
Abstract
Iterative prompt refinement is a practical approach for improving the reliability of large language models without weight updates. In this work, we study metatuning: a judge-guided prompt-refinement loop in which an evaluator critiques errors and provides targeted natural-language corrections or demonstrations that are incorporated into the prompt. We evaluate metatuning on axiomatic deductive reasoning (MATH-500), on combinations with chain-of-thought and self-reflection prompting, and on video-based physical reasoning (CLEVRER). Our results show that metatuning can improve baseline performance in static, rule-like domains, but offers limited benefit when paired with strong reasoning baselines and does not generalize to spatiotemporal video reasoning. Overall, we identify boundary conditions for judge-guided prompt refinement and motivate future work on integrating feedback at the level of reasoning traces.
Introduction
Large language models (LLMs) have become strong general-purpose systems, yet they still exhibit brittleness in complex reasoning and can fail systematically on recurring error patterns (Capitanelli & Mastrogiovanni, 2024). A practical family of approaches to improve reliability without weight updates is prompt refinement: iteratively modifying prompts and demonstrations based on observed failures. In this paper, we study metatuning, 1 a judge-guided prompt-refinement loop in which a separate evaluator critiques errors and produces targeted corrections or demonstrations that are incorporated into the prompt.
In this work, we frame metatuning as a form of symbolic feedback in an operational sense: the feedback signal is expressed in discrete natural-language instructions and examples that can be inspected, edited, and reused. This perspective connects to neurosymbolic motivations (Colelough & Regli, 2024; Fang et al., 2024; Sheth et al., 2024), but our claims in this revision are deliberately empirical: we evaluate when judge-guided prompt refinement helps, when it becomes redundant, and when it fails to transfer across domains. Future work should complement this operational framing with direct representation probing to test stronger grounding/alignment hypotheses (Bisk et al., 2022; Blank & Piantadosi, 2023).
Can judge-guided, error-driven prompt refinement reliably improve LLM reasoning, and what are its boundary conditions?
Under such a learning regime, there are direct analogs to the traditional learning setup—train–validation–test splits, number of training runs through the dataset (epochs), gradient accumulation (when to trigger a prompt revision), model saving (saving the history of interactions and prompt-revisions, along with the final prompt), and model loading at inference time on the test set (loading the same history and warm starting with a few sample generations before testing begins).
We evaluate metatuning on axiomatic deductive reasoning (MATH-500), study its interaction with chain-of-thought (CoT) and self-reflection prompting, and test transfer to a multimodal, spatiotemporal video reasoning domain (CLEVRER). Our goal is to empirically characterize where iterative prompt refinement improves reliability and where it breaks down.
To further explore the boundaries of our framework, we investigate its interaction with other advanced reasoning techniques. Recently, methods such as CoT and self-reflection have been proposed to enhance LLM reasoning by guiding the model to produce a step-by-step reasoning trace. This raises a crucial question: Do the benefits of our metatuning approach complement or become redundant when combined with these powerful prompting techniques? Our experiments reveal that while COT and self-reflection significantly boost baseline accuracy on mathematical problems, adding metatuning provides no further benefit to GPT-4o and, in some cases, even degrades performance for Gemini 1.5 Flash.
Furthermore, we extend our evaluation to a new domain: video-based physical reasoning. Using the CLEVRER dataset, we assess whether our metatuning approach can improve an LLM’s ability to answer descriptive, explanatory, predictive, and counterfactual questions about object trajectories and collisions in short video clips. We find that in this dynamic and visual domain, metatuning has a negligible effect on performance. These findings provide valuable insights into the limitations of metatuning and suggest that its effectiveness is highly dependent on the nature of the task and the symbolic domain (e.g., static, discrete logical rules vs. dynamic, continuous physical laws).
Thus, our main contributions are:
Our work is also related to recent methods for automatic prompt optimization and meta-prompting, where prompts are improved via search or feedback loops rather than parameter updates. Examples include human-level prompt engineering via automatic prompt search (Zhou et al., 2023), optimizing prompts using LLMs as optimizers (Yang et al., 2024), and iterative refinement with self-feedback (Madaan et al., 2023). Metatuning differs in that it uses judge-driven critiques and error-driven example selection to construct a learned prompt artifact focused on specific failure modes.
The rest of the paper is organized as follows. Section 2 introduces the operational framing of symbolic feedback and situates metatuning relative to prompt optimization and in-context learning (ICL). Section 3 presents our judge-guided prompt-refinement loop and Algorithm 1. Section 4 compares our approach to conventional backpropagation training. Section 5 reports experiments on MATH-500, CoT/self-reflection prompting, and CLEVRER. Section 6 concludes, and the Appendix provides qualitative examples.
Background: Symbolic Feedback and Prompt Refinement
Operational View
We use symbolic feedback in an operational sense: feedback is communicated through discrete natural-language artifacts (instructions, critiques, and demonstrations) that can be appended to a prompt and directly inspected. This differs from weight updates, and it does not require claiming that the model is symbol-grounded in a philosophical or representational-probing sense (Bisk et al., 2022). Our goal is to study whether such feedback improves empirical task performance and how its effects depend on the task and prompting baseline.
Relation to Prompt Optimization and ICL
Metatuning is closely related to prompt optimization and meta-prompting methods that search over prompts or iteratively refine them based on feedback (Madaan et al., 2023; Yang et al., 2024; Zhou et al., 2023). It also resembles ICL at inference time because it conditions on demonstrations; however, metatuning emphasizes error-driven construction of those demonstrations via judge-guided correction, rather than static or similarity-retrieved examples. We make this distinction explicit in our CLEVRER experiments (Section 5.3).
Method: Metatuning (Judge-Guided Prompt Refinement)
Illustrative Example
Imagine an LLM-based agent in a text-based adventure game (a simple “world”). The agent’s policy is given by an LLM, but we also maintain a symbolic memory of facts the agent has discovered (e.g., a natural language-based description of the game’s map, items, etc.), and perhaps a similar description of explicit goals or rules (e.g., “you must not harm innocents” as a rule in the game). As the agent acts, an external prompt-based probe/judge model (another LLM) could check its actions against these rules and the known facts of the world. If the agent attempts something against the rules or logically inconsistent with its knowledge, the evaluator can intervene—for instance, by giving a natural language feedback (“You recall that harming innocents is against your code.”) or by adjusting the agent’s state (inserting a reminder into the agent’s context window). The agent (LLM) thus receives symbolic interactions (in this case, a textual message that encodes a rule or a fact) that alter its subsequent processing. In this learning scenario, the agent refines its internal model based on such interactions. Note that this does not involve directly tweaking weights each time; it instead involves an iterative procedure where each episode of interaction produces a trace that is used to slightly adjust the model’s state (it’s current prompt, history of interactions, prompt-revisions, and judge critiques). Over time, the model internalizes the rules so that it no longer needs the intervention. This viewpoint reframes symbolic
Task Learning Algorithm
We propose an iterative learning paradigm for judge-guided prompt refinement that mirrors gradient-based optimization but uses symbolic feedback and intervention (expressed in natural language) to update the prompt state. The loop can be summarized at a high level in four steps:
This cycle repeats for a fixed number of iterations (or until the judge indicates that no further improvement is being made). The process is formally described in Algorithm 1.
Algorithm 1 details our proposed perspective on learning. This iterative cycle aims to
The
The
The update mechanism for the model is in the effective model behavior, modulated by providing a better prompt or adding a memory of previous corrections. For example, we can use a persistent prompt that accumulates instructions (a form of prompt tuning or using the model in a closed-loop system). This can be interpreted as a kind of supervised training loop where the new examples from corrections serve as training data with the judge acting as an
Comparison to Conventional Backpropagation Training
We compare our paradigm to standard
Experiments and Discussion
Metatuning With Zero-shot Prompting
In this section, we evaluate the impact of metatuning on the performance of an LLM using the Maths 500 Dataset. We begin by selecting a subsample of 100 problems from the dataset. As illustrated in Figures 1 to 3, we assess the model’s zero-shot performance by prompting it to generate answers without any prior fine-tuning. The generated responses, along with the corresponding ground-truth answers, are then evaluated by an LLM-based judge. The subsampled dataset contains problems of various levels from Level 1 to Level 5 of varying difficulty. One example from each level is given in Figure 2.
Following this, we implement a train–test split on the dataset. For the training set, we identify instances where the LLM’s initial responses were incorrect. For these incorrect cases, we construct a solution-infused chat history by incorporating the correct answers and their corresponding solutions. This enriched context is then provided to the model during inference on the test set. Finally, we compare the model’s zero-shot accuracy with its performance after metatuning. The results highlight the effectiveness of metatuning in enhancing the model’s ability to solve mathematical problems by leveraging solution-infused contextual learning.
Initial experiments were conducted with smaller language models, such as LLaMA 3.2 (1B parameters), inferred via Ollama. However, these models exhibited extremely low baseline accuracy, making them unsuitable for the study. Furthermore, given the critical role of the Judge LLM, we found that employing a large, state-of-the-art (SOTA) model as the judge is essential. If the Judge LLM’s evaluations lack high fidelity, the entire metatuning process becomes unreliable.
Therefore, this study focuses exclusively on SOTA models. Future work could explore the impact of metatuning on reasoning-focused models compared to non-reasoning models, using both as candidate and judge LLMs. In this study, all models used are non-reasoning models, but the candidate LLMs are explicitly prompted to provide both a reasoning process and a final solution. In the experimentation, the candidate LLMs used are GPT-4o and Gemini-1.5-Flash, and the judge model used is Gemini-2.0-Flash.
Benchmarking Results
We conducted experiments on

Level of problems distribution in the dataset.
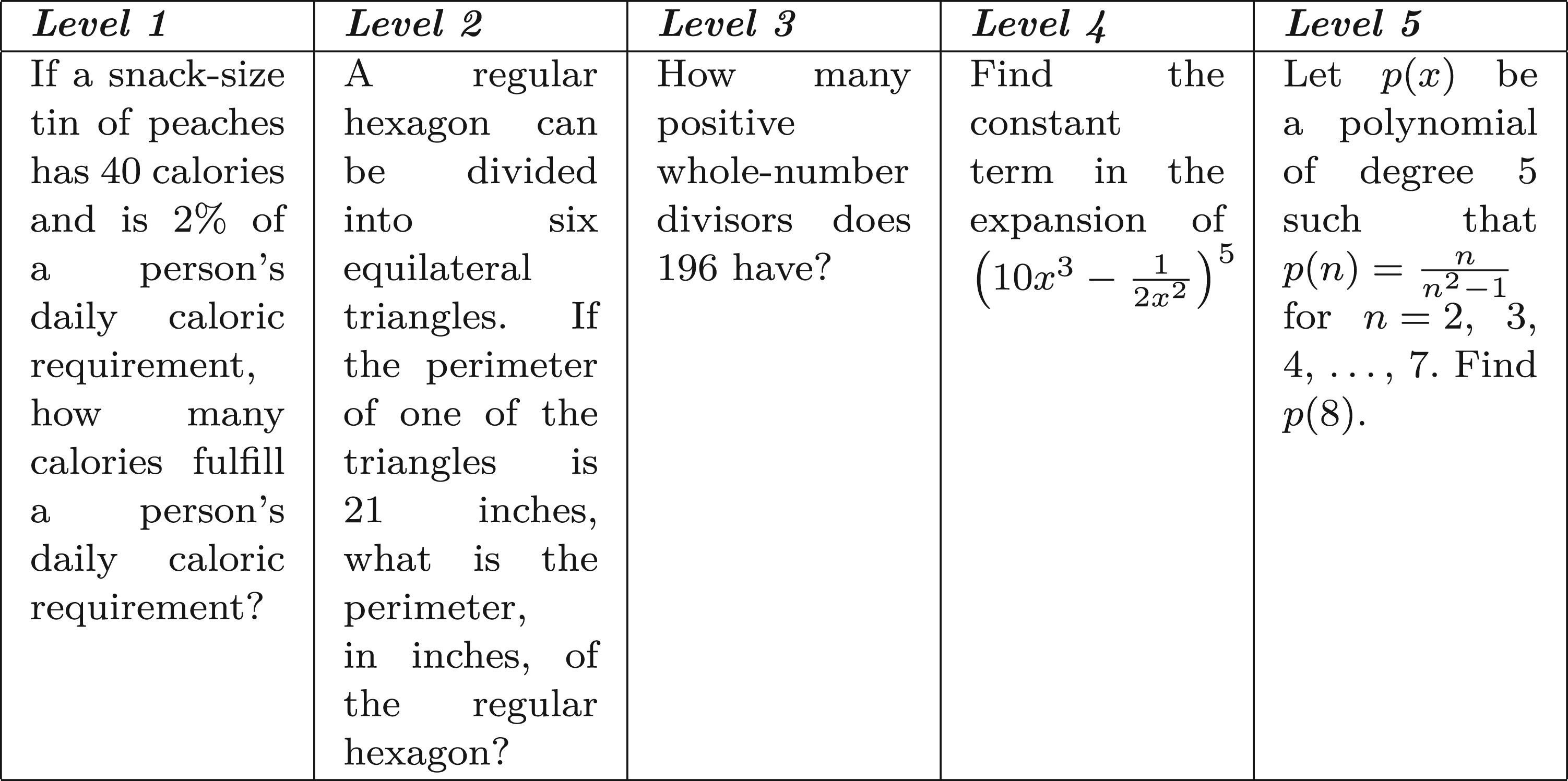
Dataset examples.

Workflow for evaluating metatuning on MATH500.
Performance of GPT-4o With and Without Metatuning.

Performance of Gemini 1.5 Flash With and Without Metatuning.

Analysis
From the results, we observe that metatuning improves the accuracy of both models in most cases.
These results highlight that metatuning can be beneficial for improving model accuracy but may exhibit diminishing returns or even slight regressions depending on context size and model architecture.
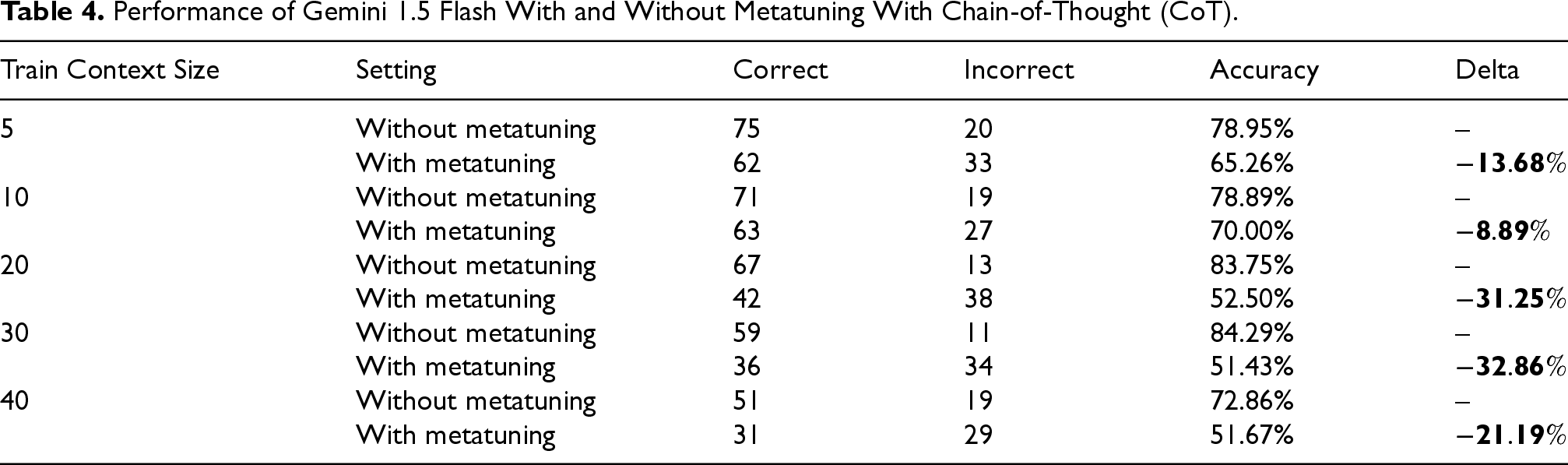
In this section, we extend the experimentation on the same subsection of the dataset with advanced prompting instead of using zero-shot prompting as a baseline. We use a CoT prompt with two steps: (1) ask the LLM to think step by step, and (2) ask it to reflect on its own answer from Step 1. What we find is a high jump in accuracy from zero-shot to this new CoT-based prompting, but a negligible change in accuracy (or degrading accuracy) when metatuning is incorporated with CoT, as can be seen in Tables 3 and 4.
Performance of GPT-4o With and Without Metatuning With Chain-of-Thought (CoT).

Performance of GPT-4o With and Without Metatuning With Chain-of-Thought (CoT).
Performance of Gemini 1.5 Flash With and Without Metatuning With Chain-of-Thought (CoT).
Analysis
The results suggest that metatuning is not reliably additive with strong reasoning prompts. For GPT-4o, metatuning yields small gains or plateaus once CoT is enabled. For Gemini 1.5 Flash, adding metatuning to CoT consistently reduces accuracy, indicating a boundary condition rather than a stable improvement. A plausible explanation is context saturation: the model must attend to both the injected metatuning demonstrations (which encode symbolic corrections) and a long CoT + self-reflection trace; the additional context may become redundant, compete for attention, or introduce noise that disrupts reasoning.
Finally, our current implementation uses the judge to evaluate and correct the final answer rather than the intermediate CoT trace. This may limit how metatuning can complement CoT, since the feedback does not target flawed intermediate reasoning steps. A key direction for future work is to incorporate trace-level critiques so that the judge can correct the reasoning process, not only the outcome. Another important direction is to replicate these metatuning + CoT interactions across additional candidate models.
To assess the generalizability of our metatuning approach beyond text-based mathematical problems, we conducted an experiment on a video-based physical reasoning task. For this, we used the CLEVRER dataset, which consists of short video clips depicting interactions between various 3D objects (e.g., cubes and spheres) and a set of associated questions for each video. The questions fall into four categories: descriptive (e.g., “How many spheres are moving?”), explanatory (e.g., “Which of the following is responsible for the collision between the gray object and the cube?”), predictive (e.g., “What will happen next?”), and counterfactual (e.g., “What will happen if the gray sphere is removed?”).
For our methodology, we selected a total of 50 videos from the dataset, each containing multiple questions, for a total of 620 questions. We used Gemini 2.0 Flash as the candidate model. In the baseline condition, we provided the video and its questions to the model without any additional examples in the prompt. For the metatuning condition, we first ran a short sweep to identify questions the model answered incorrectly and used the judge to obtain corrected solutions; we then prepended two representative failure cases (question + corrected solution) as demonstrations before asking the remaining questions. The model’s answers were then evaluated by a judge against the ground-truth solutions.
Although the resulting inference-time prompt resembles standard ICL, the key distinction is how the examples are constructed. In standard ICL, demonstrations are typically static or retrieved by similarity. In metatuning, the demonstrations are a learned artifact derived from the model’s prior errors and the judge’s critiques during a training sweep (consistent with Algorithm 1). This distinction matters because it shifts the method from “using examples” to “using error-driven example selection.”
The results of this experiment are summarized in Table 5 and Figure 4.
Performance on CLEVRER Video Reasoning Task.

Performance on CLEVRER Video Reasoning Task.

CLEVRER data distribution and accuracy across each question type.
Analysis
The central finding from this experiment is that metatuning had a negligible impact on the model’s performance, resulting in only a marginal improvement of +0.16%. This outcome stands in contrast to our findings on the mathematical reasoning tasks, where metatuning consistently improved accuracy.
This result leads us to a key insight regarding the limitations of our metatuning framework. Our initial hypothesis was that providing solved examples would help the LLM identify patterns and improve its reasoning, much like it did for the logical and arithmetic problems. However, the nature of the “symbols” and “rules” in the video domain is fundamentally different. In mathematical reasoning, the symbols (e.g., numbers and variables) are discrete, and the rules (e.g., logical identities and algebraic formulas) are static and well-defined. The model can effectively learn to apply these explicit, high-level rules from a few examples in the context window.
In contrast, the symbols in the CLEVRER dataset (e.g., the position, velocity, and interactions of objects) are continuous and dynamic. The underlying “rules” are the laws of physics, which are far more complex and only implicitly reflected in the model’s learned representations. The two examples provided via metatuning are likely insufficient to teach the model a complex new physical law or to correct a fundamental misunderstanding of spatiotemporal dynamics. This suggests that representation-mediated prompt steering, while effective for discrete linguistic error patterns, may be too weak or noisy for metatuning to be effective in domains requiring complex, continuous reasoning. The context-based learning of our approach appears to be most effective when the task-relevant knowledge can be distilled into clear, symbolic, and rule-based examples.
In this work, we presented an empirical study of iterative prompt refinement using symbolic feedback expressed in natural language. We investigated metatuning, a judge-guided loop that accumulates targeted corrections and demonstrations into the model’s prompt, and evaluated when this style of symbolic feedback helps—and when it does not.
Across axiomatic deductive reasoning (MATH-500), metatuning improved baseline performance most clearly at smaller context sizes, consistent with the intuition that a small number of carefully selected examples can help correct recurring error patterns. However, when combined with strong prompting strategies such as CoT and self-reflection, metatuning provided little additional benefit and, for some models, degraded performance. These negative results suggest a boundary condition: the added metatuning context can become redundant with, or compete for attention against, a long reasoning trace (a form of context saturation).
We also evaluated metatuning on a video-based physical reasoning task (CLEVRER), where gains were negligible. This further emphasizes that prompt-based symbolic feedback is highly task-dependent and may fail to transfer to domains requiring rich spatiotemporal understanding and continuous dynamics.
Overall, our results highlight boundary conditions for metatuning: it is best viewed as a tool for improving weaker baselines and for domains with crisp, symbolic structure, rather than a universal method that consistently improves strong reasoning traces or dynamic visual reasoning. A key direction for future work is to incorporate feedback at the level of the reasoning process—for example, having the judge critique and correct intermediate CoT traces rather than only the final answer—and to replicate these findings across additional candidate models. We also see representation probing as an important future step for evaluating stronger claims about grounding/alignment that go beyond the operational framing adopted here.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix A. LLM Reasoning: Pre- and Postmetatuning
This appendix presents examples of problems along with the corresponding reasoning and answers generated by GPT-4o and Gemini 1.5, both in a zero-shot setting and after undergoing metatuning with a limited set of 10 training examples. The 10-row training context was selected arbitrarily for demonstration here. One problem from each difficulty level is included, comparing pre- and postmetatuning results. Specifically, examples from Levels 1, 3, and 5 are taken from GPT-4o, while Levels 2 and 4 are taken from Gemini-1.5-flash. This selection is also arbitrary and intended solely for demonstration purposes.
The distribution of problems where a 10-row context training produced the correct result only after metatuning is shown here in Figure 1.
Note that neither GPT4o nor Gemini has reasoning models. In the prompt, it was asked of both models to provide reasoning as well as the final answer.
Appendix B. Discussion
The results demonstrate how metatuning helps align LLMs with correct mathematical reasoning to arrive at the correct solution by leveraging a small set of training data in the context window.