
Abstract
Entertainment venues like theaters are key to social engagement, but the lack of assistive technologies for people with visual impairments limits their participation. Our research aims to enhance theater accessibility using computer vision techniques to detect visual information about objects and actor gestures and convey them to blind audiences through non-visual modalities. In this work, we focus on providing a novel dataset, TS-RGBD, containing theater scenes to guide the development of computer-vision-based systems for theater scene description. It includes RGB, depth, and skeleton sequences captured by Microsoft Kinect in a theatrical setting. The dataset features untrimmed theater scenes as well as trimmed sequences consisting of individual gestures for actor gesture recognition. We test state-of-the-art image captioning models on untrimmed scenes, revealing that dense captioning models generate redundant captions with fixed numbers, leading to imprecise descriptions and a lack of context. These challenges hinder visually impaired individuals from comprehending theater scenes descriptions effectively. Additionally, we assess the performance of skeleton-based graph convolution networks for human action recognition in a theater environment using trimmed skeleton sequences. The results highlight limitations in recognizing human actions in this setting. Based on these findings, we propose solutions for overcoming these challenges, paving the way for future improvements in making theater performances more accessible to individuals with visual impairments.
Keywords
Introduction
Accessibility research aims to create tools that assist individuals with disabilities, particularly those with visual impairments. Recently, technologies such as artificial intelligence and computer vision have been applied in various contexts to assist blind and visually impaired (BVI) individuals in everyday tasks, including navigation and wayfinding (Bouzit et al., 2004; Lavanya Narayani et al., 2021; Nazri et al., 2020), education (Kim et al., 2020; Shilkrot et al., 2015; Srmist & Student, 2018), face and object recognition (Francis et al., 2020; Ijaz et al., 2021), etc. However, entertainment venues, especially cinemas and theaters, remain largely inaccessible to BVI audiences due to their high reliance on visual cues, with few solutions available to make these experiences fully inclusive. Despite the growing use of computer vision in accessibility, little research has focused on its application within live performances. Our work addresses this gap by exploring how computer vision and deep learning models can detect visual cues in theater performances to be conveyed to the BVI audience members. Specifically, we work on two key objectives, although further details of these works are not within the scope of this article:
Theater scene description: Providing BVI audience members with a textual description of important regions in a theater scene by providing positions of every object or region present on the stage regarding them (left, right, front) using image captioning deep learning models. Actors’ gestures recognition: Conveying actors’ gestures to the BVI audience via tactile stimuli, by recognizing the actions performed on stage using human action recognition deep learning models, and thus representing the recognized actions on a tactile device (Benhamida & Larabi, 2022).
Therefore, in this article, we present a novel dataset, TS-RGBD, created to contribute to the works defined above by evaluating the state-of-the-art deep learning models for scene description and action recognition in theater environments. The dataset consists of untrimmed videos of theater scenes and trimmed sequences of actors’ gestures, captured by depth sensor. The inclusion of depth data provides a rich spatial information, enhancing the accuracy of detection and recognition.
This paper is organized as follows: Section 2 reviews the existing approaches and some benchmarks for both image captioning and human action recognition tasks. Section 3 introduces the proposed theatre dataset: TS-RGBD, its structure, annotation process, and detailed information. Then, Section 4 is devoted to present our solution for egocentric captioning, followed by the experimental results of human action recognition models (skeleton-based) on the proposed dataset, detailed in Section 5.
Related Works
Image Captioning
Image captioning consists of describing the content of any given image using text. The automatically generated captions are expected to be grammatically correct, with logical order. Image captioning relies on deep learning models that are based either on retrieval (auto-encoders or features extraction, etc.), template (sentence generation after object detection and recognition), or end-to-end learning (Liu et al., 2019). Generated captions can be a single sentence or multiple sentences that constitute a paragraph.
There are various architectures for single sentence captioning models, from scene description graphs (Aditya et al., 2018; Shambharkar et al., 2021) to attention mechanisms (Tan et al., 2022; Wei et al., 2021; Xian et al., 2022; Zha et al., 2022; Zhang et al., 2021), transformers, and even CNN-LSTM and GANs networks (Che et al., 2020; Li et al., 2021; Su et al., 2019).
Solutions for paragraph captioning are based on end-to-end dense captioning models. They are based on single-sentence captioning to generate a set of sentences that will be combined to form a coherent paragraph (Liu et al., 2019). These solutions are built using encoder-decoder architectures and recurrent networks (Johnson et al., 2016; Li et al., 2020; Xu et al., 2021; Zha et al., 2022).
Kong et al. proposed in Kong et al. (2014) a solution for RGB-D image captioning, but it only focuses on enriching descriptions by positional relationships between objects, while training their model on a dataset that does not include theatre images.
Whether single sentence or paragraph, image captioning models achieved remarkable results regarding different metrics (BLEU, ROUGE, METEOR, CIDrE, etc.). However, they do not generate detailed captions when it comes to complex scenes. Single sentence models focus on moving objects ignoring background, and paragraph captioning models do not consider positional descriptions.
Giving blind and visually impaired people sentences that lack descriptions of static objects and background, or paragraphs that lack positional descriptions of said objects makes it difficult or even impossible for them to re-imagine and rebuild the scene in their minds.
We highlight the fact that most models are trained only on indoor or outdoor scenes, which leads to bad captioning when the images are extracted from theatre scenes.
Well-known computer vision datasets, even those of considerable acclaim, notably lack theatre images, let alone comprehensive RGB-D data specifically capturing theatre scenes. Table 1 gives a summary of available RGB datasets.
RGB Datasets.

RGB Datasets.
As Table 2 for depth datasets.
RGB-D Datasets.

From both tables, we conclude that there are no available datasets with theatre plays in them.
Human action recognition is a fundamental task in computer vision with numerous applications, ranging from surveillance and human-computer interaction to robotics and virtual reality. Due to its wide range of applications, many methods were proposed that succeeded at achieving considerable performance. The earliest methods were based on RGB sequences (Bregonzio et al., 2009; Laptev et al., 2008) but their performance is relatively low due to different factors such as illumination and clothing colors. After the release of the Microsoft Kinect sensor, many RGB-D human action benchmarks emerged (Rahmani et al., 2016; Shahroudy et al., 2016; Wang et al., 2012) presenting richer information by providing the depth modality resulting in more accurate action features. They mostly consist of three modalities: RGB, depth, and skeleton sequences.
Some of the well-known RGB-D human action benchmarks include:
UWA3D Activity Dataset (Rahmani et al., 2016) contains 30 activities performed at different speeds by 10 people of varying heights in congested settings. This dataset has high inter-class similarity and contains frequent self-occlusions. MSR Daily Activity3D dataset (Wang et al., 2012) includes 16 daily activities in the living room. This dataset can be used to assess the modeling of human-object interactions as well as the robustness of proposed algorithms to pose changes. MSR Action Pairs (Oreifej & Liu, 2013) provides 6 pairs of actions in which two actions in a pair involve the interactions with the same object in distinct ways. This dataset can be used to evaluate the algorithms’ ability to model the temporal structure of actions. NTU-RGBD (Shahroudy et al., 2016) was first containing 56880 sequences of 60 action classes. Then, the extended version (Liu et al., 2020) was introduced with 57367 additional sequences and 60 other action classes making it the largest action benchmark so far.
As a result, other action recognition methods were developed based on the RGB-D datasets that surpass the earliest approaches. Some methods considered the use of depth maps only (Li et al., 2018; Zhang et al., 2018) which achieved better performance compared to RGB methods but they remain very sensitive to view-point variations.
Recently, the skeleton-based approach is widely investigated using skeleton sequences and it achieved considerable performance compared to the other approaches, especially after the rise of graph convolution networks (GCNs) (Li et al., 2019; Xu et al., 2021; Yan et al., 2018). GCNs are designed to extract features from graph-based data such as skeleton sequences that can be modeled as graphs by linking different body joints. However, all existing datasets were captured in outdoor or indoor environments (e.g., kitchens, rooms, offices), with none specifically addressing a theater setting. As a result, recognition model performance may decline when applied in a theater context. To address this gap, our proposed dataset provides a means to evaluate these models specifically in a theater environment.
In conclusion, in this work, we make the following contributions:
To the best of our knowledge, we are the first to collect and provide RGB-D sequences captured in a theatrical setting. We provide image captions that contain the direction of each region, with captioning model retrained on our theatre scenes dataset. We analyze the performance of skeleton-based human action recognition GCN models when deployed in a new environment, different then the source domain, using our proposed dataset, and discuss their performance.
TS-RGBD Dataset Description
In this section, we describe the data collection process, and dataset statistics in detail as well as annotation and cleaning methodologies.
Setup
In order to collect samples in a theatre environment, we sought cooperation with national theaters. Thus, we contacted the UK National Theater, but because of the terms of the actors’ contracts, it was not possible to use their visual content. Our local National Theater on the other hand was open for a partnership with the laboratory to achieve the task. However, the limited range of the Kinect sensor hindered us from accurately capturing the depth information of actors situated at a distance beyond four meters.
Finally, we opted to film various scenarios at the auditorium of the university (Figure 1) where the distances are convenient for the Kinect sensor.

Scene capturing at the auditorium of the university.
Two Kinect v1 sensors were used and positioned at the same height in two different viewpoints (front view and side view) as shown in Figure 2. We also used more than 76 objects in total to vary the setups and the used/background objects. The use of two sensors at different positions and varying background setups results in the diversity of the collected samples.
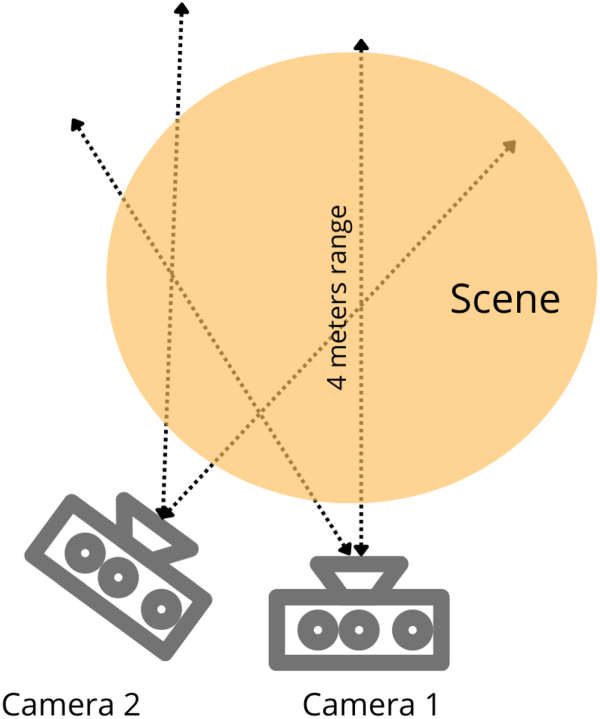
Illustration of the Kinects setup.
We enlisted a team of 8 male students with different body shapes and heights, to interpret on stage the prepared scenarios. The students signed a legal document granting us permission to use and distribute their visual content among the scientific society.
Data Modalities
The Microsoft Kinect v1 provides three data modalities: RGB images, depth, and skeleton data. The resolution of each captured RGB and depth sequence is
The skeleton data, on the other hand, consists of three-dimensional positions of 20 body joints for each tracked human body, knowing that Kinect v1 can only detect and track at most two human bodies. Figure 3 illustrates the configuration of the 20 captured joints.
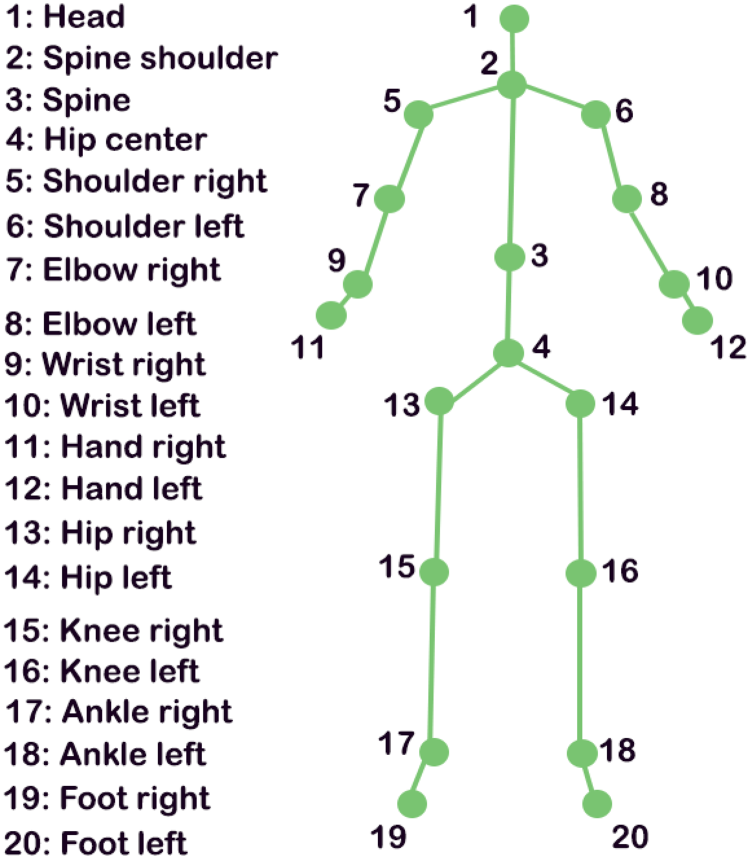
Joints configuration provided by Kinect v1.
Our dataset consists of two categories of data: segmented theatre actions and untrimmed theatre scenes.
Segmented Theatre Actions
This category contains 36 action classes that are common in theatre scenes such as walking, sitting down, drinking, jumping, eating, and throwing…setc. We tried to collect similar actions to the existing benchmarks action classes, as the purpose of this part of the dataset is to evaluate the performance of existing trained models in a theater environment and not to train the models on new action classes.
Each viewpoint comprises around 230 sequences, with an average of 170 frames for each sequence. Each action was carried out by 3 males and was repeated at least 3 times with varying speeds.
TS-RGBD action classes with number of samples are listed in Table 3.
Number of Samples Per Action Class.
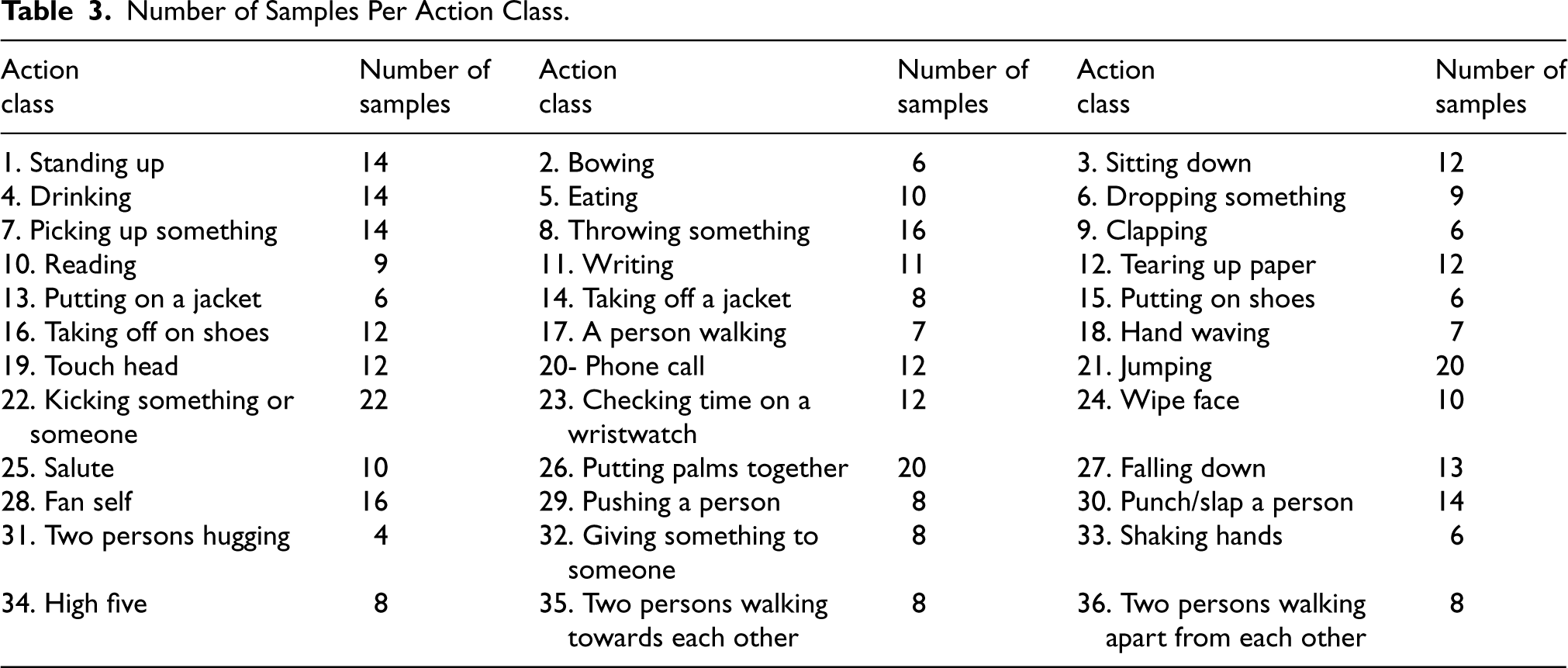
Number of Samples Per Action Class.
This category includes 38 written theatre scene scenarios. It contains, in total, 75 sequences for each viewpoint, with a mean of 1119 frames per sequence. The scenes are divided into three types:

Example of an interpreted solo scenario.

Example of an interpreted two-person scenario.

Example of an interpreted group scenario.
Summarily, with 8 male actors (females were not available) we could gather 610 sequences with an average of 373 frames per sequence (25 frames per second), and a total of 123 149 frames.
Table 4 presents a summary:
Captured RGB-D Data from Written Scenarios.

Figure 7 shows the number of sequences per type of scenario. There are more solo scenes since the Kinect v1 range is limited to
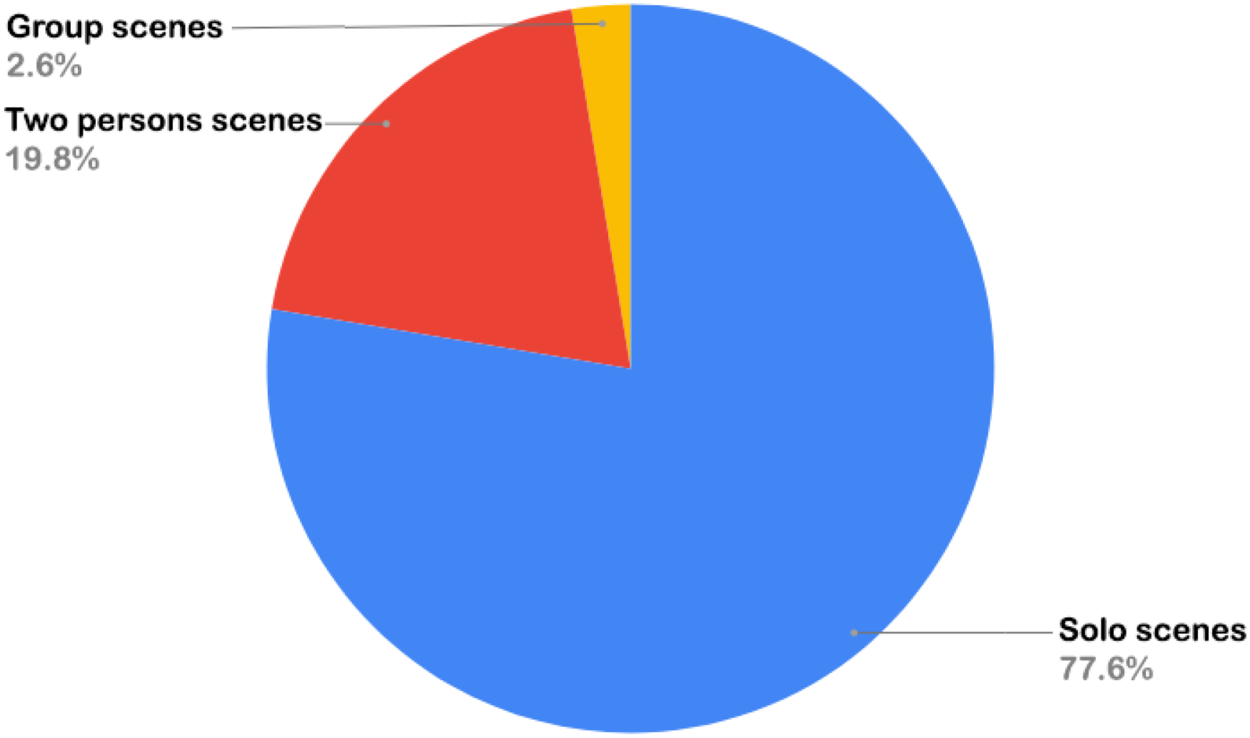
Pie chart for the number of sequences by type of scenario.
For the image captioning task, we created an application to manually select frames with smooth depth maps, that mark a transition in the video to avoid redundancies. In addition, we had to go over all selected frames to keep only the ones with smooth corresponding depth maps. In the end, 1480 key-frames were kept.
Data Annotation
Many data annotation applications available today offer powerful functionality for annotating data, but they often come with a trade-off: either our data become publicly accessible, or these applications come at a cost and are not available for free.
Even so, we could find a multi-platform desktop application developed by Wada and LabelMe (2021) available to download and install from GitHub. The developer was inspired by the original “LabelMe” application that was created by MIT for manually annotating data for object detection/recognition and instance or semantic segmentation, with the possibility of drawing a box or a polygonal envelope around a region of interest and adding labels to these boxes and envelopes.
We could annotate 50 images so far, resulting in 504 regions, and 109 words as shown in Table 5.
Numbers of Annotated Data.

Numbers of Annotated Data.
Figure 8 shows the interface of the “LabelMe” application as well as the process of polygonal annotations. For each region of interest, we create a polygonal boundary by enclosing it with relevant points (points in green Figure 8). Instead of assigning a single-word label, we provide a full descriptive sentence. All information, including the region ID, point coordinates, and descriptive label, is stored in a .json file. The selected regions of interest include every area in the image that is meaningful for describing its content.

LabelMe interface.
In this article, we propose an approach to offer the blind and visually impaired detailed descriptions of the environment they are in, while giving them the opportunity to attend theatre plays. Those descriptions will be generated by the DenseCap module that outputs captions for both mobile and static objects and regions in a given scene. These generated captions are not enough for the users to re-imagine the scene, they will need to know where each object or region is situated regarding their own position (Egocentric Description). To give the users this information, we will need depth data alongside RGB image of the scenes, specifically theatre scenes.
An example of the expected description is shown in Figure 9.

Example of egocentric scene description.
To do that, we had to retrain the DenseCap model on our dataset. Proposed in Johnson et al. (2016), it is a model based on fully convolutional localization networks (FCLNs) that outputs boxes surrounding detected regions, each box with its caption and confidence score. DenseCap was trained on the Visual Genome dataset (VG dataset), a collection of images from MS-COCO and Flicker datasets where each image is associated with a rich set of information: regions of interest are delimited with bounding boxes, and each box has multiple captions describing its content. We chose DenseCap because it does not focus only on salient objects and provides background descriptions as VG dataset annotations describe every region present in the image, be it an object, a person, an animal, or the surrounding environment.
After detecting regions and generating the corresponding captions, we applied the algorithm proposed in our precedent work to get the directions (Delloul & Larabi, 2022).
Since Depth information is not present for the VG dataset, we used AdaBins model to estimate depth maps for VG images.
We modified the DenseCap code provided in GitHub to be trained on custom data and we applied transfer learning by reusing the models’ weights provided by the authors to train it on our data for 10 more epochs.
Table 6 shows evaluation results after using DenseCap on our data before and after retraining, using evaluation metrics METEOR, BLEU, ROUGE, and CIDEr to measure the quality of generated phrases by comparing them to human-generated references.
Captions Evaluation.

Captions Evaluation.
The higher the better.
We then chose 20 random images from VG and our dataset to manually annotate the direction of each generated region.
Table 7 summarizes results, where accuracy is the ratio of correct directions to the total directions, expressed as a percentage. Qualitative results are shown in Figure 10.

Multiple examples from TS-RGBD dataset.
Egocentric Description Evaluation on Our Images.

Captions are redundant due to the fact that DenseCap generates Egocentric description lacks precision for some regions. Final description doesn’t mention that the image is about a theatre play.
Human Action Recognition: Experimental Evaluations with TS-RGBD
In this part, we evaluate the performance of three Graph Convolution Networks: ST-GCN (Yan et al., 2018), 2S-AGCN (Shi et al., 2019), and MS-G3D (Liu et al., 2020) for skeleton-based human action recognition, in a theater environment using the trimmed skeleton sequences from our TS-RGBD dataset (Figure 11).

Examples of skeleton data sequences from TS-RGBD dataset.
These models fall under spatio-temporal GCN models that extract both spatial and temporal features from skeletal sequences, and they are known for their high recognition performance compared to the state-of-the-art models. They were trained on two challenging human action benchmarks: NTU-RGBD (Shahroudy et al., 2016) and Kinetics (Kay et al., 2017) and their attained accuracies are illustrated in Table 8.
Obtained Accuracies by ST-GCN, 2s-AGCN, and MS-G3D on NTU-RGBD and Kinetics.

We load the pre-trained weights of each model trained on NTU-RGBD as a source domain. The choice of NTU-RGBD benchmark as source domain is motivated by the fact that it’s the most similar one to TS-RGBD in the skeleton data structure, and they are both captured in an indoor environment.
The obtained accuracies of the pre-trained models on TS-RGBD are presented in Table 9.
Test Results of ST-GCN, 2s-AGCN, and MS-G3D With TS-RGBD.

We observe that the performance of all models has decreased compared to the source domain. This demonstrates the need for a such new dataset captured in theater for the development of a theater action recognition system. However, training a model from scratch necessitates a large dataset which requires a lot of effort and time. Potential solution is to apply transfer learning on these models using our dataset with our provided sequences. The transfer learning technique has proved its effectiveness, particularly with CNNs (Convolution neural networks) but few works investigated this technique with GCNs, which presents a potential area of future research.
On the other hand, we also observe that MS-G3D model outperformed the other models, so we pursued more comprehensive data from its experiment in order to further discuss the struggles and challenges encountered with skeleton-based recognition. We analyzed its confusion matrix and extracted the most well-classified as well as the most misclassified action classes (Table 10 and Figure 12).
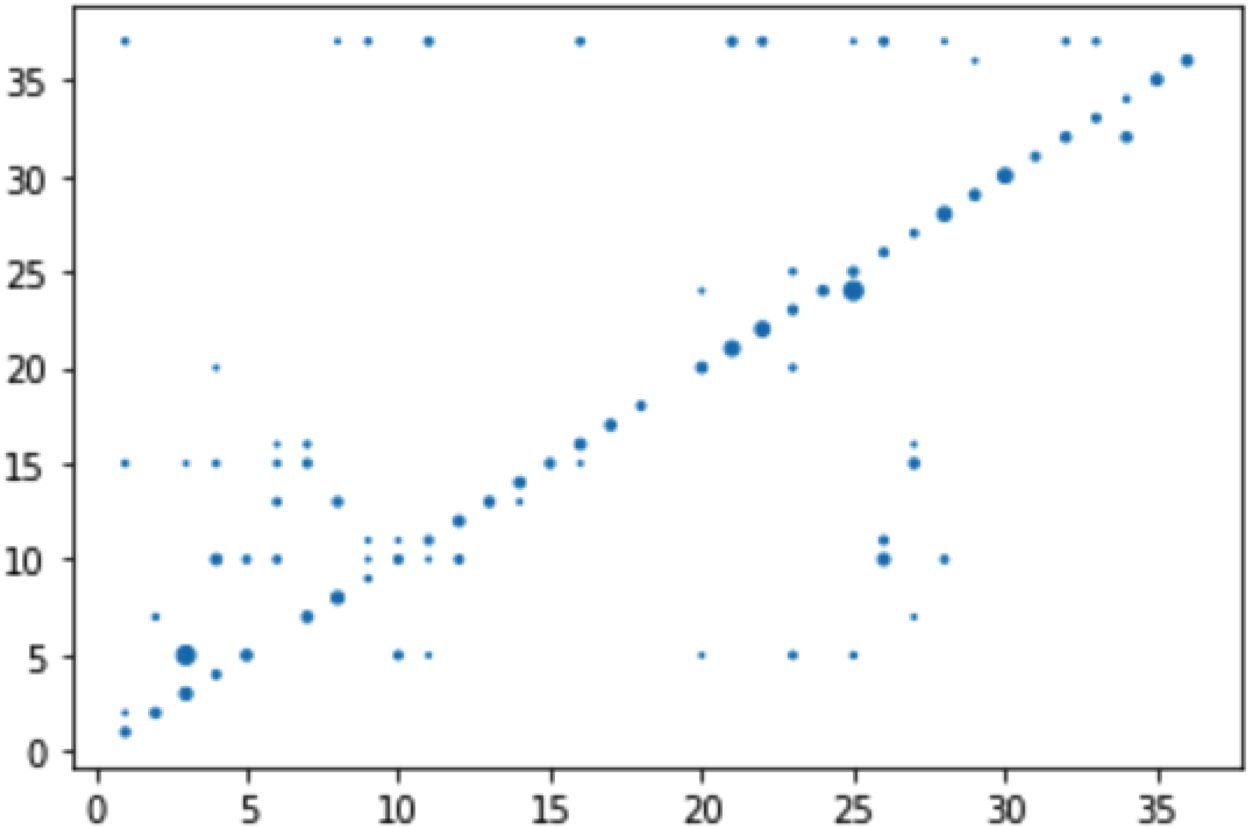
Confusion matrix of MS-G3D with TS-RGBD.
Most Well-Classified and Misclassified Action Classes.

Based on Table 10 and Figure 12, we distinguish that the model struggles in recognizing actions that require details about specific body parts, such as the hand shape, or about the involved object in case of human-object interaction. For instance, the action “write” necessitates additional information on the hand form and the used object, which are not included in the skeleton representation. As a result, it was frequently confused with the action “play with phone” due to the similarity of their skeleton motion trajectories. Same for action ’Drop’ which the model failed to recognize due to missing information about the dropped object and similarities in skeleton motion with other actions, making it difficult to differentiate them based solely on skeleton joint positions.
In conclusion, there are two major elements that have a large impact on the skeleton-based approach recognition performance. The first factor is the precision of the provided joints’ positions. The recognition performance can be low if the skeleton joints are not very well captured and cluttered. The second factor is the number of characteristics that can be extracted from the skeleton modality only. The tested models were unable to recognize some actions that require details about specific body parts’ characteristics such as hands or about the involved object in case of human-object interaction. As a possible solution, future works may consider combining skeleton modality with other modalities to encounter the lack of information problem, which may aid in differentiating between some confusing actions with similar skeleton motions.
Further works on RGB-D human action recognition field using the TS-RGBD dataset would boost the development of an assistive system that can accurately recognize human actions on stage. Furthermore, future works might explore the untrimmed scenes within the TS-RGBD dataset to develop systems that can detect the temporal boundaries of actions. Such advancements would enable real-time action recognition, facilitating a more dynamic and interactive experience for visually impaired and blind audience members.
We introduced the TS-RGBD dataset, a novel RGB-D dataset designed specifically for theater scene description. Captured in a theatrical setting using the Microsoft Kinect sensor, the dataset includes synchronized RGB, depth, and skeleton sequences. It contains two types of data: trimmed sequences for actor gesture recognition and untrimmed theater scenes, primarily for image captioning.
By incorporating depth data, the TS-RGBD dataset enhances the performance of image captioning and human action recognition models in live performances, particularly in theaters. The results of testing image captioning models and skeleton-based human action recognition models on the TS-RGBD dataset demonstrate its potential to expand the range of environment types where visually disabled individuals can navigate with the aid of computer vision technology. The combination of accurate human action recognition and textual description of theatre scenes can provide valuable assistance to visually impaired individuals in accessing entertainment places and enjoying theatrical experiences.
The availability of the TS-RGBD dataset opens the door for the development of more inclusive assistive technologies, expanding the accessibility of entertainment venues for BVI individuals and promoting their full integration into society.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.