
Abstract
With the rapid development of Deepfake technologies, the prevalence of forged facial images and videos on social media has surged. However, these technologies have also been exploited for malicious purposes, posing significant threats to social security. Although existing detection methods have shown effectiveness in identifying high-quality facial forgeries, their performance drops significantly for low-quality forgeries, as compression causes detail loss and feature blurring. To address this problem, a Frequency Assisted Multiscale Dual-Stream Network (FAMDnet) is proposed for low-quality Deepfake detection in this article. First, the multiscale spatial feature extraction module is designed to extract RGB features from image patches of different sizes, thereby capturing forgery traces within multiscale regions. Then, the dynamic global frequency feature extraction module is constructed by combining learnable dynamic filters with the Fast Fourier Transform to extract frequency domain features, supplementing the forgery artifacts that may vanish in the spatial domain. Finally, the multimodal attention fusion module is utilized to explore the correlation between RGB features and frequency domain features, effectively capturing local texture details and global context patterns in facial images, thereby achieving better fusion of RGB features and frequency domain features. Moreover, a parameter-free attention mechanism is introduced into the classifier to enhance the fused features, further improving the model's discriminative ability for facial forgery. Comparative experiments on the FaceForensics++, Celeb-DF, and WildDeepfake datasets demonstrate that FAMDnet has better performance in detecting low-quality fake images and videos. The code is available at https://github.com/daisy-12138/FAMDnet.
Introduction
In recent years, the rapid advancement of Deepfake technologies (Krichen, 2023) has enabled the generation of increasingly realistic images and videos, raising significant concerns about ethical abuses such as identity theft and online fraud, which pose tangible threats to social security. Consequently, developing effective methods for detecting Deepfake facial images has become a critical priority. However, due to bandwidth constraints, many forged facial images or videos experience substantial quality degradation after being uploaded to social media platforms. These low-quality Deepfakes, characterized by subtle forgery traces and smaller file sizes, are more likely to spread widely in real-world scenarios, presenting unique detection challenges (Zhou et al., 2024). This is primarily because low-quality facial images inherently suffer from reduced clarity, detail, and color accuracy, often caused by low resolution or excessive compression. Such degradation obscures the already subtle artifacts introduced by Deepfake algorithms, making it difficult for detection models to distinguish forged regions from authentic content. Consequently, the combination of compressed formats (for easier sharing) and obscured forgery traces creates a “double hurdle” for detection methods, enabling these low-quality forgeries to proliferate across platforms.
Most existing Deepfake detection methods (Afchar et al., 2018; Chen et al., 2021; Cozzolino et al., 2017; Li, Bao, et al., 2020; Nguyen, Fang, et al., 2019; Zhao et al., 2021) rely on Convolutional Neural Networks (CNNs), which are inherently constrained by their local receptive fields. This limitation restricts their capacity to model relationships between distant image regions, a critical shortfall for detecting low-quality forgeries. Subtle forgery artifacts in such images, including inconsistent lighting, texture mismatches, and color discrepancies, often span spatial scales larger than the networks’ receptive fields. As a result, CNNs fail to capture the global contextual inconsistencies that distinguish forged and authentic content, leading to fragmented feature analysis and diminished detection accuracy for degraded images. In contrast, Transformers (Vaswani et al., 2017) model long-range dependencies through their self-attention mechanism, which allows each image patch, or token, to attend to all others, enabling direct capture of global spatial relationships across the entire input. Wodajo et al. (Wodajo and Atnafu, 2021) pioneered the use of Vision Transformers (ViTs) (Dosovitskiy et al., 2020) for detecting forged video frames, achieving promising results. Varying patch sizes in Transformers prompt the model to analyze image features at multiple scales, where smaller patches focus on fine-grained local details like pixel-level artifacts and larger patches capture coarse-grained global structures like structural inconsistencies (Wang et al., 2021). This multiscale feature integration enhances the model's ability to detect subtle forgeries across both local and global levels, particularly in compressed low-quality content. Consequently, this article employs multiscale Transformers to extract forged facial features, leveraging their capacity to fuse diverse contextual information and overcome CNNs’ local receptive field limitations. However, compressed images complicate the task of distinguishing global feature discrepancies in the RGB color space, as compression artifacts such as blocky distortions from JPEG quantization often mask subtle spatial inconsistencies introduced by Deepfake algorithms. These artifacts disrupt the natural correlation between adjacent pixels in the spatial domain, making it difficult to isolate forged regions based on RGB intensity or texture alone (Durall et al., 1999; Huang et al., 2020; Qian et al., 2020; Wang, Wang, et al., 2019). In contrast, frequency domain analysis offers a critical advantage, as it decomposes images into spatial frequency components, including low-frequency structural trends and high-frequency texture details, to reveal intrinsic differences in the spectral distribution of forged and authentic content. Forged regions, often generated by neural networks with distinct synthesis patterns, exhibit anomalous frequency distributions including unnatural periodicity in high-frequency bands or inconsistent low-frequency gradient structures that persist even after compression. These frequency domain anomalies are less susceptible to degradation by compression algorithms, which typically alter spatial coherence rather than fundamentally changing the spectral signature of image content (Zhou et al., 2024). Consequently, recent studies (Zhou et al., 2024; Durall et al., 1999; Qian et al., 2020) have turned to frequency domain analysis to address these challenges because the significant differences in frequency distributions between forged and authentic regions provide a robust basis for detection, enabling models to bypass compression-induced noise while targeting the inherent spectral mismatches that characterize Deepfake manipulations.
In summary, inspired by references (Tatsunami and Taki, 2024; Wang et al., 2021; Yang et al., 2021; Zhou et al., 2023), a Frequency-Assisted Multiscale Dual-Stream Network (FAMDnet) for low-quality Deepfake detection is proposed in this article. First, the multiscale spatial feature extraction module is designed by employing a ViT to capture RGB features from image patches of varying sizes, thereby accurately pinpointing structural anomalies in forged regions (such as unnatural boundaries and texture inconsistencies) and addressing the limitation of traditional methods in capturing the association between local details and global structure. Then, to overcome the limitations of previous static global filters, the dynamic global frequency feature extraction module is constructed, combining learnable dynamic filters with Fast Fourier Transform (FFT) to extract frequency-domain features. This dynamic filter can adaptively adjust the feature extraction pattern according to input characteristics, effectively supplementing the forgery traces that tend to disappear in the spatial domain. Next, the multimodal attention fusion module is proposed to achieve efficient integration of local texture details and global contextual patterns by deeply mining the intrinsic correlation between RGB and frequency-domain features. This module contains three components: linear angular attention, which leverages multihead attention to compute query-key-value relationships and generate weighted features to enhance spatial inconsistencies such as boundary mismatches in spliced regions; intercovariance matrix attention, which generates attention weights through dot product operations to capture channel dependencies of forgery-related frequency components, thereby enhancing the discriminability of frequency features; and cross-attention fusion, which adopts parallel average and max pooling strategies to fuse the enhanced spatial-frequency features while preserving complementary statistical information. Finally, the parameter-free attention mechanism is introduced into the classifier, which utilizes mean statistics along the channel dimension to adaptively calibrate the features in the fused feature space, significantly boosting the model's ability to recognize subtle forgery clues without increasing the parameter count. Experimental results on the FaceForensics++, Celeb-DF, and WildDeepfake datasets demonstrate that FAMDnet achieves superior detection performance on highly compressed facial forgeries.
The main contributions of this article are as follows: The multiscale spatial feature extraction module is designed to extract multiscale RGB features from image patches of varying sizes, thereby identifying structural mismatches in forged regions of different sizes. The dynamic global frequency feature extraction module is constructed by combining learnable dynamic filters with the FFT to extract frequency domain features, supplementing the forgery artifacts that may vanish in the spatial domain. The multimodal attention fusion module is utilized to integrate spatial and frequency features, strategically exploiting the correlation between RGB and frequency domains to effectively capture both local texture details and global contextual patterns in facial images. A parameter-free attention mechanism is introduced into the classifier, through which channel-wise mean statistics are used to adaptively recalibrate features in the fused feature space without introducing extra parameters, thereby enhancing the model's ability to distinguish facial forgeries.
Early approaches for facial forgery detection predominantly employ CNNs to extract subtle forgery traces from manipulated images in the spatial domain. MesoNet (Afchar et al., 2018) and FakeSpotter (Wang, Juefei-Xu, et al., 2019) leverage CNNs to automatically learn discriminative features of forged facial images by analyzing manipulated facial regions. MaDD (Zhao et al., 2021) frames Deepfake detection as a fine-grained classification task, utilizing multiple spatial attention heads to enhance texture feature representation and aggregating low-level texture cues with high-level semantic features. Miao et al. (Miao, Chu, et al., 2022) improve model generalization by introducing a forged region-guided self-attention module. Wang et al. (Wang and Deng, 2021) achieve significant detection performance by integrating spatial attention mechanisms to capture local forgery artifacts. Stehouwer et al. (2019) employ attention mechanisms to strengthen the classification of real/fake facial images and visualize manipulated regions. While CNNs effectively learn local features through restricted receptive fields, they face inherent limitations in modeling global contextual information. This constraint makes CNNs particularly challenged in detecting low-quality forgeries, as their local receptive fields often overlook subtle inconsistencies and artifacts that are more apparent in a global context, leading to failures in assessing overall image coherence. In contrast, the self-attention mechanism in Transformer architectures enables modeling of global relationships and long-range feature dependencies, thereby enhancing visual representation capabilities. Wodajo et al. (Wodajo and Atnafu, 2021) establish long-distance correlations between image patches using a hybrid CNN-ViT framework. Miao et al. (Miao et al., 2021) adopt a pure ViT backbone with feature bagging to encode interblock relationships, enabling forgery feature learning without explicit mask supervision. LiSiam (Wang et al., 2022) combines Transformer and CNNs by using original images and quality-degraded counterparts as paired inputs to generate segmentation maps, employing a local invariance loss to enforce consistency between outputs. Trans-FCA (Tan et al., 2022) introduces a local compensation module to fuse global Transformer features with local convolutional features, addressing Transformer's limitations in capturing fine-grained local details. Notably, most existing Transformer-based methods rely on fixed-size image patches for single-scale RGB feature extraction, with limited research on multiscale spatial feature learning using variable patch sizes. Wang et al. (2021) propose a multimodal multiscale Transformer that captures subtle manipulation artifacts through image patches of diverse sizes, enabling detection of local inconsistencies across multiple spatial levels. Zhou et al. (2024) develop a multiscale dual-branch network for facial forgery detection, leveraging Transformer to extract fine-grained multiscale texture features from raw RGB images.
A critical limitation of most detection methods is their exclusive focus on RGB features, which leads to performance degradation when handling low-quality Deepfake images and videos. To address this, recent studies have incorporated frequency domain information. Masi et al. (2020) demonstrate improved performance by amplifying artifacts and suppressing high-level content through Laplacian Gaussian multiband feature extraction. GFF (Luo et al., 2021) uses high-frequency noise signals to guide RGB feature extractors toward forgery traces. IAW (Jia et al., 2021) employs a dual-branch network to model inter- and intra-image inconsistencies, separately predicting image-level and pixel-level forgery labels. Dzanic et al. (2020) adopt spectral detection techniques, modifying networks to generate high-frequency attributes that better mimic real-image statistics. While most prior work remains single-domain, emerging studies explore dual-stream networks combining spatial and frequency domains for Deepfake detection (Nguyen, Yamagishi, et al., 2019). Liu et al. (2021) integrate spatial images with phase spectra to capture upsampling artifacts in facial forgeries, enhancing detection generalizability by shallowing network architectures to reduce receptive fields and focus on local regions. M2TR (Wang et al., 2021) fuses RGB and frequency domain information, using multiscale image patches to detect cross-level spatial inconsistencies. Liang et al. (2023) design a dual-stream framework integrating conventional spatial flow and frequency flow, effectively distinguishing high-quality and low-quality faces across diverse generation methods.
Methodology
This article proposes a FAMDnet designed to enhance the robustness of detecting low-quality Deepfake images and videos by uncovering subtle forgery traces within them. The overall structure of the method, illustrated in Figure 1, primarily consists of the multiscale spatial feature extraction module, the dynamic global frequency feature extraction module, the multimodal attention fusion module, and a classifier incorporating the simple parameter-free attention mechanism. First, the low-level texture features
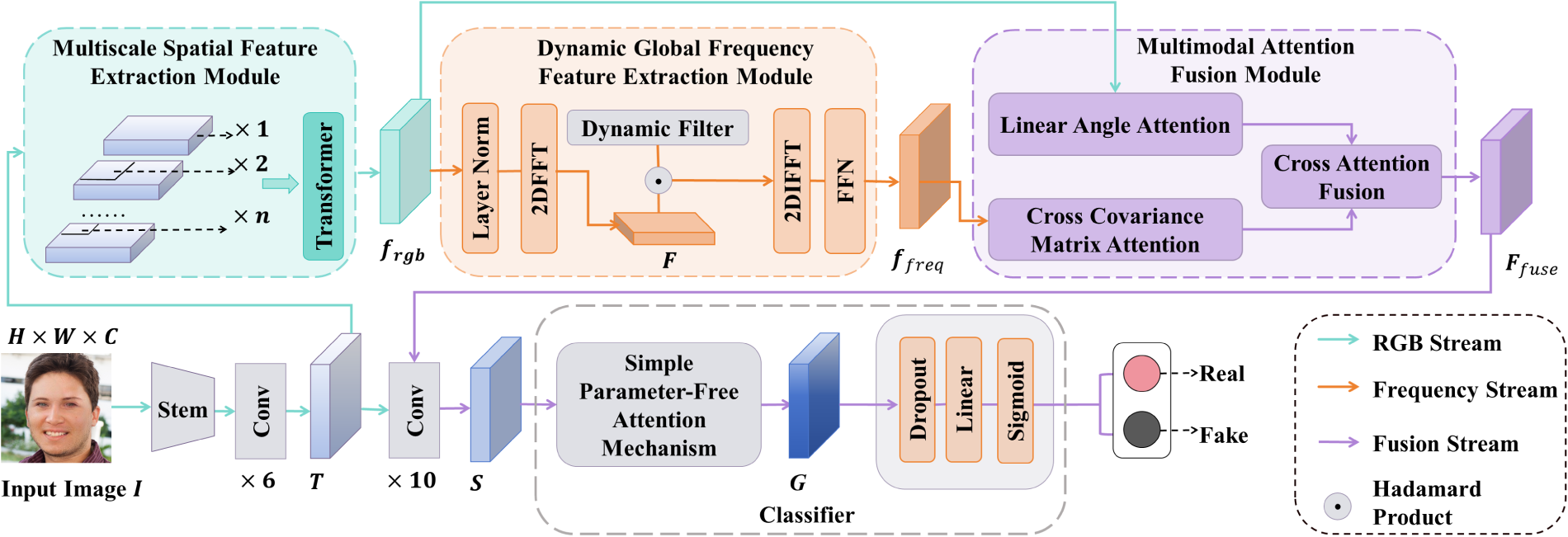
The Overall Structure of the Frequency Assisted Multiscale Dual-Stream Network.
The multiscale spatial feature extraction module constructs Transformer encodings on image patches of varying scales. By employing the multihead self-attention mechanism, it extracts local anomaly patterns under different receptive fields, thereby capturing multiscale RGB features and revealing artifacts of varying scales in low-quality forged facial images. Initially, low-level texture features


In this article, four different sizes of image patches (original size,
The dynamic global frequency feature extraction module employs the FFT with the integration of dynamic filters to extract frequency features. Unlike static global filters used in previous work, these dynamic filters adaptively generate flexible feature extraction patterns that adjust to input characteristics, thereby capturing artifacts that are difficult to discern in the spatial domain. The structure is illustrated in Figure 2. Firstly, the FFT is applied to the multiscale spatial features




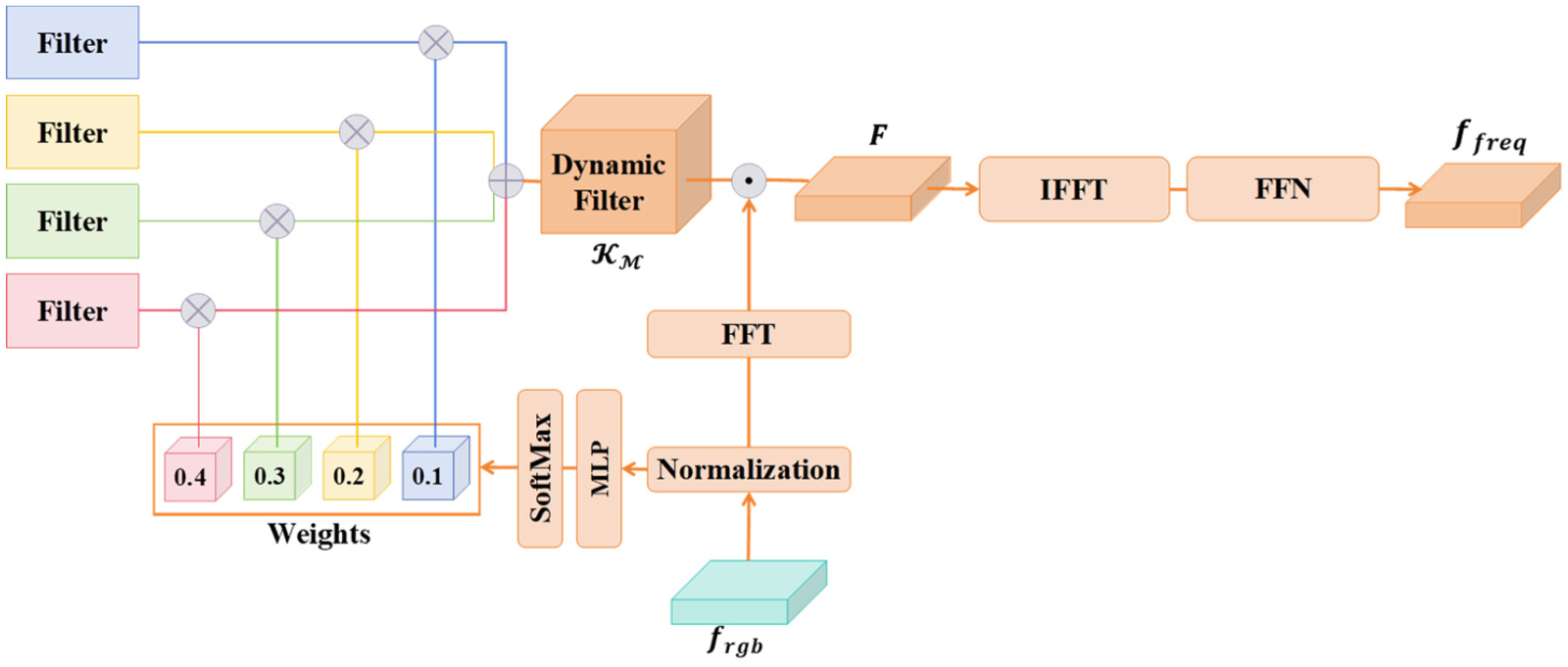
The Structure of the Dynamic Global Frequency Feature Extraction Module.
Here,


The multimodal attention fusion module effectively captures the correlation between RGB and frequency features to integrate multiscale RGB features
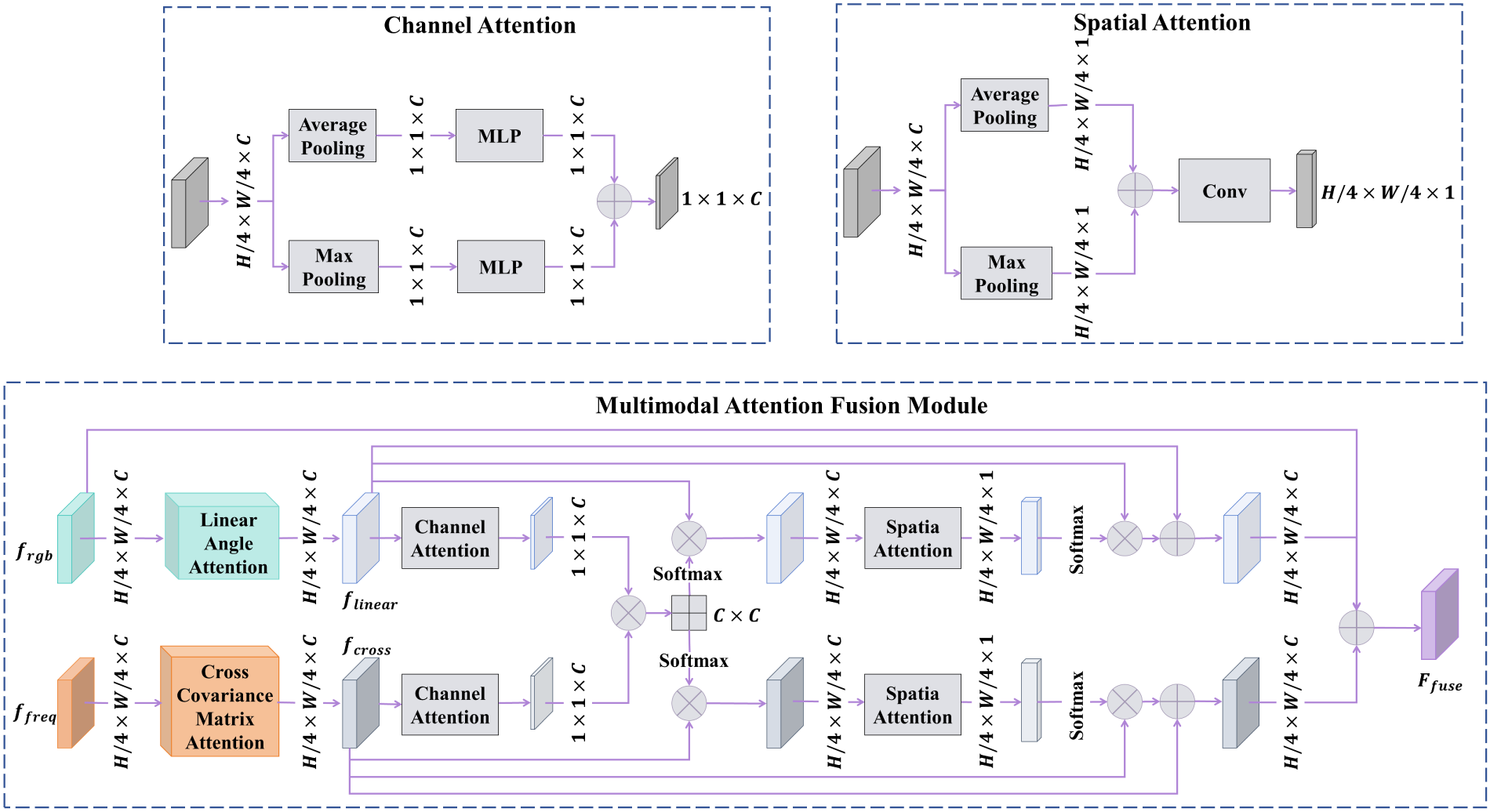
The Structure of the Multimodal Attention Fusion Module.
Linear angular attention is introduced to enhance multiscale spatial features
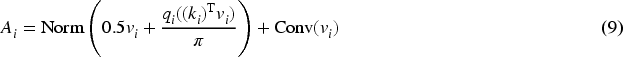
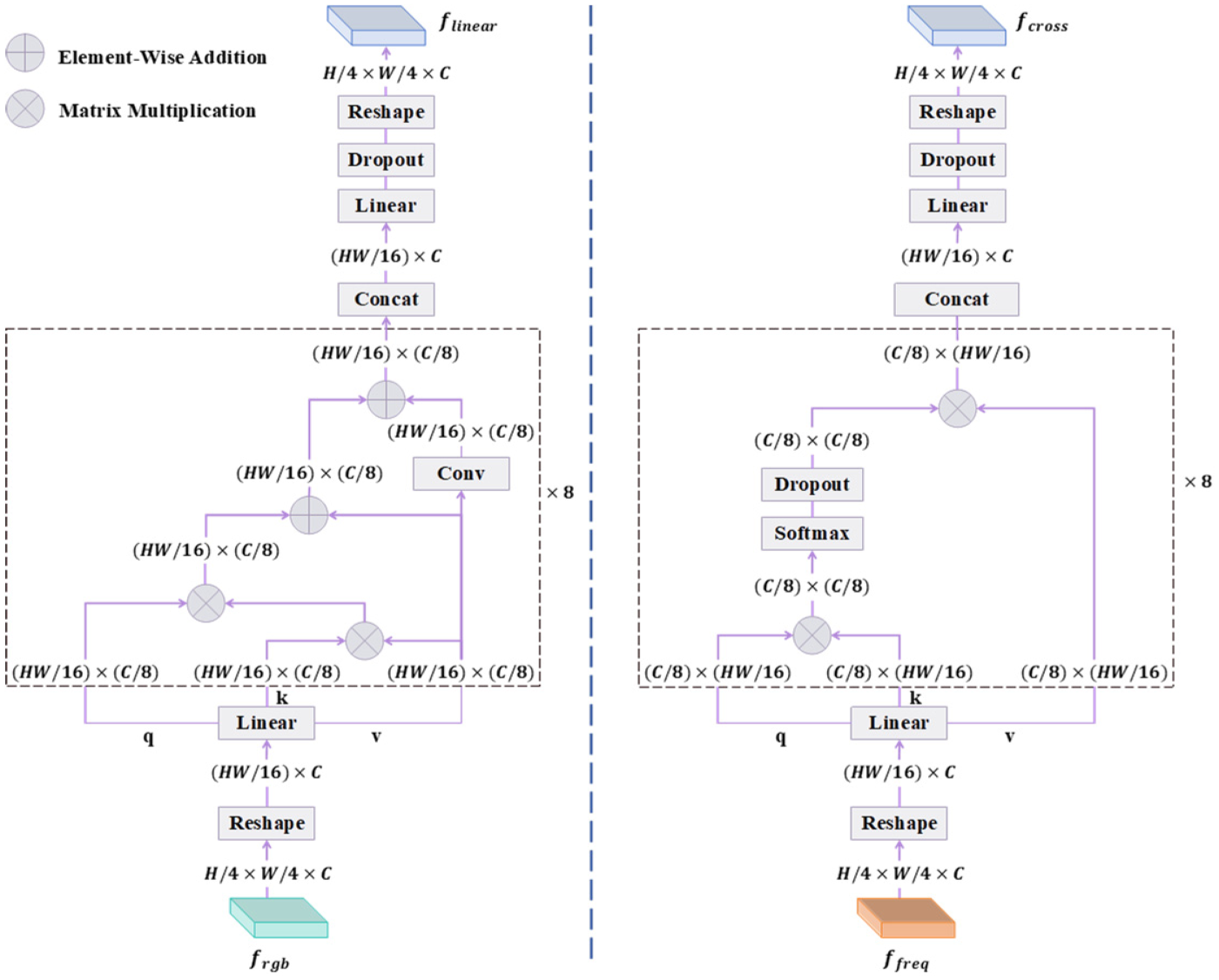
The Structure of Linear Angular Attention and Cross-Covariance Matrix Attention.
The weight of v is set to 0.5 to balance its contribution in the final output, preventing it from dominating the output and avoiding gradient explosion.


Dynamic global frequency features

In this article, N is set to 8. Then, the outputs of each head will be concatenated along the channel dimension. After passing through the linear layer and Dropout, the frequency features enhanced by the cross-covariance matrix attention are reshaped to obtain the output


Cross-attention fusion is employed to fuse
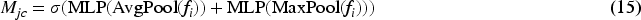



Subsequently, spatial attention mechanism is performed on the two feature maps. For each feature map
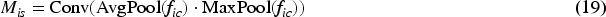


Finally, the features

The variable i denotes the output feature of the i-th cross-attention fusion. Subsequently, the multiscale spatial feature extraction module, dynamic global frequency feature extraction module, and multimodal attention fusion module are iteratively repeated and stacked four times to generate the final fused features
To effectively amplify the key information embedded in input features and thereby enhance the classifier's performance, a parameter-free attention mechanism is incorporated prior to fully connected layers after the entire feature extraction and fusion process is completed. Initially, the spatial-wise mean

Subsequently, the weighted coefficient y and the features



Here, y is conceptualized as the parameter-free attention mechanism that modulates the output by leveraging statistical properties (i.e., mean and variance) of the input, thereby accentuating discriminative features. By element-wise multiplication of S with y, the model dynamically adjusts the saliency of each pixel, enhancing the classification accuracy and robustness. Subsequently, the refined features
Experimental Settings
Datasets
We employ intra-dataset and cross-dataset evaluations to validate the effectiveness of the proposed method. For intra-dataset evaluation, the model is trained and tested on the FaceForensics++ (FF++) dataset (Rössler et al., 2019), which is composed of 1,000 authentic videos and 4,000 corresponding manipulated videos generated via four distinct methods: Deepfakes (DF), Face2Face (F2F), FaceSwap (FS), and NeuralTextures (NT). Following the partitioning strategy of FF++, 720 videos per manipulation category are selected for training, 140 for validation, and 140 for testing in the experiment, with 270 frames extracted per video. In this article, authentic images are replicated four times through resampling to mitigate class imbalance. To evaluate the stability of the model under different data splits on the same dataset, we design five independent experiments. In each experiment, a different random seed is used to control frame sampling and resampling processes, ensuring the independence of data partitioning. The final results are presented as the mean ± standard deviation across the five runs, which serve to assess the model's robustness to the internal data distribution of the FF++ dataset. To comprehensively assess generalization of FAMDnet across unseen distributions and manipulation techniques, the FAMDnet trained solely on FF++ is evaluated on two external benchmarks: Celeb-DF (Li, Yang, et al., 2020) and WildDeepfake (Zi et al., 2020) datasets. The Celeb-DF dataset is composed of 590 source videos with diverse demographics from public platforms, along with 5,639 synthesized Deepfake counterparts. The WildDeepfake dataset is aggregated from 3,509 forged sequences and 3,805 authentic sequences directly extracted from uncurated online environments, exhibiting substantial heterogeneity in scenarios, subjects, and activities. This uncontrolled acquisition method presents significant challenges due to the prevalence of low-resolution artifacts characteristic of real-world dissemination. To ensure standardized evaluation, 20,000 randomly selected authentic frames and 20,000 forged frames are selected by each external dataset for testing. We perform three independent random sampling operations from the Celeb-DF and WildDeepfake datasets. The model's adaptability to unseen data distributions and tampering techniques is quantified by computing the mean ± standard deviation of the results across multiple testing rounds. This design effectively mitigates the impact of single-sampling bias on the evaluation of generalization performance.
Implementation Details
We utilize RetinaFace (Deng et al., 2020) to detect facial regions in the input images, align the extracted facial images, and resize them to 320 × 320. For the backbone network, we select EfficientNet-B4 that has been pretrained on ImageNet (Deng et al., 2009). The learning rate is set to 0.0001 with a decay factor of 10 applied every 5 epochs, and the batch size is configured as 8. The model is trained over 30 epochs and optimized using binary cross-entropy loss. We evaluate the classification performance of FAMDnet with Accuracy (ACC) and the area under the receiver operating characteristic curve (AUC), and adopt an image-level evaluation approach applicable to both image forgery detection and video forgery detection. The model is implemented based on PyTorch and trained on the NVIDIA GeForce RTX 4090.
Intra-Dataset Evaluation
Evaluation on Four Deepfake Methods of FaceForensics++ Dataset
The comparative experimental results of the FAMDnet and other state-of-the-art detection methods in detecting low-quality facial images generated by four forgery algorithms are presented in Table 1. The terms DF, FS, F2F, and NT in Table 1 refer to Deepfakes, FS, F2F, and NT, respectively. The model is trained on the high-quality dataset of FF++ and tested on the low-quality dataset of FF++. As illustrated in Table 1, our FAMDnet exhibits better performance, particularly in detecting forged images generated by NT, which are capable of producing intricate details and textures that are challenging to distinguish from real faces. Compared to DDBD (Nirkin et al., 2022), our method achieves AUC improvements of 3.3%, 12.87%, 15.62%, and 14.55% respectively in detecting facial forgery images generated by four different forgery methods. DDBD (Nirkin et al., 2022) first detects faces and expands the bounding boxes to include contextual regions, then utilizes a segmentation network to divide the image into facial and background regions, which are separately fed into an Xception-based facial recognition network and a contextual recognition network. By calculating the identity probability difference vector between their outputs, it captures forgery cues. Additionally, it trains dedicated networks to detect face swapping and reenactment manipulations, concatenating the difference vector with the feature activation values from these two networks before inputting them into a classifier. However, the performance of this method falls short of our FAMDnet. DDBD (Nirkin et al., 2022) merely distinguishes facial and background regions via a segmentation network before feeding them into Xception networks, failing to account for the distortion of multiscale details in low-quality images and thus struggling to capture pixel-level long-range dependencies. In contrast, FAMDnet employs ViTs to perform multiscale feature extraction on image patches of varying sizes, enabling effective capture of detail distortions at different resolutions in low-quality images. Furthermore, DDBD (Nirkin et al., 2022) relies solely on spatial-domain identity probability difference vectors to capture forgery cues, making it incapable of identifying periodic artifacts introduced by forgery operations such as resampling and compression in the frequency domain. When detecting face images generated by four forgery methods, the average AUC of our method exceeds that of DCDD (Hu, Liao, Wang, et al., 2022) by 8.3%. DCDD (Hu, Liao, Wang, et al., 2022) proposes a dual-dimensional compression-based Deepfake video detection method. At the frame level, it targets compression-induced artifacts such as block boundary distortions and quantization noise, employing a CNN with a pruning module to extract features and validating compression noise and structural distortions using peak signal-to-noise ratio and structure similarity index measure. At the temporal level, leveraging the characteristic of Deepfake videos being encoded frame-by-frame, which results in a lack of interframe temporal consistency, it confirms the low inter-frame correlation of forged videos through Hamming distance. By combining the principles of encoding, it derives the correlation between residual features and temporal information to capture sequential anomalies. The frame-level stream extracts facial regions from I-frames using MesoNet combined with an iterative pruning network for feature extraction, while the temporal-level stream divides the video into three segments, extracts residual features, and inputs them into ResNet18, subsequently fusing the outputs of both streams. However, when DCDD (Hu, Liao, Wang, et al., 2022) relies on a CNN with a pruning module at the frame level to extract compression features, block boundary artifacts and quantization noise in low-quality forged images are easily blurred, making it difficult for the CNN to capture spatial-domain anomalies. At the temporal level, when analyzing inter-frame correlation through Hamming distance, it struggles to accurately capture the nonlinear inter-frame dependencies caused by dynamic lighting changes or multiframe synthesis resulting from frame-by-frame encoding of Deepfakes. These limitations may contribute to its performance being inferior to our method. The average AUC of our method exceeds that of PRRNet (Shang et al., 2021) by 4.73%. PRRNet (Shang et al., 2021), which is primarily designed for spliced facial image detection, locates tampered regions at the pixel level and extracts features from both tampered and original regions. By capturing inter-regional correlations and integrating three metric methods (cosine distance, Euclidean distance, and inner product), it calculates regional inconsistency scores. This approach not only leverages multilevel relationships to pinpoint tampered regions but also facilitates the classification of real and fake images. However, PRRNet (Shang et al., 2021) exhibits two limitations. First, it solely focuses on spatial-domain pixel and regional relationships. When confronted with low-quality forged facial images where artifacts vanish in the spatial domain, PRRNet (Shang et al., 2021) fails to capture the unique distortion traces left by forgery operations such as Deepfake in the frequency domain. Second, during global feature classification via fully connected layers, it lacks an adaptive weighting mechanism for noise in low-quality images, which may lead to misclassifying noise as tampered features or overlooking genuine tampering signals. These shortcomings may contribute to its inferior detection performance compared to the proposed method. When detecting face images generated by four forgery methods, the average AUC of our method outperforms SARB-DF (Prathibha et al., 2024) by 3.38%. SARB-DF combines self-attention mechanisms with continual learning, capturing long-range inter-frame dependencies through residual self-attention and integrating them into the XceptionNet backbone network to fuse local and global features. Additionally, it employs an elastic weight consolidation continual learning approach, leveraging the Fisher information matrix to constrain critical weights and prevent catastrophic forgetting. Furthermore, it introduces an uncertainty-based dynamic sampling strategy, selecting high-information samples near the decision boundary to optimize the model, thereby enhancing its generalization capability in detecting compressed videos and novel synthetic data. However, SARB-DF (Prathibha et al., 2024) solely relies on spatial-domain self-attention for feature extraction, failing to exploit frequency domain forgery traces. Under low-quality compression conditions, salient region features in the spatial domain are often obscured by noise. In comparison, our FAMDnet employs FFT and adaptive dynamic filters to capture frequency domain forgery artifacts, demonstrating heightened sensitivity to frequency anomalies induced by compression. FAMDnet effectively compensates for the lack of frequency domain features and improves the detection capability for low-quality Deepfake samples. The average AUC of our method exceeds that of Ensemble (Omar et al., 2024) by 3.8%. The Ensemble (Omar et al., 2024) combines the CoAtNet integrated model with CutMix augmentation, addressing the issue of ViT's lack of image inductive bias. CoAtNet integrates MBConv and self-attention with relative bias. The former employs a three-layer structure of expansion-depth convolution-projection along with residual connections to achieve lightweight and efficient feature extraction, while the latter leverages patch-based sequential modeling and 2D relative positional encoding to capture global dependencies. Additionally, it generates independent models through Bagging bootstrap sampling and fuses predictions using rules such as majority voting. By incorporating CutMix regional replacement to enhance data diversity, it synergistically optimizes convolutional local features and global modeling via self-attention, thereby improving detection robustness. However, the Ensemble (Omar et al., 2024) relies on the traditional majority voting strategy of conventional ensemble methods. This strategy fails to account for differences in feature importance and exhibits insufficient robustness in classifying low-quality samples sensitive to noise. In contrast, our method enhances robustness by introducing a parameter-free attention mechanism before the classifier. This mechanism calculates weighted coefficients based on feature mean and variance, dynamically amplifying the weights of critical forgery features in low-quality images to improve classification robustness. When detecting face images generated by four forgery methods, the average AUC of our method exceeds that of MLP-Mixer (Essa, 2024) by 3.61%. MLP-Mixer (Essa, 2024) integrates DaViT, iFormer, and GPViT. DaViT employs a dual spatial-channel self-attention mechanism to balance image details and global context. IFormer utilizes an Inception token mixer to decompose features into high-frequency and low-frequency paths, capturing different frequency information through pooling-convolution and self-attention operations, respectively. GPViT leverages group propagation blocks to efficiently propagate global information in high-resolution features. Additionally, MLP-Mixer (Essa, 2024) performs feature fusion via token mixing and channel mixing operations, and after multilayer processing, outputs classification results to enhance its detection capability for various Deepfake types. However, MLP-Mixer (Essa, 2024) only processes features in the spatial domain, making it difficult to capture forgery traces such as spectral anomalies in NT synthesis, which vanish in the spatial domain. In contrast, FAMDnet transforms spatial features into the frequency domain through two-dimensional Fourier transform, combines dynamic filters to select key frequency components, and then maps the frequency features back to the spatial domain via inverse transform. Our approach enhances the detection capability of subtle frequency domain forgery artifacts in low-quality samples. Overall, our FAMDnet achieves better performance in detecting low-quality forged images generated by four different forgery algorithms compared to other methods.
Comparative Experimental Results of Detecting Low-Quality Facial Images Generated by Four Forgery Methods.
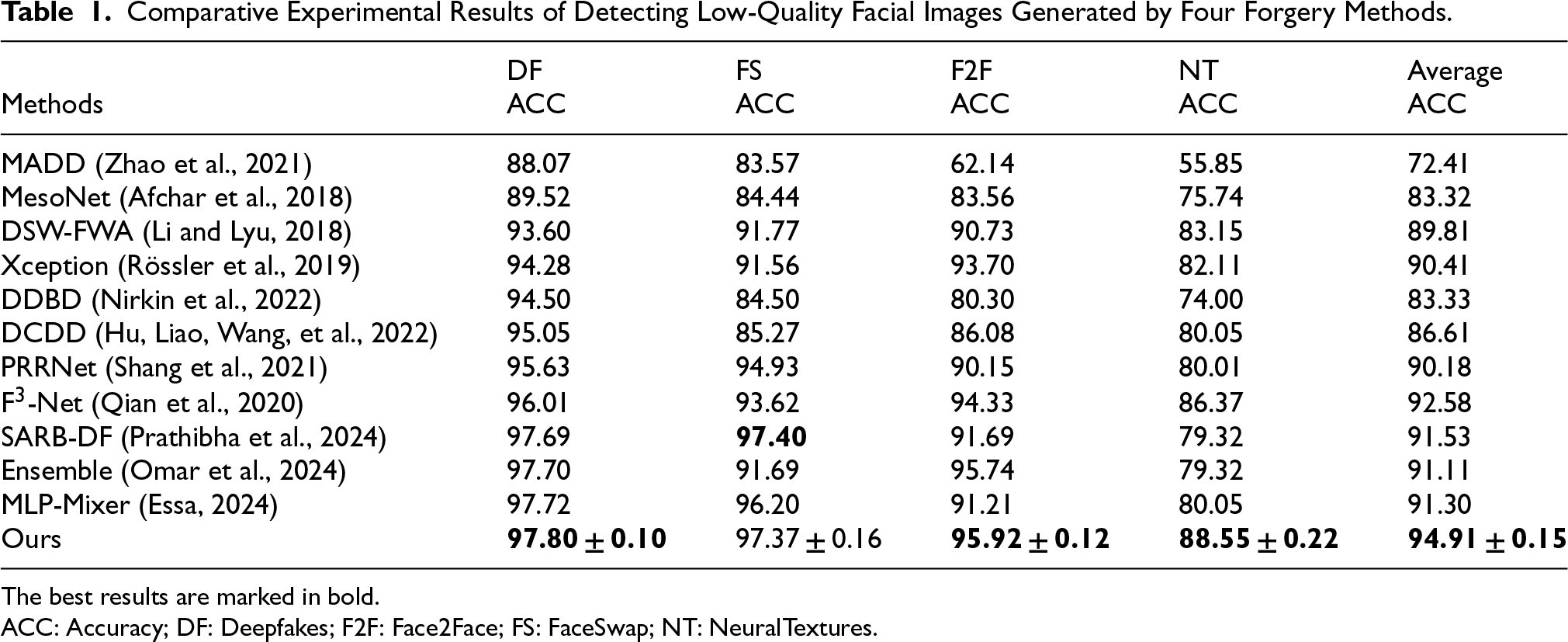
Comparative Experimental Results of Detecting Low-Quality Facial Images Generated by Four Forgery Methods.
The best results are marked in bold.
ACC: Accuracy; DF: Deepfakes; F2F: Face2Face; FS: FaceSwap; NT: NeuralTextures.
The comparative experimental results of FAMDnet and other state-of-the-art detection methods on the high-quality (HQ) and low-quality (LQ) datasets of FF++ are presented in Table 2. Our FAMDnet achieves better performance on both datasets, indicating its effectiveness in detecting Deepfakes across varying levels of compression, particularly demonstrating superior detection accuracy on the low-quality dataset. As shown in Table 2, most methods perform exceptionally well on the high-quality dataset. However, they perform significantly worse when applied to the low-quality dataset. Compared with MH-FFNet (Zhou et al., 2025), our method achieves an 8.76% higher AUC on low-quality datasets while only trailing by 0.04% on high-quality ones. MH-FFNet (Zhou et al., 2025) uses ConvNeXt as the backbone, enhancing local mid-high-frequency textures via DCT in shallow features and capturing global frequency domain semantics with self-attention in mid-level features. However, its low-quality performance declines due to the lack of noise alignment, making shallow features vulnerable and mid-level semantics insufficient in blurred regions. Our method leverages FFT and dynamic filters to mine imperceptible spatial forgery artifacts, enhancing frequency-spatial interaction through a multimodal attention fusion module. Its linear angular attention and cross-covariance matrix attentions suppress noise and boost discriminability, addressing low-quality issues like blurring and compression artifacts. Thus, it excels in low-quality scenarios, while MH-FFNet (Zhou et al., 2025) suits high-texture detection. Compared with FFD (Zhang et al., 2025), our method surpasses it by 6.45% and 0.7% in AUC on low-quality and high-quality datasets, respectively. FFD (Zhang et al., 2025) uses a dual-branch structure with EfficientNet-b4 as the backbone, inputting RGB images and extracting high-frequency noise features via trainable SRM convolutions. It employs multiscale convolutions for intermediate features, cross-stream attention matrices with learnable weighting, and multiscale global features via pooling and MLP channel weighting to filter noise. In contrast, our FAMDnet adopts FFT and learnable filters to adaptively extract frequency domain forgery traces, which are more flexible than FFD's fixed SRM convolutions. Additionally, it achieves bidirectional guidance and refined interaction between spatial and frequency features, which are more precise than FFD's single cross-stream attention, suppressing irrelevant noise and enhancing key cues. Compared with HFI-Net (Miao, Tan, et al., 2022), our method exceeds it by 5.45% and 0.74% in AUC on the low-quality and high-quality datasets, respectively. HFI-Net (Miao, Tan, et al., 2022) is a dual-branch hierarchical network composed of a Transformer branch for capturing global context and a CNN branch for extracting local details. It suppresses high-level semantic interference via mid-high-frequency forgery traces, purifies mid-high-frequency features via discrete cosine transform to generate attention weights, and calibrates feature responses to enhance forgery cues. However, its performance on both low-quality and high-quality datasets is inferior to ours. Our FAMDnet captures frequency domain artifacts in low-quality images via FFT and dynamic filters, while HFI-Net's frequency domain processing has weaker dynamic adaptability and global filtering capabilities. Our multiscale spatial feature extraction module leverages ViT to process image patches of different sizes, capturing subtle cross-scale pixel correlations in high-quality images and making up for HFI-Net's insufficient fine-grained feature modeling of high-quality images by its Transformer branch. Our parameter-free attention classifier dynamically enhances key information to adapt to different quality data, while HFI-Net's dual-classifier average output lacks flexibility. Compared with DFDT (Khormali and Yuan, 2022), our method achieves 1.72% and 0.14% higher AUC on low-quality and high-quality datasets, respectively. DFDT (Khormali and Yuan, 2022) uses overlapping patch extraction to process images. It forms input sequences with latent embeddings and positional embeddings, fuses Transformer attention weights to extract key tokens, and employs multistream Transformers. The low-level branches of these Transformers learn local features via small-sized. The high-level branches extract global features via large-sized patches. DFDT (Khormali and Yuan, 2022) makes initial predictions via residual blocks in low-level and high-level Transformers, then averages multiscale prediction results for final detection. However, it relies on spatial-domain multiscale patch extraction and attention averaging without frequency domain support. Our FAMDnet leverages FFT and dynamic filters to mine imperceptible artifacts in the frequency domain. This enhances its robustness to blurred features in low-quality datasets, thus enabling it to outperform DFDT (Khormali and Yuan, 2022). Compared with SGF (Khormali and Yuan, 2024), our method achieves 1.04% and 0.06% higher AUC on low-quality and high-quality datasets, respectively. SGF (Khormali and Yuan, 2024) first partitions images into patches and constructs graphs, using feature embeddings as graph nodes and spatial proximity as edges. Then it employs ViT combined with self-supervised contrastive learning. Through masked modeling and student–teacher networks, it generates cross-view features, while improving feature generalization via contrastive loss and self-distillation loss. Subsequently, it extracts node local features through graph convolutional layers and fuses global dependencies via Transformer attention mechanisms. Finally, it performs classification after reducing the number of nodes via min-cut pooling. However, its performance on the low-quality dataset is inferior. This may stem from SGF's insufficient global semantic modeling in spatial proximity graphs while our FAMDnet uses ViT to compute cross-scale self-attention for multisize patches, capturing global–local dependencies and adapting to low-quality's pixel relationship changes. Additionally, SGF (Khormali and Yuan, 2024) lacks frequency domain artifact mining, whereas low-quality forged traces often reside in the frequency domain, leading to SGF's incomplete feature representation and poor low-quality performance. Overall, our FAMDnet demonstrates better performance in detecting forgeries across various compression levels.
Comparative Experimental Results of Detecting High-Quality and Low-Quality Deepfake Facial Images.
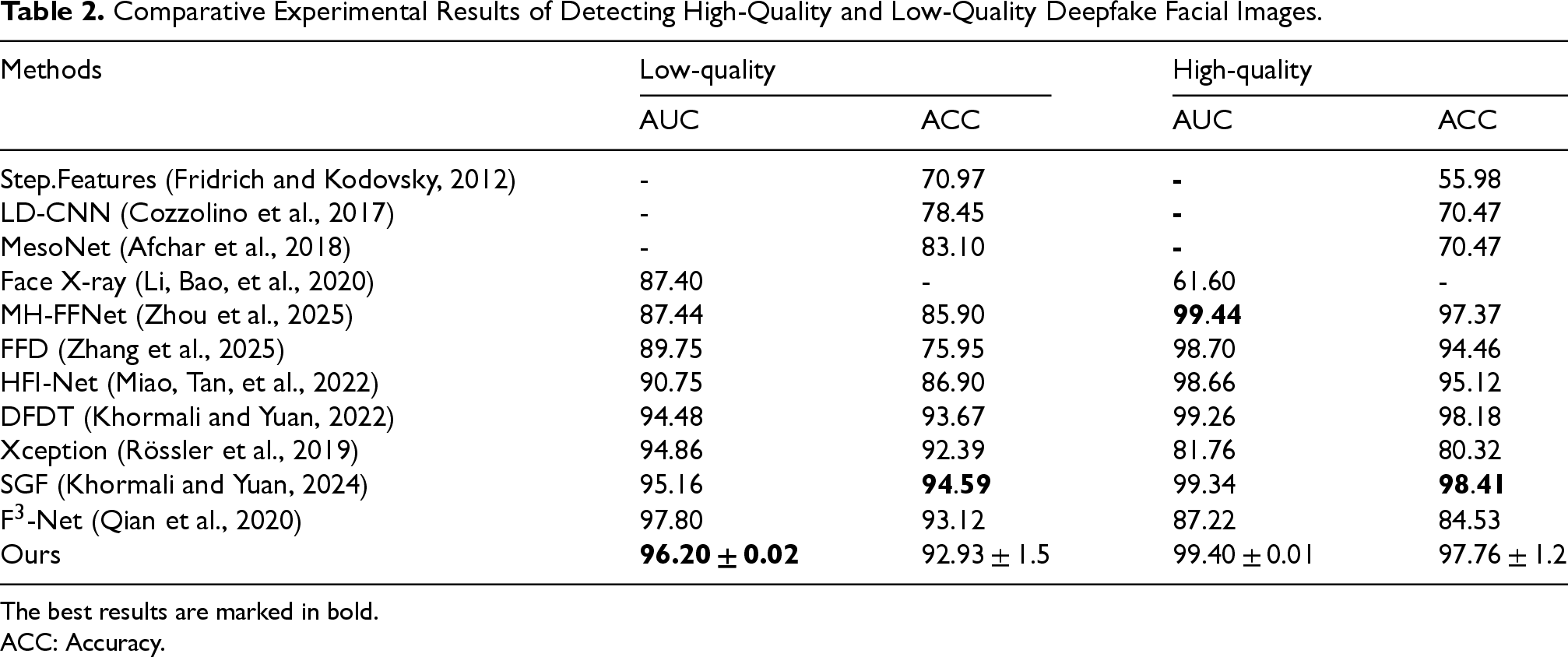
Comparative Experimental Results of Detecting High-Quality and Low-Quality Deepfake Facial Images.
The best results are marked in bold.
ACC: Accuracy.
The AUC of FAMDnet, compared with that of other state-of-the-art methods on the Celeb-DF and WildDeepfake datasets, is presented in Table 3. FAMDnet is trained on the high-quality dataset of FF++ and tested on Celeb-DF and WildDeepfake to evaluate its effectiveness and robustness when confronting low-quality forged images and videos in real-world scenarios. As shown in Table 3, our FAMDnet demonstrates superior performance on both datasets. Our method achieves AUC improvements of 12.2% and 10.3% over DCViT (Wodajo and Atnafu, 2021) on two datasets, respectively. DCViT (Wodajo and Atnafu, 2021) adopts a hybrid architecture combining VGG and ViT, where its feature learning module first extracts spatial texture features from images using VGG, and then utilizes ViT to serialize these features into classification inputs. The model exhibits weak generalization capability, primarily because it relies solely on the VGG convolutional layers to extract spatial features, making it difficult to adapt to distributional differences across various datasets. Additionally, its Softmax classifier performs discrimination directly based on global features, which is easily susceptible to noise interference from low-quality images. Our method achieves AUC improvements of 7.79% and 7.61% over RFM (Wang and Deng, 2021) on two datasets, respectively. RFM (Wang and Deng, 2021) identifies detector-sensitive regions by computing the gradient differences between authentic and forged image outputs. Unlike class activation mapping, it generates sensitive regions at the image level and focuses on critical areas. By occluding the top N sensitive regions, this method can preserve more facial information while mitigating detector overfitting caused by information leakage. However, RFM (Wang and Deng, 2021) has two limitations. First, it relies on detector-sensitive region localization specific to a particular dataset, and cross-dataset application may lead to shifts in sensitive regions due to variations in forgery patterns. Second, the occlusion operation (e.g., random rectangular patches) may disrupt facial key information, and cross-dataset application may disrupt the balance between information retention and forgery region erasure due to differences in data distributions. In contrast, our FADMnet does not depend on gradient information from specific detectors but instead directly mines forgery cues from the spatial and frequency domain correlations within the image itself. Our method achieves an AUC score on the Celeb-DF dataset that surpasses LDFnet (Guo et al., 2024) by 7.3%. LDFnet (Guo et al., 2024) is designed to capture local salient artifacts and global subtle texture variations through two complementary approaches. The local artifact representation is obtained via five depthwise separable convolutional layers, which focus on local operational cues, while the global texture representation is extracted using depthwise separable convolutions to capture local features and multilayer perceptrons combined with max-pooling to capture global features, thereby extracting both low-level and high-level texture features. The local and global features are then concatenated and processed through depthwise separable convolutions to generate hybrid features. Subsequently, an attention matrix is generated from the global features to refine the features and ultimately produce the fused features. However, its dynamic fusion mechanism relies on fixed concatenation and depthwise separable convolutions for feature fusion, making it difficult to adapt the fusion weights to different data distributions across datasets. In contrast, our FAMDnet incorporates a multimodal attention fusion module, which enhances long-range dependencies in spatial features through linear angular attention and captures channel correlations in frequency-domain features via cross-covariance matrix attention. Furthermore, the dual channel-spatial attention mechanism within the cross-attention fusion module adaptively learns the fusion weights for spatial and frequency-domain features, thereby improving the flexibility of feature fusion across different datasets. Our method achieves AUC improvements of 7.3% and 4.3% over M2TR (Wang et al., 2021) on two datasets, respectively. M2TR (Wang et al., 2021) first partitions features into patches of varying sizes to compute patch-level self-attention. Subsequently, it transforms the features into the frequency domain via 2D FFT and performs Hadamard product operations with learnable filters to obtain frequency-aware features. Finally, the RGB spatial features and frequency features are embedded as query-key-value pairs for fusion. The loss function framework of M2TR (Wang et al., 2021) includes cross-entropy loss for classification tasks, segmentation loss for forgery mask prediction, and contrastive loss to drive real sample features toward a feature center. However, the static global frequency filters employed by M2TR (Wang et al., 2021) struggle to adapt to frequency feature variations caused by differing compression levels and forgery algorithms across datasets. To address this, our FAMDnet dynamically generates adaptive filters via MLP, which can adjust frequency-domain weights in real time based on input features. This effectively captures the concealed frequency-domain traces of forgery obscured by compression in different datasets, significantly enhancing cross-dataset robustness. At the cross-modal fusion level, M2TR (Wang et al., 2021) merely implements feature fusion through a simple query-key-value mechanism, insufficiently exploring the interactions between spatial and frequency-domain features. In contrast, FAMDnet's multimodal attention fusion module introduces linear angle attention to strengthen long-range dependencies in spatial features. It employs cross-covariance matrix attention to enhance interchannel correlations in frequency features and further reinforces the complementarity of cross-modal features through a dual channel-space attention mechanism in cross-attention fusion, achieving deeper feature interactions. Our method achieves AUC improvements of 3.57% and 8.04% over FFD (Zhang et al., 2025) on two datasets, respectively. FFD (Zhang et al., 2025) employs trainable SRM convolutions to extract high-frequency noise, but its convolutional kernel parameters are fixed, making it difficult to adapt to variations in noise characteristics caused by differences in generation algorithms, compression quality, and other factors across different forgery datasets. This limitation hinders its effectiveness in cross-domain detection, as it cannot efficiently extract noise features under such conditions. In contrast, our FAMDnet can adaptively adjust filter weights based on input features through MLPs, while also leveraging FFT to extract frequency-domain features. Our approach enables dynamic optimization of filtering strategies according to the frequency distributions of different datasets, significantly enhancing the ability to capture cross-domain noise features. Consequently, our method outperforms FFD in performance. Our method achieves AUC improvements of 3.16% and 7.56% over FFDM (Zhang et al., 2024) on two datasets, respectively. FFDM (Zhang et al., 2024) employs EfficientNet as the backbone network to extract spatial features while utilizing learnable SRM filters to capture noise features. By generating noise attention maps and fusing them with spatial features, the model further processes these features through a channel attention mechanism to enhance feature representation. Additionally, it integrates Bi-Level Routing Attention mechanisms with 4 × 4 and 7 × 7 scales, leveraging self-attention to capture long-range dependencies, thereby improving the expressiveness of local features. The enhanced features are ultimately fed back into the backbone network to complete the classification task. However, FFDM (Zhang et al., 2024) suffers from insufficient cross-dataset generalization. It directly utilizes the backbone network for classification without optimizing for feature distribution discrepancies across datasets. Our FAMDnet introduces a parameter-free attention mechanism before the classifier. By computing the mean and variance of features to generate weighting coefficients, it dynamically enhances critical forgery features while suppressing noise interference, effectively improving the model's classification robustness across different datasets. On the Celeb-DF dataset, our method achieved a 2.95% improvement in AUC compared to MLP-Mixer (Essa, 2024). Although MLP-Mixer (Essa, 2024) relies on the integration of different Transformer modules, it lacks flexibility in capturing cross-scale pixel relationships in low-quality images, particularly in modeling small-scale forgery traces such as compression artifacts and edge halos. In contrast, our FAMDnet leverages ViT to perform self-attention computation on image patches of varying sizes, and combines residual blocks to achieve multiscale feature fusion, effectively capturing forgery cues at different scales in low-quality images. Our method achieves an AUC that surpasses FInfer's (Hu, Liao, Liang, et al., 2022) AUC by 2.4% on the Celeb-DF dataset. FInfer (Hu, Liao, Liang, et al., 2022) first extracts frames from videos and detects faces, then employs Laplacian of Gaussian pyramid transformations on facial data to reveal tampering boundaries. Subsequently, it encodes the source and target faces into a 128-dimensional low-dimensional space using an encoder to mitigate the curse of dimensionality and extract effective features. A Gated Recurrent Unit is then adopted to construct a regression model, leveraging gating mechanisms to handle temporal dependencies and predict target face representations based on source face representations. Finally, correlation learning is applied to compute the correlation between predicted and actual representations, with the model optimized end-to-end through cross-entropy loss. This approach is particularly effective for detecting high-visual-quality deepfakes. However, FInfer (Hu, Liao, Liang, et al., 2022) relies on temporal predictions between the current frame and future frames, and cross-dataset variations in temporal dynamics due to different forgery techniques (such as frame rates and expression patterns) lead to reduced generalization capability. In contrast, our FAMDnet weakens the dependency on temporal information through multiscale spatial feature extraction and dynamic global frequency feature extraction, directly capturing spatial and frequency-domain traces of forgery to enhance cross-dataset robustness. Overall, our method demonstrates commendable effectiveness when addressing low-quality forged images and videos in real-world scenarios.
Evaluation on Celeb-DF and WildDeepfake Datasets.
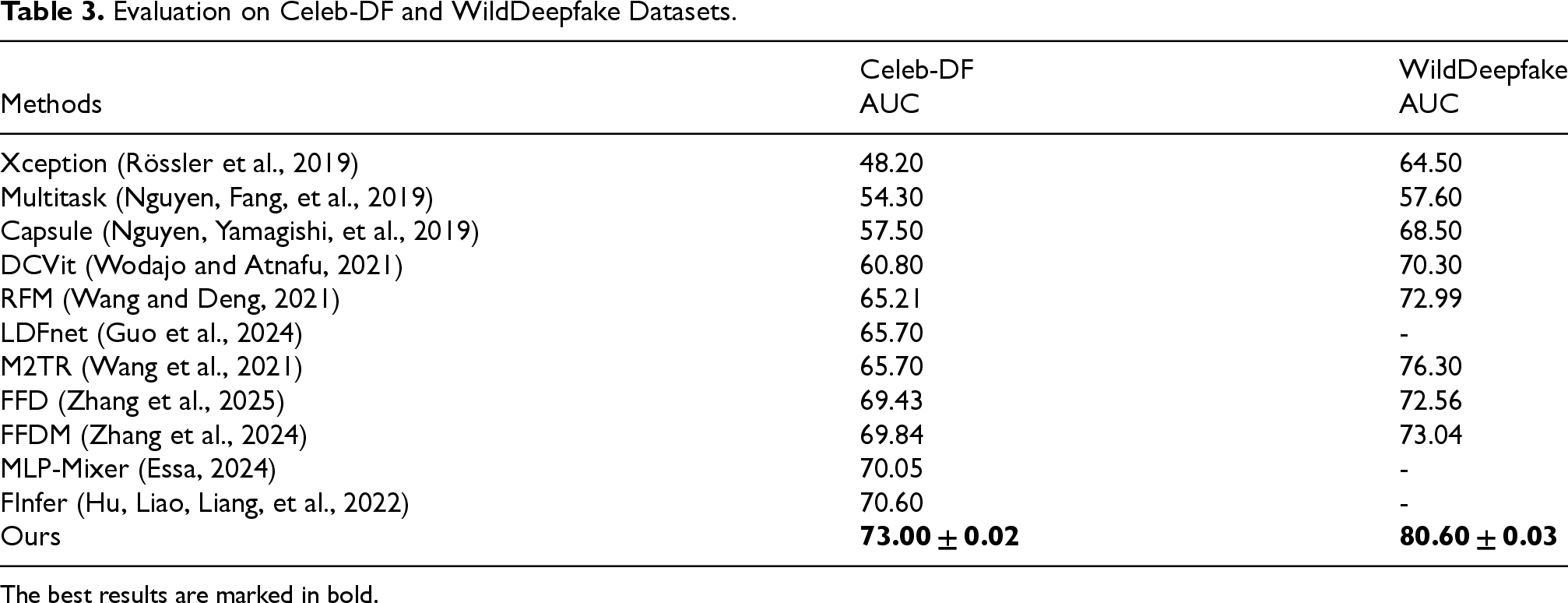
Evaluation on Celeb-DF and WildDeepfake Datasets.
The best results are marked in bold.
Effectiveness of Different Modules
Our FAMDnet is primarily composed of the multiscale spatial feature extraction module, the dynamic global frequency feature extraction module, the multimodal attention fusion module, and the classifier based on the parameter-free attention mechanism. To verify the effectiveness of each module of FAMDnet, experiments are conducted on the FF++ dataset, comparing the changes in ACC and AUC of detection performance for various module combinations in two datasets of different qualities. The experimental results are shown in Table 4. In Table 4, “RGB” represents the multiscale spatial feature extraction module, “Freq.” denotes the dynamic global frequency feature extraction module, “Fusion” indicates the use of the multimodal attention fusion module to integrate spatial and frequency features. “SimAM” refers to the classifier based on parameter-free attention mechanism. As shown in Table 4, when all modules are combined, the model exhibits optimal performance on both low-quality and high-quality datasets. In the low-quality dataset, using only the multiscale spatial feature module causes a significant decrease of 12.90% in ACC and 10.20% in AUC, which is particularly obvious because image and video compression can lead to the disappearance of certain artifacts in the spatial domain. By contrast, the dynamic global frequency feature extraction module outperforms the multiscale spatial feature extraction module when used alone, as artifacts that vanish in the spatial domain can still be detected in the frequency domain. However, compared with FAMDnet, using only frequency features leads to a decrease of 7.08% in ACC and 4.80% in AUC. In the high-quality dataset, using only the multiscale spatial feature module causes a decrease of 0.55% in ACC and 0.60% in AUC, while using only the dynamic global frequency feature extraction module results in a decrease of 2.74% in ACC and 1.30% in AUC, indicating that RGB features play a more critical role in identifying forgery traces in high-quality datasets. For the multimodal attention fusion module, using simple feature concatenation instead of the proposed fusion mechanism causes a 7.14% decrease in ACC and 4.40% decrease in AUC on the low-quality dataset. On the high-quality dataset, this simple concatenation leads to a 7.24% drop in ACC and 2.20% drop in AUC. These results suggest that the multimodal attention fusion module effectively integrates spatial and frequency features to enhance FAMDnet's performance. For the classifier with the simple parameter-free attention mechanism, removing this mechanism in the low-quality dataset leads to a decrease of 3.33% in ACC and 2.30% in AUC. To more clearly understand the roles of different modules in facial forgery detection, the features learned by different module combinations are visualized. Figure 5 shows a comparative analysis of feature maps generated by these combinations, including original images and fake images generated by four different forgery methods of the FF++ dataset. It can be seen from Figure 5 that multiscale spatial features mainly focus on global facial images, while frequency features emphasize the acquisition of detailed information, with the frequency domain particularly focusing on the high-frequency components of images that usually contain complex details. When comparing the use and nonuse of the multimodal attention fusion module, it is found that using the fusion module allows simultaneous attention to both the overall facial images and their detailed aspects. Overall, the modules proposed in this article demonstrate significant effectiveness.
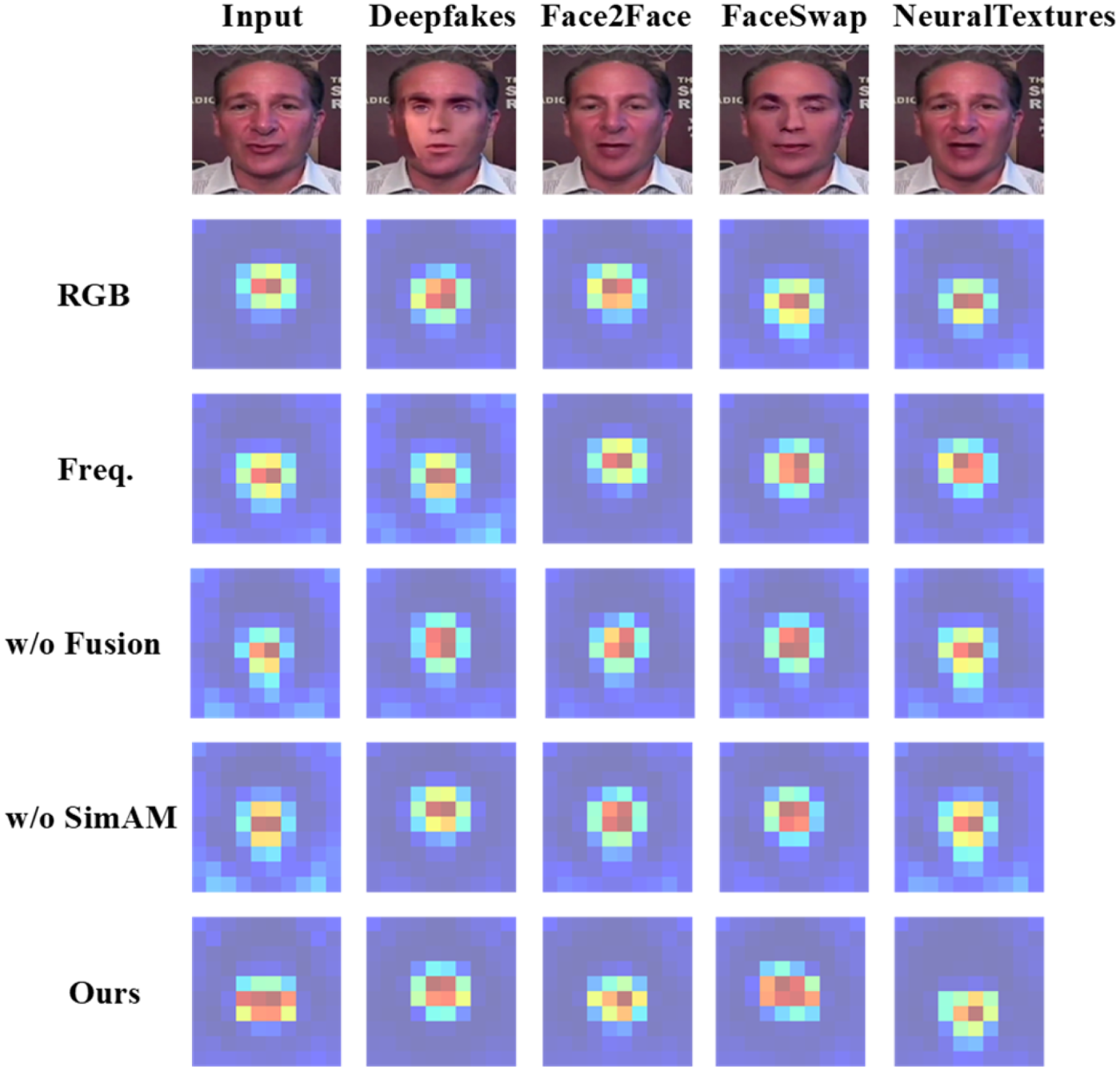
Comparison of Feature Maps of Different Module Combinations.
Experimental Ablation Results of Combination of Each Module.
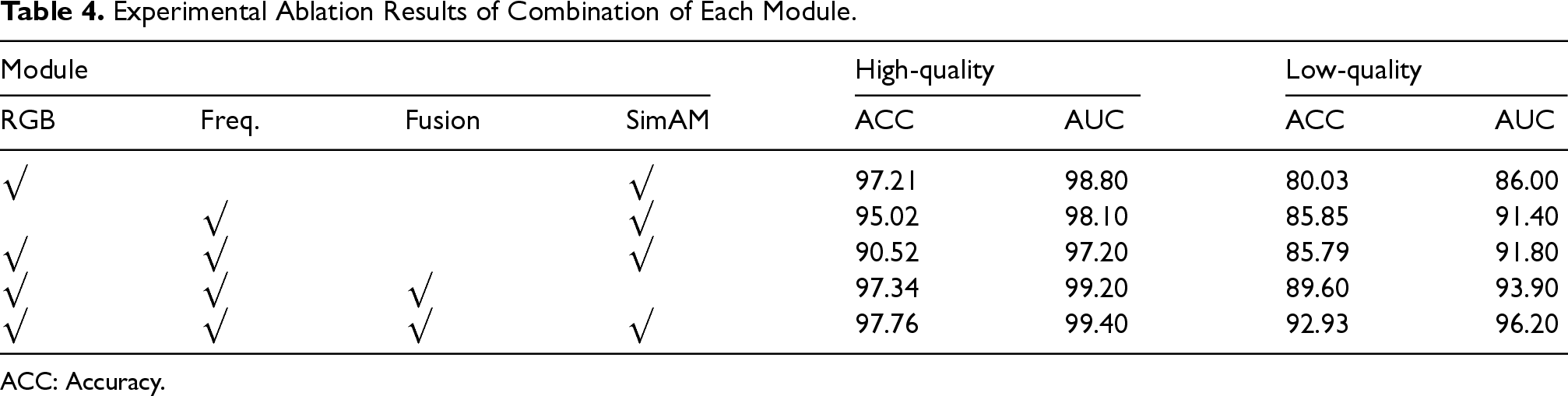
ACC: Accuracy.
Our FAMDnet extracts frequency features via FFT with dynamic filters that adapt based on input contextual information to apply distinct filters at different spatial locations and feature channels, unlike traditional global filters that use uniform transformations, thereby enabling the model to more effectively capture and model local features and complex patterns while enhancing its capability to discern fine-grained details in diverse contexts. To assess the impact of the number of dynamic filters on the performance of FAMDnet, the model is trained on the high-quality dataset of FF++ while tested on the low-quality dataset, with experiments utilizing 2, 4, 6, and 8 dynamic filters, as presented in Table 5. As is evident from Table 5, when the number of dynamic filters is set to 2, FAMDnet has fewer parameters and lower complexity, yet exhibits low ACC and AUC, likely due to its limited expressive capacity hindering the capture of sufficient feature information and the effective discrimination of forged facial images or videos. Increasing the number of dynamic filters to 8 results in the highest complexity and parameter count, yet test ACC and AUC remain low, potentially attributed to the model's over-optimization of training data leading to overfitting. When comparing models with 4 and 6 dynamic filters, similar ACC and AUC values are observed. Though the FAMDnet with 6 dynamic filters has more parameters than the model with 4 filters, both perform comparably in performance metrics, while the model with 6 dynamic filters may incur higher computational costs and longer training times. Considering the balance between performance and efficiency, the number of dynamic filters is set to 4 in this article.
Experimental Results of the Number of the Dynamic Filters.

Experimental Results of the Number of the Dynamic Filters.
ACC: Accuracy.
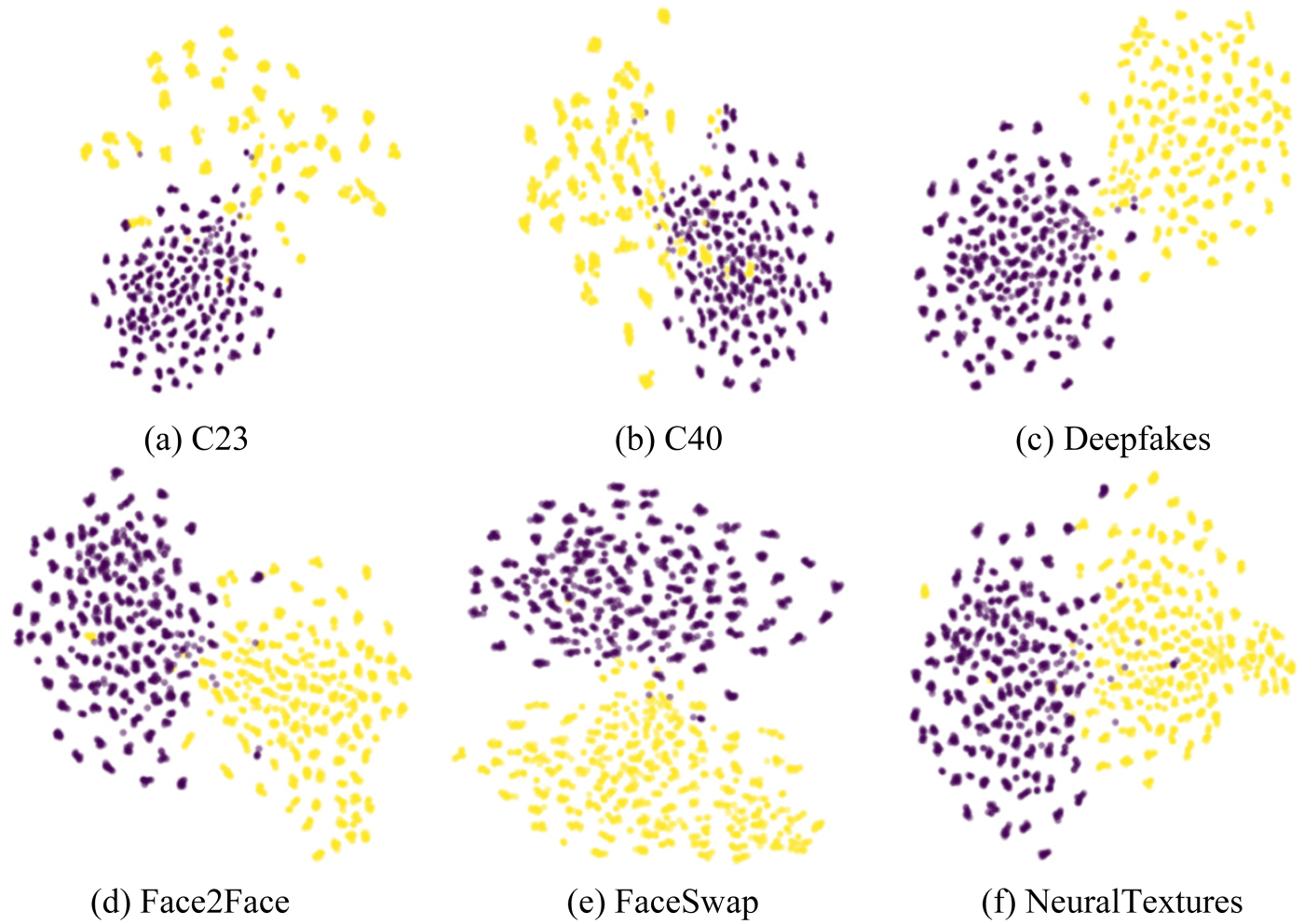
Visualization of the Distribution of Features Extracted by FAMDnet in the Feature Space. FAMDnet: Frequency Assisted Multi-Scale Dual-Stream Network.
To intuitively demonstrate the distribution of the features extracted by the proposed method in the feature space, a visual analysis is conducted using t-SNE on 1,000 images of each type (real and fake) selected from the FF++ dataset. As illustrated in Figure 6, yellow represents forged facial images, while purple denotes real facial images. From Figure 6, it can be observed that a small overlap exists between the real and fake categories in each subfigure, which may be attributed to misclassifications caused by our FAMDnet. Although this overlap exists, clear classification boundaries are evident in both categories of each subfigure. Specifically, the visual results from DF, F2F, FS, and NT show that each category forms a relatively concentrated cluster, highlighting the effectiveness of FAMDnet in the feature space. The distinct separation between these clusters further demonstrates the substantial robustness of FAMDnet in discriminating between real and forged facial images, including low-quality facial images.
Conclusion and Future Work
The existing Deepfake detection methods demonstrate high accuracy on high-quality facial datasets but perform poorly on low-quality datasets. To address this issue, a FAMDnet is proposed for low-quality Deepfake detection in this article. The FAMDnet employs a dual-stream network that leverages multiscale spatial features extracted by the multiscale spatial feature extraction module and dynamic global frequency features extracted by the dynamic global frequency feature extraction module to reveal traces of forgery. Additionally, the multimodal attention fusion module of the FAMDnet is utilized to integrate spatial features with frequency features, and the fused features are further enhanced by the simple parameter-free attention mechanism. This enhancement significantly improves detection performance in scenarios involving low-quality forged images and videos. Comparative experiments conducted on publicly available datasets indicate that the proposed FAMDnet exhibits superior detection performance, particularly on low-quality datasets, surpassing many existing detection methods. In future work, we will continue to explore various interaction methods between spatial and frequency features to enhance the performance of the model, as well as investigate fusion methods between Transformer and CNN to fully leverage the advantages of both structures, thereby adapting more effectively to diverse data distributions.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (62076246).
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.