
Abstract
Due to the vast popularity of sensors, cloud computing, mobile computing, and intelligent devices, the Internet of Things has seen tremendous growth in recent years. Operating system type recognition is the core technology of network security assessment. Due to inherit security problems of Internet of Things such as the situation of risk and threat of information, the operating system recognition seeks research attention for Internet of Things network security. In view of the current identification method of active operating system, it is prone to be detected by intrusion detection system. The operating system identification technology based on transmission control protocol/Internet protocol fingerprint library is more complicated than to distinguish the operating system types of unknown fingerprints. In this work, a passive operating system identification method based on RIPPER model is proposed. Also, it is compared with the existing support vector machine and C45 decision tree classification algorithms. Experiments reveal that RIPPER-based algorithm has better recognition accuracy and recognition efficiency.
Keywords
Introduction
The integration of wireless communication ways such as RFID and sensors with Internet, developed by the Massachusetts Institute of Technology laboratory, has opened new vistas in world of network. Therefore, such a network can be called as Internet of Things (IOT). Even the definition of the IOT shows its omnipotent role and importance. The IOT provides a shared platform that can interconnect information and enable automatic identification of items. There are two aspects to be exact: one is the remote user terminal and the other terminal corresponding to it, extending to any object between them, then exchanging information and communicating. On the other hand, it is mainly on the basis of the Internet to extend and expand to form a new type of network.
With the rapid development of the IOT, network security problems are incurred. Whether it is the property safety of e-commerce, the privacy protection of chatting communication, the file protection in office, or even the national security, all come under the umbrella of network security. In any type of network attack, the importance of collection and classification of information system cannot be ignored. Remote hosts and hackers usually exploit this as primary starting point because the operating system has certain types of vulnerabilities, which can be exploited with least effort. Thus, the key vulnerability is the identification of operating system of devices. The protection of network security also needs to identify the type of the host operating system and protect the user from forgery and other attackers. So the type and version of the operating system play an important role in it. Accurate and fast operating system recognition is a hot research area, yet to be explored in domain of IOT.
With the unbelievable popularity of machine learning methods, more and more operating system recognition technology is being combined with it. In 2004, R Beverly 1 proposed the application of the simple bias classifier to the unknown operating system fingerprint recognition. Two experiments are performed to verify that the first fingerprint database p0f operating system as a data set to train the second time. This uses data collected from a network of packet application layer identifier as a type of operating system for training, two times the recognition results and the recognition rate are not much differing from between 2 the unknown fingerprint identification method. It also gives a good solution, although not to identify unknown fingerprint problems. But there still exist some shortcomings, that is, its performance in stability is not good. It shows an excessive dependence on the spatial distribution of the sample. In 2009, on the basis of the Nmap fingerprint library, T Zhou et al. 3 proposed the unknown operating system recognition technology of support vector machine (SVM). The technology gives a solution to the problem that the unknown operating system cannot identify. However, this method only gives the identification of the type of the operating system. Specifically, it cannot be used with more detail for the identification of the publication of this number. 4 When vector machine is used for fingerprint recognition of unknown operating system, it does not reduce dimension processing for vector machine, so the accuracy and efficiency of recognition need to be improved. In order to improve the accuracy and speed of the unknown fingerprint, in 2015, Y Yi et al. 5 proposed a method based on the passive operating system identification of decision tree. The method of decision tree in the unknown operating system is based on fingerprint identification, which is based on decision tree of unknown fingerprint classification. Its test results obtained by testing a large number of the data, and SVM, C45 algorithms are compared. The results show that the accuracy of this method of identification has been further improved. This is due to the fact that it is easier to understand based on the rules of the decision tree. 6
Aiming at the problems of existing technology, and based on the existing research results on the passive operating system identification, we propose a model based on RIPPER algorithm and its application in identification, and compared with other methods. We make use of existing machine learning algorithm for system identification operation. We verify the validity of the model with experiments.
Related work
Identification method of IOT terminal operating system based on transmission control protocol/Internet protocol
Generally, the IOT terminals and ordinary hosts have the same transmission control protocol/Internet protocol (TCP/IP) stack, 7 which is used for communication. TCP/IP stack adopts a five-layer network model structure, which is mainly divided into physical layer, data link layer, network layer, transmission layer, and application layer, as shown in Figure 1. Network layer belongs to IP, which provides non-guaranteed communication. Using a router to connect all local area networks with the Internet, the use of the same private IP address, implementation is hidden from outside world. 8 There are mainly two transport layer protocols: User Datagram Protocol (UDP) and TCP. TCP provides connection-oriented services, through the exchange of three data packets to connect the parameters of the consultation. The connection termination is done with the wave of four times to provide reliable data packet transmission services. On the other side, UDP without establishing a connection to provide non-guaranteed data transmission services offers fast transfer, without requirement of reliable data transmission.

Network architecture model.
IP data packets are usually composed of IP header and data part, 9 length is not fixed. Fixed part is usually 20 bytes, will be added according to different needs of different options; TCP provides a reliable connection-oriented byte stream service. Besides other features, its important one is the connection establishment before transmitting data, the famous three-way handshake process. Since different operating systems have different implementation of the TCP/IP stack, we call them TCP/IP fingerprinting, which is similar to human fingerprinting. It can identify the fingerprint database in the public security system. In regard of operating system, implementation differences are mainly reflected in window size, survival time, fragmentation, maximum segment size, and options. 10
Table 1 shows some specific differences between the famous operating system types. So these different combinations of fields can be referred to as TCP/IP fingerprints that identify the operating system, which can be used to distinguish between different operating system types. The main reason for these differences is that the TCP/IP unifies the process of network communication; it does not specify the implementation of TCP and IP options. 11 Therefore, companies of different operating systems have different implementations according to their needs. Therefore, it makes the operating system recognizable. These differences usually do not exist in conventional data packets but often exist in a handshake packet and connection abortion packet.
Different operating system TCP/IP comparison of differences.

TCP/IP: transmission control protocol/Internet protocol.
Data classification is one of the main steps of data mining, mainly through the analysis of data samples to generate accurate description of different categories. At the same time, classification technology to solve the problem depends on how to gracefully construct a classifier model. There are many classifiers available including decision tree, SVM, and Bayesian classification, to name a few. Compared with other classification algorithms, the RIPPER algorithm based on rule induction has been applied to the recognition of operating system types. Major benefit of RIPPER classification method is simplicity, minimum calculation yet high accuracy. 12
Unknown operating system type identification model design based on RIPPER algorithm
RIPPER classification model
The main framework of RIPPER algorithm is divided into two parts: generating rules and optimizing rules. 13 The former is a two-tier cycle, in which the outer loop each generates a rule after pruning added to the rule base, the inner loop each time for the rule adds an antecedent. The latter part constructs the alternative rule according to the rules in base and selects the best rule to join the base by minimum description length (MDL) criterion. Figure 2 shows the learning and training process of the RIPPER classifier based on operating system identification. The detailed description of each step is as follows:
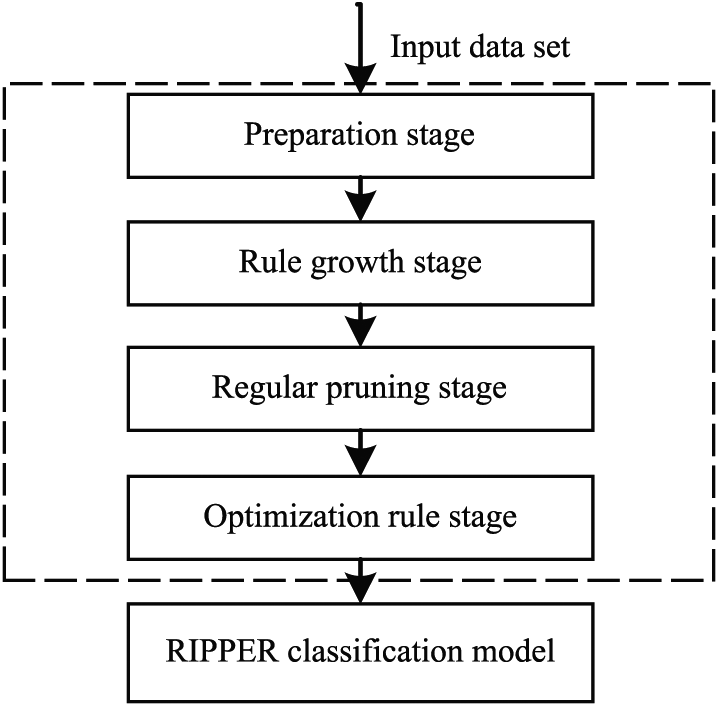
RIPPER classifier learning and training process.
Preparation stage
This stage initially calculates the priori probabilities for each operating system type in the data set.14,15 The RIPPER algorithm itself is a dichotomous algorithm, and the operating system type data set is a multi-classed data set. So for multi-class data needs to be converted into dichotomous problems according to the descending order of prior probability, each time a rule is established for a class with a lower prior probability.
Generation rule stage
The input to this stage is the data set D of the operating system’s fingerprint, positive operating system type C and its prior probability p, noting that the data set D here is the data set after the partial data was partially generated during the generation rule phase. The first one to be calculated is the description length under the default rule. The description length is further used as a reference value. The generated algorithm should not have a longer description length than the default rule. At this stage, 16 there are a number of rules until they cannot continue, the rules of the consequent are operating system type C. Each rule is generated by growing and pruning two stages, the growth stage from the empty rules. The next phase is pruned from the reverse of the last antecedent added. What is more, the first step is to divide data set D into independent growth sets Prune and prune sets, usually with a ratio of 2:1. Specific can be divided into regular growth phase and the rule of pruning stage, expanding the following detailed description.
Rule growth phase: The data set used for this phase is Growth set. The growth of a rule starts with an empty rule (any instance is covered by an empty rule), similar to the decision tree’s build process, which is added to the rule as a preceding piece each time, a suitable combination of all possible attributes and thresholds is selected. The measure of the metric is the information gain, a reduction in the bits needed for a positive code in information theory, unlike other decision trees where the information gain is not a reduction in the expected entropy. The exact definition of the information gain here is as equation (1)

where cover refers to the number of positive cases covered by the rule added, antd and
Rule trim stage: This stage uses pruning sets Prune to test the generalization of rules. At this stage, one antecedent of the rule is deleted one by one from the antecedent of the last item to be added, and the accuracy rate (i.e. the proportion of the real positive cases in the data covered by the rule) on the trimming set is calculated. The algorithm chooses the one with the highest accuracy and the least number of antecedents, but the accuracy of the rule is at least higher than the null rule. Once the rule is pruned, it tries to add it to the rule base, calculates the description length of the rule base, and obviously updates the minimum description length. If the length of the description after adding a rule is 64 bits longer than the minimum description length, it stops adding the rule and deletion of the rule may become a part. If the number of instances covered by the rule is too small or the accuracy rate is too low, the addition will fail. If the rule is successfully added, the instance it covers is deleted from D, and Grow and Prune are divided again to enter the rule growth and pruning phase. Until a rule fails to be added, the loop ends and no new rules are generated, but into the optimization phase.
Optimization stage
In this case, the rule base generated in Stage 2 is carefully optimized. By constructing alternative rules, the algorithm optimizes each operating system rule in the rule base. Similar to Phase 2, this phase also uses the operating system fingerprint data set D, and each optimization of a rule requires deleting the instance covered by the final rule from D and then optimizing the next ones iteratively until all the rules are optimized. The order of optimization rules is the same as the order of generation rules.
Unknown operating system identification model based on RIPPER classifier
RIPPER algorithm based on unknown operating system identification model flow is shown in Figure 3.

RIPPER algorithm based on unknown operating system identification model flow chart.
Specific identification process is as follows:
Collection of data sets: Obtain the current updated version of the p0f fingerprint library to join the data set and the network traffic data to enrich and improve the data set.
Fingerprint data processing: By collecting a large amount of network traffic, using the customized tools based on libpcap to process the data packets, obtaining the information about the operating system in the header, and generating the p0f format fingerprint together with the p0f fingerprint database as a training and learning data set.
Feature preprocessing of fingerprints: Analyze the extracted value range of each attribute of the fingerprints of p0f, represent each attribute uniformly by a numerical value, and generate akff format for Weka to use the classification test, and the specific mode will be prepared and introduced.
Learning and training of RIPPER model: Put the preprocessed data set into RIPPER for training to generate RIPPER model that can identify unknown operating system types.
Unknown operating system identification: The new unknown operating system fingerprint input classifier gives a prediction of the unknown operating system type.
Experimental simulation
Experimental environment
This experiment is based on Weka. Weka is a tool that is a completely free, non-profit, open-source machine learning and data mining integrated environment. In order to verify the accuracy, universality, and performance of the experiment, a large amount of test data was collected before the experiment. In order to complete this study, the experimental data in this article are based on the 3.0.8 version of the p0f fingerprint feature library. In addition to the collection of a network node at Harbin Engineering University between 12 November 2017 and 13 November, network traffic has extracted their fingerprints and added to the fingerprint feature library. We build a large number of operating system fingerprints. In this way, from the 20 GB of traffic we got more than 1000 fingerprints, which contain 32 different types of systems.
Experimental results and analysis
This article uses the real rate, false positive (FP) rate, and accuracy and modeling time to do the performance indicators of this experiment. The samples are divided into positive and negative, where true positive TP represents the number of positive samples correctly predicted, false negative FN depicts the number of negative samples predicted positive, FP is the number of negative samples predicted to be positive, true negative TN shows the number of negative samples correctly identified as negative.
Real rate: the probability that the positive sample is correctly predicted is given by TPR=TP/(TP+FN).
FP rate: it indicates the probability that the negative sample is predicted to be a positive sample error, FPR = FP/(FP + TN); in the ideal case, the true rate is 1, and the FP rate is 0.
The accuracy rate, which is recognized by the classifier as the recognition result of operating system type A, accounts for the correct result. That is, the probability of being recognized correctly as the result of operating system type A, Precision = TP/(TP + FP).
Modeling speed: it is used to indicate recognition efficiency. Usually the faster the modeling time, we argue that the algorithm is more efficient.
In order to complete the process of identifying unknown fingerprints, we need a large number of unknown fingerprints to verify. Unfortunately, the real unknown fingerprints are hard to obtain in the network. However, as long as the fingerprint is not in the fingerprint database, it is called as unknown fingerprint. In this article, we use the 10-fold cross-validation method to complete the experiment of unknown fingerprinting, divide the data set to be identified into 10, use 9 of the data as the training data, and 1 of the data is used to make the experimental data. The data cannot be identified in training data and can therefore be considered as unknown fingerprints. The above process is repeated 10 times, each time using a different subset as a verification subset, and the rest as training data of the model. Each verification will calculate the correctness of the response and the average of the correctness of the 10 results as the algorithm accuracy.
Taking the fingerprints in the p0f fingerprint database and the fingerprints collected from the network data as experimental data sets, the real rate, FP rate, precision, and modeling time of C45 decision tree, SVM and RIPPER are compared. Table 2 shows the results of C45 decision tree, SVM, and RIPPER on the current experimental data set. It can be seen from the experimental results that the accuracy of different algorithms and the execution time of the algorithm are obviously different. As depicted in table, the SVM has the longest modeling time, reaching tens of times more than other algorithms. This reveals that SVM has a drastic performance disadvantage and its accuracy is much lower than the other two algorithms. Besides this, when the current data set is large, the modeling speed of SVM is much faster than the other two algorithms, but the calculation efficiency is poor. On the contrary, the modeling time of C45 decision tree algorithm is much less than that of SVM, and its recognition accuracy has also been improved relative to SVM. The reason behind is that the C45 decision tree algorithm often does not need the prior probability of the sample when dealing with large-scale data. It can effectively solve the bad influence caused by the large variance of the sample variation distribution. When processing the recognition, it is a simple comparison of attribute values, which is simpler than the SVM process. It can be observed from the table that the RIPPER algorithm is the best among the three in terms of modeling speed and accuracy of recognition. In a nutshell, experiment proves that the RIPPER algorithm is better than SVM and C45 for handling unknown operating system identification.
SVM, RIPPER, C45 unknown operating system recognition performance comparison.

SVM: support vector machine.
Conclusion
In this article, the application of RIPPER algorithm to unknown operating system identification is put forward to improve the deficiencies of SVM and C45 decision tree on unknown fingerprinting. We improve the accuracy and efficiency of unknown operating system identification. This chapter first introduces the process of unknown operating identification based on RIPPER algorithm and introduces the key steps of the process in detail. First of all, in order to enrich the training data set, a method of operating system fingerprinting based on libpcap is proposed, which converts network traffic into p0f fingerprint format and adds it to p0f fingerprint database as a training data set. Second, preprocessing features in p0f fingerprints, due to Weka’s experimental environment, must be converted to a data format known as akff in order to be able to use Weka. Therefore, the attributes of p0f fingerprints are preprocessed and expressed in numerical form for classifier training. Finally, it is pointed out that SVM and decision making are the disadvantages of unknown operating system identification, and the advantage of unknown operating system identification based on RIPPER algorithm is unveiled. The learning and training process of RIPPER algorithm based on operating system fingerprint feature is investigated in detail. The resulting RIPPER classification model for unknown operating system identification is finally generated. At the end of this chapter, we compare the real rate, FP rate, accuracy rate, and modeling time of RIPPER, SVM, and C45 decision trees by 10-fold cross-validation method. Our experiments verify that the RIPPER algorithm performs identifications of unknown operating system fingerprints more accurately and efficiently.
Footnotes
Acknowledgements
The authors would like to extend their heartfelt gratitude to editors and anonymous reviewers for their valuable comments and feedback, which helped improve this paper.
Handling Editor: Sheng Wen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program (2016YFB0801204) and the Fundamental Research Funds for the Central Universities (HEUCF180605). The funding agency had no role in the study design, the collection, analysis, or interpretation of data, the writing of the report, or the decision to submit the article for publication.