
Abstract
With the significant success of transformers in natural language processing, an increasing number of researchers are introducing them into the field of computer vision, particularly for action recognition. As a crucial task in video understanding, action recognition has significant applications in live broadcasting, autonomous driving, and medical diagnostics. The attention mechanisms in transformers mimicking human visual attention allocation, thereby enhancing the processing capabilities and comprehension of long video sequences. However, they often overlook the aggregation of multiscale detail features and the hierarchical representations of early visual information. Additionally, attention networks are computationally intensive and parameter-heavy, complicating model training and extending inference times, rendering them unsuitable for real-time applications. To crack these nuts, we propose a lightweight multiscale action recognition model based on convolutional enhancement block (ConvEB) and multiscale average pooling encoder. The ConvEB aims to establish long-range dependencies among multiscale local features in the early stages of the network, providing effective inductive biases for the attention network to compensate for the loss of detailed information. Moreover, we introduce a parallel pooling mixer to replace the original attention mixer, ensuring model lightweight while maintaining recognition accuracy. Finally, we deploy this model in the construction of a virtual panorama live broadcasting system. Experimental results demonstrate that our action recognition algorithm achieves competitive performance, and the constructed panoramic system basically meets the needs of daily live broadcasting.
Keywords
Introduction
The rapid growth of internet multimedia technologies and the explosive popularity of short video platforms have led to an unprecedented surge in video content. Analyzing and understanding such vast video streams has become a critical challenge in computer vision. Among these tasks, action recognition—the process of enabling machines to interpret human behaviors in videos through spatiotemporal feature extraction and classification—plays a foundational role. Its applications span intelligent surveillance, human–computer interaction, and immersive entertainment systems (Figure 1). However, action recognition faces inherent challenges: actions vary widely in duration, exhibit complex spatiotemporal dynamics, and often occur against cluttered backgrounds, demanding robust and efficient models for accurate analysis.

Action recognition technology application scenarios.
Early approaches relied on handcrafted features (e.g., Histogram of Oriented Gradients and Scale-Invariant Feature Transform) combined with traditional machine learning methods. While effective in constrained scenarios, these methods struggled with scalability and failed to capture the temporal evolution of actions in complex real-world videos. The advent of deep learning, particularly convolutional neural networks (CNNs), revolutionized the field by enabling automatic hierarchical feature extraction. CNNs excel at capturing local spatial patterns, yet their limited receptive fields hinder the modeling of long-range dependencies and multiscale contextual relationships—critical for distinguishing fine-grained actions (e.g., walking vs. jogging).
Transformers, renowned for their global self-attention mechanisms, emerged as a powerful alternative. By dynamically focusing on critical spatiotemporal regions, transformers achieve superior sequence modeling, as evidenced by their success in natural language processing and image recognition (Vaswani et al., 2017). However, their direct application to video action recognition faces two key limitations: (a) the quadratic computational complexity of self-attention (relative to input length) imposes prohibitive costs for long video sequences (Vaswani et al., 2017) and (b) excessive emphasis on global interactions often neglects subtle local details (e.g., limb movements), degrading performance in fine-grained recognition tasks (Yang et al., 2021). These issues are exacerbated in resource-constrained scenarios such as real-time live broadcasting, where latency and model size are critical.
To address these challenges, we propose ConvEB-MAPFormer, a lightweight architecture that synergizes convolutional enhancement block (ConvEB) and multiscale average pooling encoder (MAPFormer). Our key innovations are:
We propose a ConvEB that leverages the excellent local spatial feature capturing capabilities of a CNN to provide effective local detail information for subsequent attention networks. We improve the MAPFormer, reducing parameters and lightweighting the model while mitigating their negative impacts, thereby maintaining model accuracy. We apply the complete action recognition model to a virtual panoramic live broadcasting system, demonstrating the feasibility and effectiveness of the model in real-world application.
In recent years, emerging action recognition methods can be broadly categorized into CNN-based and transformer-based approaches, depending on how they handle features.
CNN-Based Action Recognition Methods
Two-dimensional (2D) CNN
Early 2D CNN-based action recognition methods typically employed a two-stream architecture. Simonyan and Zisserman (2014) introduced a revolutionary approach with the two-stream network, which models spatial and temporal relationships by processing single-frame Red–Green–Blue and multiframe dense optical flow fields separately. However, the late fusion strategy used in this method may result in the loss of critical information. Feichtenhofer et al. (2016) proposed various convolutional feature fusion strategies, shifting the fusion point from the SoftMax layer to the convolutional layers to match features at the same location across the two streams, effectively reducing the parameter count. Subsequently, in order to improve the depth of the network, Feichtenhofer et al. (2017) replaced the backbone network of the two-stream network with residual network (He et al., 2016) and trained the model end-to-end, achieving excellent results in short video recognition tasks. Liu et al. (2025) proposed active redundancy reduction for static images but lacked video-temporal modeling.
Despite these advancements, 2D CNN models fail to effectively model temporal information and rely heavily on optical flow, which incurs significant computational costs, limiting their further development in action recognition.
Three-Dimensional (3D) CNN
Unlike 2D CNNs, 3D CNN-based action recognition methods add a depth dimension to the input images, resulting in an additional dimension for convolution kernels and output feature maps. Carreira and Zisserman (2017) extended the 2D CNN convolution kernels into the temporal dimension, forming the “Inflated” 3D (I3D) structure, which demonstrated excellent performance across multiple action recognition datasets. Extensible 3D Graphics (Feichtenhofer, 2020) attempted to extend the 2D convolutions from different dimensions (temporal depth, sampling rate, spatial resolution, width, etc.) to handle different dimensions of 3D spatiotemporal data. Conversely, R(2+1)D (Tran et al., 2018) decomposed 3D convolutions into 2D convolutions for spatial information and one-dimensional convolutions for temporal information, aiming to reduce model complexity while maintaining spatiotemporal feature capture capabilities. Separated 3D convolutional network (Xie et al., 2018) further reduced parameter count and improved model performance by learning spatial and temporal features separately based on the R(2+1)D structure. Manakitsa et al. (2024) systematically reviewed deep learning approaches, identifying temporal occlusion handling as a critical gap despite advancements in transformer architectures. While their survey highlights 3D CNNs for global temporal dependencies, these methods struggle with localized actor-specific occlusions.
Although 3D CNNs enhance recognition performance at the cost of increased computational resources and parameters, they pose a challenge to model generalization and fail to improve the capture of global contextual information.
Transformer-Based Action Recognition Methods
Compared to CNNs, transformer-based action recognition networks exhibit significant advantages in handling video sequences and capturing long-term dependencies. Girdhar et al. (2019) first introduced the action transformer model for video action recognition, which autonomously learns semantic contextual information from human behaviors. Subsequently, Dosovitskiy et al. (2020) proposed the vision transformer (ViT), which cleverly transformed the classification problem into a sequence modeling problem by dividing images into multiple
However, transformer networks contain a large number of parameters, necessitating substantial computational resources for training and inference. Recent studies (Yang et al., 2021) further indicate that while transformers excel at modeling global dependencies, their self-attention mechanisms tend to underemphasize fine-grained local features, such as subtle limb movements or transient spatial patterns, which are critical for distinguishing similar action categories (e.g., walking vs. jogging). This limitation stems from the dominance of global token interactions over localized spatial modeling. Nevertheless, transformer-based action recognition methods are still an active research area and will continue to improve the model efficiency and recognition performance in the future by improving the network structure of the transformer and other methods.
Action Recognition Algorithm
In this section, we present a lightweight multiscale action recognition model based on ConvEB and MAPFormer. The overall framework is illustrated in Figure 2. ConvEB is utilized early in the network to capture rich multiscale local features across channels, providing effective inductive biases and more expressive feature representations for the subsequent MAPFormer. The parallel pooling mixer with multiscale pooling receptive fields captures global contextual information at different spatial scales, aggregating multiscale spatial features from different channels. Experimental results show that this model achieves higher accuracy and fewer parameters compared to several baseline models. This paper presents two core innovations: (1) ConvEB module incorporating pyramid squeeze attention (PSA) to enhance multiscale local features and (2) lightweight MAPFormer to replace the attention mechanism with parallel pooling to significantly reduce the computational overhead.
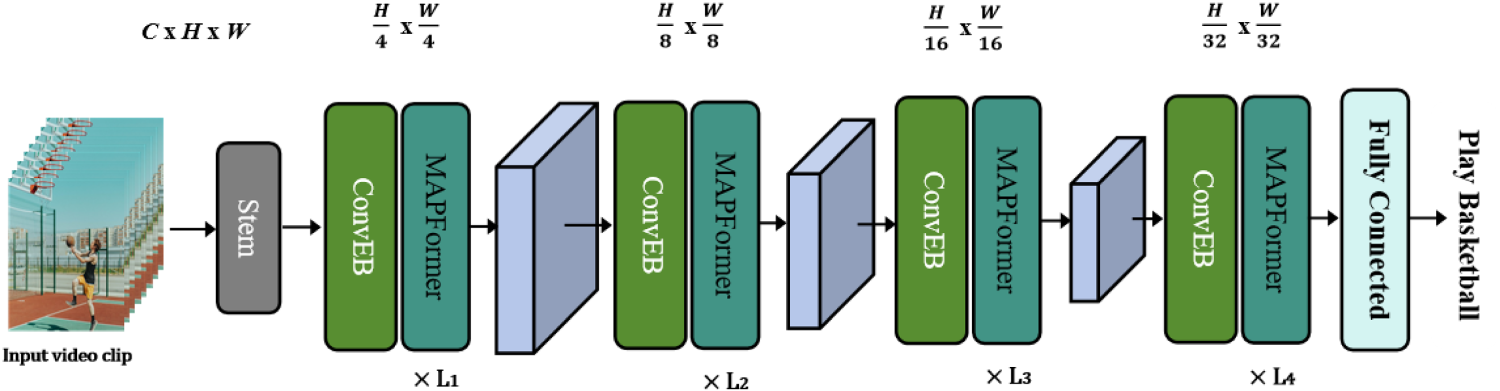
Action recognition model framework based on ConvEB-MAPFormer. Note. ConvEB = convolutional enhancement block; MAPFormer = multiscale average pooling encoder.
The proposed ConvEB is primarily based on the mobile inverted bottleneck convolution (MBConv) structure introduced by Sandler et al. (2018). As shown in Figure 3(a), an MBConv block typically consists of a
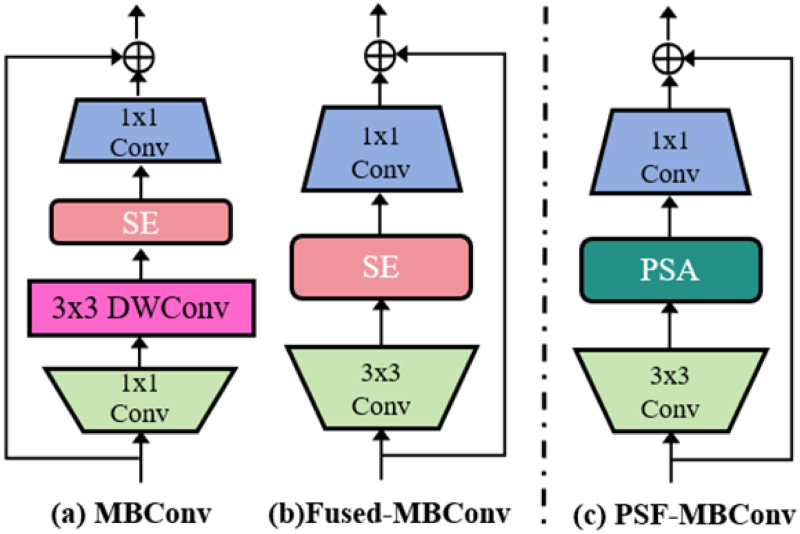
Basic unit of convolutional enhancement block (ConvEB).
However, understanding and analyzing complex, subtle action categories is also crucial in action recognition tasks. For example, running and walking may appear similar but differ subtly in leg and arm movements and duration. Recognizing and classifying these actions typically involves integrating highly abstract and multidimensional feature information. The SE module in the Fused-MBConv structure uses global average pooling to squeeze spatial dimension information, which may result in the loss of spatial structural information crucial for recognition tasks. Additionally, the SE module focuses on single-channel feature reshaping, limiting its ability to learn complex spatial patterns. To address this, we replace the SE module in the Fused-MBConv with pyramid squeeze attention (Zhang et al., 2022), proposing the pyramid squeeze fused-MBConv (PSF-MBConv) structure as shown in Figure 3(c). PSA is a lightweight channel attention mechanism that dynamically adjusts the importance of features across channels and spatial positions, enhancing the model’s adaptability and generalization in handling action diversity and temporal scale variations. PSA can significantly improve the model’s ability to recognize and express key features. Its lightweight design effectively mitigates the challenge faced when applying attention mechanisms in resource-constrained environments, making it an optimal choice for integrating multiscale spatial information across channels.
PSA dynamically enhances critical spatial regions by adaptively weighting multiscale channel features. Specifically, it employs grouped convolutions with varying kernel sizes to extract multiscale local patterns (see Appendix A for implementation details). The channel-wise attention weights are then recalibrated via Softmax-based fusion, enabling the model to focus on discriminative regions while suppressing redundant information.
In recent years, ViTs have shown impressive performance in video action recognition tasks, leading to the development of various ViT-based models for this field. A traditional transformer encoder comprises two components: the attention module, which mixes information from different tokens, and the feedforward network, which includes a channel multilayer perceptron (MLP) for learning complex and abstract feature representations. Both components integrate residual connections and normalization. To verify which part of the transformer encoder contributes more to the model, researchers (Tolstikhin et al., 2021) have done extensive experiments. It was ultimately demonstrated that ViT’s superior performance in action recognition tasks is attributed to the general architecture of MetaFormer (Yu et al., 2023), as shown in Figure 4(a), rather than a specific token mixer. Consequently, researchers (Liu et al., 2022; Yu et al., 2022) have begun replacing the traditional attention mixer with various token mixers. For instance, Guibas et al. (2021) used an adaptive Fourier neural operator as a mixer and achieved high recognition accuracy. To reduce computational complexity and parameter count, making the model lightweight and reducing memory burden during training, Lee-Thorp et al. (2021) replaced the token mixer in MetaFormer with a parameter-free pooling operation, resulting in PoolFormer, as illustrated in Figure 4(b). Applying PoolFormer in video action recognition tasks enhances computational efficiency and reduces parameters. However, related research (Tan et al., 2021) indicates that using separate max-pooling or average-pooling layers in pooling mixer for dimensionality reduction can lead to the loss of critical local detailed spatial information, blurring spatial relationships, and affecting multiscale spatial dimension feature representations. These impacts are crucial for capturing dynamic action changes and modeling long-term dependencies in sequential features.
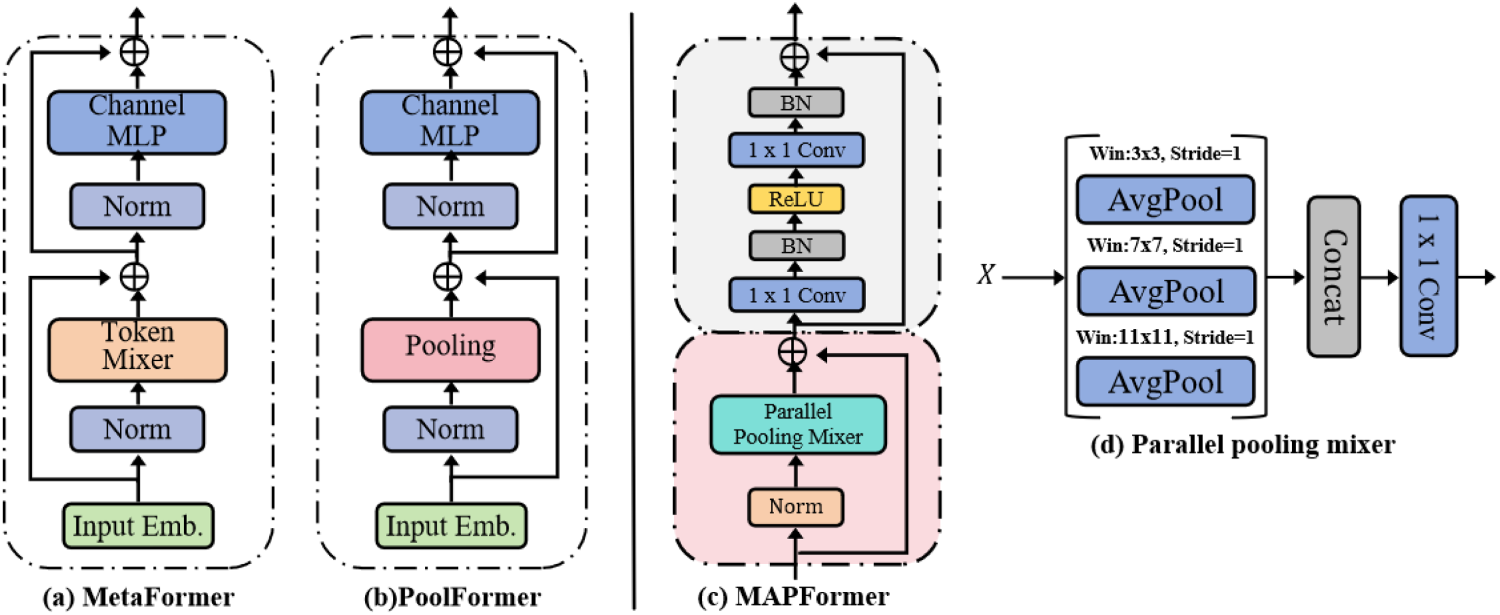
Basic composition of multiscale average pooling encoder (MAPFormer).
To address this issue, we propose replacing the attention mixer with a parallel pooling mixer, which substitutes the simple average pooling mixer in PoolFormer with a parallel combination of average pooling layers of different kernel sizes. Combined with the convolutional-batch normalization (Conv-BN) fully connected layer structure, we introduce a novel encoder structure, MAPFormer. As shown in Figure 4(c), MAPFormer consists of two parts: the parallel pooling mixer residual block and the Conv-BN residual block. The parallel pooling technique used in the parallel pooling mixer is a common feature processing method in image processing and action recognition tasks. By applying multiple pooling layers with different kernel sizes in parallel, the features of the input data at different scales are captured, thus aggregating different types of spatial feature information. This approach enables the model to comprehensively understand the input data from multiple perspectives, enhancing feature extraction quality and capturing richer fine-grained features.
Research (Doğan, 2023) indicates that average pooling layers generally outperform max-pooling layers in image classification tasks. Therefore, the proposed parallel pooling mixer primarily comprises average pooling layers of different kernel sizes, and each layer performs pooling operations on the input sequence with different pooling windows, respectively. After concatenation and dimensionality reduction, this yields different levels of feature information. Specifically, for an input sequence
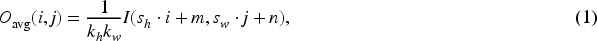
The structure of the parallel pooling mixer, shown in Figure 4(d), includes three parallel average pooling layers. For an input sequence
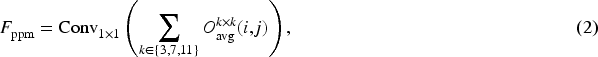
By merging the pooling results on multiple layers, the shortcoming of a single pooling layer’s weak extraction of image information can be effectively compensated, allowing the model to generalize to different data and scenes. This enhancement is especially important for the model to understand subtle actions and complex scenes. Additionally, a recent study (Li et al., 2022) suggests that layer normalization (LN) or group normalization (GN) followed by linear operations in MLPs require computing statistics of the current data, leading to increased parameter count and latency. To further lightweight the model, we replace the standard fully connected layer and LN (or GN) with
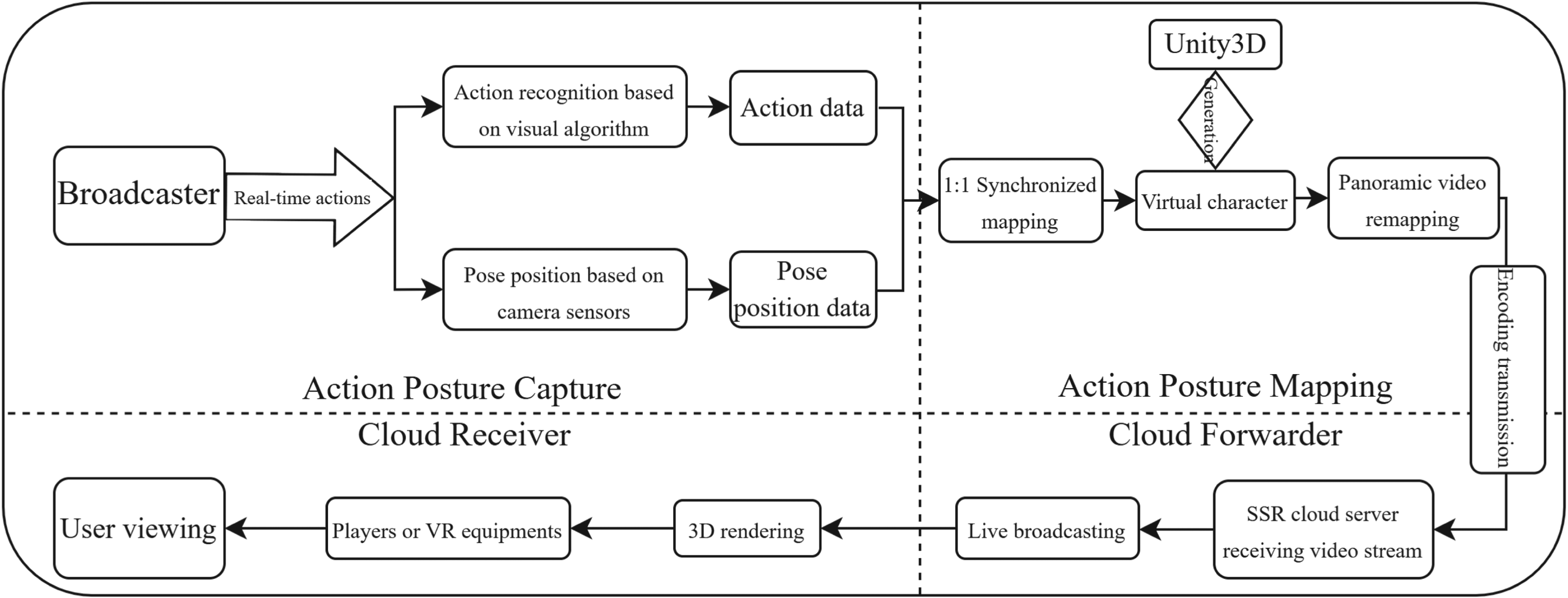
To validate the performance of the action recognition model proposed in this paper, we applied it to a panoramic live broadcasting system. By recognizing human actions in panoramic videos across different scenarios, the system enhances the smoothness and intuitiveness of user interactions. Furthermore, we develop a virtual panoramic live broadcasting system based on action and pose recognition, utilizing Unity3D to synchronize human actions with virtual animation model poses in panoramic broadcasting. Finally, we conduct experiments to verify the reliability and stability of this system.
System Composition
Collector
The system employs eight iZugar MKX22 fisheye cameras (Blackmagic micro Studio 8K) for panoramic video capture. Each camera features a 220-degree ultra-wide-angle lens with an f/2.5 aperture, ensuring clear image capture even in low-light conditions. The cameras are arranged in four groups, each containing two cameras, forming binocular camera groups, which achieve a 360-degree full-view perspective. To achieve real-time panoramic video stitching and smooth streaming, a virtual reality (VR) live broadcasting tool is used to read the real-time footage from the binocular camera groups (see Figure 5(a)). Precise stitching is performed using PT Gui to create a complete image template (see Figure 5(b)). Finally, remapping technology is used to output the panoramic video, providing a seamless immersive viewing experience.

Schematic diagram of panoramic video generation.
Virtual panoramic system based on action and gesture recognition.
The system uses the H.266/VVC encoding standard to compress and encode the panoramic video, then streams it to a cloud server. Compared to H.265/HEVC, H.266/VVC offers a higher data compression rate, reducing transmission data volume by 50%, and occupying less bandwidth and storage space, ensuring a smooth high definition visual experience. During transmission, the system uses the real-time messaging protocol (RTMP) to encode the video data, transmitting it via a 5G network to the Simple Real-time Server streaming server for forwarding. RTMP offers high compatibility, stability, and low latency, supporting various video encoding formats and dynamic adjustment of video stream quality, ensuring an excellent viewing experience.
Receiver
The receiver uses PotPlayer and HTC Vive device to create an efficient immersive viewing environment. PotPlayer decodes the encoded video stream pulled from the cloud server and restores it to clear image frames, supporting 8K video decoding to ensure extreme clarity. After decoding, PotPlayer generates left-eye and right-eye images to simulate human eye parallax effects (see Figure 5(c)). It renders panoramic images through depth information estimation and spherical projection technology. HTC Vive provides a high-resolution display and precise head tracking, ensuring the viewpoint moves with the user’s gaze, achieving a 360-degree panoramic view. Additionally, HTC Vive supports controllers and other input devices, enhancing immersion and interactivity.
Algorithm Deployment
To validate the practical application of the proposed action recognition model, this section builds a virtual panoramic live broadcasting system based on the panoramic system described in Section 4.1. The framework is shown in Figure 6. Before the live broadcasting, the system uses the Mixamo tool to generate various common action types of virtual 3D animation models and configure an Animation Controller to define transition logic between different animation states. During the live broadcasting, a vision-based deep learning model and camera position sensors capture the broadcaster’s action categories and body pose data, synchronizing them with Unity3D. C# script receives and parses these data, dynamically setting parameters of the Animator Controller to trigger corresponding animations, achieving synchronization between the broadcaster’s actions and the virtual animation model. After testing in Unity3D, the built-in virtual camera renders the virtual animation model in real-time and outputs it to the live broadcasting interface. Users can experience the virtual panoramic live broadcasting immersively through VR devices or players. During the action and pose capture, the proposed action recognition model captures the broadcaster’s action features and determines the action commands based on a preset action category library, achieving more accurate synchronization. The visual output is shown in Figure 7. Additionally, camera and pose recognition sensors acquire the broadcaster’s pose and position data, synchronously mapping them to the virtual character animation controllers in Unity3D for temporal and spatial calibration and adjustment.

Visualization of action recognition results in panoramic video.
To achieve synchronization between the broadcaster’s actions and the virtual character animations, Unity3D is used. Precreated 3D character models with common action categories are imported into Unity3D. For each model, an animation controller is created, setting the state for each action and assigning an animation clip. C# script receives and analyzes the action categories and poses position data mapped into Unity3D, dynamically setting parameters (e.g., booleans and triggers) in the Animator Controller to trigger corresponding animation states, ultimately achieving animation state transitions. The specific process is shown in Figure 8.
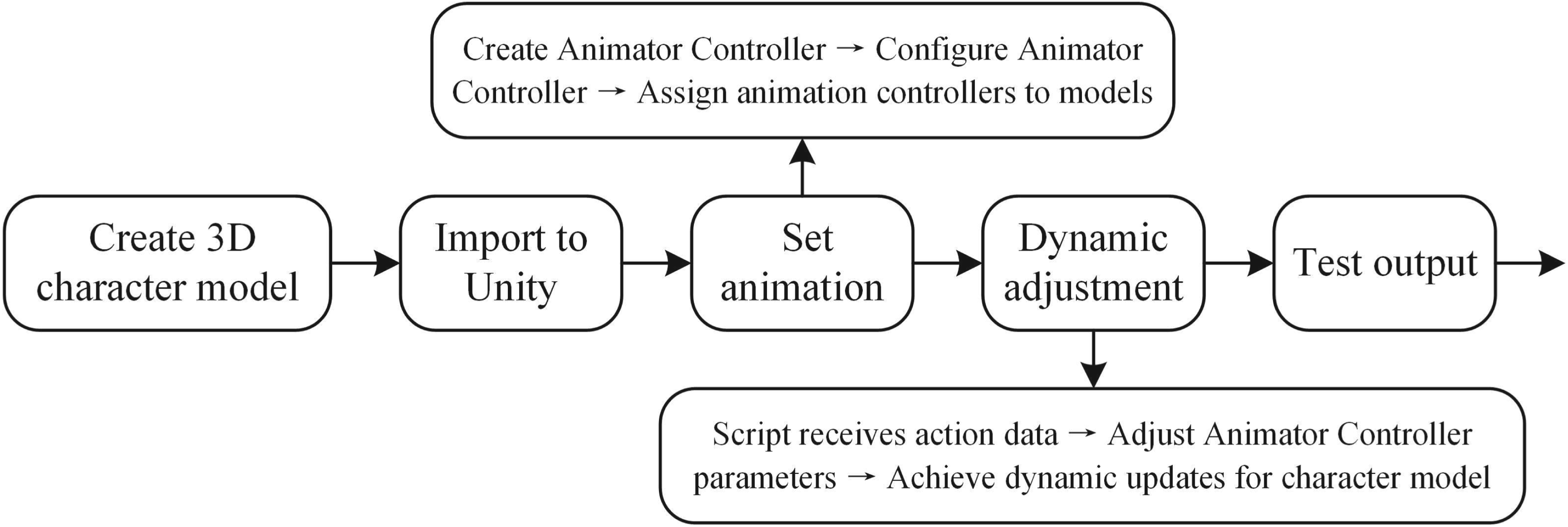
Unity realizes virtual character model action synchronization operation flow.
HMDB51 and UCF101 are classic benchmark datasets in the field of action recognition, covering diverse action categories across indoor and outdoor scenarios. They are suitable for validating the model’s robustness to complex backgrounds and varying lighting conditions. Kinetics-400 contains large-scale long video sequences with rich spatiotemporal dynamics, which effectively evaluates the model’s capability for multiscale feature modeling. This paper adheres strictly to the official training and test set splits of the HMDB51, UCF101, and Kinetics-400 datasets to verify the model’s training effectiveness. We adopt a sparse sampling strategy to process video clips, evenly dividing the input video into
During the training phase, dropout is set to 0.9, the batch size is 64, and the frame size is
Action Recognition Performance
This section presents extensive experiments to evaluate the proposed method on relevant datasets, comparing it with several state-of-the-art methods. The results are shown in Tables 1 and 2. Our action recognition model achieves recognition accuracies of 74.9% on the HMDB51 dataset and 95.8% on the UCF101 dataset, which are improvements of 1.4% and 1.2%, respectively, over the PoolFormer-S24 using a single average pooling mixer. ConvEB enriches low-level details through multiscale local feature enhancement, while MAPFormer’s parallel pooling strategy efficiently aggregates global context. Their synergy achieves complementary local–global feature integration. Ablation studies (last two rows of Table 1) demonstrate that removing ConvEB alone leads to a 1% decrease in accuracy for HMDB51 and a 0.9% decrease for UCF101, thus validating the tight coupling between these two modules. Additionally, the proposed method achieves Top-1 and Top-5 accuracies of 83.8% and 95.9% on the Kinetics-400 dataset, respectively, surpassing CETNet-S, which uses convolutional enhancement and multihead attention network, by 0.4% and 0.3%, and multimodal video transformer (MM-ViT), which employs cross-attention mixer, by 0.3% and 0.8%. Although their recognition results are close to our method, their computational cost is 158% and 385% higher, and their parameter counts are 63% and 319% higher, respectively. The experimental results demonstrate that our model not only outperforms existing methods in terms of recognition accuracy, but also effectively reduces computational and parameter costs, shortening training times and improving model generalization.
Comparison of Accuracy on HMDB51 and UCF101.

Comparison of Accuracy on HMDB51 and UCF101.
Note. MM-ViT=multimodal video transformer; I3D = Inflated three-dimensional; MAPFormer = multiscale average pooling encoder; ConvEB = convolutional enhancement block; STA-CNN = spatial–temporal attention convolutional neural network.
Comparison of Accuracy, Computation and Parameter Count on Kinetics-400.
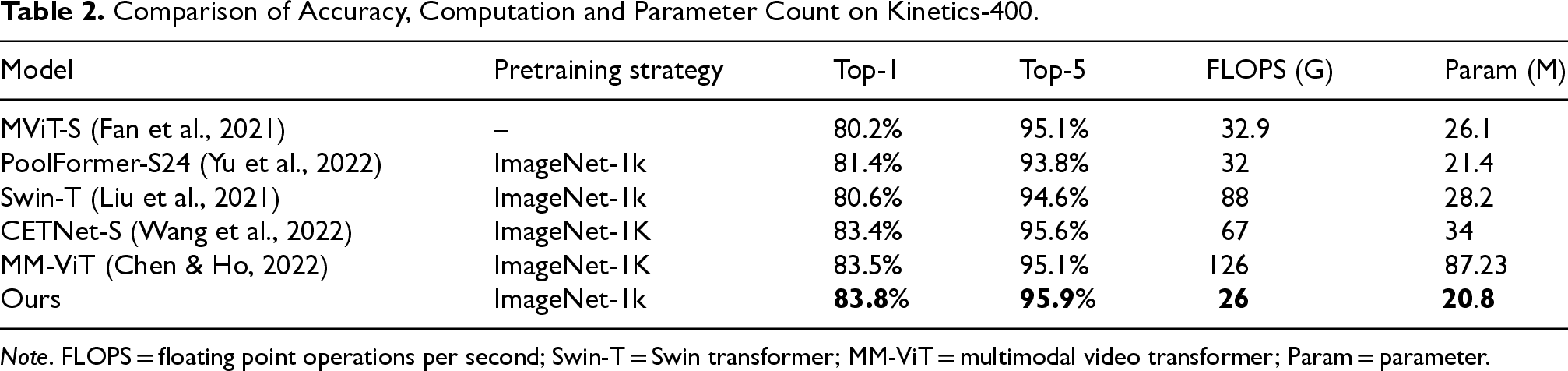
Note. FLOPS = floating point operations per second; Swin-T = Swin transformer; MM-ViT = multimodal video transformer; Param = parameter.
To systematically evaluate the contributions and optimal configurations of various modules in the proposed action recognition model based on ConvEB-MAPFormer, this section conducts ablation studies in several aspects. First, to explore the generalization of the proposed ConvEB when combined with other types of attention backbone networks for action recognition tasks, we combine the ConvEB with several advanced attention networks and conduct comparative experiments on the Kinetics-400 dataset under the same experimental settings. The results are shown in Table 3.
Comparison of Accuracy of ConvEB in Combination With Other Different Models.
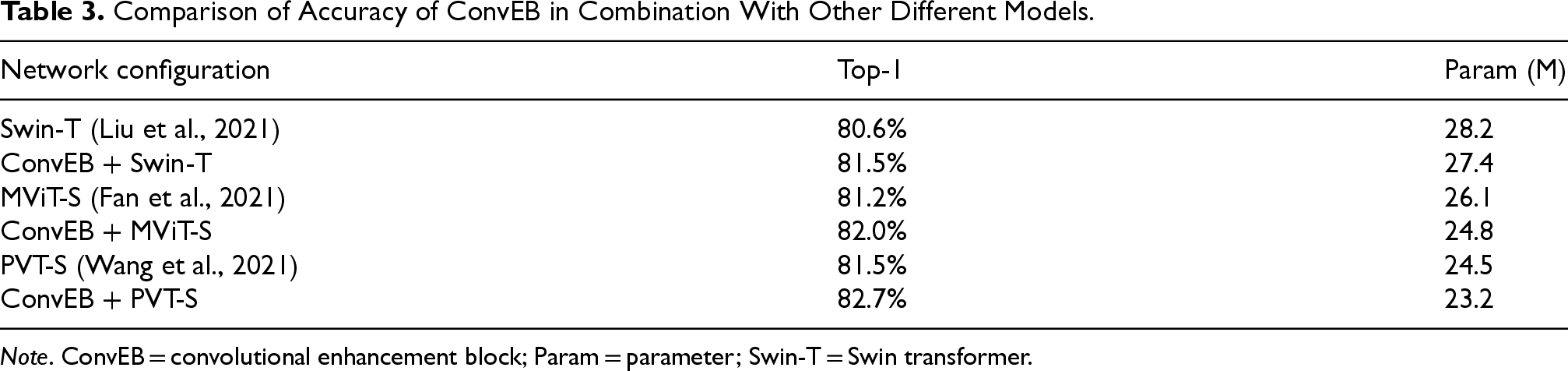
Comparison of Accuracy of ConvEB in Combination With Other Different Models.
Note. ConvEB = convolutional enhancement block; Param = parameter; Swin-T = Swin transformer.
The table shows that when combined with ConvEB to form hybrid models, operations such as patch embedding and positional embedding in the original models are replaced by convolutional embedding, resulting in a slight reduction in the number of model parameters. In terms of recognition accuracy, ConvEB effectively extracts multiscale local features and preserves spatial information. When combined with ConvEB, the accuracy of Swin-T increases by 0.9%, MViT-S by 0.8%, and PVT-S by 1.2%, verifying the effectiveness and generalizability of the ConvEB.
Furthermore, this section compares the configurations of the MAPFormer. Based on the composition of the parallel pooling layer, several groups of average pooling layers with different numbers and kernel sizes are used. The results are shown in Figure 9, the parallel pooling mixer used in this paper adopts the (3, 7, 11) kernel size combination. The choice of pooling kernel sizes is empirically determined through experimental validation: smaller kernels (
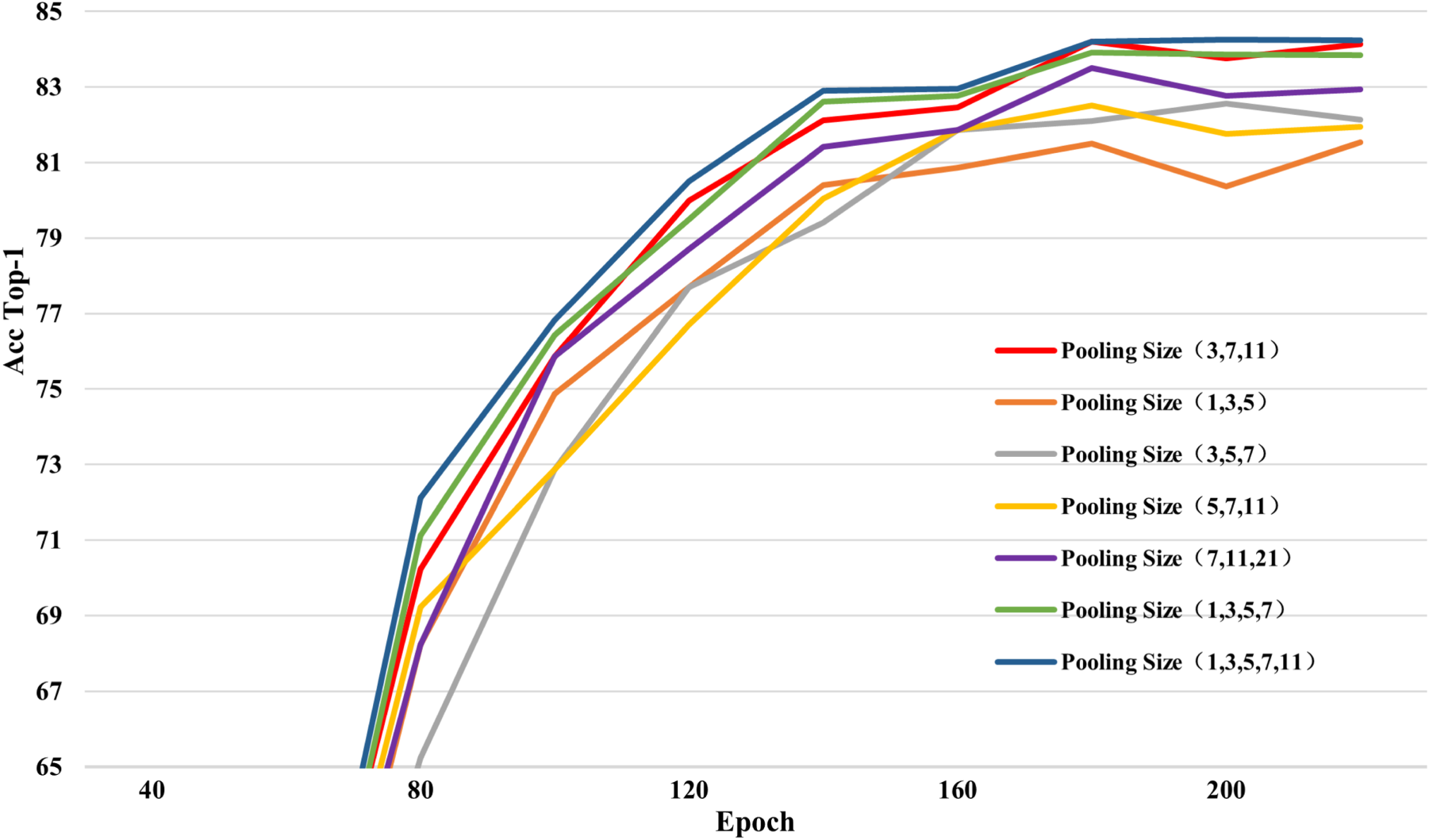
Accuracy variation curves for different combinations of pooling sizes.
Performance Comparison of Different Perceptual Layer Structures of MAPFormer.

Note. MAPFormer = multiscale average pooling encoder; Param = parameter; MLP = multilayer perceptron; Conv-BN = convolutional-batch normalization.
To test the accuracy of the proposed action recognition model in the panoramic live broadcasting system, we record numerous panoramic videos in various scenarios, including library interior, indoor laboratory scene, and outdoor campus environment. In each scenario, 10 different individuals perform 20 common action categories (e.g., waving, drinking, touching the nose, standing up, squatting, walking, and jumping). Ensure the video quality and that each clip contains the corresponding action category, and each video segment is 15 s long. For system performance testing, we use a sparse sampling strategy and apply the trained ConvEB-MAPFormer model to recognize actions in panoramic videos. The video action recognition accuracies in different scenarios are shown in Table 5.
Recognition Accuracy of ConvEB-MAPFormer Model in Panoramic System.

Recognition Accuracy of ConvEB-MAPFormer Model in Panoramic System.
Note. ConvEB = convolutional enhancement block; MAPFormer = multiscale average pooling encoder.
The table shows that in the relatively simple indoor laboratory scene, the recognition accuracy reaches 93%. In the library, also an indoor environment but with a more complex background and lighting, the accuracy drops to 91.5%. In the outdoor campus environment, affected by outdoor lighting, background, and meteorological conditions, the recognition rate is lower. However, the overall accuracy remains above 90%.
Additionally, this section conducts an action recognition experiment in virtual panoramic live broadcasting within a laboratory scene. According to Section 4.2, the receiver of the panoramic video achieves synchronization between live actions and virtual character animation model postures. As shown in Figure 10, a scene from the virtual panoramic live broadcasting captured from the PotPlayer window shows that when the broadcaster makes a hand-raising gesture, the 3D virtual character animation model also synchronizes with the hand-raising gesture. Finally, this section tests the system latency before and after applying the action recognition algorithm. During live broadcasting in the laboratory scene, the real-time performance of the system is obtained by calculating the time difference between the collector and receiver. Specifically, the latency test is conducted in five rounds, with 10 sets of latency data collected at different times in each round, and the average value of each round is obtained, as shown in Table 6.

Virtual panoramic live broadcasting screen.
Latency Test Results of the Live Broadcasting System.
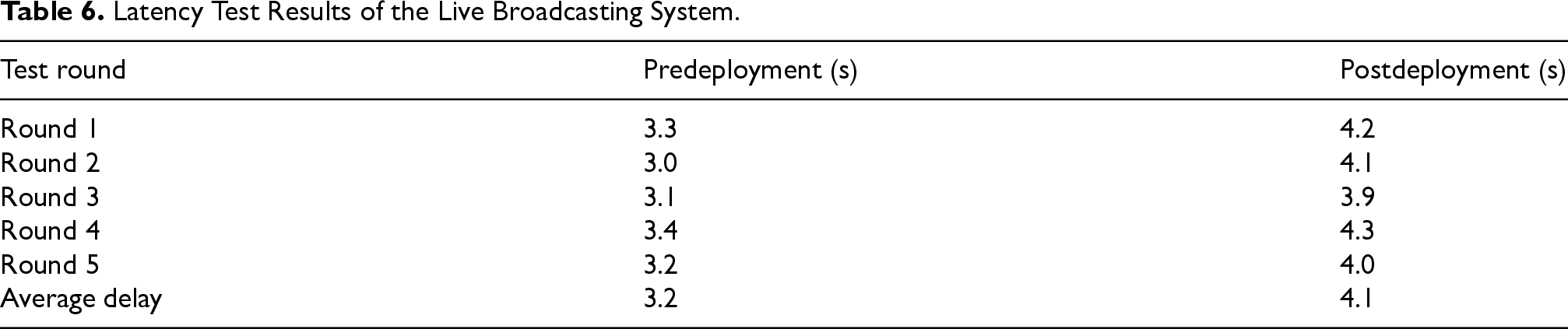
The table indicates that the average latency of the system without the action recognition algorithm is 3.2 s, while the average latency with the ConvEB-MAPFormer model is 4.1 s. This demonstrates that the application of the action recognition algorithm in panoramic live broadcasting only causes a slight delay, which is generally acceptable for daily live broadcasting needs. The main reasons for the system latency are as follows: limited hardware resources in the laboratory, leading to latency during video collection, panoramic video stitching, and action recognition; small network bandwidth in the laboratory, resulting in slower video transmission at the cloud forwarder; and the time-consuming of real-time rendering of panoramic videos.
While the proposed model achieves competitive performance, several limitations remain. First, the recognition accuracy in outdoor complex scenarios (e.g., dynamic lighting changes, occlusions, or crowded backgrounds) still has room for improvement. Second, the system latency is constrained by hardware computational power and network bandwidth. Future work could explore model quantization or knowledge distillation techniques to further lightweight the architecture while maintaining accuracy. Additionally, integrating multimodal signals (e.g., audio–visual joint modeling) may enhance action understanding in scenarios where visual cues are ambiguous.
Conclusion
In this paper, we proposed a lightweight multiscale action recognition model based on ConvEB and MAPFormer, and deployed it in practical application. The ConvEB incorporates PSA into the Fused-MBConv structure to form PSF-MBConv, which serves as the building block of the network. This module aims to establish long-range dependencies of multiscale features between channels in the early stages of the network, providing effective inductive biases for the attention network. The MAPFormer employs multiple average pooling layers with different pooling sizes in parallel to create a parallel pooling mixer, replacing the traditional attention mixer in the attention network and integrating it with Conv-BN structure. This design seeks to maintain recognition accuracy while further enhancing the model’s computational and inference efficiency.
Experimental results on various datasets demonstrated the effective improvement of the proposed action recognition algorithm in terms of accuracy, parameter count, and computational volume. Ablation studies indicated that the proposal and optimization of our two-part modules have achieved positive effects. Tests on panoramic systems have shown that our algorithm can indeed be applied effectively in real-world scenarios. In the future, we plan to explore methods to reduce hardware dependency and runtime, thereby minimizing system latency and improving real-time performance.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A. Implementation Details of PSA Module
PSA primarily consists of a squeeze pyramid concat (SPC) module, SEWeight module, Softmax operation, and Concat fusion, as illustrated in Figure 11. The SPC module (Lin et al., 2017) divides the channels and extracts multiscale spatial information from the channel feature maps. As shown in Figure 12, for the feature map
For the different channel-fused feature maps obtained from the SPC module, the PSA employs the SEWeight module to process them and derive channel attention for the multiscale feature maps. The SEWeight module consists of two parts: squeeze and excitation. The squeeze part utilizes global average pooling to process the input feature maps, generating channel-wise data and embedding spatial information into the channel description for global information encoding. The excitation part uses two fully connected layers and a linear mapping unit to linearly combine the information across channels to help the interaction of channel information in different dimensions. The calculation is as follows:
Finally, PSA uses the Softmax operation to recalibrate the weights of the channel attention weight vectors obtained from the SEWeight module, resulting in the final attention weights. These attention weights are then multiplied with the corresponding scale feature maps and fused to produce the final output, as shown below:
Thus, the ConvEB effectively integrates multiscale spatial information across channels, enhancing the information flow between different feature levels and aiding subsequent attention layers in learning higher-level abstract features more effectively.