
Abstract
Continuous learning of object affordances in a cognitive robot is a challenging problem, the solution to which arguably requires a developmental approach. In this paper, we describe scenarios where robotic systems interact with household objects by pushing them using robot arms while observing the scene with cameras, and which must incrementally learn, without external supervision, both the effect classes that emerge from these interactions as well as a discriminative model for predicting them from object properties. We formalize the scenario as a multi-view learning problem where data co-occur over two separate data views over time, and we present an online learning framework that uses a self-supervised form of learning vector quantization to build the discriminative model. In various experiments, we demonstrate the effectiveness of this approach in comparison with related supervised methods using data from experiments performed using two different robotic platforms.
1. Introduction
One of the fundamental enabling mechanisms of human and animal intelligence- and equally, one of the great challenges of modern-day robotics- is the ability to perceive and to exploit environmental affordances [13]. To recognize how to interact with objects in the world, that is to recognize what types of interactions they afford, is tantamount to understanding cause and effect relationships; moreover, from what we know of human and animal cognition, practice and experience help forge a path towards such understanding. This is clear from early childhood development. Through countless hours of motor babbling, children gain a wealth of experience from basic interactions with the world around them, from which they are able to learn basic affordances and, gradually, more complex ones. This is indicative of a continuous learning process involving the assimilation of novel concepts over time, though it is not yet evident precisely how this learning process proceeds. Consequently, implementing such capabilities in a robot is no trivial matter. This is an inherently multi-disciplinary challenge, drawing on such fields as computer vision, machine learning, artificial intelligence, psychology, neuroscience, and others.
For this paper, we approached the problem by using real robotic systems, as depicted in Figures 1 and 2, to perform experiments involving simple push manipulations on household objects. This allowed us to implement and explore the main idea behind our approach to object affordance learning, as visualized in Figure 3. Cameras record images, video and 3D data of these object interactions from which computer vision algorithms extract interesting features, separated into two data views: object features extracted prior to interaction and effect features extracted during and after interaction. These features are used as data for a machine learning algorithm; a self-supervised multi-view online discriminative learner that dynamically forms class clusters in one data view that are used to drive supervised learning in another.

An object affordance learning experimental setup using a Katana arm, a Bumblebee stereo camera and a Flea RGB camera

A second experimental setup using a KUKA-LWR arm, a BarrettHand and a Microsoft Kinect RGB-D sensor
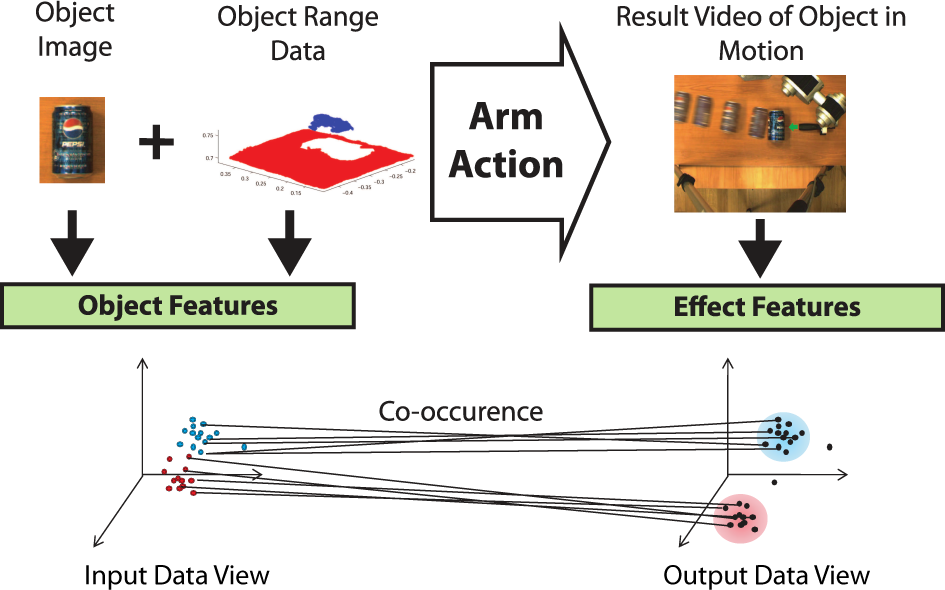
Main idea of our object affordance learning framework
Our main objective in designing this algorithm was that it would enable our robot, when presented with objects, to gradually learn how they behave from experiences interacting with them. When presented with a new object, the algorithm should be able to predict, from object features, how that object will behave in terms of possible effects of actions grounded in effect features. Given feature data from such interactions, we wanted the algorithm to be able to form its own affordance models online dynamically from a naive starting point. To that end, our main requirements were that it adhere to the following learning constraints:
The algorithm should be capable of incremental learning and should be able to commence learning from scratch without access to an initial batch of training data. This is desirable since, given the complexity and diversity of real-world environments, robots often encounter entirely novel objects and scenarios not contained in any prior training data.
Since the robot designer may not know in advance what types of objects the robot will encounter or how they will behave when the robot interacts with them, task-specific prior object models should be avoided in favour of providing the system with a sufficiently rich sensory feature set from which to derive its own models.
The algorithm should learn autonomously/unsupervised, such that, as the robot gains experience encountering different objects, acting upon them, and observing the effects, the exploration and exploitation aspects of learning would be interleaved and proceed automatically in the following ways:
Affordance classes grounded in object effect features (e.g., motion features observed both during and after object interaction) would be derived based on qualitative differences between data clusters.
Object features (e.g., shape features observed prior to interaction) that are most relevant for affordance class prediction, would be identified.
Relationships between affordance classes and the predictive object features would be modeled.
Taken together, the above constraints may be regarded as guiding principles for developing a type of self-supervised online discriminative learning, an idea that forms the core of the learning approach in this paper.
Much of the research work related to the present work stems from the domain of cognitive robotics. Perhaps the most closely related work in the literature with respect to affordance learning to our work is by Fitzpatrick et al. [11]. The authors trained a humanoid robot to recognize “rolling” affordances of four household objects using a fixed set of actions to poke the objects in different directions, as well as simple visual descriptors for object recognition. There are two main differences between their method and ours. Firstly, in [11, 22], the feature associated with the rolling direction affordance was predetermined, whereas in our system, the learning algorithm is provided with a number of different output features and it must determine for itself the affordance classes within that feature space. Secondly, their system used object recognition to identify the affordances of individual objects, whereas our system determines the affordance class of objects (grounded in object effect features) based, not on their individual identity, but on input features representing a broad set of general object properties (e.g., shape).
Saxena et al. [31] used the same Katana robotic arm used in the present work (see Sec. 3.1) to attempt to grasp novel objects based on a probabilistic model trained on synthetic images of various other objects labelled with grasp points. Later, Detry et al. [7] tackled a similar problem and, rather than training their learning algorithm on synthetically generated objects, they enabled an autonomous robotic arm to grasp objects in an exploratory manner, trained on these interactions with real objects. They described a method for learning object grasp affordance densities, i.e., continuous probabilistic models of object grasp success over object-relative grasp poses. In both of these works the two possible affordances were specified in advance: graspable or non-graspable. The system presented in this paper, by comparison, generates its own affordance classes through interaction with objects. The authors of [35] worked with a robotic system consisting of a range scanner and a robotic arm that learned affordances of objects in a table-top setting using an unsupervised two-step approach of effect class discovery and discriminative learning for class prediction. They also applied similar techniques to a scenario involving self-discovery of motor primitives and learning grasp affordances [36].
Our learning approach is based on vector quantization via the use of self-organizing maps (SOMs) [17], which have been employed in past works on affordance learning in various different ways [6, 26, 32]. In [6], a SOM was applied to a simulated mobile robot learning how to prosper in an artificial environment by exploiting affordances of objects with survival values, such as nutrition and stamina. The SOM was used to cluster visual sensor data in the input space where nodes were assigned weights based on the success or failure of actions. In our case, by comparison, SOMs are used in two separate feature spaces in a multi-view learning configuration similarly to recent work by Sinapov et al. [32], where SOMs were used to cluster data in both the proprioceptive and auditory sensory streams of a humanoid robot while performing performing various exploratory behaviours on objects. In [24], the authors used a humanoid robot to push, grasp and tap objects on a table as well as a Bayesian network to form associations between actions, objects and effects. Though the goals were similar to those expressed in this paper, the learning method is less amenable to online learning, as a certain amount of data must be gathered initially to find categories before the network can be trained.
In the next section, we give an overview of our proposed learning algorithm, which was developed to adhere to the learning constraints outlined previously. The remainder of the paper consists of Section 3, where we review the robotic systems we used for performing experiments, Section 4, where we describe the experiments themselves, and Section 5, where we provide concluding thoughts.
2. Self-supervised Multi-view Online Learning
Multi-view learning [33], sometimes also referred to using the terms ‘cross-modal learning’, ‘multi-modal learning’ or ‘co-clustering’ [9, 2, 1, 4, 8] is an area of machine learning where, rather than having learning performed on data in a single feature space, it is instead performed over multiple separate feature spaces, otherwise known as ‘data views’ or ‘modalities’, in which data co-occur. Given this common theme, the learning goal may otherwise differ depending on the particular context [33]. In our scenario, object properties such as shape features define the feature space in one data view, the input space X ⊆ ℝ n , whereas object effects under interaction, such as motion features and changes in shape features, define the feature space in another data view, the output space Y ⊆ ℝ n . We assume that matching data co-occur in each of them.
Our learning goal is to find significant clusters in Y that may be projected back to X and used as class labels to train a classifier, thus forming a mapping

where the γ jk are weights that are used to record the level of data co-occurrence between nearest-neighbour prototypes in each of the codebooks.
Thus, we aim to find significant clusters of prototypes in the output view (effect features) which we dub class clusters and which we treat as classes to be used for discriminative learning in the input-view (object features). However, these clusters are not fully-formed during online codebook training; thus, we use the information contained within the codebook network to infer their development and to guide the training process until the clusters are derived outside of training during classification. Codebook training within the input view, therefore, uses two learning phases. The first phase (cf. Section 2.1), involves unsupervised clustering of the prototypes such that the data distributions are roughly approximated. The second phase (cf. Section 2.2), involves self-supervised discriminative learning such that the positions of the prototypes are refined for classification purposes using cross-view co-occurrence information. The classification process, which may be applied at any given time-step during training and involves clustering the output view prototypes to discover the class clusters, is described below in Section 2.3. Finally, in Section 2.4, we describe feature relevance determination mechanisms that allow the algorithm to both infer and exploit the most relevant features in each view for both class discovery and class prediction.
2.1 Training Phase 1: Unsupervised Learning
For the first phase of codebook training, we employ the SOM algorithm [17] to perform unsupervised vector quantization of the prototypes in W and V. We describe this learning procedure with respect to input view codebook W only without loss of generality; the same algorithm is applied to output codebook V. The prototypes in W partition the input space into Voronoi regions or receptive fields such that each prototype represents those data vectors for which it is the nearest neighbour, and that thus fall within its receptive field as dictated by the squared Euclidean distance:

in which case the definition of the receptive field for prototype
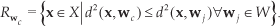
In (2) above, the λ i are weighting factors for each dimension, which allows for the possibility of an adaptive distance function for the purposes of feature relevance determination, as discussed later in Section 2.4.
Given
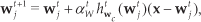
where ht is a weighted neighbourhood function (cf. (5) below) for the nearest-neighbour prototype
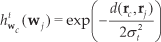
where the vectors

which is the conditional probability of the activation of prototype

to be the discrete spatial probability density function of the activation of codebook W given
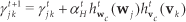
where aHt refers to a learning rate for the co-occurrence mapping, which may be specified differently from the learning rates for the individual codebooks.
2.2 Training Phase 2: Self-supervised Learning
After the unsupervised training phase has proceeded for long enough to provide a robust Hebbian mapping the self-supervised training phase may be initiated. In this phase the output view codebook continues to be trained with the usual SOM algorithm, while the input view codebook switches to a modified version of learning vector quantization (LVQ) [17] training that employs a cross-view probabilistic supervision signal to improve its discriminative model. To develop this idea, we make use of two additional theoretical concepts, cross-view Hebbian projection and the Hellinger distance, which we discuss next. Phase 2 training is illustrated in Figure 4.

Visualisations of the self-supervised training rules from (12). The first figure shows the case when
2.2.1 Cross-view Hebbian Projection
The Hebbian co-occurrence mapping can be used to map the relationship between the prototypes in the different views, and one way to achieve this is through the use of Hebbian projection [4, 5]. A Hebbian projection is a spatial probability distribution over a codebook and is the result of selecting a prototype in one codebook and normalizing the Hebbian co-occurrence weights that map from it onto another codebook. This is a useful tool that allows us to measure how one data view looks from the perspective of another in terms of past co-occurrences of data. Taking our two data view codebooks W and V as before, given prototype

to be the conditional probability of data co-occurring in the receptive field of prototype

2.2.2 Measuring Similarity Between Data Views
Using the definition from [12], for a countable state space Ω and given probability measures μ and v:
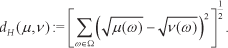
We use this to create a heuristic that allows us to measure the similarity between prototypes in the input view codebook and the output view codebook with respect to the Hebbian mapping. The Hellinger distance takes values in the bounded interval [
2.2.3 Self-Supervised Learning Vector Quantization
In traditional LVQ training [17], prototypes are given fixed class labels a priori. Subsequently, as training samples with accompanying class labels are encountered, the nearest neighbour prototypes are updated according to a set of update rules. If the prototype class label matches that of the training sample, the prototype vector is moved towards the sample. If the labels do not match, the prototype vector is moved away from the sample. In the modified form of LVQ we present here, we do not label the prototypes a priori. Given co-occurring (

where, aLt is the LVQ learning rate and, assuming
2.3 Cross-View Classification
For cross-view classification, we require a mapping f : ℝ m → L (V) that maps input view samples to class labels, where L () is some labelling function. Our approach to this is as follows. After clustering the data via vector quantization using the prototypes in each of the separate data views, we wish to form class clusters by clustering the prototypes themselves in the output view which we treat as classes that may be projected back to the input view prototypes as class labels. The means for achieving this are described in the following sub-sections.
2.3.1 Class Discovery
In order to find the class clusters of prototypes, we treat the prototype vectors as data points and employ traditional unsupervised clustering specifically, the k-means clustering algorithm. One issue with regular k-means is that k must be selected in advance. It is possible, however, to augment the algorithm such that k is selected automatically. We achieve this by running k-means for multiple different values of k, then evaluating each of the clusterings using multiple different cluster validity indices, and finally selecting the k*-value which is most consistently selected as the best value by these. The validity indices we use are Davies-Bouldin [3]; Dunn [3]; Calinski-Harabasz [10]; Krzanowski-Lai [10]; and the silhouette index [3]. Thus, given multiple potential k-clusterings K1V, …,KkV,… as generated by k-means, e.g. for k = 1,…,10, where
2.3.2 Cross-View Class Projection
For cross-view classification, we require a mapping f : ℝ
m
→ L (V) that maps input space samples to class labels, where L () is some labelling function. To realise this labelling function, the

Cross-view classification
By summing the posterior probabilities P(
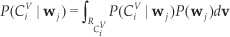

where

that labels the input view prototypes on that basis and we may then also define class clusters
2.3.3 Class Prediction
Given an input space test sample

2.4 Feature Relevance Determination
Some feature dimensions can prove to be more relevant than others, both for class discovery and class prediction, and determining the extent of their relevance and exploiting this information can improve accuracy. To this end, we make use of the Fisher criterion score, a concept that has been shown to be useful for feature relevance determination in learning vector quantization settings in previous work [25].
2.4.1 Input Feature Relevance
We exploit the positioning of the prototypes in the input feature space to estimate Fisher criterion scores for the input dimensions. These scores, once normalised, are used as the λ i weighting factors in (2) for an adaptive distance function that accounts for dimensional relevance with respect to classifier output. To summarise this, the Fisher criterion score Fi(X) may be estimated for the i-th dimension of X as
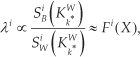
where the λ i are assigned to normalized values of the fractional term, of which

is the estimated between-class variance over the i-th dimension summed over each class c = 1,…,k*, where M and Mc are the cardinalities of the entire set of prototypes W and the c-class prototypes CcW respectively, and

are weighted means over the i-th dimension of the prototypes in W and CcW respectively, where pj is a weighting factor that is proportional to the number of times prototype

is the estimated within-class variance over the i-th dimension.
2.4.2 Output Feature Relevance
The obvious application of the Fisher criterion score lies in the input space where, after a given point in training when class prediction is attempted, the class clusters discovered in the output space are projected onto the input space prototypes as class labels, thereby making the class information available a priori. However, we also make use of it in the output space to augment the class discovery process. In the output space, even though the class cluster structure is initially unknown, it is still possible to select features that are more likely to be relevant to forming good cluster hypotheses. Firstly, given i, we split the i-th dimension of V into multiple histogram partitions
3. Robot and Vision Systems
We used two different experimental platforms for our experiments. Section 3.1 below gives an overview of each of these setups, after which Section 3.2 discusses the object push actions, while Sections 3.3 and 3.4 describe our visual feature extraction implementations for object features and effect features respectively. The feature choices were motivated by the types of affordances we intended on studying in our experiments: rolling and translating affordances with the first platform using both flat and curved-surfaced objects, and rolling, translating and toppling affordances in experiments with the second platform using both flat-surfaced and spherical objects.
3.1 Experimental Platforms
In the first setup we used a 5-DOF Neuronics Katana 6M robotic arm for manipulation, as well as two Point Gray Research cameras for vision- the Flea monocular camera and the Bumblebee 2 grayscale stereo camera, which recorded images, video and 3D point clouds from range data. The arm was mounted on a flat wooden table and was made to produce linear pushing motions via the use of a modified version of the Golem [18], control software for the Katana arm. Further details are described in [27]. In the second setup, as depicted in Figure 2, a 7–DOF KUKA-LWR with an attached 3–fingered Barrett Hand was used for object push interactions, while a Microsoft Kinect RGB-D sensor was used to gather 3D point clouds of the scene. The Point Cloud Library (PCL) 2 was used to extract and manipulate object clouds from the resulting data.
3.2 Object Push Actions
Fixed robot arm pushing actions were used in both of the experimental setups, with objects being placed at predefined start positions through which the push action trajectories would intersect. Theoretical models of object affordances are often approached in the literature [29, 24] as being ternary relationships between objects, actions and effects, and although we restricted the action component in this way, our focus in this paper was on learning the relations between the other two components. Even when operating under such experimental assumptions, the use of a variety of objects in various configurations in the experiments presented in this paper nevertheless resulted in reasonably diverse object effects, as illustrated in Figure 17. In a separate study [28], we relaxed this restriction and placed the emphasis on how information from varied push actions may be incorporated into the learning framework, something that is discussed later in Section 5.

Katana/Camera setup object segmentation pipeline

Examples of segmented images and 3D point clouds with fitted quadratic surfaces taken with the stereo camera for two different types of objects: a book which slides when pushed by the robotic arm, and a Pepsi can which rolls when pushed by the arm

Top row: original object point cloud. Middle row: partitioning planes divide the point cloud evenly in each dimension to create sub-parts. Bottom row: planes are fitted to each sub-part for feature extraction.

Object tracking in the Katana/Camera setup. Upper row: Outer rectangle is a likelihood window around the object from the particle filter. Inner rectangle is the result histogram back-projection further localizing the object. Lower row: Close-ups show how the appearance of the object changes during motion.

PCL-based particle filter tracking from the KUKA-LWR/Kinect experiment. Blue points: model of the ball object derived from segmenting the ball from the table prior to interaction. Orange points: particle filter points used to track the object during interaction and update the model.

Object image segmentations (not to scale) from the Katana/Cameras experiment

LOOOCV (cf. Section 4.1) class prediction results for the Katana/Camera 3D + 2D object feature experiment (cf. Section 4.2.1). The vertical dashed line indicates the transition from unsupervised to self-supervised learning (cf. Section 2).

Feature relevance results for the Katana/Camera 3D + 2D object features experiment (cf. Section 4.2.1). The vertical dashed line in the lower figure separates the input-view feature histograms for two supervised and two self-supervised learners. The upper figure shows output view results which were applicable to self-supervised learners only and were the same in both cases (SSSOM & SSLVQ). Features are colour-coded (see legends).

Input view feature relevance results from the Katana/Camera experiment using the 3–D object features (cf. Section 4.2.2)

LOOOCV class prediction results for the Katana/Camera 3-D object feature experiment (cf. Section 4.2.2)

Object clouds from the KUKA-LWR/Kinect experiment
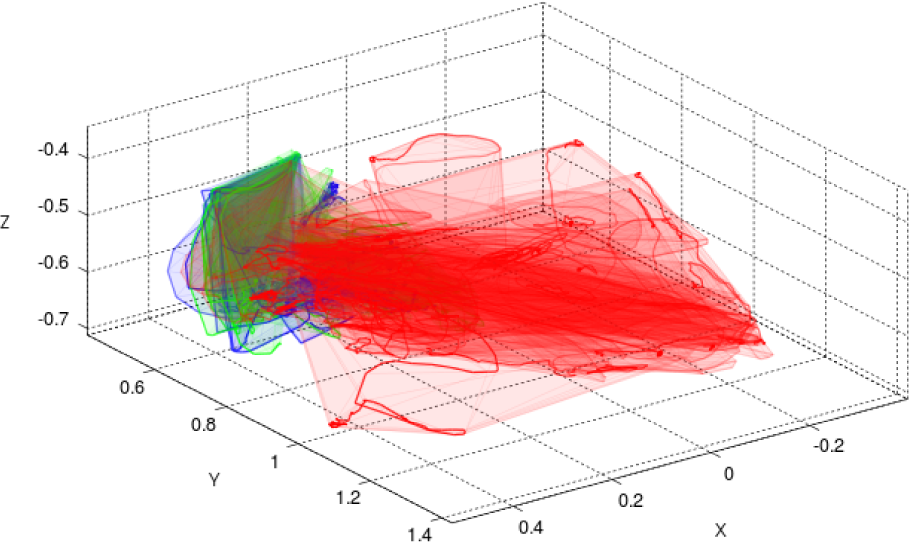
Object trajectories and trajectory convex hulls from the KUKA-LWR/Kinect experiment, colour-coded by ground-truth; red: rolling; green: toppling; blue: translating
3.3 Object Feature Extraction
With regard to the object features, for our particular scenario we were primarily interested in extracting features that describe the global shape of an object, as they were likely to be more relevant in determining how the object would behave when pushed than the types of local invariant visual features used predominantly in object recognition scenarios.
3.3.1 Object Detection and Segmentation
To extract such global shape features, we required a means of detecting and segmenting the objects from the scene. In the case of the Katana/Camera setup, objects were segmented both from the image data and from the 3D point clouds derived from the range data produced by the stereo camera. To this end, we used the algorithm visually outlined in Figure 6, for multi-modally segmenting the objects from both regular images and their corresponding 3D point clouds, that leverages a notable feature of our affordance learning environment, i.e., that the objects always lie on a flat table surface (cf. [27] for further details). In the case of the KUKA-LWR/Kinect setup, once again the objects always lie on a flat table surface, so we were able to make use of the Dominant Plane Segmentation module from the PCL library to segment the objects from the scene point cloud captured by the Kinect.
3.3.2 Visual Shape Features from Object Images
In the case of the Katana/Camera setup, visual features were extracted from objects segmented from the greyscale scene images produced by the Bumblebee camera. The segmentation technique outlined in Figure 6 yielded reasonably robust image silhouettes of objects, and these were then used to calculate the following nine shape features:
O1 a : Area: number of pixels in the object region.
O2 a :: Convex area: number of pixels in the convex hull of the object region.
O3 a :: Eccentricity: ratio of the distance between the foci of the ellipse that has the same second-moments as the object region and its major axis length.
O4 a :: Equivalent circular diameter: diameter of a circle with the same area as the object region.
O5 a :: Extent: ratio of pixels in the object region to the pixels in its bounding box.
O6 a :: Filled area: number of pixels in the filled object region.
O7 a :: Major axis length: length of the major axis of the ellipse that has the same normalized second central moments as the object region.
O8 a :: Minor axis length: length of the minor axis of the ellipse that has the same normalized second central moments as the object region.
O9 a :: Perimeter: of the boundary of the object region.
3.3.3 3D Shape Features from Object Point Clouds
In order to capture object surface properties, 3D shape features were extracted from segmented object point clouds derived from both the Katana/Camera and the KUKA-LWR/Kinect experimental setups, in both cases we adopted a strategy of surface fitting. For instance, in the case of the Katana/Camera setup, a quadratic surface was fitted to an object point cloud, or to a part of an object point cloud, in order to derive curvature features from the object surface. Given the points for an object or part of an object, we fit the following quadratic polynomial function:

solving for the coefficients a,b,c,d,e and f. The principal curvatures of the surface are then given by taking eigenvalues of the matrix:
Using these four surface features (two for planar orientation and two for curvature) in the Katana/Camera setup, we divided the object cloud into parts and extracted the four features for each part. These parts consisted of the global object cloud itself, as well as eight other parts found by dividing the object cloud evenly along two of its axes in various ways. This yielded the following list of features:
O1…4 b : Global object point cloud plane/curve features.
O5…8 b : x-axis split, left plane/curve features.
O9…12 b : x-axis split, right plane/curve features.
O13…16 b : y-axis split, front plane/curve features.
O17…20 b : y-axis split, back plane/curve features.
O21…24 b : x-y-axis split, front-left plane/curve features.
O25…28 b : x-y-axis split, front-right plane/curve features.
O29…32 b : x-y-axis split, back-left plane/curve features.
O33…26 b : x-y-axis split, back-right plane/curve features.
In the case of the KUKA-LWR/Kinect setup, we partitioned the object point clouds slightly differently, as depicted in Figure 8, this time dividing each of the x, y and z axes evenly into two parts each and fitting planes to each of their respective part point clouds as well as to the entire object point cloud. The part division along the third dimension was motivated by the need to detect the additional object toppling affordance that resulted from the experiments performed with this setup. This time, object part centroids as well as plane normals and curvature features were used, resulting in seven features per part, three for part centroids, as well as two for the plane normals and two for the curvature features as before, resulting in the following list of features:
O1…7 c : Global point cloud centroid/plane/curve features.
O8…14 c : x-split, left centroid/plane/curve features.
O15…21 c : x-split, right centroid/plane/curve features.
O22…28 c : y-split, front centroid/plane/curve features.
O29…35 c : y-split, back centroid/plane/curve features.
O36…42 c : z-split, top centroid/plane/curve features.
O43…49 c : z-split, bottom centroid/plane/curve features.
3.4 Effect Feature Extraction
When it came to the effect features, we chose to both track the objects in motion globally in the workspace and to compare changes in object properties locally, deriving three main sets of features based on the global motion of the object, changes in 3D shape, and local appearance changes of the object, respectively, depending on the platform.
3.4.1 Tracking Object Motion
In the Katana/Camera setup, after an arm action was performed on an object, the resulting videos of the interaction gathered from the Flea camera were processed for tracked object motion features. This was primarily achieved using a probabilistic tracker from [19], which is in essence a colour-based particle filter that also makes use of background subtraction using a pre-learned background image. Object shapes were approximated by elliptical regions, while their colour was encoded using colour histograms and their motion was modelled using a dynamic model from [20]. In order to compensate for tracking overshoots and thereby produce more accurate local object appearance change features (cf. Figure 9 and Section 3.4.4), the estimates of object position from this tracker were then further refined using colour histogram back-projection [34]. See [27] for further details on this method.
The KUKA-LWR/Kinect setup, on the other hand, made use of the libpcl_tracking library from the PCL, which also uses a particle filter to estimate 3D object poses using Monte Carlo sampling techniques and calculates the likelihood using combined weighted metrics for hyper-dimensional spaces including Cartesian data, colors, and surface normals. These 3D object models were gathered from scene point clouds using the same dominant surface segmentation method discussed in Section 3.3.1. The real-time 3D object tracking provided by this method is illustrated in Figure 10.
3.4.2 Object Motion Features
Using the output of the visually-based particle filter tracker of the Katana/Camera setup, the following nine features were calculated:
E1…2 a : Total distance travelled in x & y dimensions,
E3 a : Total Euclidean distance travelled,
E4…5 a : Mean velocity in x & y dimensions,
E6…7 a : Velocity variance in x & y dimensions,
E8…9 a : Final x & y positions.
In the case of the KUKA-LWR/Kinect setup, since the 3D point cloud-based particle filter tracker from the PCL library allowed for tracking objects in three dimensions, we were able to extend some of the 2D features used on the previous setup into the z dimension. Some alternative features were also designed- in addition- to suit the experiments performed with this platform. The 17 resulting features are listed as follows:
E1…2 b : Total distance travelled in x, y & z dimensions.
E4 b : Total Euclidean distance travelled in ℝ2.
E5 b : Total Euclidean distance travelled in ℝ2.
E6…8 b : Final x, y & z positions.
E9 b : Time in motion.
E10 b : Trajectory extent volume.
E11 b : Trajectory convex hull volume.
E12 b : Trajectory convex hull surface area.
E13 b : Summed trajectory point distance from start position.
E14 b : Mean trajectory point distance from start position.
E15 b : Trajectory point distance variance from start position.
E16 b :E14 b , weighted to favour points near end of trajectory.
E71 b :E15 b , weighted to favour points near end of trajectory.
3.4.3 Object Shape-change Features
In the case of the experiments performed using the KUKA-LWR/Kinect setup, since we intended to study toppling affordances, we required features capable of detecting the types of changes in object shape in three dimensions that would result from such affordances. Thus, using a similar methodology to that of Ugur et al. [36], we derived a set of 3D shape change features by taking the difference between the O1…49 c 3D shape features from Section 3.3.3 recorded from the object pre-interaction and the same features recorded from the object post-interaction. These new features, E1…49 c , were therefore derived as follows:
E1…49 c :Oi c (te)−Oi c (ts) for i = 1 … 49, where Oi c (ts) and Oi c (te) are the object shape features Oi c extracted from the object at time ts, when it is at its start position, and at time te, when at its end position, respectively.
3.4.4 Object Appearance Change Features
In the experiments involving the Katana/Camera setup, in order to estimate appearance changes of objects during motion (cf. Figure 9), and thus potentially capture some of the differences in visual effects between rolling and non-rolling objects, we calculated the average difference of both colour and edge histograms between video frames of the objects, the aim being to detect both motion blur and the texture changes characteristic of many rotating objects. Histogram difference averages were then calculated from the start of object motion until the end. We derived three effect features from this procedure:
E1 d :: Average colour histogram difference.
E2 d : Average edge histogram difference.
E3 d : Product of E1 d and E2 d .
4. Experiments
We performed experiments using both of the robotic platforms described in Section 3, gathering real world data from affordance learning trials, and comparing our proposed self-supervised algorithm to well-known supervised vector quantization algorithms. The learning trials were divided into a number of sub-experiments, using different combinations of the feature sets described in Sections 3.3 and 3.4 depending on the particular platform being used and the goals of the experiment. The Katana/Camera experiment involved objects and pushes that resulted in two different affordance ground-truth effect classes being produced- rolling and non-rolling classes-whereas in the KUKA-LWR/Kinect experiment, more complex effects were produced from the objects used, their poses and the scenario, resulting in three different ground-truth classes: rolling, non-rolling and toppling. The supervised algorithms that were compared were generalized learning vector quantization (GLVQ) [30], generalized relevance learning vector quantization (GRLVQ) [15] and supervised relevance neural gas (SRNG) [14], the latter two of which also provide feature relevance estimates. We compared their performance relative to our self-supervised learning approach by applying the evaluation procedure described below.
4.1 Evaluation Procedure
In the following, a modified form of leave-one-out cross-validation, which we call leave-one-object-out cross-validation (LOOOCV) was employed. In order to evaluate our learning approach, given an {X,Y} dataset of features extracted from interactions with various objects from a given experiment, LOOOCV involved splitting the dataset into a test set consisting of all of the samples for a given object, and a training set of all of the samples for the remaining objects. The learning task was then to train learners using the training set, find the affordance classes in the output view and try to classify the test set samples of the left-out object on that basis. Cross-validation was performed by using each of the objects in the full dataset in turn as the test object to form multiple test and training sets, performing the learning task using each of these, and averaging class discovery and class prediction scores across all of them. Performing the evaluation in this way, using LOOOCV, allowed us to test the performance of affordance prediction for novel objects that the algorithms do not encounter during training, a more stringent evaluation than would otherwise be provided by LOOCV or k-folds cross validation.
Our self-supervised learning vector quantization algorithm (SSLVQ) was compared to a self-supervised self-organizing map (SSSOM), as well as variations employing feature relevance determination at classification time (SSLVQ (FRC) and SSSOM (FRC)) alongside the supervised algorithms GLVQ GRLVQ and SRNG. SSSOM differed from SSLVQ in that it only made use of the update in (4) in both input and output views, whereas SSLVQ also employed the self-supervised update of (12) in the input view. In the case of the experiments with the Katana/Camera setup presented below in Section 4.2, codebooks in each data view consisted of 49 prototypes arranged in a 7 × 7 hexagonal lattice with a sheet-shaped topology [17], whereas in the experiments using the KUKA-LWR/Kinect setup presented in Section 4.3, larger 10 × 10 codebooks were used. The feature weights of the codebook prototype vectors were randomly initialized to test the abilities of the algorithms to learn from scratch. LOOOCV was therefore performed in 10 trials and results were averaged in order to account for the variation in codebook initialization between trials. Constant learning rates of αWt=0.1, αVt=0.1, were used for the prototype update of (4) in codebooks W and V, respectively, in the unsupervised learning phase, and αLt = 0.1 was used for (12) in the self-supervised learning phase. Learning phases were switched from unsupervised to self-supervised halfway through training in the Katana/Camera experiments, and one tenth of the way through training in the KUKA-LWR/Kinect experiments where a longer training period was employed over multiple epochs.
The results examine three different aspects of our learning framework: class discovery, class prediction and feature relevance determination. An important consideration in evaluating whether or not our algorithm is capable of self-supervised multi-view learning is to examine whether it is capable of successfully finding class clusters in the output-view, without which self-supervised discriminative learning in the input-view would not be possible. But how quickly do the prototypes position themselves, such that this clustering can happen successfully? Lo answer this question, clusters of prototypes were found in the output view as described in Section 2.3.1 and subsequently matched to the ground truth classes by first matching all ground truth labelled training data to nearest-neighbour output view prototypes, then assigning each cluster the ground truth label which their respective prototypes matched to most frequently. Then, to evaluate prediction, given a test sample consisting of an input view test vector x1 and an output view test vector
4.2 Experiments using Katana/Camera Platform
To test our affordance learning system with the Katana/Camera platform, the experimental environment was set up as shown in Figure 1. During the experiments, objects were placed at a fixed starting position prior to interaction. The two camera systems were used to provide both sufficiently detailed close-up range data of the object surfaces and a sufficiently wide field of view to capture object motion over the entire work area. Lo achieve this, the stereo camera was positioned above the start position, while the monocular camera was positioned at a higher position in front of the workspace, giving both cameras a top-down viewpoint of the work surface.
We selected eight household objects (cf. Figure 11) for the experiments: four flat-surfaced objects (a book, a CD box, a box of tea and a drink carton) and four curved-surfaced objects (a box of cleaning wipes, a cola can, a soda can and a tennis ball box. A dataset was gathered consisting of 20 object push tests for each of the eight objects and the resulting data was processed, leaving 160 data samples. During tests, the curved objects would tend to roll after being pushed, whereas the flat objects would stop suddenly; accordingly, the samples were then hand-labelled with two ground-truth labels: rolling and non-rolling. These ground-truth labels were not used to train the self-supervised learners but they were required for the performance evaluation. Lhis data was processed to produce the visual shape features
4.2.1 Results: 3D + 2D Object Features
In this experiment, the self-supervised learners were trained using data from
Class Discovery: Optimal performance was achieved very early in training after 10 samples, with class-cluster-to-ground-truth match accuracy being maintained at 100% throughout, meaning that cross-view prediction from input view test samples should at least have the opportunity to reach optimal ground truth prediction rates within the training period.
Class Prediction: When it comes to predicting these newly discovered classes, Figure 12 shows how the various self-supervised learners perform and how they compare to supervised classifiers predicting ground-truth labels using input view features. In this test, only a small subset of the object features (curvature features
Feature Relevance Determination: Figure 13 illustrates the mean results of feature relevance determination at the end of training for both the input and output views. The input view graph features comparisons with the supervised learners GRLVQ and SRNG that feature feature relevance determination mechanisms. The features
4.2.2 Results: 3D Object Features
Class Discovery: In this experiment, both the output view data and the learning parameters were the same as in the previous experiment; thus class discovery results were indistinguishable, with optimal performance again being attained early in training and maintained throughout.
Class Prediction: In this experiment, the 2D visual object features were removed in favour of purely 3D surface features of feature space Xb, and since many more of these features were relevant for class prediction than in the previous case, there were correlated improvements in the class prediction capabilities of all learners, as illustrated in Figure 15. This time, all of the self-supervised learners performed comparably well, reaching 100% performance early in training, as well as beating the supervised classifiers over one epoch of training.
Feature Relevance Determination: Since both the features that were used in the output view- as well as the output view learning parameters- were identical to those used in the previous experiment, the results for output feature relevance determination were almost identical, and so we omit those results here. The input-view feature relevances, on the other hand, as shown in Figure 14, reveal that many of the features of Xb are relevant for class prediction. Features O3 b , O9 b , O19 b , and O33 b are favoured prominently by both the supervised and self-supervised learners. The selection of O3 b matches with the results from the previous experiment, where it was one of two curvature features included in input space X a,b , and was selected as the most relevant feature. The right side of the x-axis split that generated the O9 b plane normal feature was the closest side to the stereo camera, and so produced more 3D points (thus yielding more reliable surface fits and resulting features). Similarly, O19 b is generated from the back side of the y-axis split, which is the closest object part to the camera along that dimension. Finally, feature O33 b is generated from the part at the intersection between the previous two, and so benefits from the increased reliability of both.
4.3 Experiment using the KUKA-LWR/Kinect Platform
In the KUKA-LWR/Kinect platform experiment, we set out to apply our learning framework to a slightly more complex pushing scenario that would yield more than two affordance classes: rolling, toppling and translating. The environment was set up in similar fashion to the experiments with the Katana/Camera system (cf. Figure 2). This time, we selected 10 household objects (cf. Figure 16) for the experiments: six flat-surfaced objects and four curved-surfaced objects. During the experiment, objects were again placed at a fixed starting position prior to interaction. This time, however, objects were placed in more varied poses when possible in order to generate more varied affordance effects: flat, sideways or upright, and either with the major axis of the object perpendicular to or parallel to the push direction vector if that was well-defined, i.e., for the non-ball objects. These descriptions are provided here for the readers' benefit and were not used for training (except for the pose information potentially being encoded in the input feature vectors). During these trials, the flat-surfaced objects would either tend to translate forward or topple over after being pushed, depending on their pose, and the balls would tend to roll, though along much more complex and varied trajectories than in the Katana/Camera experiments, as illustrated in Figure 17.
The samples were again hand-labelled with the ground-truth labels: rolling, translating and toppling. 126 samples were collected, in total, of a biscuit box (12 samples: eight toppling, four translating), a coffee box (20 samples: five toppling 15 translating), a cookie packet (eight samples: all translating), a contact lens solution box (16 samples: all toppling), a marshmallow box (23 samples: nine toppling, 14 translating), a book (14 samples: six toppling eight translating), a handball (eight samples), a small football (six samples), and both lightly coloured (eight samples) and darkly coloured (11 samples) larger plastic toy balls. This time, the data was used to generate the 3D shape features described in Section 3.3.3 for the input view space Xc consisting of feature vectors of the form
4.3.1 Staged Feature Relevance Determination
Initial learning trials with the full {Xc,Ya,d} feature set proved inconsistent, so we opted for a more advanced learning strategy: staged self-supervised learning, in which the most relevant features are determined via thresholding feature relevance at each stage, and where the there remaining features were discarded before retraining with the reduced feature set at the next stage. This emulates an aspect of developmental learning where concepts are refined over multiple learning stages. We thus performed three rounds of self-supervised learning using LOOOCV on the SSLVQ (FRC) learner over 10 epochs for the first two stages, before performing a final run of LOOOCV on all of the learners over 50 epochs using the remaining features. After the first stage, only the features from the output view were reduced, whereas after the second stage, both the input and output view feature sets were reduced. When reducing feature sets, thresholds were set to the mean feature relevance value plus one standard deviation. Output feature relevances were calculated separately for the shape difference features and for the motion features.
4.3.2 Results
Feature Relevance Determination: The input vectors used in the first stage were of the form

Mean feature relevance results for both input and output views in staged feature relevance learning for the KUKA-LWR/Kinect experiment as described in Section 4.3.1. The upper figure shows the relevance histogram of the reduced output feature set after the second learning stage with a vertical line separating the shape and motion features, which were clustered and reduced separately at each stage. The lower figure shows reduced feature relevance histograms for the input view after the third stage where the vertical dashed line separates supervised and self-supervised learners.
Class Discovery: Figure 19 shows the average class discovery results for each of the self-supervised learners over 10 trials of the 50–epoch third stage LOOOCV evaluation. The learning parameters were the same in the output-view in all cases, so the results are similar for each of the learners. The learners discover the ground-truth classes with a mean accuracy of 90% after 50 epochs of training, which sets a limit on their potential results for class prediction.
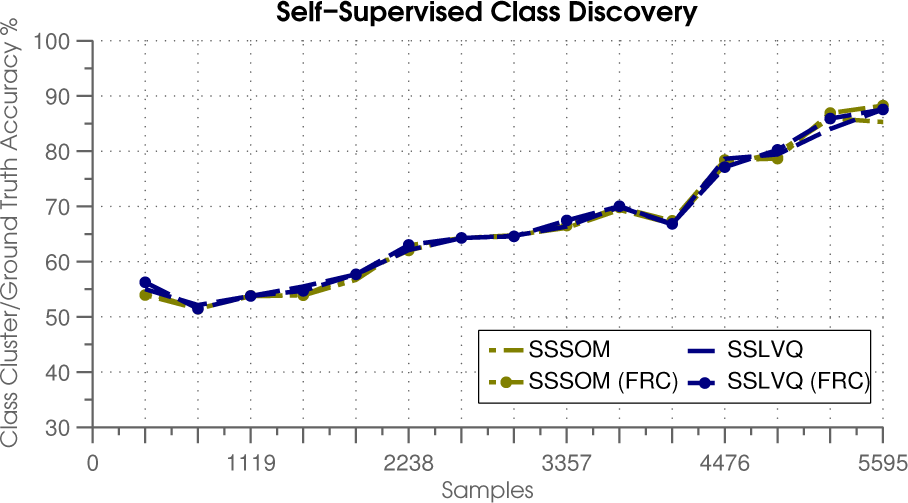
Mean class discovery results for the third stage of LOOOCV (cf. Section 4.1) run over 50 training epochs in the KUKA-LWR/Kinect experiment as described in Section 4.3
Class Prediction:Figare 20 shows both average class prediction results for all learners and the average SSLVQ (FRC) class prediction for specific test objects. While GRLVQ and SRNG achieve just over 85% accuracy on average during most of the 50–epoch training period, the self-supervised leaners start out quite poorly, before reaching 75% accuracy by the end of training. SSLVQ (FRC) appears to give slightly better performance over the other self-supervised learners, but the results are inconclusive. This might be explained by the fact that the feature sets have been significantly refined by this final learning stage. The lower graph of Figure 20 shows that SSLVQ (FRC) appears to struggle most when either the dark- or the light-coloured large balls are left out of the training set. This may be due to the fact that when either of these objects are left out, there are far fewer training samples that are both curved in the direction of the push (O28 c feature) and are relatively tall (O45 c feature). For example, when the dark ball is left out, there are 115 total training samples, 22 of which are rolling samples, and only eight of which are samples of relatively tall ball-shaped rolling objects. By comparison, when the small football is left out, there are 120 total training samples, 27 of which are rolling samples and 19 of which are samples of relatively tall rolling balls. Without adequate numbers of samples of tall rolling balls in the training set, the self-supervised learner struggles when it encounters them as novel samples in the test set.
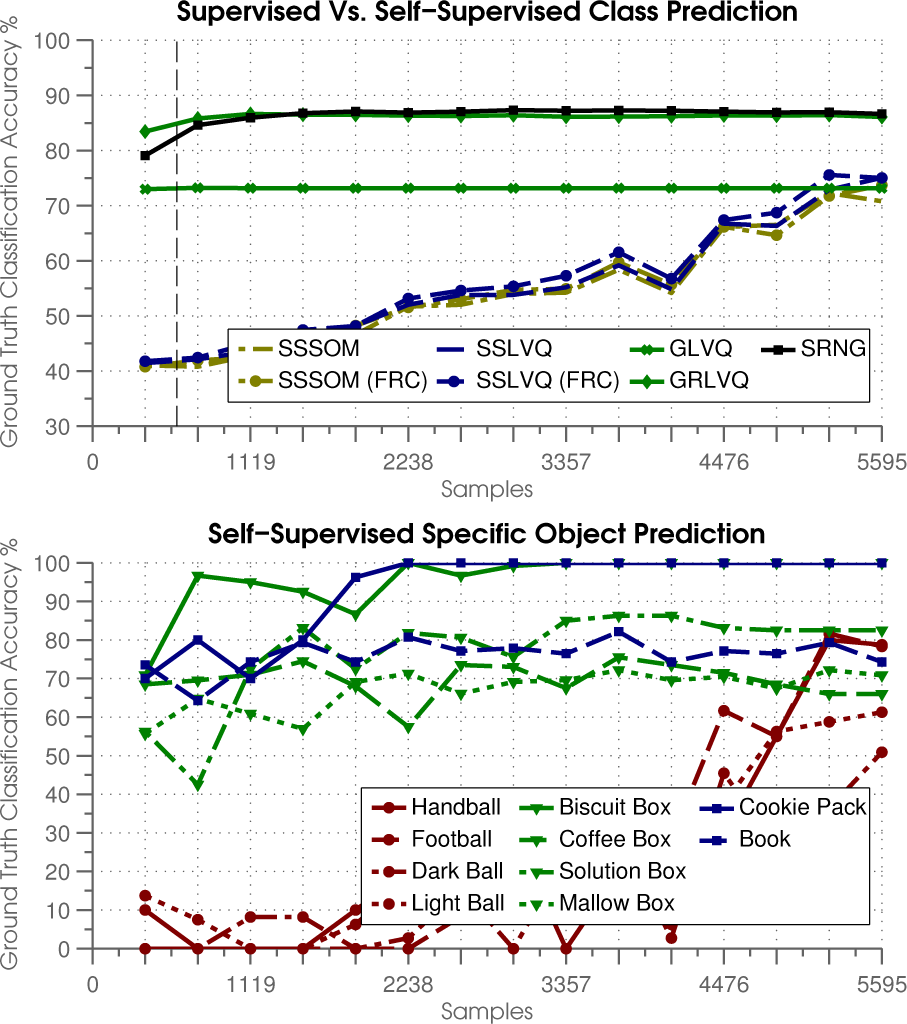
Mean class prediction results for all learners (upper graph) & for SSLVQ (FRC) with specific test objects (lower graph) for the third stage of LOOOCV (cf. Section 4.1) run over training 50 epochs in the KUKA-LWR/Kinect experiment (cf. Section 4.3)
5. Conclusion
In this paper, we presented a self-supervised multi-view online learning algorithm along with two robotic systems used for performing object push-affordance learning experiments and demonstrated how the algorithm could be used to enable the autonomous acquisition of novel affordance concepts. We formalized a multi-view learning scenario where data co-occur over two separate data views over time, and where the task is to exploit significant clusters that emerge in one view as classes that can be used to perform online discriminative learning in the other view. Our proposed algorithm uses a self-supervised form of learning vector quantization to build the discriminative model by mapping information between the data views using the co-occurrence information gained from online learning experience. We tested our approach using data from real-world experiments by comparing it with related supervised methods and showed how the inclusion of a feature relevance determination mechanism can boost predictive accuracy when many redundant features are present in the data. In particular, we demonstrated how a such self-supervised learning process can be applied in developmental stages where the feature set is refined at each stage in order to enhance the learning process.
In future work, we aim to expand on the number of classes and objects used, perhaps by training multiple learners under a mixture of experts model. We would also extend the model so that more data views are included, which could be useful when other sensory modalities, e.g., haptic, are used alongside the visual ones. Actions are a crucial component of affordance learning and although a more thorough investigation of their potential in our learning setup went beyond the scope of this work, there are many possible ways in which they could be exploited, one avenue of which we have explored elsewhere [28]. Otherwise, learning by imitation could help select the initial feature set and guide exploratory behaviours in a goal-directed manner. Reinforcement learning could also help the robot guide its own exploration once the goals are defined, thus improving the learning-rate. In this sense, our approach is complementary to such approaches, and we hope to explore these connections in future.