optimal model architecture was experimentally evaluated using a hyperparameter grid search. To test segmentation robustness, we evaluated both pixel-level and object-level metrics. The dice coefficient was used to track pixel-level segmentation performance, while object-level segmentation quality was evaluated by calculating intersection over union (IoU). We treated the predicted nuclei as true positive if at least 50% of the predicted nuclei area overlapped with the ground truth nuclei mask. In order to prevent multiple predicted objects mapping to the same ground truth nucleus, ground truth nucleus mask could only be mapped to a single predicted object. Results of hyperparameter tuning are provided in Table 3. Hyperparameter space was investigated by changing dropout rates, convolution filters per network layer, and activation functions. Due to multiple image down-sampling and concatenation operations in CNN architecture, models with parameter size higher than 500 000 have exceeded memory limitations. Our experiments indicate that expansion of model layer width (tested kernel sizes 16, 32, 48) did not dramatically affect the model prediction metrics – which suggests that texture block component may ensure consistent feature extraction in a wide range of model width.
Performance metrics of convolutional autoencoders (CAE) used for the hyperparameter grid search for nuclei segmentation. Dice coefficients (mean Dice coefficient ± standard deviation). Mean and standard deviation values were calculated from stand-alone dice coefficients for each tile from the testing set. DO – drop out rate, BN – batch normalization.
Performance metrics of convolutional autoencoders (CAE) used for the hyperparameter grid search for nuclei segmentation. Dice coefficients (mean Dice coefficient ± standard deviation). Mean and standard deviation values were calculated from stand-alone dice coefficients for each tile from the testing set. DO – drop out rate, BN – batch normalization.
Instead of basing our optimal model selection rationale solely on the Dice coefficient and object-level testing metrics, we evaluated the gridsearch models based on its loading and image prediction time relative to the original Micro-Net model. Since no significant changes were observed between dropout rates, we chose a custom model of a 0.2 dropout rate, elu activation function, and sigmoid activation function with differing layer widths of 16, 32, and 48 kernels. The testing results provided in Table 4 indicate that the lowest relative image prediction and model loading time was observed for segmentation autoencoder consisting of 32 convolutional kernels per layer, 0.2 dropout rate using elu activation function and sigmoid activation function for output layer with total parameter size lower than 280.000. In comparison to U-Net autoencoder (>1.9 M parameters), which has reached
A comparison table of autoencoder parameter size and performance speed. Model loading and prediction times were obtained relative to the original Micro-Net model. The best performing model is highlighted in bold.
A comparison table of autoencoder parameter size and performance speed. Model loading and prediction times were obtained relative to the original Micro-Net model. The best performing model is highlighted in bold.
To evaluate the impact of the active contour layer on nuclei separation, we trained convolutional autoencoder using single-layered nuclei masks and compared the results with an identical model trained on two-layered annotations. During this experiment, we used the best-scoring model architecture from the hyperparameter search experiment. Nuclei segmentation using masks supplemented with the active contour layer has outperformed the model with single-layered masks both on pixel-level and object-level measurements, as shown in Table 5. Active-contour increased object segmentation accuracy and f-score by 1 percent (
The active contour layer effect on nuclei segmentation autoencoder performance. Pixel-level Dice coefficients (mean Dice coefficient ± standard deviation) were obtained from a testing set consisting of 96
RGB tiles, where mean and standard deviation values were calculated from stand-alone dice coefficients for each tile. Object-level accuracy, precision, recall, and f-score metrics collected if at least 50% overlap between annotated and predicted nuclei masks (mean intersection over union IoU).
The active contour layer effect on nuclei segmentation autoencoder performance. Pixel-level Dice coefficients (mean Dice coefficient ± standard deviation) were obtained from a testing set consisting of 96
Hyper Parameter Tuning and Model Comparison
The cell classification problem was approached with several different statistical models. Random Forest was chosen as a baseline machine learning algorithm. We used Python implementation of a random forest classifier from the sklearn machine learning library (Feurer et al., 2015) (using the Gini impurity criterion as split quality measurement and 10 estimators). Random forest classifier was trained on linearized nuclei images (
The hyperparameter grid search results for cell nuclei classifier (mean ± standard deviation). The model performance was evaluated on the testing set. Mean and standard deviation values were obtained by running each experiment 5 times.
The hyperparameter grid search results for cell nuclei classifier (mean ± standard deviation). The model performance was evaluated on the testing set. Mean and standard deviation values were obtained by running each experiment 5 times.
The confusion matrix for our cell classification model demonstrates that out of 2046 labelled lymphocytes, 310 were falsely misclassified as other cell types, while 13 false-positive observations were registered out of 2235 nuclei labelled as other cell types as shown in Fig. 3B. Receiver-operating curve (ROC) shown in Fig. 3C indicates the low false-positive rate of our lymphocyte classifier.
Of note, the proposed two-step lymphocyte detection model can potentially be adapted to detect more cell types by replacing existing lymphocyte classifier with a model trained on several classes.
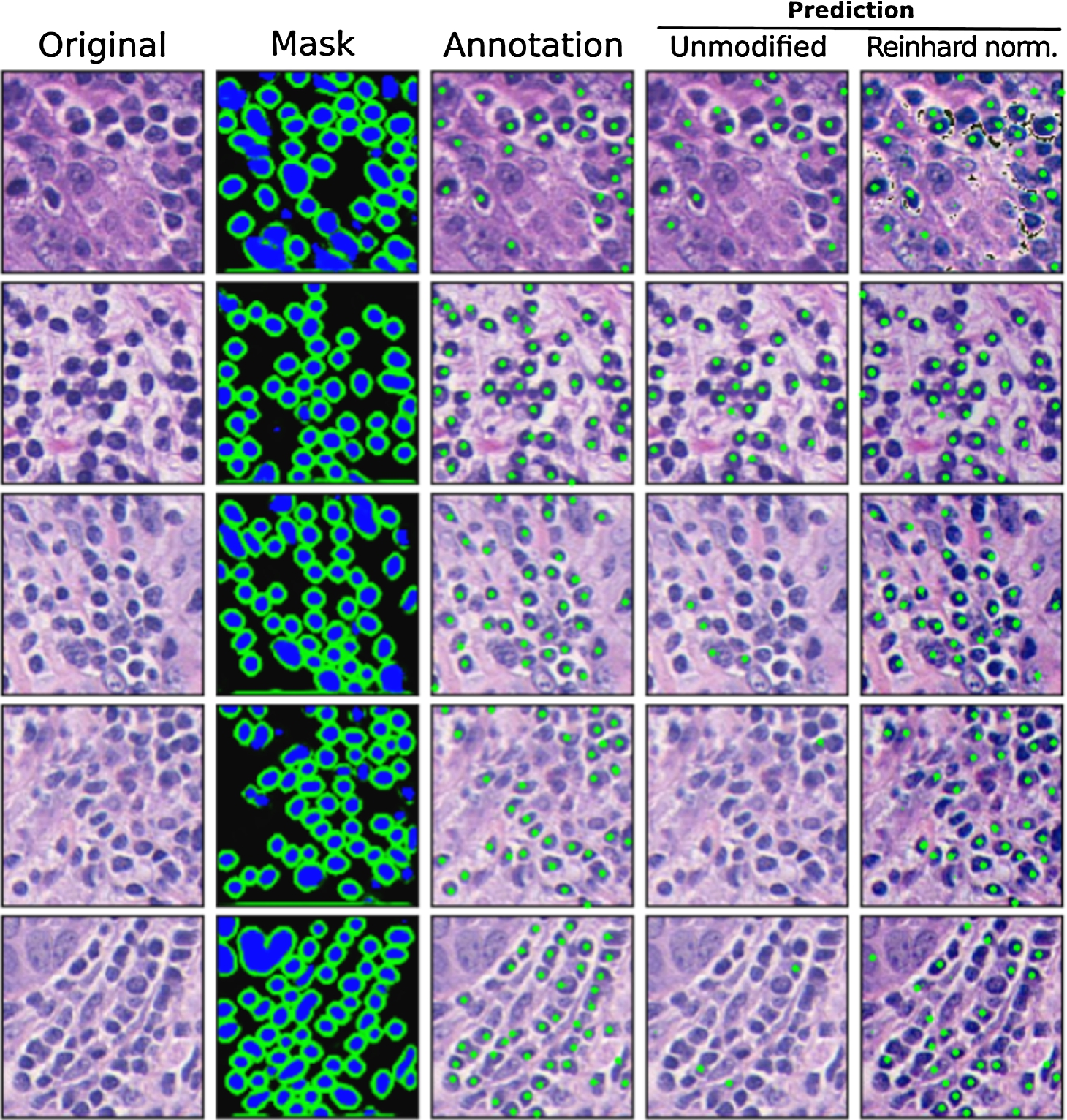
Exemplary 5 testing images from breast cancer lymphocyte dataset (Janowczyk and Madabhushi, 2016) with corresponding lymphocyte identification model outputs. From left to right: 1st column- original testing image from the lymphocyte dataset. 2nd column: nuclei segmentation masks predicted by autoencoder. 3rd column: Expert pathologist’s annotation supplied in the dataset. 4th column: lymphocyte classifier result (if the nucleus was predicted as a lymphocyte, its centre was labelled with a green dot). 5th column: lymphocyte classifier result after Reinhard stain normalization.
The proposed lymphocyte identification workflow has been tested on the lymphocyte dataset published by Janowczyk and Madabhushi (2016).2 The dataset is composed of 100 breast cancer images stained with hematoxylin and eosin and digitized using
The first analysis results – nuclei segmentation – are shown in the second column of Fig. 4. Nuclei segmentation masks generated by autoencoder demonstrate consistent cell nuclei detection efficiency regardless of image staining intensity. This can be explained by two factors. Due to robust image colour augmentation during autoencoder training, the CAE model learned to generalize the input image by texture, rather than colour. Secondly, our modified Micro-Net model architecture incorporates texture convolutional blocks shown in Fig. 2, which facilitate relevant feature extraction for the autoencoder.
The confusion matrix in Fig. 5A shows a low false-positive lymphocyte misclassification rate. However, the high false-negative rate suggests that the lymphocyte classification model is sensitive to image stain intensity. This is well reflected in Fig. 4 Unmodified image column, where lymphocyte detection efficiency conspicuously decreases as image staining intensity fades. This is not a surprising result, given that a multilayer perceptron was trained on lymphocytes cropped from histology samples prepared in a different laboratory, where image staining is more consistent across different histology samples. This result illustrates the main limitations of the lymphocyte classification model: cropped nuclei images lose image background information, which otherwise could be leveraged in differentiating nucleus stain intensity versus its background colour intensity.
To address high staining variability between different histological samples, the lymphocyte testing dataset was normalized using the Reinhard stain normalization method. Reinhard algorithm adjusts the source image’s colour distribution to the colour distribution of the target image by equalizing the mean and standard deviation pixel values in each channel (Reinhard et al., 2001).
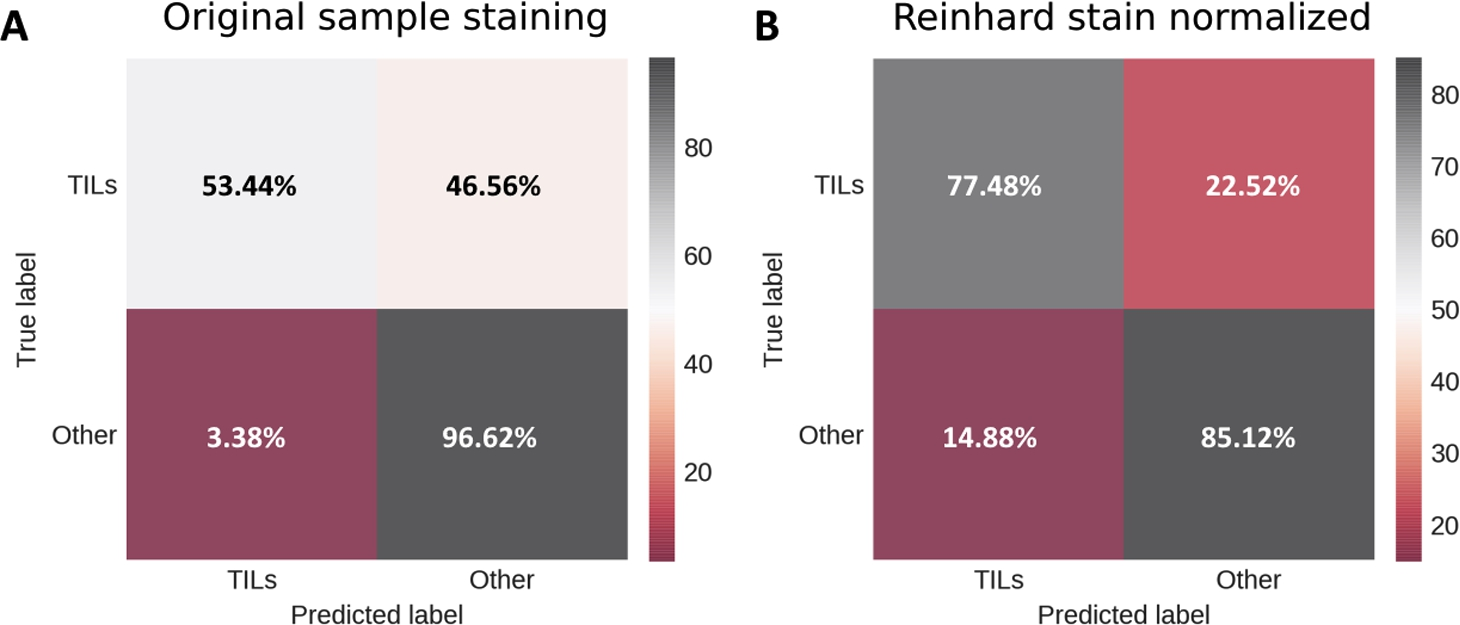
Testing metrics for breast cancer lymphocyte dataset. A: confusion matrix for testing images with original sample staining; B: confusion matrix for testing images with Reinhard stain normalization applied on image stain.
Stain normalization effect on cell lymphocyte detection was evaluated by comparing testing metrics before stain normalization and after Reinhard algorithm implementation. The confusion matrix in Fig. 5B indicates a lower false-negative rate for lymphocytes. Stain normalization has increased accuracy, precision, recall, and f-score values by approximately 10%, as shown in Table 7. These results indicate that the stain normalization step is an effective pre-processing part which can mitigate high staining intensity variance between histology samples. Observed improvement of lymphocyte classification accuracy by applied relatively simple Reinhard stain normalization suggests this part of our workflow can be further explored. Structure-preserving image normalization methods (Vahadane et al., 2016; Mahapatra et al., 2020) demonstrate promising results; also, certain medical image denoising techniques (Meiniel et al., 2018; Pham et al., 2020) could appear useful in future work.
A comparison table depicting the effect of stain normalization on lymphocyte identification efficiency is presented. For comparison, we give here the results of the studies that utilized the same dataset. It is important to note that we only used this dataset to test our method, while studies referenced in the table used part of this dataset for training as well.
Both Janowczyk and Madabhushi (2016) and Alom et al. (2019) used the same dataset to train and evaluate their proposed models; therefore, to deal with overfitting, authors had to apply some sort of cross-validation. 5-fold cross-validation was used in Janowczyk and Madabhushi (2016), and Alom et al. (2019) reserved 10% of the dataset for testing purposes. In contrast, we used the whole dataset exclusively for the proposed model evaluation, thus completely eliminating the possibility of overfitting. Our result (f-score = 0.80) indicates good model generalization and comparable performance to both the above-mentioned methods.
In this paper, we propose an end-to-end deep learning-based algorithm for cell nuclei segmentation and consecutive lymphocyte identification in H&E stained
Our proposed autoencoder structure component – convolutional texture blocks – can achieve Dice nuclei segmentation score similar to that of the Micro-Net model (our model achieved 1% higher testing Dice coefficient).
Additional active contour layer in nuclei annotation masks increases nuclei segmentation accuracy by 1.5%.
Lymphocyte classification by multilayer perceptron network achieves
Nuclei segmentation autoencoder architecture investigated in this paper has lower model complexity compared to U-Net and Micro-Net models, which brings the advantage of lower computational resource usage. Our suggested pipeline shows good generalization properties, eliminates overfitting, and can be easily extended for multi-class nuclei identification by replacing the nuclei classification MLP model and re-employing the same pre-trained segmentation autoencoder.
Footnotes
Link to GitHub repository of the project:
Link to the dataset:
Acknowledgements
The authors are thankful for the HPC resources provided by the IT APC at the Faculty of Mathematics and Informatics of Vilnius University Information Technology Research Centre.