
Abstract
The image manipulation detection localization task differs from traditional computer vision tasks in that we focus more on capturing subtle and generic manipulation detection features in images. In this paper, we propose a novel method called irrelevant visual information suppression, which aims to alleviate the interference of irrelevant visual information in images on manipulation detection feature extraction, thereby obtaining generic manipulation traces that are more subtle and unrelated to semantic visual information. In general, most manipulation operations leave traces at manipulation edges. Therefore, we introduce a specially designed manipulated edge information enhancement branch aimed at identifying these edge artifacts more accurately. We construct a dual-branch network, where each branch uses ResNet-50 as the backbone to capture as many multi-scale manipulation features as possible. Finally, we adopt a multi-view feature learning method that combines the manipulated edge information enhancement branch with the irrelevant visual information suppression branch and is trained with multi-scale (pixel/edge/image/irrelevant visual information suppression) supervision. To validate the effectiveness of the proposed method, we conducted extensive experiments using five image manipulation localization datasets, including CASIAv1, CASIAv2, COVER, Columbia, and NIST16. The experimental results demonstrate that our proposed method can outperform state-of-the-art methods by a significant margin in terms of F1 score. Taking CASIAv1, COVER, and Columbia datasets as examples, compared with MVSS-Net published in ICCV 2021, our method has improved F1 scores by 7.1%, 6.3%, and 12.5%, respectively. The code used in this paper can be found at the following URL: https://github.com/ginwins/ISIE-Net.
Keywords
Introduction
The editability of digital images has reached astonishing levels, enabling individuals to make virtually imperceptible modifications visually. The rapid development of this technology poses a challenge to the authenticity of digital photos, as individuals can easily manipulate various details of an image, altering colors, contrast, brightness, and even adding or removing objects from the image. In terms of manipulation methods, copy-move, splicing, and removal are three of the most common and relatively easy to achieve, which can be easily achieved through software such as Photoshop, Meitu Xiu Xiu, and so on, as shown in Figure 1. However, the misuse of these technologies, such as generating deepfakes (Song et al., 2019), forged signatures (Liu et al., 2021), and rumors (Luo et al., 2021), has severely challenged the normal functioning of society, prompting widespread public concern (Zampoglou et al., 2017). Therefore, there is an urgent need to detect and localize these manipulated images in order to maintain the authenticity and credibility of the information.

Example of manipulated images with different manipulation techniques. Copy-move is to copy some areas of an image and move them to other locations. Splicing is utilized to cut some objects from another image and mask the target image with these objects. Removal is to remove some unwanted elements.
Image manipulation detection is fundamentally different from general computer vision tasks such as object detection and semantic segmentation (Yang et al., 2022; Yi et al., 2022). While usual computer vision tasks focus on learning the visual semantic content of an image, image manipulation detection focuses more on capturing the minute traces and details left by manipulation operations. Traditional image manipulation detection methods are categorized based on different manipulation techniques, including those based on overlapping blocks (Luo et al., 2006), feature points (Amerini et al., 2013), image properties (Dong et al., 2009), and compression properties (Luo et al., 2007). However, these methods suffer from poor feature applicability and low efficiency. Currently, there is no single method in traditional approaches that can universally apply to all types of image manipulation techniques, and they fail to provide accurate pixel-level detection results.
In recent years, some researchers have attempted to perform image manipulation detection by deep learning methods and have achieved significant results in the recognition of multiple manipulation types. Existing deep learning image manipulation detection methods can usually be categorized into two types: noise-aware methods and edge-aware methods. The core idea of noise-aware methods lies in the fact that tampered regions and normal image regions are significantly different in terms of noise. Therefore, these methods employ a predefined noise filter (Fridrich Kodovsky, 2012) to generate another noisy image, which is then fused with the original red–green–blue (RGB) features for manipulation detection. However, for those image manipulation operations that are performed only on the target image, such as the copy-move type (Wu et al., 2018; Zhong et al., 2022), the noise introduced is almost negligible for the original image since the copy-move does not introduce new elements. Therefore, in this type of image manipulation situation, noise-aware methods are relatively ineffective and are considered suboptimal choices. In contrast, edge-aware methods try to find boundary visual artifacts around the tampered region and use the visual artifacts as cues to locate the edges of the manipulation. This method is able to be independent of the type of manipulation, as visual artifacts often show inconsistencies in edge regions. Therefore, a common strategy is to introduce another branch for detecting edge artifacts (Zhou et al., 2020). However, the simple feature concatenation method used in previous methods is not ideal because the manipulated features exhibit obvious differences in feature maps at different scales. Linear aggregation of feature maps ignores that deep features may make the detected manipulation features semantically relevant, while it also ignores the importance of shallow features, resulting in suboptimal performance. Additionally, previous edge detection methods fail to establish an effective link between RGB features and edge features, resulting in underutilized spatial contextual information and ineffective mining of unique and effective key information at each scale. Furthermore, distinguishing between edge artifacts of natural objects and genuine edges becomes even more challenging when edge artifacts are concealed by carefully designed post-processing methods such as local smoothing, image compression, and filtering.
To overcome the two limitations mentioned above, we propose a dual-supervised network ISIE-Net, based on irrelevant information suppression and critical information enhancement. This is a novel end-to-end multi-scale supervised framework designed for image manipulation detection and localization. ISIE-Net can be divided into three parts: the manipulated edge information enhancement branch (MEIEB), irrelevant visual information suppression branch (IVISB), and dual attention (DA) feature fusion. It aims to capture edge artifacts, subtle and generic signs of manipulation, and information of high-level semantic objects. The MEIEB and theIVISB are jointly optimized through a DA feature fusion module, and the information at each scale is effectively utilized. In the MEIEB, we are inspired by Chen et al. (2021) and Ma et al. (2021) to gradually aggregate features from shallow to deep to predict the target edge. In order to jointly use shallow and deep feature information at multiple scales, this branch extracts edge features based on the features output from each layer of the network. Firstly, the features are fed into the Sobel layer to extract the edge-related information, which is then processed by the edge extraction module, and then these edge features are concatenated and fed into the edge attention module as the edge prediction features. The edge attention module achieves mutual optimization between the main task of manipulation segmentation and the task of the manipulated edge information enhancement, effectively improving the performance of the entire network. In the IVISB, we employ multiple resolution down ( We develop a new end-to-end multi-scale supervised framework for image manipulation detection localization tasks, called ISIE-Net. As shown in Figure 2, the MEIEB and the IVISB are jointly optimized by a DA feature fusion module, and the information at each scale is used efficiently. We propose a new image manipulation detection and localization method based on the idea of irrelevant visual information suppression, which utilizes a subtraction operation to alleviate the impact of irrelevant visual information on manipulation feature extraction to obtain generic manipulation traces that are more subtle and unrelated to semantic visual information. In addition, we introduce an MEIEB, which establishes an effective link between the backbone segmentation task and the manipulated edge information enhancement task, and accurately locates tampered regions based on multi-scale edge artifact features, which makes full use of the inconsistency of edge artifact features. Extensive experiments on five publicly available datasets show that our proposed method can outperform state-of-the-art (SOTA) methods in terms of pixel-level F1 score and area under the curve (AUC). The rest of our work is organized as follows: Section 2 introduces related work, and Section 3 describes the proposed ISIE-Net model approach. Section 4 describes the experiments and discussions. Section 5 provides concluding remarks.
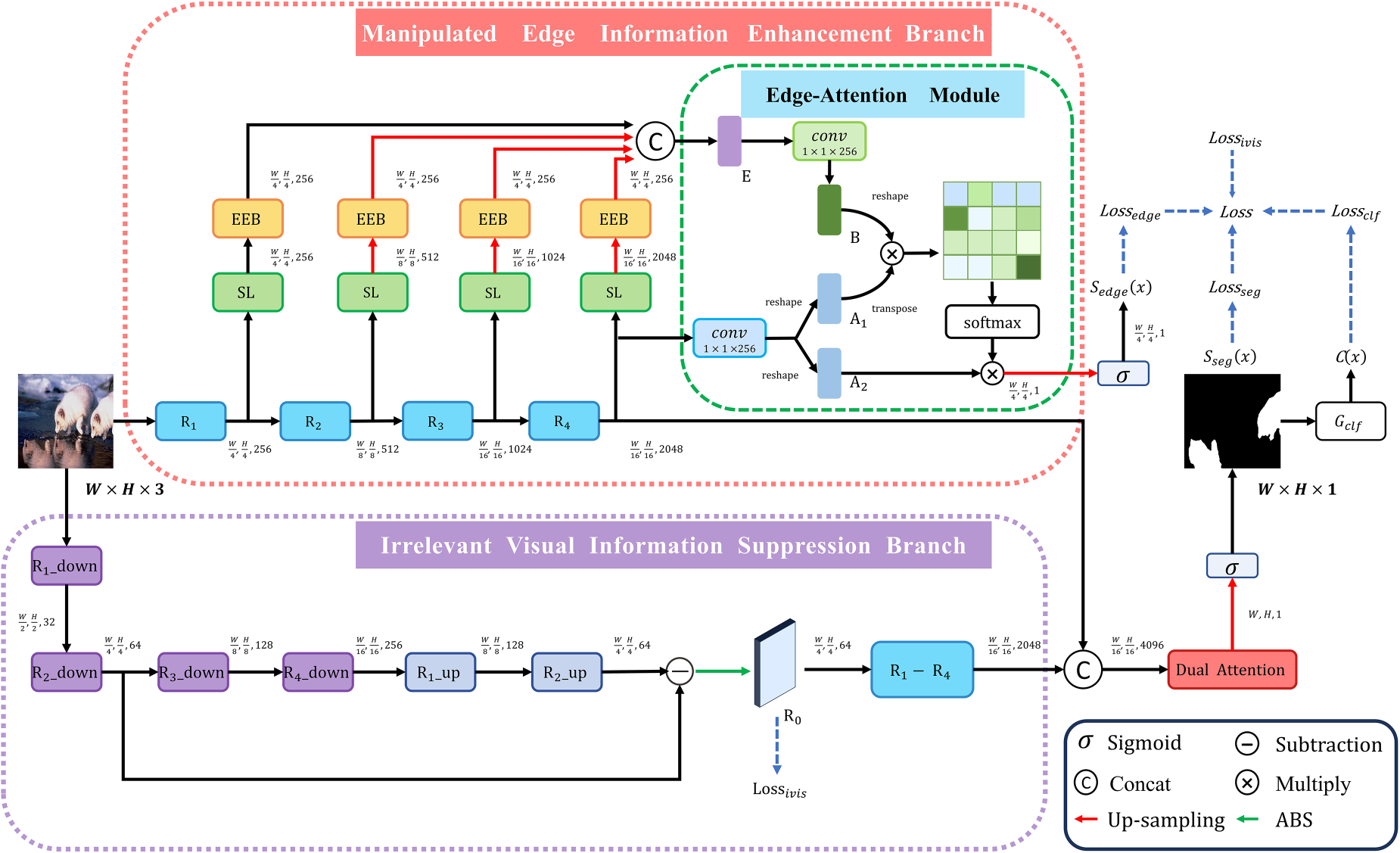
Network architecture of the ISIE-Net method. ISIE-Net has two branches, both using ResNet-50 as the backbone. The top MEIEB is specifically designed to enhance subtle boundary artifacts around the tampered region, while the bottom IVISB is used to learn subtle and generic manipulation cues in the image. Finally, the MEIEB and the IVISB are feature fused by a DA fusion module. Note. MEIEB = manipulated edge information enhancement branch; IVISB = irrelevant visual suppression branch; DA = dual attention.
This section reviews the most relevant research on deep learning methods for manipulation detection and localization. Then, we briefly introduce the attention mechanism, one of the core components of this network.
Image Manipulation Detection and Localization
The deep learning-based methods for image manipulation detection and localization have brought a new perspective to the field of image tampering detection. In recent years, many research works have made significant advancements in this area.
Bappy et al. (2017) introduced a hybrid convolutional neural network (CNN)-long short-term memory (LSTM) model called J-LSTM. After segmenting the input image into multiple blocks, this model utilizes the LSTM network to extract discriminative features regarding the correlation between blocks, aiming to discern manipulated and unmanipulated regions. Similarly, a novel high-confidence manipulation localization structure, H-LSTM, was proposed in Bappy et al. (2019), based on resampling features. Comprising LSTM and CNN, this structure is designed to locate manipulation regions, albeit constrained by the size of the partitioned blocks. Zhou et al. (2018) introduced a dual-stream localization architecture called RGB-N. In this architecture, the dual streams consist of an RGB stream, which extracts features from the RGB image, and a noise stream, which utilizes a steganalysis-rich model filter to extract noise features to discover the consistency of noise between the authentic and tampered regions. However, the method mainly focuses on the semantic information of the image, and there are some limitations in using it to detect tampered images, the untampered region features can affect the judgmental features of the tampered region, leading to an increase in the false detection rate. In addition, the method uses rectangular boxes to outline the falsified regions and does not achieve pixel-level localization. Yang et al. (2020) used BayarConv as the initial convolutional layer of their CR-CNN for more accurate prediction. Zhou et al. (2020) proposed a generative adversarial network structure-based stitching detection model GSR-Net, which constructs an edge detection task by selecting features from the middle three blocks of DeepLab (Chen et al., 2017) and uses the predicted manipulated edges to optimize the overall manipulation region prediction. Additionally, Zhuang et al. (2021) designed a fully convolutional encoder–decoder architecture, DenseFCN, that contains dense connectivity and expansive convolution to improve the operation localization performance. Kwon et al. (2021) proposed CAT-Net, an end-to-end fully convolutional neural network containing RGB and dual clutch transmission (DCT) streams to jointly learn forensic features for compression artifacts in both the RGB and DCT domains. Wu et al. (2019) proposed an end-to-end ManTra-Net network, which consists of two sub-networks: a manipulation trace feature extractor and a local anomaly detection network. It treats the manipulation detection task as a local anomaly detection task, capturing local anomalies using
Attention Mechanisms
When a CNN is used to process images, we prefer to focus on important content rather than considering all information comprehensively. However, manually specifying what needs attention is impractical (Dai et al., 2023). Therefore, attention mechanisms in deep learning have become a crucial technology, mimicking the attentional mechanisms and information-processing methods of the human visual system. This allows models to selectively concentrate on specific parts of input data, thereby enhancing the recognition and utilization of critical information. In summary, attention mechanisms serve two purposes: determining which parts of the input should be attended to and how to effectively allocate limited information-processing resources to these important parts. For image manipulation detection tasks, the global correlation between each pixel and other pixels in the image is crucial. Ma et al. (2021) proposed BCANet, which introduced a boundary-guided context aggregation module based on an attention mechanism, aiming to capture distant dependencies between pixels in boundary regions and those inside the target. Fu et al. (2019) designed a positional attention module to encode broader contextual information into local features and devised a channel attention mechanism to model the interdependencies among channels.
The Proposed Model
Given an input RGB image
Manipulated Edge Information Enhancement Branch
In the image manipulation detection task, edge information is crucial for identifying manipulation traces. Therefore, edge information is used as a supervisory signal to guide the image manipulation detection task. However, the linear aggregation of feature maps adopted in previous research ignores that deep features may make the detected manipulation features semantically relevant, while also not fully considering the importance of shallow features. Therefore, in order to better utilize the feature contents at different scales and to establish an effective link between the main segmentation task and the manipulated edge information enhancement task, we propose a multi-scale MEIEB, as shown in Figure 2, ResNet50 is used as the backbone network, and R1, R2, R3, and R4 are, respectively, the layers of conv1-x, conv2x, conv3-x, and conv4-x in ResNet50, and we extract manipulation edge information by utilizing the features output from each layer of the ResNet50 backbone network. In order to obtain stronger edge information, we introduce the Sobel layer, which helps to enhance the edge-related information in the image to locate the tampered regions more precisely. Immediately after that, we employ the edge extraction block (EEB) to process the edge features extracted by the Sobel layer and join all this edge information as the edge feature. Furthermore, we believe that the manipulated edge information enhancement task and the backbone segmentation task are interrelated and mutually optimized. The focus of the manipulated edge information enhancement task is to capture the boundaries and transitions between the tampered and untampered regions of an image, and this boundary information is crucial for structural and semantic analysis of the image. At the same time, the backbone segmentation task can also provide enhanced contextual information for the edge detection task. Therefore, we introduced the edge attention module to mine manipulation position information more accurately. The introduction of this module not only helps to enhance the performance of edge detection, but also improves the performance of the backbone network in the manipulation segmentation task.
Specifically, assume there is a natural RGB image
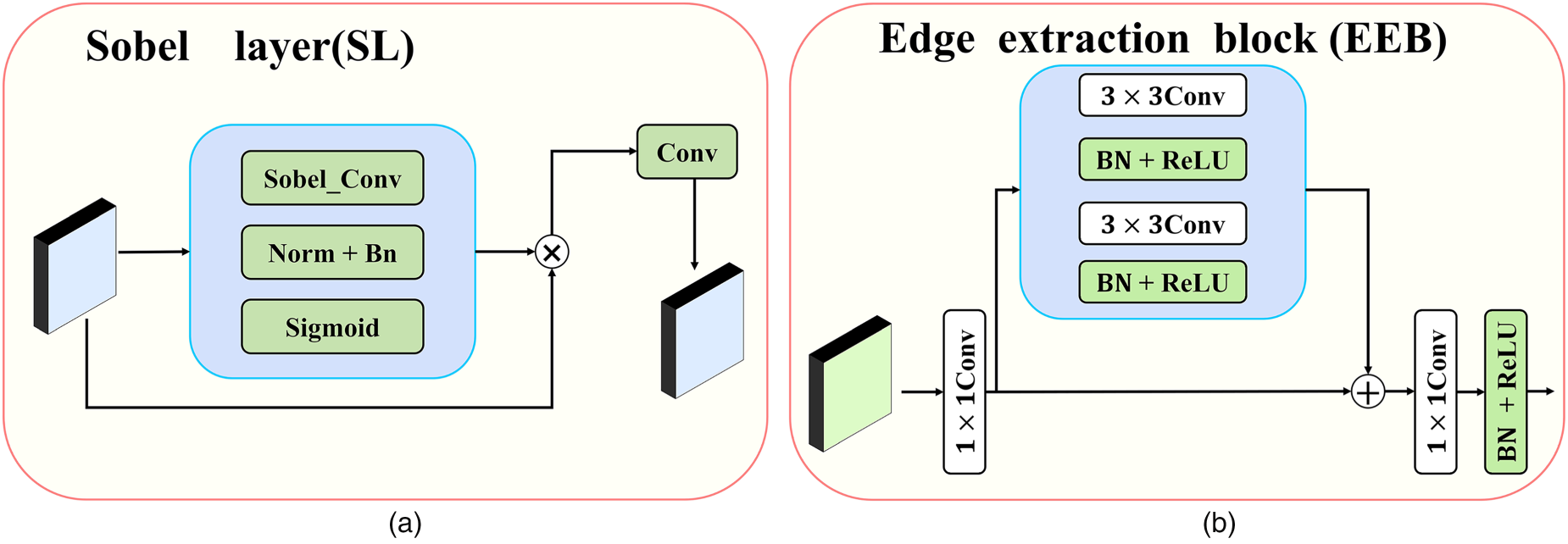
(a) Sobel layer and (b) EEB for manipulating edge detection in the manipulated edge information enhancement branch. Note. EEB = edge extraction block.
In order to establish an effective link between the RGB features and edge features of the backbone network, we introduce the edge attention module, which aims to mine the manipulation location information more precisely. The structure is shown in Figure 2. Specifically, given the semantic feature map

In the image manipulation detection task, the traces of image manipulation are very subtle, and in order to capture the subtle and semantically irrelevant generic manipulation features of an image, we constructed an IVISB in parallel with MEIEB. Unlike AMTEN proposed by Guo et al. (2021), which subtracts image content from low-level features, the proposed IVISB obtains an irrelevant visual information suppression view by performing a subtraction operation on a set of feature maps obtained from a set of resolution down blocks and a set of feature maps reconstructed from a set of resolution up blocks and then taking the absolute value. The structures of the resolution down block (
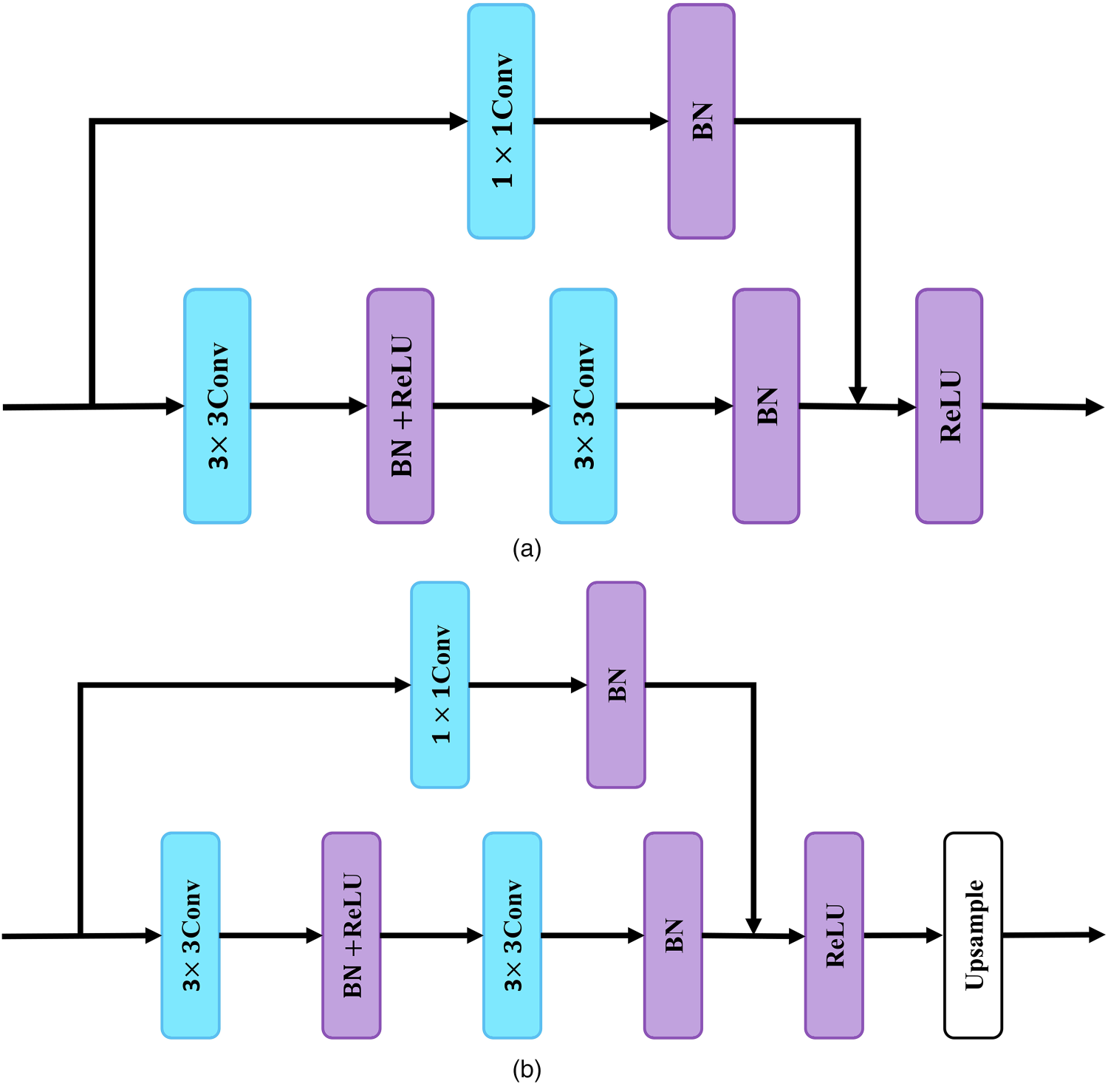
(a) Resolution down block (
Specifically, as shown in Figure 2, given an input RGB image
We concatenate two feature map arrays,
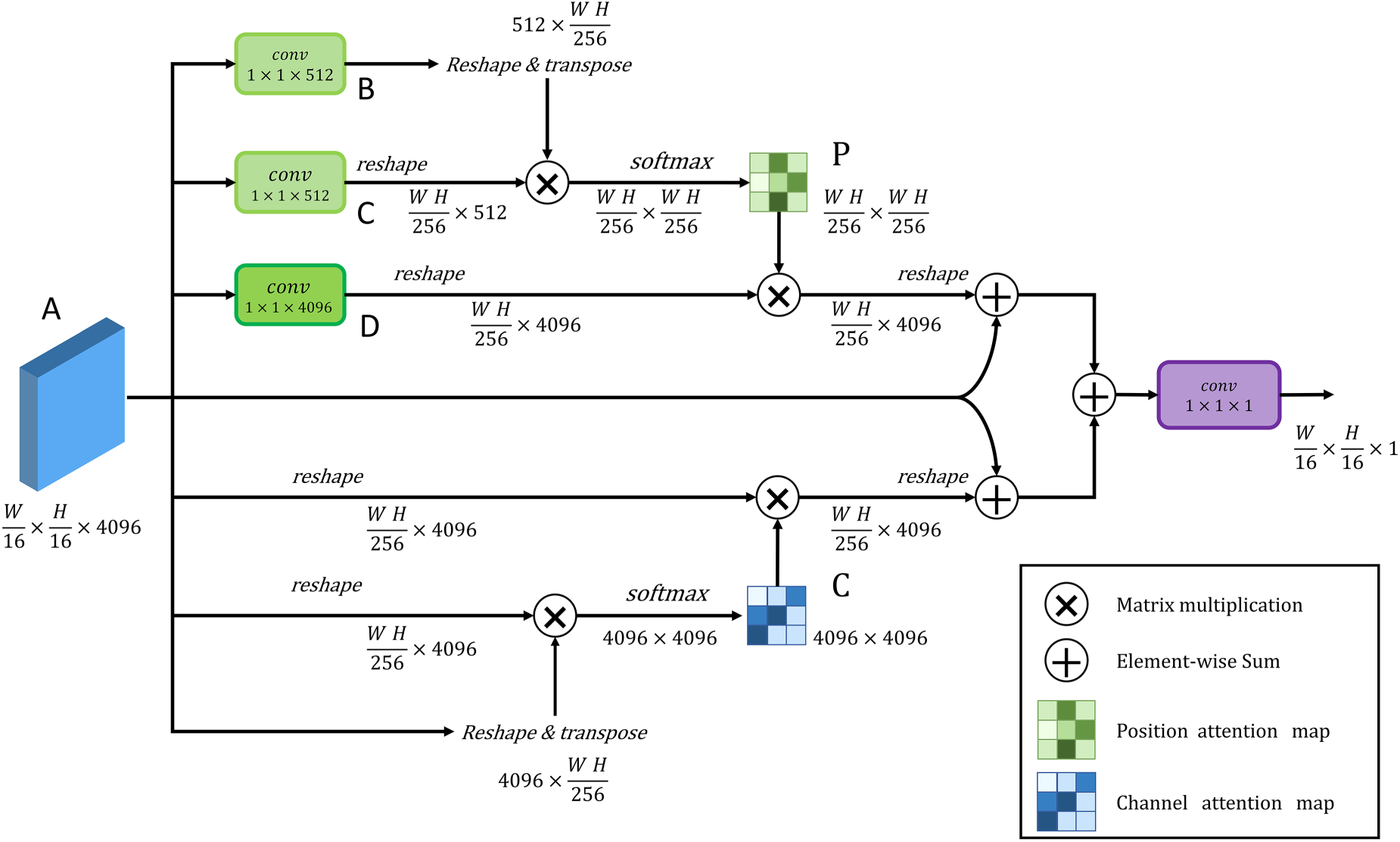
DA Module With Position Attention Module on Top and Channel Attention Module on Bottom. Note. DA = dual attention.
The MEIEB provides powerful supervised signals through multi-scale edge information, while the IVISB enhances the detection performance by learning subtle and generic manipulation features in the image. Since the image context information and edge information can enhance each other, we jointly optimize the parameters of the MEIEB, the IVISB, and the DA fusion module in order to fully exploit the potential complementary relationship between them. We consider four different scales of losses, each with its own specific objective: a pixel-scale loss is employed to enhance the sensitivity of the model to pixel-level manipulation detection, an edge information loss is utilized to strengthen crucial information at the manipulation edges, an irrelevant visual information suppression loss is designed to learn subtle and generic manipulation features in the image and an image-scale loss is used to improve the specificity of the model for image-level manipulation detection. The optimized loss function can be defined as follows:
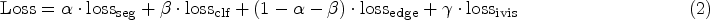
Due to the imbalance in the ratio of tampered edge pixels to other pixels, pixel level loss employs dice loss as a loss function, as it is very effective for learning from extremely imbalanced data (Wei et al., 2021). Its definition can be given by the following equation:
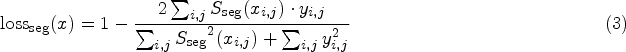
Since edge pixels are overwhelmed by non-edge pixels, we again use the Dice loss for manipulation edge detection, denoted as
Image-Scale Loss
In order to reduce false alarms, real images must be considered during the training phase. As shown in Figure 2, the
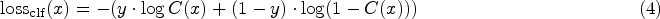
As shown in Figure 2, the irrelevant visual information suppression view is obtained by subtracting a set of feature maps generated by a resolution down block from those reconstructed by a resolution up block. Our goal is to reduce the difference between these two feature maps,

Datasets
To evaluate the performance of ISIE-Net, we conducted experiments on public image processing localization datasets, namely CASIA (Dong et al., 2013), COVER (Wen et al., 2016), Columbia (Hsu Chang, 2006), and NIST16 (Guan et al., 2019). The composition of the operational image types of the dataset is shown in Table 1. CASIA consists of two components (CASIAv1 and CASIAv2), both providing authentic masks. CASIA provides images with splicing and copy-move manipulations, as well as images affected by post-processing operations such as rotation, blur, distortion, so on. COVER is a small-scale manipulation dataset based on copy-move, comprising 100 manipulated samples along with their corresponding authentic masks. Columbia is a small dataset generated by stitching arbitrary regions into an image. NIST16 is a challenging dataset containing three manipulation types: copy-move, splicing, and removal. Manipulation traces are obscured by some post-processing operations in NIST16.
Details of Training and Test Images for the Five Datasets Used in Our Experiments.

Details of Training and Test Images for the Five Datasets Used in Our Experiments.
Implementation Details
The proposed ISIE-Net is built based on PyTorch and uses the Adam optimizer, where the learning rate is periodically decayed from 10–4 to 10–6, with a batch size of 12. All the training processes are run on an NVIDIA GeForce RTX 3090 with 24 GB of RAM. We chose ResNet-50 to be used as the backbone of ISIE-Net and pre-trained by the ImageNet dataset. The input images were uniformly set to
Evaluation Metrics
To evaluate the performance of our model, we follow previous work (Chen et al., 2021; Zhou et al., 2018, 2020) and use pixel-level F1 scores and AUC as our evaluation metrics. F1 scores and AUC are two widely used metrics for measuring per-pixel binary classification performance, and their scoring values are in the range of
F1 score combines precision and recall. Precision is the ratio of correctly predicted positive data to the total data predicted to be positive, while recall is the ratio of correctly predicted positive data to all data marked as positive. The F1 score is calculated according to






For a fair comparison, we chose results from the baseline dataset that follows a public evaluation protocol and fulfill one of the following two criteria: (a) results published by SOTA or representative methods, and (b) results obtained by retraining using the publicly available code of the method in question. We evaluated and compared ISIE-Net with six currently published leading methods, namely ManTra-Net 1 (Wu et al., 2019), GSR-Net 2 (Zhou et al., 2020), Constrained R-CNN 3 (Yang et al., 2020), DenseFCN 4 (Zhuang et al., 2021), CAT-Net 5 (Kwon et al., 2021), and MVSS-Net 6 (Chen et al., 2021). All models and methods either follow the same evaluation protocol or are retrained on the CASIAv2 dataset.
Comparison With SOTA Methods
In this section, the proposed ISIE-Net is compared quantitatively (pixel level and image level) and qualitatively with SOTA methods. The pixel-level and image-level quantitative comparison (corresponding to Section 4.4.1) and the qualitative evaluation (corresponding to Section 4.4.2) give a comparison of the visualization results corresponding to the different methods.
Quantitative Comparison
We first evaluate the performance of ISIE-Net on five public image processing localization datasets, and then compare the ISIE-Net results with the F1 and AUC values of the previous SOTA methods. Our experiments train the model only on the CASIAv2 dataset and then test it directly on the remaining datasets. If the code was not available, the results reported in the corresponding references were used. The comparison results are given in Tables 2 and 3, respectively (some experimental results are from Chen et al., 2021).
AUC Comparison Results Obtained on Three Standard Datasets and NIST16 is Excluded as it has no Authentic Image.
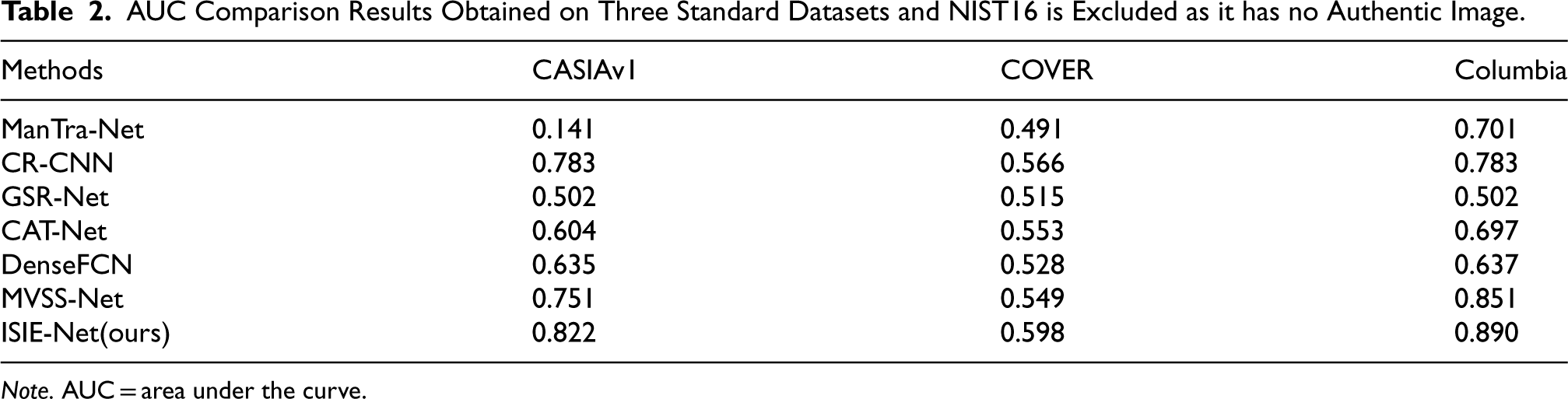
AUC Comparison Results Obtained on Three Standard Datasets and NIST16 is Excluded as it has no Authentic Image.
Note. AUC = area under the curve.
F1 Score Comparison Results Obtained on Three Standard Datasets.
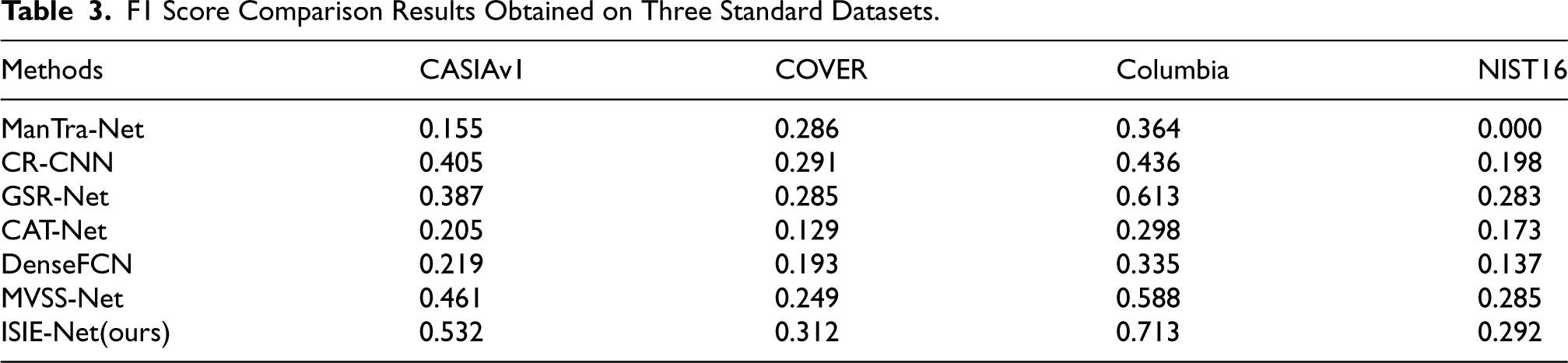
The AUC comparison results are shown in Table 2, while NIST16 is excluded due to the lack of real images. It is clear from Table 2 that our proposed model obtains the highest AUC scores of 82.2%, 59.8%, and 89.0% on the CASIAv1, COVER, and Columbia datasets, respectively, and these results clearly outperform ManTra-Net, GSR-Net, Constrained R-CNN, DenseFCN, CAT-Net, and MVSS-Net.
The results of the F1 score comparison are shown in Table 3, from which it can be seen that our proposed model achieves the highest F1 scores of 53.2%, 31.2%, 71.3%, and 29.2% on the CASIAv1, COVER, Columbia, and NIST16 datasets, respectively. ISIE-Net shows the best performance in both AUC and F1 scores, especially on the CASIAv1 and Columbia datasets, where the F1 scores are significantly improved compared to the SOTA algorithms. For example, the F1 score of ISIE-Net on the Columbia dataset is as high as 0.713, while that of MVSS-Net is only 0.588, and its improvement can be as high as 12.5%. There are two key reasons why ISIE-Net outperforms previous methods. First, our proposed IVISB method successfully suppresses the interference of irrelevant visual information in the image, while enhancing the learning ability of subtle and generic tampering features and tampering edge critical features. Specifically, we pay special attention to those subtle and generic manipulation features that have been neglected in previous methods, thus improving the generalization performance of ISIE-Net. In addition, we introduce am MEIEB that establishes an effective link between edge features and RGB features. This branch enhances the manipulated edge information enhancement performance through the constraint of edge artifacts, while ensuring that the backbone network maintains high accuracy in predicting segmentation results. In contrast, other methods fail to fully utilize the details of the edge information around the tampered region.
To further demonstrate the effectiveness of ISIE-Net, we performed result visualization. The visualization results of manipulation detection and localization are shown in Figure 6, which clearly demonstrate the significant advantages of our ISIE-Net over the baseline approach. Specifically, regardless of which manipulation operation is used, ISIE-Net generates segmentation results that are very close to the actual situation, and mis-segmentation is very much the case. In contrast, ManTra-Net, GSR-Net, CAT-Net, and DenseFCN produce unsatisfactory results with a large number of missegmented regions. In addition, ManTra-Net, CAT-Net, DenseFCN, and CR-CNN perform poorly in boundary detection and are far less accurate than ISIE-Net, as they ignore the importance of edge artifact information. In contrast, MVSS-Net and ISIE-Net employ edge supervision branches to enhance detection and localization performance by learning edge features. However, in the third line (copy-move), it is known from the basic facts that both the Arctic fox and the shadow in the water are tampered regions. When ISIE-Net is used, it can detect these regions well and the boundaries are very clear, and when MVSS-Net is used, although the Arctic Fox and the shadow in the water can also be found, their boundaries are relatively fuzzy. Again, for the example in the first row (splicing operation), ISIE-Net gets more accurate prediction results. Therefore, ISIE-Net can locate the tampered region more accurately and divide the edges more finely, and its results are closer to the real labels.

Qualitative results of different manipulation localization algorithms. The first column shows the manipulated images on the CAISA dataset. The second column shows the basic facts. From the third to the eighth columns, the final manipulation segmentation predictions are represented for ManTra-Net, GSR-Net, CR-CNN, Dense-FCN, CAT-Net, and MVSS-Net, respectively. The last column shows the results of our proposed ISIE-Net. Note that the first two rows of images are operated by splicing, the third and fourth rows are operated by copy-move, while the other rows are operated by removal.
In the ablation study, all modules were trained by the CASIAv2 dataset. The results of the ablation experiments are shown in Table 4. As mentioned earlier, ISIE-Net consists of three modules: the MEIEB, the IVISB, and the DA fusion module. To better illustrate the effect of each module in the model, we gradually added each component to ResNet-50 for training and compared the results. The model for the ablation experiment is as follows:
Ablation Experiment Results.
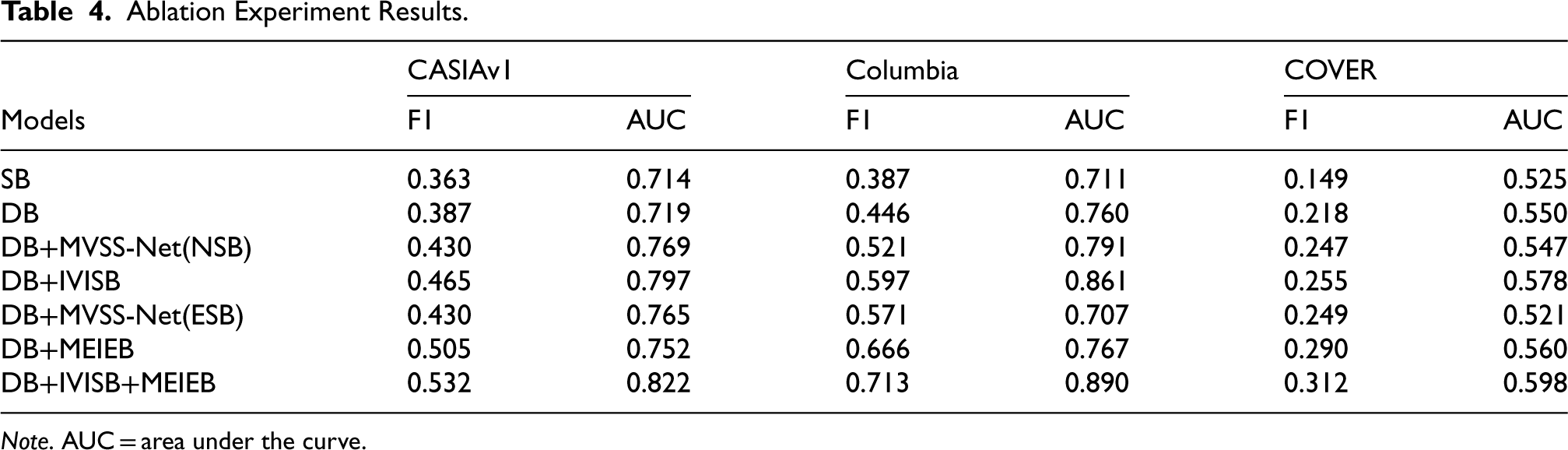
Ablation Experiment Results.
Note. AUC = area under the curve.
Comparing SB and DB shows that the dual-branch network captures more detailed information and facilitates manipulation detection. The comparison results of DB, DB+IVISB, and DB+MVSS-Net (NSB) validate the low validity of the noisy view that we mentioned in the introductory section, and also highlight the validity of the IVISB branch that we proposed. Since DB+IVISB is obtained by adding IVISB to DB, its better performance validates the effectiveness of IVISB in improving the detection of pixel-level and image-level manipulations. The overall performance of DB+MVSS-Net (NSB) is lower than that of DB+IVISB, and the results clearly demonstrate the superiority of the proposed IVISB with respect to the existing techniques.
The comparison between DB and DB+MEIEB reveals that the MEIEB significantly contributes to the overall detection performance. The results of DB+MEIEB compared to DB+MVSS-Net(ESB) further confirm the importance of the edge attention module in the MEIEB. The introduction of this module establishes a close connection between edge features and RGB features, more accurately mining manipulation location information. The incorporation of the edge attention module not only significantly improves edge detection performance but also enhances the performance of the backbone network in segmentation tasks.
In this paper, we introduce a novel approach based on enhancing critical information and suppressing irrelevant visual information to address the problem of image manipulation detection. Specifically, we propose a new supervised deep learning model called ISIE-Net, designed to detect tampered regions in digital images and predict manipulated mask mappings. We discuss in detail the process of designing and implementing the network architecture, along with the convolutional neural network architecture layers used therein, to learn a universal representation for image manipulation detection and forgery localization. By designing a branch based on edge information enhancement to capture enhanced edge artifacts and a branch based on suppressing irrelevant visual information to capture more subtle and generic manipulation cues in images, and by utilizing a DA module to fuse the MEIEB with the IVISB, the network is able to fully exploit the clues difference between tampered and untampered regions.
In comparison to previous methods, our model captures manipulation cues from both enhancement and suppression aspects, as the loss of critical edge artifact information can disrupt the results of manipulation detection, which can be supplemented by edge enhancement. Therefore, this method is more versatile and effective for complex image forgery. Additionally, an abundance of semantic information can interfere with tampering detection results, which can be effectively addressed by the suppression branch of irrelevant visual information. Furthermore, the introduced edge attention module optimizes the enhancement task of manipulated edge information and the main segmentation task, effectively improving the overall network performance. Experimental results demonstrate that our method achieves the best quantitative and qualitative results on all five standard datasets, and extensive ablation experiments also confirm the significant advantage of obtaining universal manipulation features by strengthening key information enhancement and suppressing irrelevant visual information. Moreover, our method performs well on images without reference evaluation and on images subjected to post-processing, which is one of the most important challenges in detecting small manipulated areas and unclear images. Additionally, another advantage of this method is its ability to simultaneously detect multiple tampered regions.
Based on the methods and results of this study, it is evident that our proposed approach of enhancing key information and suppressing irrelevant visual information is effective in tampering detection and localization, further advancing the practical application of image forensics. Since our proposed model has relatively few parameters, it can be trained end-to-end using large-scale datasets in a lightweight manner. Therefore, an important direction for future research is to establish large-scale, high-quality dataset benchmarks containing known instances of image forgeries and continuously incorporate additional forged data for model training. This will enable the model to maintain high discriminative power when faced with various novel manipulation operations in internet scenarios. Additionally, the accuracy and precision of image manipulation detection network models will also be enhanced. Furthermore, exploring various other network architectures can further accelerate the proposed methods. Future work involves exploring concepts such as feature fusion techniques and attention modules to further enhance the performance of the proposed approach. Additionally, investigating the vulnerability of the proposed network to adversarial attacks is another important task for future consideration.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China under grant no. 62376017, and Fundamental Research Funds for the Central Universities (grant no. BUCTRC202221).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.