
Abstract
Currently, the significance of multimodal sentiment analysis is progressively increasing. However, the heterogeneity of multimodal signals poses a challenge in learning modality representation and fusing information. To address it, the BiMSA (multimodal sentiment analysis based on BiGRU and bidirectional interactive attention) is proposed in this paper. In the modality representation learning layer, BiMSA incorporates a structure consisting of BiGRU to extract contextual information from video and audio inputs. Subsequently, modality features are projected into modality internal representations and interactive representations for extracting information. This practice allows the model to take into account more aspects of modality information. In terms of the modality fusion layer, a bidirectional interactive attention mechanism is used to focus on the key representations of key modalities, and integrate multimodal information flexibly and efficiently. Attention weights are concentrated on modality representations that synergistically contribute toward overall sentiment orientation. Additionally, the constraints of similarity loss and difference loss are introduced to align with representations while mitigating redundant information and achieving a better fusion effect. Experimental results on public datasets (CMU-MOSI and CMU-MOSEI) demonstrate the effectiveness of the BiMSA model.
Keywords
Introduction
Sentiment analysis refers to the automated process of interpreting and classifying sentiment based on data, with the aim of determining whether expressed opinions are positive, negative, or neutral. Traditional sentiment analysis primarily focuses on text-based discrimination of sentiment. However, due to the rapid growth of social networks, an increasing number of users now express their attitudes through multiple modalities instead of relying solely on textual information in the past.
Multimodal data serves as a transmission medium for encompassing textual, visual, and auditory elements. Incorporating facial expressions’ descriptive quality conveys precise and nuanced emotional information, as well as unveils latent textual cues. Consequently, analyzing sentiment in data rich with affective content has emerged as the primary approach to discern users’ sentiment tendencies. Multimodal sentiment analysis holds immense value in social media sentiment analysis, user experience research, sentiment perception in autonomous vehicles, and sentiment monitoring in healthcare.
In the early stages of multimodal sentiment analysis, features were primarily extracted independently from text and image then fused using methods (Ren et al., 2021), before connected network for classification. Experimental results demonstrate that utilizing multimodal data leads to higher accuracy in classification compared to single-modality data usage, approaches mainly focused on developing intricate fusion mechanisms ranging from attention-based models to tensor-based fusion (Poria et al., 2017). Despite these advancements, challenges persist regarding how best to apply multimodal information in sentiment analysis. Firstly, extracting features from multiple modalities often leads to information redundancy or loss due to the potential mixing of repeated information across modalities while missing out on unique modality-privately details. Secondly, after feature extraction, it is necessary to overcome the heterogeneity of different modalities and perfectly integrate the features of different modalities.
This paper proposes utilizing a neural network constructed by BiGRU (Liu et al., 2019) to extract video and audio features in the modality representation learning layer, while using bidirectional encoder representation with transformers (BERT) to extract text features. The BiGRU structure can process sequence data bidirectional, and extract contextual information from sequences. The model can fully capture the contextual information in video and audio data when processing sequence data, and deepen the understanding and learning of video and audio features. Previous models typically employ convolutional neural network (Lecun & Bottou, 1998) and recurrent neural network (RNN; Zaremba et al., 2014) for feature extraction, neglecting the fact that sequence data should not only consider subsequent information but also take into account preceding information. Therefore, the BiGRU units are utilized. Additionally, inspired by Hazarika et al.’s (2020) ideas, modality internal representations and modality interactive representations based on the extracted features are investigated. The modality internal representations refer to independent representations of the modalities themselves, while modality interactive representations refer to interaction between multiple modalities. The interactive representations can relevant information between modalities, such as emphasizing the sentiment of the speaker, which enables the model to consider more aspects of the modality characteristics. In the modality fusion layer, the paper incorporates a bidirectional interactive attention mechanism to ensure each unique modality representation is aware of other cross-modality representations. This enables each representation to generalize latent information from other representations, extract crucial information from a substantial volume of data, ignore most unimportant information, and focus on important information. Furthermore, during the model training process, similarity loss and difference loss are added to task loss, which helps to align with the modality interactive representations, reduce redundant information, and achieve better fusion results.
The main contributions of this paper can be summarized as follows:
In the modality representation learning layer of multimodal sentiment analysis, this paper proposes a neural network constructed by BiGRU to extract features from video and audio inputs, so that the model can effectively capture context information when processing sequence data.
In the modality fusion layer, a bidirectional interactive attention mechanism is used to fuse all representations. This allows the model to focus on representations that have a synergistic effect on overall sentiment orientation.
Additionally, similarity constraints and difference constraints are incorporated to align interactive representations between modalities and reduce redundant information.
In order to improve the problems encountered in modality representation learning and modality fusion, perform multimodal sentiment analysis more accurately, and exert the value of multimodal sentiment analysis in the fields of economy and scientific research, this paper proposes BiMSA, a hybrid model based on BiGRU, bidirectional interactive attention mechanism, and constraint function. Experiments on the publicly available datasets CMU-MOSI and CMU-MOSEI demonstrate that the BiMSA model outperforms a series of baseline models, and ablation experiments demonstrate the importance of each component of the model.
Related Work
Multimodal sentiment analysis has two major challenges, one is modality representation learning, and the other is modality fusion.
Modality Representation Learning
For the modality representation of text, which is mainly to convert the text into a language that can be recognized by the machine, the word vector model such as Word2vec is commonly used (Goldberg & Levy, 2014), which represents text as vectors. GLOVE word vectors used a co-occurrence matrix to consider global information (Pennington et al., 2014); ELMo word vector can capture the context-related meanings of words as the language environment changes (Peters et al., 2018). BERT made scholars use the large-scale corpus for pre-training and input word vectors for downstream tasks after learning semantic relations (Devlin et al., 2018). Stappen et al. (2021) transcribed video clips into textual format, employed one-hot vectors for text encoding, and subsequently utilized an support vector machine classifier to achieve excellent sentiment analysis results.
The feature extraction of video modality primarily relies on the analysis of geometric and texture features exhibited by faces. Python’s OpenCV and Dlib libraries are often used for face feature key recognition. For example, Liu et al. (2021) used OpenCV to detect faces. The OpenFace tool proposed by Baltrušaitis et al. (2016) can also extract facial features and obtain low-dimensional representations. Cambria et al. (2018) used deep convolutional neural networks to extract text and visual features, and Wang et al. (2020) used neural networks to extract facial features.
The Mel frequency cepstral coefficient and linear predictor cepstral coefficients are commonly used audio features in audio modality. In 2015, Schuller’s team developed OpenSmile tool, which can preprocess and extract features of speech (Eyben et al., 2010). Degottex et al. (2014) developed the COVAREP for feature extraction of speech.
Banerjee et al. (2021) aimed to quantitatively demonstrate the influence of non-verbal cues on the results of multimodal sentiment analysis, focusing on facial emotion. Taking the Spanish data set as an example, the results show that the feature analysis results of the Spanish text combined with visual features are superior to the English text feature analysis, which indicates that there is an intrinsic correlation between the Spanish visual cues and the Spanish text (Banerjee et al., 2021).
Additionally, Hazarika et al. (2020) proposed MISA, which projects each modality into two subspaces. One facilitates the learning of commonalities and the reduction of gaps across different modalities. The other represents the unique representation of each modality. These representations offer a comprehensive perspective on multimodal data fusion for enabling predictions.
The work presented in this paper differs from the above research. To capture contextual information of sequential data, BERT is used for extracting textual representations. For representation learning of video and audio modalities, a neural network constructed with BiGRU is utilized to extract representation information.
Modality Fusion
In multimodal sentiment analysis, the modality fusion method determines the effect of the model, so it is important to choose an appropriate fusion method. Currently, there exist three primary modality fusion methods: feature-level fusion, decision-level fusion, and hybrid fusion (Wang, 2021).
On the basis of feature-level fusion, after feature extraction from video, audio, and text, (Poria et al., 2018) concatenated features in the fusion layer to form a combination vector which is then inputted into the classifier for obtaining the result (Poria et al., 2018). Li et al. (2022) proposed the contrastive learning and multi-layer fusion (CLMLF). The multi-layer fusion (MLF) module proposed a label-based fusion of multimodal features, simultaneously, a contrastive learning-based task is designed to aid the model in acquiring sentiment-related features and enhancing its ability to extract and integrate features effectively. CLMLF exhibits strong competitiveness, particularly through visualization techniques, comparative learning tasks, and MLF modules. Li et al. (2023) proposed the Mutual Information Maximization and Feature Space Separation and Bi-Bimodal Modality Fusion model and designed the mutual information (MI) maximization module and feature space separation module. The MI module maximizes the MI between the two modalities to retain more correlated information, while the feature separation module separates the fusion features to prevent the loss of independent information during the fusion process.
Decision-level fusion enables each modality to learn features using their most suitable models, but a disadvantage is internal connections between features cannot be learned, and the process is time-consuming. Huang et al. (2019) proposed a sentiment analysis model, which used the connections and differences between images and texts to classify sentiment. The model fuses the results of three models to obtain the prediction results. Poria et al. (2015) proposed a short text feature extraction method based on deep convolutional neural networks and proposed a parallel decision-level data fusion method to improve the running speed.
Hybrid fusion mainly considers the fusion modality of the model. The proposed two-layer multimodal learning model by Ji et al. (2018) addresses the dependence between modality effectively. This model consists of two layers: the first layer focuses on capturing the correlation between tweets and tweet features to predict sentiment, while the second layer emphasizes on learning the relationship among multiple modalities. Experimental results demonstrate that the model shows excellent performance.
In addition, many scholars have made contributions to modality fusion. Han et al. (2021) proposed a hierarchical MI maximization framework for multimodal sentiment analysis, MultiModal InfoMax model, which maximizes MI at the input and fusion levels to reduce the loss of valuable task-related information . This is the first time that MI is included in multimodal sentiment analysis.
BiMSA’s approach in the modality fusion layer differs from previous methods by using a bidirectional interactive attention mechanism to construct the fusion network. It incorporates both internal representations and interaction of the modalities into the network, enabling the model to ignore redundant information and focus on relevant feature information for accurate sentiment polarity prediction. Additionally, the model assigns higher weights to features that contribute significantly toward predicting the model’s outcomes, thereby selecting focused features.
Method
In order to use multimodal data to judge sentiment in video and audio, fully extract modalities features, and fuse modalities features, a multimodal information sentiment analysis model is proposed. The overall structure of the model is illustrated in Figure 1. There are three components: modality representation learning, modality fusion, and sentiment prediction.
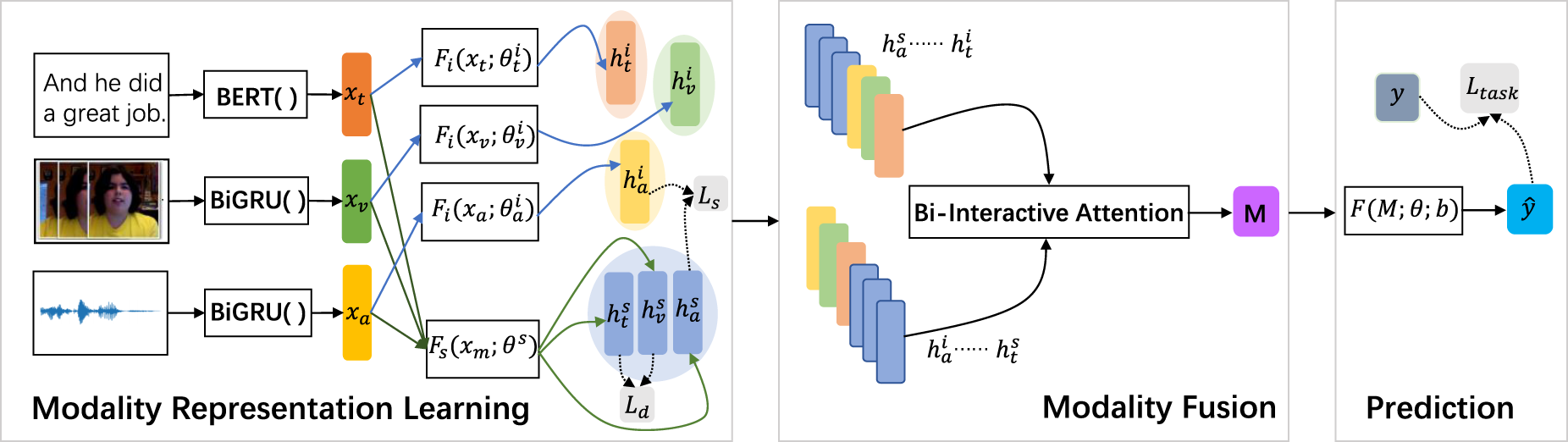
The overall structure of the BiMSA model.
Each video in the dataset represents a sample sequence
First, BiMSA extracts the raw features of the data.
For text data, the bidirectional encoding capability of the BERT pre-trained model is used to extract raw features. BERT pre-trained model is based on the Transformer architecture, which understands and encodes the semantic and syntactic structures of input text at different levels. This makes the model perform well in handling long-distance dependencies and contextual understanding. Thus, the context and relevant information in the text can be better understood, and the extracted features can be more comprehensive and accurate.
For video data, Facet tools can extract key features from video quickly and accurately. Moreover, various types of video features can be extracted, such as facial expressions, postural movements, voice emotions, etc., to help users quickly analyze and understand video content from multiple angles. Therefore, Facet tools are used in this paper to extract visual features.
For audio data, BiMSA uses COVAREP to analyze the sound characteristics of speech signals. COVAREP can extract a variety of sound features, and these multi-dimensional features can provide rich information about the speech signal and facilitate more comprehensive acoustic analysis. Moreover, the sound features extracted by COVAREP can be used to analyze the speaker’s sentiment state and intonation change, which is helpful for sentiment recognition and other applications.
With this approach, the sequence of raw video clips will be represented as a feature vector
Then, the representation learning is conducted based on acquired original features. The rationale behind not directly utilizing the raw feature lies in its relative simplicity, requiring a non-linear combination to fully exert its role. Moreover, there exists a considerable redundancy among features, rendering not all of them useful for prediction purposes. Additionally, many characteristics often exhibit variability and noise.
For each modality
BiGRU is composed of two gated recurrent units in opposite directions, which can effectively capture the long dependency of the context in the sequence and solve the problem of gradient disappearance and gradient explosion during RNN training (Cho et al., 2014; Chung et al., 2014; Liu et al., 2019). In BiGRU, forward and reverse inputs obtain hidden layer representations at corresponding time steps. The concatenation operation then yields video and audio features with contextual information. The formulae can be expressed as follows:





After obtaining modality internal representations and modality interactive representations, a modality fusion module is performed. The approach employed here involves utilizing the bidirectional interactive attention mechanism, and subsequently concatenates the transformed two-layer vectors.
The bidirectional interactive attention mechanism can be used to optimize the model from three perspectives: multimodal information fusion, cross-modal association learning, and dynamic attention allocation.
In terms of multimodal information fusion, through the bidirectional interactive attention mechanism, the model can better integrate and understand the information of different modalities when dealing with multiple modal inputs, so as to improve the model’s understanding ability of complex scenes.
In cross-modal association learning, the bidirectional interactive attention mechanism can make each modal feature aware of other cross-modal features, taking into account not only the global relations between different modalities, but also the local relations between different representations of the same modality. On the basis of these relations, the correlation between different modalities can be identified and modeled. Allowing each representation to capture features from other representations, inducing underlying information (Vaswani et al., 2017), these representations have a synergistic effect on overall affective orientation.
As for dynamic attention allocation, the multimodal bidirectional interactive attention mechanism can dynamically adjust the attention allocation according to the modal input, so as to make better use of the information of different modalities and make the model more flexible and efficient in processing multimodal information.
First of all, modality internal representations and modality interactive representations of three modalities are stacked into matrixes
Then, each input matrix containing representations is divided into multiple “heads,” and each “head” will independently perform self-attention calculation and get its own attention output. Each head performs the next steps independently. Compute the Query, Key, and Value vectors for each element based on the input sequence data. Suppose there are h “heads”, and the input sequence for each “head” is



The attention score between different representations is computed to quantify the level of attention that each representation pays to other representations. This score is calculated using the following formula:

The model calculates the attention weight coefficient between different representations. Through the softmax function, the attention score is converted to the value before 0 and 1 and the sum is 1, and the attention weight is obtained:

The value is weighted and summed according to the weight coefficient. Multiply the value vector of each element with its corresponding attention weight coefficient, and then sum. This process aims to combine the input multimodal feature sequence to generate a new context-dependent sequence vector:

After that, the output
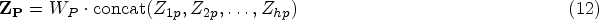
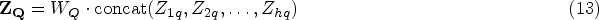
Finally, the output vectors of matrices
The task of multimodal sentiment analysis is to input a data series pair

The learning is achieved through the process of minimizing:


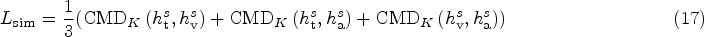
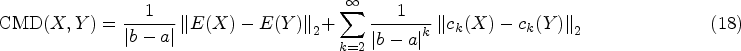

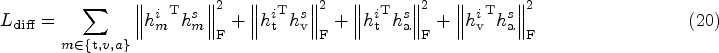
The difference loss is calculated by imposing an orthogonality constraint between two types of representations (Bousmalis et al., 2016; Hazarika et al., 2020; Liu et al., 2017; Ruder & Plank, 2018). In addition to the constraints between modality internal representations and modality interactive representations, orthogonal constraints between modality internal representations are also added.
Datasets
CMU-MOSI
The CMU-MOSI dataset consists of 2,198 discourse-level video clips, comprising independent reviews of the film by 89 speakers (Zadeh et al., 2016). It is worth noting that the dataset maintains a rough gender balance. Each statement within it is accompanied by a continuous variable denoting a sentiment score ranging from
CMU-MOSEI
The CMU-MOSEI dataset surpasses its predecessor, the CMU-MOSI dataset (Zadeh et al., 2018). It comprises over 65 hours of monologue video from more than 1,000 speakers, encompassing 23,453 annotated clips across 250 topics.
Evaluation Criteria
The CMU-MOSI and CMU-MOSEI datasets involve regression tasks, evaluated using mean absolute error (MAE) and Pearson correlation (Corr). Additionally, the baseline includes classification metrics such as seven accuracy levels ranging from
MAE
The MAE is the mean of the distance between predicted value

Corr is the correlation between the prediction matrix and the actual value matrix. The higher the correlation, the more effective the BiMSA model is. The formula for the correlation coefficient is as follows:
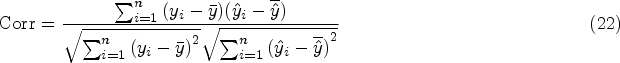
The Acc-7 is determined by applying the round function to map regression-based prediction results onto a discrete variable range of
Binary Accuracy (Acc-2)
In the part of binary classification (Acc-2), the confusion matrix is considered for binary classification. Both the predicted score and true score are mapped to the binary label and compared to calculate the binary classification accuracy:

F1-score is the weighted average of precision and recall:



The following multimodal sentiment analysis baseline models are selected to compare with BiMSA:
BC-LSTM: The proposed model presents a hierarchical concept, comprising of two components (Poria et al., 2017). The initial level involves the extraction of single-modality features, while the level entails feeding the extracted features from the first layer into long short-term memory. Finally, fusion is performed on the features extracted from three modalities to derive the final prediction outcome.
TFN: The fundamental concept of the model is to learn intra-modality and inter-modality dynamics end-to-end. The inter-modality dynamics are modeled by tensor fusion, and intra-modality dynamics are modeled by three modal embedding subnetworks (Zadeh et al., 2017).
LMF: The study proposes a model that decomposes the weights into low-rank factors, which effectively reduces the number of parameters in the model (Liu et al., 2018).
MulT: The core of the model is the cross-modality attention module, which focuses on cross-modality interactions at the utterance scale. This module potentially adjusts the data stream from one modality to another by repeatedly reinforcing the features of one modality with those of the others (Tsai et al., 2019).
MISA: MISA emphasizes the significance of multimodal representation learning as a prerequisite for fusion. MISA acquires modality-shared and modality-unique representations that facilitate the prediction of sentiment state fusion.
ConFEDE: ConFEDE believes that multimodal sentiment analysis depends to a large extent on learning a good representation of multimodal information, which should include modal invariant representations consistent across modes and modal specific representations (Yang et al., 2023). Thus, ConFEDE jointly performs contrast representation learning and contrast feature decomposition to enhance the representation of multimodal information.
Results and Analysis
Quantitative Results
Tables 1 and 2 show the results of experiments on the CMU-MOSI dataset and CMU-MOSEI dataset for the model in baseline and the BiMSA model. Regardless of the dataset used, the BiMSA model outperforms the baseline model in terms of regression evaluation indicators as well as classification.
Experimental Performance of BiMSA Model on CMU-MOSI Dataset.
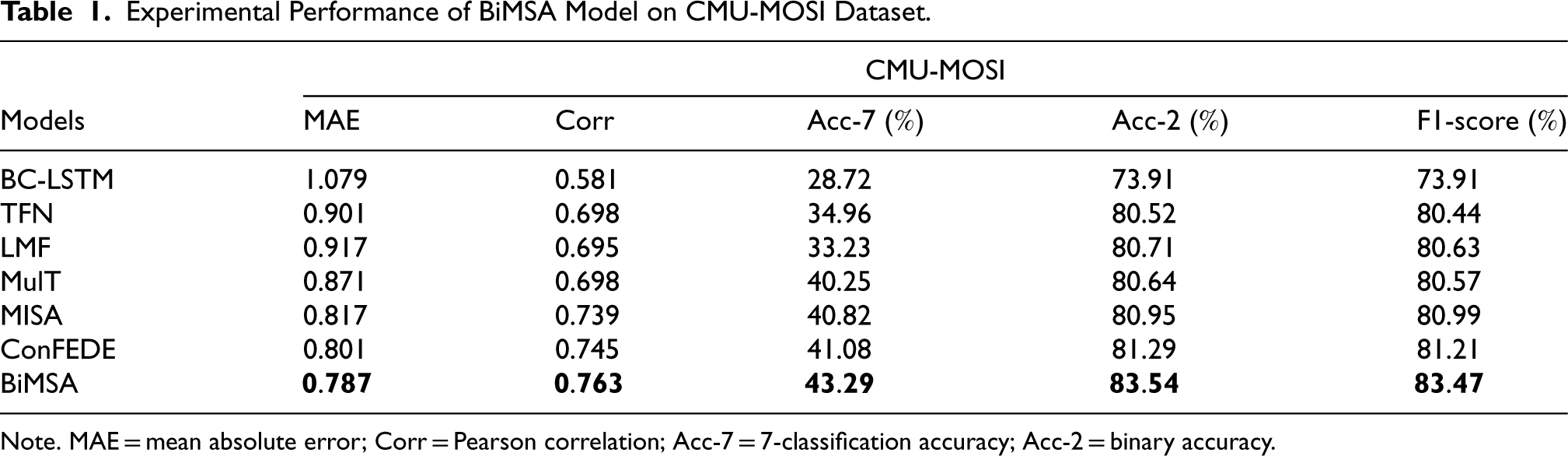
Experimental Performance of BiMSA Model on CMU-MOSI Dataset.
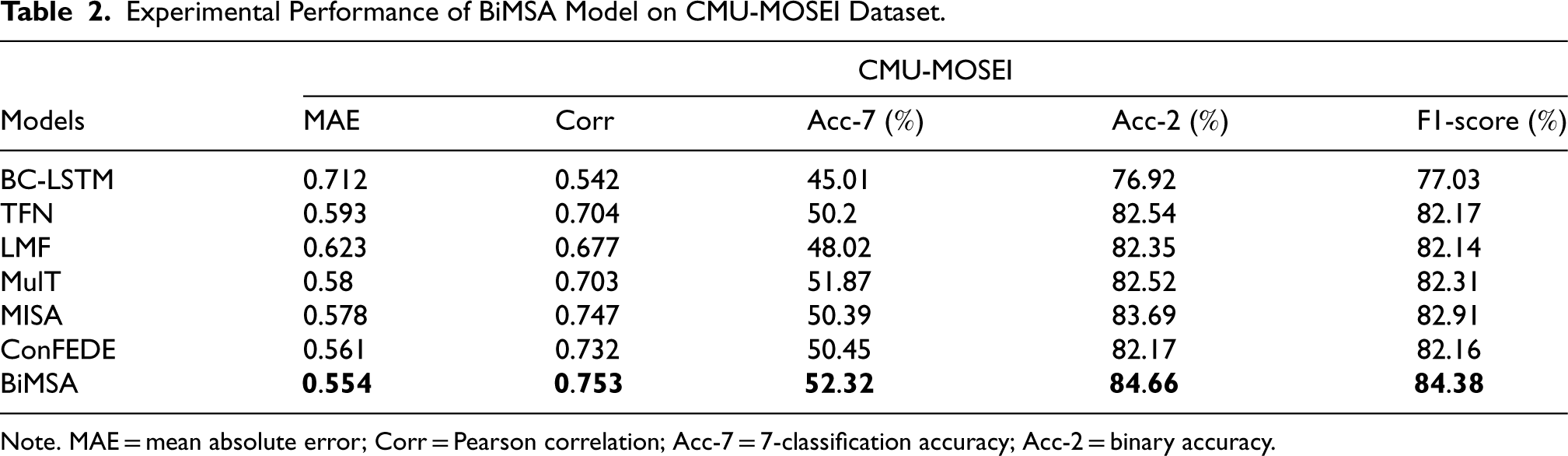
Experimental Performance of BiMSA Model on CMU-MOSEI Dataset.
On the CMU-MOSI dataset, compared to the ConFEDE model, which has better performance at present, the MAE of the BiMSA model is reduced by 0.014. The correlation increased by 0.018. The accuracy of the 7-classification is higher than that of the ConFEDE model by 2.21
The performance is the same on the MOSEI dataset, compared to the ConFEDE model, the MAE of BiMSA is also decreased by 0.007. The correlation increased by 0.021. BiMSA demonstrates an enhancement of 1.87
The above experiments illustrate that BiMSA combining the BiGRU structure and the bidirectional interactive attention mechanism module can better splice the modality representation learning layer and the modality fusion layer of the model, making the context information richer. BiGRU structure can consider the historical information and future information of the current moment and can make use of the context information to predict more comprehensively. The bidirectional interactive attention mechanism module can enhance the model’s attention to the information of different positions in the input sequence, so that the model can make full use of the context information and improve the model’s understanding of the sequence data. At the same time, adding the similarity constraint and the difference constraint to the loss function can make the interaction features closer in the feature space and reduce the redundancy. The difference constraint can make different features more dispersed in the space, thus improving the effect of feature representation learning, making features more discriminative, and improving the robustness and generalization ability of the model. This also validates the effectiveness and advancement offered by BiMSA within multimodal sentiment analysis tasks.
On both datasets, ablation experiments were performed. The ablation experiment was divided into three parts: modality ablation, model component ablation, and loss function ablation. Tables 3 and 4 show results.
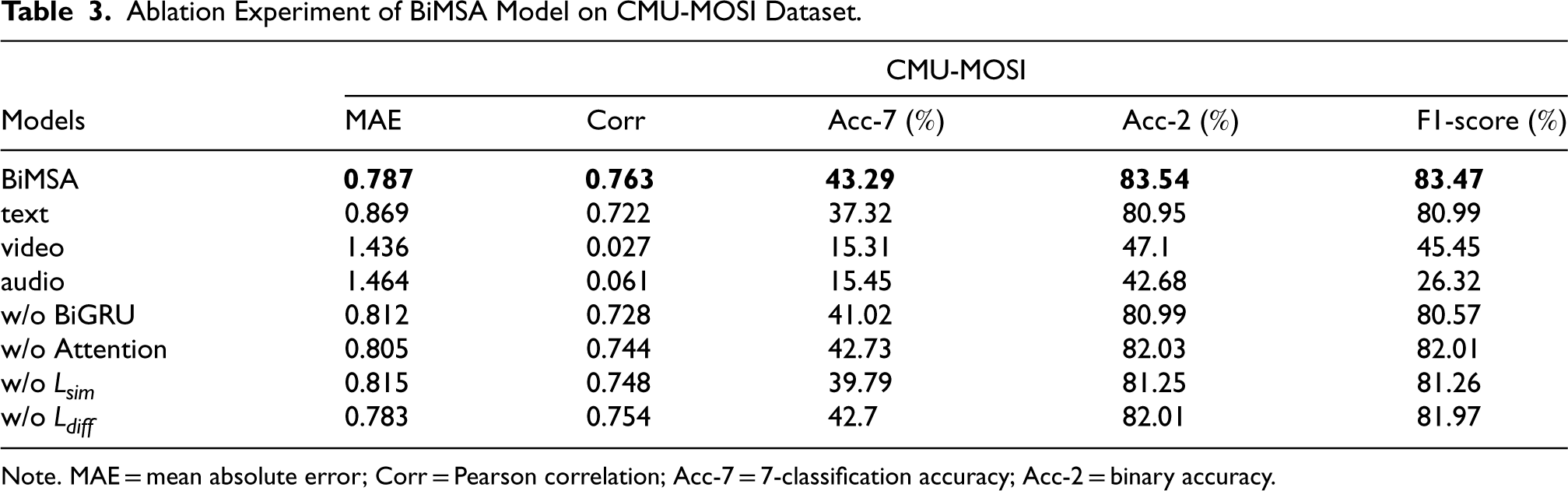
Ablation Experiment of BiMSA Model on CMU-MOSI Dataset.
Ablation Experiment of BiMSA Model on CMU-MOSI Dataset.
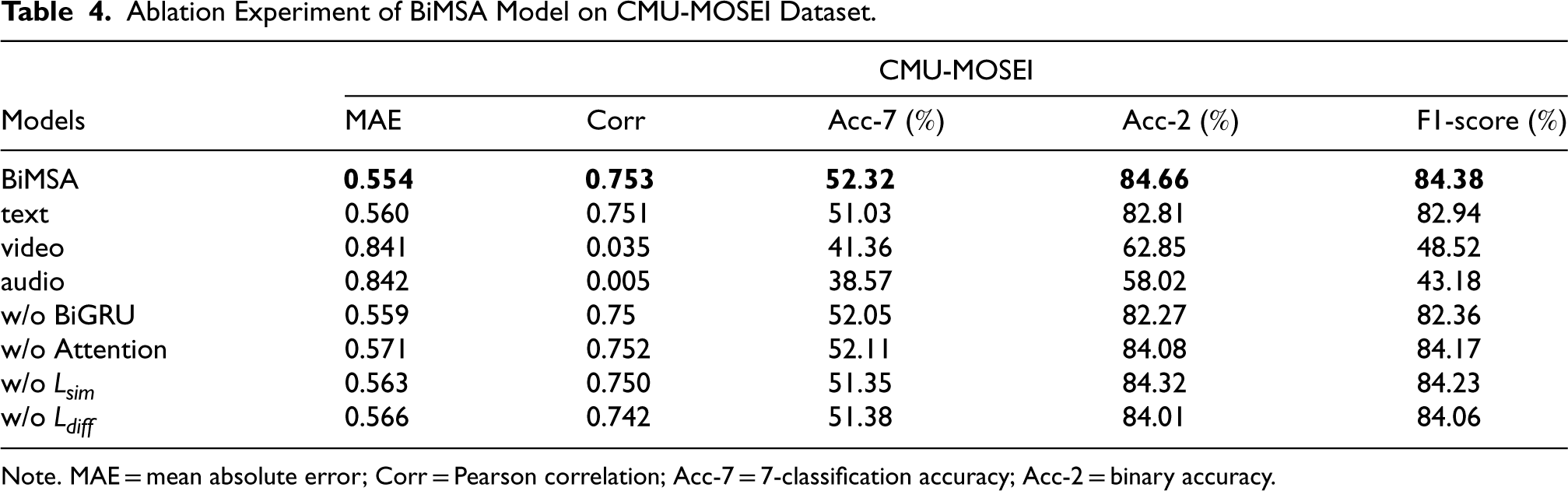
Ablation Experiment of BiMSA Model on CMU-MOSEI Dataset.
In the modality ablation section, this paper mainly observes the difference between the influence of a single modality on sentiment analysis and the influence of a multimodal on sentiment analysis. In other words, in addition to the BiMSA model, only text, video, and audio are used for sentiment analysis, respectively.
The results in Tables 3 and 4 demonstrate that BiMSA model has better performance than any single-modal sentiment analysis model in the table, and the multimodal sentiment analysis model has the lowest average absolute error, the highest correlation, the highest classification accuracy and the highest F1-score. This proves the advantages of multimodal sentiment analysis over single-modal sentiment analysis.
In addition, in single-modal sentiment analysis, the model using only text mode performs significantly better than the model using only video mode, and the model using only audio mode performs the worst. Among them, in the two datasets, the accuracy of the text model decreased by 2.59
Model Component Ablation
Firstly, the component of extracting modality representations from the network constructed by BiGRU is eliminated. On the CMU-MOSI dataset, the model without the BiGRU module is significantly weaker than the model with the BiGRU module. Compared with the latter, the MAE of the former is higher, and the binary classification accuracy is reduced by 2.55
Additionally, the bidirectional interactive attention mechanism component is also excluded in the modality fusion module. It can be observed that upon removing the bidirectional interactive attention mechanism component, there is a decline in the performance of regression and classification indicators of the model. Specifically, on the CMU-MOSI dataset, the binary classification accuracy decreased by 1.51
Loss Function Ablation
For the ablation of the loss function, the similarity loss function and the difference loss function are removed, respectively. In terms of binary classification accuracy index on the CMU-MOSI dataset, the performance of the model without similarity loss function decreased by 2.29
Loss Curve
The error curves of the loss function are traced. In Figure 2, the left picture is the trace diagram of the loss function on the CMU-MOSI dataset, and the right picture is the trace diagram of the loss function on the CMU-MOSI dataset. It is found that no matter on which dataset, the loss function curves of the training dataset and the verification dataset gradually decline and converge with the increase of epoch, and the gap between them is very small, which indicates that the model does not have the problem of overfitting or underfitting, and the model possesses generalization capabilities.
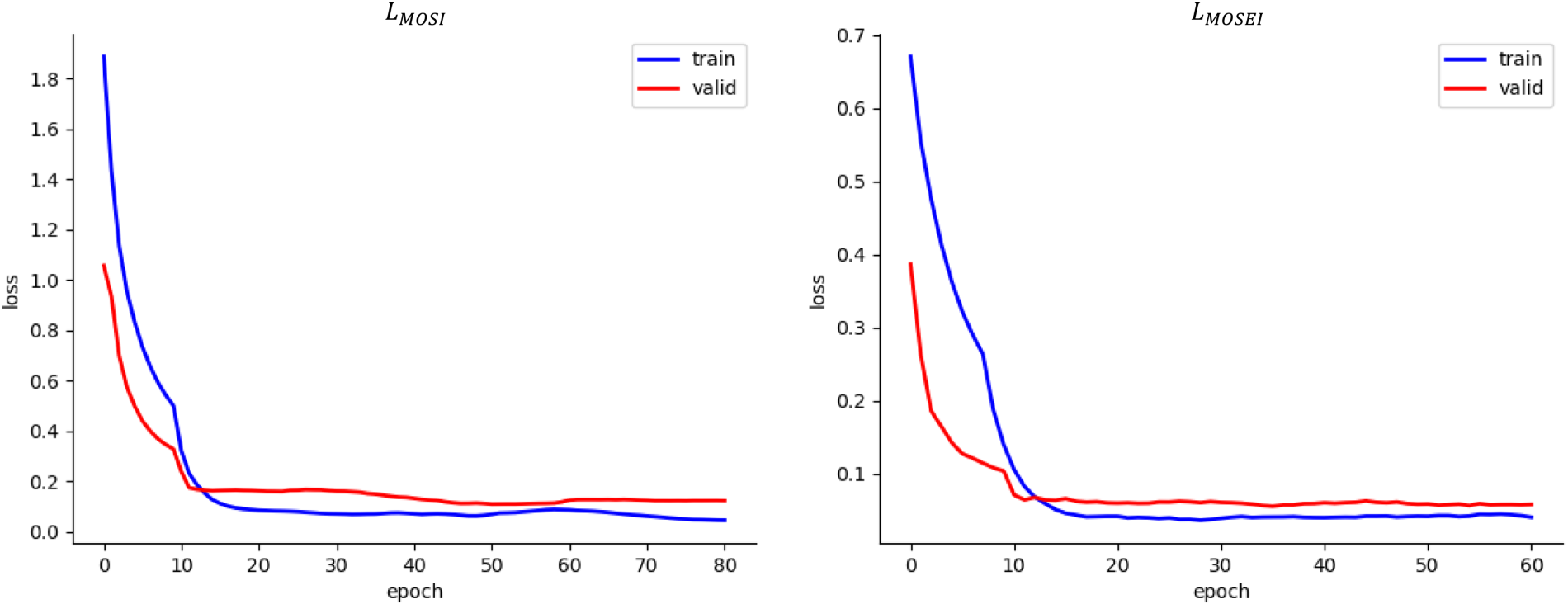
Loss function locus of BiMSA model.
In this paper, BiMSA, a multimodal sentiment analysis model, is proposed. The representation learning module utilizes BERT to extract features from text and utilizes a unit structure composed of BiGRU to extract deep features from video and audio modalities, so that the model can capture context information more effectively. This is important for understanding continuous motion in video and audio. Then, the features of the three modalities are transferred to the modality internal representations and the modality interactive representations through linear transformation, becoming six representations. In the modality fusion module, a bidirectional interactive attention mechanism is employed to enable each modality to be aware of potential information from other representations and fuse them synergistically for sentiment analysis purposes, which makes the model more flexible in processing multimodal information. Finally, during training, three loss functions including task function, similarity loss function, and difference loss function are combined to minimize differences between modality interactive representations while maximizing differences between the modality internal representations and the modality interactive representations, reducing redundancy and maximizing information extraction.
The experimental results demonstrate the high effectiveness of BiMSA, surpassing some previous models in performance. Ablation experiments and visualization analysis further validate the generalization capability of the representation learning module and the rationality of the component. In general, the idea proposed in this paper is to focus on the extraction and fusion of feature information been empirically proven to be effective. Moving forward, we plan to incorporate additional modalities for sentiment analysis, such as exploring the impact of physiological signals.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the National Natural Science Foundation of China (12361072) and Xinjiang Natural Science Foundation of China (2023D01A36).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.