
Abstract
This article proposes a generative adversarial networks (MiniGAN) to tackle both informative and uninformative image transferring. The generator of MiniGAN is based on the structure of StyleGANv2, in which the encoder and style transform block are proposed to extract the high-level feature maps of the source image and capture the latent representation of the target image, respectively. This information guides the generator for the final image generation. The proposed MiniGAN outperforms other models in style transferring while preserving the color information on the informative images. To test the performance of MiniGAN on the uninformative images, a new data set consisting of 10,000 fashion hand drawings is proposed. Extensive experiments and detailed analysis are presented to demonstrate the performance of MiniGAN.
Keywords
Introduction
The task of image-to-image translation1,2 is to learn an appropriate mapping function from source image to target image. Recently generative adversarial network (GAN)-based methods perform well to colorize the gray-scale real images,3,4 combine the content image with the style of the target image1,5,6 and two or multi-objects translation,2,7 and so on. Although these methods achieve promising results in some scenarios that deal with informative images, such as day scene to night scene and real photo to Monet-style photo, to the best of our knowledge, tackling the problem of uninformative image transforms is absent.
As shown in Figure 1(a), most images that we can easily access in our daily life are informative enough. However, there still are large amounts of images that belong to minimalism (as shown in Figure 1(b)). This kind of image mainly appears in the design creation process, such as illustration, technical drawing, or hand sketches. Uninformative image transferring thus has high practical value similar to informative image transferring.
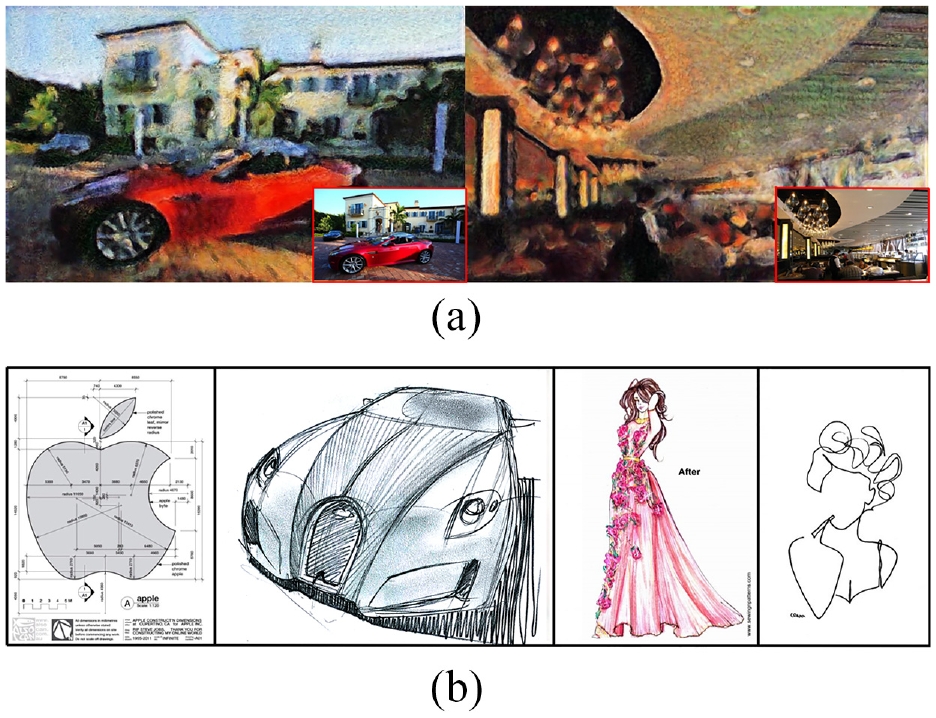
Samples of the informative images and uninformative images. The upper image shows the samples of informative images. While the input image is full of details, there is no pure color present in the big region. Besides, the image is layered. The lower images illustrate the samples of uninformative images. The background of the input is clean, and the color of the input is simple and pure. Besides, there is no multi depth in the sketch: (a) samples of informative images and (b) samples of uninformative images.
In this work, we tackle the problem of both informative and uninformative image transferring. The informative images we mentioned here have characteristics including (1) rich colors, (2) diverse space distribution, and (3) multi-level depth. On the other side, the characteristics of uninformative images are (1) relatively simple color, (2) line drawings, and (3) less feeling of spaciousness.
To this end, we propose MiniGAN based on an encoder–decoder network. Specifically, we propose a style transform block that contains nine independent residual blocks to carry out target-style image transferring. Besides, we use a style coder to support pixel-wise image generation. The style coder, inspired by the structure of StyleGANv2, 8 captures the multi-level features of the target image, which then guides the synthesis network to generate images. The network creates new target-style images with the support of multi-scale least square discriminator. To verify the effectiveness of our model, we evaluate the aforementioned model in qualitative and quantitative ways. In addition, to test the performance in uninformative data sets, we introduce a new data set with images that are composed of fashion line drawings. Extensive experiments in both informative and uninformative images show that our model outperforms the aforementioned models in preserving the image details. Analysing the challenges of uninformative image transferring can be a good reference for future exploration in the related tasks.
In summary, the contributions of this article are as follow:
We define the differences between informative and uninformative images and introduce a novel task that synthesizes images in uninformative domains.
We propose the MiniGAN, a neat and effective model that achieves good result in unsupervised style transfer while preserving the color information of the source image.
We introduce an uninformative data set that is composed of 10,000 high-resolution sketches to support this task and further explorations.
Related Work
GAN
GAN 9 is an algorithm used for carrying out image synthesis. In GAN-based models, there are two key issues we need to address. The first is to improve the quality of the generated image, and the other is to avoid mode collapse when carrying out image synthesis. In recent years, the GAN-based model has achieved many promising results. Radford et al. 10 (deep convolutional generative adversarial network (DCGAN)) first used the convolutional neural network (CNN) to perform GAN-based image synthesis. More recently, to ensure high-resolution image generation, a set of progressive-like generators8,11–13 has been proposed to generate images with textures and details. However, these algorithms need expensive computation cost and detailed data sets. Earth-Mover distance-based GAN 14 is proposed to address the problem of mode collapse. Later, methods like Wasserstein GANs 15 and Spectral normalization for GANs 16 have been proposed to stablize the quality of image generation. Methods which achieved promising results in image generation still lack the ability to control the mode of the generated image during image synthesis.
Style Transfer
In addition to basic quality-improved and diversity image synthesis, GAN-based image generation has been adopted in other works. Style transfer is a task to generate a new target-like image using linear mapping methods based on the content information and style information extracted from the content input and the target input. Gatys et al. 17 first proposed a novel algorithm where a generator using iterative optimization ways learns the matrices-wise correlation in deep feature space extracted by pre-trained deep neural networks. Later, they introduced additional constrains 18 to guide the stylization of the generated image from color and texture. While the generated image fuses the content from the content input and style from the target input to generate a positive result, the computation cost is relatively high. To achieve faster style mixing, single forward neural networks19–23 are introduced to sharply decrease computation time. In order to generate artistic generated images, Jing et al. 24 first took multi-scale strokes into consideration by utilizing a multi-scale encoder and discriminator. Yao et al. 25 adopted the advantage of single forward network with multi-stroke consideration and proposed an attention-aware method to improve the quality of generated image. However, these methods require more or less style images as necessary input. Furthermore, this type of method alters not only the texture and details but also color distribution during style mixing. In other words, these methods are limited to transferring the source images to the target-like images while preserving the color information of the source image.
Image-to-Image Translation
The aim of image-to-image translation is to learn a mapping from source domain to target domain. Recently, some researches have achieved promising outcomes. Pix2pix 1 is the first GAN-based method to transfer the image from two different domains. However, it still needs a paired data set to generate images with high quality. To overcome this, several architectures like cycle consistency 2 and shared latent space 26 were introduced. Very recently, algorithms7,27,28 based on these two architectures have been introduced to improve image quality. Although image-to-image translation can achieve good quality as well as multi-modal results, the scenario is limited as the two unpaired data sets are both all informative data sets. Furthermore, at present, there is no research focused on uninformative style transferring.
Methodology
The main goal of this work is to deal with informative image and uninformative image transferring. For GAN-related algorithms, the task is to generate vivid images with rich details like reasonable texture and easily recognized shape. Several image-to-image-based models7,28,29 work in two information-rich domains like real photos to paintings. However, as indicated in Figure 2, those methods do not perform well enough when the two domains information.
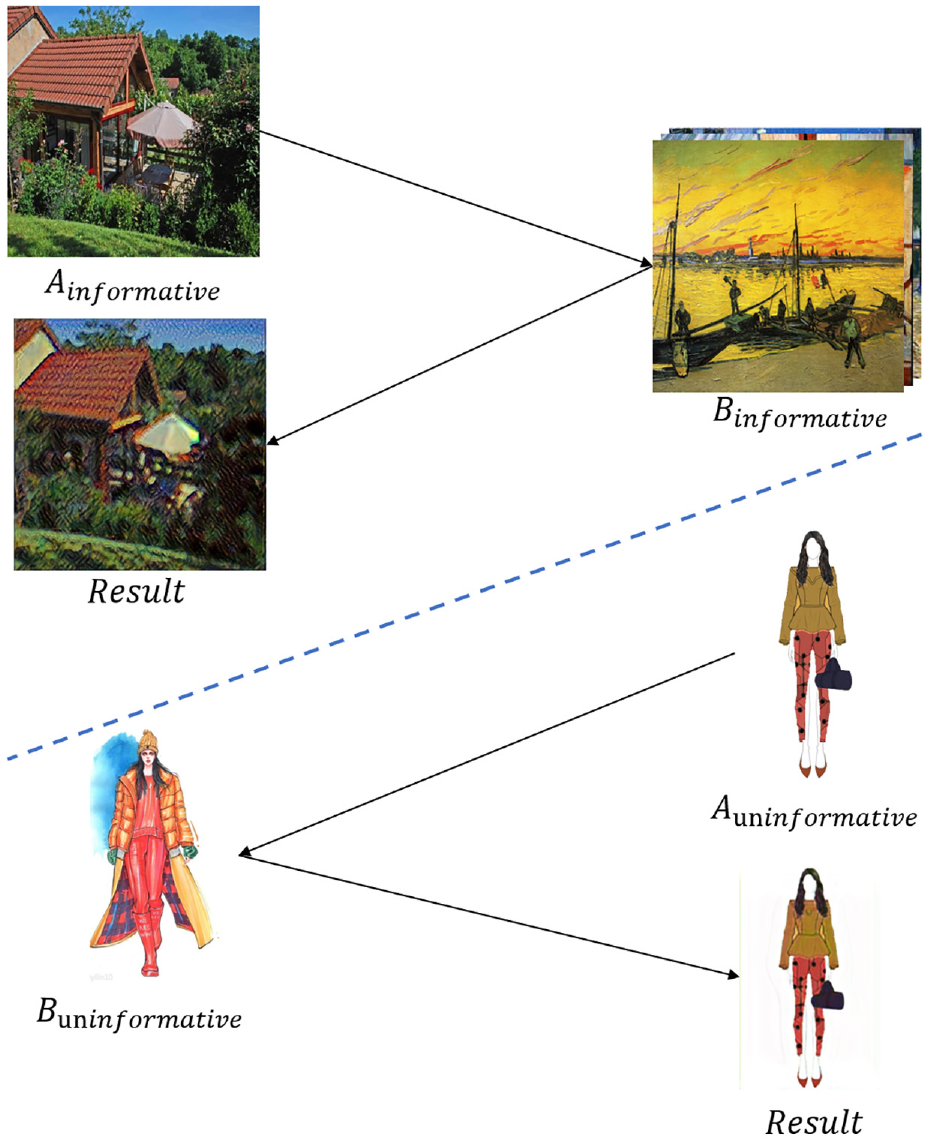
Different scenarios when doing image-to-image style transfer. The top of the figure illustrates the sample of two traditional informative image domains. The left-hand side is from the real image data set while the right-hand side shows the artistic image. In the bottom of the figure are,
In order to fix this problem, we adopt gram matrices, which capture the high-level target-specific style statistics, to carry out image style transfer. Moreover, several loss functions are applied to help construct the final output. Figure 3 illustrates the main structure of generator. In Figure 3(a), given a source image as an input, the model applies an encoder with residual blocks
30
to extract low-level details as well as high-level features of the source image. After being transferred by the style transform block, high-level feature maps will be fed into the generator to support the generation of the target-style image. Inspired by StyleGAN,8,13 style coder
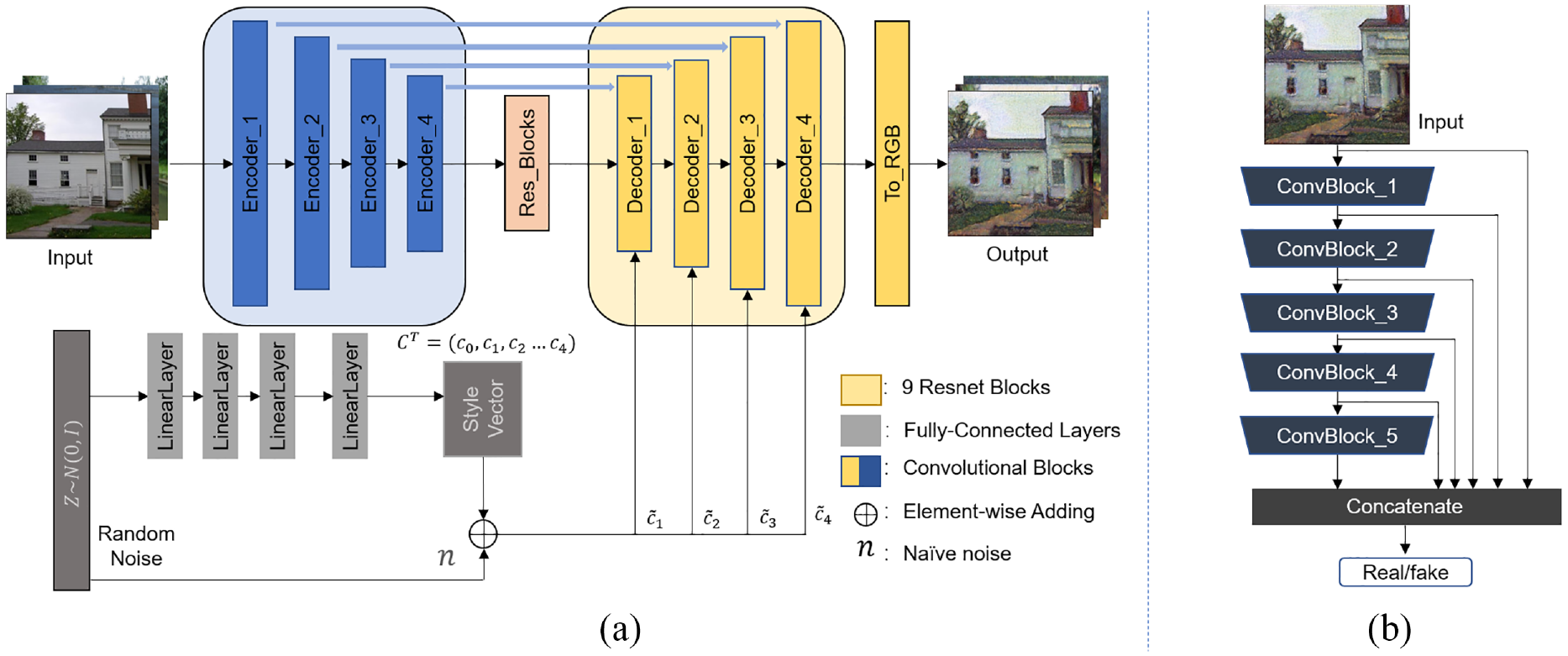
Overview of the main architecture of an encoder–decoder-based network. (a) Details of the generator. In addition to the style latent vector applied in StyleGAN and StyleGANv2, deep-level feature maps extracted by encoder are also considered during skip-connection to help image generation. The style transform block contains nine residual convolutional layers transferring the style from content image to target image. (b) Process of multi-scale discriminator. From multi-scale values, the discriminator-support generator captures both low-level information and high-level features.
Encoder
In order to get latent feature maps, networks based on four residual-based blocks
30
are adopted to extract features from the source image. We denoted
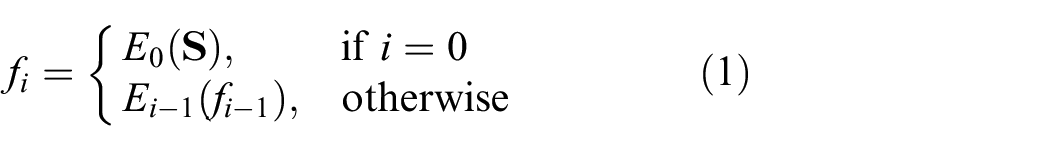
where
On the other side, an intermediate latent vector was applied8,13 for style refinement. Like the implementation in StyleGANv2, we sampled the input
Style Transform Block
From the previous style transfer methods, we found that models do style transfer effectively in global representation. Taking conditional style transfer 31 as an example, generated images are high quality with fine details and rational textures. However, the shortcoming is the color distribution of the output image which is similar to that of the target image, making it unreasonable when comparing with the original input. To tackle this problem, inspired by Style-aware, 6 we use a style transform block which is composed of nine residual convolutional blocks to transfer the image to the target-like image in latent representation.
Generator
Given the multi-scale features
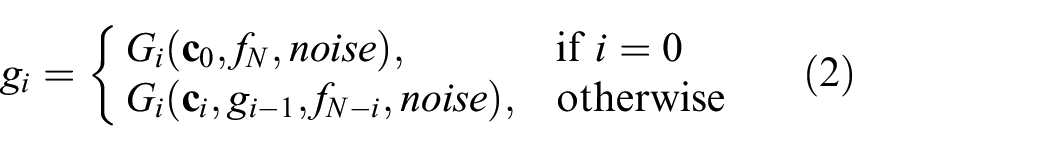
where
At the end of the generator, there is an additional convolutional block named the RGB block, which represents the output to the final image.
Loss Functions
Adversarial Loss
GAN-based adversarial loss GANs 9 is an effective tool to help match the distribution of the source image to that of the target image by playing an min–max game. In other words, the generator tries to deceive the discriminators by generating the same distributions of target domain as much as it can while the discriminator learns to distinguish the differences between real target domain and fake output. Instead of using prevalent methods14,15 with which it is difficult to achieve balance between this adversarial loss and other loss in scale, least square adversarial loss 33 is applied to supervise the generator
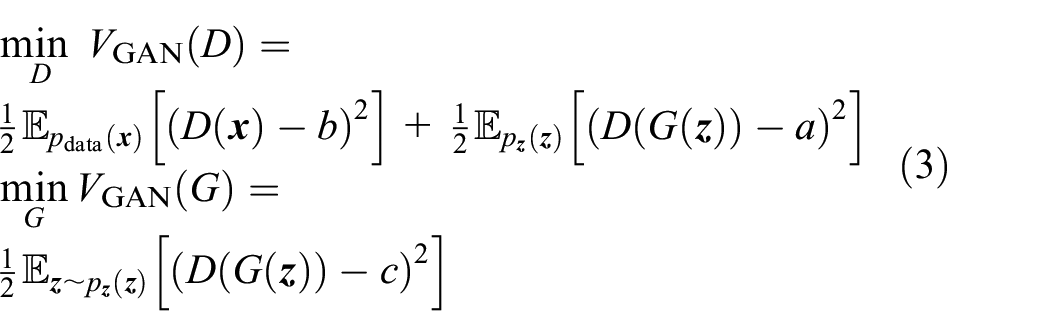
where
Inspired by Wang and Yu 34 and, Lu et al. 35 two more feature maps are extracted as guided feature maps. These two empirical priors are applied to support discriminators to distinguish. To obtain margin features from the image, traditional Sobel kernel is utilized to extract the margin of the image. Besides the structure difference in various image, texture difference is another key objective. Although it is challenging to obtain texture features in traditional RGB channel images, transferring images into luminance and color information like YUV or laboratory domain reduces the difficulty as the first channel represents the texture information and the other two channels show the color information which influences texture little. In order to obtain more information from shape to details, the multi-scale discriminator is employed as shown in Figure 3(b), where the discriminator is composed of several convolution blocks, to distinguish input in both low- and high-level feature maps.
Style Loss
Style loss is introduced to capture the high-level feature structure as well as the texture information. Gram-matrices-based style loss
17
is adopted in our work. Given gram metrices
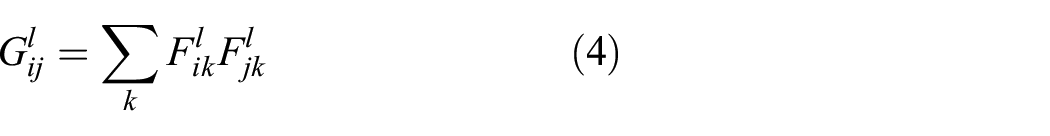
where
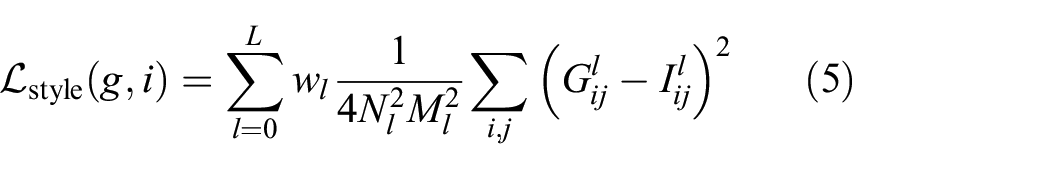
where
Content Loss
Content loss is utilized to preserve the global structure of the input image. Mean square loss is adopted to calculate the distance of deep feature maps extracted by the content extractor. The content extractor is defined as
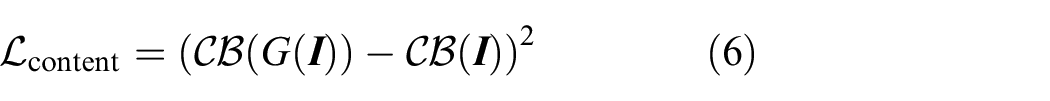
where
Total Variance Loss
Due to the specific characteristics, the frequency information of painting images is different from that of real photos, which makes it difficult to generalize. To maintain the continuity of the image, total variance loss was adopted to decrease the probability of unwanted noise. The loss function is illustrated as follows:
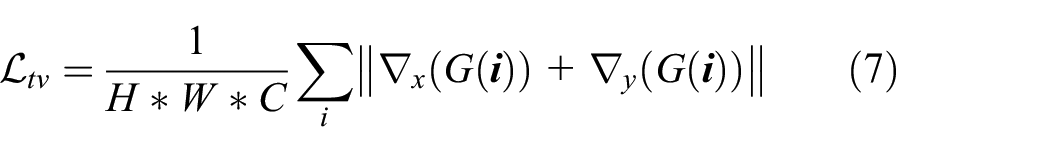
where
Full Structure
Overall, our model can be illustrated as a network composed of an encoder, a style transformer, a generator, and a multi-scale discriminator. The full-loss function is used to optimize generator in high-level features as well as textures and details representation. The formula is shown as follows
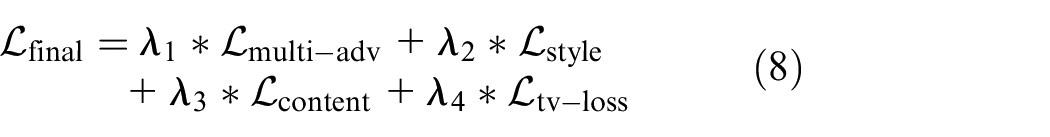
where
Experiment
In this section, extensive experiments on state-of-the-art cycle consistency 2 -based models, that is, GDWCT, 36 MUNIT, 27 DRIT, 28 CycleGAN, 2 and style transfer-based models like Style-aware 6 and our model were conducted to evaluate the performance in both the informative data set and the uninformative data set. Training performance and general results analysis in both informative and uninformative domains are presented in the following subsection.
Implementation
For the optimization problem, Adam’s
37
algorithm was used in both the generator and the discriminator with
Hyper-parameter: The default hyper-parameters were set as:
Data set: We sampled images from the Places365
38
training data set as our source domain. For the target domain, the collection of Cezanne and Van Gogh images is adopted from WikiArt (https://www.wikiart.org/). For the source domain, there are more than

Sample of images from Place365 (real photo), artworks, BeautyU (illustrations) and sketches, respectively: (a) informative images and (b) uninformative images.
Evaluation
To evaluate the performance of style transferring, four other algorithms including image-domain style transferring, 36 content style disentangled transferring,27,28 and zero-shot image style transferring 22 are benchmarked.
Qualitative evaluations: Figure 5 illustrates the comparison between the four benchmarked methods and our method in informative domain image style transfer. Due to the effectiveness of skip-connection, the image generated from our method has clear contours and details. For images generated by style image-guided algorithms, in terms of of style, generated images contain rich information of texture. However, they inevitably have the color information from guided images, which is opposite to our expectation. For unsupervised algorithms such as MUNIT and DRIT, while they capture both content and style latent representation of target images, the outputs lose the color information in style transferring process. For image-guided algorithm GDWCT, it is difficult for outputs to obtain the style of target images. Furthermore, to obtain color-invariant generated images is another challenge.

Informative style transfer. To get the stroke of the target domain as well as retain the global structure of the content image, our models outperforms other models in detail preserving as well as style representation. For Style-aware, the content of the generated image loses much so that the contour of the image looks messy.
To compare more specifically, Figure 6 illustrates the comparisons in details between the Style-aware, CycleGAN and our algorithm. While the style in the target domain is abstract, the model cannot obtain both characteristics and clear boundaries. For CycleGAN, the generated images have clear boundaries and background. However, the main difference between input images and generated images is the color distribution. For global representation, the generated images are shown more like photos than paintings. In other words, generated images do not carry the characteristics of the painting. For Style-aware, while it transfers the style of the target domain successfully, the details from the image show that it has messy contours and unreasonable line strokes. Taking the images below as an example, the chair is in mess and the roof of the pavilion is mixed up with the trees right side. In the image above, Style-aware distorts the shape of those people and generates irregular noise. Although our method still has limitations in style representation and high-frequency artifacts reducing, it preserves the details such as clear contours and reduces the noise. In summary, our model outperforms all baselines in generating images with clear contours, and more rational trade-off between real image and target image.

Details in generated images, results from our model get clear contours as well as less color difference and more detail. Compared with (c), the image generated by our model gets cleaner boundaries as well as rational distribution. For (d), there is little change in style transfer: (a) input, (b) ours, (c) Style-aware, and (d) CycleGAN.
Quantitative Evaluations: Frechet inception distance (FID) 39 which is an algorithm to calculate the Frechet distance between two Gaussian-mixed-based probabilities is adopted in this work as it is an ideal distance to evaluate how close two probabilities are and evaluate the quality of generated images. As is illustrated below
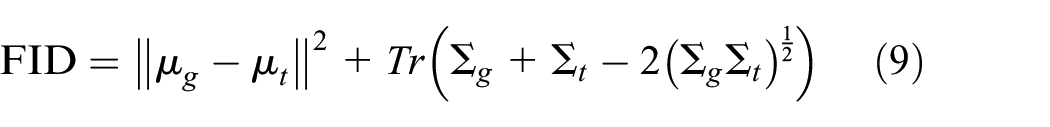
where in the format
Furthermore, a evaluation algorithm named learned perceptual image patch similarity is also adopted to measure the quality of generated images in our work. 41 In Table 1, three cycle consistency-based models obtain the best three FID scores in the photo domain, and their scores in the painting domain are relatively high. FID score is relatively more important in the painting domain compared with that in the photo domain. Our model obtains relatively low FID scores when comparing with other methods, which means that our model could catch the latent style representation from the target images. MUNIT obtains the lowest FID scores in both the photo domain and the painting domain. However, the change of color distribution is undesirable. Furthermore, extremely low FID scores in the real data set means the model changes little in source image. With relatively lower scores compared with other methods, our method preserves the details of the content images. For Learned Perceptual Image Patch Similarity (LPIPS), our method and Style-aware obtain the best two scores, which means that the generated images from Style-aware and ours outperform the other methods in semantic structure representation.
Table illustrates the FID distance as well as LPIPS scores between the real photo data set and painting data set.
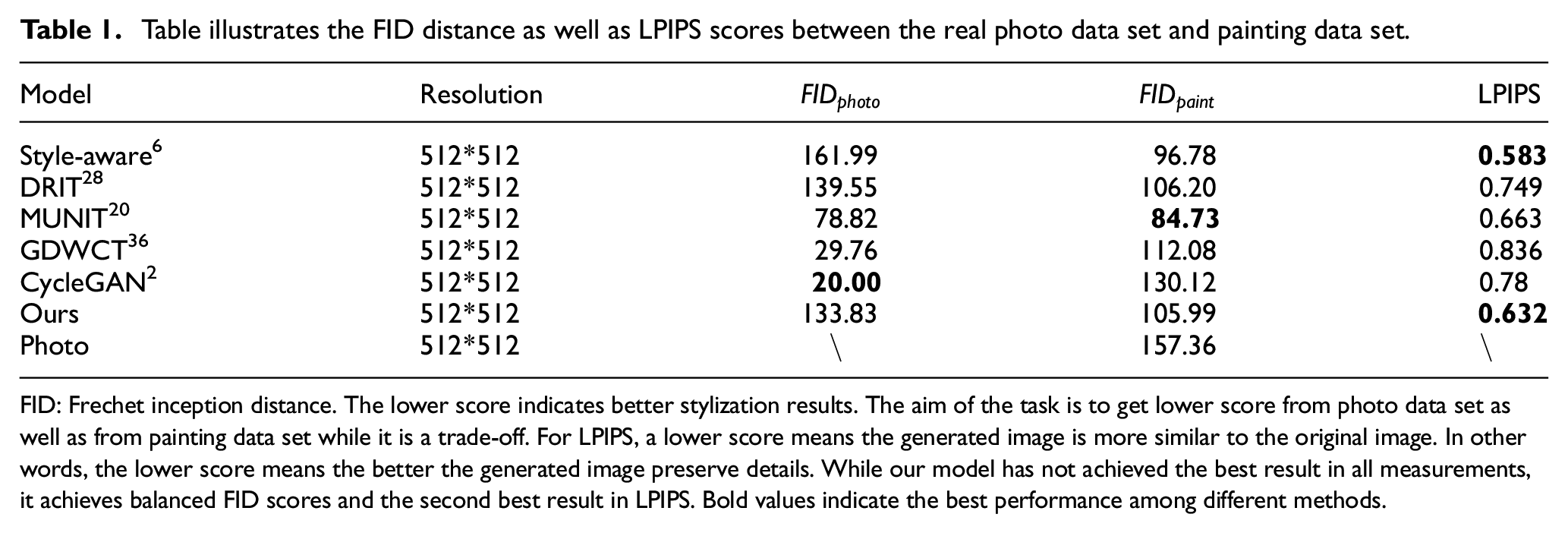
FID: Frechet inception distance. The lower score indicates better stylization results. The aim of the task is to get lower score from photo data set as well as from painting data set while it is a trade-off. For LPIPS, a lower score means the generated image is more similar to the original image. In other words, the lower score means the better the generated image preserve details. While our model has not achieved the best result in all measurements, it achieves balanced FID scores and the second best result in LPIPS. Bold values indicate the best performance among different methods.
Ablation Study
In order to carry out style transferring while preserving the color information, we use regular encoder–decoder structure model Style-aware 6 with multi-scale discriminator as our baseline. Several components were added into our model for the sake of higher-quality image generation. We compared these outputs generated with or without these blocks to see the effectiveness of them.
Figure 7 shows the ablation studies. In Figure 7(b), the images are generated with normal GAN loss. There is irrational color distribution on the whole image. Besides, the tree in the first image is in a amess, which means the model is limited to transfer some objects. As the structure representation of Figure 7(b) is similar to the input, this means that the skip-connection can catch both low- and high-frequency information. However, it preserves the details of the content image so well that it cannot catch the style of the target images. In Figure 7(c), output images are generated by the model when it is trained without adding the noise. The color distribution of generated image is shifting when comparing with the input. Besides, mode collapse appeared in several places like the branch of the trees and the top of the car. Images generated from the full model alleviate the color difference while learning the latent representation of style image.

Ablation studies with or without some components. From the figure (b) while it performs well in the under image, there are some irrational black lines on the trees. For (c) two images are not realistic, and for the upper image there is black blob in some places. Also, the color distribution is not as natural as in the original image. For our model, the generated image has more realistic color distribution as well as the painting-like stroke: (a) input, (b) w/o sq. loss, (c) w/o noise, and (d) full model.
In addition to image demonstration, Table 2 illustrates the FID distance and LPIPS scores among three models. Model (b) obtained the highest FID distance in the deal data set and LPIPS scores, which means that preserving the content of the source image and the style of target image is limited. For model (c), while it achieved the best result of LPIPS scores, the FID distance between real data set and generated images is relatively low and that between the paint data set and generated images is high. This means the ability of style transferring is ineffective. The full model gained the lowest FID distance between paint data set and relatively high distance between the real data set. It indicates the model captured the style of the target image and preserved the information of the source image well.
Table illustrates the FID distance and LPIPS scores between the real photo data set painting data set in the ablation study.
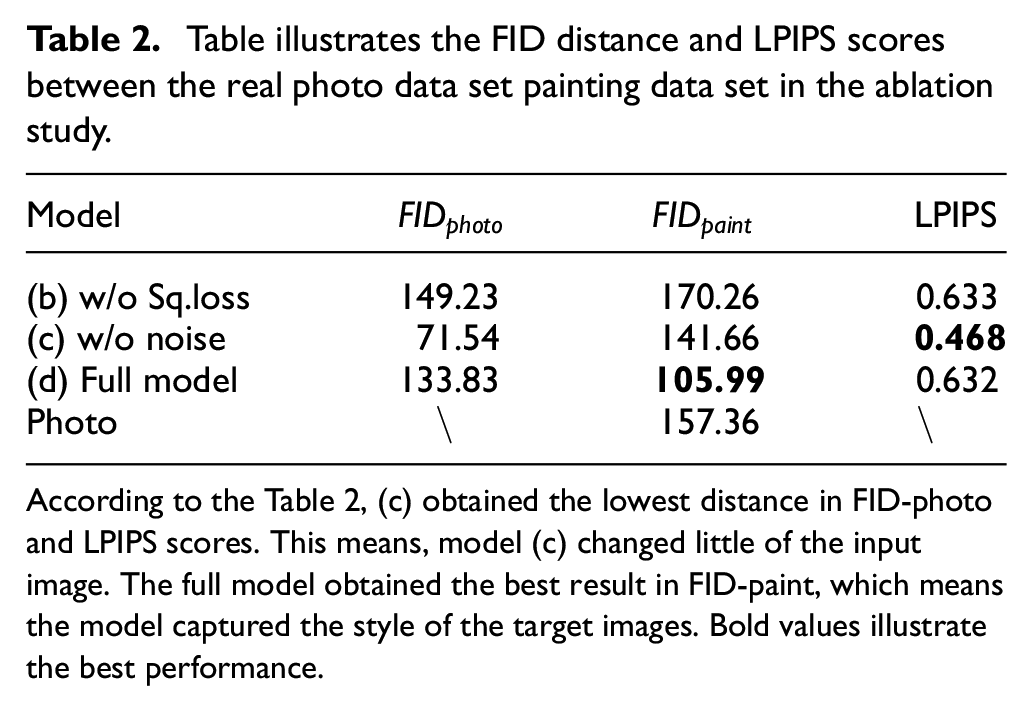
According to the Table 2, (c) obtained the lowest distance in FID-photo and LPIPS scores. This means, model (c) changed little of the input image. The full model obtained the best result in FID-paint, which means the model captured the style of the target images. Bold values illustrate the best performance.
Analysis on Uninformative Data set
From the human vision perspective, some images generated from existing algorithms can deceive the expert to a certain extent from layout to texture and color distribution. Those well-performed image transferring models stand with two informative image domains. In other words, there is little research focused on uninformative image transfer. For our images which belongs to the uninformative domain, the aforementioned five algorithms and ours are compared and the result is illustrated in Figure 8.

Uninformative style transfer. For the first three algorithms, there is more or less mode collapse. Images generated from the latter three algorithms changes little from the original domain but stroke and color distribution.
In Figure 8, the above methods do not perform well in this task. For the four cycle consistency-based image translation methods (MUNIT, GDWCT, DRIT, and CycleGAN), CycleGAN preserved the content of the source image in this scenario, but the style of the generated image changed little. For the other three aforementioned methods, mode collapse more or less appeared when they carried out image synthesis. In Figure 5, DRIT can carry the style of target domain. However, it is limited to preserving the content of the input image. For MUNIT and GDWCT, while the generated images somehow capture the style representation of the target image, the color and full shape of the body in images are out of control. For Style-aware, the strokes in the images are different from both that of input images and that of target images. It has thick, straight lines, which is same as its performance in real-painting image transfer, instead of thin and curved lines. However, this method preserves body shape well. For our model, it preserves well the details in the content domain but still lacks style representation from the target domain. Moreover, the output has a blurry background, which decreases the quality. In order to remove the unexpected blurring, two more methods are proposed. One method is to use a mask to extract the main part and remove the other region to white clean. The other method is to combine the input with its mask to generate new four-dimensional input. And the new input will be fed into the network. In the latter method, the added mask can be seen as a white-box attention. Figure 9 shows its results. It is noted that in the third and the fourth line, the generated image is background clean. However, the model cannot learn the layout and stroke of the target image. For the former method, using a mask to get foreground it is easy to understand that the region of interest is the same as that of the mask. In other words, only the regions of interests remain. For the latter method, while the channel of the mask shares the region of interest, it supports too much about the ability of shape generation and limits the style of image synthesis.

Methods to clean the background from the image generated by our method. For the third and fourth lines the background is cleaned while the styles of generated images are limited.
Conclusion
In this article, we propose the MiniGAN to improve the performance of image style transferring in informative and uninformative image data sets. Through this model, we can generate high-quality target-style images when the input images are informative like real-life photos. The main structure of MiniGAN is a basic encoder–decoder network with residual blocks. To achieve better detail generation, we apply StyleGAN-like modulated convolution layers to facilitate the representation of content. In order to make the generated image look more like the target image, multi-scale discriminator is applied to constrain the generator. Furthermore, total variation loss is applied to reduce the irrational part of the generated image. Qualitative and quantitative results show that our method can generate images with target style when the data set belongs to the informative data set. For uninformative data, our method performs well in detail preservation but still is not satisfactory in preserving style which will be our future work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by the Laboratory for Artificial Intelligence in Design (Project Code: RP3-1), Innovation and Technology Fund, Hong Kong Special Administrative Region.