
Abstract
This work compares large language models (LLMs) and neuro-symbolic approaches in solving Raven’s progressive matrices (RPMs), a visual abstract reasoning test that involves the understanding of mathematical rules such as progression or arithmetic addition. Providing the visual attributes directly as textual prompts, which assumes an oracle visual perception module, allows us to measure the model’s abstract reasoning capability in isolation. Despite providing such compositionally-structured representations from the oracle visual perception and advanced prompting techniques, both GPT-4 and Llama-3 70B cannot achieve perfect accuracy on the
Introduction
Abstract reasoning is often regarded as a core feature of human intelligence. This cognitive process involves abstracting rules from observed patterns in a source domain, and applying them in an unseen target domain. With the ultimate aim of achieving human-level intelligence, abstract reasoning tasks have sparked the interest of many in machine learning research. Thanks to the availability of large datasets (Barrett et al., 2018; Hu et al., 2021; Zhang et al., 2019), various learning-based methods, ranging from pure connectionist (Benny et al., 2021; Wu et al., 2020) to neuro-symbolic (Camposampiero et al., 2024; Hersche et al., 2023a, 2023b; Sun et al., 2025; Zhang et al., 2021, 2022) approaches, achieved promising results in this domain.

This work compares the abstract reasoning capabilities of large language models (LLMs) and neuro-symbolic abductive rule learner with context-awareness (ARLC) on Raven’s progressive matrices (RPMs) tests. (a) An RPM example taken from the
More recently, the zero- and few-shot capabilities of large language models (LLMs) and their multi-modal variants have been tested on various abstract reasoning tasks such as verbal (Gendron et al., 2024; Lewis & Mitchell, 2025; Stevenson et al., 2023; Webb et al., 2023) or visual (Ahrabian et al., 2024; Camposampiero et al., 2023; Cao et al., 2024; Hu et al., 2023; Jiang et al., 2024; Latif et al., 2024; Lewis & Mitchell, 2025; Mitchell et al., 2024; Webb et al., 2023; Wüst et al., 2024; Zhang et al., 2024) analogies. One natural approach towards zero-shot visual abstract reasoning is to leverage multi-modal LLM’s vision capabilities to solve the task end-to-end. However, these multi-modal models perform significantly worse than their text-only version (Mitchell et al., 2024), which might stem from a missing fine-grained compositional feature comprehension (Cao et al., 2024). As an additional help, LLMs have been provided with text-only inputs by giving them access to an oracle perception, that is, providing perfectly disentangled representations (Hu et al., 2023; Webb et al., 2023). While this generally improves their reasoning abilities, LLMs still fail to achieve perfect accuracy on many simple tasks. One example is represented by Raven’s progressive matrices (RPMs) (Raven et al., 1938), a benchmark that tests visual abstract reasoning capabilities by measuring the fluid intelligence of humans. Here, the state-of-the-art (SOTA) LLM-based approach (Hu et al., 2023) achieves only 86.4% accuracy in the
This article extends on the initial work on ARLC (Camposampiero et al., 2024), by comparing its abstract reasoning capability with two prominent LLMs (GPT-4 (Achiam et al., 2024) and Llama-3 70B (Dubey et al., 2024)) (see Figure 1). Circumventing the perception by providing ground-truth attribute labels to the models allows us to measure their analogical and mathematical reasoning capabilities in isolation. Hence, we evaluate the reasoning capabilities of LLMs under conditions that play to their strengths, namely, language understanding, when such compositionally structured (i.e., disentangled) representations are provided. Our comprehensive prompting efforts lead to very high accuracy for Llama-3 70B (85.0%) and GPT-4 (93.2%), where the latter notably outperforms previous reports with GPT-3 (Hu et al., 2023) (86.4%) and GPT-4 o1-preview (Latif et al., 2024) (18.00%). This LLM’s imperfect accuracy on the isolated task motivated us to further analyze their capability of detecting and executing different rules. In both GPT-4 and Llama-3 70B, we find a notable weakness in performing arithmetic rules that require row-wise additions or subtractions (e.g., see the last prompt in Figure 2). To gain more insight about this behavior, we set up a new RPM dataset (I-RAVEN-X) that increases the grid size from 3
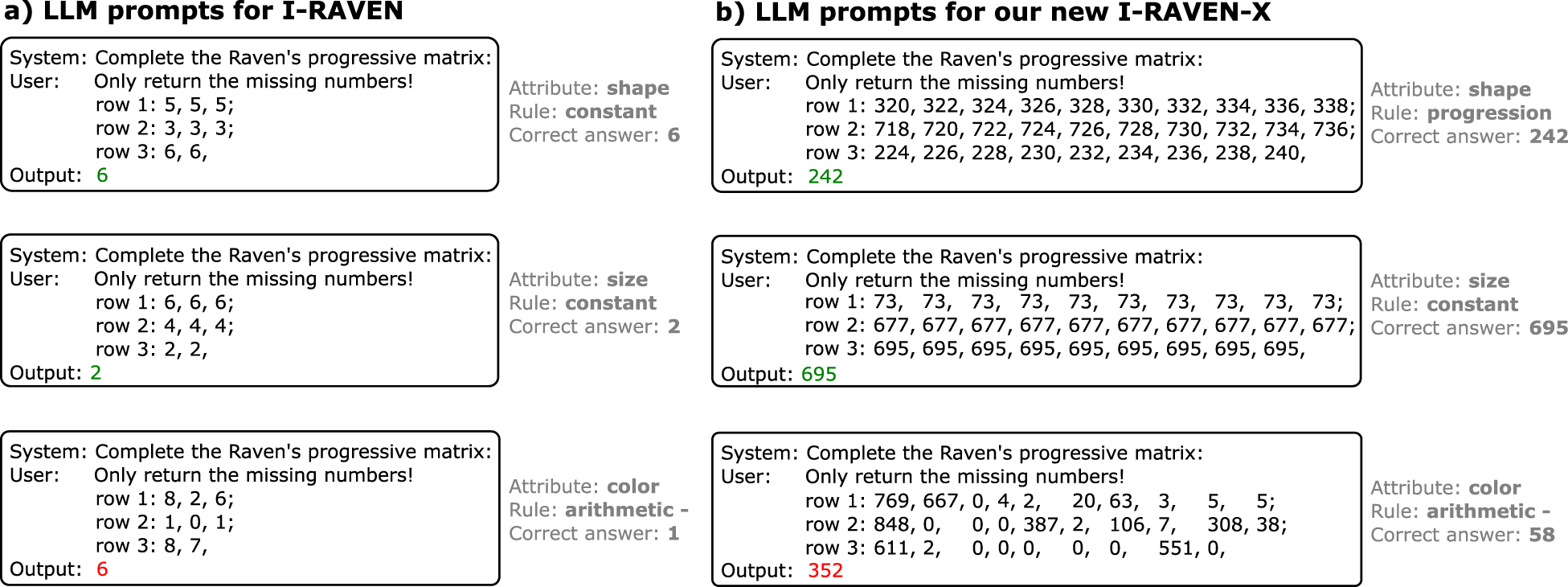
(a) Individual per-attribute text-only prompts to solve Raven’s progressive matrices (RPMs) tasks from I-RAVEN. (b) Example prompts with of our novel configurable I-RAVEN-X dataset of size 3
I-RAVEN
We test the models on the
The task is to infer the rule governing each attribute in the context matrix and use it to determine the content of the missing (bottom-right) panel, selecting it within the eight candidate answers. Compared to other RPMs benchmarks that have been used to evaluate LLMs (Webb et al., 2023), I-RAVEN tests a more comprehensive range of logical and arithmetic skills. While I-RAVEN provides tests in various constellations with more objects that may intuitively appear more arduous to solve, LLMs are more challenged with the seemingly simple constellations. For instance, GPT-3 achieved a higher accuracy on the
To further evaluate the mathematical reasoning capabilities at scale, we introduce an extension of the I-RAVEN’s
Finally, we generate the candidate answers using I-RAVEN’s attribute bisection tree (Hu et al., 2021). The original RAVEN dataset had a flaw in the generation of the answer set. Each distractor in the answer set (i.e., a wrong answer candidate) was generated by randomly altering one attribute of the correct answer. As a result, one could predict the correct answer by taking the mode of the answer candidates without looking at the context matrix, therefore bypassing the actual reasoning task. As a remedy, the attribute bisection tree generates unbiased answers that are well balanced. Figure 2(b) shows example prompts generated from samples of our new dataset.
Models
We focused our evaluations on text-only LLMs. There exist attempts (Ahrabian et al., 2024; Cao et al., 2024; Jiang et al., 2024; Mitchell et al., 2024; Zhang et al., 2024) that leverage vision support of multi-modal LLMs (e.g., GPT-4V) directly feeding the models with visual RPMs data; however, they achieve consistently lower reasoning performance than with text-only prompting. The SOTA LLM-based abstract reasoning approach (Hu et al., 2023) relied on reading out GPT-3’s (
Prompting and Classification
Entangled and disentangled prompts
Following (Hu et al., 2023), we use numerical descriptions of the attribute values that has lead to better performance than textual descriptions (Latif et al., 2024). Moreover, we evaluate two different prompting strategies, entangled and disentangled prompting. The entangled prompting provides all the attributes’ values in a single prompt (see Appendix A.1). The disentangled prompting, on the other hand, is a compositionally structured approach that queries the LLM for individual attribute prediction. Disentangled prompting simplifies the task, but increases the number of queries by 3
Discriminative and predictive classification
Similarly to (Gendron et al., 2024), we consider two approaches to solve RPM tests with LLMs. In the discriminative approach, we provide the attribute descriptions of both the context matrix and the answer candidates. The LLM is then asked to return the panel number of the predicted answer. Appendix A.2 provides an example prompt of the discriminative approach. In the predictive approach, we prompt the LLM only with the context matrix without the candidate answers. The LLM has to predict the value of the empty panel (see Figure 2). For selecting the final answer, we compare the predicted values with the answer panels and pick the one with the highest number of overlapping values. While the predictive approach may appear more difficult, it implicitly biases the LLM to approach the task as humans usually do, that is, first applying a generative process to abduce rules and execute them to synthesize a possible solution, and then discriminatively selecting the most similar answer from choices (Holyoak & Morrison, 2013). Moreover, the final answer selection is done without the intervention of the LLM, rendering phenomena like hallucinations less likely. Thus, the predictive classification can be seen as a more guided approach that helps LLM to solve the task.
Self-consistency
As an optional extension, we employ self-consistency (Lewkowycz et al., 2022; Wang et al., 2023) by querying the model multiple times (
In-context learning
For a better understanding of the RPM task, we optionally prefix 16 in-context examples to the prompt (Brown et al., 2020). In the predictive classification approach (where no answer candidates are provided), we simply provide complete example RPMs. The in-context samples are randomly selected from I-RAVEN’s training set. Examples that had the same context matrix as the actual task are discarded and re-sampled to prevent shortcut solutions.
ARLC: Learning Abductive Reasoning Using VSA Distributed Representations
This section presents the ARLC, which performs neuro-symbolic reasoning with distributed VSA representations (see Figure 3). ARLC projects each panel’s attribute value (or distributions of values) into a high-dimensional VSA space. The resulting VSA vectors preserve the semantic similarity between attribute values: the dot products between corresponding VSA encoded vectors define a similarity kernel (Frady et al., 2022; Plate, 2003). Moreover, simple component-wise operations on these vectors, binding and unbinding, perform addition and subtraction, respectively, on the encoded values. For rule learning, ARLC introduces a generic rule template with several terms forming a series of binding and unbinding operations between vectors. The problem of learning the rules from data is reduced to a differentiable assignment problem between the terms of the general rule template and the VSA vectors encoding the contents of the panels, which can be learned with standard SGD. ARLC was initially presented by Camposampiero et al. (2024); this work mainly compares it to the reasoning capabilities of LLMs on I-RAVEN, and demonstrates its extension to larger grid sizes and dynamic ranges on our novel I-RAVEN-X.

ARLC architecture. ARLC maps attribute values, or distributions of values, to distributed VSA representations, where the semantic similarity between values is preserved via a notion of kernel. Learnable rules (
ARLC’s key concept is to represent attribute values with high-dimensional, distributed VSA vectors that preserve the semantic similarity between the attribute values thanks to an introduced kernel notion. We start by defining a VSA that equips the space with dimensionality-preserving vector operations. Bundling (
Specifically, ARLC uses binary generalized sparse block codes (GSBCs) (Hersche et al., 2024) as a particular VSA instance. In binary GSBCs, the
Supported VSA Operations and Their Equivalent in
.

Supported VSA Operations and Their Equivalent in
VSA = vector-symbolic architecture; GSBCs = generalized sparse block codes; FPE = fractional power encoding.
Next, we define a mapping 
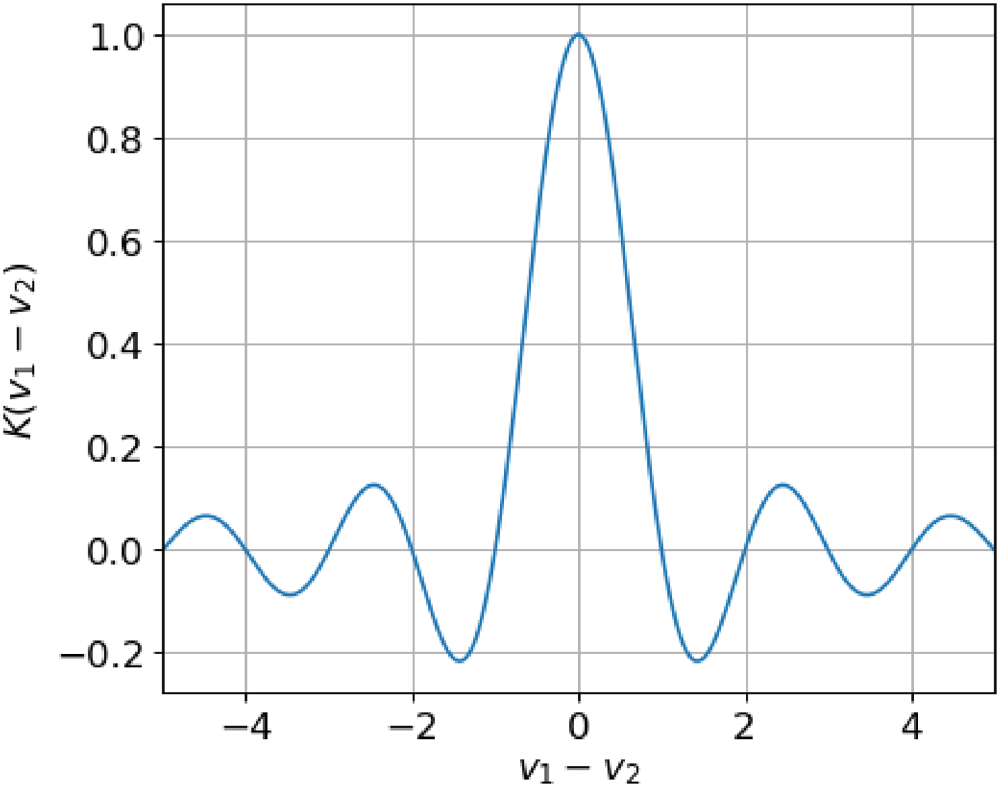
Similarity kernel in VSA. Mapping two values (
Let us assume two variables with values
One advantage of performing reasoning with distributed VSA representations is its capability to represent perceptual uncertainty in the variable values. Connecting to the previous example, let us assume that the first variable takes value 

In the RPM application, each panel’s label is translated to a PMF 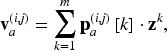

Here we introduce a general framework for interpreting RPM rule learning as an assignment problem, where VSA vectors are mapped to placeholders in a rule expression composed of binding and unbinding operations. The previous example demonstrates that executing the 

Motivated by works in cognitive sciences and psychology that argue for the importance of context in the solution of analogies for humans (Chalmers et al., 1992; Cheng, 1990), ARLC uses a general formulation of the soft-assignment problem which relies on the notion of context:



Visualization of current samples (
ARLC learns a set of 

We follow the training recipe provided by Learn-VRF (Hersche et al., 2023a). The model is trained using SGD with a learning rate 
As in Learn-VRF, we set the number of rules to
While ARLC was initially designed for I-RAVEN, it can be seamlessly extended to our I-RAVEN-X with minor modifications. First, the number of binding/unbinding terms in equation (4) is increased, for example, from 12 to 22 to support the larger grid size of
Results
Main Results on I-RAVEN
Table 2 compares our LLM results with ARLC on the
Task Accuracy (%) on the Center Constellation of I-RAVEN.

Task Accuracy (%) on the
Among the baselines, we replicate Learn-VRF (Hersche et al., 2023a); the other results are taken from (Hersche et al., 2023b). The standard deviations are reported over 10 random seeds. Llama-3 and GPT-4 are queried with the corresponding best prompting technique (see Table 3). ARLC’s weights are either manually programmed (
Among the LLM approaches, our GPT-4-based approach achieved the highest accuracy (93.2%) notably outperforming previous SOTA LLM-based abstract reasoning approaches on this benchmark (86.4%) (Hu et al., 2023). Yet, all LLM approaches fall behind the tailored connectionist and neuro-symbolic solutions. Notably, with only 480 learnable parameters, ARLC achieves a high accuracy of 98.4%. Moreover, we show that post-programming training allows for maintaining the knowledge of the model, rather than completely erasing it as shown in other settings (Wu et al., 2019).
Table 3 shows the task accuracy on I-RAVEN using GPT-4 and Llama-3 70B in various prompting configurations. Overall, both models benefit from the additional guidance provided by our prompting techniques. Concretely, using a predictive approach and querying for individual disentangled attributes yielded already high accuracies (91.4% and 83.2% for GPT-4 and Llama-3 70B, respectively). Introducing self-consistency further improves the accuracy for both models. Llama-3 70B’s performance can be further pushed (to 85.0%) by using self-consistency and in-context learning. On the contrary, GPT-4 cannot make use of the additional in-context samples, yielding a lower accuracy instead. Indeed, recent work on LLM reasoning models (Guo et al., 2025) made a similar observation, where “few-shot prompting consistently degrades its performance.” To test the potential impact of instruction-tuning, we conducted experiments with Llama 3 70B Instruct. We found that the instruction-tuned model generally performs worse, achieving 64.6% and 79.2% with and without in-context learning, respectively. We leave the exploration of finding an optimized set and sequence of in-context examples, which has been shown to improve the performance of instruction-tuned models (Liu et al., 2024), for future work.
Ablation Study Considering Various LLM Prompting techniques. We Report the Task Accuracy (%) on the Center Constellation of I-RAVEN.

Ablation Study Considering Various LLM Prompting techniques. We Report the Task Accuracy (%) on the
LLM = large language models.
Even though both LLMs achieve a reasonable overall task accuracy, they fail in some instances. We shed more light on the reasoning capability of the two models by analyzing the accuracy of predicting the correct value for a given rule. As shown in Table 4, both models perform well on
Accuracy (%) of Predicting the Correct Attribute Value.

Accuracy (%) of Predicting the Correct Attribute Value.
Self-consistency (n=7) is used. Results are averaged across all attributes.
Finally, we conduct experiments on our novel I-RAVEN-X test, which allows us to configure the matrix size and the dynamic range of the attribute values. We fix the grid size to
Task Accuracy (%) on I-RAVEN and Our Novel I-RAVEN-X.

Task Accuracy (%) on I-RAVEN and Our Novel I-RAVEN-X.
The large language models (LLMs) use self-consistency (n=7). For ARLC
Arithmetic Accuracy (%) on I-RAVEN and Our Novel I-RAVEN-X.

The large language models (LLMs) use self-consistency (n=7). For ARLC
This work revealed LLM’s limitations in recognizing and executing arithmetic rules in abstract reasoning tasks, despite being provided disentangled prompts with ground-truth visual attributes and using advanced prompting techniques. We further showed the serious limitation on a larger (3
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix A Prompting Details
This appendix provides more details on our prompting strategy. While the prompt design was mainly inspired by Hu et al. (2023), we extended it with predictive and discriminative classification and fine-tuned it for the different models. For example, we found that adding a prefix (“Only return the missing number”) helped to slightly improve GPT4’s accuracy, whereas it reduced Llama-3 70B’s performance. Thus, we used individual prompts for the different models.