
Abstract
Fine-grained image retrieval (FGIR) is a challenging task that demands precise representation of subtle inter-class variations and intra-class similarities. Traditional methods, heavily reliant on labeled data, face scalability and cost-efficiency challenges, limiting their applicability in real-world scenarios. To address these limitations, this study introduces a novel self-supervised pre-training framework tailored for FGIR. Central to our approach is the adaptive sample selector module, which dynamically selects training samples of varying difficulties, enhancing the learning of discriminative features without significantly increasing training costs. Additionally, we propose an integrated learning strategy that synergistically combines contrastive and generative learning, enabling the model to capture both intra-image contextual information and inter-image similarities. This approach significantly improves feature extraction, setting a new benchmark for FGIR tasks. Extensive experiments on multiple FGIR benchmarks demonstrate that our model achieves state-of-the-art performance, consistently surpassing existing methods. By reducing reliance on labeled data and advancing self-supervised learning for fine-grained image analysis, this framework offers a scalable and efficient solution for FGIR and beyond.
Keywords
Introduction
Fine-grained image retrieval (FGIR) has become a significant research area within computer vision (CV), focused on retrieving images belonging to the same subclass within broader categories. Unlike general image retrieval, FGIR emphasizes capturing subtle visual differences essential for distinguishing between subclasses, marking a developmental trend in content-based image retrieval research. FGIR applications span several domains, including pedestrian reidentification (Han et al., 2025; Sun et al., 2024), fashion image retrieval (Islam et al., 2024; Vagena et al., 2025), remote sensing image retrieval (Zhou et al., 2024), and medical image retrieval (Shetty et al., 2024; Wang et al., 2024).
Early FGIR approaches relied mainly on hand-crafted features and traditional machine learning, which often struggled to differentiate visually similar objects at a fine-grained level. With deep learning’s rise, FGIR has seen notable advancements in retrieval accuracy, primarily through models pre-trained on large labeled datasets. Supervised learning models, such as convolutional neural network (CNN)-based architectures such as ResNet and VGG, demonstrate strong feature extraction capabilities but rely heavily on annotated data, creating a significant bottleneck. Obtaining fine-grained annotations is both time-intensive and costly. To address this, self-supervised learning (SSL) has emerged as an effective solution, enabling models to learn representations from unlabeled data by solving pretext tasks. Self-supervised models in CV generally fall into two categories: contrastive learning and generative learning. Contrastive learning models, such as MoCo (He et al., 2020) and SimCLR (Chen et al., 2020), learn representations by contrasting positive and negative samples (Figure 1(b)). This method effectively brings similar images closer in feature space while pushing dissimilar images apart. Generative learning models, such as MAE (He et al., 2022) and SimMIM (Xie et al., 2022), focus on reconstructing masked portions of images to learn representations (Figure 1(c)). Both paradigms are effective for exploiting large-scale unlabeled data and have proven beneficial for downstream tasks such as object recognition, semantic segmentation, and image understanding.
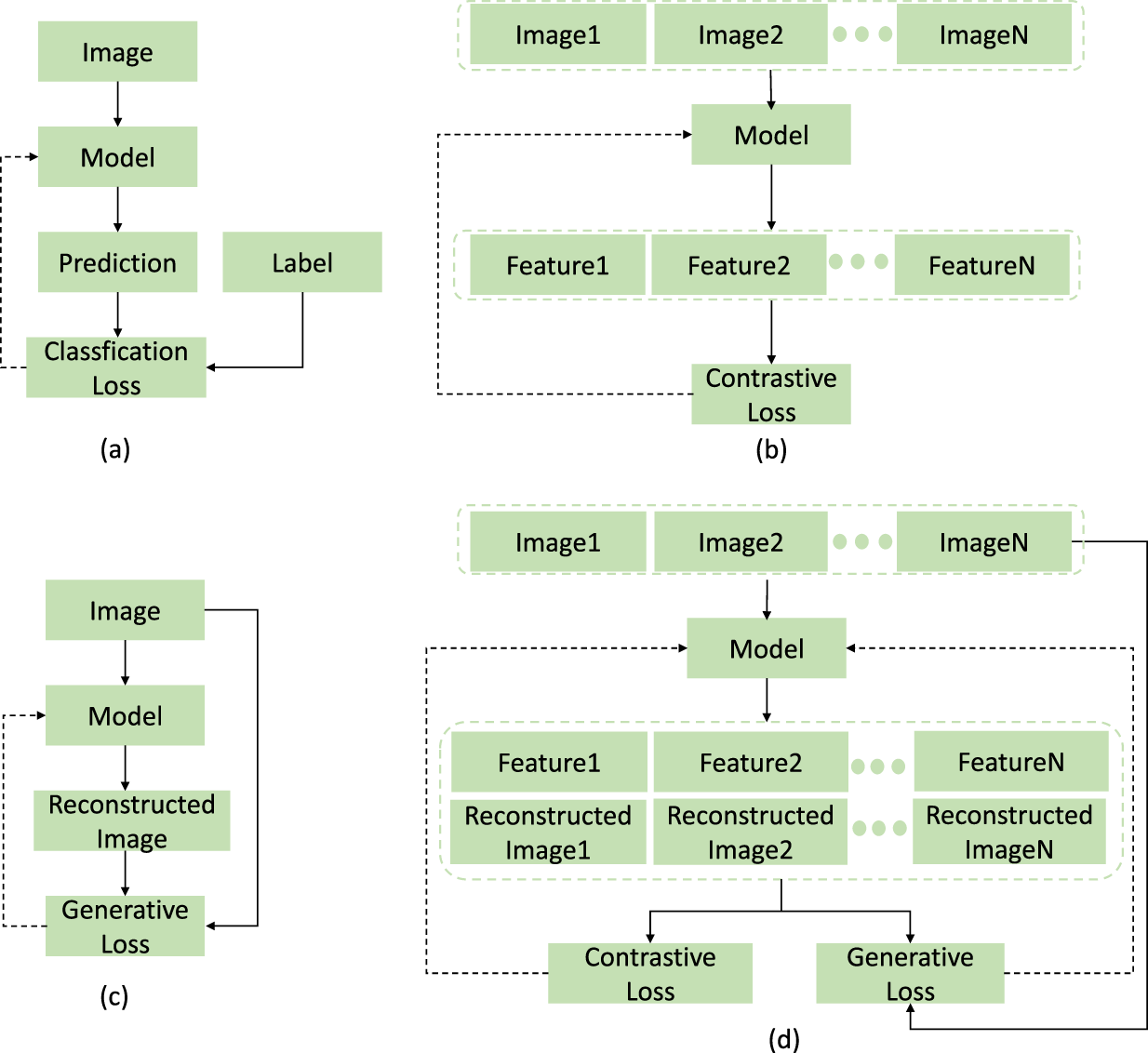
Supervised Learning Versus Contrastive Learning Versus Generative Learning Versus Self-Supervised Learning. “
While SSL has shown substantial potential, current pre-trained models face notable challenges when applied to FGIR tasks. First, in contrastive learning-based models, the choice of the level of difficulty of the training sample significantly impacts FGIR performance. Random pair selection can lead to overly simplistic training or, conversely, overfitting to complex samples. Some researchers employ strategies such as self-paced learning (Kumar et al., 2010) or hard negative mining (Schroff et al., 2015) to address this; however, these methods often increase computational complexity and training costs. Additionally, the application of self-paced learning in self-supervised pre-training remains in an early exploratory phase with limited findings. These strategies are generally suited for closed-set problems with pre-defined classes, making them less effective for the open-set nature of self-supervised tasks where only sample embeddings are available. Furthermore, contrastive learning-based models rely solely on image similarity to learn features, limiting their ability to capture contextual information critical for fine-grained detail in FGIR. In contrast, generative learning-based models focus on contextual information within image content but overlook inter-image similarity. Effective FGIR requires leveraging both intra-image contextual information and inter-image similarity. However, current self-supervised pre-training models lack effective integration of these two paradigms, which restricts their applicability for FGIR tasks.
To address these limitations, we propose a novel self-supervised pre-trained model tailored for FGIR. Our contributions are as follows: We introduce an adaptive sample selector (ASS) module that dynamically selects training sample pairs with varying difficulty levels based on the model’s learning progress. Unlike existing strategies, ASS efficiently selects samples of different difficulties without a significant increase in computational cost, thereby reducing the overall training cost while enhancing model performance. Its plug-and-play design allows easy integration into various image processing frameworks, making ASS a versatile tool for multiple tasks. We propose a novel SSL strategy that integrates contrastive and generative learning through a masking mechanism, as illustrated in Figure 1(d). This approach allows the model to leverage both contextual information within images (from generative learning) and inter-image similarities (from contrastive learning), leading to significantly enhanced feature extraction for FGIR tasks. Our model achieves new state-of-the-art results on challenging FGIR benchmarks, validating the effectiveness of our approach and demonstrating its superiority over existing FGIR methods.
The remainder of this paper is organized as follows: Section 2 provides a comprehensive review of related work on FGIR, self-supervised pre-trained models, and sample selection techniques in contrastive learning. Section 3 describes our proposed method, including the construction of the ASS module and the design of a SSL strategy tailored for FGIR. Section 4 presents experimental results and ablation studies, demonstrating the efficacy of our approach. Finally, Section 5 concludes the paper and explores potential directions for future research.
In this section, we review the related work on FGIR, self-supervised pre-trained models, and sample selection techniques in contrastive learning, highlighting key developments and challenges that motivate our work.
Fine-Grained Image Retrieval (FGIR)
FGIR focuses on retrieving images within the same subclass of a specific category, a critical task in computer vision. Traditional FGIR methods relied on hand-crafted features such as HOG (Yu et al., 2013), color histograms (Han & Ma, 2002), and SIFT (Lowe, 2004), often paired with traditional machine learning methods such as support vector machines (Suthaharan, 2016). However, these techniques struggle to capture the subtle distinctions required for FGIR tasks.
The advent of deep learning marked a significant shift in FGIR. CNNs can extract features at different levels, significantly improving retrieval performance (Wei et al., 2017). Supervised learning models, such as VGGNet and ResNet, leverage large labeled datasets to develop robust feature representations (He et al., 2016; Simonyan & Zisserman, 2014). Building on these networks, some FGIR methods explore attention mechanisms (Li & Ma, 2023; Zeng et al., 2024) to focus on discriminative image regions, while others integrate CNNs with metric learning (Duan et al., 2022; Yang et al., 2023; Zhang et al., 2024) to develop similarity measures tailored to FGIR’s unique challenges. Despite their success, these models are constrained by the need for annotated data, a limitation particularly pronounced in fine-grained categories due to the high cost and effort of labeling.
To relieve the annotation burden, several recent works explore SSL for FGIR. LCR (Shu et al., 2023) pools gradient-weighted class activation mapping (Grad-CAM) foreground responses as a common rationale before contrastive training and boosts recall over MoCov2. DMCAC (Trivedy & Latecki, 2024) aligns query–gallery similarity distributions via a divergence loss, narrowing the gap to supervised baselines. A2-SSL Hu et al. (2024) leverages asymmetric view augmentation and part-oriented dense contrast to learn compact hashing codes, while CMD (Bi et al., 2025) distills patch-crop cues into whole-image tokens, improving the retrieval recall rate. All the above methods rely on heuristic or fixed strategies to form positive/negative pairs and do not consider masked reconstruction. Our ASS schedules pairs from easy to hard and is combined with a masking branch, resulting in consistently higher retrieval accuracy without additional labels.
Self-Supervised Pre-Trained Models
To address the limitations of supervised learning, SSL has emerged as a viable alternative. Self-supervised models learn useful representations from unlabeled data by solving pretext tasks, enabling them to generalize effectively to downstream tasks. These models, which achieve state-of-the-art performance across diverse downstream applications, primarily fall into two categories: generative learning and contrastive learning models. Generative models, such as CAE (Chen et al., 2024), MAE (He et al., 2022), SimMIM (Xie et al., 2022), and DeepMIM (Ren et al., 2025), adopt a masked-image-modeling (MIM) objective in which random patches are removed and subsequently reconstructed. Recent evidence shows that MIM can benefit fine-grained tasks: SemMAE employs semantic-guided masking and boosts fine-grained recognition accuracy (Li et al., 2022), while BirdSAT leverages cross-view masked autoencoding to enhance bird-species retrieval (Sastry et al., 2024). Although these models capture rich contextual cues, they generally overlook inter-image similarity relations that are critical for retrieval. Contrastive learning models such as SimCLR (Chen et al., 2020), MoCo (Chen et al., 2021), and DINO (Caron et al., 2021) address this by comparing positive and negative samples, bringing similar features closer in the feature space while pushing dissimilar ones apart. However, contrastive models struggle to capture the fine-grained contextual information essential for FGIR, and their performance is often impacted by sample selection strategies.
Recent efforts attempt to combine generative and contrastive learning to leverage the strengths of both approaches, such as the iBOT model (Zhou et al., 2021). Despite these efforts, there remains a significant gap in effectively integrating these learning paradigms to meet the specific demands of FGIR. Firstly, the contrastive learning component does not pay sufficient attention to the strategic selection of training samples, which can lead to high training costs and suboptimal feature extraction. Additionally, current methods fail to balance the extraction of contextual and discriminative features, essential for accurate FGIR.
Sample Selection Techniques in Contrastive Learning
In contrastive learning, the selection of positive and negative pairs significantly impacts model performance. Simple pairs may result in learning only basic features, whereas overly challenging pairs can lead to overfitting and degraded performance. Hard negative mining and semi-hard negative selection techniques (He et al., 2020; Oh Song et al., 2017; Schroff et al., 2015) address these issues but often increase training complexity and cost. Some approaches apply self-paced learning Kumar et al. (2010), enabling the model to start with simpler samples and gradually tackle harder ones (Liu et al., 2023, 2022). However, these methods are unsuitable for SSL. First, they are generally based on closed-set problems with pre-defined classes, not applicable to SSL frameworks, where only sample embeddings are available (Franco et al., 2023). Secondly, they need to pre-define the sample difficulty evaluation and sample selection, which significantly increases computational complexity and training time. Additionally, they do not consider how to reasonably use hard samples for training, which is not conducive to improving the model’s learning ability (Ge et al., 2020).
In self-supervised pre-trained models, dynamic sample selection based on difficulty is relatively underexplored, yet it is especially needed for FGIR, where intra-class variance is high and inter-class variance is low. Effective sample selection strategies can significantly enhance the training efficiency and performance of self-supervised models, benefiting downstream tasks such as FGIR.
To address these gaps, we propose a self-supervised pre-training method tailored to FGIR tasks. Our approach effectively combines generative and contrastive learning, enabling models to extract fine-grained contextual and discriminative features during pre-training. Additionally, we introduce an ASS module to dynamically select training pairs based on difficulty level as the model’s training progresses, improving training efficiency and effectiveness without significantly increasing computational complexity. This method empowers the pre-trained model to develop discriminative fine-grained features, enhancing FGIR performance.
Proposed Method
Our self-supervised pre-training method for FGIR consists of two main stages: the ASS module and the SSL task. Firstly, the ASS module adaptively selects training sample pairs with varying levels of difficulty. By dynamically adjusting the difficulty of the selected pairs as training progresses, the module optimizes the learning process. This allows the model to efficiently capture fine-grained differences across images without significantly increasing training costs. Building on the pairs selected by the ASS, we design a novel SSL that integrates generative and contrastive learning. This enables the pre-trained model to simultaneously capture contextual information within images and similarity relationships across images, resulting in the extraction of discriminative features enriched with contextual details, enhancing its capability for FGIR tasks. The following subsections provide detailed explanations of these components.
ASS Module

Training SSL pre-trained models is resource-intensive in both computation and time. In contrastive learning, the choice of difficulty for positive and negative sample pairs significantly impacts the effectiveness and efficiency of model training. To address this, we propose an ASS module. The ASS dynamically selects positive and negative sample pairs with progressively increasing difficulty based on the training progress. As illustrated in Figure 2, we first pre-train an independent ASS network whose backbone is a lightweight ViT-S/16 optimized with a joint generative–contrastive objective (training strategy in Section 3.2). The network follows the standard ViT-S/16 configuration (12 transformer layers, six attention heads, and 384-d patch embeddings), and adds a 128-d projection head. It is trained with a 75% random-masking ratio, and the complete training recipe is listed in Section 4.1. This stage is inexpensive, yet it equips the encoder with strong discrimination. Once converged, the decoder is discarded and the encoder is frozen, becoming the feature extractor
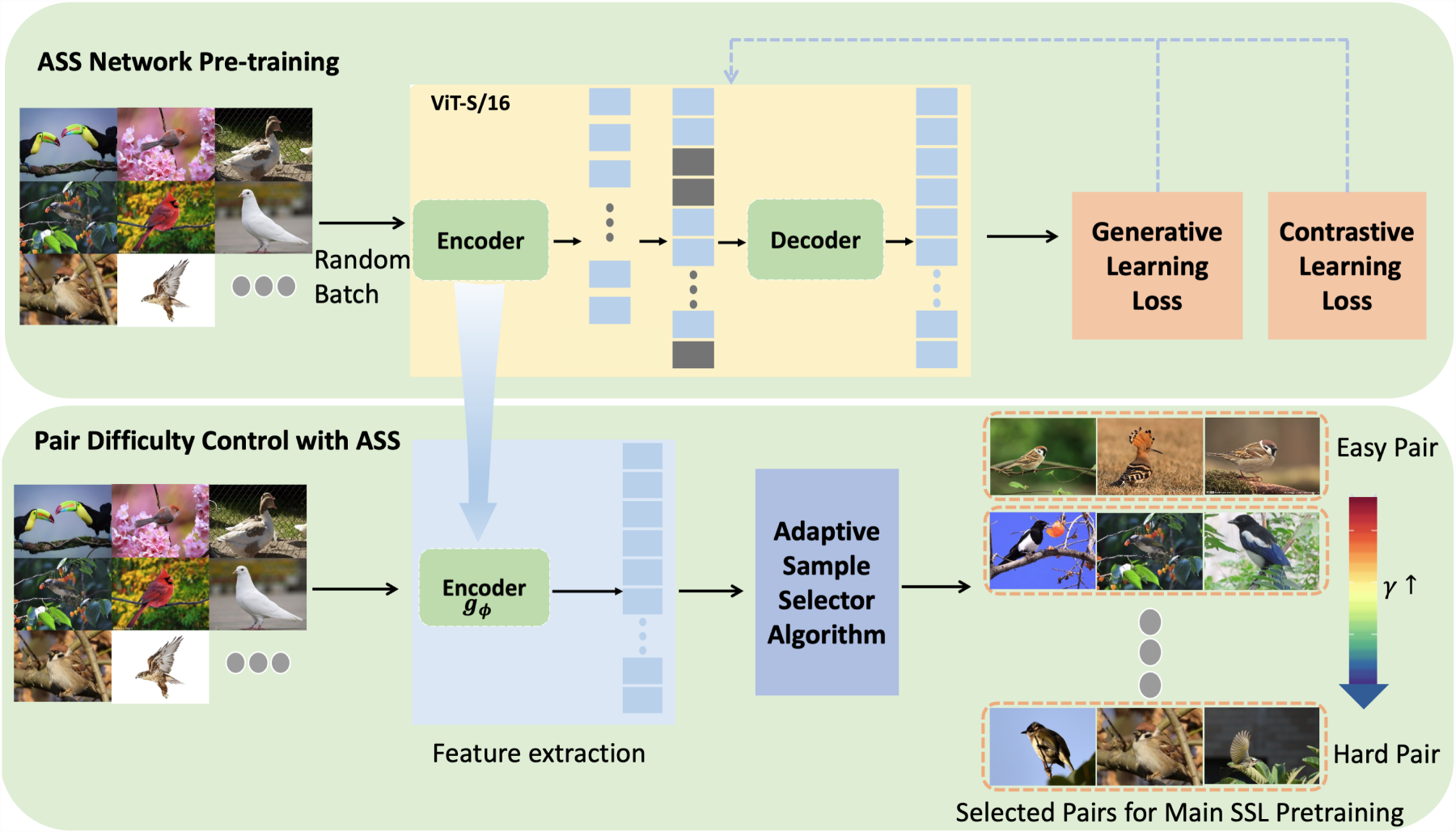
Top: ASS Network Is Self-Trained with a Lightweight ViT-S/16 Encoder–Decoder and Dual Objectives. Bottom: After Training, the Encoder
In Algorithm 1, the parameter
It is worth noting that, due to the small size of the ASS module, the cost associated with selecting candidate hard samples is significantly low. This process can be further optimized by pre-extracting the feature vectors for all data using the ASS. Consequently, during model training, each sample only needs to pass through the ASS once, effectively minimizing the computational and time costs of sample selection to nearly negligible levels.
Using Algorithm 1, the large-scale model is designed to learn from a broad set of easily distinguishable sample pairs during the early stages of training. This approach helps the model acquire foundational coarse-grained feature representations. As training progresses to later stages, the model transitions to learning from more challenging sample pairs, fostering a deeper understanding and acquisition of fine-grained feature representations.
With difficulty-aware training pairs supplied by ASS, we design a self-supervised regimen that tightly couples generative and contrastive learning (Figure 3). The synergy between these two objectives allows the network to recover global context while learning instance-level distinctions that are critical for FGIR.
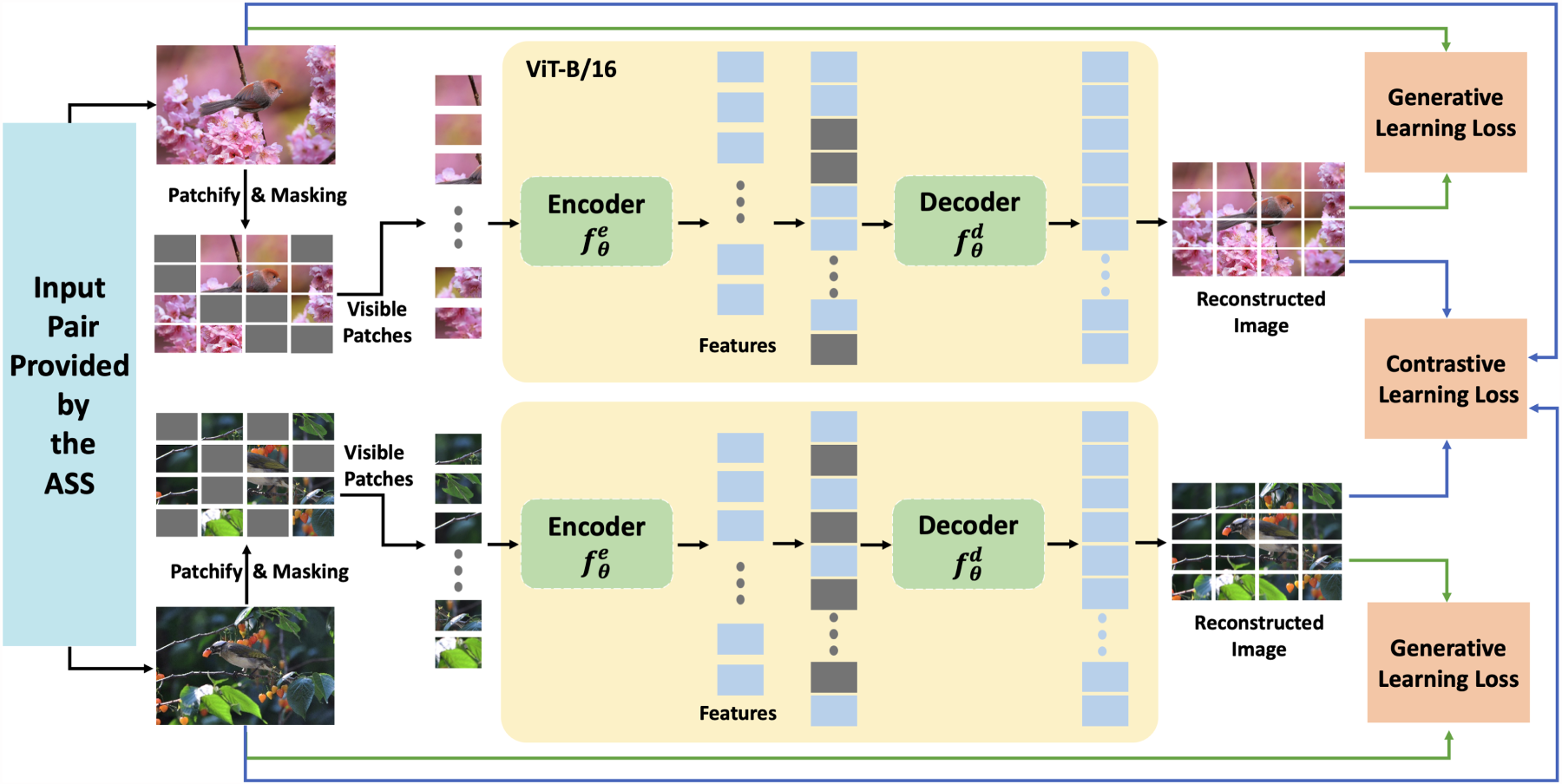
Dual-Objective Pre-Training Driven by Adaptive Sample Selector (ASS)-Selected Image Pairs. For Each Pair, We Patchify and Randomly Mask the Images, Encode the Visible Tokens with a ViT-B/16 Encoder
Given an image 



This process enables the model to learn both local and global contextual relationships, crucial for FGIR tasks. To enhance the synergy between generative and contrastive learning, we use shared and auxiliary representations. The shared representation, generated by the encoder
Masking of patches compels the encoder to recover missing details from the visible context, thereby establishing long-range part–whole dependencies that complement local texture cues. Such holistic reasoning is particularly valuable in fine-grained categories where discriminative regions (e.g., a bird’s beak or a car emblem) occupy only a small fraction of the image. MIM has already proved effective on fine-grained benchmarks: MAE achieves competitive transfer accuracy without labels (He et al., 2022), and the hybrid iBOT framework further improves CUB-200-2011 performance by combining masking with self-distillation (Zhou et al., 2021). Building on these insights, our design unifies MAE-style masking with an adaptive contrastive schedule, allowing the network to learn global context and progressively sharpen subtle inter-class distinctions.
The contrastive learning component is designed to enhance the discriminative capability of image features. Denote the reconstructed image as 
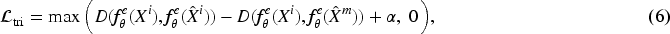
To further enhance representation learning, we introduce a dual contrastive objective that maximizes the similarity between the encoder’s shared representation and the decoder’s auxiliary representation for the same image. This intra-image contrastive loss 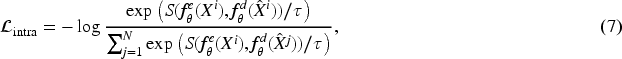
We unify the above objectives into a single cost function:

Implementation Details
We use ImageNet as the pre-training dataset for our self-supervised model. Our framework employs a two-tiered backbone strategy for efficiency. The main self-supervised model, which learns the final feature representations, is built upon a ViT-B/16 backbone (Dosovitskiy et al., 2020). For the lightweight ASS module, whose purpose is the efficient pre-selection of training pairs, we utilize a smaller ViT-S/16 backbone, where “/16” represents a patch size of 16 pixels. This design significantly reduces the computational cost of the adaptive sampling process. During pre-training, we employ random cropping and random horizontal flipping as the only data augmentation techniques. We set the batch size to 64. The key hyperparameters are set as
For FGIR-specific fine-tuning, we further optimize the ViT-B/16 model using AdamW. The input resolution is increased to
Datasets
We evaluate the effectiveness of our self-supervised pre-training model on four widely used FGIR benchmark datasets: CUB-200-2011 (Wah et al., 2011), a fine-grained bird image dataset with 200 species; Cars-196 (Krause et al., 2013), which contains images of 196 cars with varying visual similarities; Stanford Online Products (SOP; Oh Song et al., 2016), featuring over 22,000 product categories from online stores; and In-Shop Clothes Retrieval (Liu et al., 2016), a dataset focused on fashion item retrieval with complex intra-class variations across 11,735 categories. For dataset partitioning, we adhere to the splits widely adopted in prior works (An et al., 2023; El-Nouby et al., 2021; Patel et al., 2022). To ensure consistent evaluation, we use the Recall@K metric, a standard measure for retrieval tasks, enabling fair comparisons with state-of-the-art methods.
Comparison With State-of-the-art Methods
We compare our approach with three categories of state-of-the-art methods: Supervised FGIR methods, including AMCICIR (Li & Ma, 2023), SGSL (Yang et al., 2023), IRTr (El-Nouby et al., 2021), DVF (Jiang et al., 2024), and RS@k (ViT-B/16, supervised ImageNet-1k baseline;Patel et al., 2022); and self-supervised pre-trained models, including SimCLR (Chen et al., 2020), SwAV (Zhu et al., 2020), DINO (Caron et al., 2021), MoCo v3 (Chen et al., 2021), MAE (He et al., 2022), CAE (Chen et al., 2024), iBOT (Zhou et al., 2021), and DeepMIM (Ren et al., 2025). These self-supervised pre-trained models are further categorized by their objectives—contrastive learning, generative learning, or a combination of both. And recent self-supervised models tailored for FGIR, including LCR (Shu et al., 2023), DMCAC (Trivedy & Latecki, 2024), and CMD (Bi et al., 2025). For fairness, whenever we report a supervised ImageNet-1k baseline (e.g., RS@k), we fine-tune it with exactly the same ViT-B/16 backbone, data-augmentation pipeline,
Overview of Representative State-of-the-art Methods Used in Comparative Experiments.
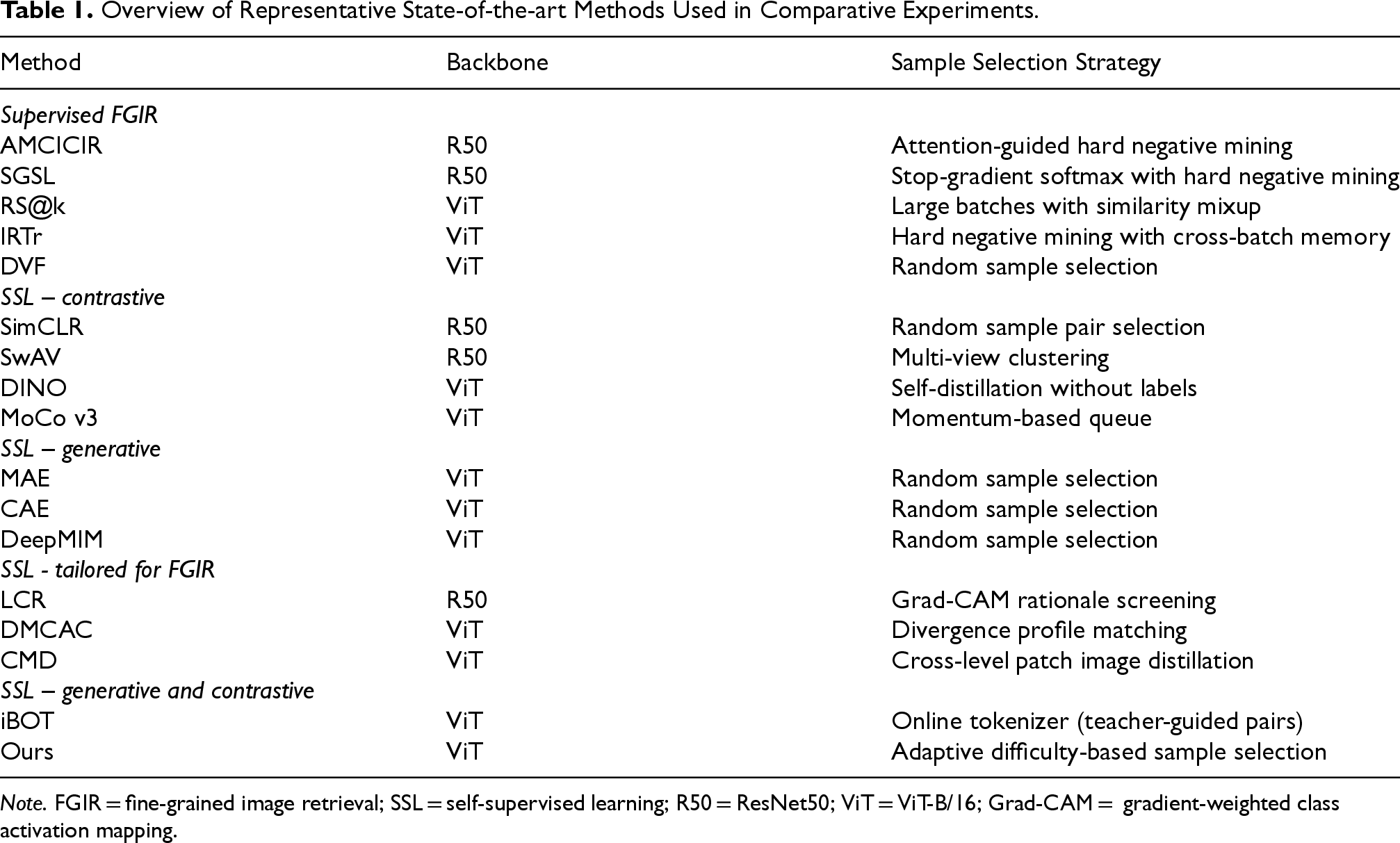
Overview of Representative State-of-the-art Methods Used in Comparative Experiments.
Note. FGIR = fine-grained image retrieval; SSL = self-supervised learning; R50 = ResNet50; ViT = ViT-B/16; Grad-CAM = gradient-weighted class activation mapping.
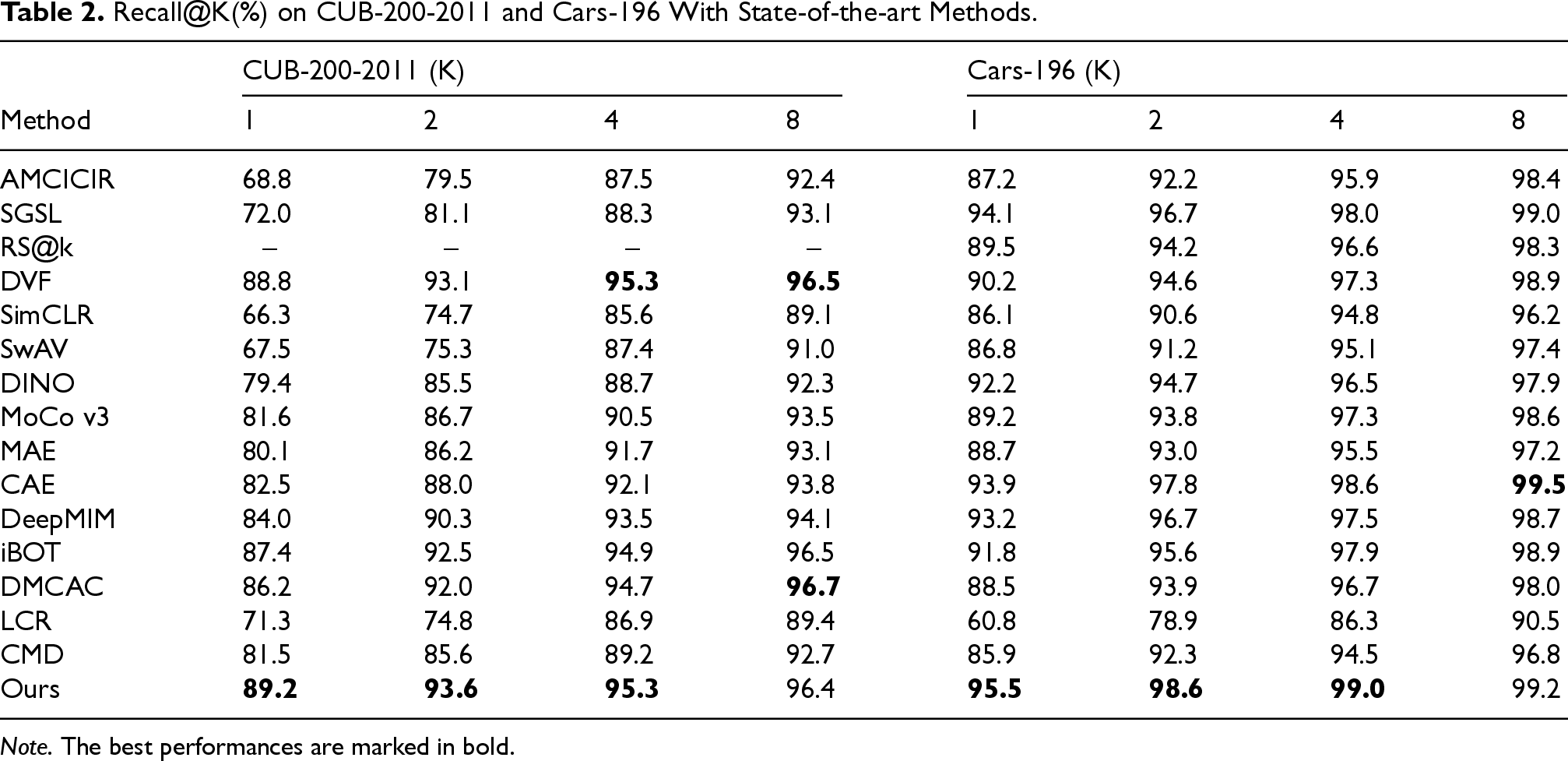
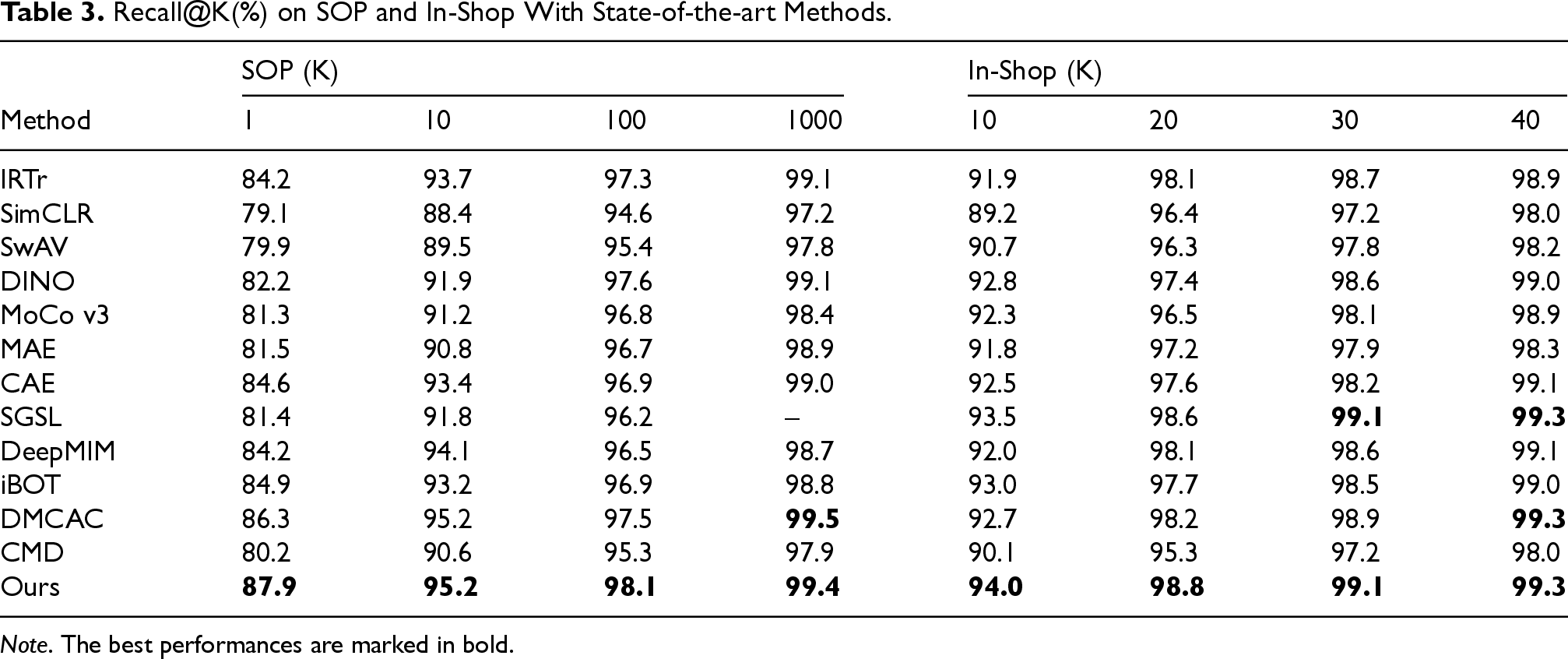
Table 2 shows the experimental results on CUB-200-2011 and Cars-196 datasets, while Table 3 presents the experimental results of these methods on SOP and In-Shop datasets. From these experimental results, we can observe that with the improvement of SSL, self-supervised pre-trained models can be effectively applied to the FGIR tasks. And, they have the potential to outperform FGIR methods using supervised pre-training. Under matched conditions (ViT-B/16 backbone, ImageNet-1k pre-training, and identical fine-tuning), the self-supervised DeepMIM model outperforms the supervised baseline RS@k by
Recall@K(%) on CUB-200-2011 and Cars-196 With State-of-the-art Methods.
Note. The best performances are marked in bold.
Recall@K(%) on SOP and In-Shop With State-of-the-art Methods.
Note. The best performances are marked in bold.
Moreover, our model, which combines contrastive and generative learning, consistently outperforms methods relying on a single paradigm. For instance, on the SOP dataset, our method achieves an R@1 of 87.9%, surpassing contrastive-only models such as SimCLR (79.1%) and MoCo v3 (81.3%), as well as generative-only models such as MAE (81.5%) and CAE (84.6%). This demonstrates the strength of integrating contrastive and generative approaches, enabling the model to capture both inter-image similarities and intra-image contextual details, leading to superior feature learning and retrieval performance. Furthermore, the ASS module plays a critical role in enhancing retrieval performance. On Cars-196, our model achieves an R@1 of 95.5% and an R@2 of 98.6%, outperforming strong competitors such as CAE (R@1 of 93.9%) and DeepMIM (R@1 of 93.2%). By dynamically adjusting sample difficulty during training, ASS ensures the model learns from a balanced mix of simple and challenging examples, improving generalization and overall performance across datasets.
We further benchmark against three very recent methods specifically designed for fine-grained retrieval—LCR, DMCAC, and CMD—and the hybrid SSL baseline iBOT. iBOT, which unifies masked reconstruction with teacher–student distillation, achieves Recall@1 values of 87.4% on CUB-200-2011 and 91.8% on Cars-196. These figures remain 1.8 and 3.7 percentage points below those of our model, respectively, indicating that adaptive difficulty sampling offers additional benefits beyond online token distillation. On the large-scale product datasets SOP and In-Shop, iBOT trails our approach by 3.0–4.0 percentage points, reinforcing the same observation. Compared with the most recent FGIR-oriented method, DMCAC, our model improves Recall@1 by 3.0 percentage points on CUB, 7.0 percentage points on Cars, and 1.6 percentage points on SOP. CMD and LCR exhibit substantially lower performance, emphasizing their limited scalability to transformer backbones.
In summary, these experimental results decisively demonstrate that our self-supervised method surpasses state-of-the-art supervised methods in FGIR. The integration of contrastive and generative learning paradigms proves superior to relying on a single learning mode, while the adaptive difficulty-based sample selection strategy further enhances performance, establishing our model as a new benchmark in FGIR tasks.
To assess the contribution of individual components of our self-supervised pre-training method, we conducted a series of ablation experiments on the CUB-200-2011 dataset. The components examined include the ASS module, the model backbone, the use of random masking, and the loss weights
The ablation studies validate the effectiveness of each key component in our self-supervised pre-training framework. Specifically, the integration of the ASS module, the adoption of the ViT-B/16 backbone, the use of random masking, and the tuning of the loss weight
Ablation Study of Adaptive Sample Selector (ASS).

Ablation Study of Adaptive Sample Selector (ASS).
Note. The best performances are marked in bold.
Ablation Study of Model Backbone.

Note. The best performances are marked in bold.
Ablation Study of Weights
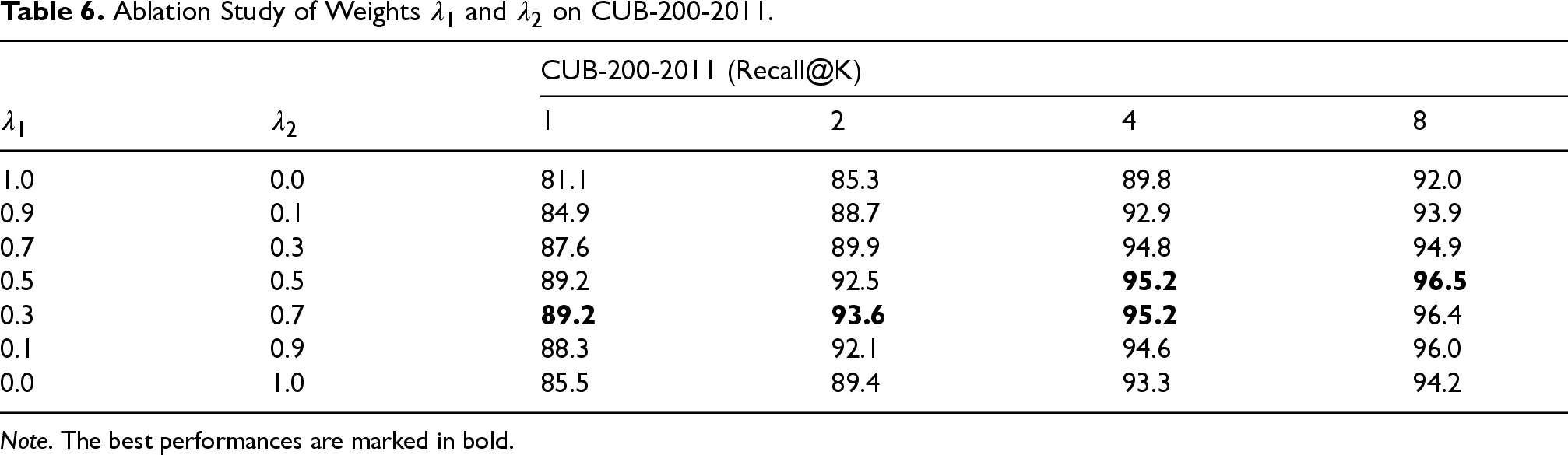
Note. The best performances are marked in bold.
Ablation Study of Random Masking.

Note. The best performances are marked in bold.
To evaluate the focus and attention mechanisms of our model, we generated feature heat maps for images in the CUB-200-2011 dataset, as shown in Figure 4. These heat maps demonstrate how different learning configurations influence the model’s ability to capture fine-grained details that are essential for accurate image retrieval.

Feature Heat Maps Comparing Different Learning Configurations on the CUB-200-2011 Dataset. Each row Represents a Different Bird Species, With Columns Showing the Original Image, Only Contrastive Learning, Only Generative Learning, and our Proposed Method.
The figure is organized into five columns for comparison, as described below. The first column displays the original bird images. In the second column, the results of using only contrastive learning are shown. The heat maps reveal that the model’s attention is scattered and only partially focused on key features of the birds. This limited attention reduces the model’s ability to capture fine-grained details effectively, leading to suboptimal retrieval performance. The third column illustrates the effects of applying only generative learning, where the heat maps display broader and more continuous attention across the bird’s body. However, this approach lacks a distinct focus on discriminative features, such as the beak or unique plumage patterns, which are crucial for distinguishing between visually similar bird species. The fourth column highlights the results of our proposed method, which combines contrastive learning, generative learning, and the ASS module. The heat maps produced by this configuration demonstrate clear, consistent, and highly focused attention on critical areas, such as feather texture, color patterns, and specific body parts such as the beak and wings. This focused attention reflects the model’s ability to dynamically adjust sample difficulty through the ASS, thereby enhancing feature learning and enabling the identification of subtle distinctions essential for FGIR tasks.
The comparison of heat maps across these configurations highlights the advantage of our method. By integrating contrastive and generative learning with adaptive sample selection through the ASS, our approach achieves superior focus on discriminative regions, thereby enhancing the model’s ability to capture essential fine-grained details for image retrieval tasks.
This study presents a novel self-supervised pre-training framework specifically tailored for the challenging task of FGIR. Traditional FGIR approaches, which rely heavily on labeled datasets, are constrained by scalability and cost limitations, hindering their real-world applicability. To address these challenges, we propose a framework that combines an ASS module with an integrated learning strategy that synergizes contrastive and generative learning. The ASS module plays a critical role in dynamically selecting training samples of varying difficulty, enabling the model to focus on learning discriminative features progressively. This dynamic sample selection not only enhances the learning process but also maintains computational efficiency, making the approach practical for large-scale applications. Additionally, the integration of contrastive and generative learning provides the model with the ability to capture both intra-image contextual details and inter-image similarities, resulting in robust and discriminative fine-grained feature representations. Extensive experimental results on widely used FGIR benchmarks, including CUB-200-2011, Cars-196, SOP, and In-Shop Clothes Retrieval, demonstrate that our framework achieves state-of-the-art performance. By consistently outperforming existing supervised and self-supervised methods, our approach highlights the power of SSL for FGIR tasks. Furthermore, the framework significantly reduces dependence on costly labeled data, offering a scalable and cost-effective solution for fine-grained image analysis.
The ASS module proposed in this study holds promise for a broader application in other image processing tasks, where it could improve training efficiency by dynamically adjusting sample difficulty. Furthermore, the training approach and integrated learning strategy presented here can be generalized to various fine-grained image-related tasks, extending the impact of this work beyond the FGIR. Future research can explore these applications and investigate further improvements in SSL pre-trained techniques to reduce reliance on labeled data while advancing model performance.
Footnotes
Acknowledgments
We would like to express our sincere gratitude to colleagues who participated in discussions and offered valuable suggestions.
Author Contributions
Xiaoqing Li conceived and designed the experiments, performed the experiments, analyzed the data, performed the computation work, prepared figures and tables, reviewed drafts of the article, and approved the final draft. Ya Wang conceived and designed the experiments, analyzed the data, reviewed drafts of the article, and approved the final draft.
Ethical Considerations
This study did not involve any human participants, animal subjects, or sensitive data, and therefore did not require ethical approval.
Consent to Participate
No human participants were involved in this study; informed consent was not required.
Consent for Publication
This study does not include any individual person’s data in any form; therefore, consent for publication is not required.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Capital University of Economics and Business (Project No. XRZ2022065). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The datasets used in this study are publicly available: iCartoonFace: https://github.com/luxiangju-PersonAI/iCartoonFace?tab=readme-ov-file#Dataset CIFAR-100: https://pytorch.org/vision/stable/generated/torchvision.datasets.CIFAR100.html Flowers102: https://pytorch.org/vision/stable/generated/torchvision.datasets.Flowers102.html Stanford Cars: https://pytorch.org/vision/stable/generated/torchvision.datasets.StanfordCars.html