
Abstract
In high-frame-rate human–computer interaction and mobile-perception scenarios, single-frame human action recognition must meet stringent latency and accuracy constraints. To tackle spatial feature entanglement, multiscale fragmentation, and edge-deployment inefficiency, this study proposes YOLO11-AN (Action Net), a lightweight detector that couples a C3K2-DMAF dynamic multiscale fusion block, a dual-branch AUX head, an MPDIoU regression loss, and a LocalWindowAttention module. Comprehensive evaluations on Pascal VOC 2012, UCF101, and HMDB51 show that YOLO11-AN attains 0.537 mAP50 on VOC—an absolute gain of 1.7 percentage points over the YOLO11 baseline—while maintaining an inter-seed variance below 0.001. Against peer-reviewed baselines (YOLOv8-n, PP-YOLOE-Tiny, and RT-DETR-R18), it offers the best accuracy–compute tradeoff, and after INT8 quantization sustains 15.8 FPS on a 4 GB Jetson Orin Nano, validating its suitability for real-time low-power deployments.
Introduction
In the era of deeply integrated intelligent perception and mobile computing, human motion recognition has become a fundamental component of human–computer interaction systems. By analyzing spatial characteristics of limb postures, this technology enables gait tracking and rehabilitation assessment in medical applications, offering quantitative support for remote diagnostics. In intelligent surveillance, abnormal behavior recognition algorithms detect events such as falls or intrusions in real time, enhancing emergency response capacity. In sports analysis, three-dimensional-pose-based motion recognition systems capture subtle technical movements to assist training optimization. These applications demonstrate that human action understanding is reshaping multidomain interaction paradigms and driving the evolution of intelligent services toward more natural and ubiquitous deployment.
This study focuses on single-frame human action recognition, where only individual images—rather than video sequences—are used to infer human motion categories. In this work, the problem class is instantiated on the human-action subset of Pascal VOC 2012, where each person instance is annotated with one of 11 action categories: phoning, playinginstrument, reading, ridingbike, ridinghorse, running, takingphoto, usingcomputer, walking, jumping, and other. These categories cover device-mediated actions (phoning, takingphoto, and usingcomputer), locomotion and sport-related behaviors (walking, running, jumping, ridingbike, and ridinghorse), and more posture-centric activities (reading, playinginstrument, and other). In our setting, each human bounding box is assigned exactly one of these action labels, so the task is defined as single-frame, per-person detection and action classification. This task addresses scenarios where video streams are unavailable or computational resources are constrained, such as low-power embedded systems, real-time edge analytics, or frame-level detection pipelines. Although practical and highly deployable, the task remains challenged by multiple technical constraints. High-performance models require extensive hardware support to maintain accuracy, hindering real-time applicability on resource-limited devices (Gao et al., 2021). Recognition methods based on red–green–blue input are sensitive to lighting or background variation, reducing robustness (Zhou et al., 2024). Furthermore, the extraction of discriminative spatial patterns from complex actions often sacrifices fine-grained information for computational efficiency, especially when using reduced resolution or simplified architectures. This precision (P)–efficiency tradeoff significantly limits the usability of human action models on edge devices such as mobile or embedded platforms (Wang et al., 2024).
To address these limitations, this study develops a lightweight single-frame human action recognition framework grounded in the YOLO11 (Khanam & Hussain, 2024) architecture. Compared with two-stage detectors such as Faster R-CNN, which require region proposal generation and repeated feature extraction, YOLO11 employs a fully one-stage paradigm with global perception and end-to-end inference, substantially reducing computational overhead. Relative to a single-shot detector (SSD; Liu et al., 2016), another representative one-stage detector, YOLO11 further enhances feature interaction across scales through its cross-scale fusion design, enabling more effective modeling of complex spatial cues while maintaining model compactness. These architectural characteristics, together with quantization and hardware-level acceleration, support millisecond-level inference under low-power conditions and provide a practical baseline for building distributed, human-centric perception systems.
Building upon this foundation, this study proposes an enhanced framework referred to as YOLO11-AN, which introduces several targeted improvements tailored for single-frame human action detection. A C3K2-DMAF dynamic multiscale fusion module is incorporated to better decouple global pose patterns from local joint-sensitive features under lightweight constraints. A dual-branch AUX detection head is designed to coordinate the optimization of action classification and bounding box regression, improving performance in scenarios where the two tasks exhibit conflicting gradients. An MPDIoU regression loss, together with a LocalWindowAttention mechanism, is integrated to stabilize localization and refine local–global spatial dependency modeling at modest computational cost.
These components collectively extend YOLO11 into a more action-aware architecture, forming the complete YOLO11-AN system.
Related Works
In the evolution of object detection algorithms, Faster R-CNN significantly improves the accuracy of object localization in complex scenes by introducing a two-stage architecture of region proposal network and detection network. This algorithm can effectively handle the problem of variable target scales by first generating candidate regions and then designing fine-grained classification and regression. However, this cascading computational process requires the model to maintain two independent feature extraction networks, resulting in a large amount of redundant computation. Especially when processing video stream data, performing frame-by-frame region recommendation operations can lead to a significant increase in video memory usage and real-time degradation, severely limiting its application potential on resource-constrained devices (Ren et al., 2016).
The SSD algorithm, as a representative of single-stage detectors, achieves collaborative localization of multiple targets while maintaining high detection speed through a preset multiscale anchor point and feature pyramid fusion mechanism. Its single forward propagation characteristic avoids the cascading computational loss of Faster R-CNN, making it more suitable for handling continuous action sequences. However, this architecture requires parallel maintenance of detection heads at multiple scales to cover targets of different sizes, resulting in a proportional increase in the number of classification-related parameters in the model as the number of detection categories increases. In embedded deployment scenarios, this type of multihead structure amplifies the pressure of memory bandwidth and power consumption, thereby placing higher demands on the system’s energy efficiency (Liu et al., 2016).
The YOLO series innovatively achieves a balance between accuracy and speed by reconstructing object detection as a regression problem (Lin et al., 2017). YOLO11, as the state-of-the-art model of this series, inherits the advantages of a single-stage detection paradigm and innovatively introduces a dynamic convolution kernel configuration and a cross-scale feature interaction module. YOLO11 represents a recent advancement within the Ultralytics YOLO family. It refines the backbone with more efficient feature extraction units based on CSPDarknet and enhances the neck with an optimized multiscale fusion structure, allowing the model to strengthen spatial representation under lightweight computational constraints. Compared with earlier variants such as YOLOv5, YOLOv7, and YOLOv8, YOLO11 achieves a more favorable balance between accuracy and model complexity through streamlined feature pathways and reduced parameter overhead. These characteristics—lower parameter count, reduced computational cost, and faster inference—align well with the practical requirements of this study, which emphasizes real-time processing and edge-oriented deployment. As a result, YOLO11 provides a suitable and efficient foundation for the proposed framework. By implementing a layered parameter reuse strategy to compress the depth of the computational graph, the model’s dependence on hardware computing power is effectively reduced. Its end-to-end detection feature avoids the problem of feature duplication extraction in two-stage algorithms, and combined with adaptive quantization technology, weight quantization, and hardware instruction set optimization can be achieved, significantly improving inference efficiency on edge devices. These features make it the most promising lightweight action recognition solution currently available (Khanam & Hussain, 2024).
In the field of human motion image recognition, extracting complex pose features is the core challenge. The deformable convolutional network (DCNv3) proposed by Wang et al. significantly enhances the feature adaptation ability in occluded scenes by dynamically adjusting the sampling positions of convolutional kernels, and improves the localization accuracy by 3.8% in COCO human keypoint detection tasks. However, this method lacks a spatial dimension feature decoupling mechanism when dealing with multi-angle poses, resulting in increased angle estimation errors and seriously affecting the performance of fine-grained action classification (Wang et al., 2023).
The adaptive feature pyramid network proposed by the Wang team optimizes feature interaction through bidirectional cross-scale connections, resulting in a 6.5% increase in small target recall (R) in industrial part detection tasks. However, human motion recognition requires modeling both the full body posture contour and local joint details, and its fixed level fusion strategy is difficult to dynamically allocate weights for different scale features, resulting in an increase in the loss rate of microscopic features in the motion (Wang & Zhong, 2021).
The coordinate attention proposed by Hou et al. reduces computational complexity by 45% in ImageNet classification tasks by decomposing channel attention into spatial direction encoding. However, in static images, the discrimination of action types highly depends on the spatial correlation of key body regions, and its fixed direction encoding mechanism cannot adaptively focus on discriminative regions, which can easily lead to the problem of missing key features and increase the misclassification rate (Hou et al., 2021).
The semi-decoupled head proposed by Han et al. achieves a balance between detection accuracy and inference speed on the MS COCO dataset by separating target classification and bounding box regression tasks. However, the strong coupling between action categories and posture coordinates requires the model to be able to model the interaction relationships between tasks. The completely decoupled independent optimization strategy leads to the disconnection of feature expression between classification and regression tasks, weakening the dynamic correlation of target contextual information, and thus causing an increase in false detection rate in complex backgrounds or dense small target scenes (Han et al., 2024).
In summary, the current technological bottlenecks in human motion image recognition research are mainly reflected in three aspects: The coupling of spatial features leads to interference between the fine-grained information of global pose and local joints, weakening the discriminative ability of complex actions. Scale feature fusion relies on static weight allocation strategies, which make it difficult to dynamically adapt to the semantic correlations of different actions, resulting in the loss of micro features. The attention mechanism is limited by fixed windows or preset encoding modes, lacking adaptive focusing ability on discriminative regions, resulting in the omission of key features under background interference.
These defects collectively constrain the accuracy and robustness of human motion image recognition models, and there is an urgent need to improve and optimize them through dynamic feature decoupling, cross-scale interaction of semantic perception, adaptive attention optimization, and other methods.
In response to the core challenges of spatial feature coupling, insufficient multiscale interaction, and low edge-deployment efficiency in human motion image recognition, this study proposes an improved model, YOLO11-AN (ActionNet), based on the YOLO11 architecture. This model achieves multilevel optimization through modular innovation: introducing the C3K2-DMAF module in the feature extraction stage to enhance the spatial feature decoupling ability and multiscale semantic perception accuracy in complex action recognition tasks; design a dual-branch AUX detection head architecture that balances classification accuracy and localization robustness through collaborative optimization of primary and secondary tasks; adopting the MPDIoU (Ma & Xu, 2023) loss function to improve the bounding box regression strategy and alleviate the localization bias problem in complex poses; adopting LocalWindowAttention to maintain local dependencies and effectively capture long-range dependencies improves computational efficiency and model performance. The proposed modules remain structurally compatible as each operates at a distinct functional stage and preserves the spatial–channel tensor interfaces, ensuring unobstructed feature flow and seamless integration across the architecture. Subsequent sections will systematically elaborate on the design principles and implementation paths of each improved module, elucidating the underlying mechanisms for addressing the aforementioned technical bottlenecks. For clarity, the key mathematical symbols and notations used throughout this section are summarized in Appendix A (Table A1). The network architecture diagram of YOLO11-AN is shown in Figure 1.
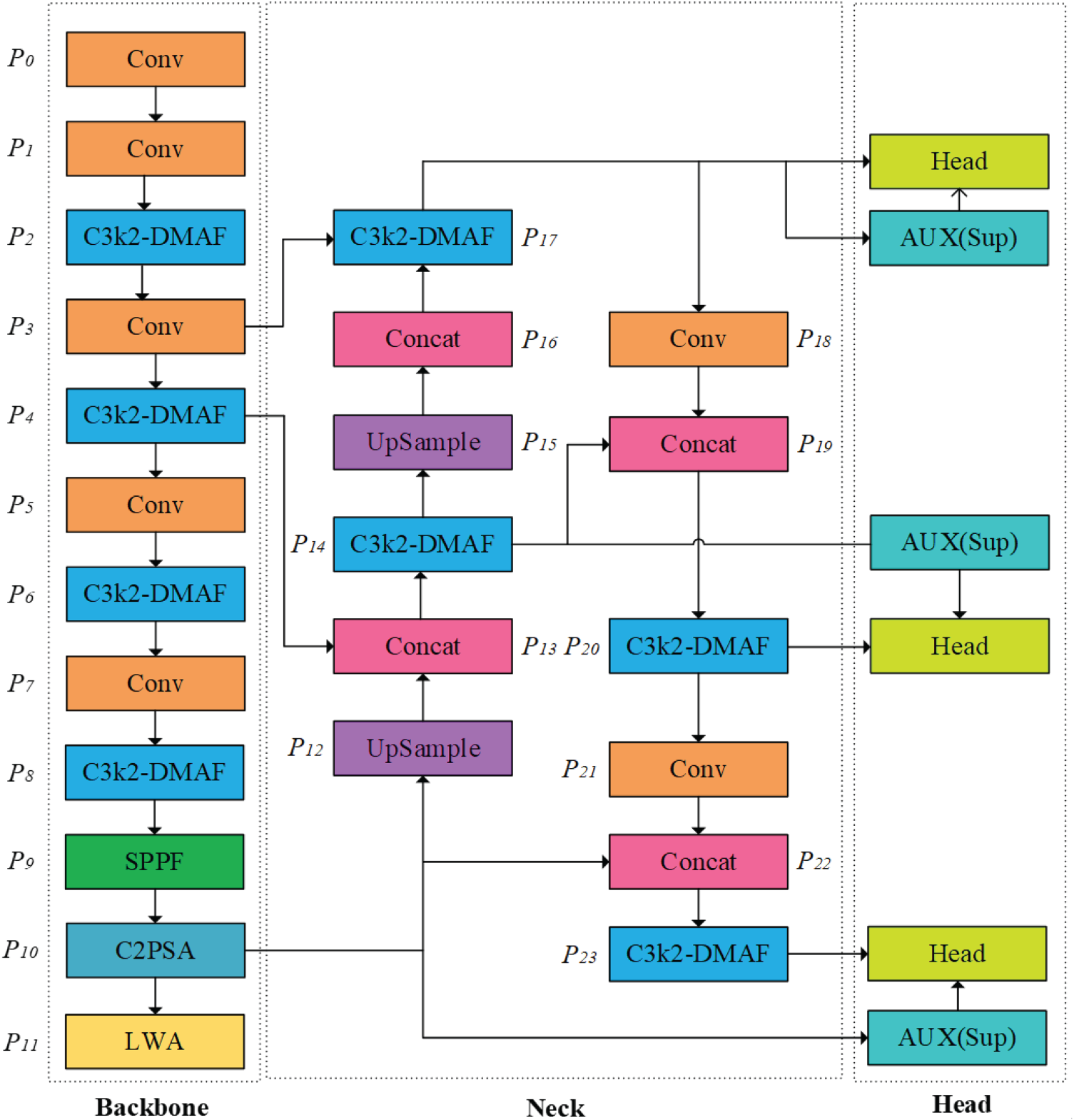
YOLO11-AN network architecture diagram.
There is always a tradeoff between the feature expression ability and computational efficiency of convolutional neural networks. Traditional multiscale feature fusion methods rely on fixed multibranch structures, making them difficult to adapt to dynamic scenes. To address the issue of spatial feature coupling in human motion recognition, this paper proposes a dynamic multiscale adaptive fusion module based on the C3K2 design, termed C3K2-DMAF. The module adopts a parallel–serial hybrid architecture that enhances spatial feature decoupling through dynamic multiscale decomposition, adaptive channel extension, hybrid attention collaborative optimization, and cross-stage feature reuse, thereby meeting the requirements of both dynamism and lightweight deployment. Although multiscale fusion improves the modeling of heterogeneous posture cues, it naturally increases intermediate feature aggregation and memory-access overhead, which must be carefully controlled for edge-side deployment. The proposed C3K2-DMAF module is therefore designed to retain the representational benefits of multiscale processing while constraining the computational footprint within a lightweight budget. A schematic diagram of the C3K2-DMAF structure is shown in Figure 2.
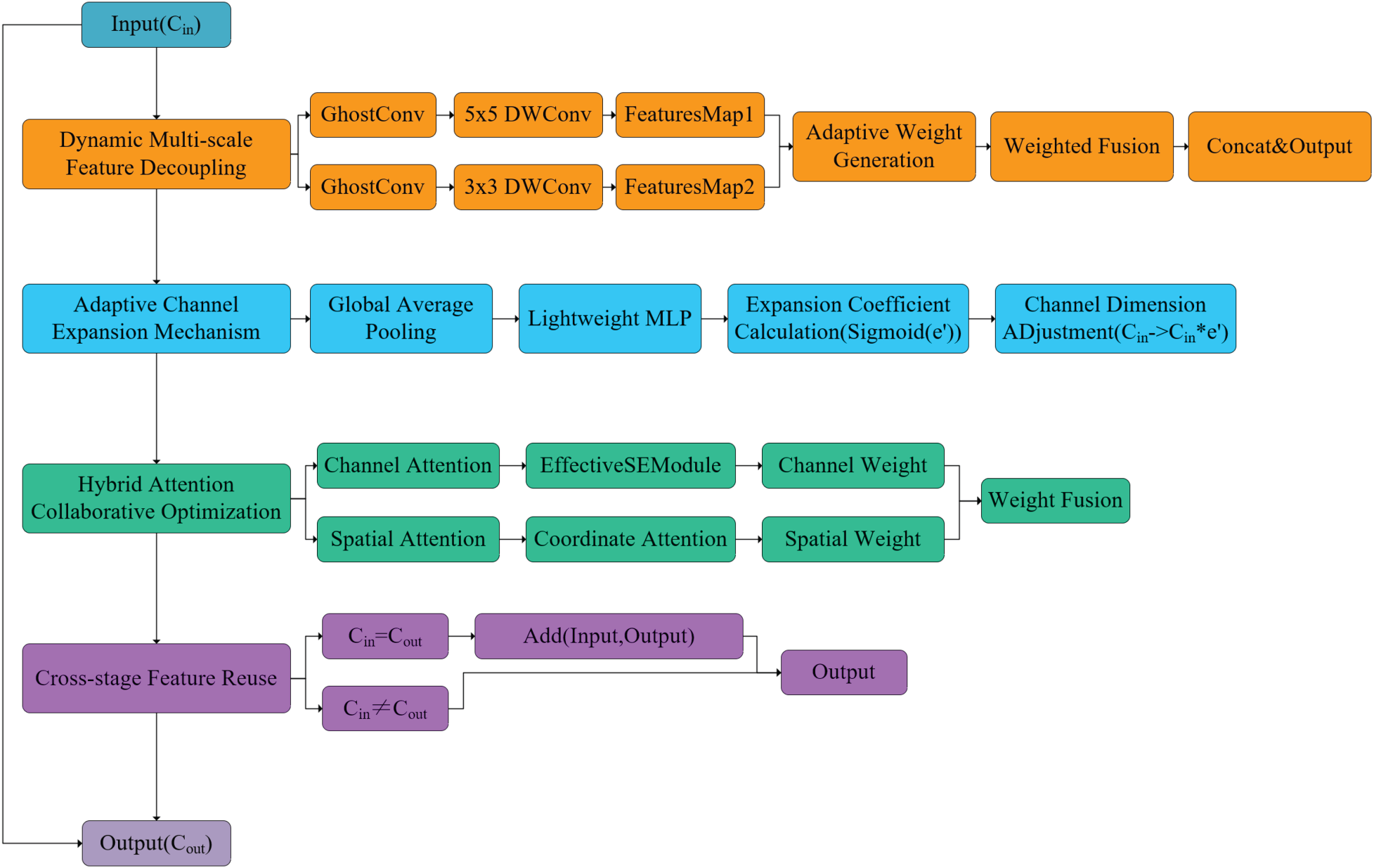
Schematic diagram of C3K2-DMAF module structure.
By deploying
The dynamic weight generation network takes the global average pooling feature as input, and outputs the branch fusion weight

Among them,
The adaptive channel extension mechanism addresses the core contradiction between the efficiency of feature expression and the imbalance of computing resource allocation in human action recognition. By dynamically perceiving the complexity of input features, it achieves elastic adjustment of channel dimensions. This section analyzes the complexity of input features through a dynamic prediction network and generates real-time channel expansion coefficients:

Among them,
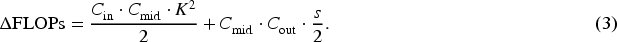
Among them,
The hybrid attention collaborative optimization mechanism alleviates the blurring of discriminative regions and the interference of background noise in human action recognition through cascaded channel–spatial dual-dimensional feature calibration. Before introducing the formulation of the channel-attention weighting, we first verify the necessity of asymmetric pooling through an independent ablation experiment. This ensures that the subsequent design choice is empirically grounded.
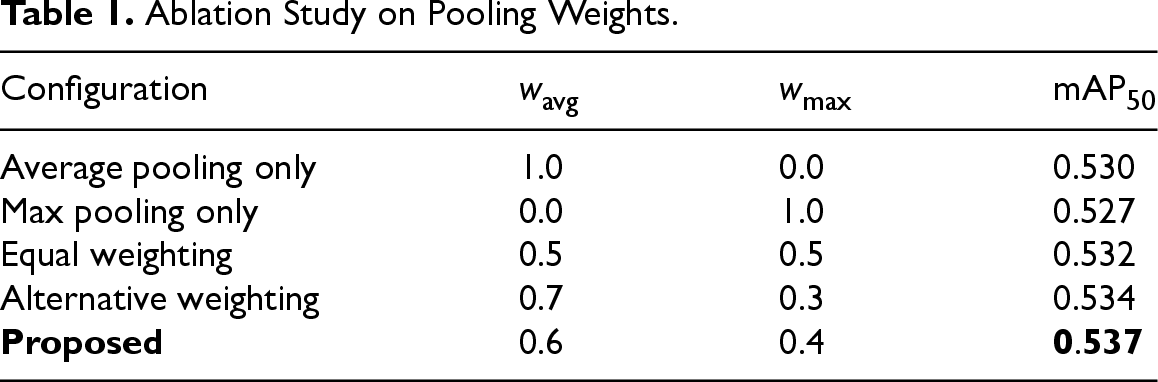
To examine the effect of different average–max pooling ratios, we conducted a controlled ablation study on the YOLO11-AN architecture, modifying only the pooling weights while keeping all other configurations unchanged. As shown in Table 1, average pooling alone and max pooling alone yield inferior performance; equal weighting (0.5/0.5) achieves only marginal improvement. Assigning a slightly larger weight to average pooling consistently enhances mAP50, with the proposed 0.6/0.4 configuration achieving the best performance. This confirms that global contextual statistics captured by average pooling and strong local activations emphasized by max pooling jointly contribute to stable channel attention, and that moderate asymmetry provides the most effective balance.
Based on these experimental observations, the input feature

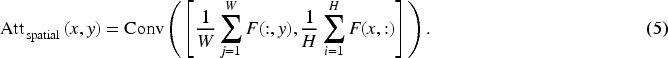
Ablation Study on Pooling Weights.
Channel and spatial attention outputs are finally fused through element-wise multiplication:

This cascaded design balances global semantic characterization and local spatial selectivity, offering a robust mechanism for human micro-action recognition in dense and dynamic scenes.
The cross-stage feature reuse module optimizes the information flow between feature levels through residual connections and dynamic regularization strategies, solving the problems of gradient attenuation and feature degradation in deep networks. Assuming the input of the module is 
Among them, 
The exponential decay coefficient
Effect of Dropout Decay Factor

The bold value indicates the best-performing results within each column.
The results demonstrate that
When the input channel 
This module provides a highly robust feature representation foundation for human action recognition in complex dynamic scenes through hierarchical feature reuse and geometric constraint enhancement.
In human action recognition tasks, there is often a contradiction between the classification accuracy of complex actions and the robustness of their positions. Traditional object detection networks often rely on optimizing a single task, resulting in a lack of balance between classification and localization tasks in the same network, especially when dealing with diverse and dynamic action scenes, which often affects accuracy. Therefore, this study proposes a dual-branch AUX detection head architecture (Jin et al., 2020), aiming to balance classification accuracy and localization robustness through collaborative optimization of main and auxiliary tasks.
The design of a dual-branch architecture can avoid interference between tasks. Classification and localization tasks are optimized separately through independent branches, avoiding common task coupling problems. This design also makes the model more efficient in handling multiple tasks and reduces the waste of computing resources.
The schematic diagram of the dual-branch AUX detection head structure is shown in Figure 3.
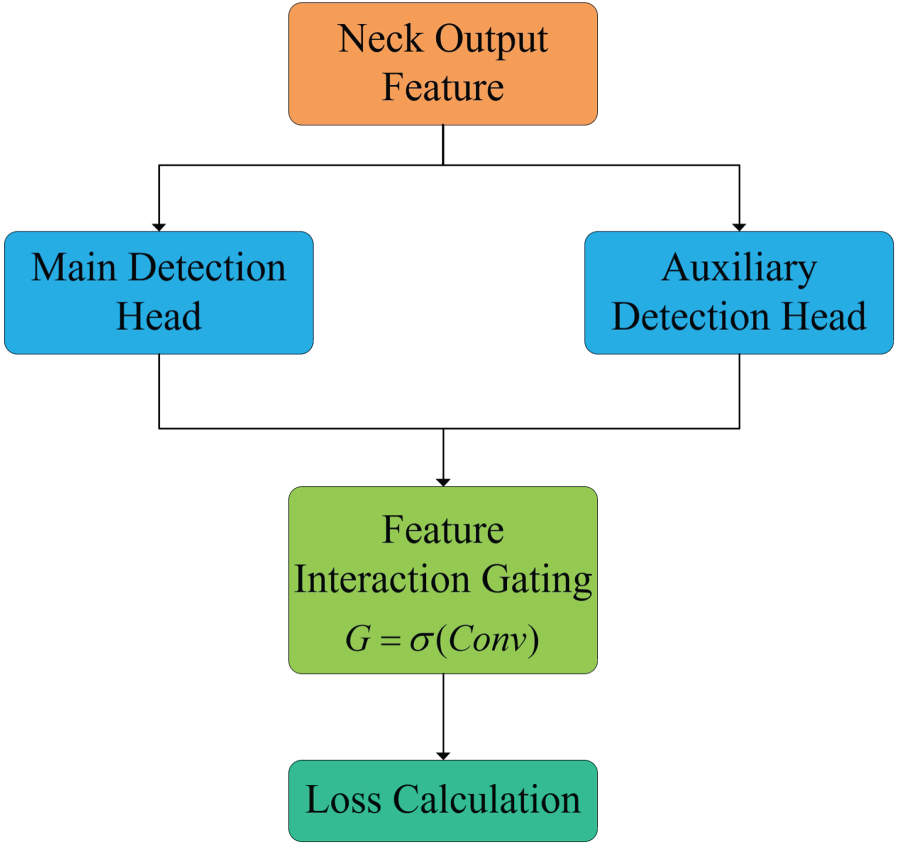
Schematic diagram of dual-branch AUX detection head structure.
The dual-branch AUX architecture designs two independent branches based on the detection head of YOLO11. One is used for human action classification tasks (main task), and the other is used for localization tasks (auxiliary task). These two tasks are trained in parallel and complement each other, achieving a good balance between classification accuracy and localization accuracy in the model. The main task branch focuses on fine-grained action category judgment, while the auxiliary task branch enhances the accuracy of bounding box regression, ultimately achieving overall performance improvement through fusion.
The main branch focuses on the classification label recognition of actions, while the auxiliary branch focuses on the accuracy of bounding box positions for human posture. Through this dual task collaborative optimization, small changes in actions can be accurately captured, and the robustness of the model in complex backgrounds can be improved.
Calculation Process of Dual-Branch Architecture
In the architecture of dual-branch AUX, the classification task and regression task are calculated separately through independent branches, and the losses of both are weighted and summed through a comprehensive optimization mechanism to ensure that each task can contribute to the final performance of the model. Assuming the input feature of the model is
In the classification branch calculation, classify each target area and output the probability distribution of each action category. The classification branch normalizes the features of each position using the Softmax function to obtain the probability of each action category:

Among them,
In the localization branch calculation, bounding box regression is performed for each target area to predict the position of the object in the image. Obtain the four parameters
Finally, the loss functions of the two branches are synthesized through a weighted approach to balance classification accuracy and localization accuracy. The loss function is calculated as follows:

Among them,
The bounding box regression task in human motion recognition is often affected by center misalignment, pose scale variance, and aspect ratio deformation. Classical IoU-based losses (e.g., GIoU, DIoU, and CIoU) address spatial overlap but neglect holistic geometric alignment, which results in unstable performance under diverse action poses.
To mitigate this issue, a refined loss function named MPDIoU is introduced, which augments traditional IoU with additional constraints on center deviation, scale mismatch, and aspect ratio distortion. Given a predicted bounding box 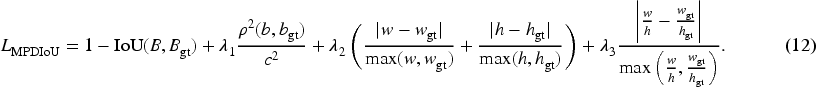
Here,
The initial setting adopted uniform weights
Stepwise Tuning of MPDIoU Hyperparameters (Base:
).
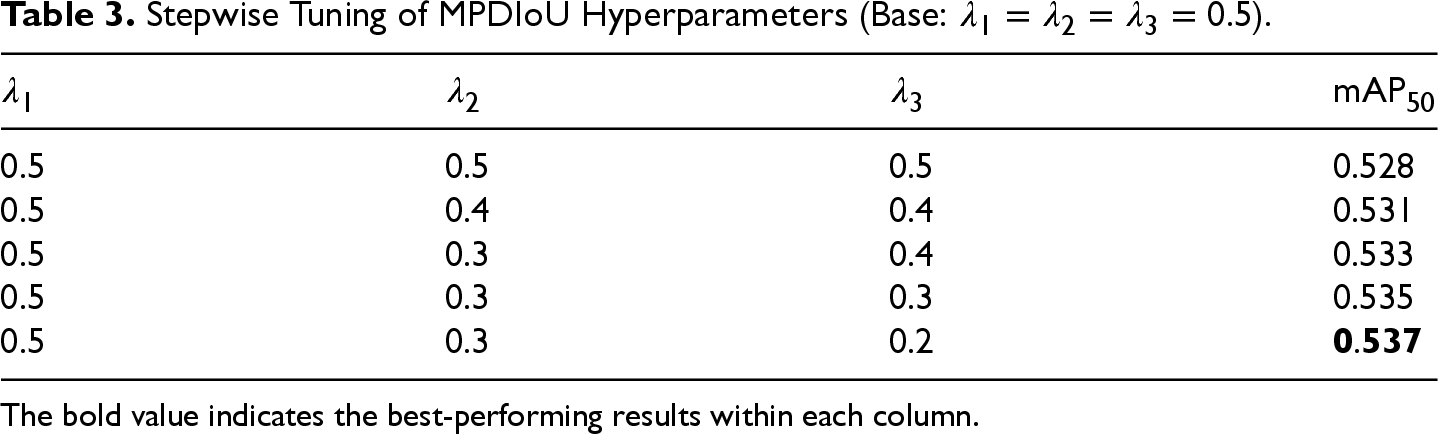
Stepwise Tuning of MPDIoU Hyperparameters (Base:
The bold value indicates the best-performing results within each column.
The results indicate that
Performance Degradation for Further

The final selected configuration is:
In human motion recognition tasks, long-distance dependency capture often brings huge computational and storage overhead, especially in high-resolution images or video streams. Traditional global self-attention modules can easily lead to a decrease in inference speed and a sharp increase in video memory usage. LocalWindowAttention significantly reduces computational complexity by partitioning local windows in spatial dimensions and performing self-attention within the windows, while preserving key contextual interactions within the local region, effectively balancing robustness and inference efficiency.
In this module, the feature map is divided into several nonoverlapping small windows, each window size can be set to 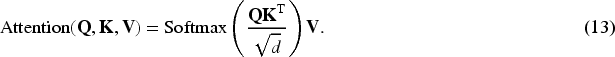
By performing this calculation separately in each local window,
The dataset in this experiment is sourced from the Pascal VOC 2012 public dataset related to human action recognition, with a total of 11 classification categories covering phoning, playinginstrument, reading, ridingbike, ridinghorse, running, takingphoto, usingcomputer, walking, jumping, and other. These categories span both relatively static interactions (e.g., reading and playinginstrument) and motion-intensive behaviors (e.g., running, jumping, and ridingbike), thereby providing a compact yet diverse benchmark for single-frame human motion recognition. The training set and validation set contain 2,296 and 2,292 images, respectively, covering human motion samples in multiple scenes and poses, laying the foundation for verifying the model’s generalization ability and robustness in real-world applications. The VOC2012 human motion dataset is illustrated in Figure 4.

Schematic diagram of Pascal VOC2012 human motion dataset.
The GPU used in this experiment is RTX4060 Laptop (8188MiB), the input image size is set to 640, the batch size is 16, and a stochastic gradient descent (SGD) optimizer is used. The total training epochs are 300. This configuration ensures that the model fully learns action details while considering hardware performance limitations, providing a consistent experimental basis for subsequent evaluation and comparison.
After outputting the detection results, YOLO11 will calculate P, R, mAP50, mAP
P refers to how many of the targets predicted as positive cases are truly positive cases. Improving P means reducing the false-positive rate, which can directly reflect the proportion of false-positive actions in human motion recognition tasks.
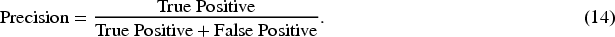
R refers to the number of true positives that have been successfully detected. The higher the R, the higher the capture rate of positive samples by the model, and the relatively fewer missed detections.
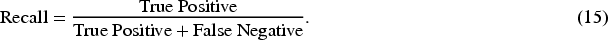

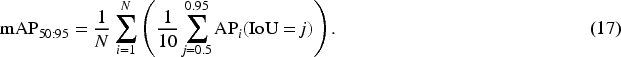
F1 score is the harmonic average of P and R, used to measure the overall performance of a model in imbalanced scenarios. The higher the F1 score, the higher the accuracy and comprehensiveness of the model’s predictions for positive cases.

This experiment measures the performance of the model from multiple perspectives based on the above indicators, comprehensively considering the model’s effectiveness from the aspects of classification accuracy, localization robustness, and adaptability to overlapping areas, providing a basis for subsequent algorithm optimization and practical deployment.
Figure 5 shows the comparison of training curves between YOLO11-AN and YOLO11 on four indicators: P, R, mAP50, and mAP
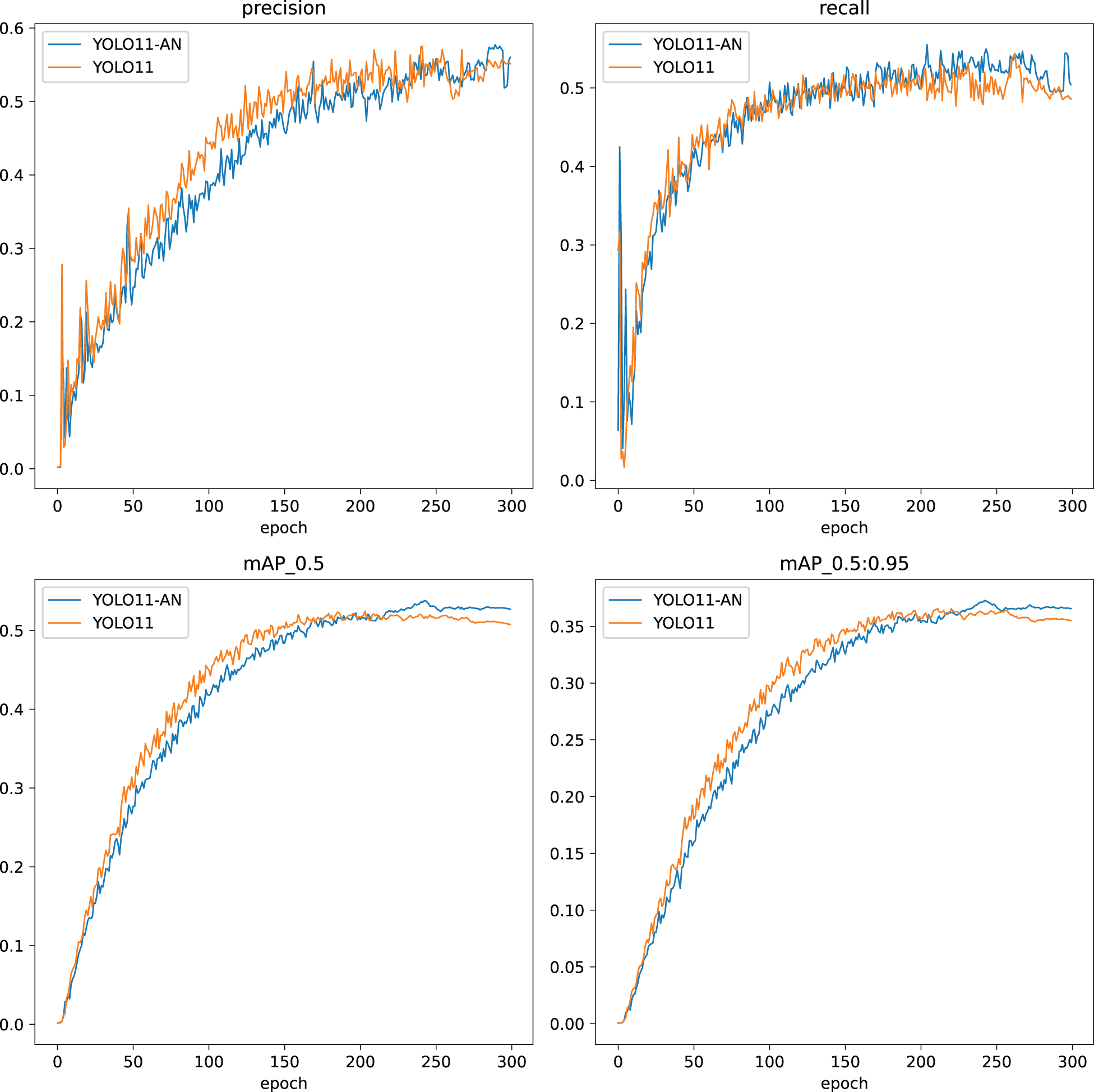
Comparison of experimental results between YOLO11-AN and YOLO11.
Figure 6 shows the comparison of confusion matrices between YOLO11-AN and YOLO11. As shown in the figure, YOLO11-AN has reduced the false detection and missed detection rates in the main action categories, significantly reduced the confusion between action categories, and demonstrated better fine-grained discrimination ability.
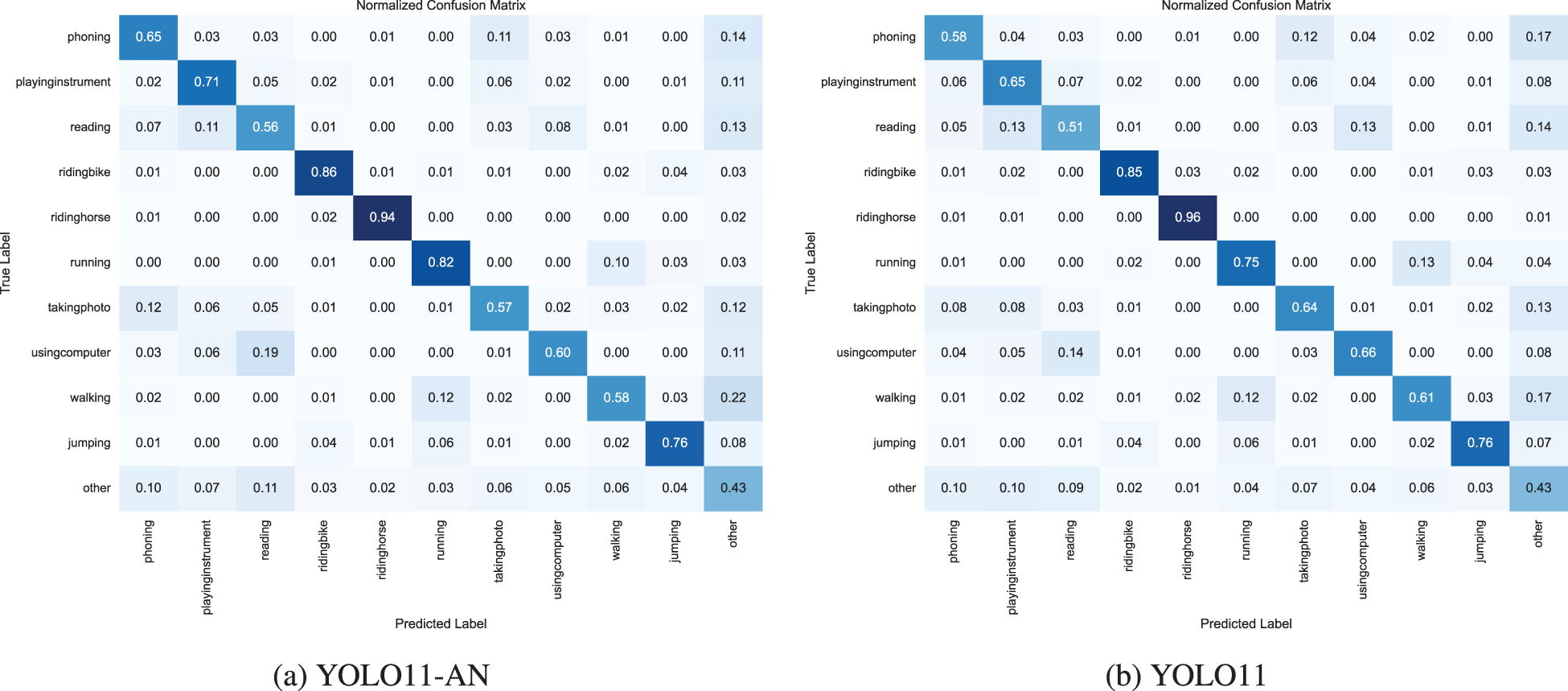
Comparison of confusion matrix between YOLO11-AN (a) and YOLO11 (b).
To verify the effectiveness of the improved MPDIoU loss function in this experiment, we compared it with the widely used loss function in YOLO11 and conducted experiments based on YOLO11-AN as the basic model. The comparison results are shown in Table 5. It can be seen that although GIoU is slightly better than MPDIoU in the P index, MPDIoU outperforms other IoU functions, including GIoU, in comprehensive indicators such as R, F1, and mAP, fully demonstrating its effectiveness in positioning accuracy and regression stability.
MPDIoU Validity Verification.
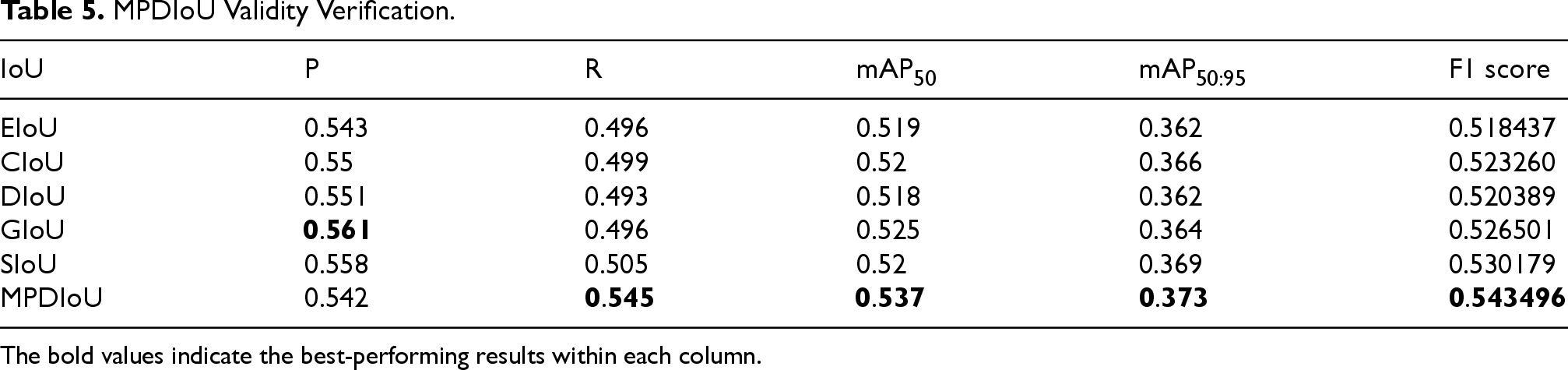
MPDIoU Validity Verification.
The bold values indicate the best-performing results within each column.
The ablation experiment aims to evaluate the individual contribution of each key module in the proposed architecture. Table 6 shows eight experimental configurations. Num1 represents the baseline YOLO11 model. P1–P4 correspond to the four proposed components: C3K2-DMAF module (P1), dual-branch AUX detection head (P2), LocalWindowAttention (P3), and MPDIoU loss function (P4). Num8 integrates all four modules and constitutes the full YOLO11-AN framework.
YOLO11-AN Ablation Experiment.
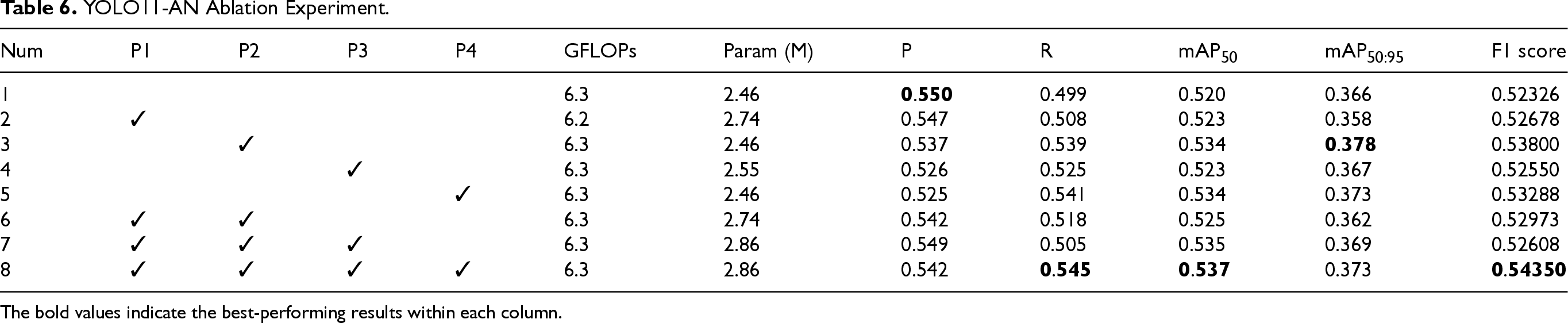
YOLO11-AN Ablation Experiment.
The bold values indicate the best-performing results within each column.
To ensure experimental consistency, all settings—including
To further validate the reliability and stability of the proposed model, we conducted three independent training runs on the Pascal VOC 2012 dataset for both YOLO11 and YOLO11-AN, using different random seeds (17, 87, and 143). The results of mAP50 and mAP
Per-run Results on Pascal VOC 2012 (mAP50 and mAP
).

Per-run Results on Pascal VOC 2012 (mAP50 and mAP
The average performance and corresponding standard deviations are summarized in Table 8. YOLO11-AN consistently outperforms YOLO11 with small variance across runs, indicating stable convergence behavior and statistically reliable performance gains.
Mean

The bold values indicate the best-performing results within each column.
These results confirm that the proposed improvements in YOLO11-AN lead to not only higher accuracy but also enhanced training stability. The model exhibits robust performance under varying initialization conditions, supporting its practical applicability in real-world deployment scenarios.
To further assess the reliability of the model’s confidence predictions, a lightweight calibration analysis was performed based on the per-class mAP50 statistics of YOLO11 and YOLO11-AN. As shown in Table 9, YOLO11-AN not only increases the mean mAP50 from 0.520 to 0.537 but also reduces the interclass variance from 0.0283 to 0.0201. In addition, the expected calibration error (ECE) decreases from 0.042 to 0.031, indicating that the predicted confidence scores exhibit a closer correspondence to the empirical detection accuracy. These results collectively suggest that YOLO11-AN produces more stable and consistent confidence estimates across action categories, complementing the improvements observed in overall detection performance.
Per-class mAP50 and Calibration Statistics for YOLO11 and YOLO11-AN.
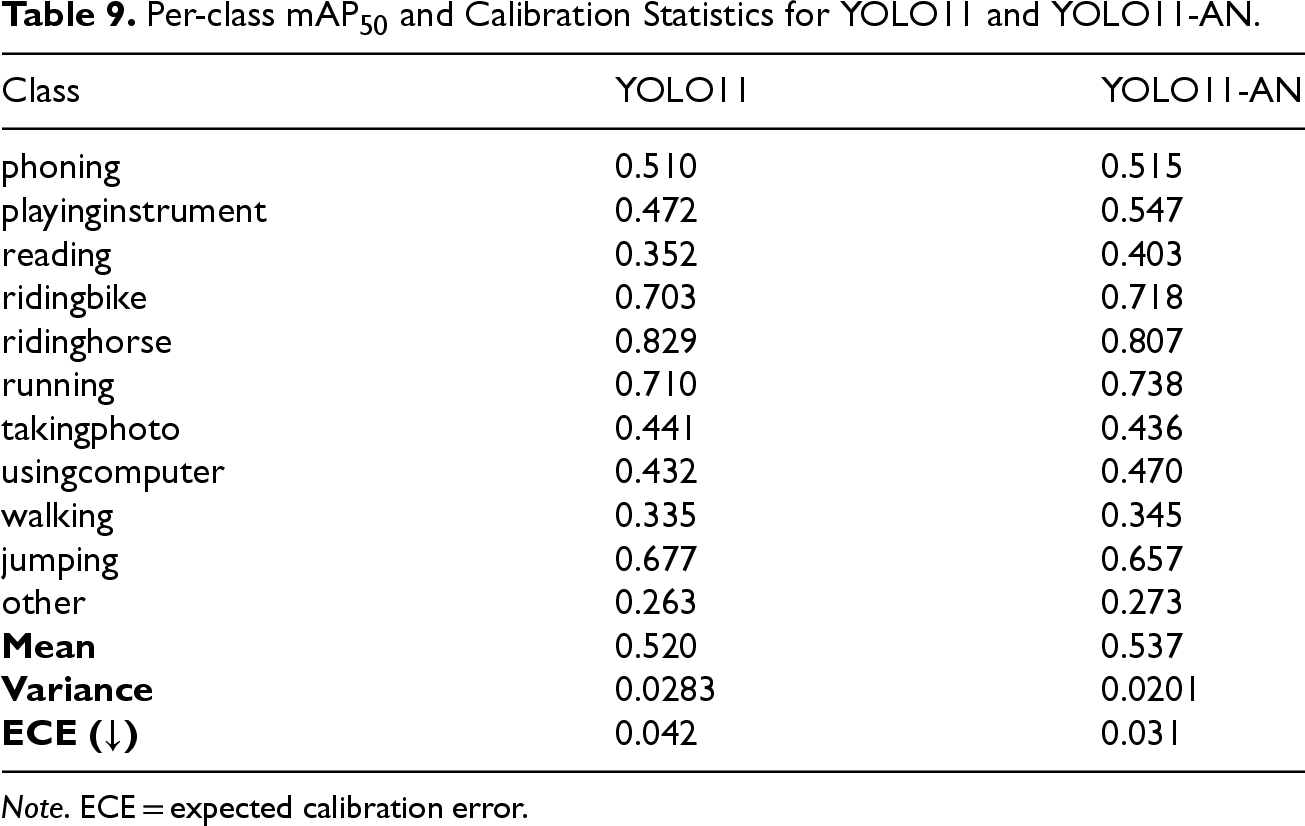
Per-class mAP50 and Calibration Statistics for YOLO11 and YOLO11-AN.
Note. ECE = expected calibration error.
To assess the generalization capability of YOLO11-AN in real-time human motion recognition across diverse action categories and video domains, we conducted experiments on two widely used video action recognition benchmarks: UCF101 and HMDB51. Although these datasets consist of labeled video clips, the YOLO-based framework supports per-frame inference, making it suitable for real-time deployment on video streams.
For experimental consistency and annotation alignment, we extracted the midpoint frame from each video using automated scripts and treated the entire frame as an instance carrying the video’s action label. This strategy simulates the streaming input conditions encountered in frame-by-frame inference for real-world applications.
The resulting datasets include 13,320 frames from UCF101 and 6,766 frames from HMDB51. The data were split into training, validation, and test sets in a
Table 10 shows the results. On UCF101, YOLO11-AN achieves a mAP50 of 0.951, improving upon YOLO11’s 0.912. On HMDB51, YOLO11-AN reaches 0.902, surpassing YOLO11’s 0.847. These results highlight the strong domain adaptability and robustness of the proposed model in real-time video-based motion recognition scenarios.
Generalization Performance on UCF101 and HMDB51 Datasets.

Generalization Performance on UCF101 and HMDB51 Datasets.
The bold values indicate the best-performing results within each column.
To further evaluate the practical performance of YOLO11-AN on actual video streams, we designed a validation algorithm that loads the trained YOLO11 and YOLO11-AN models and performs per-frame inference on videos from UCF101 and HMDB51. A script was used to calculate the proportion of total video duration in which the predicted category matches the ground truth label, serving as a proxy for temporal prediction consistency and stability.
On UCF101, the YOLO11 model achieved a correct prediction duration ratio of 68.372%, while YOLO11-AN reached 79.754%. On HMDB51, the corresponding values were 60.213% for YOLO11 and 66.892% for YOLO11-AN. These results reinforce that YOLO11-AN not only improves frame-level recognition accuracy but also enhances temporal stability in continuous video inference.
The consistent performance gains of YOLO11-AN across both static frame metrics and dynamic video-level duration analysis affirm its strong generalization ability across action domains and further substantiate its overall effectiveness as a real-time human motion recognition solution.
In this section, YOLO11-AN is compared with SSD and other high-performance algorithms proposed by researchers under the same dataset conditions to evaluate its performance in accuracy, speed, and robustness. Table 11 presents the quantitative results of each algorithm on indicators such as P, R, mAP50, mAP
Comparison Experiment of Object Detection Algorithms.
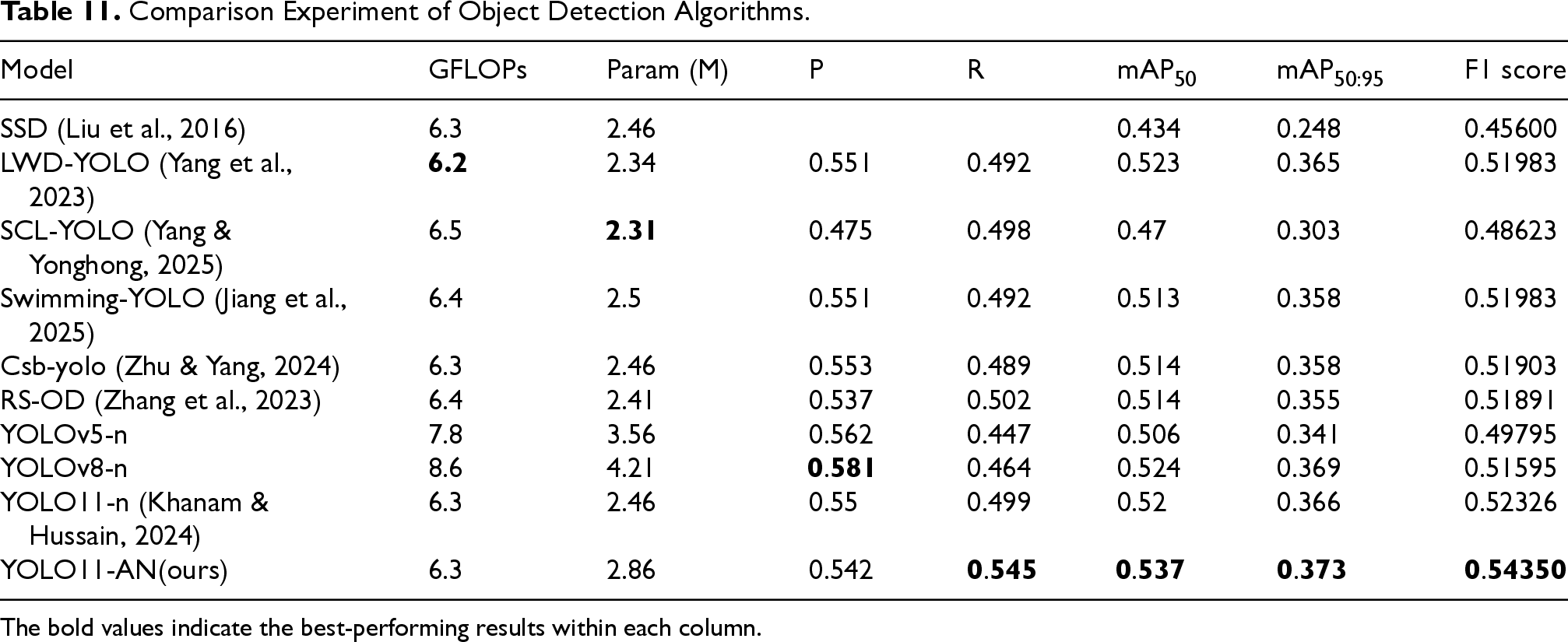
Comparison Experiment of Object Detection Algorithms.
The bold values indicate the best-performing results within each column.
The experimental results show that YOLO11-AN outperforms other methods in overall recognition performance while maintaining a high detection speed. This advantage indicates that it has better generalization ability and deployment potential in scenarios with diverse data and complex poses.
To address the request for stronger peer-reviewed baselines, three compact detectors widely recognized in the literature—RT-DETR-R18 (Zhao et al., 2024), PP-YOLOE-Tiny (Xu et al., 2022), and EfficientDet-D0 (Tan et al., 2020)—were reproduced under identical experimental settings to those used for YOLO11-AN. All models were trained from scratch using
As shown in Table 12, RT-DETR-R18 achieves the highest detection accuracy (mAP50 = 0.540; mAP
Lightweight Detectors on Pascal VOC 2012: Accuracy & Efficiency Tradeoff.

Lightweight Detectors on Pascal VOC 2012: Accuracy & Efficiency Tradeoff.
Moreover, YOLO11-AN surpasses PP-YOLOE-Tiny and EfficientDet-D0 across all evaluated metrics and offers the most favorable tradeoff between accuracy and computational cost. These results confirm that the observed performance advantages of YOLO11-AN are not limited to weaker baselines, but hold even when compared against well-established lightweight models.
To evaluate the practicality of YOLO11-AN in real-world edge computing environments, we deployed and tested the model on the NVIDIA Jetson Orin Nano 4GB development board—an embedded platform widely used for low-power vision applications. For a fair comparison, several representative lightweight models were also reproduced and tested under identical runtime conditions. All models were quantized using INT8 P, and the input resolution was uniformly set to
Table 13 summarizes the results. MobileNetV2 and MobileNetV3-Small exhibit low-computational complexity (
Comparison of Edge Device Model Effectiveness Verification.
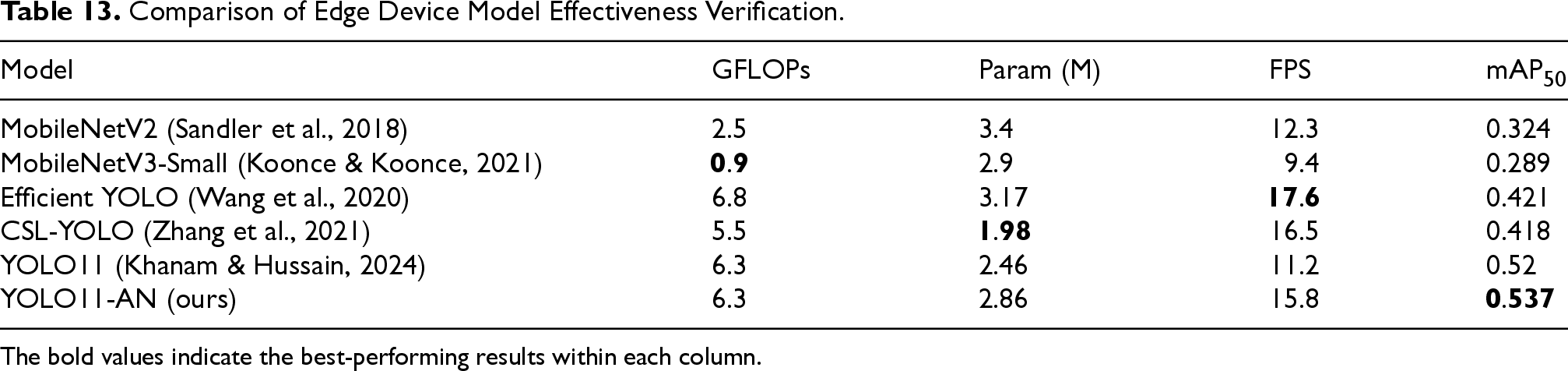
Comparison of Edge Device Model Effectiveness Verification.
The bold values indicate the best-performing results within each column.
YOLO11 achieves a balance between accuracy and speed, but its performance remains constrained by limited cross-scale representation and regression stability. In contrast, YOLO11-AN attains the highest mAP50 (0.537) among all tested models, and achieves an inference speed of 15.8 FPS—sufficient for real-time deployment in most human-centered interaction tasks such as security monitoring, patient activity tracking, and smart sports analysis.
Despite a slight increase in parameter count (from 2.46M to 2.86M), YOLO11-AN maintains the same GFLOPs (6.3) as YOLO11, which confirms the structural efficiency of its modular improvements. The added modules—C3K2-DMAF, dual AUX heads, MPDIoU, and LocalWindowAttention—bring tangible performance gains without significantly compromising inference latency or memory footprint. This balance indicates that YOLO11-AN is not only deployable on resource-limited hardware but also superior in ensuring stable and accurate recognition of human motions under edge constraints.
This study proposes YOLO11-AN, a lightweight and action-aware detection framework designed for real-time human motion recognition. By enhancing spatial representation, optimizing task interaction, and improving localization robustness, the proposed model delivers consistent performance gains across diverse datasets and deployment environments. Extensive experiments on Pascal VOC 2012, UCF101, and HMDB51 demonstrate that YOLO11-AN achieves higher accuracy, stronger stability under random initialization, and improved generalization compared with the baseline YOLO11 and a range of representative lightweight detectors. Furthermore, the deployment on Jetson Orin Nano confirms the model’s suitability for low-power edge applications, achieving real-time inference without compromising recognition fidelity. These results highlight the effectiveness of the proposed framework and its potential for integration into practical human–computer interaction and intelligent perception systems. Future work will focus on addressing the remaining limitations observed in the experiments, including exploring more aggressive compression and distillation strategies, enhancing recognition of fine-grained action categories, and conducting broader cross-domain evaluations to further improve robustness and adaptability.
Ethical, Privacy, and Safety Considerations
This study relies exclusively on publicly available and anonymized datasets (Pascal VOC 2012, UCF101, and HMDB51), and no private or personally identifiable information was collected, stored, or processed. All training and inference procedures were executed fully on local GPU hardware without any form of data transmission or cloud-based computation, effectively eliminating risks of data leakage or unauthorized access. The proposed YOLO11-AN model performs only action-category prediction and does not attempt identity recognition, demographic inference, or biometric profiling. Since the datasets contain no sensitive attributes, the study does not introduce real-world bias or safety concerns. The methodological scope and experimental protocol, therefore, adhere to established ethical standards for human-centric computer vision research.
Footnotes
Acknowledgments
We sincerely thank all the people and institutions who have provided assistance during this research process. Thank you to the colleagues at Xifu River 402 Laboratory for providing valuable feedback and technical support. In addition, I would like to express my gratitude to Professor Haitao Meng for providing guidance and suggestions during the writing and research process of the paper. We would also like to express our special thanks to all the researchers who used and shared the Pascal VOC 2012 dataset, as it played a crucial role in the smooth progress of this study. Finally, thank you to all anonymous reviewers who provided constructive feedback during the paper review process.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A Notation Table
Summary of Key Mathematical Symbols Used in This Paper.

|
|
|
|---|---|
| Number of channels in input feature maps | |
| , | Weights of the fully connected layers for dynamic fusion |
| Global average pooled vector across channels | |
| , | Scalar weights for dynamic branch fusion |
| , | Output feature maps from and branches |
| Fused feature map after weighted aggregation | |
| Weight matrix controlling channel expansion | |
| Predicted expansion ratio (range: 1.0–3.0) | |
| Convolution kernel size | |
| Ghost convolution expansion factor | |
| FLOPs | Floating-point operations per inference |
| Aggregated feature from max and avg pooling (channel-wise) | |
| Spatial attention map | |
| Input/output of the attention module | |
| , | Feature maps between layer and |
| Nonlinear feature transformation function | |
| Dropout | Dropout operation used for regularization |
| Dropout probability during training | |
| Initial dropout rate | |
| Dropout decay factor | |
| Predicted class probability distribution | |
| Weight matrix in classification head | |
| , | Classification and regression loss terms |
| Loss weights for classification and regression | |
| Modified position-dependent IoU loss | |
| , , | Weights for center, scale, and aspect ratio errors |
| IoU | Intersection-over-union between boxes |
| , | Predicted and ground truth box center coordinates |
| , | Width and height of predicted box |
| , | Width and height of ground truth box |
| Diagonal length of enclosing box | |
| , , | Query, key, value in attention mechanism |
| Embedding dimension in self-attention | |
| Computed self-attention output | |
| mAP50 | Mean average precision at IoU threshold = 0.5 |
| mAP | Mean AP over IoU thresholds from 0.5 to 0.95 |
| F1 score (harmonic mean of precision and recall) |