
Abstract
Camouflaged object detection (COD) aims to identify objects seamlessly embedded in the surrounding environment. Due to the high inherent similarity between the texture of the camouflaged object and its complex background, making COD far more challenging than traditional target detection. To solve these problems, we propose a method that uses holistic boundary information to optimize COD through a two-stage strategy. Specifically, the feature enhancement module is initially implemented to refine features at different scales and emphasize boundary details of camouflaged entities. Then, our network employs a boundary localization module to guide low-level local edge features through high-level global semantic. Furthermore, the boundary-embedded feature aggregation module is introduced to achieve cross-level fusion of multi-scale features, by embedding and effectively activating boundary information, which reduces the interference from cluttered backgrounds. Extensive experiments on four benchmark datasets demonstrate that our proposed model outperforms the other 17 state-of-the-art COD methods. The source code and results of our method are available at https://github.com/WObaibai/BSNet.
Introduction
In nature, animals often blend perfectly with their surroundings to avoid predators by changing color, shape, and patterns (Price et al., 2019). Unlike generic object detection tasks, camouflaged objects are difficult to detect in their essence since hidden targets are often indistinguishable from the background. The camouflaged object detection (COD) task confronts two main challenges: inherent similarity and complex backgrounds. In the former, the camouflaged object shares similar color and texture with its background, making it difficult to distinguish the target accurately. In the latter, the background partially occludes the camouflaged object, often leading to inaccurate detection in challenging and complex scenes. Recently, researchers have proposed many methods based on deep learning and have made certain progress. Fan et al. (2020a) created COD10K, the largest camouflage dataset at present, and designed the SINet network, proposing a predatory bionic structure that uses two stages of search recognition to accurately distinguish camouflage from the background. The bio-inspired solutions also produce good results in Jia et al. (2022), Li et al. (2021), and Mei et al. (2021). Zhou et al. (2022) in their work on FAP-Net demonstrate the efficacy of using boundary auxiliary information to accurately locate targets in complex scenes, as shown in Figure 1.
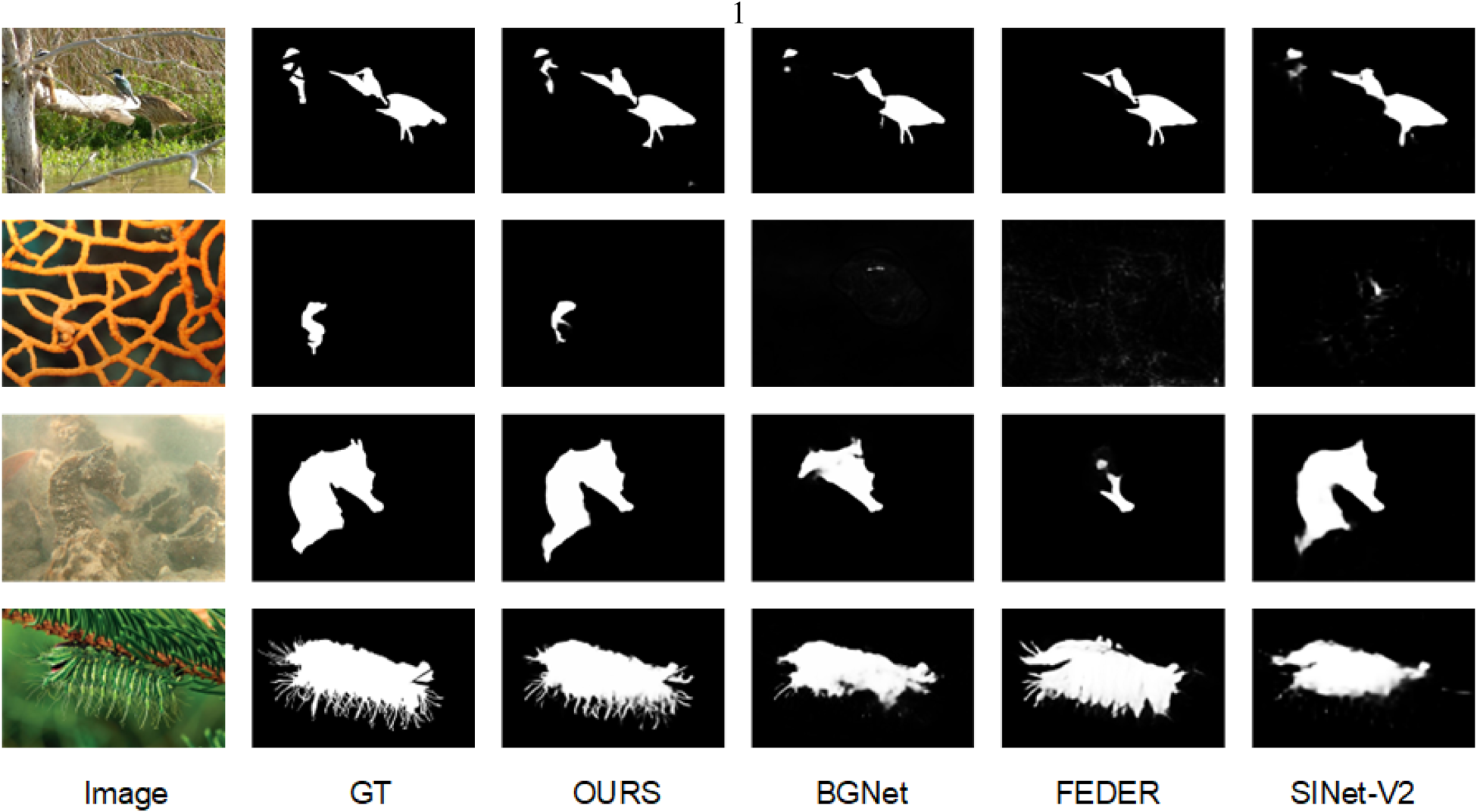
Existing COD methods such as BGNet, FERDE, and SINet-V2 often cannot fully detect camouflaged objects in scenes where the camouflaged objects are highly similar to the background or have complex boundaries. In contrast, our method can accurately detect camouflaged objects. Note. COD = camouflaged object detection.
However, in a wide field of view, we usually regard low-contrast camouflaged objects and the background as a whole, resulting in misleading vision (Stevens et al., 2006). When the field of view is reduced, we can only see a local area of the camouflage object or background, making it challenging to categorize pixels accurately and increasing vulnerability to interference from similar details. To address this, we can integrate various receptive fields in our networks, to match the boundary features of camouflaged objects of different sizes and shapes, which is beneficial to the localization of object structures. Secondly, camouflage objects are often in complex environments (Jung, 1973), such as background occlusion, which easily introduces background noise. Therefore, how to effectively suppress background interference and obtain accurate camouflage images become crucial.
Although previous researchers used boundary information to help networks find the approximate location of camouflage objects, they adopted a simple fusion method of boundary information and feature maps (He et al., 2023; Song et al., 2023; Sun et al., 2022; Zhu et al., 2022). However, their guidance mechanism relied too much on the global context and neglected the accurate modeling of local boundary details of objects, especially when dealing with camouflage objects with rich details but fuzzy local boundaries, which performed poorly as shown in the fourth column of Figure 1. Based on the above shortcomings and inspirations, we propose a new COD framework BSNet. Unlike general boundary guidance, we adopt a method of first locating the boundary and then integrating the complete target. This framework uses precise boundary semantic information to improve the performance of disguised object detection. Specifically, our method uses a two-stage strategy, which is different from the general stage of coarse positioning and then precise segmentation. The model focuses first on precise boundary location and then on feature fusion and refinement to minimize noisy background interference. BSNet consists of three key modules. We first design the feature enhancement module (FEM) to refine features at different scales. Then we employ the boundary localization module (BLM), which aims to use different receptive fields in the spatial dimension to locate diverse camouflage edge areas forming more accurate edges. In addition, we have constructed an architecture that gradually integrates multi-level features from top to bottom to integrate more complete and accurate boundaries. Finally, we propose the boundary-embedded feature aggregation module (BFM), featuring a simple multiple residual structure for cross-level fusion of multi-scale features. This module activates precise boundary information from the BLM to refine the object structure and reduce cluttered background noise. Experimental results show that compared with current advanced methods, the proposed model effectively improves detection accuracy. In summary, our contributions are as follows:
We propose BSNet, a new two-stage strategy network. It initially locates and integrates comprehensive boundary semantics, then directs the fusion of cross-layer, multi-scale features for precise segmentation. We carefully designed the BLM to extract local edge details and global structure from the spatial dimension to enhance boundary semantics. In order to utilize contextual information to explore the integrity of the camouflage boundary, we propose a boundary refinement architecture to gradually fuse multi-scale edge features from bottom to top. We introduce the BFM to enhance cross-level context interaction and feature discrimination. This module facilitates the correlations among multi-level features and diminishes background interference by embedding object boundary information, thus fostering more distinct feature generation.
Camouflaged Object Detection (COD)
Since the pattern and color of the camouflaged object are similar to the background, it is difficult to separate it from the background, resulting in poor detection results. Earlier COD adopted manual detection methods, using texture, color, or brightness to distinguish the target and the background. However, since the camouflaged object is highly similar in color and texture to the background, it usually does not work well. Recent work utilizes deep neural network, convolutional neural network (CNN), to identify complex attributes of camouflage objects and achieves excellent performance (Le et al., 2019; Ren et al., 2021; Song et al., 2023; Yan et al., 2023).
Some studies were inspired by the hunting process. They first conducted target search and positioning and then identified target motivations one by one, and designed search modules and recognition modules (Fan et al., 2020a). Since then, a series of biologically inspired models have been designed (Jia et al., 2022; Mei et al., 2021; Wang et al., 2023). But this type of model only roughly locates the area containing the camouflaged object, and still cannot clarify the fuzzy boundary between the camouflaged object and its surrounding environment, resulting in fuzzy segmentation. Yan et al. (2020) used the original image and its flip as input and passed them to a two-stream mirror network to change the perspective to identify camouflaged objects. In addition, these models (Cong et al., 2023; Xie et al., 2023; Zhong et al., 2022) also propose using frequency representation to integrate networks to obtain high-frequency and low-frequency information, respectively, and design frequency reasoning modules to mine information clues. However, in areas with fuzzy boundaries, the background still causes interference, affecting COD accuracy.
Transformers provide richer background–foreground interaction information by modeling global context and complex pixel-to-pixel relationships. This allows them to effectively identify camouflaged objects when the background and target are similar in color or texture. Lyu et al. (2024) and Yang et al. (2021, 2023) take advantage of probabilistic models, uncertainty guidance, and transformer-based reasoning to learn deterministic and probabilistic information about camouflaged objects. However, these methods still suffer from high computational costs and may not be the best choice for real-time applications and large-scale dataset processing.
Multi-Task Learning
Compared to single-task learning paradigms (Chen et al., 2022; Fan et al., 2020a) that develop attention modules to identify target regions. Nowadays, some research is more focused on using multi-task learning frameworks, such as using texture information (Ren et al., 2021; Song et al., 2023) to help the network locate camouflaged objects more accurately. However, these algorithms may still mistake the camouflaged object as the background due to its similar texture, resulting in detection errors. At the same time, MGL (Zhai et al., 2021) is the first model to encode edge features together with object features into a graph convolutional network to improve COD performance. And UGTR (Yang et al., 2021) learn the certainty of disguised objects by taking advantage of confidence estimation models and transformer-based backbone. The multi-task framework can also achieve robust COD learning by locating, segmenting, and ranking camouflaged objects (Wang et al., 2021). And Zhou et al. (2022) proposed a boundary auxiliary module to enhance feature representation. However, this type of network only uses low-level features, and the edge cues contain redundant background information, which can easily cause interference to the network.
Multi-Scale Contextual Information Learning
It aims to effectively process feature information at different scales in images. For example, C2FNet (Sun et al., 2021) uses a design in which darker features gradually enhance shallower features to improve hidden features from coarse to fine levels. In addition, some networks also use contextual information to effectively enhance feature representation capabilities, which is crucial in target detection tasks, such as salient target detection and small sample detection tasks. In order to supplement global information, these models integrate low-level detailed features and advanced semantic features to alleviate the scale change problem and improve detection accuracy (Chen et al., 2020; Guo et al., 2023; Hu et al., 2021; Wang et al., 2021). By extracting features at different levels of the feature pyramid network (Lin et al., 2016) and fusing them, dense top-down and bottom-up propagation combines more comprehensive multi-context information to improve the model recognition and localization capability (Chen et al., 2022; Cheng et al., 2022; Chou et al., 2022; Huang et al., 2023; Wang et al., 2021; Zhang et al., 2022a, 2022c).
Boundary-Guided Learning
Since the boundaries of camouflaged targets are usually slightly different from the background, using this boundary information can effectively improve the accuracy of target detection (He et al., 2023; Song et al., 2023; Sun et al., 2022; Zhu et al., 2022). BGNet (Sun et al., 2022) adds a boundary guidance mechanism to its network, which helps the network focus on the edge area of the camouflaged target by generating a boundary guidance feature map. However, its boundary guidance relies on the direct extraction and fusion of boundary information. For camouflaged targets with blurred boundaries or highly integrated with the background, it is impossible to fully extract details, resulting in limited detection performance and target loss. BSANet (Zhu et al., 2022) introduces a separation attention mechanism and a boundary guidance module to enhance attention to boundary areas through attention guidance. FSNet (Song et al., 2023) dynamically focuses on the key areas of the camouflaged target boundary through a scanning mechanism. However, the size and shape of camouflaged targets may vary greatly. The above methods cannot effectively capture smaller or farther boundary targets, and are weak in multi-scale adaptation and complex background capabilities, resulting in performance limitations.
In contrast, our method pays more attention to highlighting the overall edge details of the camouflage and provides effective constraints in the fusion stage using multi-scale features at different levels to reduce the interference of redundant background information, thus improving the accuracy of the detection model.
Proposed Method
Overview
The overall architecture of the proposed BSNet is illustrated in Figure 2, which consists of two stages: the first stage aggregates different levels to generate the accurate target boundary map, and the second stage integrates boundary information with the camouflaged object features to produce the final prediction result. Our network comprises three key components: the FEM, BLM, and BFM.
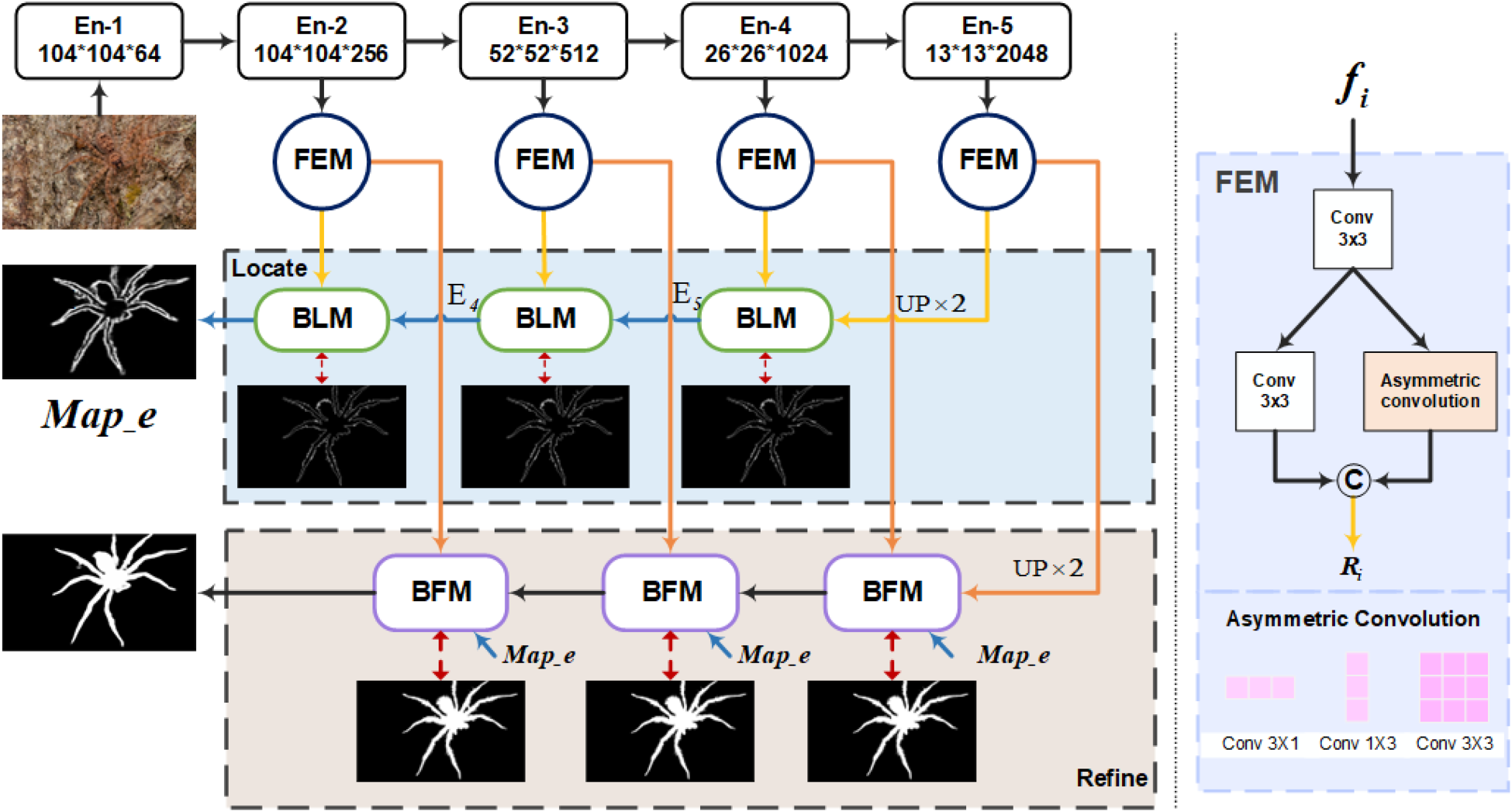
The overall architecture of BSNet for camouflage target detection. It mainly contains three key modules, namely, FEM, BLM, and BFM. The dashed red line represents supervision between the ground truth and predictions. The BSNet performs supervised training on the edge maps obtained by three BLMs and the prediction maps obtained by all BFMs at the same time. See Section 3 for details. Note. FEM = feature enhancement module; BLM = boundary localization module; BFM = boundary-embedded feature aggregation module.
Specifically, an image
Since the detailed information about the camouflage, such as edges, textures, etc., is helpful for network detection, it is particularly critical to effectively capture the difference between the camouflage and the background, especially in complex scenes. Compared to existing networks (Song et al., 2023; Xu et al., 2022) that directly feed the encoder features into the localization and recognition module, such methods tend to incorporate background information. In contrast, in order to improve the perception of the boundaries of camouflaged targets by integrating information from different perspectives, we adopt an asymmetric convolution strategy. By extracting features in the horizontal and vertical directions and capturing subtle feature differences in specific directions, the network pays more attention to the directional information and boundary details of the camouflaged target.
As shown in Figure 2, asymmetric convolution is used to add residual connections to better capture and emphasize features in specific directions, and thereby improve the perceptual information of structures such as object boundaries. Specifically, the process can be expressed as:

Our asymmetric convolution consists of a standard

The previous studies (Zhen et al., 2020) have demonstrated that incorporating boundary information contributes to improving the performance of computer vision tasks. In COD tasks, there is no obvious dividing line between the boundary of the camouflage object and the background. The colors and textures are likely to be consistent with the background, and the shapes of the boundaries may be similar to the shapes of the surrounding scene. This integration of boundaries with the surroundings poses a challenge. Therefore, accurately locating the boundaries of camouflaged targets is crucial. And boundary information serves as an effective constraint for detecting features of camouflaged targets, reducing interference from redundant background information. The network (Sun et al., 2022; Zhou et al., 2022) of the boundary guidance mechanism only obtains the boundary map through global features as additional information input and is not suitable for the complex features of camouflage objects with different shapes and boundary pixels. The difference is that we first generate boundary positioning information, obtain the target position, and form a clear contour map. We adopt a multi-scale receptive field to adapt to camouflage targets of different sizes, and gradually refine the boundary information. The design of this module pays more attention to the adaptability of boundary details, especially for target boundaries of different sizes and shapes.
We use different receptive fields in the spatial dimension to match the edge regions of disguised objects of different sizes and shapes, forming more accurate edge information and obtaining preliminary boundary localization. This is the first step, as shown in Figure 3. Specifically, the process involves first upsampling the features of


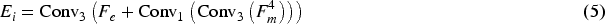
The architecture of our boundary localization module.
Compared with the simple way of obtaining edges in recent methods (Liu et al., 2023; Sun et al., 2022; Zhou et al., 2022), we adopt the strategy of gradually refining edges and focus on learning boundary-enhanced representations to preserve local features and boundary information, incorporating them into the decoder network. Notably, for
Figure 4 shows the visual feature maps of the input and output of the three-layer BLM, as well as the final generated edges. By comparing Figure 4(c), (d), and (e), we can find that the strip structure of the edge of the camouflage target is highlighted, indicating that the network effectively learns the fine-grained detail information of the boundary and better highlights the integrity of the camouflage object boundaries.

Visualization feature maps in different layers of BLMs and BFMs. Note. BLM = boundary localization module; BFM = boundary-embedded feature aggregation module.
Different levels of features typically contain different information. Low-level features are closer to the original information and are important for detecting small targets, while high-level features contain richer semantic information and are more sensitive to large targets.
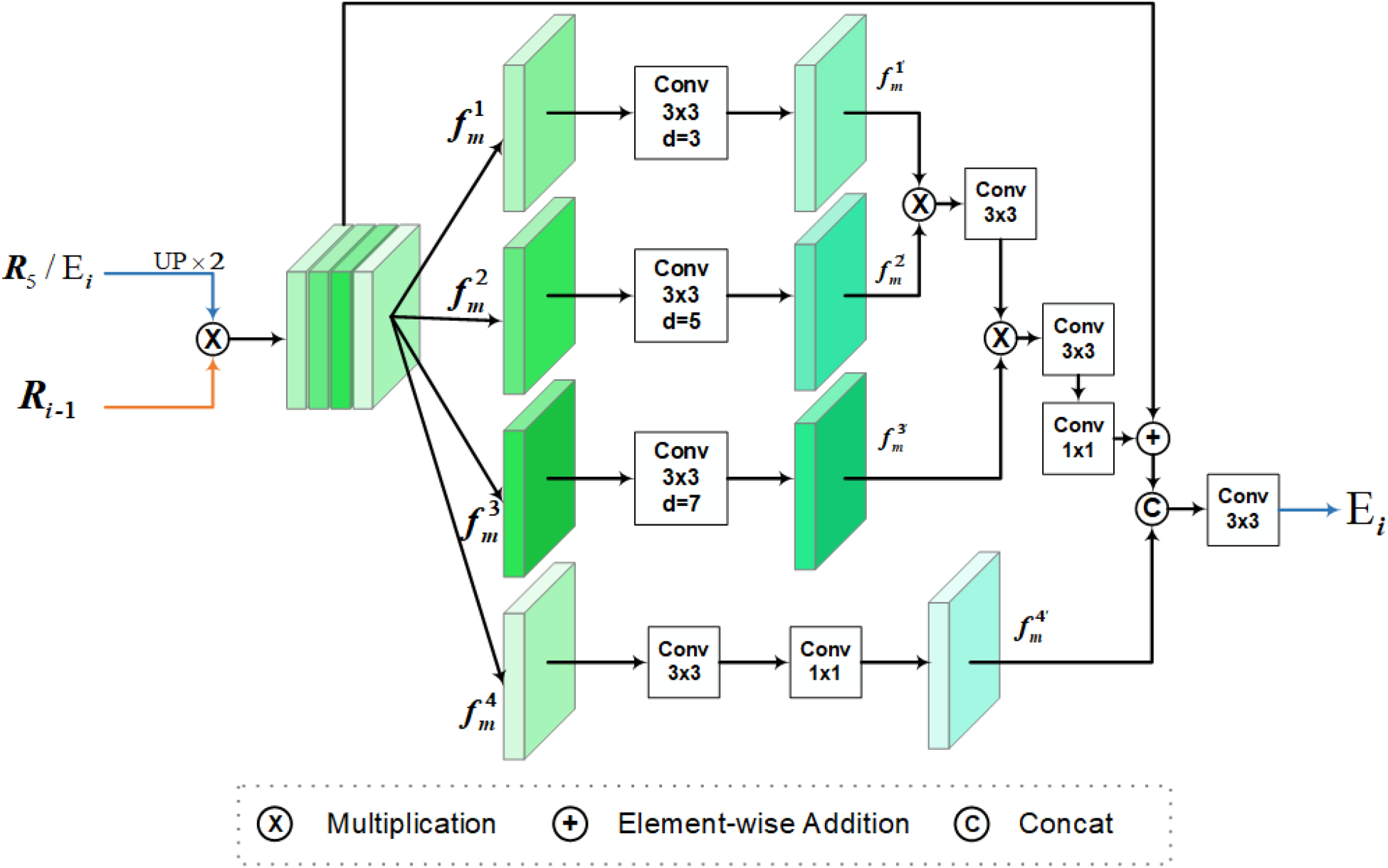
Due to obtaining accurate edge information in the first stage (as shown in the figure), in order to effectively utilize the edge information localization capability in BLM and the enhanced features obtained by FEM, we propose the second stage of the network: integrating and designing BFM. Unlike network models such as BGNet, boundary maps, and feature maps are fused using simple convolution operations. This module can interactively integrate contextual information while embedding the position and size information of the target edge. Better capture global contextual information through attention mechanisms and dynamically adjust the importance of features at different scales. Deep fusion of local and global features can better handle complex scenes of disguised objects, while ensuring details and fully considering global semantic information.
As shown in Figure 5,

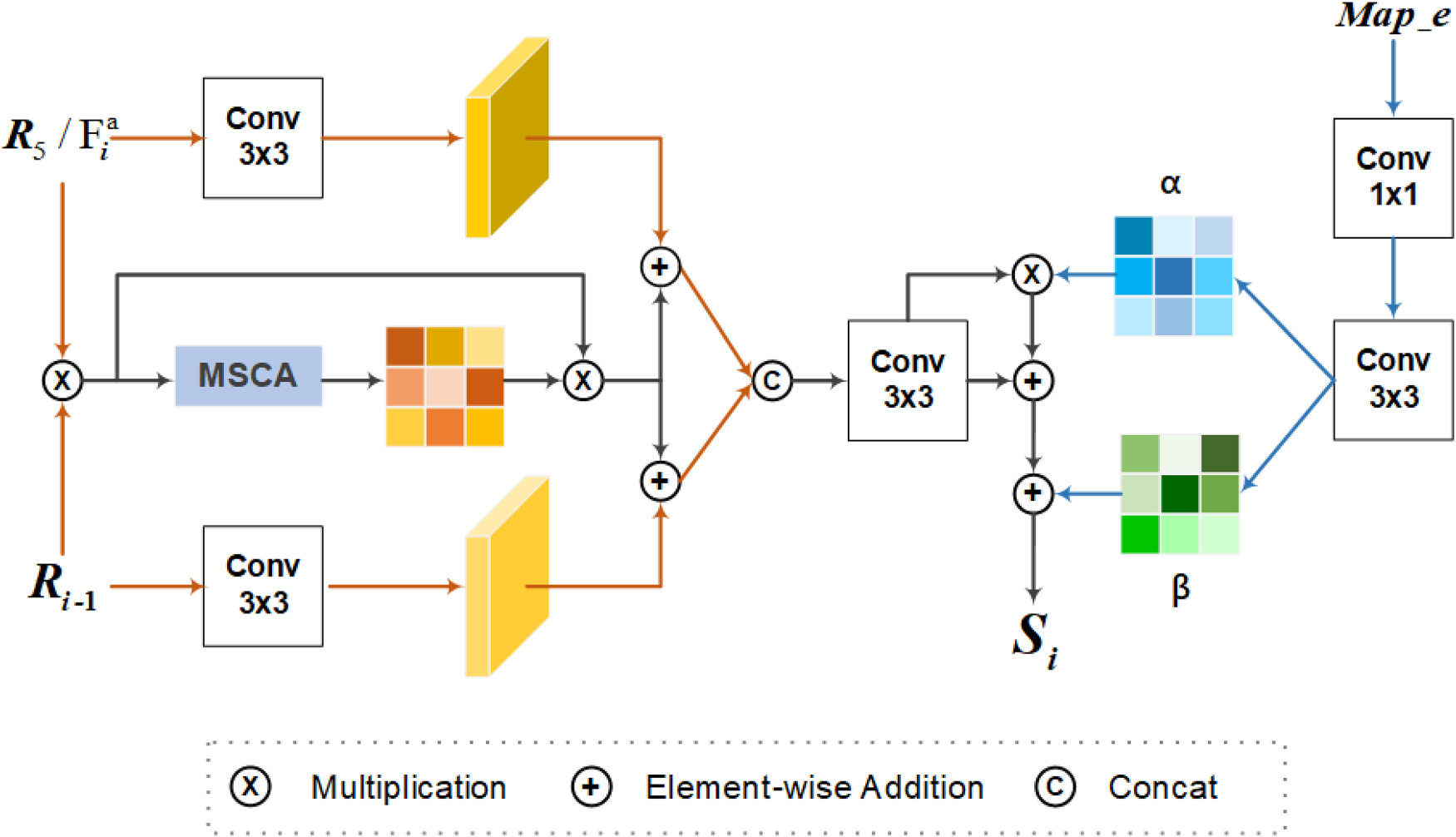
The architecture of our boundary-embedded feature aggregation module.
Moreover,

Finally, the detailed boundary map

The loss function of the proposed BSNet comprises two types of supervision: the camouflaged object mask (
In summary, the loss function for our model is defined as follows:
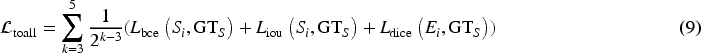
Implementation Details
We implemented the network with PyTorch and used Res2Net50 pretrained on ImageNet as our backbone. All input images and ground truth are resized to
Datasets
To verify the effectiveness of the proposed model, we perform performance evaluation on four COD benchmark datasets: CAMO (Le et al., 2019), CHAMELEON (Przemysław et al., 2018), COD10K (Fan et al., 2020a), and NC4K (Lyu et al., 2021). NC4K is the newly largest dataset, which covers a variety of different camouflaged object scenes and environments, with a total of 4,121 images. COD10K is currently the largest dataset with pixel-level annotations, containing 3,040 training images and 2,026 testing images. It consists of 10 super-classes and 78 subclasses gathered from several photography websites. CAMO contains eight categories and has 1,250 camouflage images. CHAMELEON is a small dataset consisting of 76 COD images. Following the common training settings with existing methods, this work uses 3,040 samples from COD10K and 1,000 images from CAMO for training. During the testing phase, we tested and compared the performance of our model and other competing models on the test sets of CAMO and COD10K as well as the entire CHAMELEON and NC4K datasets.
Evaluation Metrics
Quantitatively evaluate the effectiveness of the model based on four metrics commonly used in COD tasks: the structure-measure (
Comparison to State-of-the-Arts
To demonstrate the effectiveness of our method, it is compared with 17 state-of-the-art (SOTA) COD methods, including SINet (Fan et al., 2020a), JSCOD (Li et al., 2021), S-MGL (Zhai et al., 2021), R-MGL (Zhai et al., 2021), PFNet (Mei et al., 2021), LSR (Lyu et al., 2021), C2FNet (Sun et al., 2021), BSANet (Zhu et al., 2022), BGNet (Sun et al., 2022), SINet-V2 (Fan et al., 2021), UGTR (Yang et al., 2021), SegMaR (Jia et al., 2022), CubeNet (Zhuge et al., 2022), C2FNet-pre (Chen et al., 2022), FEDER-R2N (He et al., 2023), OAformer (Yang et al., 2023), UEDG (Lyu et al., 2024), FSPNet (Huang et al., 2023), NCHIT (Zhang et al., 2022a), OCEnet (Liu et al., 2022), and PreyNet (Zhang et al., 2022b). To be fair, all predictions from these methods are either provided by the authors or produced by models retrained with open-source code.

Qualitative comparisons of our BSNet with state-of-the-art methods.
The Performance Comparison With Eight State-of-the-Art Models on Four Datasets. Maximum-F-Measure (
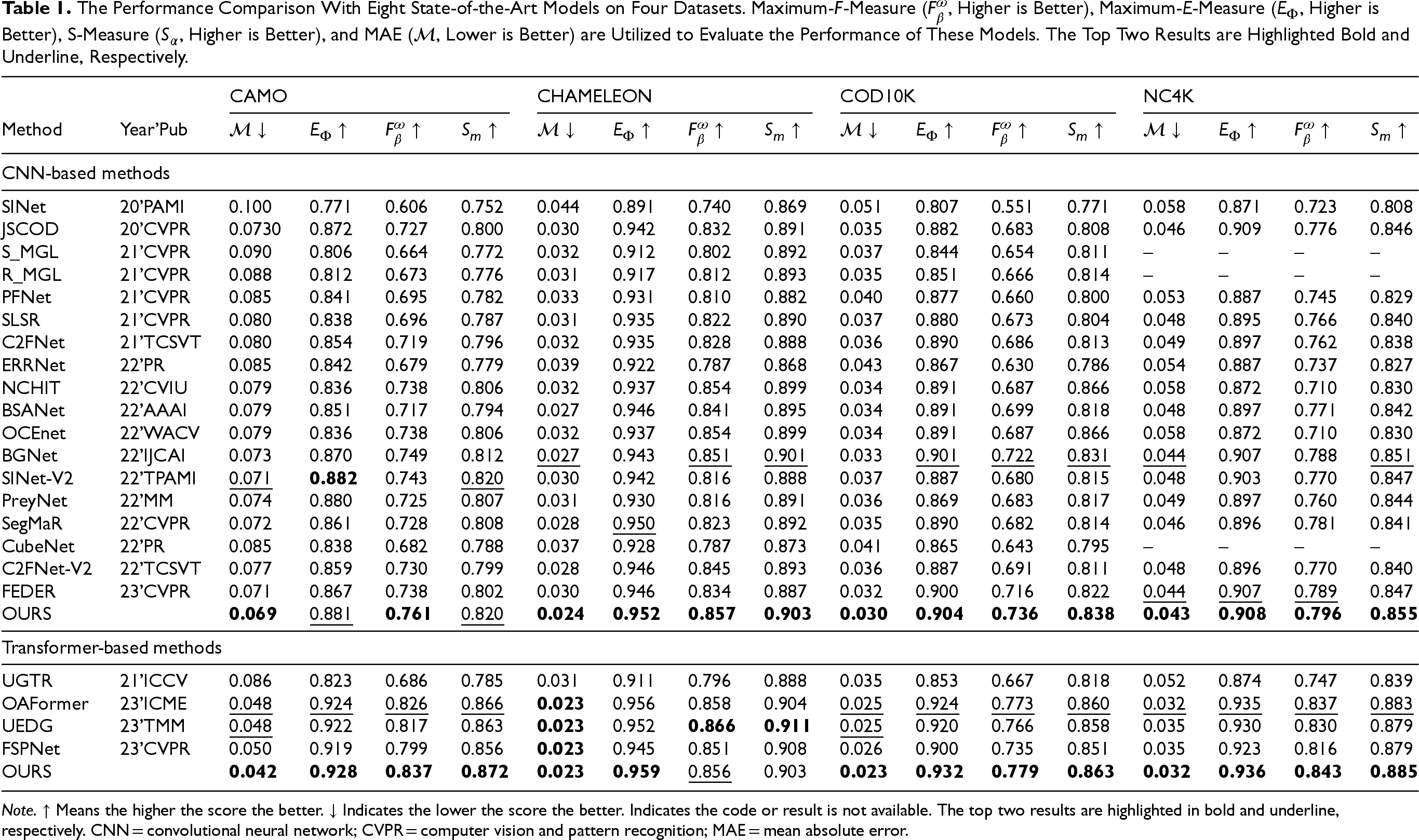
Note.
Comparison of the Number of Model Params, the Number of FLOPs, and the Inference Speed (Speed).
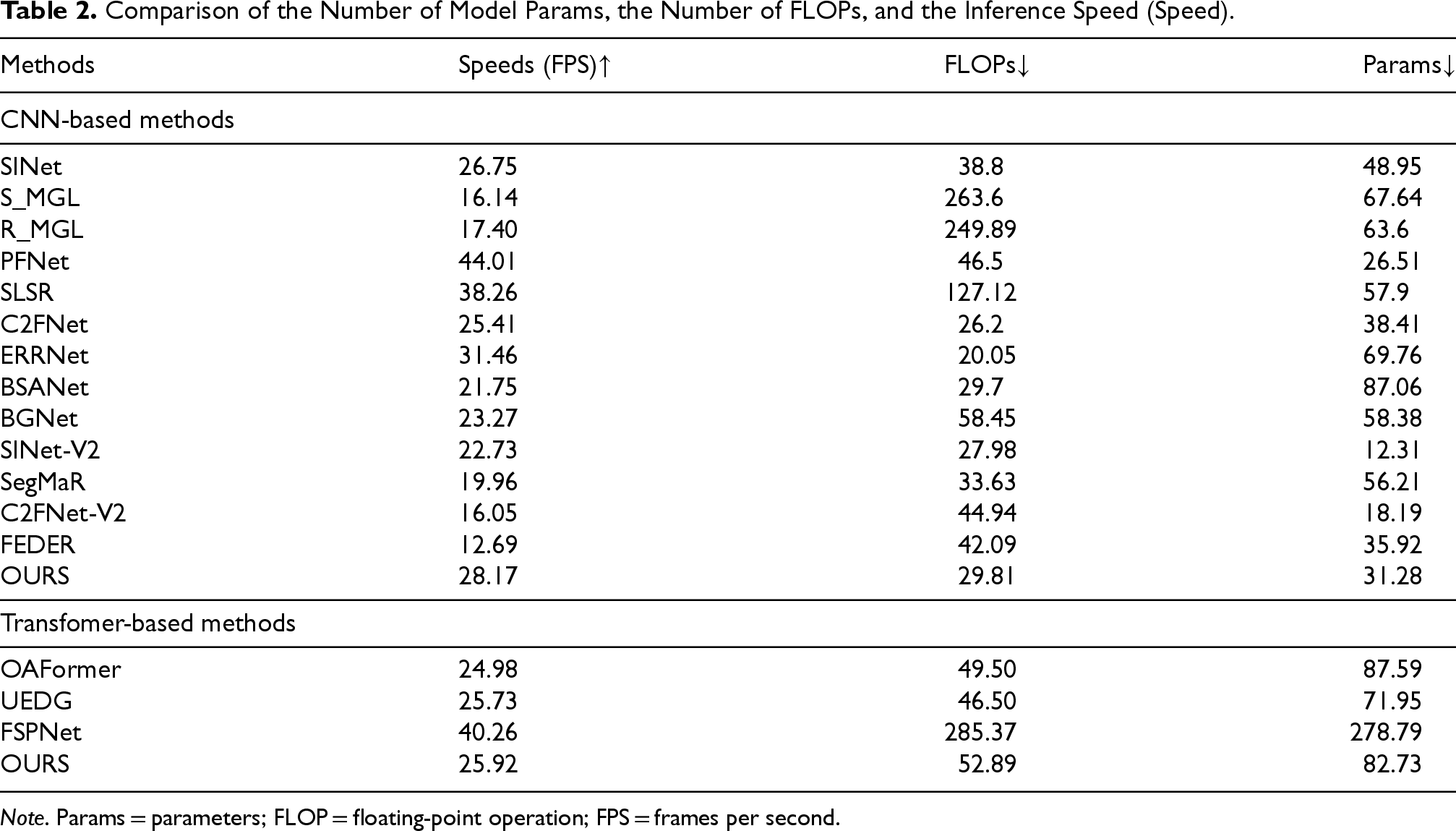
Note. Params = parameters; FLOP = floating-point operation; FPS = frames per second.
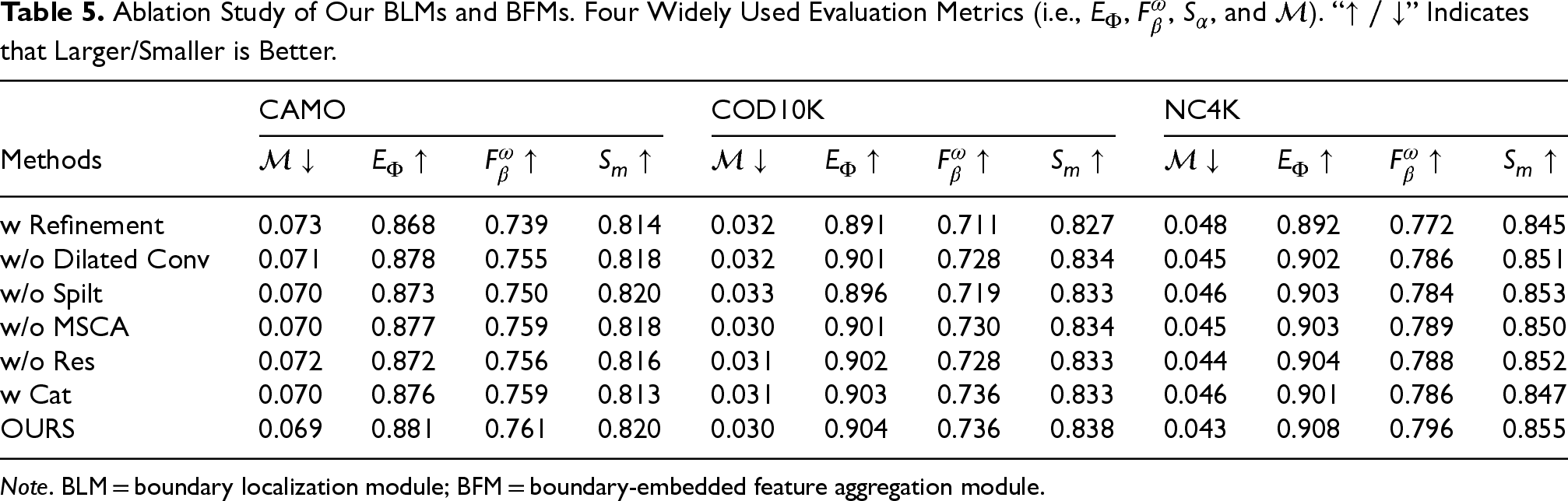
In this part, we conduct comprehensive ablation experiments to verify the effectiveness of various parts and configurations. For the baseline, we remove all extra modules (FEM, BLM, and BFM) and boundary refinement architecture, leaving only four
Basic (A1): The basic model is equivalent to all FEMs, BLMs, and BFMs from our network.
Basic + FEMs (A2): Add the FEM to the basic model (A1).
Basic + ERF (A3): Add the BLM to the basic model (A1). The BLM used in this example only retains the
Basic + BFMs (A4): Add the BFMs to the basic model (A1).
Basic + FEMs + BLMs (B1): Add all BLMs in the Basic + FEMs model (A2).
Basic + FEMs + BFMs (B2): Equivalent to adding all BFMs in the Basic + FEMs model (A2).
According to the qualitative comparison results shown in Figure 7, we can see that our model performs best, which produces satisfactory maps. The structure of the target becomes increasingly complete, and the boundaries become clearer. Our final result image is closer to the ground truth and achieves the best visual effect.

Visual comparisons of different variations. (a) RGB image, (b) ground truth, (c) A2, (d) B1, (e) w/o dilated conv, (f) w/o MSCA, (g) w/o res, (h) our. Note. RGB = red–green–blue; MSCA = multi-scale channel attention.
Ablation Studies for Different Baseline Methods and Key Components of Our Model.
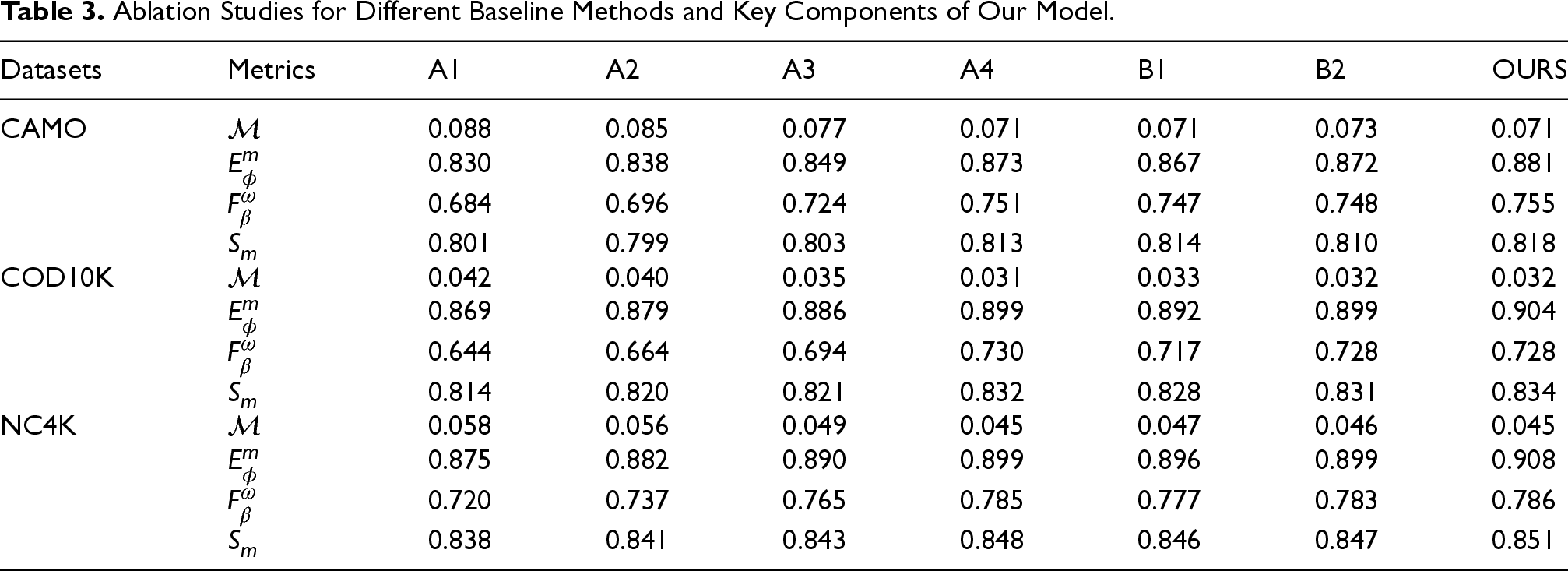
Ablation Study of the Input Size. Four Widely Used Evaluation Metrics (i.e.,
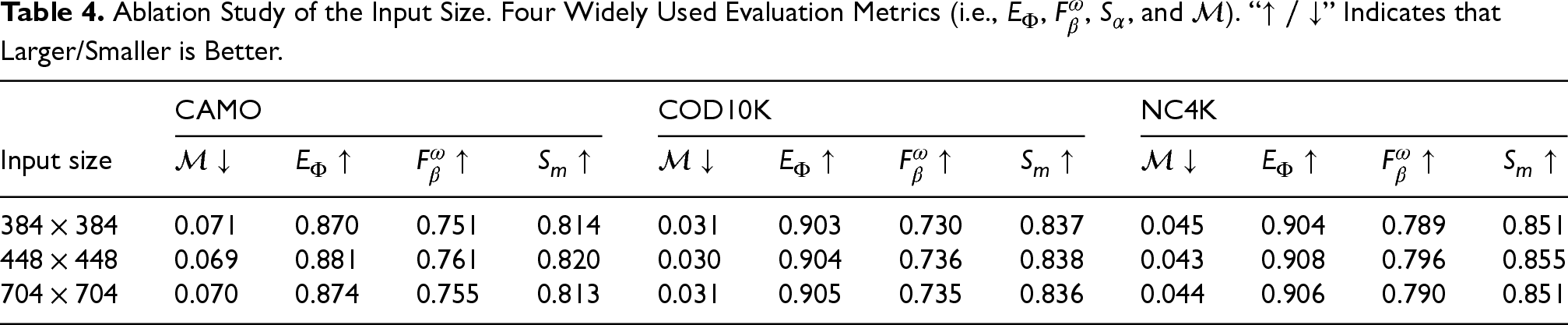
Ablation Study of Our BLMs and BFMs. Four Widely Used Evaluation Metrics (i.e.,
Note. BLM = boundary localization module; BFM = boundary-embedded feature aggregation module.
Quantitative Results for Validating the Effectiveness of the Supervision Strategy Adopted in the Proposed Methods. Four Widely Used Evaluation Metrics (i.e.,

Although our COD network model performs well in accuracy and efficiency, it still lags behind some popular models in terms of parameter quantity. As shown in Table 7, the BFM has a significant impact on the speed, floating point operation, and parameters of the entire network. This indicates that the BFM plays a crucial role in determining overall computational cost and model complexity. Therefore, this is a sector that I need to pay attention to in the future. Specifically, efforts will be made to find a good balance between performance and the number of parameters, with the aim of optimizing the efficiency of the model while not compromising its ability to provide high-quality results. We plan to explore strategies such as implementing lightweight backbones, employing knowledge distillation, or developing more efficient network architectures.
Comparison of Three Modules in BSNet: Number of Model Params, Number of FLOPs, and Reasoning Speed (Speed).

Comparison of Three Modules in BSNet: Number of Model Params, Number of FLOPs, and Reasoning Speed (Speed).
Note. Params = parameters; FLOP = floating point operation; FPS = frames per second; FEM = feature enhancement module; BLM = boundary localization module; BFM = boundary-embedded feature aggregation module.
Polyps are tumor-like lesions that grow in the colon. Accurate segmentation of polyps is crucial for detecting them in colonoscopy images, enabling timely surgical intervention. To evaluate the effectiveness of our method in polyp segmentation, we followed the same benchmark protocol as Fan et al. (2020b). Our BSNet was retrained on the Kvasir-SEG (Jha et al., 2019) and CVC-ClinicDB (Bernal et al., 2015) datasets, and tested on five commonly used datasets for polyp segmentation. Table 8 lists the quantitative evaluation results of different polyp segmentation methods. It can be seen that our Net achieved better metrics on all five datasets, demonstrating significant advantages. The visual comparison results of different polyp segmentation methods are shown in Figure 8. For each dataset, one sample was selected for comparison. The proposed method achieves significantly better performance than other SOTA methods.

The visual comparison of detection results obtained by different polyp segmentation methods.
Compare Performance With Five State-of-the-Art Models on Five Datasets.

In this paper, we propose a COD framework, namely BSNet, that addresses blurred boundaries and background occlusions, Focusing on employing clear and complete edge semantic information to finely disguise object detection through a two-stage strategy. We carefully design FEM to refine features at different scales. At the same time, BLM is introduced, which uses high-level global semantic information to guide low-level local edge information to achieve an orderly fusion of target edge-related semantic information. BSNet uses a unique top-down structure that gradually integrates multi-level features to more accurately integrate boundary information. Finally, the introduction of the BFM enables the cross-level fusion of multi-scale features, thereby greatly reducing the interference of cluttered backgrounds. Extensive experiments prove that BSNet significantly outperforms the current SOTA methods on four widely used COD datasets, providing a more effective solution in the field of camouflage object detection and promoting research in this field level. In addition, we also plan to continuously promote the development of the field of camouflage object detection by adding some super-resolution strategies to improve model performance.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Evaluation Metrics
Quantitatively evaluate the effectiveness of the model based on four metrics commonly used in COD tasks: the structure-measure (
Average enhanced-measure (
Weight-F-measure (
MAE (Perazzi et al., 2012) is designed to directly measure the absolute difference between the ground-truth value and the predicted value, which is formulated as MAE is computed as: