
Abstract
Fabric defect detection is crucial in the textile industry, as it suffers from challenges such as small defect sizes, diverse morphologies, and imbalanced sample distributions. Current mainstream methods approach it as an object detection problem. Many fabric defects, particularly small ones, are caused by production faults that disrupt the fabric texture. These defects often lack distinct structural information, which poses a challenge for object detection methods that rely heavily on such features. To address these limitations, we propose a multi-scale detection channel based on Low-level Texture Feature Retention (LTFR), which significantly enhances the detection capability for small-size defects. Additionally, we introduce Powerful-IoU (PIoU) to guide anchors along effective paths for regression, improving localization accuracy for defects with extreme aspect ratios. To further tackle the issue of imbalanced sample distribution, we adopt the SlideLoss function, which adaptively adjusts the weights of easy and hard samples, offering a more effective solution than the traditional binary cross-entropy classification loss. Experimental results on the publicly available fabric defect dataset from Alibaba Cloud Tianchi show that the model achieves mAP@0.5 and mAP@0.5:0.95 values of 49% and 24%, respectively, which represent improvements of 8.4% and 4.8% over the baseline YOLOv8. Even compared to the state-of-the-art YOLOv9-c, the mAP@0.5 value shows a further improvement of 5.1%. These results confirm the effectiveness of the proposed method and highlight its potential as a valuable guide for researchers in the field of fabric defect detection.
Introduction
In manufacturing industries such as apparel, medical, and military instruments, fabric is an essential raw material. However, during the production process, human errors and machine failures are inevitable, leading to potential defects in fabric products. Traditional manual inspection methods heavily rely on human visual perception and personal experience, leading to potential fatigue and other limitations. Over the past few decades, researchers have developed machine vision models and algorithms to automate defect detection processes. These models and algorithms improve the accuracy and efficiency of defect detection, ensuring consistent product quality. 1 However, the increasing complexity of fabric textures and the need for real-time, high-precision detection have posed significant challenges, especially for small defects that are difficult to detect.
Traditional fabric detection methods include statistical methods, spectral analysis methods, model-based methods, and dictionary learning methods. Statistical methods2–14 discriminate defect regions by calculating the statistical feature differences between the pixels under test and the surrounding pixels. These methods lack global feature analysis, making it difficult to effectively handle fabric images with complex textures and insufficiently detect small defects. Spectral analysis methods, such as Fourier transform 6 and Wavelet transform 15 transform the test image into the frequency domain and then locate defects through energy functions. The detection performance of these methods depends on the selection of filters and lacks adaptability. Model-based methods model fabric image textures as Gaussian mixture models, Gaussian-Markov random field models, 16 and then discriminate defects by analyzing the model parameters of the test images. These methods have high computational complexity and cannot effectively locate small defect areas. Dictionary learning methods 7 train a set of dictionaries from normal images and then reconstruct normal images based on the test set, locating defect areas through differencing. These methods require training a dictionary set for each type of fabric image, lack adaptability, and are relatively slow. Despite the advancements, traditional methods still struggle with adapting to the complex and varied nature of fabric defect detection.
With the advancement of deep learning, the use of convolutional neural networks for fabric defect detection has emerged as a significant focus in academic research. Fabric defects are regions of interest characterized by significant differences in shape, color, and texture from their surroundings and can be localized using bounding boxes. Researchers have applied object detection techniques, including Single Shot MultiBox Detector(SSD), 17 Faster R-CNN, 18 Cascade R-CNN, 19 and You Only Look Once(YOLO), 20 to achieve high detection accuracy in fabric defect detection. Although directly applying object detection algorithms to fabric defect detection can yield good results, the specific nature of fabric defect detection differs significantly from general object detection. These fabric defect detection methods emphasize extracting structural information from objects while disregarding variations in lighting, viewing angles, and texture. However, candidate images for fabric defects mainly come from specific cameras on production lines, with fixed lighting and viewing angles. Smaller defects primarily reflect disruptions in texture rather than structure, often caused by various faults during the production process. Detection of such defects typically relies on texture rather than structural information. Moreover, fabric defects are usually small, difficult to localize, challenging to classify, and often suffer from an imbalance between easy and hard samples. Therefore, traditional object detection algorithms are often insufficient to detect fabric defects effectively.
To address these challenges, we propose several innovative strategies to enhance the YOLOv8 architecture, with the improved version named LTFR-YOLOv8. First, we propose a multi-scale detection channel based on Low-level Texture Feature Retention (LTFR), which retains finer-grained defect features, thereby improving the detection capability for small-size defects. Additionally, we use Powerful-IoU (PIoU) (See the Methodology section for details), a novel anchor-guidance mechanism, which enhances localization accuracy for defects with extreme aspect ratios. Finally, we adopt the SlideLoss function (For details, see Section 3.3) to address the issue of imbalanced sample distribution, further improving detection accuracy by focusing on hard samples that are often overlooked by traditional methods. The main contributions of our work are summarized as follows: 1. We propose a detection channel with low-level texture feature retention as part of the YOLOv8, preserving rich low-level texture information and enhancing the network’s ability to detect small defects; 2. By incorporating the PIoU, along with adaptive penalty factors and non-monotonic attention layers, we enhance the model’s ability to accurately locate defects, particularly those with disparate aspect ratios; 3. We adopt the SlideLoss function, which increases the relative loss for hard-to-classify samples, encouraging the model to focus more on difficult and misclassified fabric samples.
Related work
Fabric defect detection is an application of CNN-based multi-scale detection algorithms in industrial production. Therefore, we review related work through the following two aspects.
Fabric detection algorithm based on CNN
Convolutional Neural Networks (CNN) consist of convolutional layers and pooling layers. 21 Object detection models based CNN have been widely applied in computer vision tasks.22,23 Currently, neural network models in object detection can be broadly categorized into two types: anchor-based detectors and anchor-free detectors. Anchor-based detectors can be further classified into two-stage and single-stage detectors. Two-stage detectors, such as the R-CNN series,24–26 and Task-aware Spatial Disentanglement (TSD), 27 begin by generating a set of candidate boxes as proposals. Subsequently, these proposals are classified and refined using CNN.
Single-stage detectors, such as YOLO series,28,29 SSD, 30 RetinaNet, 31 and EfficientDet, 32 directly perform classification and regression tasks without the need for a separate proposal generation step. In recent years, anchor-free detectors such as CornerNet, 33 ExtremeNet, 34 and FCOS 35 have been proposed to overcome the reliance on anchor priors in object detection methods. In the context of fabric detection tasks, anchor-based detection methods outperform anchor-free detection methods due to the multi-scale and spatially random distribution of defect objects. Additionally, single-stage detectors excel in meeting real-time detection speed requirements, even though two-stage detectors exhibit higher accuracy performance. 36 However, existing single-stage detectors are more effective for natural scenes than textile images due to significant differences in object attributes such as texture structure, size, and spatial distribution. As such, the accuracy and speed of current deep convolutional neural networks (DCNNs) remain insufficient for fulfilling the requirements of fabric defect detection tasks.
Inspired by the success of deep convolutional neural networks (DCNNs) in various fields,37,38 researchers are leveraging deep learning-based methods to improve the performance of fabric defect detection models. The adaptability of fabric defect detection models has been a key research focus due to the diversity of textures and backgrounds. For example, Li et al. 39 utilized a compact convolutional neural network (CNN) architecture for detecting several common fabric defects. Xie and Wu 40 achieved improved detection results for fabric images with plain backgrounds, regular patterns, and irregular patterns by enhancing the refineDet method. Liu et al. 41 proposed an effective shallow network called DLSE-Net, which utilized the expansion Up-Weight CAM and Link-SE module to highlight defect regions and improve the adaptability to complex textures. Zhang et al. 42 achieved improved detection accuracy on yarn-dyed fabric defect detection by optimizing the hyperparameters of the YOLOv2 network. Jing et al. 43 enhanced the YOLOv3 framework by incorporating the k-means algorithm for dimension clustering of target frames. They further optimized the detection layer, leading to an improved fabric detection algorithm with enhanced real-time performance. Jin and Niu 44 improved the defect detection capability of the YOLOv5 model by utilizing a teacher-student architecture and incorporating multitask learning to enhance its classification abilities. To enhance the real-time detection efficiency, Jing et al. 45 proposed a highly effective end-to-end defect segmentation CNN called Mobile-Unet. However, these methods did not adequately consider the underlying texture information of fabric defects, leading to a lack of effective preservation of multi-scale contextual information. As a result, a proper balance between detection efficiency, accuracy, and generalization was not achieved.
Application of multi-scale detection
Research exploring the application of multi-scale object detection techniques for industrial-scale multi-scale defect detection is scarce. In 2017, Zhou et al. 46 resolved the issue of detecting small-sized solder ball defects in high-density chips by constructing a three-dimensional inductive heating finite element model. In a study conducted in 2021 Li et al. 47 proposed a belt layer defect detection method based on an improved Faster R-CNN for detecting small-sized defects in the carcass layer of radial tires. The method employs feature fusion and DIoU to tackle the problems of inadequate feature extraction for small-sized defects and loose bounding boxes. In view of the shortcomings of small target detection methods in image remote sensing applications.
The characteristics of the objects investigated in the aforementioned studies on small object detection are different from the fabric studied in this paper, as they do not involve the complexities of texture and pattern backgrounds. Additionally, conventional small object detection methods have limited research and application in the multi-scale detection of fabric defects, as they are primarily used for tasks like PCB detection and small object recognition in remote sensing imagery. This paper focuses on improving the detection accuracy of fabric defects and addressing the multi-scale detection challenge, specifically targeting small defects on fabric surfaces.
Methodology
YOLOv8 is one of the YOLO series, an efficient real-time object detection algorithm. It is based on deep learning and convolutional neural networks (CNN), capable of simultaneously performing object classification and localization, achieving efficient detection through a single forward pass. The YOLOv8 algorithm has gained significant attention in object detection due to its remarkable detection capability and efficient processing speed. The YOLOv8 architecture consists of three primary components: backbone, neck, and head. In the backbone component, the Cross-stage Local Network (CSP) is introduced to enhance feature extraction. Specifically, the CSPDarknet53
48
network is used as the backbone for extracting rich and discriminative features from the input images. The PAN-FPN
49
method is used to fuse multi-scale features from the output of the backbone. During prediction, a decoupled head structure is used, and the bounding box regression loss is computed using the CIoU loss function. To address the challenges of locating small fabric defects with diverse morphologies and the imbalance in sample difficulty distribution, this paper proposes a multi-scale detection channel with low-level feature retention. This approach enhances the model’s ability to preserve low-level texture information and improves the accuracy of detecting defects, especially small ones. In the prediction stage, PIoU is utilized to guide the effective regression of anchor boxes, resulting in improved localization accuracy, and then the SlideLoss function is used to solve the problem of unbalanced distribution of hard and easy samples. The model structure is illustrated in Figure 1. Architecture of the LTFR-YOLOv8. The feature map first passes through the feature extraction backbone network and then enters the multi-scale feature fusion Neck network to enhance rich multi-scale information. Finally, classification and regression are performed through the Head. Among them, the Detect head, with a size of 160 × 160 × 45, serves as a detection head for preserving low-level texture features, thereby improving the model’s ability to detect small objects.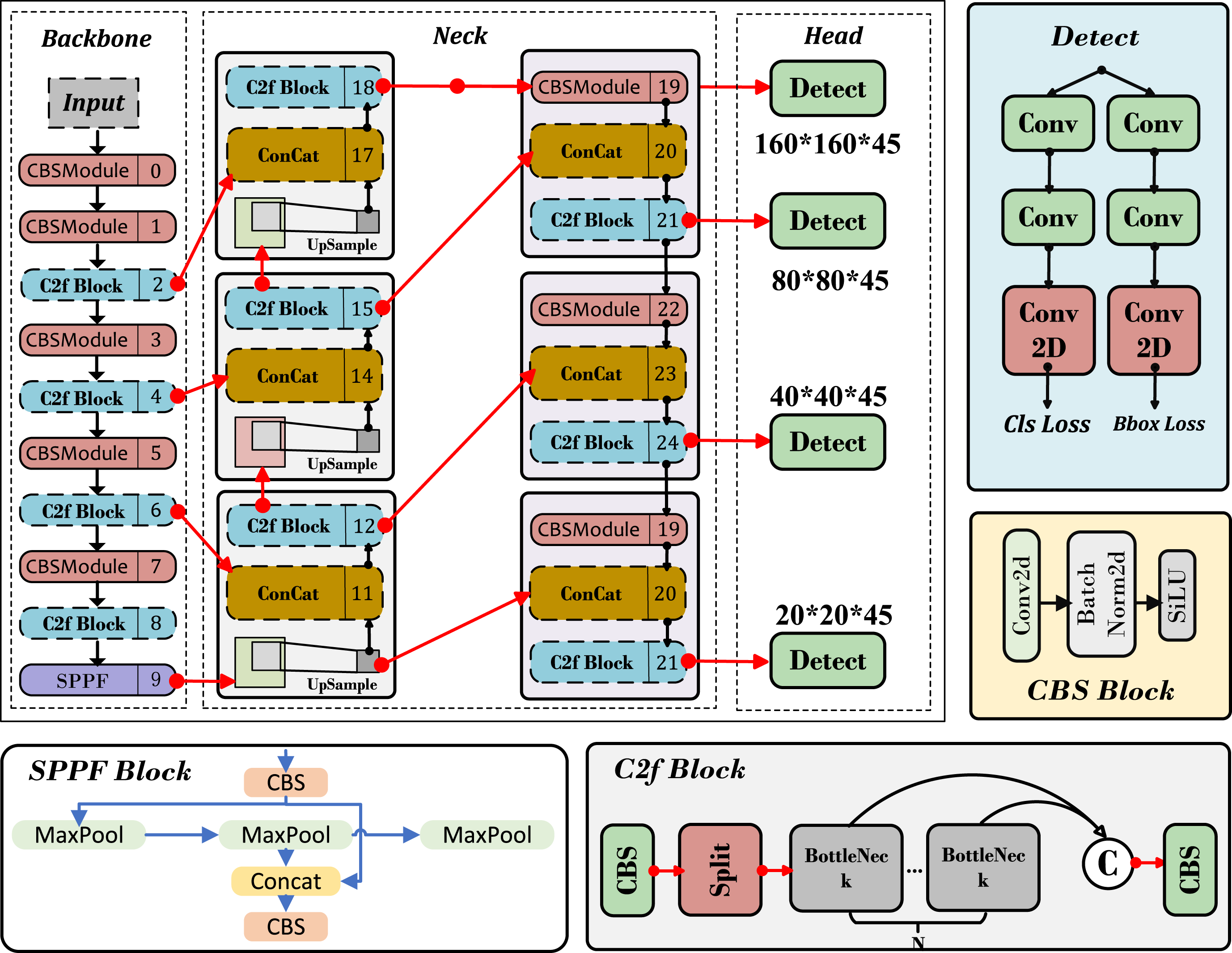
Multi-scale detection channel based LTFR(M-LTFR)
For defect detection tasks, the early layers of the feature extraction backbone network capture rich texture structural information. However, as the network deepens and the receptive field expands, the clarity of image texture details diminishes, leading to increased blurring. This may result in the gradual disappearance of texture details while semantic information continues to increase. Figure 2 depicts the feature maps at different layers of the input image: layers B1 and B2 contain rich low-level information, with B2 having less noise than B1, while B3, B4, and B5 contain more structural information and high-level semantic information. The neck of YOLOv8 uses a Path Aggregation Network with Feature Pyramid Network (PAN-FPN) structure to build a top-down and bottom-up network architecture. Through feature fusion, this structure achieves the complementarity of positional information and semantic information, ensuring feature diversity and completeness. However, it overlooks the retention of B2 feature information. Fabric images differ significantly from natural scene images, as they possess abundant texture information and simple semantic information. To retain more low-level features, the PAN-FPN needs to provide more fine-grained information. Visualization of feature maps at all levels.
Therefore, we design a Multi-scale detection channel based LTFR(M-LTFR), whose structure diagram is shown in Figure 3. M-LTFR combines feature information from the backbone, preserving rich shallow-level texture features, and transfers the enriched texture and semantic information to the feature fusion stage. To provide a detailed description of the feature fusion process in M-LTFR, the feature mappings (if present) at each layer are defined as follows: M-LTFR architecture design. From 
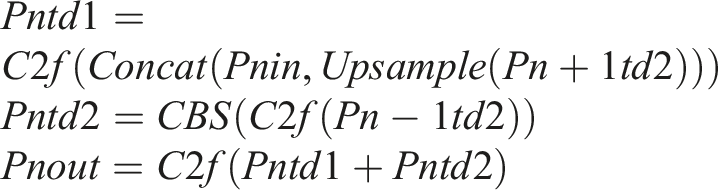
Here,
Compared with PAN-FPN, M-LTFR has three improvements. First, under the premise of retaining the original structure, the low-level feature fusion is added, at this time, the high-level fusion nodes {P3, P4, P5} remain unaffected. This ensures that the additional information from the input node to the output node is completely preserved. Second, M-LTFR maximizes the utilization of initial features by incorporating the intermediate features of the low-level P2, enhancing the integration of rich bottom-level features without incurring significant computational overhead. Third, by utilizing intermediate features, we design a new detection scale to address the difficulty of detecting small defects. Experiments show that this method significantly improves the accuracy of fabric defect detection while maintaining a detection speed that meets the requirements of industrial applications.
In M-LTFR, features are independently transmitted from each relevant layer ({P2, P3, P4, P5}) to two separate classification/regression subnets for subsequent stages of bounding box regression and defect classification.
Enhancement of bounding box regression loss function
At present, commonly used loss functions for bounding box regression include IoU loss
50
and its improved variants, such as GIoU loss,
51
DIoU loss,
52
CIoU loss, EIoU loss,
53
and WIoU.
54
The IoU expression is defined as follows:
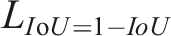

Here, IoU-based losses. (a) presents the graphical structure and formulas of GIoU, DioU, CioU, and EIoU. (b) presents the graphical structure and specific formulas of WIoU and PIoU.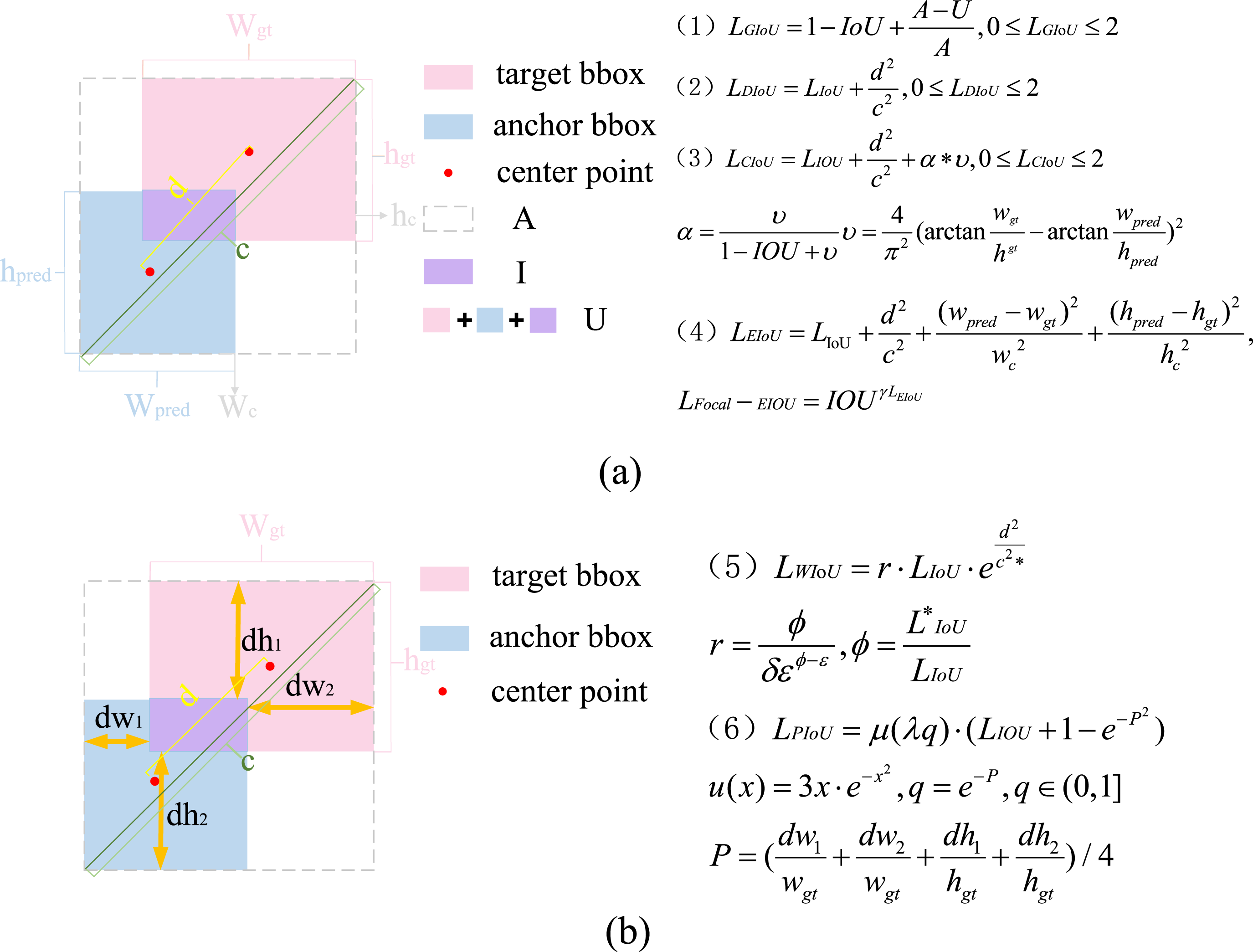
The aforementioned bounding box regression loss functions do not account for the directional mismatch between anchor boxes and target boxes. Without constraining the orientation between target box and anchor, the anchor box is likely to expand during training, failing to adapt to the target box and resulting in a poor model. This defect can lead to slower model convergence and lower learning efficiency. Additionally, EIoU loss and WIoU have shortcomings in optimizing anchor box quality.
Pseudo-code of the PIoU algorithm.

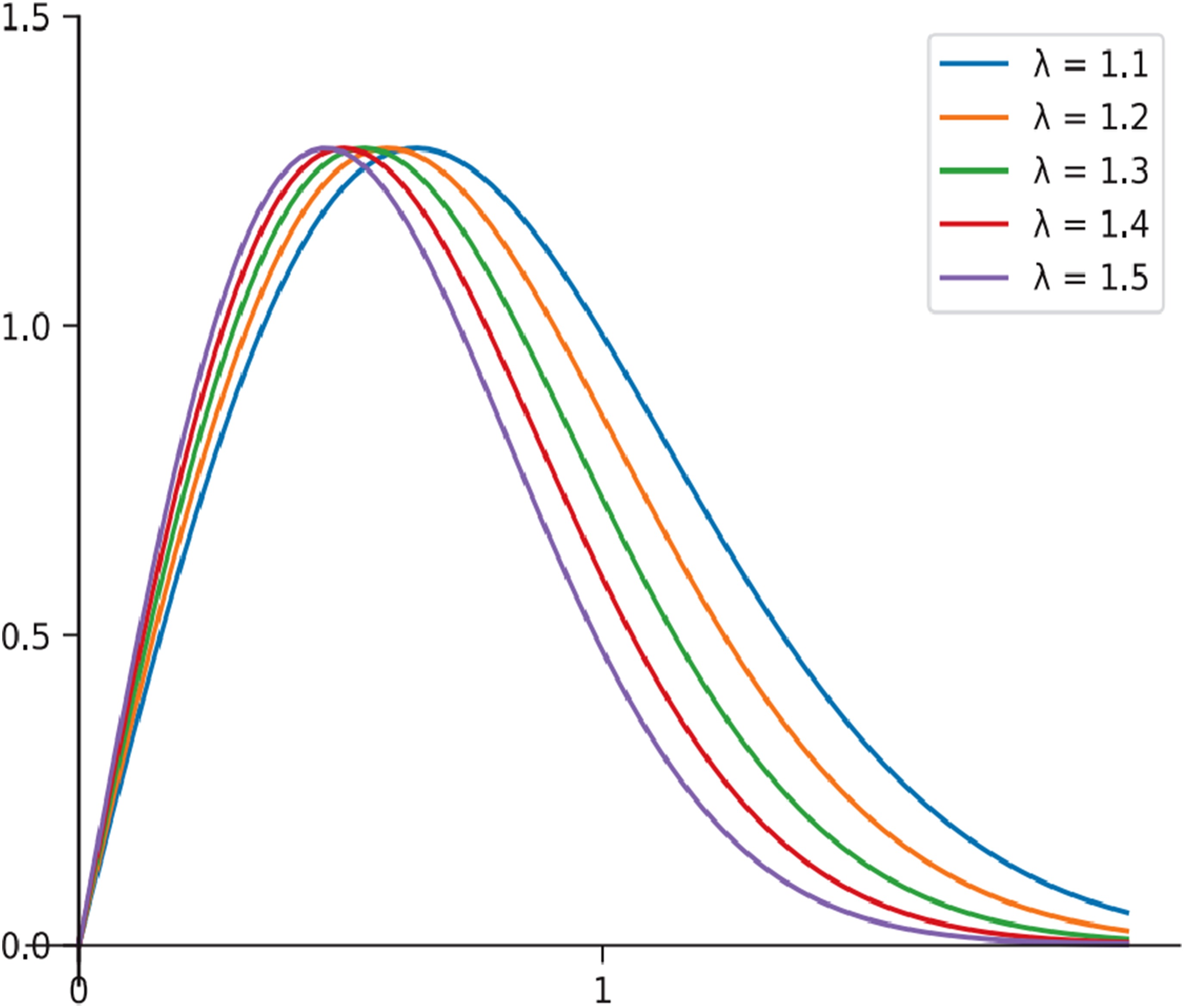
Curves of different values of λ for µ(λx).
Experiments show that PIoU loss can make YOLOv8 model converge faster, improve positioning accuracy, and perform better in locating defects with disparate aspect ratio. Therefore, this paper adopt PIoU loss with better performance to replace the CIoU loss as the bounding box regression loss function of YOLOv8 network.
Enhancement of classification loss function
The choice of the loss function has an impact on the stability of the neural network model during training. YOLOv8 employs the second hospital’s cross-entropy loss function for classification. For binary classification, the formula is as follows: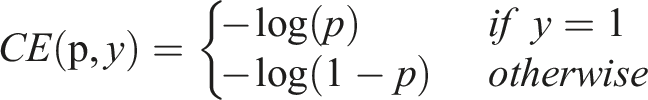
In fabric defect detection, the size of the defect area is significantly smaller compared to the background area. The fabric defect detection process often results in an imbalance between easy-to-classify and difficult-to-classify samples, with a higher proportion of the former. This imbalance extends to positive and negative samples as well. As a result, the loss function used during model training can be skewed, giving more weight to negative samples and easy-to-classify samples. This imbalance can negatively impact the model’s performance on positive samples and difficult-to-classify samples, as they may receive less attention and emphasis within the training process. In order to solve this problem, Shrivastava et al. 55 proposed the OHEM algorithm, which selected challenging samples based on their loss and incorporates the loss of these difficult samples into the training process using stochastic gradient descent. Aiming at the problem that OHEM algorithm ignores simple samples, Focal Loss 56 achieved higher accuracy by effectively leveraging all samples through weighting SRNS 57 also followed this idea. Faceboxes 58 utilizes IoU loss for sample classification and ensures that the ratio between positive and negative samples remains within 1:3. Although the aforementioned methods effectively address the issue of sample imbalance, they also introduce additional hyperparameters, making the adjustment process more challenging.
SlideLoss is a classification loss function that can adaptively adjust the weight size and improve sample imbalance. SlideLoss adopts the average IoU value of all bounding boxes as the threshold Output curves of SlideLoss functions.

Experimental conclusion and analysis
Experimental setting
Experimental environment and evaluation parameter
All experiments were conducted on an Ubuntu 22.04.4 LTS platform utilizing an NVIDIA L40 GPU (48 GB VRAM) and an Intel® Xeon® Platinum 8458P CPU, with PyTorch 2.1.0 accelerated by CUDA 12.1 and Python 3.8. The enhanced YOLOv8 architecture was optimized using SGD with a base learning rate of 0.01, momentum coefficient 0.937, and L2 regularization weight decay 0.0005 over 300 maximum training epochs. Deterministic modes with fixed random seed (0) and CUDA-configured reproducibility ensured experimental repeatability. Training employed 32-image batches of 640 × 640 resolution inputs processed through 8 parallelized data-loading workers. Critical regularization mechanisms included early stopping (50-epoch patience threshold) to mitigate overfitting and progressive deactivation of mosaic augmentation in the final 10 epochs for loss convergence stability. Initializations excluded pretrained weights to isolate model improvements, while rigorous baseline comparisons maintained identical dataset partitioning (6:2:2 train:val:test ratio). Quantitative evaluations measured detection quality via AP@0.5 (IoU = 50%) and mAP@[0.5:0.95] while assessing computational efficiency through FPS rates and GFLOPs. Memory optimization protocols incorporated gradient checkpointing alongside disabled data caching (RAM/disk), complemented by directory overwrite protection to preserve training environment integrity.
To evaluate the performance of the enhanced YOLOv8 algorithm, key evaluation metrics are employed, including average precision, frames per second (fps), mean average precision (mAP), and parameter count. Among these metrics, mAP holds particular significance as it offers a comprehensive evaluation of the model’s performance.



Dataset and preprocessing
This paper performed experiments on the publicly available Alibaba Cloud Tianchi fabric defect dataset, which is widely recognized for its high-quality defect data. It includes 5913 images with a resolution of 2446 × 1000 pixels and covers 34 defect categories: Knot, Head, Three, strands, Coarse, weft, Broken spandex, Warping knot, Weft contraction, Loose warp, Starch stain, Hole, Broken ends, Thin file, Stain, Star jump, Thick end, Gouge, Capillus, Centipede, Suspending warp, Retouching, Check jump, Deathfold, Skip, Oil stain, Darts, Grinding mark, Water stain, Reed path, Poor weft, Singe mark, Chromatic crotch, Wavy crotch, Double weft, Double ends, Cloud weaving. An example plot of each defect category is shown in Figure 7. The training, validation, and testing dataset were split in a standard 6:2:2 ratio, with the model’s performance on the test set being the final criterion. After collation, the analysis visualization is shown in Figure 8. Where (a) is the distribution of the centroid position of the fabric defect, (b) is the distribution of the size of the fabric defect, and the abscissa width and ordinate height denote the width and height of the object, respectively. The annotation files of this dataset are in JSON format based on the PASCAL VOC standard. They need to be converted into TXT files in the YOLO format using the following conversion formula: Sample images of each type of defect. Dataset analysis. (a) is the distribution of the centroid position of the fabric defect, (b) is the distribution of the size of the fabric defect.




Experiment results and analysis
Both the YOLOv8 and LTFR-YOLOv8 models were trained using the same parameter settings and dataset. Figure 9 compares the bounding box regression loss, classification loss, and distribution focusing loss during training. The x-axis is the number of training batches, while the y-axis is the corresponding loss values. It is evident from these figures that the LTFR-YOLOv8 model exhibits lower values for both bounding box loss and distribution focusing loss, indicating faster convergence during training. The classification loss increases with the number of iterations, and the value is larger than that of the YOLOv8 model, which is due to the high weight value assigned by SlideLoss to difficult samples. The training batches are all 300 epochs, but LTFR-YOLOv8 converges faster with less than 250 training times, which confirms the significant improvement in the performance of the LTFR-YOLOv8. Comparison curves of different loss functions.
Comparison of AP values each class of detection results on YOLOv8 and LTFR-YOLOv8.

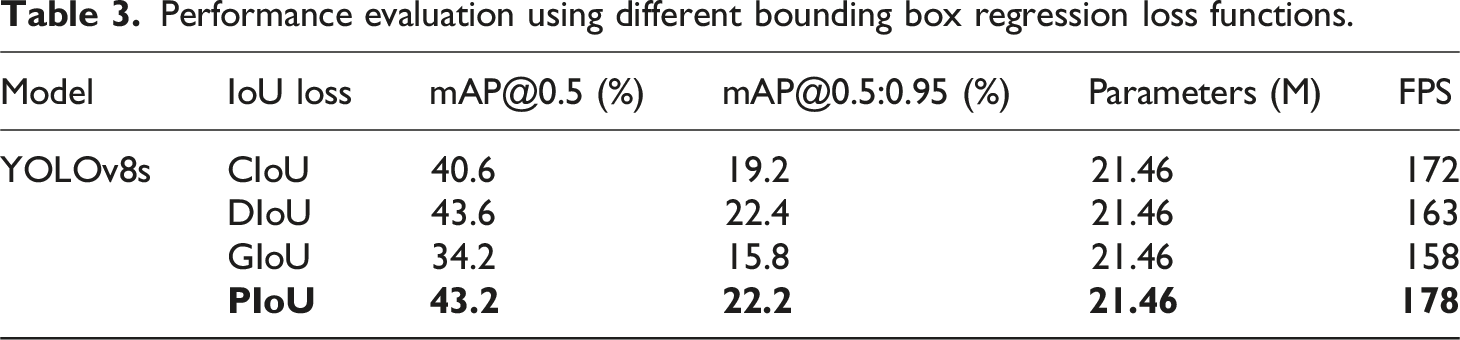
Performance evaluation using different bounding box regression loss functions.
Performance evaluation using different classification loss functions.

Performance evaluation using different λ for PIoU.

Ablation experiment
Results of ablation experiments on Tianchi dataset.


Comparison of detection effect on Tianchi dataset.
Comparison of results on TianChi dataset between LTFR-YOLOv8 and others models.

Performance of PIoU for different hyperparameter values.


Model performance on the Demin dataset.
Conclusion and future work
In this paper, we proposed an enhanced fabric defect detection network that effectively retains low-level texture features and incorporates adaptive anchor boxes to improve detection performance. The M-LTFR technique was introduced to preserve crucial fabric texture information, significantly boosting the accuracy of small defect detection. Furthermore, by integrating PIoU loss with an adaptive penalty factor and a non-monotonic attention layer, our approach guided anchor boxes along effective regression paths, improving their quality and enabling better localization of defects with extreme aspect ratios. The use of the SlideLoss function addressed the issue of sample imbalance in fabric datasets, offering more effective weight adjustment for easy and hard samples compared to traditional loss functions. Experimental results showed that our model outperformed the baseline YOLOv8s in terms of detection accuracy, parameters, and deployment ease, meeting both high detection accuracy and real-time performance requirements in industrial settings.
In the future, we plan to apply the multi-scale fusion method with low-level texture feature retention to other industrial defect detection tasks, such as in electronics manufacturing and automotive components. We also aim to improve the robustness of the model by testing it on a wider range of fabric types and under various environmental conditions, which will help assess its generalization ability in more diverse real-world scenarios. Additionally, we will explore potential optimizations in the model’s architecture and training strategies to further improve its efficiency and accuracy for fabric defect detection. These future studies will help refine our method and expand its practical applications in industry.
Footnotes
Statements and declarations
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NSFC (No.61873293), Leading talents of science and technology in the Central Plain of China (234200510009), Henan province key science and technology research projects (222102210008, 232102211002, 232102211030).
conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.