
Abstract
Videogame developers typically conduct user experience surveys to gather feedback from users once they have played. Nevertheless, as users may not recall all the details once finished, we propose an ethical conversational agent that respectfully conducts the survey during gameplay. To achieve this without hindering user’s engagement, we resort to reinforcement learning and an ethical embedding algorithm. Specifically, we transform the learning environment so that it guarantees that the agent learns to be respectful (i.e. aligned with the moral value of respect) while pursuing its individual objective of eliciting as much feedback information as possible. When applying this approach to a simple videogame, our comparative tests between the two agents (ethical and unethical) empirically demonstrate that endowing a survey-oriented conversational agent with this moral value of respect avoids disturbing user’s engagement while still pursuing its individual objective, which is to gather as much information as possible.
Introduction
Conversational agents are intelligent software systems capable of engaging in conversations with users (Adamopoulou & Moussiades, 2020; Cassell, 2001), thereby providing a natural interface for interaction. Their naturalness has promoted their adoption across various domains such as education, healthcare, business and entertainment. They have been used for diverse purposes including facilitating learning (Kuhail et al., 2022), screening for medical conditions and promoting behaviour change (Bates, 2019), providing customer service (Thomas, 2016) and enhancing gaming experiences (Seering et al., 2020). Moreover, with the recent release of openAI’s ChatGPT (Thorp, 2023), conversational agents have become more accessible to the general public, who prompt them for tasks such as generating code, writing essays, composing music among others.
Academics and researchers have also been drawn to the versatility of chatbots, leading to exploration of their potential for innovation. Specifically, they are being utilised for user research (Baxter et al., 2015) and User eXperience (UX) evaluation (Hartson & Pyla, 2018) in the field of human–computer interaction (HCI), where chatbots take on the role of an evaluator and interact with users in natural language to gather their opinions and feelings (Han et al., 2021; Xiao et al., 2020). These evaluations have proven to be effective, as they increase both users’ commitment with the survey and the quality of the information elicited in terms of informativeness and relevance (Han et al., 2021; Xiao et al., 2020).
These advancements on humans–chatbots interactions demonstrate that AI (artificial intelligence) is promoting a shift from HCI to human-artificial intelligence collaboration (HAIC) (Li et al., 2022). The traditional approach of HCI involves designing user experiences that facilitate the interaction between humans and computers; experiences which are evaluated by and with humans, that is, test moderators and users. As part of this evaluation process, testing methodologies require moderators to consider ethical and privacy aspects (Molich et al., 2001). Moderators are responsible for informing users about the goals and procedures of the test, ensuring their physical and psychological comfort, and respecting their willingness to participate, time and decision to leave the test at any point.
But in the context of HAIC where the evaluator is an AI, ethical and privacy aspects must also be considered. Actually, the Ethics Guidelines for Trustworthy AI European Commission (2019) proposed by the European Commission (EU) promote responsible and sustainable AI innovation, highlighting the importance of aligning these systems with ethical principles to maximise their benefits while identifying and preventing possible risks. These guidelines put forth three principles for a trustworthy AI: to be lawful, complying with regulations; to be ethical, standing by ethical values; to be robust, to avoid causing unintentional side effects. The EC has continued the dicussion on AI regulations with The EU AI Act (European Commission, 2021), which is near to its implementation, and aims to establish a comprehensive legal framework for the development, deployment, and use of AI in the European Union. The Act is designed to promote trustworthy AI that is aligned with ethical principles, safe and effective, while also mitigating potential risks. Machine ethics is, therefore, a necessary foundation to build these intelligent systems.
In this article, we propose the use of an ethical conversational agent to act as an evaluator of UXs. Unlike traditional post-experience questionnaires, the agent would conduct the evaluation throughout the entire user experience, thereby avoiding the fatigue and non-remembering effects associated with these questionnaires. However, there is a risk of disturbing the user’s experience if the chatbot does not prompt the user at appropriate times, or even result in the abandonment of the interview due to cognitive overload (Han et al., 2021). We argue that the conversational agent should be respectful with the user and therefore we propose embedding the chatbot with a moral value of respect, which should guide the agent to perform the questionnaire without disturbing the user experience. To illustrate our proposal, we present a case study that involves a simple game (i.e. a game with few rules without requiring strategy or complex thinking) played by a (simulated) user and evaluated by our ethical conversational agent through an in-game questionnaire.
To ensure ethical behaviour, our proposal involves the application of ethical embedding, which is a reinforcement learning approach founded in the framework of multi-objective reinforcement learning (Roijers et al., 2013), and used in the literature for integrating moral values into the design of intelligent agents (Rodriguez-Soto et al., 2022, 2021a). We follow the philosophical stance outlined by Arnold et al. (2017), Gabriel (2020), Sutrop (2020) & Van de Poel and Royakkers (2011) and consider that moral values are ethical principles that discern good from bad, and express what ought to be promoted. Some examples of human values 1 are privacy, fairness, respect, freedom, security or prosperity (Cheng & Fleischmann, 2010).
A variety of models have been recently introduced that aim to tackle how these values can be embedded in the design of an agent (Noothigattu et al., 2019; Svegliato et al., 2021; Vamplew et al., 2021). Our proposal redesigns the learning environment to promote ethical behaviour, ensuring the agent learns to pursue its individual objective of asking as many questions as possible, while fulfilling the ethical objective. This approach would, hence, transform the learning environment into one in which the ethical objective, the value of respect, is learned to be fulfilled. We consider as respectful to ask questions when the user engagement is minimum. Therefore, the contribution of this research is twofold: firstly, we apply ethical embedding in a real-world computer game application; and secondly, we integrate the moral value of respect into a survey conversational agent. Specifically, this research expands upon our previous work (Roselló-Marín et al., 2022) by conducting a thorough conceptual examination of HAIC, particularly by positioning the discussion of agents’ ethics within the context of activity theory (Leont’ev, 1978). Additionally, it offers a more exhaustive experimental evaluation of ethical versus non-ethical agents, assessing further both their training process performance and their in-game behaviour.
Conceptual Background
In this section, we examine how activity theory (AT) helps to understand AI-human collaboration and the ethical implications of this collaboration. Moreover, we conceptualise engagement since it is crucial for our ethical survey agent to distinguish the different phases of engagement in the UX.
Activity Theory
AT is a psychosocial theory that studies human behaviour and cognition and how they are shaped by their context (Bedny et al., 2000; Leont’ev, 1978), which not only includes the physical environment but also the social structures and cultural norms and values that shape people’s lives. It has been applied in a variety of fields, including education (Roth, 2004), organisational psychology (Holt & Morris, 1993), HCI and design (Kaptelinin & Nardi, 2012, 2006).
At the core of AT is the concept of an ‘Activity System’, which is a group of people who are engaged in a shared activity or goal. It is composed of various components (see Figure 1): the subject (the individual or group that is the focus of the activity); the object (the goal or outcome of the activity); the tools (physical or symbolic artefacts that are used in the activity); the rules (norms and procedures that govern the activity); the community (the social relationships and structures that support the activity); and the division of labour (the distribution of roles and responsibilities among participants).
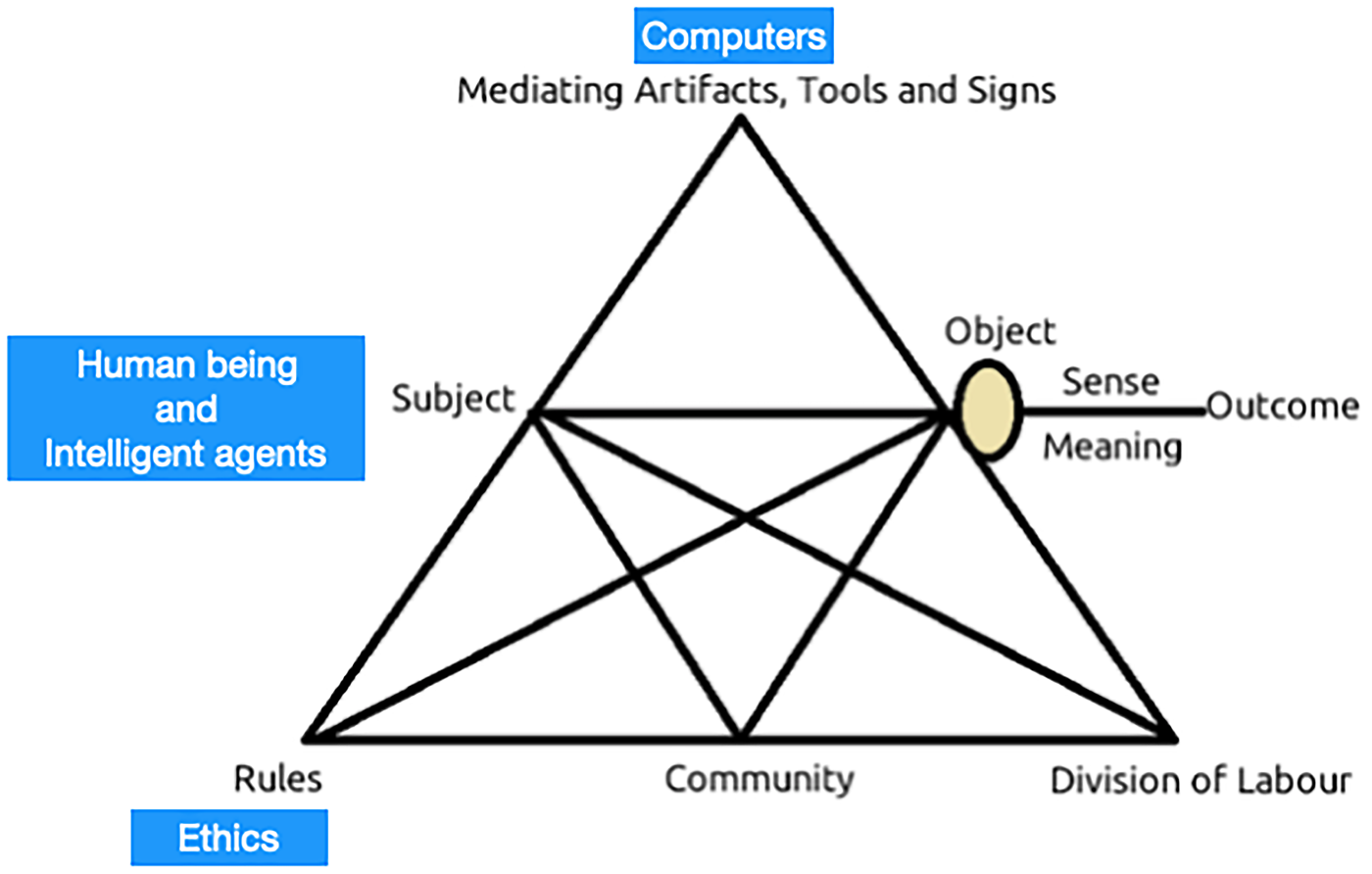
Activity theory (AT) elements including intelligent agents as subjects that collaborate with the human (diagram adapted from Cañas, 2022).
Considering computers and technological tools as artefacts for the humans to achieve their goals, AT provides a useful framework for understanding how people interact with technology and how technology can be designed to support users’ activities and goals. Blue squares in Figure 1 show how the components of the activity are redefined when intelligent machines join the activity system and collaborate with humans. Incorporating intelligence into machines within this conceptual framework implies that machines will not only serve as tools at the upper vertex of the AT triangle but will also become active subjects of activity. Thus, we have to consider that the resulting intelligent agents ‘collaborate’ with humans to achieve the objectives of the activity, which is the focus of the HAIC field.
Moreover, the AT suggests that ethical behaviour is not simply a matter of following rules or principles, but rather involves active engagement with one’s environment and context. Thus, ethical behaviour requires individuals – now both human beings and intelligent agents – to consider the values and norms of their community, balancing their own interests and desires with the needs and expectations of others. Indeed, several institutions and organisations including the UNESCO’s recommendation on ethical AI regulation (UNESCO, 2020) and the EU’s guidelines for trustworthy AI European Commission (2019) have recently put the effort on analysing the impact that AI may have both in individuals and the society.
Regarding ethics of conversational agents, the French National Pilot Committee for Digital Ethics (CNPEN) CNPEN (2021) suggests specific principles for designing conversational agents. They aim to ensure that developers integrate human values into the design process, address potential ethical concerns, avoid language bias and adapt the agents to different cultural contexts. The principles also emphasize the need for transparency, requiring chatbots to disclose their features and purposes, particularly for affective conversational agents that recognise and model human emotions. Additionally, users must be able to comprehend the agent’s behaviour, and chatbots must comply with GDPR (general data protection regulation) (European Union, 2016) regulations.
There are multiple interpretations of engagement in the literature, we follow O’Brien and Toms (2008) framework and assume the existence of a state of optimal and enjoyable experience (Cowley et al., 2008). This framework defines engagement as a quality of users experiences with technology, characterised by different attributes. In the case of video games these attributes correspond to challenge, aesthetic, feedback, novelty and interactivity.
Figure 2 depicts the model of engagement consisting of four stages. First, the Point of engagement, where attributes such as aesthetic and novelty may capture the users’ attention at the beginning of the experience. Second, during the period of Engagement attributes such as feedback, novelty or challenge reach different levels of intensity. It is in high intensity moments of this period where the agent should avoid disturbing the user. Third, several causes may lead to Disengagement when the user voluntary stops the interaction, the survey agent asks a question to the user, or voluntary or involuntary distractions occur. Finally, the Re-engagement phase comes after disengagement whether the user resumes the interaction with the game. Thus, a new cycle of engagement starts.
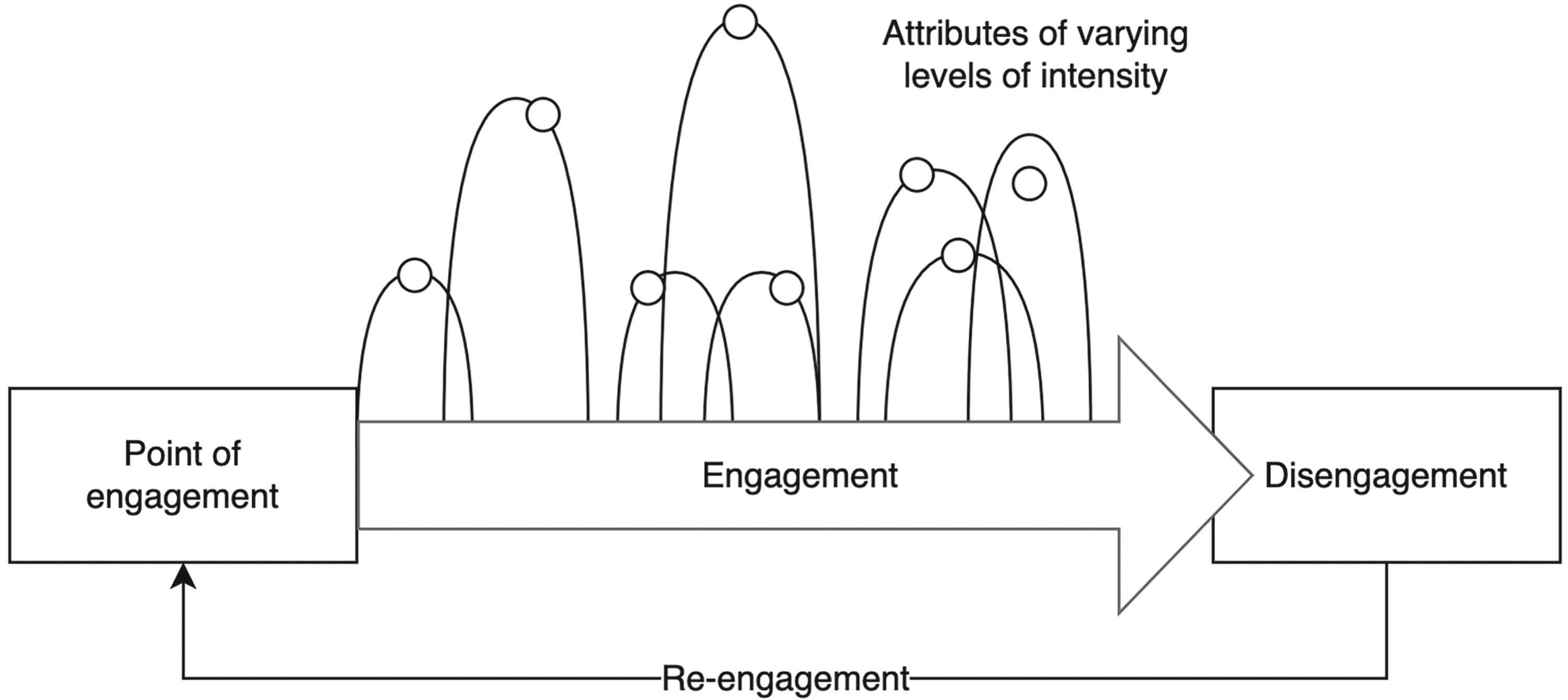
Model of engagement (O’Brien & Toms, 2008).
Considering that game sessions consist of multiple cycles of engagement as described above, we require the survey agent to behave respectfully with the user by avoiding interrupting the user engagement throughout all these cycles. To do so, it should recognise when a period of high engagement takes place, in order to avoid asking questions that could interrupt and disengage the player, waiting thus for moments of lower engagement or even disengagement to prompt the user to answer a question.
As previously introduced, we take a HAIC perspective and apply it in the context of games evaluation. We propose an approach where the conversational agent interacts with the user to gather their opinions and feelings by means of in-game questionnaires. Moreover, we require the conversational agent to be ethical, so it should evaluate the experience without disturbing the user engagement. In particular, we consider a Pong game played by a simulated user.
Pong Game and Its Phases of Engagement
Our case study is a simple version of a single-player Pong game. Along three different levels, the player controls a paddle and competes against a computer-controlled opponent. The goal is to score the most points by hitting the ball past the computer opponent’s paddle.
Figure 3 shows the phases of our Pong game. In-game phases are characterised by high engagement, while the other phases are characterised by low engagement. These intermediate phases correspond to starting menus to greet and inform the user about the level, menus to change game settings between levels, and menus to announce the winner at the end of each level.
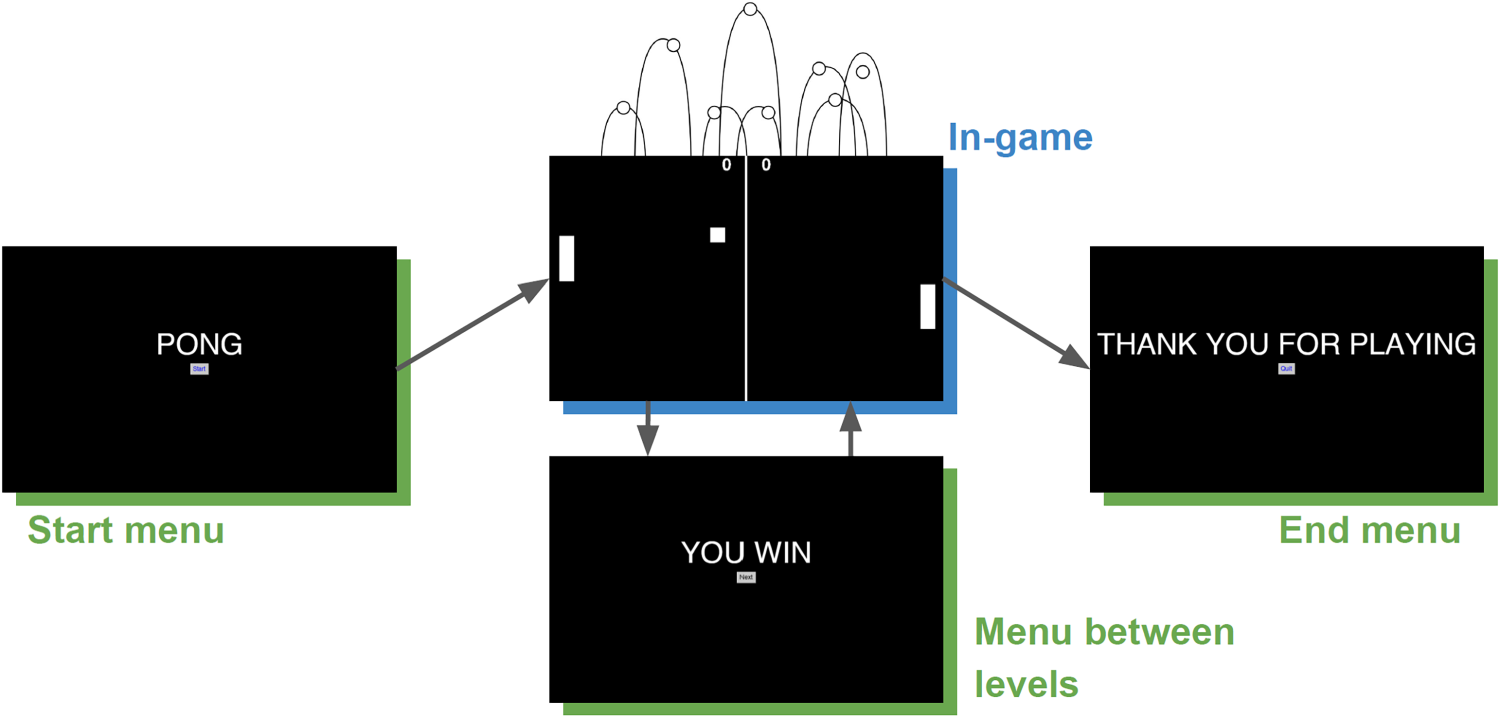
Pong game phases.
Figure 4 shows a gameplay session with the conversational agent visible at the bottom of the screen. It can ask the user questions at any time. These questions are drawn from the GUESS-18, a shortened version of the Game User Experience Satisfaction Scale (GUESS). Specifically, the agent presents the user 12 questions related to enjoyment, usability/playability and visual aesthetics. We disregard those related to narrative, audio and social connectivity that are not relevant to Pong.
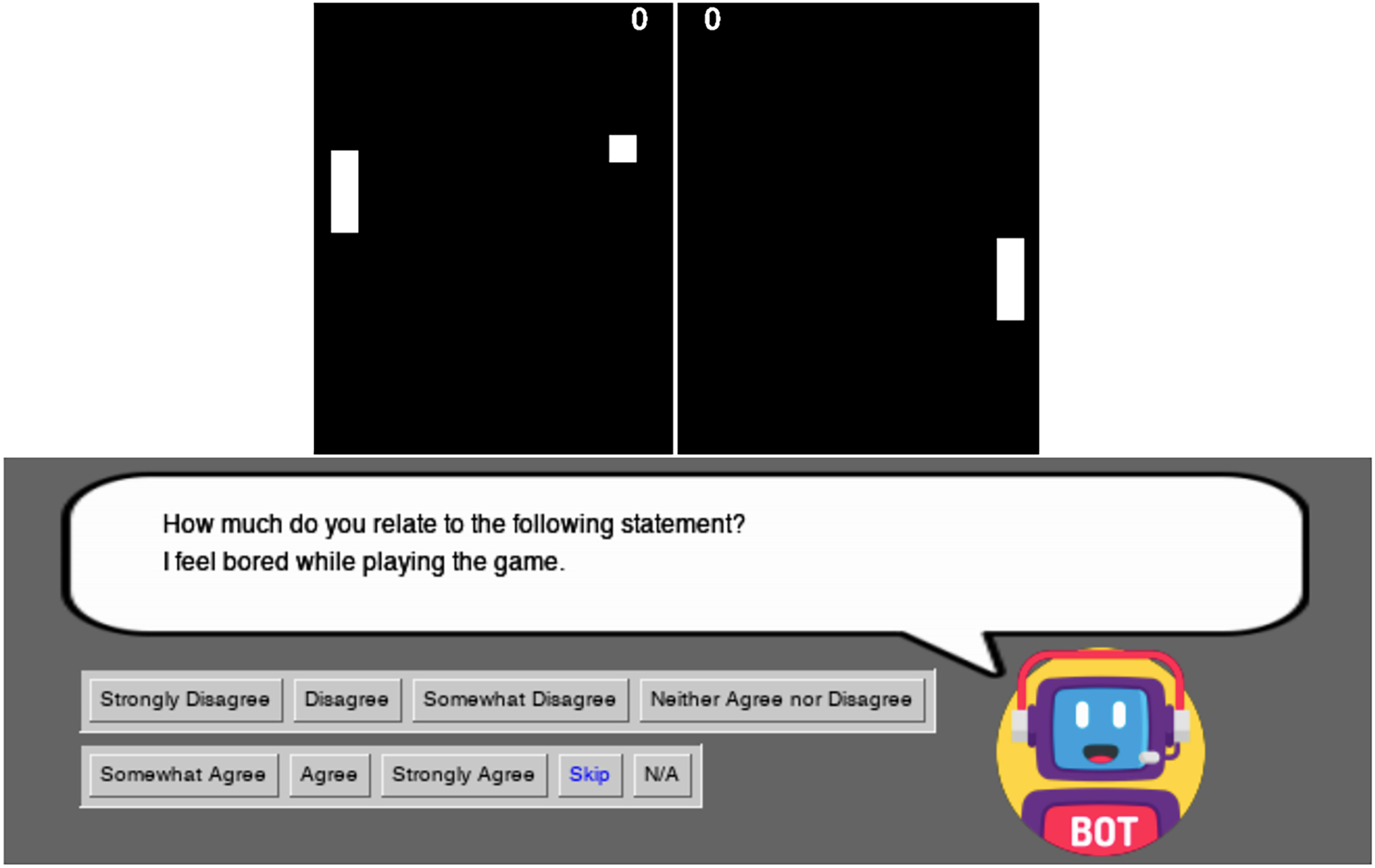
Pong game with the conversational agent asking a question.
The user answers the questions by selecting the corresponding button. There are two types of responses: valid and non-valid. With valid responses the user specifies the level of agreement or disagreement with a game-related statement, providing thus useful data about the game experience. Non-valid responses include ‘Skip’ and ‘N/A’. If the user selects ‘Skip’, the corresponding question is removed from the pool, as the user is not willing to answer it. If the user selects ‘N/A’, the chatbot can ask the question again at a later time. Additionally, the player can choose to ignore the survey question, and continue playing, in which case the question disappears from the screen but remains waiting for an answer as it happens with ‘N/A’ response.
We propose to use reinforcement learning (RL) to train the ethical agent (Sutton & Barto, 2018). However, RL requires numerous episodes to learn a policy so that conducting human trials can be costly and time-consuming. As a result, acquiring participants and ensuring repeatability can be difficult (Bignold et al., 2021). To address this challenge, simulated users have been proposed as a useful alternative for agent training since they offer flexibility and repeatability (Levin et al., 2000; Schatzmann et al., 2006). These simulators can be based on probabilistic, heuristic, or stochastic models, or a combination thereof.
In this research, we have created the simulated user utilising heuristic techniques Bignold et al. (2021) implemented through hierarchical patterns and rule sets. The decision tree in Figure 5 depicts the behaviour of the simulator. Non-terminal nodes of the tree represent probabilistic choice points (Scheffler & Young, 2002) and terminal nodes indicate the action that the simulated user takes (Ignore question, Skip the question, N/A – don’t respond to the question yet and Valid answer). When the chatbot poses a question, the simulated user traverses the tree to determine its response. The probabilities depicted in Figure 5 are linked with choice point nodes, which enable the random selection of the outgoing edge to follow. They fluctuate based on whether the user is playing the game (In-game) or is navigating a menu (Starting menu, Other menus).
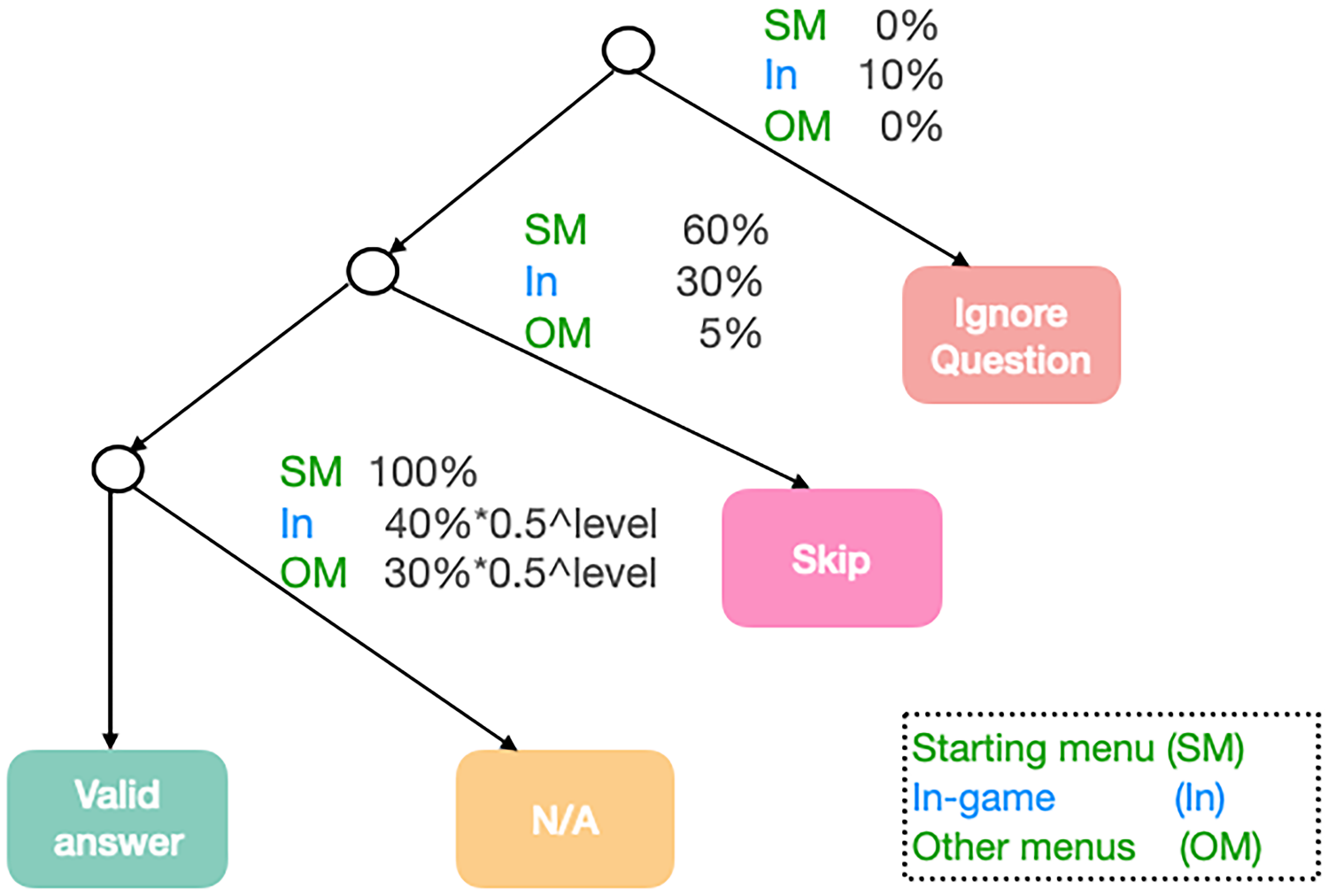
The rule tree that defines the simulated user’s behaviour and associated probabilities.
In the rule tree, the first decision point determines whether the user will continue playing (i.e. ignore question) or give an answer. Note that the simulated user playing the game is crucial for executing and training our agent since it provides information on engagement. However, the performance of the simulated player has no impact on the behaviour of the chatbot. Note that we consider the user is collaborative and, therefore, it never ignores questions while being in a menu (i.e. the ‘Ignore question’ branch in Figure 5 has 0% probability of being selected by the simulated user in starting menu and other menus) and just does it 10% in-game (which means it will select any other branch 90% of the times).
The subsequent two decision points let the simulated user either skip the question (i.e. choose not to answer it), or to select N/A ( if not yet far enough into the experience to provide an answer). Notice that the user cannot provide a valid answer at the very beginning of the game because the gameplay has not started yet (starting menu with N/A set to 100%), and the likelihood of the user selecting the N/A option decreases as the user progress through the game. Finally, if the simulated user decides neither to ignore the question nor to skip it, and knows the answer, thus not choosing N/A, it will respond with a valid answer.
In this section, we aim at presenting the required background to guarantee that a conversational agent learns to be respectful to the user while performing in-game surveys. Firstly, next subsection briefly introduces the necessary mathematical constructs that are used to formalise the learning environment of the agent: Markov decision process (MDP) and multi-objective MDP (MOMDP). Secondly, subsequent subsection describes how the learned behaviour of the agent can be guaranteed to be ethical (i.e. value aligned).
MDP and MOMDP
We consider the paradigm of RL (Sutton & Barto, 2018) for the conversational agent to learn the expected behaviour, which is defined in terms of learning objectives. Briefly, MDP characterise the agent’s learning environment in terms of the states of the environment, the actions that the agent can perform, how actions induce the transitions of states, and the rewards that an agent receives upon the performance of actions if they lead to the accomplishment of learning objectives. Formally:
A (single-objective) MDP is defined as a tuple
The behaviour of an agent can be formally defined as a (deterministic) policy
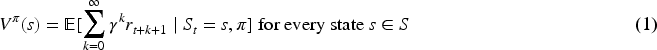
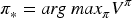
When considering more than one objective, the paradigm of Multi-Objective RL (MORL) Roijers & Whiteson (2017) extends the MDP definition into a Multi-Objective MDP (MOMDP), which has a vectorial reward function with as many components as objectives. Formally:
An
Value function
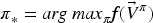
Applying the framework of MOMDPs, we can design environments that incentivise the learning of ethical or value-aligned behaviours. Following the approach by Rodriguez-Soto et al. (2021b), Figure 6 illustrates value alignment as a process consisting of two steps: reward specification and ethical embedding.

The ethical environment design process (as by Rodriguez-Soto et al., 2021b) for value alignment.
First step involves creating an MOMDP by specifying the rewards for both the individual objective
Second step consists of applying an ethical embedding, as shown in Figure 6 (right), to transform this ethical MOMDP into a single-objective MDP, where the agent is incentivised to learn an ethical-optimal policy. In other words, in the obtained single-objective MDP it is guaranteed that an agent learning with single-objective algorithms will learn to fulfil the ethical objective while pursuing its individual objective. The ethical embedding process obtains this scalarised environment by applying a linear scalarisation function over the ethical MOMDP.
This function has the form of:

Notice how the ethical embedding algorithm guarantees ethical behaviour learning even if we could not control the learning algorithm of the agent. By guaranteeing that its only optimal policy will be ethical, any learning agent (even if it was totally external to us) will ultimately learn to behave ethically aligned.
Algorithm 1 provides the pseudo-code from Rodriguez-Soto et al. (2021b) for computing an ethical embedding. In the first line, it computes the convex hull of the input ethical MOMDP by applying convex hull value iteration (CHVI) (Barrett & Narayanan, 2008). Formally, we are guaranteed to find inside the convex hull all policies that are optimal for some value of the ethical weight
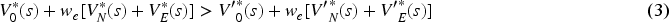

As previously introduced, our problem is that of designing an ethical conversational agent that performs in-game surveys. Considering a classical RL approach, the learning environment of this agent would be set to just reward the elicitation of player feedback. However, we also consider an ethical dimension in the learning environment so that the agent learns to be respectful with a user playing the game while asking him/her as many questions as possible. In this manner, we formalise this problem as the transformation of a multi-objective environment into a single-objective environment that guarantees that the conversational agent learns to behave ethically while conducting the survey.
The learning environment for the conversational agent is initially specified as a MOMDP (see Definition 2) that represents a Pong game played by a simulated user (see Section 2.2). In this context, we understand respect as not hindering the user engagement (see Section 3.2). Subsequently, we apply the ethical embedding algorithm to transform the ethical MOMDP
Ethical Environment Design
As Figure 6 illustrates, the ethical environment design process starts by defining an ethical MOMDP from the individual and ethical objectives. This definition involves, among other components, the specification of rewards, which are derived from the individual objective and the ethical knowledge that is relevant to the scenario at hand. In our particular game setting, we define our ethical MOMDP
Firstly, states in
On the other hand, we propose to characterise the user’s activity by means of three additional state attributes that do not depend on the particular mechanics of each game. First, we relate the Boolean variable
Secondly, as the conversational agent aims at conducting an in-game survey, the agent is expected to learn a policy that determines for each given state, whether it is respectful to ask questions or if it should wait to avoid disturbing user’s engagement. Therefore, the agent must choose between two basic actions
Thirdly, the reward vector
Therefore, the ethical reward 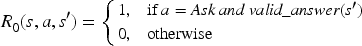

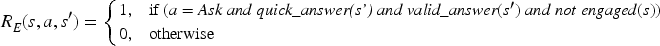
Finally, we characterise state transition function
Once the ethical MOMDP is defined, we are ready to apply the second process in Figure 6: the ethical embedding algorithm. The first step of this algorithm corresponds to the computation of the convex hull, that is, those policies that are maximal for some value of
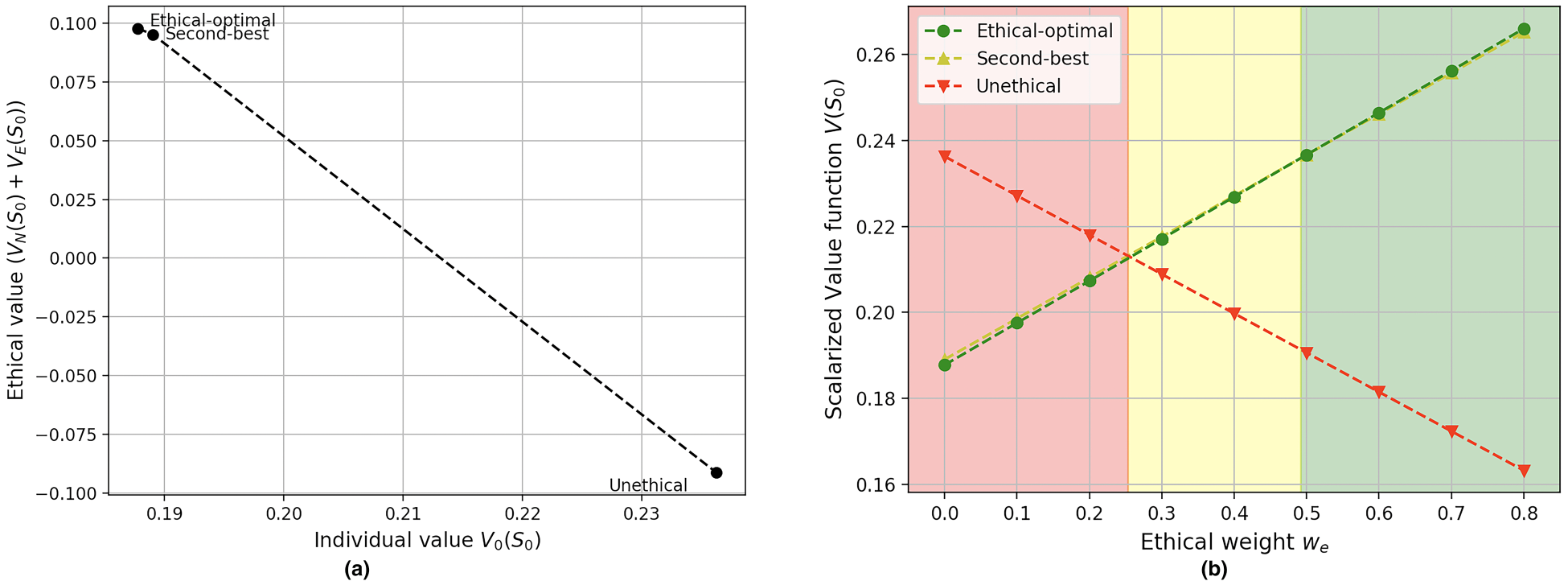
The ethical embedding process: (a) visualising the convex hull, and (b) finding the ethical weight. (a) The convex hull for our ethical multi-objective Markov decision process (MOMDP); and (b) scalarised policies in the weight space.
Although, by construction, we have formal guarantees that any agent applying a learning method in the resulting ethical MDP will always learn a survey policy that will be respectful with the user, this section is devoted to show it empirically. Moreover, as the resulting learning environment is a single-objective MDP, our conversational agent simply applies tabular Q-learning (Sutton & Barto, 2018) to learn to be respectful while asking survey questions. In particular, we limit a learning experiment to 1000 episodes, set a learning rate
We assess learning convergence in terms of the accumulated reward. Figure 8 illustrates the discounted sum of the rewards accumulated by two agents. The green line below represents our ethical agent while the red line above corresponds to an unethical agent that just considers the individual reward
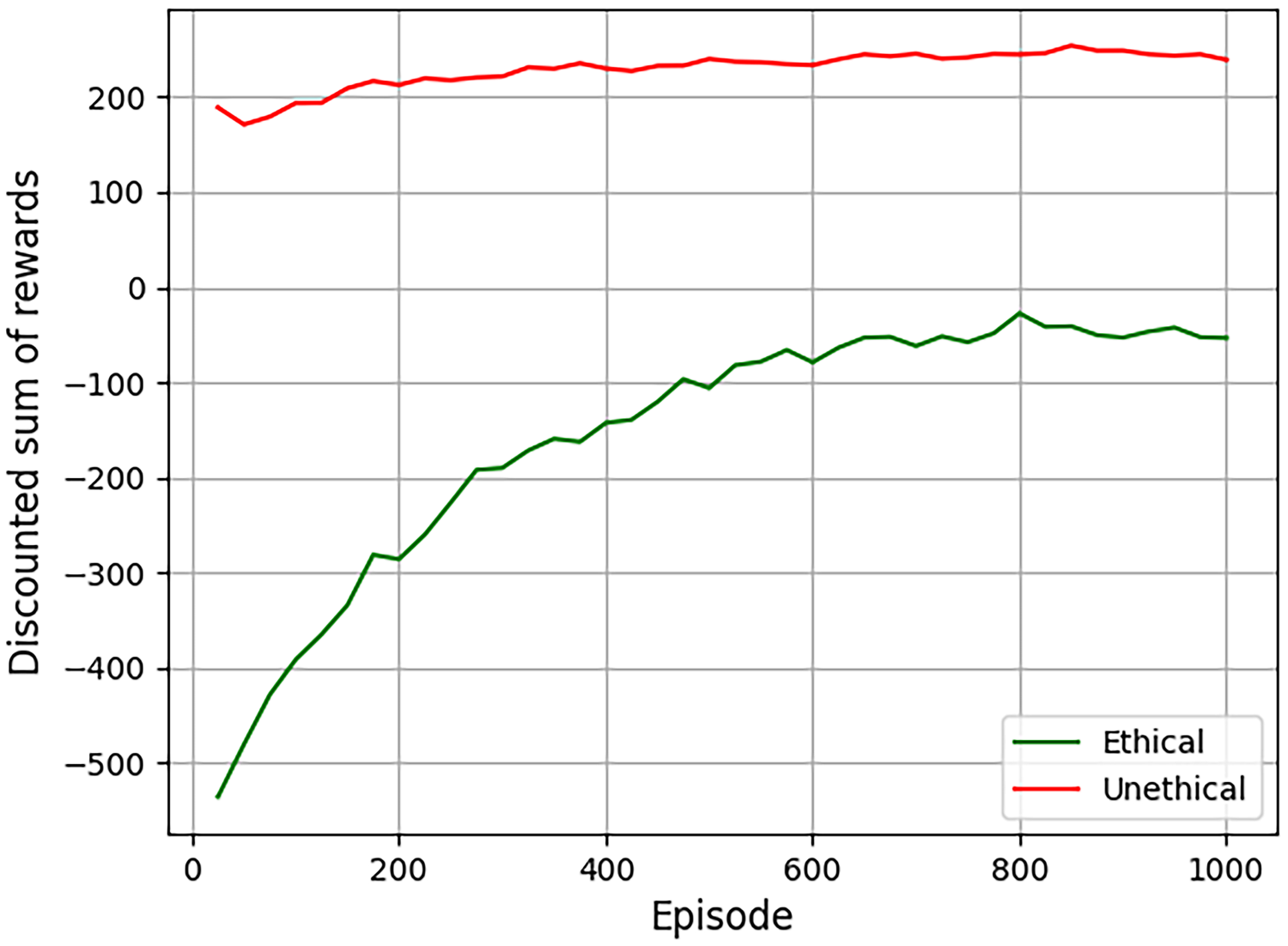
Accumulated discounted reward.
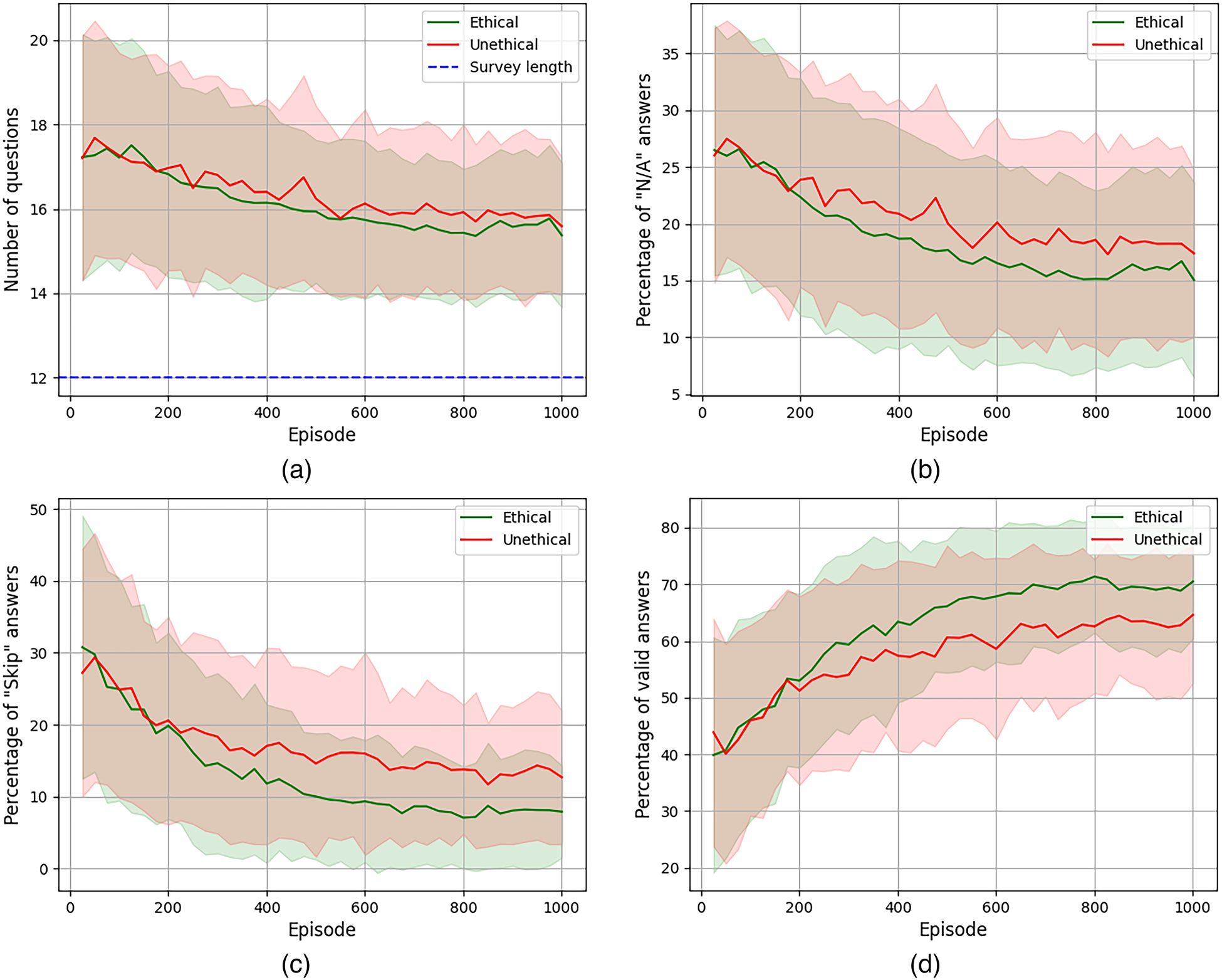
Evolution of mean number/percentage of questions asked throughout the learning process. Shadowed areas correspond to standard deviations. (a) Total number of questions; (b) % of questions with an N/A answer; (c) % of questions with a skip answer; and (d) % of questions that received a valid answer.
Regarding the number of questions asked, both agents behave similarly. Figure 9(a) illustrates that, in average, they ask about 17 questions during the initial learning episodes and they both reduce the number of questions asked throughout the learning down to about 15 (circa
However, it is worth noticing that not all questions may be answered, as the user has the option to skip a question. Figure 9(c) illustrates the mean percentage of skip answers over the total number of asked questions. Initial episodes have about 30% of skips answers – which correspond to about five answers –, whereas last episodes in the learning just have about 8% or 12% – which amounts to one or two answers. Despite the fact that only the ethical agent is penalised by these answers whilst the unethical agent does not get any reward, both agents try to minimise the amount of skipped questions because they reduce the potential of an eventual individual reward.
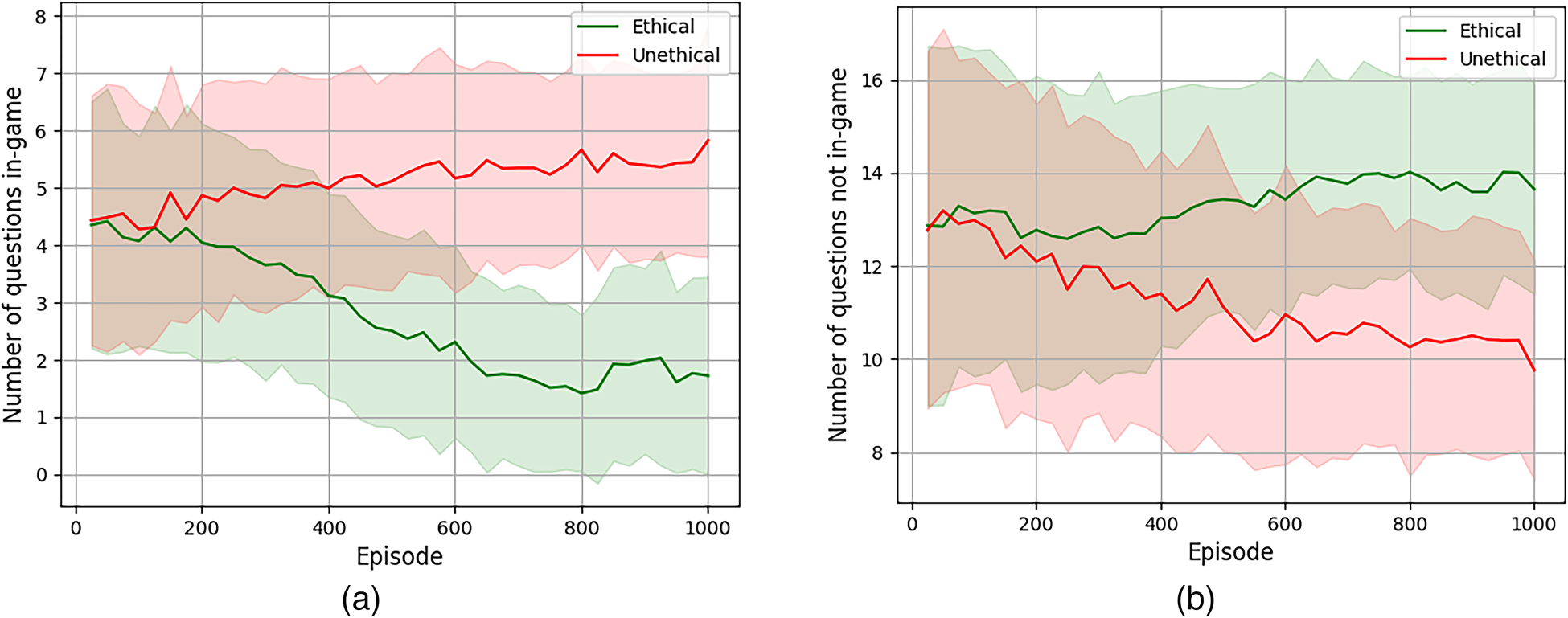
Mean number of in-game and in-menu questions asked by the learning agent. Shadowed areas represent standard deviations. (a) Number of questions in-game; and (b) number of questions in menus.
Additionally, Figure 9(d) shows the mean percentage of questions that received a valid answer over the total number of questions. As it can be seen, this percentage is substantially increased along the learning process, going from a 40% or 44% up to about 65% or 70% in the last episodes. In terms of number of questions, this amounts to getting about six or seven valid answers at the beginning, and increasing these numbers up to 10 or 11. Overall, we can see how, once they learn, both agents manage to accomplish the individual objective of eliciting as much user information as possible.
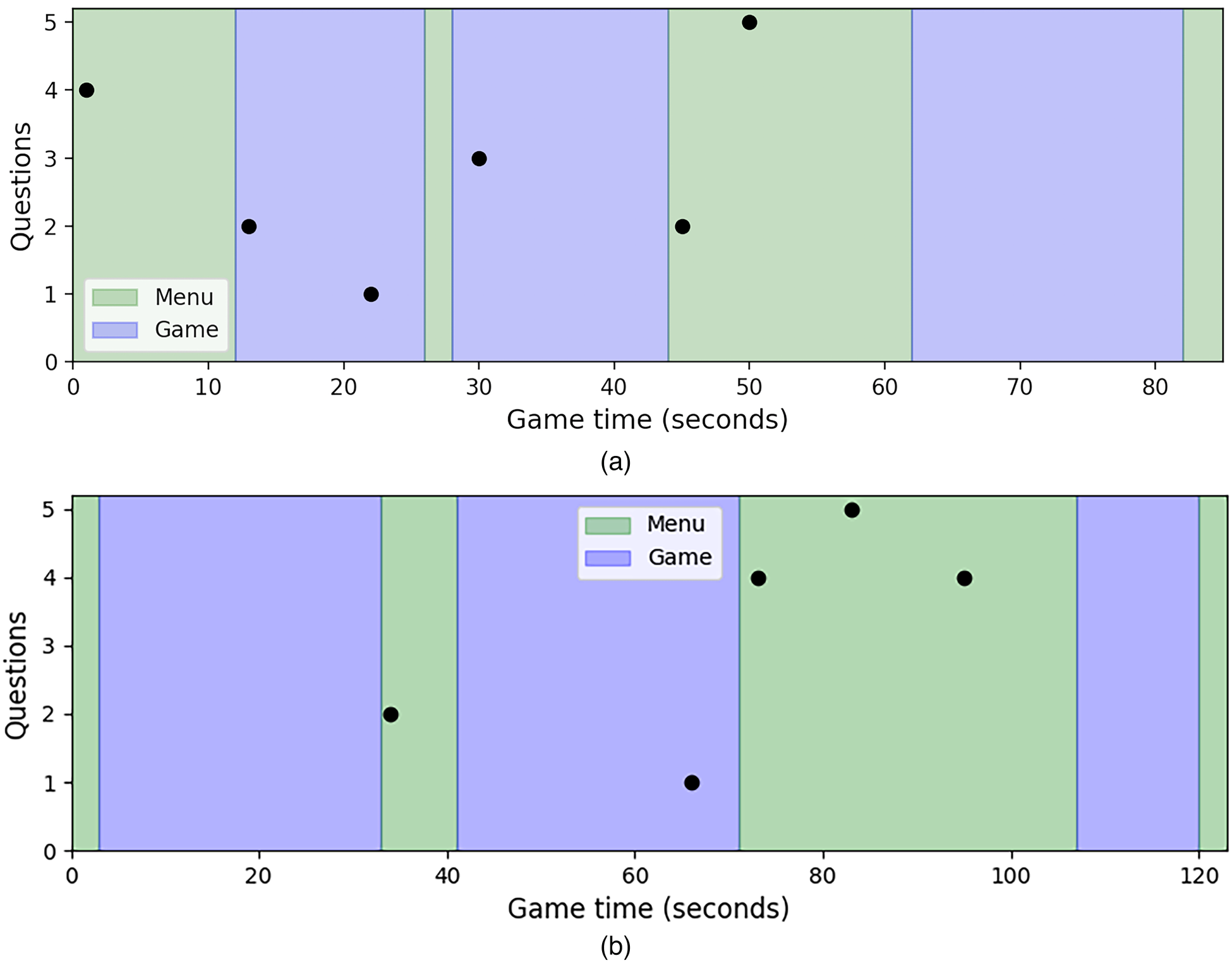
Example of three-level Pong play sessions illustrating when interactions were performed: in-game (blue) or in-menu (green). (a) Number of consecutive questions asked by the unethical agent; and (b) number of consecutive questions asked by the ethical agent.
Nevertheless, our aim is to empirically assess that the ethical agent learns a respectful behaviour, which amounts to asking questions when the user’s engagement is low. As user activity is low in menus, Figure 10 compares the mean number of questions prompted in-game and in menus and shows how the behaviour of the green ethical agent differs from the red unethical one: it manages to drastically reduce the number of questions in-game (see Figure 10(a)) and focuses on asking most of the questions in menus (see Figure 10(b)). In particular, the ethical agent learns to ask about 14 questions in menus and just asks about two questions during the first level of the game, when the play is slow enough. This behaviour is clearly in contrast with the unethical agent – which learns to ask about six questions in-game – and illustrates that the ethical agent learns to ask survey questions without disturbing the user play, that is, behaving in alignment with the moral value of respect.
To better illustrate how an actual survey is conducted, Figure 11(a) and (b) represents two example play sessions performed by the unethical and the ethical agents, respectively. The unethical agent asked 17 questions grouped in six interactions, half of these during in-game sections. It asked four questions in the initial menu, prompting the user even before playing the first level and it interrupted the game in three occasions to ask a total of six questions. The ethical agent, on the other hand, started five interactions, asking a total of 16 questions. The ethical agent asked first two questions in the second menu – once the user played the first level –, one question during the second game at a time when the ball moved towards the user’s paddle – so no action was needed from the user and thus the engagement was not disturbed – and 13 questions during the second menu. Although the number of questions is similar, this example play illustrates how our ethical agent waits for the user to have played the game before start asking questions, and mostly avoids asking in-game, managing not to disturb the users’ playing experience.
This article proposes an ethical conversational agent that collects user’s opinions and feelings while she/he is engaged in the experience. Aligned with EU’s Ethics Guidelines for Trustworthy AI, the ethical embedding algorithm provided a robust solution to endow the agent with the ethical value of respect, minimising so adverse impacts on the UX. Our approach was applied in the case study of a simple version of Pong game, where the agent acquired the ability to conduct the in-game survey in a respectful manner.
The ethical embedding method transforms an ethical MOMDP into an ethical MDP that can be solved by state-of-the-art RL algorithms. By tailoring the rewards that a learning agent receives, we ensure the agent will learn the ethical-optimal policy, the one that corresponds to the desired ethical behaviour. Specifically, we defined the learning environment based on the Pong game, and used Q-learning with a simulated user to assess the ethical agent’s learning. Our findings show that the ethical survey agent interacts with the user in more appropriate situations, such as those with low user engagement (in menus), than the unethical agent. Also importantly, the ethical agent prompts the user fewer times during games (mean 2 SD
Lines of future work include to apply our approach to other games genres with more complex mechanics and to extend the study to other applications using immersive technologies such as virtual reality and augmented reality . In particular, in the context of serious games, we plan to incorporate the conversational agent as a virtual character within the game itself. This will facilitate students’ participation in questionnaires and will allow the evaluation of educational experiences without disturbing the engagement, immersion and learning process. Finally, being respectful is one aspect of being ethical, therefore, the consideration of other moral values such as fairness is another interesting line of research.
Footnotes
Acknowledgements
This research was partially supported by projects VAE TED2021-131295B-C31, funded by MCIN/AEI/10.13 039/501100011033 and NextGenerationEU/PRTR, VALAWAI (Horizon Europe #101070930), ACISUD (PID2022-136787NB-I00 funded by MICIU/AEI/10.13039/501100011033), AUTODEMO (SR21-00329) by Fundación La Caixa, Crowd4SDG (H2020-872944), COREDEM (H2020-785907) and FairTransNLP-Language (PID2021-124361OB-C33). Maite Lopez-Sanchez and Inmaculada Rodriguez belong to the WAI research group (University of Barcelona) associated unit to CSIC by IIIA. Rodriguez-Aguilar is also supported by the ‘YOMA Operational Research’ project funded by the Botnar Foundation.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.