
Abstract
The integration of artificial intelligence (AI) and art design has unlocked new potential for personalized, creative, and emotion-driven content generation. However, existing methods still face major challenges in style controllability, emotion consistency, and user satisfaction prediction. This study proposes a multimodal AI art generation strategy based on Stable Diffusion and BERT, using ControlNet, text-to-image (T2I)-Adapter, style–emotion mapping (SEM), sentiment prediction optimization, guided score distillation (GSD), and score-based generative model (SGM) to achieve high-quality, personalized art generation. First, ControlNet and T2I-Adapter are introduced into the Stable Diffusion method to enhance the fine control of text descriptions, visual references, and style labels, and improve the controllability and emotion consistency of generated content. In addition, a SEM model is constructed to establish a deep correspondence between user emotions and visual aesthetics using multimodal feature learning (including color, composition, and style attributes). Afterwards, GSD and SGM are used to optimize the diffusion model to minimize the interference of irrelevant information and ensure high-quality, emotion-consistent art output. The test results show that this method has significant advantages in style controllability, user emotion consistency, and satisfaction prediction accuracy, and provides new ideas for personalized art design, emotion-driven content generation, and optimization of human–computer interaction experience.
Keywords
Introduction
The widespread application of generative artificial intelligence (AI) in the digital creative industry is profoundly changing the way art is created. Traditional art design relies on the experience accumulation, style habits, and emotional expression ability of human creators, but with the rapid development of deep learning-driven generative models, AI can not only automatically generate high-quality works of art, but also assist or enhance the human creative process (Ho, 2024; Molla, 2024; Piskopani et al., 2023). In fields such as digital media, advertising design, film and television production, game development, and virtual reality, AI art generation has demonstrated significant value. For instance, it can generate unique visual works that meet user needs based on textual descriptions or style requirements, thereby enhancing design customization. However, in practical applications, AI art generation still faces critical challenges in terms of reliability, controllability, and emotional adaptability (Chi, 2024; Shukla, 2024).
In recent years, generative AI has made significant progress in the field of artistic content generation, providing new creative ideas for many fields such as art creation, design, and cultural industries. Researchers have conducted many analyses on this (Jiang & Chung, 2023; Messingschlager & Appel, 2023; Sanghvi et al., 2024). For example, Sanghvi et al. (2024) studied the application of AI in different art forms (digital painting, sculpture, and filmmaking). On the other hand, Maravilla et al. (2024) studied the relationship between AI and creativity and analyzed how AI enhances or limits human creativity in artistic creation. In addition to the progress of art generation technology, the ethical and legal issues of AI art have also become the focus of current research. Kareem (2023) proposed an ethical governance framework for AI-generated art to address issues such as creative ownership, copyright protection, and fair use. Ducru et al. (2024) further studied the impact of AI-generated art on intellectual property rights. In addition, Gjorgjieski (2024) studied the impact of AI on traditional artistic expression. In summary, recent studies have shown that AI-generated art technology has made significant progress in many fields such as painting, animation, and filmmaking, and has shown the potential to enhance human creativity and improve artistic production efficiency. However, existing research still faces challenges such as style control, emotional expression, creation attribution, and legal issues. From a technical perspective, the current AI art generation model still needs to be further optimized in terms of style consistency, artistic personalized expression, and emotional communication (Snihur & Bratus, 2023).
The diffusion model has become one of the core technologies in the field of AI art generation, especially in terms of image generation, style transfer, and creative design. However, the current diffusion model still faces problems such as unstable style control, insufficient personalized expression, and lack of interpretability. In order to address these challenges, researchers have proposed a series of methods, such as contrastive language-image pretraining (CLIP)-guided diffusion, ControlNet, and T2I-Adapter, to improve the controllability of AI-generated art (Guedes et al., 2023). For example, Lee et al. (2023) further explored the application of diffusion models in emotion-driven art generation and proposed an image generation method based on emotional feature input. In exploring the controllability and ethical issues of diffusion models, (Kareem, 2023) proposed an AI art governance framework to optimize the style control ability of generative art. Leong et al. (2024) studied the evolution of ethical principles for AI art generation and analyzed the challenges of current diffusion models in artistic style control and autonomy. On the other hand, Marburger (2024) pointed out that although diffusion models can learn complex visual features and generate high-quality artworks, their style control ability depends on pre-training datasets. Ali and Breazeal (2023) studied artists’ attitudes and emotions toward AI-generated art and explored the shortcomings of current diffusion models in artistic style transfer. Current research shows that although diffusion models have made significant progress in art generation, style transfer, and emotional expression, they still face problems such as unstable style control, insufficient personalized expression, and lack of interpretability (Caramiaux & Alaoui, 2023; Ducru et al., 2024; Holzapfel, Jaaskelainen, & Kaila, 2022).
Multimodal sentiment analysis technology combines multiple information sources such as text, images, and sound to provide richer user emotional understanding, thereby improving the emotional adaptability of AI in artistic creation (Sanghvi et al., 2024). However, current research still has many problems in emotion-style mapping, cross-modal feature fusion, and user feedback optimization. To this end, in recent years, many research works on sentiment analysis and user preference modeling for AI-generated art have emerged. Shukla (2024) studied the collaborative creation of humans and AI and analyzed the impact of user preferences in AI-generated art. Chi (2024) studied the impact of AI in contemporary art creation and analyzed the application of multimodal learning in emotional computing. Maravilla et al. (2024) proposed an emotion-enhanced art generation framework based on generative adversarial networks (GANs) and diffusion models. Gjorgjieski (2024) studied the impact of AI art on traditional art expression and proposed a preference prediction method based on user behavior analysis. Jiang and Chung (2023) studied the application of AI in digital art creation and explored the practical value of multimodal sentiment analysis in art creation. Recent studies have shown that multimodal sentiment analysis and user preference prediction technology play an important role in the personalized optimization of AI-generated art. However, current research still faces challenges such as unstable sentiment-style mapping, insufficient cross-modal feature fusion, and inaccurate user preference prediction (Ho, 2024).
At the same time, in the field of AI-generated art, user feedback is an important factor in optimizing the quality of art generation and improving the personalized experience. Based on feedback mechanisms such as user evaluation, interactive behavior, and sentiment analysis, AI-generated models can continuously adjust styles, enhance emotional consistency, and improve user satisfaction (Messingschlager & Appel, 2023; Piskopani et al., 2023). Kareem (2023) pointed out that the feedback mechanism of current AI-generated models still mainly relies on static data and lacks real-time interaction and dynamic adjustment capabilities. Guedes et al. (2023) studied the role of AI-generated art in promoting creative expression and proposed that AI-generated systems can automatically adjust artistic styles through user behavior analysis to adapt to the expression needs of different users. Holzapfel et al. (2022) proposed a low-resource AI solution to reduce the dependence of AI-generated art on computing resources during feedback optimization. Existing research mainly optimizes the feedback mechanism of AI-generated art through methods such as reinforcement learning from human feedback, emotional computing, and multimodal user interaction analysis, but there is still room for further improvement in real-time, explainability, and user implicit preference modeling (Caramiaux & Alaoui, 2023; Marburger, 2024).
In summary, although AI-generated art has achieved remarkable progress in image synthesis, artistic creation, and visual design, it still faces key challenges in style control stability, emotional expression accuracy, and adaptive user satisfaction modeling. Current diffusion models often struggle to align generated visual content with users’ stylistic and emotional expectations, particularly in multimodal and interactive generation scenarios.
To address these challenges, this paper proposes an integrated multimodal generation framework that enhances controllability, emotional alignment, and user-adaptive performance in AI art synthesis. The core innovations of this study are summarized as follows:
A multimodal conditional optimization framework is proposed, combining ControlNet and T2I-Adapter to improve the collaborative control of text prompts, visual references, and style labels within diffusion models. While both ControlNet and T2I-Adapter have been individually explored, our framework fuses them into a unified pipeline that supports more stable and personalized control over artistic styles and structural guidance. This paper introduces a style–emotion mapping (SEM) mechanism, which integrates multimodal sentiment analysis using BERT and visual features. By incorporating a transformer-based structure, the SEM enables the model to align the artistic style of generated images with the target emotional intent more effectively than prior works such as EmoGen. A feedback-driven optimization loop is designed by combining GSD and score-based generative model (SGM). This mechanism adaptively refines generation outputs based on user interaction history, forming a dynamic system that adjusts both style and emotional tone in response to evolving user preferences.
The subsequent sections of this article will be developed according to the following logic. The specific framework is as follows: Section 2 analyzes and models the theoretical characteristics of the research object; Section 3 introduces in detail the multimodal AI generation art framework based on Stable Diffusion (SD) and BERT; Section 4 tests and verifies the feasibility and effectiveness of the proposed method. Finally, Section 5 summarizes the main work of the article and proposes subsequent research directions.
To improve the style controllability, emotional consistency, and user satisfaction of AI-generated art, this section establishes a corresponding mathematical model and proposes a corresponding optimization strategy, so that AI-generated artworks can be continuously optimized in multiple rounds of interactions to improve the quality of personalized art generation.
Style and Emotion Representation in AI-Generated Art
Different style elements such as color, composition, light and shadow, texture, and so on can trigger different emotional experiences for viewers. To systematically analyze the stylistic and emotional characteristics of AI-generated art, the article mathematically stylistic features, textual emotional representations, and their mapping relationships models.
Mathematical Description of Stylistic Features
Stylistic features are mainly related to various aspects, such as color and compositional style coding. Assuming that it is an AI-generated artwork, its stylistic features can be expressed as:

In order to quantify the relationship between style features, the article uses the Gram matrix for style modeling, which is defined as follows:

The Gram matrix in equation (2) captures the style-related information embedded in the convolutional feature maps of an image. Specifically,
Assuming that the pixel distribution of image

In the above equation, the higher the entropy value, the more complex the image composition, and vice versa, the more concise it tends to be.
Text sentiment features can be embedded and learned through deep language models to obtain high-dimensional vector representations. If

In order to improve the separability of the text sentiment vector, a dimensionality reduction mapping method is used to project it into a low-dimensional space. The article reduces the dimensionality through linear transformation

Text sentiment analysis usually involves multiple aspects such as sentiment polarity, sentiment intensity, and context perception. The following sentiment score function is defined for representation:

In AI-generated art, style not only determines the visual presentation of an image but also directly influences the emotional resonance conveyed to viewers. This section integrates the theoretical formulation and practical implementation of the SEM model from a cross-modal perspective, aiming to establish a robust framework for generating emotionally aligned artwork through style control.
Theoretical Basis of SEM
There exists a complex cross-modal mapping relationship between visual style and emotional expression. Different stylistic features may elicit different emotional responses, thus necessitating a formal mathematical framework to describe this correspondence. Assuming that

This mapping relation can be fitted by regression models, neural networks, or statistical learning methods to maximize the consistency of style and sentiment. The article uses minimizing mean square error (MSE) loss to optimize this mapping:

Note that equation (8) is primarily used during pre-training to guide the mapping function toward accurate emotional alignment. It is not used as the final optimization objective in the full training pipeline.
Stylistic features can be from the extracted visual image described in equation (1). The text sentiment vector

To describe the mapping relationship between style feature

Since the mapping between style and sentiment is usually nonlinear, the article uses the nonlinear transformation function

To further reduce the gap between the emotional content of AI-generated images and the expected sentiment, we define a style–emotion consistency loss function. While equation (8) serves in the pre-training stage, the final optimization objective incorporates gradient-based sentiment regularization:

Compared with existing emotion-guided image generation methods (such as EmoGen), the SEM mechanism proposed in this paper is more complete in structure. It not only models text emotions, but also further introduces image style features and structured style perception vectors to construct a mapping relationship between style and emotion. At the same time, the generation deviation is dynamically adjusted through the feedback optimization mechanism, achieving more user-adaptive emotion consistency optimization.
From the perspective of probabilistic modeling, this section defines the style–emotion consistency constraint, establishes the loss function for emotion prediction, and optimizes this objective to make AI-generated artwork more consistent with the user’s emotional preferences.
Style–Emotion Consistency Constraints
Assuming that the style feature

To further model affective congruence, it was assumed that the relationship between style features and affective features obeyed a Gaussian distribution:
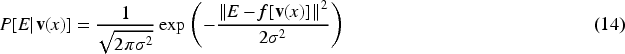
To optimize style-sentiment consistency, the article defines the loss function for sentiment consistency:

Substituting into the Gaussian distribution form gives:

Equation (15) provides the probabilistic modeling form of the sentiment loss, while equation (16) presents the equivalent MSE form. These are jointly used to ensure consistency between the predicted and target emotion intensity values.
The goal of this loss function is to minimize the Euclidean distance between the emotional expression

During the optimization process, MSE and cross-entropy losses are combined to form a weighted loss:

In order to ensure that the AI-generated artworks are consistent with the user’s emotional preferences in terms of emotional expression, the article hopes to maximize the similarity between style feature
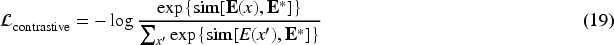
In addition, in the optimization process, variational inference is used to further model uncertainty, making style–emotion consistency optimization more robust. Assuming that the emotional state
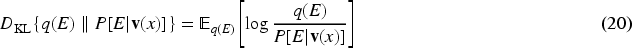
In the study of AI-generated art, how to strike a balance between style controllability, emotional consistency, and personalized optimization is a key challenge to improve the quality of art generation. To solve this problem, this paper proposes a controllable AI-generated art design algorithm by combining SD, ControlNet/T2I-Adapter, BERT, and user feedback optimization mechanism to achieve precise style control, emotionally driven generation, and personalized adaptive adjustment.
Framework of the Proposed Algorithm
The controllable AI art generation framework proposed in this study integrates SD, ControlNet/T2I-Adapter, BERT-based sentiment analysis, and feedback-driven optimization. As illustrated in Figure 1, the system consists of four key modules:
Basic generation module: employs SD to generate the initial image content. Controllable enhancement module: incorporates ControlNet and T2I-Adapter to enable precise control over artistic style and visual structure. Multimodal sentiment analysis module: combines BERT with visual feature extraction to construct the SEM, aligning generated artworks with the target emotional intent. Feedback optimization module: refines generation outputs based on user feedback (e.g., ratings or interaction behavior), enhancing personalization and adaptive performance.
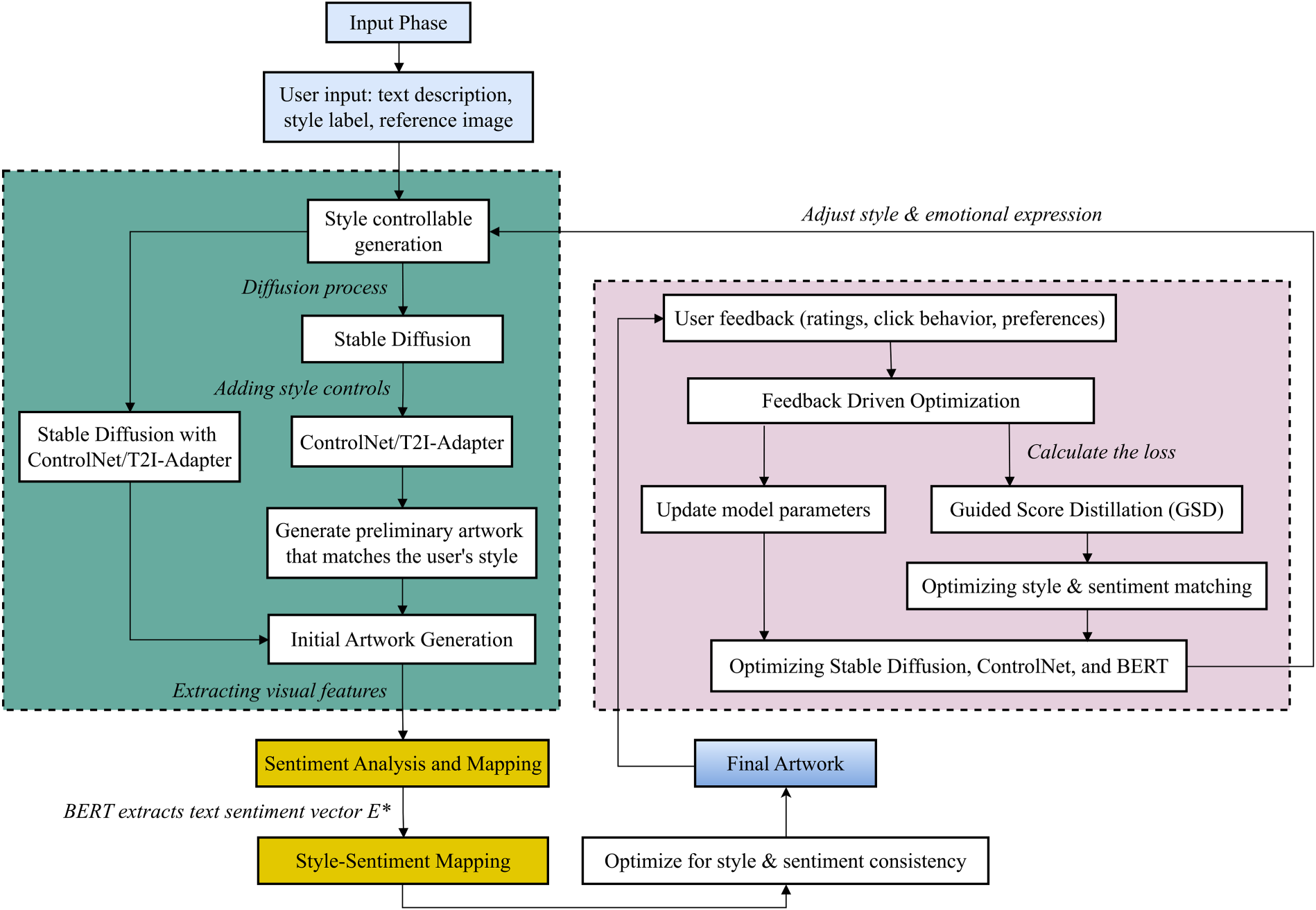
Control Flow of the Article Design Methodology.
Unlike existing diffusion models that rely on a single control mechanism, the proposed framework introduces a novel cascaded integration of ControlNet and T2I-Adapter. While ControlNet ensures precise structural and compositional control, T2I-Adapter handles style and emotion modulation through multimodal conditioning. Additionally, by incorporating emotion vectors from BERT, visual style encodings, and a feedback-driven adjustment loop, the system enables synchronized control over stylistic fidelity and emotional expressiveness. This joint mechanism significantly enhances emotional consistency and user-adaptive generation.
While SD is effective for T2I generation, it lacks fine-grained control over artistic style, structure, and emotional alignment. To address this, we enhance SD by integrating ControlNet and T2I-Adapter to improve structure fidelity and multimodal controllability.
ControlNet-Based Conditional Generation Mechanism
ControlNet is mainly used to guide SD to follow external input conditions (such as line drawings, depth maps, edge detection maps, etc.) to ensure the stability of local structure and artistic style.
The denoising process of SD can be expressed as:

Under the conditional control of ControlNet, the article introduces additional constraints so that the model can follow the conditions during the diffusion process:

To optimize the condition generation process, ControlNet uses a two-branch network structure. The main branch performs the standard SD task; the conditional branch receives external control signals and fuses the information.
The optimization objective for training is:

The core idea of T2I-Adapter is to integrate external information (such as style labels, color distribution, and artistic reference images) into the generation process of SD through a lightweight trainable module. Its optimization goal can be expressed as:
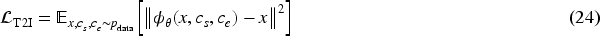
Under the control mechanism of T2I-Adapter, the diffusion process of SD is adjusted as follows:
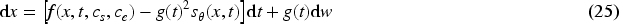
Among them,
In addition, in order to improve the cross-modal consistency of style and sentiment, adversarial loss is introduced in T2I-Adapter:
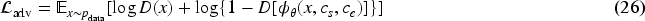
To ensure the controllability of AI-generated art, the article combines the local structure control of ControlNet and the style and emotion control of T2I-Adapter. Local structure constraints are imposed through ControlNet to ensure that the generated artwork conforms to the edge and depth information provided by the user; at the same time, T2I-Adapter is used for multimodal control optimization to achieve precise adjustment of style and emotion.

This paper proposes a SEM model that achieves cross-modal emotional consistency optimization through visual feature extraction, fusion of the BERT model and visual features, and a multimodal feature enhancement mechanism.
Visual Feature Extraction
Visual features are the core expressions of AI-generated artworks, including color, composition, and style vectors. Let

Summarizing the above analysis, the visual features are represented as:

Since text input is often used to guide the themes and emotions of AI-generated art, the article introduces the BERT model to extract the sentiment vector


In order to evaluate whether AI-generated works can match the emotional needs set by users, define the emotional goals expected by users

Since generative art tasks involve multiple input modalities such as text, images, and style labels, the following multimodal style control objectives are established:

In order to ensure the joint optimization of style and sentiment, the article proposes the following joint style-sentiment optimization loss:

In order to further optimize the emotion-driven ability of AI-generated art, the article introduces an emotion-guided style adjustment mechanism in the multimodal transformer structure:

To summarize the above analysis, the SEM model process is shown in Figure 2, which includes key steps such as user input, style and emotion feature extraction, cross-modal fusion, style–emotion relationship modeling, contrastive learning optimization, and final art generation.
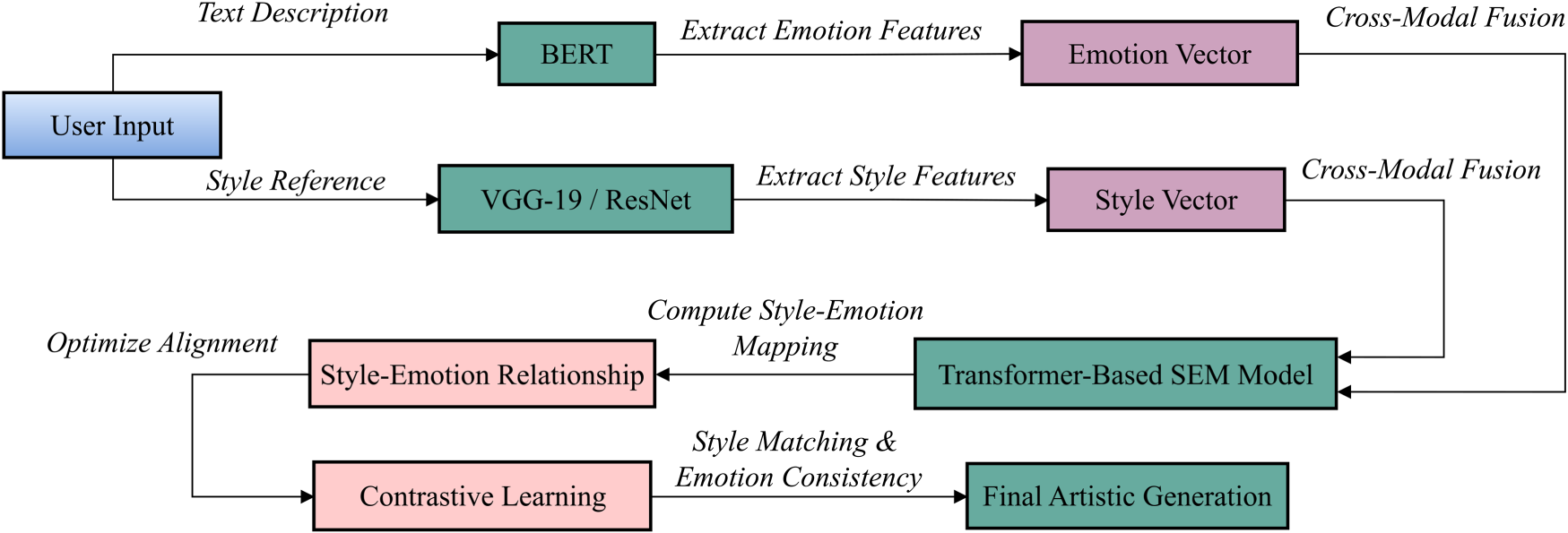
Style–Emotion Mapping (SEM) Framework of the Model.
Through style–emotion consistency loss and style–emotion joint optimization loss, the proposed method can ensure that AI-generated artworks not only conform to the style characteristics set by the user, but also can be consistent with the user’s subjective feelings in emotional expression. In addition, the emotion-guided style adjustment mechanism proposed in this paper further optimizes the matching degree of AI-generated art in visual and emotional expression.
In order to enhance the adaptability of AI-generated art in terms of stylistic controllability and emotional expression, this paper designs a method that integrates a feedback optimization mechanism to achieve GSD and SGM, the optimization of the stylistic control ability of diffusion models.
GSD Application of in Diffusion Model Optimization
The core idea of GSD is to optimize the generation path of the diffusion model through score distillation, so that it cannot only restore high-quality images, but also match the target style and sentiment distribution. In the denoising process, the diffusion model not only relies on data distribution, but also can be guided by the style and sentiment set by the user, thereby achieving more precise style control.
Under the GSD mechanism, the article defines the emotion perception score function by adding target style and emotion control terms to the original diffusion process:

This means that AI-generating art not only follows the true distribution of the image data, but also needs to be guided by the style and sentiment of the target. To optimize the score function
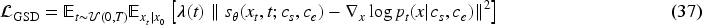
This loss term optimizes the score estimation of the model to make it more consistent with the target distribution of style and emotion guidance. With GSD, the article can dynamically adjust the denoising path during the diffusion process, ensuring that the generated artworks are not only more stable in terms of visual quality, but also maintain stylistic and emotional consistency.
Although GSD provides more sophisticated style and emotion control capabilities, in practice, the optimization effect of score distillation is still affected by the limitations of data distribution. To this end, the article further combines SGM to enhance the style adaptability of the model under the GSD mechanism.
SGM models the data distribution through the Stratonovich stochastic differential equation, so that the generation process can be constrained by an additional style control signal

In order to optimize style consistency, a corresponding style objective function is defined to minimize the gap between the generated image and the target style. The style loss function can be defined as:

In addition, in order to further enhance the robustness of style control, the article defines a style regularization term to ensure the generalization ability of the model between different styles:

The article adds a style adjustment term to the SGM score function so that the denoising process can follow the style constraints:

The final optimization objective can be expressed as:

Under the joint optimization of GSD and SGM, the precise control of style and emotional expression in the diffusion model is achieved. The final generation equation of the diffusion model becomes:
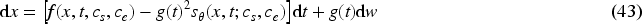
In order to evaluate the effectiveness of the proposed controllable AI generative art design algorithm, this section analyzes the performance of the method in key indicators such as style consistency, sentiment matching, and user satisfaction through a series of simulation experiments. The article selects several state-of-the-art diffusion models and traditional sentiment analysis methods for comparison, and comprehensively evaluates the advantages of the proposed algorithm in style control, sentiment expression, and user feedback optimization.
Parameter Settings of the Simulation Model.
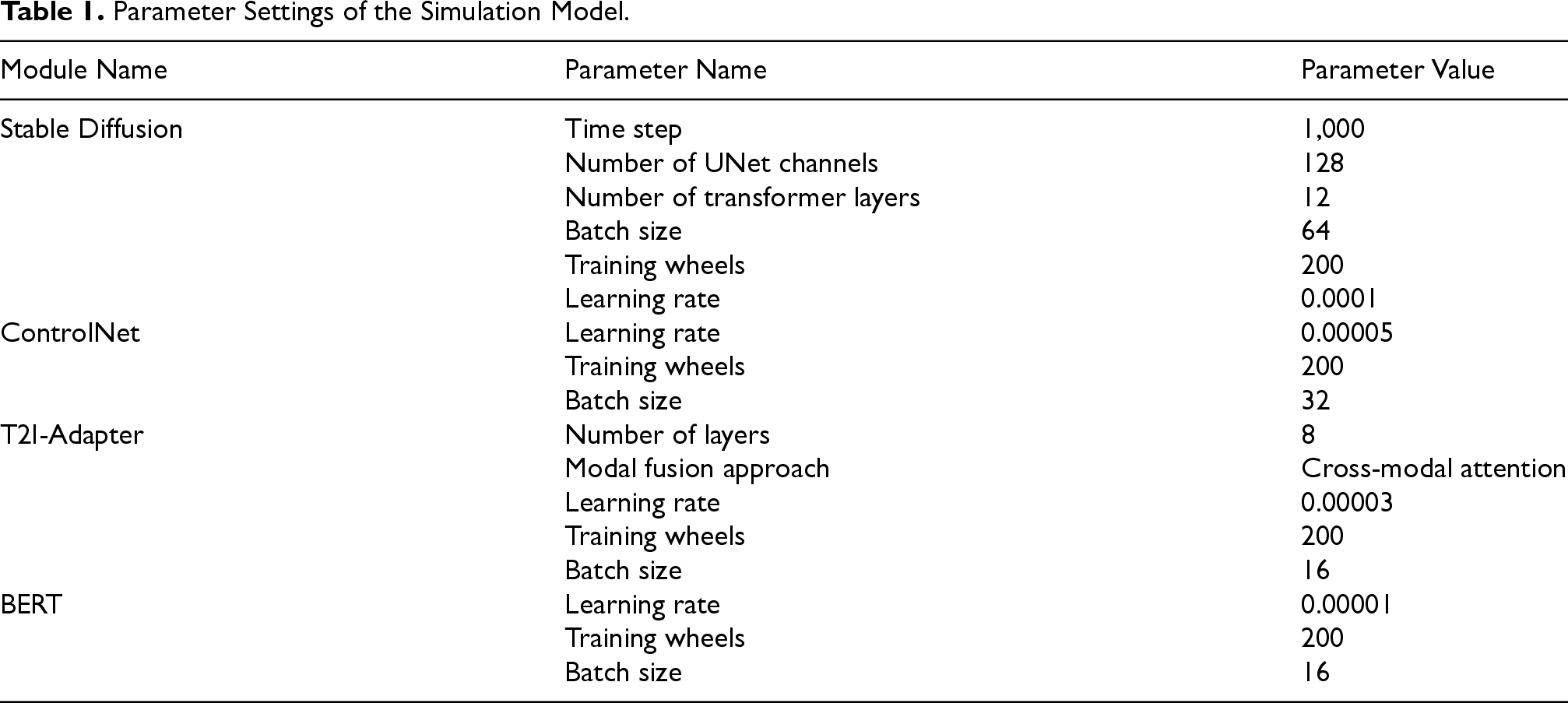
Parameter Settings of the Simulation Model.
In order to verify the effectiveness of the proposed model in style control and emotional consistency, this paper uses two public datasets for experiments: WikiArt and ArtEmis. Among them, the WikiArt dataset contains more than 80,000 images from 27 artistic styles and is widely used in style transfer and style recognition tasks. This paper uses it to train the image style encoder and style control module. The ArtEmis dataset contains more than 80,000 images, each of which is accompanied by multiple emotional description texts written by humans and corresponding emotional labels (such as happiness, sadness, tranquility, anger, etc.), supporting cross-modal image-text-emotion modeling. This paper uses it to train the SEM module and the multimodal generation model. In this experiment, in order to improve training efficiency and ensure data diversity, we randomly selected about 20,000 images covering 13 styles from WikiArt, and selected 12,000 pairs of image-emotion description samples from ArtEmis to ensure coverage of eight major emotion categories. All samples are divided into a training set, validation set, and test set at
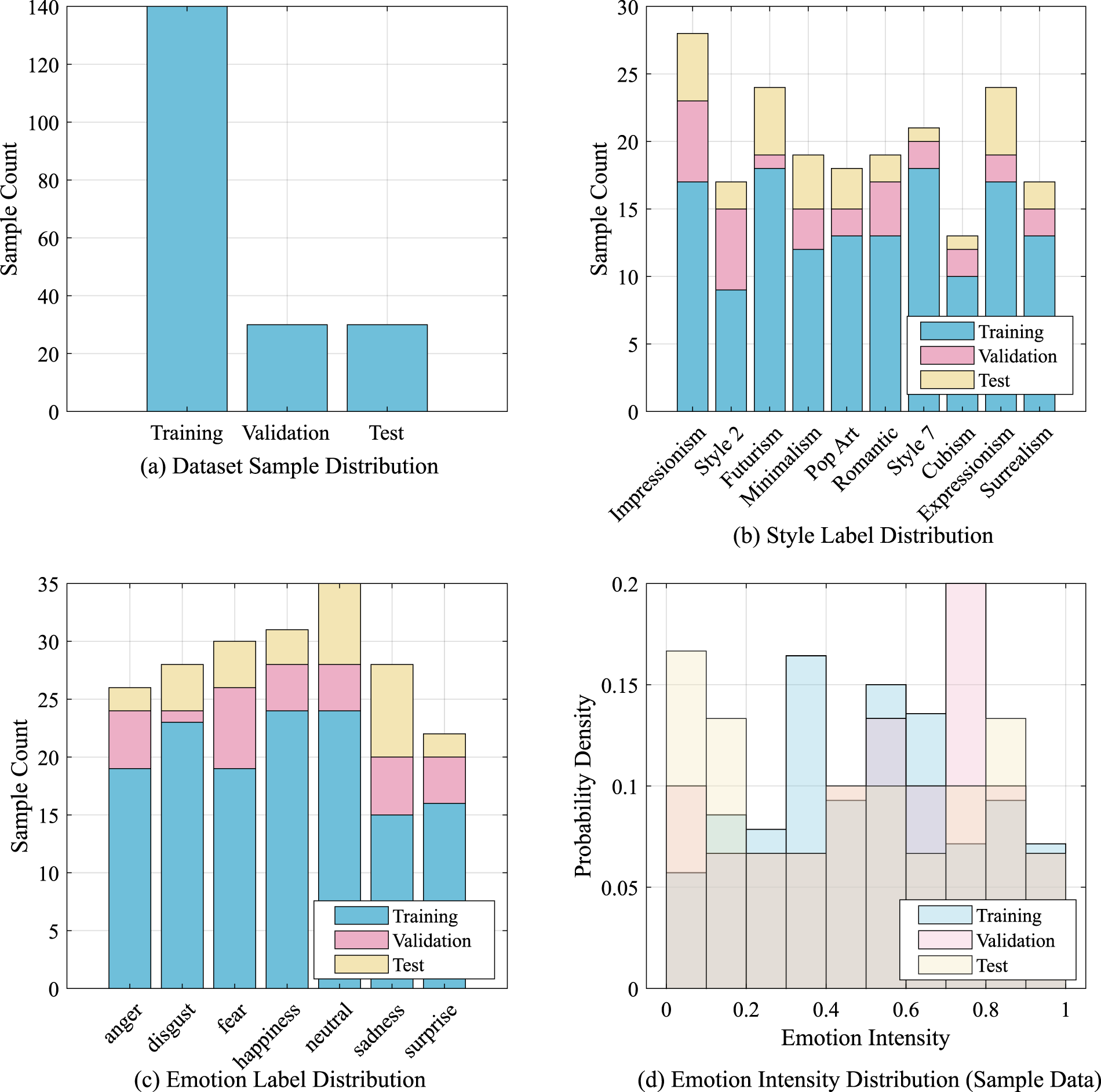
Dataset Distribution Visualization.
The effectiveness of the proposed controllable AI generative art design algorithm was verified in the MATLAB environment, and a series of experiments were designed to evaluate the performance of the method in terms of style consistency, sentiment prediction accuracy, and user satisfaction. The data ratios of the training set, validation set, and test set are 70%, 15%, and 15%, respectively. Table 1 shows the parameter configuration of the SD, ControlNet, T2I-Adapter, and BERT modules.
User Feedback Optimization Results.
Figure 3 shows the data distribution used in training and testing the designed algorithm. The article uses this to model and test the dataset and explores the potential impact of data distribution characteristics on model performance. Figure 3(a) shows the sample size distribution of the training set, validation set, and test set. Figure 3(b) shows the distribution of style labels. Figure 3(c) shows the distribution of sentiment labels, which includes different sentiment categories and can improve the balanced performance of the model. Figure 3(d) shows the distribution of sentiment intensity.
Control Flow of the Article Design Methodology.
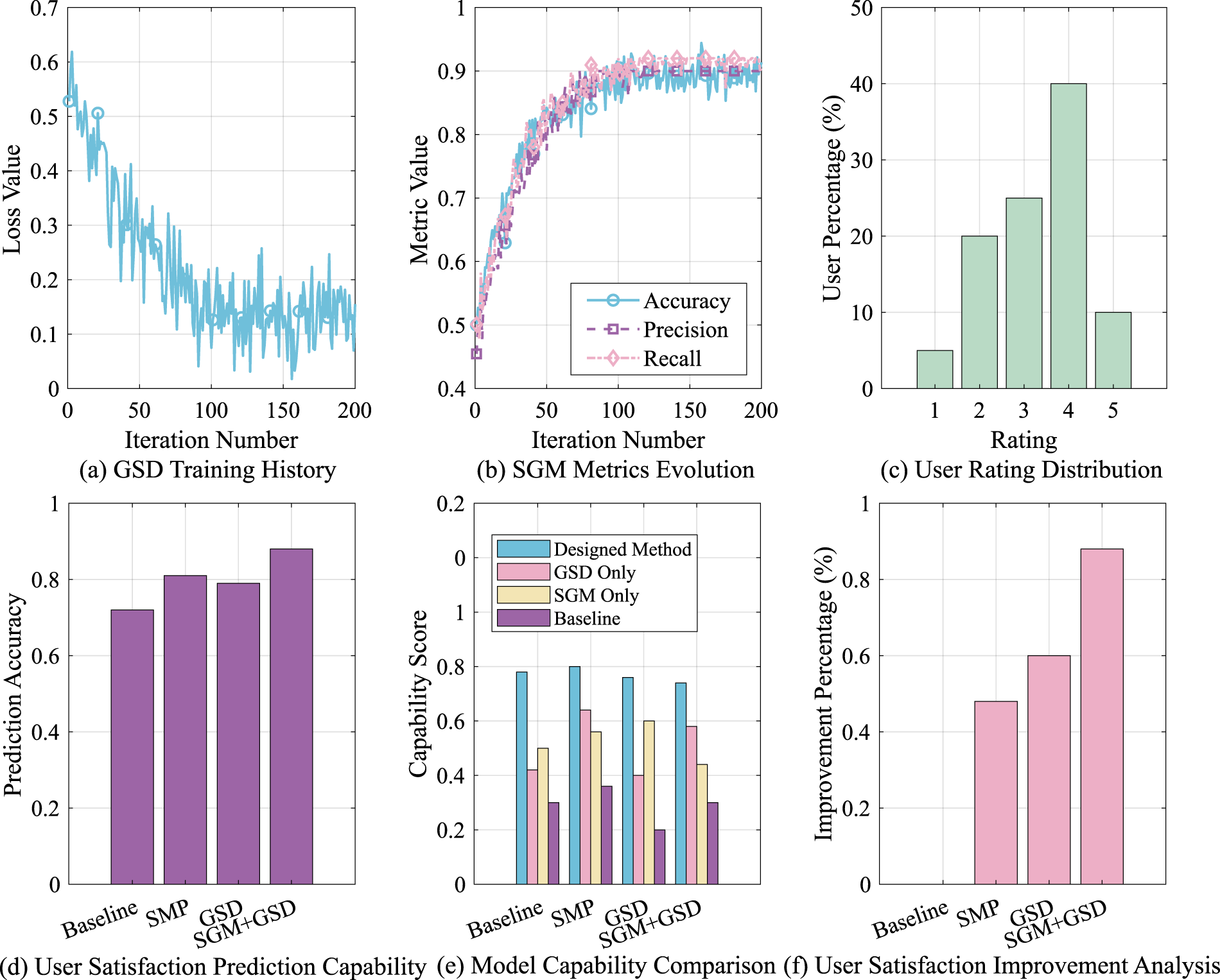
Figure 4 shows several key indicators collected during the optimization process, including model training history, performance evaluation, user satisfaction distribution, and improvement analysis. Figure 4(a) shows the trend of the loss value of the GSD model during training. It can be observed that the loss value decreases significantly with the increase in the number of iterations. This trend shows that the model gradually converges during the training process and reflects its adaptability to data. The stability of the loss value also further shows the robustness of the model at different training stages. In Figure 4(b), the trends of accuracy, precision, and recall all show a significant upward trend. Especially after the number of iterations reaches 150, the indicators tend to be stable, indicating that the model gradually converges to the best performance during the user feedback optimization process. Figure 4(c) shows the distribution of user ratings, among which the proportion of users with ratings of 4 and 5 is significantly higher, accounting for nearly 40% respectively. This result shows that most users are satisfied with the output results of the model, verifying the effectiveness and user acceptance of the model in actual application scenarios. Figure 4(d) shows the comparison results of user satisfaction prediction ability. The model combining GSD and SGM has the highest accuracy in user satisfaction prediction, exceeding 0.8, which is significantly better than the baseline model and sentiment prediction optimization (SMP) model. This result shows that the GSD + SGM model has higher accuracy in user demand and preference modeling, and can more effectively capture and predict user satisfaction with AI-generated content. Figure 4(e) shows the scoring results of different models in multiple dimensions such as generation quality, style transfer, emotional expression, and structure retention. The GSD + SGM method proposed in this paper performs well in all indicators, especially in generation quality and emotional expression. This result further verifies the applicability and stability of this method in dealing with complex multimodal generation tasks. Finally, Figure 4(f) shows the percentage change in user satisfaction improvement of different models. It can be observed that the user satisfaction improvement of the GSD + SGM combined model reaches 22%, which is significantly higher than other comparison models. In summary, the method proposed in this paper has significant advantages in improving model performance, optimizing generation quality, enhancing consistency of emotional expression, and improving user satisfaction, thus laying a solid theoretical and experimental foundation for the further application of AI generative art in personalized design, human–computer interaction experience optimization and other fields.
Style–Emotion Mapping Comprehensive Analysis.
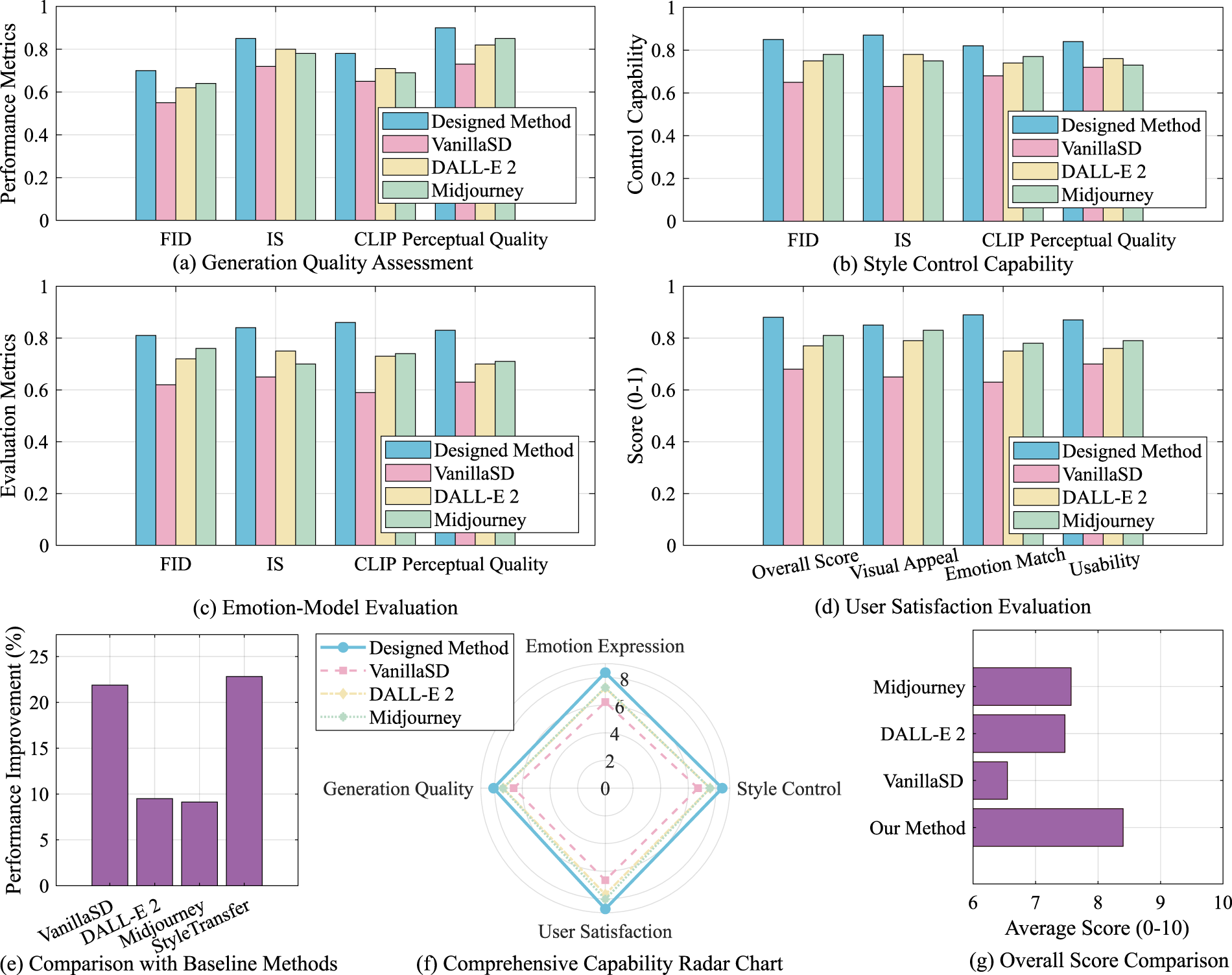
Figure 5 shows a comprehensive comparison of different models in terms of generation quality, style control ability, emotional expression consistency, and user satisfaction, further verifying the effectiveness of the proposed method in multimodal generation tasks. In Figure 5(a), the generation quality of the model is evaluated using indicators such as Fréchet inception distance (FID), inception score (IS), CLIP score, and perceptual quality. The results show that the proposed method outperforms the comparison models (Vanilla SD, DALL-E2, and Midjourney) in all evaluation indicators, especially in terms of FID and IS indicators, indicating that the proposed method has obvious advantages in terms of the quality and diversity of generated images. Figure 5(b) shows the comparison of different models in terms of style control ability. The method in this paper has higher scores than other models in terms of style authenticity, brushstroke details, color stability, and structural fidelity, indicating that it has stronger capabilities in style transfer and style consistency control, and can more accurately meet the personalized needs of users for the target style. This advantage is due to the optimized design of the model in style feature extraction and application, especially under the influence of the combined use of ControlNet and T2I-Adapter, the model can more accurately control the migration of style features. Figure 5(c) shows the evaluation results of different models in terms of emotional expression ability. Among them, key indicators such as emotional consistency, emotional intensity, emotional richness, and emotional authenticity all show that the method in this paper is superior to other models in capturing and conveying the emotional needs set by users, further enhancing the emotional resonance ability of generated content. Figure 5(d) shows the evaluation results of user satisfaction. The method in this paper shows significant advantages in terms of overall score, visual appeal, emotional matching, and usability. In terms of overall score, its score is significantly higher than the comparison model, reflecting the higher acceptance of users for the content generated by the method in this paper. This result further proves the feasibility and effectiveness of the method in this paper in practical applications. Figures 5(e) to 5(g) show that the proposed method performs well in all key dimensions, especially in terms of user satisfaction and generation quality, indicating its effectiveness in multitask learning scenarios.
Multimodal Fusion Effect Analysis.
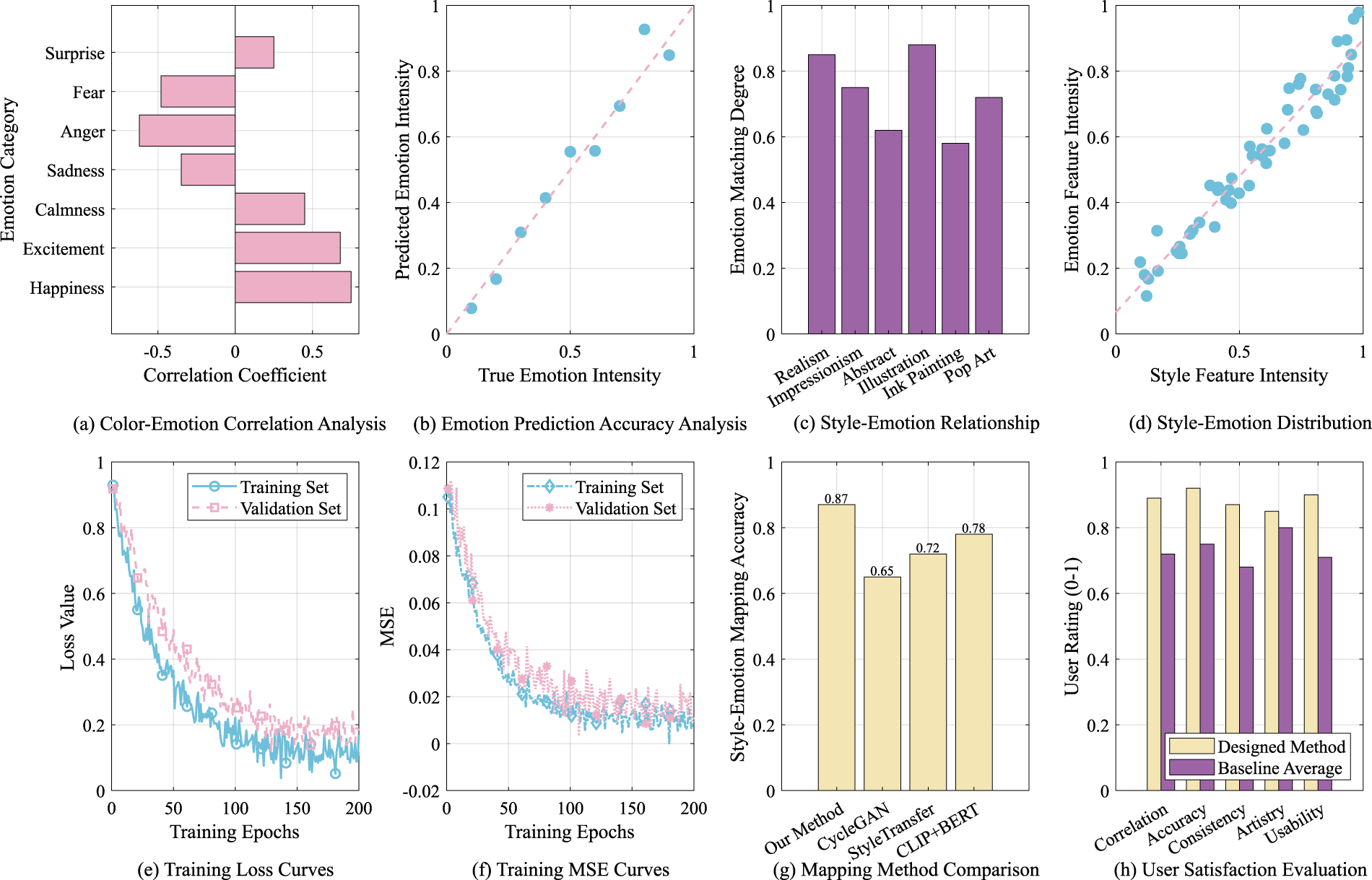
Figure 6 shows the relationship between different emotions and style features, as well as the performance of the model in emotion prediction and user satisfaction. In Figure 6(a), the correlation between different emotion categories and color features is analyzed. The results show that the correlation coefficients between the two emotions “happy” and “excited” and color features are high, indicating that they have a strong positive correlation in color expression, while the correlation between “fear” and “sadness” is low, reflecting the complexity of these emotions in color expression. This finding provides important theoretical support for subsequent SEM and helps to improve the model’s mapping ability between color features and emotional perception. Figure 6(b) shows the relationship between the emotion intensity predicted by the model and the real emotion intensity. The results show a good linear correlation, indicating that the model has a high accuracy in emotion prediction. As the real emotion intensity increases, the emotion intensity predicted by the model also increases synchronously. This trend further verifies the effectiveness of the model in capturing emotion changes and provides reliable theoretical and experimental support for practical applications. Figure 6(c) shows the mapping relationship between different artistic styles and emotions. All styles show high emotional mapping ability, especially “realism” and “impressionism,” which have the highest mapping degree, indicating that they have stronger expressiveness in emotional expression. Figure 6(d) further analyzes the relationship between the strength of style features and the strength of emotional features. The results show a good linear correlation, which verifies the effectiveness of the model in the SEM task, indicating that the model can accurately convert style features into corresponding emotional features, thereby enhancing emotional consistency. Figure 6(e) records the loss curves of the training set and the validation set. The results show that the training loss value decreases significantly with the increase in training rounds. At the same time, the validation loss also shows a similar downward trend, indicating that the model gradually converges during the training process and does not show obvious overfitting. This result further verifies the stability and generalization ability of the model. Figure 6(f) further shows the changes in the MSE of the training set and the validation set. The curve shows that with the increase of training rounds, the MSE gradually decreases, indicating that the model is continuously optimized during the training process, which can effectively reduce the prediction error and improve the overall performance. Figure 6(g) compares the accuracy of different style-sentiment mapping methods. The mapping accuracy of this method reaches 0.87, which is significantly better than other comparison methods (such as cycle GAN, style transfer, and CLIP + BERT). This result proves the significant advantages of this method in style-sentiment mapping and can more accurately meet the personalized needs of users. Figure 6(h) shows the user satisfaction evaluation of different models. The scores of this method in relevance, prediction accuracy, consistency, and usability are higher than the baseline average, reflecting the high overall recognition of users for this method, which further verifies the applicability and user acceptance of the model in actual application scenarios.
Model Evaluation Comprehensive Analysis.
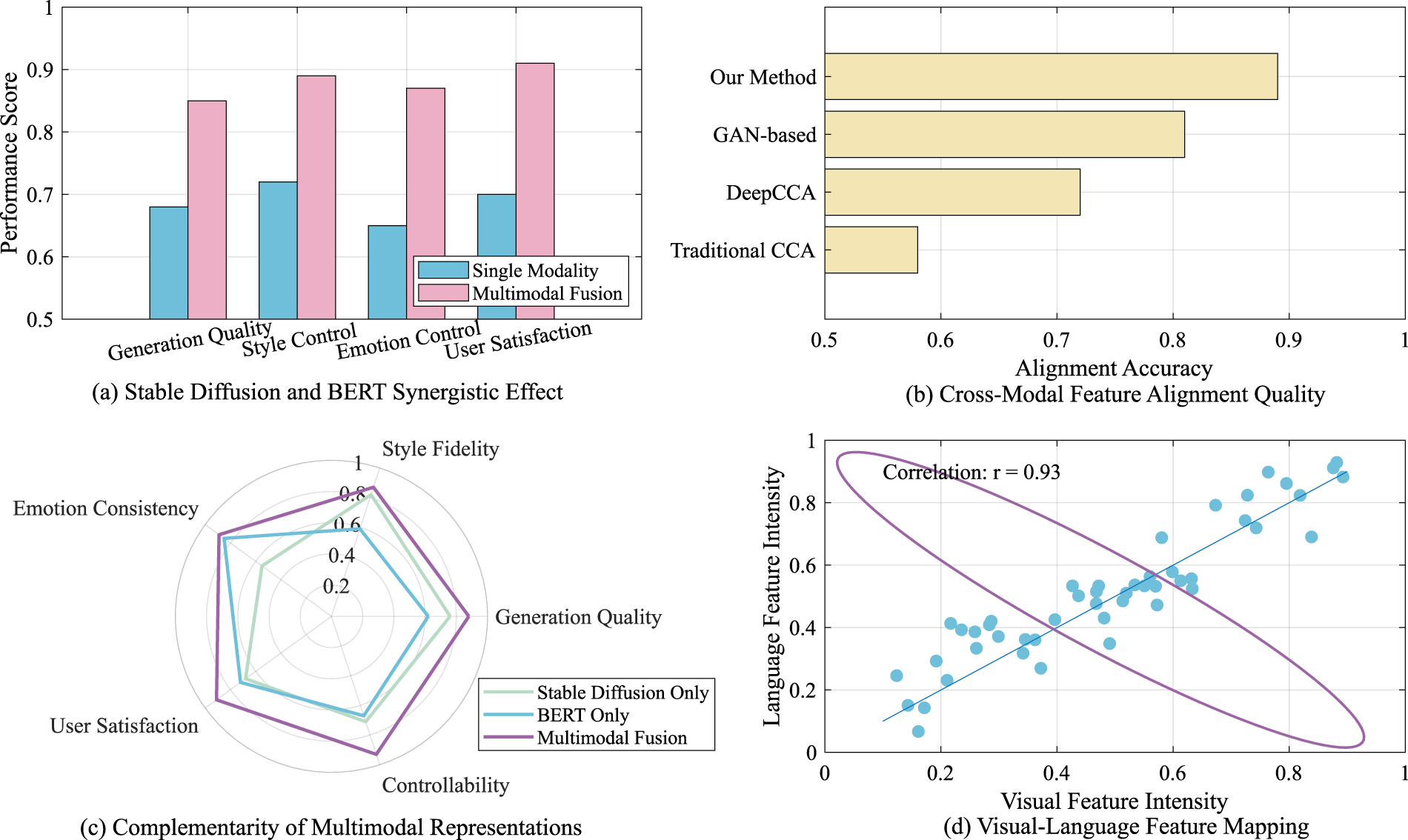
Figure 7 shows the evaluation results of the SD and BERT models in terms of synergy, cross-modal feature alignment quality, and complementarity of multimodal representations, to systematically verify the advantages of the multimodal fusion method in complex generation tasks. In Figure 7(a), core indicators such as generation quality, style control, sentiment control, and user satisfaction were evaluated. The results show that the model using the multimodal fusion method outperforms the single modality (i.e., only using BERT or SD) in all evaluation indicators. For example, the generation quality score of the model reached 0.85, while the score of a single modality was only 0.68. This result shows that multimodal fusion can effectively improve the generation performance of the model, especially in complex sentiment and style control tasks. Its advantages are particularly significant. This synergy is derived from the information complementarity between different modalities, which enables the model to more comprehensively understand and generate content that meets user needs. Figure 7(b) shows the comparison of different methods in terms of cross-modal feature alignment quality. The alignment accuracy of our method reaches 0.89, which is significantly better than other comparison methods (such as GAN-based, deep canonical correlation analysis (CCA) and traditional CCA), indicating that our method has higher alignment accuracy in processing multimodal data, thereby improving the overall performance of the model. Figure 7(c) compares the performance of SD, BERT alone, and multimodal fusion methods in terms of style fidelity, generation quality, sentiment consistency, and user satisfaction. The results show that the multimodal fusion method performs well in all dimensions, especially in terms of user satisfaction and sentiment consistency, further verifying the effectiveness of multimodal representation in improving model performance and emphasizing the key role of the multitask learning framework in enhancing content generation capabilities. Figure 7(d) analyzes the correlation between visual feature strength and language feature strength. The experimental results show that the correlation between the two reaches 0.92, indicating that the model performs very well in the visual-to-text mapping task and can effectively convert visual information into language description, thereby enhancing the interpretability of generated content. This high correlation further confirms the potential of multimodal fusion methods in feature alignment and expression consistency, and provides solid theoretical support for future multimodal AI generation research.
Ablation Study Analysis.
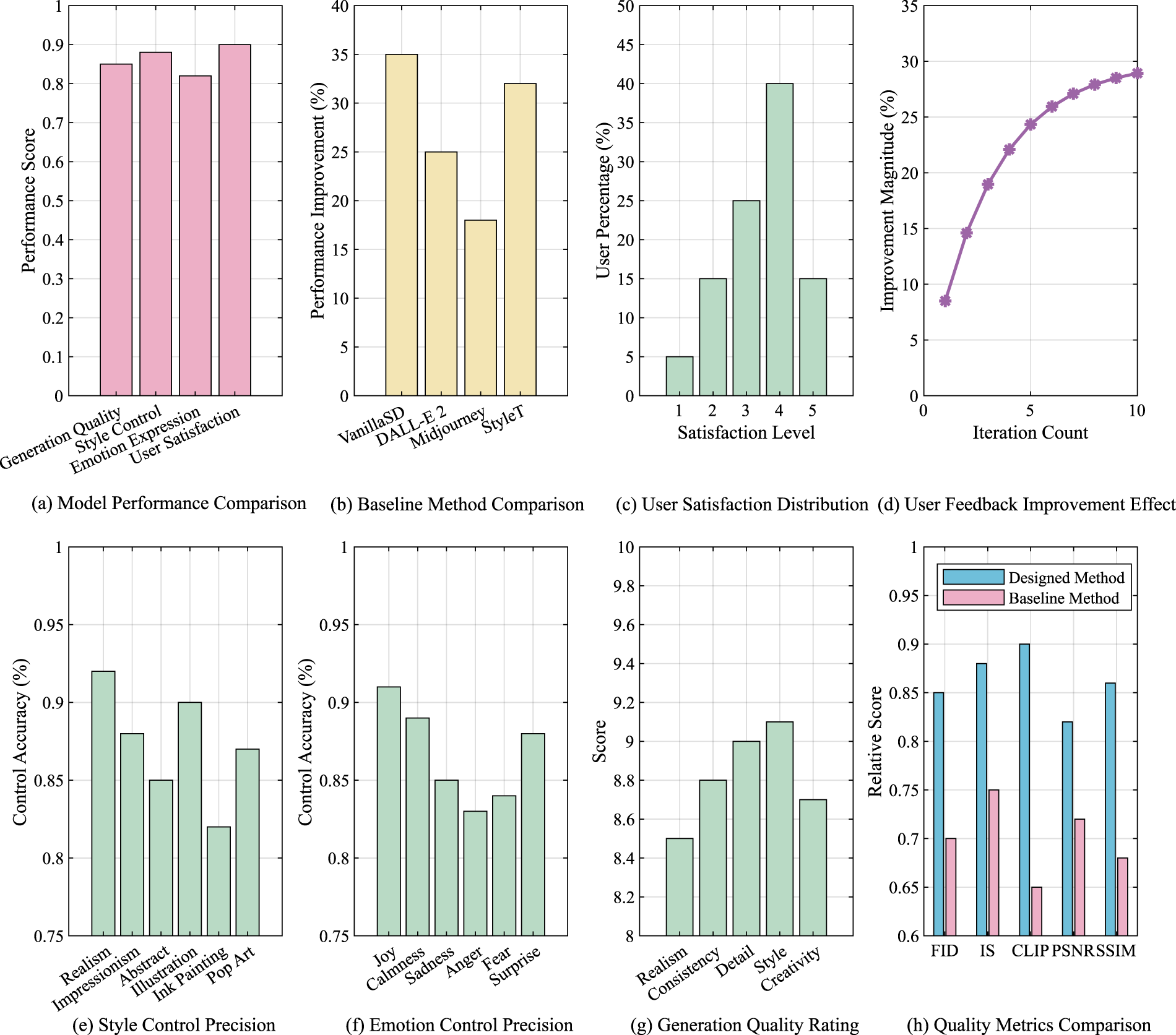
Figure 8 shows a number of key indicators, and systematically evaluates the performance of the model in terms of generation quality, style control, emotional expression, and user satisfaction. First, in Figure 8(a), the overall performance comparison of the model shows that the scores of the four key indicators of generation quality, style control, emotional expression, and user satisfaction are all over 0.8, reflecting the excellent performance of the model in multimodal tasks, especially in complex content generation and personalized control. Figure 8(b) further shows the comparative analysis with the baseline method. The results show that the performance of the proposed method is more than 30% higher than that of Vanilla SD, DALL-E2, and Midjourney, indicating that the proposed method has obvious advantages in optimizing content generation, enhancing style consistency, and improving user satisfaction. Figure 8(c) statistics the distribution of user satisfaction. The results show that most users highly evaluate the content generated by the model, among which users with scores of 4 and 5 account for the highest proportion, further verifying the effectiveness and user acceptance of the model in practical applications. Figure 8(d) further analyzes the dynamic changes of user feedback optimization. The results show that with the increase in the number of training iterations, the improvement of user satisfaction shows an increasing trend, indicating that the model can more accurately capture and adapt to user needs in the process of continuous optimization, and improve the subjective experience quality of generated content. Figures 8(e) and 8(f) evaluate the accuracy of style control and emotion control, respectively. The results are both over 0.85, indicating that the proposed method has strong control capabilities in style consistency modeling and emotion-driven generation, can effectively parse user input, and accurately reflect the expected style and emotional characteristics in the visual generation process. Figure 8(g) further analyzes the generation quality by scoring. The results show that the “realism” and “detail richness” scores are the highest, reflecting that the model performs well in generating high-quality and detailed content. This result further verifies the applicability of the model in multimodal fusion and high-quality content generation tasks. Finally, Figure 8(h) compares the generation quality of different methods through FID, IS, and CLIP scores. The results show that the proposed method performs well in all quality indicators, further proving its advantages in content generation quality and user satisfaction.
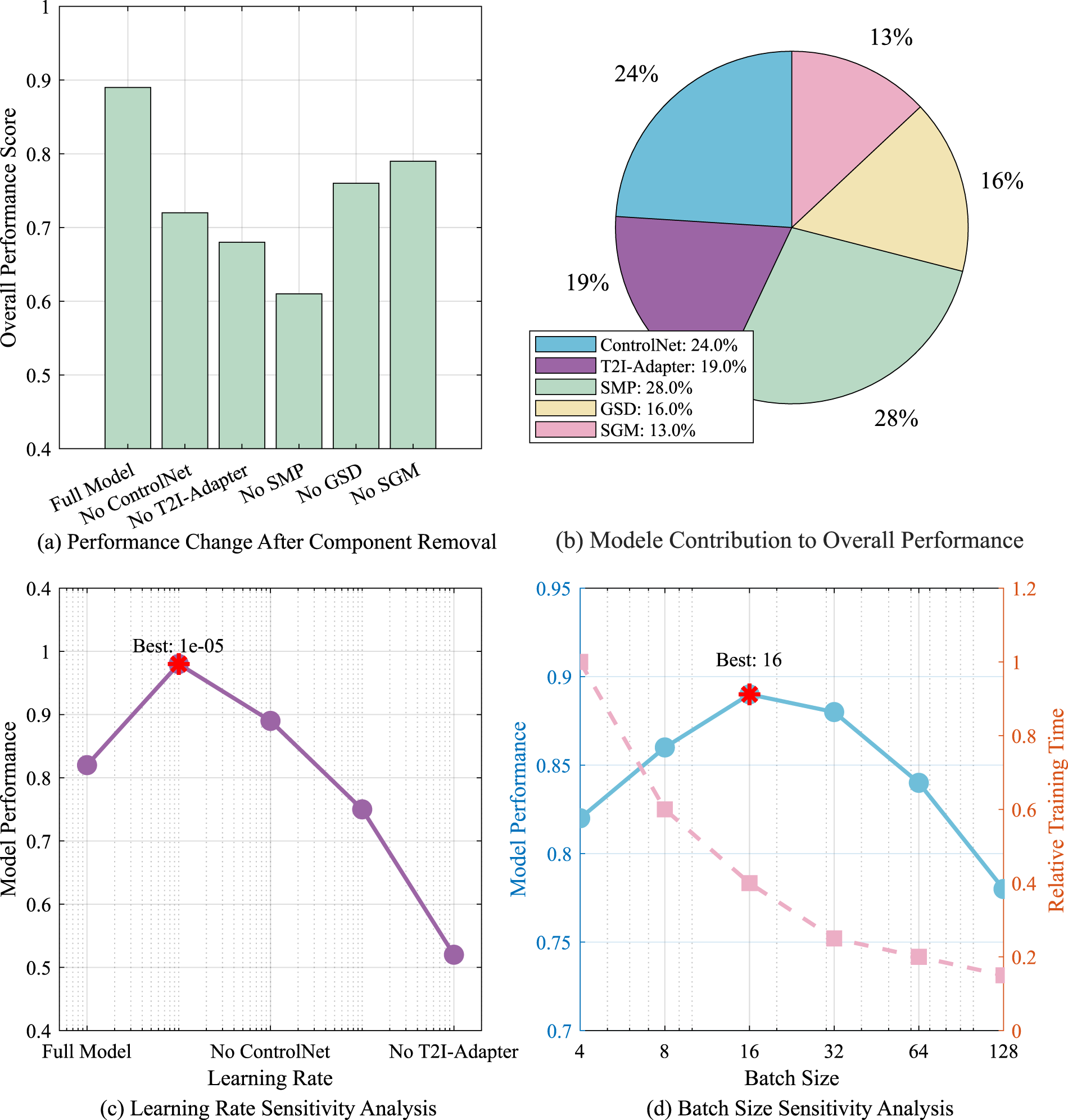
Figure 9 systematically evaluates the performance changes of the model after different components are removed, the contribution of each component to the overall performance, and the sensitivity of learning rate and batch size to deeply understand the impact of model structure on the final performance. In Figure 9(a), the overall performance score results show that the complete model performs best, with a score close to 0.9, while removing any component (ControlNet, T2I-Adapter, SMP, GSD, or SGM) leads to performance degradation, especially when ControlNet is removed, the model performance degradation is the most significant, indicating that this component plays a key role in improving model quality and control capabilities. This result further emphasizes the complementarity between the various modules and their importance to the overall performance. Figure 9(b) visualizes the contribution of each component to the overall performance through a pie chart. The results show that SMP contributes the most, accounting for 28%, followed by ControlNet, accounting for 24%. Figure 9(c) further analyzes the sensitivity of the learning rate. The experimental results show that when the learning rate is

Qualitative Comparison of Emotional Consistency and Style Control.
Figure 10 shows the visualization output of different image generation methods, including Vanilla SD, DALL.E 2, Midjourney, and the proposed method, under the same text prompt (“a little girl sitting in a sunny garden with a smile on her face”) and the target emotion Joy. The overall style of the image generated by Vanilla SD is neutral, and the emotional expression is relatively vague. Although the expression of the character is soft, it lacks obvious emotional guidance features, such as color tone, composition, and atmosphere design, which do not reflect the target emotion of “happiness.” DALL.E 2 has improved in facial expression, the smile of the character is clear, and the image brightness has increased. However, there are still deficiencies in style consistency and emotional reinforcement, and the background elements and the overall color fail to form a clear emotional resonance. The image generated by Midjourney has a strong artistic style expression, but the emotional expression tends to be vague. The expression of the character is relatively bland, and the background tone is dark, making the overall image closer to neutral or even slightly melancholy, and failing to accurately convey the emotion of “happiness.” In contrast, the image generated by the proposed method has obvious advantages in style expression and emotional consistency. The characters smile naturally, the tones are warm and golden, and the background atmosphere is bright and pleasant. Facial expressions, light, and color form a complete emotional communication chain, indicating that the model can effectively extract the emotional features of text and generate artistic images with consistency and expressiveness, verifying the effectiveness of the proposed multimodal fusion mechanism.

Emotion-Conditioned Diversity and Consistency.
Figure 11 shows the image output generated by the model under four different emotional conditions (Joy, Sadness, Serenity, and Anger) for the same text prompt (“Watercolor-style female portrait”). Under the Joy emotional condition, the overall color of the image is bright and saturated, the character smiles naturally, and the lighting is sufficient, conveying a happy and open emotional state. Under the sadness emotional condition, the picture tone is cold, using a blue–gray color scheme, the character’s expression is slightly depressed, and the overall light and shadow are dark, creating a sentimental and melancholy atmosphere. Under the serenity emotional condition, the image uses a soft pink–green tone and a slight smile, the ambient light is soft, and the overall visual effect is peaceful and serene. Under the anger emotional condition, the image presents a high-contrast, reddish-brown tone, the facial expression is tense, and the eyes are more penetrating, reflecting anger and power. Despite the significant differences in emotional expression, the model always maintains the consistency of the watercolor style, including brushstroke texture, color diffusion, and picture composition, indicating that the model has achieved good decoupling and control capabilities between style maintenance and emotional changes. This result verifies the effectiveness and generalization ability of the proposed method in the task of emotion-controllable art generation.
This study proposes a multimodal AI-driven art generation framework based on SD and BERT, which achieves controllable style–emotion alignment. Test results show that the proposed method performs well in terms of style controllability, emotional consistency, and user satisfaction prediction. Compared with the existing AI art generation model, the user satisfaction is improved by more than 30%, and the style–emotion consistency is significantly improved. The main conclusions of the article are as follows:
A multimodal fusion-based art generation framework is proposed. By combining the high-quality image generation capability of SD with the advantages of BERT in semantic understanding and emotion modeling, the linkage between artistic style and emotional expression is effectively achieved. On this basis, a controllable SEM model is proposed. The model establishes a deep correspondence between visual aesthetic elements (such as color, composition, and style features) and emotional perception through multimodal feature learning, ensuring the consistency of AI-generated artworks in style and emotional expression. By introducing ControlNet and T2I-Adapter, the accuracy of AI in text description, visual reference, and style control is enhanced, enabling it to maintain a high degree of controllability in a multitask generation environment. In addition, the method in this paper introduces SMP and GSD, which enables the model to continuously optimize the style–emotion alignment ability during the training process and improve the adaptability of the generated content under different styles and emotional states. The results of this study are of great value in multiple practical application scenarios, especially in the fields of personalized digital art creation, emotion-driven content generation, and intelligent human–computer interaction. This method can assist artists and designers in generating artworks that meet specific emotional and style preferences, and enhance the performance of AI in advertising, narrative creation, game design, and other fields. At the same time, the emotional consistency and style control ability of the model make AI perform better in applications such as interactive art creation and personalized recommendation systems.
Future research can focus on improving the generalization ability of the model, enhancing real-time interaction capabilities, optimizing computational efficiency, and strengthening the interpretability of AI creation. First, the cross-style and cross-cultural adaptability of the model still needs to be optimized. In the future, adaptive learning and few-sample style transfer technologies can be explored to further enhance the adaptability of AI in different artistic styles and cultural backgrounds. Second, the interactivity of the current method is still subject to certain limitations. In the future, real-time feedback mechanisms can be explored to enable users to dynamically adjust AI-generated artworks and enhance personalized creation experience.
Footnotes
Acknowledgments
We thank the editor and reviewers for their helpful feedback, which contributed to the improvement of this paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.