
Abstract
This paper looks at predictability problems, that is, wherein an agent must choose its strategy in order to optimize the predictions that an external observer could make. We address these problems while taking into account uncertainties in the environment dynamics and the observed agent’s policy. To that end, we assume that the observer (1) seeks to predict the agent’s future action or state at each time step, and (2) models the agent using a stochastic policy computed from a known underlying problem, and we leverage on the framework of observer-aware Markov decision processes (OAMDPs). We design reward functions for the agent which encode her goal to make next states or actions predictable by the observer; show that these induced predictable OAMDPs can be represented by goal-oriented or discounted MDPs; and analyze the properties of the proposed reward functions theoretically. Experiments have been conducted, generating and interpreting policies on two types of grid-world problems, and then confronting human observers to these policies on some of these problems.
Introduction
In a human–agent collaboration scenario, some properties of the agent behavior can be useful for the human and sometimes allow a better collaboration. Recent papers suggest ways of obtaining such behaviors. In particular, when an agent is aware that it is being observed by a passive human, as in Figure 1, it can control the information disclosed to the observer through its behavior.
Chakraborti et al. (2019) build on previous work to derive a taxonomy of these concepts. In particular, they distinguish between (1) transmitting information, with properties such as legibility (legible behaviors convey intentions, that is, actual task at hand, via action choices), explicability (explicable behaviors conform to observers’ expectations, that is, they appear to have some purpose), and predictability (a behavior is predictable if it is easy to guess the end of an on-going trajectory); or (2) hiding information, as through obfuscation, when the agent tries to hide its real goal. They propose a general framework for such problems under the hypothesis that transitions are deterministic and work mostly with plans (a sequence of actions inducing a state sequence). In their approach, the human is modeled by the robot as having a model of the robot + environment system (including the robot’s possible tasks), and is thus able to predict the robot’s behavior and adapt to it.
Each of the properties they discuss can be relevant in some situations. They convey different kinds of information to the observer and can be mutually exclusive. Chakraborti et al. (2019) point out that an explicable plan can be unpredictable, for example, when multiple explicable plans exist. Similarly, Fisac et al. (2020) suggest that, if an agent acts legibly, then one can infer its goal but not necessarily how it is going to achieve this goal.
Predictability is meant to ensure that the agent’s behavior conveys this information.
Schadenberg et al. (2021) explain that Predictability has a real interest when considering human–robot interaction. Their work mainly focuses on how human observers react to a hand-coded social robot behavior depending on whether the cause of responsive actions is visible or not. As we do in our experiments, they distinguish the participants’ performance in predicting the robot’s behavior, called the behavioral predictability, and their perception of the predictability of the robot’s behavior, called the attributed predictability. They observe that both predictabilities are not necessarily aligned, and point out that, depending on the scenario, one may want to optimize either behavioral predictability, for instance with industrial robots, or attributed predictability, for instance with social robots. Unlike them, we are interested in automatically deriving predictable behaviors, and only consider fully observable settings.
Miura and Zilberstein (2021) build a unifying framework while assuming stochastic transitions, namely observer-aware Markov decision processes (OAMDPs), adopting a similar approach as Chakraborti et al., as illustrated in Figure 2. Among other things, they work also on legibility, explicability, and predictability. Yet, as we will further discuss in Section 2, the two OAMDP approaches to predictability they consider are not fully satisfying: one amounts to returning an optimal policy for the low-level MDP, and the other reasons on full trajectories, which does not seem appropriate in a stochastic environment (and turns out to be prohibitively complex).
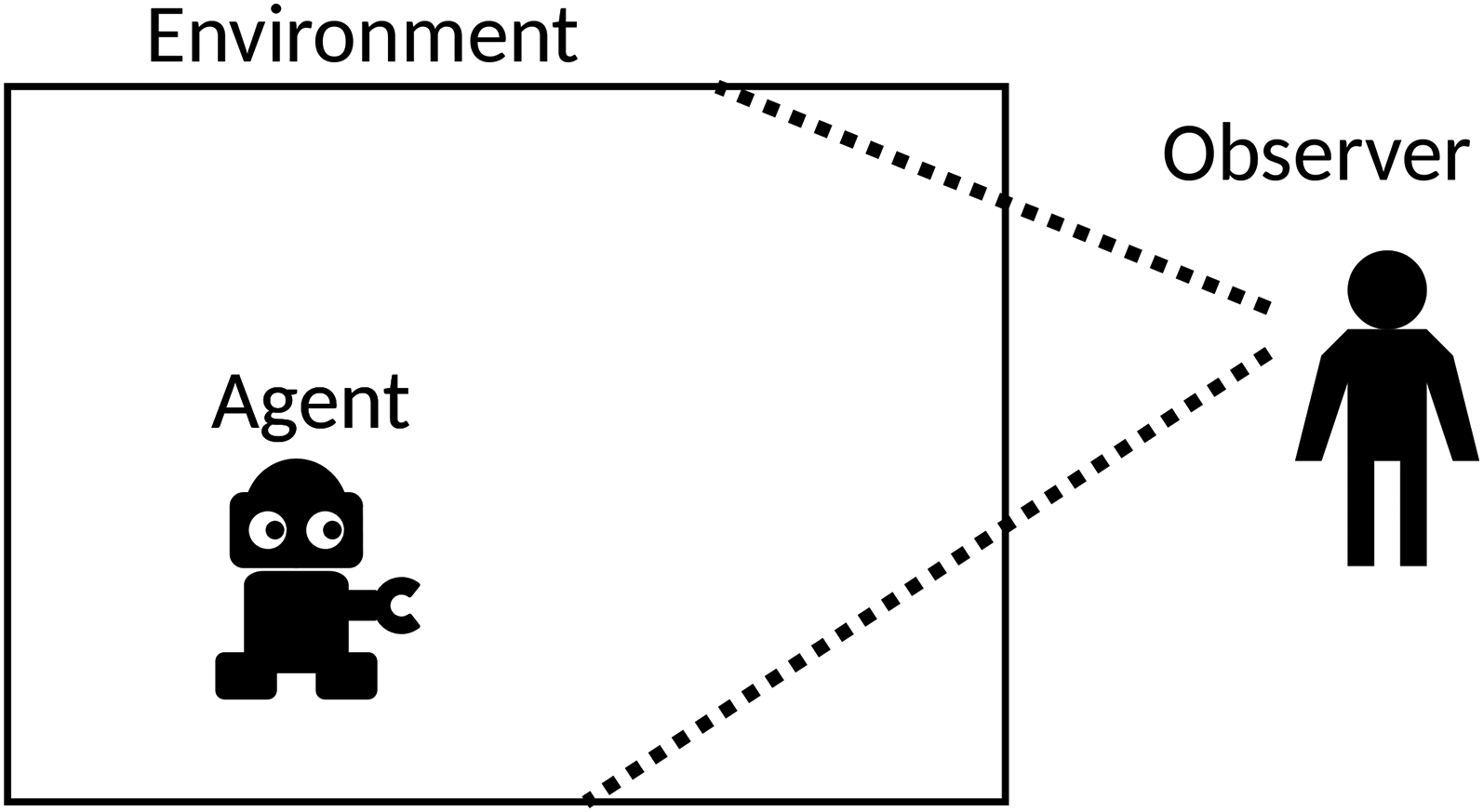
Agent in Its Environment and a Passive Observer.
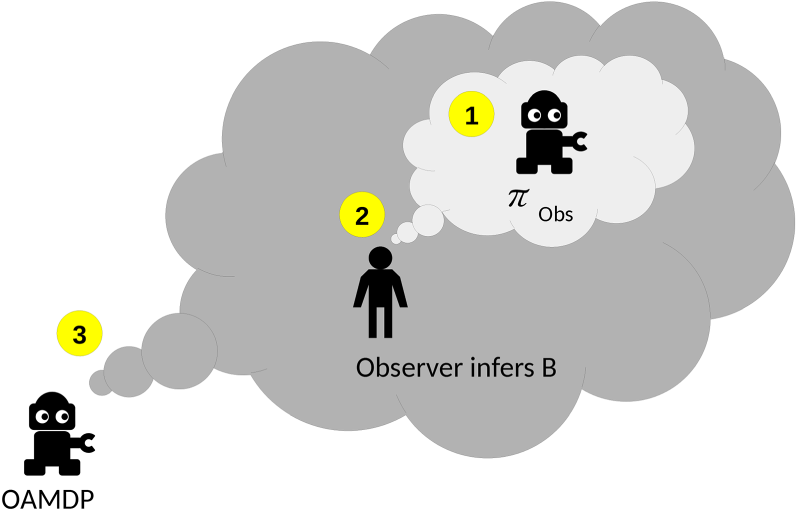
An Observer-Aware Markov Decision Process (OAMDP) Agent (3) Assumes that the Observer’s Expectation (2) Is that the Agent Behaves so as to Achieve Some Task (1).
Our objective in this paper is to propose a more satisfying approach to predictability by working not with complete trajectories, but with actions or states at each time step. This implies reasoning on dynamic variables, which requires introducing a variant of the OAMDP formalism. Moreover, we also consider not only discounted problems, but also stochastic shortest-path (i.e., goal-oriented) problems.
Section 2 provides background on MDPs and observer-aware MDPs. Our approach to action and state predictability, through dedicated reward functions, is described in Section 3, along with proof that well-defined problems are induced. Experiments are then presented in Section 4, where we generate and interpret policies on two types of grid-world problems, comparing with standard MDP solution policies, and then, in Section 5, where human observers are confronted with these policies on some of these problems.
Notations: Sets will be denoted with calligraphic capital letters, for example,
Markov Decision Processes (MDPs)
An MDP (Bellman, 1957) is specified through a tuple
Then, a (stochastic) policy
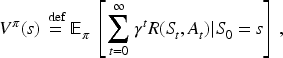
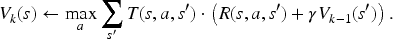
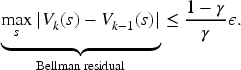
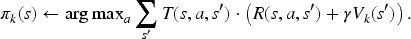
Let us call proper a policy
(A1) for any policy
In particular, the first assumption holds if, for all
Observer-Aware MDPs (OAMDPs)
As introduced by Miura and Zilberstein (2021), an OAMDP models a situation wherein an agent attempts to maximize an observer’s information regarding some target random variable, called type, under some model of the observer’s evolving belief about this type. Formally, an OAMDP is described by aneight-tuple
In most of the cases they consider, Miura and Zilberstein derive using a corresponding reward function solving the discounted MDP building a stochastic “softmax” policy—that is, the policy that the agent is supposed to follow if of type
With
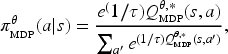
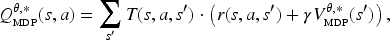
Miura and Zilberstein (2021) use the OAMDP framework to formalize various observer-aware problems from the literature, including legibility, explainability, and predictability. For predictability, which we now focus on, they mention two approaches. The first one builds on Dragan et al.’s (2013) idea to “model the predictability of a trajectory as simply proportional to the value (negative cost) of a trajectory,” which, in the OAMDP setting, translates into (1) having a single type
To wrap up, in the OAMDP framework, typically using the BST update, the agent (i) assumes that the observer models the agent, when of type
In the following, we propose an alternative approach to predictability and discuss its properties.
Contribution
As a preliminary contribution, while Miura and Zilberstein consider only discounted OAMDPs, we introduce observer-aware SSPs (OASSPs; thus, using
Predictable Observer-Aware MDPs (pOAMDPs)
Both approaches to predictability mentioned by Miura and Zilberstein are inspired by work in deterministic settings, reasoning on trajectories. Because both the softmax policy
The following sections describe, respectively, both action and state predictability: (1) how to derive
Belief Function and Properties of pOAMDPs
For action predictability,
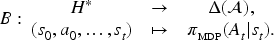
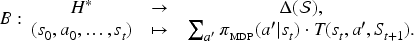
The agent’s sequential decision-making problem can then be expressed as an MDP
pOAMDP Reward Function
Reward Definition
When in state
Then, considering an SSP (thus with
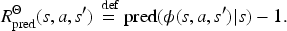
Valid SSPs?
An important question is whether this reward function induces a valid SSP, that is, whether assumptions (A1) and (A2) are satisfied.
Let us assume that (i)
(A1) Let Assume Assume
This proves that (A1) holds.
(A2) Let us point out that whether a policy is proper or not depends on the reachability of terminal states, not on the reward function. Since the observer SSP satisfies assumption (A2) and only differs from the predictable observer-aware shortest-path problem (pOASSP) in its rewards function, the induced SSP also satisfies assumption (A2).
This result does not hold for state predictability.
Let us assume that (i)
The proof that assumption (A2) holds is the same as for action predictability.
To prove that assumption (A1) may not hold, let us consider an OAMDP with:
the transition function described in Figure 3; the state-predictability reward function. Transition Function of an Ill-Defined Predictable Observer-Aware Shortest-Path Problem (pOASSP) for State Predictability, with Transition Probabilities as Edge Labels.
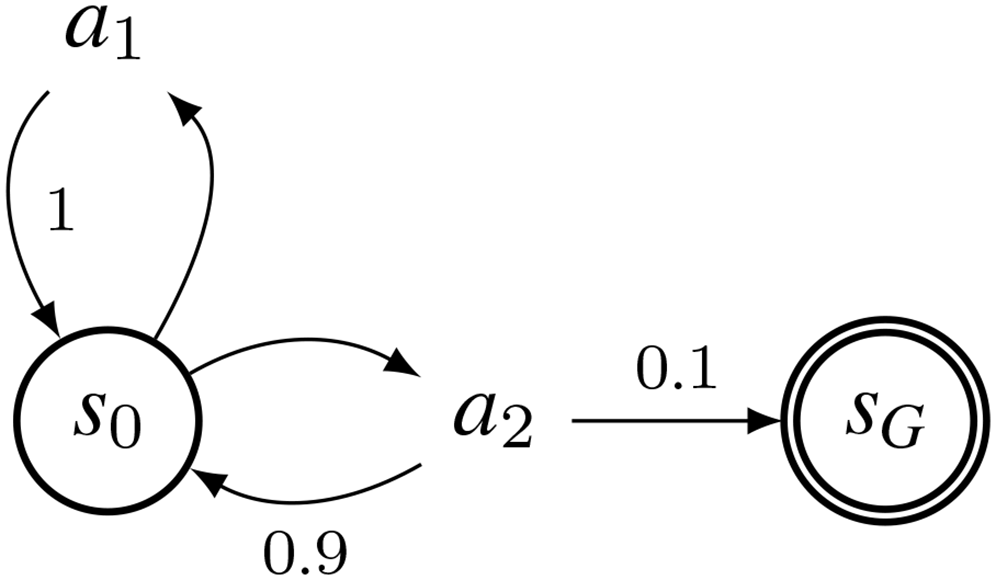
In this setting, due to the transition function, when applying
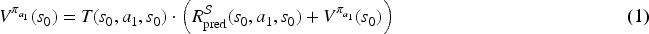


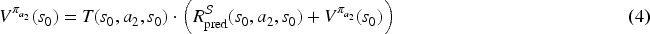
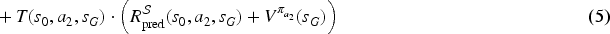



This negative result does not prevent from using if linearly combined with another reward function that necessarily induces a valid SSP, for example, in case of deterministic dynamics; indeed, if a policy
In the case of (discounted) MDPs, we will rely on the same reward definition. The interpretation of
This section introduced the pOAMDP formalism, including two reward functions—based on the idea of rewarding successful guesses—to express action- and state-predictability problems. It also showed that OAMDPs with BST updates are addressed by solving two MDPs consecutively, and demonstrated that, while action predictability induces valid SSPs, this may not be the case for state predictability.
The next two sections study this approach to action and state predictability on simple examples: (1) in silico, observing and analyzing the policies obtained through our approach, and compared with simple MDP policies; and (2) in vivo, that is, confronting actual human observers with several policies.
These first experiments aim at illustrating and better understanding the policies induced by the proposed reward function, and in particular at determining whether they can be considered as predictable. The code is available under an open license here: https://gitlab.inria.fr/po-OAMDP/predictable-OAMDP_ejai25.
Protocol
To describe the two types of pOAMDPs considered in our experiments, let us just detail the corresponding MDPs, both set in four-connected grid worlds, that the observer will take into account:
an SSP, named maze, in which a robot wants to reach a terminal goal state; and a discounted MDP (with no terminal state), named firefighter, in which a robot uses water sources to extinguish fires.
To facilitate the analysis, the dynamics of both problems is mostly deterministic.
Maze problem
A maze (cf. Figure 4) contains walls (in dark gray), normal cells (in white), slippery cells (in cyan), and terminal cells (pink disks). The starting cell is marked by a circle. More formally, in this SSP:
each state a default penalty of
This SSP trivially satisfies assumptions (A1) and (A2).

Action Predictability Results Showing, for Mazes
Firefighter Problem
Similar grids are used for the firefighter problem, but with terminal cells replaced by fires and water sources (cf. Figure 6). The robot now has a water tank, which is emptied upon reaching a (never extinguished) fire, and filled upon reaching a (never emptied) water source. More formally, in this each state a default penalty of
Optimal MDP policies consist of endlessly going back and forth between a water source and a fire.
Baseline Policies
The pOAMDP solution policy, denoted
In practice, algorithms will often be biased, having a preference order over actions. We thus also consider the policies that, in each state
pOAMDP Model
For both types of problems and each grid environment, a pOAMDP is derived using the previously proposed reward function for predictability
The figures present both stochastic MDP policies
Maze Problem
Grids Used
The mazes mainly consist of corridors and (empty) rooms.
For action predictability, we expect the pOAMDP policies to prefer corridors over rooms (which allow for more possible optimal actions). Figure 4 shows mazes
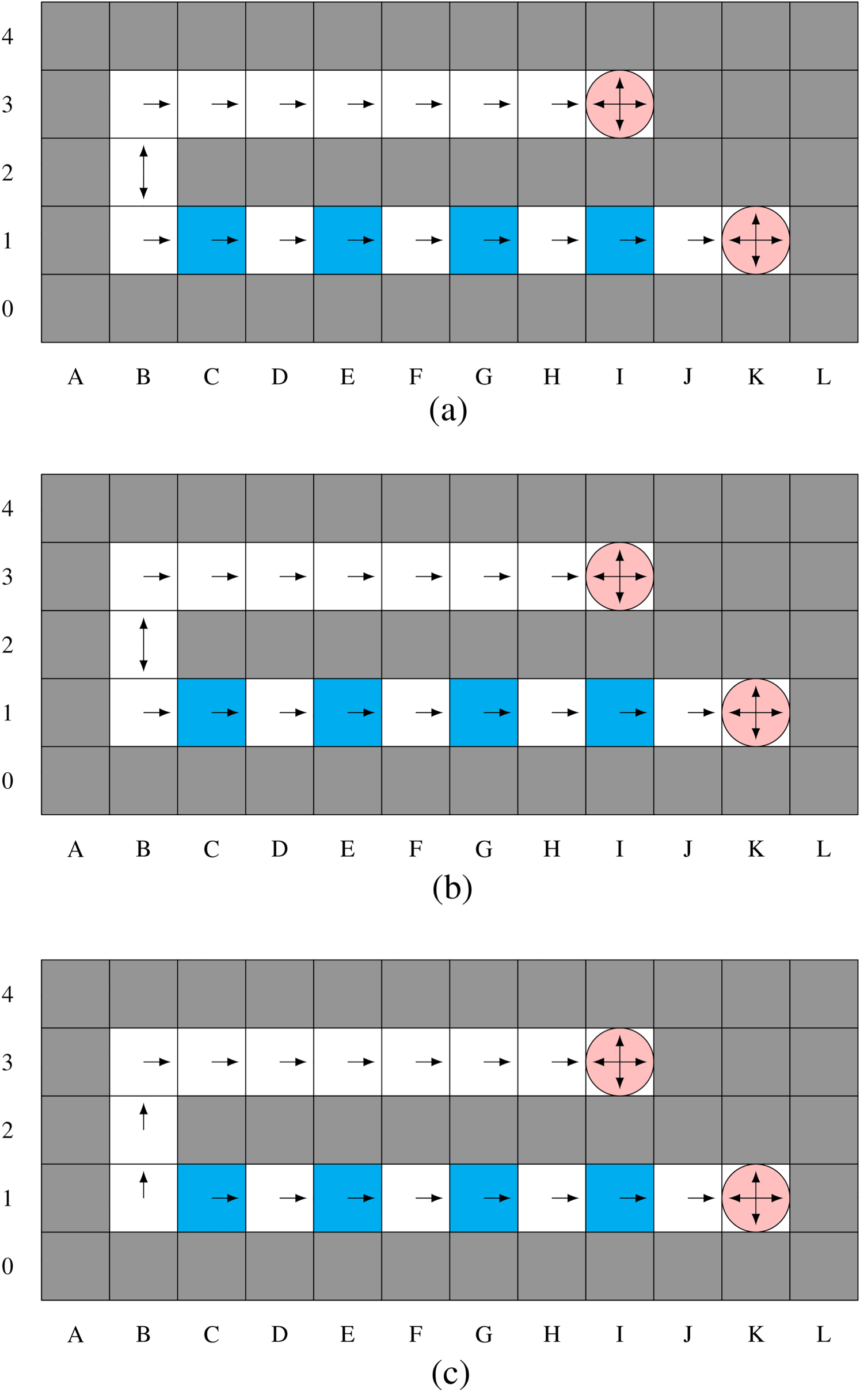
Results for Maze
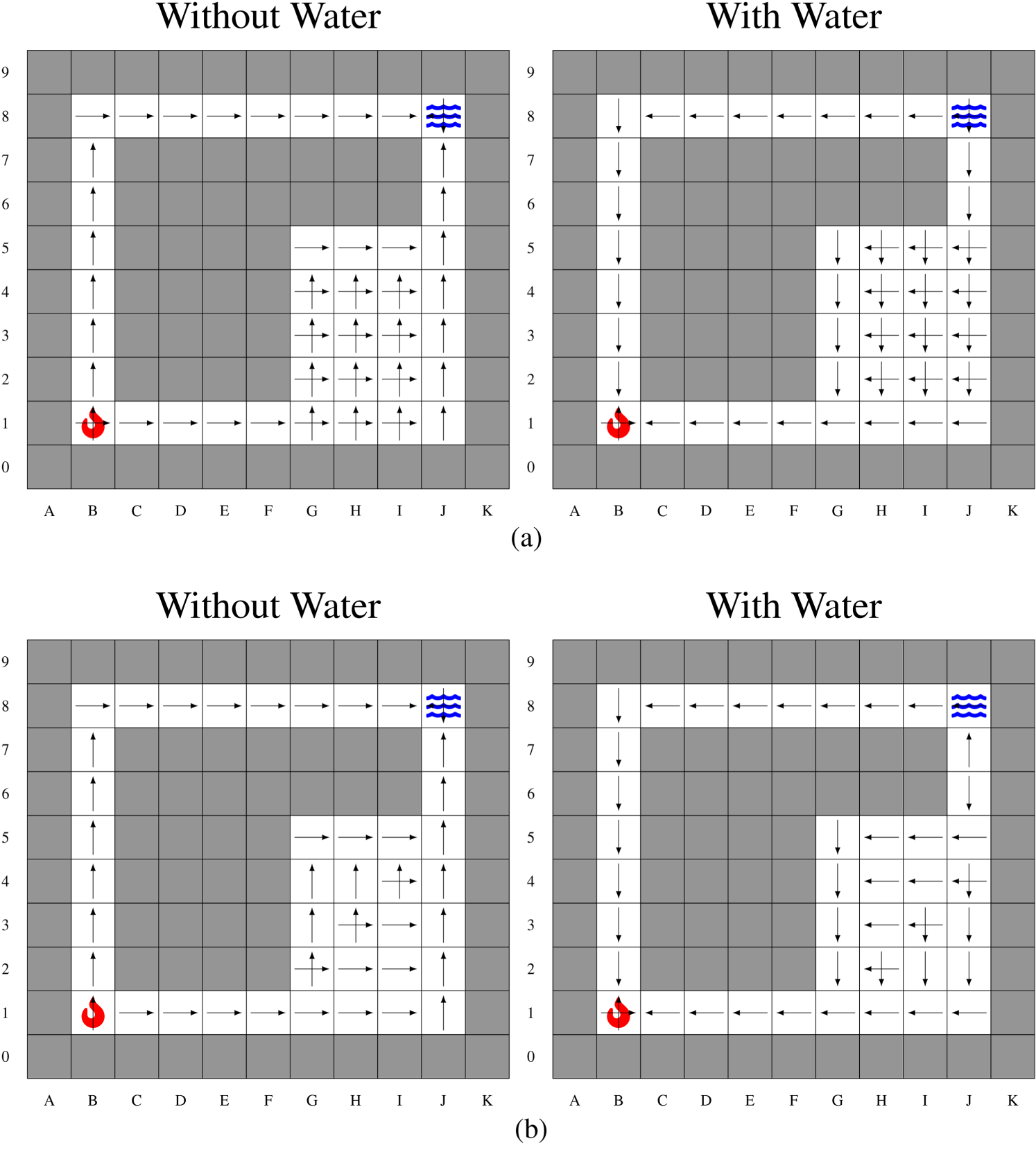
Results for Firefighter Problem F1. (a) Stochastic Policy
Each SSP is solved with
Note: In the following, we mainly focus on action predictability because, here, solution policies turn out to be identical to state predictability. This is favored in deterministic environments, where predicting the next state is often equivalent to predicting the next action.
Analysis of
and
We observe several interesting behaviors with The pOAMDP robot (/agent) will plan a longer path through a narrow corridor, where its next action will be easy to predict, rather than a shorter path going through one or multiple rooms as illustrated on In rooms, In In In Figure 5, cell
Quantitative results in the second column of Table 1 (#Err.p) are obtained by computing the value of each policy wrt
Results for Maze Problems
In most of these problems,
Grids Used
The following grids were used to test the reward functions:
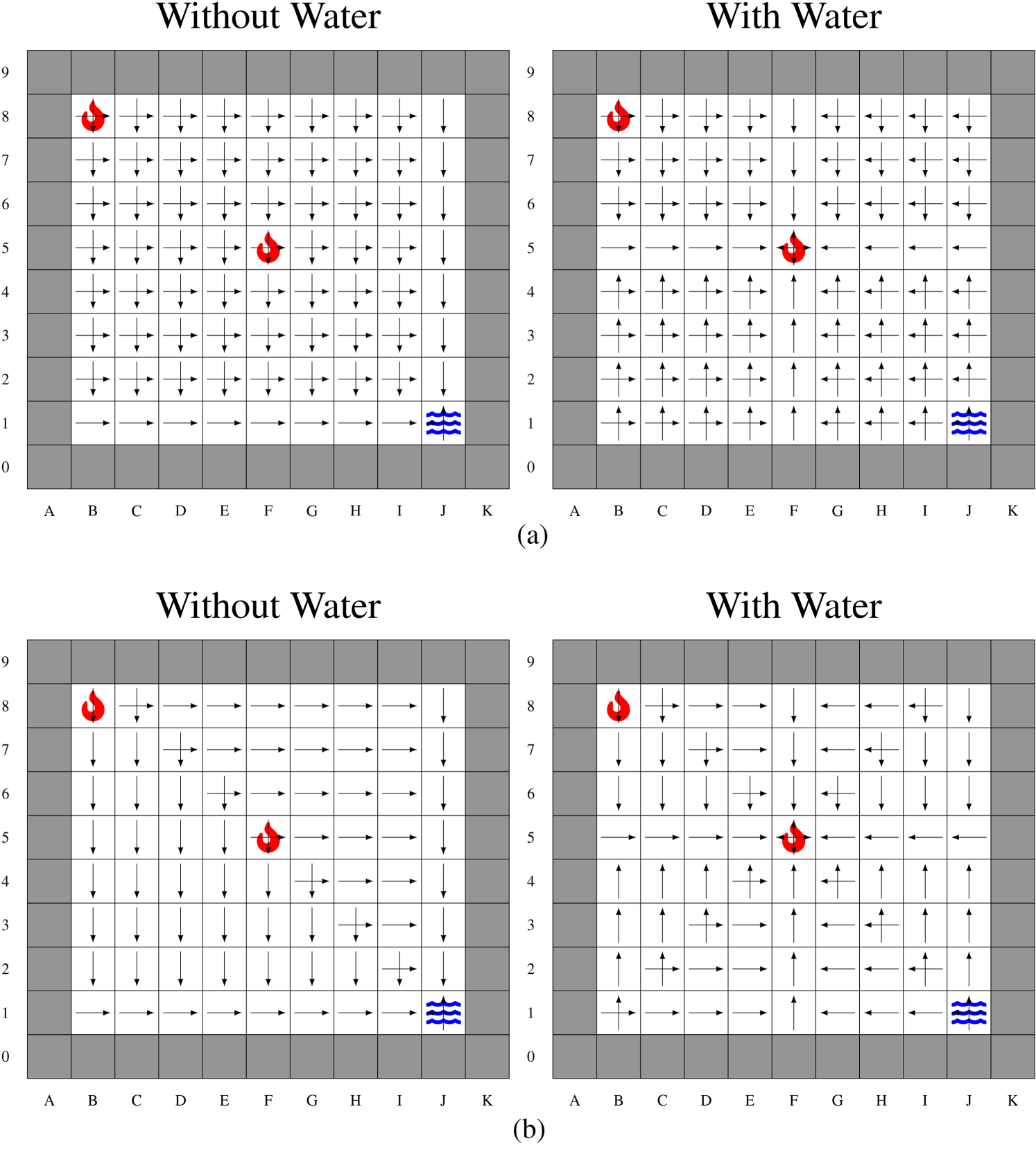
Results for Firefighter Problem F2. (a) Stochastic Policy
Results for Firefighter Problem F3. (a) Stochastic Policy
The underlying MDPs are not SSPs anymore, so that we use
Analysis of
A behavior similar to the maze problem can be observed. In Figure 6,
The objective of pOAMDP solution policies is to make it easier for an observer to predict actions or states. Of particular interest is the case of human observers. An experiment was thus conducted to confront actual human participants with stochastic and biased MDP policies ( assessing how predictable each type of policy was for humans, by measuring the number of prediction errors; assessing whether predictions were easy to make, by measuring their response times; and knowing how the various robot behaviors were perceived by humans.
Protocol
Participants
Experiments have been conducted with 20 human participants (four women; aged
Task
Participants were seated in front of a computer displaying a maze containing a robot and the robot’s goal. For each position of the robot, at each time step, the participant had to indicate the next action by pressing one of the four arrow keys. The robot then moved to the next position according to the policy, independently of the participant’s response, and the participant had to indicate the next action, and so on along the trajectory to the goal.
Experimental Process
Participants began with a learning phase lasting about 1 min, consisting of a maze with a random policy. Then came the test phase, consisting of three sequences of seven mazes each, each sequence associated with a policy. Participants were told that the robot’s behavior was going to change at each sequence. Each robot was identified by a color. The ordering of policies was randomized, as well as the ordering of mazes within a sequence, with the exception that
At the end of each sequence (to avoid any forgetting of what he/she just experienced), the participant completed a 3-item questionnaire. For each item, the participant answered on a 7-point Likert scale from “strongly disagree” to “strongly agree.” The three items related to the policy they had just seen and were as follows: (1) this robot was easy to anticipate (Anticipation); (2) its decisions seemed generally logical (Logic); and (3) some of its decisions surprised me (Surprise). Each participant completed this questionnaire three times, once per policy. Once the test phase was over, they completed a questionnaire including: sociodemographic questions; a request to rank the three policies from easiest to most difficult, and another from most sensible to most unexpected.
On average, the experiment lasted 30 min.
Data Analysis
The data recorded during each maze were: the number of errors, that is, the number of times the next move predicted by the participant did not correspond to the move subsequently chosen by the robot; the response time (in ms), that is, from the instant when the robot finished a move to the instant when the participant indicated the position he thought would be the next. Each maze began with a two-square corridor to control the start of each trajectory, and the first square (the first response given by the participants) of each maze was removed from the analyses. One participant was removed from the analyses in Sections 5.2.1 and 5.2.2, as his response times were more than 3 standard deviations above the overall mean. Data processing on errors and response times was therefore carried out on 19 participants.
For the questionnaire, each of the three items was analyzed (Anticipation, Logic, and Surprise), see Section 5.2.3.
To determine whether there were any significant differences between the three policies, standard errors were calculated for the quantitative variables, as well as for the questionnaire.
Results
Numbers of Errors and Response Times
The main quantitative results are presented in Table 1, page 25, as well as in Figure 9 for errors and in Figure 10 for response times, for each policy–maze combination, plus a fake maze
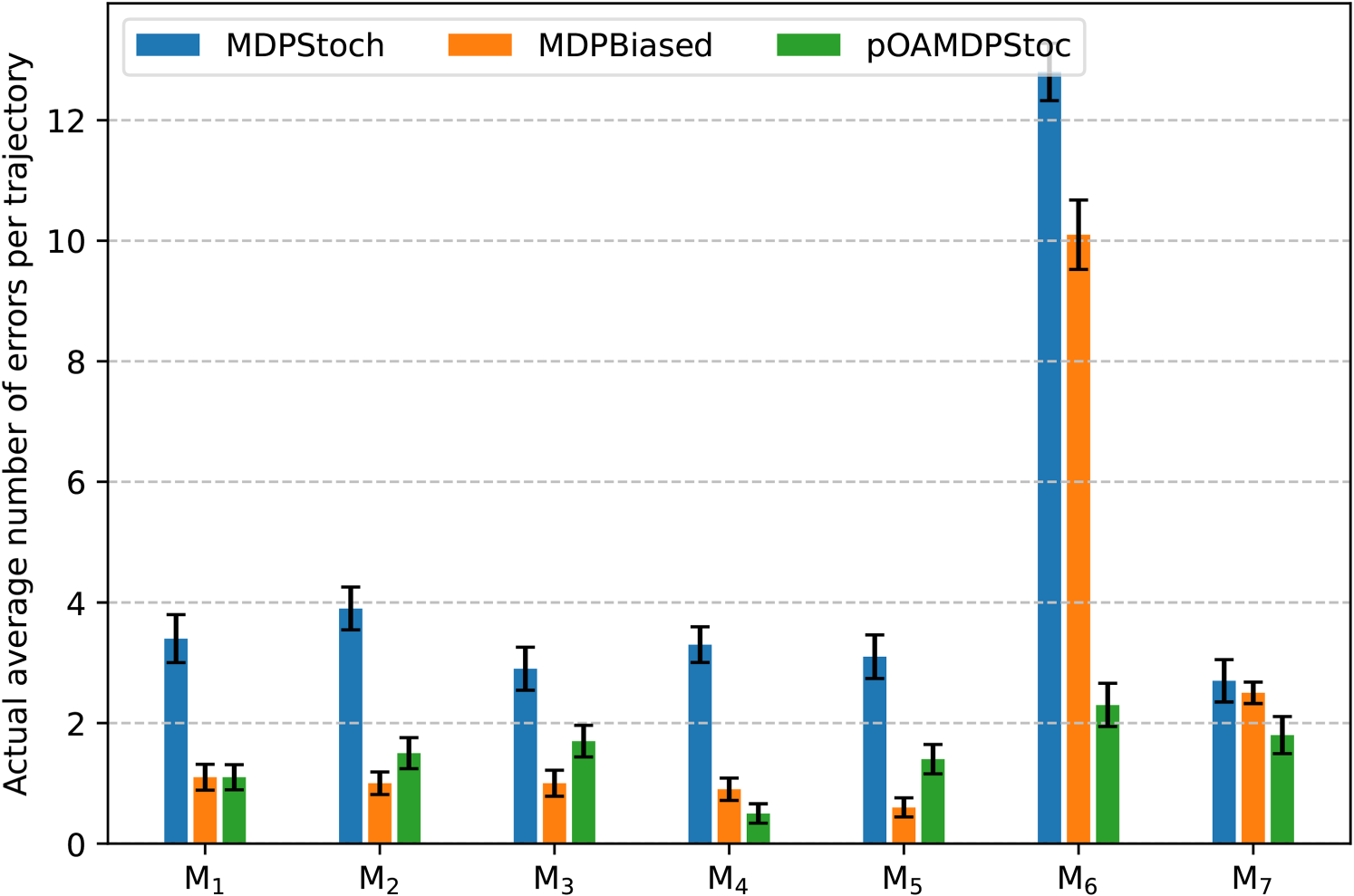
Graph Representing the Average Number of Errors Made by the Participants for Each Maze.
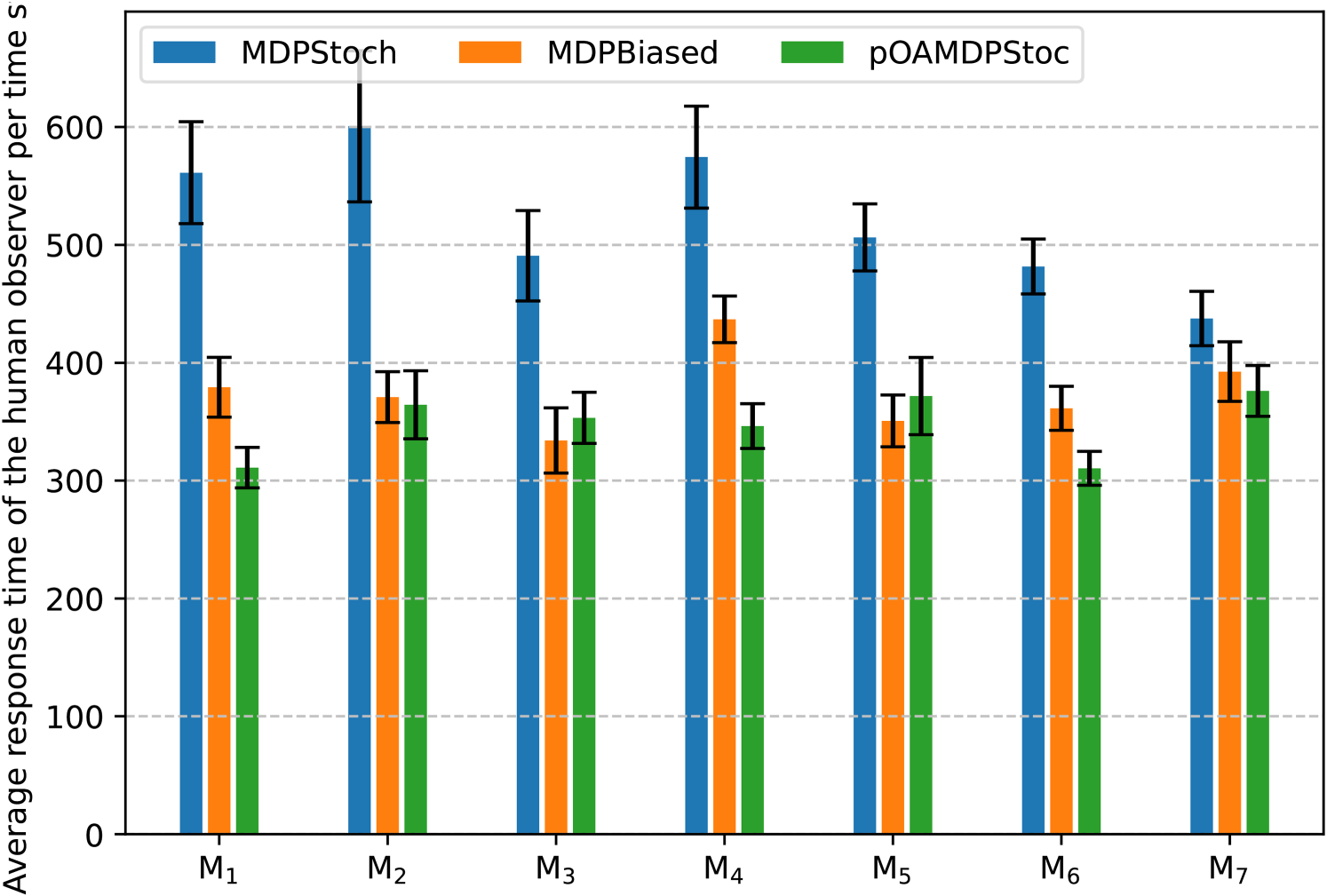
Graph Representing the Average Response Time of the Participants for Each Maze.

[Error Rate] Heatmaps Showing, for Each Cell, (1) [in Background] the Probability of Visit During a Trajectory from Dark Blue (
The first column provides the (constant) lengths of trajectories in each case as an indicator of the problem size. As anticipated,
The second column then shows the expected number of errors per trajectory according to our model (
The fourth column indicates the average response time (in ms) per cell, which appears to increase with the probability of making errors. These average response times are lower for
Heatmaps allow us to visualize where in the maze the participants made mistakes or were faster/slower to make a decision.
Error Rate Heatmaps
Error rate heatmaps for each maze in each policy are shown Figure 11. They are defined as follows:
the blue color represents the average number of visits computed as the red color represents the average error rate computed as
Note that, in cells with a low number of visits (light blue background color), the error rate estimate is poor compared to often-visited cells (dark blue background color). In unvisited cells (white background color), there is no error rate to estimate, hence the lack of an inner square.
The results given by the error rate heatmaps show that:
as expected, participants made many mistakes in open areas with the stochastic MDP policy; in the pOAMDP policy, mistakes were mostly made in the beginning when participants needed to make a choice, for example, in maze in some cases, as in maze for the pOAMDP policy, participants tend to make mistakes whenever the robot changes direction. It seems that, for a human observer, changing direction is more costly than going forward; except for maze
Response-Time Heatmaps
Response-time heatmaps for each maze in each policy are shown in Figure 12. The response-time heatmap is defined as follows:
the blue color represents the average number of visits computed as the green color represents the average response time computed as
To make the heatmaps more readable, we cap the values to 1,000 ms, any value above 1,000 ms being indicated by a black cell. The goal of these heatmaps was to see where the participants’ decision-making was slow, if there was any kind of anticipation, and the overall response time depending on the policies.

[Response-Time] Heatmaps Showing, for Each Cell, (1) [in Background] the Probability of Visit During a Trajectory From Dark Blue (
The response-time heatmaps show that:
in open areas, the participants take more time to make a decision; consistent with the error heat map, for the pOAMDP policy, participants take more time to make a decision at the beginning, where they need to make a choice; in the pOAMDP policy, we can notice that, after unexpected actions, the participants take more time for the next prediction. For example, in the response time in corridors is less important, which is due to the participants’ anticipation.
Heatmaps of “Reflex” Responses
Heatmaps of “reflex” responses for each maze in each policy are shown in Figure 13. In case of a response time below 150 ms, the decision is more of a reflex, and the participant will not be able to correct his choice if needed (Henry & Rogers, 1960; Marin & Danion, 2019). These heatmaps show which portion of participants answer in <150 ms in a state. They are more precisely defined as follows:
the blue color represents the average number of visits computed as the black color represents the rate of response times below 150 ms, computed as
To make the heatmaps more readable, we cap the values to a 50% rate of response times below 150 ms. The goal of this heatmap was to see where humans tend to predict the robot’s action using anticipation or reflex responses. For example, when asked to predict the robot’s move in a corridor at time

[“Reflex” Responses] Heatmaps Showing, for Each Cell, (1) [in Background] the Probability of Visit During a Trajectory From Dark Blue (
This is also the reason why we use the 50% cap.
These response time heatmaps show that:
in rooms, most response times are above 150 ms, except along walls, either because following the wall is optimal, or because the robot is obviously going in a straight line. Note that the stochastic MDP policy has more chances to go through the center of rooms than to follow walls; in the corridors, many participants answer in <150 ms, as can be seen in
After each sequence of mazes corresponding to a policy, participants were asked to rate this policy on a scale of 1 to 7 according to three dimensions: Anticipation, Logic, and Surprise (see Section 5.1). The average scores obtained, as well as standard errors, are shown in Figure 14. Overlapping error bars (based on standard errors) indicate no differences, while nonoverlapping error bars indicate significant differences. Concerning Anticipation, the results seem to indicate that
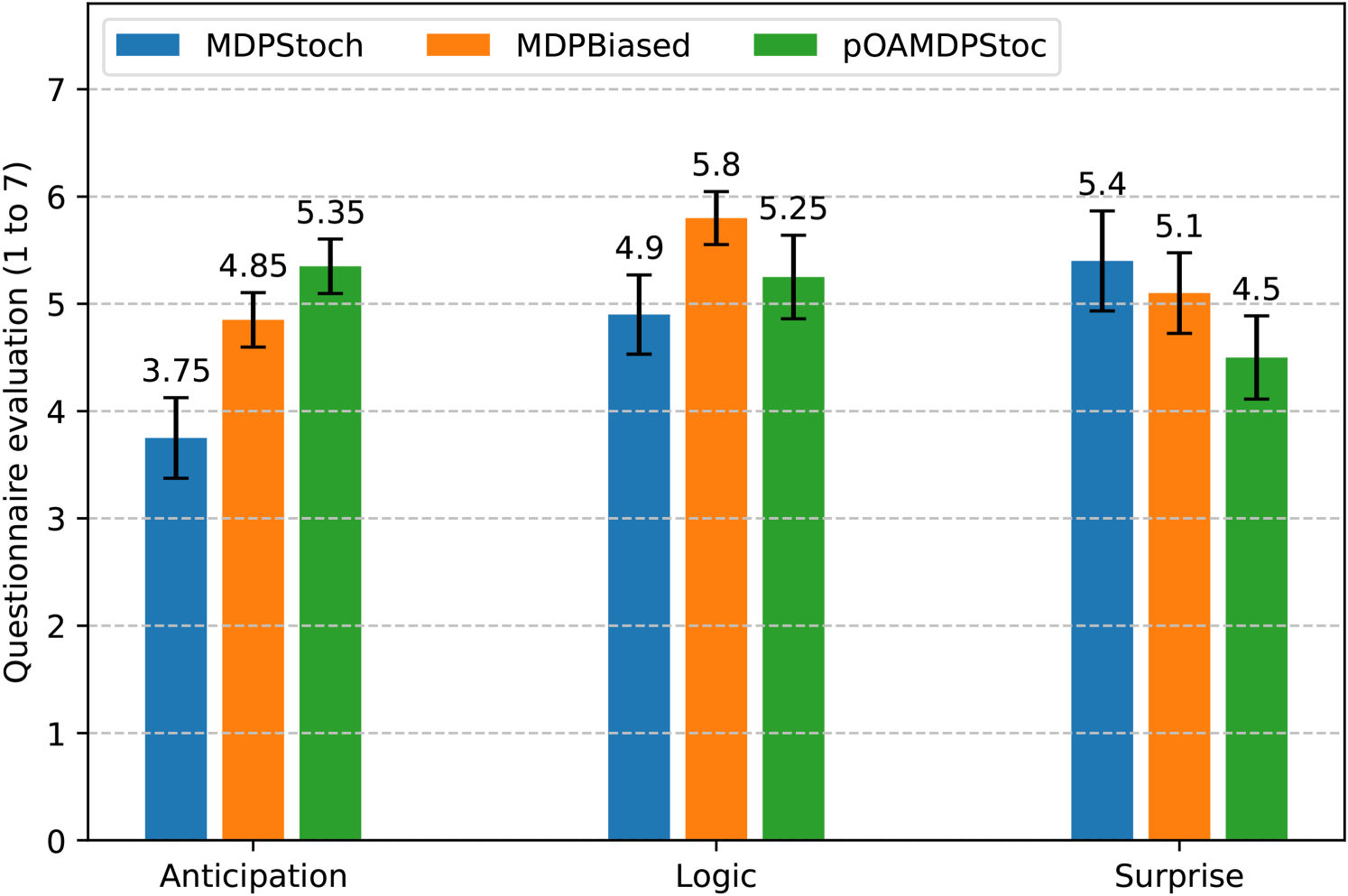
Graph Showing Questionnaire Results (Mean Score and Standard Error) on a 7-Point Likert Scale for Each of the Three Policies and for the Three Dimensions Assessed (Anticipation, Logic, and Surprise).
The results of the ranking of the three policies given at the end by the participants in terms of Anticipation and Logic are given by Table 2 (complete orderings). Note that one participant only returned a partial ordering in terms of Anticipation, hence some columns summing to 19 instead of 20. The two rankings show very similar patterns. For both Anticipation and Logic, as presented in Table 2 (score rankings), (1)
Human Preferences Over Policies, Where S
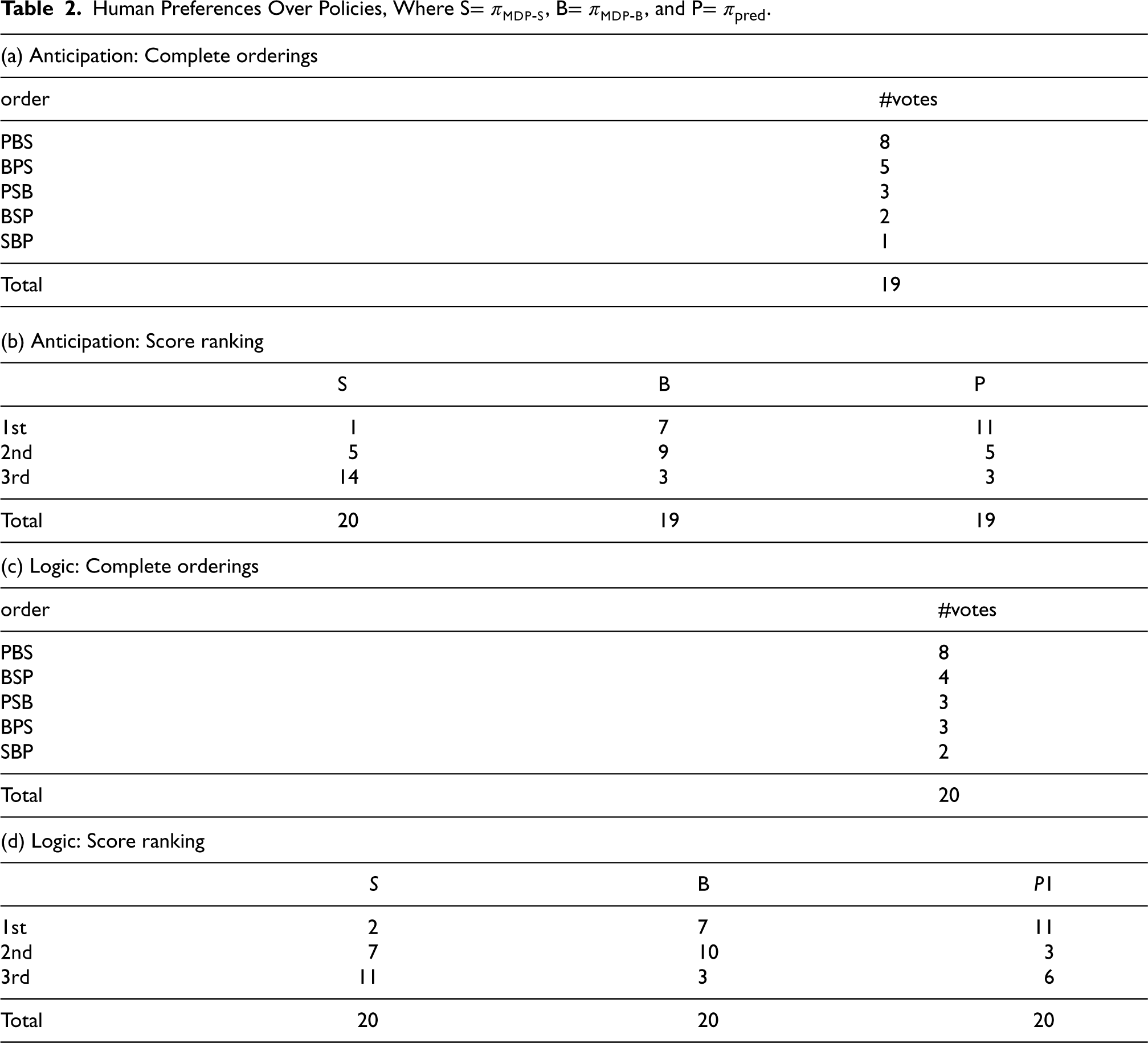
Participants often declare that the initial choice of
There are a few differences between the biased MDP policy and the pOAMDP policy in terms of errors, response times, and human perception, in comparison with the stochastic MDP policy, whose behavior is much harder to predict. The pOAMDP policies’ response times are better on some mazes (
The pOAMDP policy is more predictable in complex mazes such as
Conclusion
We have introduced a new formalism, predictable observer-aware MDPs (pOAMDPs), that allows deriving policies whose next actions or next states are more predictable and proposed accounting not only for discounted problems, but also for stochastic shortest-path problems (which requires ensuring that valid solution policies can be found). With the objective of minimizing the number of prediction errors along a trajectory in an undiscounted setting, and assuming rational observer predictions, we derived two reward functions, respectively, for action and state predictability, and demonstrated that they both induce valid stochastic shortest-path problems, that is, the solution predictable policies reach terminal states with probability 1. A notable property is that the solving complexity of pOAMDPs is comparable to MDPs, thus much less than OAMDPs. In some cases, the resulting policies select counter-intuitive actions early on to increase predictability later on. The interpretation of generated policies shows significant reductions in the expected number of errors when using pOAMDP solutions on some scenarios (up to fourfold), and also benefits from using biased MDP policies, which often follow walls. The results of the experiment with human participants are consistent with these observations.
As illustrated by some benchmark problems, the proposed performance criterion can lead to less efficient policies in terms of the original performance criterion (here used only for the observer predictions). This can be addressed in various ways as, for instance, by linearly combining both reward functions, or, using constrained MDPs (Altman, 1999; Trevizan et al., 2017b), by minimizing the prediction error while constraining the value of the original criterion.
On another note, considering goal-oriented problems as we did would of course also be relevant for Miura and Zilberstein’s OAMDPs, first to determine which of their scenarios result in valid SSPs. Then, to handle SSPs with traps, that is, subsets of (nonterminal) states that cannot be escaped, an interesting direction would be to extend our work to generalized SSPs (Kolobov et al., 2011; Trevizan et al., 2017a).
Finally, we had to depart from Miura and Zilberstein’s original formalism and their static types (Miura & Zilberstein, 2021), but an important perspective is to generalize both formalisms, making for a more unified theory of observer-aware sequential decision-making. We believe that a key point to achieve this is to restrict the observer’s observability of states and actions so that the target variable, whether static or dynamic, can be a state variable, even for action predictability. What is more, this partial observability would also allow covering more real-world scenarios. In this setting, we envision looking at the continuity properties of the optimal value function to possibly propose bounding approximators and derive point-based solvers (as was done for partially observable MDPs and related models Dibangoye et al., 2016; Horák & Bošanský, 2019; Horák et al., 2017; Kurniawati et al., 2008; Pineau et al., 2006; Shani et al., 2013; Smith & Simmons, 2005; Spaan & Vlassis, 2005).
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.