
Abstract
The degradation of images captured in hazy weather can severely affect practical applications. However, most existing learning-based methods ignore the varied haze distribution in an image, resulting in incomplete dehazing of some areas. Also, the presence of haze can blur the textures and details, which will heavily impact the subsequent image processing. In this paper, we propose a transformer-based framework for dehazing tasks called HITFormer. Firstly, we introduce a texture recovery and enhance module as a preprocess to strengthen details. Then, we propose an adaptive haze intensity prediction subnet to predict the haze intensity of different areas. Lastly, we use a semantic-based luminance and chrominance adjustment module to fuse the feature maps in YUV color space and form a transformation coefficient to get a recovery image. The extensive experiments demonstrate that our HITFormer achieves state-of-the-art performance on several image dehazing datasets.
Introduction
In recent years, image dehazing has become increasingly important due to its critical role in various applications such as autonomous driving, surveillance systems, and remote sensing. Hazy weather conditions, characterized by the presence of a large number of tiny suspended particles in the air (dust, water droplets, smoke, etc.), significantly degrade image quality by absorbing or scattering light. This degradation manifests as reduced contrast and blurred details, which in turn adversely affects the performance of subsequent advanced vision tasks such as image classification, target tracking, and detection. Despite numerous advancements, current dehazing methods often struggle with two significant challenges: the accurate restoration of fine details and the handling of heterogeneous haze distributions in real-world scenes.
Traditional image dehazing methods, such as those based on handcrafted priors (Fattal, 2014; He et al., 2011; Ju et al., 2021; Zhu et al., 2015), estimate the parameters of the hazy image formation model to recover haze-free images. However, these methods often struggle with regions that do not satisfy the assumed priors, leading to incorrect parameter estimation and unwanted artifacts. More recently, deep learning approaches (Guo et al., 2022; Liu et al., 2023; Song et al., 2023; Ye et al., 2022) have leveraged the robust feature representation capabilities of convolutional neural networks (CNNs) to enhance dehazing performance. Early CNN-based methods (Cai et al., 2016; Zhang & Patel, 2018) improved parameter estimation accuracy, while current trends focus on end-to-end mappings between hazy and haze-free images, achieving superior results (Dong et al., 2020; Liu et al., 2019; Wu et al., 2021). Additionally, the advent of vision transformers (ViTs; Liu et al., 2021; Wang et al., 2021; Dosovitskiy et al., 2021) has provided a compelling alternative to CNNs, showcasing powerful modeling capabilities in a variety of computer vision tasks. It is important to acknowledge, however, that while ViTs excel in many areas, CNNs still outperform them in certain specific tasks due to their established architecture and specialized design. Moreover, significant challenges remain unaddressed by current methods, including the degradation of edge and detail information and the varied distribution of haze in complex scenes, which are often overlooked.
To the best of our knowledge, there are two reasons that limit the effectiveness of current dehazing methods. First, due to the presence of haze, the edge and detail information of hazy images is usually degraded, leading to a loss of information in the recovered haze-free images. Second, the distribution of haze can vary significantly in real-world scenes, but most existing dehazing networks only extract semantic features directly related to the dehazing task, ignoring the local variations in haze intensity. This results in suboptimal dehazing performance in dense haze regions. Additionally, most methods process hazy images in the red–green–blue (RGB) color space, whereas we propose to extract features and process hazy images in the YUV domain to fully utilize brightness and energy information, enhancing the dehazing process.
In order to solve the problem of loss of detail in hazy images and incomplete image dehazing due to uneven distribution of haze, we propose a novel transformer-based framework for dehazing tasks called HITFormer. Our contributions are summarized as follows:
We propose the texture recovery and enhance (TRE) module as a preprocessing step, which enhances details that are blurred by haze. We design the adaptive haze intensity prediction (AHIP) subnet to predict the haze intensity for each image patch, allowing the model to focus on areas with higher haze concentrations, thus improving overall dehazing performance. We transform the RGB input hazy image to the YUV color space, enabling the model to extract luminance and chrominance features at different stages and use a constant transformation coefficient to recover the haze-free image.
The rest of this paper is organized as follows: Section 2 discusses the related work. Section 3 presents the proposed method. Then, Section 4 reports and analyzes the relevant experimental results. Section 5 presents a conclusion and discusses the limitations and future work of this paper.
Related Works
Prior-Based Methods
Prior-based methods are based on the hazy image formation model. The most widely used model is the atmospheric scattering model (ASM) McCartney et al. (1977). As shown in Figure 1, the light intensity obtained by the imaging device under hazy conditions consists of two parts. The first part is the direct attenuation of the reflected light energy caused by the suspended particles in the atmosphere, which can cause a decrease in image brightness and contrast. The second part is airlight, which describes the scattered atmospheric light (airlight) that reaches the imaging device and participates in the formation of a hazy image, leading to the details of the image being blurred.
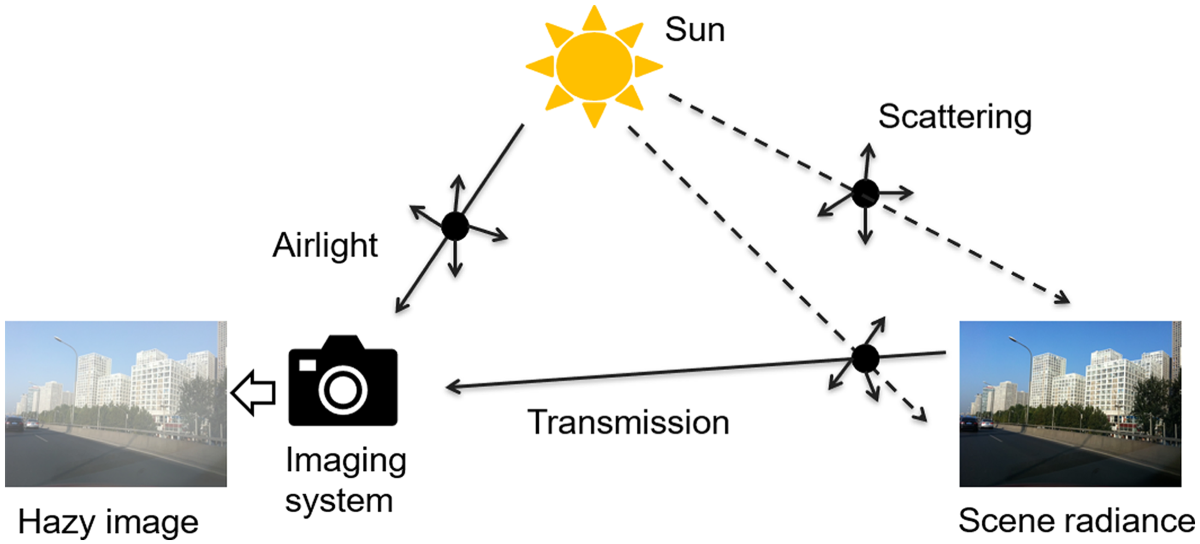
Atmospheric scattering model.
The ASM can be expressed mathematically as follows, which includes the two parts mentioned above:
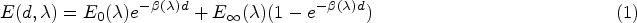
Let

In equation (2), there is only one known quantity
The most well-known prior knowledge for image dehazing is dark channel prior (DCP) proposed by He et al. (2011). After counting a large number of outdoor haze-free images, they found that some pixels always have at least one color channel with very low values. Using this prior information achieved an excellent dehazing effect. Many modified methods are based on DCP for improvement (Hsieh et al., 2018; Pei & Lee, 2012; Zhang et al., 2018). Although these methods are effective, the prior assumption does not always hold in real complex scenarios. They tend to output inaccurate parameter estimation when the regions of the image do not satisfy the priors, which can lead to unsatisfactory dehazing effects.
As deep learning becomes increasingly popular, scholars have tried to use CNN to predict parameters of ASM, which can output more accurate results compared to prior-based methods. Cai et al. (2016) proposed an end-to-end dehazing network, DehazeNet, which estimates the transmission map and finally uses ASM to get a haze-free image. Ren et al. (2016) proposed MSCNN, which uses coarse-scale and fine-scale networks to estimate the transmission map, avoiding the loss of image details. Li et al. (2017) integrated transmission
Vision Transformer
As transformer continues to demonstrate powerful modeling capabilities in natural language processing, more and more researchers apply them to vision tasks. The ViT (Dosovitskiy et al., 2021) converts images into a sequence of image patches and feds them into the transformer, which has an excellent effect on image classification tasks. However, it is difficult to apply ViT directly to some downstream tasks due to its large computational resource requirements and weak inductive bias. Many modified frameworks based on ViT have been proposed. For example, pyramid ViT (Wang et al., 2021) introduced a pyramid structure to output multiple different levels of feature, which enabled the processing of high-resolution images more efficiently and granted access to various downstream tasks. Chen et al. (2021) proposed an image processing transformer for low-level vision tasks, which applied a structure with multiple heads and tails for different image processing tasks. Swin transformer (Liu et al., 2021) provided a more general backbone for various computer vision tasks. It constructed hierarchical feature maps that enable the model to handle images of different scales. Also, it proposed shifted window self-attention, which introduced cross-connections between windows to improve the performance of the model and reduce computational complexity. A great deal of work has demonstrated that the swin transformer has excellent performance on different visual tasks and outperforms most CNN-based methods.
Method
The overall architecture of the HITFormer is presented in Figure 2. Firstly, we convert an input RGB hazy image to YUV color space and enhance its local details via a TRE module. Then, the processed image is split into nonoverlapping patches, and several swin transformer blocks are applied to them to extract global features. In this process, we introduce an AHIP subnet to predict the haze intensity of each patch. At last, the haze-free image is obtained through a semantic-based luminance and chrominance adjustment (SLCA) module.
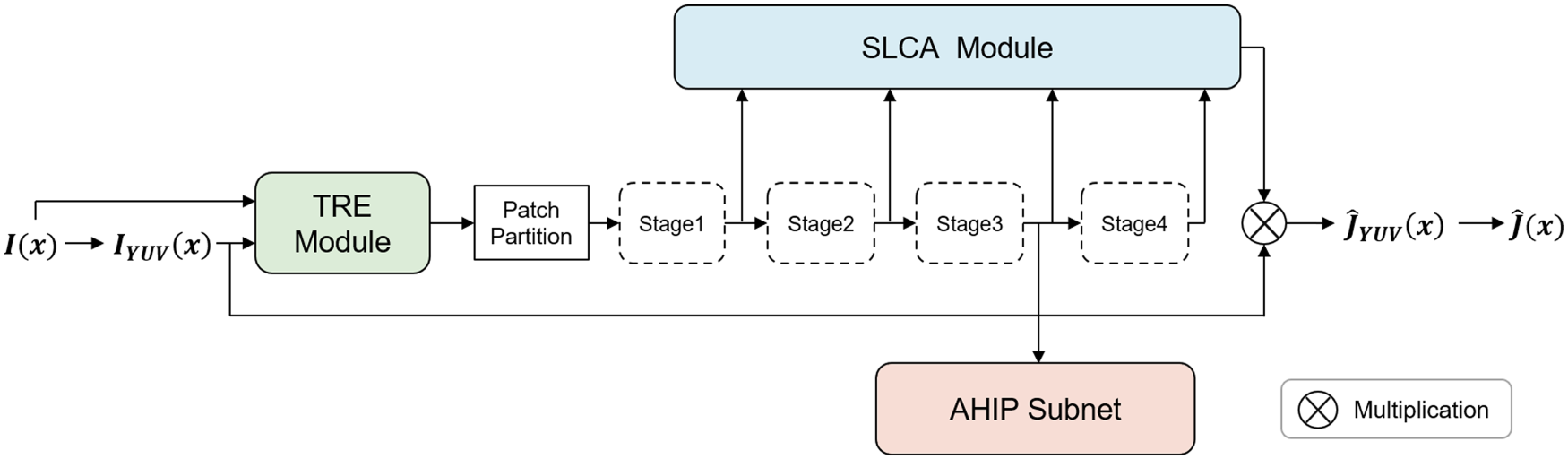
The overall architecture of the HITFormer. Our model is a modified swin transformer, and each of the four stages is illustrated with the dashed box containing a swin transformer block. Our method incorporates three important components: TRE module, AHIP subnet, and SLCA module.
The degradation of images met up with the camera in hazy weather can be various, such as contrast reduction, color shift, and color distortion. Many features and details of the image information are covered or blurred, which sets great limits on the subsequent processing of the image. Therefore, in our HITFormer, we introduce a TRE module, which can effectively restore and enhance details. As seen in Figure 3.



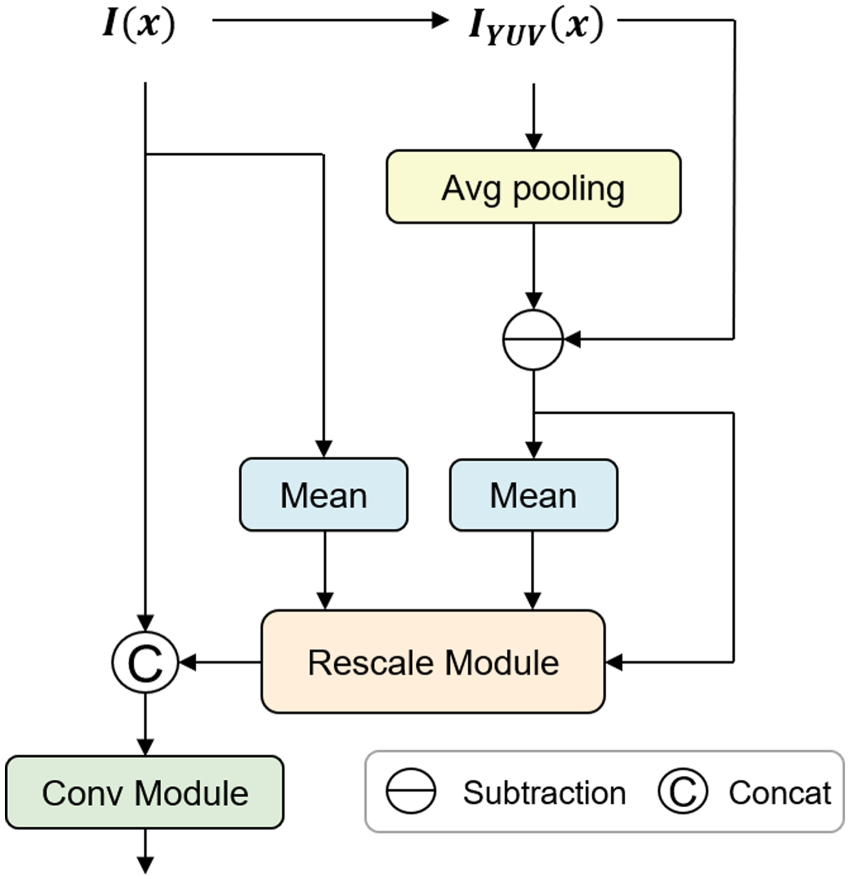
Illustration of TRE module. Note. TRE = texture recovery and enhance.
As shown in Figure 3, subtract and scale operations are included in the rescale module.
In order to preserve the integrity of the original image
In hazy weather conditions, images often exhibit varying degrees of haze intensity across different regions, which poses a significant challenge for effective image dehazing. To address this variability, we introduce the AHIP subnet within the HITFormer framework. The primary objective of the AHIP subnet is to predict the haze intensity of each patch within an image, enabling targeted enhancement of heavily hazed regions to improve overall image clarity and detail preservation.
Methods based on the DCP (He et al., 2011), although effective in certain cases, do not always hold true. These methods rely on the lowest brightness value in the image to estimate haze, but in some complex scenarios, this assumption might be inaccurate. In our approach, we still utilize the DCP to estimate haze intensity, but we improve this method by combining it with gradient information, thus enhancing its accuracy, as shown in Figure 4.
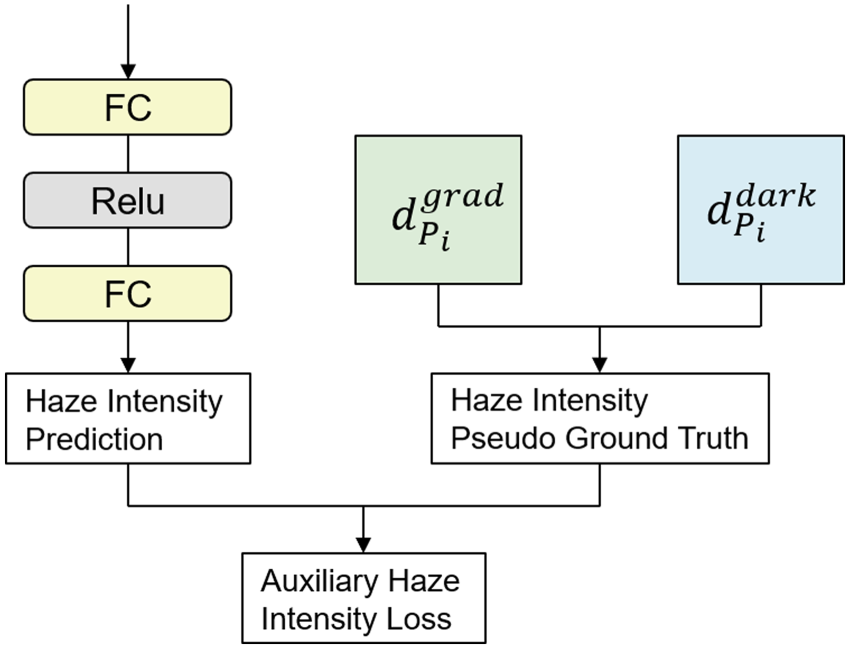
Illustration of AHIP subnet. Note. AHIP=adaptive haze intensity prediction.
According to He et al. (2011), given an arbitrary image
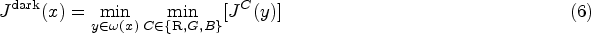
Specifically, to accurately predict the haze intensity, we incorporate both gradient variation and a physical prior into the pseudo ground truth haze intensity for each patch:

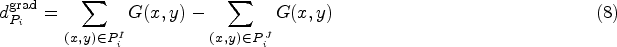
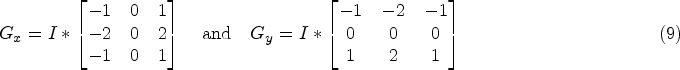

Concurrently, our

In our approach, we divide the range of haze intensity values into

The AHIP subnet employs a fully connected layer with ReLU activation and another fully connected layer to predict the distribution of haze intensity for each patch,

This loss guides the AHIP subnet to accurately predict and prioritize regions with higher haze intensity during training. Additionally, the overall loss function for HITFormer includes a peak signal-to-noise ratio (PSNR) loss
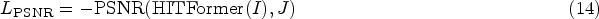
Overall, the combined loss for HITFormer is formulated as follows:

By integrating the AHIP subnet with HITFormer, our approach enhances the model’s ability to handle varying haze intensities. This leads to improved dehazing results by prioritizing regions most affected by haze.
In ASM (as shown in equation (1)), the value of transmission
As shown in Figure 5, the previous swin transformer blocks build hierarchical feature maps with different resolutions (
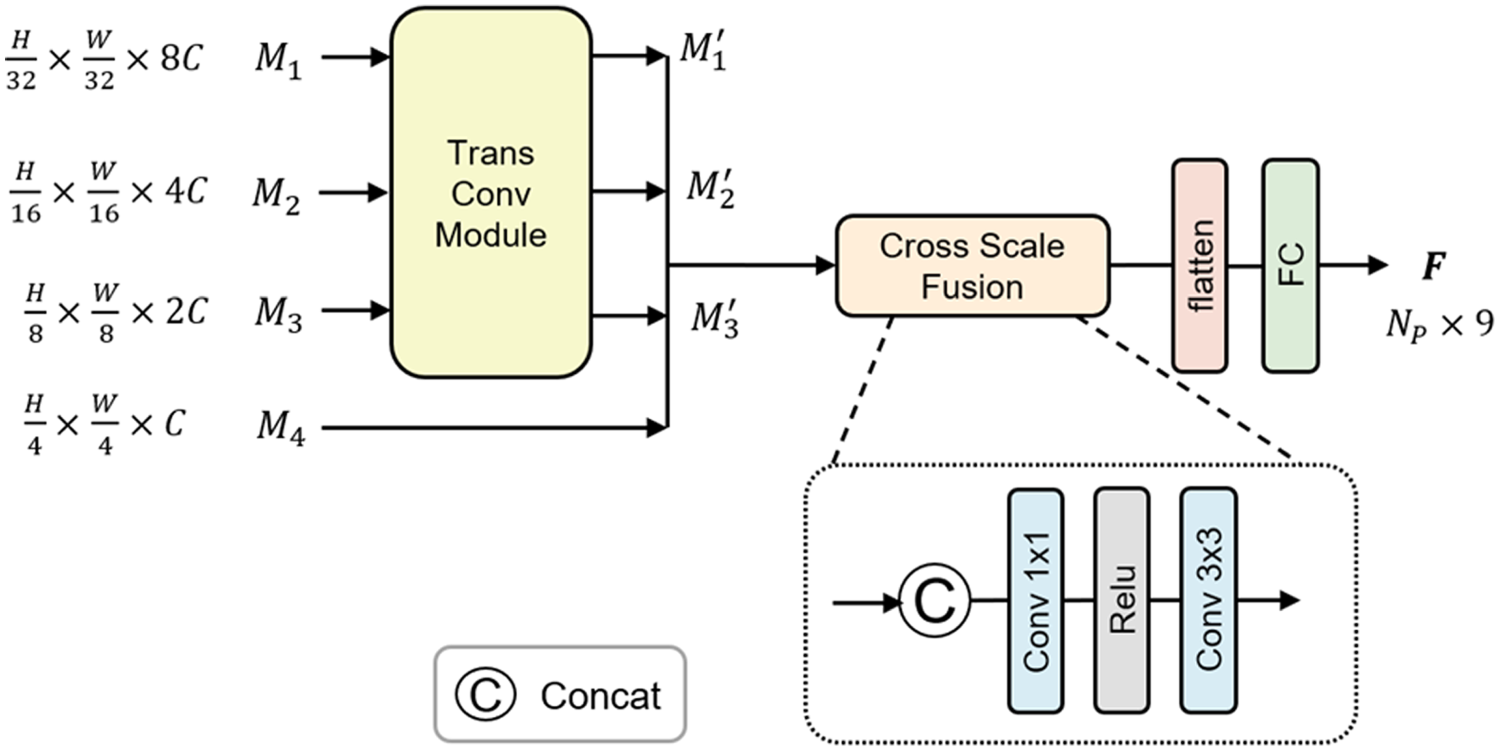
Illustration of SLCA module. Note. SLCA =semantic-based luminance and chrominance adjustment.
We reshape

Experimental Settings
Datasets
RESIDE (Li et al., 2019) is a widely used benchmark dataset for image dehazing. It consists of five subsets, of which the three most commonly used are indoor training set (ITS), outdoor training set (OTS), and synthetic objective testing set (SOTS). In addition, we also use NH-HAZE (Ancuti et al., 2020) and Dense-Haze (Ancuti et al., 2019) datasets for real-world image dehazing.
Our model is trained on ITS and OTS subsets of RESIDE dataset, Dense-Haze dataset, and NH-HAZE dataset, and is tested on SOTS. The OTS contains 2,061 real outdoor haze-free images from Beijing and 72,135 synthesized hazy images, that is, one haze-free image corresponds to 35 hazy images with different haze intensities. The ITS contains 1,399 indoor haze-free images and 13,990 synthesized indoor hazy images. NH-HAZE contains 55 pairs of outdoor real hazy and corresponding haze-free images. Dense-Haze contains 33 pairs of outdoor real hazy and corresponding haze-free images. Figure 6 shows example images of the datasets.

Examples of the datasets. (a) and (b) are from RESIDE, (c) is from NH-HAZE, and (d) is from dense-haze. Hazy images and corresponding haze-free images are in the top and bottom rows, respectively.
All the above datasets are officially available. Thus, we can ensure that each hazy image in our training set corresponds to a haze-free image (i.e. the ground truth).
Our framework is implemented using PyTorch 1.13.0 with an NVIDIA RTX 3090 GPU (24 GB). The model is trained for
Evaluation Metrics
PSNR and structural similarity index measure (SSIM) (Wang et al., 2004) are used to objectively evaluate the results on the datasets. For subjective comparison, we use the mean opinion score (MOS). The three metrics are discussed briefly as follows.
PSNR PSNR assesses image quality by comparing the mean square error (MSE) between two images in decibels. Given a SSIM SSIM is a quality evaluation metric that measures the similarity of two images. A larger value of SSIM indicates that the recovered haze-free image retains more structural information and is of better quality. Its calculation involves the comparison of luminance, contrast, and structure of two images. They are computed as follows:
Combining MOS In our experimental evaluation, we used the MOS to subjectively assess the results on the datasets. We collected the opinions of 50 evaluators from various industries, who rated the quality of the result images according to their subjective experience and gave them a score from 1 to 5. We used 20 randomly selected images from each testing set’s result images to get MOS scores, where a higher MOS score indicates a better image quality. To ensure diverse perspectives, evaluators were selected from fields such as computer vision, photography, medical imaging, automotive, and academia. These evaluators were identified through professional networks, industry contacts, and academic collaborations. Meanwhile, in order to avoid bias, evaluators were not informed about the specific methods behind the images they were assessing. Images were presented in a randomized order, and the evaluation criteria were standardized, covering aspects such as clarity, contrast, and color accuracy. Each evaluator conducted their assessments independently, ensuring no influence from other evaluators.
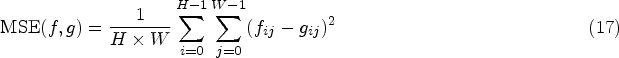





We perform ablation studies on the SOTS-outdoor dataset to demonstrate the effectiveness of HITFormer. We first utilize swin transformer (Liu et al., 2021) as our baseline for the dehazing task, and then we add different components of our model to the baseline. Thus, we conduct the ablation experiments as follows: (a) baseline, (b) adding TRE module to baseline, (c) adding AHIP subnet to baseline, (d) adding AHIP and SLCA to baseline, (e) adding TRE and AHIP to baseline, and (f) our model.
As shown in Table 1, by adding the TRE module, the performance of the model is improved by 2.71 dB in PSNR. By adding the AHIP subnet, there is a significant increase of 3.38 dB in PSNR. This result indicates that our TRE module and AHIP subnet are significant components to improve the dehazing effect. After adding the SLCA module to baseline + TRE + AHIP, the full model performance improved by 0.42 dB in PSNR. This is because the SLCA starts from an energy-based ASM model (McCartney et al., 1977), which is related to haze intensity (the higher the intensity, the faster the energy decay). Besides, the AHIP subnet also gives the model the ability to perceive the haze intensity, which is slightly overlapping with SLCA in terms of functionality, but the different starting points and modeling process of AHIP and SLCA give the final model a stronger ability to further enhance the dehazing effect.
Ablation Study on Different Modules and Configurations of HITFormer on the SOTS-Outdoor Dataset. The Bold Numbers Indicate the Best Results.

Ablation Study on Different Modules and Configurations of HITFormer on the SOTS-Outdoor Dataset. The Bold Numbers Indicate the Best Results.
Note. SOTS = synthetic objective testing set; TRE = texture receovery and enhance; AHIP = adaptive haze intensity prediction; SLCA = sematic-based luminance and chrominance adjustment; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index measure.
Quantitative Comparison
We first compare the quantitative results (PSNR and SSIM scores) of our HITFormer with several state-of-the-art (SOTA) methods, including DCP (He et al., 2011), DehazeNet (Cai et al., 2016), AOD-Net (Li et al., 2017), GridDehazeNet (Liu et al., 2019), MSBDN (Dong et al., 2020), FFA-Net (Qin et al., 2020), and DehazeFormer-B (Song et al., 2023). We conduct comparisons on SOTS (Li et al., 2019), NH-Haze (Ancuti et al., 2020), and Dense-Haze (Ancuti et al., 2019) datasets. As shown in Tables 2 and 3, the HITFormer achieves the highest PSNR and SSIM scores compared to other methods on SOTS-indoor, SOTS-outdoor, and NH-HAZE datasets. On the Dense-Haze dataset, the SSIM score of the HITFormer is the highest compared to the other methods, while the PSNR score is just 0.04 dB lower than the SOTA method. Table 4 shows that our method outperforms other methods in terms of MOS on all testing sets. The results demonstrate the effectiveness and advantages of our method.
Quantitative Evaluations With the State-of-the-Art Methods on SOTS-Indoor, SOTS-Outdoor Datasets (PSNR (dB) and SSIM). The Bold Numbers Indicate the Best Results.
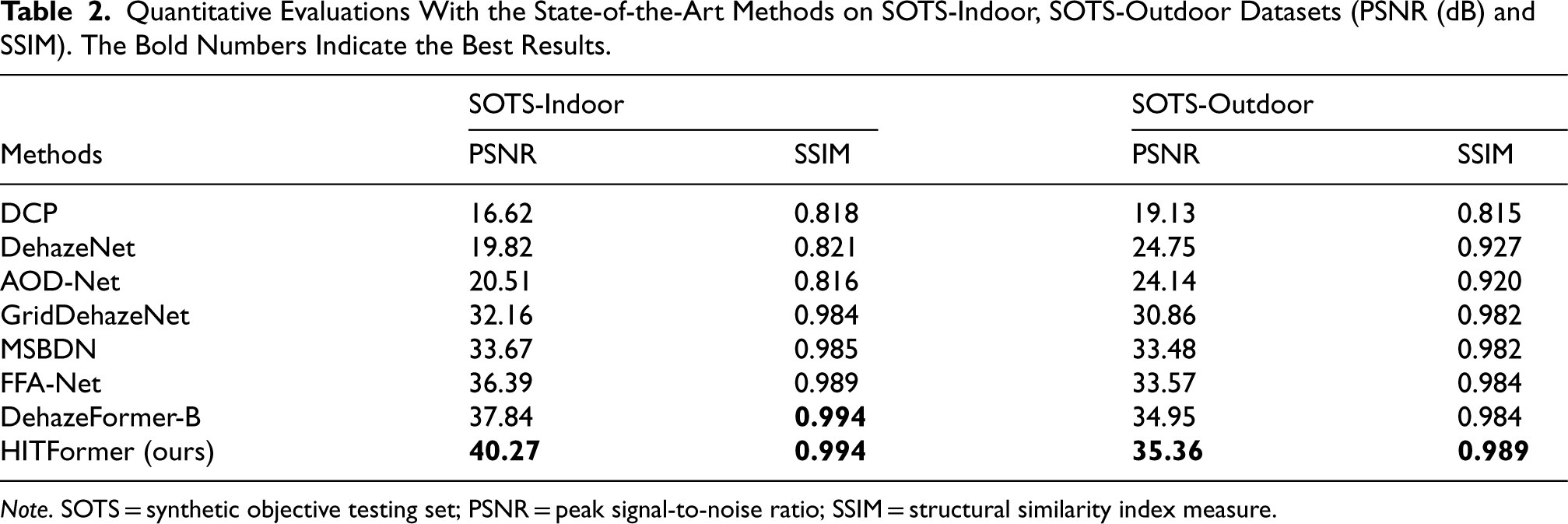
Quantitative Evaluations With the State-of-the-Art Methods on SOTS-Indoor, SOTS-Outdoor Datasets (PSNR (dB) and SSIM). The Bold Numbers Indicate the Best Results.
Note. SOTS = synthetic objective testing set; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index measure.
Quantitative Evaluations with the State-of-the-Art Methods on NH-HAZE and Dense-Haze Datasets (PSNR (dB) and SSIM). The Bold Numbers Indicate the Best Results.
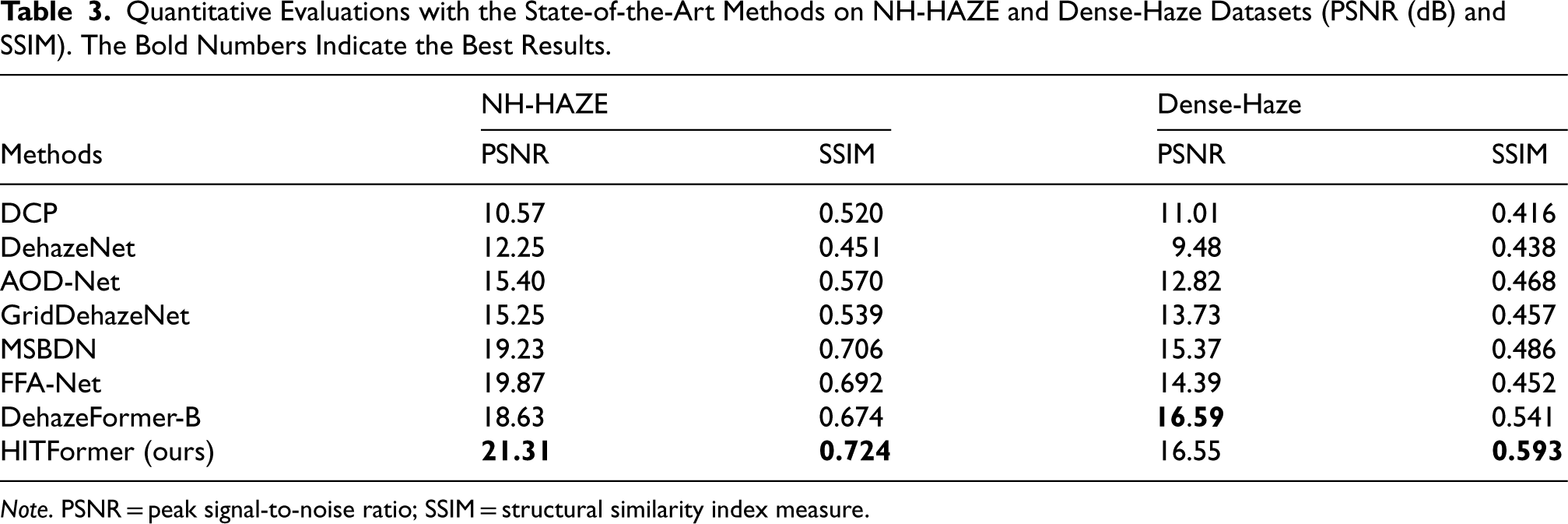
Note. PSNR = peak signal-to-noise ratio; SSIM = structural similarity index measure.
Quantitative Evaluations with the State-of-the-Art Methods on SOTS-Indoor, SOTS-Outdoor, NH-HAZE, and Dense-Haze Datasets (MOS). The Bold Numbers Indicate the Best Results.
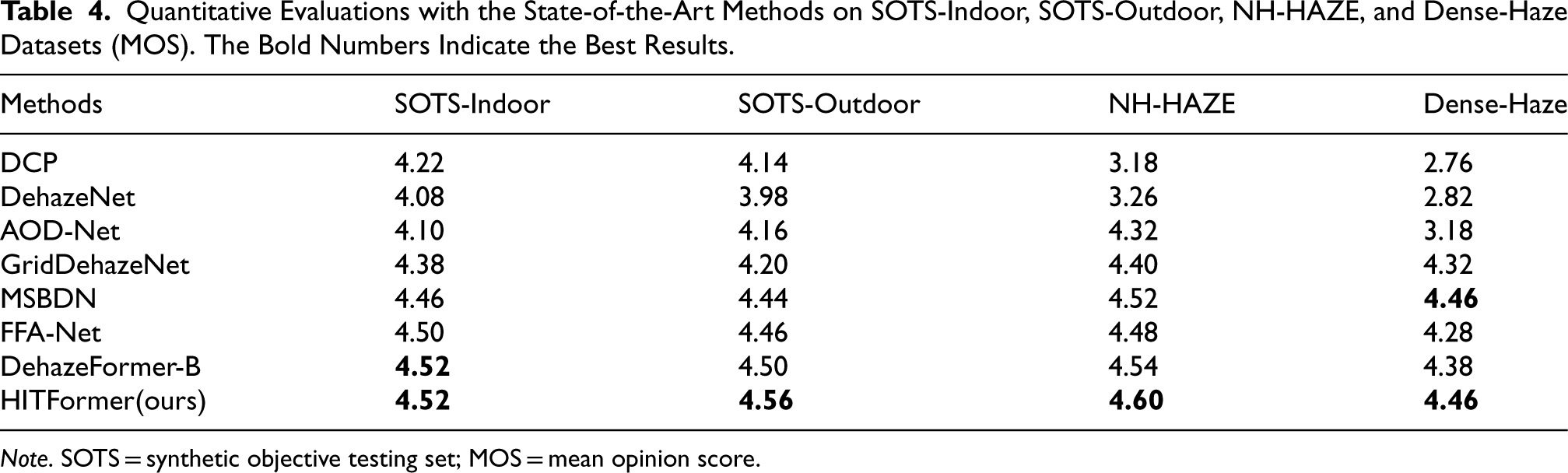
Note. SOTS = synthetic objective testing set; MOS = mean opinion score.
In order to further demonstrate the effectiveness of our model, we compare our visual results with several selected effective methods on real-world hazy images obtained from the internet. The visual comparisons are presented in Figure 7. It can be observed obviously that DCP and AOD-Net can effectively remove haze, but the color of the images recovered by DCP is distorted, and the overall images recovered by both methods are too dark. The visual results of GridDehazeNet have a good dehazing effect in nonsky regions, such as scenery and buildings, but there are artifacts in sky regions. In the recovery images of FFA-Net and Dehazeformer-B, the haze is not completely removed in all the cases, and the texture and details are not fully restored. In contrast, our HITFormer shows great performance in haze removal and texture enhancement, which indicates the superiority of our method.

Visual comparisons on real-world hazy images.
In this paper, we proposed a transformer-based single-image dehazing framework called HITFormer. To summarize, we propose a TRE module to better strengthen the blurred detail information. In particular, a patch-wise relative haze intensity prediction subnet is designed to estimate the degree of haze intensity of each patch, which enables the model to focus on patches with dense haze. Besides, our model extracts luminance and chromatic-related features in YUV color space, which makes better use of the domain knowledge from the hazy image formation model and improves the dehazing performance. Extensive comparisons demonstrate that our HITFormer achieves superior performance on several datasets.
Limitations: The method proposed in this paper mainly focuses on daytime outdoor image dehazing. However, the scenarios in real life can be more complex. Following the main idea of this work, we will further study more physical priors in different scenarios, such as nighttime or rainy days, and guide the model to learn features that are more suitable for real-world scenes.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.