
Abstract
Fabric defect detection plays a critical role for measuring quality control in the textile manufacturing industry. Deep learning-based saliency models can quickly spot the most interesting regions that attract human attention from the complex background, which have been successfully applied in fabric defect detection. However, most of the previous methods mainly adopted multi-level feature aggregation yet ignored the complementary relationship among different features, and thus resulted in poor representation capability for the tiny and slender defects. To remedy these issues, we propose a novel saliency-based fabric defect detection network, which can exploit the complementary information between different layers to enhance the representation features ability and discrimination of defects. Specifically, a multi-scale feature aggregation unit (MFAU) is proposed to effectively characterize the multi-scale contextual features. Besides, a feature fusion refinement module (FFR) composed of an attention fusion unit (AFU) and an auxiliary refinement unit (ARU) is designed to exploit complementary important information and further refine the input features for enhancing the discriminative ability of defect features. Finally, a multi-level deep supervision (MDS) is adopted to guide the model to generate more accurate saliency maps. Under different evaluation metrics, our proposed method outperforms most state-of-the-art methods on our developed fabric datasets.
Keywords
Introduction
The defect detection on the fabric surface is essential for the textile industry. During the production process, due to the influence of machine or human factors, various defects such as warp, weft, or point defect, often appear on the fabric surface. 1 Traditional manual visual detection methods tend to be susceptible to human factors such as inattentiveness or human fatigue, resulting in the low detection accuracy and efficiency. Importantly, unlike the automated detection method, the manual method is typically based on human expertise’s experience in practice, so it cannot provide a quantifiable measurement for the effectiveness of defect detection. It has been reported that the accuracy of manual inspections can only reach 60–75% 2 based on feedback from the textile industry. A number of automatic detection methods have been proposed recently to replace manual detection with the development of digital image processing and machine vision, which are mainly divided into four categories: statistical methods,3,4 structural methods,5,6 spectrum methods,7–10 model-based methods.11,12 Nevertheless, these traditional detection methods are susceptible to the change of illumination, background texture and camera angle, and thus limited its usage in the real-world applications.
Visual saliency detection is a method by imitating human visual characteristics 13 for determining where objects or regions are most likely to attract human attention in images that has attracted increasing attention and shown great success in a variety of fields, including hyper-spectral anomaly detection, 14 saliency detection, 15 and real-time wood classification. 16 As fabric defects generally are salient in fabric images compared to the complex texture background, the fabric defect detection can be regarded as a salient object detection (SOD) problem, and thus several visual saliency-based fabric defect detection methods17–19 have been developed and achieved good performance. Earlier saliency-based approaches, however, rely on hand-crafted features, such as color, intensity, and contrast, to characterize local details and global contexts, leaving them unable to characterize high-level features with semantic clues, which limits their capability to locate complete defect objects in complex scenarios.
With the rapid development of convolutional neural network (CNN), CNN-based methods has broken the restrictions of traditional SOD methods that are dependent on hand-crafted features and pushed the performance of SOD to a new level owing to the powerful capability of extracting both high-level semantics and low-level texture details, which has been widely applied in various vision tasks, such as image classification, 20 semantic segmentation, 21 image retrieval, 22 image and video compression, 23 scene classification, 24 and object recognition. 25 Benefiting from that, some learning-based methods25–34 have been proposed to perform fabric defect detection, which have achieved remarkable detection performance and can ensure a promising speed-accuracy trade-off. However, there still remains two main challenges for the saliency-based defect detection task.
First, most of the existing saliency models based on feature fusion mainly use multi-mode fusion of multi-level features, ignoring the complementary relationship between different scales of features at different layers, which result in poor characterization ability of small and slender defects, leading to unsatisfactory detection results. As shown in Figure 1, the hole (see Figure 1(a)) and stain defects (see Figure 1(b)), as the common defects, have regular shapes and scales, which are relatively easy to detect. However, the defects such as slender defects (see Figure 1(c)), small scale defects (see Figure 1(d)), broken yarn (see Figure 1(e)), and off-yarn (see Figure 1(f)) are usually tiny and irregular in shape, which are more difficult to capture the effective features compared with the defects with regular shapes. Second, owing to the lower contrast with the background texture (see Figure 1(g) and (h)), the existing methods cannot effectively extract the defect features to improve the detection accuracy.

Different types of defects: (a) hole, (b) stains, (c) slender stains, (d) tiny holes, (e) broken yarn, (f) off-yarn, (g) indentation, and (h) ribbon yarn.
To address the above issues, we propose a novel saliency-based context-aware progressive attention aggregation network for fabric defect detection, named CPA 2 Net, which achieves brilliant performance in detecting all kinds of defects, especially the tiny and slender defects. Specially, a context-aware multi-scale module (CAMS) comprised of multi-scale feature aggregation unit (MFAU) is proposed to leverage a series of dilated convolutional layers for enlarging the receptive fields without increasing any computational load, which is conductive to defects detection with various scales and the representation learning of the model. MFAU cascades multiple dilated branches, in which the cross-level dense connection is added in a top-down manner to sufficiently aggregate the context-aware multi-scale multi-receptive-field feature for better predictions.
However, the aggregated features obtained by MFAU may contain redundant information, which may result in noise and blurry boundaries. Furthermore, considering that the defects commonly have low contrast with the background texture, it is essential to enhance the visibility or discrimination of the defects. As such, a feature fusion refinement module (FFM) is proposed to mitigate the above mentioned issues, which is mainly composed of the attention fusion unit (AFU) and the auxiliary refinement unit (ARU). Specifically, AFU is innovatively designed to reduce redundancy and adaptively select useful information for concentrating on important regions while suppressing the background interference, where a coordinate attention (CA) 35 module followed by sum and concatenation operations is adopted for embedding the positional information into channel attention to enhance the discriminant capability of defects features for complete predictions. In addition, the low-level features commonly contain rich detailed information, while the high-level features commonly contain more global semantic clues. Therefore, to take advantage of the cross-level complementary information for optimizing the training phase, the feedback operation is performed in a top-down pathway to transfer the semantic information from deeper layers to shallower layers. Then, ARU is designed for further refinement and highlighting the input features. More importantly, we adopt a multi-layer loss function as done in Hou et al.36,37 to supervise the side outputs for more accurate prediction maps.
The contributions of our work can be summarized as follows:
A novel saliency-based method named CPA 2 Net is proposed for fabric defect detection, which highlights the discrimination ability of defects features representations for accurate detection.
CAMS is designed to enlarge the receptive field by cascading several parallel MAFUs with dilated convolution layers for better copping with the scale variation of fabric defects, especially the tiny and liner defects.
FFR composed of AFU and ARU is designed to make our model can not only combine spatial and channel information to focus on defective areas, but also enhance the contrast between the defects and the background to further enhance the discrimination of defects features.
Compared with 14 state-of-the-art saliency models in terms of six evaluation metrics, our proposed method has shown superior performance on our built datasets.
The rest of this paper is organized as follows. Section 2 briefly discusses the related researches. Section 3 presents the details of our proposed saliency-based fabric defect detection method, in which we specifically describe the proposed CAMS, FFR, and the multi-level deep supervision (MDS) techniques. Section 4 reports the experimental results of our method and Section 5 gives the conclusions of the whole paper.
Related work
Traditional fabric defect detection methods
In this section, previous detection methods based on fabric defects were introduced in detail from two aspects, and the advantages and disadvantages of previous work were listed in detail, as shown in Table 1.
Advantages and disadvantages of previous works.

Statistical methods
Statistical methods usually distinguish defective and defect-free regions by analyzing the first-order and the second-order statistics, such as histogram features, mathematical morphology, greyscale co-occurrence matrices and auto-correlation functions. Hamdi et al. 38 combined a greyscale co-occurrence matrix and Euclidean distance followed by a selection threshold to achieve fabric defect detection, however this method is not suitable for the color images. Zhang and Bresee 39 combined morphology with an auto-correlation function for defect detection, and is robust to illumination and noise, but it suffers from the higher complexity and computational cost.
Spectral methods
Spectral methods locate defects by outstanding differences between defective and defect-free regions in the spectral domain, which have a good effect on highlighting the defects edges. Fourier 7 and wavelet transforms10,40 and Gabor filtering8,9 are commonly used in the spectral methods. Jing et al. 47 combined genetic algorithm and Gabor filter to filter the fabric image with pattern, and then segment the processed image for localizing the defects. Hu et al. 40 combined wavelet transform and Fourier analysis to examine fabrics with periodic texture background through an unsupervised algorithm. However, these models only work with repetitive textured or unpatterned fabric images, whose accuracy is highly dependent upon the specified parameters and filters, making them an inefficient tool for generalizing and adapting to new situations.
Structural methods
The structural method regards the texture as a primitive, extracts the structural features of the fabric texture and speculates on the position law, which can infer the texture background of the entire fabric image through the simple texture background structure law. Li et al. 41 do not match with those provided in the reference list. Please revise accordingly.] proposed an algorithm with self-adaptive partition block modeling via utilizing the characteristic of strong correlation among the patterned fabric image for defect detection. However, the structural methods are low in detection rate, and it is only suitable for fabric texture images with extremely regular texture structure.
Model-based methods
Model-based fabric defect detection algorithms, which model the pattern and texture information to generate the model parameters, and perform defect detection by judging whether the model parameters are satisfied, such as Markov random field, 42 Bayesian model 43 and low-rank decomposition models. 48 Zhang et al. 49 segment the jacquard warp-knitted fabric image through jacquard fabric characteristics and Markov random field theory. Mottalib et al. 50 used Bayesian model to accurately classify fabric defects based on geometric features of defects. Nevertheless, the model-based methods are seldom utilized due to their high dependency on data and complex calculation.
Salient object detection-based fabric defect detection methods
Handcrafted feature-based salient object detection
In recent years, visual saliency has gained more research interest and has been successfully applied in many research fields. Inspired by that, many researchers have tried to model the visual saliency for fabric defect detection field and achieved great progress. By analyzing the saliency of local textures in context, Liu et al. 44 proposed a fabric defect detection model that performed significantly better than other models on plain fabric images. A learned dictionary was employed by Li et al. 19 to generate saliency maps, and a modified valley emphasis method was used to segment the defective regions. According to Zhang et al., 51 global and background features were characterized using visual saliency maps, and then a support vector machine (SVM) was utilized to classify fabric defects. However, the traditional visual saliency methods mainly rely on hand-crafted low-level features, which limits their capability to locate complete defects regions in cluttered background because of lacking the high-level semantic knowledge,.
Deep-learning-based salient object detection
With the development of convolutional neural network (CNN) which has powerful capacity of extracting multi-scale features at different levels that contain both rich details and rich semantic cues, CNN-based SOD methods have achieved unprecedented success and been successfully applied in fabric defect detection. Xie et al. 45 divided detection process into model training and defect location, in which stacked denoising convolutional auto-encoder was used for image reconstruction in the training stage, and the detected images are divided into several blocks for localizing in the positioning stage. RBG (Ross B. Girshick) et al. 46 proposed the regional convolutional neural network using candidate regions plus convolutional neural networks instead of the traditional handcrafted design to detect defects. Liu et al. 52 used convolutional neural networks to detect fabric flaws based on a point-to-point approach, and this method performed well for the fabric image with the complex background texture. The deep saliency model developed by Wang et al. 53 incorporates self-attention mechanisms into a convolutional neural network to detect fabric defects. Liu et al. 54 used CNNs-based SOD model to capture fabrics features and combined with low-rank models to display the defects. However, these methods only concentrate on designing a delicate structure to fuse multi-level features, ignoring how to extract powerful and discriminative features and how to effectively fuse them, which cannot efficiently extract the discriminative features and may result in undesirable predication results.
Proposed method
The overall network architecture is shown in Figure 2, which mainly consists of four parts: 1) initail feature extraction block (IFEB); 2) context-aware multi-scale module (CAMS); 3) feature fusion refinement module (FFR); 4) multi-level deep supervision (MDS). The detailed process can be concluded as follows: First, IFEB pre-extracts the low-level, mid-level, and high-level defect features with different scales, and then optimize parameters through forward and backward feedback using the training fabric images and corresponding ground truth. Second, CAMS characterize the multi-scale multi-receptive-field defects features via a series of parallel multi-scale feature aggregation unit (MFAU) with cascaded dilation layers, which makes all level output features have the same channels. Then, FFR transfers the complementary and effective information from deeper layers to shallower layers through a set of attention fusion units (AFUs). In order to refine the defects boundaries for correctly segment the defects regions, the output features generated by AFU are fed into the auxiliary refinement unit (ARU). Finally, four side output predictions are generated and the first side output is chosen as the final prediction. Moreover, the MDS is of great importance in the training phase, which facilitates the optimization and the performance improvement of the proposed model.

Architecture of our proposed network.
Initial feature extraction block
Initial feature extraction block (IFEB) pre-extracts the multiscale defect features at different layers, which applies CNNs as the initial network. CNNs has been widely adopted in the computer vision field, in which the VGG 55 and ResNet 56 are the most popular backbone network, but both of them are not applicable to all object detection task. Specially, ResNet has outstanding classification performance, but it has too many layers and complex structure, which makes the model more difficult to train or test due to the large parameters and heavy computation load. In contrast, the VGG has excellent generalization capability and relatively simple architecture, which is relatively easier to train and deploy. Therefore, we choose the VGG16 as our backbone network, which is constructed only by 13 convolutional layers and 3 fully connected (FC) layers. In our model, we cast away the three FC layers and remove the last pooling layer of VGG16 for preserving the details of last convolutional layer in IFEB.
Context-aware multi-scale module
Due to the complex and diverse texture of the fabric, and the different sizes and irregular shape of the fabric defects, the fabric defect detection is more difficult and challenging. To realize the accurate detection, we have to utilize as much context information as possible for coping with the sales variation of the fabric defects. In CNN, the context information is closely related to the size of the receptive field. Convolution kernels with different sizes have different receptive fields, and the larger convolution kernel will cause the larger computation load. Fortunately, the dilated convolution provides a promising solution, which can capture more context information without increasing computation amount. Inspired by Yang et al., 57 Dong et al., 58 and Liu et al., 59 CAMS composed of a series of parallel MFAUs is designed to capture the context-aware multi-scale defects features and effectively fuse them for coping with the scales variation of defects, especially the tiny and liner defects.
The detailed structure of MFAU are shown in Figure 3. Formally, let

Detailed structure of MFAU. C denotes the concatenation.
The spatial information of the original feature maps and the

Where
In addition, a residual connection is applied for avoiding information loss. Then, the output features of the five branches are concatenated with the input features to effectively fuse multi-scale context information for better adapting to scale variation of the fabric defects. Finally, the fused features are performed by a convolution layer followed by a batch normalization layer (BN
60
) and non-linear activation layer (ReLU
61
). The final feature maps
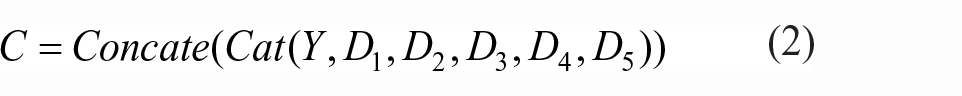
where
Feature fusion refinement module
The output features generated by MAFU may suffer from information redundancy, we should remove the redundancy to avoid the information interference for avoiding generating inaccurate predictions and improving the detection speed. Moreover, the different layers have different characteristics, so the complementary information between different layers plays an important role for accurate fabric defect detection. However, how to effectively utilize this cross-scale complementary information and how to enhance the discriminant capability of defects features are still two great challenges in fabric defect detection. More importantly, the defects boundaries are usually blurry due to the low contrast with the background texture, which will result in incomplete or even false segment results. To mitigate the aforementioned issues, FFR is proposed to enhance the discrimination of defects features and generate more clear boundaries, and it mainly contains two parts including attention fusion part which aims to select important information for integration while removing the information redundancy, and feature refinement part which aims to enhance input features and refine boundaries.
Firstly, we design the AFU for attention fusion part, whose details are shown in Figure 2. Formally,
Then, ARU is designed for refinement part, whose structure is illustrated in Figure 4, which takes

The architecture of ARU.


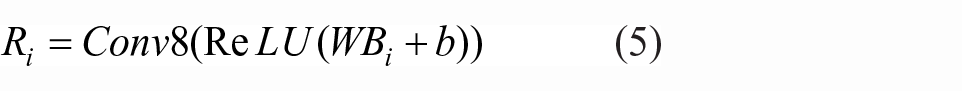
Where
Multi-level deep supervision
Recent works have pointed out that the effective integration of multi-scale features is essential for saliency detection.62,63 Specifically, low-level features contain rich details and high-level features contain rich semantic information, but the information may be diluted or removed after the poling layers. Therefore, for reconstructing this information, we have to further optimize the side outputs to compensate for the dilution and loss of information. Through the interpolation operation, MDS can generate supervised defects feature maps that are the same spatial resolution as the fabric defect image, hence accelerating the feature learning process and improving defect detection performance. Moreover, we apply the binary cross-entropy loss with logits function as our loss function to mitigate the class imbalance problem, and it can be calculated by:

Where
Experimental results
Experimental setup
Evaluation datasets
We evaluate our model on our two built fabric datasets: plain dataset and pattern dataset. The plain dataset is comprised of 2200 images for training and 500 images for testing, which concludes many slender defects with low contrast with the texture background and tiny defects. The pattern dataset contains 5948 images for training and 500 images for testing, which has more complex background texture and irregular shape defects. For data augmentation, we adopt the horizontal flipping and rotation for data augmentation to alleviate over-fitting risk. Note that, the plain dataset mainly contains five types of defects: indentation, crease, off-line, stains, and holes. The pattern dataset contains six types of defects: yarn shedding, yarn breakage, yarn belt, cotton ball, holes, and stains. In general, our datasets are challenging, which contain more defects with low contrast with background texture, more small scale defects and more different types of defects.
Evaluation metrics
To evaluate the performance of our proposed method and other saliency models, in this paper, we adopt six popularly-used metrics: precision-recall (PR) curves, F-Measure curves, maximum F-Measure (

where
MAE 65 is defined as the average pixel-wise absolute difference between the predicted saliency map S and the binary ground truth L, which is the smaller, the better, it can be expressed as

where W and H denote the width and height of a given image, respectively.
S-measure (

where
E-measure (

where
A better saliency detection model should have a larger F-measure, a larger S-measure, a larger E-measure, and a smaller MAE. In order to make a fair comparison, we report the values of all metrics to comprehensively evaluate the detection performance of all saliency models.
Implementation details
Pre-trained VGG16 on ImageNet is used as backbone network. In the training phase, we randomly initialize the weights of each convolution layers in the network to a standard normal distribution. In addition, in order to avoid too large the weight value that is not conducive to model learning, we multiply the weight by a constant of 0.01, and the biases are initialized to 0. We implement our model on PyTorch platform and train on an NVIDIA V100 GPU for 43 epochs. Finally, the hyper-parameters include: batch size (4), epoch (43), momentum (0.9), weight decay (5e-4), and learning rate (5e-5). The following experiments are conducted with all these parameters fixed. Additionally, the network optimizes the model using stochastic gradient descent (SGD) during training. We apply data augmentation like random flipping and multi-scale input images to alleviate over-fitting risk. All the images are resized into
Performance comparison with state-of-the-art
We compare the proposed model with 14 previous state-of-the-art salient object detection approaches on our two datasets, including NLDF, 66 DSS, 36 R 3 Net, 63 BASNet, 67 PiCANet, 64 GateNet, 68 PoolNet, 59 RAS, 69 AADF, 70 F 3 Net, 71 GCPA, 72 C2FNet 73 PSGLoss, 74 PFNet, 75 and ICON. 76 To make fair comparisons, we run public codes with released training models or use implementations with recommended parameters by authors.
Visual comparison
In Figure 5, we present a visual comparison between the proposed method and the other approaches on our own two fabric datasets. Benefiting from the feature pyramid structure of CAMS, our model can detect different defects with different shapes and sizes due to the powerful feature extraction capability. It can be clearly seen that our model not only highlights the defects regions clearly of all kinds of fabric defects, especially the linear defects (see 5th, 7th, 8th, 11th), but also well outlines the boundary of the defects of all sizes, such as tiny defects (see 1st, 2nd, 6th, 9th, 10th, 12th), medium sized defects (see 3rd, 8th) and large defects (see 4th). Specially, as shown in the last row, we can see that some models detect defects with noise (see BASNet, PoolNet, and GateNet) or can not even identify the defects (see NLDF, R3Net, and AADFNet) when faced with tiny defects with low contrast to the background. However, our model can not only effectively suppress redundant information to accurately detect and locate the position of defects, but also outline the defects clearly and completely. Importantly, our model can also achieve excellent detection performance in low contrast occasions (see 7th, 9th, 10th, 11th, 12th), where the fabric defects are blend into the background texture. The reason why our model achieves the superior performance is that our proposed FFR can remove the redundancy, pay more attention on important and salient regions and refine features to force our model learn more useful features for generating more accurate and complete saliency maps. In addition, the MDS can enhance the generality of our model, making it more robust to variations in input images. The advantages we mentioned above make our results more closer to the ground truth, making them superior to other state-of-the-art saliency detection methods.

Visual comparisons of the proposed method and the state-of-the-art methods.
Quantitative comparison
We compare the quantitative evaluation results with the state-of-the-art saliency detectors on our two fabric test datasets in terms of
Comparison of different methods on three metrics including

The best results are shown in bold.
Results comparison with different backbone networks on plain and pattern datasets.

The best results are shown in bold.

PR curves and F-measure curves on two fabric datasets.
Model performance
Our network only takes about 0.056 seconds to process a image on a NVIDIA GTX 1080Ti GPU. For fair comparison, all competing methods are reimplemented using the source code provided by the authors with the same hardware configuration. We can see that our model can run at a speed of 18 FPS (FPS: frames per second) when processing a
Model performance compared with other models.

FPS: frames per second.
Ablation study
With different model settings, a series of experiments are conducted in this section to investigate the effectiveness of context-aware multi-scale module (CAMS), feature fusion refinement module (FFR), and multi-level deep supervision (MDS). All models in this section are trained on the augmented fabric datasets and share the same hyper-parameters described in the subsection 4.1. We firstly conduct a series of experiments with different popularly used backbone networks, the results are shown in Table 3. As can be seen that, our selected backbone network has achieved the best results on two fabric datasets. Figure 7 shows the feature maps of different modules, which indicates that all modules are beneficial for performance improvement. Table 5 presents the effectiveness of CAMS and FFR in terms of
Quantitative results for different networks presented in the ablation study on plain dataset.


Visual comparison saliency maps for showing the effectiveness of each model. The first column is the original image, the second column is the ground truth, and the third to last columns are the output results after FPS, CAMS, FFR, respectively.
Effectiveness of CAMS
We introduce the CAMS to expand the receptive field without increasing any computation load, which is conductive to the proposed model to capture more context-aware information for coping with the variation of defects scales. Furthermore, we evaluate the performance of CAMS with respect to different dilation rates
The comparisons of parameters

The best results are shown in bold.
First, we investigate the effectiveness of different dilation rates
In addition, we study the fusion strategy of MFAU in CAMS. The concatenation operation is a popularly utilized technique for feature aggregation, which is conductive to extend the feature matrix dimension. In this model, we use the concatenation operation to fuse multi-scale multi-receptive-field feature progressively. Figure 8(d) and (h) shows the visual saliency maps after the concatenation operation. It can be clearly seen that the model with the concatenation operation in MFAU can locate fabric defects accurately and depict the defects boundaries clearly. Moreover, all the experimental results presented in this paper testify the effectiveness and superiority of the MAFU with the concatenation operation, which is capable of characterizing the contextual multi-receptive-field features of different levels for fabric defect detection.

Comparison of saliency maps between different MFAU fusion strategies: (a) image, (b) GT, (c) summation, (d) concatenation, (e) image, (f) GT, (g) summation, and (h) concatenation.
The summation operation is another commonly used feature fusion technique, which is able to fuse different responses of different features while preserving the original information at the same time. We change the concatenation operation to summation operation when performing feature aggregation in MFAU and the feature maps after summation operation are shown in Figure 8(c) and (g). As can be seen in Figure 8, the feature maps through summation operation are with unclear defects boundaries and incomplete defects regions compared with the feature maps through concatenation operation. Furthermore, it is clear from Table 7 that concatenation operation realizes better results compared with summation operation. Therefore, we can make a conclusion that compared to the concatenation operation, the summation operation cannot well enhance the discrimination and representation ability of defects features between different dilation convolution layers in MFAU. With the consideration of the above analysis, we adopt the concatenation operation in this paper to integrate the multi-scale features of MFAU.

The best results are shown in bold.
Effectiveness of FFR
To prove the effectiveness of FFR and its two main components, we compare three variants and the results are reported in Table 6 and Figure 9. From Table 6, it can be seen that after adding AFU and ARU on the basis of CAMS, various indicators scores are also increasing steadily, except for MAE score, which has proved the effectiveness of the two main components of FFR. Especially, we can see from Figure 9, the feature maps generated by FFR are more clear than FFR without ARU, which has more clear boundaries and less texture information. Furthermore, from the fifth column of Figure 7, we can see that the feature maps after FFR are much clear and accurate compared with the first two columns. Therefore, we can make a conclusion that the feature fusion part of our proposed FFR can pay attention important defect regions and effectively aggregate cross-level features, which is conductive to enable the model learn more useful features to further enhance the feature representation capability of our model. Additionally, the refinement part can further refine the features to generate more accurate saliency maps with clear boundaries (Table 8).

The best results are shown in bold.

Visual feature maps of AFU with ARU and without ARU: (a) AFU only and (b) AFU + ARU.
Effectiveness of MDS
To demonstrate the effectiveness of adopted multi-level deep supervision (MDS), we compare it with the single-level deep supervision (SDS). Note that only the supervision learning is different and the remaining steps are the same. Compared with the MDS utilizes deep supervision learning for each side output prediction map, SDS means the loss function is only supervised on the last layer. Importantly, MDS means that we use more loss function to supervise and guide our model to locate the defect regions more accurately and learn useful defect features for model training. Here, we show the quantitative results and visualization saliency maps in Table 9 and Figure 10. We can obviously see from Figure 10 that compared to Ours(SDS), the side outputs of four layers obtained by Ours(MDS) are able to locate the defects regions and sketch the defect boundaries well simultaneously. These features generated by Ours(MDS) will be beneficial for better defects localization. In addition, Table 9 presents the experimental results of Ours(SDS) and Ours(MDS) in terms of

The best results are shown in bold.

Visual feature maps and saliency maps of different supervision learning techniques.
Conclusion
In this paper, we propose a novel end-to-end saliency-based fabric defect detection network named CPA 2 Net, which is mainly comprised of two components: context-aware multi-scale module (CAMS) and feature fusion refinement module (FFR). CAMS composed of several parallel multi-scale feature aggregation unit (MFAU) with dilated convolution layers is proposed to capture the context-aware multi-scale multi-receptive-field information for coping with the variation of defects scales. To further enhance the discriminative capability of defects features, FFR is proposed to effectively fuse features and refine them, where the AFU with feedback mechanisms is designed to remove redundancy and exploit the complementary information of different layers and the ARU is designed to further refine the features generated by AFU and meanwhile highlight the defects boundaries. Moreover, we adopt a multi-level deep supervision (MDS) to supervise each side output for guiding training and generating more accurate and complete prediction maps. Extensive experimental results demonstrate that our proposed model achieves state-of-the-art performance both in quantitative and qualitative evaluations. More experiments will be conducted in the future to further improve the accuracy and stability of this model or to compress the model for getting a lightweight model while remaining the existing performance of our model. We hope our proposed method could provide promising future research directions in fabric defect detection and other related research fields.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NSFC (No. 61772576, No.62072489, U1804157), Henan science and technology innovation team (CXTD2017091), IRTSTHN (21IRTSTHN013), 2022 Henan Province Key R&D and Promotion Special Project (Science and Technology Research) Program (222102210008), ZhongYuan Science and Technology Innovation Leading Talent Program (214200510013).