
Abstract
Machine learning fairness enhancement methods based on data bias correction are usually divided into two processes: The determination of sensitive attributes (such as race and gender) and the correction of data bias. In terms of determining sensitive attributes, existing studies tend to rely too heavily on sociological knowledge and neglect the importance of exploring potential sensitive attributes directly from the data itself. The accuracy of this approach is limited when dealing with data that cannot be fully explained by sociological factors. Regarding data bias correction, existing methods are primarily categorized into causality-based and association-based methods. The former requires a deep understanding of the underlying causal structure in the dataset, which is often difficult to achieve in practice. The latter method correlates sensitive attributes with algorithmic results through statistical measures, but this approach often tends to ignore the impact of sensitive attributes on other attributes. In this paper, we formalize the identification of sensitive attributes as a problem solvable through data analysis, without relying on commonly recognized knowledge in social science. We also propose a data pre-processing method that considers the effects of attributes correlated with sensitive attributes to enhance algorithmic fairness by combining the association-based bias reduction method. We evaluated our proposed method on a public dataset. The evaluation results indicate that our method can accurately identify sensitive attributes and improve the fairness of machine learning algorithms compared to existing methods.
Introduction
The application of machine learning algorithms has brought significant progress to various public affairs, such as finance, anti-terrorism, taxation, justice, medical care, and insurance, directly impacting the well-being of citizens. However, in recent years, issues of unfairness and discrimination have caused by widely applied machine learning algorithms in areas such as credit scoring (Khandani et al., 2010), crime prediction (Brennan et al., 2009), and loan evaluation (Mahoney & Mohen, 2007) . As a result, the ethics of algorithm, especially concerning the fairness of machine learning algorithms, has gained considerable attention from the public and the government (Kearns & Roth, 2019).
The problem of algorithmic fairness may exacerbate the bias to the groups that have historically been discriminated against. For example, in 2014, a team at Amazon developed an automated hiring system to screen the resumes of the job applicants. According to Reuters (Dastin, 2018), the hiring system was trained based on 10 years of Amazon’s hiring data and it gives a score from 1 to 5 to each job applicant. However, in 2015, the team realized that the system showed a significant gender bias for male candidates and female candidates due to historical discrimination (bias) in the training data. Although Amazon improved the system to hide gender attributes, there was no guarantee that there are biases still in other ways. Therefore, the project was abandoned entirely in 2017. Furthermore, similar examples include gender bias in online advertising and Google image search for occupations (Kay et al., 2015).
Based on the above examples, it is known that the analytical judgments supported by machine learning systems may influence the decision maker. The discrimination presented in these machine learning systems are caused by the bias in training data. And, this discrimination will be reinforced and legitimized by the increasing deployment of machine learning algorithms. How to avoid perpetuating and amplifying the discrimination by machine learning systems have become a critical issue of the algorithmic fairness. The methods of discrimination reduction for machine learning systems are divided into three categories, pre-processing methods (Feldman et al., 2015; Kamishima et al., 2012a), in-processing methods (Kilbertus et al., 2017; Russell et al., 2017) and post-processing (Hardt et al., 2016; Woodworth et al., 2017) methods as shown in Figure 1. Pre-processing methods apply certain operations, like , to remove bias from the training dataset; in-processing methods most commonly add tuning constraints to the training model, such as adjusting the hyperparameters of the classifier; post-processing methods remove bias by adjusting the results of prediction and classification.
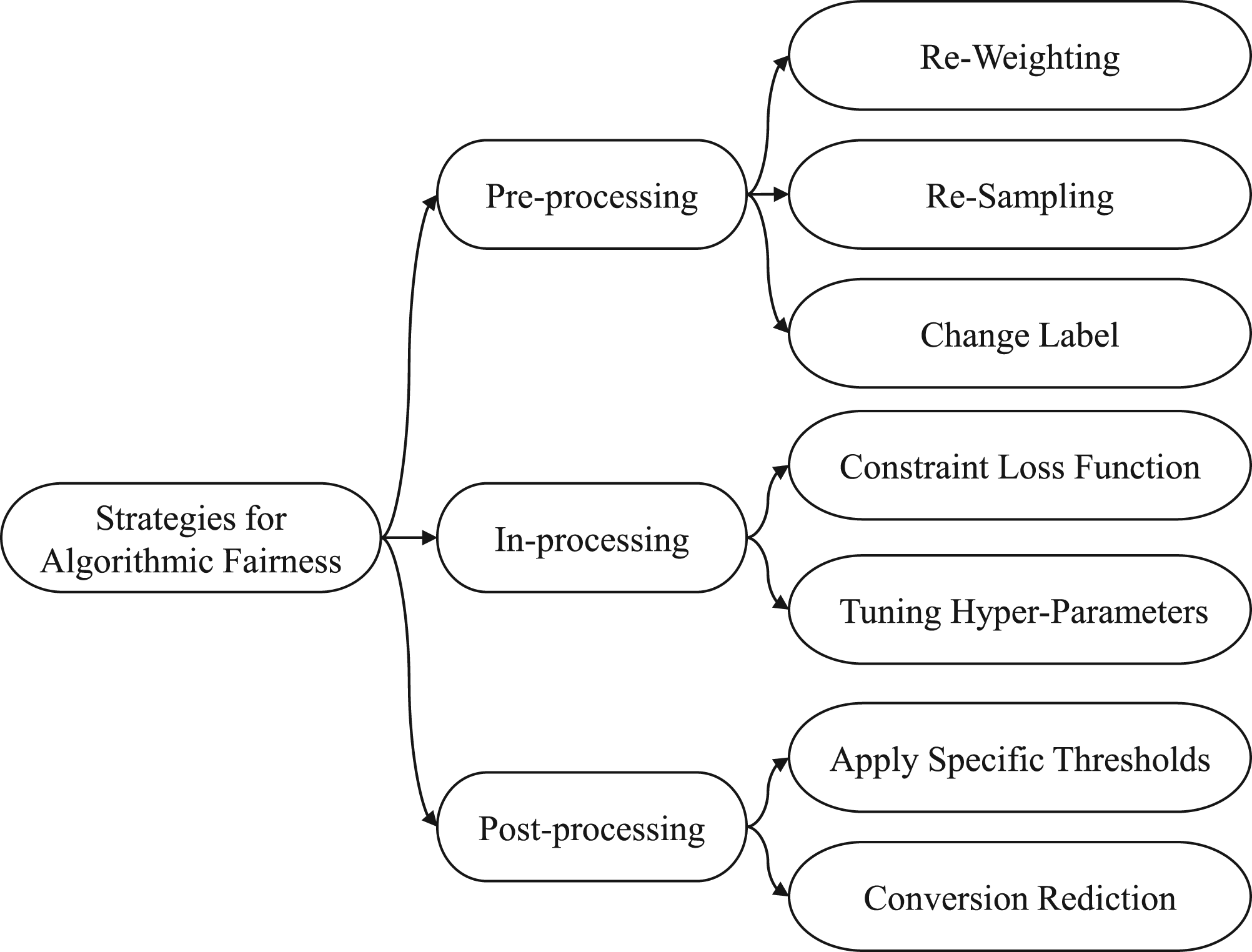
Strategies for algorithmic fairness.
Data bias correction algorithms, also known as algorithmic fairness pre-processing methods, consist of two main processes, determining sensitive attributes and correcting biases caused by sensitive attributes (Yan & Kao, 2020). Sensitive attributes refer to those attributes that may be associated with sensitive characteristics or groups, such as age, gender, race, etc. These attributes may have an impact on the results of the algorithm, leading to unfair results, and therefore require special treatment. After finding the sensitive attributes, the goal of improving the fairness of the algorithm can be achieved by adjusting the algorithm’s input, output or processing process to ensure that the algorithm does not discriminate against the sensitive attributes when processing the data. In the aspect of identifying sensitive attributes, we find that many current studies have resorted to social science help such as seeking expert advice, conducting interviews, surveys (Mehrabi et al., 2021), etc. in identifying sensitive attributes in the dataset. But not to explore the dataset as the first step to reveal the data biases and discover the possible sensitive attributes.
Once the sensitive attributes are identified, the next procedure is bias reduction from dataset. Usually, there are two main bias reduction algorithms, causality based methods (Galhotra et al., 2017; Nabi & Shpitser, 2018) and association based methods (Calders & Verwer, 2010; Dwork et al., 2012). The causality based methods need the expert knowledge of the underlying causal structure in the dataset. This approach is not practical for applying in different areas without domain knowledge. The association based methods require applying heuristic restrictions in bias reduction process, without considering the influence of attributes that correlated with sensitive attributes. When performing bias reduction operations on sensitive attributes, two different strategies can be applied. One is horizontal approach (Salimi et al., 2019), which performs operations on the tuples of the dataset. The other is vertical approach (Salazar et al., 2021), which performs operations on the attributes of the dataset. However, the horizontal approach can be considered invasive because it changes the distribution of the dataset. In practice, the vertical approach is the common way to remove the identified sensitive features directly (Grgic-Hlaca et al., 2016). Doing by this can ensure fairness without tampering the dataset. However, there are multiple attributes correlated with identified sensitive features. If we do not consider the impact of indirect sensitive attributes and remove their effects on fairness, the discrimination reduction operation cannot achieve the expected effectiveness. The discrimination problem of the machine learning system will exist as before. Furthermore, the problem of discrimination detection and processing will become more complex.
In summary, finding a unique approach to optimize the original dataset and maintain the accuracy and fairness of machine learning algorithms is a challenge. In order to reduce the discrimination of machine learning algorithms at the root and increase their fairness, in this paper, we combine the method of principal component analysis to determine the sensitive attributes in the dataset, and select the pre-processing algorithm in algorithmic fairness, and optimize the correlation method in bias reduction algorithm to improve fairness. Overall, the contributions of the work are listed as following.
We demonstrate that the identification of sensitive attributes can be achieved by prior analysis of the dataset and combining the results with the principal component analysis algorithm without directly using sociological scientific methods. We propose an algorithm combining feature deletion and correlation removal between features to improve fairness, and measure the performance of our algorithm in terms of fairness and accuracy. We conducted a series of experiments on a known dataset to demonstrate the various steps of our algorithm, including sensitive attribute determination, fairness enhancement, and performance evaluation.
In this section, we will provide a review of relevant works of fairness definitions, three bias reduction algorithms and problems in existing works. In the following chapters, we will improve on the shortcomings of the existing methods to realize our approach.
Fairness Definitions and Research
Fairness machine learning algorithms need to consider two closely related aspects: Firstly, how fairness is defined in a given social scenario, and secondly, the level of social acceptability. If sensitive attribute are not used in a machine learning algorithm for classification and prediction, the algorithm satisfies fairness without awareness (fairness through unawareness [FTU]). Individual fairness, on the other hand, was proposed by Grgic-Hlaca et al. (2016) in 2012 and is achieved when the algorithm predicts the same outcome for similar individuals. In other words, if two individuals are similar according to a certain metric, their predictions should also be similar (Joseph et al., 2016; Zemel et al., 2013). Kim et al. improved on this concept by introducing preference-informed individual fairness, which allows for some deviation from individual fairness to meet personal preferences and provide more favorable solutions for individuals.
In legal contexts, fairness of decision-making processes is typically evaluated based on two main criteria: differential treatment and differential impact. The above definitions have inspired various researchers to explore ways to promote fairness in decision-making processes. For instance, Zafar et al. (2017) have investigated how to remove sensitive attributes from decision-making to avoid differential treatment, and how to add fairness constraints to eliminate differential impact. They have also introduced covariance to transform non-convex problems into convex shapes and examined the sensitive attributes of multi-classification and the analysis of multiple sensitive attributes. On the other hand, Beretta et al. (2019) have combined different democratic ideals with the concept of fairness to propose evaluation criteria for fairness that are suitable for different democratic backgrounds. They have suggested that counterfactual fairness, unconscious fairness, and fairness based on group conditional fairness are more suitable for competitive democracy, while individual fairness is more appropriate for liberal democracy, and preference-based fairness is more fitting for egalitarian democracy.
Salimi et al. (2019) introduced a user-centric approach for feature classification by allowing users to categorize features as sensitive, acceptable, or unacceptable. Acceptable features are those that the user allows to influence the classifier’s predictions, while unacceptable features are those that may introduce biases based on sensitive attributes. They also proposed a Capuchin (CA) system that can repair data that does not conform to the user’s feature classifications by adding or removing tuples. This system is designed to provide users with greater control over the fairness of the model by allowing them to specify which features are considered sensitive and ensuring that the model is not influenced by them. The CA system can also help to reduce the impact of biases by repairing the data that may leak sensitive attribute biases.
Bias Reduction Algorithm
To address the problem of algorithmic discrimination, different bias reduction strategies are discussed and categorized in pre-processing methods, in-process processing methods, and post-processing methods.
Pre-processing Methods
The unfairness present in the training data is learned by the algorithm, and pre-processing fairness can be obtained if the training algorithm is made incapable of learning that bias, which can be categorized into two types: Firstly, changing the values of sensitive attributes or class labels of individual items in the training data, secondly mapping the training data into a transformation space where the dependency between sensitive attributes and class labels disappears. Feldman et al. (2015) modified each attribute so that the marginal distributions based on a given subset of sensitive attributes are all equal, and this change does not affect other variables. The transformed data retains most of the feature signals of the non-sensitive attributes. Cross-sensitive attributes are also proposed and the effects of the two sensitive attributes are not superimposed. Other approaches include having binary sensitive attributes and binary classification problems, improvements in pre-processing techniques, suppressing sensitive attributes, adapting the dataset by changing the class labels, re-weighting or re-sampling the data to eliminate discrimination without re-labeling the instances Calders (2012). Calmon et al proposed a convex optimization for learning data transformations with the objectives of controlling discrimination, limiting the individual data samples in distortion, and preserving utility.
In-processing Methods
The most common improvement to a specific machine learning algorithm is to attach constraints to the algorithm. Kusner et al. (2017) introduced causal modeling to the algorithms and gave three ways to achieve fairness in different classes of algorithms. (1) Modeling by using attributes that are not directly or indirectly related to the sensitive attributes; (2) modeling by latent variables, which are non-deterministic elements of observable variables ; and (3) modeling through deterministic models with latent variables (e.g., additive error models). Grgi-Hlaa et al. (2019) improved logistic regression and support vector machine algorithms under different misclassification rates based on the absence of bias in the historical information, which provides a flexible trade-off between fairness and accuracy based on different misclassification rates. This method works better when sensitive attribute information is not available. Zemel et al. (2013) combined preprocessing and algorithm modification to learn canonical data representation to achieve efficiency in classification while achieving independence from sensitive attribute values. Kearns et al. (2017) combined ex ante fairness and ex post fairness by utilizing the cumulative distribution function of different individuals given a set of individual scores based on the candidate’s empirical values to provide confidence intervals, and then assigning the scores to the candidates with the used bias bounds, running the NoisyTop algorithm to provide an approximation of fairness. Kamishima et al. (2012a) introduced a regularization term centered on fairness and applied it to a logistic regression classification algorithm. Calders and Verwer (2010) constructed a separate model for each value of a sensitive attribute and based on the corresponding values of the input attributes to appropriately select the model, and evaluated the fairness of the iterative combined model under the CV metric. Bose and Hamilton (2019) addressed the problem that existing graph embedding algorithms could not handle the fairness constraints, and imposed fairness constraints on graph embeddings by introducing an adversarial framework that removes more sensitive information using a composite framework under the condition of ensuring that the learned representations are not correlated with the sensitive attributes.
Post-processing Methods
Hardt et al. (2016) consider post-processing the probability estimates of unfair categories in the case of sensitive attributes by learning different decision thresholds for different sensitive attributes and applying these specific thresholds at the time of decision making Kamishima et al. (2012b) satisfy the fairness constraints by modifying the leaf labels in the decision tree after training. Woodworth et al. (2017) take the first order moments of statistical and computational theory to learn nondiscriminatory predictions, and proposed a statistically optimal second-order moment procedure, while being more relaxed about nondiscrimination on second-order moments, making the algorithm easy to learn.
Problems in Existing Works
Although the existing methods can improve the fairness of the algorithm to some extent, there are still some problems. For example, there are some shortcomings in the definition of fairness, such as Unawareness proposed by Zafar et al., which overemphasizes the constraint of sensitive attributes while ignoring the agent attributes highly related to sensitive attributes. As a result, the generated model cannot improve fairness well. The individual fairness proposed by DWork et al. cannot properly quantify the gap between individuals. The most advanced bias reduction algorithm, CA, breaks the causal chain of these attributes by adding and removing tuples. However, this horizontal approach can be considered invasive because it alters the data distribution. The vertical method in addition to the horizontal method is to completely remove the sensitive features. While this would ensure fairness and not tampering with data, it could also compromise the accuracy of machine learning.
Problem Definition
In this section, we introduce several definitions about algorithm fairness, sensitive attributes and indirect sensitive attributes. The symbols used in definitions are listed in Table1.
Symbols Used in the Paper.
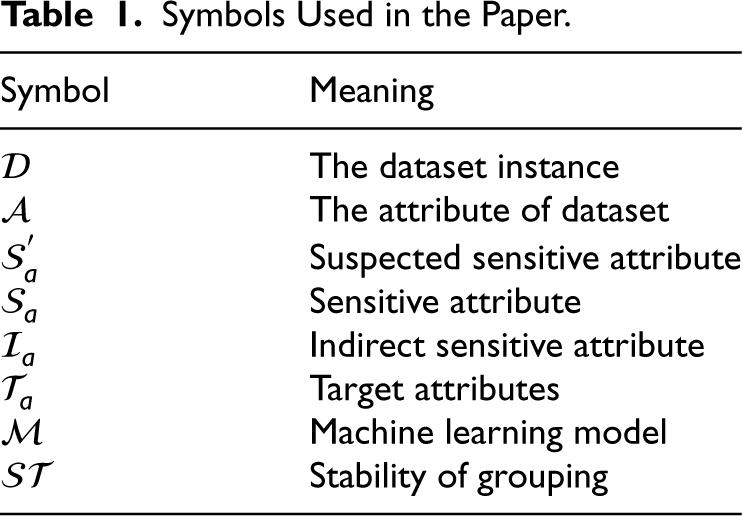
Symbols Used in the Paper.
In contrast to previous works, this paper does not use social science expert experience directly to identify sensitive attributes. Firstly, we used data analysis methods, analyzing and comparing attributes in the dataset to identify sensitive attributes. Following, we used principal component analysis to validate the sensitive attributes we identified. Finally, to prove the credibility of this method, we compared the consistency of the identified sensitive attributes with those identified using social science methods.The specific process is shown in Figure 2.

Sensitive attributes identification.
The 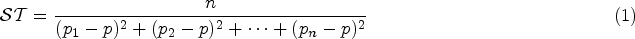

In previous studies, a lot of association based methods only considered the impact of sensitive attributes
Given a dataset and one of its sensitive attribute 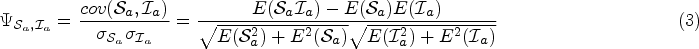
We used the pre-processing method of algorithmic fairness to improve the fairness of machine learning models. Our aim is to reduce the problem of discrimination in machine learning models by reducing bias in the dataset. In practice, we used association based methods among the data bias reduction algorithms to reduce the bias of dataset. Firstly, we will introduce several definitions of fairness.

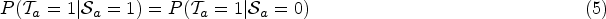

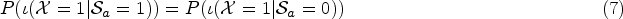


We conducted experiments on two datasets commonly used for algorithmic fairness, we present these two datasets separately. The experimental procedure are as follow.
Dataset Introduction
Adult Dataset
The Adult dataset (Dua et al., 2017) 1 contains information from U.S. Census of the 1994. The prediction task is to determine whether a person’s annual income exceeds 50k dollars. In the above section, we have used the adult dataset to demonstrate how to identify sensitive attributes, and improving the fairness of the prediction model.
Correctional Offender Management Profiling for Alternative Sanctions Dataset
Correctional offender management profiling for alternative sanctions (COMPAS) (Larson et al., 2016) 2 is a commonly used crime risk assessment tool that is widely used in the criminal justice system in the U.S. The COMPAS dataset is the dataset associated with this tool for training and evaluating crime risk assessment algorithms. It is often used for prediction tasks related to crime, such as whether the offender will reoffend within two years, whether the offender will return to violent crime within two years and whether the defendant will evade court when he appears in court. Afterwords, we used COMPAS dataset to validate our method again.
Sensitive Attributes Identification
Data Exploration and Analyzing
We perform data exploration on the Adult dataset, which is widely used to predict whether annual income exceeds 50 k dollars. So, we used the income attribute as its target attribute
The Probability Distribution of the High-income Group in Different Values 1.
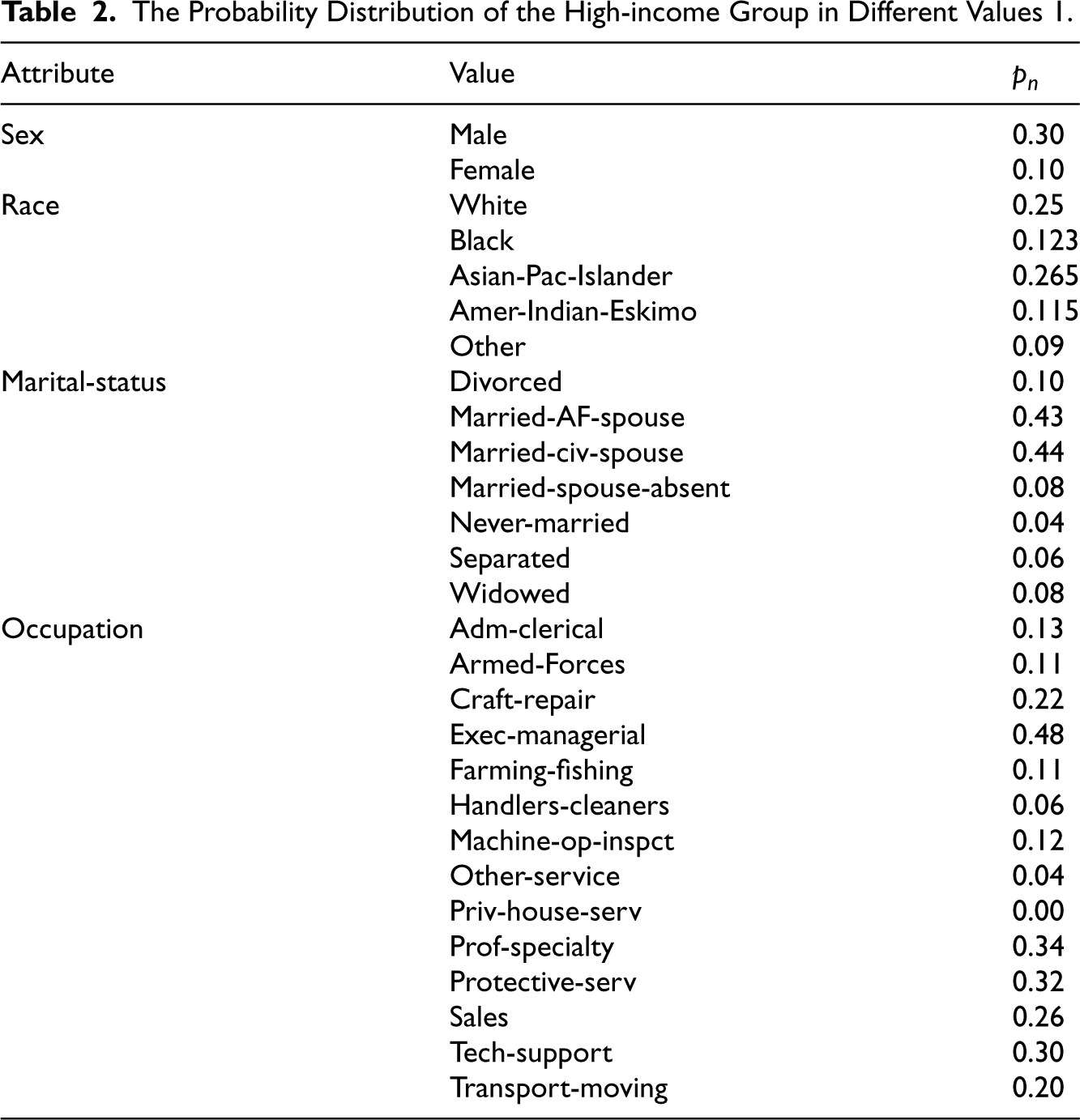
The Probability Distribution of the High-income Group in Different Values 1.
The Probability Distribution of the High-income Group in Different Values 1.
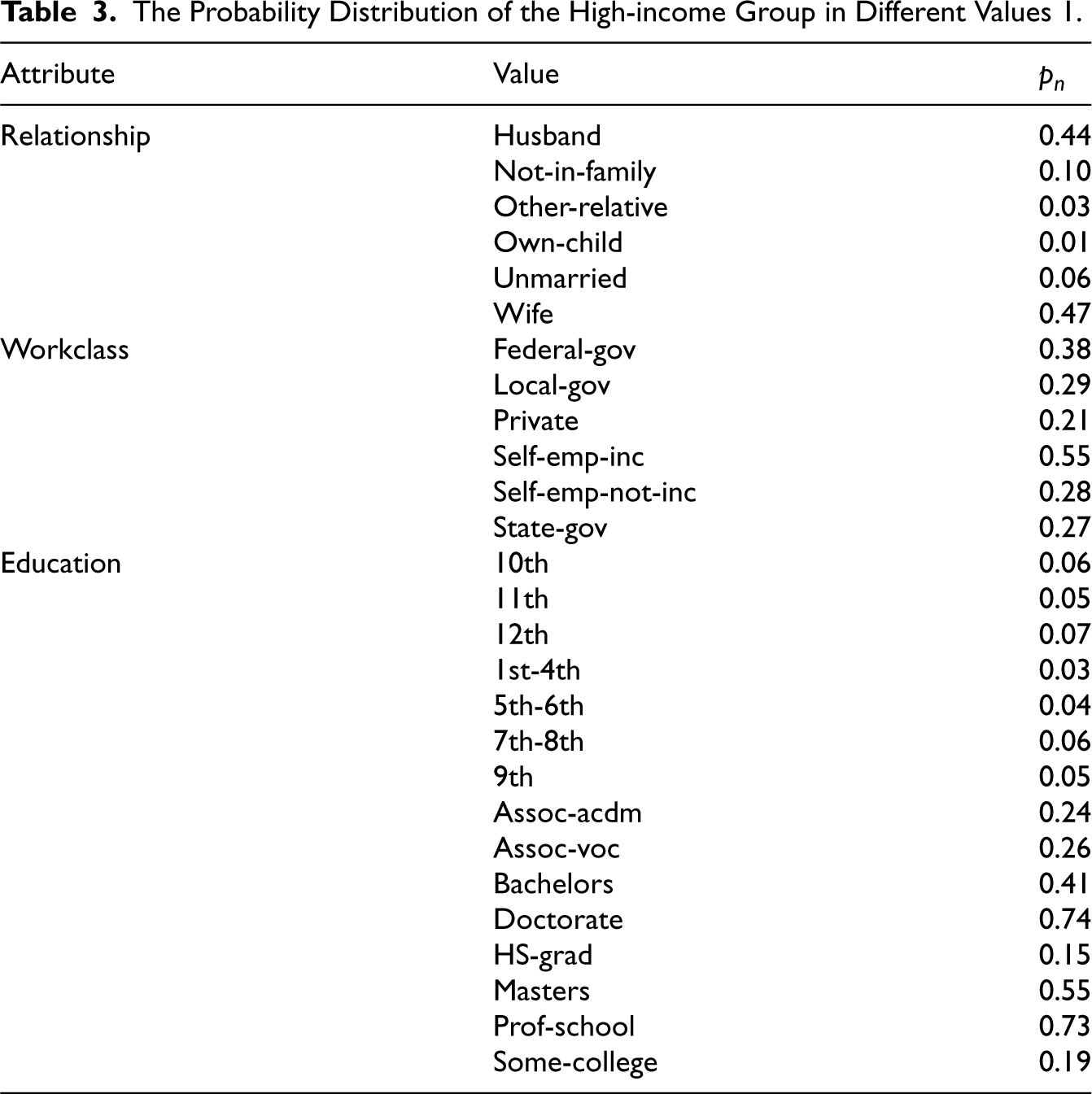
Group attributes.
Take the attribute of race as an example, we can find in Table 2 the shares of high-income groups among different values on race attribute: the White is
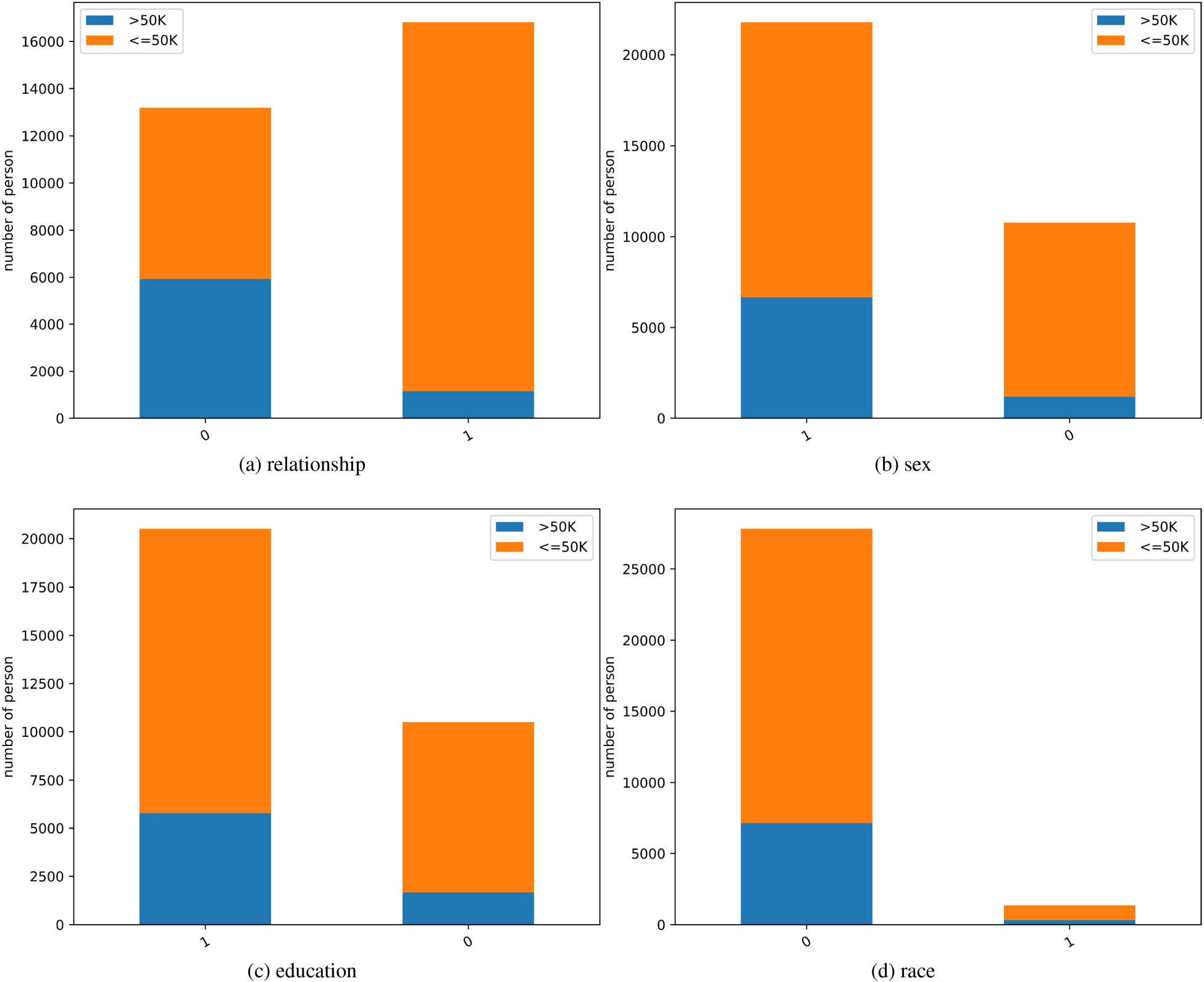
In algorithmic fairness, sensitive attributes are usually considered to be a binary attribute. Because in many instances, they can be grouped into two different values or categories. By turning sensitive attributes into binary attributes, fairness criteria can be more easily defined and measured. In our work, we also define sensitive attributes as binary attributes, so we can divide the values of each attributes into two groups. Divide the values with the largest sample size into one group and the other values into another group. For example, for the attribute of race, we divide the race of White into one group as the sample size of White in race is the largest. And then, we divide the races of Black, Asian-Pac-Islander, Amer-Indian-Eskimo and Other into another group. The grouping results are shown in Figure 3, we use group
After that, we compute the stability of the attribute grouping
The Grouping Stability of Each Attribute.
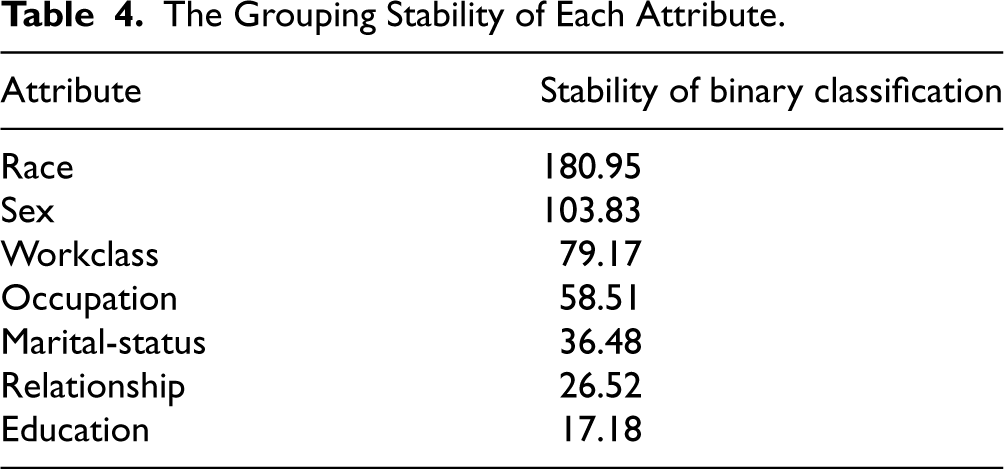
The Grouping Stability of Each Attribute.
In Table 4, we can observe that the grouping stability of race attribute is the highest, the following is the attribute of sex. We identified race and sex are the more desirable binary attributes. After that, we should compute the probability distribution of the target attribute
The Probability Distribution of
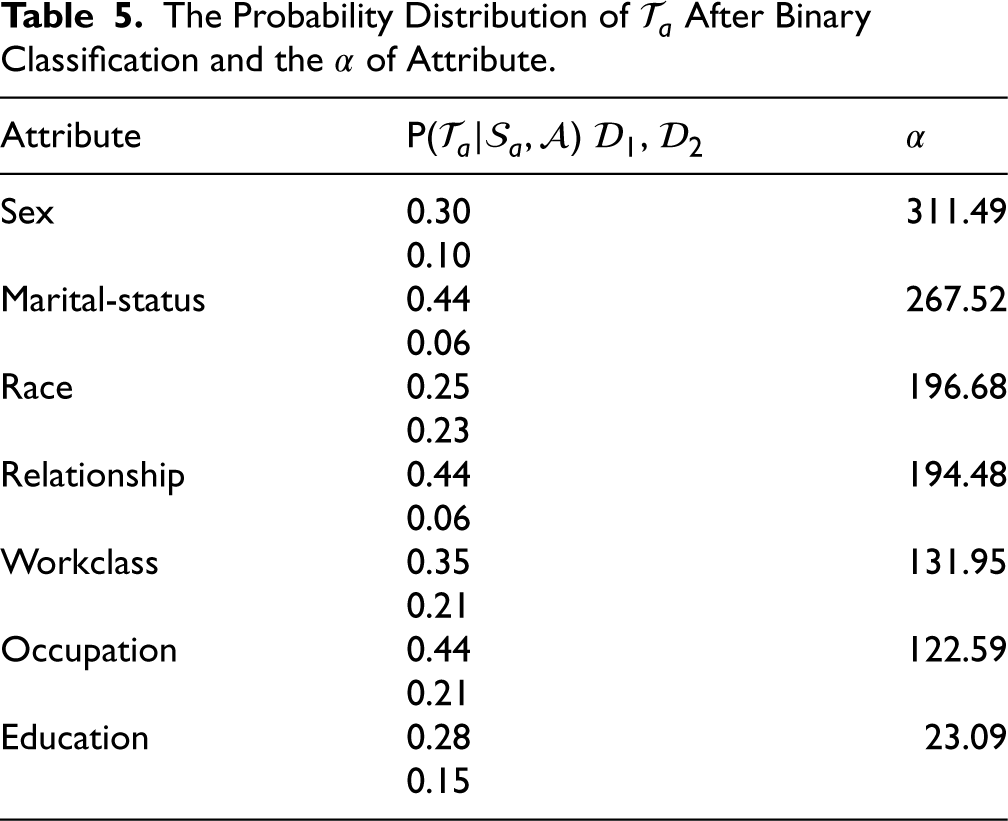
In this table, we divided values of each attribute into two groups
Afterwards, we calculate
SVD (Hoecker & Kartvelishvili, 1996) is used widely in the field of machine learning, which mainly used in dimensionality reduction algorithm. SVD can help us to represent complex datasets more simply. After performing SVD dimensionality reduction on the dataset, we can observe the data relationship more clearly.
To get a clear view of the effects of sensitive attributes on the dataset, We also use the SVD method for dimension reduction of the Adult dataset. First, we use the income attribute as the target
The change of target attribute
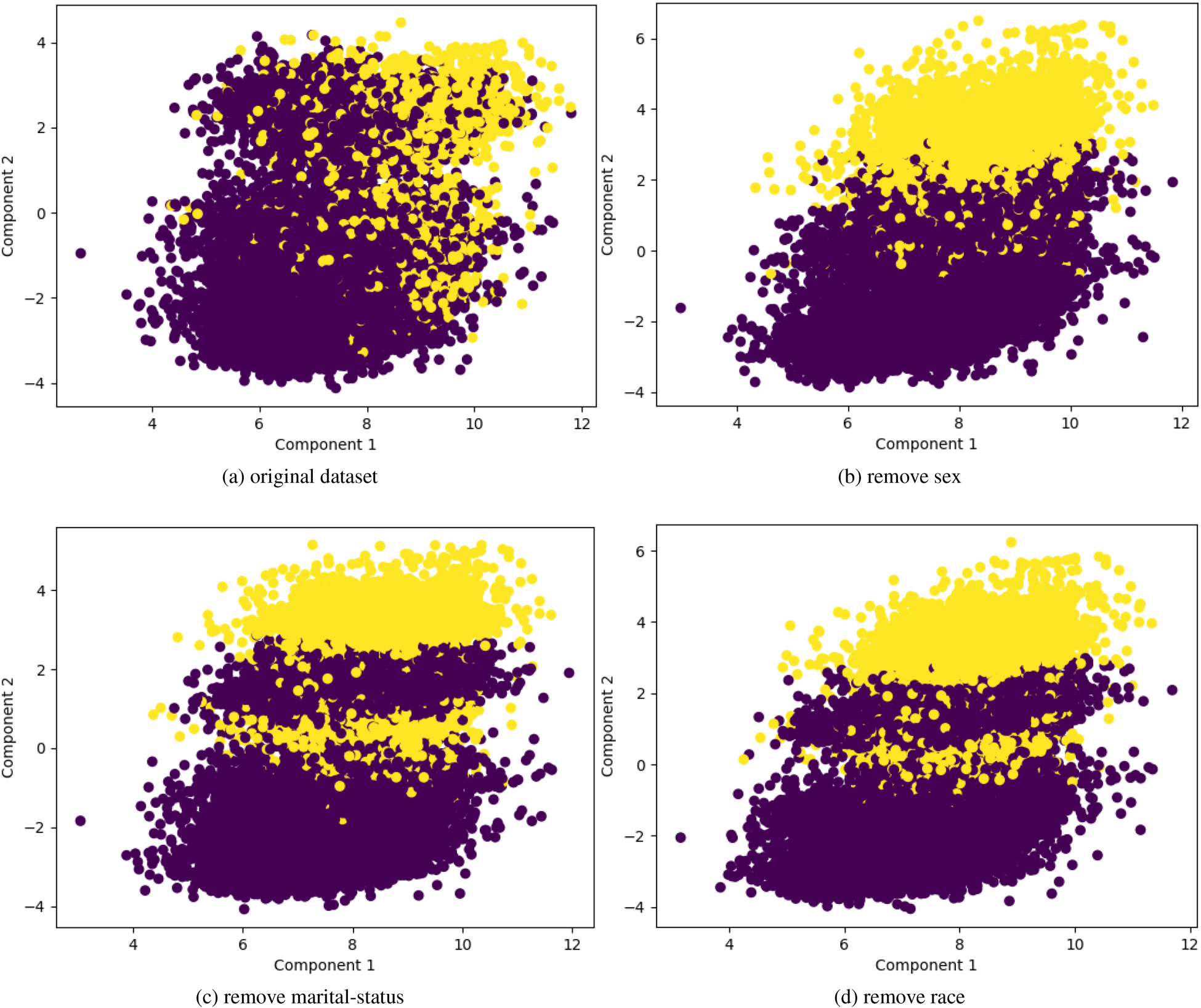
Sensitive attributes verification using singular value decomposition (SVD). (a) original dataset, (b) remove sex, (c) remove marital-status and (d) remove race.
In this section, we used the pre-processing method of algorithmic fairness to improve the fairness of machine learning models. Our aim is to reduce the problem of discrimination in machine learning models by reducing bias in the dataset. In practice, we used association based methods among the data bias reduction algorithms to reduce the bias of dataset. The specific process is shown as follows.
Indirect Sensitive Attributes Identification
Before identifying indirect sensitive attributes, we need to analyze the correlation (Asuero et al., 2006) between other attributes in addition to sensitive attribute
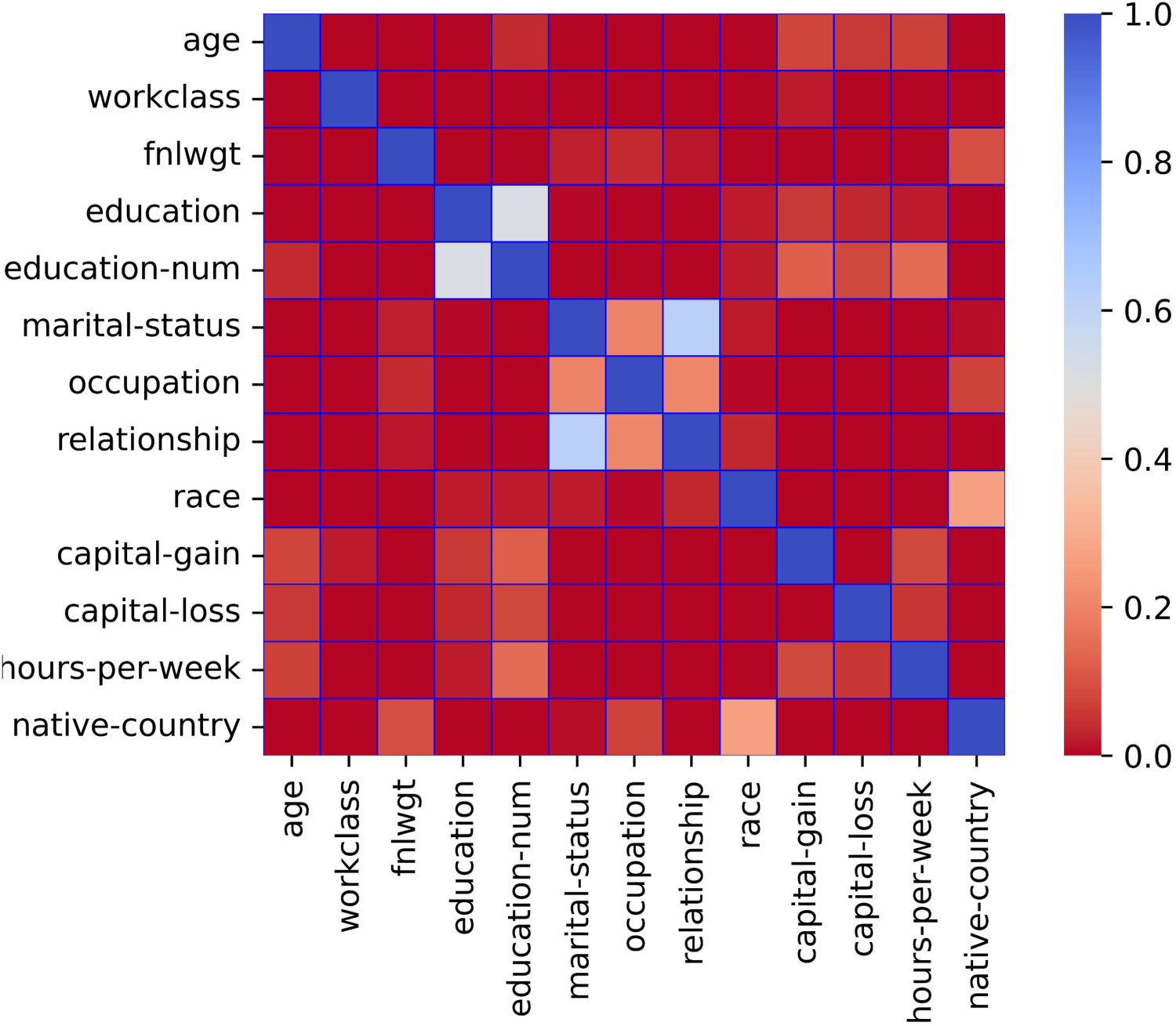
Correlations among attributes.
After correlation analysis between each attribute is performed, we need to determine indirect sensitive attributes
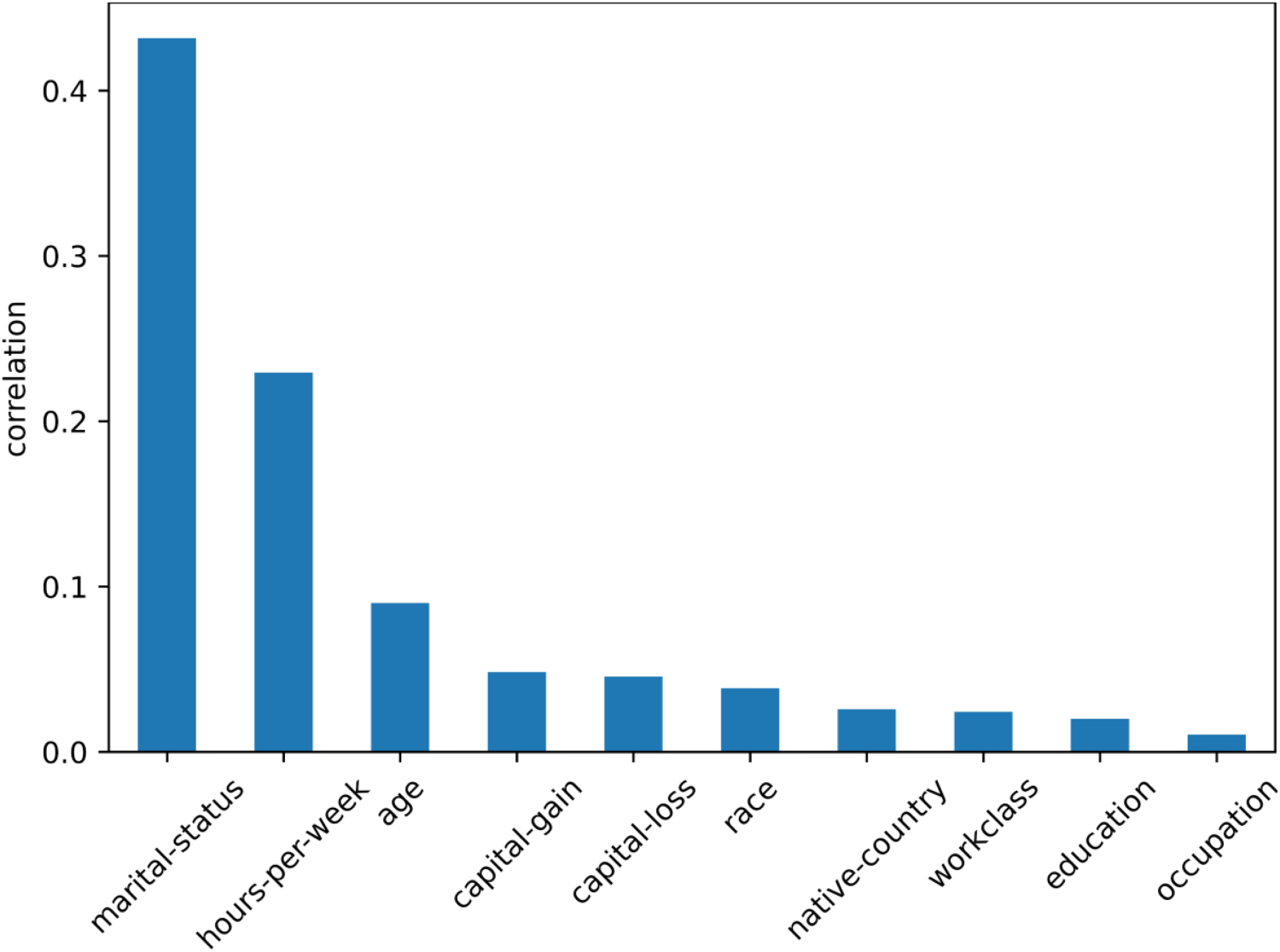
Correlation of other attributes with
Having already identified the sensitive attribute
We will use the Adult dataset to train a predictor, the Adult dataset was originally a categorical dataset used to predict whether a person’s annual income would exceed
First of all, We divide the Adult dataset into a training set and a test set, where we use
The Prediction Results of Predictor that does not Consider Fairness.
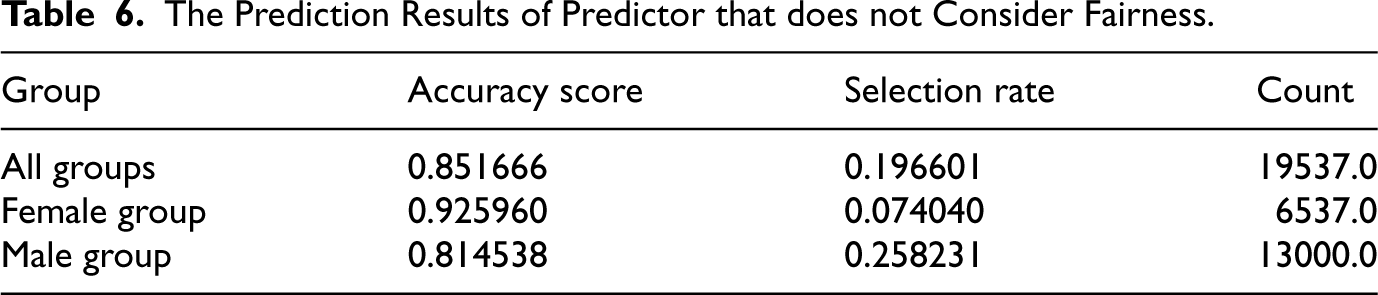
The Prediction Results of Predictor that does not Consider Fairness.
Next, we will improve the fairness of this model
The Prediction Results of Predictor under FTU.
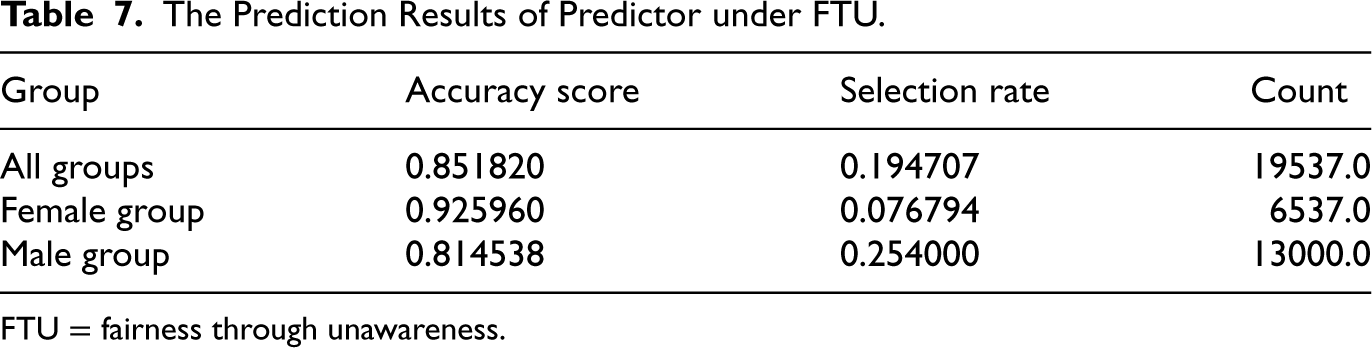
FTU = fairness through unawareness.
In the Table 7 we can find, the fairness don’t have significant improvement, the error rate for male is about three times greater than female, and the more interesting phenomenon is that the selection rate of male is also three times greater than female, this means that probability of getting a loan of male are three times more than female. Although we removed the sensitive attribute of sex from the training data, our predictor still discriminates based on sex. This indicates that simply ignoring a sensitive attribute
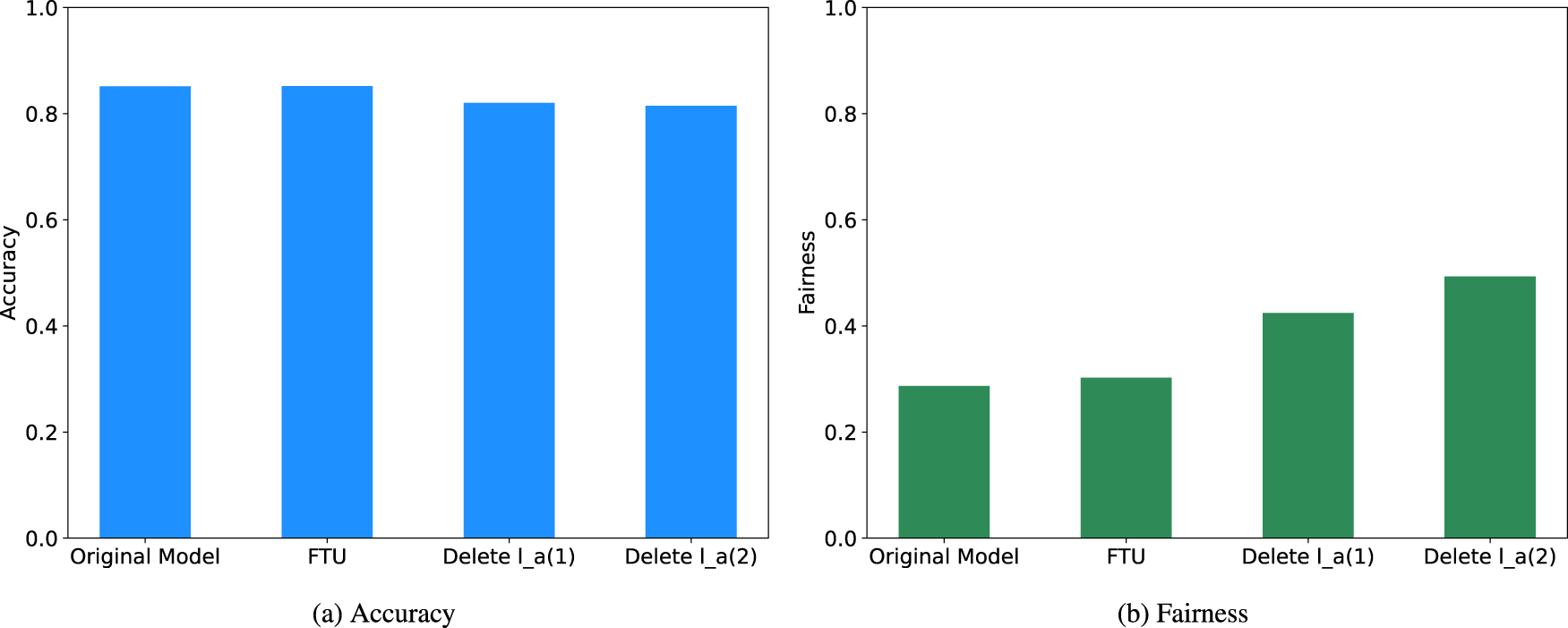
The variations of accuracy and fairness with sensitive attributes removed from adult dataset. (a) Accuracy and (b) fairness.
Experiment on the COMPAS Dataset
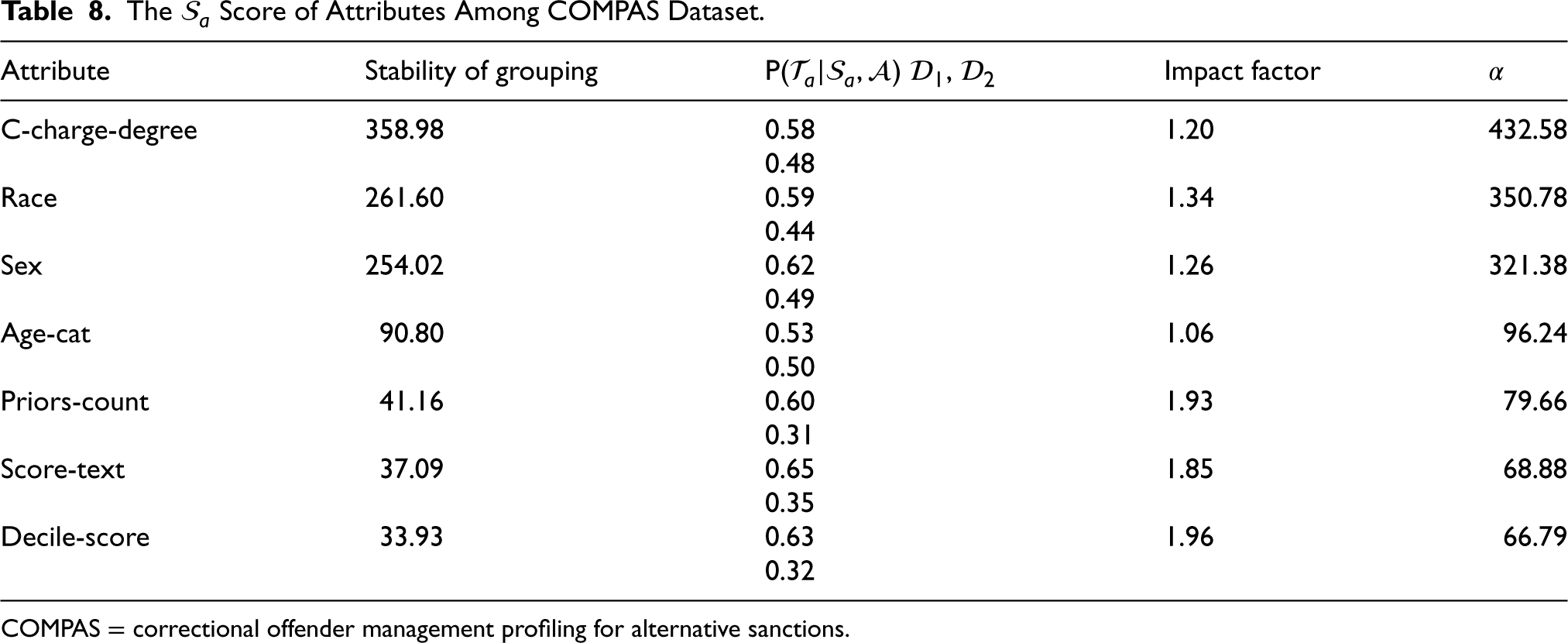
Firstly, we demonstrate our method again on the COMPAS dataset. We determined the sensitive attribute
The
Score of Attributes Among COMPAS Dataset.
The
COMPAS = correctional offender management profiling for alternative sanctions.
In Table 8, we can find the c-charge-degree attribute and race attribute have high probability of being a sensitive attribute. After verification by SVD, we considered the race attribute is the most likely sensitive attribute
After determining sensitive attribute
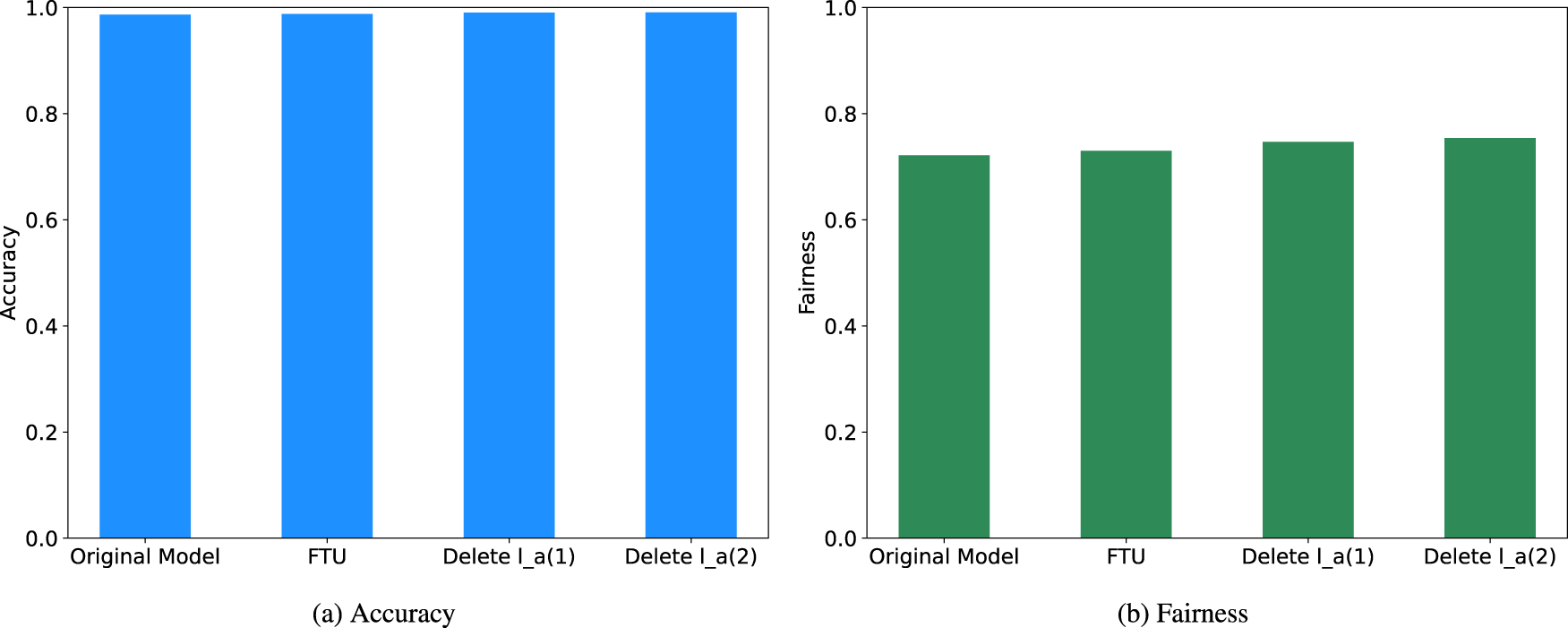
The variations of accuracy and fairness with sensitive attributes removed from compas dataset. (a) Accuracy and (b) Fairness.
In a previous study, the race attribute is designated as the sensitive attribute
Compare with Social Science Methods.
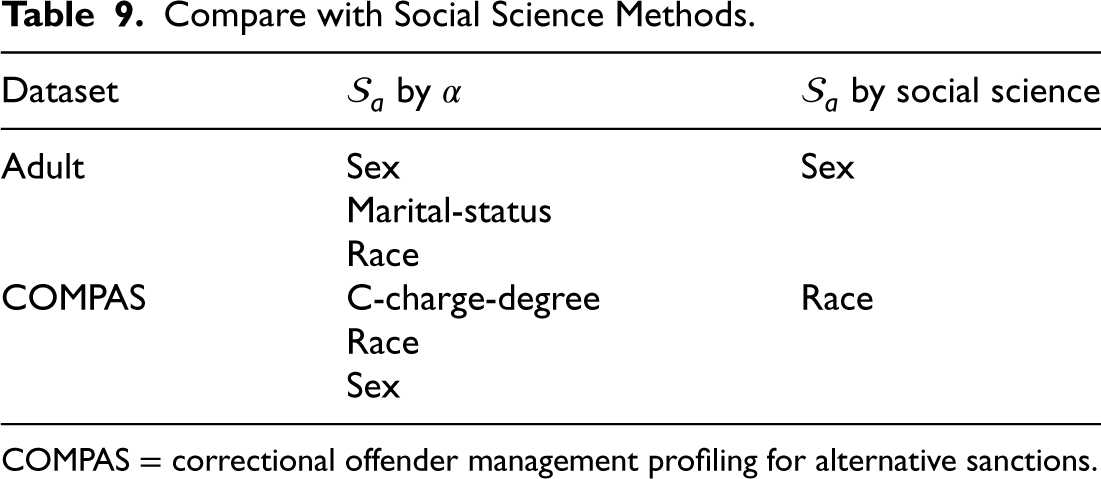
COMPAS = correctional offender management profiling for alternative sanctions.
To further verify the effectiveness of our method, we compared our method with other association based methods on the UCI Adult dataset and the COMPAS dataset. Those methods respectively:
In addition, we use three evaluation metrics to compare the fairness among models, which are:
Demographic parity (DP) : True positive rate balance (TPB) : True negative rate balance (TNB) :
Where C is the classifier, the experiment uses a logistic regression model,
Experimental Results of Comparison.
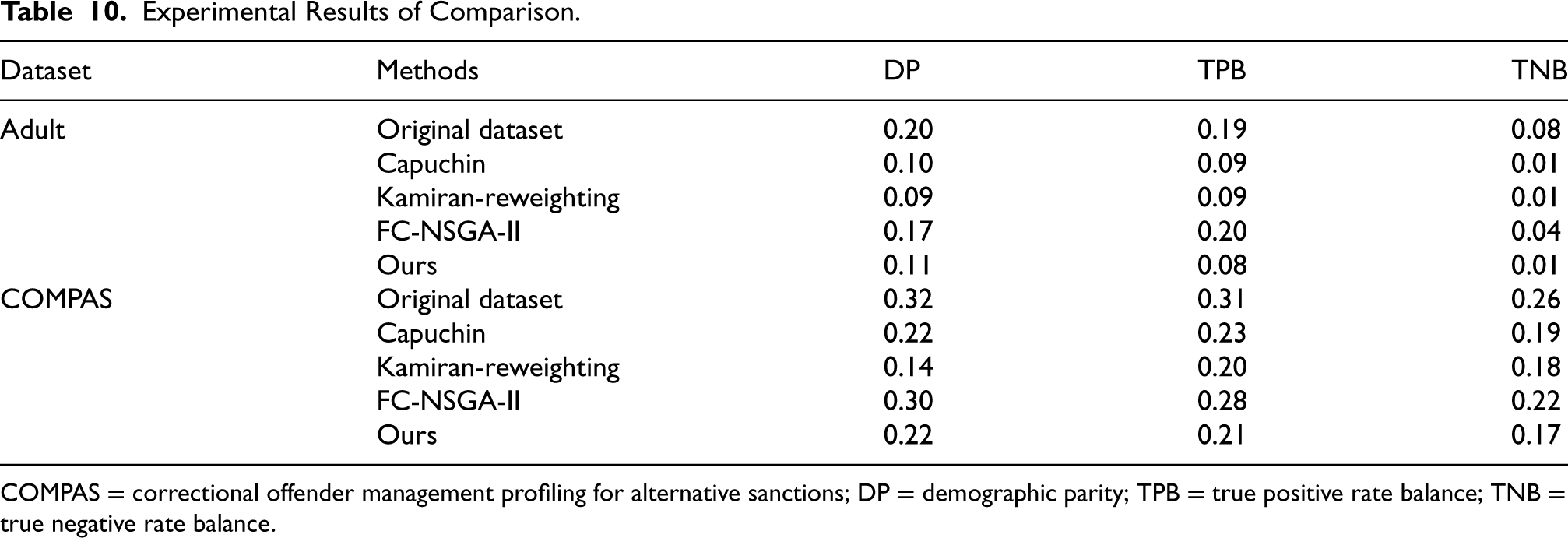
Experimental Results of Comparison.
COMPAS = correctional offender management profiling for alternative sanctions; DP = demographic parity; TPB = true positive rate balance; TNB = true negative rate balance.
From Table 10, we can find that our proposed method for algorithm fairness can outperform other three methods under different fairness definitions on two different datasets.
At first, we propose a method for identifying sensitive attributes based on data analysis; we found that traditional methods for determining sensitive attributes rely too much on social science and the experience of experts; this approach is easily influenced by people’s previous knowledge. However, converting the problem of determining sensitive attributes into a problem of data analysis, this effect of previous knowledge can be avoided by focusing the problem on the dataset itself. Next, we have improved the previous association-based methods, we define attributes that are highly correlated with sensitive attributes
Although our method achieves good performance and can accurately identify sensitive attributes and improve fairness in the machine learning model, there are still some limitations. Our method cannot perform very well on small datasets. Therefore, in the future, we will explore the space for further development based on some of the ideas presented in this paper.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work was supported by the project of the Natural Science Foundation of China (No.61402329, No.61972456) and the Natural Science Foundation of Tianjin( No.19JCYBJC15400, No.21YDTPJC00440).