
Abstract
Digital labour platforms such as Amazon Mechanical Turk, Deliveroo, and Uber concentrate large volumes of socially relevant data while severely limiting independent research access, creating deep asymmetries in what can be empirically known about their operations. This paper provides the first systematic analysis of how these asymmetries shape academic knowledge production, drawing on 397 empirical studies of 57 labour platforms operating in Europe. We show that only 7% of studies rely on platform-provided data and that these are disproportionately concentrated on topics aligned with platform interests, such as sustainability and consumer welfare, while contentious issues such as labour rights, earnings, discrimination, and safety are overwhelmingly studied using user-reported or scraped data. We conceptualise this pattern as epistemic selectivity: a structural dynamic through which platform-controlled data environments selectively enable some research agendas while constraining others. The study advances current debates on business-to-science data asymmetry and platform observability by showing that platforms shape the contours of public interest knowledge itself and highlights the need for regulatory frameworks that ensure more equitable and accountable data access.
Keywords
Introduction
Digital labour platforms such as Amazon Mechanical Turk, Deliveroo, and Uber have become central infrastructures for the organisation of work across diverse sectors. Their expansion has sparked longstanding societal concerns over low pay, safety, unfair competition, working conditions, and privacy (Aloisi, 2022; Frenken et al., 2020). Addressing these concerns through evidence-based policymaking requires robust empirical research, which is constrained by data scarcity and by business-to-science (B2S) data asymmetry, that is, the concentration of large volumes of socially relevant data in the hands of platform companies, coupled with limited access for independent research. 1
Beyond questions of whether researchers can access platform data, we argue in this paper that access is shaped by platforms’ selective data-sharing practices. By systematically examining how academic 2 researchers access and use platform data, we show that labour platforms engage in what we term epistemic selectivity: They share data in ways that privilege business-aligned research questions while restricting access to data relevant to contentious public interest topics.
The concept of epistemic selectivities has been mobilised in different scholarly traditions to capture how knowledge production is unevenly structured, although with distinct meanings and analytical scopes. In philosophy of science, Lyons (2016) uses epistemic selectivity to describe a realist strategy of selectively committing belief only to specific components of successful scientific theories, focusing on epistemic justification and the limits of scientific realism. While this usage is important, it remains largely internal to debates about theory choice and belief. Closer to our own approach are the contributions by Vadrot (2014, 2017), who develops epistemic selectivities as a political and institutional concept to analyse how certain forms of knowledge, problem framings, and narratives are systematically privileged over others within science–policy interfaces. For Vadrot, epistemic selectivities are embedded in institutional arrangements and power relations, shaping what counts as relevant, credible, and actionable knowledge. This perspective foregrounds how knowledge production is co-constituted with governance structures and strategic interests, particularly in contested policy domains. Building on this latter tradition, our use of epistemic selectivity extends the concept to digital labour platforms, conceptualising how platform-controlled data environments selectively enable and constrain academic research agendas, thereby influencing which public interest topics can be empirically addressed and which remain structurally obscured.
Several concerns have been raised regarding researchers’ ability to obtain data and produce evidence on the societal and economic impact of platformisation. As Rieder and Hofmann (2020: 11) observe, ‘it is symptomatic that [platform] companies refuse access to the data necessary for in-depth, independent studies and then use the lack of in-depth, independent studies as evidence for lack of harm’. In response, researchers have often resorted to risky and unsanctioned data collection methods, such as scraping platform data using browser extensions, which may result in low-quality evidence and unrealised research potential (Morten et al., 2024). Existing work further suggests that when platforms do share data with researchers, such sharing may be selective, primarily supporting studies that highlight the benefits platforms bring to the economy and society, thereby skewing the available evidence base. For example, Uber has been criticised for withholding detailed data and collaborating primarily with researchers whose findings were favourable to the company (WIRED, 2018). Such practices raise concerns about ‘academic capture’ (Zingales, 2019), whereby academic research becomes entangled with platforms’ lobbying and strategic interests (Berg and Johnston, 2019; Horan, 2019; Lawrence, 2022).
Within this debate, Verhulst and Young (2022) describe business-to-science (B2S) data asymmetry as a condition in which private companies hold large volumes of data valuable for scientific inquiry that nevertheless remain siloed. One commonly proposed response is to increase the ‘liquidity of data’, that is, the ease with which data can be reused and recombined through initiatives such as open data schemes, bilateral data-sharing agreements, or challenge-based collaborations (Perkmann and Schildt, 2015; Susha et al., 2017). Examples include Uber Movement, which provides aggregated mobility data, as well as bilateral agreements granting researchers access to more detailed datasets. While such initiatives create new opportunities for scrutiny, they also introduce challenges regarding the quality, scope, and selectivity of the resulting evidence base.
Despite growing recognition of these limitations, their implications for the structure of academic research itself remain insufficiently examined. The lack of access to high-quality platform data is widely recognised as a key constraint facing researchers (Leerssen, 2024), yet there has been no systematic investigation of how platform data-sharing practices shape the empirical study of labour platforms across different public interest topics. In this paper, we ask: How is platform data used as an evidence base in empirical academic research to examine the functioning and effects of labour platforms in relation to various public interests? We analyse 397 empirical scientific publications covering 57 digital labour platforms operating in Europe, systematically examining how different data access methods are used across seven public interest topics to assess patterns of selective platform data sharing.
Our findings reveal a worrying pattern: labour platforms’ data-sharing practices are conditional on the research topic. Platforms collaborate more frequently on studies aligned with business interests, such as sustainability or consumer welfare, while restricting access more often to research addressing contentious issues, particularly labour rights. Furthermore, when data sharing occurs, platforms use different B2S data-sharing models that regulate the research group's autonomy regarding permissible (re-)use and circulation of that data. This involves governance via application programming interface (API) (of approved uses of data) but also co-authorship requirements and non-availability of data for replication (in collaborative uses of data).
This pattern complements existing discussions of data scarcity and B2S asymmetry by highlighting epistemic selectivity, showing that platforms not only control data but also shape which forms of knowledge about them can emerge. As such, this study contributes to understanding how platform data governance influences the direction of academic research on public interest topics, especially those related to labour.
The remainder of this article is structured as follows. The second section situates the study within current debates on data governance and platform observability. The third section outlines the methodological approach, detailing the corpus construction, classification strategy, and analytical procedures used to map data practices across academic research on labour platforms. The fourth section presents the empirical results, highlighting patterns of data use, access asymmetries, and disciplinary differences. The fifth section discusses the implications of these findings for research autonomy and knowledge governance, and the sixth section concludes by reflecting on the epistemic and policy consequences of platform-controlled data environments.
Related literature
Platform observability
The challenge to research digital labour platforms empirically is a well-known issue in platform research. Data from platform systems is hard to obtain, limiting research on their effects (Greene et al., 2022). One of the reasons is that platforms operate without society's oversight, in technical and institutional black boxes, that is, platforms’ practices lack transparency, an essential public value rooted in democratic principles (van Dijck et al., 2018). Labour platforms are no different: researchers documented labour platforms’ operations as opaque in several aspects, such as transparency in relation to the management of gig workers by algorithms (Hu et al., 2024).
Given these limitations, scholars have advocated for meaningful transparency (Geng, 2024) and platform observability (Rieder and Hofmann, 2020). For Geng (2024: 90), meaningful transparency requires a change of perspective: Transparency ceases to be objective and becomes a tool. Platform observability is less of a concept and more of a regulatory programme, which takes the focus away from algorithms and their supposed black box, towards a more institutional and systemic view on platforms, their operations, and effects. The programme to regulate platform observability ‘adopts as a starting point the analytical capacities of platforms and data needs of knowledge production institutions’ (Leerssen, 2024: 3). It starts from three underlying principles of platform observability.
The first principle is to expand the normative and analytical horizon. This means going beyond critical algorithmic studies. Platforms should be framed in all their complexity, depicting their ecosystems and taking their participants into account. By expanding the scope, authors reposition the issue of transparency in the social context. As platforms are entangled with public interests and have become powerful nodes in economic and political networks, understanding their behaviour and effects requires looking beyond their algorithms and data alone. In this repositioning, Rieder and Hofmann (2020) argue that the notion of ‘public interest’ can be the normative horizon for regulating platforms.
The second principle of the platform observability regulatory programme is to observe platform behaviour over time. Rieder and Hofmann (2020: 9) emphasise that the conduct and effects of algorithmically driven platforms are ephemeral, a ‘result from assemblage-like contexts whose components are not only spatially and functionally distributed but also subject to continuous change, which is partly driven by users or markets facilitated by platforms’. Given the complexity and fluidity of digital platforms as socio-technical systems, and the information asymmetry between platforms and outsiders trying to construct knowledge about them, the authors list four strategies that have been used so far: data access agreements, accountability interfaces, developer API, and scraping. Of these four approaches, only scraping, that is, the collection of data directly from the user interface, does not need the collaboration of platforms to take place – although in some cases it does, because platforms can put up technical and legal barriers to prevent scraping from happening. While each of these approaches has its advantages, the authors argue that they fall short of promoting a continuous, secure, and privacy-preserving interface between platform systems and those building public interest knowledge on them.
The third principle of the platform observability regulatory program is to strengthen capacities for collaborative knowledge creation. To generate public interest knowledge about the platforms, various societal actors must participate in this process. Not only researchers but also regulators, journalists, and NGOs must be part of this engaged audience. This broad coalition would allow for the epistemological variability of platform observation, which also implies that observability goes beyond just access to digital data on platform operations, as many of these perspectives create narratives and knowledge from other sources. The same authors argue that for this type of collective knowledge-building to be viable, investments are needed in analytical capacity, computing power, expertise, and knowledge of societal problems.
These three principles set the context for our study by emphasising the need to observe platforms to safeguard public interests, continuously and over time, and through collaborative and participatory forms of stakeholder engagement. In our research, we aim to empirically ascertain empirically to what extent this is happening or being prevented, by focusing on academic research on digital labour platforms.
Business-to-science engagement
Concerns regarding adherence to the principles of meaningful transparency in general and platform observability specifically, as well as the translation of these principles into functional business-to-science data-sharing practices, have been voiced from the first decade of 2000 onwards, when large social media platforms such as Facebook, Twitter, YouTube, and other social networks gained prominence. Burgess (2022: 16) mentions that ‘platform companies have had a patchy—at times hostile—relationship to independent research into their societal role, leading to data lockouts and even public attacks on researchers’. As an example, Twitter sought to monetise access to its data and restrict access for researchers to limit research that would damage the platform's image. The measures taken by Twitter created an asymmetrical data access situation, in which large organisations with resources could pay for special access (Burgess and Bruns, 2015). Moreover, following the Cambridge Analytica data-sharing crisis on Facebook, several social networks restricted access to their data, claiming to protect users’ data and privacy. In response, academic researchers claimed that the dysfunction of the APIs that previously functioned as an access route to the platforms’ data serves the interests of these companies in limiting independent research into their operations (Bruns, 2019; Puschmann, 2019).
Concerns about limited access extend to experiences of academic researchers in accessing the field for data collection purposes, such as interviews and observations. Karjalainen et al. (2015) discuss different levels of access, not only relating to data but also to gatekeepers, documents, and individual company members. This general view on access gained prominence in recent literature providing accounts of so-called black-boxing strategies by the big technology companies concerning researchers (Marrazzo, 2022). For instance, Bonini and Gandini (2020) elaborate on the attempts of academic researchers to get access to platform employees for research interviews and discuss alternative tactics for accessing the field that those researchers had to resort to, such as being undercover or interviewing ex-workers.
These concerns and tactics resonate with a broader literature in the field of science and technology studies (STS), which have examined issues relating to data access and academic publishing in fields that exhibit strong ties between academic researchers and industry. It has been shown, for instance, that industry-sponsored clinical trials of drugs and devices are associated with biases in the reporting of scientific data and results, particularly if co-authors are affiliated with the sponsoring company (Salandra, 2018). Research also showed that pharmaceutical companies develop publication plans to maximise the scientific and commercial value of their available data, sometimes publishing findings under the name of independent medical researchers or so-called key opinion leaders (Sismondo, 2009). Critical scholars in STS have also highlighted the value of deliberately not acquiring knowledge, stressing uncertainties, and practising strategic ignorance in high-stakes regulatory contexts that strongly prioritize evidence-based assessment and decision-making (e.g. on the risks of chemicals and pharmaceuticals) (McGoey, 2019; Oreskes and Conway, 2011). Moreover, akin to mechanisms of regulatory capture by industry (Carpenter and Moss, 2013), Zingales (2013) introduces the notion of ‘academic capture’, referring to incentive structures in economics that lead academics to focus on building a reputation with industry to obtain access to their proprietary data in a highly competitive academic environment.
In the context of research on platforms, various data-sharing mechanisms underpin ‘operational models’ of business-to-science data-sharing (Morten et al., 2024; Shapiro et al., 2021). These models underpin the sharing of platform data, that is, the digital traces generated through interactions between workers, users, and algorithmic systems. These traces include behavioural data (e.g. logins or task completions), transactional data (payments and commissions), geospatial data (routes and delivery times), reputational data (ratings and reviews), and communicative data (chat messages or feedback). The specific forms and granularity of these data vary across platforms.
Platform data can be collected with or without the collaboration of platform controllers. When there is collaboration between platform controllers and researchers, researchers access what we call platform-provided data. Platform-provided data can be further subcategorised into three operational models (Susha et al., 2017; Verhulst and Young, 2022) which in our view span a spectrum from more to less openness in B2S data-sharing:
Independent uses of data (open) – approaches that make datasets available for download or enable users to manipulate and analyse data online and do not require any specific procedure to gain access to the data, for example, research data platforms. Collaborative uses of data (closed) – approaches that, on an agreement basis, make available data that would be unfeasible or unlikely to be made fully accessible. This allows data providers to retain greater control over how the data is used, for example, bilateral partnerships. Approved uses or data – a middle-ground approach that makes data accessible for approved use cases through certain procedures. Such selection can be made based on the researcher's credentials or the intended use of data, for example, research passports (providing access to the data upon authorisation that the researcher meets certain criteria).
When researchers independently develop techniques to collect platform data, they access what we call platform-generated data. Therefore, platform-generated data is also platform data as defined above but obtained without the consent and/or collaboration of the platform controllers (e.g. through scraping).
There is still a third group of data collection methods: user-reported data that clusters methods such as interviews and surveys. User-reported data is reported by participants in the platform ecosystem, such as customers and workers. Figure 1 below outlines all types of data that are relevant for academic researchers in their quest to investigate platforms. We have highlighted in bold the categories where there is B2S collaboration.

Types of data that inform platform research with emphasis on business-to-science data-sharing models (in bold).
Research design
Digital labour platforms and public interest
The empirical focus of our study is on the use of platform data in empirical academic research on labour platforms. Labour platforms (also known as ‘gig economy’ platforms) match clients to one-off service providers online in sectors like taxi, delivery, cleaning, programming, and translating and have become more relevant to the job market, both in the European Union (EU) and worldwide (Koutsimpogiorgos et al., 2020). The literature distinguishes among multiple types of platform labour, such as crowdwork and gig work, or online versus location-based services (De Stefano, 2016; Howcroft and Bergvall-Kåreborn, 2019), each of which operates through different technological infrastructures and data affordances. However, as the issue of data access concerns all labour platforms in principle, we make no further distinctions. We employ labour platforms as an umbrella category encompassing these diverse forms, even if they may entail specific configurations of data generation and accessibility.
We focus on labour platforms as a revealing case within the broader platform economy. While many transparency and data access issues are common across platforms, they are particularly acute in labour platforms, which mediate not only transactions but also the organisation, monitoring, and valuation of labour itself (van Doorn and Badger, 2020; van Doorn and Shapiro, 2023). Empirically, the Centre for European Policy Studies (CEPS) database offers the most comprehensive public mapping of platform-mediated labour in Europe, providing a transparent and reproducible sampling frame. Analytically, labour platforms concentrate key dimensions of platformisation – algorithmic control, user dependence, and data opacity – thereby exemplifying broader dynamics of data enclosure.
The significance of focusing on labour platforms becomes clearer when viewed against the scale and diffusion of platform-mediated work in Europe. Piasna et al. (2022) conducted surveys in 14 EU countries and found that, on average, 4.3% of respondents are platform workers. Kilhoffer (2020), based on JRC-COLLEEM (Collaborative Economy and Employment) data, demonstrates that for 14 EU countries, frequent platform workers range from 4% to 10% of the population, a similar number to that of Brancati et al. (2019). In some countries, such as the UK, 12% of the population would have already performed work on a platform.
Given these figures, academic research has increasingly focused on examining key public interest topics related to these platforms (Frenken et al., 2020; van Dijck et al., 2018). We distinguish between the following public interest topics:
Earnings: The effects of platformisation on gig workers’ earnings vary by sector. While some online gig workers, especially in less developed countries, see increased incomes, on-location platforms often tie wages to lower alternatives. Gender pay gaps persist in both online and on-location platforms (Agrawal, Lacetera and Lyons, 2016; Berger et al., 2019; Berger, Chen and Frey, 2018; Cook et al., 2021; Foong et al., 2018). Labour rights: Platform work often bypasses traditional labour protections by classifying workers as independent contractors. This undermines benefits like social security, paid leave, and collective bargaining. Scholars call for new regulations to address these topics (Cockayne, 2016; Rogers, 2016; van Doorn, 2017). Safety: Safety involves both worker well-being and customer security. Delivery riders and drivers face health and psychological risks, and ride-hailing services raise concerns about road accidents and sexual assaults. Platforms are criticised for failing to adequately protect gig workers (Acheampong, 2021; Bartel et al., 2019; Ladegaard et al., 2022; Nielsen et al., 2022; Tubaro and Casilli, 2024) Discrimination: Online platforms sometimes mitigate gender-based hiring discrimination but still exhibit job segregation. In on-location gig work, pay gaps and rating penalties disadvantage women. Discrimination in early stages of platform engagement remains underexamined (Chan and Wang, 2018; Cook et al., 2021; Fiers, 2023; Galperin, 2021). Privacy: Algorithmic control collects real-time data on worker activities. Workers tolerate some monitoring (e.g. navigation) but resist gatekeeping functions that limit access to work. Online gig workers may leave platforms or demand higher pay when data collection intensifies (Liang et al., 2023; Wiener et al., 2023). Sustainability: Platforms can reorganise urban transport, potentially reducing emissions and parking needs. Their overall environmental impact, however, remains debated. Some scholars point to possibilities of greener mobility and logistics (Henao and Marshall, 2019). Consumer welfare: Platforms can reduce costs and expand consumer access to goods and services. Ride-hailing apps, for example, often charge less than traditional taxis. This can increase consumer surplus and convenience (Yan et al., 2020).
To examine the types of platform data used in empirical academic research on labour platforms, including data-sharing agreements and the public interest topics addressed, we proceeded in three stages:
Figure 2 illustrates the corpus of articles included in our study and the corresponding analyses for the full corpus and subset.

Research design.
Stage 1: Article selection
The set of articles used in this study has been collected following four steps. In the first step, we collect a set of empirical publications on labour platforms that use user-generated or platform data. Our search strategy starts with defining labour platforms for inclusion in our study. De Groen et al. (2021) offer a public database (hereinafter referred to as the CEPS database) with 593 labour platform companies that operate in at least one EU member country (after the exit of the UK). A platform company is defined in the database as ‘private internet-based companies that act as intermediaries, with greater or lesser extent of control, for on-demand services requested by individual or corporate consumers’ (De Groen et al., 2021: 7). Out of 593 companies, 135 also operate globally. We include all 593 companies in our analysis, providing a rich sample of the labour platform universe.
In the second step, we collect scientific publications using Scopus Elsevier between 2 and 7 March 2024. We conducted individual Scopus searches, by platform, which means 593 searches were performed. As a rule, we used the names of the platforms according to the CEPS database in the search strings. In 51 cases (out of 593), it was necessary to develop specific search strings (48 cases due to the high number of returns related to other topics, i.e. polysemy, see Annex I (online appendix); 3 cases due to the high number of returns related to the platform enabling crowdsourced surveys, see Annex II (online appendix). We included journal articles and conference papers written in English, up to and including 2023. All the subject areas were included. Scopus returns 3200 entries for all these searches.
In the third step, we read the titles (and, where necessary, the abstracts) of the 3200 scientific publications to determine whether they (a) approached the labour platforms of interest in (b) an empirical way. This means that conceptual articles that did not involve the collection/use of empirical data were excluded. Based on this initial filter, we obtained a set of 520 publications on the 593 labour platforms (Figure 3).

Step-by-step search strategy for empirical scientific publications on labour platforms in the Scopus database.
In a fourth step, we performed an additional assessment of the 520 empirical papers to determine whether papers leverage user-generated or platform-generated data as a data source (assessed based on abstract and, if necessary, methodological sections) as well as whether the paper investigates topics related to the platform. We considered the paper to use platform data in case it collects platform-provided or platform-generated data, including profiles, transactions, reviews, ratings, or algorithm dynamics, or in case it collects user-reported data, including data on customers, workers, and managers associated with the platform. We assessed whether the paper investigated a question about labour platforms as some, generally more technical papers, collect data from platforms to test the accuracy of algorithms that are often not exclusive to labour platforms. This type of document was excluded.
We obtain a final set of 397 empirical articles on labour platforms. We conduct a descriptive analysis of this corpus which is presented in the Empirical research on labour platforms: descriptive analysis subsection. We analysed the number of scientific publications per platform and over time as well as their distributions by subject area and the geographic location of authors. We also used the CEPS database to provide a characterisation of the platforms that were subject to research.
Stage 2: annotating data collection methods and public interests
In the second stage, we annotate the data collection methods used by each of the 397 scientific publications in our corpus. First, based on abstracts (and when necessary, full texts), we identified the data collection method of each document in our corpus. All data collection methods can be grouped into three broad categories, which we discussed in the Business-to-science engagement subsection: platform-provided data, platform-generated data (e.g. scraping), and user-reported data (e.g. interviews, surveys). Scientific publications sometimes use more than one data collection method, for example, the same scientific publication can use interviews and surveys.
Next, two researchers independently coded each of the 397 scientific publications in terms of the public interest topics that were the focus of the publication and added labels to each publication with a possibility for multiple labels per publication. The labels for attribution in the articles are the seven topics introduced in the Platform observability subsection: labour rights, security, earnings, sustainability, consumer welfare, discrimination, and privacy plus the label ‘others’, for scientific publications that do not address any of the seven topics. The definition of the seven possible labels, which correspond to the seven relevant public interest topics, was established based on an inductive iteration approach. The topics of ‘discrimination’ and ‘security’, for example, emerged from the analysis of the topics of the articles as an important group that has been addressed in the literature. More than one code can be assigned to the same document. The first round of coding ended with a low inter-coder reliability Holsti index (Mao, 2017) for the use of the labels ‘consumer welfare’ (80%), ‘labour rights’ (82%), and ‘other’ (67%). The coders then refined the criteria for using these three labels and sought consensus on a second round of coding for those scientific publications where they differed regarding the usage of the above-mentioned labels. The results related to the distribution of data collection methods and topics of public interest are presented in the Data collection methods and topics subsection.
Stage 3: Analysing platform-provided data
Platform-provided data is the provision of platform data to researchers, with the consent and facilitation of the platform's controlling entity. In the third stage, we focused on the subset of 31 articles in which we explicitly identified mechanisms of platform-provided data. Details and metadata for each of the 31 scientific publications in this subset are shown in Annex IV in the online appendix.
We identified which mechanism was used, including which platforms shared what type of data and with whom. We used the three operational models of B2S data sharing from the Business-to-science engagement subsection as a basis for this analysis. Based on the literature reviewed in the same subsection, we also extracted information from each article characterising business-to-science engagement (see Table 1).
Diagnostic questions on platform data sharing.

Results
Empirical research on labour platforms: Descriptive analysis
We identified 397 publications on labour platforms. Figure 4 shows the growth of empirical scientific publications on these labour platforms over time. There is a clear upward trend in academic attention to labour platforms. This may be in large part due to the growth of the platforms and their increasingly contested nature.
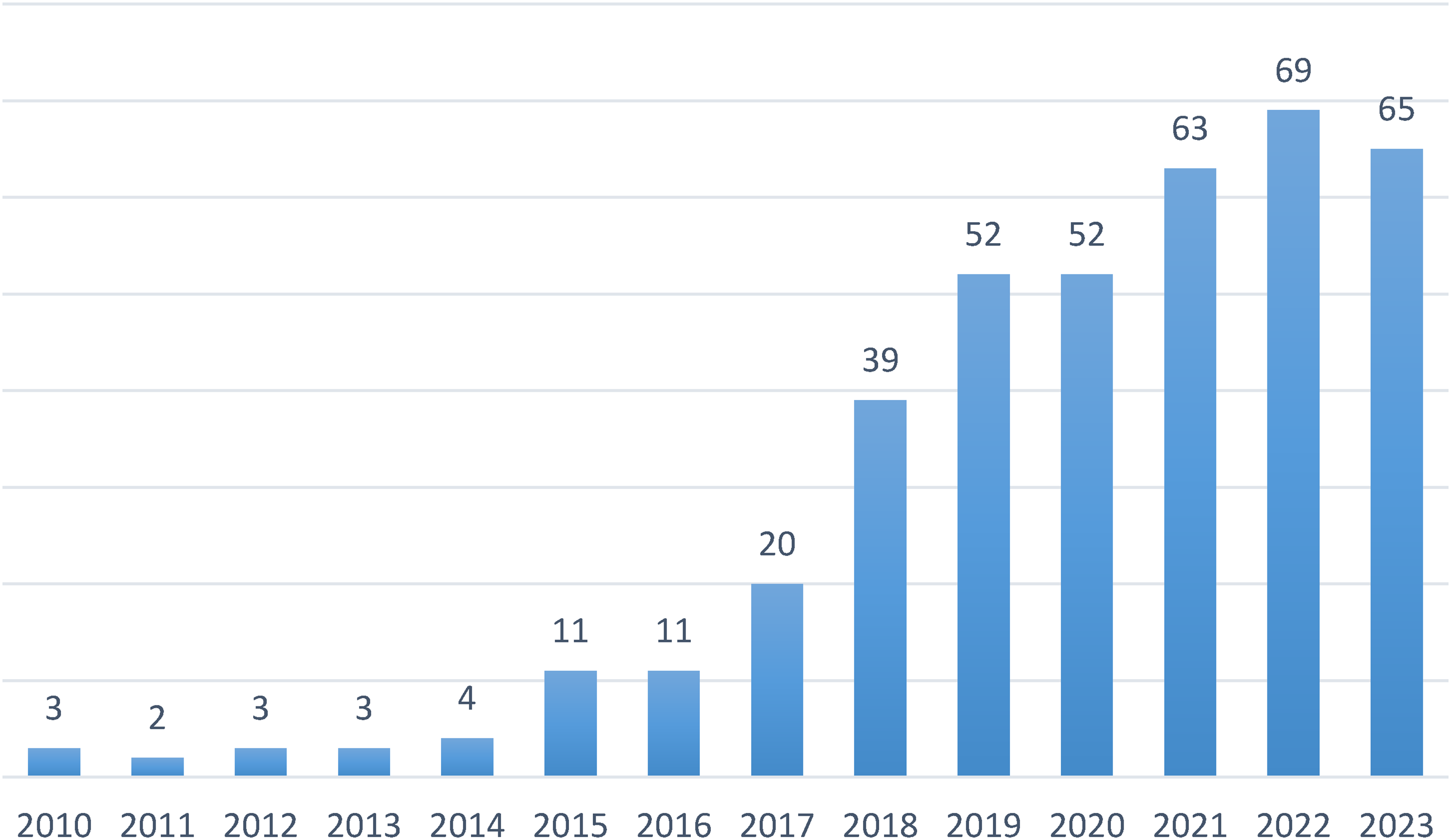
Annual number of publications.
Most articles come from the subject area of social sciences (188), computer sciences (151), and business, management, and accounting (130). Concerning the countries of origin, by far the most articles have authors affiliated with institutions in the USA (159), followed by the UK (47), China (26), and Germany (24).
Some publications examined more than one platform, resulting in 479 instances of platforms being studied. However, these instances cover only 57 out of the 593 labour platforms in the CEPS database. Thus, most platforms (89.9%) have not been subject to research published in scientific publications.
Out of the 57 platforms being researched, Uber stands out as the focus of 180 articles. Upwork and Amazon Mechanical Turk rank second and third with 34 and 26 articles, respectively. Figure 5 shows the 17 platforms that were researched in more than five publications. Of the 479 times that a platform is studied in one of the 397 scientific publications in our corpus, 401 entries target these 17 platforms; that is, they get 83% of research attention. This result suggests that current academic research on labour platforms is concentrated on a few platforms and poorly reflects the sheer number and heterogeneity of labour platforms currently active in Europe (and beyond). In Annex III (online appendix), we provide the complete list of platforms and the number of publications for each platform.

Number of scientific publications focused on specific labour platforms. Note: the figure shows only labour platforms that have been investigated in at least six scientific publications.
Data from the CEPS database allowed us to profile the labour platforms that are the subject of scientific investigation. Figure 6 summarises some of these aspects. Reading the figure in a clockwise manner, we observe that most attention falls on platforms that require a level between low and medium to complete their tasks (70%). Most studies look at active labour platforms (97%), meaning that little (if any) research is devoted to understanding platform exit (inactivation). Regarding the delivery location of the services, 62% of researchers’ attention focuses on platforms whose service is delivered locally. Finally, sector-wise, taxi service is the most researched (41%) (with a predominant focus on Uber), followed by freelance (22%) and delivery (16%). It is noteworthy that some types of services receive practically no attention from the scientific community such as domestic labour platforms (2%).

Characteristics of the platforms under study in the corpus. Note: From the pie charts above and to the right, shown clockwise, the distribution of scientific publications in the corpus by platform is presented in terms of: (a) skill level required to complete the tasks; (b) platform status (active or inactive); (c) place of service delivery; (d) type of service.
Concerning the origin of the platforms studied in our corpus, platforms from outside the European Union (EU) predominate. This data is particularly interesting because the CEPS database was built focusing on labour platforms operating in the EU. Of the total of 479 times that a platform was the focus of research in our corpus, 415 targeted platforms whose origin is outside the EU, and only 64 times platforms native to the EU were the object of study. This could mean that the European platform labour market has been dominated by foreign platforms, that European platform labour is under-researched, or both. On 328 times out of 479, platforms originating in the USA are the focus of researchers. In Europe, platforms native to Great Britain receive the largest share of attention (43), while within the European Union, platforms native to Germany (27) receive more attention than those from other member states.
Data collection methods and topics
For each publication, we identified the data collection method and coded the public interests (consumer welfare, discrimination, earnings, labour rights, safety, sustainability, privacy, other) that were the topic of research. We found that the 397 scientific publications register 476 data collection methods to study labour platforms empirically. Table 2 aggregates these data collection methods by type.
Data collection methods of scientific publications in the corpus per type of data, count, and percentage.

Note: The sum of the count is greater than the number of scientific publications in the corpus, because one scientific publication may resort to multiple data collection methods.
Across the corpus, 249 scientific publications (63%) collect user-reported data, 134 (34%) collect platform-generated/platform-provided data, and 14 (3%) employ a mix of both. Out of all studies, only 31 (7%) make use of platform-provided data, indicating how limited the practice of B2S data sharing is in this context. Third-party data is a category that refers to platform-generated data (e.g. Uber ride data), but which the researchers accessed from the database of a third party, usually municipal and regional governments that receive the data from the platforms.
Table 2 shows that to obtain platform-generated data, researchers frequently resort to alternative methods, such as scraping and data donation (from customers or workers). We found that, in many cases, this occurs not by researchers’ choice but because platforms are unwilling to collaborate. To overcome this data gap, researchers resort to alternative data collection strategies. For instance, one scientific publication in the corpus highlights that ‘The resistance of ridesharing services in making the information of their availability (supply, utilisation, idle time, and idle distance) and surge pricing public creates a barrier for researchers to investigate the usage of these services across different regions’ (Khan et al., 2022: 16). Thus, Khan et al. (2022) resort to scraping this data without the collaboration of the platforms. In other cases, researchers gave up efforts to obtain platform-generated data and resorted to user-reported data collection methods. Pollio (2019) points out that companies like Uber are largely inaccessible, deliberately concealing their operations, corporate structures, and internal performance data. The author mentions unsuccessful efforts to reach the local marketing team in Cape Town and the even greater difficulty in accessing the software developers responsible for local adaptations of the platform: ‘Hence, to observe the platform, my strategic choice was to engage ethnographically’ (Pollio, 2019: 762). Statements such as ‘(r)ealizing the difficulty in obtaining data directly from Uber and Lyft, we designed a quasi-natural experiment—by one of the authors driving for both companies—to collect primary data’ (Henao and Marshall, 2019: 2173) are also found in the methodology section of other scientific publications.

Distribution of public interest topics in the corpus. Note: Topics are not exclusive (except for ‘other’). ‘Other’ spans studies on innovation and crowdsourcing, consumer trust in the sharing economy, and the institutional disruptions of platformisation.
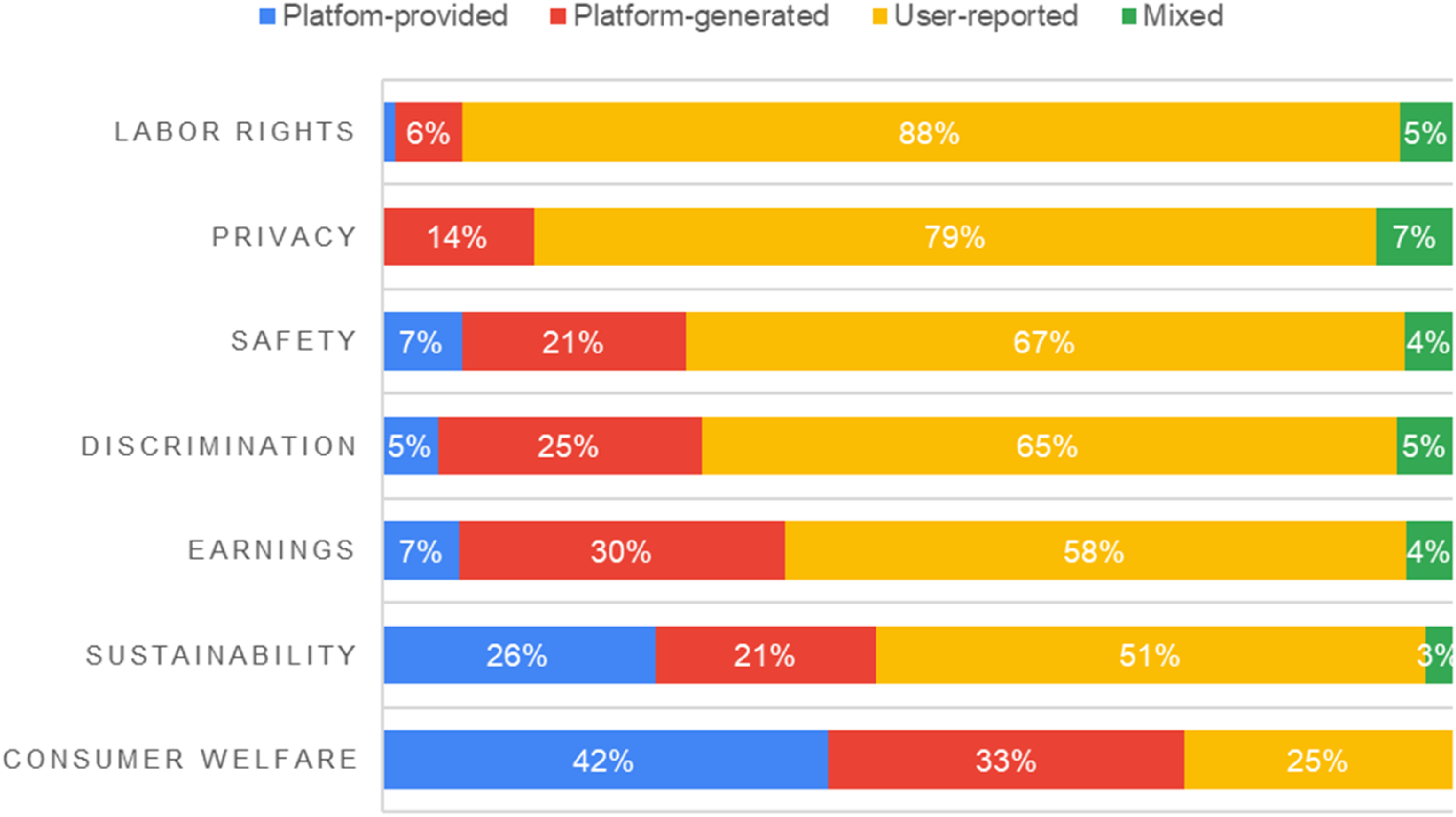
Percentage of data access methods for each type of public interest researched.
Figure 8 reveals that there is an uneven distribution in terms of the nature of the data collection methods for each public interest studied. Platform-provided data are over-represented in publications on sustainability and consumer welfare, which are societal benefits often emphasised by platforms. In contrast, out of the 80 publications that researched labour rights, only 5 used platform-generated data (or 6% of all labour rights studies) and one publication used platform-provided data (or 1% of all labour right studies); thus, most studies on labour rights are based on user-reported data (88% of all labour rights studies), a public interest often emphasised by unions. Platform-generated data tends to be used most often for the investigation of earnings, discrimination, and safety, which are topics highlighted by unions and labour inspection agencies. In all, the results indicate that studies that use platform-provided data tend to focus on public interests that platforms often indicate as societal benefits such as sustainability and consumer welfare, while studies focusing on other public interests such as labour rights, earnings, discrimination, and safety more often make use of platform-generated data such as through scraping and user-reported methods for their data collection.
Platform-provided data: Different ‘shades’ of platform data openness
In this section, we zoom in on the subset of articles (n = 31) that conducted empirical research based on platform-provided data, that is, platform data shared through sanctioned channels. We shed light on how platforms share data with academic researchers and the terms of business-to-science engagement around that. The articles’ details and their metadata can be consulted in Annexes IV and V (online appendix).
Out of 31 scientific publications, 26 are articles published in peer-reviewed journals, and 5 are conference proceedings. Figure 9 shows the number of scientific publications per platform and type of data-sharing mechanism. Uber accounts for 22 out of the 31 scientific publications, while seven other platforms have also collaborated with researchers on at least 1 publication. The most popular mechanism for enabling platform-provided data is through approved uses of data via an API (n = 16, 51.6%). Eleven scientific publications (35.5%) draw data from bilateral agreements (collaborative uses of data), whereas four scientific publications (12.9%) draw data from open data platforms (independent uses of data), such as Uber Movement.

Scientific publications registering platform-provided data, per platform and type of data-sharing mechanism.
In the following three subsections, we elaborate on the results of these three groups of articles, divided according to their data-sharing mechanism: via an open data platform, API, or bilateral agreements.
Open data platform
The four scientific publications leveraging an open data platform (Annex IV, online appendix) use data from the Uber Movement 3 and Meta Kaggle 4 platforms. The use of the open data platforms entails no non-disclosure agreement, and there are no restrictions for non-commercial use of the data (creative commons, attribution non-commercial licence). These articles do not involve platform co-authorship, nor do they use other data collection methods. This data collection method is justified as a way to begin closing the data gap on the topics covered (Annex IV, online appendix, #1), which other researchers were unable to address and had to resort to qualitative data or abstract quantitative data (Perlman and Roy, 2021). The scientific publications deal with sustainability and consumer welfare. Perhaps, due to the content of the data and the architecture of the platform, the articles that used Uber Movement focus on topics related to sustainability in the urban context (Annex IV, online appendix, #1, #2, and #3).
Application programming interface
Sixteen scientific publications resorted to API (Annex IV, online appendix), thirteen on Uber, two on TopCoder, and one on Dribbble. Concerning the research focus, the scientific publications mainly deal with consumer welfare (n = 7) and sustainability (n = 4), but we also see the topics of earnings addressed three times, discrimination and security twice, and labour rights once. None of these articles was co-authored with platform employees. Via the API, researchers obtain data better suited to their needs and can customise it beyond what is offered on open data platforms, for example, Uber Movement. This is reflected in the specificity of the data, which is more varied for these articles than for those using open data platforms.
Only one of the scientific publications (Annex IV, online appendix, #16) offers the specific dataset collected through the API, but in theory, after obtaining the approval of access by the platform, the data should be available. Because platform APIs embed technical barriers, they restrict public scrutiny of data and make research less reproducible than in the case of open data platforms (van Drunen and Noroozian, 2024). The control platforms can exercise through API data sharing (Morten et al., 2024; van Drunen and Noroozian, 2024), is likely to explain why no scientific publications sign an NDA to obtain such data. In the end, as Randerath (2024) argues, APIs should be understood not merely as technical interfaces but as mechanisms of governance. By determining which data can be accessed, by whom, and under what terms, APIs effectively mediate both the control of workers and the control of researchers.
It is interesting to note that the legitimisation of API data is multiple: The availability of data, the size of data, the quality of data, the relevance of the provider, and the real-time analysis enabled by this data are all praised by the researchers. At the same time, it is common to find complaints from researchers regarding what is made available via APIs: ‘We also explored collecting data for UberX for a greater frequency of trips—every 10 minutes—but Uber's API would not allow us to do so’ (Chang et al., 2022: S450); ‘Ideally, information concerning origin-destination flow, speed, and congestion will provide a more comprehensive view of the accessibility issue. However, due to the regulations of Uber's API and privacy concerns, this is the best data we can obtain in the public domain’ (Wang et al., 2020: 9); ‘Uber imposes a rate limit of 1000 API requests per hour per user account’ (Chen et al., 2015: 497). Limitations, and sometimes the complete suspension of access, in APIs is a decade-old struggle in social media platforms research (Bruns, 2019; Puschmann, 2019).
To circumvent the limitations, Chen et al. (2015) created fake accounts as if they were Uber customers and collected data using these accounts. They then self-assessed whether they conducted this data collection ethically. We find mixed results concerning ethical considerations among this group of scientific publications: Some present a declaration of interest, and others carry out self-assessments. In contrast, others went through ethics committees at their institutions.
Bilateral agreements
Bilateral agreements refer to the transfer of data by the platform company to the researchers. This assignment can take place in several ways, such as through data usage agreements (DUA) or simply bona fide. Eleven scientific publications document bilateral agreements, six on Uber, while Free Now, CleverShuttle, InnoCentive, OpenClassrooms, and CodeChef count one scientific publication each. Five out of six articles on Uber were co-authored by the platform, that is, Uber employees are co-authors of the scientific publications. The only exception concerns Uber's electric vehicle fleet (Jenn, 2020). Scientific publications that received data through bilateral agreements, but targeted other platforms, are not co-authored by employees of the platforms When there is co-authorship, there are indications that the platform has a ‘supervisory’ capacity for the research and the results that end up being included in the articles: ‘the study has been conducted according to the terms of agreement set out by the platform’ (Das et al., 2022: 113).
In terms of data shared, access to proprietary data via bilateral agreements shows a richer picture in terms of data types and variety. Scientific publications on Uber leveraged data about users and drivers, not just trips. Data referring to the other platforms also pertains to users (whereas easily scraped data would be related to transactions, projects, and bids on these platforms). There is an attempt to make ‘supplementary data’ or ‘replication codes’ available. Primary data invariably remains inaccessible: ‘The dataset is not publicly available’ (Das et al., 2022: 113). Finally, a striking feature of this set of scientific publications is their affiliation. The authors are almost always associated with renowned universities 5 in the country of origin of the platform under scrutiny.
Discussion
Our first objective was to collect and analyse a comprehensive set of empirical studies on labour platforms. We found a dual bias in this literature. First, publications are heavily skewed towards a few platforms, and particularly Uber, likely due to its global reach and controversies. Second, research on labour platforms is concentrated in North American universities, which may influence the types of questions asked, methods employed, and perspectives adopted.
Our second objective was to analyse the data collection methods in these empirical studies and the public interest topics covered. The most common methods relied on user-reported data such as interviews, surveys, and platform-generated data such as scraping. Only 7% of studies use platform-provided data, revealing the limited access researchers have to sanctioned platform data. Most empirical research focuses on labour rights, with earnings, safety, and discrimination also receiving attention. Topics such as consumer welfare, sustainability, and privacy are notably less studied.
We observe that studies on labour rights are typically explored through user-reported data – interviews, surveys, and ethnographies. Scraping and mixed methods are employed for questions related to earnings and discrimination. In contrast, the few studies based on platform-provided data focused more on consumer welfare and sustainability. This suggests that platforms have the power to selectively share data that supports narratives of societal benefit rather than research aligned with union or worker advocacy concerns.
Our argument does not imply that platform-provided data is inherently preferable for studying all public interest topics. What is at stake, rather, is the possibility of epistemic diversity 6 : enabling scholars to access and interrogate these data critically, while also combining them with platform-independent sources such as surveys, interviews, and ethnographies. The value of platform data lies not in its completeness but in how it can be juxtaposed with independent evidence to produce a more comprehensive and accountable understanding of platformisation's economic and social effects. 7
The reliance on qualitative, user-reported methods in many scientific publications limits the scope of empirical inquiry (Giglietto et al., 2012). Qualitative and participatory approaches, such as surveys, interviews, and ethnographic observation, offer forms of analytical richness that large-scale datasets cannot reproduce, especially in capturing workers’ lived experiences, interpretations, and agency. Access to large platform datasets could complement the insights that have already been developed, offering an even more complete overview of the phenomenon of platformisation. This aligns with broader concerns about restricted access to platform data in adjacent domains, such as social media research 8 (Burgess and Bruns, 2015) and university–industry collaborations more generally (Perkmann and Schildt, 2015). Our study offers new empirical evidence that restricted platform data access not only constrains the methodological approaches available to researchers but also shapes the direction of academic inquiry on labour platforms. This finding has important policy implications for regulating academic access to platform data which we elaborate on below.
Our third objective was to explore how platforms engage with academic researchers and the nature of platform-provided data relationships. We found that only 31 out of 397 articles were based on platform-provided data. Multiple factors may explain this: platforms may hesitate to share data due to reputational or strategic concerns, while researchers may avoid requesting data due to anticipated refusal, ethical concerns, or lack of awareness.
Crucially, when data is shared, it tends to support research into areas that platforms publicly frame as beneficial 9 , especially consumer welfare and sustainability. This suggests an ‘implicit policy’ in which access to data is conditional on the public interest served. This reveals how platform observability is currently governed by platforms themselves, with little transparency or public oversight, far from the multi-stakeholder governance models advocated by scholars such as Rieder and Hofmann (2020).
It is particularly troubling that bilateral data-sharing agreements are mostly established with elite academic institutions, creating a dual regime of access (Burgess and Bruns, 2015). Researchers in smaller or less-resourced institutions, particularly in the Global South, may be excluded from access to high-quality data, reinforcing existing inequalities in knowledge production. This situation contributes to a broader problem of ‘access to the field’ in platform research (Perkmann and Schildt, 2015; Susha et al., 2017; Verhulst and Young, 2022). Without equitable access, not only is research capacity unevenly distributed, but entire categories of questions, especially those critical of platform labour regimes, may remain underexplored.
Taken together, these findings allow us to specify more precisely how epistemic selectivity operates in practice. Epistemic selectivity operates along two main mechanisms. First, platforms privilege data access for research agendas that reinforce narratives aligned with their organisational interests, while studies addressing labour rights, earnings, or discrimination face greater barriers. Second, B2S data-sharing models themselves calibrate researchers’ autonomy: while some platforms offer open, aggregated datasets that permit independent use, richer data are typically accessible only via APIs governed by platform-defined terms, and the most granular datasets often involve co-authorship with platform employees and cannot be replicated. Together, these mechanisms narrow the scope of questions researchers can pursue and limit the diversity of interpretative frameworks that can be applied to platform labour.
These constraints also encourage a shift towards methods such as scraping, which, while valuable, raise challenges related to validity, generalisability, and ethical robustness. This dynamic sits uneasily with the epistemic sensitivity that Rieder and Hofmann (2020) identify as essential to advancing platform observability. Our findings therefore speak not only to the practical limitations of data access but also to the broader governance role labour platforms play in defining the boundaries of public knowledge about platform-mediated work. In this sense, the study contributes to research calling for analyses of platform systems ‘beyond the gig’ (van Doorn and Shapiro, 2023) by highlighting their influence over knowledge infrastructures as well as labour processes.
Finally, the growing reliance on alternative methods such as scraping underscores the need for field-specific ethical frameworks. Existing debates in social media research offer useful precedents, but labour platforms raise distinct challenges, particularly when data concern precarious or vulnerable workers (Molina et al., 2023). Addressing these challenges becomes even more pressing considering the EU Platform Work Directive, which from 2027 will require platforms to provide key labour metrics to competent authorities and worker representatives (Directive EU, 2024). This regulatory development offers a critical opportunity to institutionalise more transparent, equitable, and research-oriented data-sharing mechanisms. We hope that the evidence presented in this study informs these emerging frameworks and contributes to more robust, accountable forms of knowledge production about digital labour platforms.
Conclusions
Research on digital labour platforms remains largely disconnected from the data these systems generate, and our analysis of 397 published empirical studies shows that data sharing with academic researchers is not only rare but also selectively granted. Previous uses of the concept of epistemic selectivity have either focused on selective epistemic commitment within philosophy of science (Lyons, 2016) or on how institutional and political arrangements privilege certain forms of knowledge within science–policy interfaces (Vadrot, 2014, 2017). In contrast, we use epistemic selectivity to capture how digital labour platforms, through their control over data access and data-sharing modalities, actively shape the empirical research agenda itself, selectively enabling knowledge production aligned with platform interests. Epistemic selectivity constrains the range of questions that can be asked (Rieder and Hofmann, 2020: 22) and limits ‘different forms of sense-making’ (Rieder and Hofmann, 2020: 20) about the public interest topics in which labour platforms are involved. In doing so, platforms shape how labour markets are understood, not only by organising work, but also by influencing what can be empirically known about it.
Several limitations also shape the scope of this study. We concentrated on platforms operating in Europe, leaving out important cases from other regions. Our method was primarily descriptive, drawing from published empirical studies, which constrains our ability to fully explain researchers’ methodological decisions. We rely on published empirical research, which restricts our ability to observe unpublished or failed data access attempts that likely further illustrate epistemic selectivity. Moreover, while the corpus spans diverse disciplines, we did not disaggregate results by field, and our simplified categorisation of labour platforms does not capture variations in observability regimes across crowdwork, gig work, and hybrid freelance platforms. Future research could address these gaps through interviews with researchers and platform representatives, cross-disciplinary comparisons, and closer scrutiny of emerging data access practices.
Supplemental Material
sj-pdf-1-pns-10.1177_29768624261425376 - Supplemental material for The epistemic selectivity of online platforms: The case of data sharing for academic research on labour platforms
Supplemental material, sj-pdf-1-pns-10.1177_29768624261425376 for The epistemic selectivity of online platforms: The case of data sharing for academic research on labour platforms by Victo Silva, Iryna Susha, Jarno Hoekman and Koen Frenken in Platforms & Society
Footnotes
Acknowledgements
KF acknowledges NWO funding under the NWA scheme for the project ‘Platform Work and its Regulations’ (PlatWork-R). We thank August Knaap for his contribution as the second coder. We are grateful to the two anonymous reviewers for their constructive suggestions, which significantly improved the final version of this article. We also thank the editors of Platforms & Society for their guidance throughout the review process.
Ethical approval
The authors declare ethical approval from the Faculty of Geosciences at Utrecht University (NWO NWA PlatWork-R project).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Nederlandse Organisatie voor Wetenschappelijk Onderzoek.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Complete data will be made available in an online appendix.
Supplemental material
Supplemental material for this article is available online.