
Abstract
In high-stakes settings, Machine Learning models that can provide predictions that are interpretable for humans are crucial. This is even more true with the advent of complex deep learning based models with a huge number of tunable parameters. Recently, prototype-based methods have emerged as a promising approach to make deep learning interpretable. We particularly focus on the analysis of deepfake videos in a forensics context. Although prototype-based methods have been introduced for the detection of deepfake videos, their use in real-world scenarios still presents major challenges, in that prototypes tend to be overly similar and interpretability varies between prototypes. This paper proposes a Visual Analytics process model for prototype learning, and, based on this, presents ProtoExplorer, a Visual Analytics system for the exploration and refinement of prototype-based deepfake detection models. ProtoExplorer offers tools for visualizing and temporally filtering prototype-based predictions when working with video data. It disentangles the complexity of working with spatio-temporal prototypes, facilitating their visualization. It further enables the refinement of models by interactively deleting and replacing prototypes with the aim to achieve more interpretable and less biased predictions while preserving detection accuracy. The system was designed with forensic experts and evaluated in a number of rounds based on both open-ended think aloud evaluation and interviews. These sessions have confirmed the strength of our prototype-based exploration of deepfake videos while they provided the feedback needed to continuously improve the system.
Introduction
Due to the growing fidelity of deepfake videos, it is becoming increasingly difficult to determine whether a video has been manipulated. As such, they pose a serious risk to our society. Tools for deepfake generation are more accessible than ever, including open source tools, 1 and easy-to-use apps2,3 that do not require expert knowledge. In this paper we focus on video forensics, where the aim is to make judgments on the authenticity of a video which can be defended in court. The high fidelity of deepfakes, combined with their proliferation and the accessibility of the tools to generate them, will present an increasingly large challenge as investigators are expected to get confronted with growing volumes of disputed material.
In recent years, in parallel with methods for deepfake generation, we have witnessed a rise in the availability of deepfake detection methods. Open Kaggle competitions such as the Deepfake Detection Challenge (DFDC), associated with the release of the dataset of the same name, 4 have contributed to the availability of deepfake detectors that were open sourced as an outcome of the competition. Although the release of these detectors may initially seem to address the needs of video forensic experts, the rules of the competition led to completely automated detectors that do not allow for input from the expert.
In forensics, the video expert, in search of visual evidence that can be presented in court, conducts an in-depth analysis of the parts of the video that are in dispute. In this process, the expert looks for subtle indicators such as face wobble, blurred edges, missing facial features, or overly smooth skin. 5 Modern automatic deepfake detectors are more and more based on Deep Neural Networks (DNNs) as they outperform traditional methods used in video forensics.6,7 The opaque nature of DNNs is a cause of concern when used in a high-stakes setting such as forensics. In general DNNs do not allow for interaction with the internals of the model and even if that is the case, many of them are not interpretable in terms of the indicators forensic experts use.
Concerns regarding explainability has led to the development of methods that aim to provide more understandable predictions.8–12 An increasingly common approach is prototype learning.
13
In image recognition with DNNs,
For video forensics, prototype-based learning methods have been developed
20
by building on methods that use prototypes for image classification21,22 which provide predictions based on similarity to these prototypes. For video, the prototypes are
There are few existing VA systems for interactive prototype learning. The early method proposed in Migut et al. 23 for prototype exploration in relation to performance was conceived before DNNs became the prime image recognition model and is therefore less suitable for our purpose. In Zhao et al., 24 a post-hoc approach is used. 25 Their method takes the embedding layer in a network and factorizes it into a number of prototypes. Thus, they build a surrogate model that mimics the behavior of the analyzed model. This has the advantage that it can be applied to any existing deep learned model. The prototypes, however, are not learned during the training of the original network. Hence, their approach does not lead to a visual analytics solution in which the user can interact with the model directly. In Li et al., 21 Chen et al., 22 prototypes were incorporated directly in the DNN architectures, to make interpretable predictions a characteristic of the model rather than a post-hoc explanation. But these have not been embedded in a visual analytics solution. None of these approaches are suitable when analyzing video data and using more complex dynamic prototypes that contain spatial and temporal information.
Based on the above considerations, we introduce ProtoExplorer, a VA system for prototype-based exploration and refinement of neural networks in the forensic analysis of deepfake videos. This system allows forensic experts to:
This manuscript describes the first steps taken toward integrating this type of software in the workflow of the Netherlands Forensic Institute, where the experts we work with are employed. In summary, ProtoExplorer targets a specific task, that is, the forensic analysis of deepfake videos, designed with and for video forensic experts. Our VA system enhances their expertise with meaningful visualizations and intuitive interactions with prototype-based models. Our contributions include:
A
A
A thorough
Related work
Ever since the start of the deep learning era, the opaque nature of neural networks has been a concern and has been addressed both in the visual analytics community as well as in the machine learning community. Before discussing related VA systems for prototype refinement, we will introduce relevant existing methods in the realm of visual analytics systems for AI and interpretable and explainable AI.
Visual analytics systems for AI
Building interactive systems to understand deep learning models has been an active research topic in the visual analytics community (see e.g., Wongsuphasawat et al. 26 , Kahng et al. 27 , Wang et al. 28 , Strobelt et al. 29 ) as the inherent complexity of deep neural networks and the overwhelming number of parameters makes it impossible for humans to easily understand the inner working of the network. The layered architecture of networks helps in this respect, as it provides natural levels of abstraction, but due to the the huge number of parameters it remains challenging. A number of excellent surveys on the topic have appeared, such as Alicioglu and Sun, 30 Yuan et al. 31 We are particularly interested in prototype-based methods. In literature, the only visual analytics system targeting prototype-based deep neural networks we know of is ProtoSteer, 32 which targets recurrent neural networks, a specific class of deep sequence networks.
Apart from the concerns pertaining to the black-box nature of neural networks, there is an increasing awareness that the training data and the way the networks learn might lead to biased results. Typical observations, found when analyzing results of DNNs are biases toward specific gender, race, or demographics. Recently, visual analytics solutions have been proposed that aim to make this bias visible.33,34 The problem of bias has also been identified for deepfake detection. 35 Our method aims to reduce the bias by letting experts refine the set of prototypes to assure that they are diverse and representative.
Interpretable and explainable machine learning
In recent years, there has been increased attention for methods that help make predictions from Machine Learning (ML) models more understandable to humans. Yet, there is a lack of consensus in literature13,15,36 regarding the differences between an ML model being interpretable versus explainable. In this paper, we use the term interpretability based on the definition in Molnar, 36 Miller 37 that defines interpretability as “the degree to which a human can consistently predict the model’s result.”
Methods in this field can also be distinguished based on whether they are intrinsic or post-hoc. Post-hoc methods for DNNs can be applied to a model after it has been trained. There are various approaches which use post-hoc methods, with the most prominent being visualization methods based on back-propagation. For images, these methods produce heatmaps or activation maps that show to what extent each pixel in the input image contributes to the final output, with different colors representing varying degrees of relevance. Gradient-weighted Class Activation Mapping (Grad-CAM) 8 uses the gradient of the final output, Layer-Wise Relevance Propagation 9 predefined calculation rules, and DeepLIFT 10 the outputs of all neurons in the network to estimate how important each input pixel is in determining the network’s output.
However, recent research has demonstrated that post-hoc visualization methods are not always reliable in their visual explanations. 38 Another post-hoc approach is to build a surrogate interpretable model that locally approximates the original model. This surrogate model can explain the predictions of a classifier or regressor in a faithful way. 12 An approach with two models adds an extra layer of complexity, making it harder to troubleshoot as it can be unclear whether the opaque model or the surrogate model is wrong. 15
The number of visualization papers focusing on other types of post-hoc explanation models seems limited. One noteworthy paper is Zhao et al., 39 which describes how a VA system can be used to make concept-based post-hoc models more interpretable. Concepts are usually generated automatically, but this VA system enables a human-in-the-loop approach to generate user-defined visual concepts for different ML tasks.
Intrinsic methods, when based on DNNs, modify the architecture of the network before training the model in order to provide more understandable predictions. Among intrinsic methods that have recently been introduced, prototype-based methods, like ProtoPNet, 22 stand out in the image recognition field because of their potential to provide explanations using visual similarity. ProtoPNet, which is based on case-based reasoning, relates to the way humans recognize objects and subjects. The idea behind this approach is that a prototype, which is automatically chosen from the training data, contains a characteristic that is representative for one of the classes. For example, when tackling a bird classification problem, a prototype could represent a certain feather pattern or a specific beak. Activation maps are used to visualize what part of the prototypical image the network deems relevant. By calculating the similarity between the input and each of the prototypes, the score for each of the classes is calculated. After ProtoPNet, more prototype learning methods were developed, including methods that use decision trees, 40 hierarchically structured prototypes based on predefined taxonomies, 41 and deformable prototypes that adapt to pose variations of objects. 42
Prototype-based methods are also used in high-stakes settings, in which their more interpretable predictions are very valuable. One example is XProtoNet, which uses prototypes for medical diagnoses based on X-ray imagery. 43 XProtoNet uses both activation maps and contours to indicate the most relevant part of prototypical images. In video forensics, and more specifically in deepfake detection tasks, the subject of analysis is not a still image but a video. DPNet 20 was conceived to detect deepfake videos. It uses dynamic prototypes containing not only spatial but also temporal information provided by pre-computed optical flow fields. DPNet is, to our knowledge, the only existing prototype-based neural network specifically conceived for deepfake detection. Our VA system provides a series of functionalities that allow the forensic expert to refine the prototype selection of models trained with DPNet and hence directly interact with the model.
Refinement of prototype-based models
As automatic prototype selection methods are not always optimal, different approaches have been introduced to refine the selection of prototypes. Chen et al. 22 introduce a post-training pruning method to remove “background” prototypes from the model. Ming et al. 44 provide a task-agnostic method that allows the user to create, revise and delete prototypes of the model. They subsequently built the VA system ProtoSteer 32 around their method. These methods are either fully automated, without expert user input, or are task-agnostic, that is, not designed for working with prototypes conceived for a specific task like deepfake detection. None of the current methods offers a VA system that allows a suitable workflow for model inference and prototype refinement.
Despite the proliferation of VA systems that aim to increase the explainability of DNNs in multiple tasks,39,45–51 there is a lack of VA systems for prototype-based models. The only VA system that uses prototypes to explain the behavior of neural networks that we are aware of, 24 was not conceived to work with temporal media such as deepfake videos, nor with prototypes that combine spatial and temporal information. More importantly, it follows a post-hoc approach, building a surrogate model that mimics the behavior of the analyzed one. 25 This approach can only indirectly interact with the model as the prototypes are only part of the surrogate model. If by examining the prototypes and their contribution to predictions the user decides that the model has to be updated, they can only do so via the hyperparameters which have no direct connection to the prototypes. Our system uses prototype-based networks as its backbone, and hence, it allows the user to directly analyze and refine prototype-based models without the need for surrogate models. Furthermore, our system targets a specific task, deepfake detection, and is specifically designed to manipulate the more complex prototypes used in this task.
System design
Design process
The system was designed with and for video forensic experts. One of the co-authors of the paper is an expert witness in court on deepfake analysis, and based on his experience, informal conversations with other experts from the Netherlands Forensic Institute, and the literature review given in Westerlund, 5 the first version of ProtoExplorer was developed. We extracted the following system requirements from these sources:
The system we initially developed was evaluated by five experts from the Netherlands Forensic Institute using think-aloud sessions while using the system (see the ’Evaluation’ section for details), followed by interviews. Based on this, a second version of the system was built taking into account the comments. This version was shown to the experts in subsequent in-depth interviews. This has led to the current version of the system as well as suggestions for future developments.
Forensic deepfake analysis workflow
The workflow for forensic experts is composed of three main tasks. The first task is video fragment selection. Whether this task is present depends on the type of forensic question being posed. If the evidence is a large collection of videos, a selection has to be made of most likely candidates for manipulated fragments. For this automatic tools are most suited. In other cases, the expert receives a specific disputed fragment and should provide evidence whether this fragment is pristine or manipulated. Both cases lead to the second task which is forensic deepfake analysis where an individual video fragment is inspected for signs of manipulation. To provide trustworthy evidence in court this decision should be interpretable and the forensic expert should provide an understanding on how the model aided in making that decision. In our design this is represented by the model exploration and refinement task. In this paper we focus on the last two tasks as this is where interactive solutions are most appropriate. Note, however, that a refined model can also give a better basis for informed decisions in the selection process. This work can in due time be incorporated into the workflow of the Netherlands Forensic Institute.
Network architecture
The backbone of our VA solution is an automatic deepfake detection network, in particular the Dynamic Prototype Network (DPNet). 20 Here we elaborate on its structure and parameters, illustrated in Figure 1, as these provide the levers which we can manipulate and which we need to visualize in our ProtoExplorer system. Deepfake detection methods take a video sequence as input and make a decision, optionally represented as a score, on whether it is pristine or manipulated. The videos in the dataset are pre-processed such that the input to the network consists of a stack of an RGB frame containing the face crop detected in the video, followed by pre-computed optical flow fields from the nine consecutive frames. The optical flow fields capture the motion between frames. The network architecture for DPNet is composed of three different components, a feature encoder, a prototype layer, and a class layer, which are described concisely below. For a more detailed explanation, the reader is referred to Trinh et al. 20
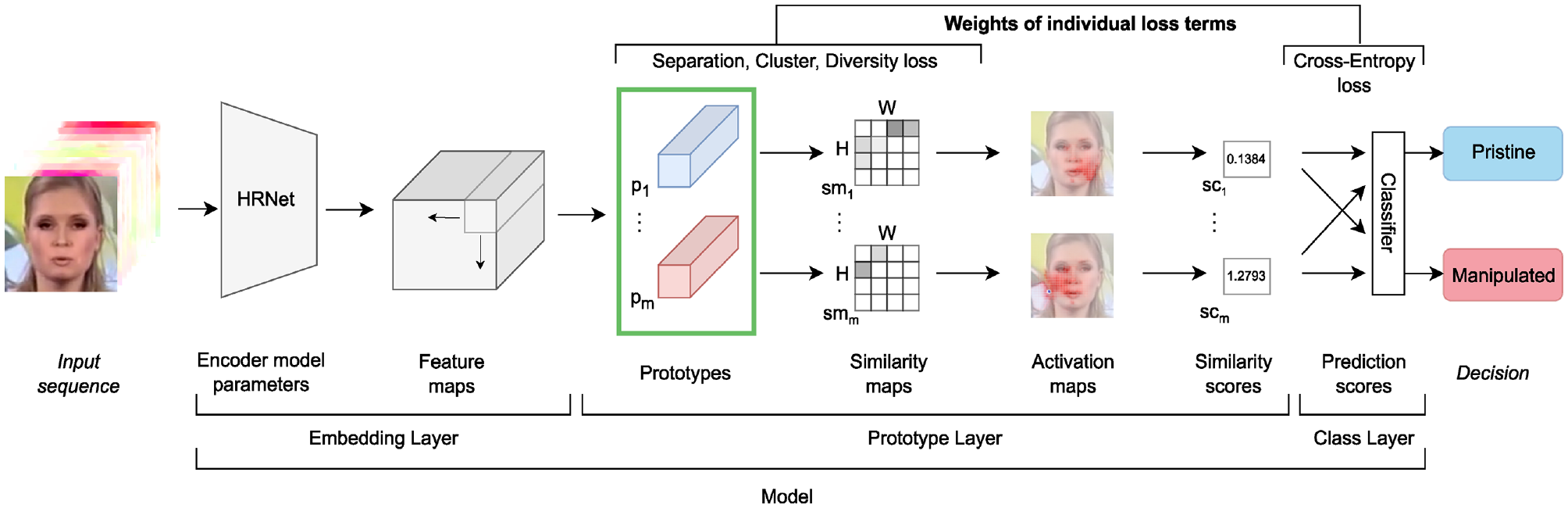
Architecture of the deepfake detection model DPNet. Based on a large set of pristine and manipulated video fragments, the feature encoder produces an embedding in the latent space. This space is used to select a set of prototypical training samples. The final classification of a train/test video is done in the class layer based on the similarities of the sample to the prototypes. Before training, the
The feature encoder takes the input and extracts the features required for classification. This is done with HRNet,
52
a network with a large number of model parameters, which was designed to preserve high resolution feature maps throughout the network. This is appropriate, as in deepfake detection, details are of the utmost importance. The feature encoder produces a latent representation of size
The next component is the prototype layer which calculates a similarity score between the latent representation of the input, and each of a predetermined number of prototype vectors for the two classes (pristine and manipulated). The prototype vectors are latent representations of crops from representative samples from the training set. These prototype vectors are learnable parameters of the network. We use 20 prototypes of size
In the final class layer, the maximum similarity score for each prototype is used as input to a fully connected classifier which outputs a score for the fragment being pristine, and being manipulated.
For details describing how the network was trained, the reader is referred to the Appendix.
The architecture of DPNet was conceived to automatically assign scores to the labels pristine and manipulated. The use of prototypes in DPNet makes it easier for human experts to understand how the decisions are made by the system. This process of understanding the model is completely post-hoc, that is, it takes place after the model has been fully trained. The only way for the user to interact with the system is to change the weights of the loss terms and retrain the model. These weights steer the loss function of the model and consequently the prototypes of the model are changed. This indirect way of working with the prototypes in the model is difficult for a user as the system optimizes for representation learning and not for interpretability. We propose to make prototypes the prime object of interaction and make them the central part of our visual analytics process.
Visual analytics process
The overall diagram representing our process model is presented in Figure 2.
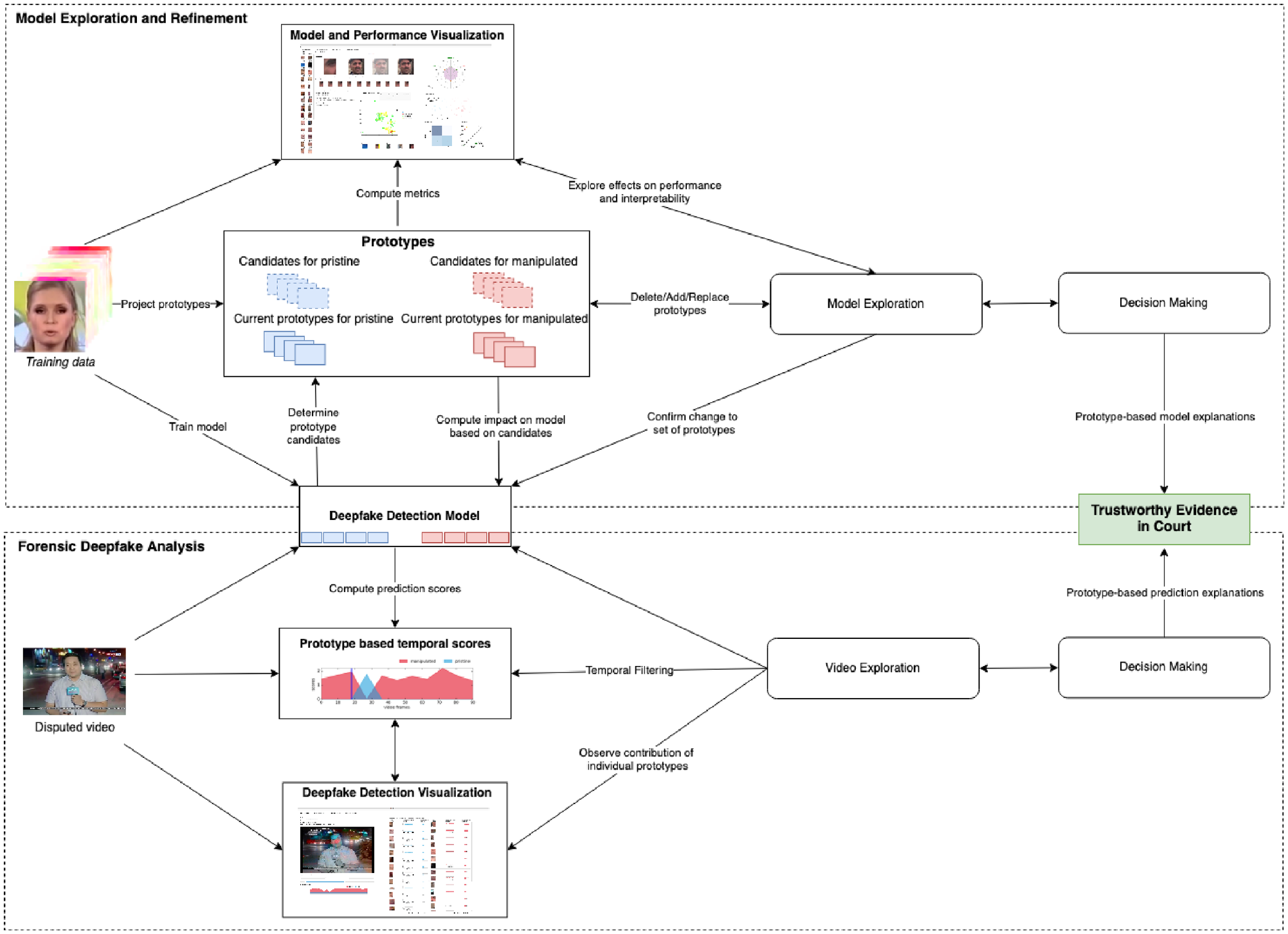
Diagram of our VA model for prototype-based interactive deepfake detection inspired by the knowledge generation model for visual analytics defined by Sacha et al. 53 The diagram shows and models the two main tasks ProtoExplorer can aid the forensic expert in. Through model and video exploration the experts can make informed decisions at the model and video level, leading to trustworthy evidence in court.
The aim of our interactive solution is to support the exploration and reasoning process of the forensic expert. To that end we rely mainly on the knowledge generation model defined by Sacha et al. 53 This model shares the four main components (data, visualization, models, and knowledge) in the process model for VA defined by Keim et al. 54 and expands it by making human reasoning part of the VA process. In our case we model the tasks as intertwined decision making processes focusing respectively on the video and the model. Together they lead to informed decisions for trustworthy evidence in court. The two processes are coupled through the deepfake detection model, in particular DPNet. The whole model is centered around the prototypes in the detection model which on the one hand form the basis to explore and refine the model characteristics and on the other hand provide a decomposition of the prediction scores in the automatic analysis of a video fragment.
From an interaction point of view the forensic deepfake analysis is relatively simple. It shows the prediction scores for the two classes for every frame in the video. The main action the forensic expert can perform is temporally zooming in on the part of the video that is of interest. By observing the contribution of individual prototypes to the overall prediction score, the expert can explain the decision made in terms of the prototypes contributing most.
The model exploration and refinement task is more involved as it requires understanding the complex deep learning-based detection model. To reduce the cognitive load on the expert in understanding the model, we focus the exploration on the prototype layer in the model for two reasons. Firstly, this is the easiest layer to map to the characteristics experts use to manually analyze disputed videos and, secondly, prototypes are known to play an important role in cognitive processes.19,55 The interaction with the model revolves around the set of prototypes the system is using and a set of candidate prototypes the model provides. The exploration of the model consists of considering the set of current prototypes, deleting ones that are not deemed useful, or replacing them with a candidate prototype from the candidate set that might make the predictions more interpretable or less biased. However, changing the prototypes directly influences the performance of the detection model, so the visualization should emphasize the impact of the choices made. It is up to the expert to balance the quality of the detection versus the interpretability of the resulting model.
By making the prototype layer the primary target of interaction, we create a methodology where the expert can directly manipulate the deepfake detection model, while keeping a large part of the model intact. In particular, we are not altering the large parameter set of the encoder.
System overview
We will now describe the visualizations developed to support forensic experts in performing their tasks. From there we will describe the two main interactive interfaces created to support their workflow.
Visualizations
The layered architecture of the deepfake detection model provides a blueprint for the visualizations that are needed for the system. We consider here the main visualization components and do so from the perspective that prototypes form the core of our visual analytics model so these steer the different visualizations of the model.

Sequence of the face crops generated in the pre-processing of an input video from the FaceForensics++ dataset. It includes 10 frames: the first is the extracted face crop, and the rest were calculated by inputting the consecutive frames into the DeepFlow Optical Flow algorithm. 59
Having defined the core visualizations it is time to connect them to the proposed visual analytics process. This leads to two main interactive visual interfaces, corresponding to the forensic deepfake analysis task and the model exploration and refinement task.
Forensic deepfake analysis interface
The deepfake analysis screen allows the user to conduct deepfake detection using interpretable prototype-based models. The screen is depicted in Figure 4.
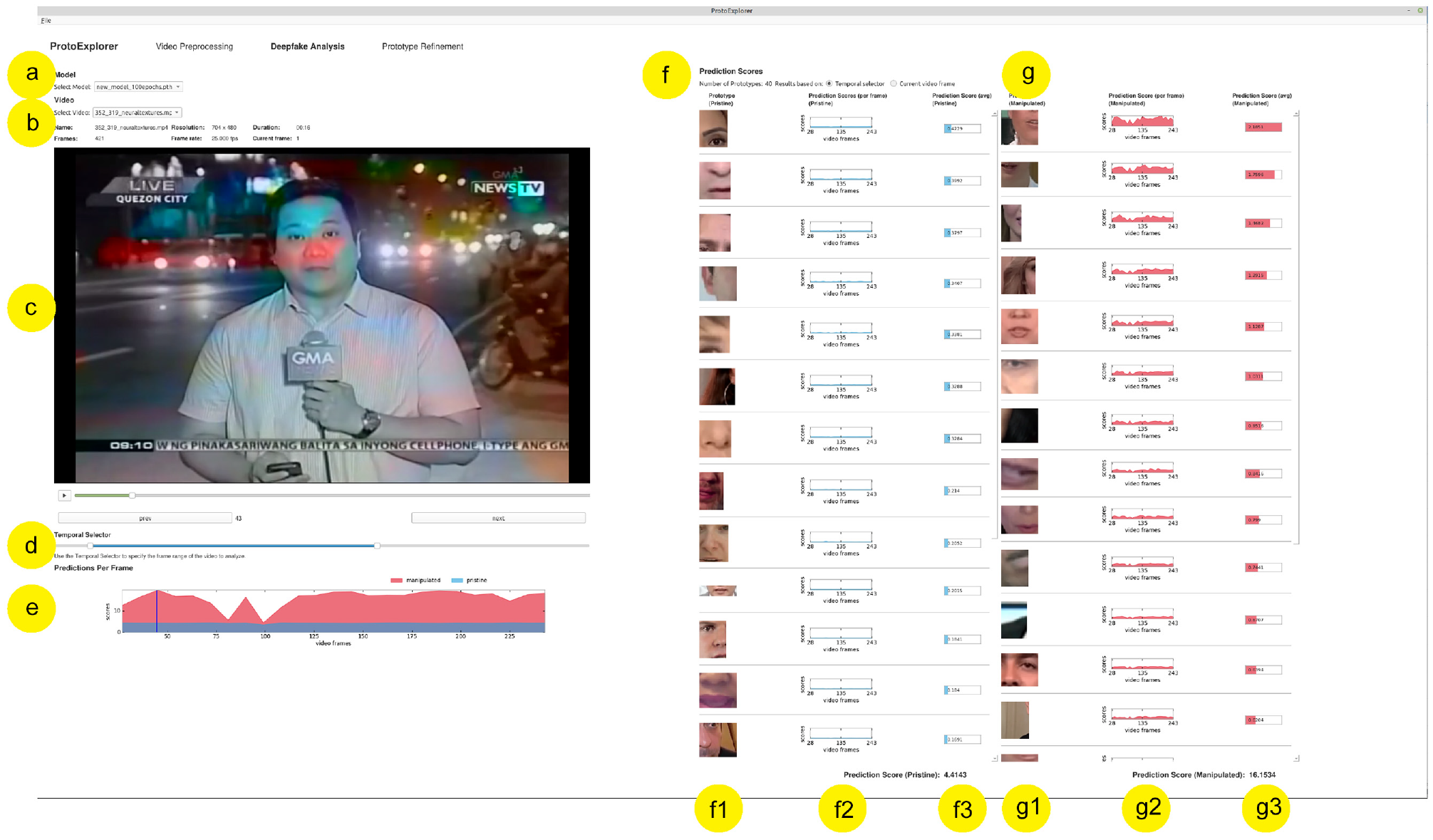
The deepfake analysis screen in ProtoExplorer. (a) model selection; (b) input video selection and its metadata; (c) input video player; (d) video navigator including temporal selection; (e) visualization of the total prediction scores per frame for the selected temporal fragment of the video; (f and g) visualization of the prototypes and prediction scores obtained by each prototype for both categories: pristine (columns f1, f2, and f3) and manipulated (columns g1, g2, and g3).
The user starts by selecting the model from a list of pre-trained DPNet models (a) and a video from the list of pre-processed videos in the video panel (b) presenting some basic information on the video. The video player (c) allows the user to play, pause, scroll, and step frame by frame through the video via the playback timeline. With the temporal selector (d) the user can define the temporal fragment of the video to be analyzed. The temporal selector was added to help the forensic expert select the range of frames within the video that is of interest (REQ4).
The predictions per frame (e) visualization shows the predictions for each of the two categories: pristine and manipulated. The total prediction scores are shown on the vertical axis, and frames of the video are on the horizontal axis. Initially, the horizontal axis displays all video frames. The prediction score panels (f, g) visualize the individual contributions of the prototypes (f1, g1) to the overall predictions. When the single frame mode is selected, a visualization similar to the prototype viewer in the prototype refinement screen (see Figure 5) is given. For a temporal fragment, the contribution of each prototype to the total predictions per frame is given in (f2, g2) where the contribution to the final score is given in (f3, g3) according to REQ1. When the user adjusts the temporal video range in the temporal selector, all prediction charts are automatically updated.
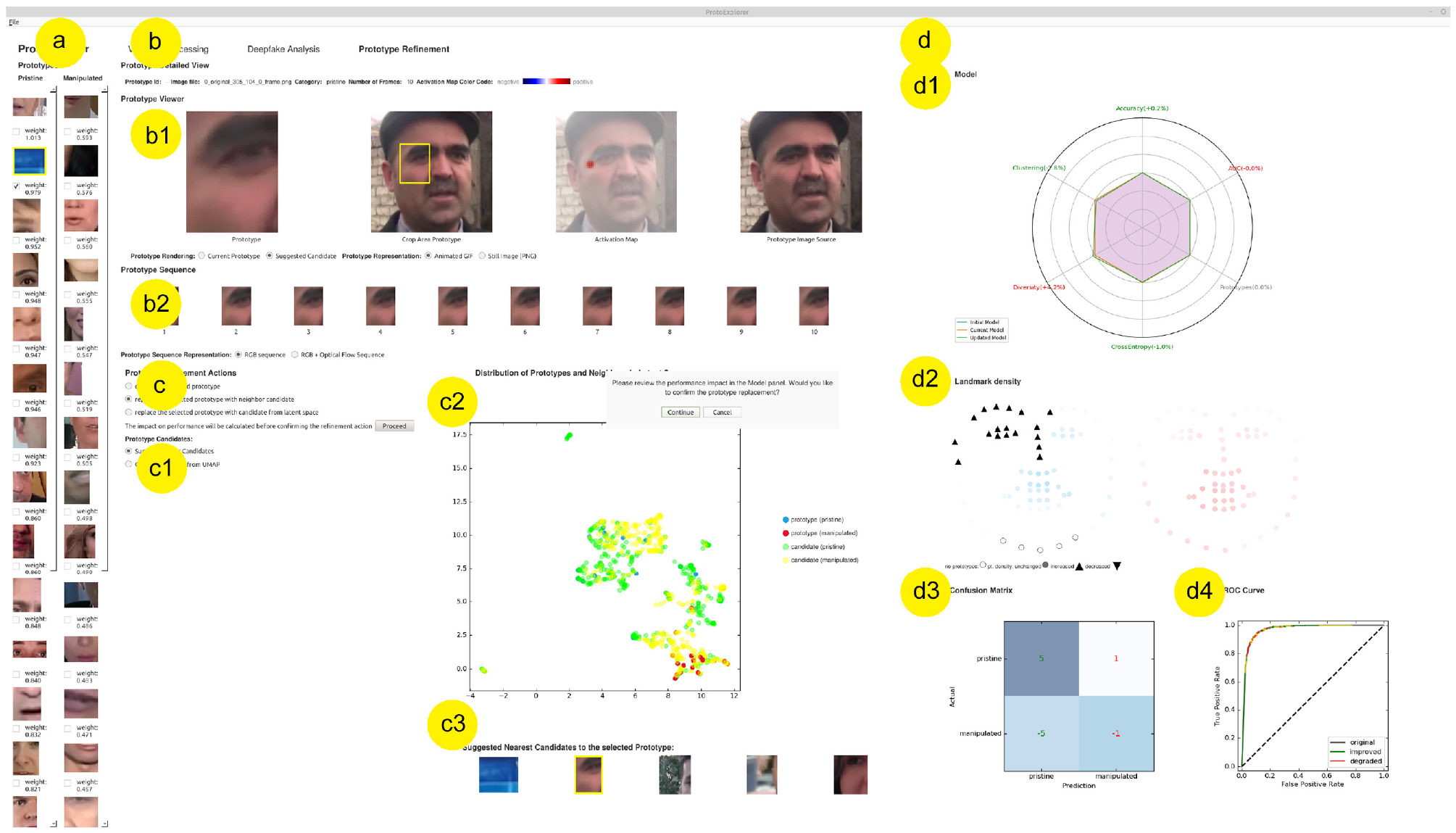
The model exploration and refinement screen in ProtoExplorer. The list of prototypes (a) can be viewed in detail (b) and revised through deletion, replacement, or addition of prototypes (c), the impact of which can be observed in the performance panel (d).
Using this interface the expert can drill down to a specific fragment of the video that, according to the system, has the most prominent signs of being non-pristine material. The system explains itself in terms of the prototypes and how they contribute to the final score, which coincides with REQ2. By looking at the prototypes that contribute most, and possibly switching to the frame visualization mode where more details of the prototype are given, the expert can validate whether the prototypes indeed give a good explanation. Furthermore, the expert can also verify that the pristine part of the video is also recognized in the correct way. If the prototypes do not provide a convincing explanation because, for example, no clear artifacts are visible in the manipulated class or if the prototypes are not diverse enough, the expert can decide to move to the model exploration and refinement interface to find a better set of prototypes.
Model exploration and refinement interface
The model exploration and refinement screen addresses REQ2 and REQ3. It was inspired by ProtoSteer. 32 This visual analytics system is built around a prototype-based deep sequence model, and is mainly demonstrated on a problem regarding sentiment analysis. In this system, the domain user can inspect and revise the model’s prototypes interactively. The altered prototypes are subsequently incorporated into the model. Their results show that more interpretable models with concise prototypes and a comparable accuracy can be obtained by involving domain users.
In the model exploration and refinement screen, the user can import a pre-trained initial model and conduct a series of operations to refine its prototypes. This screen consists of the following panels, shown in Figure 5:
The prototypes panel (a) contains the prototypes of the model for the pristine and manipulated categories. These are displayed in two vertical scrollable lists so they can be viewed properly, even when the number of prototypes differs between models. Underneath each prototype, the weight associated with it in the final linear layer of DPNet is shown, and the prototypes are sorted according to their weights. The user can then select one prototype from the list to inspect in the prototype detail view (b), or several of them when aiming to delete multiple prototypes at once.
The prototype detail view offers different representations of the selected prototype. The prototype viewer (b1) consists of four display panels that visualize (from left to right): the selected prototype, the dataset sample that was the source of the prototype including its cropping area, the PRP map that determined the cropping area, and the same but unmodified dataset sample. The user can choose to view the prototypes as animated GIFs or as still images. The prototype Sequence viewer (b2) consists of the 10 consecutive images that were used to generate the prototype, either showing all individual frames of the prototype, or the first frame and the subsequent flow fields.
The prototype refinement panel (c) allows the user to delete or replace prototypes (c1). The user can delete one or more prototypes at once allowing for a faster refinement when working with models having a high number of prototypes. When reducing the number of prototypes is not desired, replacing a prototype with an alternative might help increase the interpretability of the predictions. There are two options for replacing a selected prototype. Candidates near to the selected prototype are displayed and can be selected in an image gallery (c3). Alternatively, a choice can be made from a larger set of prototype candidates in an interactive UMAP 56 visualization (c2) alongside the selected prototype. When a prototype candidate is selected, it is displayed in the prototype viewer. As the UMAP gives a convenient overview of the relative positioning of prototypes and candidates, the expert can choose candidates in regions of the space that are under-represented.
The performance panel (d) gives an overview of the performance of the current model and prototypes in a radar mplot (d1), landmark density plot (d2), confusion matrix (d3), and ROC curve (d4). This provides the expert with information on where improvements are necessary in terms of a better classification performance (in the confusion matrix), a better balance between false and true positives (in the ROC curve), more diverse, clustered, or separated distribution of prototypes (the radar plot) or an improved distribution over the landmarks in the image (the landmark density plot).
When the user changes the set of prototypes it impacts the performance of the model as well as several other characteristics of the model. Before the user confirms the change, the system computes the characteristics of the model by evaluating the model on a test set independent from the training set used for DPNet. This takes a few seconds. The result of the evaluation is shown in the performance panel. As the task of the expert is to assess the impact of the change, the visualizations switch to a mode in which differences are highlighted. The radar plot shows three curves namely the initial model (where all characteristics are displayed as 100%), the current model, and the new model. The labels provide the relative changes of the new model with respect to the current model. The landmark density plot gives an indication of which landmarks are affected and whether they go up or down. In the confusion matrix the actual change is indicated. To make it clear whether these are improvements or degradations, the color of the text is made green or red respectively. The ROC curve simply shows the two curves at the same time as this is a familiar way of viewing the improvement of a model.
System implementation
In this section we describe the technologies and methods used to implement the system, and to train the prototype-based deep learning models included in the system. The system consists of a standalone desktop application developed in Python. The framework used for the Graphical User Interface is Qt in its python binding.
The model trained for ProtoExplorer are based on the Dynamic Prototypes Net (DPNet).
20
As mentioned in the ’Background’ section, DPNet’s neural network architecture includes HRNet
52
as a feature encoder, which was pre-trained on ImageNet.
60
To train this model, we used weights
The network was trained on the HQ (c = 23) variant of the FaceForensics++ 6 dataset, broadly used in deepfake detection. Although FaceForensics++, in its latest revision, includes five different deepfake generation techniques for training the models we used the four that were included in its initial release and used them to train DPNet, 20 namely Deepfakes, 61 Neural Textures, 62 FaceSwap, 63 and Face2Face. 64
Before the network was trained, the training set from FaceForensics++ needed to be pre-processed. Once the frames of the input video were extracted, MTCNN
65
was used for face detection, storing bounding box coordinates of the detected faces. We sampled a frame every
Evaluation
To validate our system we involved five anonymous video forensic experts. All the experts have more than 9 years of experience at the Netherlands Forensic Institute. They all have experience with doing deepfake detection in the forensic setting and have knowledge of deep learning models. In their current workflow they do use different automatic deepfake detection tools, but rely heavily on visual inspection of the disputed video to make their judgments. It should be noted here that it would be difficult to take their current systems as baselines for a direct comparison to ProtoExplorer. There would be too many dimensions which are different starting from the training data used for the different systems, the underlying deep learning model, and the different ways of interacting with the system. Furthermore, the systems in use have no visual analytics component so cannot interact with the model directly.
The evaluation was done in two rounds. The first round was based on sessions where the experts interacted with the system and in-depth interviews while the second round was based on interviews only. During the first round, the experts experienced the graphical user interface of ProtoExplorer for the first time. We will now elaborate on the setup and results for those rounds and how they have led to improvements to the intermediate versions of the system and finally how they lead to ideas for further improvements.
First evaluation round
The evaluation took place in individual sessions with a duration of 90–110 min. In the first 10 min, prototype-based models were introduced to the forensic expert. For the next 10–15 min a demo was presented showing how to explore the prototypes of the model, refine the model by replacing and deleting prototypes, and use the model to conduct deepfake detection. The experts were then invited to perform a series of four interactive tasks for 30–40 min. As protocol we used the “Thinking aloud” 66 method for usability testing, asking the users to verbally express their thoughts while they interact with the system. The audio containing their spoken thought process was recorded.
The tasks given to the experts were as follows:
After the session we interviewed the expert for 15–20 min, asking questions about their impression of the system and how to improve different aspects of the system. The audio recordings of the interactive sessions and the interviews were transcribed and manually categorized into six different categories namely “Prototype Exploration,”“Prototype Refinement”, “Model information and metrics”, “Deepfake Analysis”, “Interpretability and Forensics” and “General Remarks.”
Our findings are given below. Paragraphs containing expert feedback start with a  symbol.
symbol.
Prototype exploration
For this first task of the evaluation, the expert users were asked to inspect the prototypes of the given model. They made extensive use of all the options available in the prototype detailed view, switching back and forth between visualizing the image sequence and specific frames of the prototypes. Their interaction with the system was fluent. The system enabled them to intuitively visualize and explore the prototypes of the model.
The feedback was positive, with a few suggestions for future work such as allowing the user to hide panels to maximize screen space, re-positioning some selectors, and adding interpolation-free image scaling options.
Deepfake analysis
During the second part, the experts evaluated the deepfake analysis screen. To inspect the video under investigation, they used both prediction modes: based on the temporal selector and based on the current video frame selected in the video player. When evaluating only the current video frame, the user can visually analyze the regions of the input crops that are compared to the prototypes.
The experts found both prediction modes useful. When analyzing the results for the longer fragment, they highlighted the benefits of the system allowing them to interactively select and adjust the frame range for analysis and calculate an average of the predictions. One of the experts mentioned that this functionality was not available in other software for deepfake detection that they were familiar with. The video forensic experts highlighted the usefulness of being able to display the predictions scores for both categories at the same time, which made it possible for them to easily compare the total scores and the prototypes with a higher contribution to the scores. When they felt the need to take a closer look at a specific frame sequence of the disputed video, the expert users appreciated that the system provided predictions for the video frame selected in the video player. Suggestions focused on basic elements like the video player and its relation to the temporal visualization.
Interpretability and forensics
Thirdly, the experts were asked to provide feedback regarding the interpretability of the model and its prototypes. An important consideration for the experts is that to defend the decision in court they have to make clear that they looked at all aspects of the face like eyebrows, mouth, teeth, and hairline to substantiate their decision.
The prototypes automatically derived by the system did not cover all facial regions and thus it is important to add additional prototypes to increase the diversity. As indicated earlier they are, however, not always available for selection. The interpretation of the comparison between the input and prototypes of the network that led to the scores based on similarity was a recurrent topic of discussion in the evaluation of the system. The thorough evaluation with the video forensic experts indicated that the promise of prototype-based methods of providing human understandable predictions based on visual similarity could not reach its full potential when using spatio-temporal prototypes. The activation maps that are generated when the model is applied to a disputed video show which patches of the input face crops are compared to the prototypes. However, these maps do not always point toward the facial region that is shown in the prototype. One of the reasons for this could be that the model is not only comparing visual but also temporal information captured in the optical flow fields. This has a negative impact on the explainability of the predictions. Although the flow fields are visualized it is difficult to grasp this aspect.
Prototype refinement
The fourth part of the evaluation focused on the refinement of prototypes. We noticed that all experts were quick to delete prototype duplicates, or almost identical prototypes. Whenever they chose to replace a prototype, see Figure 6, the forensic expert evaluated the prototype candidates suggested by the system.
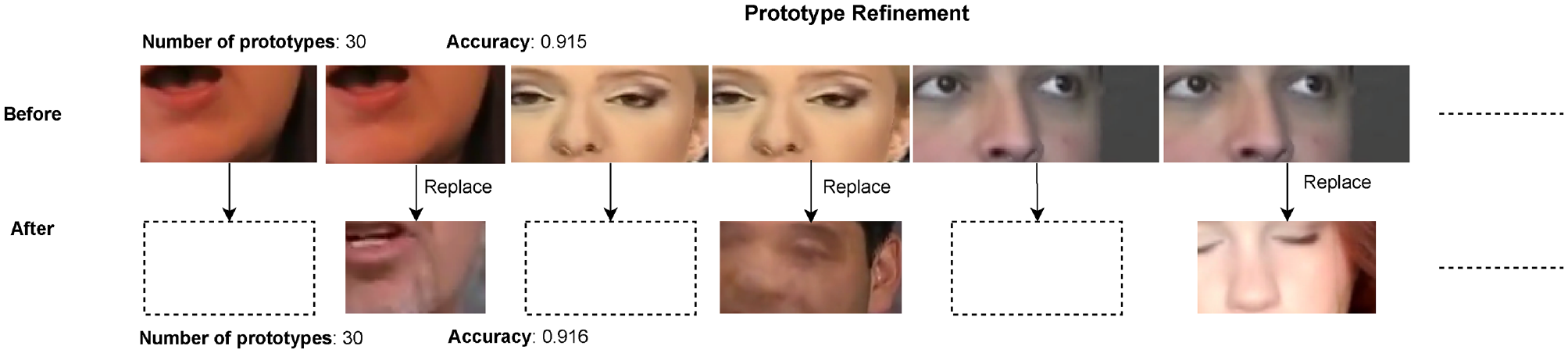
Information about the prototype refinement, including the impact on the accuracy, conducted in the evaluation by one of the experts. The top row shows the original prototypes which exhibit nearly identical prototypes. The expert selected three new prototypes to replace the similar ones and thus increased diversity while getting (slightly) better accuracy.
One of the topics of discussion was the matter of what criteria to consider when deciding whether a prototype should be replaced or deleted. When analyzing the candidates for a prototype belonging to the manipulated category, an approach mentioned by the forensic experts was to look for prototypes that contain visual artifacts that are representative of deepfakes. The other criterion that was mentioned was to consider prototype candidates that provide a more diverse prototype selection. Several experts noted that the prototype selection does not necessarily cover all facial regions. This was highlighted multiple times during the evaluation as a factor that has a negative impact on the interpretability of the predictions. Clearly, some experts, when evaluating candidates to replace a prototype, looked for prototypes that contained facial regions that were not yet represented in the selection.
Another aspect that was mentioned was that the prototypes from one category cover a different facial region (e.g. nose) than the other category (e.g. chin) This was considered by the experts to have a negative impact on interpretability. They suggested adding functionality that makes it possible to search for prototype candidates based on the facial region, as well as other criteria such as the angle of the face, or skin tone.
During the refinement of the model, calculating the impact of the changes in the prototype selection was a key design requirement. This provides relevant information to the expert user before committing changes in the model. The feedback received during the evaluation reaffirmed the utility of this functionality, but the experts suggested reducing the number of waiting intervals. In cases when the expert user is certain about the need for a refinement operation, it would be helpful to be able to immediately make the change, without any calculation. This could create a more fluent refinement process for the user. The use of entire new sets of similar prototypes (that maintain the performance of the model) rather than focusing on replacing individual prototypes was also suggested as an option which could minimize the waiting time needed to refine the model.
When searching for prototypes, the experts often mentioned semantic attributes of the input video sequences like having prototypes corresponding to a certain skin color or angle of the face like a side view instead of a frontal view.
The candidates that were suggested by the system, namely the neighbors of the current prototype, were difficult to interpret (and often quite similar) and it was difficult to make a choice for one of those. A suggestion made by one expert was to start without any prototype and start adding prototypes from specific artifacts found one-by-one. Although this seems attractive, the setup of a prototype based system like DPNet requires a set of initial prototypes for the model.
Model information and metrics
Next, the experts were asked to provide input on the model information panel. This panel provides an overview of the model’s performance, and demonstrates how refining the prototypes affects the performance metrics.
Apart from some general comments on the number of decimals for measures or whether they were given in percentages or not, the main discussion elements were focused on two parts. The first was the indication of change in the confusion matrix. It was not always clear that these were relative compared to the current model or the actual performance of the candidate model. Their suggestion was to use colors to indicate whether the change was considered desirable or not. In general it should be clearer that the model has changed. Secondly, the use of the word similarity to describe the contribution of a prototype to the final result, and whether a high score indicated a larger or smaller contribution, led to some confusion.
General remarks
Finally, there was space for general remarks regarding ProtoExplorer.
There were two recurring topics. Firstly, there is a multitude of useful visualizations but for many users it is sufficient to simply have an indication of whether the video is pristine or manipulated. This is similar to the previously mentioned use of automatic methods for selecting videos. However, that is not the scope of the current paper. However, it would be possible to make certain visualizations optional. The second topic was computational efficiency when testing the model given a set of prototypes. At the time of the interviews, reviewing the performance of a refined model took 60–120 seconds. A suggestion for improvement was to perform multiple prototype refinement steps (like deleting multiple prototypes) before calculating the impact on performance.
System improvements after first evaluation round
The first evaluation round led to a number of improvements to the system. Some of the changes were simple like making the layout more consistent, grouping elements in a more logical way, and adding some elements to the video player to allow stepping through, frame-by-frame. Other changes were more involved.
One of the main changes we implemented was a speedup of the training and testing procedure which takes place after prototype refinement. In the initial version of ProtoExplorer, the weights in the last layer were not optimized after prototype refinement. Simply testing the model on the testing data took minutes, and training was not considered. In the most recent version, we saved the intermediate outputs of the first model to be able to efficiently retrain and test refined models, as described in the ’Background’ section. This reduces the combined retraining and testing time to less than a second for prototype deletion and a few seconds for prototype replacement.
To improve the selection of candidate prototypes we added the UMAP visualization to give an overview of the different candidates and their distribution in the embedding layer. In this way the investigator can more easily spot areas that are not represented or find close elements having different labels to allow for more subtle distinctions (see (c2) in Figure 5).
A second focus of changes was the model performance and metrics panel. Here we made the suggested changes to the confusion matrix, adding green/red colors when used in comparison mode. We also added the radar plot to have an instant view of the changes in the model characteristics as a whole (replacing a text-based indication of multiple characteristics). One of the most important changes was developing the landmark density visualization as the distribution of prototypes over different regions of the face was one of the major discussion points in the evaluation.
The experts found the interpolated activation maps as typically used in prototypical networks lacking in clarity and spatial precision. Based on this, we replaced these by maps generated using Prototypical Relevance Propagation, as described in the `System implementation’ section.
Second evaluation round
During the second evaluation round, we asked the forensic experts for feedback on the improved version of ProtoExplorer, described above.
The second round of interviews confirmed the usefulness of (most of) the changes, identified some minor issues, and led to a number of new directions to pursue. Two interrelated elements kept coming back in the different interviews, namely expertise and workflow. The current system is mostly geared toward forensic experts, and it would be beneficial to create a different profile for police officers. A more explicit visualization of the workflow in using the system would help for both profiles. As one expert stated, what the experts need to do in the end is simply being able to state which frames in the video are suspicious and in what part of the frame the manipulation is visible. The steps in the workflow should lead the expert to that decision.
Although the experts indicated in the first round that more elaborate search methods for prototypes are needed they found it difficult to understand what was depicted in the UMAP visualization. More guidance to help them pick candidates from this visualization is needed.
Additionally, there were some desired functionalities which define interesting avenues for further research. These all revolve around the selection of prototypes. Notable improvements include being able to select candidate prototypes based on semantic characteristics such as putting prototypes at the mouth or eyelashes at the top of the candidate list, and providing a ranking of prototypes based on their impact on the different performance metrics.
Discussion and future work
Although ProtoExplorer was developed for forensic experts, it also yields good opportunities for further development of prototype-based automatic deepfake detection methods. Building models using DPNet and visualizing them in ProtoExplorer revealed that although classification performance is quite good the prototypes are not always distributed over the whole face. To study this problem we should aim to vary the weights corresponding to the different loss terms for the automatic system and evaluate the result using our landmark density visualization to see the distribution on the face, our radar plot to see the impact on loss functions, and our UMAP visualization to see the distribution in latent space. As mentioned in the `System implementation’ section, the dataset we used for training the models was FaceForensics++. This is the dataset used in Trinh et al. 20 to benchmark the performance of the DPNet network that we used. A recent study 35 concluded the existence of a representation bias in this dataset in terms of race and gender, a phenomenon we also saw in using the system. To improve on this we would have to automatically label the training data for those characteristics. From there we could see whether the above explorations could contribute to less bias or that additional loss terms should be considered.
As mentioned in the `System implementation' section, the models used by our systems were trained following the DPNet network introduced in Trinh et al. 20 This network, rooted in ProtoPNet, 22 uses spatio-temporal prototypes instead of ones based exclusively on still images. The addition of this temporal information is the most significant contribution of this method, aiming to capture temporal inconsistencies present in deepfake videos. Based on the performance comparison in Trinh et al., 20 DPNet outperforms ProtoPNet in deepfake detection, initially validating the intuition that temporal information would be beneficial for this task. However, this decision had pitfalls that were only revealed when explored in an interactive setting.
The evaluation with the experts indeed revealed the gap between the system prototypes that are good for classification and the prototypical examples experts use. In this paper we took the automatic system as the starting point and let experts refine the prototypes. An interesting alternative would be to let experts build up a rich vocabulary of prototypical situations with good spatio-temporal examples and see how the system can be adapted to take those as the starting point. The expert could then use ProtoExplorer to browse these prototypes whenever they are presented with new disputed material.
Conclusion
In this paper, we proposed a Visual Analytics process model for prototype learning inspired by Sacha et al. 53 composed of two intertwined decision-making loops. The model is specifically designed for deepfake analysis but gives a blueprint for any scenario in which there is a balance needed between optimal performance and interpretability using a prototype-based deep neural network. Based on the model we presented ProtoExplorer, a VA system allowing for the exploration of prototypes and the refinement of prototype-based models for the forensic detection of deepfake videos. Our system facilitates the exploration, deletion, and replacement of complex dynamic prototypes that combine spatial and temporal information. We conducted an evaluation with five video forensic experts in which we assessed the contributions of ProtoExplorer. The evaluation reaffirmed that ProtoExplorer is a significant step in the right direction of closing the gap between the characteristics experts use in analyzing disputed videos and automatic methods. The evaluation gave insights into the complex challenges remaining in achieving highly interpretable, prototype-based predictions in the analysis of video sequences and yielded a number of promising new research directions for deepfake analysis as well as for more generic visual analytics using prototype-based systems.
Footnotes
Appendix
Acknowledgements
The authors wish to thank the anonymous video forensic experts from the Netherlands Forensic Institute who participated in the evaluation of ProtoExplorer.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially funded by the Netherlands Forensic Institute, an agency of the Ministry of Justice and Security in the Netherlands.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.