
Abstract

The expansion of transcatheter aortic valve replacement (TAVR) into increasingly heterogeneous patient populations has sharpened attention on an uncomfortable reality: not all patients benefit meaningfully from the procedure. As TAVR has extended to older and more comorbid individuals, the concept of “TAVR futility” has become clinically pressing, capturing cases in which patients survive the intervention but fail to experience improvement in symptoms, quality of life, or functional capacity. 1 Traditional surgical risk scores, originally designed for operative mortality, have shown limited ability to anticipate mid-term outcomes after TAVR. 2 Machine learning (ML) uses computational algorithms to identify complex patterns within high-dimensional data and can leverage these patterns to predict adverse clinical outcomes with greater accuracy. 3 In this context, the study by Sun et al represents an important attempt to redefine risk stratification through interpretable ML.
Their work draws on a multicenter cohort of 213 patients undergoing TAVR, focusing on two six-month endpoints: a primary composite of cardiovascular death or heart failure rehospitalization, and a broader endpoint incorporating functional status and quality-of-life metrics. By applying a supervised ML approach with random forest and comparing its performance to logistic regression and conventional risk scores, the authors report improved discrimination, with performance approaching an AUC of 0.79 for both endpoints. Logistic regression relies on a predefined linear relationship between each predictor and the outcome, assuming proportional effects and limited interactions. In contrast, the supervised ML model, like random forest, constructs a large ensemble of decision trees, automatically capturing complex, nonlinear patterns and interactions between clinical, biological and functional variables. 4 This data-driven structure enables the model to identify subtle risk patterns that may be missed by conventional statistical approaches, ultimately enhancing predictive performance for mid-term TAVR outcomes (Figure 1). The analysis is strengthened by interpretability techniques, notably SHAP values, which clarify the variables that most strongly drive the model's predictions. 4
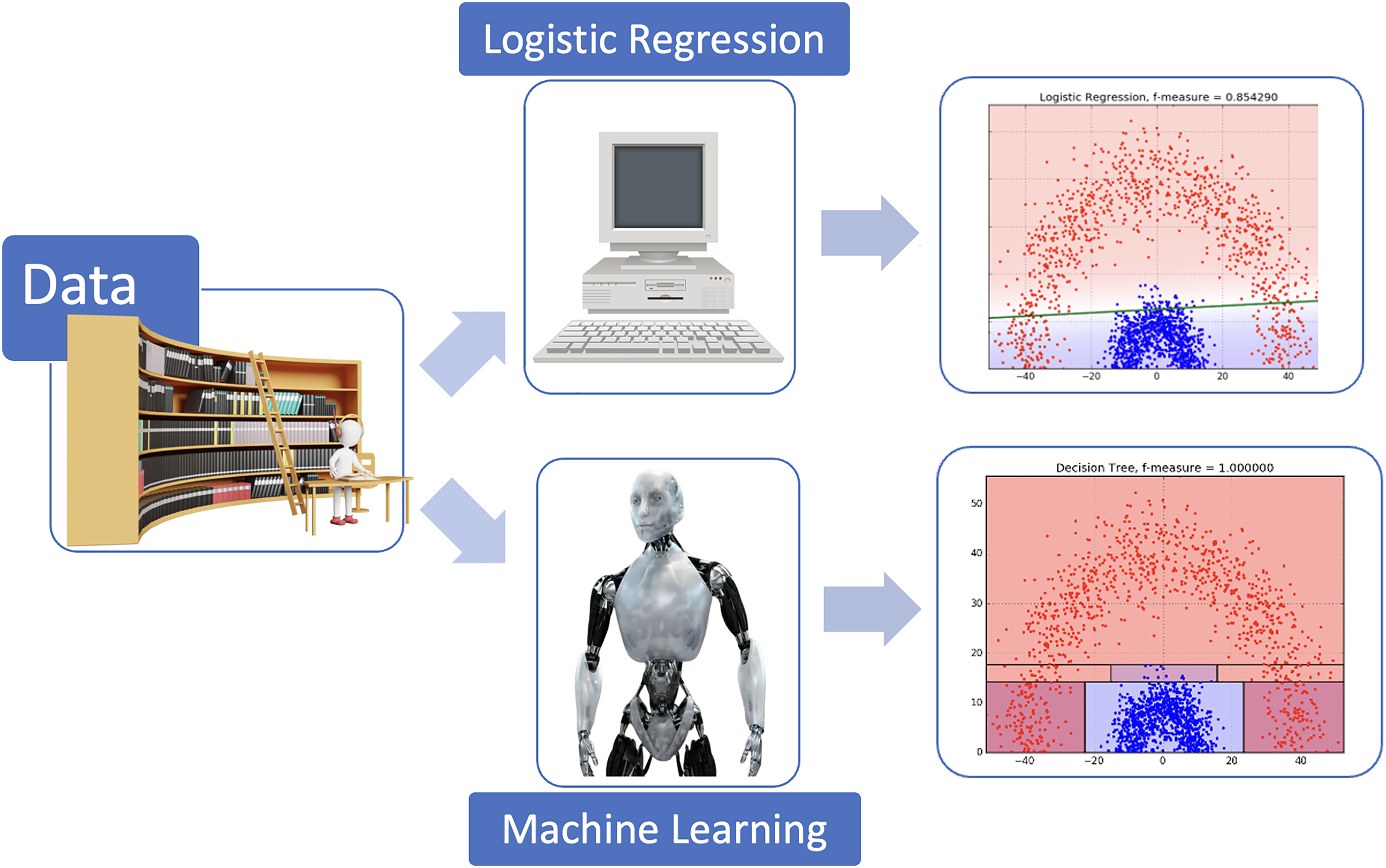
Comparison of traditional logistic regression and a random forest model for predicting clinical events after transcatheter aortic valve replacement (TAVR). This figure illustrates the conceptual differences between a traditional logistic regression model and a supervised machine learning model (random forest) when predicting post-TAVR clinical events. Red dots represent the patients who experienced TAVR outcomes, whereas blue dots represent those who did not. In the upper panel, which illustrates logistic regression, all patients positioned above the green line are predicted to be at risk for TAVR outcomes, while those below the line are predicted to remain event-free. A substantial proportion of patients classified as low risk by logistic regression in fact went on to experience TAVR outcomes. In contrast, the lower panel shows the supervised machine learning model using random forest, which achieves a more effective mathematical partitioning of the feature space. This approach improves the reclassification of high-risk patients who ultimately developed TAVR outcomes.
Among the most striking findings is the emergence of a frailty-related biomarker profile. Lower levels of LDL-cholesterol, HDL-cholesterol, and serum creatine kinase consistently predicted poorer outcomes, while elevated arterial stiffness and reduced renal function further characterized higher-risk patients. What is particularly compelling is the physiological coherence of these markers: low lipid levels may reflect malnutrition and chronic inflammation; low creatine kinase is increasingly viewed as a signature of sarcopenia and impaired muscular energetics; and arterial stiffness integrates long-standing vascular damage and reduced capacity for reverse remodeling. Together, these variables form a plausible biological substrate for the diminished resilience observed in frail TAVR candidates.
The clinical appeal of this approach lies partly in its accessibility. All of the highlighted biomarkers are routinely measured, inexpensive, and widely available. Pulse wave velocity, though less commonly incorporated into standard preprocedural work-ups, is noninvasive and feasible to measure. If externally validated, the identified pattern could complement existing frailty scales and support more nuanced discussions within Heart Teams when faced with borderline candidates.
The authors should also be commended for prioritizing interpretability rather than relying on opaque “black-box” methods. By choosing a tree-based model and applying structured interpretability techniques, they generate insights that clinicians can understand, question, and potentially integrate into practice. 4 At a time when enthusiasm for artificial intelligence can sometimes exceed its evidentiary basis, this emphasis on transparency is welcome. Nevertheless, some limitations must temper our enthusiasm. The first limitation relates to sample size and number of events. The final analytic cohort comprised 189 patients, with only 22 meeting the primary endpoint and 28 the expanded endpoint. For supervised ML models, even relatively conservative ones such as random forests, this represents a small number of outcomes. 5 Even when using cross-validation and restricting the number of features, the risk of overfitting remains substantial. Internal validation alone cannot fully guarantee that the observed performance will generalize to new populations. 4 The authors appropriately describe their findings as exploratory.
Second, the modeling pipeline involves several steps that, although reasonable individually, collectively introduce uncertainty. The pruning of correlated features based on clinical judgment, the choice of median imputation for missing values, and the search for optimal feature subsets all reflect decisions that can materially affect which variables emerge as influential. In small datasets, minor changes in preprocessing can lead to different thresholds or even different predictors. It is entirely possible that the specific LDL-cholesterol or creatine kinase thresholds highlighted by the model reflect the particular distribution within this dataset rather than universal biological inflection points.
Furthermore, interpretability techniques must be used with caution. While they offer valuable insight into how a model uses available information, they do not establish causality. That low cholesterol or low creatine kinase is associated with worse outcomes does not imply that modifying these parameters would alter prognosis. These biomarkers may simply reflect underlying frailty, comorbidities, or unmeasured confounding.
Calibration and clinical utility are additional considerations. 4 Although the model discriminates better than traditional risk scores, the practical implications of an AUC near 0.79 are uncertain. TAVR decision-making rarely hinges on a continuous probability estimate alone. Frailty assessment, gait speed, comorbidity burden, patient preference, and quality-of-life expectations all influence the final recommendation. Whether a model such as this would change decisions, especially in a population where frailty and comorbidity are ubiquitous, remains to be demonstrated. Simplified, parsimonious models that integrate a small set of biomarkers with functional measures may achieve similar performance with greater ease of implementation. In addition, this result is also explained by the strong ability of supervised ML to capture heterogeneous types of variables. This is one of its major strengths, highlighting the value of a multimodal approach to enhance predictive performance, as previously demonstrated in earlier studies. 6
The question of generalizability looms large. The cohort includes patients from two countries with different healthcare structures, referral pathways, and practice guidelines. These contextual factors can shape the characteristics of patients who ultimately undergo TAVR, particularly regarding frailty and timing of referral. Without external validation across larger, more diverse populations, it remains unclear whether the identified ML model will replicate consistently in terms of accuracy. The field urgently needs collaborative, multicenter datasets to support robust ML development and validation. Until such resources become routinely available, caution is warranted when extrapolating internally validated findings.
Despite these limitations, the study provides valuable contributions. It strengthens the argument that TAVR risk prediction must incorporate frailty in a more granular and biologically grounded manner. It highlights the potential for readily available biomarkers to augment clinical judgment. And it illustrates that interpretable ML, thoughtfully applied, can reveal patterns that may otherwise go unrecognized.
Looking ahead, several avenues for future work emerge. Larger multicenter cohorts should test whether this frailty-related model identified here generalizes across diverse populations. Prospective studies should examine whether integrating these biomarkers into frailty assessments improves decision-making or patient outcomes. Methodologically, alternative modeling approaches, such as time-to-event models (random survival forests) or dynamic prediction frameworks, may provide richer prognostic information if paired with careful attention to interpretability. In addition, unsupervised ML methods, such as clustering, could help uncover distinct underlying pathophysiological mechanisms within patients with severe aortic stenosis. Such data-driven phenotyping may support improved prognostic stratification and potentially enable physiopathology-guided personalized medicine, as has already been suggested in other areas of cardiology. 7
Ultimately, the study by Sun et al invites us to rethink how we define and predict benefit after TAVR. Rather than focusing solely on procedural success or operative risk, it encourages a more holistic view that incorporates biological reserve, resilience, and the capacity for functional recovery. ML, when used judiciously, can help illuminate these dimensions. Yet it is equally important to maintain a critical perspective, ensuring that the sophistication of our analytical tools does not outpace the robustness of the data on which they are built.
The path forward will require collaboration between data scientists, clinicians, and methodologists, as well as rigorous external validation. But the underlying vision, a more personalized and frailty-informed approach to TAVR risk assessment, is both timely and compelling. This study represents an important early step toward that goal, and it sets the stage for future work aimed at refining, validating, and ultimately operationalizing these insights to improve patient care.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.