
Abstract
Camouflaged object detection (COD) is an emerging research direction in computer vision in recent years, aiming to segment objects that are visually integrated with the background, which is a valuable task and has attracted increasing interest from researchers. Since camouflaged objects are integrated with their surroundings, their boundaries are also very blurred, and it becomes an important issue in COD to segment the edges of the objects accurately and completely. To address the above issues, in this article, we propose a novel multi-level edge-enhanced fusion for camouflaged object detection network (ME
Introduction
There are many camouflaged objects in nature, which refer to objects that are highly similar to the background or visually blend in with the environment. It is an important hiding mechanism to protect themselves from predator detection. Camouflaged object detection (COD), which aims to detect camouflaged objects in the visual scene and segment them from the background, has attracted the interest of many researchers in recent years. It promotes many valuable applications in different fields with broad prospects, such as applications in computer vision (search and rescue efforts or rare species discovery), medicine (polyp segmentation Fan et al., 2020a, lung infection segmentation Fan et al., 2020b, retinal image segmentation), agriculture (disaster detection Amit et al., 2016, locust detection Chudzik et al., 2020; Yi et al., 2019), content creation (recreational art Chu et al., 2010) and so on. However, COD remains a very challenging task due to the high similarity between the camouflaged objects and the environment.
In order to address these challenges, deep learning has shown strong potential in this area in recent years. Fan et al. (2020) collected the first large-scale dataset COD10K for COD and proposed SINet to simulate the hunting process of hunters, using search and recognition modules to locate and recognize camouflaged objects, which makes it possible to use deep learning algorithms to learn segmentation of camouflaged objects from data. Mei et al. (2021) proposed a distraction mining strategy and used it to construct a PFNet (positioning and focus metwork), which simulates predatory processes in nature. Lv et al. (2021) proposed a model for simultaneously locating, segmenting, and sorting camouflaged objects, in which the sorting module can sort the ability of COD.
Although many of the approaches now proposed have made significant progress in this task, there are still many questions that need to be explored and addressed. Due to the missing edge or the high integration of the edge of the camouflaged objects with the environment, it is often difficult for the existing methods to segment the camouflaged object completely and cannot overcome the edge blurring problem well.
To this end, we propose a novel multi-level edge-enhanced fusion for camouflaged object detection network (ME For COD, we propose a multi-level edge-enhanced fusion network (ME We design a RTEM, which uses multi-scale receptive field expansion and residual feature fusion to obtain better feature representation. We design an EEM and a BGFM, EEM can capture the edge semantics through the local channel attention mechanism, BGFM can promote the fusion of different levels of features with edge features to optimize the prediction. Extensive experiments on three challenging benchmark datasets have shown that ME
Related Work
Early work (Bhajantri & Nagabhushan, 2006; Ge et al., 2018; Pan et al., 2011) mainly relied on handmade texture, convexity, color boundaries, and other underlying features to distinguish foreground and background, which was subject to many limitations.
In recent years, with the booming development of deep learning, researchers have proposed many effective COD methods and achieved good results. Fan et al. (2020) proposed SINet (search identification network), which mimics the hunter’s hunting process by using a search module with an identification module to locate and identify camouflaged targets, and improved SINet in subsequent work to propose SINetV2 (Fan et al., 2021), which became an important baseline model in COD. Fan et al. (2020a) proposed PraNet (parallel reverse attention network), which first predicts rough regions and then refines boundaries. Yan et al. (2021) observed that flipped images can help detect disguised targets, and proposed MirrorNet, which takes the original image and flipped image as input data. Li et al. (2021) proposed an adversarial network combining SOD (salient object detection) and COD to enhance SOD and COD using contradictory information. Yang et al. (2021) proposed UGTR (uncertainty-guided transformer reasoning), which first learns the conditional distribution of backbone outputs to obtain initial estimates and associated uncertainties, and then reason about these uncertainty regions through an attention mechanism to produce final predictions. Sun et al. (2021) proposed C
COD Methods Based on Edge-Focused
In the COD task, the segmentation of the boundary is critical, because the camouflaged objects are visually embedded in the background, which lead to the unclear boundary between the camouflaged objects and the background, and the edge semantic provides useful constraints to guide the feature extraction during detection. Therefore, Zhai et al. (2021) proposed the mutual graph learning (MGL) model , it decouples an image into two task-specific feature maps—one for roughly locating the target and the other for accurately capturing its boundary details—and fully exploits the mutual benefits by recurrently reasoning their high-order relations through graphs. Ji et al. (2022) proposed the edge-based reversible re-calibration network (ERRNet) and designed two modules, selective edge aggregation (SEA) and reversible recalibration unit (RRU), to simulate visual perception behavior, achieve effective edge priors and cross comparison between potential camouflage areas and backdrops, and achieve advanced results in detecting frame rates. Zhu et al. (2022) proposed BSANet (boundary-guided separated attention network) utilizes two stream-separated attention modules to highlight the separation between the background and foreground of an image, this separation is also known as the boundary, and the two streams are followed by a boundary-guided module (BGM) which combines them to enhance the understanding of the boundary and further improve the COD accuracy. Zhou et al. (2022) proposed FAPNet (feature aggregation and propagation network) for COD tasks and designed a BGM to explicitly model boundary features. This module can provide boundary features to improve COD performance. In order to capture the scale changes of disguised objects, they also designed a multi-scale feature aggregation module (MFAM) to characterize the multi-scale information of each layer and obtain aggregated feature representations. He et al. (2023a) designed the ordinary differential equation (ODE)-inspired edge reconstruction (OER) module to reconstruct accurate and complete edge prediction maps using a highorder ODE solver, specifically, the second-order RungeKutta. Incorporating this auxiliary task with the COD task can facilitate the generation of precise segmentation results with accurate object boundaries. He et al. (2023b) proposed an edge-guided separated calibration (ESC) module. ESC leverages edge features to adaptively guide segmentation and reinforce the feature-level edge information to achieve the sharp edge for segmentation results.
In contrast to the above work, we propose a new scheme to achieve more accurate camouflage object location and edge segmentation. The obvious difference and advantage of this scheme is that the features we introduce at the decoder stage are finely extracted and rich prior features, and we experimentally show that this leads to better results.
Method
Overall Architecture
The overall architecture of our proposed ME
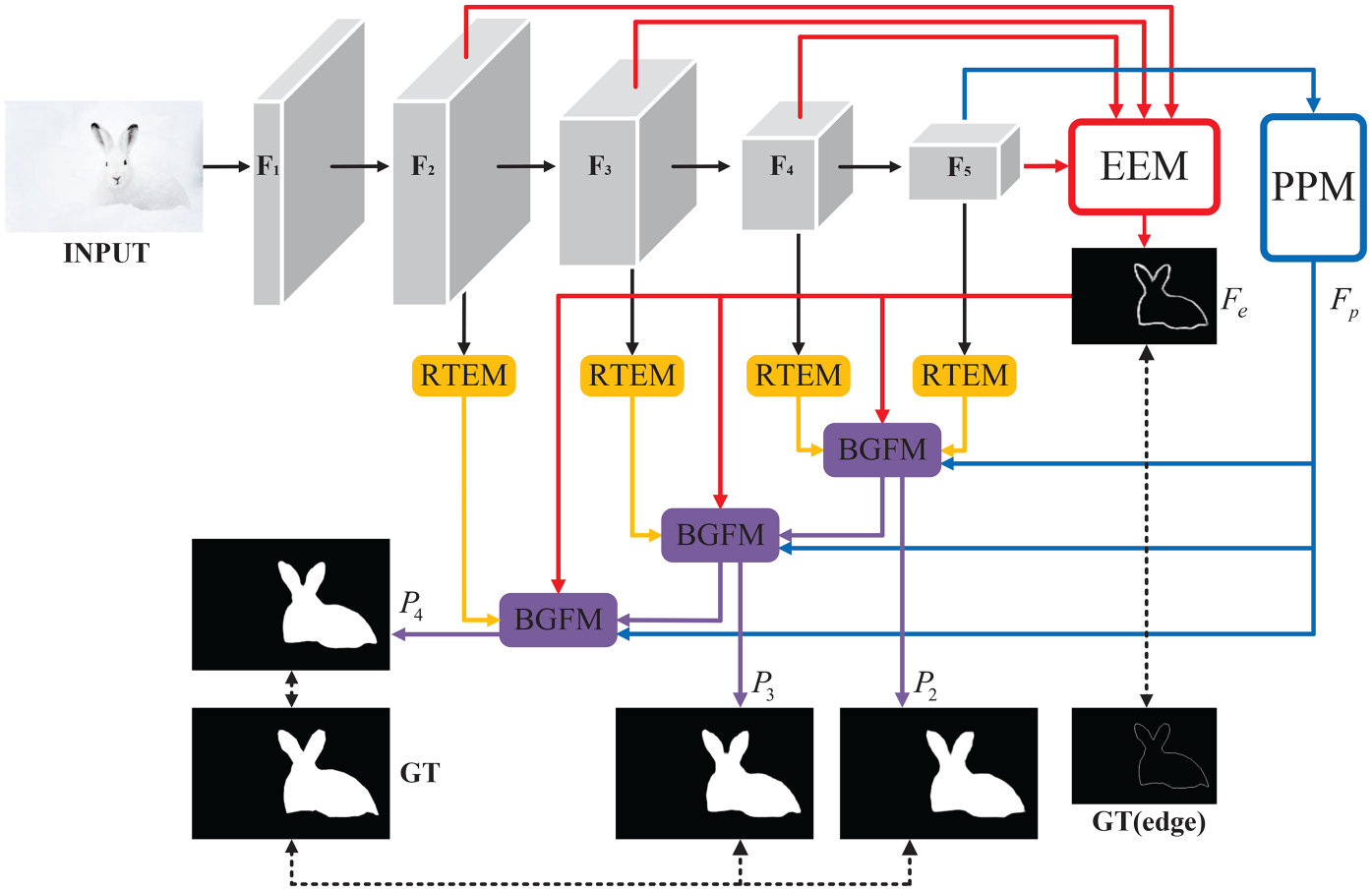
Overall network structure of the proposed model.
Inspired by the human visual system, Liu et al. (2018) designed the receptive field block (RFB) to enhance feature discriminability and robustness. Fan et al. (2021) added a branch with larger expansion rate to expand the receptive field in RFB and further designed a TEM with two asymmetric convolution layers instead of the standard convolution, achieving better results. As the backbone network uses a large number of convolutional operations, it is unable to extract features containing rich context information, which is not conducive to the segmentation of camouflaged objects. Inspired by Res2Net module (Gao et al., 2019), we design a RTEM based on TEM to refine the features of the backbone network, so as to provide more effective prior information in the subsequent fusion. Specifically, as shown in Figure 2, the RTEM contain four sub-branches

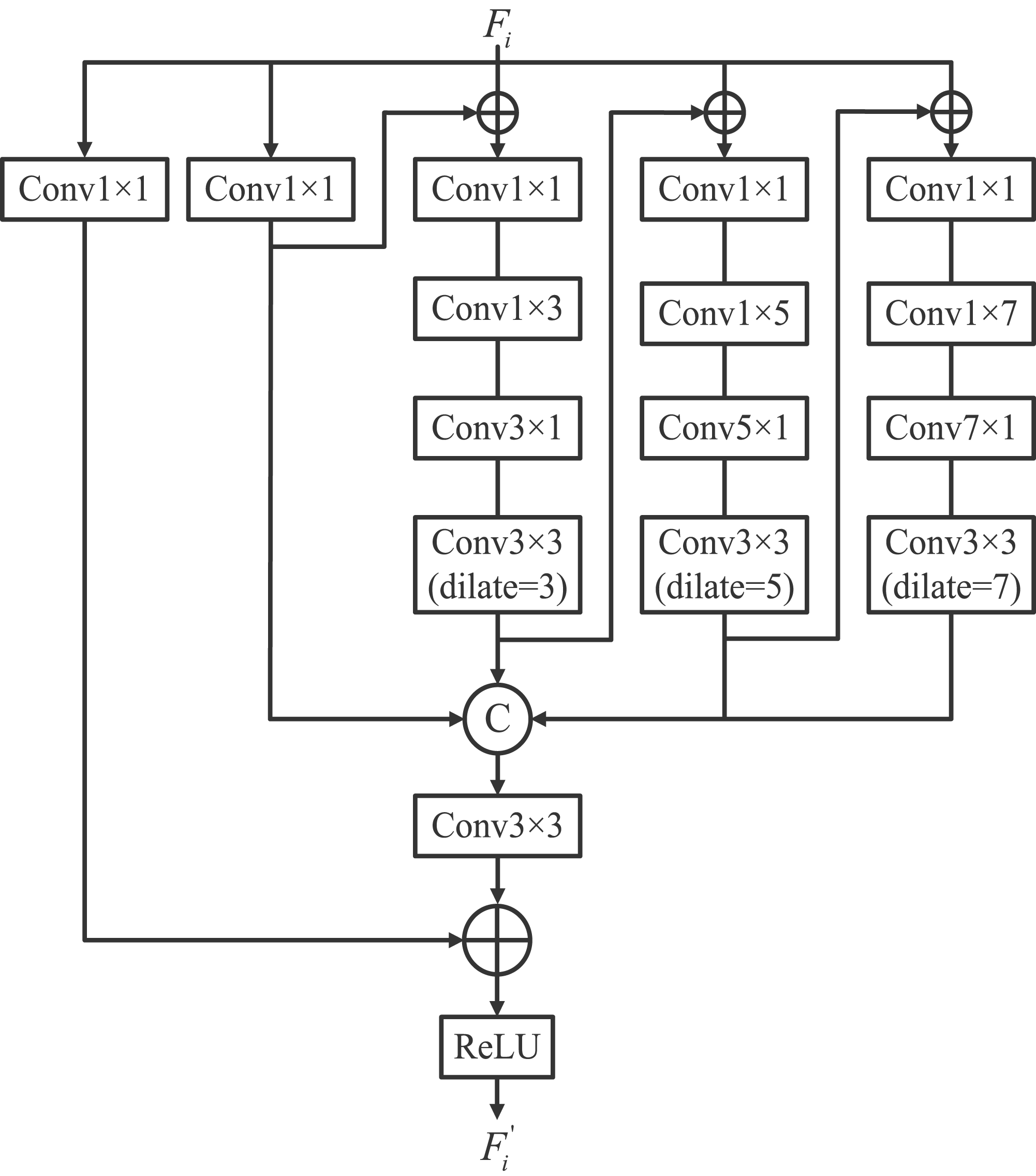
The detailed architecture of the proposed residual texture enhanced module (RTEM).
It has been demonstrated in several previous works (Ding et al., 2019; Ji et al., 2022; Zhai et al., 2021; Zhou et al., 2022) that edge semantic contributes to COD and provides useful constraints in the process of detection. In COD missions, as the edges of camouflaged objects are embedded in the surrounding background, locating their boundaries becomes a critical issue. Usually, information such as edges and contours of objects are preserved in low-level features, but there is also a lot of extraneous noise in low-level features, while in high-level features, after operations such as deep convolution of the backbone network, the location information of objects is more prominent and the boundaries become blurred. Therefore, in order to better explore the semantic information of edges, we combine low-level features with high-level features and design the EEM Figures 3 to 5. Specifically, we reduce the features
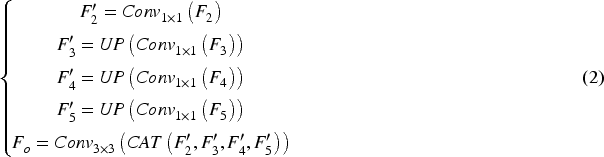
However, different feature channels often contain different semantic information. We are inspired by Wang et al. (2020) to introduce a simple local channel attention mechanism to explore critical feature channels. So, we aggregate the features by a global average pooling (GAP), then we reshape the features and use a 1D convolution to obtain the effective local channels. Finally, the channel attention is obtained by the Sigmoid function. We multiply the attention weights with the integrated features and output the edge features
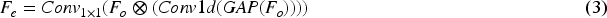
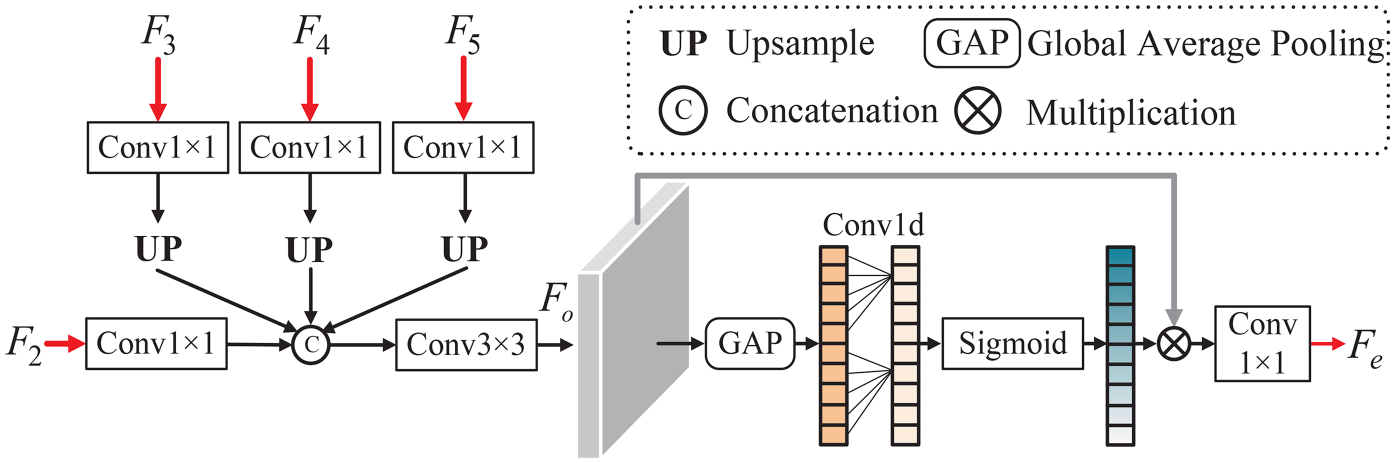
The detailed architecture of the proposed edge extraction module (EEM), which is designed to extract edge features.

Visualization of edge feature maps extracted by edge extraction module (EEM).
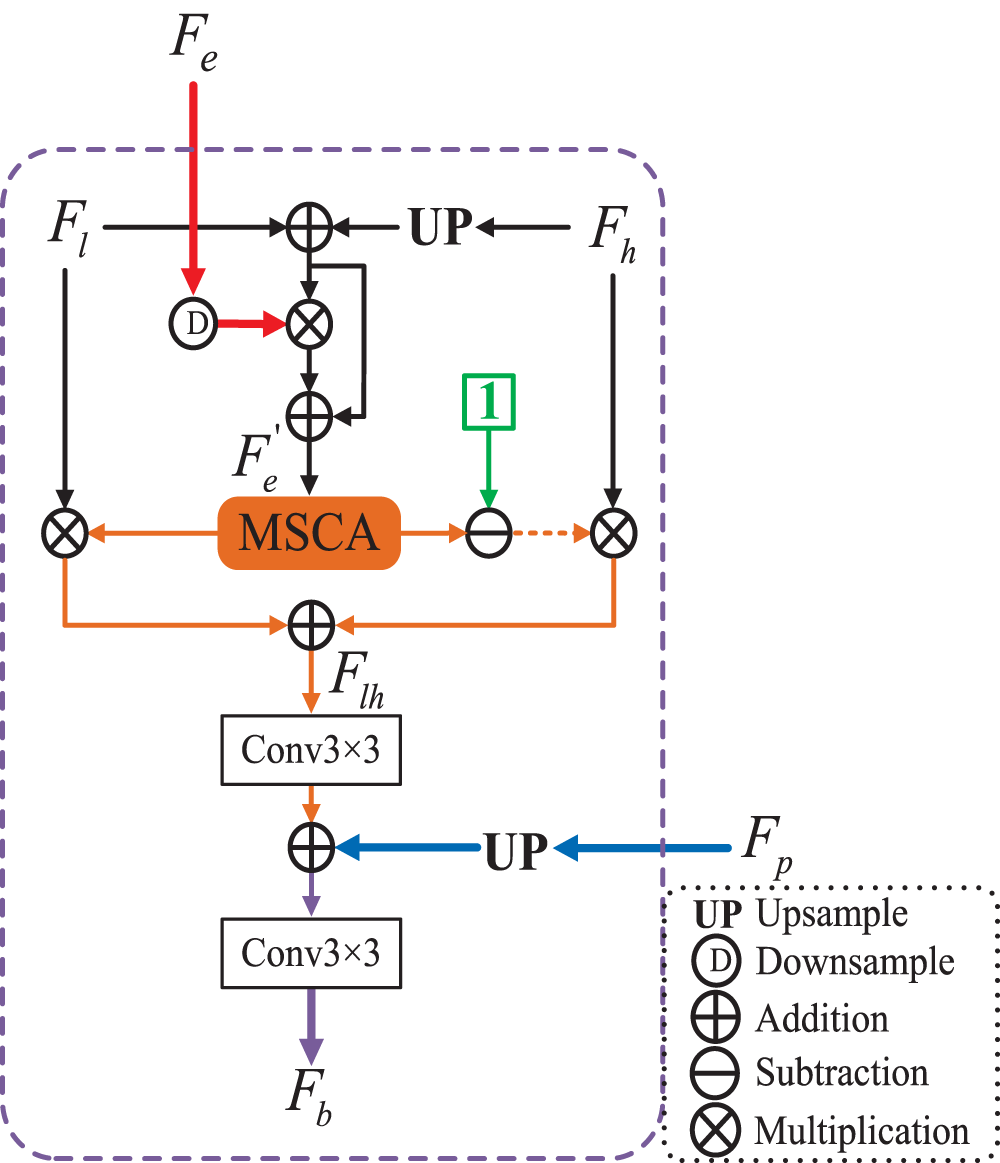
The detailed architecture of the proposed boundary-guided fusion module (BGFM).
In order to incorporate the extracted target edge semantic information into the network to guide learning as well as to fuse features from different levels, we design a BGFM to fuse the edge semantic information extracted by EEM and the global context information extracted by the PPM, which can also aggregate features across levels. Unlike attention-induced cross-level fusion module (Sun et al., 2021), which only the fusion of cross-level features is considered, BGFM considers not only the fusion of cross-level features, but also the fusion of edge features and global features. It injects edge feature
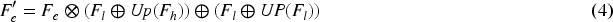
Similarly, we use the multi-scale channel attention (MSCA) (Dai et al., 2021)module to aggregate the fused features and explore context information to enhance detection. MSCA is based on a double-branch structure, in which one branch uses global average pooling to obtain global contexts to emphasize globally distributed large objects, and the other branch maintains the original feature size to obtain local contexts to avoid small objects being ignored. Finally, aggregating multi-scale context information. The attention weights obtained by MSCA are multiplied with the low-resolution features and the attention background is multiplied with the high-resolution features, they are added and passed through a
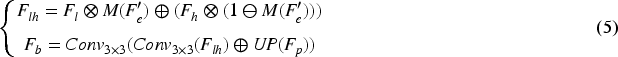
The binary cross-entropy loss function is widely used in most COD methods. In the approach of this article, there are two types of supervisions, one for the camouflaged object mask (
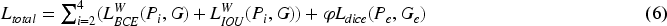
Implementation Details
The operating system of the experimental platform is Ubuntu 16.04.7 LTS, configured with Python 3.8. Based on PyTorch to implement our network model, the GPU is NVIDIA Tesla V100 32GB. We adopt the pre-trained model of Res2Net-50 on ImageNet as the backbone network and resize all the input images to 416
Datasets
We evaluate our method on three public benchmark datasets, which are also the most widely used three datasets in COD: (1) CAMO (Le et al., 2019), which contains 1250 images (1000 for training set and 250 for test set), (2) COD10K (Fan et al., 2020), which contains 5066 camouflaged images (3040 for training set and 2026 for test set); (3) NC4K (Lv et al., 2021), which contains 4121 images and is the largest test set. We are consistent with most COD model setups, using the training set of CAMO with COD10K as the training set of our model, and using the test set of CAMO, the test set of COD10K, and NC4K as the test set.
Evaluation Metrics
E-measure (Fan et al., 2021), which is an enhanced alignment measure that combines local pixels with image-level averages, thus taking into account both local and global information:
S-measure (Fan et al., 2017), which is a structure-based measure that considers the similarity of object-aware ( Weighted F-measure (Margolin et al., 2014), which is an overall performance measure that comprehensively considers weighted precision and weighted recall:
MAE (Perazzi et al., 2012), mean absolute error, evaluates the average pixel-level relative error between normalized prediction and true label values:


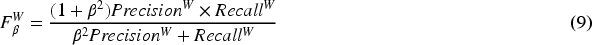
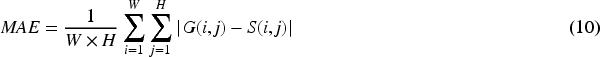
To demonstrate the effectiveness of our method, we compare it against 15 leading-edge methods, including PoolNet (Liu et al., 2019), EGNet (Zhao et al., 2019), UCNet (Zhang et al., 2020), PraNet (Fan et al., 2020a), SINet (Fan et al., 2020), C2FNet (Sun et al., 2021), PFNet (Mei et al., 2021), UGTR (Yang et al., 2021), LSR (Li et al., 2021), ERRNet (Ji et al., 2022), PreyNet (Zhang et al., 2022), BSANet (Zhu et al., 2022), TPRNet (Zhang et al., 2022), FAPNet (Zhou et al., 2022), and SINetV2 (Fan et al., 2021). For fair comparison, all evaluation data comes from various papers or retraining using open source code.
Quantitative Evaluation
As shown in Table 1, we quantitatively compare our method with 15 advanced models on three benchmark datasets, obviously, our method outperforms the other 15 models overall on three datasets under four evaluation metrics. Furthermore, Our method also has significant advantages over methods that also use edge semantics to improve COD capability (ERRNet, BSANet, and FAPNet), we significantly increase wFm by 9
Quantitative Comparison With Advanced Methods for COD on Three Benchmarks Using Four Widely Used Evaluation Metrics.
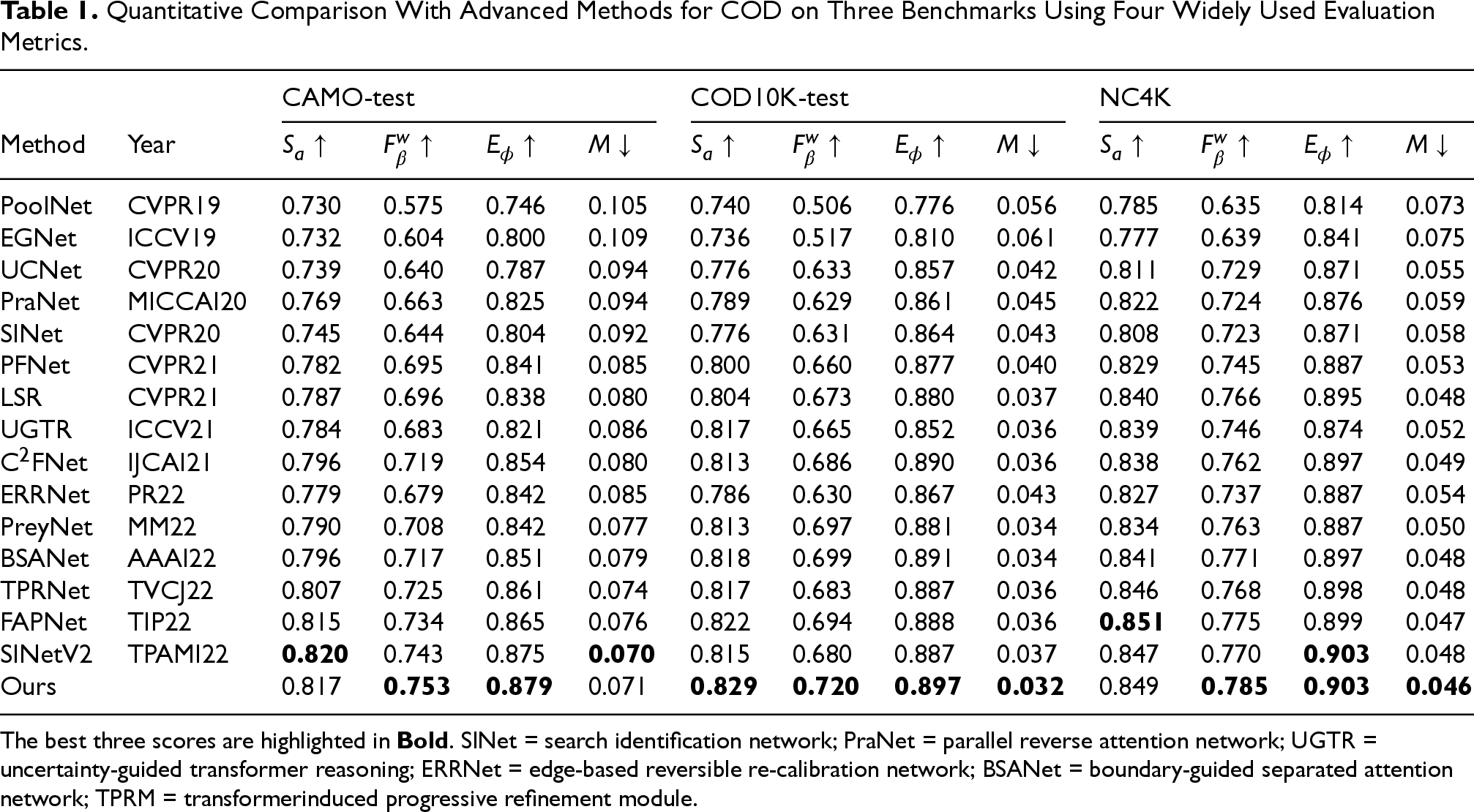
Quantitative Comparison With Advanced Methods for COD on Three Benchmarks Using Four Widely Used Evaluation Metrics.
The best three scores are highlighted in
As shown in Figure 6, a qualitative comparison of the prediction results of six methods on several typical samples in the datasets. In the figure, third row and fourth row, the edge of the camouflaged object is particularly blurred, in this case, it can be seen that other models for segmentation are inaccurate, while our model can still accurately detect camouflaged objects with rich edge details. As shown in the last line of the image, it can be seen that the predicted results of our model are more complete, showing enhancement of the edge information for improving the detection capability of camouflaged objects.

Qualitative visual comparison of our model with six advanced methods.
To verify the effectiveness of the designed modules, as shown in Table 2, we design several ablation experiments. The No.1 is the baseline model, we remove all modules that we designed and only retain TEM and PPM. And we use simple addition to fuse features. In experiment No.2, we add EEM on top of baseline model, and fuse it with each layer feature by multiplication. It can be seen that after adding EEM, all metrics have improved, which shows EEM effectiveness; In experiment No.3, we added a boundary guided fusion module to the baseline model. Compared with experiment No.1, we can see that all metrics are steadily improving, which demonstrates the effectiveness of the BGFM. In the fourth experiment No.4, we add EEM with BGFM to the baseline model and could see that the overall performance is higher than when the two modules are used alone. In experiment No.5, we replace TEM from the fourth experiment with the RTEM designed in this article and remove the PPM. The final experiment is our complete model. Compared with our model in experiment No.4, it can be seen that after replacing the TEM with the RTEM we designed, all metrics improved, which proves the effectiveness of RTEM. Comparison between experiment No.5 and our model, it is clear that the model with the PPM added has higher metrics and better performance, which demonstrates the effectiveness of the global context information captured by the PPM in improving the performance of the detection of camouflaged object. Overall, every component in the model is crucial.
Ablation Studies for Each Component on Three Test Datasets.
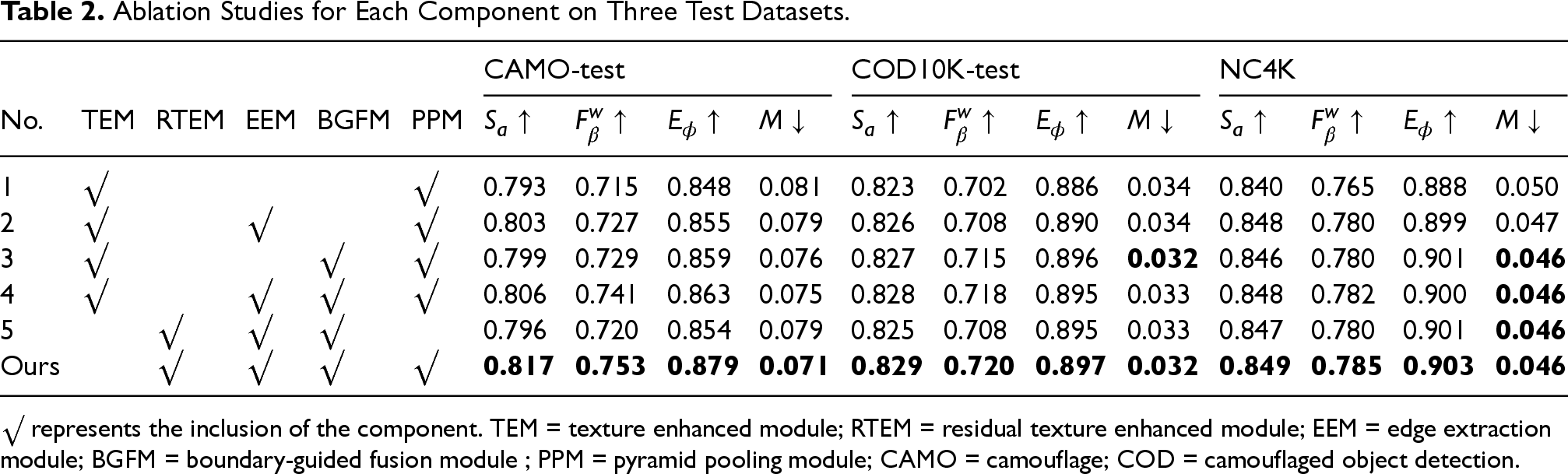
Ablation Studies for Each Component on Three Test Datasets.
In this article, we propose a novel ME
It still has the following limitations: (1) Adaptability to complex dynamic scenarios. Segmentation accuracy may degrade in scenarios with extreme dynamic backgrounds (e.g., rapidly moving camouflaged objects or drastic lighting changes). For example, when camouflaged objects dynamically synchronize with background textures (e.g., chameleons in changing environments), the EEM may struggle to distinguish motion artifacts from true boundaries. (2) Segmentation of small-scale and highly fragmented targets. The model may miss pixel-level small targets (e.g., insect antennae) or highly fragmented camouflaged regions (e.g., broken twigs) due to limited receptive fields. This stems from the RTEM’s insufficient sensitivity to micro-features during multi-scale feature fusion. In future research, we will optimize the above two aspects through multimodal fusion and small target attention.
Footnotes
Ethical Considerations
The study did not involve moral and ethical issues.
Author Contributions
All authors contributed to the study conception and design. The experiment was completed by Xuwei Tong under the guidance of Guangjian Zhang. Yuhao Yang was responsible for writing some papers and using experimental equipment. The first draft of the manuscript was written by Xuwei Tong and all authors commented on previous versions of the article. All authors read and approved the final article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
This study adopts the public datasets, which can be downloaded on the Internet.The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code Availability
The code are available from the corresponding author on reasonable request.