
Abstract
Heterogeneous information networks significantly enhance the performance of recommendation systems by integrating rich structural and semantic information. However, most existing methods are designed for homogeneous networks and utilize techniques such as attention mechanisms and multi-layer architectures, which often introduce unnecessary parameter complexity. Furthermore, meta-path-based approaches typically rely on manually predefined meta-paths, which limit the models’ generalization capabilities. This article conducts an in-depth investigation into meta-path identification and proposes an Automatic Meta-Path Identification Recommendation (AMPIRec) framework. The framework optimizes the semantic representation of meta-paths through matrix self-transformation properties using weighted aggregation, while simultaneously reducing model complexity. Additionally, AMPIRec employs a multi-head attention mechanism for the joint training and optimization of user and item features, with its primary advantages being numerical stability and high prediction accuracy. To enhance recommendation precision, we specifically design a tailored top-k smoothed loss function that aligns recommendation objectives with real-world requirements. Extensive experiments on multiple real-world heterogeneous graph datasets demonstrate that AMPIRec achieves outstanding performance in both accuracy and stability.
Keywords
Introduction
The entire world is a universally interconnected organic whole. The connections between all entities can be abstracted into a vast heterogeneous information network (HIN) (Sun & Han, 2013). Extracting appropriate subgraphs from this extensive HIN allows us to study and analyze specific phenomena and relationships. In the field of recommendation systems, researchers have previously extracted subgraphs of user-item interaction data and applied powerful graph neural networks (GNNs) (Scarselli et al., 2008) to recommendation tasks, utilizing graph representation learning to simulate and analyze user interaction behaviors. Traditionally, GNNs have been primarily applied to homogeneous graphs, and this non-linear model has demonstrated superior performance compared to algorithmic reasoning models in recommendation tasks involving single relational data (Liu et al., 2022; Wu et al., 2020). However, GNN-based recommendation models typically rely on continuous message passing and aggregation using interaction information between users and items (Kipf & Welling, 2016). During this message-passing process, they often assume that all messages are homogeneous, which is inadequate for analyzing these information-rich datasets, as it fails to capture the structural information inherent in single relationships. In contrast, HIN recommendation models fully leverage real-world information and generally outperform traditional recommendation models in terms of recommendation accuracy. Consequently, the development of robust representation learning methods specifically designed for HINs has become essential.
In GNNs designed for HINs, meta-paths serve as a sophisticated analytical tool that effectively captures higher-order semantic relationships between instances. These meta-paths are utilized to identify neighbors along paths of specific lengths and relationships. By analyzing the connections between instances, the innovative design of meta-paths allows for a deeper exploration of these higher-order semantic relationships, thereby overcoming the limitations associated with analyzing complex networks from a singular perspective. This approach significantly enhances the interpretability of the model. However, the advantage of improved model explanation can only be realized after experts assess and establish the importance and effectiveness of particular meta-paths. In large networks, this process can lead to a notable decrease in processing efficiency. Furthermore, in practical applications, the effectiveness of meta-paths is often constrained by the quality and completeness of the network data. In neural network, recommendation models that utilize meta-path design, it is common practice to first assign weights to different meta-paths based on their statistical information or through machine learning techniques. Alternatively, an average weight may be directly assigned to each meta-path. These weight assignment methods are heavily dependent on specific datasets and contexts, making them unsuitable for universal application across different networks. Subsequently, deep learning techniques are employed to integrate the features of the meta-paths. Finally, various neural network methods are used to process the fused data. The multi-parameter learning involved in this process demands substantial computational resources and time.
In light of these limitations, this article introduces the automatic meta-path identification recommendation (AMPIRec) model, which builds upon the meta-path concept to address the complexities of representation learning in HINs. AMPIRec is designed to automatically identify the optimal meta-path prior to training, thereby reducing the need for exhaustive computations and expert intervention. To further enhance the original user-item interactions and simplify the complexities associated with multi-layer neural network aggregation methods, AMPIRec employs a conditional weighted mean meta-path neighbor strategy for aggregating semantic information. This enriched interaction data is then utilized to learn user and item embeddings through a self-attention mechanism, enabling a more precise analysis of their correlations.
To validate the effectiveness of AMPIRec, we conducted experiments using two real-world datasets: an extended version of the MovieLens dataset, released by the GroupLens research group at the University of Minnesota, and the Amazon-Book Recommendations Database hosted on the Kaggle platform. The results indicate that AMPIRec consistently outperforms state-of-the-art methods in recommendations within HINs. This article presents the following contributions: We propose an automatic meta-path identification method based on the properties of the meta-path matrix prior to training. We have developed a conditional weighted average aggregation method for meta-path semantic information. This approach enhances the original interactions and optimizes the complexity of semantic aggregation. Extensive experiments conducted on two real-world datasets validate the effectiveness of the AMPIRec model, demonstrating its superiority over existing advanced methods.
In this section, we review the key developments in HIN recommendations and embeddings. We explore both early methods that rely on similarity measures and more recent approaches that incorporate GNNs and embeddings, discussing their contributions and limitations in handling heterogeneous data.
Embedding Techniques for HINs
In recent years, HINs and their rich semantic information have significantly enhanced the performance of recommendation systems. By leveraging various edge relationships, HINs can establish indirect connections between new users or items and existing users and items, thereby alleviating the cold-start problem faced by recommendation models. HIN embedding techniques capture the network’s topological structure, node attributes, and the complex relationships among different types of nodes and edges, transforming the high-dimensional HIN into a low-dimensional representation. HIN2Vec is a prominent model used for embedding HINs (Fu et al., 2017), it generates low-dimensional node embeddings by integrating random walks with the skip-gram (Mikolov et al., 2013). This approach predicts the existence of edges between pairs of nodes while simultaneously learning both node and meta-path representations.
The rich edge relationships in HINs allow nodes to be interconnected through various paths of differing lengths. However, as the path length increases, there is a recurrence of node pairs, resulting in a substantial number of repeated pairs. While these repetitions convey distinct information, they also introduce unnecessary noise into the model. Meta-paths enable researchers to analyze the similarity between users and items from multiple perspectives. Sun and Han (2013) were the first to propose the method of utilizing meta-paths to mine neighbors, which mitigates the explosion of node pair counts associated with paths that contain specific semantic relationships and provides enhanced interpretability. PathSim Sun et al. (2011) evaluates the similarity between nodes of the same type by analyzing their shared meta-paths. Building on this concept, HeteSim Shi et al. (2014) introduced a comprehensive framework for assessing the similarity between nodes of different types. The embedding vectors generated by HeteSim effectively capture the heterogeneity and structural characteristics of the network. HERec (Shi et al., 2018) captures the intricate relationships between users and items by extracting various types of meta-paths within the network and utilizes these meta-paths to construct a recommendation model. Metapath2Vec (Dong et al., 2017) employs specifically designed meta-paths to guide random walks, ensuring that the embedding process effectively captures particular semantic relationships within the network.
GNNs for HINs
GNNs, a deep learning technique, have been widely applied to manage graph-structured data. Their primary advantage is the ability to effectively capture and leverage the dependencies between nodes. One notable example is the LightGCN (He et al., 2020) algorithm, a recommendation model based on a simplified graph convolutional network (GCN). LightGCN streamlines the GNN architecture by eliminating non-essential components, such as feature transformations and activation functions. This simplification not only enhances training efficiency but also improves recommendation performance. The remarkable success of GNNs has inspired numerous researchers to develop various recommendation models specifically tailored for heterogeneous GNNs (HGNNs).
HGNNs that utilize meta-paths typically enhance the learning process by aggregating the features of adjacent nodes with similar semantics. One notable example of this approach is the RGCN (Schlichtkrull et al., 2018), which learns low-dimensional representations of nodes by stacking multiple graph convolutional layers and aggregating features from local neighborhood information. Additionally, the self-attention mechanism (Vaswani, 2017), as an advanced component of GNNs, enables models to adaptively focus on the most significant adjacent nodes during the information aggregation process. This mechanism allows the model to dynamically adjust weights, thereby improving the effectiveness and flexibility of representation learning. Self-attention and similar methods, such as the GAT (Veličković et al., 2017), are particularly effective in capturing relationships and dependencies between nodes while being adaptable to various topological structures. However, these methods are sensitive to hyperparameters, such as the number of attention heads and learning rates, which can significantly impact their overall performance. For instance, the meta-path-based HAN (Wang et al., 2019) takes into account multiple types of nodes and edges in heterogeneous networks and implements two levels of attention mechanisms to learn node representations through a hierarchical attention process. SeHGNN (Yang et al., 2023) learns node representations by considering both the structural and semantic roles of the nodes. To alleviate computational burden, CGGP (Liu et al., 2023) establishes a set of comprehensive pruning criteria to progressively eliminate unimportant nodes and edges from the graph, resulting in a sparser network.
In this article, we present a recommendation model that automatically selects and weights meta-paths utilizing graph transformation capabilities. It also learns node embedding representations based on the transformer architecture to effectively
Preliminaries
An example, which serves as a concise HIN as illustrated in Figure 1, there are a total of nine nodes, which consist of two users (U), five movies (M), a director (D), and an actor (A). For instance, for user Example of heterogeneous information network (HIN).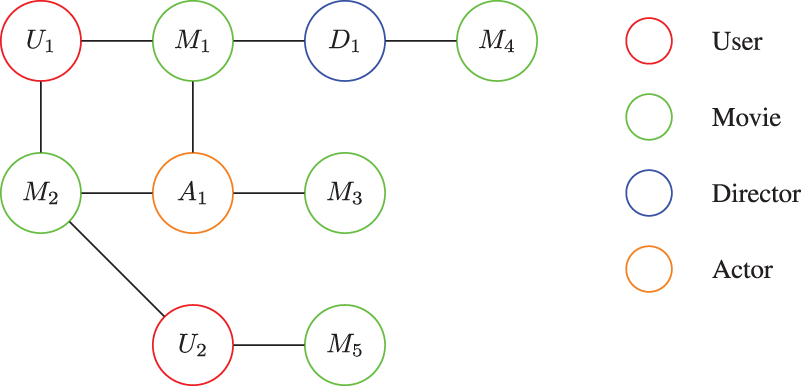
In the HIN illustrated in Figure 1, multiple distinct meta-paths can be derived, each representing different semantic relationships between nodes. One such meta-path, referred to as UMAM, captures a higher-order semantic relationship: an user who has expressed interest in a particular movie may be inclined to watch other movies featuring the same actor as the initially selected movie. This meta-path reflects the user’s potential preferences based on their interest in specific actors, thereby facilitating more personalized and contextually relevant recommendations.
This section introduces the automatic meta-path identification recommendation (AMPIRec). AMPIRec is designed to automatically identify optimal Meta-Paths within HINs and generate effective embedding representations for recommendations. As illustrated in Figure 2, AMPIRec comprises three key modules: the meta-path recognition module, which identifies the most relevant meta-paths. The interaction information enhancement module, which enriches interaction data by incorporating these meta-paths; and the context-aware user-item embedding module, which refines node embeddings and captures complex dependencies between users and items. Together, these modules enable AMPIRec to deliver precise and contextually relevant recommendations by leveraging both structural and semantic information in HINs.
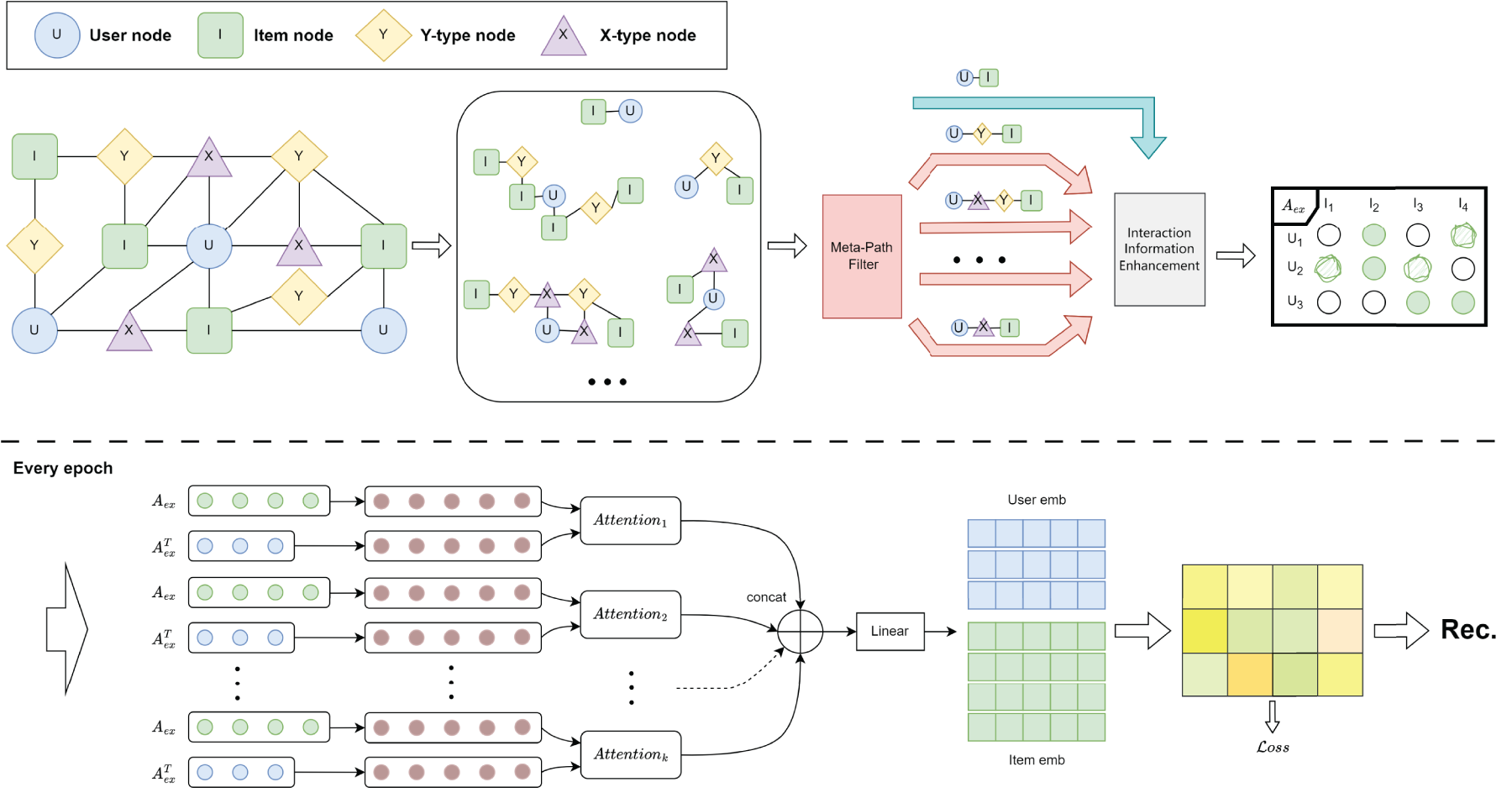
The model of automatic meta-path identification recommendation (AMPIRec).
At a macro level, the abstract representation of the model is
Inspired by matrix perturbation analysis from Matrix Theory (Franklin, 2012), we examine how perturbations to the weight vector
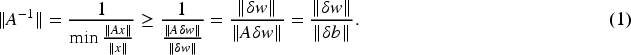
By taking the norm of both sides of the equation

Based on the non-negativity of norms and by combining equation (1) with equation (2), we obtain as follows:

From equation (3), we can derive the infimum of the change in the feedback adjustment weight matrix,
Similarly, considering
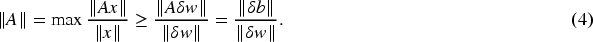
Furthermore, for
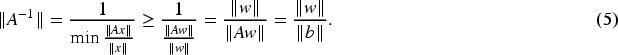
By combining equation (4) with equation (5), we can determine the supremum of the change in output,

For the actual input

To evaluate the stability of meta-paths, we perform eigenvalue decomposition on each meta-path and calculate its condition number:



To mitigate the excessive number of parameters in neural networks and the associated computational overhead that can result in extended training times, we refrain from using the conventional method of employing a multi-layer perceptron (MLP) to aggregate neighbors during each training iteration. Instead, drawing inspiration from the high-order interaction information captured through multiple convolutions in LightGCN, we treat the meta-path reachability matrix as analogous to the high-order information derived from these convolutions, with the length of the meta-path coresponding the number of GCN layers. In our model, the stability of various meta-path reachability matrices is a crucial factor in assessing their effectiveness as auxiliary information.
In the abstract model of AMPIRec, the equation
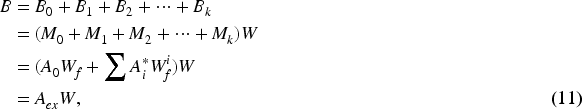
To minimize the impact of the meta-path reachability matrices, which serve as auxiliary information for the output matrix

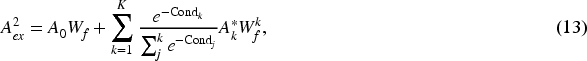
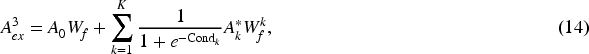
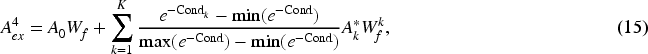


After incorporating the
This module aims to leverage the powerful context-awareness of multi-head attention mechanisms to uncover latent relationships between users and items within the preference matrix and audience matrix, thereby generating more representative node embeddings. Attention mechanism enhances the model’s ability to adaptively focus on the most significant neighboring nodes, thereby improving its capacity to uncover the relevance between users and items. The specific steps are as follows: The preference matrix and audience matrix are vertically concatenated to form the matrix
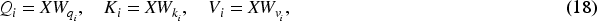
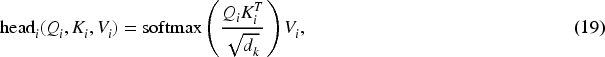
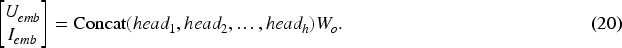
Here,

The row vectors in

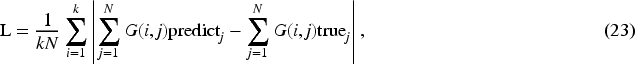


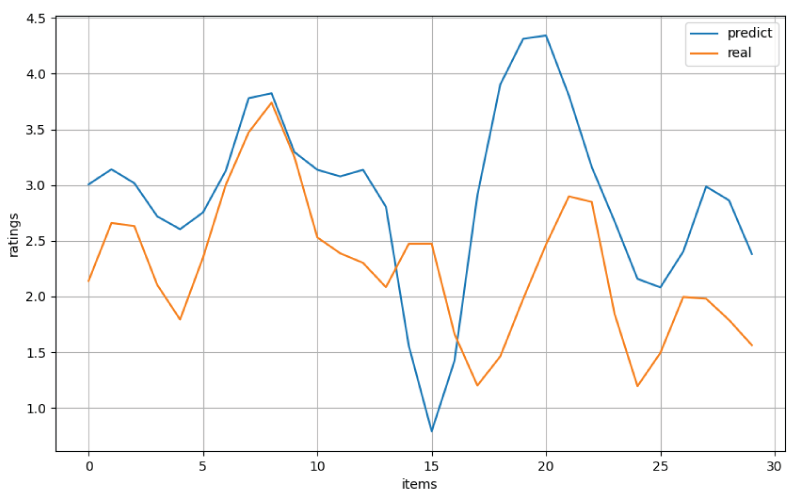
Demonstration of Top-30 smoothed distribution discrepancy between user’s ground-truth ratings and predicted ratings.

In this section, we introduce the two datasets utilized in our experiments, present the results obtained from these datasets, and compare our findings with those of state-of-the-art recommendation methods.
Datasets and Metrics
The datasets utilized in this experiment are an extension of the MovieLens 1M dataset, 1 published by the GroupLens research team (Harper & Konstan, 2015), and the Amazon-Book Reviews Database available on Kaggle. 2
The MovieLens dataset includes ratings from 6,040 users (
Statistics of the Datasets.
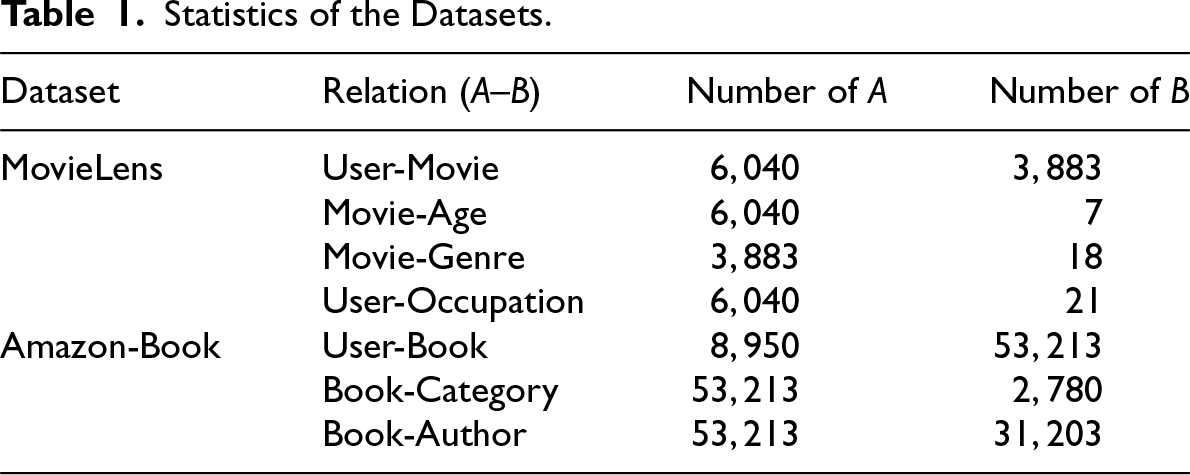
Statistics of the Datasets.
To comprehensively evaluate the performance of various recommendation models, we employ three core metrics that are widely used in the assessment of recommendation systems:recall, normalized discounted cumulative gain (NDCG), and precision. These indicators align with those established in the latest MIMA method, and these metrics assess the quality and effectiveness of the recommendation system from various perspectives.
To provide a comprehensive comparison and evaluate the performance of our proposed model, we employ five well-established baseline models. These baselines are selected to represent a diverse array of approaches in graph-based recommendation systems, enabling us to benchmark our model against various state-of-the-art techniques and demonstrate its effectiveness across different methodologies.
Experiments Results
In this article, three meta-paths are identified as auxiliary information within the meta-path identification module, specifically
Meta-Path Identification
Following the meta-path identification process applied to both datasets, the condition numbers
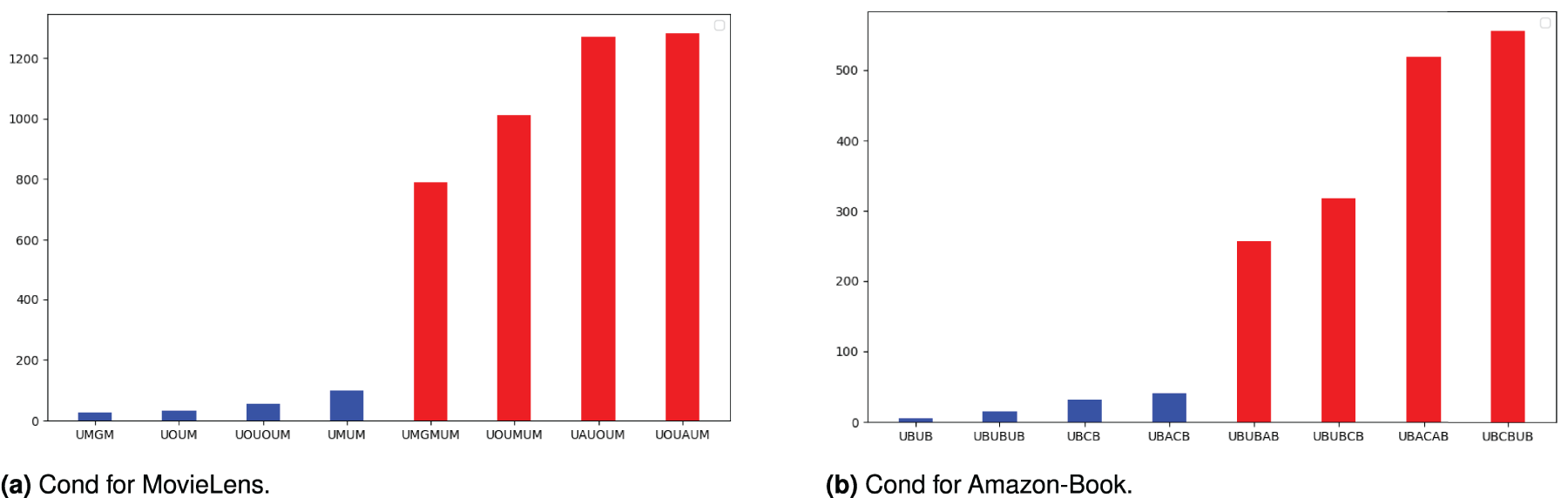
Cond for the datasets: (a) cond for MovieLens and (b) cond for Amazon-Book.
From Figure 4, it is evident that the top three meta-paths with the highest condition numbers in the MovieLens dataset are UMGM, UOUM, and UOUOUM. In contrast, the top three meta-paths in the Amazon-Book dataset are UBUB, UBUBUB, and UBCB. A semantic analysis of these meta-paths revealed that the most stable adjacency matrix meta-path in the MovieLens dataset is UMGM, indicating that users select movies primarily based on genre. The second most stable meta-path, UOUM, suggests that users with different occupations tend to have similar tastes in films. UOUOUM pertains to movies that are widely circulated among users within their respective occupations. In the Amazon-Book dataset, UBUB ranks the highest, reflecting that users who enjoy the same book often share common preferences, which indicates a transfer of preferences among users. The meta-path UBUBUB encompasses a broader range of users with shared interests. Meanwhile, the meta-path UBCB illustrates users’ preferences for specific book categories. Overall, the identified meta-paths align well with the patterns and preferences commonly observed in everyday choices.
In this subsection, we have chosen equation (12) as our information enhancement module. Effectiveness experiments were conducted to evaluate the performance of all baseline methods, as well as our proposed model. Table 2 presents a comparison of the performance of AMPIRec against the baseline methods across both datasets. This comparison highlights the effectiveness of AMPIRec in relation to state-of-the-art approaches, providing a comprehensive overview of its performance in various scenarios.
Comparative Results Between Baselines and AMPIRec.
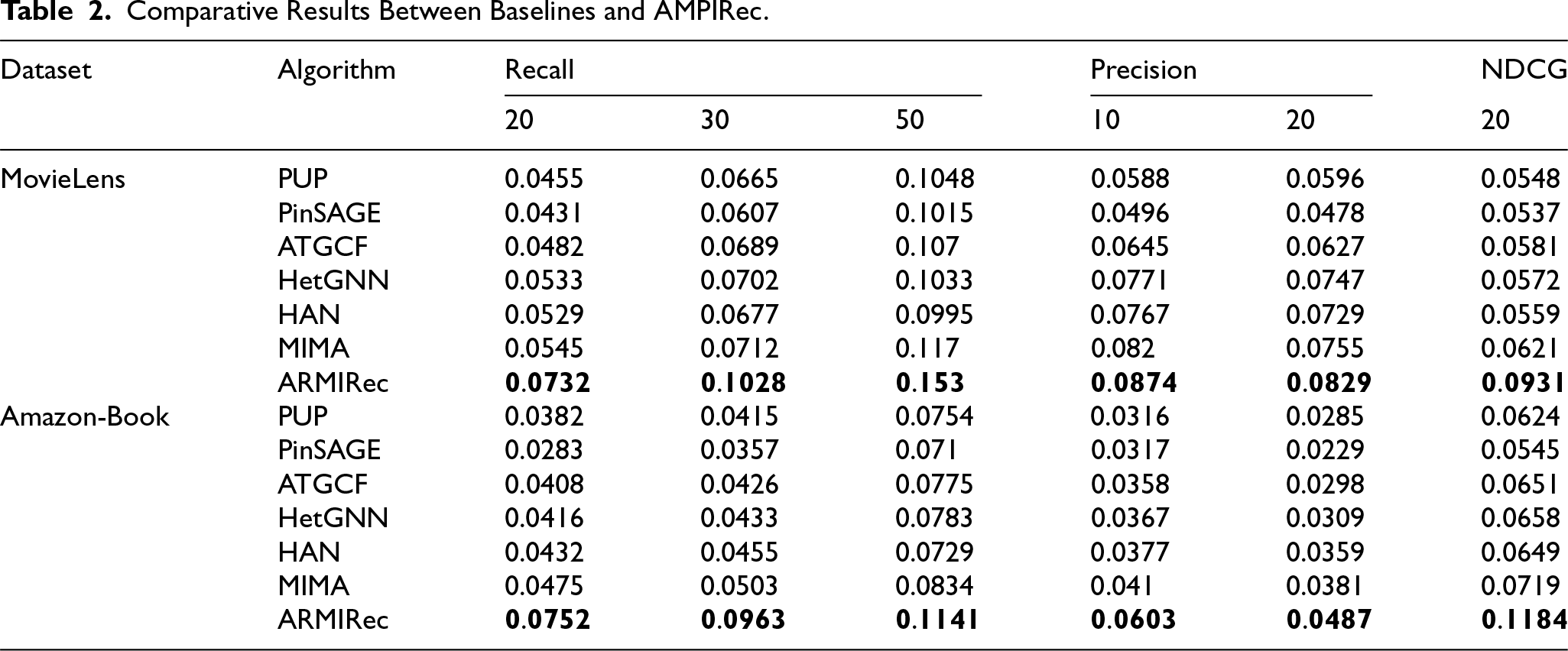
Comparative Results Between Baselines and AMPIRec.
The results demonstrate that our model, AMPIRec, significantly outperforms all baseline models across both datasets. In the MovieLens dataset, AMPIRec excels in all evaluation metrics, particularly in NDCG@20, where it achieves nearly an 50% improvement over the state-of-the-art method. In the Amazon-Book dataset, AMPIRec achieves approximately a great improvement in Recall@K compared to the best-performing baseline model, MIMA, and also exhibits substantial enhancements in PRECISION@K and NDCG@20. AMPIRec’s exceptional performance across a variety of tasks and datasets underscores its remarkable generalization capability. The advantages of this model become increasingly evident when the value of
In this section, we explore various information enhancement modules to identify the most effective one. Specifically, we evaluate four variations of our model: AMPIRec
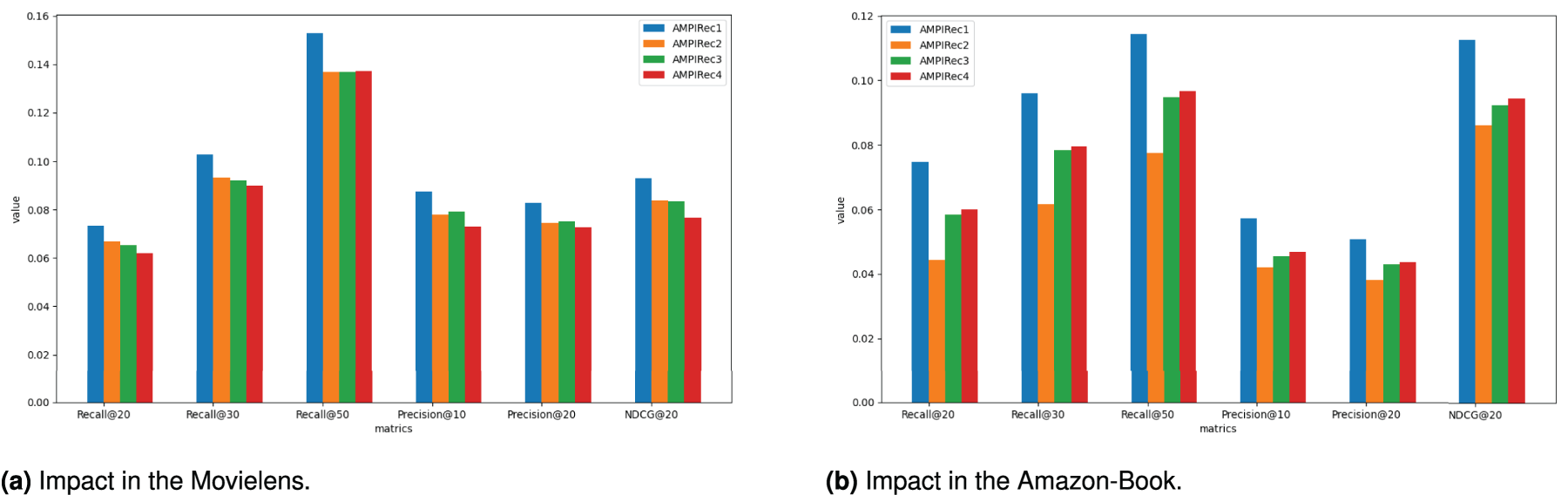
Results of four coefficient calculation methods: (a) impact in the MovieLens and (b) impact in the Amazon-Book.
As shown in Figure 5, the information enhancement module, which employs the reciprocal of the condition number as a coefficient, demonstrates optimal performance across all evaluated metrics. Consequently, we recommend utilizing equation (12) as the practical computation method for the interaction information enhancement module.
Next, we conducted experiments utilizing different meta-paths with AMPIRec
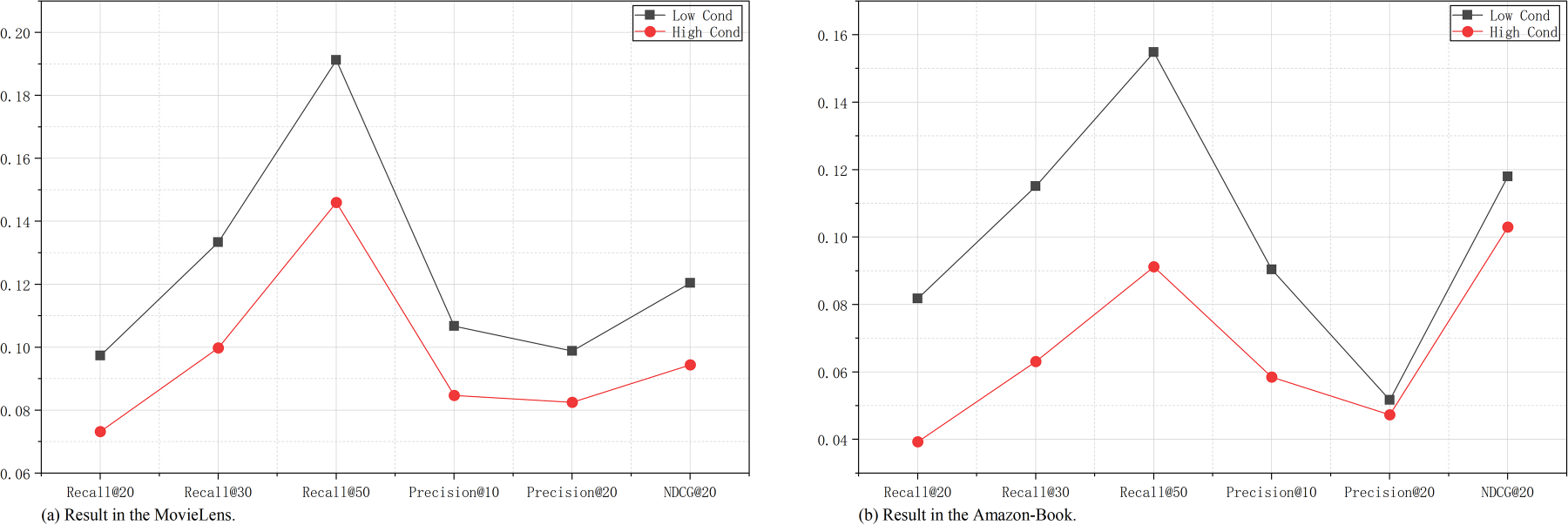
Results of the two meta-path combination selection modes in each datasets: (a) result in the MovieLens and (b) result in the Amazon-Book.
In this article, we introduce AMPIRec, a novel HGNN model aimed at enhancing recommendation systems by leveraging intricate relationships within HINs. AMPIRec integrates various types of node interactions and incorporates extensive attribute information, providing a comprehensive framework for accurately capturing user preferences and item characteristics.
Our comprehensive evaluation of AMPIRec on two real-world datasets, Amazon-Book and MovieLens, demonstrates its superior performance compared to several advanced baseline models. The results indicate significant improvements in key metrics such as Recall, Precision, and NDCG, underscoring AMPIRec’s effectiveness in predicting user preferences and enhancing recommendation accuracy. Notably, AMPIRec excels by not only capturing direct interactions but also leveraging auxiliary information from various Meta-Paths. This holistic approach enables AMPIRec to outperform both traditional and contemporary methods that rely on HINs.
Looking ahead, future research could explore extending AMPIRec to additional domains and incorporating a broader range of interaction types and attributes. Such developments would further enhance the model’s versatility and performance. By building on the principles demonstrated in AMPIRec, we aim to push the boundaries of personalized recommendation systems, ultimately delivering more precise and meaningful recommendations to users.
Footnotes
Acknowledgments
We extend our sincere gratitude to the editors and reviewers for their invaluable efforts in facilitating the publication of this manuscript. We also thank the curators of the Movielens and Amazon-Book databases for making their valuable datasets publicly available.
Funding
This work was supported by the National Natural Science Foundation of China grant No. 12261027.
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.