
Abstract
In recent years, vision-language pretraining (VLP) models have become a crucial driving force in the advancement of artificial intelligence. Besides, studies such as contrastive language-image pretraining (CLIP) have demonstrated that incorporating prompt learning within VLP models can significantly enhance the performance of downstream tasks. However, we believe that CLIP’s visual encoder suffers from feature extraction bias in image classification tasks, which is because of the uneven quantity and distribution of image features CLIP learned between the pretraining and fine-tuning stages. This can be further summarized as an inherent bias in feature extraction for differently distributed samples during the pretraining phase. To address the above problem this paper proposes (i) text-semantic hierarchical injection prompt learning method, which constructs self-attention layers and prompt mapping structures and injects text semantic features into the visual encoder layer by layer to generate visual prompt features and (ii) visual-semantic attention interactive prompt learning method, which further integrates text embeddings with the output features of the visual encoder through cross-attention and constructs instance-level text prompt features for each image. Based on the two above methods, this paper further proposes the multimodal coupling prompt learning CLIP (MCPL-CLIP) to enhance CLIP’s performance in image classification tasks. Experiments conducted on 15 image classification datasets demonstrate that MCPL-CLIP outperforms baseline models such as MaPLe, CoCoOp, and CoOp in cross-dataset transfer, domain generalization, and base-to-novel class generalization tasks, showcasing its superior text semantic representation and visual feature extraction capabilities.
Introduction
The field of artificial intelligence (AI) is witnessing a significant convergence of computer vision (CV) and natural language processing (NLP), where the combined learning paradigm of CV and NLP, known as vision-language pretraining (VLP) models, has emerged as a critical driving force in the development of AI.
To advance VLP models’ ability to perceive the real world, they need to understand, interpret, and reason with multimodal information. By pretraining on large-scale image-text corpora, VLP models can learn general cross-modal representations beneficial for downstream vision-language tasks (Zellers et al., 2019). For example, LXMERT (Tan & Bansal, 2019) employs a dual-stream fusion encoder to learn vision-language joint representations, significantly outperforming traditional models in tasks such as VQA (Antol et al., 2015) and NLVR2 (Suhr et al., 2018) by pretraining on 9.18 million image–text pairs.
However, fine-tuning VLP models is both expensive and complex, making the effective transfer of VLP models to downstream tasks an exciting and valuable problem. Prompt learning offers an effective solution to this issue. By using a small number of task-specific parameters, VLP models can achieve huge performance gains on numerous vision-language tasks.
Our motivation derives from retrieval augmented (RA)-contrastive language-image pretraining (CLIP), which points out the semantic structure mismatch of CLIP’s (Radford et al., 2021) text encoder between pretraining text data and image classification label text. Taking a further step, we believe that CLIP’s visual encoder also suffers from feature extraction bias between the pretraining and fine-tuning stages in image classification tasks. The primary cause stems from the uneven quantity and distribution of image features learned during the pretraining stage. This can be further summarized as an inherent bias in feature extraction for differently distributed samples during the pretraining phase.
Considering that language features are generally more stable in semantic structure compared to visual features (less dependent on specific visual representations), we think it is necessary to inject the rich semantic information from CLIP’s text encoder into the visual encoder to supplement the semantic information of rare samples from the pretraining stage, thereby enhancing the recognition accuracy and robustness of CLIP’s visual encoder in handling various fine-grained image classification tasks.
To address the issues of feature extraction biases and domain shifts between the pretraining and fine-tuning phases of CLIP’s visual encoders, this paper conducts the following research:
This paper proposes a two-stage prompt method to tackle the feature extraction bias of CLIP’s vision encoder: (a) text-semantic hierarchical injection prompt learning (THIPL) method, which constructs a prompt mapping structure (PMS) and injects learnable prompt vectors from the text encoder into each layer of the visual encoder’s transformer structure to construct visual prompt features. (b) Visual-semantic attention interactive prompt learning (VAIPL) method, which integrates text embeddings and visual encoder output features through cross-attention to build instance-level text prompt features, and enhances CLIP’s cross-modal alignment capability. Based on the two-stage prompt method, this paper further proposes multimodal coupling prompt learning CLIP (MCPL-CLIP) to enhance CLIP’s performance in image classification tasks. MCPL-CLIP is evaluated on 15 image classification datasets, showing performance improvements in cross-dataset transfer, domain generalization, and base-to-novel class generalization scenarios compared to multiple baseline models such as CLIP, CoOp, CoCoOp, and MaPLe. For instance, MCPL-CLIP achieves leading margins of 3.35% to 0.93% in cross-dataset transfer, 3.88% to 0.78% in domain generalization, and 7.55% to 0.70% in base-to-novel class generalization. This indicates that MCPL-CLIP’s paradigm of using multimodal interactive information to construct prompts is more effective for image classification tasks and their generalization scenarios compared to using single-modal features.
VLP Models
Given the success of pretrained models in the fields of CV and NLP, numerous studies have attempted to pretrain large-scale models on the joint modality of vision and language. These pretrained models are known as VLP models. The rise of VLP paradigms began with the transfer of BERT (Devlin et al., 2018) to cross-modal representation learning, followed by a series of studies Lu et al. (2019) introducing BERT into multimodal pretraining. Recently, the encoder–decoder framework’s multimodal pretraining paradigms have gained attention, with many encoder–decoder models achieving state-of-the-art performance in cross-modal understanding and generation tasks (Bao et al., 2022).
Another research trend in the VLP field is contrastive learning. The most typical contrastive learning-based VLP models is CLIP, which uses vision transformer (ViT) (Dosovitskiy et al., 2020) or ResNet (He et al., 2016) as the image encoder, transformer (Vaswani et al., 2017) as the text encoder, and a contrastive loss objective to jointly train the two encoders. CLIP’s pretraining dataset is extensive, comprising approximately 400 million image–text pairs. Following CLIP, a series of studies have demonstrated that successful pretraining with contrastive learning methods on large-scale data is not accidental (Jia et al., 2021).
Prompt Learning
The motivation behind prompt learning is to leverage the prior knowledge learned by large-scale pretrained models to perform various downstream tasks. Prompt learning can be summarized as “pretraining, prompting, predicting” reorganizing downstream tasks into forms similar to pretraining tasks, thereby better guiding models to utilize pretrained knowledge to complete specific downstream tasks.
Schick and Schütze (2020) proposed PET (Pattern-Exploiting Training), transforming the input of text classification tasks into cloze questions to convert the reasoning process into a text generation task, fully utilizing the text generation capabilities of language models. Petroni et al. (2019) proposed LAMA (LAnguage Model Analysis), modifying the relation extraction task into cloze questions without altering the pretrained language model, achieving better relation extraction performance than knowledge bases. Compared to fine-tuning, prompt learning freezes most of the pretrained model’s parameters, adjusting the pretrained model with minimal parameter amounts (e.g., 1%). Recent advancements indicate that prompt learning can help pretrained models achieve performance comparable to fine-tuning across different NLP downstream tasks, including natural language understanding and generation (Liu et al., 2021).
Prompt Learning in VLP Models
Recent studies in the vision-language learning field have also demonstrated the effectiveness of prompt learning. Khattak et al. (2023) showed that visual prompt learning could surpass fine-tuning in a series of tasks, with significant advantages in training efficiency. In cross-modal representation learning, prompt learning for CLIP has become a major focus. CLIP is a contrastive learning-based multimodal pretraining model. By using handcrafted prompt templates to convert labels into text descriptions, CLIP achieves remarkable performance in zero-shot image classification tasks. To further enhance performance, CLIP also proposed prompt ensemble methods by manually creating multiple prompt templates. Creating fixed prompts can be a labor-intensive process, which has led to the adoption of continuous prompts or the integration of adapters (Adapter) for CLIP. In addition to CLIP, another area of research explores the use of visual prompts with pretrained language models for multimodal representation learning. These studies demonstrate that even when large-scale pretrained language models are frozen during downstream transfer, they can still effectively adapt to few-shot learning scenarios in multimodal tasks. Similarly, the combination of adapters with CLIP has been shown to yield promising performance. CoOp Zhou et al. (2022b) enhances CLIP for few-shot transfer by fine-tuning a continuous set of prompt vectors within its language branch. On the other hand, CoCoOp (Zhou et al., 2022a) addresses the generalization challenges of CoOp, particularly its underperformance in novel classes. This is achieved by explicitly conditioning the prompts on specific image instances, thus improving its adaptability to previously unseen data. MaPLe (Khattak et al., 2023) adds learnable context tokens in the language branch and conditions vision prompts on language prompts through a coupling function to enable interaction. Inspired by Maple, we add self-attention to the text encoder and project features to the visual encoder, enriching text and guiding visual learning. Cross-modal interaction between text and visual outputs generates prompt features that guide contrastive learning.
Methodology
In this section, we first analyze the feature extraction bias of CLIP’s visual encoder. Then we propose a two-stage prompt method: THIPL method and VAIPL method. Finally, based on THIPL and VAIPL, we propose MCPL-CLIP to enhance CLIP’s performance in image classification tasks.
Problem Description and Analysis for CLIP’s Feature Extraction Bias
Based on RA-CLIP, we believe that CLIP’s visual encoder also suffers from feature extraction bias between the pretraining and fine-tuning stages in image classification tasks. The primary cause is the uneven quantity and distribution of image features learned during the pretraining stage. This can be further summarized as an inherent bias in feature extraction for differently distributed samples during the pretraining phase.
For example, the VLP models may predominantly learn features of common flowers such as “roses,” “carnations,” and “tulips” during the pretraining stage. These common flowers form the VLP models’ prior knowledge and recognition capability for the concept of “flowers.” However, when the VLP models are deployed on a downstream image classification dataset that includes a wide variety of flower species, including many rare ones that the VLP models did not encounter during the pretraining stage, such as “ghost orchids,” “blue cat’s face orchids,” and so on, it struggles to recognize and correctly classify these rare flower species. This visual feature recognition bias due to the uneven image distribution between pretraining and fine-tuning stages is particularly detrimental to fine-grained image classification datasets such as Flower101 (flower species dataset), StanfordCars (vehicle dataset), and FGVC Aircraft (aircraft dataset).
In summary, the model tends to more effectively recognize categories frequently appearing in the pretraining dataset, whereas its feature extraction and recognition abilities significantly diminish for less frequent categories due to insufficient sample support. This learning imbalance directly reflects the model’s prior knowledge bias, where the knowledge base formed during the pretraining stage is not comprehensive but rather overly optimized for certain categories and lacks necessary adaptability for others. When these pretrained models are deployed on specific downstream image classification datasets, the aforementioned feature extraction bias further impacts the model’s recognition accuracy on those datasets. This impact is typically caused by distribution differences between datasets, that is, the visual feature space distance between the pretraining dataset and the downstream task dataset. To narrow this distance, it is essential for the model to capture a broader and more balanced range of visual features during the pretraining stage, thereby enhancing its adaptability to various categories and scenarios.
Multimodal Coupling Prompt Learning CLIP (MCPL-CLIP)
THIPL Method
As shown in Figure 1, this section proposes the THIPL method, which optimizes both the visual and text encoders of CLIP by creating learnable prompt embeddings in the text modality and injecting them into the corresponding prompt embeddings of the visual modality. The specific implementation of THIPL involves adding learnable prompt vectors to several layers of the text encoder’s transformer structure, which are then introduced into the corresponding layers of the visual encoder’s transformer structure through a bottleneck mapping structure. This method retains the prior knowledge learned by the visual encoder during the pretraining stage and allows it to more easily capture the classification features of new image samples during the generalization process.
Essentially, THIPL is based on the principle of complementarity in cross-modal learning, achieving deeper semantic alignment between images and text to better understand and express the intrinsic features of image data. Text-semantic hierarchy injection prompt learning includes the following components:
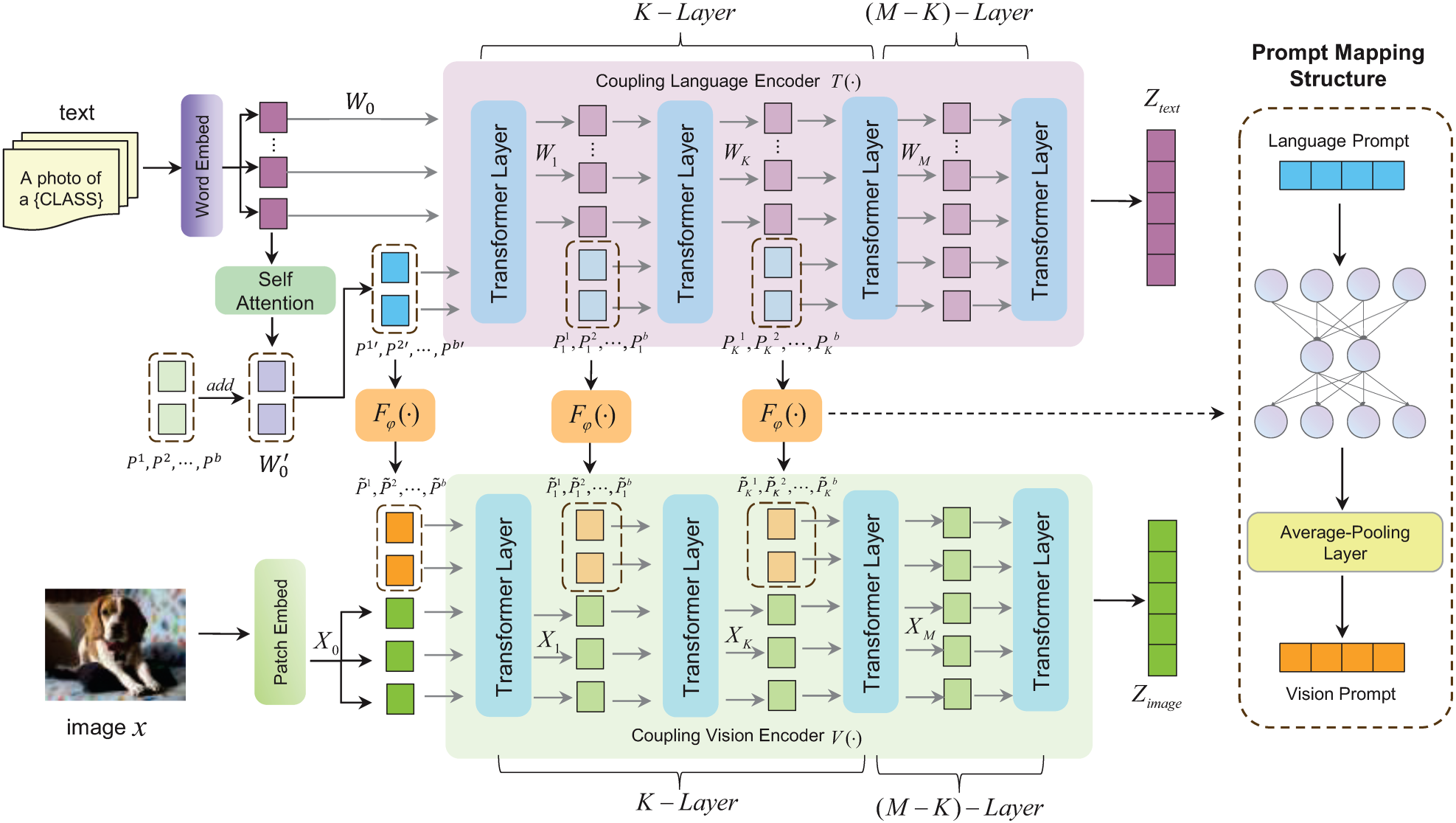
THIPL, where “add” denotes element-wise addition, Word Embed represents the word embedding method, Patch Embed represents the image patch embedding method, and
Let
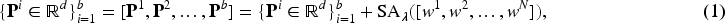
Thus, the input embedding features in CLIP’s text encoder
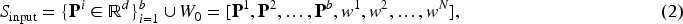
We introduce this structure into the first

The features transmitted in the rear
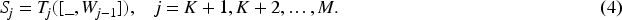

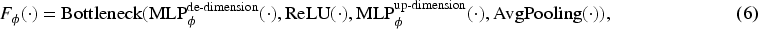
Based on the definition of PMS, visual prompt vectors

Assuming CLIP’s visual encoder is represented by
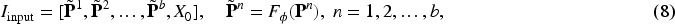
Similar to the text encoder

The features transmitted in the rear
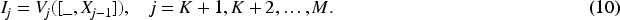

Optimizing and improving text descriptions in the text encoder is a crucial research direction for CLIP models, as it significantly impacts the model’s generalization performance. In the past, during generalization from source to target datasets, it was often difficult to capture concrete visual features that express key semantic information. This is because the text encoder cannot provide a text description that adapts to the new data distribution, making it difficult for the vision-language model to activate its pretrained knowledge circuits for vision-language alignment.
Building on THIPL, we further propose the VAIPL method, as shown in Figure 2. VAIPL method introduces information from the visual encoder under specific data distributions into the text encoder, using the visual information under the specific data distribution to construct instance-level enhanced text features, thereby reducing or compensating for the feature expression differences between modalities in cross-data distribution generalization scenarios.
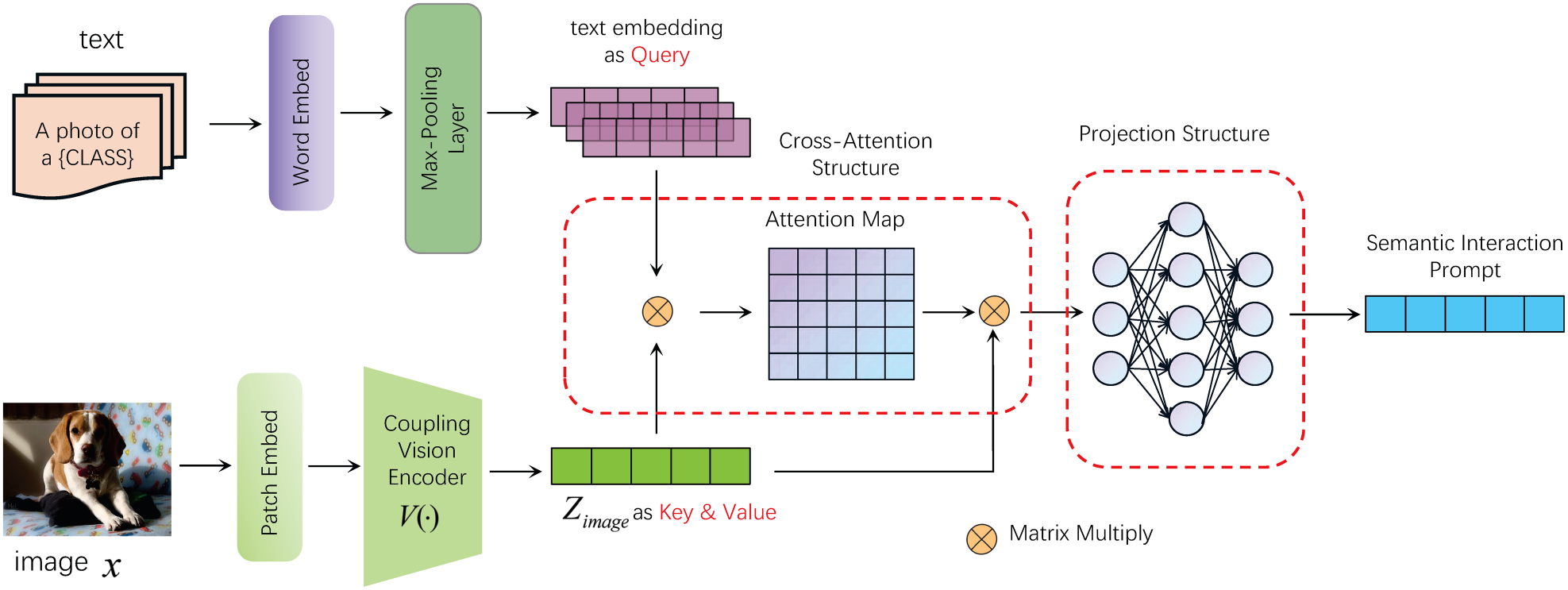
Structure of visual-semantic attention interaction prompt learning (VAIPL). It uses the text embeddings as query vectors after max-pooling, and the visual encoder’s output features as key and value vectors. The first multiplication sign represents the product of text features (Q) and image features (K), while the second multiplication sign represents the product of the attention map (the product of Q and K) and image features (V).
The implementation of the VAIPL method is to apply cross-attention between instance-level image features from the visual encoder and text input embeddings and generate instance-level image-weighted text features through a nonlinear projection structure, referred to as semantic interaction prompt features. VAIPL helps the vision-language model learn patterns that identify and extract features beneficial for cross-modal alignment from specific data distributions. VAIPL ensures that semantic interaction prompt features can be integrated into text features in a language-compatible form, thereby enhancing the vision-language model’s modality alignment capability in generalization scenarios.
Additionally, we use CLIP’s handcrafted template “a photo of a CLASS” to nest the annotations of different datasets at the text embedding input layer. This method alleviates text feature mismatches and training instability issues during the domain generalization process.
VAIPL consists of multiple transformer decoder layers, a max-pooling function, and a nonlinear projection structure. Assuming
VAIPL can be defined by equation (13):
Assuming
We propose a two-stage MCPL-CLIP model to enhance CLIP’s performance in image classification tasks. The MCPL-CLIP structure, shown in Figure 3, includes two stages: the THIPL method and the VAIPL method. The THIPL method introduces learnable text prompt vectors into the text encoder’s various transformer layers and constructs a PMS to inject text prompt features into the visual encoder’s corresponding transformer layers, leveraging the semantic information of the text encoder to build visual prompt features. On this basis, the VAIPL method further integrates text embeddings with the visual encoder output of the text-semantic hierarchy injection prompt framework through cross-attention, constructing text prompt features for each image.
MCPL-CLIP essentially embodies a bidirectional information flow prompt design strategy. It injects semantic features from the text encoder into the visual encoder to construct visual prompts and incorporates feedback from the visual encoder to generate text prompts, achieving bidirectional mapping and joint optimization of text and visual prompts. This ultimately improves MCPL-CLIP’s classification accuracy and robustness across various fine-grained image classification scenarios, such as cross-dataset transfer, domain generalization, and base-to-novel class scenarios.
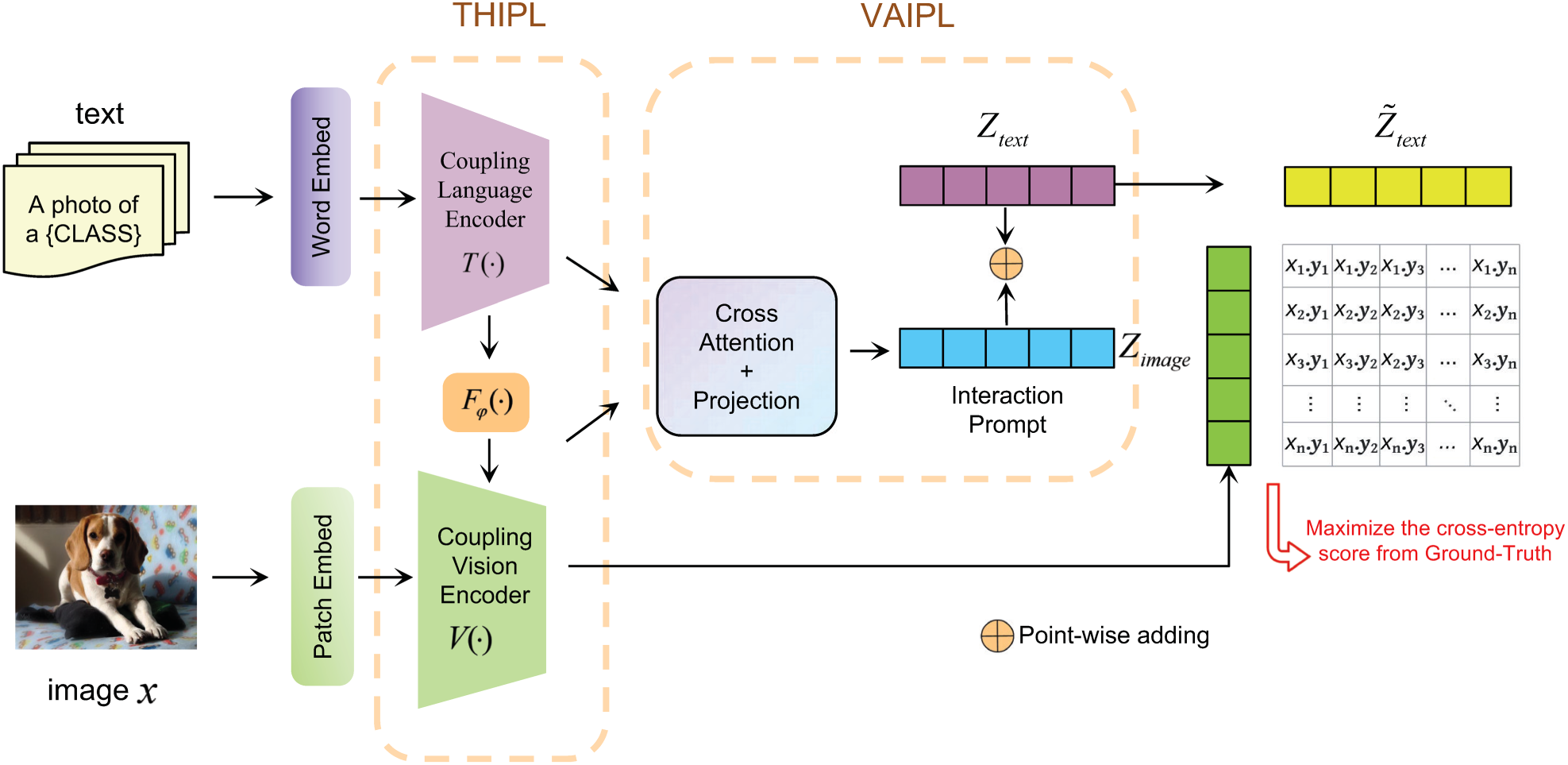
Structure of MCPL-CLIP. MCPL-CLIP includes THIPL with text prompt vectors, visual prompt vectors, PMSs, self-attention layers, and VAIPL with transformer decoder structures, max-pooling functions, and nonlinear projection structures. Point-wise adding represents the word embedding method, and Patch Embed represents the image patch embedding method. Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining; THIPL=text-semantic hierarchical injection prompt learning; VAIPL = visual-semantic attention interactive prompt learning; PMS = prompt mapping structure.
MCPL-CLIP comprises the following parts:
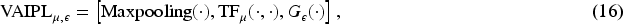
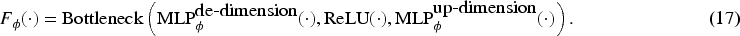

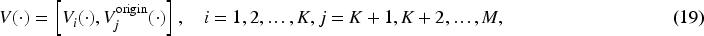

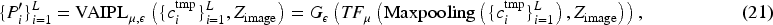
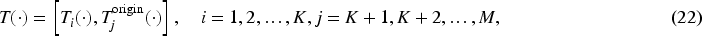

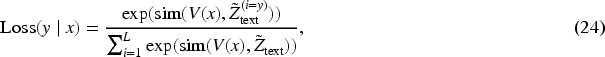
Baselines and Datasets
The baselines include CLIP, CoOp, CoCoOp, and MaPLe. CLIP uses manually designed templates as text prompts; CoOp optimizes only learnable context vectors as text prompt features; CoCoOp uses a lightweight neural network to learn an instance-level image input token and adds it to the text encoder’s prompt embeddings; MaPLe introduces learnable context vectors in the text encoder and maps them to the visual encoder.
We use a total of 15 image classification datasets (11 image classification datasets and four ImageNet variant datasets) for evaluation. For base-to-new class generalization and cross-dataset transfer test scenarios, we evaluate the proposed method on 11 image classification datasets. These datasets cover a wide range of recognition tasks, including two general object datasets, ImageNet and Caltech101; five fine-grained datasets, Oxford Pets, Stanford Cars, Flowers102, Food101, and FGVC Aircraft; scene recognition dataset SUN397; action recognition dataset UCF101; texture dataset DTD; and satellite image dataset EuroSAT.
For the cross-dataset transfer experiment and domain generalization experiment, MCPL-CLIP is trained on the ImageNet dataset and tested on 10 image classification datasets and four ImageNet variant datasets. Detailed dataset statistics are shown in Table 1.
Datasets Statistics.
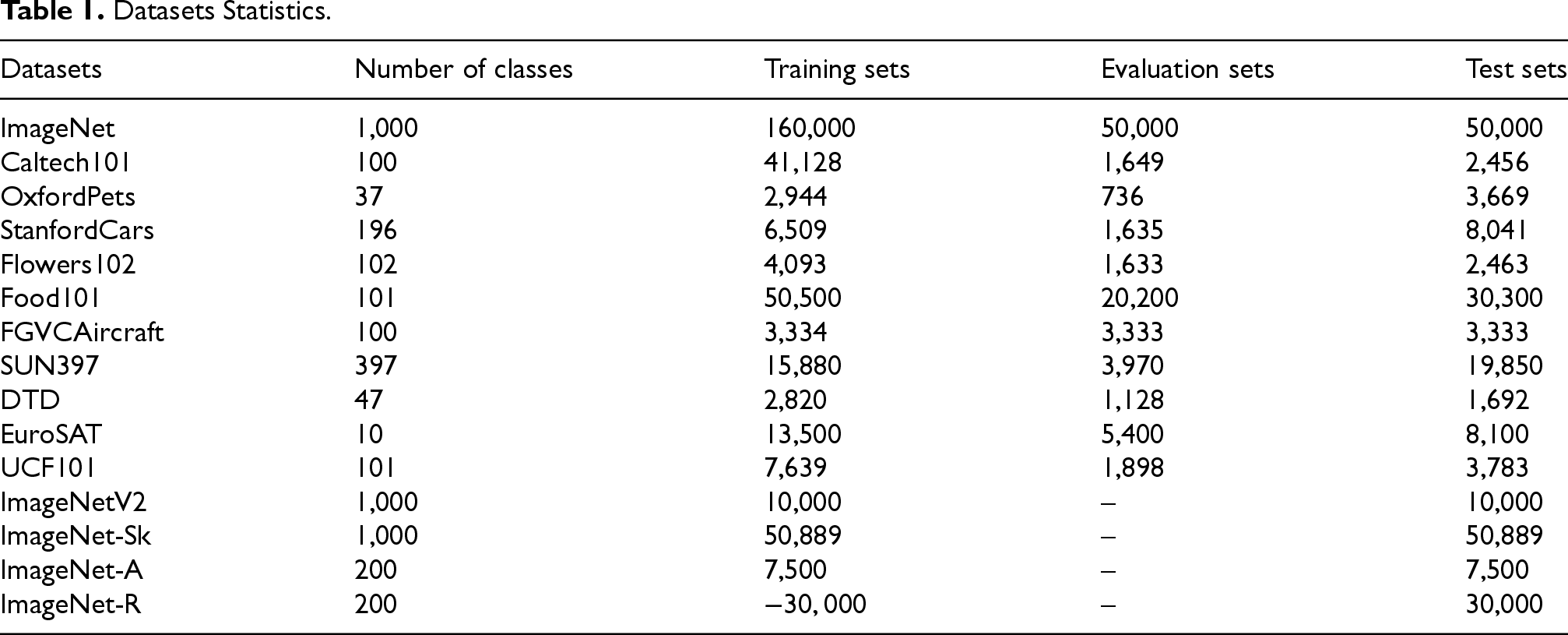
Datasets Statistics.
For the visual encoder, we use ViT-B/16 as the backbone structure, and for the text encoder, we use the original CLIP text encoder. During training, only the training parameters of
All experiments use a few-shot training strategy, randomly selecting 16 samples per category. The prompt embedding depth
Both MCPL-CLIP and benchmark models are trained on a single NVIDIA 3090 GPU for two epochs. The training process is optimized using the stochastic gradient descent optimizer with a learning rate of 0.0035. The training and test datasets are run three times, and the average result is taken as the final result.
Cross-Dataset Transfer Experiment
This experiment focuses on verifying the image classification performance of the model on new data distributions different from the training data distribution. This section evaluates the robustness of the proposed method on out-of-distribution datasets. The emphasis is on the model’s ability to transfer from one dataset to another, highlighting the model’s adaptability to different data sources and potential data variations. Consistent with CoCoOp (Zhou et al., 2022a), the proposed MCPL-CLIP is trained in a few-shot manner on all 1000 classes of the ImageNet dataset.
Table 2(a) shows the experimental results of MCPL-CLIP transferring to 10 datasets. It can be seen that MCPL-CLIP outperforms other benchmark models on multiple datasets. Overall, MCPL-CLIP achieves the highest average accuracy of 67.23%, surpassing other baseline models.
Comparison of MCPL-CLIP and Baselines in Cross-Data Transfer Setting.
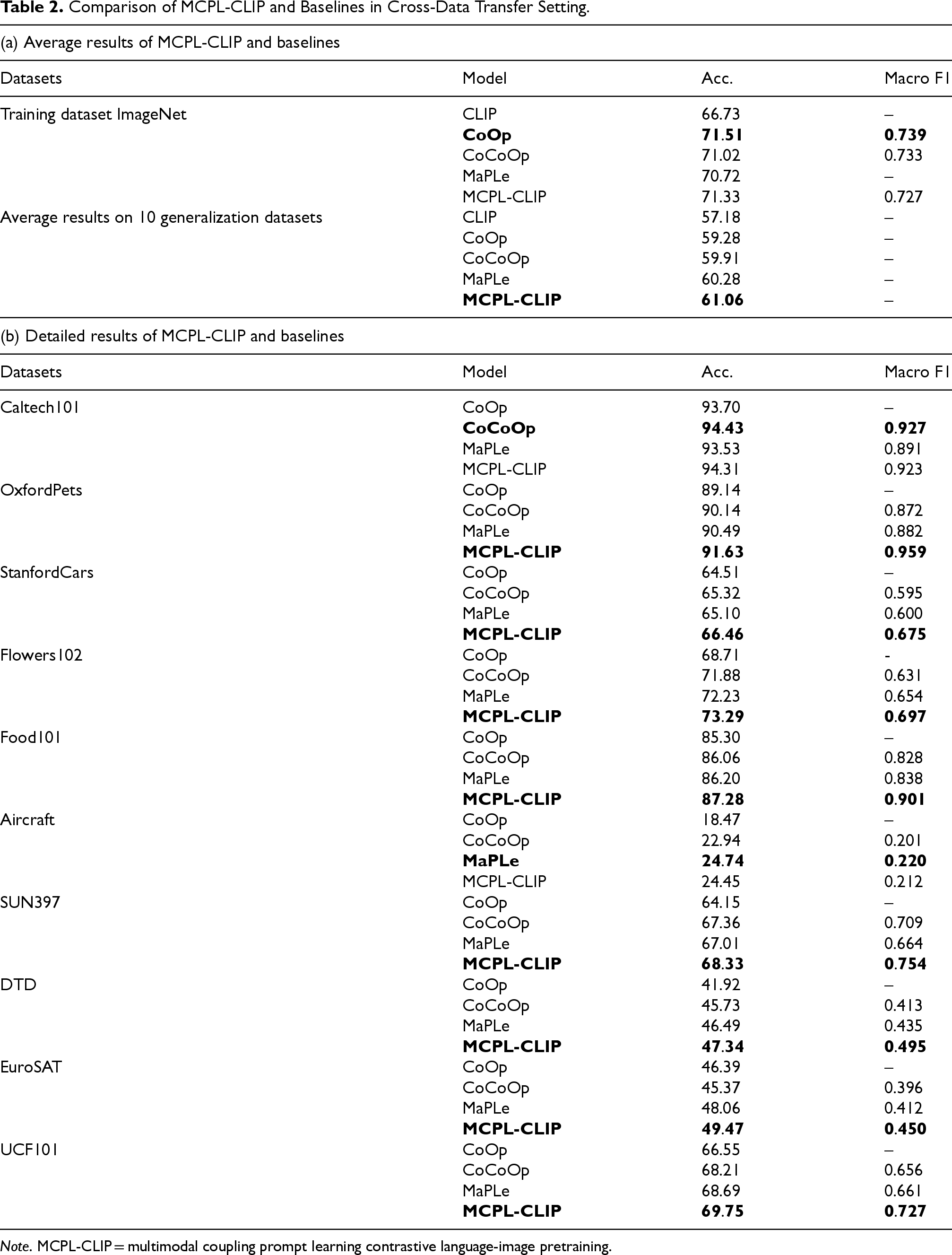
Comparison of MCPL-CLIP and Baselines in Cross-Data Transfer Setting.
Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining.
MCPL-CLIP can capture image-region-to-text correlation features that adapt to new datasets during the transfer to new datasets, which is crucial for handling complex image classification tasks. For example, in fine-grained image classification datasets such as StanfordCars and Flowers102, where the model needs to understand and distinguish highly similar categories, MCPL-CLIP effectively utilizes its cross-modal prompts to capture these nuances. Additionally, VAIPL further enhances MCPL-CLIP’s cross-modal alignment capability. By applying cross-attention between instance-level image features from the visual encoder and text input embeddings, and generating weighted text features through nonlinear projection, VAIPL allows MCPL-CLIP to identify and extract features beneficial for cross-modal alignment when learning from specific data distributions. This might explain MCPL-CLIP’s excellent performance on datasets such as EuroSAT (satellite image dataset) and UCF101 (action recognition dataset), as these datasets require the model to identify complex, task-relevant patterns from visual features.
However, in some datasets such as Aircraft, although MCPL-CLIP’s performance has improved, the improvement is relatively small. This might be due to the high similarity in visual features of aircraft in the Aircraft dataset, posing a greater challenge to the model’s discrimination ability. While MCPL-CLIP helps the model identify features beneficial for cross-modal alignment, distinguishing such highly similar visual features may require more refined model adjustments or specially designed feature extraction strategies. The Caltech 101 dataset contains 101 different object categories, with each category having several dozen images. The images exhibit variations in background and shooting angles. CoCoOp may be better at extracting stable features from images of objects with multiple categories and angles, which gives it an advantage on datasets such as Caltech 101. In contrast, MCPL-CLIP might not achieve optimal performance when handling these features.
The design concept of MCPL-CLIP is to inject textual features into the visual encoder and enhance the text prompts through a feedback mechanism. While this may help improve performance on specific datasets, this feedback mechanism could introduce additional noise in cross-dataset transfer tasks, thereby affecting generalization performance. Moreover, the complex prompt coupling in the MCPL-CLIP model may not be as stable and effective across different datasets as MaPLe and CoCoOp, as the complex feedback mechanism may be inefficient when handling domain shifts.
This experiment focuses on verifying the model’s ability to transfer from one dataset to another, highlighting the model’s adaptability to different data sources and potential data variations. The performance of MCPL-CLIP is tested on four ImageNet variant datasets.
Table 3 shows the experimental results of MCPL-CLIP in the domain generalization evaluation scenario. MCPL-CLIP performs comparably to other benchmark models on the ImageNet training set, showing good baseline performance. Overall, MCPL-CLIP achieves the best performance with an average accuracy of 61.06% across the four domain generalization datasets.
Comparison MCPL-CLIP and Baselines in Domain Generalization Settings.
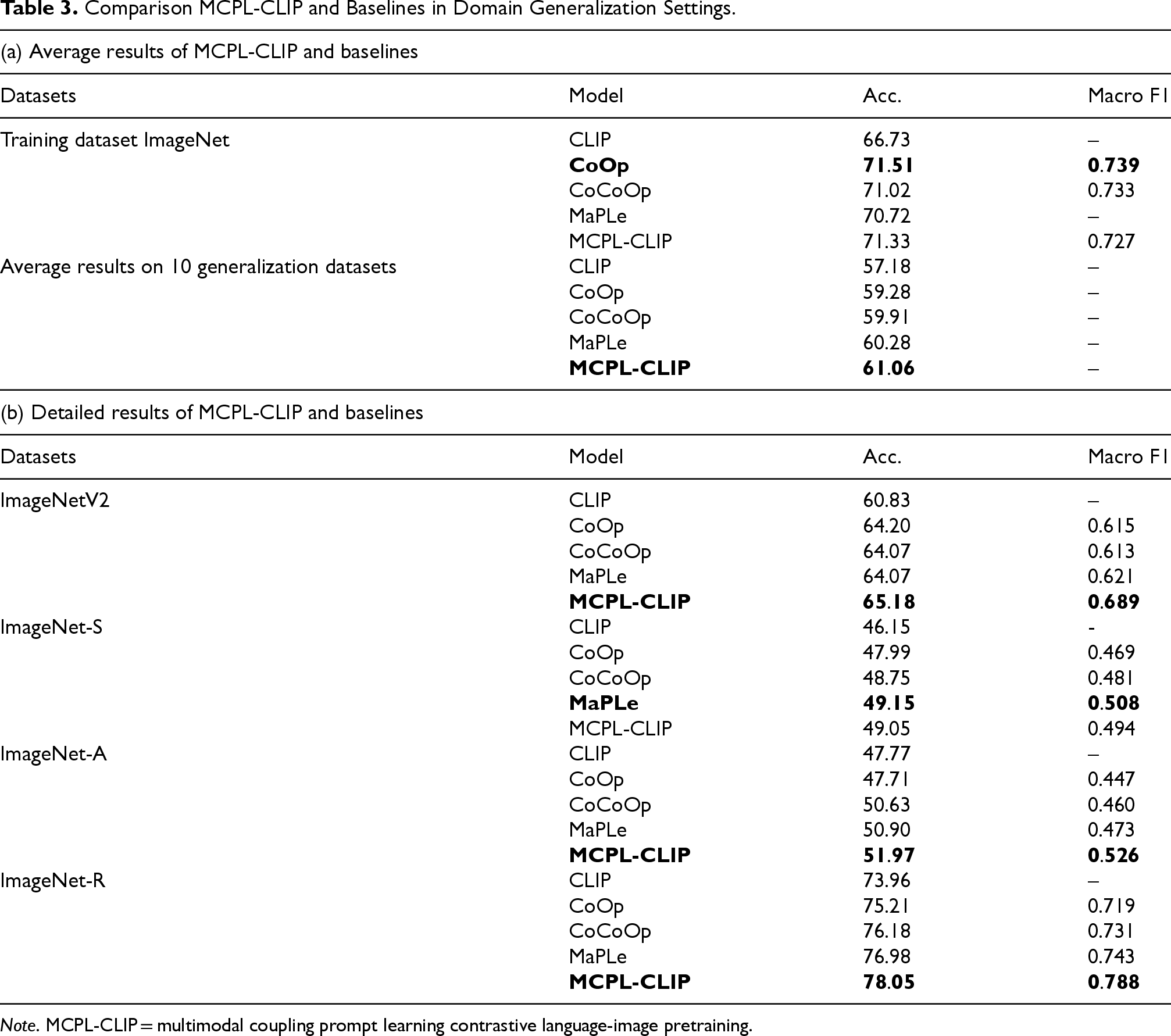
Comparison MCPL-CLIP and Baselines in Domain Generalization Settings.
Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining.
On the ImageNetV2 dataset, which has a slight distribution shift, MCPL-CLIP achieves the highest accuracy of 65.18% and a Macro F1 score of 0.689, indicating that it can better maintain its performance when dealing with slight distribution changes. ImageNet-S (Sketch) contains sketch images with styles significantly different from the original ImageNet images. Although MCPL-CLIP performs slightly lower than MaPLe on this dataset, it still outperforms other models, demonstrating its robustness to significant style differences in data.
ImageNet-A (Adversarial) contains difficult-to-classify image samples from natural images. MCPL-CLIP achieves the best accuracy of 51.97% and a Macro F1 score of 0.526, showing its strong adaptability and generalization ability to challenging samples. ImageNet-R (Rendition) includes artistic renditions of various images. The experimental results of MCPL-CLIP again lead, further proving the effectiveness of its cross-modal prompt and interaction mechanism in handling highly diverse image style data samples.
From the provided experimental results, it can be seen that MCPL-CLIP shows varying performance in domain generalization tasks compared to other baseline models. MCPL-CLIP’s multimodal coupling mechanism may cause feature combinations from the original data to lose effectiveness on stylized data. For stylized images, simpler feature extraction (e.g., lines and shapes) may be more effective than complex bidirectional information flow. This is why MCPL-CLIP underperforms MaPLe on the ImageNet-S dataset in domain generalization tasks, where the model needs strong feature abstraction and recognition despite domain shifts and reduced details. The complexity of MCPL-CLIP may not always be beneficial in such cases, suggesting that optimizations and adaptations are needed for stylized datasets to improve their domain generalization and robustness.
Table 4 shows the experimental results of MCPL-CLIP in base-to-new class generalization within the same data distribution. It can be seen that MCPL-CLIP maintains good generalization ability for unseen classes while ensuring the accuracy of base classes, with the harmonic mean (HM) score outperforming other benchmark models on most datasets. This indicates that MCPL-CLIP can capture and utilize cross-modal features to construct more effective and enriched cross-modal prompt features, providing the model with the ability to understand and adapt to unseen classes.
Comparison of MCPL-CLIP and Baselines in Base-to-new Generalization Settings.
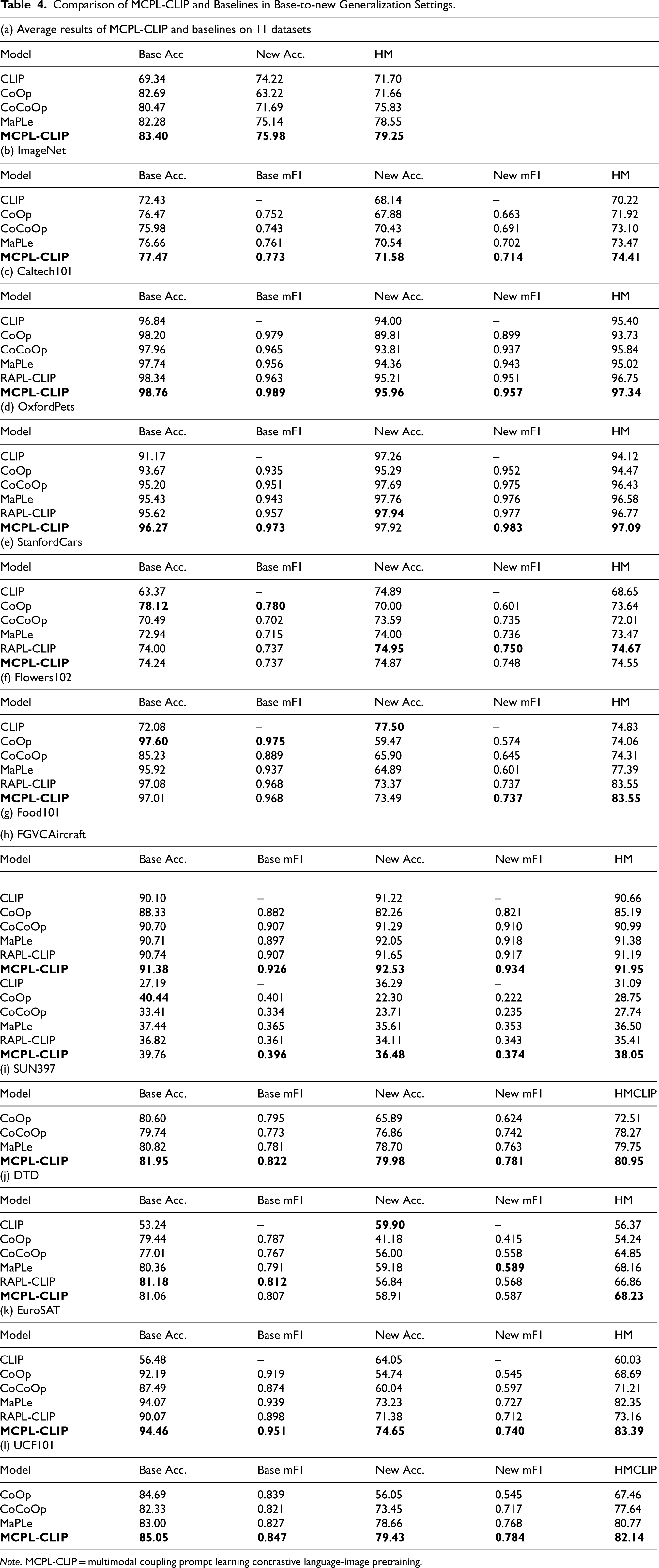
Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining.
On general image classification datasets such as ImageNet and Caltech101, MCPL-CLIP achieves the best results in base class accuracy, new class accuracy, and HM. This proves that MCPL-CLIP can effectively leverage the knowledge learned during the pretraining stage and apply it to new, unseen classes through vision-language coupled interaction prompt learning. On fine-grained datasets such as StanfordCars and Flowers102, MCPL-CLIP’s performance still leads other benchmark models, indicating that MCPL-CLIP is more advantageous in handling data samples with subtle differences in categories. On other datasets such as satellite images (EuroSAT), scene understanding (SUN397), and action recognition (UCF101), MCPL-CLIP also generally leads, demonstrating its robust visual-language alignment and generalization capabilities.
MCPL-CLIP couples text and visual features through bidirectional information flow, a complex mechanism that may not effectively generalize the fine-grained features required when handling new classes, especially in tasks that demand capturing subtle differences. In tasks that require fine-grained feature extraction and recognition (such as Stanford Cars), MCPL-CLIP may not be as effective as some models specifically optimized for such tasks, such as CoOp. The bidirectional information flow and complex prompt design may introduce interference or noise in certain cases, leading to insufficient extraction and generalization of features for new classes.
Prompt Mapping Structure (PMS)
To verify the importance and effectiveness of the PMS, we conducted an ablation study by removing PMS and directly adding the text prompt vectors to the visual encoder (i.e., the text prompt vectors are the same as the visual prompt vectors). Other training parameters and model structures were kept unchanged. MCPL-CLIP was trained on ImageNet and tested on the cross-dataset transfer scenarios of StanfordCars, OxfordPets, and EuroSAT, as well as the domain generalization scenarios of ImageNet-A and ImageNet-R. The specific experimental results are shown in Figures 4 and 5.
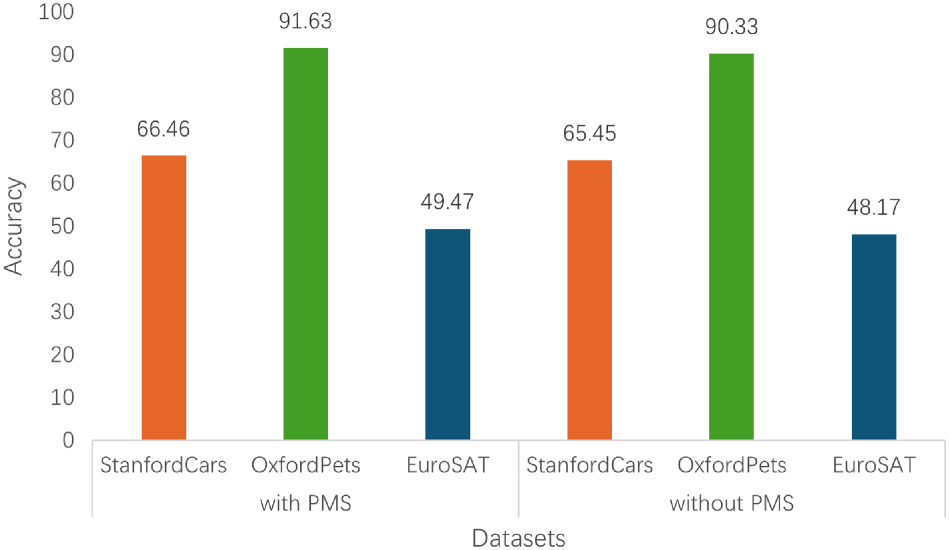
Ablation experiments of prompt mapping structure (PMS) on Stanford Cars, Oxford Pets, and EuroSAT.
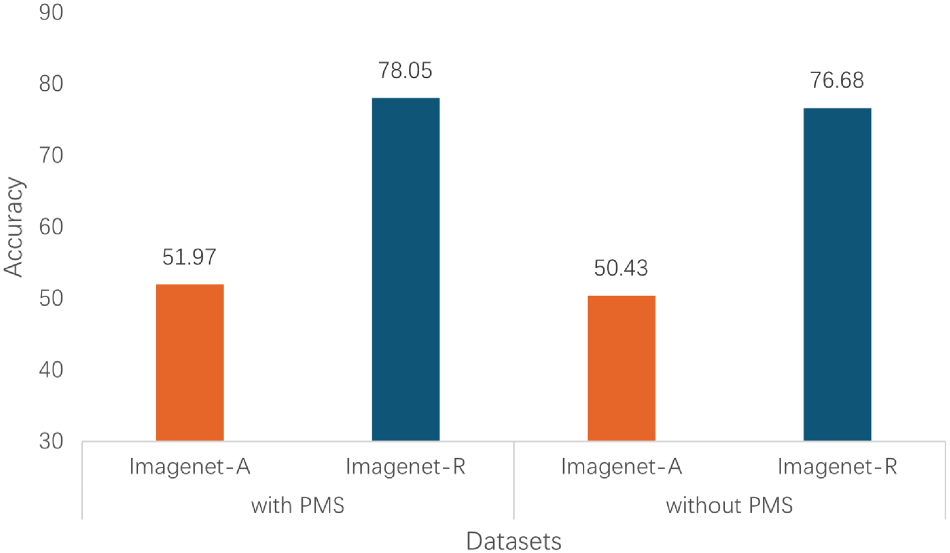
Ablation experiments of prompt mapping structure (PMS) on Imagnet-A and Imagnet-R.
The results show that the PMS plays a crucial role in extracting higher-level abstract semantic features. Removing the PMS causes the vision-language model to lose the ability to transform text prompt vectors into visual-compatible prompt vectors, leading to a collapse of the multimodal feature representation in the visual encoder.
To verify the role of the VAIPL in image classification tasks, we proposed a cross-modal adding-pooling prompting (CMPP) method for comparison experiments. CMPP averages the input embedding features of the text description and directly adds them point-wise to the output features of the visual encoder to construct prompts.
In the ablation study, VAIPL was replaced with CMPP, and MCPL-CLIP was trained on the source dataset ImageNet and tested on the cross-dataset transfer scenarios of Flower102, Food101, and SUN397, as well as the domain generalization scenarios of ImageNetV2 and ImageNet-R. The specific experimental results are shown in Figures 6 and 7.
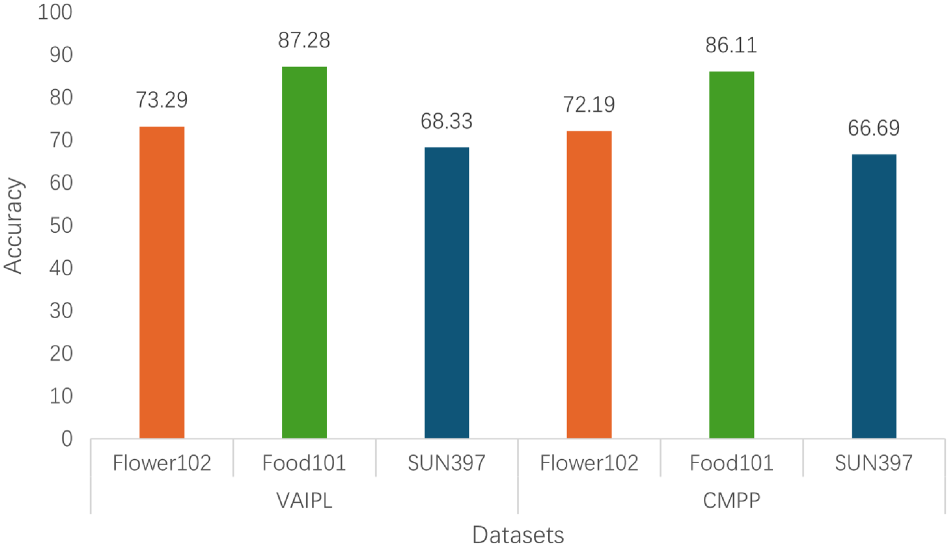
Ablation study of VAIPL and CMPP on Flower 102, Food 101, and SUN397. Note. CMPP = cross-modal adding-pooling prompting; VAIPL = visual-semantic attention interactive prompt learning
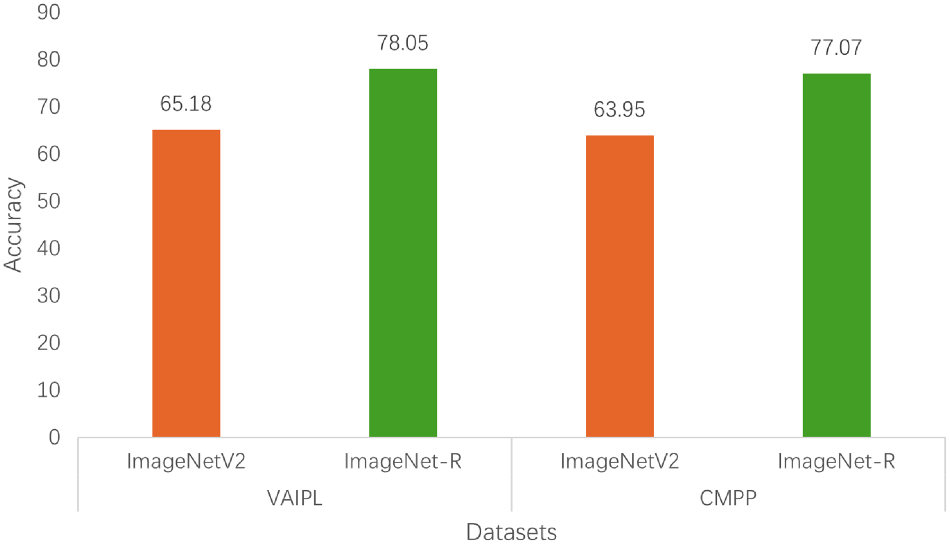
Ablation study of VAIPL and CMPP on ImageNetV2 and ImageNet-R. Note. CMPP = cross-modal adding-pooling prompting; VAIPL = visual-semantic attention interactive prompt learning.
Figures 6 and 7 show that in cross-dataset transfer and domain generalization evaluations, VAIPL achieves higher accuracy on all three datasets compared to the CMPP module. This indicates that VAIPL, by introducing cross-attention and projection mechanisms, not only achieves deeper semantic alignment between visual and language modalities but also captures and integrates semantic information at different levels. This is crucial for improving CLIP’s cross-dataset transfer ability, domain generalization ability, and alignment capability.
In contrast, CMPP, although using a more direct feature fusion method, may be less effective in handling more complex semantic relationships because it lacks deep interaction and nonlinear feature fusion capabilities. Therefore, we believe that compared to simpler prompt construction methods, VAIPL can provide more enriched and multilayered semantic alignment prompts for vision-language models.
Analysis of PMS Scale
This experiment explores whether different scales of the PMS affect MCPL-CLIP’s performance in cross-dataset generalization and domain generalization scenarios. Three different sizes of PMS, namely PMS-Standard, PMS-Large, and PMS-XLarge, were designed and trained on the source dataset ImageNet and tested on the cross-dataset transfer scenarios of Caltech101, Food101, and UCF101, and the domain generalization scenarios of ImageNetV2 and ImageNet-R.
PMS-Standard is the standard parameter scale used in this section, which is a two-layer bottleneck MLP structure (linear-ReLU-linear) with a hidden layer of 128 dimensions; PMS-Large is a four-layer bottleneck MLP structure (linear-ReLU-linear) with a hidden layer of 128 dimensions; PMS-XLarge is a four-layer bottleneck MLP structure (linear-ReLU-linear) with a hidden layer of 256 dimensions. The experimental results are shown in Figures 8 and 9:
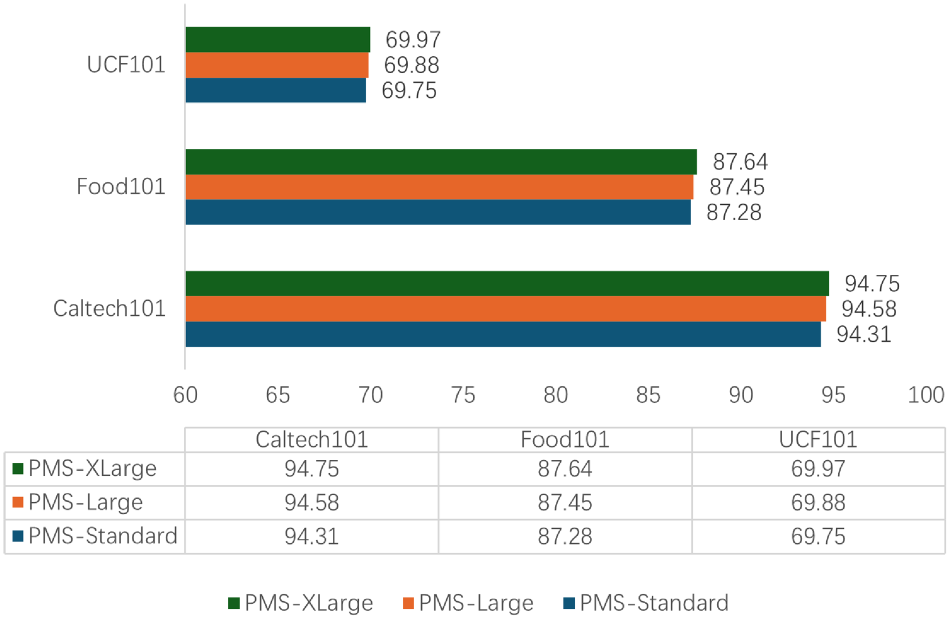
Experiments of different scales of prompt mapping structure (PMS) on StanfordCars, OxfordPets, and EuroSAT datasets.
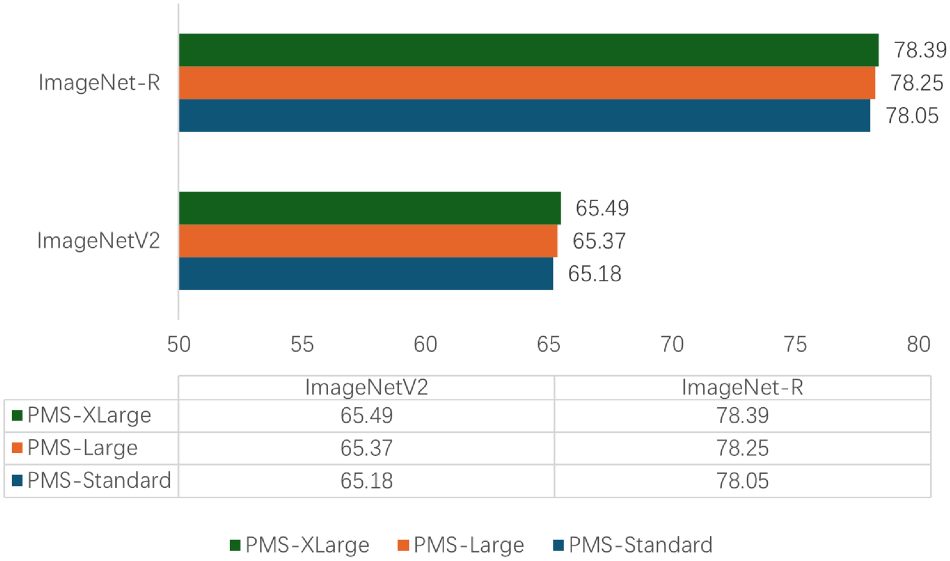
Experiments of different scales of prompt mapping structure (PMS) on Imagnet-A and Imagnet-R datasets.
Figures 8 and 9 show that larger-scale PMS does provide a certain degree of generalization performance improvement, indicating that larger hidden layer dimensions may offer more parameters to capture complex features, thereby enhancing the model’s ability to recognize samples in new data distributions.
However, it is important to note that excessively increasing the size of PMS may lead to overfitting the source training dataset and significant computational resource consumption. Meanwhile, on the Food101 dataset, the performance difference between PMS-XLarge and PMS-Standard is minimal, indicating that for this type of dataset, a larger-scale PMS does not bring significant benefits.
To explore whether the scale of the VAIPL affects the image classification performance of MCPL-CLIP, we proposed three different scales, namely VAIPL-Small, VAIPL-Standard, and VAIPL-Large, which were trained on the source dataset ImageNet and evaluated on the cross-dataset transfer scenarios of Caltech101, StanfordCars, and OxfordPets, as well as the domain generalization scenarios of ImageNetV2 and ImageNet-S. The detailed structure settings of the different scales of VAIPL are shown in Table 5:
Detailed Structure Settings for Different Prompt Embedding Depths.

Detailed Structure Settings for Different Prompt Embedding Depths.
Ablation experiments were conducted on the prompt embedding depth in both the text encoder and the visual encoder to explore whether different prompt embedding depths affect the classification performance of MCPL-CLIP. The experiments were trained on ImageNet and tested on the cross-dataset transfer scenarios of DTD, Food101, and EuroSAT, as well as the domain generalization scenarios of ImageNet-A and ImageNet-S.
Tables 6 and 7 indicate that as the prompt embedding depth increases, the generalization performance of MCPL-CLIP also improves, but the improvement is not significant. This suggests that deeper prompt embedding can indeed bring performance improvements, possibly because deeper embeddings provide more complex feature representations, helping the model better understand and adapt to new domain data. However, the marginal performance improvement indicates that beyond a certain depth, additional complexity may not bring significant performance gains. In practical applications, this means finding a balance between performance and computational efficiency. If additional depth does not yield noticeable performance improvements, simpler structures may be the optimal choice as they achieve similar performance at lower computational costs.
Experiments of MCPL-CLIP with Different Prompt Embedding Depths on Food101 and EuroSAT Datasets.

Experiments of MCPL-CLIP with Different Prompt Embedding Depths on Food101 and EuroSAT Datasets.
Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining.
Experiments of MCPL-CLIP with Different Prompt Embedding Depths on ImageNet-A and ImageNet-S Datasets.

Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining.
Therefore, we believe that while increasing prompt embedding depth positively impacts the model’s generalization performance, considering the diminishing marginal benefits and the need to maintain computational efficiency, choosing a “standard” depth of prompt embedding is a reasonable solution.
We conducted an analysis experiment on training epochs to explore whether different training epochs affect MCPL-CLIP’s generalization performance and to investigate whether MCPL-CLIP faces overfitting or underfitting during the ImageNet dataset training process. The training epochs of MCPL-CLIP were set to 1, 2, 3, and 4, respectively, and the training dataset was ImageNet. The generalization scenarios were evaluated on the EuroSAT and ImageNet-R datasets. The experimental results of MaPLe under the same training settings were introduced for comparison. The specific experimental results are shown in Figures 10 to 12.
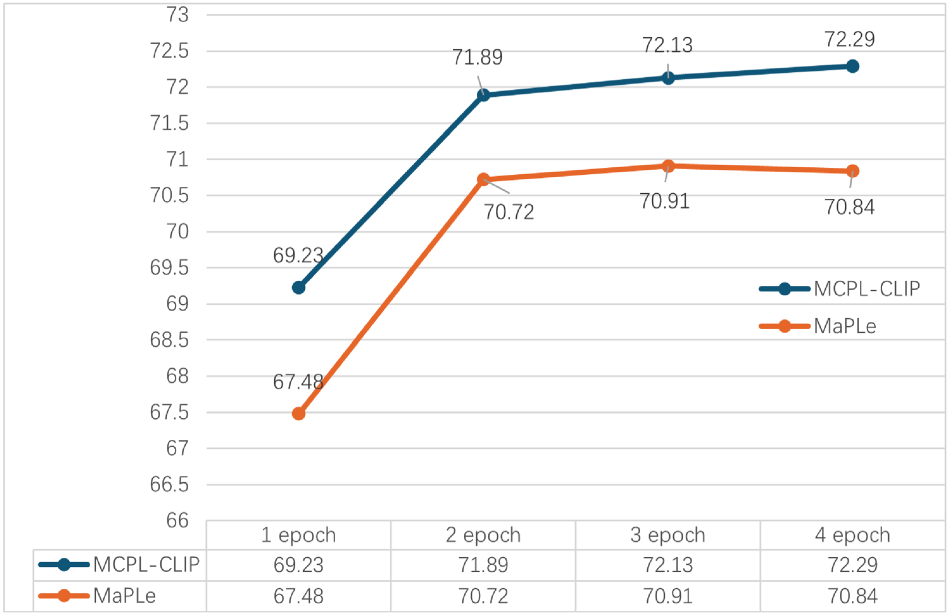
Experiments of multimodal coupling prompt learning contrastive language-image pretraining (MCPL-CLIP) and MaPLe for different training epochs on ImageNet.
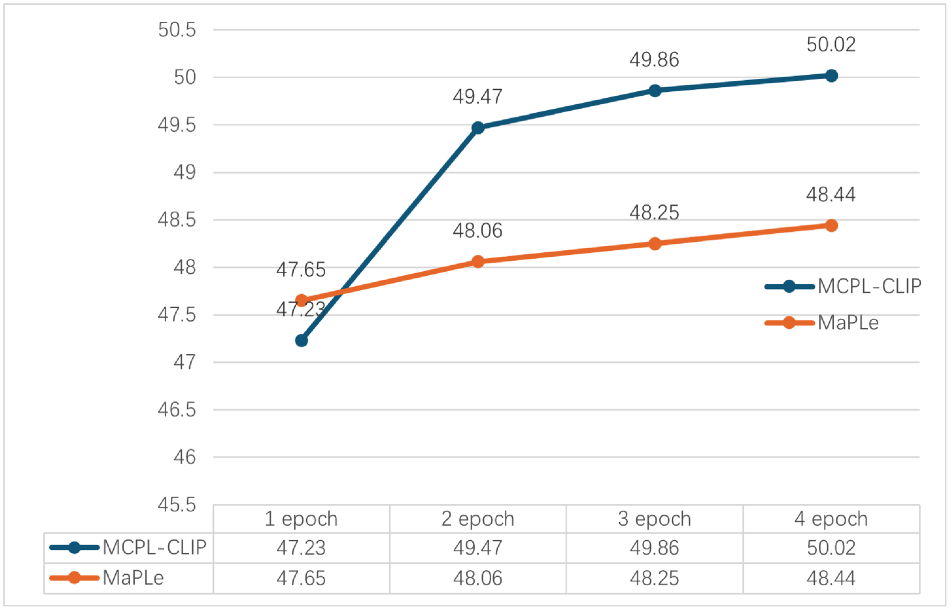
Experiments of multimodal coupling prompt learning contrastive language-image pretraining (MCPL-CLIP) and MaPLe for different training epochs on EuroSAT.
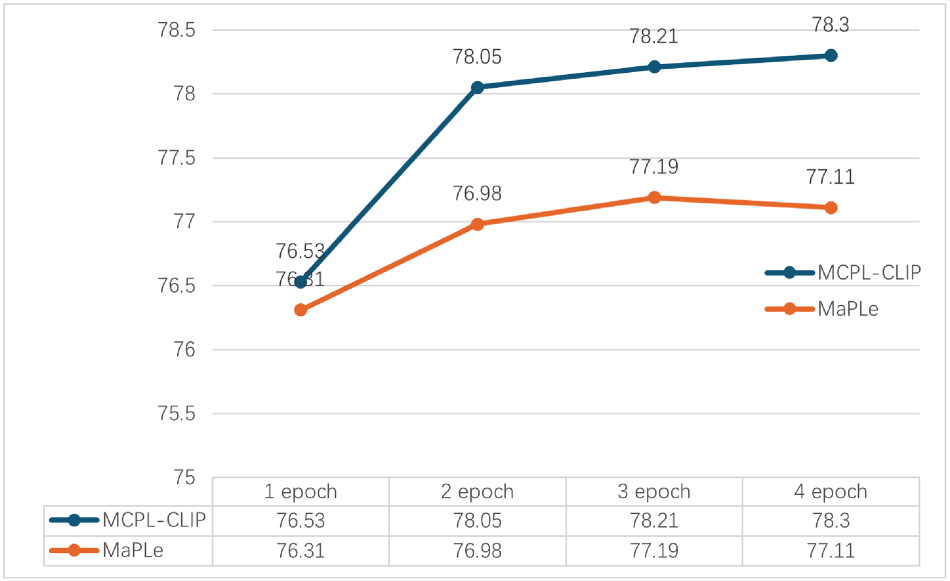
Experiments of multimodal coupling prompt learning contrastive language-image pretraining (MCPL-CLIP) and MaPLe for different training epochs on Imagnet-R dataset.
Figure 10 shows that during the ImageNet training phase, the accuracy of MCPL-CLIP gradually improves with the increase in training epochs, from 69.23% in one epoch to 72.29% in four epochs. This indicates that MCPL-CLIP can better learn the features of the ImageNet dataset as training progresses. The accuracy of MaPLe also increases with the number of epochs but shows a slight decline in the fourth epoch, from 70.91% to 70.84%, indicating a slight overfitting phenomenon.
Figures 11 and 12 show that during the generalization to EuroSAT/ImageNet-R, MCPL-CLIP improves from 47.23%/76.53% in one epoch to 50.02%/78.30% in four epochs. This shows that MCPL-CLIP does not exhibit significant overfitting and can improve its adaptation and generalization ability to new datasets with more training epochs. In contrast, the performance of MaPLe tends to stabilize and even regress to some extent in four epochs. This may indicate that MaPLe’s fewer training parameters lead to saturation and reaching its performance bottleneck earlier in the training phase.
In summary, MCPL-CLIP can more effectively benefit from the increased training epochs, showing stronger generalization ability and sustained learning capability.
This section conducted resource consumption analysis experiments on three different computing platforms. The experiments were conducted on NVIDIA 3090 GPU, Nvidia 3080Ti GPU, and Nvidia Tesla T4 GPU platforms, and all 14 target datasets were tested. The metrics reported include test duration, GPU memory consumption, and memory consumption. Due to the high memory usage during the training phase, MCPL-CLIP was trained only on the NVIDIA 3090 GPU platform, and the training duration for the source dataset ImageNet was additionally reported. The detailed resource consumption on each computing platform is shown in Table 8.
Computational Cost and Resource Overhead Analysis of MCPL-CLIP.
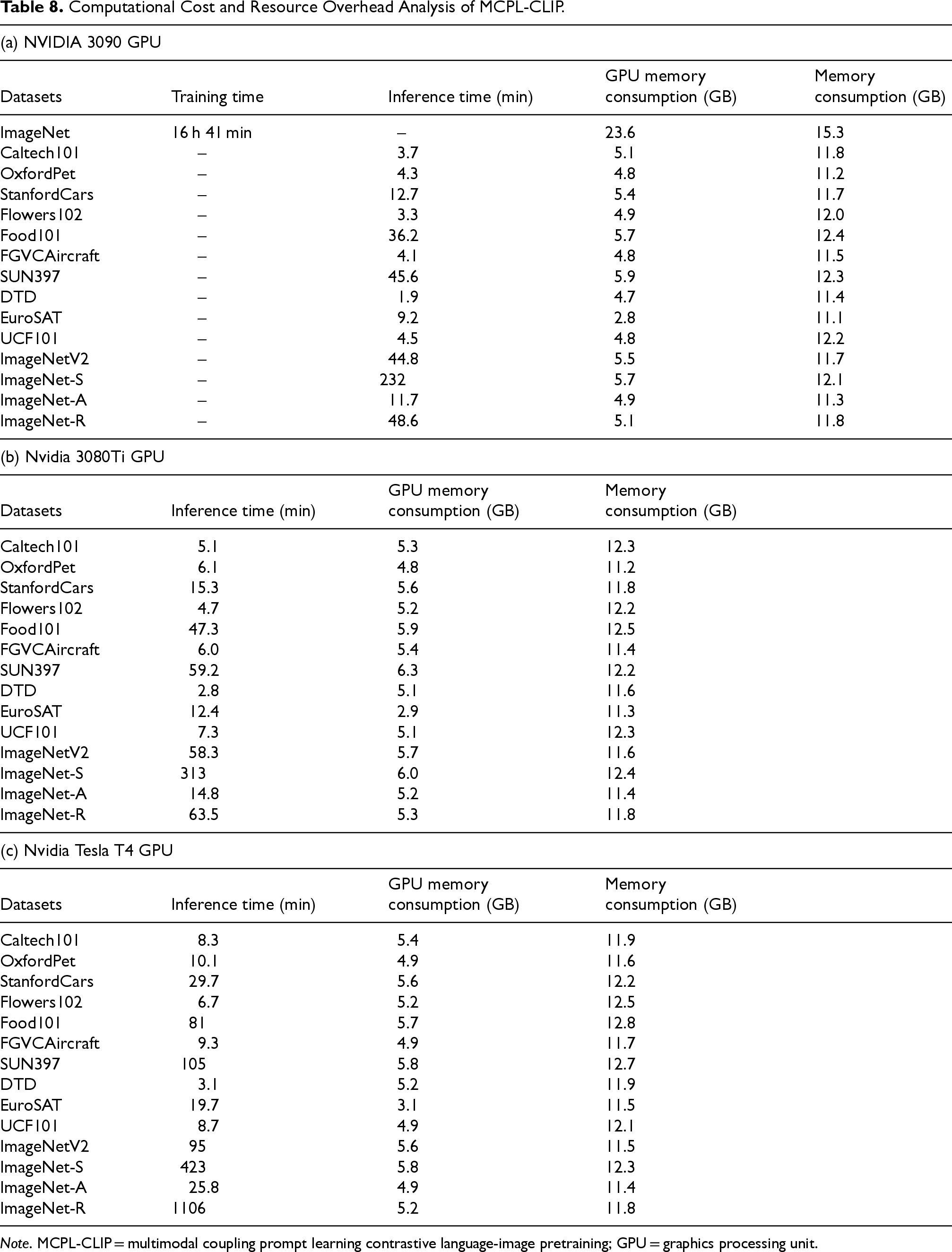
Computational Cost and Resource Overhead Analysis of MCPL-CLIP.
Note. MCPL-CLIP = multimodal coupling prompt learning contrastive language-image pretraining; GPU = graphics processing unit.
Conclusion
The main research work of this paper includes:
Identification of feature extraction bias and domain shift issues in CLIP’s visual encoder between pretraining and fine-tuning phases. To address these, we propose a two-stage MCPL framework that synergistically constructs and optimizes text-visual prompts through cross-modal interactions. The first stage employs text-semantic hierarchical injection to embed learnable prompts from the text encoder into visual transformer layers. The second stage enhances cross-modal alignment via visual-semantic attention interaction, generating instance-aware text prompts. This paper proposes MCPL-CLIP to improve CLIP’s performance in image classification and generalization tasks. Experiments demonstrate that MCPL-CLIP achieves varying degrees of performance improvement over multiple baseline models such as CLIP, CoOp, CoCoOp, and MaPLe in cross-dataset transfer, domain generalization, and base-to-new class generalization settings. For example, MCPL-CLIP leads by 3.35% to 0.93% in cross-dataset transfer scenarios, 3.88% to 0.78% in domain generalization scenarios, and 7.55% to 0.70% in base-to-new class generalization scenarios. This indicates that compared to using single-modal features to construct prompts, the paradigm of constructing prompts using multimodal interactive information in MCPL-CLIP is more effective for image classification tasks and their generalization scenarios.
Through systematic analysis of experimental results, we identify the following key limitations of the MCPL-CLIP approach: (1) performance improvement remains limited on datasets with highly similar visual features (e.g., Aircraft) due to insufficient sensitivity to fine-grained differences; (2) cross-modal feedback mechanisms may introduce noise interference in complex domain transfer tasks, leading to suboptimal performance on datasets with multiperspective variations such as Caltech101; (3) the multimodal coupling structure shows limited adaptability to stylized data (e.g., ImageNet-S sketches), where bidirectional information flow becomes less efficient in simplified feature extraction scenarios; (4) computational cost and resource consumption are higher than baseline models, restricting deployment in resource-constrained environments; and (5) complex prompt designs may induce feature interference in fine-grained classification tasks (e.g., Stanford Cars), compromising novel class generalization. To address these findings, future work will focus on:
Fine-Grained Feature Enhancement Developing dynamic attention-focusing mechanisms with differentiable feature masks to strengthen learning of local discriminative regions, particularly in aerospace recognition scenarios requiring subclass differentiation. Robust Cross-Modal Interaction Designing noise-suppressed hierarchical gating structures integrated with self-supervised contrastive learning to enhance feature stability in cross-dataset transfer. Adaptive Architecture Optimization Constructing configurable modal coupling units that automatically switch feature extraction paradigms based on input data style complexity (e.g., sketches vs natural images). Resource-Efficient Training Exploring parameter-shared lightweight prompt mapping networks combined with gradient accumulation strategies to reduce training memory requirements below 18 GB. Interference-Aware Learning Introducing feature purity assessment modules to implement selective feature fusion in bidirectional information flow, improving generalization accuracy in fine-grained classification tasks.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.