
Abstract
Defect detection in mobile phone cameras constitutes a critical aspect of the manufacturing process. Nonetheless, this task remains challenging due to the complexities introduced by intricate backgrounds and low-contrast defects, such as minor scratches and subtle dust particles. To address these issues, a Bilateral Feature Fusion Network (BFFN) has been proposed. This network incorporates a bilateral feature fusion module, engineered to enrich feature representation by fusing feature maps from multiple scales. Such fusion allows the capture of both fine and coarse-grained details inherent in the images. Additionally, a Self-Attention Mechanism is deployed to garner more comprehensive contextual information, thereby enhancing feature discriminability. The proposed Bilateral Feature Fusion Network has been rigorously evaluated on a dataset of 12,018 mobile camera images. Our network surpasses existing state-of-the-art methods, such as U-Net and Deeplab V3+, particularly in mitigating false positive detection caused by complex backgrounds and false negative detection caused by slight defects. It achieves an F1-score of 97.59%, which is 1.16% better than Deeplab V3+ and 0.99% better than U-Net. This high level of accuracy is evidenced by an outstanding precision of 96.93% and recall of 98.26%. Furthermore, our approach realizes a detection speed of 63.8 frames per second (FPS), notably faster than Deeplab V3+ at 57.1 FPS and U-Net at 50.3 FPS. This enhanced computational efficiency makes our network particularly well-suited for real-time defect detection applications within the realm of mobile camera manufacturing.
Introduction
The mobile camera has become a key feature affecting the overall performance of modern smartphones. During the production process of mobile cameras, defects such as scratches, dirt, and foreign objects, are often unavoidable. These defects will negatively affect the final photographic quality of the cameras. Among them, certain minor ones have low contrast with the background, making them especially difficult to identify.
Due to the complexity of mobile camera defects, there are two main challenges in defect detection: (1) Low contrast: Defects such as slight dust and shallow scratches can be particularly difficult to detect due to their low contrast with the background. This can lead to false negative detections, as shown in Fig. 1(a); (2) Interference of complex features in the background area: The mobile camera is divided into a white transparent glass area with a center circle and a black ink area with ink on the surrounding glass screen. Some normal features in the ink area are very similar to the defect features in the glass area, which can easily result in false positive detection. As highlighted in the red box in Fig. 1(b), the normal features of the background are identical to defects in the glass area.

Challenges in mobile camera defect detection. (a) In the red box are low-contrast defects, and in the yellow box are common defects; (b) Confusing normal background features.
Traditional defect detection of mobile cameras relies on manual identification, which is inefficient and may result in inaccuracies due to human error and fatigue, particularly when identifying subtle defects. Alternatively, image processing techniques can be utilized to augment the contrast between defects and the background in mobile phone camera images, thereby enhancing the visibility of defects [1]. However, this method also fails to meet the industrial demand
As machine vision technology has progressed, researchers have successfully applied it to defect detection across various fields [2, 3]. However, traditional machine vision methods rely on manually designed features, which may not be effective when dealing with complex backgrounds, image noise, and low-contrast defects, such as those found in mobile cameras. For example, machine vision technology is combined with near-infrared spectroscopy technology to detect pinholes, cracks, and other defects on the surface of wood materials, achieving high detection accuracy [4]. Similarly, in the context of wine bottle detection, a defect detection method based on residual analysis and threshold segmentation was adopted to address low detection accuracy of bottle mouth defects [5].
However, these methods face challenges when dealing with mobile cameras due to complex backgrounds, image noise, and low-contrast defects, making effective feature design and extraction difficult. Moreover, such methods may not generalize well to other defect detection scenarios.
Deep learning has shown great success in various visual tasks, including image classification, object detection, and semantic segmentation. Unlike traditional machine vision methods, deep learning can automatically extract useful features without complex manual feature design and can be applied to different scenarios. In defect detection, many studies have applied deep learning techniques. For example, Convolutional Neural Networks (CNNs) have been used to detect defects and classify images [6], while object detection networks have been used to detect and locate defects with greater accuracy [7, 8]. Semantic segmentation methods can determine whether each pixel in an image has defects, providing detailed information such as defect shape and area. The Fully Convolutional Network (FCN) [9] and U-Net [10] have been successfully used for defect segmentation in various domains, including concrete and highway tunnel defects [11, 12].
However, deep learning-based detection methods still face challenges when dealing with low-contrast and complex background images. To address this, attention modules have been designed to emphasize areas with defects, resulting in more effective feature extraction [13–15]. While the attention mechanism served to highlight the defects, it falls short in utilizing the interdependence of features across a global perspective. This contextual information is crucial for reducing false positive detection in complex backgrounds. In general, a larger receptive field brings more comprehensive contextual information. To address this, other mechanisms have been introduced, such as dilated convolutions that expand the receptive field without losing image resolution [16], and a new upsampling operator with a larger field of perception to better perceive contextual information [17]. In contrast to other mechanisms, the self-attention mechanism is not limited by the receptive field and can access global contextual information [18, 19], making it well-suited for defect detection tasks.
Different layers of convolutional networks have different sensitivities to features [20]. Features extracted by the shallow layers have higher resolution and contain more shape and boundary details but less semantic information. In contrast, features extracted by the deep layers have abstract semantic information commonly used for classification but weaker shape and location information. Although high-level features are adopted from the deep layers of the network, the prediction performance was unsatisfactory due to insufficient acquisition of information from the shallow layers [21].
Therefore, features from all levels of the network are essential for effective defect detection. Simple merging of features from different levels may lead to the loss of information [22]. To solve this problem, the ES-Net is proposed to fuse multi-level feature maps to obtain richer information [23]. A feature fusion network to integrate shallow details with deep semantics is designed to detect cell phones mobile phone lenses [24]. Some other works used a backbone network to extract the multi-level feature maps of images, and the feature fusion module is applied to fuse feature maps of different scales [25, 26].
However, most of these methods fuse multi-level feature maps from many layers of the backbone network at the same time, which provides richer information but adds significant computational consumption and affects the speed of defect detection. Moreover, there is no selection based on feature importance during the fusion. Therefore, a new module is proposed to fuse two levels of feature maps to obtain complementary information, utilizing the sigmoid function and attention mechanism to evaluate the significance of information from different layers fully.
According to the above analysis and discussion, this paper proposes a novel segmentation network based on the self-attention module (SAM) and the bilateral feature fusion module (BFFM) to construct an end-to-end detection method. The proposed network performs more effectively than other networks on the mobile camera defect dataset. The main contributions of this paper are as follows:
(1) Focusing on the application of a deep learning-based semantic segmentation network for defect detection on mobile cameras. Additionally, enhancements have been made to the network architecture of the semantic segmentation model to improve both the accuracy and speed of the detection process.
(2) The proposed bilateral feature fusion module fuses two levels of feature maps extracted by the backbone network using the sigmoid function and attention mechanism to evaluate the significance of information from different layers and improve detection accuracy while minimizing computational consumption.
(3) The self-attention module is incorporated to capture more comprehensive contextual information and discriminative features, especially for detecting slight defects.
(4) Experimental results show that the proposed method achieves state-of-the-art performance on the mobile camera defect dataset. Additionally, the proposed network maintains a high detection speed.
The rest of this paper is organized as follows: In Section 2, we provide a detailed description of the proposed segmentation network based on the bilateral feature fusion module and self-attention module. In Section 3, we introduce the dataset used for evaluation and the experiment setup. Section 4 presents the experimental results of detection performance and ablation study. Finally, in Section 5, we summarize the full context of the paper and provide a conclusion.
In this section, we present the proposed segmentation network in detail. Firstly, we introduce the overall network architecture, followed by detailed explanations of some essential modules, including the self-attention module, the bilateral feature fusion module, and the loss function, in subsequent subsections.
Network architecture
The proposed segmentation network, called the Bilateral Feature Fusion Network, has an overall architecture shown in Fig. 2. It consists of three key components: the backbone network, the self-attention module, and the bilateral feature fusion module.
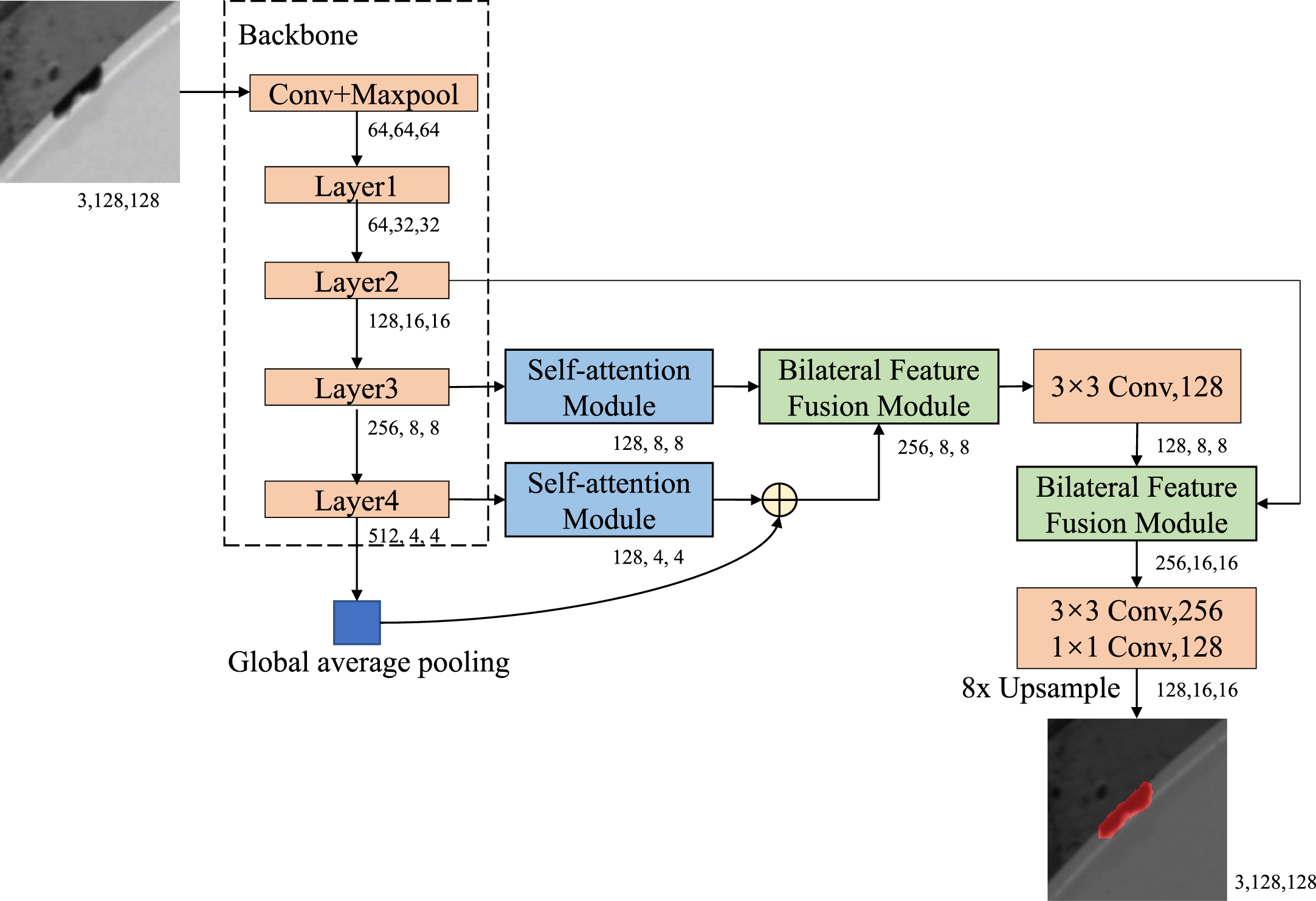
The architecture of the proposed network. The input image is fed into a lightweight CNN to extract feature maps at each layer. These feature maps are then processed by the self-attention modules to enhance the perception of defects by capturing richer contextual information and discriminative features. Finally, the bilateral feature fusion module is used to fuse the two levels of feature maps to obtain complementary information and improve detection accuracy.
In our proposed method, a lightweight backbone network is adopted, such as Resnet18 [27]. Such a lightweight backbone is computationally cheap and can rapidly down-sample features to obtain semantic information with a larger receptive field. Firstly, feature maps are extracted at different scales through the backbone network. Then, the feature maps extracted from the last two layers of the backbone network are processed by self-attention modules to obtain more contextual information and discriminative features. Meanwhile, a global average pooling has been incorporated at the tail of the backbone network to capture global contextual information. The feature maps from the pooling layer and the self-attention module of the final layer are simply summed together. Then the summed feature maps are fused with the feature maps from the upper layer self-attention module utilizing the bilateral feature fusion module. Finally, the fused feature maps are further fused with the feature maps from the shallow layer of the backbone network, and subsequently processed by a convolutional block before being upsampled to obtain the full-sized defect segmentation map.
The self-attention module is mainly to obtain more contextual information and discriminative features, which is essential for defect detection in mobile cameras. In general, larger receptive field brings more comprehensive contextual information, resulting in better performance. Contextual information is especially important in defect detection of mobile cameras. Limited receptive field of a network can lead to misclassification of certain normal background features in the ink area as defects in the glass area, as shown in Fig. 1(b).
Therefore, a large receptive field is required to achieve overall perception of defects in the image [28]. While CNNs require multiple convolutional layers to obtain global information [29, 30], self-attention is not restricted by the receptive field and can obtain global contextual information and long-range dependencies more efficiently. Then, the self-attention mechanism achieves refined feature extraction by adding corresponding weight matrices to the defect feature maps [31], enhancing the capability to highlight slight defects. The proposed self-attention modules are inspired by Bottleneck Transformers [18], and are used to process the feature maps extracted from the backbone network.
The input feature maps are passed through a convolution layer, a multi-head self-attention layer, and a convolution layer sequentially. After each convolution layer, layer normalization and rectified linear unit (ReLU) activation are applied. The final output is obtained by residual calculation.
Bilateral feature fusion module
The bilateral feature fusion module aims to fuse the feature maps extracted from different layers to obtain richer and more effective information for semantic segmentation tasks.
Convolutional layers exhibit diverse sensitivities to features based on their depth within the network, shallow layers extract low-level feature maps with elevated resolution, providing intricate details regarding shapes and boundaries, but with a comparatively limited amount of semantic information. Conversely, high-level feature maps extracted by deep layers having more abstract semantic information while potentially sacrificing the shape and boundary details [20]. With the complementary information obtained from different layers, the bilateral feature fusion module is proposed to fuse the feature maps effectively.
There are various ways to fuse two levels of features, e.g., element-wise summation [32] and concatenation [33]. However, these simple methods tend to overlook the diversity of information, leading to suboptimal performance. The proposed bilateral feature fusion module is inspired by the bilateral guided aggregation layer in [34]. The details of this structure are shown in Fig. 3. The high-level feature maps containing more semantic information guide the representation of low-level features through a sigmoid function, following two layers of convolution operation.
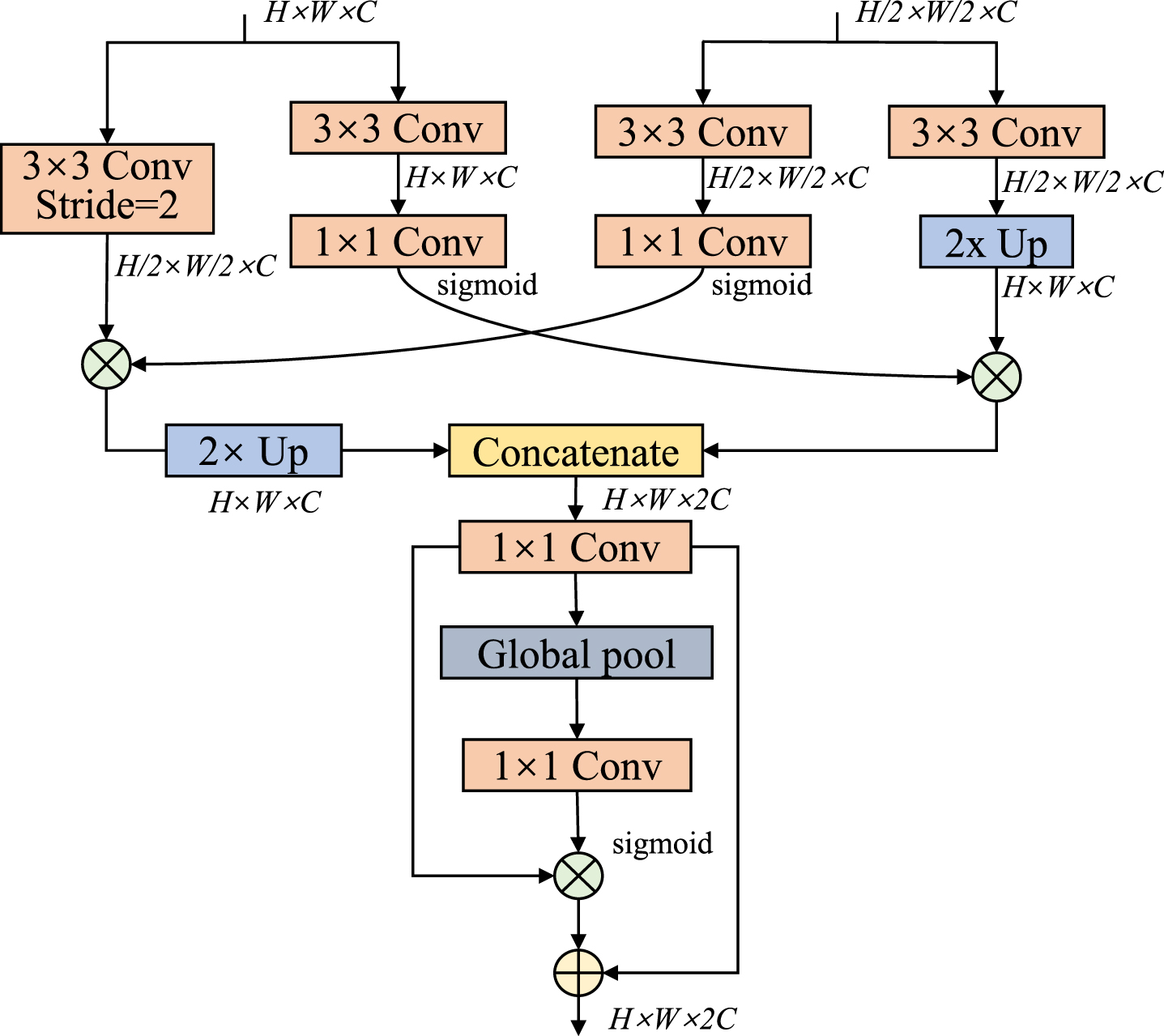
The architecture of bilateral feature fusion module, where Up represents the upsampling, and +, × represent element wise sum and matrix multiplication respectively.
Similarly, the low-level feature maps guide the high-level feature representation. The bilateral feature fusion module filters the effective information for each level of feature maps, enabling different levels of feature maps to guide each other effectively and capture essential information. The guided feature maps are upsampled to the same size for concatenation, and the weight vector of the feature is calculated like SENet [35], which is then used to re-weight the feature maps. This method allows for the interaction of information between different levels of feature maps, thus improving the final detection accuracy.
Cross-entropy loss function is commonly used as a loss function for image segmentation tasks. In this method, a principal loss function and two auxiliary loss functions are adopted to supervise the training [36]. The principal loss function is used to supervise the output of the whole network, while the auxiliary loss functions are used to supervise the output of deep layers. Both the principal and auxiliary loss functions are cross-entropy loss function.
The overall loss function is defined as:
The cross-entropy loss of principal and auxiliary loss function is as:
Dataset
To evaluate the defect detection performance of the proposed network, a dataset of actual mobile camera defect images are collected and labeled by professionals. The dataset images contain a white transparent glass area and a surrounding black ink area that is smeared with ink on glass. Six types of defects need to be detected on the glass area, including scratches, foreign objects, white spots, dust, dirt, and collapsing edge, as shown in Fig. 4. Because the surrounding ink area is black and does not affect the performance of cameras, no defects on it need to be detected. To save the training time of the model, the images are cropped to a size of 128 * 128. The dataset contains a total of 12,018 images in the cropped format. The evaluation is performed by 4-fold cross-validation. For each fold, 25% of the samples are taken out as test set, and the remaining 75% are using as training set. When tuning hyperparameters, ten percent of the training samples are taken aside as evaluation set.

Types of defects. First row are images, while second row are corresponding labels. (a) Scratches; (b) Foreign objects; (c) White spots; (d) Dust; (e) Dirt; (f) Collapsing edge.
In the task of defect detection with segmentation networks, many works have used segmentation metrics such as Intersection over Union (IoU) and Dice coefficient to evaluate the quality of the detection results. These metrics calculate the overlap between predicted and actual defects and can represent the pixels correctly classified by the network. However, in practical industrial production, while pixel classification accuracy remains a significant factor, the primary focus is on accurately detecting the defective areas [37].
To better evaluate the network’s defect detection performance, the problem is translated into a classification problem. The classification errors of the defects are evaluated, and the segmentation results are only used for visualizing the defect detection. The following metrics are used to assess the network’s performance: F1-score, Recall, Precision, FN, and FP. The formulas for these metrics are as follows:
All experiments were implemented with PyTorch and trained for 30 epochs on Nvidia P100 GPU with 16 GB of memory. The optimizer used was RMSprop with an initial learning rate of 5e-4, and the training batch size was set to 16. The self-attention module has Embedding dim of 64, Number of heads of 4, Dropout rate of 0.1.
Experimental results and analysis
In this section, the performance of the bilateral feature fusion network is evaluated by comparison experiments with state-of-the-art methods, and a comparison of detection efficiency was also provided. Furthermore, some ablation studies of the proposed network are presented.
Performance analysis
To further validate the detection performance of the proposed network, we compared it with state-of-the-art segmentation networks such as FCN and U-Net, all using resnet18 as their backbone network.
Performance comparison
The results of the experiment are summarized in Table 1 with metrics of F1-score, Recall, precision, and FP+FN. The experimental values are the mean of the 4-fold cross-validation results, and the standard deviation between each fold is calculated.
Comparison of different network detection performance
Comparison of different network detection performance
Due to the presence of slight defects and complex backgrounds in the dataset, FCN fails to demonstrate superior detection performance. Deeplab V3+ tends to miss slight defects, resulting in lower Recall. As a representative network of pixel-level segmentation, the U-Net performs well in detecting slight defects. However, the skip connections of U-Net simply connect the low-level features extracted during Encode to Decode. These low-level features only contain shape and texture information, which cannot obtain contextual information well because of the small receptive field. It leads to false positive detection on the ink area, resulting in low Precision. The performance of Bisenet in detecting slight defects was also unsatisfactory. In contrast, the proposed network is more accurate than other segmentation networks in detecting mobile camera defects.
To demonstrate the detection performance of the proposed network effectively, the segmentation results are shown in Fig. 5. The first and second columns in the figure represent the original image and the ground truth, and the third to seventh columns represent the segmentation result of the different networks.

Comparison of the detection performance of each network (The yellow box in the figure is the false negative detection area, and the red box is the false positive detection area).
As shown in the yellow box of Fig. 5, there is a high likelihood of false negative detection when defects are slight or the contrast between objects and background is low. In addition, some images have complex backgrounds with geometric features similar to the defects, as shown in the red box in Fig. 5. Detecting these types of defects correctly is challenging. FCN does not perform well on these kinds of defects, and false negative detection of slight defects and false positive detection of normal areas occur from time to time. Deeplab V3+ outperforms FCN but still has many false negative detections of slight defects. U-Net demonstrates satisfactory performance in detecting slight defects, but it tends to misclassify certain normal background features as defects. Bisenet does not perform as accurately as U-Net in false negative detection. Our proposed network with the addition of SAM and BFFM yields significantly better detection performance than other state-of-the-art methods.
The efficiency of defect detection is also an essential metric for industrial applications. To compare the detection speed of the methods, the number of images detected per second are measured and presented in Table 2. Our proposed method, with the addition of SAM and BFFM modules, achieves a detection speed of around 63.8 FPS, which is significantly faster than most other methods. These improvements in efficiency make our proposed method easier to apply in production environments with lower requirements for high-end hardware.
Ablation of different backbones
Ablation of different backbones
To better understand the decision choices of the bilateral feature fusion network, some ablation experiments are conducted.
Effects of different backbones
To make clear the impact of different sizes of backbone networks on our proposed method, experiments were conducted to compare the detection accuracy of Resnet18, Resnet34, and Resnet50 as backbone networks, as summarized in Table 3.
Ablation of different configurations
Ablation of different configurations
Although Resnet 50 performs better than other backbone networks, the improvement is not significant. This could potentially be attributed to the limited size of the training dataset. Additionally, as resnet50 takes more computing time, resnet18 is preferred as the backbone network.
The proposed model with various configurations was evaluated, as shown in Table 4. It can be seen that the addition of the self-attention module improved both recall and precision, indicating that the module helped to focus on critical defect areas and achieve better overall defect perception. In addition, the bilateral feature fusion module was found to suppress background noise and reduce false positive detections in non-defective areas, leading to higher precision. When both modules were used together, the proposed method achieved the best overall performance.
Processing times of the networks
Processing times of the networks
This paper proposes an efficient and accurate network for detecting defects in mobile cameras in industrial settings. The network has the capability to autonomously extract complex defect features from images, facilitating precise and efficient defect detection without the need for human intervention. Advancements and further investigation within this domain have the potential to profoundly transform defect detection in mobile cameras, enhancing performance, customer satisfaction, and overall industry quality.
The network comprises two key components: the self-attention module and the bilateral feature fusion module. The self-attention module provides rich contextual information and helps the network focus on defect areas, reducing false negatives and suppressing background interference. The bilateral feature fusion module allows for interaction between different levels of feature maps, improving defect segmentation accuracy. The proposed network is evaluated on a dataset of mobile camera defects from industrial production, and outperforms other state-of-the-art methods, particularly in detecting defects with complex backgrounds and low contrast.
However, it is worth noting that the network’s ability to generalize has only been tested on datasets specific to mobile cameras. To more thoroughly validate its utility, it would be beneficial to extend the testing to include different types of materials and defect contexts. In addition, exploring the integration of self-supervised learning techniques into defect detection could be a promising avenue for future studies.
Acknowledgement
This work is supported by the Graduate Research & Innovation Projects of Jiangsu Province (Project SJCX21-1526).