
Abstract
Graph neural networks (GNNs) and graph transformers (GTs) have shown significant potential in handling graph-structured data. However, GNNs face challenges with over-squashing and over-smoothing, hindering their ability to capture long-range dependencies. GTs can address this through a global attention mechanism, but suffer from high computational overhead due to their quadratic complexity. The selective state space model (SSM), Mamba, known for its linear complexity and excellent performance, offers an attractive alternative. However, Mamba lacks graph inductive biases and handles only sequential data. To ress hese challenges, we propose a new SSM framework with global receptive fields and structure-aware capabilities. We address Mamba’s limitations by repeating node sequences and incorporating a structural encoder to enhance inductive bias. Experiments on eight benchmarks demonstrate competitive accuracy as well as superior speed and scalability over GTs, underscoring the potential of SSMs for graph learning.
Keywords
Introduction
Graph-structured data are a crucial and ubiquitous form in real-world applications. Social networks (Yang et al., 2017), traffic networks (Bai et al., 2020), and protein molecules (Wang et al., 2023) can all be effectively modeled as graphs. Consequently, the processing and analysis of graph-structured data constitute a significant and widely studied research field.
In recent years, graph neural networks (GNNs) (Kipf & Welling, 2017) have been extensively researched and widely applied. These deep learning techniques are specifically designed for graph-structured data, enabling them to effectively capture the complex relationships between nodes and edges. A classic GNN framework is the message passing neural network (MPNN) (Gilmer et al., 2017). MPNNs iteratively update node features, enabling each node to progressively perceive a broader context. However, due to issues such as over-smoothing (Chen et al., 2020) and over-squashing (Topping et al., 2022), GNNs are primarily suited for extracting local features and perform poorly in capturing long-range dependencies between nodes.
The Transformer (Vaswani et al., 2017), with its global attention mechanism, has achieved remarkable results in natural language processing and computer vision. Applying it to graph learning tasks to address the limitations of GNNs is a natural idea. Graph transformers (GTs) have emerged as a popular alternative to MPNNs (He et al., 2023; Ma et al., 2023; Rampášek et al., 2022; Yun et al., 2019), demonstrating remarkable performance across various graph tasks. The global attention mechanism facilitates direct modeling of long-range interactions between nodes by enabling attention to any node pair within the graph. This mechanism effectively mitigates issues such as over-smoothing and over-squashing by adaptively learning interaction relationships(Diao & Loynd, 2023; Kreuzer et al., 2021). However, the global attention mechanism overlooks the inherent inductive bias in graphs, namely the structural information, which leads to suboptimal performance of GTs on certain datasets (Liu et al., 2024a; Xing et al., 2024).
Furthermore, because GTs calculate attention for each pair of nodes with a complexity of
In recent years, state space models (SSMs) have witnessed significant advancements. Numerous SSM-based methods, such as linear state-space layers (LSSL) (Gu et al., 2021), structured state space sequence model (S4) (Gu et al., 2022b), and S4D (Gu et al., 2022a), excel at handling sequential data across various tasks and modes, particularly in modeling long-range dependencies (Zhu et al., 2024). These methods exhibit near-linear computational complexity, which is lower than that of Transformers, making them more efficient for processing long sequences. However, these SSM methods compress the context into smaller states, which restricts their memory capacity and consequently limits their performance. Furthermore, the parameters of SSMs remain static across different inputs, which means they lack the ability to perform input-specific reasoning. As a result, SSMs often exhibit inferior performance compared to Transformers.
To address this, Gu and Dao (2023) proposed Mamba, a selective state space model (SSM). Unlike traditional SSMs that compress all historical information, Mamba incorporates a simple selection mechanism by parameterizing the inputs of the SSM. This allows the model to selectively process information, focusing on or ignoring specific inputs. Mamba can filter out irrelevant information while retaining relevant information for an extended period. It is characterized by a balance between efficiency and effectiveness, outperforming Transformers of the same scale in text sequence tasks. In addition, its computational complexity scales linearly with sequence length.
Given Mamba’s exceptional performance in text modeling, applying it to the graph domain presents a promising strategy. However, graph-structured data differ significantly from text sequences, posing two primary challenges for using Mamba on graphs.First, it is necessary to transform graph data into sequence data similar to text to fit Mamba’s ordered input requirements. Second, Mamba must learn and utilize the structural information inherent to graphs. Graph-Mamba (Wang et al., 2024) addresses these challenges by sorting node sequences based on node degree, thereby converting the graph structure into a sequence structure, and by replacing the Transformer with Mamba in the GraphGPS framework to apply Mamba to graphs. Additionally, Graph Mamba (Behrouz & Hashemi, 2024) enhances the structural information of input sequences through multiple random walks and uses a bidirectional Mamba to process unordered graph data.
However, these methods do not adequately address the two primary challenges Mamba encounters on graphs: unidirectional modeling and the lack of structural awareness. To tackle these challenges, we propose the structure-aware Mamba (SAM) framework. As shown in Figure 1, this framework combines a structure-aware selective mechanism for leveraging graph structural features and a symmetric input mechanism for global context modeling. First, we input the graph data into the Structural Information Encoder (SAMEncoder) to extract structural features. Next, we input the node features, edge features, and structural features of the graph into multiple SAMLayers. Finally, the learned graph node representations are fed into the prediction layer for downstream tasks. Each SAMLayer integrates both a structure-aware selective mechanism and a symmetric input mechanism. Additionally, each SAMLayer includes both an MPNN and an MLP to enhance model performance.
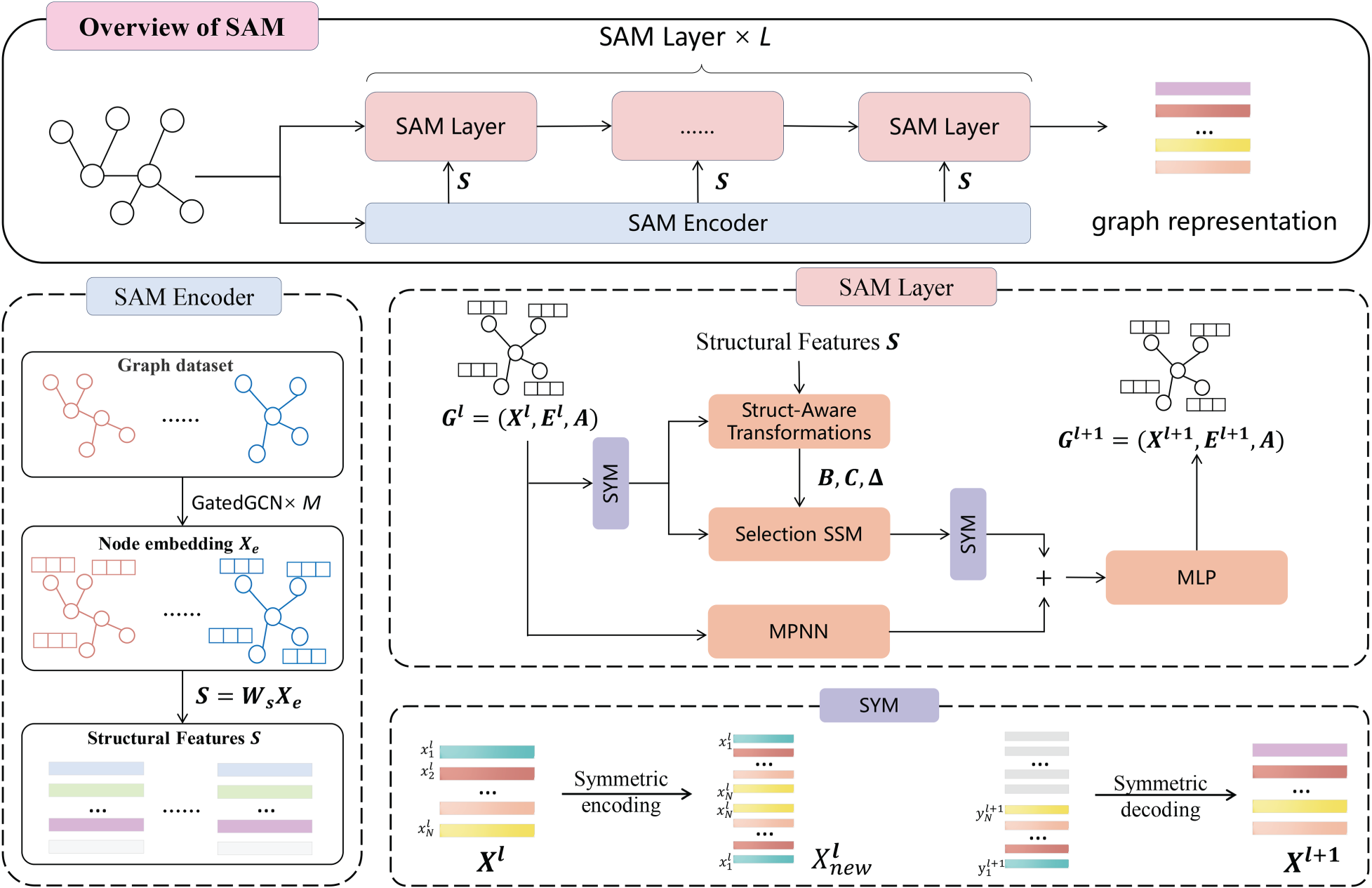
The overview of structural-aware Mamba (SAM) framework. We first extract the structural features of the graph through the SAMEncoder. Then, we input the structural features, node features, and edge features into multiple SAMLayers to obtain the graph representation. Each SAMLayer consists of a structure-aware selection SSM, a symmetric input mechanism (SYM), an MPNN, and an MLP.
Compared to GNNs and GTs, SAM is a method featuring a global receptive field, low computational cost, and high scalability. Unlike direct fusion, which simply sums forward and backward Mamba outputs without distinction, the symmetric input mechanism enables each node to perceive the entire graph before entering the Mamba module. Leveraging Mamba’s selective gating, the model adaptively integrates signals from multiple directions. This design mitigates the performance degradation observed in direct fusion (see Table 1). The structure-aware selective mechanism leverages the structural information of the graph to focus on or filter context information, enabling SAM to concentrate on important nodes with strong inductive biases. Compared to other methods, the SAM shows competitive results across all datasets and outperforms others on multiple datasets. Additionally, our method is more cost-effective than GTs, exhibiting linear scalability and the capability to scale to graphs with thousands of nodes.
Comparison of Direct Fusion and Symmetric Input Mechanism.

Our main contributions can be summarized as follows: We propose a SAM framework that applies Mamba to graph-related tasks. This framework integrates a structure-aware selective mechanism, a symmetrical input mechanism, and MPNN to enhance the modeling capability for graph-structured data. Our method demonstrates low computational complexity and high scalability, with a lower computational cost than GTs. The runtime of the proposed method is similar to that of linear attention with achieving higher accuracy. We perform extensive experiments across multiple datasets. The results demonstrate that the proposed method consistently and significantly outperforms GNNs and GTs in terms of accuracy and precision across different datasets.
Message Passing Neural Networks
Traditional GNNs, such as MPNN (Gilmer et al., 2017) and GCN (Kipf & Welling, 2017), use message passing to aggregate neighbor information. However, they face limitations like over-smoothing (Chen et al., 2020) and over-squashing (Topping et al., 2022), which hinder the effectiveness of stacking multiple layers and restrict their receptive fields. To tackle these issues, expanding the receptive field of GNNs is crucial. One strategy is altering the graph’s topology. For instance, Half-hop (Azabou et al., 2023) introduces slow nodes to each edge, effectively upsampling the graph and mitigating over-smoothing and over-squashing by decelerating message passing. Another strategy is graph rewiring (Abboud et al., 2022; Barbero et al., 2024; Deac et al., 2022; Di Giovanni et al., 2023; Gutteridge et al., 2023; Karhadkar et al., 2023; Qian et al., 2024; Sonthalia et al., 2023), which enables direct communication between originally non-adjacent nodes, thus breaking information bottlenecks and enhancing learning efficiency.
The essence of these methods is to modify the scope of message passing while adhering to traditional messaging constraints. Traditional mechanisms compel each node to pass messages indiscriminately, without assessing the importance of the messages. Consequently, novel paradigms have been proposed (Finkelshtein et al., 2024), offering more flexible and dynamic strategies. In these paradigms, nodes autonomously determine their update strategies based on their states, thereby exploring the graph’s topological structure more effectively. Busch et al. (2020), Errica et al. (2023), Faber and Wattenhofer (2024), Park et al. (2023) also address this issue by introducing new mechanisms to enhance message passing flexibility.
Graph Transformers
GTs establish a fully connected graph through a global attention mechanism, providing a comprehensive receptive field and addressing issues like over-squashing and over-smoothing inherent in GNNs. However, GTs often overlook the inductive biases intrinsic to graphs, such as structural information, making it challenging to effectively utilize this information. Hence, recent research has focused on integrating graph structural information into GTs to enhance their effectiveness.
Current methods to achieve this can be categorized into three main approaches (Min et al., 2022):
Transformers Costs
Transformers often face challenges related to high complexity and overhead, particularly GTs compared to MPNNs. One solution is reducing attention mechanism complexity or the number of nodes involved in attention computation (Chen et al., 2023; Kong et al., 2023; Rampášek et al., 2022; Shirzad et al., 2023; Wu et al., 2022). However, these methods often lead to performance loss or compromise the global receptive field, highlighting the trade-off between computational cost and effectiveness.
SSMs
Recently, Structured State Space Models (SSMs) have emerged as promising architectures in sequence modeling (Gu et al., 2022a, 2022b, 2021). A notable example is Mamba (Gu & Dao, 2023), known for its strong and efficient performance. Unlike traditional SSMs, Mamba uses a selection mechanism to filter irrelevant information, retaining relevant data for longer periods. This efficiency and effectiveness allow Mamba to outperform similarly scaled Transformers on text sequence tasks, with linear computational complexity with respect to sequence length. Consequently, researchers are exploring Mamba’s applications in various fields, including vision (Liu et al., 2024b; Zhu et al., 2024), video understanding (Li et al., 2024a), point cloud analysis (Liang et al., 2024), spatio-temporal graph learning (Li et al., 2024b), and graph representation learning (Behrouz & Hashemi, 2024; Wang et al., 2024).
Applying Mamba to graph-structured data presents two challenges: converting graph data into sequence-like data and utilizing structural information. Wang et al. (2024) integrate Mamba into the GraphGPS framework, replacing its attention mechanism with a degree-based ordering to handle Mamba’s unidirectional input. Behrouz and Hashemi (2024) adopts a similar approach by tokenizing node subgraphs and using bidirectional Mamba. However, these methods do not fully resolve Mamba’s unidirectional input problem. Bidirectional Mamba increases sensitivity to input order, but simply concatenating directions does not leverage information from both effectively. Additionally, these methods do not integrate graph structural information into the state space model to guide node updates.
Method
The goal of SAM is to incorporate the SSM, Mamba, into graph structures. This section first introduces the foundational concepts of the state space model. Next, an overview of the SAM framework is provided. Then, we describe in detail how our method leverages the structure-aware selective mechanism and the symmetric input mechanism to process graph data, and continue to explain the architectural details of the SAM framework. Finally, this section analyzes the efficiency of the proposed SAM framework.
Preliminaries
State space models, inspired by continuous systems, utilize an implicit latent state 
Mamba is an enhancement of the S4 architecture. The SSM S4 represents a discrete version of continuous systems, converting continuous parameters into discrete parameters via a time step parameter 
After discretization transformation, given an input sequence 
A key challenge for sequence models such as RNNs and SSMs is the compression of context into a reduced state, which limits their effectiveness based on the extent of context compression. Mamba’s selective mechanism aims to retain a compact yet informative state, balancing efficiency and performance. Specifically, Mamba learns various transformations and applies them to
An overview of the proposed SAM framework is shown in Figure 1. The original Mamba is designed for one-dimensional sequential data. To handle graph-structured data, this paper proposes the SAM framework. The SAM framework includes a structural information encoder, a structure-aware selective mechanism, a symmetric input mechanism, as well as MPNN and final MLP modules. The SAM framework first inputs the graph into the SAM Encoder to extract structural features. The symmetric input mechanism addresses the unidirectional memory problem of Mamba (Figure 2(a)), enabling it to comprehensively consider information from all nodes in the graph. The structure-aware selective mechanism enhances Mamba’s inductive bias, giving it structural awareness to consider the graph’s structural information. The MPNN and MLP modules are used to further enhance SAM. To simplify the presentation, we omit the normalization and residual connections after each module. As shown in Figure 1, in the framework, we stack multiple SAMLayers. Each SAMLayer consists of a structure-aware selection SSM, a symmetric input mechanism(SYM), an MPNN, and an MLP.
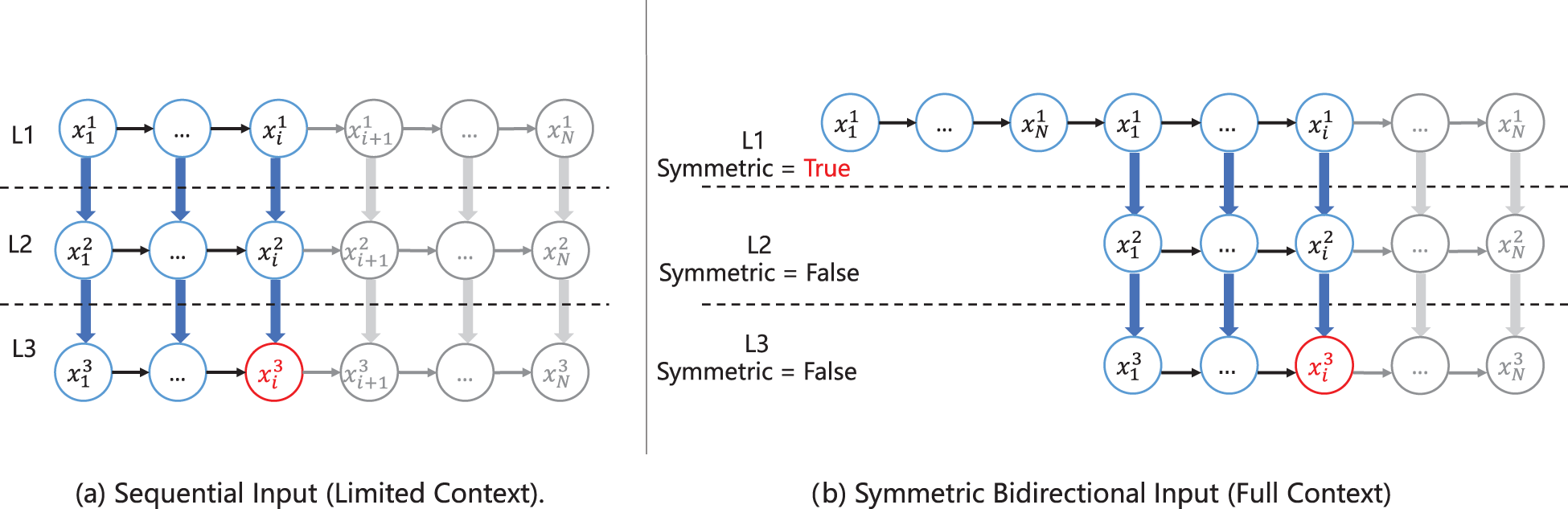
Comparison of input mechanisms for state space models.
The original Mamba is designed for 1-dimensional sequential data, aligning well with inputs for NLP tasks. However, graph-structured data is inherently unordered, lacking a specific sequence, and node sequences do not contain structural information. Mamba is thus unsuitable for graph tasks that require structure-aware understanding. To address graph-structured data, we proposes a structure-aware module. The structure-aware module consists of a structural aware encoder and a structure-aware transformation function. The structural aware encoder is a trainable module used to extract structural information from the graph. As show in Figure 1, the input to the structural aware encoder is the entire graph, and the output is the structural information contained in each node of the graph.

To enable the model to incorporate structural information from the graph to focus on or filter context information, we modified Mamba’s selective mechanism. The structure-aware transformation is a learnable weight that allows 
Then, according to Equations (2) and (3), the discretization and SSM processes yield the output
Since graph data does not have a fixed input order, directly inputting the node features of the graph into Mamba will result in most nodes being unable to utilize information from the entire graph. This is because nodes inputted earlier cannot use information from nodes inputted later. As illustrated in Figure 2(a), suppose the input to the 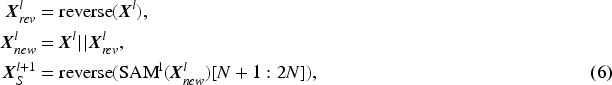
After reversing and concatenating, the sequence
The structural information encoder can be any neural network. In this paper, we use GatedGCN as an example of the structural information encoder in Equation (4). GatedGCN can aggregate and extract structural information from nodes and their neighborhoods, capturing the local structural features of the nodes. For structure-aware transformation 
According to previous research (Dwivedi et al., 2022a; Rampášek et al., 2022), positional encodings (PE) provide positional information to the model, whereas structural encodings (SEs) supply structural information. To enhance the structure-aware framework, we consider an optional step to incorporate structural and positional encodings into the initial features of the nodes. Following the approach of GPS (Rampášek et al., 2022), we concatenate PE or SE with the node features. Additionally, at each layer, we aggregate the outputs of the MPNN layer with those of the global attention layer to update the features:

In SAM, converting graph nodes into sequential inputs is a key design choice aimed at overcoming the limitations of traditional MPNN in terms of receptive field and computational efficiency. Although this serialization process may intuitively seem to weaken the structural inductive bias inherent to graphs, the model appears less ”aligned” with the graph structure compared to message passing; in fact, it offers several advantages. Both SAM and a range of GT-based methods adopt sequence modeling techniques that possess strong capabilities for capturing long-range dependencies, enabling each node to directly access information from any other node without suffering from the inefficiency of multi-hop propagation. To compensate for the potential loss of structural information during serialization, we design a structure encoder that leverages the strengths of message passing to explicitly inject structural constraints. This allows SSMs like Mamba to become aware of nodes’ relative positions and structural roles within the graph, thereby enhancing their overall representational capacity.
Experiment
We evaluated our framework on eight datasets, covering scenarios with long-range dependencies, small-scale (tens of thousands of graphs), large-scale (60,000 graphs), and large-graph (ten thousands of nodes) cases. Our framework demonstrated state-of-the-art performance in many situations. Finally, we conducted ablation studies on three datasets to evaluate the contributions of each module, including the symmetric input mechanism, SAM mechanism, MPNN, and structural or positional encoding.
Experiment Details
We evaluated our framework on datasets from various sources to ensure diversity. Initially, we conducted tests on two datasets from Benchmarking GNNs (Dwivedi et al., 2023), which are classical graph benchmarks intended to assess model performance on various graph prediction tasks, including graph classification (CIFAR10) and node classification (PATTERN). Next, we evaluated our method on the Long-Range Graph Benchmark (LRGB) (Dwivedi et al., 2022b), encompassing datasets designed to test the model’s ability to capture long-range dependencies in input graphs. We chose two datasets that cover graph classification (Peptides-func) and node classification (PascalVOC-SP). Furthermore, we evaluated the scalability and efficiency of our method using the Coauthor Physics dataset (Shchur et al., 2018), a large-graph dataset containing graphs with up to 34493 nodes each. In this evaluation, we compared our approach with Graph-Mamba, GatedGCN and traditional graph attention mechanisms and linear attention mechanisms under the GraphGPS framework. We assessed the training and inference times per epoch and the final accuracy of each method. Finally, we conducted ablation studies on three datasets to evaluate the contributions of the symmetric input mechanism, the SAM mechanism, the Graph-to-Sequence conversion and MPNN. Moreover, we performed a controlled comparison between our symmetric input mechanism and the direct fusion strategy adopted in bidirectional Mamba, further clarifying their distinctions and highlighting the advantages of our adaptive fusion design. Results are averaged over three runs with random seeds 0, 1, and 2, and are reported as mean and standard deviation. Additional details are provided as follows.
Dataset Description
The descriptions and details of the datasets used in our experiments are provided below. Table 2 shows the statistical data of the datasets.
Dataset Statistics.
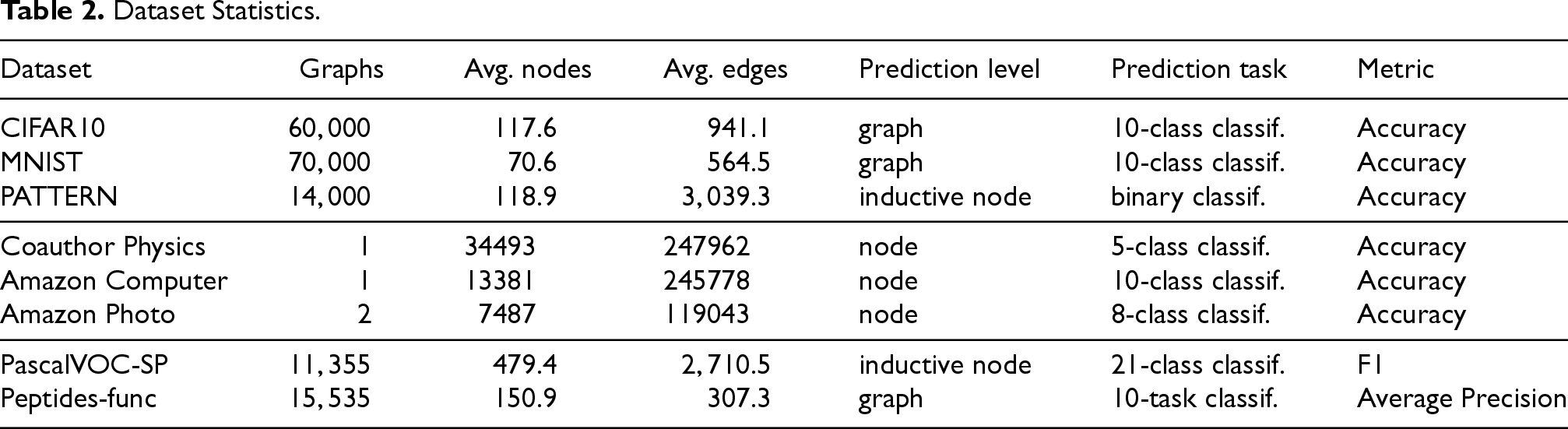
Dataset Statistics.
We compared SAM with a set of popular MPNNs (GCN, GIN, GatedGCN), Graph Transformers (GraphGPS, SAN, Exphormer), and Graph-Mamba, which is related to our work.
Hyperparameters
Given the large number of hyperparameters and datasets, we did not conduct an exhaustive or a grid search. We adopted several hyperparameter settings from GraphGPS(Rampášek et al., 2022). The final hyperparameter configurations are summarized in Table 3.
SAM Hyperparameters for Eight Datasets.
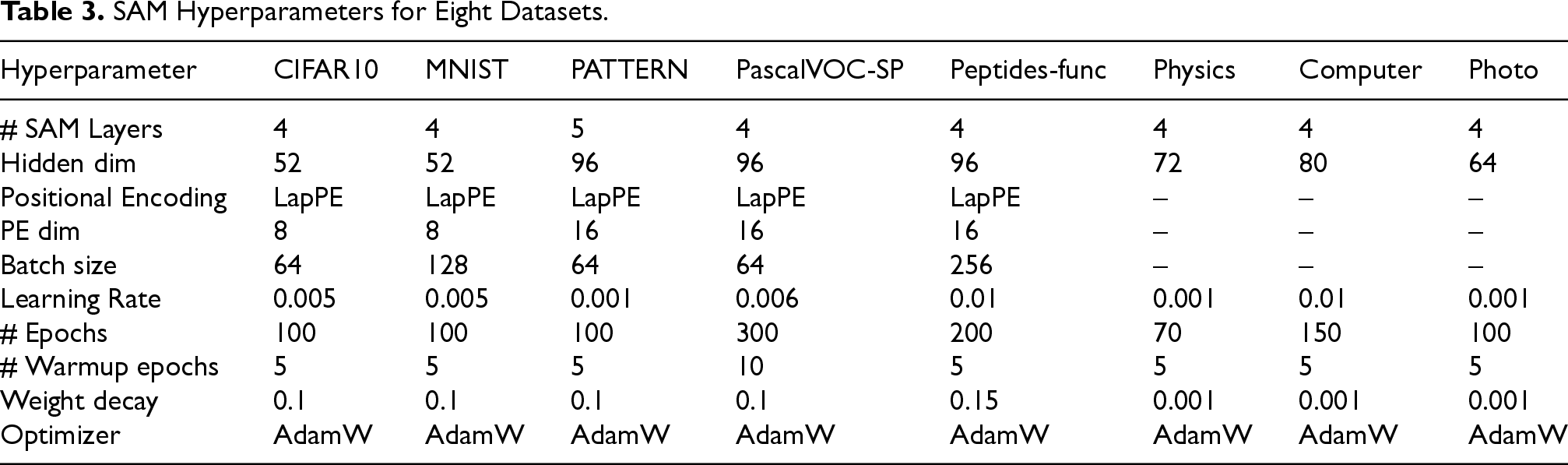
SAM Hyperparameters for Eight Datasets.
We evaluated our method on two datasets from the Benchmarking GNNs (i.e., CIFAR10, and PATTERN). The results are shown in Table 4. We observe that our method outperforms all baseline methods across these datasets, achieving the highest performance. This indicates that our method outperforms attention mechanisms in both node and graph classification tasks, highlighting the strong modeling capability of our structure-aware SSM in effectively handling common graph-based prediction tasks.
Test Performance on Benchmarking GNNs.
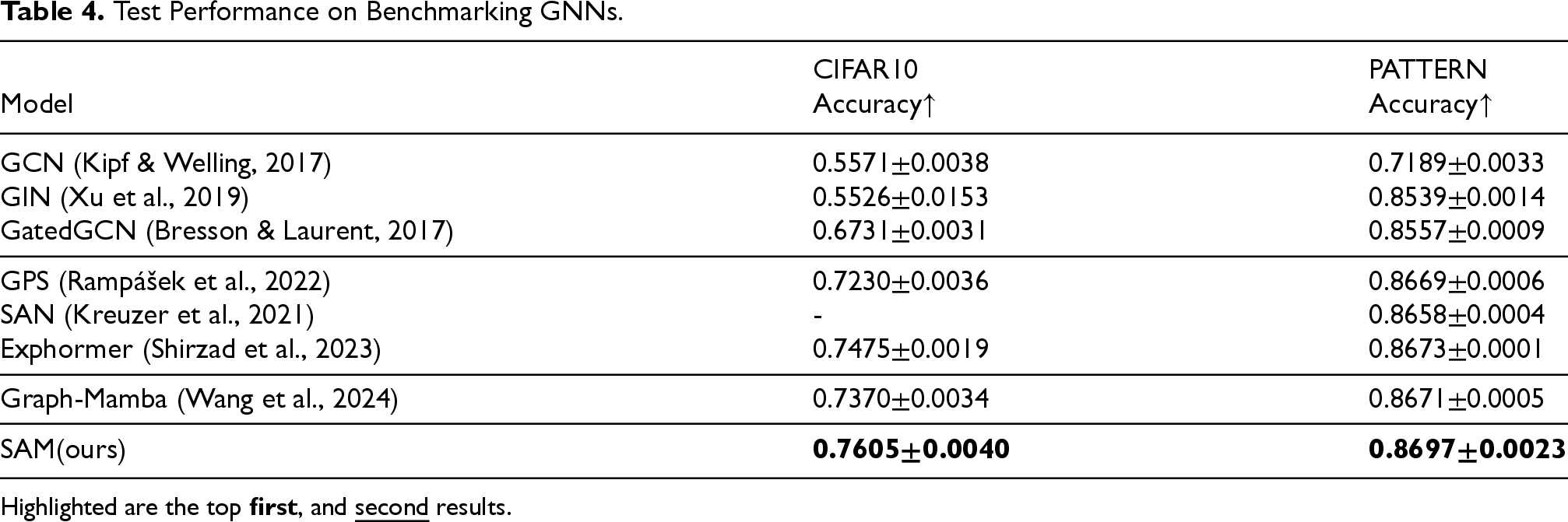
Test Performance on Benchmarking GNNs.
Highlighted are the top
We evaluated our method on two datasets from the Long-Range Graph Benchmark (LRGB). The evaluation results of our method on these datasets are shown in Table 5. Our method achieved competitive performance on these datasets, outperforming all MPNN and GT-based methods on the PascalVOC-SP, and Peptides-func datasets. This indicates that our framework possesses a significant advantage in capturing long-range dependencies in graph data compared to MPNN and GT. This advantage is attributable to our symmetric input mechanism and structure-aware mechanism, which endow Mamba with a global receptive field. This enables it to fully consider the structural information of the graph, thereby better capturing long-range dependencies in graph data.
Test Performance on Long-Range Graph Benchmarks (LRGBs).
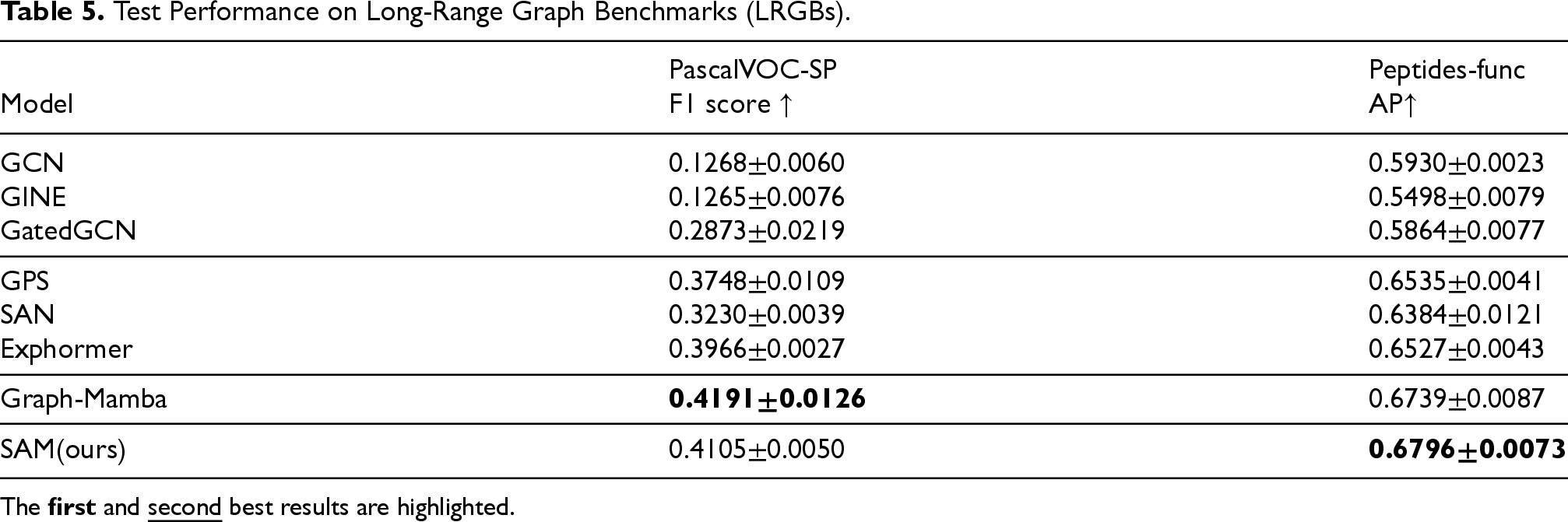
Test Performance on Long-Range Graph Benchmarks (LRGBs).
The
Traditional GT methods, owing to their quadratic complexity, exhibit poor scalability on large graphs and are typically restricted to molecular graphs with relatively few nodes. In contrast, our approach has linear complexity, prompting the question of whether it can scale to larger graphs.We evaluated our method on three large datasets, the largest of which is Physics, containing 34,493 nodes and 247,962 edges. GraphGPS and SAN, both of which also rely on quadratic attention mechanisms, encountered out-of-memory (OOM) errors on Physics (34,493 nodes) and Computer (13,381 nodes). Since each of these datasets consists of a single large graph, reducing the batch size was not feasible. We therefore attempted to lower the hidden dimension to 32, yet the quadratic memory growth still resulted in OOM, whereas Photo (7,487 nodes) could be processed successfully. As shown in Table 6, SAM scales to these large graphs and achieves the best performance among all baselines, demonstrating its ability to handle large-scale graphs with low resource overhead.
Accuracy of Models on Transductive Graph Datasets.

Accuracy of Models on Transductive Graph Datasets.
We report the efficiency evaluation of our method on two large-scale graph datasets: Physics (34,493 nodes and 247,962 edges) and Photo (7,487 nodes and 119,043 edges). The efficiency and accuracy on both datasets are shown in Figure 3. To ensure fairness, we kept the number of layers, feature dimensions, and other parameters consistent across all models and conducted experiments on an A100 (40GB) GPU. We compare the models in terms of parameters, training time and accuracy, and evaluate their performance at 3, 5, and 8 layers. In the figure, line graphs connect scatter points for the same model with different layer counts. Since the traditional quadratic complexity Transformer used in GraphGPS causes out-of-memory issues, the GPS models shown in the figure all use lower-complexity alternatives.
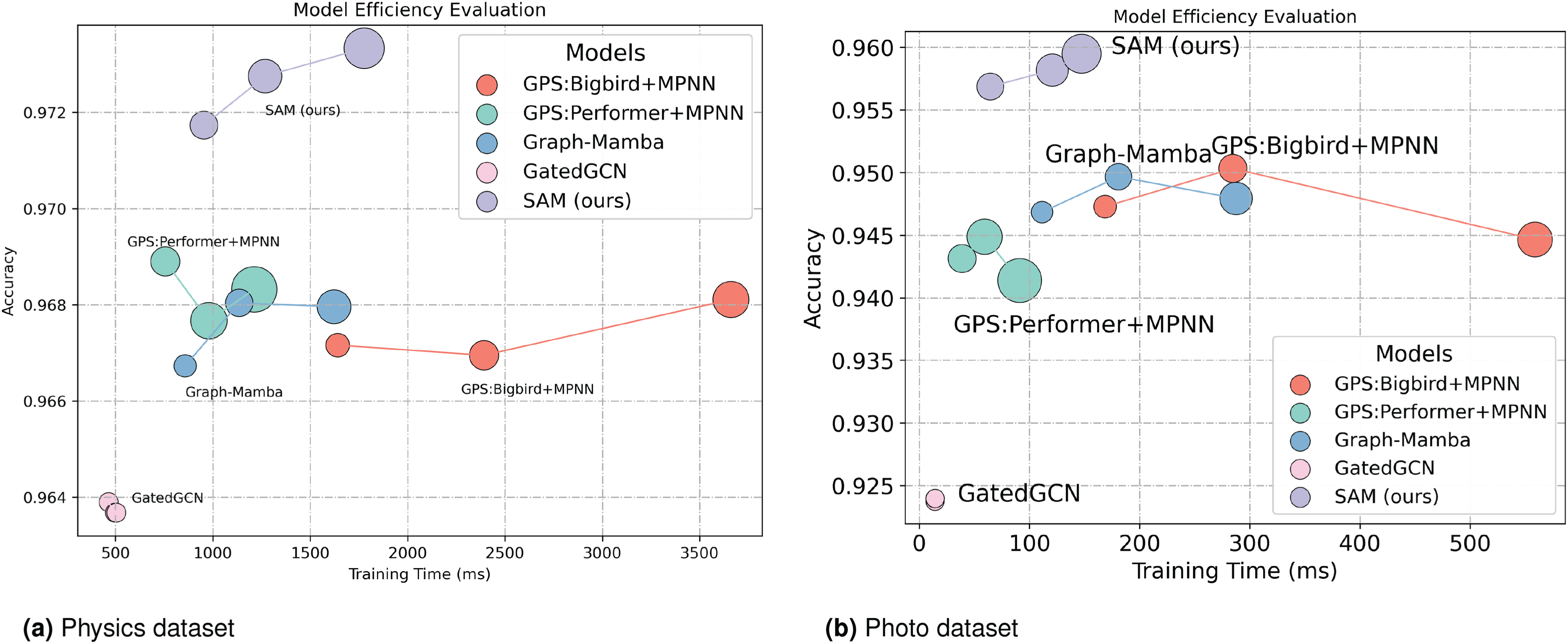
Evaluation of efficiency and accuracy of SAM and baseline methods. We plot model performance for 3, 5, and 8 layers, connecting scatter points for the same model with different layer configurations. The size of each scatter point corresponds to the number of parameters in the model. (a) Physics dataset and (b) Photo dataset.
Figure 3 shows that GatedGCN, despite having the shortest training time, attains lower accuracy and exhibits limited improvement as the number of layers increases on the Physics and Photo datasets. Our proposed SAM method outperforms all other methods in terms of accuracy. Its training speed is comparable to Graph-Mamba and other methods, and as the number of layers increases, accuracy improves. Moreover, as the number of layers grows, the training time of our method does not increase significantly compared to GPS:Bigbird. Compared to GPS:Performer, our method requires fewer parameters, demonstrating its good scalability and higher accuracy when handling large-scale graphs, outperforming attention-based mechanisms.
Component Ablation
To ensure diversity, we evaluated the three main components of our framework—symmetric input mechanism, SAS mechanism, and MPNN—on datasets from Benchmarking GNNs (CIFAR10, PATTERN, and MNIST) and LRGB(Peptides-func). Additionally, we investigated the effect of flipping node features within the symmetric input mechanism. The results are shown in the Table 7: the first row presents the performance of our complete framework, while subsequent rows show the performance after removing individual components—flipping node features in the symmetric input mechanism, the symmetric input mechanism itself, the SAS mechanism, combinations of the symmetric input and SAS mechanisms, and MPNN—while keeping the other components unchanged. The results demonstrate that each component of our framework is effective, with all components contributing to performance improvements. Using flipped node features within the symmetric input mechanism further enhances model performance compared to simply repeating node features. In all datasets, combining the symmetric input mechanism with the structure-aware selective mechanism yields the best performance, demonstrating the effectiveness of our model framework.
Ablation Study on SAM Architecture.
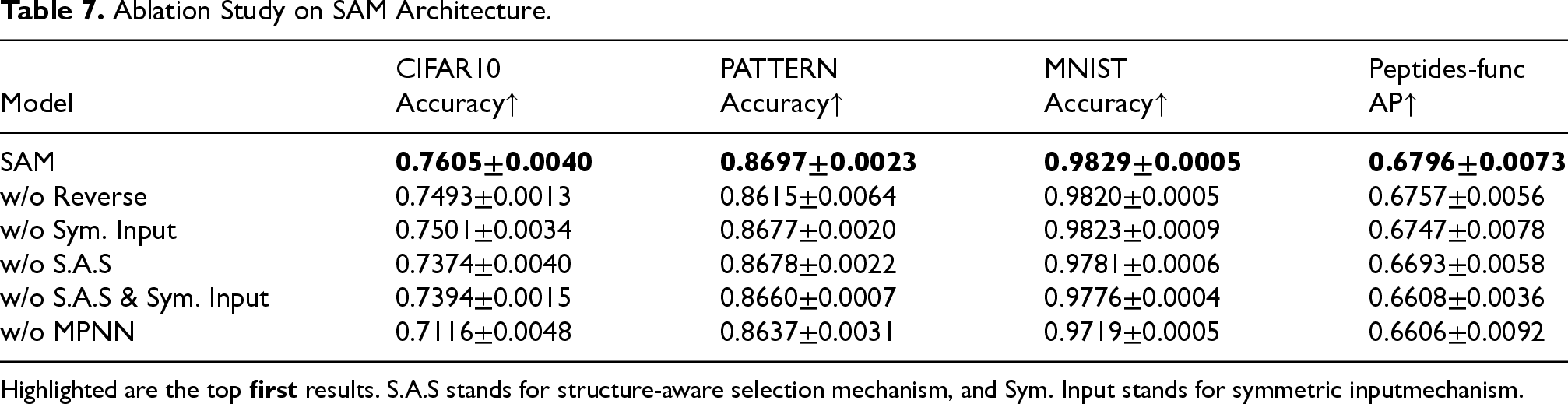
Ablation Study on SAM Architecture.
Highlighted are the top
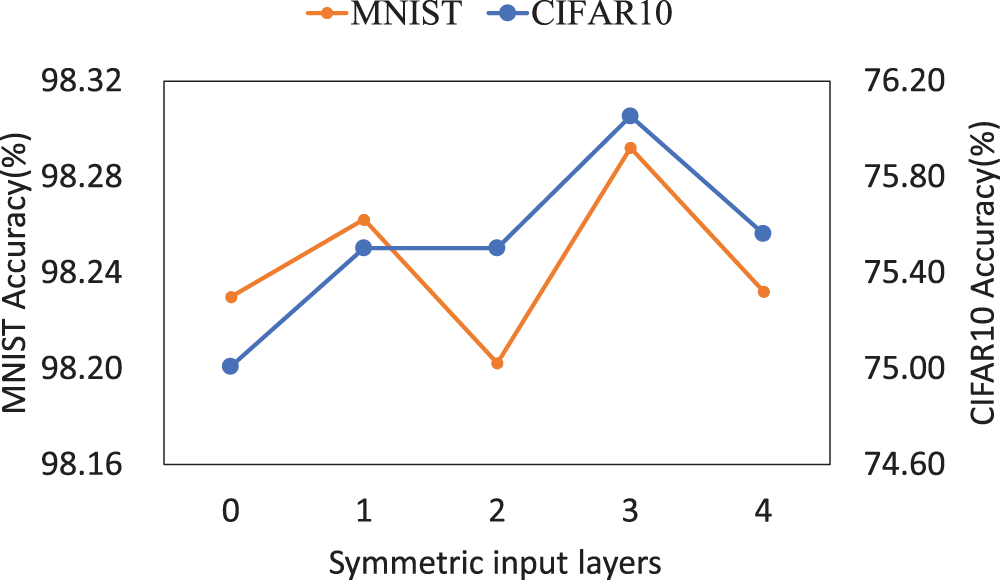
Impact of the number of symmetric input layers (L) for SAM on CIFAR10 (left) and MNIST (right). An optimal balance is achieved at
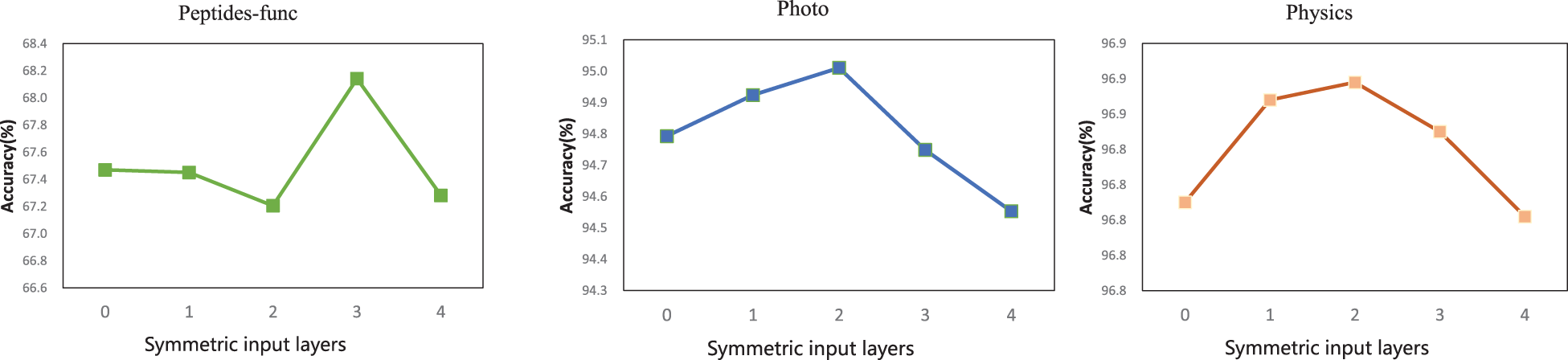
Impact of the number of symmetric input layers (L) on Peptides-func (left), Photo (middle), and Physics (right). An optimal balance is achieved at a moderate number of symmetric input layers, yielding higher accuracy with reduced computation. Performance degrades when the number of layers exceeds this optimal point due to over-parameterization.
We evaluated the impact of varying the number of symmetric input mechanism layers on the performance of SAM using the CIFAR10 and MNIST datasets. Specifically, we varied the number of symmetric input mechanism layers from 0 to 4 in both datasets, where
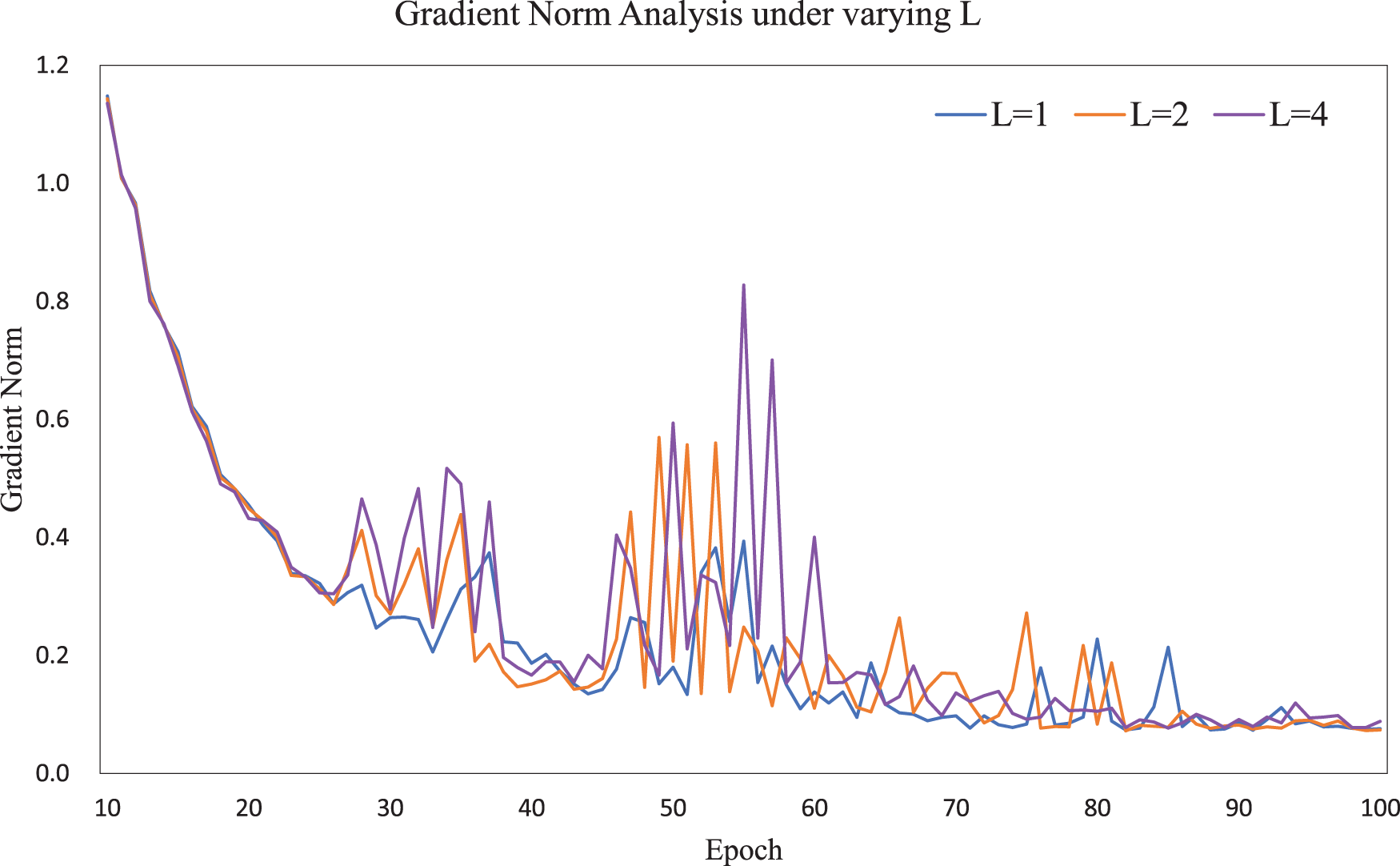
Average gradient norm across training epochs on the Photo dataset with
To further investigate whether the selection mechanism benefits from direct access to node features, we evaluated two simplified variants: (i) using only positional/structural encodings (PE/SE) to compute the parameters of the structure-aware transformation module, and (ii) replacing node features with PE/SE in both the symmetric input mechanism and the Selection SSM. As shown in Table 8, both variants consistently underperform the original design across multiple datasets. This confirms that node features provide essential complementary information to PE/SE, and that their combination yields the strongest performance.
Ablation on Selection Mechanism Inputs: Node Features vs. Only PE.

Ablation on Selection Mechanism Inputs: Node Features vs. Only PE.
Performance Comparison of Alternative Structure-Aware Encoders in SAM.

Since the structure-aware encoder is a key component of SAM, we further investigated its design by comparing different alternatives. In our default design, we adopt
As shown in Table 9, all encoders provide useful structural signals, but GatedGCN achieves the strongest or near-strongest performance across most datasets. This confirms our design choice. Moreover, GatedGCN better captures
Ablation on Graph-to-Sequence Conversion
Since Mamba requires sequential inputs, we investigated the impact of various graph-to-sequence conversion strategies. In our default design, we adopt a
Performance Comparison With Alternative Orderings.

Performance Comparison With Alternative Orderings.
To further clarify the difference between our symmetric input mechanism and the direct fusion strategy used in bidirectional Mamba (Behrouz & Hashemi, 2024; Liu et al., 2024b; Zhu et al., 2024), we conducted a controlled ablation experiment. In bidirectional Mamba, the input sequence is independently processed in both forward and backward directions, and the resulting representations are directly summed to obtain the final output. This rigid summation treats both directions equally, regardless of their contextual relevance. For fairness, we replaced our mechanism with direct fusion while keeping all other components unchanged. As shown in Table 1, direct fusion consistently underperforms our method across all datasets, confirming that rigid summation degrades performance, while our mechanism achieves adaptive and more effective fusion.
Conclusion
This work proposes a framework for graph representation learning based on selective state-space models, representing an attempt to apply selective state-space models, exemplified by Mamba, to graph tasks. Our work demonstrates how selective state-space models can be adapted for graph tasks by processing input sequences and structural features. Experiments on two datasets from LRGB , two datasets from Benchmarking GNNs and large graph datesets show that our method achieves excellent performance, surpassing most MPNN and GT-based methods. Additionally, our method shows superior time efficiency compared to the quadratic complexity of GTs. The experimental results validate the modeling capabilities and high efficiency of our model, indicating that our framework has the potential to set a research trend for next-generation graph representation learning methods.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (grant no. 62272399), the Key Program Foundation of Fujian Province, China (grant no. 2021J02006), and the Fundamental Research Funds for the Central Universities (grant nos. 20720220005 and 20720220006)
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (grant no. 62272399), the Key Program Foundation of Fujian Province, China (grant no. 2021J02006), and the Fundamental Research Funds for the Central Universities (grant nos. 20720220005 and 20720220006).
Declaration of Conflicting Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.
Data Availability Statement
All datasets used during the current study are public, and obtained from the followings URLs: https://mal-net.org/, https://github.com/vijaydwivedi75/lrgb, https://github.com/graphdeeplearning/benchmarking-gnns and ![]() .
.