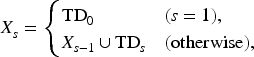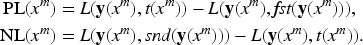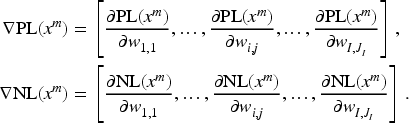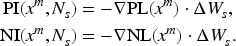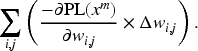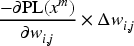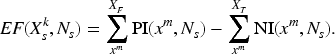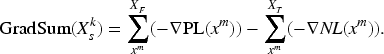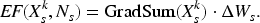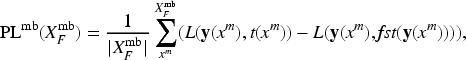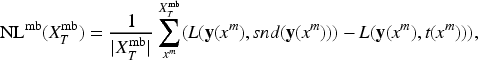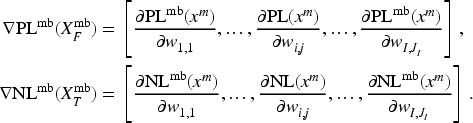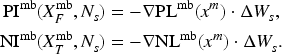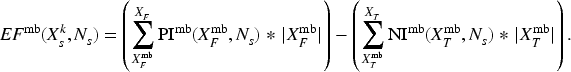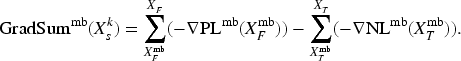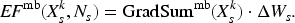During the operation of a system including a deep neural network (DNN), new input values not included in the training dataset are given to the DNN. In such a case, the DNN may be incrementally trained with the new input values; however, additional training may reduce the accuracy of the DNN in regard to the dataset that was previously obtained and used for the past training. The effect of the additional training on the accuracy for the past dataset needs to be evaluated, but evaluation by testing all the input values included in the past dataset takes time. Therefore, we propose a new method to evaluate the effect on the accuracy for the past dataset, in which the gradient of the parameter values (such as weight and bias) for the past dataset is extracted by running the DNN before the training. After the training, the effect on the accuracy with respect to the past dataset can be calculated fast from the gradient and update differences of the parameter values. To show the usefulness of the proposed method, we present experimental results with several datasets. The results show that the proposed method can estimate the accuracy change by additional training in a short constant time.
The introduction of machine-learning technologies in various industrial fields has been advancing. Among those technologies, deep neural networks (DNNs) are being widely applied. In addition to replacing human labor, in a number of fields, DNNs are outperforming people. DNNs are trained with a dataset composed of pairs of input values and their corresponding expected output values. A part of the dataset is used for training DNNs, and the rest is used to evaluate the trained DNNs. In the training, when input values are included in the training dataset, values of parameters such as weights and bias are adjusted so that the expected output values are more likely to be obtained. After the training is completed, the test dataset is used to measure the probability of obtaining the expected output value as expected. This probability—called accuracy—indicates the validity of the developed DNNs. However, the accuracy measured during development is only that with respect to the existing dataset retained at that time. When input values that are not included in the existing dataset are input to a DNN, the output values are not exclusively those expected; consequently, the DNN is less accurate during operation than during its development.
When the accuracy of DNNs decreases during operation, it is useful to apply incremental learning (Crankshaw et al., 2014; Leo & Kalita, 2024; Luo et al., 2020; Wang et al., 2024b; Xiao et al., 2014; Zhou et al., 2023), in which a DNN is trained by using a dataset newly acquired during operation. In incremental learning, parameter values of the DNN are adjusted to improve the accuracy of the newly acquired dataset. However, the result of the adjustment also affects the accuracy of the dataset used in the previous trainings. When the accuracy for the past dataset decreases, the updated DNN is not easily adopted. If a system operator finds that a concept drift of input values happens, the decrease in accuracy for the past dataset can be ignored because the past dataset and its similar data are not input thereafter. However, since the operator is not always able to detect changes in the distribution of input values, they can rarely be confident that the decrease in the accuracy for the past dataset can be ignored. Even if the distribution changes due to concept drift, a part of the input values before the change may still be included after the change. In such cases, it should maintain a certain level of accuracy for the past dataset. From the above considerations, the decision to use the updated DNN is based on the accuracy for the past dataset and the results of the concept drift evaluation. In addition, in a number of systems, the decision to adopt or discard the updated DNN should be made as soon as possible to prevent losing business opportunities. To grasp the effect of additionally conducted training on the accuracy of the past dataset, it is sufficient to run the updated DNN with all the input values included in the past dataset and acquire its accuracy again. However, when the past dataset is huge, the test takes a long time to execute. In other words, the accuracy of the DNN cannot be evaluated quickly by testing.
Therefore, we propose a fast evaluation method for the effect of additional training on the accuracy for the past dataset (Sato et al., 2018). In the proposed method, the gradient of the parameter values is extracted by executing the DNN with the input values in the past dataset before the DNN update. After the additional training, the effect on the accuracy of the past dataset is evaluated on the basis of the gradient and the update differences of parameter values of the DNN. We also leverage a linear regression analysis to estimate the increase/decrease in accuracy. The calculation to be conducted after additional training does not depend on the number of input values in the past dataset. Therefore, even if the past dataset is huge, applying the proposed method enables the effect of additional training to be evaluated fast. To demonstrate the usefulness of the proposed method, we show the experimental results using the MNIST, Fashion MNIST, and the German Traffic Sign Recognition Benchmark (GTSRB) datasets.
The rest of this paper is organized as follows. In Section 2, the structure of DNNs and a flow of incremental learning are defined. The problem that we focus on in incremental learning is also described. In Section 3, the proposed method is presented on the basis of several calculation formulas. In Section 4, the results of experiments applying the proposed method to three datasets are shown. In Section 5, the usefulness of the proposed method is evaluated and discussed on the basis of the experimental results. In Section 6, related work is described, and in Section 7, the conclusions drawn from this study are presented.
Preliminaries
Deep Neural Networks (DNNs)
For an arbitrary DNN, denoted as , handling a classification problem of class , is taken as the number of neurons making up , and each neuron (in any layer) is denoted as . Also, is taken as the number of parameters used to calculate the value of , and the parameter itself is denoted as . Note that if and are included in different layers, and can be different. A vector obtained by combining the parameters of all neurons is defined as . For a multilayer perceptron (MLP), for example, these parameters correspond to weights and biases. The formula for calculating the value of each neuron by using these parameters is not described in this paper.
For an arbitrary input value , the corresponding expected output value is expressed as , which represents the identifier of the classification class to which belongs. When is input to , the output value returned by is expressed as , which corresponds to the c-dimensional vector . The value for each dimension represents the probability that the input value belongs to class . If has the largest value in , class is denoted as . That is, holds. When holds, it is said that can correctly classify . Likewise, if has the second largest value, class is denoted as . Specifically, holds.
Since the number of layers, neurons, and parameters are generalized in the definition of DNNs, and types of activation functions are not specified, the proposed method can be applied to any neural network in which the gradient of parameters is computable.
Incremental Learning
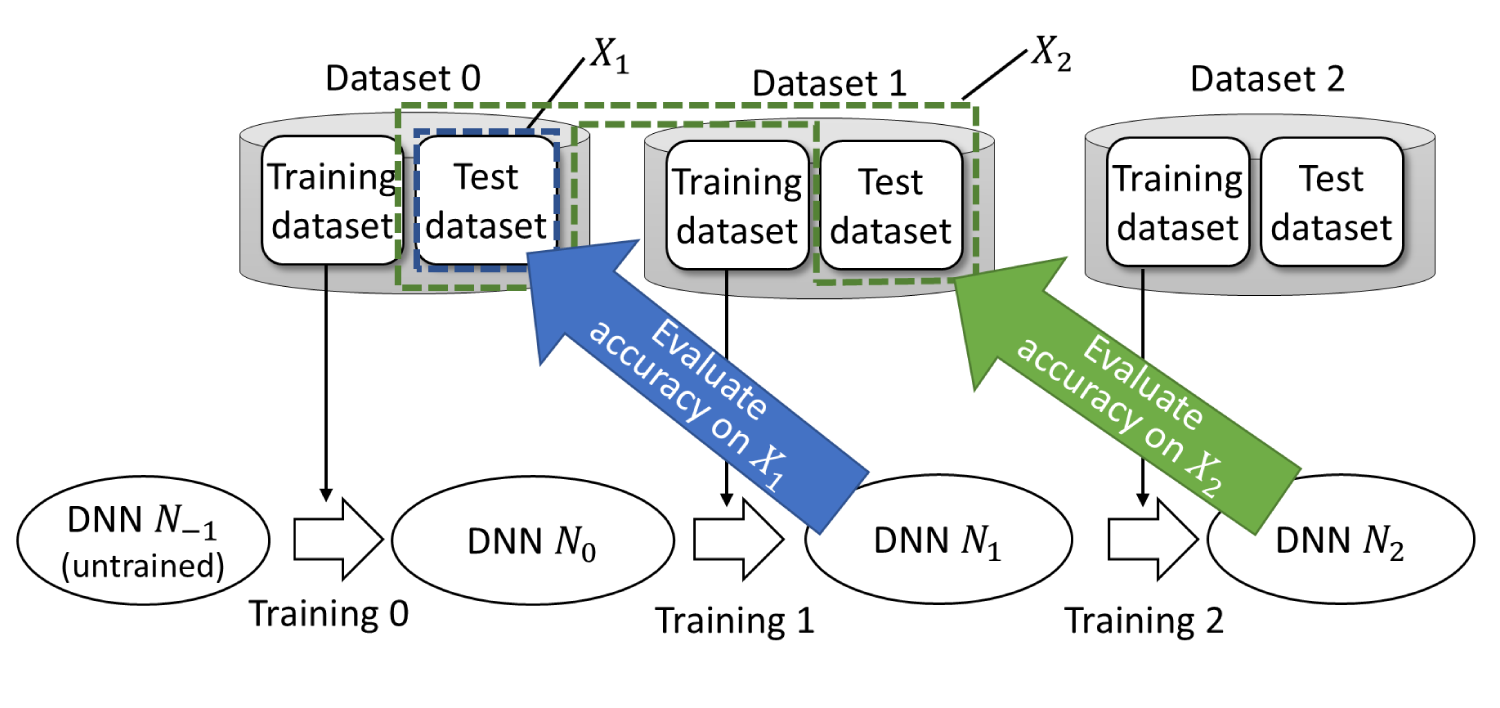
The flow of incremental learning is shown in Figure 1. An untrained DNN is trained first by using the training dataset of Dataset 0. The trained DNN is evaluated by using the test dataset of Dataset 0. After testing, starts to be used. During its use, Dataset 1 is newly acquired. At that time, is trained again using the training dataset of Dataset 1, and the updated DNN is evaluated in the same way using the corresponding test dataset. However, does not always maintain sufficient accuracy for Dataset 0. Accordingly, the effect of training 1 on the accuracy for Dataset 0 needs to be evaluated. That necessity holds for the following incremental learning.
Flow of incremental learning. An untrained deep neural network (DNN) is trained by the training dataset of Dataset 0. The trained DNN is evaluated by using the test dataset of Dataset 0. After that, is trained again and updated to using the training dataset of Dataset 1 that is newly obtained. The updated DNN is evaluated by using the test dataset of Dataset 1. At that time, should also be evaluated for the test dataset of Dataset 0, which is denoted as . Similarly, DNN should be evaluated not only for the test dataset of Dataset 2 but also for the test datasets of Dataset 0 and Dataset 1, which is denoted as .
Incremental learning can be categorized as domain-, task-, and class-incremental learning (Van de Ven & Tolias, 2019). We focus only on domain-incremental learning (Mirza et al., 2022; Wang et al., 2024a). Specifically, we assume that the input distribution may change, but the number of classification classes is not increased, and no other tasks are added through the incremental learning.
As for a DNN , a dataset for which the effect should be evaluated is denoted as . It is defined as follows:
where represents the test dataset of Dataset .
Problem Statement
Incremental learning is useful to adjust a DNN to changes in the distribution of input values, which is known as concept drift. However, even if the distribution of input values changes, it does not necessarily mean that the input values are completely changed to different values. For example, when the range of input values is expanded, the past input values are included in the new ones. In such cases, an operator of the system using the DNN is concerned about accuracy with respect to the past dataset. In actual operations, the operator may not be able to determine if concept drift actually occurs. Therefore, if the operator finds that the accuracy for the past dataset decreases unexpectedly, the use of the updated DNN may be rejected. Thus, the tradeoff between adjusting to the new dataset and maintaining performance for the past dataset needs to be balanced. The decision to operate the updated DNN should be carefully made on the basis of the accuracy of the newly obtained dataset, the accuracy of the past dataset, and the results of the concept drift evaluation. When the updated DNN is not adopted, either the training is retried, or a rollback to the past DNNs is executed.
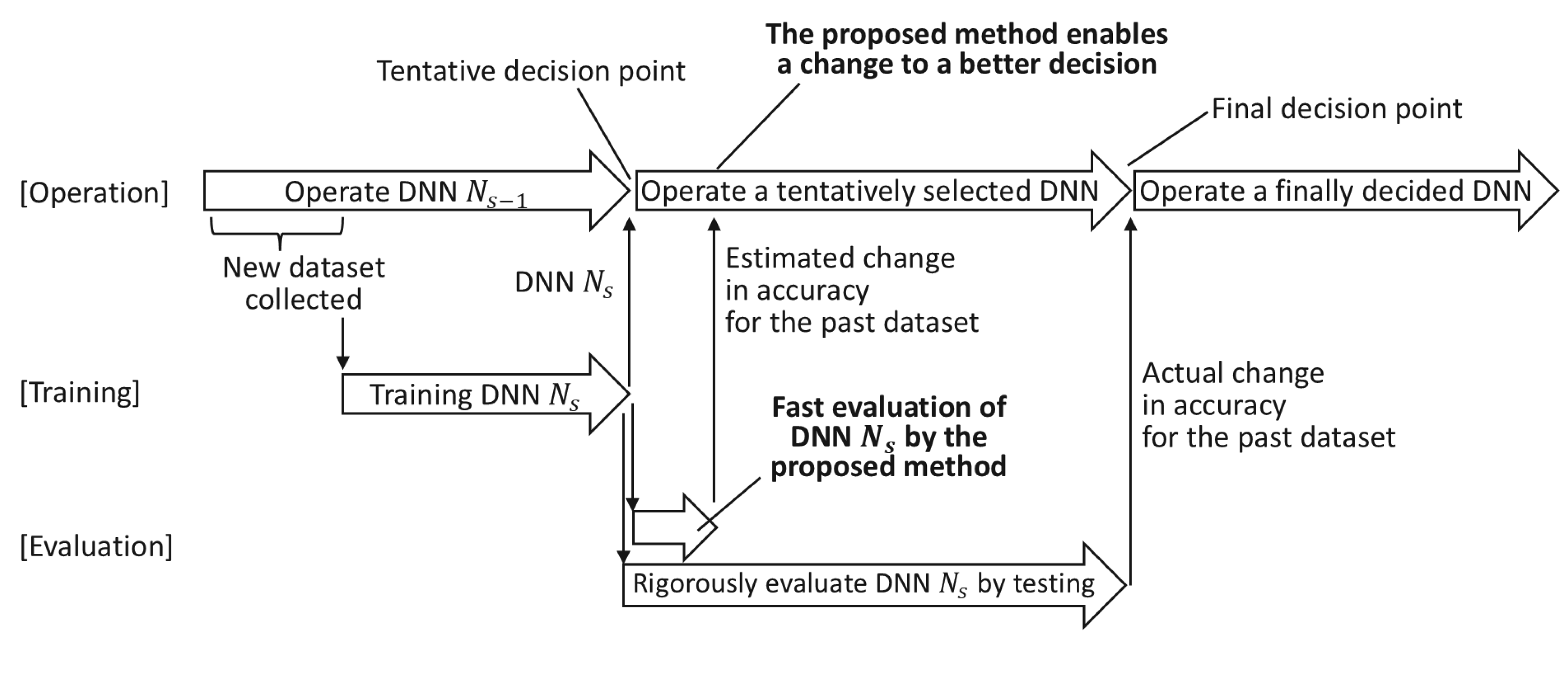
To evaluate the accuracy of the updated DNNs with respect to the past dataset, it is sufficient to test the DNNs with all the past data as input. In incremental learning, the size of the past dataset gradually increases, and then the time required to evaluate the change in accuracy with respect to the past dataset also increases. Until the test execution on the past dataset is completed, the DNN before or after the update is tentatively selected and used. If the operator does not have any information on the change in accuracy for the past dataset, the worst DNN may be selected. This results in undesirable business losses. Therefore, we propose a method to estimate the change in accuracy “fast” even if the past dataset is huge. This enables the operator to select a tentative DNN with consideration of the change in accuracy for the past dataset. As shown in Figure 2, by using the proposed method, the operator can make an early decision on DNN selection by referring to the estimated change of the updated DNN in terms of accuracy for the past dataset until the actual change is obtained by testing. This could enable better DNN operation and potentially reduce business losses.
Usage of the proposed method. During the operation of deep neural network (DNN) , a new dataset is collected. By using this dataset, is trained and updated to . The operator tentatively selects whether to use or at the tentative decision point, and this decision can be reviewed at the final decision point from the test result of . Before the test execution of is completed, the proposed method provides the fast evaluation result of for the change in accuracy for the past dataset. This enables the operator to decide whether to continue using the tentatively selected DNN before the actual change in accuracy is obtained by testing at the final decision point. After is rigorously evaluated by testing, we can review the decision again.
The proposed method is useful for systems with the following characteristics. First, the external environment of the system, that is, the distribution of input values, gradually changes, and there are both micro and macro trends of change. Second, the system learns continuously from data streams and follows changes in its external environment. Examples of such systems are social infrastructure systems, such as weather prediction, power control, and so on. In the case of a system that forecasts electricity demand, even if there is a change in the past several weeks, it may be transient due to peculiar weather conditions. Therefore, the operator may be discouraged from updating the DNN if the accuracy for the past datasets is significantly decreased. Another example is a stock price forecasting system. Updating the DNN on the basis of micro trend changes could lead to significant business losses.
Proposed Method
Positive and Negative Gradients
It is supposed that DNN is developed by the th training on DNN . The DNN deals with a classification problem with class . For any input value contained in , the corresponding expected output value is given. Since the effect of the DNN update is evaluated for each classification class in the proposed method, we define as a set of input values with the same classification class . The purpose of the proposed method is to estimate the change in accuracy for when is updated to .
Consider the case where DNN fails in the inference for input value , that is, . In this case, can be a factor that improves the accuracy of . When is updated to , if succeeds in the inference for , then the accuracy is increased. On the basis of this, we want to estimate how much the likelihood of successful inference for increases when updating DNN to . Therefore, in the proposed method, we focus on value changes of the c-dimensional vector . To avoid confusion between in and in , the output value of is hereafter described as and the output value of is .
If fails in the inference for , it means that is not the largest in , that is, . Assume that the updated DNN infers the output value for successfully. In that case, has increased or has decreased so that holds. Therefore, we focus on the value change of and to estimate the likelihood of successfully inferring the output value for with . The more increases, the more likely the output value for is successfully inferred. It is also true that the more decreases, the more likely the output value for is successfully inferred. Note that is the value with respect to . This means that represents the value after , the largest element value of , is changed by updating the DNN from to .
Similarly, consider the case where accuracy is decreased by updating the DNN. When the inference result of is changed from success to failure, that is, from to . The factors that cause the accuracy to decrease are the values of and . Here, denotes the class with the largest element value in . Since the aim of this method is to estimate the effect on without running with including , it is assumed that is not known. Therefore, we use instead of in the proposed method. This is based on the assumption that “If the inference result changes from success to failure when updating the DNN from to , the class with the largest probability in is likely to be that with the second largest probability in .” Here, since we assumed that succeeds in the inference for , the class with the largest probability in is . If a class different from has the largest value in , the class is highly likely to be , the class with the second largest probability in , from the above assumption. Therefore, to estimate the possibility that fails in the inference after updating the DNN, we focus on changes in and . The more decreases, the more likely inference for is to fail. It is also true that the more increases, the more likely the inference for is to fail. The validity of the above assumption is experimentally evaluated in Appendix A.
In the proposed method, is input into and infers the output values before updating from to . The sets of input values that fail and succeed in the inference are denoted as and , respectively, where . For simplicity, and are not given and as subscripts. For , holds. Similarly, for , holds.
For , we define the positive loss to evaluate the change in value of and , which cause an accuracy increase, as shown in Definition 2. Let be an arbitrary loss function used in the training. Assume that the first and second parameters of are the output value and the supervisory signal, respectively. If the DNN is updated so that decreases, the likelihood of a successful inference for is increased. For , we evaluate the value changes of and , which cause accuracy to decrease. We similarly define the negative loss, as shown in Definition 2. If the DNN is updated so that decreases, it is more likely to fail in the inference for .
Next, we calculate the gradient of parameter of with respect to . The gradient of , called the positive gradient, is expressed by . Similarly, the gradient of , called the negative gradient, is expressed by . and are defined as follows:
Effect Estimation
After and are created for , training is additionally executed, and DNN is created. Parameter of is compared with parameter of , and the update difference of parameter is acquired. By using , positive effect and negative effect to are calculated as follows:
approximates the amount by which is decreased by updating parameter to . Likewise, corresponds to the approximate decrease in . If is denoted as , corresponds to
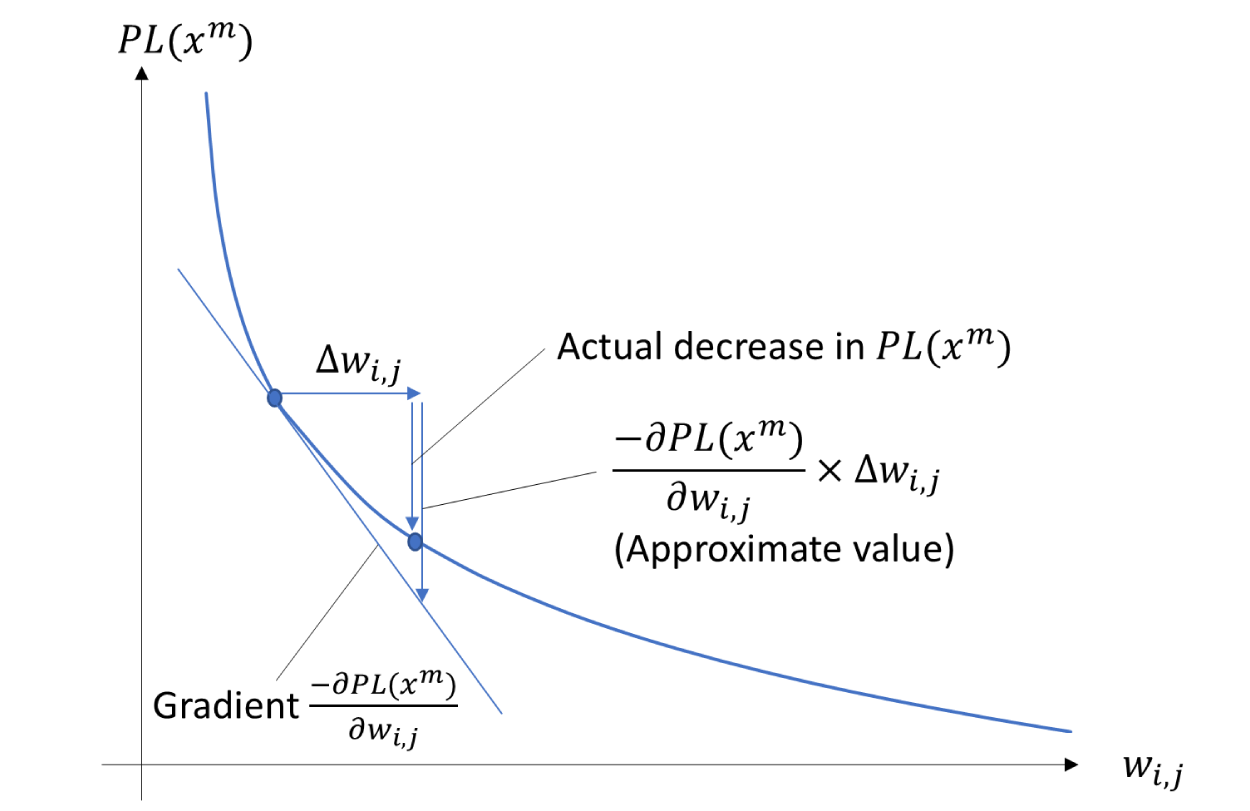
For example, in the case that loss function is cross-entropy, the relationship between the decrease in due to updating by , and its approximate value
Decrease in and its approximate value. When parameter increases by , decreases. Since the gradient of the loss function is , the change in is approximated as .
We assume that the same loss function is used for training and . The training aims to reduce the loss calculated on the basis of (hereafter, training loss), in which the expected output value is the supervisory signal of the training. If the training loss for decreases, the output value of in regard to is more likely correct. This means that the decrease in training loss is a barometer for evaluating the change in accuracy. It can therefore be assumed that , which is an approximate decrease in , can be taken as a barometer for evaluating the change of the output value with respect to . More precisely, the decrease in indicates the extent to which the likelihood of successfully inferring the output value for is increased. This is also true for . The decrease in indicates the extent to which the likelihood of failing in inferring the correct output value for is increased.
The sum of for all is the barometer of the accuracy increase in . Similarly, the sum of for all is a barometer of the accuracy decrease in . On the basis of the aforementioned considerations, the following in Definition 5 can be used as a barometer for evaluating the change in accuracy with respect to .
The purpose of the proposed method is to estimate the change in accuracy for the past dataset immediately after updating the DNN. To achieve this, we conduct some calculations in advance before updating the DNN, so that the amount of calculation after updating the DNN is minimized as much as possible. However, only formulas of Definitions 2 and 3 can be performed before the DNN is updated. Parameter of the updated DNN is required for the calculation in Definition 4, so subsequent calculations can only be executed after updating the DNN. Moreover, since the computational complexity of the formulas in Definitions 4 and 5 depends on the number of input values contained in , the amount of calculations conducted after updating the DNN will increase as incremental learning progresses ( is increased as incremental learning progresses). Therefore, we replace the calculations in Definitions 4 and 5 with the following ones given in Definition 6 and Formula 1.
Formula 1.
In Definition 4, and are created by multiplying and by . After that, sum and subtraction calculations are conducted on them in Definition 5. To reduce the amount of calculations after updating the DNN, the sum and subtraction calculations are performed in Definition 6 before the DNN is updated. After the DNN is updated, , which can only be obtained from the updated DNN , is multiplied in Formula 1. The computation time of Formula 1 is constant and independent of the number of input values contained in .
Regression Model
can be used as a barometer to evaluate changes in accuracy. More specifically, and accuracy are expected to have a linear relationship, which means that increases and decreases along with accuracy. This relationship is expected regardless of the dataset. However, the scale of values and the scale of accuracy values are different for each dataset. In other words, these scales depend on dataset type (i.e., the problem solved by the DNN) and DNN structure. Thus, there is no general way to estimate the change in accuracy from . However, if we target a specific dataset and DNN, we are able to derive a formula regressionally from the actual calculation results of the and the change in accuracy. Therefore, the proposed method creates a linear regression model to estimate the increase/decrease in accuracy from .
First, we calculate of DNN to for , that is, , respectively. Also, by performing the inference of to with , respectively, the actual increase or decrease in accuracy with respect to is measured. By using these values of and the actual increase/decrease in accuracy, we create a linear regression model, where an value is the input of the model and the increase/decrease in accuracy is the output. Note that the past dataset used for these calculations is because what we want to estimate at training is the effect of additional training on , not . The effect of on will be estimated on the basis of the actual effects of training 1 to on . Since is created from Dataset 0 to Dataset , it can be obtained at training . In other words, these calculations can be performed before training .
Next, the formulas of Definitions 2, 3, and 6 are performed, and is obtained. These calculations can also be performed before training since , which is the update difference of the parameters between and , is not used. After updating the DNN from to by training , is then calculated in accordance with Formula 1. is input to the linear regression model to estimate the value of the increase or decrease in accuracy with respect to due to the update from to . This enables us to estimate the effect on before executing the test of with .
The number of samples to create the linear regression model depends on the number of training . In the experiment shown in Section 4, the number of training is 100 (). We create the regression model using the results of training 1 to 99. When creating the regression model, the interquartile range (IQR) is calculated, and outliers are removed from the samples. In more detail, let IQR denote the interquartile range, denote the lower quartile and denote the upper quartile. Samples smaller than and larger than are removed as outliers. The samples larger than , and are also removed.
The amount of calculation of Formula 1, which is executed after training , depends on the number of elements of , not the number of input values contained in . For an MLP, the number of elements of is given as for the number of neurons constituting the DNN. Moreover, the computational complexity of inference by the linear regression model is independent of and . Therefore, the calculation order of the proposed method after training is given as . This means that even if is enormous, a change in accuracy can be evaluated in a short time.
Mini-Batch for PL and NL
The proposed method assumes that there is sufficient time between training and . More specifically, there is sufficient time to calculate for 1 for creating a regression model, by executing DNNs to with to measure changes in accuracy, and to calculate from the formulas in Definitions 2, 3, and 6. However, depending on the number of input values contained in , these calculations may not be finished. In particular, since the formulas in Definition 3 calculate the gradient for each input value , they require much time if is enormous. In such a case, positive and negative losses for mini-batch, denoted as and , respectively, are calculated as follows:
where and represent a mini-batch, and and hold. and denote the number of data contained in and , respectively.
Correspondingly, and are calculated from the gradient of and , and , respectively, as shown in Definitions 8 and 9.
The larger mini-batch is, the more its inference results change from failure to success for more input values, so accuracy is likely to increase. Similarly, the larger mini-batch is, the more its inference results change from success to failure for more input values, so accuracy is likely to decrease. Thus, we calculate by multiplying by and by , as shown in Definition 10.
Similar to the formulas of Definition 4, appears in Definition 9, so it can only be executed after the DNN is updated. Since the computational complexities of Definitions 9 and 10 depend on the size of , the amount of calculation after the DNN update will increase as incremental learning proceeds. Therefore, just as the formulas of Definitions 4 and 5 were placed with Definition 6 and Formula 1, the formulas in Definitions 9 and 10 are placed with the following formulas in Definition 11 and Formula 2.
Formula 2.
Experiment
We experimentally applied the proposed method to the MNIST (Liu et al., 2003), Fashion MNIST (Xiao et al., 2017), and GTSRB (Stallkamp et al., 2011) datasets. In the following sections, arguments of the functions clear from the context have been omitted.
Setup
In this experiment, trainings are conducted from to . Two-thirds of the entire dataset is used as Dataset 0 (see Figure 1). The remaining is divided equally to create Datasets 1 through 100. In incremental learning, a well-learned model is continuously updated, so if Dataset 0 is too small and then DNN is not sufficiently trained, an appropriate simulation of incremental learning cannot be performed. On the other hand, if Datasets 1 to 100 are too small, problems such as overfitting may occur. Based on our system development experiences, we believe that the system will never be launched with the initial DNN that is not trained sufficiently. From the above consideration, we decided to prioritize Dataset 0 and made it from two-thirds of the entire dataset. For example, for the MNIST dataset, which contains 70,000 image data, 46,666 data are designated as Dataset 0, and Datasets 1 through 100 each consist of approximately 233 data. The ratio of dividing each dataset into the training and test datasets should be the same as the ratio of the training to test datasets in the original dataset. For the MNIST dataset, 60,000 and 10,000 data are provided for the training and testing datasets, respectively, resulting in a split ratio of .
As for the DNN models, we use an MLP with one hidden layer (composed of 1,000 neurons) in addition to the input and output layers and a convolutional neural network (CNN) with two convolutional layers with a kernel size of and a stride size of 1. For the GTSRB dataset, we use the mini-batch method described in Section 3.4 because the images (color channels) are too large to calculate the gradient for every input value in accordance with the formulas in Definition 3. In this experiment, the size of the mini-batch is set to 50.
We assume that we have finished training 100 and obtained DNN . Before that, past dataset was created from Datasets 0 to 99, and then were calculated. In addition, the actual increases or decreases in accuracy for to were also calculated by running to with as the input. By using these data as samples, a linear regression model was created before training 100. After finishing training 100, we can calculate by comparing DNN and . By inputting into the linear regression model, the change in accuracy at training 100 is estimated. Therefore, the proposed method can be evaluated by the performance of the regression model.
If possible, we want to calculate the coefficient of determination for the created regression model with test data. However, the test data to evaluate the created regression model cannot be sufficiently obtained since only the data to evaluate the regression model is that from training 100. Even if training 101 is conducted subsequently, the target dataset will be updated to , and thus a different regression model will be created at training 101. This means that only one data is used as input for each regression model. Therefore, for the evaluation of the proposed method, we calculate the score of the regression model at training 100 using the data of training 1 to 99 that are used to create the regression model. If the score is high, the regression estimation performance for the data from training 1 to 99 is also high. Furthermore, we can say that the estimation performance for the data of training 100 should be high since it is calculated in the same way as that from trainings 1 to 99.
In each training, cross-entropy is used as the loss function . The experiment was performed on an Ubuntu 20.04.4 LTS machine equipped with two Intel® Xeon® Gold 6132 2.6-GHz processors with 14 cores, 786-GB memory. It also has eight NVIDIA® Tesla®V100 NVLink GPUs.
Results
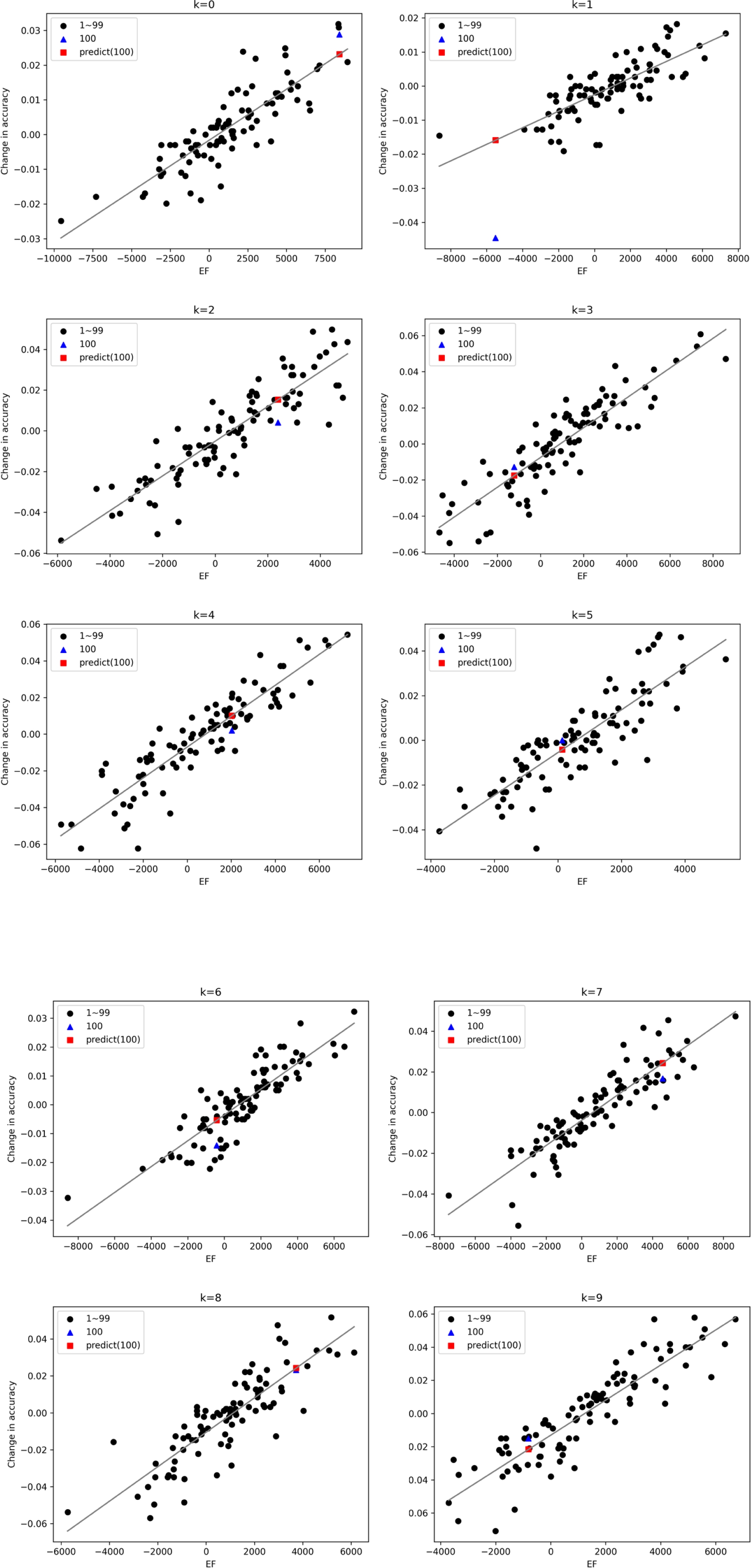
For the MNIST dataset, the linear regression model of the MLP resulting from the experiment is shown in Figure 4. The x- and y-axes show the values of and the change in accuracy between before and after training 100, respectively.
(1/2) Regression models of the MLP for the MNIST dataset. Each graph represents the result of applying the proposed method to each classification class. The x- and y-axes show the values of and the change in accuracy between before and after training 100. The black dots are plotted from the values of calculated by the proposed method and the actual change in accuracy in training 1 to 99. They are used to create the regression models, which are represented by straight black lines. The blue triangles represent the accuracy change estimated by the proposed method in training 100. The red rectangles represent the actual accuracy change in training 100, calculated by executing the DNN with all input values included in . (2/2). Note. MLP = multilayer perceptron; DNN = deep neural network.
The black dots in Figure 4 represent the data from trainings 1 to 99 used to create the regression model. However, outliers excluded on the basis of the IQR are not shown. The blue triangles represent the accuracy change estimated by the proposed method in training 100. The red rectangles represent the actual accuracy change in training 100, calculated by executing the DNN with all input values included in . The results for the other datasets were generally similar, with a few exceptions. Cases where the results were not as expected are discussed in Section 5.
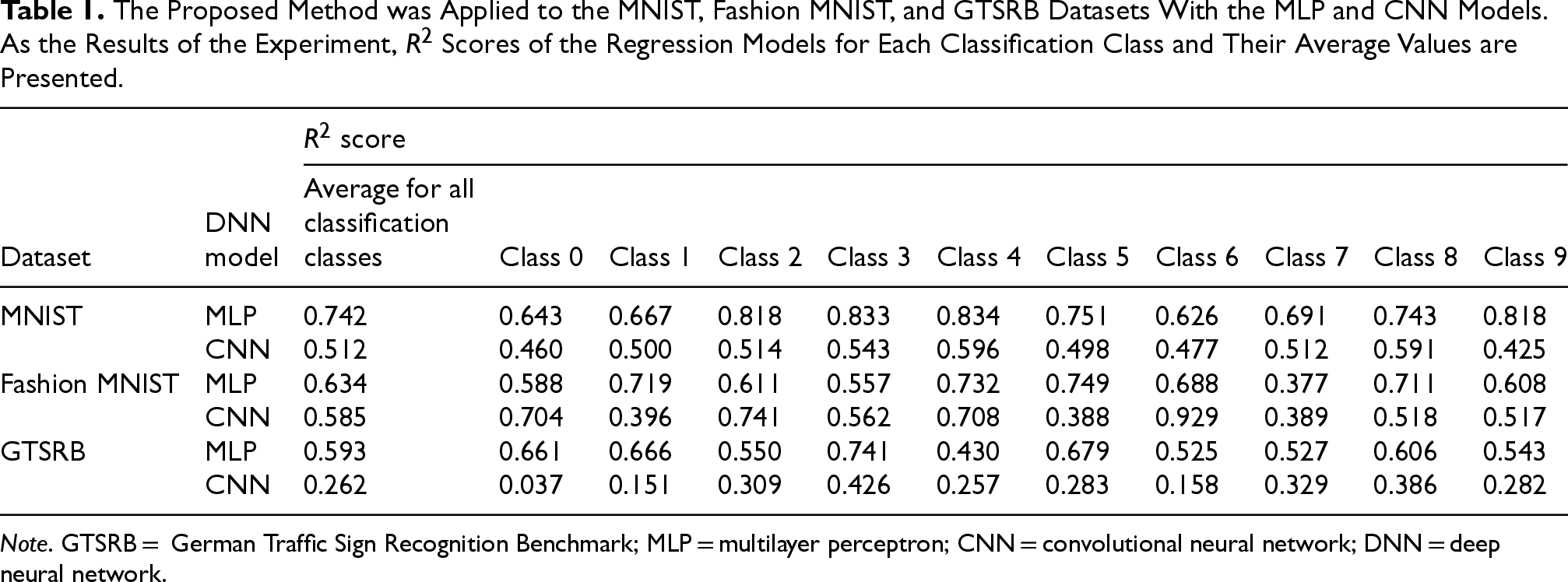
The scores of the linear regression models created for the MNIST, Fashion MNIST, and GTSRB datasets are shown in Table 1. Only scores for classification classes 0 through 9 are shown. For the GTSRB dataset, the column “Average for all classification classes” shows the average of all 43 classes. These results are discussed in Section 5.
The Proposed Method was Applied to the MNIST, Fashion MNIST, and GTSRB Datasets With the MLP and CNN Models. As the Results of the Experiment, Scores of the Regression Models for Each Classification Class and Their Average Values are Presented.
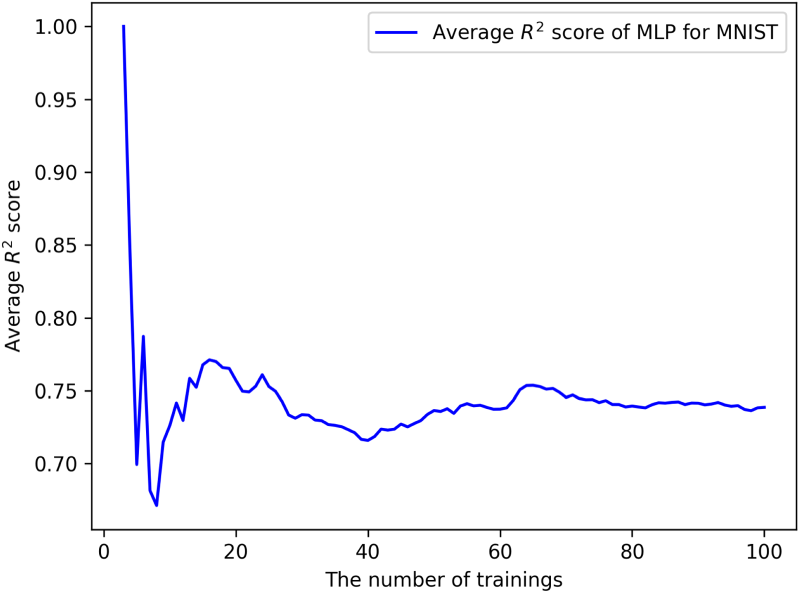
In training 3 to 99, the proposed method can also be applied to estimate each change in accuracy. Since at least two samples are required to create a linear regression model, the proposed method can be applied when the number of training is three or more. We conducted an additional experiment applying the proposed method to the MLP for the MNIST dataset in training 3 to 99. Figure 5 shows the average scores of the MLP from training 3 to 100 for the MNIST dataset. When the number of training is small, the number of data used to create the regression model is also small. As described in Section 4.1, scores are calculated from the data that are used to create the regression model since we have only one data for each training to evaluate the regression model. If these data can be connected by a straight line, the score is likely to be high. If they are scattered, the regression model is created at the center of the data, so the score is likely to be low. For example, in training , , (and their corresponding actual changes in accuracy) are used to create a regression model. These two data are also used to calculate the score. Since the regression model is formed as a line connecting these two data points, the score is 1. From around training 20, the score generally remained at 0.75 in Figure 5. This suggests that the proposed method is useful from the early stages of incremental learning.
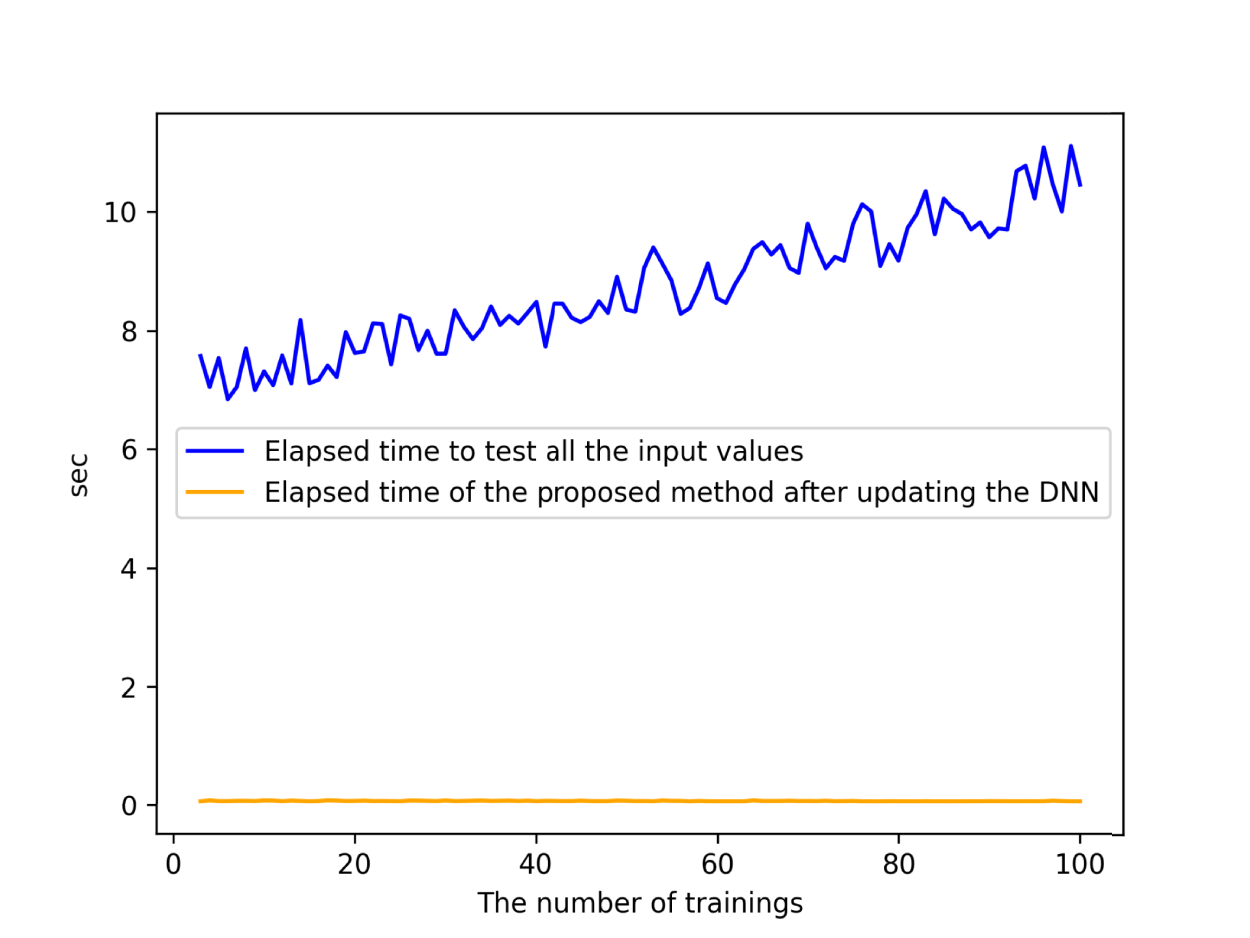
The time taken after updating the DNN, which is the MLP for the MNIST dataset, in the proposed method and that taken to test the DNN with all input values contained in for are plotted in Figure 6. In the proposed method, the calculations conducted after updating the DNN are to obtain from in accordance with Formula 1 and the value of increase or decrease in accuracy by inputting the value of into the regression model. , , and are calculated before updating the DNN, so they are not included in the time shown in Figure 6. Figure 6 indicates that the calculation after updating the DNN can be performed in almost the same time regardless of the increase in the number of input values (orange line). In contrast, the test execution time increases with the number of training since the number of input values in increases (blue line). Similar results were obtained for the other datasets.
As shown in Figure 6, in the proposed method, the calculation after updating the DNN does not depend on the number of input values in the past dataset. The larger the past dataset is, the more useful the proposed method is to obtain reference information for tentatively selecting a DNN until the accurate change in accuracy is confirmed by test execution. It is evident that the calculation order of Formula 1, which is performed after updating the DNN, is for each classification class as mentioned in Section 3.3. The amount of calculations corresponding to the formulas in Definitions 2, 3, and 6 increases in accordance with the size of the past dataset, but those calculations are carried out before the DNN is updated. This means that after the DNN is updated, the proposed method can estimate the change in accuracy in a constant time, even if the number of data included in the past dataset is enormous. However, the proposed method is useful only when the past dataset is not small. For example, in Figure 6, about 10,000 input values of the MNIST dataset are inferred in training 100, which takes only about 10 s. If the proposed method is used for tentatively selecting DNNs as described in Section 2.3, the shorter the time until the accurate change in accuracy is confirmed by testing, the less useful the proposed method will be. Assuming that the proposed method is effective if it takes more than 1 h to confirm the accurate change in accuracy, the past dataset should contain more than 3 million input values, as calculated from the results in Figure 6.
Average scores in trainings 3 to 100 when the proposed method is applied to the multilayer perceptron (MLP) for the MNIST dataset. The x- and y-axes show the number of trainings and the average score, respectively.
Calculation times in training to when the proposed method is applied to the MLP for the MNIST dataset. The yellow line represents the times taken after updating the DNN in the proposed method. The blue line represents the times taken to test the DNN with all input values contained in . Note. MLP = multilayer perceptron; DNN = deep neural network.
Evaluation and Discussion
Validity of the Evaluation
As mentioned in Section 4.1, the score shown in Table 1 is calculated using the data used to create the regression model. is updated each time the number of training increases. Hence, in the proposed method, the regression model is recreated for each training. That is, in training , the regression model is only used to estimate the change in accuracy for when the DNN is updated from to and is not used thereafter. In other words, the only data that can be used to evaluate the regression model is the data of training , but one data is not sufficient for evaluation. Therefore, the score calculated from the data of training 1 to is used to evaluate the regression models alternatively. These data are calculated from a DNN with the same structure and dataset as the data of training . Therefore, it can be used to evaluate the performance of the regression model. For example, suppose that the residuals between the data of training and the regression model are small. This means that the regression model can accurately estimate the effect of the DNN updates in training for the dataset . If the same is generally true for any , then it is highly likely that the same regression model can accurately estimate the effect of DNN updates in training for the same dataset . On the basis of the aforementioned consideration, we used the data of training 1 to for the evaluation.
Performance
From the results of the experiment shown in Table 1, we found that the average score is around 0.6, which indicates that the proposed method can be expected to perform at a certain level. In particular, using the proposed method is preferable if the purpose is to obtain reference information for selecting a tentative DNN, as described in Section 2.3. The results of the experiment also show that the proposed method does not always estimate accurately. As shown in Table 1, the scores of the regression models can be around 0.1 if they are low. The limitations of the proposed method should be taken into consideration when using it.
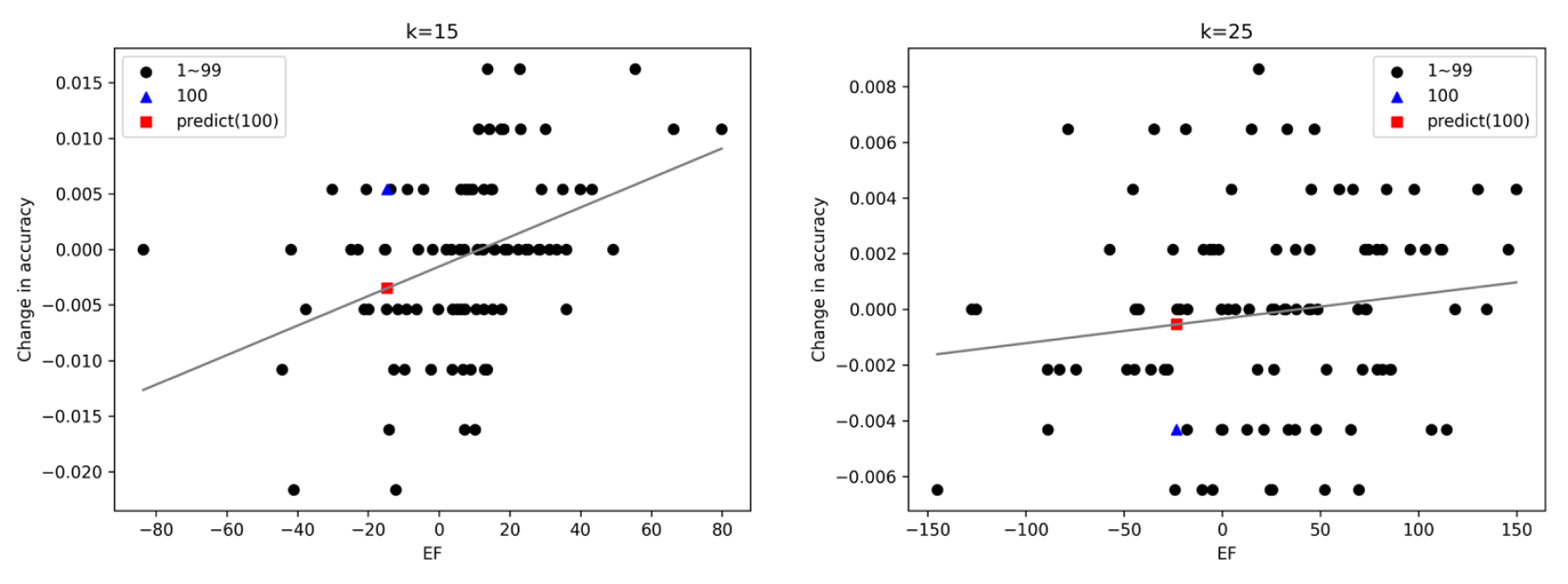
In a number of cases, especially for the CNN with the GTSRB dataset, the linear relationship between and accuracy change could not be confirmed. As examples, linear regression models for the GTSRB dataset with classification class and are shown in Figure 7. In these cases, the accuracy change is difficult to estimate by the proposed method. One common point among these cases is that the accuracy changes on the y-axis are smaller than those in Figure 4. This means that the inference results do not change significantly for most input values. In this case, the correlation between and the change in accuracy should be low.
Regression models of the CNN for classification class and of GTSRB dataset. These are examples of cases where the accuracy change is difficult to estimate by the proposed method. As in Figure 4, the x- and y-axes show the values of and the change in accuracy between before and after training 100. The black dots are plotted from the values of calculated by the proposed method and the actual change in accuracy in training 1 to 99. They are used to create the regression models, which are represented by straight black lines. The blue triangles represent the accuracy change estimated by the proposed method in training 100. The red rectangles represent the actual accuracy change in training 100, calculated by executing the DNN with all input values included in . Note. CNN = convolutional neural network; GTSRB = German Traffic Sign Recognition Benchmark; DNN = deep neural network.
When DNN before being updated succeeds in the inference (i.e., ) for many but there is a large difference between the values of and , the inference results do not change even though and change. In this case, since the number of input values in is small, the sum of will slightly change. For the same reason, accuracy will be unlikely to increase. However, since the number of input values contained in is large, the sum of is likely to increase significantly. According to the definition of (in Definition 2), when decreases or increases, increases. If there is a large difference between those values, the value of is seldom smaller than that of . That is, even if the value of increases, the relationship is likely to remain true, and then accuracy will not decrease. Thus, the closer the value of is to (one-hot representation of in reality) for most input values, the smaller the change in accuracy becomes. This determines whether the proposed method can accurately estimate the change in accuracy.
Application to Each Classification Class
The proposed method is applied to each classification class . We realized from experiments other than those described in Section 4 that when the proposed method is applied to , the score of the regression model is lower than in the cases of . In the proposed method, and are defined on the basis of the probability values of that change the inference result. The gradients of and are then calculated using the parameters of the DNN, and and are the results of evaluating the similarity with the actual DNN parameter change values . These values represent the extent to which changes of the parameters cause “changes in probability values that affect the inference result.” Since is calculated from the and of all input values, it represents the sum of the change in the probability values for each input value that affects the inference result.
Here, we note that input values in the same classification class are similar in terms of not only the probability value but also the amount of change in the probability value that flips the inference result from failure to success or vice versa. For example, for a dataset consisting of input values in the same classification class, the value of that flips the inference result of an input value is assumed to be 5. Let us assume that the dataset consists of five input values, and the value calculated as the sum of the values of those input values is 10. There can be three typical cases: value of 2 from all 5 input values, values of 10 from only 1 input value, and values of 5 from 2 input values. In each case, the number of input values whose inference result flips is 0, 1, and 2, respectively. That is, when (the sum of) is 10, the number of input values whose inference result flips can be estimated to be from 0 to 2.
Next, consider the case where input values of different classification classes are mixed. In this case, the values of that would flip the inference result are different for each input value. Suppose that if the dataset consists of the five input values, the values of that flip the inference result are 1, 1, 3, 3, 10 for each respective input value. It is also supposed that the value calculated as the sum of values of those input values is 10. In this case, the number of input values whose inference result flips could be any number from 0 to 4. In other words, in this case, we can only narrow down that the number of input values whose inference result flips to be between 0 and 4 when is 10. Thus, when input values of different classification classes are mixed, it is more difficult to narrow down the number of input values for which the inference result flips from than when only input values of the same classification class are included. This means that the correlation between and accuracy changes will be lower for a mixed dataset. For this reason, the proposed method is designed to be applied to each classification class.
We also realized from another experiment that applying the mini-batch method does not significantly change the score. This can also be explained by the fact that input values in the same classification class have similar features. If a mini-batch was composed of various input values with different characteristics, positive losses were expected to be diverse. Since is calculated as the average of , and are not similar for many in this case. However, mini-batches consist of input values from the same classification class, and their inference results are the same. Therefore, the calculated for each are all similar functions. Moreover, their average, , is also similar to . From these considerations, the value obtained by calculating for each and summing them is highly likely to be similar to the value obtained by calculating for each mini-batch and multiplying it by the number of its elements . In other words, when the proposed method is applied to each classification class, the mini-batch method is likely to provide a similar result to the normal method. In fact, when we experimented with varying the number of input values that make up the mini-batch, no significant change in scores was observed.
is calculated for each input value included in the mini-batch and the average value is used as . The gradient is obtained for this average value. The gradient indicates how to update the parameters of the DNN so that it has a good (changing from failure to success) impact on average on the inference results of the input values contained in the mini-batch. It is used to compute the impact (i.e., ) on the entire mini-batch by comparing it with the update of the DNN parameters. On the other hand, in the normal method, the gradient indicates how to update the parameters so that it positively impacts that input value. Recalling that the change in accuracy is the accumulation of the change in inference results for individual input values, the impact of the DNN update on individual input values is considered to have a higher correlation with the change in accuracy than the average impact on the mini-batch. For example, suppose that and for a mini-batch consisting of and . It is also assumed that the parameters of the DNN are updated in the direction that decreases. In that case, since increases, the inference result for remains a failure. On the other hand, since decreases, the inference result for is likely to change from failure to success, which may result in an increase in accuracy. However, if the mini-batch method is applied, since , the value of does not change, that is, even though decreases. Thus, the application of the mini-batch method can be a factor that reduces the correlation between and changes in accuracy. The same is true with . Therefore, the score of the linear regression model is likely to be lower when the mini-batch method is applied.
In the calculations of and , not only but also and are used, respectively. This is because we expect to use cross-entropy as the loss function . Cross-entropy uses only the probability value of a particular classification class given as a supervisory signal. Therefore, for , calculating the loss on the basis of only as the supervisory signal would only consider how much the value of increases. This means that the loss does not include how much the value of decreases. Similarly, for , if only is given as the supervisory signal and the loss is calculated on the basis of it, only the amount by which the value of decreases is taken into account. The loss does not include the amount by which the value of increases. Therefore, the proposed method defines the calculations of and so that the values of , , and are considered as factors affecting the change in accuracy. The mean squared error is calculated using probability values other than the class given as the supervisory signal. Therefore, if it is used as the loss function, terms in which and appear may be able to be removed from the formulas calculating and , respectively.
In the experiments described in Section 4, the original dataset was randomly split, so the distribution of the data did not change during incremental learning. This means that the effectiveness of the proposed method for concept drift was not evaluated. However, since the objective of the incremental learning shown in Section 2.2 is to adapt the DNN to concept drift as fast as possible, the DNN is assumed to be updated at a higher frequency than the frequency at which concept drift occurs. Hence, in many cases, the DNN will be updated even though concept drift has not occurred. Evaluating the effectiveness of the proposed method even when concept drift occurs is a future task.
Related Work
To the authors’ knowledge, no research on a method for the fast evaluation of incremental learning results has been published. However, there are several works on incremental learning that focus on the parameters of DNNs (weights and biases) and the gradient of a loss function.
Kirkpatrick et al. (2017) focused on a decrease in accuracy in task-incremental learning (Parisotto et al., 2015; Rusu et al., 2015). For example, when training for task 2 is carried out after training for task 1, the performance of the previously trained task (task 1) is catastrophically reduced. This is called catastrophic forgetting (Aleixo et al., 2023; Kemker et al., 2018; McCloskey & Cohen, 1989; McRae & Hetherington, 1993; Ratcliff, 1990). In response to this problem, they proposed a method of identifying the parameters important in regard to task 1, and training task 2 in a manner that minimizes changes to those parameters (important in regard to task 1). Our proposed method does not distinguish the parameters of the DNN. The accuracy change may be able to be estimated more accurately by identifying the parameters that contribute to the accuracy change for the dataset and focusing on the changes in those parameters, as in their method.
In task-incremental learning and class-incremental learning, distillation loss is used to mitigate catastrophic forgetting (Aljundi et al., 2017; Castro et al., 2018; Dhar et al., 2019; Douillard et al., 2020; Hou et al., 2018, 2019, 2019?; Kang et al., 2022; Li & Hoiem, 2017; Liu et al., 2020; Rannen et al., 2017; Rebuffi et al., 2017; Wu et al., 2019). Distillation loss represents the difference between the inference results before and after learning. The more similar the inference results, the smaller the distillation loss value. Learning to minimize distillation loss in addition to the normal loss enables inference results for the past dataset to be preserved. Kang et al. (2022) proposed a learning method that focuses on the gradient of the loss function. In this method, learning is performed so that “the increase in the loss” for the past dataset when the DNN is updated is minimized. To achieve this, they focus on the gradient of the loss function for the past dataset. On the basis of this gradient, the change in loss for the past dataset is approximated, and the DNN is updated so that it is minimized. In our proposed method, and are defined for the past dataset, and the impact of DNN update on the past dataset is estimated on the basis of their gradients. From a general point of view, our method and Kang et al.’s (2022) method are similar in that they focus on the gradient of the loss function for the past dataset and estimate the impact of the DNN update on the basis of the gradient. Unlike their method, however, our proposed method aims to estimate the change in accuracy for the past dataset. For this purpose, we propose and , which are directly related to the change in accuracy, rather than the normal loss.
In another approach, Belouadah et al. (2020) focused on the fact that the weights of a DNN before the update represent the past classes in class-incremental learning. Their method, which uses the weights to prevent catastrophic forgetting, is effective for memoryless class-incremental learning where the past dataset cannot be stored entirely. Our proposed method also utilizes the change in weight before and after DNN update, which is similar to their approach. However, our method cannot be applied to memoryless class-incremental learning since we cannot evaluate the accuracy for a past dataset without it. Although the proposed method can be applied to part of the past dataset, its accuracy estimation is expected to be lower.
Conclusion
We proposed a fast evaluation method for the effect of additional training for the past dataset in incremental learning. The gradient of the parameter values for the past dataset is extracted by running the DNN before the additional training. After the training, a barometer of the effect on the accuracy with respect to the past dataset is calculated from the gradient and update differences of the parameter values. Finally, the proposed method estimates the change in accuracy by using a regression model created from the s and actual changes in accuracy in the past training. The computational complexity of the proposed method, after the update, depends on the number of DNN parameters, not on the amount of data in the past dataset. Therefore, even if the amount of data included in the past dataset is enormous, applying the proposed method enables the effects of training to be evaluated fast. When a DNN is updated during operation, the proposed method enables a system operator to decide whether to use the updated DNN with consideration of the change in accuracy for the past dataset. The results of our experiments indicate the usefulness of the proposed method in terms of computation time and the coefficient of determination for the regression model used to estimate changes in accuracy. Even though the expected coefficient of determination could not be confirmed in a number of cases, using the proposed method to obtain reference information for selecting a tentative DNN is preferable until an accurate change in accuracy is confirmed by test execution. As for future work, the proposed method will be more elaborately evaluated using other datasets. In particular, the occurrence of concept drift should be simulated in the evaluation. Moreover, improving the means of creating will help in the search for a way to more accurately evaluate the change in accuracy. For example, distillation loss discussed in Section 6 may be effective for improving the proposed method.
Footnotes
ORCID iD
Naoto Sato
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A Additional Experiment for Validating the Assumption
In the proposed method, we adopted the assumption that “If the inference result changes from success to failure when updating the DNN from to , the class with the largest probability in is likely to be that with the second largest probability in ” as described in Section 3. We conducted an experiment to evaluate this assumption. In the experiment in Section 4, DNNs to were run with the target past dataset to create the regression model. If the above assumption holds among them, it supports the validity of the proposed method. Moreover, since we want to estimate the change in accuracy between DNNs and , the assumption should hold between them. Therefore, we first perform the inference of an arbitrary DNN by inputting . For an arbitrary input value , if the inference fails, that is, the class with the largest probability in the output vector is not , we obtain the class with the largest probability, which is denoted as . Input value is then input to . We evaluate whether the class with the second largest probability in the inference result of , which is denoted as , is equal to . If they are likely to be equal, it indicates that the above assumption holds between and . For each dataset, such as MNIST, Fashion MNIST, and GTSRB, we conduct the same evaluation with respect to and calculate the probability that coincides with . The results of the experiment are shown in Table 2. Since we are considering the case where the inference result changes from success to failure due to the update from to , holds. Thus, for example, in the case of the MNIST dataset, representing the class with the largest probability in the output vector of coincides with a class other than of . If there is no relationship between and , the probability that holds should be . However, the experimental result shows that it holds with a probability higher than 0.11. The same is true for the Fashion MNIST and GTSRB datasets. Since the number of classification classes of the GTSRB dataset is 43, it is sufficient if the probability is larger than . From these experimental results, we believe that the proposed method is reasonable.
References
1.
AleixoE. L.ColonnaJ. G.CristoM.FernandesE. (2023). Catastrophic forgetting in deep learning: A comprehensive taxonomy. arXiv preprint arXiv:2312.10549.
2.
AljundiR.ChakravartyP.TuytelaarsT. (2017). Expert gate: Lifelong learning with a network of experts. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3366–3375). IEEE.
3.
BelouadahE.PopescuA.KanellosI. (2020). Initial classifier weights replay for memoryless class incremental learning. arXiv preprint arXiv:2008.13710.
4.
CastroF. M.Marín-JiménezM. J.GuilN.SchmidC.AlahariK. (2018). End-to-end incremental learning. In Proceedings of the European conference on computer vision (ECCV) (pp. 241–257). Springer-Verlag.
5.
CrankshawD.BailisP.GonzalezJ. E.LiH.ZhangZ.FranklinM. J.GhodsiA.JordanM. I. (2014). The missing piece in complex analytics: Low latency, scalable model management and serving with Velox. arXiv preprint arXiv:1409.3809.
6.
DharP.SinghR. V.PengK. C.WuZ.ChellappaR. (2019). Learning without memorizing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5138–5146). IEEE.
7.
DouillardA.CordM.OllionC.RobertT.ValleE. (2020). PODNet: Pooled outputs distillation for small-tasks incremental learning. In Computer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings, part XX 16 (pp. 86–102). Springer.
8.
HouS.PanX.LoyC. C.WangZ.LinD. (2018). Lifelong learning via progressive distillation and retrospection. In Proceedings of the European conference on computer vision (ECCV) (pp. 437–452). Springer-Verlag.
9.
HouS.PanX.LoyC. C.WangZ.LinD. (2019). Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 831–839). IEEE.
10.
KangM.ParkJ.HanB. (2022). Class-incremental learning by knowledge distillation with adaptive feature consolidation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 16071–16080). IEEE.
11.
KemkerR.McClureM.AbitinoA.HayesT.KananC. (2018). Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, pp. 3390–3398). AAAI Press.
12.
KirkpatrickJ.PascanuR.RabinowitzN.VenessJ.DesjardinsG.RusuA. A.MilanK.QuanJ.RamalhoT.Grabska-BarwinskaA.HassabisD.ClopathC.KumaranD.HadsellR. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13), 3521–3526.
13.
LeoJ.KalitaJ. (2024). Survey of continuous deep learning methods and techniques used for incremental learning. Neurocomputing, 582, 127545.
14.
LiZ.HoiemD. (2017). Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12), 2935–2947.
LiuY.SuY.LiuA. A.SchieleB.SunQ. (2020). Mnemonics training: Multi-class incremental learning without forgetting. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (pp. 12245–12254). IEEE.
17.
LuoY.YinL.BaiW.MaoK. (2020). An appraisal of incremental learning methods. Entropy, 22(11), 1190.
18.
McCloskeyM.CohenN. J. (1989). Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation (Vol. 24, pp. 109–165). Elsevier.
MirzaM. J.MasanaM.PosseggerH.BischofH. (2022). An efficient domain-incremental learning approach to drive in all weather conditions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 3001–3011). IEEE.
21.
ParisottoE.BaJ. L.SalakhutdinovR. (2015). Actor-Mimic: Deep multitask and transfer reinforcement learning. arXiv preprint arXiv:1511.06342.
22.
RannenA.AljundiR.BlaschkoM. B.TuytelaarsT. (2017). Encoder based lifelong learning. In Proceedings of the IEEE international conference on computer vision (pp. 1320–1328). IEEE.
23.
RatcliffR. (1990). Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions. Psychological Review, 97(2), 285.
24.
RebuffiS. A.KolesnikovA.SperlG.LampertC. H. (2017). iCaRL: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 2001–2010). IEEE.
SatoN.KurumaH.NakagawaY.OgawaH. (2018). Simplified influence evaluation of additional training on deep neural networks. In 1st international workshop on machine learning systems engineering (pp. 34–39). APSEC.
27.
StallkampJ.SchlipsingM.SalmenJ.IgelC. (2011). The German traffic sign recognition benchmark: A multi-class classification competition. In The 2011 international joint conference on neural networks (pp. 1453–1460). IEEE.
28.
Van de VenG. M.ToliasA. S. (2019). Three scenarios for continual learning. arXiv preprint arXiv:1904.07734.
29.
WangK.ZhangG.YueH.LiuA.ZhangG.FengH.HanJ.DingE.WangJ. (2024a). Multi-domain incremental learning for face presentation attack detection. In Proceedings of the AAAI conference on artificial intelligence (Vol. 38, pp. 5499–5507). AAAI Press.
30.
WangL.ZhangX.SuH.ZhuJ. (2024b). A comprehensive survey of continual learning: Theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8), 5362–5383.
31.
WuY.ChenY.WangL.YeY.LiuZ.GuoY.FuY. (2019). Large scale incremental learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 374–382). IEEE.
32.
XiaoH.RasulK.VollgrafR. (2017). Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747.
33.
XiaoT.ZhangJ.YangK.PengY.ZhangZ. (2014). Error-driven incremental learning in deep convolutional neural network for large-scale image classification. In Proceedings of the 22nd ACM international conference on multimedia (pp. 177–186). Association for Computing Machinery.
34.
ZhouD. W.WangQ. W.QiZ. H.YeH. J.ZhanD. C.LiuZ. (2023). Deep class-incremental learning: A survey. arXiv preprint arXiv:2302.03648.