
Abstract
To address the challenges of urban traffic complexity, such as occlusion and lighting variations that impact road target detection, this study introduces the KGKPD algorithm. This algorithm integrates knowledge graphs with keypoint detection based on the CenterNet concept. It enhances robustness by introducing salt-and-pepper noise and uses the RepVit network as the backbone. The weighted fusion adaptive feature pyramid network module fuses multi-scale features to optimize the extraction of small target features. The efficient linear deformable convolutional head improves detection of occluded targets. The Poly-1 loss function addresses class imbalance, thereby improving accuracy. The integration of prior knowledge enhances the model’s ability to understand relationships between targets. Compared to CenterNet, the KGKPD algorithm reduces parameters and computational load by 92.32% and 91.85%, respectively, increases the mean average precision by 4.1%, and achieves a frame rate of 40.5 frames per second, meeting the requirements for real-time detection. The code is available at https://github.com/yjx-cup/kgkpd.
Keywords
Introduction
With the rapid economic development and urbanization, the surge in urban population and the popularization of new energy vehicles have led to a sharp increase in the number of vehicles, intensifying urban traffic pressure and highlighting issues such as traffic congestion, safety, and environmental pollution. Traditional manual inspection methods are costly, inefficient, and unreliable. In contrast, while infrared or radar detection technologies can accurately measure the position, speed, and types of vehicles, and possess the ability to work around the clock and strong interference resistance, these technologies are very expensive.
In recent years, the rapid advancement of deep learning technology has significantly propelled the development of object detection algorithms (Dai et al., 2021; Duan et al., 2019; Girshick, 2015; Han et al., 2020; Wang et al., 2023a). Researchers have optimized existing models to better meet the specific needs of road vehicle detection. These optimized models have achieved a dual improvement in cost-effectiveness and high detection accuracy while maintaining a small model size and excellent performance. For instance, to address the issue of occluded targets during detection, He et al. (2024) proposed a method called YOLO-OVD (YOLO for occluded vehicle detection) and a corresponding dataset, effectively handling the problem of vehicle occlusion. Yu et al. (2024) introduced an enhanced YOLOv7 for traffic systems (ETS-YOLOv7), which replaces the traditional efficient layer aggregation network (ELAN) module with a compact layer aggregation network module, reducing redundant computation and improving computational efficiency without sacrificing model accuracy. Zhou et al. (2024) proposed an fully convolutional one-stage object detection (FCOS) that combines dynamic convolution and feature enhancement. Through a dynamic convolution module (Dy-Conv), dual attention module, and multi-scale feature fusion module, it enhances feature extraction capabilities, thereby improving the efficiency and accuracy of real-time transport protocol detection. Vankdoth and Arock (2024) proposed an end-to-end model that can be easily deployed on edge devices and has a high mean average precision (mAP). Liu et al. (2024) introduced a new structure-aware fusion network, which enhances the robustness of traffic object detection by incorporating bio-inspired event cameras and designing a reliable structure generation network as well as an adaptive feature complementation module. In complex road traffic environments, the visibility and features of traffic targets are easily attenuated and lost due to factors such as lighting conditions, weather conditions, time, background elements, and traffic density. Tang et al. (2024) proposed a new YOLO network called HRYNet, which significantly improves the network’s detection performance of traffic targets in complex backgrounds by enhancing the feature extraction and fusion process.
In summary, although existing methods have made some progress in object detection in complex traffic environments, they still face several challenges: First, existing technologies have not fully considered interference factors during image transmission, which can reduce image clarity and thus affect the accuracy and robustness of object detection. Second, existing frameworks often overlook the inherent relationships between traffic targets, which are important for a deeper understanding and prediction of traffic behavior patterns. To address these issues, this study proposes a road object detection algorithm called KGKPD, which combines knowledge graphs and keypoint detection. Our contributions include: To address the issue of pixel loss during image transmission, we additionally employed the salt-and-pepper noise algorithm in the data augmentation stage. Although the salt-and-pepper noise algorithm itself is not a novel technique, we innovatively matched its parameters to the specific noise patterns in the road target detection task. Unlike previous approaches that simply added salt-and-pepper noise with fixed intensity, we dynamically adjusted the degree of salt-and-pepper noise addition based on the characteristics of road scene images. This allows the model to better adapt to the complex and variable image quality conditions encountered in practical applications. To tackle the problem of occluded traffic targets in scenes, we introduce an efficient linear deformable convolutional head (ELDHead). This head is a novel detection head structure that integrates the advantages of efficient local attention (ELA) and linear deformable convolution (LDConv), and it is specifically optimized for addressing occlusion issues in road target detection. By organically combining these two components, ELDHead achieves adaptive focusing and refined modeling of image features when dealing with occluded targets. To address the issue of detecting small targets, we propose a weighted fusion adaptive feature pyramid network (WF-AFPN). The WF-AFPN module innovatively improves upon the adaptive feature pyramid network (AFPN) to meet the requirements of small target feature extraction in road target detection. Compared with the original AFPN, we not only introduce the squeeze-and-excitation (SE) attention mechanism and learnable weight parameters, but also replace ordinary convolutions with depthwise convolutions. This enables the model to more effectively perform weighted fusion of features at different scales, while significantly reducing the computational cost and model parameters. Incorporating knowledge graphs into object detection algorithms to address practical problems, we constructed a specific knowledge graph containing relationships between road target categories using ConceptNet. Subsequently, the restart random walk (RW) algorithm was employed to quantify the graph and obtain a semantic consistency matrix. Through this approach, we were able to more accurately capture the complex relationships between target categories and effectively integrate them into the detection model, thereby enhancing the model’s ability to understand semantic associations between targets and improving detection accuracy.
Related Work
The design philosophy of CenterNet (Duan et al., 2019) is leveraged in KGKPD, where targets are treated as keypoints, specifically the center points of target bounding boxes. Compared to other anchor box-based object detection algorithms, this approach eliminates the inefficient and complex anchor operations, thereby enhancing the detection performance of the algorithm. It also improves the flexibility and accuracy of detection. Additionally, during the inference stage, prior knowledge is used to intervene in the detection results, increasing the confidence in the model’s detected classes while also enhancing the mathematical interpretability of the model. Similar to the TTFNet (Liu et al., 2020) model, an elliptical Gaussian kernel is used to generate an elliptical heatmap at the keypoint, avoiding the overflow of the true bounding box that occurs with CenterNet’s circular heatmap after a
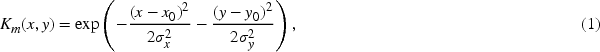
To better address the issue of class imbalance in the dataset, KGKPD employs a variant of focal loss known as Poly Loss-1 (Poly-1; Leng et al., 2022) as the keypoint loss function. This approach involves a significant enhancement by simply adding the first term of the Taylor expansion to the focal loss, which results in a qualitative improvement. The focal loss is defined as a loss function that focuses on hard examples by down-weighting well-classified examples, thereby addressing the imbalance between easy and hard examples in the dataset. The Poly-1 loss function extends this concept by incorporating the leading polynomial term, allowing for more flexibility and adaptability in handling class imbalance. This modification is achieved with minimal changes, requiring only the addition of one extra hyperparameter and a single line of code, making it an efficient and effective solution. The specific formulations of focal loss and Poly-1 are shown in equations (2) and (3), respectively.

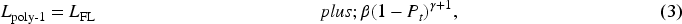
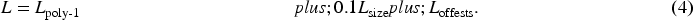
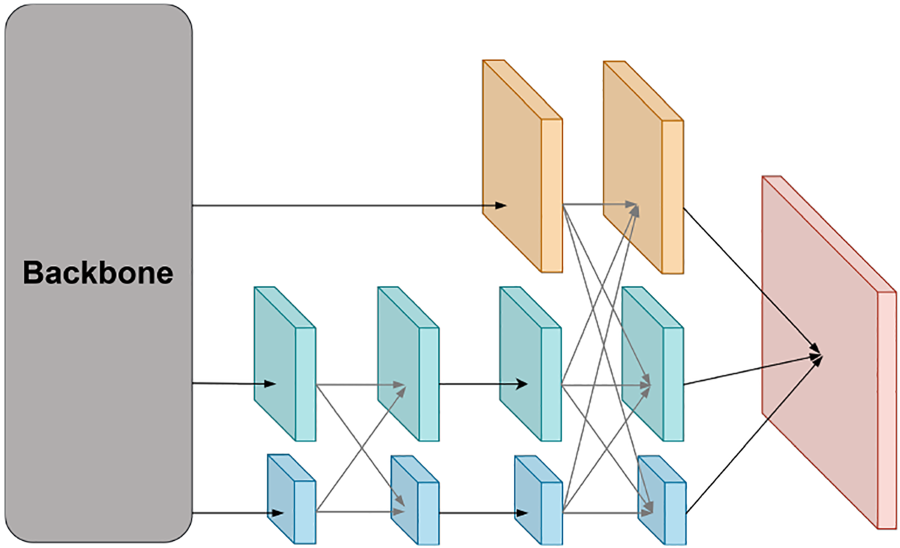
The KGKPD detection network consists of three modules: the backbone network, the neck network, and the detection head. The overall network structure is shown in Figure 1.
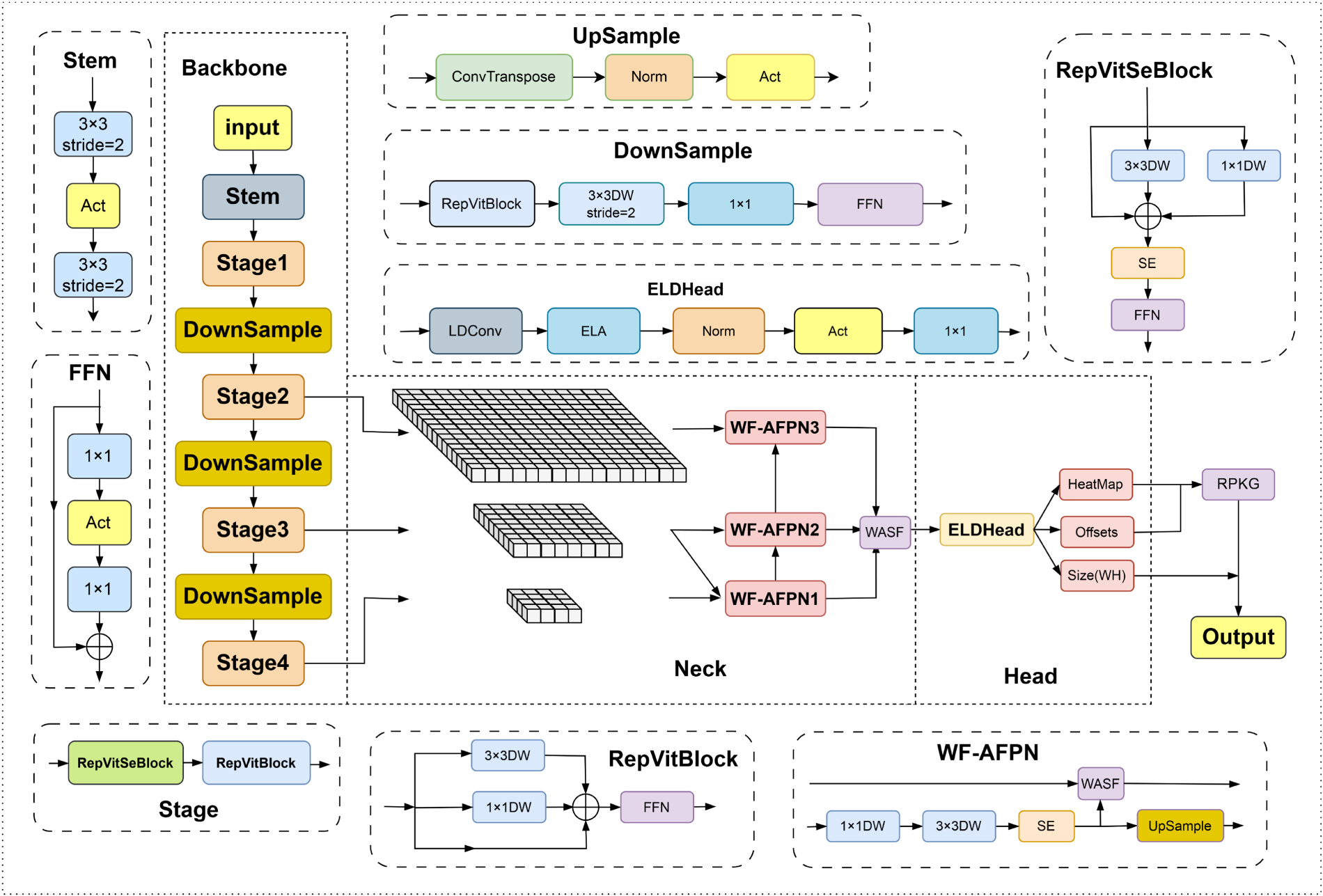
Structure of KGKPD.
To reduce the number of model parameters and computational load, we have chosen the lightweight RepVit as the backbone network for feature extraction in the KGKPD task. RepVit, proposed by Wang et al. (2024), combines the advantages of lightweight convolutional neural network (CNNs) and ViTs to enhance the performance of visual tasks on mobile devices. It is achieved through a step-by-step enhancement of the MobileNetV3 architecture, ultimately forming a new efficient pure CNN architecture. RepVit outperforms existing lightweight ViTs in multiple visual tasks and has an advantage in terms of latency. Despite having fewer parameters and faster training, RepVit still has shortcomings when directly used for feature extraction in KGKPD. This is because the feature map output by the backbone network is downsampled from a
In order to compensate for the spatial information loss in the RepVit network, a series of measures have been implemented. Initially, the outputs from the last three stages of the RepVit network were extracted as effective feature layers. While these feature layers contain rich semantic information, some detailed information may be lost during the downsampling process. Therefore, the WF-AFPN module was designed to enhance the features of each layer. This module introduces learnable weights and the adaptive spatial fusion (ASF) operation to perform weighted fusion of features from different levels, thereby improving the expressiveness of the features. Subsequently, the feature maps processed by the WF-AFPN module were upsampled to a uniform size of
Addressing the issue of feature deformation caused by target occlusion, an advanced detection head, ELDHead, has been designed to enhance the model’s adaptability to geometric transformations of targets. ELDHead employs LDConv to sparsify features, thereby increasing the model’s sensitivity to geometric transformations. LDConv achieves this by adding learnable offsets to the sampling locations of the convolution kernel, enabling the kernel to adjust its sampling positions adaptively and thus better capture geometric transformations. This adaptive adjustment capability allows the model to more flexibly deal with geometric changes such as the scale, pose, and viewpoint of targets, significantly improving the modeling ability for complex geometric transformations. ELDHead also introduces the ELA attention mechanism, which can identify and optimize the degraded feature regions caused by occlusion, thereby significantly enhancing the model’s ability to recognize occluded targets. The ELA attention mechanism acquires feature vectors in the horizontal and vertical directions through strip pooling in the spatial dimension, maintaining a narrow kernel shape to capture long-range dependencies and preventing irrelevant areas from affecting label predictions, thereby generating rich target location features in each direction. Each directional feature vector is processed independently to obtain attention predictions, which are then combined using a product operation to ensure accurate positional information of the region of interest. This lightweight attention mechanism not only accurately locates the objects of interest but also significantly improves the overall performance of CNNs with minimal additional parameters.
To construct the relationship prior knowledge graph (RPKG) module, the initial step involves processing the assertion list data provided by ConceptNet. Specifically, these assertion data are loaded and then transformed into a pruned version that retains only the English subset while filtering out all negative relationships, such as NotDesires, NotHasProperty, NotCapableOf, NotUsedFor, Antonym, DistinctFrom, and ObstructedBy. Additionally, cycles within the graph are removed. After this processing, the resulting assertions are stored in a list, with each element comprising two concepts, their relationship, and the corresponding weight. Following this step, a lookup file and the pruned knowledge graph file are generated and output. The lookup file is used to quickly locate the integer indices corresponding to the concepts, while the pruned knowledge graph file provides the necessary input data for the subsequent RW algorithm.
Subsequently, employing the RW algorithm with the category concepts from the dataset as seed nodes, an RW with restart (RWR) score vector is computed for each seed node. By extracting the scores related to other category concepts, a matrix
Through the semantic consistency matrix provided by this JSON file, the model’s output results are strategically intervened to optimize its ability to recognize relational features between objects. This enables the consideration of semantic consistency between targets during the inference process, thereby enhancing the accuracy of object detection. Moreover, by incorporating strong prior knowledge of the spatial relationships and distributions between targets, the model can reduce false detection rates and improve localization accuracy.
Weighted Fusion Adaptive Feature Pyramid Network (WF-AFPN)
The RepVit backbone network is primarily composed of stacked RepVitBlock modules and RepVitSeBlock modules. The RepVitBlock module consists of two regular convolutions, a
When feature maps enter the network, they first pass through a Stem module for preprocessing. The Stem module consists of two
RepVit employs a cross-block placement strategy for SE layers, using them in the first, third, fifth, etc., blocks of each stage. This alternating placement aims to maximize accuracy improvement while controlling the increase in latency. Since the input image size is
Yang et al. (2023b) proposed the asymptotic feature pyramid network (AFPN), which addresses the issue of information loss during feature transmission by allowing direct interaction between non-adjacent layers and introduces an ASF operation to handle conflicts between features at different levels. To further enhance feature fusion, we proposed a strategy and combine it with the SE module to produce multi-scale feature maps with channel weights. Finally, deconvolution is used to upsample feature maps of different scales to the same size, and the ASF incorporates learnable weight parameters, becoming the WASF operation, further improving the adaptive adjustment of fusion effects. Depthwise convolution replaces the original regular convolution to reduce computational load and model parameters while maintaining network performance. The structure of the WF-AFPN network is shown in Figure 2.
Structure of Weighted Fusion Adaptive Feature Pyramid Network (WF-AFPN).
Feature maps of different levels are extracted from the backbone network, denoted as
Let

When the WF-AFPN module fuses layers
In street surveillance scenarios, targets are often partially occluded by various obstacles such as pedestrians, vehicles, and buildings, which poses a significant challenge to object detection and is prone to cause missed detections. Moreover, to accurately distinguish between different categories of targets in complex surveillance environments, such as pedestrians, vehicles, and animals, it is necessary to clearly highlight the differences among various categories in the feature maps, enabling the detection model to accurately perform classification and recognition.
To address these issues, we have carefully designed a detection head named ELDHead, which is an improved and innovative version based on the classic CenterNet detection head. In the ELDHead, we have ingeniously integrated the ELA mechanism, which plays a crucial role in enhancing detection performance.
One of the core advantages of the ELDHead is its ability to flexibly adjust convolutional kernel parameters according to changes in target shapes. In street surveillance scenarios, the shapes and postures of targets are highly variable. For instance, pedestrians may present different contours due to various actions, and vehicles can exhibit different shape features from different angles. Traditional fixed convolutional kernels often struggle to handle such shape variations. However, the ELDHead introduces the concept of deformable convolution, allowing the convolutional kernels to adaptively adjust according to the actual shapes of targets. This flexible adjustment capability greatly enhances the model’s ability to recognize occluded targets. Even when targets are partially occluded, the model can capture the key features of the targets through the adjusted convolutional kernels, thereby effectively reducing the occurrence of missed detections.
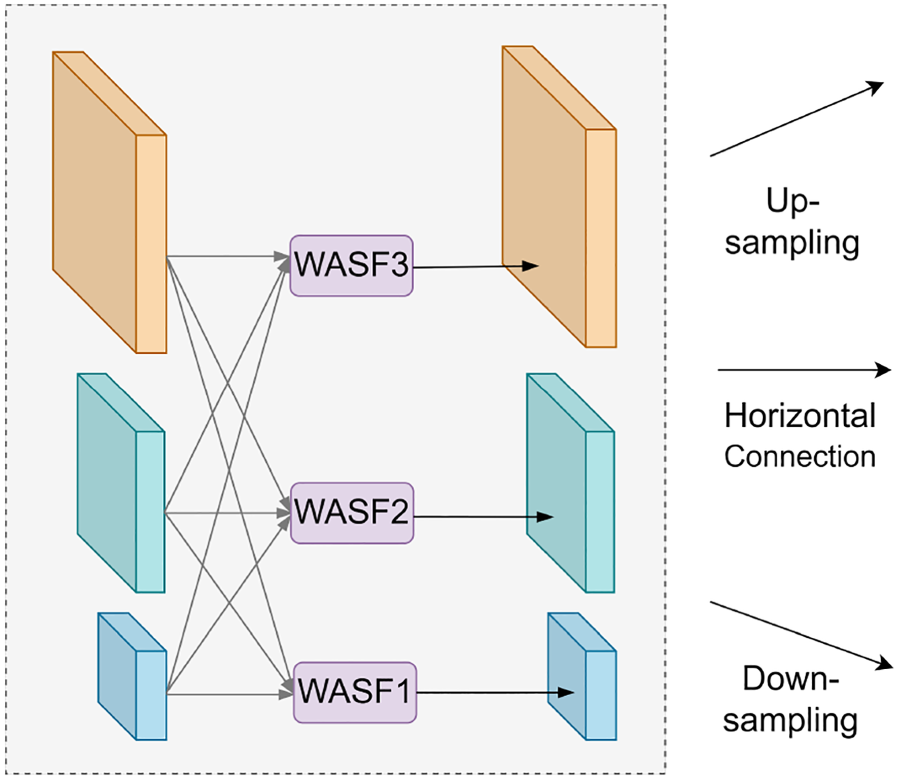
Weight Adaptive Spatial Fusion (WASF) Operation. It Demonstrates That WASF Performs Feature Fusion at Three Different Levels, Allowing for the Assignment of Different Spatial Weights to Features at Different Levels. This Enhances the Importance of Key Levels and Mitigates the Impact of Conflicting Information From Different Objects.
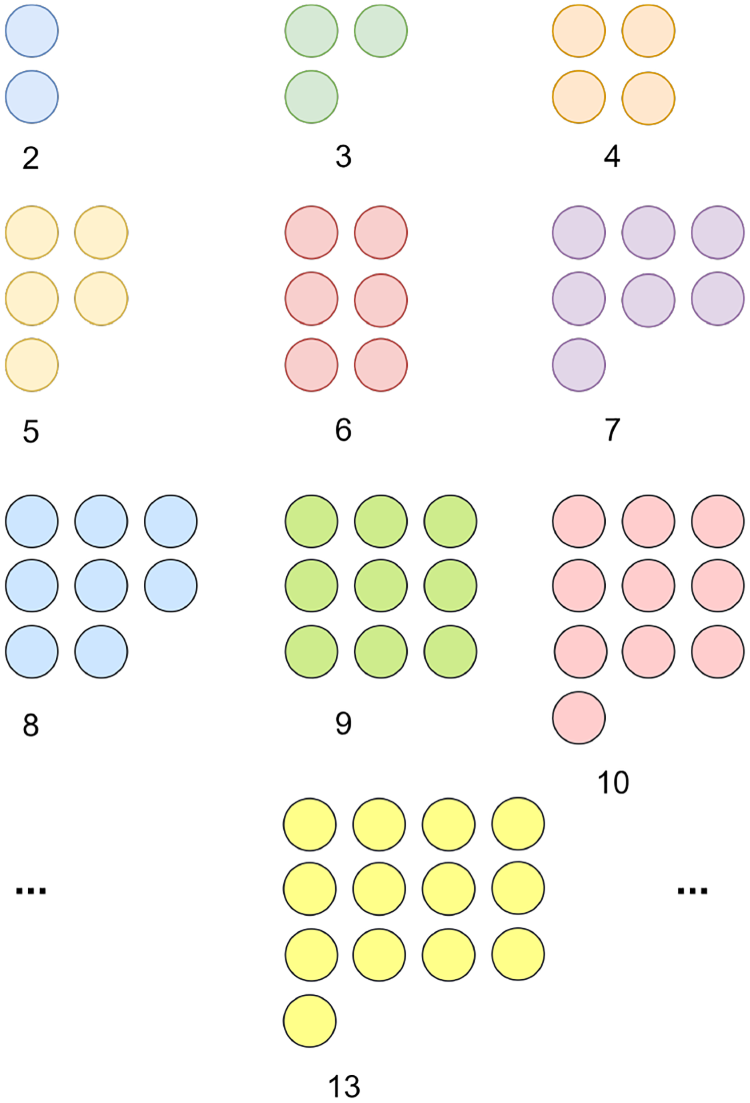
The Initial Sampled Coordinates for Arbitrary Convolutional Kernel Sizes. Adapted from Zhang et al. (2024), © Elsevier. Reproduced with permission.
LDConv is an advanced convolutional technique proposed by Zhang et al. (2024). It allows for any number of parameters and any sampling shape for convolutional kernels of arbitrary sizes. Unlike traditional convolution and deformable convolutional networks (Li et al., 2023, 2022; Su et al., 2023; Wang et al., 2023b; Xiong et al., 2024; Yang et al., 2023a) operations, LDConv does not result in a quadratic increase in the number of parameters as the kernel size increases. Instead, it achieves a linear growth in the number of parameters, thereby reducing the computational burden of the model while maintaining performance. This design makes LDConv more flexible and efficient in handling feature maps of different sizes and shapes. Different kernel shapes are shown in Figure 4.
As shown in Figure 5, it can be observed that LDConv can dynamically adjust sampling points according to the size of the target. This allows it to capture features of objects of different sizes more accurately. In contrast, traditional convolution lacks this flexibility. This characteristic enables LDConv to identify target objects more precisely when extracting high-level features. Compared to traditional convolution, it is more efficient in handling background noise, thereby extracting features that are more conducive to target recognition.
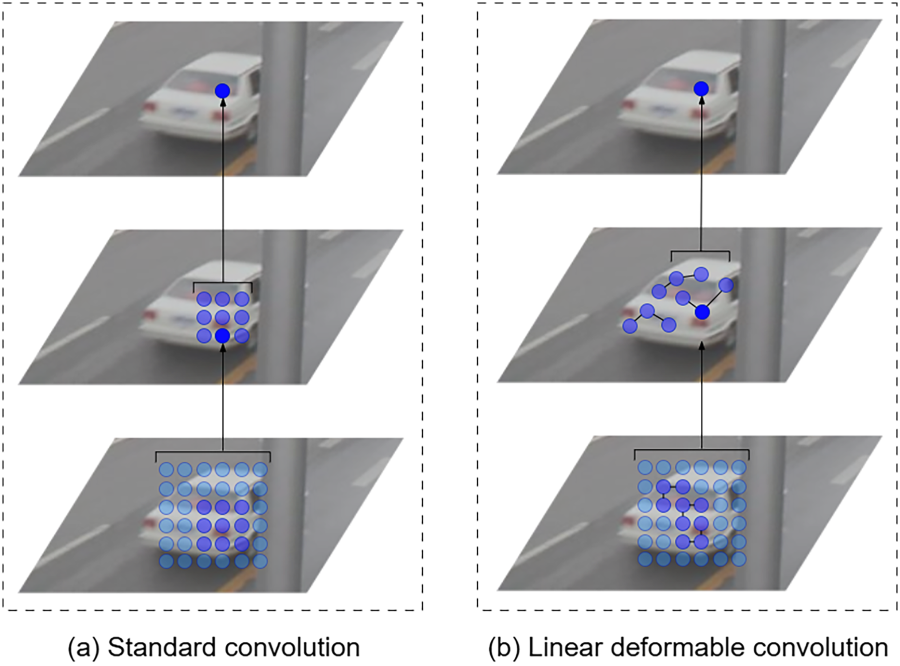
Comparison of Standard Convolution and Linear Deformable Convolution Extraction Features.
ELA was first proposed by Xu and Wan (2024). It is an ELA method that combines one-dimensional convolution and group normalization feature enhancement techniques. This approach effectively encodes two one-dimensional positional feature maps, allowing for precise localization of regions of interest without the need for dimensionality reduction, while maintaining a lightweight implementation. It uses strip pooling instead of spatial global pooling to capture long-range spatial dependencies. For a convolutional output

The two resulting feature vectors are then subjected to local interaction using one-dimensional convolution. The results are further processed through group normalization and activation functions to generate position attention predictions for two spatial directions. Finally, the prediction results are multiplied with the feature values of the



In order to effectively filter out irrelevant background noise and enhance the model’s ability to handle occlusions, the processing of the input feature maps begins with the LDConv module. This module employs LDConv operations, which can accurately capture local features of the target, thereby effectively distinguishing the target from the background. The adaptive nature of LDConv allows it to adjust according to changes in the target’s shape, minimizing the interference of background noise and capturing key features of the target even when it is partially occluded. This is crucial for street surveillance scenarios where targets are often occluded by various objects.
Subsequently, the feature maps enter the ELA module, an efficient hierarchical attention mechanism that can adaptively adjust the importance of different feature channels. In the presence of occlusions, the ELA module focuses more on features containing target information while suppressing the influence of background noise, thereby highlighting the target in complex scenes. The ELA module achieves this functionality by combining one-dimensional convolution and group normalization. The one-dimensional convolution efficiently processes feature maps along a specific dimension, capturing linear features that indicate the target’s position, while group normalization stabilizes the learning process and enhances the network’s generalization ability.
After processing by the ELA module, the feature maps undergo normalization to ensure they are on a consistent scale, which is crucial for the stability and performance of subsequent operations. The feature maps are then processed through the SiLU activation function. The SiLU function is chosen because it introduces non-linearity to the model in a controllable manner, which is beneficial for learning complex patterns in the data.
Finally, a
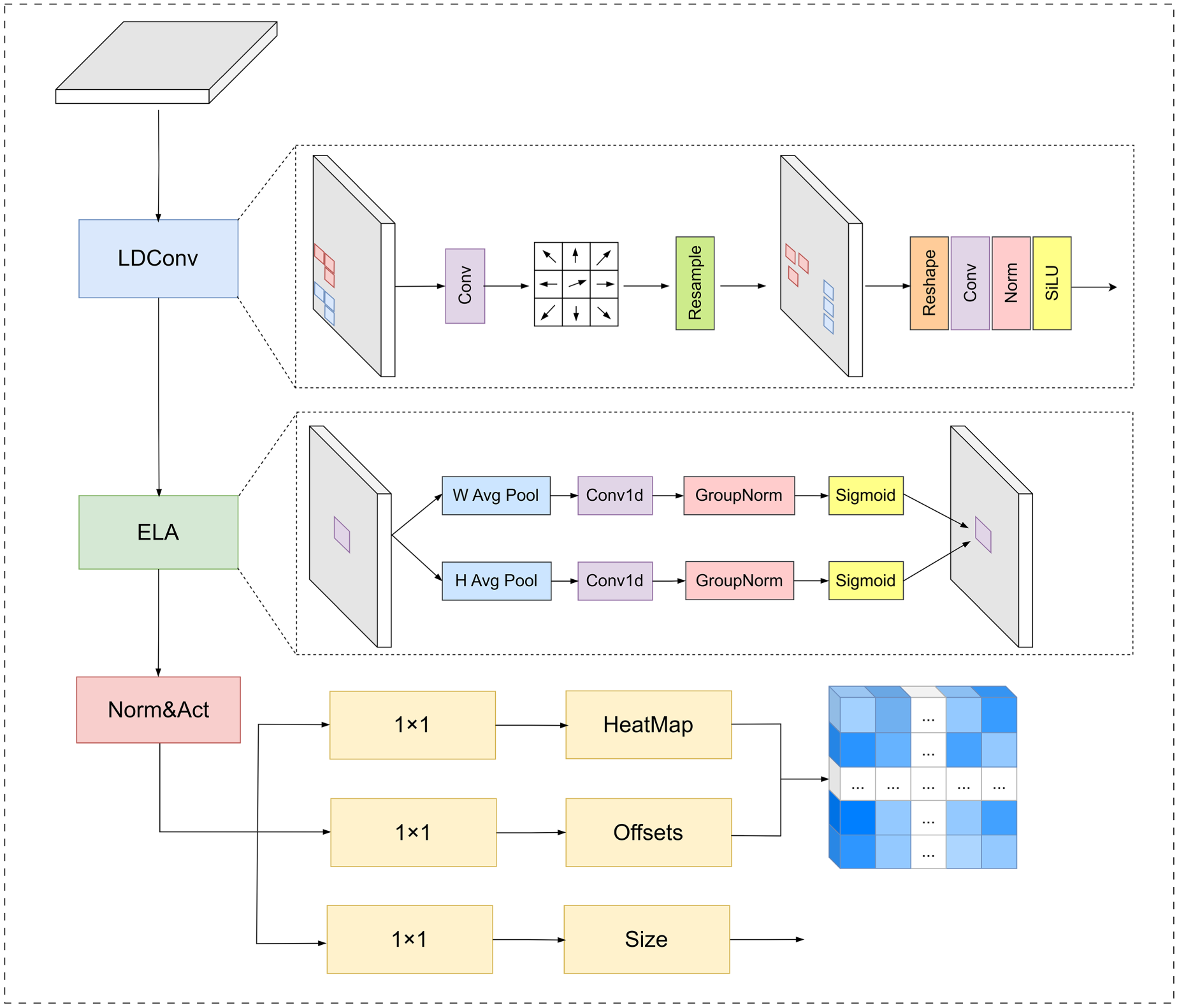
Structure of Efficient Linear Deformable Convolutional Head (ELDHead).
A knowledge graph is a method used to represent and store knowledge, organizing and displaying various relationships between entities in the form of a graph. Each entity represents a specific or abstract object, and these entities are connected through specific relationships, thereby forming a complex network. Knowledge graphs not only focus on the entities themselves but also emphasize the semantic relationships between the entities and the attributes of these relationships. This allows the knowledge graph to express deeper meanings and context. In a knowledge graph, entities are the nodes of the graph, while relationships are the edges that connect these nodes. Each edge describes a certain type of connection or interaction between entities.
In addition to entities and relationships, a knowledge graph also includes semantic descriptions, which provide additional information such as the type of relationship, the attributes of entities, or specific conditions. These elements allow the knowledge graph to represent knowledge in the world more accurately and comprehensively. Figure 7 illustrates the structure of a knowledge graph in the form of a directed graph, where each node represents an entity, each edge represents a relationship, and the semantic descriptions are supplemented through the attributes of the edges.
Knowledge Graph. Adapted from Jung et al. (2007), © Springer Nature. Reproduced with permission.
Fang et al. (2017) made a pioneering contribution to the field of object detection by integrating knowledge graph technology. They proposed two innovative methods to improve the detection accuracy of the model. The first method utilizes frequency-based knowledge, which infers the relationships between target classes by analyzing the frequency of their co-occurrence. For example, keyboards and mice often appear together, so detecting one can increase the confidence in detecting the other. The second method uses knowledge graph-based knowledge, capturing relationships between targets that have not co-appeared in actual scenes, thus complementing the shortcomings of the frequency-based approach. Ulger et al. (2023) further proposed a feature enhancement model based on relational priors (RP-FEM). This model uses relational priors to enhance target proposal features, running a graph transformer on the scene graph obtained from initial proposals to learn the relational context modeling for object detection and instance segmentation simultaneously. Experimental results show that RP-FEM can effectively suppress impossible class predictions in images and prevent the model from generating duplicate predictions, thereby improving its baseline model.
The RPKG model enhances the classification ability of the network by intervening in the class confidence in the heatmap output from the ELDHead. By integrating prior knowledge, this model is capable of simulating human reasoning, especially the relationships and contextual information between objects, thus effectively identifying specific object categories. Unlike traditional methods, the RPKG model not only relies on visual features from the image but also leverages external semantic information to enhance classification performance.
To achieve this goal, a knowledge graph containing all the categories in the dataset must first be constructed. This step is accomplished by utilizing the ConceptNet common-sense knowledge base, which is a large-scale open-source knowledge base offering rich semantic relationships and common-sense knowledge. ConceptNet helps the model understand potential connections between object categories, such as objects that frequently appear together or objects with similar characteristics.
Next, the RPKG model uses the RWR algorithm to process the constructed knowledge graph. The RWR algorithm performs repeated RWs within the knowledge graph, combined with a restart mechanism, allowing the model to extract more reliable and stable semantic information from the graph. In this way, the algorithm builds a semantic consistency matrix to quantify the relationship strength and semantic similarity between different categories, thereby improving the model’s reasoning ability in complex scenarios.
ConceptNet (Liu et al., 2018) is a large-scale open-source knowledge base dedicated to capturing the common-sense knowledge implied in natural language vocabulary. This knowledge base constructs a relational graph that emphasizes the connectivity of knowledge, using unstructured text and expressions close to natural language. The CSV format data of ConceptNet is shown in Table 1.
Content in ConceptNet.

To adapt the ConceptNet knowledge base for the construction of a semantic consistency matrix, it is necessary to preprocess the data by converting it into English triplets and excluding all entries that represent negative relationships as well as self-loops. The pseudocode for the ConceptNet Transformation Algorithm is presented in Algorithm 1.

In this conversion process, the correspondence between the symbols involved and their specific meanings is detailed and displayed in Table 2.
Symbol Explanation in ConceptNet.

The RW algorithm (Gionis et al., 2007) is a graph theory algorithm based on Markov chains. It simulates the process of random walking in a graph. Starting from a node, at each step, a neighboring node is randomly selected to move to, until a certain stopping condition is met. RWR is a variant of RW that introduces a restart probability to allow the walk to return to the starting node or a specific node, rather than solely relying on the adjacency relationships in the graph. Specifically, RWR requires solving the equation (10):



The structure of the RPKG module is shown in Figure 8. The overall idea is to enhance the original features and improve the model’s detection performance by fusing the semantic consistency matrix 
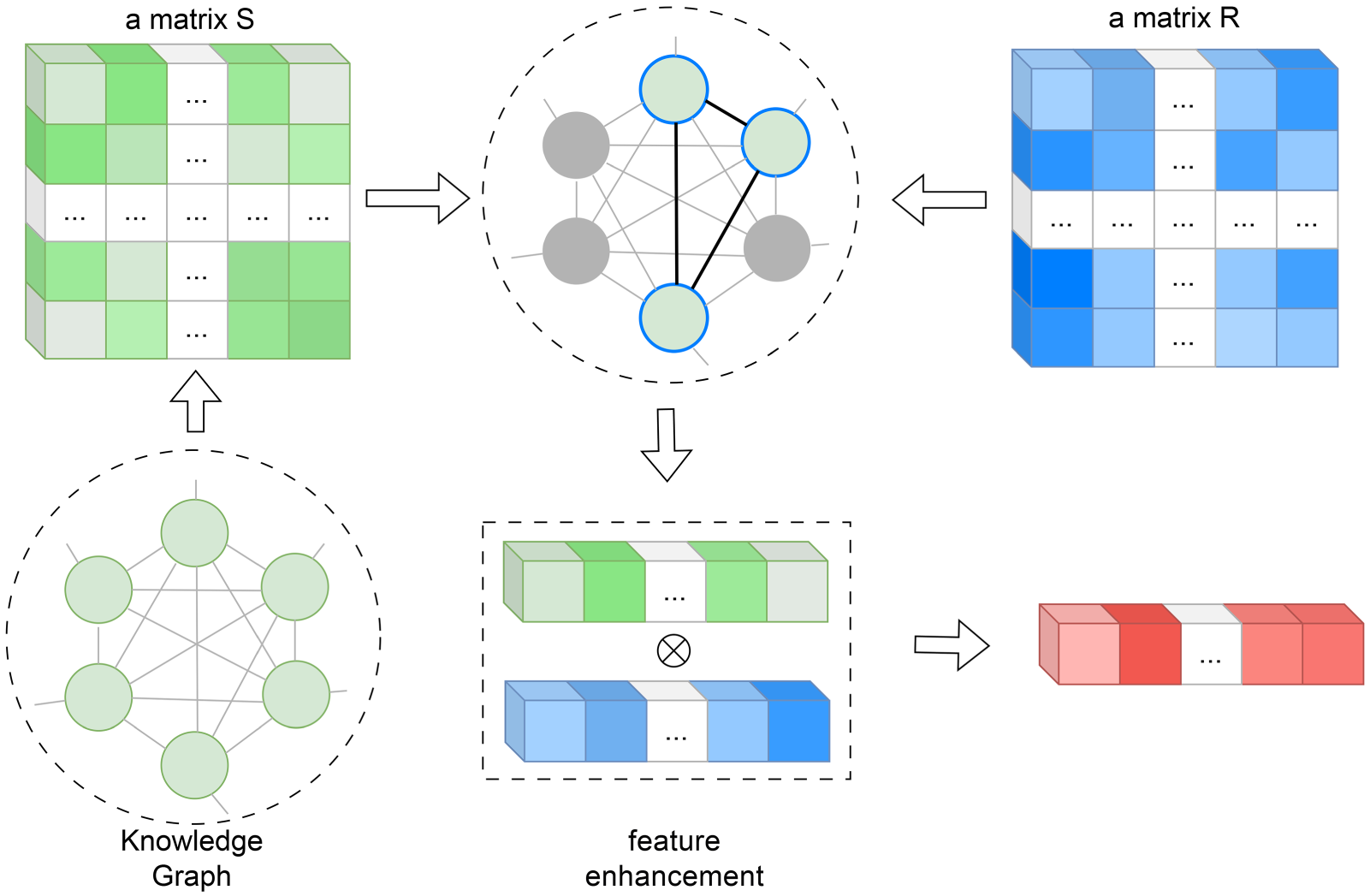
Structure of Relationship Prior Knowledge Graph (RPKG).
Data augmentation techniques play a crucial role in the fields of object detection and deep learning, enhancing model performance through various means. These methods not only expand the training dataset and improve the model’s generalization capabilities but also enhance its adaptability to abnormal situations by introducing a certain degree of perturbation. Common data augmentation techniques include image flipping, cropping, and color jittering.
To enhance the robustness of the model under adverse environmental conditions, we employ the injection of salt-and-pepper noise as a data augmentation technique, aimed at simulating noise interference during image transmission. The core idea of this technique is to introduce random noise points into the training data to mimic distortions and interferences occurring during the actual transmission process. Specifically, we present an adaptive salt-and-pepper noise addition algorithm based on local contrast. Local contrast is obtained by calculating the local mean and subtracting it from the original image. Then, the noise probability and intensity are dynamically adjusted based on the local contrast. Higher parameters are used in regions of high contrast, while lower parameters are applied elsewhere. The noise addition formula is shown in equation (14):


Schematic Diagram of the Noise Addition Process.
By doing so, the model is exposed to more noisy samples during training, allowing it to learn more generalized feature representations and avoid overfitting to clean data.
The introduction of salt-and-pepper noise not only strengthens the model’s ability to adapt to noise but also improves its stability in complex, dynamic environments. For example, in practical applications, images captured by sensors are often subject to various interferences, such as signal attenuation during transmission, changes in environmental lighting, or equipment malfunctions. By incorporating salt-and-pepper noise into the training process, the model learns to differentiate between noisy and clean signals, enabling it to make more accurate predictions in noisy environments.
Furthermore, this data augmentation technique fosters the model’s adaptability to a variety of scenarios, allowing it to maintain high performance even when facing different types of interferences. By repeatedly exposing the model to noisy data, the recognition process becomes more stable, reducing the fluctuations in predictions caused by unstable input data quality. Ultimately, the model’s robustness is significantly improved, enhancing its stability and accuracy in real-world applications.
Data Split
The UA-DETRAC dataset (Lyu, S et al., 2017; Wen et al., 2020) is a large-scale benchmark dataset specifically designed for object detection tasks from a road surveillance perspective. In this study, we carefully selected and extracted 8,127 images from the UA-DETRAC dataset, which not only have a representative quantity but also encompass a variety of traffic scenes under different lighting conditions, including both daytime and nighttime. This enables us to comprehensively simulate real-world traffic situations, providing a rich and diverse sample base for model training and evaluation.
These images were scientifically and rigorously divided into three subsets to meet the specific needs of different research stages. The training set consists of 6,582 images, offering a large sample size that provides sufficient learning material for the model, enabling it to fully learn and capture the characteristics and patterns of various traffic targets, thus ensuring accurate identification and localization of targets in complex traffic scenarios. The validation set includes 732 images and is primarily used for real-time monitoring and evaluation of model performance during training, allowing for timely detection and adjustment of issues such as overfitting or underfitting, ensuring the model’s stability and generalization ability during the training process. The test set consists of 813 images, used for comprehensive and objective evaluation of the model’s final performance after training, verifying the model’s actual application effectiveness and reliability on unseen data.
Regarding category classification, we conducted an in-depth analysis and detailed reclassification of the “Other” category in the selected 8,127 images from the UA-DETRAC dataset. Upon further investigation, we found that the “Other” category contained targets with certain common characteristics but also unique features. To enhance the granularity and usability of the dataset, making it more applicable to traffic target detection and recognition tasks, we further subdivided the “Other” category into three subcategories: “Pedestrian,” “Bicycle,” and “Motorcycle.” This subdivision not only enriched the category composition of the dataset, but also provided more precise annotation information for model training, facilitating more accurate recognition and differentiation of various target types, thereby improving the model’s application value and accuracy in real traffic scenarios. The specific categories and their respective quantities are detailed in Table 3, which provides a breakdown of the distribution of each category.
Classes and Quantities in a Dataset. It can be Observed That the Dataset has a Significant Imbalance in the Number of Classes.

Classes and Quantities in a Dataset. It can be Observed That the Dataset has a Significant Imbalance in the Number of Classes.
We use the mAP under the condition of intersection over union (IoU) 
FPS is a core metric for evaluating real-time performance in networks, reflecting the number of image frames processed per second. A higher FPS value indicates stronger real-time processing capability, which is closely related to the performance of computer hardware, the efficiency of image processing algorithms, and network bandwidth. This metric is commonly used to assess the responsiveness and smoothness of image or video processing tasks.
The number of parameters in a model is a key factor in determining its complexity and capacity. Increasing the number of parameters typically means the model has greater expressive power, enabling it to learn and capture more complex data patterns. However, an excessive number of parameters may lead to overfitting, reducing the model’s generalization ability, and it also increases the computational burden and time cost during training. Therefore, when designing a model, it is essential to balance the model’s expressive capacity with the computational resource requirements.
All experiments presented in this paper were performed on a system equipped with a Windows 11 operating system and an NVIDIA RTX 4060 Ti GPU, utilizing the PyTorch 2.4.1 deep learning framework and the Python programming language. The experimental hyperparameter settings are shown in Table 4.
Experiment Parameters.

Experiment Parameters.
Note. RWR = random walk with restart.
RepVit has variants of different sizes, including RepViT_m0.9, RepViT_m1.0, RepViT_m1.1, and RepViT_m1.5, where the suffix “_mx” indicates that the corresponding model has a latency of
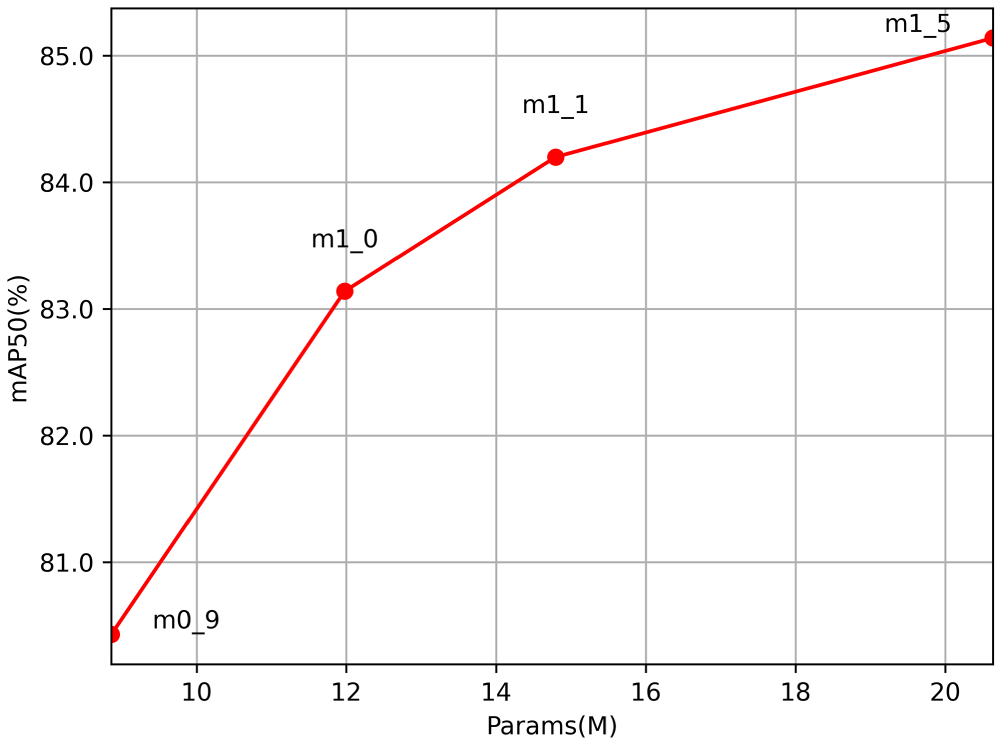
Mean Average Precision (mAP) Values of Different RepVit.
In further analyzing the data presented in Table 5, we identified several key performance metrics that are crucial for evaluating the suitability of different backbone networks in the CenterNet model.
Comparison Results of Different Backbones.
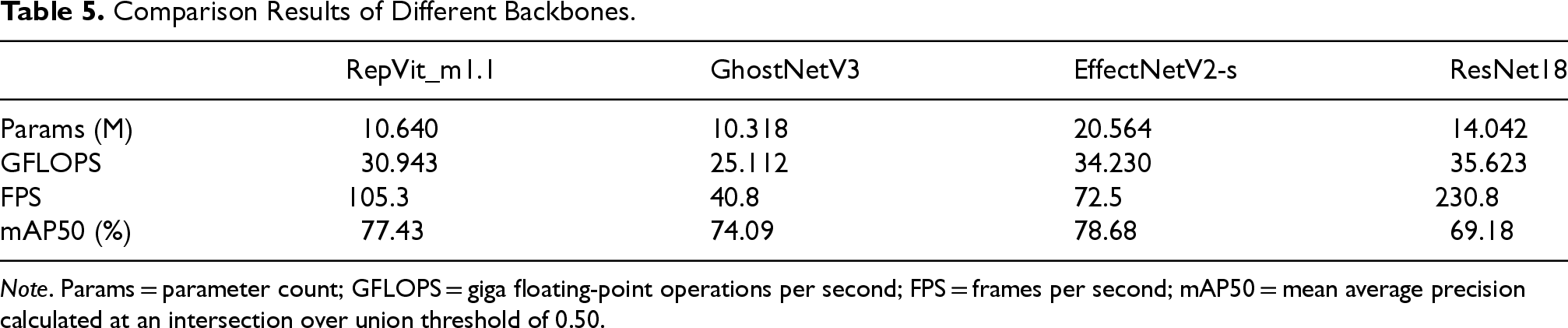
Note. Params = parameter count; GFLOPS = giga floating-point operations per second; FPS = frames per second; mAP50 = mean average precision calculated at an intersection over union threshold of 0.50.
Firstly, from the perspective of computational complexity, giga floating-point operations per second (GFLOPS) indicate the computational demands of the model when processing images. GhostNetV3 demonstrates the most efficient performance with a computational load of 25.112 GFLOPS, suggesting that it can achieve effective feature extraction while maintaining a relatively low computational cost. In contrast, EfficientNetV2-s (Tan & Le, 2021) has a higher computational load of 34.230 GFLOPS, which may limit its application in resource-constrained environments.
Secondly, FPS is directly related to the model’s real-time processing capability. ResNet18 performs exceptionally well in this regard, achieving 230.8 FPS, making it ideal for high-frame-rate applications such as video stream processing or real-time surveillance. However, despite ResNet18’s lead in FPS, its mAP50 is the lowest, indicating that a higher frame rate may come at the expense of detection accuracy.
In terms of accuracy, EfficientNetV2-s leads with an mAP50 of 78.68%, but it comes with a significantly higher GFLOPS and parameters. RepVit_m1.1, with nearly half the number of parameters as EfficientNetV2-s, only lags behind by 1.25% in mAP50.
Overall, RepVit_m1.1 strikes a good balance between parameter count, computational complexity, and real-time processing capability. It not only has the smallest parameter count but also maintains a relatively high-frame rate while offering competitive accuracy.
In deep learning research, ablation studies are a common and effective method for analyzing and validating the impact of various components on the final performance of a model. By systematically removing or replacing certain parts of the model, researchers can identify the contribution of each module, loss function, detection head, and so on, to the model’s performance. This paper presents a series of ablation experiments to test the performance improvement of different modules on the CenterNet algorithm.
To comprehensively evaluate the effects of these modules, nine sets of experiments were designed. The first experiment uses the original CenterNet algorithm as the baseline, without any modifications, and employs Hourglass104 as the backbone network. The aim of this experiment is to assess the performance of the original algorithm on a specific dataset, providing a basic performance baseline.
In the second experiment, the focal loss function in CenterNet is replaced with the Poly-1 loss function. Focal loss is the original loss function in CenterNet, designed to address the class imbalance problem, whereas Poly-1 loss is an improved loss function that, in theory, may perform better in handling different types of samples. The goal of this experiment is to evaluate the impact of the Poly-1 loss function on model training and detection accuracy.
The third experiment replaces CenterNet’s standard detection head with the ELDHead. ELDHead is a novel detection head designed to enhance the model’s ability to detect complex objects. This experiment aims to evaluate the effect of different detection heads on the model’s performance in object detection tasks.
In the fourth experiment, the RPKG module is introduced. The RPKG module is applied in object detection to enhance the feature representation capability effectively. By incorporating the RPKG module into the network, we aim to improve the model’s robustness in diverse scenarios by enhancing its feature expression capacity.
In the fifth experiment, the backbone network of CenterNet is replaced with RepVit_m1.1, a transformer-based backbone network with stronger feature learning ability. By comparing the performance of RepVit_m1.1 with the original Hourglass104 backbone network, we can evaluate the effect of a more advanced backbone network on the object detection task.
The sixth experiment builds upon the fifth experiment by further introducing the Poly-1 loss function. We aim to assess whether combining the RepVit_m1.1 backbone network with the Poly-1 loss function can further improve model performance.
The seventh experiment, based on the fifth experiment, introduces the ELDHead detection head. Compared to the sixth experiment, this experiment focuses on exploring whether the combination of a more powerful detection head and a superior backbone network leads to a significant improvement in model detection accuracy.
In the eighth experiment, the WF-AFPN module is introduced on top of the fifth experiment. WF-AFPN is an advanced feature pyramid network module that effectively enhances the network’s ability to fuse multi-scale features. By incorporating this module, we aim to further improve the model’s ability to detect targets of different scales.
The ninth experiment, which presents the proposed KGKPD algorithm, integrates all the aforementioned improvements. It comprehensively incorporates the Poly-1 loss function, ELDHead detection head, WF-AFPN module, and RPKG module, and optimizes the model based on the RepVit_m1.1 backbone network. This experiment allows us to evaluate the combined effect of all improvements and verify their impact on the overall model performance.
All the experimental results are summarized in Table 6, where key performance indicators for each group of experiments are presented. The data in the table provides a clear visualization of the specific impact of each improvement measure on performance. To clearly indicate the application of each component, the table uses “✓” to denote the use of the structure, “✗” to indicate that the structure is not used, and “-” to show that the group shares the same result as the previous line. These data allow for a comprehensive analysis of the impact of various modules and improvements on model performance, providing valuable insights for future research and practical applications.
Results of Ablation Study. It Shows That Each Individual Improvement Module can Enhance the Model’s Detection Performance to Varying Degrees.
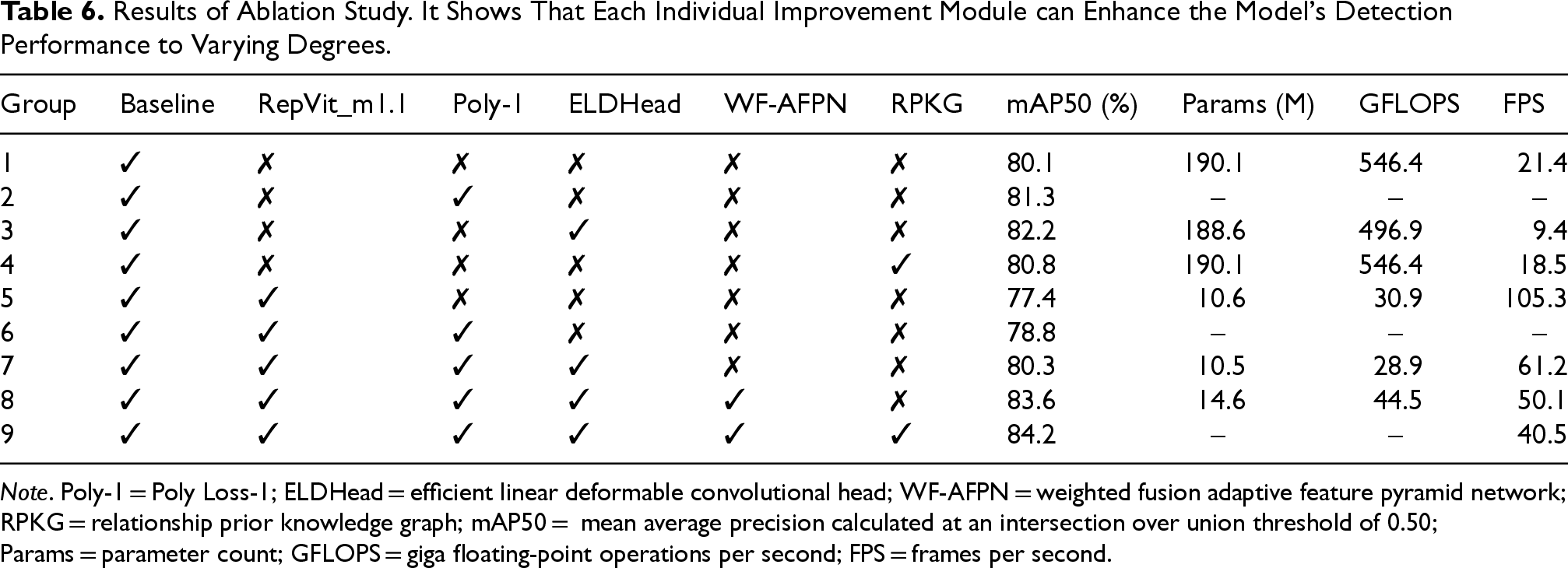
Results of Ablation Study. It Shows That Each Individual Improvement Module can Enhance the Model’s Detection Performance to Varying Degrees.
Note. Poly-1 = Poly Loss-1; ELDHead = efficient linear deformable convolutional head; WF-AFPN = weighted fusion adaptive feature pyramid network; RPKG = relationship prior knowledge graph; mAP50 = mean average precision calculated at an intersection over union threshold of 0.50; Params = parameter count; GFLOPS = giga floating-point operations per second; FPS = frames per second.
The baseline model, without any improvement modules applied, has a mAP of 80.1%, a parameter count (Params) of
The results of the ablation study indicate that the introduction of the RPKG module significantly enhances the model’s key performance metric, mAP50, preliminarily revealing the potential value of the RPKG module in improving the precision of target detection. However, the improvement was relatively limited. To ensure the robustness and reliability of these experimental results and to avoid misleading influences caused by random factors or accidental errors during the experimental process, we further adopted a more rigorous experimental validation strategy.
Specifically, for Experimental Group 1 and Experimental Group 4, we conducted 10 independent replicate experiments, respectively. Each replicate experiment was performed under identical conditions, strictly adhering to the same experimental procedures and parameter settings to maximize the reproducibility and consistency of the results. By systematically collecting and organizing the data from these 10 independent replicate experiments, we obtained more comprehensive and reliable experimental data, which provide a solid foundation for subsequent in-depth analysis. The detailed information of these experimental data is presented in Table 7, available for further statistical analysis and interpretation of the results.
Results of Independent Replicate Experiments.

Results of Independent Replicate Experiments.
Note. RPKG = relationship prior knowledge graph.
Prior to conducting the paired-samples
Performing a paired-samples
Results of the Normality Test for Paired Differences.

Note. S–W = Shapiro–Wilk; RPKG = relationship prior knowledge graph.
In this study, we conducted comprehensive comparative experiments between the proposed KGKPD algorithm and several mainstream object detection algorithms on the UA-DETRAC dataset. The experimental results, as shown in Table 9, demonstrate that the KGKPD algorithm outperforms others across multiple key performance indicators. Specifically, the KGKPD algorithm achieved an mAP50 of 84.2%, the highest among all compared algorithms, highlighting its superior accuracy in object detection tasks. Additionally, the FPS of KGKPD is 40.5, which, while not the fastest, remains satisfactory considering its high precision, especially when compared to two-stage detection algorithms such as Faster R-CNN, where KGKPD shows a clear advantage in speed.
Performance Comparison Results of Few Algorithms.
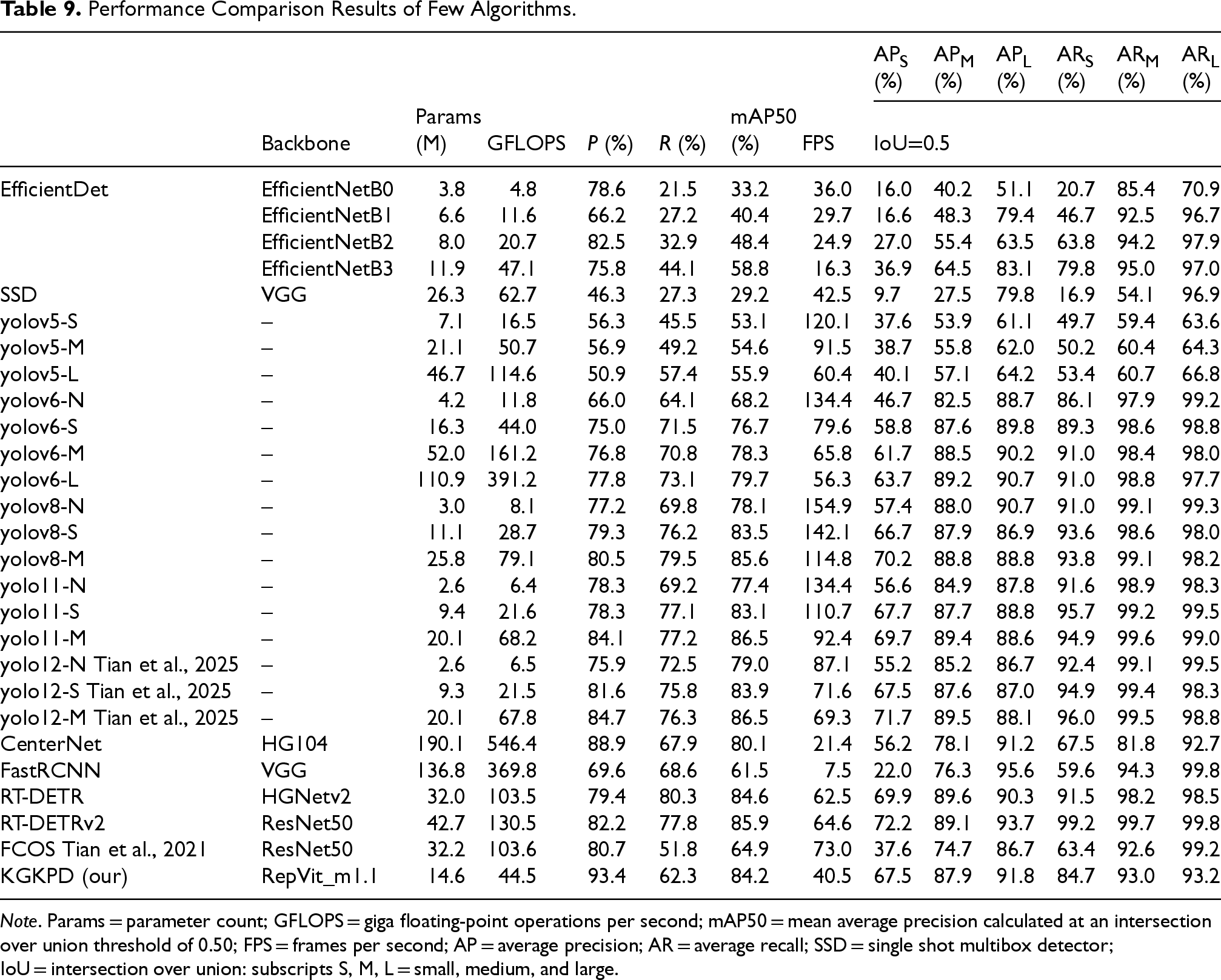
Performance Comparison Results of Few Algorithms.
Note. Params = parameter count; GFLOPS = giga floating-point operations per second; mAP50 = mean average precision calculated at an intersection over union threshold of 0.50; FPS = frames per second; AP = average precision; AR = average recall; SSD = single shot multibox detector; IoU = intersection over union: subscripts S, M, L = small, medium, and large.
In terms of model size and computational complexity, the KGKPD algorithm has 14.6M parameters and 44.5 GFLOPS, both lower than most of the compared algorithms. This indicates that KGKPD achieves a balance between high accuracy and efficient parameter usage and computational cost. Furthermore, the performance of KGKPD across different IoU thresholds is also outstanding, with its AP value for small (
Compared to other algorithms, KGKPD clearly excels in detection accuracy over Faster R-CNN while requiring fewer parameters and computational resources. In comparison with one-stage detection algorithms such as the YOLO series, EfficientDet (Tan et al., 2020) series, and single shot multibox detector (SSD; Liu et al., 2016), KGKPD not only leads in detection precision, but also maintains a relatively low model size and computational cost. When compared with real-time detection transformer (RT-DETR; Lv et al., 2024; Zhao et al., 2024), KGKPD reduces both parameter count and computational complexity by nearly half, with only a minor decline of 0.4 percentage points in accuracy. Additionally, KGKPD outperforms the original CenterNet by 4.1 percentage points in detection precision, along with an improvement in detection speed. In terms of parameters and computational complexity, KGKPD reduces CenterNet’s parameter count by
In summary, the KGKPD algorithm excels in object detection tasks, not only leading in accuracy over most comparison algorithms but also offering advantages in speed, parameter efficiency, and computational efficiency. These results indicate that KGKPD is an efficient and accurate object detection algorithm with broad application potential.
In the current era of rapid technological advancement, energy consumption has become one of the key indicators for evaluating the performance and practicality of algorithms. For road target detection algorithms, accurately estimating their energy consumption holds significant importance in multiple aspects. Firstly, energy consumption directly affects the feasibility and sustainability of an algorithm in real-world applications. In many practical deployment scenarios, such as mobile devices, edge computing devices, or resource-constrained traffic monitoring systems, energy supply is often limited. An energy-efficient algorithm can operate for longer periods, reducing the dependence on energy replenishment and thereby enhancing the overall availability and reliability of the system.
To comprehensively evaluate the efficiency and practical applicability of the KGKPD algorithm, we conducted an estimation of its energy consumption. The experiments utilized the Zeus package to calculate the energy consumption during both the training and evaluation processes of the KGKPD algorithm.

Diagram of Comparative Experimental Results.
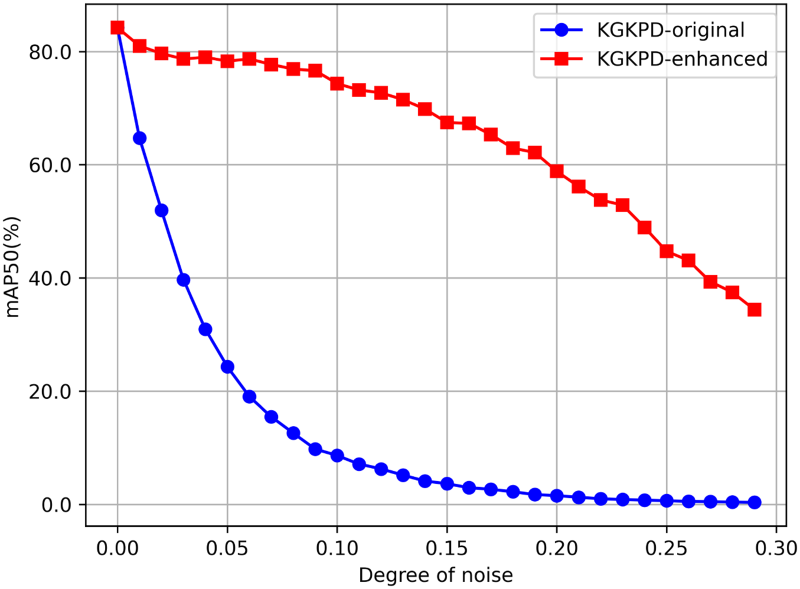
Noise Addition Experiment Comparison Figure.
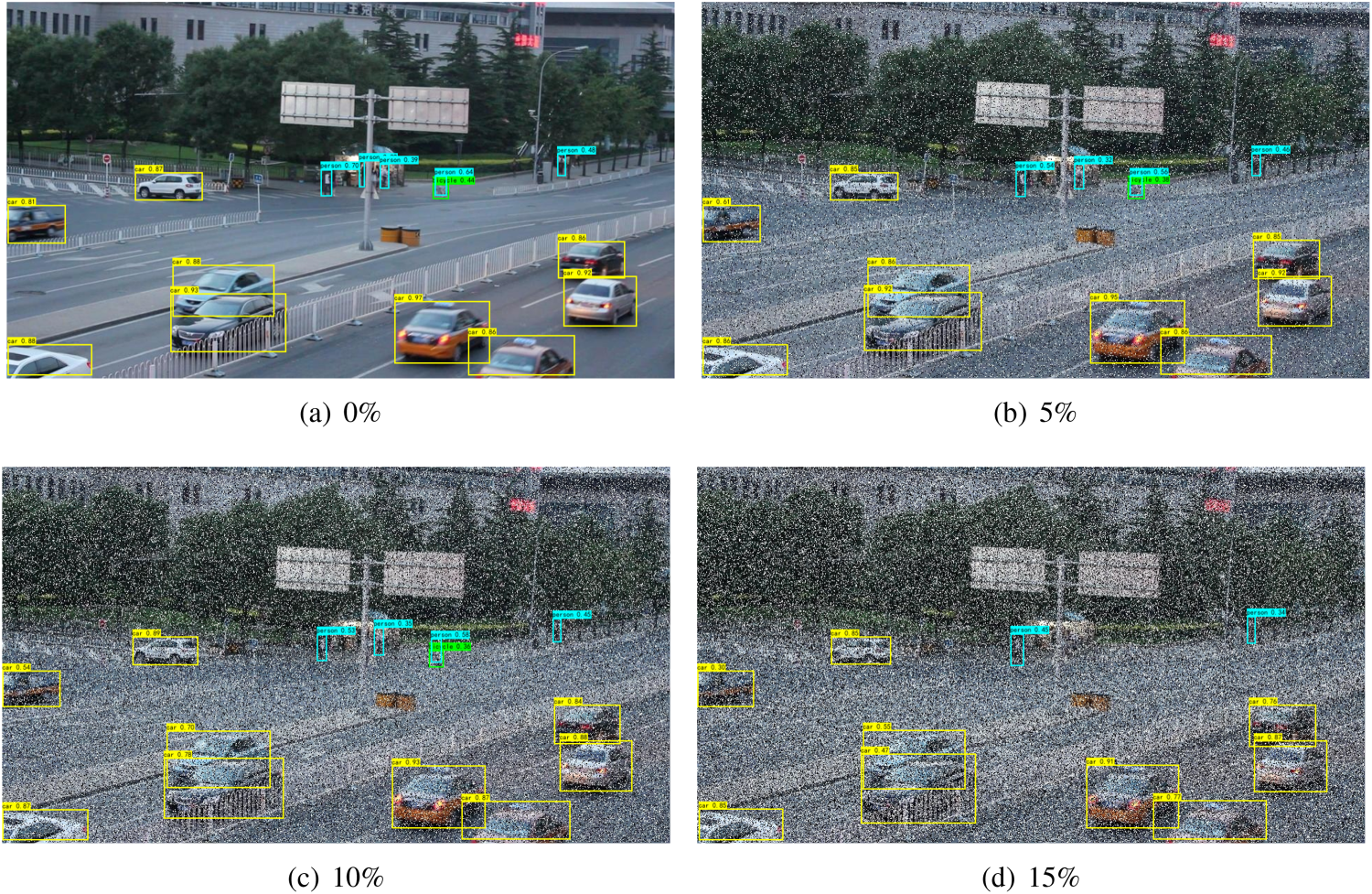
Visualization of Different Noise Levels.
Figure 11 presents a detailed comparison of the performance of various object detection algorithms. Through an in-depth analysis, it is evident that the KGKPD algorithm demonstrates outstanding performance in object detection tasks. Compared to other algorithms, the KGKPD algorithm not only accurately identifies predefined target objects but also exhibits superior suppression capability when handling non-target objects. This significantly reduces the false positive rate, thereby enhancing the reliability of the detection results. In contrast, some other algorithms often suffer from missed detections and false detections during the detection process. Missed detection refers to the failure of the algorithm to recognize an object present in the image, while false detection occurs when the algorithm mistakenly identifies background or non-target objects as targets. These issues directly affect the accuracy and reliability of the detection results, thereby impacting the effectiveness of the algorithm in practical applications. In the image on the far right, it is evident that only the KGKPD model successfully identified the two individuals in the top left corner of the image. Other models failed to accurately detect these targets, resulting in their omission or misclassification. Overall, the results presented in Figure 11 conclusively demonstrate the superiority of the KGKPD algorithm in object detection tasks.
Robustness Study
We carefully designed two sets of comparative experiments. In the experimental group, images in the training dataset were subjected to noise addition with a probability of 0.5, and the addition of salt-and-pepper noise was dynamically adjusted based on the local features of the images. For instance, in high-contrast regions of the images, the intensity and probability of noise could be appropriately increased, as the features in these regions are more pronounced and relatively more robust to noise. Conversely, in low-contrast regions, the intensity and probability of noise were reduced to avoid excessive interference with the target features.
The control group, on the other hand, maintained the original state of the images without any noise processing, providing a baseline reference for the experiment without noise interference. By comparing the network performance between the experimental and control groups, we were able to quantitatively assess the specific impact of salt-and-pepper noise on network performance, thereby providing a solid basis for network optimization and improvement.
Figure 12 illustrates the changes in detection accuracy of the network under different noise conditions, clearly presenting the differences in detection accuracy between the experimental and control groups. The experimental results showed that the experimental group with salt-and-pepper noise interference had a significantly higher robustness compared to the control group without noise, indicating that the network had developed a certain degree of adaptability to salt-and-pepper noise and could maintain a relatively stable performance in noisy environments.
Furthermore, Figure 13 displays the visualization results of KGKPD under different levels of interference. From the figure, it can be observed that as the noise intensity gradually increased, the detection results of KGKPD showed different changing trends. Under low noise levels, KGKPD was able to accurately identify targets, with the detection boxes accurately positioned and well-matched to the target contours, indicating that the network still performed excellently in detection under slight noise interference. However, when the noise intensity further increased, although it was powerless to distinguish small targets that were difficult for the naked eye to discern, it could still roughly lock the position of larger targets. This further confirmed the strong robustness of the experimental group network in the face of salt-and-pepper noise.
Conclusion
We have developed a model for road target recognition based on the CenterNet concept, employing the RepVit network as the feature extraction backbone. To enhance detection accuracy, we designed the WF-AFPN strategy, which dynamically fuses three key feature maps to improve the detection of small targets, and integrated ELDHead to enhance the recognition of occluded targets. The RPKG module was introduced to further optimize the detection results. In terms of data augmentation, salt-and-pepper noise was used to increase the model’s robustness to data loss, and the Poly-1 loss function was utilized to address class imbalance issues. Although the model demonstrated high detection accuracy on the actual highway image dataset and featured low model complexity and computational demand, it has not yet fully met the requirements for lightweight deployment. Moreover, the scale of the dataset used in the experiments was relatively small, and the model’s generalization ability still needs further validation. Therefore, future work will focus on optimizing the model’s lightweight design and expanding the dataset scale to further enhance the model’s performance and applicability.
Footnotes
Acknowledgments
I am deeply grateful to my advisor, Professor Liao, for the invaluable guidance and support throughout this research. Professor Liao played a crucial role in shaping the study’s direction, offering insightful advice and constructive feedback at each stage. His expertise and dedication have been a constant source of inspiration. I appreciate the time and effort invested in refining my research ideas and overcoming challenges. Without his guidance, this work would not have been possible.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.