
Abstract
Style transfer between images has been a research direction gaining considerable attention in the field of image generation. CycleGAN is widely used because it does not require paired image data to train, which greatly reduces the cost of collecting data. In 2018, based on CycleGAN, a new model structure, InstaGAN, was proposed and then applied in the style transfer algorithm in the special part of an image we called instance. From then on, style transfer can transform the instance in the image. Based on CycleGAN and InstaGAN, we transformed the pictures in different domains combined with shape context and thin plate splines (TPS) in the present study. Based on generative adversarial networks (GANs), we designed a fusion network to optimize the results. We combined style transfer with TPS in fashion and got convincing performance by experiments and a fusion net with good performance.
Introduction
With the dramatic development of social economy, people are paying more and more attention to the needs of individualization. In terms of fashion, for ordinary consumers, if it is relatively easy to achieve online personalized try-on, consumers will save a lot of time to choose clothes in the store, and greatly increase the interest in shopping by sliding their finger on a smartphone. Some techniques of deep learning provide the possibility of online try-on. For example, style transfer, which can already achieve online try-on. If a person wants to try on a long sleeve garment online (maybe by smartphone), but there are only short sleeve images in the database, then through style transfer and thin plate spines (TPS) used in this study, the person can see specific long sleeve images.
To achieve this goal, this work uses and modifies the framework of CycleGAN 1 with reference to the framework and design ideas of InstaGAN 2 . Fig. 1 shows our network structure. It is similar to CycleGAN at first glance, but we combined this with a TPS module, so it has become more complicated. The input data is (X, a) and (Y, b), where X and Y represent the images, and a and b are the mask corresponding to the images. Instance normalization 3 has been added to both the generator and the discriminator, and spectral normalization 5 has been added to the discriminator, the same as PatchGAN 17 . Both of these measures improved the performance in experiments. The basic GAN loss is the same as CycleGAN. To follow the theory of WGAN, the loss function of LSGAN is used. The reconstruction loss uses the L1 norm, and the loss of its own mapping is also used. Since the mask information is added, the loss function to deal with mask is needed. This study uses the context loss function to handle mask information. The details of loss function will be introduced in the following sections. The training dataset comes from ATR 6 (style transfer between trousers and shorts). There are more than 17,000 images, but we only processed 6000 images as the dataset of domain X, and 1000 images as the dataset of domain Y; The dataset of swapping T-shirts and jackets is crawled from the Zalando website, and the corresponding annotation is acquired by using the FCN model that has been pretrained on the ATR dataset.
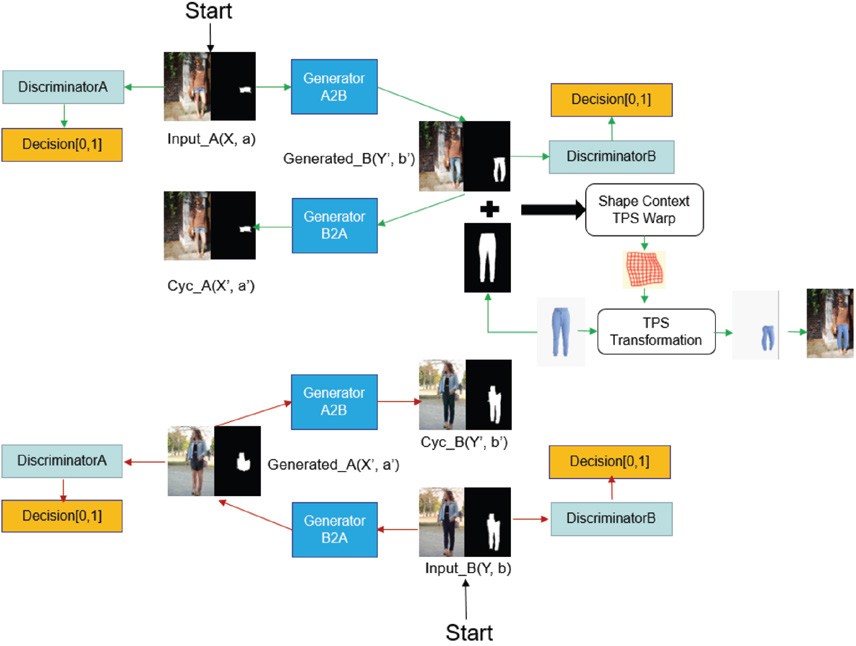
Synopsis of the network structure.
Shape context 7 can transfer objects into specific shapes. The idea of shape context is to change shape between two images by finding the feature point sets, and to determine whether two objects are similar by calculating the matching cost. The object handled in this study is the output of the generator of GAN a and the related mask b. First, the edge detector is used to detect the edges of the two binary masks, then the centroid calculation is performed to establish the log-polar coordinate system, and finally, the shape histogram of each matching point is obtained.
The shape histogram of each pair can be obtained by the above method. To judge the similarity between the feature points a and b on the above, it is necessary to calculate their matching cost. This work uses TPS 7 to minimize the bending energy to acquire the mapping relations between the point sets and the matching cost matrix.
The organization of the paper as follows. We briefly introduce the GANs family and some other work related to image-to-image translation used in fashion. Then, we introduce the details of network, including loss functions and specific network structure. Nest, experiments in two different datasets were performed and the results were analyzed. Finally, we present the conclusion and discuss future work.
Related Work
GANs
Since Goodfellow proposed the generative adversarial network GAN 4 in 2014, the idea that these two networks compete and progress together has become the mainstream idea in the field of image generation. For example, CGAN 8 adds conditional information on the original GAN structure, so that the output of network can be supervised. DCGAN 9 combines GAN and convolution networks and solves the problem of unstable GAN training. WGAN, 10 WGAN-GP, 11 LSGAN, 12 and other methods make network training more stable and faster by changing the loss function of GAN. The prediction result of the network is also greatly improved compared with the original GAN, effectively solving the problem of model collapse. In terms of image super-resolution, SRGAN 13 and ESRGAN 14 are able to generate realistic textures in the single-image super-resolution task, while TecoGAN 15 proposes a spatio-temporal discriminator to obtain more realistic and coherent video super-resolution. Now, when the amount of data is insufficient, the researchers will also consider whether GAN can be used to generate some “real” data.
Image Style Transfer
In the field of style transfer, pix2pix16,17 needs to use a pair of data to train the network, but such paired data collection brings many problems. Therefore, CycleGAN is used to solve this problem. CycleGAN is composed of two mirror-symmetrical GANs. The two GANs share two generators, each with a discriminator. That is, two discriminators and two generators in all. The model inputs an image from domain X, then it is passed to the first generator GXY, whose task is to convert a given image from domain X to an image X′ in target domain Y. At this time, the output is passed to DY. DY is a discriminator to judge if X′ is real or not. X′ is also passed to another generator GYX, whose task is to convert back to image X. This output image must be similar to the original input image to define meaningful mappings that do not exist in the unpaired data set originally. The other part of CycleGAN is analogous in the opposite direction.
Based on CycleGAN, InstaGAN adds the mask information corresponding to the images additionally, and uses the mask information to control the output of the network, which can effectively realize the style transfer just in some specific pixels while maintaining the invariance of the others. The serialized small-batch training method is proposed. When there are multiple targets in the picture that need to be converted, batch transfer is performed instead of transfer all at one time. This method uses limited GPU resources to train the dataset for a large number of instances in a single image.
Online Try-On Methods
FashionGAN 19 needs two steps. The first step is to generate a mask by extracting the mask of the original image through the fully convolutional networks (FCN) 18 and downsampling. The description of the images is encoded as a conditional information input into CGAN to generate a mask that is expected to be acquired. The second step is to generate the texture. Another CGAN network inputs the results of the previous network with related encoding. After that, the network finally outputs the image after the replacement. VITON 20 also performs virtual dressing in two steps, which can seamlessly replace the clothing, and the texture features of the clothing can also be well reflected in the dressing. Similarly, CP-VTON, 21 through the geometric matching module (GMM), converts the target garment into a shape suitable for the target. It then integrates and renders the deformed garment with the character through the Try-On module.
Our work is made of two stages. The first stage is using image style transfer to get the desired masks. Then, the TPS is used to replace the specific part. The part for replacement can be a specific piece of clothing, so that the online try-on can be achieved.
Research Methods
Network Structure and Style Transfer
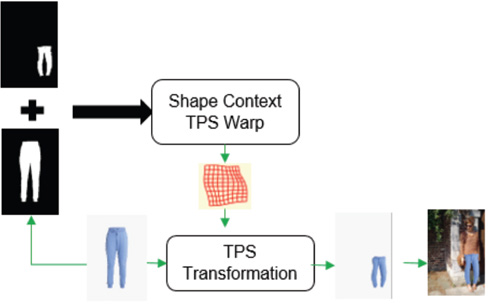
To style transfer between unmatched images, according to CycleGAN, two generators and two discriminators are required. The generator (Figs. 2 and 3) consists of three parts: encoding, transforming, and decoding. For encoding, the features of the input image are extracted by using 3 convolutional layers. In the experiment, the input image was cropped and resized to [300 (height),200 (width) px]. Transformation involves transforming an eigenvector of an image in the domain A into an eigenvector in the domain B by combining the non-similar features of the image. In this study, we used the 6-layer Resnet 23 module. Each Resnet module is a neural network layer composed of two convolutional layers, which retains the original image features as far as possible while transforming. For decoding, the deconvolution layer was used to complete the work of restoring low-level features from the feature vector, and finally obtaining the generated image. The discriminator (Fig. 3) takes an image as input and attempts to predict whether it was the original image or the output image of the generator. The discriminator itself belongs to a convolutional network, and it is necessary to extract features from the image first, and then add a convolution layer that produces a vector to determine the category.
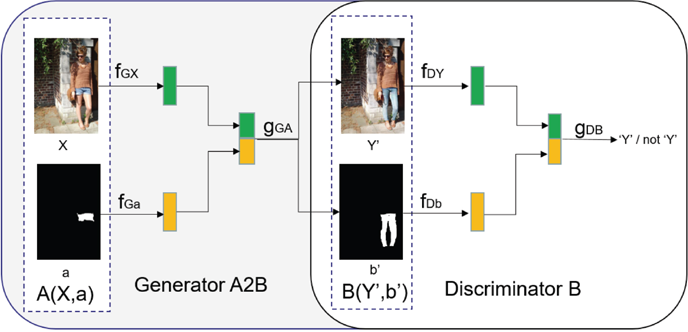
Generator and discriminator structure used for style transfer.
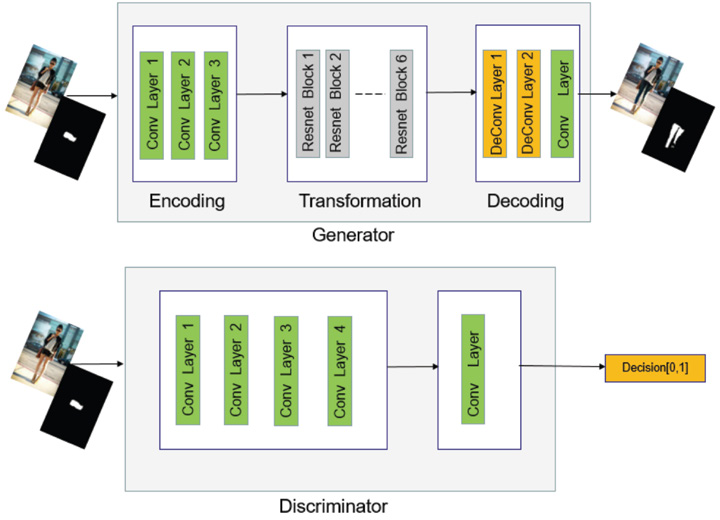
More specific generator and discriminator structure.
Loss Function
Because the loss function of LSGAN has a stable performance, we replaced the loss function of the original GAN with the loss function of LSGAN (like that in CycleGAN) as shown in Eq. 1.
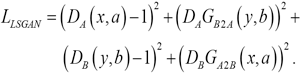
D A and D B are two different discriminators, similarly G B2A and G A2B are two different generators. The reconstruction loss Lcyc (Eq. 2) is used to keep the image invariant after being computed through the two generators. The native mapping loss Lidt (Eq. 3) ensures that the image is invariant when the input image comes from the target domain.
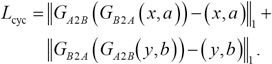
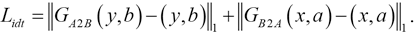
To transfer on the specific part in the image (called the instance in InstaGAN), while ensuring that the background information would be changed as little as possible, InstaGAN proposed a context loss Lctx. First calculate the weight matrix between a and b′, masked as ω(a, b′), where a and b have the value {0, 1}, 0 represents the background, and 1 represents the instance. The weight matrix is calculated according to Eq. 4.
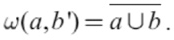
When a = 0 and b′ = 0, ω(a, b′) = 1, and in other cases ω(a, b′) = 0, which means that loss is calculated only when both represent the background, so that the background can remain as constant as possible. The loss function is given in Eq. 5.
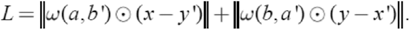
Among them, the symbol ⊙ represents the operation on the element-wise.
Finally, we weighted add all the losses together to get the total loss function (Eq. 6). total loss function (Eq. 6).
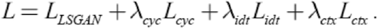
The values λ cyc , λ idt , and λ ctx are referenced to the settings in InstaGAN; we further fine-tuned these. In the experiment for shirt replacement, they were set to 8, 8, 8. In the experiment for the replacement of pants, they were set to 10, 10, 10. No more parameter sensitivity analysis was performed.
Warping a Clothing Image
TPS can be finished by two stages (Fig. 4). Given the target clothing image and a clothing mask generated from the network, we used shape context matching to estimate the TPS transformation and generate warped clothing. First, we used two masks (generate by the blue pants and the network) to produce a control points set, which can also be used in the original image just like the blue pant in Fig. 4. Second, the TPS transformation program will change the shape of these pants by the control points set.
TPS transfer process to generate a warped clothing image.
Shape Context is shape matching, so the first thing to do is to get the edge of the mask which requires edge detection. Since the Canny edge detection operator has good anti-noise interference and can accurately locate the feature points, it was chosen as the edge detection algorithm in this study. Next, we extracted the boundary contour point set p = {p 1 , p 2 , p 3 ,…, p n }. In the experiment, n was set as 200, which indicates the number of contour points extracted, and the centroid would be calculated by those points. Then, we established a polar coordinate system to calculate a shape histogram and the matching cost. This study used the TPS interpolation technique to calculate the matching cost between two sets of points. In more detail, point set A had 200 points, indicating that the edge of the clothes needed to be replaced, and point set B was also 200 points, which represents the contour extracted from a mask map generated by the network. The deformation is done by the TPS transformation to ensure 200 points were matched correctly. TPS can be used to find a smooth curved surface with the smallest curvature through all control points, and is often used to make non-rigid transformations of shapes. The shape context algorithm has a one-to-one correspondence between point sets when performing point set matching. Therefore, TPS can be used to minimize the bending energy and solve the mapping parameters and matching matrix between the point sets. In the experiment, the number of TPS transfer control points was 20, which ensured accuracy and made the algorithm not run too slowly.
Experiments
ATR Dataset
The ATR dataset has 17,706 images in all, which are females in a variety of costumes with diverse backgrounds. We show some samples in Fig. 5. The number of labels is 17, and the category range of the pixel is between 1 and 17.

Example of an ATR dataset.
We picked out about 1000 images of shorts or short skirts and about 6000 images of trousers. Their corresponding masks were also used as the two domains. These two domains were marked as (X, a) and (Y, b) respectively. X and Y represent the real picture, and a and b represent the corresponding binary mask.
Zalando Dataset
We got the pictures shown in Fig. 6 from the Zalando website, but the network does not only need image data, but also the corresponding mask. Therefore, we firstly used the ATR dataset to simply train an FCN network and then the inference of FCN regarded as mask information for the corresponding image. Specifically, we used the structure of FCN-8s (Fig. 7) and incorporated some attribute of ATR (The original ATR dataset has 17 types of label attributes). Since this research only needed to distinguish between the upper outer garment and backgrounds, we merged labels other than upper, which are considered to be the background.

Example of masks generated by the Zalando dataset.
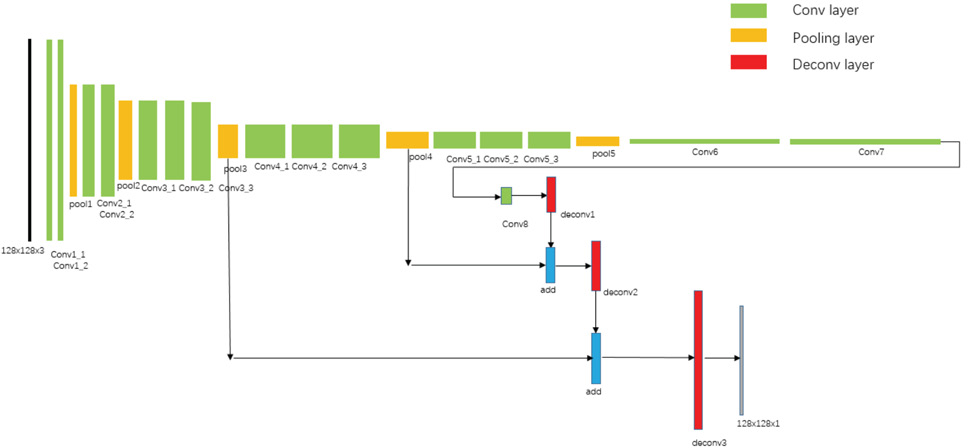
FCN-8s network structure.
The FCN input and output size was [128, 128]. We got the Zalando dataset for training: the T-shirts, jackets, and their masks were about 1000 each. In addition, standard clothing for TPS transfer were also available on the Zalando website.
TPS Transfer to get Deformed Clothing
After the style transfer, we used the mask of the pants (Fig. 8, a2 and b2), and the image of the pants and its mask (Fig. 6) to TPS transfer to obtain the deformed pants image (such as Fig. 8, a1 and b1). After that, the pants in the original picture can be replaced with this new one. From the experiments, we found that if the original mask is relatively complete, that is, the pants in the original picture are not overly obscured, the effect after TPS is good, but if the pants in the original picture are incomplete, it makes TPS unable to successfully match the contour points between them, and the performance will become poor. It can't be converted when the TPS algorithm can't find enough matching points.
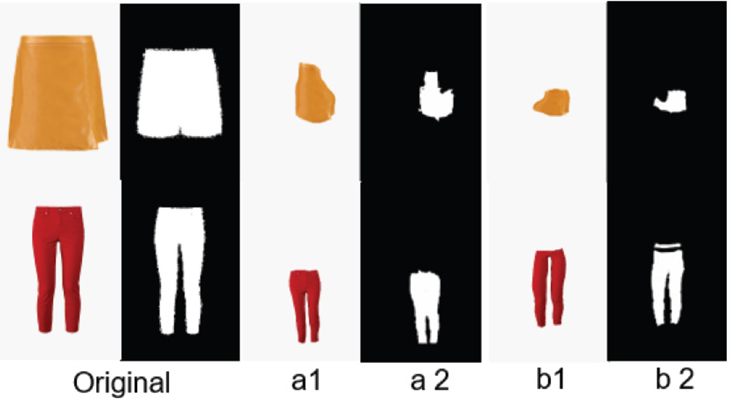
Example of TPS transfer results
Online Try-On
We evaluated the performance of the model on the ATR dataset and compared it with CycleGAN and InstaGAN. It can be seen from Figs. 9 and 10 that CycleGAN can also change style, but it also changes the background information, and the transfer performance is relatively general. For this dataset, InstaGAN's style transfer is significantly better than CycleGAN, which can ensure the invariance of the background information as much as possible, and the image is realistic after transformation. The style transfer cannot specify the color of the converted pants, the characteristics of the texture, and the replacement of specific clothes. But our results, based on InstaGAN, can replace a specific pair of pants at will, as long as there was a standard picture of the pants that needed to be replaced. As shown in Fig. 9, we randomly selected 3 different color trousers, and 3 different color shorts or skirts to be replaced. Since the TPS cannot produce the same deformation as the mask, some local mismatch will occur during the replacement process. We simply calculated the average of the RGB pixel values of the pants to fill these areas. The consequence is that the realism of the picture was significantly reduced, and the replacement part cannot be truly integrated with the surrounding environment in terms of hue and brightness.

Pants and shorts transfer results. “Original” is the original picture, the subsequent picture is the result of CycleGAN and InstaGAN, and the last three columns are the replacement results of the three pants of different color which we randomly took out from the data set.

T-shirt and jacket transfer results. “Original” is the original image, the subsequent images are the results generated by CycleGAN and InstaGAN, and the last three columns are the replacement results of the three different color uppers that we randomly took out from the dataset.
The code in this study runs on pytorch0.4, the input image was resized and cropped, and the final input to the convolution network was [300(h),200(w)]. The size of the output was the same as the input. Instance normalization (IN) was added to both the generator and the discriminator, and spectral normalization (SN) was added to the discriminator, which gave a significant improvement on the experimental results. We only trained on one GPU, with the batch size for style transfer fixed at 1. For the other hyper-parameter in the network, we set in the jacket dataset λ cyc , λ idt , and λ ctx each to 8. In the replacement pants dataset λ cyc , λ idt , and λ ctx were each set to 10. The optimizer of training was Adam, 22 with a learning rate of 0.0002 for the generator, and 0.0001 for the discriminator. The parameters of Adam were set as β1 = 0.5 and β2 = 0.999. The learning rate decayed linearly at the beginning of 10 epochs and then remained unchanged.
Next, we did an experiment on the Zalando dataset; the experimental process is basically the same as the process on the ATR dataset. Due to the different number of datasets, we adjusted the epoch of the training, using the same preprocessing process, and did not require complicated tuning procedures. Fig. 10 shows the comparison of the results of this experiment. In addition, more experiment results were shown in Fig. 11.

More experimental results.
From the results of the experiments, it can be seen that after replacement, the clothing can still maintain the characteristics of the pattern, color, text, and so forth. The clarity of the picture was effectively maintained. On the standard clothing, and when the previous generation of the mask against the network is ideal, the TPS conversion result will also be ideal, and can be preliminary. Specifically, for the ATR data set, the accuracy of the mask itself was relatively high, so the authenticity of the final dress-up image was higher than that of the Zalando data set generated by the mask through the FCN network. The output of InstaGAN was also true for virtual dress-up. However, the final synthesized image did not look particularly real; some pictures can be seen as being computer-synthesized, rather than naturally collected. We designed a fusion network to solve these problem by training a network, which makes the replacement process more real and keeps relatively high definition.
Fusion Network
The design of the fusion network mainly referred to the idea of GAN. The entire network consisted of two parts, which were the same as the general GAN. The difference is that the input of the traditional GAN network generator was random noise, and the generator input of this experiment was two RGB pictures, so the number of input channels was 6, the generator learned how to integrate the two input pictures, and output a size A 3-channel picture with the same size as the input. The network structure was similar to pix2pix, which realized the picture-to-picture translation process. Therefore, in the design process of the generator, refer to the generator structure of pix2pix in Fig. 12. Compared with the generator, the structure of the discriminator was relatively simple. As shown in Fig. 13, the input picture size was [300,200,3], similar to a binary classification network. When the input picture came from the output of the generator, it was classified as 0, and the picture was considered false; When the input picture was from a real sample, it was classified as 1, and the picture was considered to be real. Through continuous learning, the discriminator can discriminate the authenticity of the input picture, the generator reacts against it, and progress together.
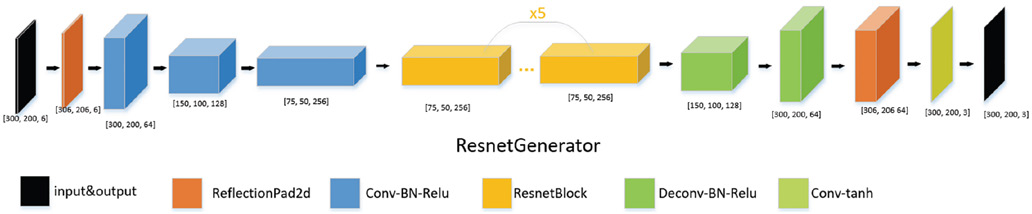
Generator of fusion network.
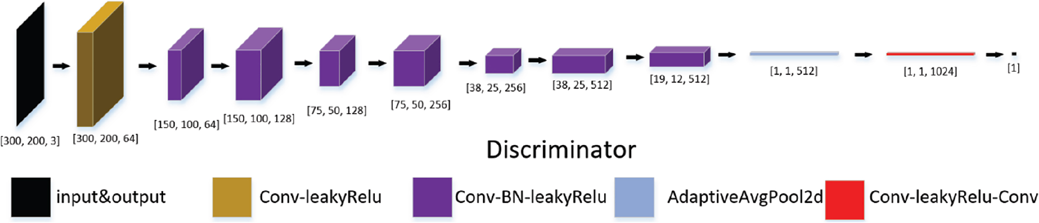
Discriminator of fusion network.
From the results of the fusion network we designed in Fig. 14, we can see that the out of the net was more real and clearer than the results in Figs. 9–11. But when compared with ground truth (GT), some details and textures are lost because of generator's performance.

The results of fusion network. In_A and In_B are the two parts of input, GT means ground truth, Out is the output if the net.
Conclusion
Online try-on can be realized in three steps using our method. The results kept good definition and trueness after the experiments using the ATR and Zalando datasets. But the method contains too many trivial details, therefore, we are continuing to look for a simpler way.
Footnotes
Acknowledgements
This work was partially supported by the National Key Research and Development Program of China (2019YFC1521300), the National Natural Science Foundation of China (61971121), the Fundamental Research Funds for the Central Universities of China, and the DHU Distinguished Young Professor Program.