
Abstract
Deep learning algorithms have been increasingly used in ship image detection and classification. To improve the ship detection and classification in photoelectric images, an improved recurrent attention convolutional neural network is proposed. The proposed network has a multi-scale architecture and consists of three cascading sub-networks, each with a VGG19 network for image feature extraction and an attention proposal network for locating feature area. A scale-dependent pooling algorithm is designed to select an appropriate convolution in the VGG19 network for classification, and a multi-feature mechanism is introduced in attention proposal network to describe the feature regions. The VGG19 and attention proposal network are cross-trained to accelerate convergence and to improve detection accuracy. The proposed method is trained and validated on a self-built ship database and effectively improve the detection accuracy to 86.7% outperforming the baseline VGG19 and recurrent attention convolutional neural network methods.
Keywords
Introduction
Ships can be detected in photoelectric images by various analog or digital imaging systems. Traditional ship photoelectric images are mostly acquired by satellite remote sensing observation systems. However, they are vulnerable to cloud occlusion and the observation angle is always overlooked, leading to deficiencies in robustness and effectiveness in ship detection.1–3
With the development of unmanned aerial vehicle (UAV), it becomes more convenient to acquire ship’s photoelectric image using high-performance airborne photoelectric equipment. The sharpness of the image is greatly improved, and, through control, multiple angular images of ships can also be obtained. As a result of these advances, rapid and accurate identification of ships becomes possible with potential important applications in early warning and accident prevention. In the meantime, since there are many types of ships, further differentiation of the types of ships can also be important. However, it remains a challenging task to classify the ship types, 4 which is essentially a fine-grained image classification problem. 5
Recently, deep learning algorithms have been increasingly used to improve the ship image detection and classification accuracy. Most of these methods use convolutional neural networks (CNNs) to extract the image features, 6 to locate the target position, and to identify the types of ships. These methods can be divided into two categories: strong supervision and weak supervision. 7 In the strong supervision mode, the model not only uses image labels, but also relies on the target bounding boxes and component points to assist feature learning. Z Ning et al. 8 proposed a part R-CNN (regions with convolutional neural networks) algorithm, which detects the target category by setting component modules. Wei et al. 9 proposed a mask CNN algorithm, which locates targets through a fully connected network (FCN) and divides them into two masks for joint discrimination. In the weak supervision mode, the classification model relies on image labels alone, possible with a compromised performance compared with strong supervised learning. However, no bounding box of the target is needed, and thus it is feasible to collect large-scale training data and easier to train the network. Simon and Rodner 10 proposed the weak supervised constellations algorithm, which is able to obtain the feature map by convolution operation and determine the position and classification by calculating the gradient of the feature map. Lin et al. 11 proposed a bilinear CNN algorithm, using two CNNs for target location and discrimination, respectively. The two networks can optimize each other and improve the overall classification effect.
In 2017, Fu et al. 12 proposed a recurrent attention CNN to solve the classification problem of fine-grained image databases. The network achieves the optimal level on three mainstream fine-grained image sets: CUB Birds, Stanford Dogs, and Stanford Cars, achieving 3.3%, 3.7%, and 3.8% improvement in accuracy, respectively. However, the network cannot make good use of the global information of the image, and the shape of the feature area is always the same. Therefore, in this article, an improved recurrent attention convolutional neural network (RA-CNN) is proposed to detect the photoelectric ship targets. The scale-dependent pooling (SDP) and multi-feature attention proposal network (MF-APN) algorithms are used to improve the network’s recognition accuracy for fine-grained images. At the same time, the use of the MF-APN algorithm will increase the amount of network calculations and reduce the real-time performance of detection.
Related works
CNN development
CNN has been the cornerstone in the deep learning field. Through a series of convolution and pooling operations in CNN, 13 the network can learn to generate the target location box and to classify the target category given a training dataset. In 1998, The LeNet-5 model was proposed by LeCun et al., 14 which established the modern structure of CNN. In 2006, Hinton and Salakhutdinov 15 proposed a multi-hidden-layer neural network demonstrating better feature learning ability, and its training complexity can be effectively alleviated by initializing each layer. In 2012, AlexNet won the ImageNet competition, 16 proving the practicability of deeper CNNs. Nowadays, a variety of complex CNN-based networks are designed to improve the detection accuracy and shorten the detection time, such as faster R-CNN, 17 Yolo,18–20 and SSD (single-shot detector). 21 The VGG19 network 22 is a deep convolutional neural network (DCNN), which uses smaller convolution and pooling kernels, making it easier to adjust and apply.
Ship detection
Due to the development of CNN, many CNN-based ship identification methods have emerged in recent years. In 2017, Kang et al. 23 proposed a contextual region-based CNN, which can effectively detect ship targets in synthetic aperture radar (SAR) images. In 2018, Zhao et al. 24 proposed a coupled CNN network for small and dense ship identification, which demonstrates the ability of CNN to detect surface targets. In the same year, Oliveau and Sahbi 25 proposed semi-supervised deep attribute networks, which enhanced the recognition effect of CNN on fine-grained images through shallow and deep attributes. In 2019, Zhang et al. 26 improved faster R-CNN, reduced the impact of environmental factors on target detection, and achieved good results in real-time surface target detection. In the same year, Lin et al. 27 proposed the squeeze and excitation mechanism to further improve the detection capability of faster R-CNN for ships in SAR images.
RA-CNN
RA-CNN consists of three cascading scale sub-networks with the same network structure, but different and independent network parameters. Each scale sub-network has two different kinds of networks, namely, a VGG19 network for classification and an attention proposal network (APN) for target location. In each scale level, the image features are extracted from the input image and classified by VGG19; then the APN locates the feature area based on the extracted features and further cut out and enlarge the feature area as the input to the next scale network. By fusing three scales’ outputs, RA-CNN can determine the category of the fine-grained image. 28
The advantage of RA-CNN is that it can gradually focus on the feature area in the learning process through its multi-scale architecture. In addition, there are two loss functions designed in the RA-CNN, namely, classification loss and inter-scale loss. Through cross-training, the classification and target localizing networks promote each other, leading to a quicker convergence of the model weights.
SDP
In 2016, F Yang et al. 29 proposed using the SDP algorithm in their paper to improve the accuracy of object detection based on CNN. The output of the last pooling layer of CNN is usually used to determine the type of objects in the image. However, this may lead to a problem that if the target feature area is too small, multiple convolutions may diminish the discriminating power of the features and affect the final classification. The SDP algorithm extracts features from different CNN convolutional layers according to the size of candidate regions. For small candidate regions, the features are selected from the front convolutional layers, and, for large candidate regions, the features are selected from the back layers.
Method
Labeling fine-grained images needs domain knowledge and careful evaluation because of their high similarity, which can be very time-consuming and labor intensive. RA-CNN, through weak supervised learning, only needs the category label of the image to classify the class and does not require the corresponding bounding box information to locate the feature area. 30 However, the shape of the feature area generated by APN in RA-CNN is fixed and thus not conducive to the learning of various special geometric appearance feature areas. In other words, APN ignores the direct connection between the feature area and VGG19 after location. Therefore, in this study, we use the SDP and multi-feature area joint discrimination method to improve the model.
Preprocessing
To standardize the input images to feed in the VGG-SDP network, we adjusted the train and test images to the

where
Network architecture
The proposed network is designed to detect and classify ship targets using the preprocessed photoelectric images as the input. In the results, we render the target in a square box and display the ship category. The ship target recognition flowchart is shown in Figure 1:
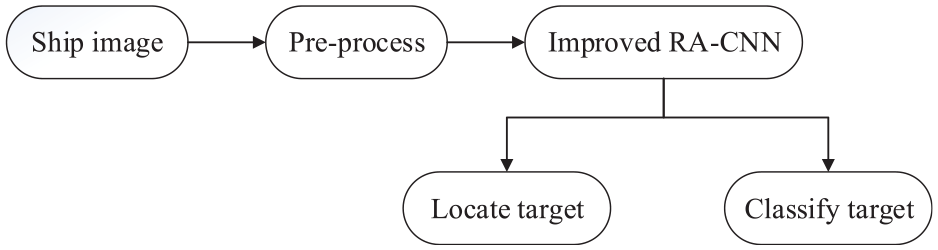
Ship photoelectric target recognition flowchart.
The improved RA-CNN network still adopts the original three-scale architecture. 12 We replace the target classification network VGG19 in each scale layer with a VGG-SDP network. Then, the feature location network APN is replaced with an MF-APN network. A generalized overview of the proposed network is shown in Figure 2. The process of feature extraction and target location is detailed as follows:
Feed the input image to the classification network
Send the output of the fifth pooling layer
Choose the most appropriate maxpooling layer’s output in
Subject to the target position and size
Send
Repeat Steps 2 and 3 to fuse the prediction probabilities of the feature maps into the prediction label
The final target is positioned as a square feature box in the first scale layer, and the target category is the fusion of the predicted labels of the three scale layers. The specific flowchart is shown in Figure 2.

Generalized overview of the proposed network.
VGG-SDP classification
Due to the robustness and superior feature extraction capability, VGG19 is used as the basic classification network in RA-CNN, which consists of 16 convolutional layers, 5 maxpooling layers, and 3 fully connected layers, where the convolutional layers and the maxpooling layers are divided into 5 convolutional blocks.
22
The fully connected layers use the output of
Sizes of the feature areas obtained by the APN can be variable. However, the classification network always determines the category based on the output of

The VGG-SDP network architecture.
The input image is first completely extracted through the classification network. Then the MF-APN network calculates

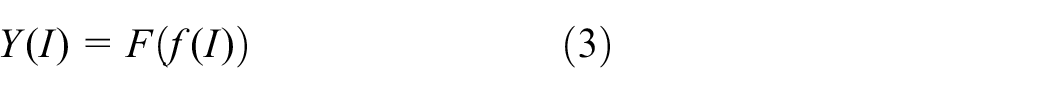
where
The classification result of the image
MF-APN location
The original location network APN contains two fully connected layers. The feature area is obtained by inputting
Assume that the APN part outputs

MF-APN output schematic diagram.
Then the following equations can be derived

Assume that the area of the a priori rectangular box is equal to the area of the output square, and there are

Substituting equation (4) into equation (5), we get a new expression

The

Considering that the neural network backpropagation algorithm is derivable, we cannot use ordinary interception functions. Therefore, we design a deductible intercept function

where

When

where the ⊗ operation represents the element point multiplication.
The bilinear interpolation method is then used to enlarge the target area to generate the inputs of the next scale. If we choose plurality of the a priori rectangular boxes in each scale after the first scale, finally, the number of feature areas will become multiplicative growth. Considering the computational cost, only
Network loss
The improved RA-CNN loss function is still divided into two parts, the same as in the original RA-CNN:
12
namely, the intra-scale classification loss

By taking the maximum value, the network is required to update when the current scale real class probability
Since there are

where
Experimental results
The hardware environment
The experimental environment is TensorFlow 1.10.0, OpenCV3, CUDA 9.0, and CUDNN 7.0. The tasks are executed on a computer with Intel Core i7-7800X with 16 GB RAM and an NVIDIA GTX1080Ti with 11 GB memory.
The dataset
Many open-source fine-grained image datasets can be found on the network such as CUB Birds, Stanford Dogs, and Stanford Cars. These datasets can well test the performance of fine-grained classification networks. However, this article proposes a special algorithm for ships and basically no datasets about the ship can be found on the network. Therefore, in this article, a self-built ship dataset is used to verify the network performance. The dataset consists of eight categories, namely, container ships, sailboats, tugs, passenger ships (PS), tankers, ocean surveillance ships (OSS), engineering ships, and fishing boats (FB). There are 2635 samples in the dataset, with about 300 samples in each category. The number of images is still relatively small and we will continue to expand the amount. You can find our dataset at https://www.dropbox.com/sh/pyyfkotec7h9r5l/AAA8yVwhr3N7VwndU_lOCsKLa?dl=0
The ratio of the samples used for training and testing is approximately
Dataset distribution.

PS: passenger ships; OSS: ocean surveillance ships; FB: fishing boats.

Samples from different perspectives in the dataset: (a) front view, (b) rear view, (c) side view, and (d) side-overhead view.
Parameter settings and evaluation metrics
In this article, we take several neural network acceleration methods to promote network convergence and accelerate network training. The drop rate of the neural network is set to 0.2, and the initial learning rate is set to 0.1. After 100,000 iterations, the learning rate is reduced to one-tenth of the original. To speed up convergence, the network will be trained 10 rounds on the ImageNet dataset in advance.
Use Accuracy as an evaluation metric to test neural network performance; 32 the accuracy calculation formula is as follows

where TP is true positive (predict the positive sample correctly), TN is true negative (correctly predict but the negative sample), FP is false positive (predict the negative sample as the positive sample), and FN is false negative (predict the positive sample as the negative sample).
Experiment 1: calculating the amount and time
For deep learning networks, computational complexity is a very important factor to evaluate the efficiency of the network. The RA-CNN is effectively designed on the network structure to improve the fine-grained detection performance. However, due to the adoption of multiple scale layers, the computational complexity of the network is increased. Meanwhile, the MF method in this article improves network accuracy by adding three feature regions at the second and third scale layers. That is, the network parameters of the second and third scale layers are increased by nearly three times, and the overall parameter amount and calculation time should be correspondingly increased. So it is necessary to test the impact of the network complexity. The overall network structure and parameters are shown in Table 2. 24 It is worth mentioning that the parameter values in the APN-FC1 layer are uncertain. This is because the input may come from one of the three different pooling layers, so the MF-APN part prepares three input entries. The computational costs of different models are illustrated in Figure 6. The Flops 33 in the figure are used to measure the amount of network calculation, and the calculation formulas for the convolutional layer and the fully connected layer are

where
Network structure and number of parameters for each layer.
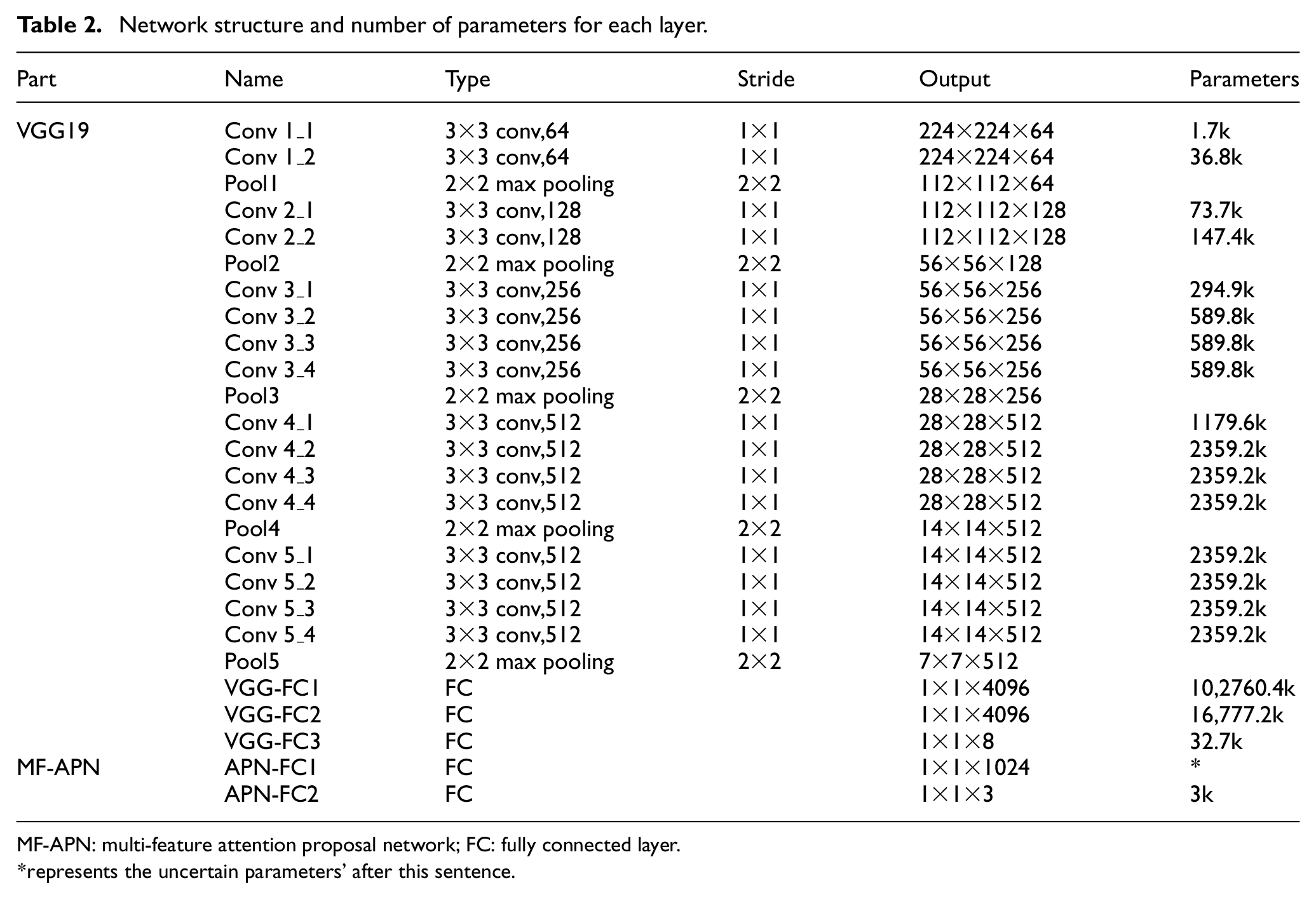
MF-APN: multi-feature attention proposal network; FC: fully connected layer.
represents the uncertain parameters’ after this sentence.
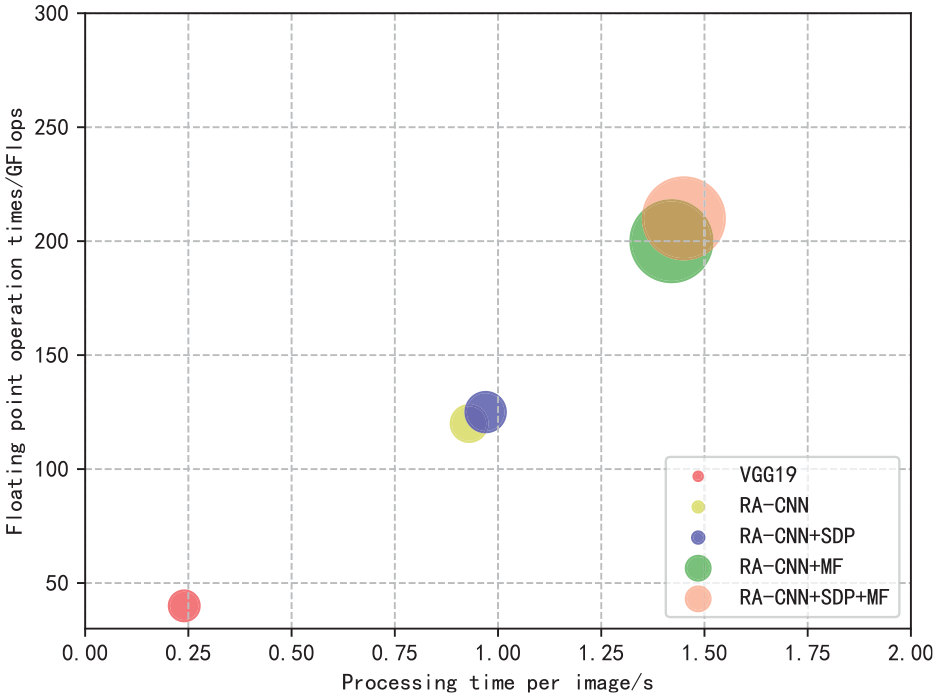
Performance analysis of the RA-CNN + SDP + MF algorithm.
From Figure 6, it can be seen that RA-CNN is nearly 0.7 s longer than the VGG19 in single-frame image processing time due to its three-layer progressive structure. The figure size in Figure 6 is proportional to the amount of network parameters. Therefore, it can also be seen from Figure 6 that the SDP algorithm hardly increases the parameters and calculation time, while the MF algorithm increases nearly 0.6 s and the floating-point calculation amount is also greatly improved.
It takes about 1.5 s for the new network to process a single frame, which is not feasible for real-time video detection. Considering that each scale’s input is calculated from the previous scale, this serial structure is difficult to optimize. However, three feature areas can be calculated independently at the same time, so the MF portion can use the distributed computing method to shorten the calculation time to 0.92 s. From the experimental results, the network studied in this article can be used for real-time recognition of single-frame images. However, when applied to video recognition, a high frame rate cannot be guaranteed. It is still necessary to optimize the reduction of the overall floating-point calculation from the network parameters.
Experiment 2: accuracy of different baseline models
The model used in this article is based on RA-CNN, while RA-CNN is based on VGG19. We propose two improvement methods, which are SDP for choosing pooling results flexibly and MF-APN for more precise category discrimination.
In this experiment, we combine the RA-CNN and two proposed methods one by one to test the effect of a single method. Finally, we compare the method of this article with baseline models. The results are shown in Table 3. The overall accuracy curve is shown in Figure 7.
Accuracy of different baseline models.

RA-CNN: recurrent attention convolutional neural network; SDP: scale-dependent pooling; MF: multi-feature.

Overall accuracy curve of different baseline models.
It can be seen from Table 3 that the accuracy of RA-CNN is 5.8% higher than that of VGG19 as the basic detection network, indicating that RA-CNN is a better network for fine-grained image detection and classification. The results of using SDP and MF alone were 0.5% and 0.9% higher than the original RA-CNN network, respectively. When using both SDP and MF, the accuracy is improved by up to 2%. This implies that the use of adaptive feature pooling and the use of multiple feature maps can effectively improve the accuracy and the combination of the two methods can achieve better results. It can be seen from Figure 7 that the unmodified VGG19 can achieve a certain accuracy faster. In contrast, the network based on RA-CNN will take more time to train on MF-APN, but the final result will be much better.
In Figure 8, the effect of the network detection ship is demonstrated. In order to better display the type of ship, the feature area generated by MF-APN is used. It must be acknowledged that, during the testing process, the network will still classify some ships into the wrong category, so in the future work it is still necessary to expand the dataset and optimize the network.

Examples of network classification. The prediction box in the figure comes from the prediction of the APN network.
Experiment 3: accuracy and attention region of different scales
The original RA-CNN model includes three scale layers to local feature map step by step. However, the accuracy of the third scale layer can be less than those of the first two layers. In this experiment, we will test the impact of new methods on the accuracy of different scales. The experimental conditions are the same as those in Experiment 1. The difference is that only the different scale layers of RA-CNN and RA-CNN + SDP + MF are tested. The results are shown in Table 4.
Accuracy of different scales.

RA-CNN: recurrent attention convolutional neural network; SDP: scale-dependent pooling; MF: multi-feature.
It can be seen from Table 4 that the accuracy of using only the second scale in the original RA-CNN is 0.9% higher than that when using only the third scale. But this gap is narrowed to 0.2% in the method proposed in this article. This proves that the new method can compensate for the accuracy impact of global information loss on a finer scale.
We also test the attention region on the trained model. Figure 9 shows the attention region of each scale of the network. Figure 9(a) shows the original picture and Figure 9(b) shows the input for the first scale after preprocessing. From Figure 9(c), we can see that, after MF-APN, the first scale selects three attention areas. These areas will be intercepted once and the corresponding pictures in Figure 9(d) will be generated. It can be seen from the results that, after training, the network can accurately locate the target’s attention region in the second scale.

Attention region of different scales: (a) original picture, (b) first scale, (c) second scale, and (d) third scale.
Conclusion
Based on the fine-grained detection network RA-CNN, this article proposes an improved identification method for intelligently distinguishing fine-grained ships. As an end-to-end weak surveillance detection network, training can be performed with no bounding boxes provided. The SDP algorithm allows the classification network to adaptively select the most representative pooling layer output, which enhances the network’s ability to learn local features. The MF method is proposed for the special geometric appearance characteristics of ships. By extracting multiple prior feature boxes in the image to comprehensively describe the feature regions, the algorithm avoids situations where the single feature area may contain too much unrelated background. At the same time, the weighted average decision prediction label is used to enhance the influence of rectangular boxes. Using batch normalization and dropout, changing the learning rate and using pre-training weights can optimize the network model and accelerate the convergence of network training. Our experiments show that this method can quickly and accurately classify and detect ship photoelectric targets in complex backgrounds and provide early warning against collisions.
Footnotes
Handling Editor: Janez Perš
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Science Foundation of China (Grant No. 61673259).