
Abstract
Can artificial intelligence provide the reasonable justifications required in judicial opinions? This study uses a survey experiment to examine how the public perceives AI-generated judicial reasoning. Results show that participants are unable to distinguish between AI-generated and judge-authored opinions, with detection accuracy at near-perfect chance; this finding holds even among participants who work in law-related fields or who have received legal education. In blinded tests, AI-generated reasoning is rated as equal in adequacy and quality to human output. However, once an opinion is identified as AI-generated, its perceived quality declines. We also find mixed evidence of a contamination effect, where the potential involvement of AI diminishes the perceived quality of actual judge-written opinions. Exploratory analysis suggests that people’s skepticism towards AI’s participation in the judicial process stems from concerns about procedural fairness as well as doubts about AI’s capability. These findings underscore the potential risks that AI involvement could pose to judicial credibility.
1. Introduction
Courts worldwide are exploring the integration of large language models (LLMs) into their decision-making processes. However, the impact of the assistance of artificial intelligence (AI) on public perception of judicial decision-making remains largely unknown. This issue is particularly critical as public responses to AI participation in the judicial system are typically the primary concerns that courts encounter when introducing AI technology. For example, the Shenzhen court in China is arguably the first in the world to systematically utilize LLMs in drafting judicial opinions (Liu & Li, 2024). In its public communications, the court appears highly concerned about potential public backlash and controversy. In official reports, the court has repeatedly highlighted that machines only assist but do not override judicial decision-making. 1 A similar emphasis on upholding the authority of human judgment can be seen in the Brazilian audit court, which integrates an LLM in its initial report drafting processes (Pereira et al., 2024). In the United States, scholars have begun to warn that LLMs may enable judges to employ artificially enhanced rhetoric to bolster their own legitimacy, while members of the public will grow more cynical in order to avoid being misled (Re, 2024), and that LLMs make judges engage in “reasoning” in a procedurally illegitimate sense (Grimmelmann et al., 2025).
Focusing on public perceptions is essential because judicial reasoning serves a dual function: it is both a technical legal justification and a public-facing act of legitimacy-building. Courts rely on “diffuse support”—the general public’s willingness to accept the court’s authority (Tyler, 2006). In an era of mass digital transparency, the audience for judicial work has included not only a narrow circle of legal experts but also the broader citizenry. As court opinions become matters of public record, the persuasiveness of these documents to the average citizen becomes a vital component of institutional authority.
This article addresses two questions: first, whether the public can accurately differentiate between AI-generated judicial opinions and those authored by human judges; and second, whether the involvement of AI impacts individuals’ perceptions of the quality of judicial opinions.
To answer these questions, we conducted an experiment with participants from China involving five actual litigation cases covering civil, criminal, and administrative law. Each participant was assigned to read one case and evaluate the quality of the judicial opinion. The reasoning section in each opinion was from one of two different sources: one was extracted directly from the original judicial documents, while the other was generated by an LLM.
The experiment was divided into three branches: the control branch, the AI treatment branch, and the AI-or-human treatment branch. In the control branch, participants (N = 1,000) were randomly assigned to groups that were presented with either AI-generated or human judge-written reasoning. However, they were unaware that the reasoning they were evaluating could possibly be written by AI. We found no statistically significant difference in quality rating between these two groups.
In the AI treatment branch, participants (N = 500) were informed about the existence and application of a generative AI (LLM) in China that assists judges in making judgments and reasoning. They were also told that the reasoning they read was AI-written. The results suggested that participants rated the quality of the judicial opinions lower than those in the control branch.
In the AI-or-human treatment branch, participants were similarly informed about the implementation of generative AI in actual judicial decision-making. They were randomly assigned to groups that were presented with either AI-generated or human-written reasoning, and asked to identify whether the reasoning they read was written by a judge or generated by AI. The accuracy of their identifications was no better than chance, with an accuracy rate of 49.8% (
Together, the results demonstrate an AI penalty in judicial reasoning. The public cannot reliably distinguish between AI-generated and human-authored judicial opinions. However, they tend to be skeptical about judicial opinions written by AI. This skepticism also appears to extend to human-written judicial decisions once participants are aware that AI could potentially be involved in formulating such opinions.
These findings contribute to existing literature in several ways. First, with the increasing integration of AI into legal practices, there are growing concerns about the potential risks that AI may introduce to legal works, most notably in judicial decision-making. An important line of research has focused on algorithmic biases, including but not limited to disparities related to race and gender (Angwin et al., 2016; Dressel & Farid, 2018; Kotek et al., 2023; Starr, 2014). That is, the training data or the inherent process of model-building has the potential to embed biases, which can in turn influence judicial decisions. Our research investigates a related, yet largely uncharted issue: Even when the outcomes generated by AI models are free from biases and commensurate with the performance of human judges, a pervasive skepticism persists regarding the involvement of AI in judicial decision-making. This skepticism directly influences public assessment of judicial reasoning.
Second, research has demonstrated a perceived human-AI fairness gap in “robot courts,” where citizens intuitively view machine presiding over court proceedings and making judgments as less fair than the human-adjudicated status quo (Chen, Stremitzer, & Tobia, 2022). This research can be seen as a natural extension to “algorithm aversion,” particularly within “human-centric” domains where individuals typically tend to value empathy and intuition over machines’ opaque decision logic (Castelo et al., 2019; Jussupow et al., 2020; Logg et al., 2019). However, the displacement of human adjudication with AI remains a futuristic, if not unlikely, prospect (Wu, 2019). For most decision-making tasks in the law, it is highly improbable that machines will take over. Much more practical is that the ultimate choice and responsibility remain with a human decision-maker, but that she is provided with machine assistance. Moreover, compared to other studies on human-machine interactions in the law (Grgic-Hlaca et al., 2018; Grgić-Hlača et al., 2019), the sequence of the human-machine interaction is different in the present study as it is not a human deciding with machine recommendation, but a machine generating reasoning based on a human preliminary ruling. We believe that this represents a distinct and understudied paradigm that warrants attention. Our research extends the perceived fairness gap literature to a more realistic setting, and answers the more pressing question of whether AI assistance in judicial opinion writing triggers public backlash.
Third, recent research has also shown that generative AI can significantly improve the accessibility of the law for laypeople. For instance, AI-generated simplified summaries of judicial opinions have been found to be more easily understood and more highly rated by non-experts than expert-written summaries (Ash et al., 2024). Our study identifies a critical boundary to this acceptance. While the public may value AI for its utility in summarizing or explaining complex texts, they exhibit significant aversion when AI is used for the normative task of reasoning. This aligns with the distinction between “objective” and “subjective” algorithm aversion: laypeople may appreciate AI as a tool for linguistic simplification, yet still penalize it as a source of judicial authority. Our research focuses on this latter, more high-stakes domain—judicial justification—and demonstrates that the perceived quality of legal reasoning remains deeply tied to its human origin.
Fourth, the findings of this paper also contribute to the broader literature examining the capabilities of generative AI, particularly LLMs. Generative language algorithms have made significant progress towards human-level performance. As technologies continue to evolve, researchers across fields have found that distinguishing AI-generated text from human-authored content has become increasingly difficult. For instance, AI-generated poetry is indistinguishable from human-written poetry and often rated more favorably (Porter & Machery, 2024), and AI-generated humor is rated as funny as human-generated jokes (Gorenz & Schwarz, 2024). Despite this, studies have consistently found a bias against AI-generated content: when told that an artwork or a poem is AI-generated, participants rate the work as lower quality (Bellaiche et al., 2023; Ragot et al., 2020). Typically, this previous literature concentrates on low-stakes decision-making scenarios, and the practical implications are unclear. Our study focuses on a high-stakes decision-making setting – judicial decision-making, and demonstrates clear real-world consequences – even though AI and human performance can be similar, AI still presents significant risks to judicial practices. Expanding this framework, the contamination effect suggests that AI integration in the judiciary does not merely trigger a preference for human output, but can devalue human labor and undermine the broader institutional credibility of the justice system.
The remainder of the article proceeds as follows. Section 2 introduces the background and literature. Section 3 introduces experiment design. Section 4 presents experiment results. Section 5 discusses the limitations of the experiment and the implications of the findings.
2. Background, Literature, and Hypothesis
The rapid development of AI technologies has sparked strong interest in the field of law. In the past, the quintessential example of AI’s legal application was its use in the decision of a judge to bail or jail a defendant. For example, in multiple jurisdictions in the US, judges have access to a machine prediction about a defendant’s recidivism risk (Dressel & Farid, 2018). Compared to machine predictions of a specific probability (recidivism, flee, conviction, etc.), LLMs provide a different type of intelligence—reasoning. Initial studies on LLMs in the law have predominantly centered around their application in scenarios such as law school exams, bar exams, addressing legal queries, or engaging in contract and legal interpretation (Blair-Stanek et al., 2023; Choi et al., 2021; Choi & Schwarcz, 2023; Hoffman & Arbel, 2024).
Beginning in 2024, courts in China and Brazil commenced integrating LLMs into their workflow (Liu & Li, 2024; Pereira et al., 2024). Particularly in China, the Shenzhen court extensively utilized an LLM to assist in drafting judicial opinions. The interaction between judges and this generative AI can be summarized as three key steps: first, judges make preliminary decisions; second, the LLM generates reasoning based on these decisions; finally, judges refine the AI-generated reasoning to deliver the final judgment (Liu & Li, 2024). In essence, AI has taken over a portion of the judges’ task of writing reasoning. While judges typically had to draft their own reasoning in the past, the advent of AI now allows them to merely tweak the drafted reasoning provided by machines.
At first reading, this collaboration promises an improvement in decision quality. Before making the final decision, judges have access to advice – drafting of reasons. The advice from the machine exploits the comparative advantages of machines over humans. The advice may for instance use a much larger training dataset (e.g., law, regulations, and precedents) that far surpasses what any individual judge could assimilate within a single lifetime. Moreover, the automation process streamlines the writing for judges, thereby freeing up more time for them to engage in thorough deliberation and reach informed decisions on the substantive matters of the case.
However, there are reasons to expect that the use of AI to assist or replace human judges in writing reasoning could potentially trigger public backlash.
A substantial literature in judgment and decision-making documents widespread distrust of algorithmic outputs, often labeled “algorithm aversion.” In a seminal study, Dietvorst et al. (2015) show that people lose confidence in an algorithm more quickly than in a human after observing both make the same mistake (Dietvorst et al. 2015). At the same time, other work finds the opposite pattern—“algorithm appreciation”—where individuals place greater weight on advice when they believe it comes from an algorithm rather than a person (Logg et al., 2019). The difference seems to lie in whether a task is perceived as “objective” or “subjective.” Research indicates that people are more likely to trust algorithms for “objective” tasks—those involving numbers, logic, and predictable data. Conversely, they exhibit aversion when a task is perceived as “subjective,” requiring social intelligence or emotional depth (Castelo et al., 2019). In “human-centric” domains, such as medicine, psychological counseling, and the creative arts, individuals typically tend to value empathy and intuition over mathematical precision. In these fields, the “human touch” is seen as a prerequisite for quality. Law also appears to be such an area. It is a domain where “justice” is not merely a calculation of statutes, but a complex negotiation of morality, social norms, and equity. It is thus natural to think there will be machine aversion in the field of judicial work.
Two strands of legal theory are particularly relevant to the use of AI in drafting judicial opinions. First, AI reasoning can be perceived as a negative signal of decision quality, insofar as it can reduce judges’ own effort in crafting the reasoning and, in turn, their opportunity to critically reflect on the decision. Legal practitioners have long noted that the articulation of written reasons helps enhance decision quality (Oldfather, 2007). Reason-giving is described as fostering introspection and reflective thinking, while preventing intuition from dominating the decision-making process. This is often referred to as the “it won’t write” phenomenon, where judges may realize that their initial opinions do not translate effectively into written form (Cohen, 2015; Liu, 2018). The discipline of crafting a written opinion thus serves as a crucial check on judicial arbitrariness, as it ensures a thoughtful review of facts and legal implications in a case, reducing snap judgments and lazy theorizing (Cohen, 2015; Waits, 1983). The act of writing can also lead to insights that may not have been apparent through mental contemplation alone (Posner, 1995). If AI takes over a significant portion of this reasoning process, it may diminish the role of reason-giving as a cognitive discipline for judges, potentially increasing the risk that decisions lack the depth and scrutiny ordinarily produced by writing.
Second, AI involvement in drafting opinions may undermine perceptions of procedural fairness. Legal scholars have long posited that the court system’s primary justification lies in providing a sense of procedural fairness to participants (Tyler, 2006). Empirical studies conducted by Tyler and his colleagues indicate that when litigants feel that they are treated with respect, they tend to be more accepting of decisions, even adverse outcomes (Lind & Tyler, 1988). Procedural fairness is considered a clear advantage that human judges hold as compared to their artificial counterparts (Wu, 2019). People tend to endorse a procedure as fair if decisions are openly justified. By giving reasons, decision-makers reassure the parties that they have acted on the presented viewpoints in an impartial and unbiased manner. Indeed, reasoned elaboration is a cornerstone of any judicial system (Rawls, 1993; Schauer, 1994; Sunstein, 2007). Reason-giving limits judicial discretion by ensuring that written decisions can be read and reviewed (Shapiro, 1987). It encourages public monitoring and participation in the judicial decision-making process (Eisenberg, 1978; Fuller 1978). Henry Hart and Albert Sacks (Hart & Sacks, 1958, pp. 147–48) famously argue that “reasoned elaboration” distinguishes judicial decision making from an exercise in “discretionary fiat.” In Law’s Empire, Ronald Dworkin (Dworkin, 1986, pp. 94–96) describes reasoning as a source of integrity in law. Against this backdrop, delegating opinion drafting to AI may be seen as inconsistent with the seriousness, attention, and respect that proper judicial deliberation demands, thereby weakening perceptions of procedural fairness and threatening the perceived integrity of the legal system.
Recent debates about using LLMs for legal and contractual interpretation further underscore these concerns. Grimmelmann, Sobel and Stein (Grimmelmann et al., 2025) compare AI-generated judicial opinions to “Paul the Octopus,” the animal that became famous for “predicting” soccer match outcomes by choosing between food boxes. Even if the octopus—or the AI—often selects the “right” result, it is not engaging in legally meaningful reasoning. In their view, the fluent surface of AI-generated text severs the connection between a legal conclusion and its principled justification. If judges rely on an LLM because it “sounds right” and aligns with their intuitions, they are not truly interpreting the law; they are using a sophisticated mirror to reflect their own biases while outsourcing their judicial responsibilities to a black-box system. Grimmelmann and co-authors conceptualize “reasonableness” in terms of institutional legitimacy and procedural rationality: a result is reasonable only if it emerges from a process that society recognizes as valid legal reasoning—one that involves transparency, accountability, and a duty to give reasons. This perspective naturally suggests that AI-generated reasoning will be evaluated less favorably and trusted less than human-authored opinions, even when the substantive content appears similar.
These debates share a common, largely untested empirical premise: that LLMs can already produce judicial reasoning comparable to that of human judges, and perhaps even enhance or surpass the quality of human-written opinions. For example, Re (Re, 2024) hypothesizes that LLMs may trigger an “arms race” between courts and the public: judges might use AI-boosted rhetoric to shore up their legitimacy, while members of the public grow more skeptical and resistant in an effort not to be misled. Yet this premise about LLMs’ reasoning quality has not been systematically examined. Our first hypothesis addresses this gap:
LLMs can generate judicial opinions that the public evaluates as being of similar quality to those crafted by human judges.
At the same time, the theoretical literature discussed above also implies a systematic preference for human over AI decision-making. Even if AI-authored and human-authored opinions are substantively equivalent, AI authorship may itself depress public acceptance and satisfaction. This leads to our second hypothesis:
Holding the content of an opinion constant, disclosing that it was generated by AI lowers the public’s evaluation of its quality.
If both Hypotheses 1 and 2 are supported, a significant institutional concern arises: if the public cannot distinguish between human and machine output, they may grow suspicious of all judicial reasoning if they believe AI is being used “behind the scenes.” We therefore propose a third hypothesis regarding a contamination or spillover effect:
The “AI penalty” spills over to human-authored opinions: when people are informed that AI may have been involved in drafting judicial opinions, their evaluations of even judge-written opinions will decline.
2.1. A Note on the Chinese Context
Although the Chinese judicial system has distinctive institutional characteristics, it shares with many other systems a strong commitment to persuasive reasoning as a foundation of judicial authority and legitimacy. For decades, Chinese courts have emphasized improving the quality of written opinions. As early as the First Five-Year Reform Program of the People’s Courts (starting in 1999), the Supreme People’s Court (SPC) identified weak judicial reasoning as a systemic problem and called for efforts to “accelerate the reform of written judgments and enhance their quality.” 2 The reform agenda focused on improving overall reasoning.
Importantly, the SPC has consistently treated the audience for judicial opinions as extending beyond the immediate parties to the broader public. The Reform Program explicitly framed judicial opinions as a vehicle for “demonstrating the image of judicial justice to society” and as “vibrant educational materials for the rule of law.” As a result, the challenges of judicial writing—and techniques for making it more persuasive—remain central topics among judges, lawyers, and scholars. 3
Since 2014, with the launch of the China Judgments Online platform, court opinions nationwide have been centralized and made widely accessible (Chen, Liu, & Tang, 2022; Liu et al., 2022). In today’s highly developed media environment, courts are acutely aware that most citizens encounter the judiciary primarily through high-profile cases reported in news and social media. The quality of publicly available reasoning therefore plays a crucial role in shaping societal perceptions of the judiciary and, ultimately, courts’ institutional credibility (Tang & Liu, 2019). Against this backdrop, the introduction of LLMs into judicial opinion drafting in China provides an especially salient context in which to study how AI assistance affects public evaluations of judicial reasoning.
3. Experiment Design
3.1. Overview
We used a survey experiment (including five cases) to answer the above questions. An important caveat is that the experiment was not pre-registered; as such, the analyses and results reported herein should be regarded as exploratory. To cover a broad spectrum of legal domains, the five experimental cases selected for the study spanned civil, criminal, and administrative law cases. The experimental design was between-subject, wherein each participant was assigned to read and analyze one specific case presented with one type of reasoning. The experiment was structured into three distinct branches. The first was the control branch where participants were not informed about the possibility of AI authorship in the reasoning. The second was the AI treatment branch, where participants were explicitly told that the reasoning they were assessing was produced by a LLM. The final was the AI-or-human treatment branch, where participants were informed that the reasoning could be either AI-generated or human-authored, and their task was to discern its origin. In total, there were five experimental conditions, shown in Figure 1. Experiment Design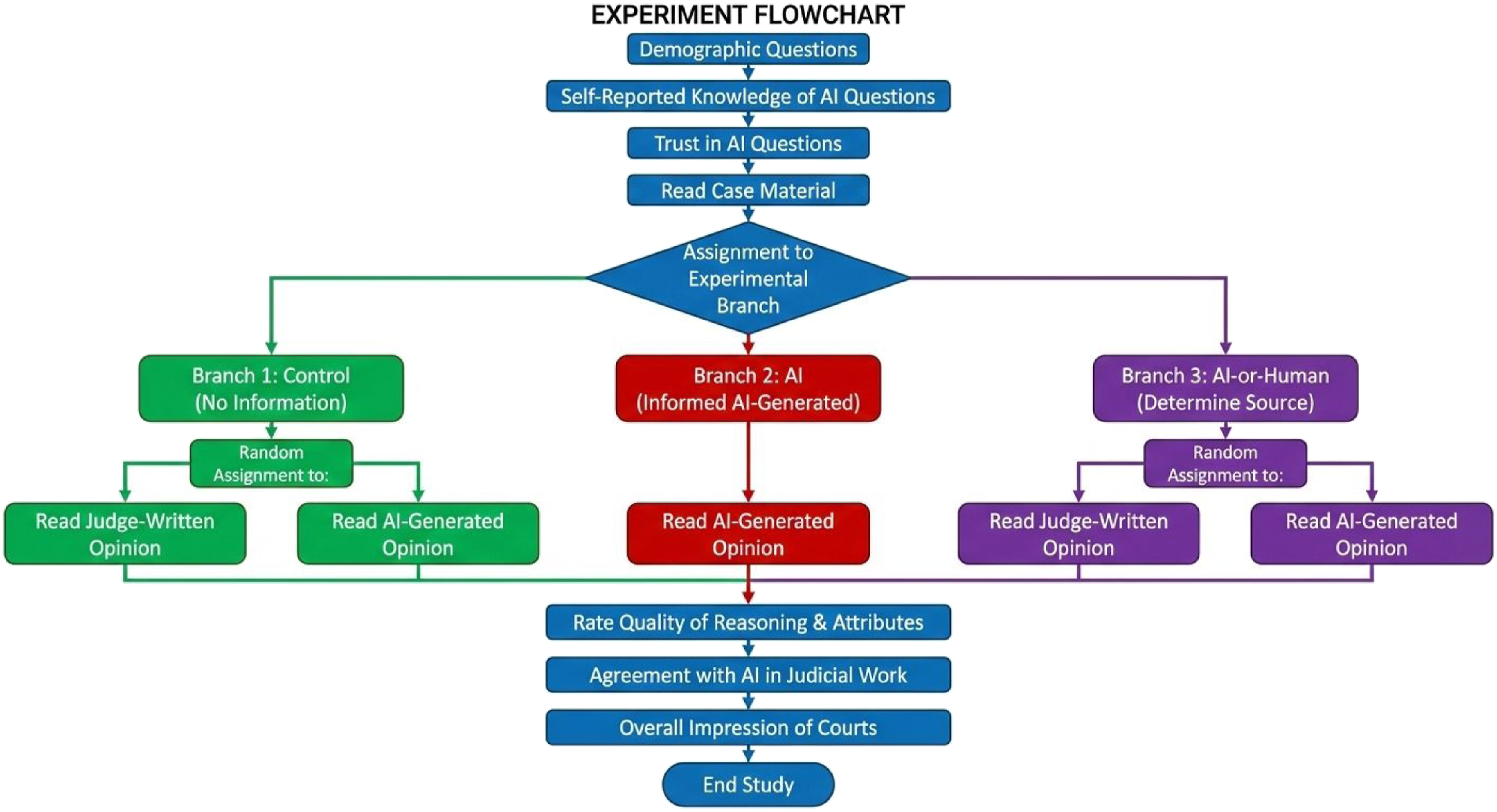
3.2. Setup
We recruited 2,500 experimental participants through Credamo, a Chinese online survey platform. 4 Survey studies that use the Credamo platform to recruit subjects have been published in leading scientific and social science journals such as PNAS (Jin et al., 2024; Lu et al., 2022) and Journal of Consumer Research (Gai & Puntoni, 2021). Credamo’s recruitment mechanism reaches individuals from diverse backgrounds, which enabled us to include some participants with legal education or work experience in law. A key caveat is that this sample is not representative of the general Chinese population. Summary statistics regarding participants’ demographic features can be found in Table A.1 in the Appendix. 5
We randomly assigned 500 subjects to read one of the five cases. Each participant was provided with a case vignette, which was adapted from a real-life litigation case, derived from actual judicial opinions. They were then required to read both the judicial decision and the reasoning related to the case. The reasoning came in two different forms: one was extracted directly from the original judicial opinions, while the other was generated by a popular Chinese LLM, Ernie Bot 3.5 (“wenxin yiyan”).
To ensure ecological validity, we utilized a “Decision-First” prompting strategy that mirrors actual judicial practice in China. In this paradigm, the LLM is provided with the case facts, the human judge’s ruling, and the relevant statutes, and is tasked with generating the justifying reasoning. Crucially, we performed no post-processing or editorial refinements on the AI output. The reasoning evaluated by participants was the direct, raw text generated by the model. While prompts were slightly tailored to the specific facts of each of the five cases to ensure natural legal expression, the underlying instructions remained consistent: the model was directed to match the length and citation density of the original human-authored opinion. Ernie Bot 3.5 is a leading Chinese LLM particularly well-suited for this task due to its extensive training on massive corpus of Chinese texts. The case materials, reasoning, and prompts used to generate the reasoning are in Appendices B and D.
We employed two methods to ensure data quality and assess participants’ attention. First, recognizing that excessively short or long response times often indicate inattention or distraction, we excluded questionnaires with completion times falling outside a pre-defined window of 100 to 1,000 s. The final sample yielded an average completion time of 406 s (SD = 165), suggesting that participants spent sufficient time reviewing the case materials. Second, we included a mandatory numerical attention-check item (6 + 3 × 4 = ?) with four randomly ordered response options. Only participants who answered this item correctly were retained for analysis, ensuring that the final dataset consists of individuals who were actively reading and following instructions.
After going through the reasoning, we asked the participants to rate the extent to which they found the judicial opinions to be sufficient and reasonable (0−100, measuring quality of judicial opinions). They were also asked to evaluate the specific quality attributes of the reasoning. This evaluation included assessing whether the reasoning was logically smooth and clearly organized, whether the language expression was standard and professional, whether the meaning was expressed in a clear and concise manner that was accessible to laypersons, and whether the legal interpretation was reasonable and persuasive (0−100). The experiment instructions can be found in Appendix C (English translation) and Appendix E (Chinese).
In the control branch, participants were randomly assigned to groups that were presented with either AI-generated or human-written reasoning. They were unaware that the reasoning they were evaluating could possibly be written by AI.
In the AI treatment branch, participants were informed that the reasoning they read was AI-written. They were also briefed on the existence and application of a generative AI (large language model) in China, which aids judges in decision-making and reasoning. This introduction was rooted entirely in actual practice (Liu & Li, 2024), aiming to infuse a sense of realism into the exercise. Currently, AI is being applied in many fields, including in court rulings. In our country, generative AI (large language models) has been developed to assist judges in making judgments and reasoning. These AI models have been widely used in actual judicial practice. (For example, see the Supreme Court's report on Shenzhen Court's use of AI to assist in judgments and reasoning: https://www.court.gov.cn/zixun/xiangqing/436981.html). The main function of the large AI model is to generate judicial opinions, especially the reasoning for the judgment (judicial reasoning), based on the preliminary decision given by the judge. Many judges have stated that they now use the AI system to generate judgments and reasoning for each case, and then make modifications themselves.
In the AI-or-human treatment branch, participants were similarly informed about the real-world application of AI that assists judges in making judgments and reasoning. They were then asked to identify whether the reasoning they read was written by a human judge or generated by an AI model. To be clear, the stimulus in the AI-or-human branch was the possibility that the reasoning was AI-generated, coupled with an introduction to the actual implementation of AI in the country’s judicial decision-making process.
We verified random assignments across the three experimental branches and the five experimental groups. As detailed in the balance tests reported in Figure A.1 (Appendix), there were no statistically significant differences between the branches or the groups in terms of participants’ age, gender, educational background, law-related work experience, participation in legal education, or prior litigation experience.
4. Results
4.1. Main Results
4.1.1. Testing Hypothesis 1
Accuracy of Distinguishing Between AI-Generated and Judge-Authored Judicial Opinions
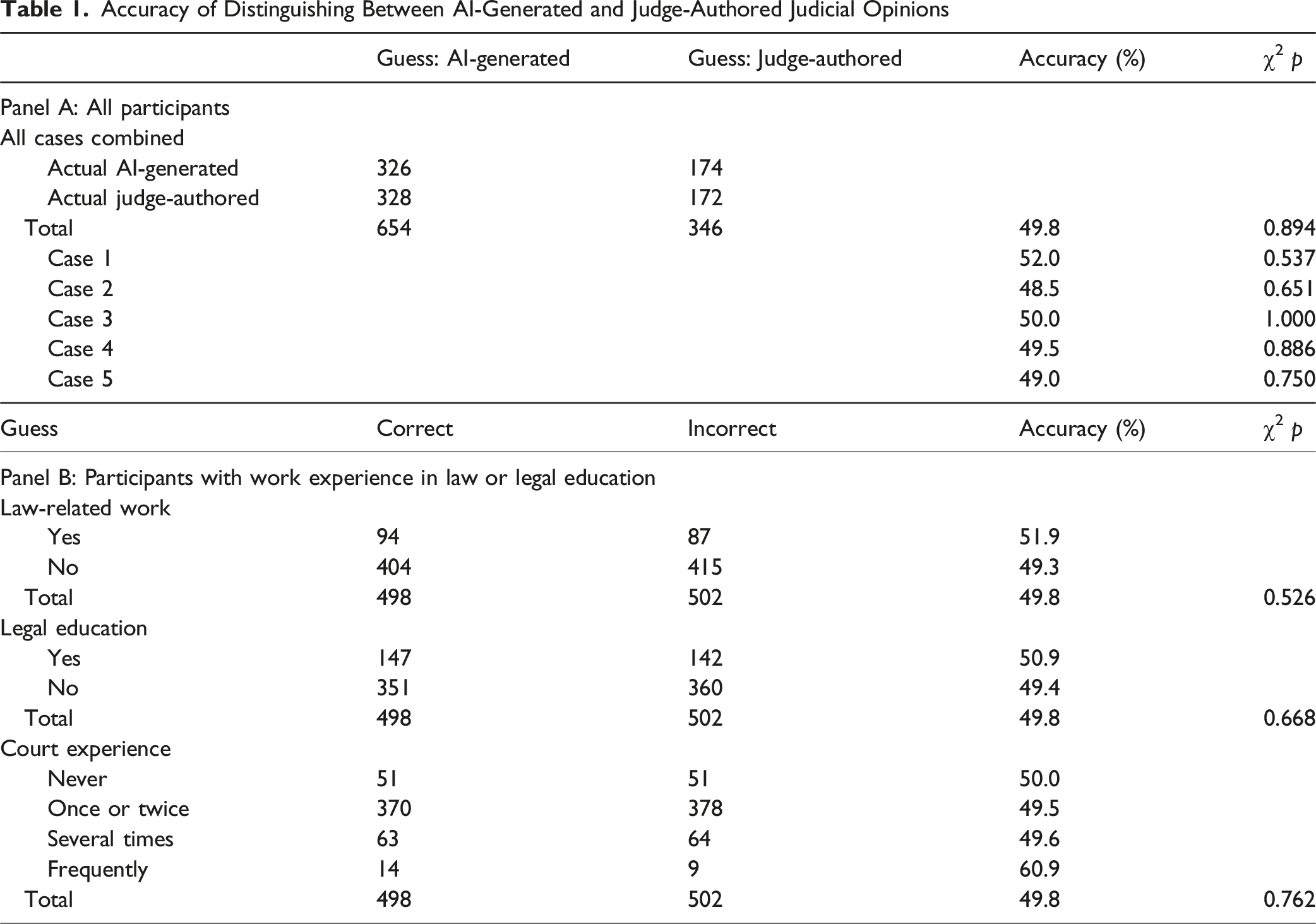
This result holds even among the subset of participants who work in law-related fields or who have received legal education. In the questionnaire, we asked participants: “Are you currently engaged in (or have you ever engaged in) legal work?” “Have you ever systematically studied law?” and “Have you or your family/friends ever interacted with the courts (or judges)?” As shown in Table 1 Panel B, none of these factors significantly improved performance. These results suggest that the generative AI utilized in this study (Ernie Bot 3.5) produces reasoning that is, in practice, indistinguishable from judge-written opinions even to readers with a trained legal eye, although it should be noted that respondents’ actual litigation experience is generally modest.
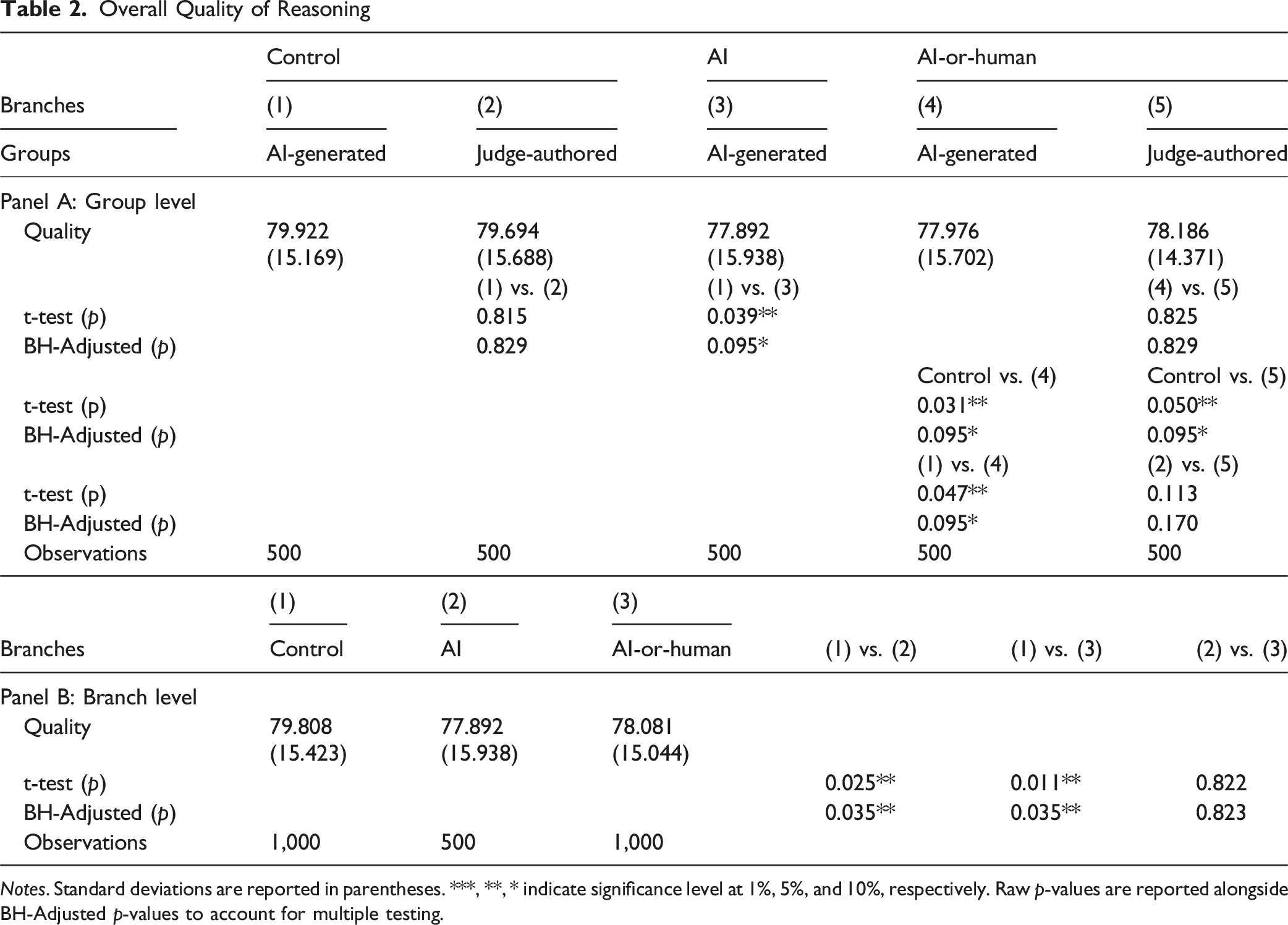
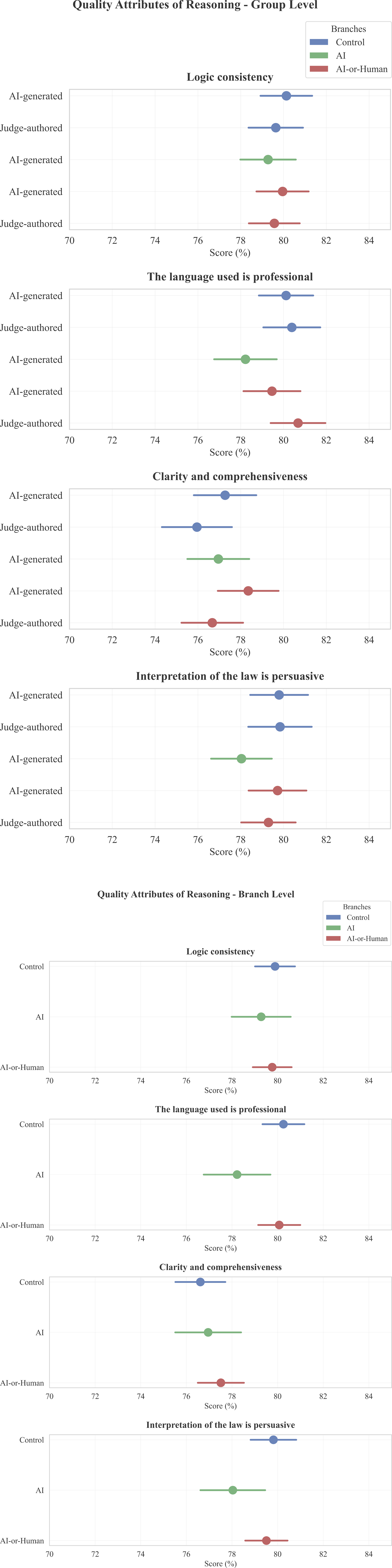
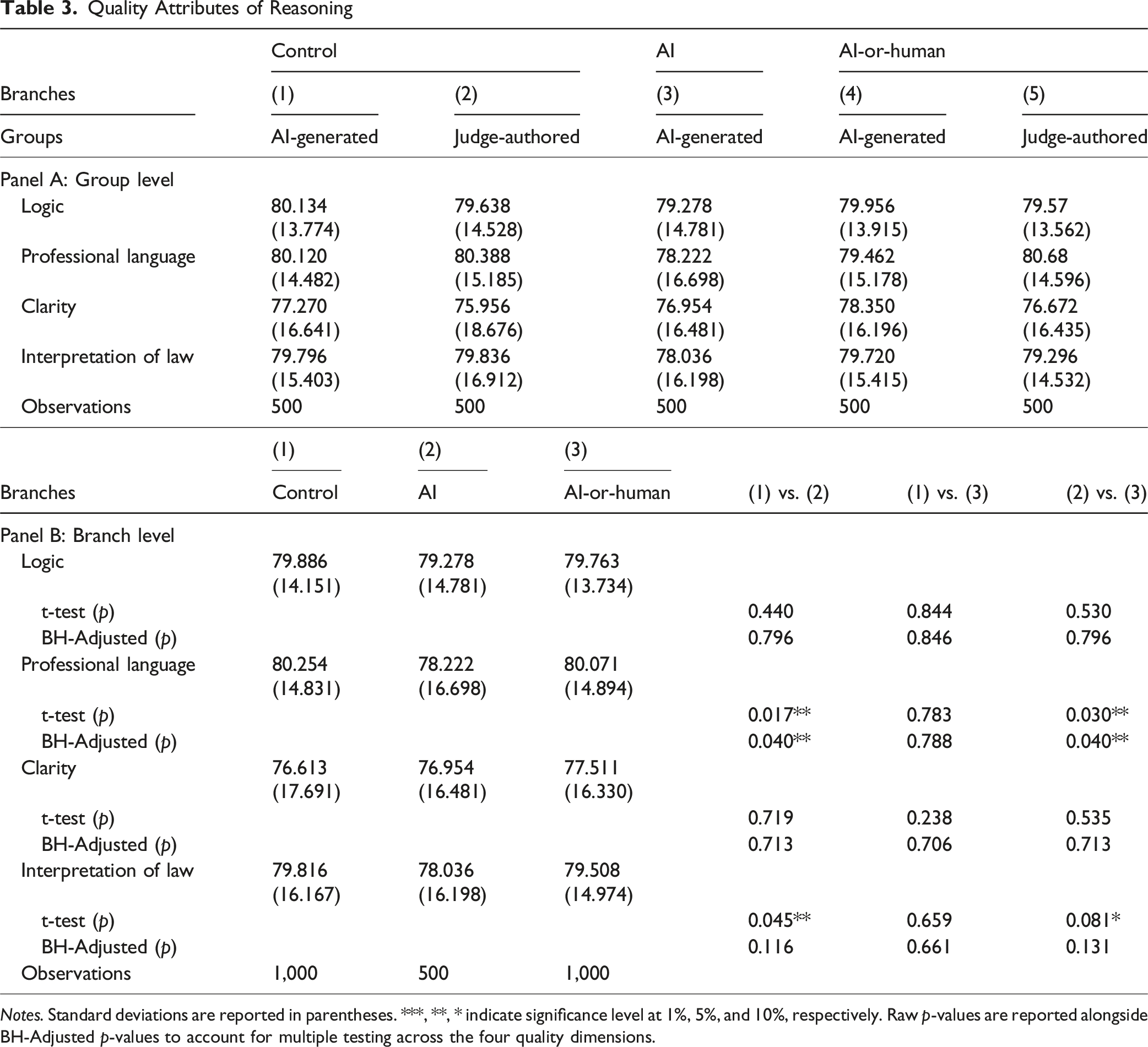
When participants were unaware of the source of the opinions (as in the control branch), we do not find a statistically distinguishable difference in rated quality between AI-generated and human-written judicial opinions (79.922 vs. 79.694, p =.815) as shown in Figure 2 Panel A, and Table 2 Panel A. Their assessments of the specific quality attributes were also similar, as shown in Figure 3 Panel A, and Table 3 Panel A settings (1) and (2), except that AI-generated reasoning was rated higher in terms of clarity compared to human-written reasoning. Quality of Reasoning. Panel A: Group Level, Panel B: Branch Level Overall Quality of Reasoning Notes. Standard deviations are reported in parentheses. ***, **, * indicate significance level at 1%, 5%, and 10%, respectively. Raw p-values are reported alongside BH-Adjusted p-values to account for multiple testing. Specific Quality Attributes of Reasoning. Panel A: Group Level, Panel B: Branch Level Quality Attributes of Reasoning Notes. Standard deviations are reported in parentheses. ***, **, * indicate significance level at 1%, 5%, and 10%, respectively. Raw p-values are reported alongside BH-Adjusted p-values to account for multiple testing across the four quality dimensions.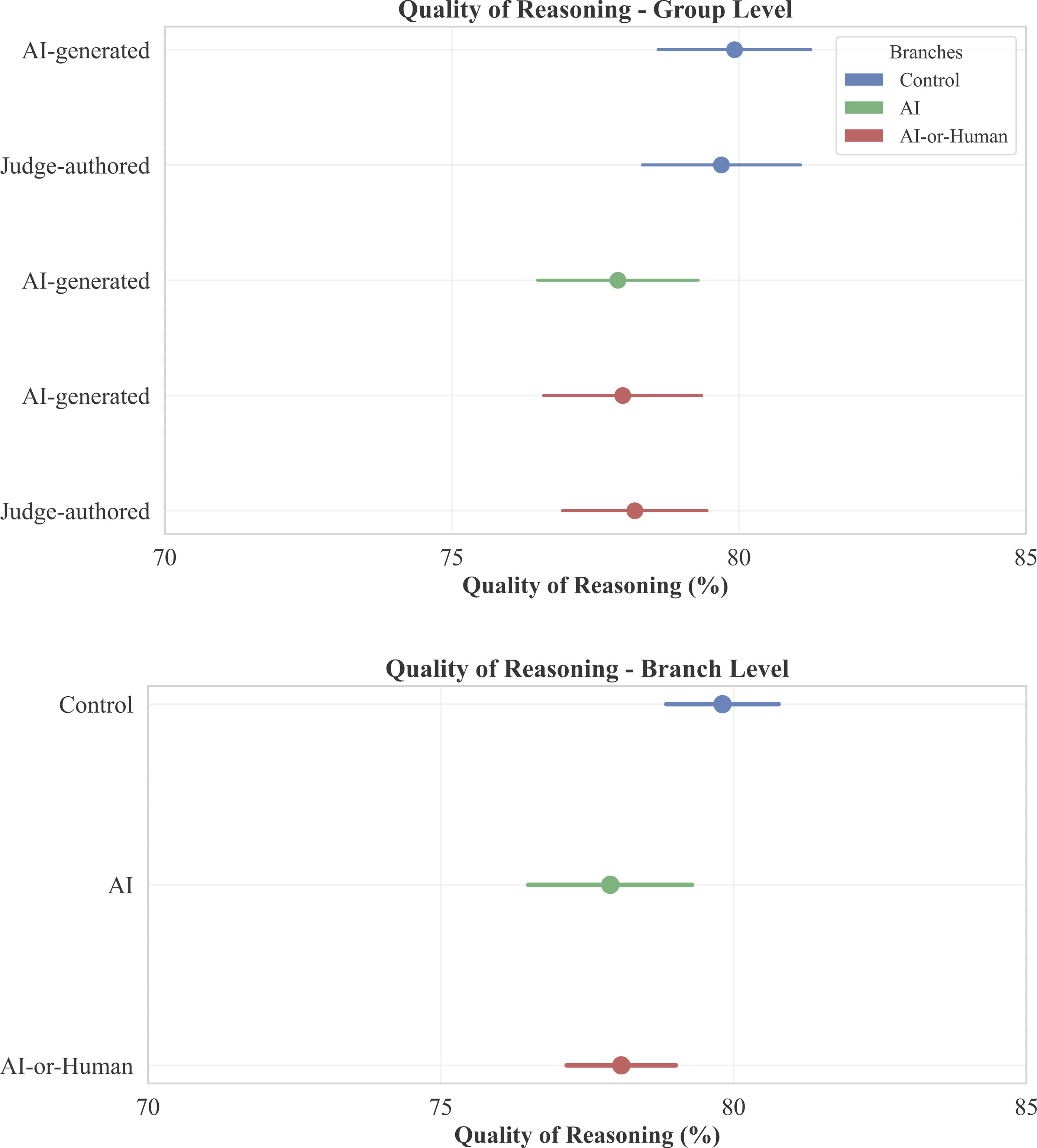
4.1.2. Testing Hypothesis 2
When informed that the opinions were AI-generated, participants rated the quality of the opinions lower. In the AI treatment branch, participants rated the quality of the opinions at 77.892, which was significantly lower than in the control branch (Figure 2 Panel B, and Table 2 Panel B). The ratings for professional language use (78.222) and persuasive legal interpretation (78.036) were also lower than in the control branch (Figure 3 Panel B, and Table 3 Panel B), while the latter is only suggestive since it did not retain statistical significance after adjustment for multiple testing (p =.116). The ratings for logical consistency, as well as clarity and comprehensiveness, were statistically indistinguishable from the control branch. 6
The disclosure that some opinions could be AI-generated also reduced rated quality in judicial opinions, including both AI-generated and judge-authored opinions. In the AI-or-human treatment branch, participants rated the quality of the opinions at 78.081, statistically significantly lower than in the control branch (Figure 2 Panel B, and Table 2 Panel B).
Kernel density plots, presented in Figure 4, visually reinforce the findings that AI involvement reduces participants’ rating of reasoning quality. Relative to the control branch, the distributions of quality ratings in both AI-related branches shift downward, indicating that AI involvement does not merely reduce mean evaluations but also alters the overall pattern of how participants assess judicial reasoning. Distribution of Quality Rating. Panel A: Group Level, Panel B: Branch Level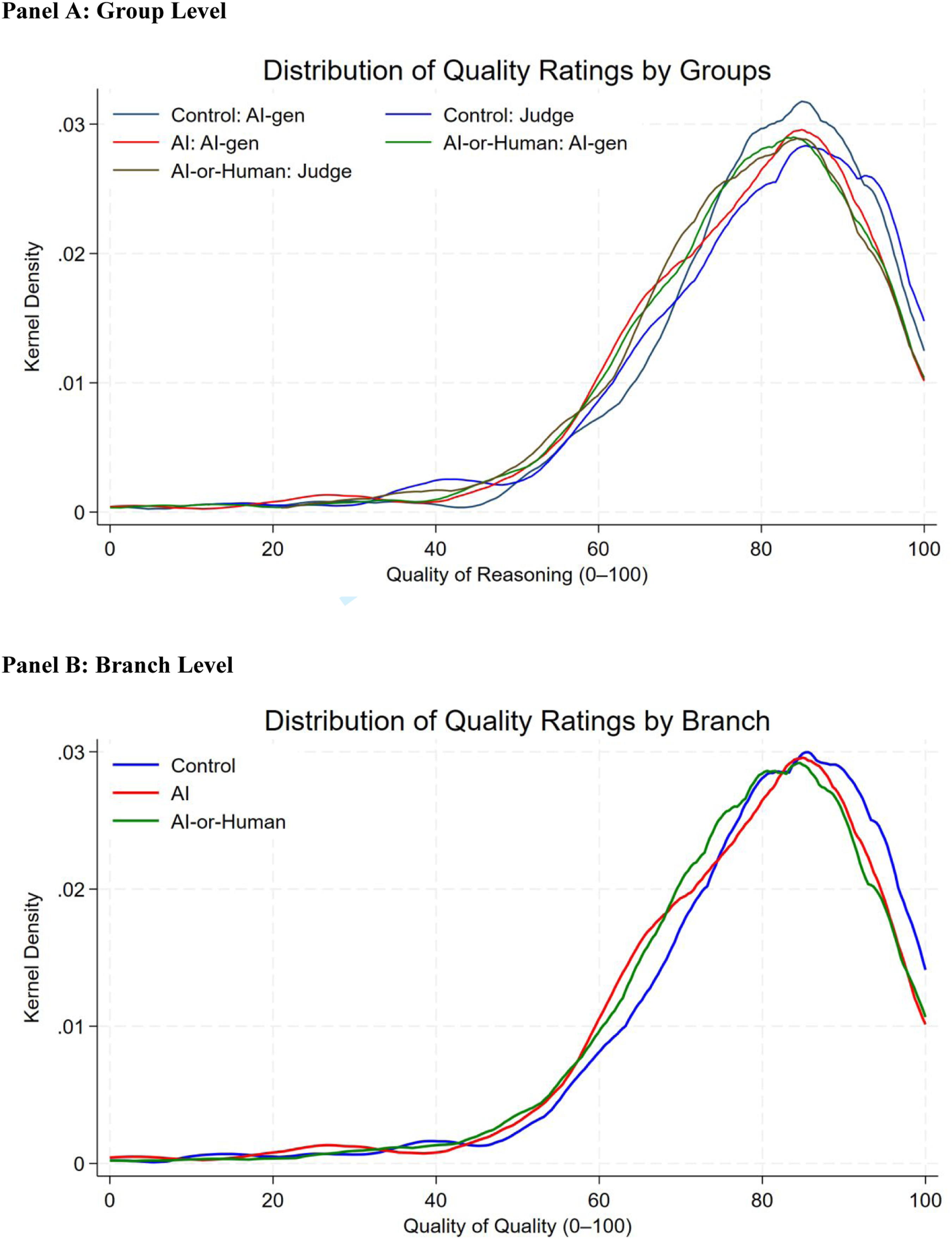
To account for multiple testing, we apply the Benjamini–Hochberg False Discovery Rate (FDR) procedure to the above analyses. This approach balances the need to control false positives while maintaining sufficient statistical power to detect meaningful differences. As shown in Table 2, the branch-level results remain unchanged after FDR adjustment, whereas several group-level comparisons become marginally statistically significant; the result regarding one of the quality attributes – persuasive legal interpretation -- did not retain statistical significance after adjustment for multiple testing. These results suggest that our core findings—regarding the negative impact of AI disclosure on perceived quality—are robust to multiple-comparison concerns, but that some fine-grained differences should be interpreted with greater caution.
4.1.3. Testing Hypothesis 3
In the AI-or-human branch, participants rated both AI-generated opinions (77.976) and judge-authored opinions (78.186) lower than those in the control branch (see Figure 2 Panel A, and Table 2 Panel A: Control vs. (4); Control vs. (5)). This suggests a “contamination effect,” where the potential involvement of AI negatively impacts the perceived quality of not only machine-generated text but also, more importantly, human-authored judicial opinions.
Quality Rating: Actual vs. Perceived Authorship
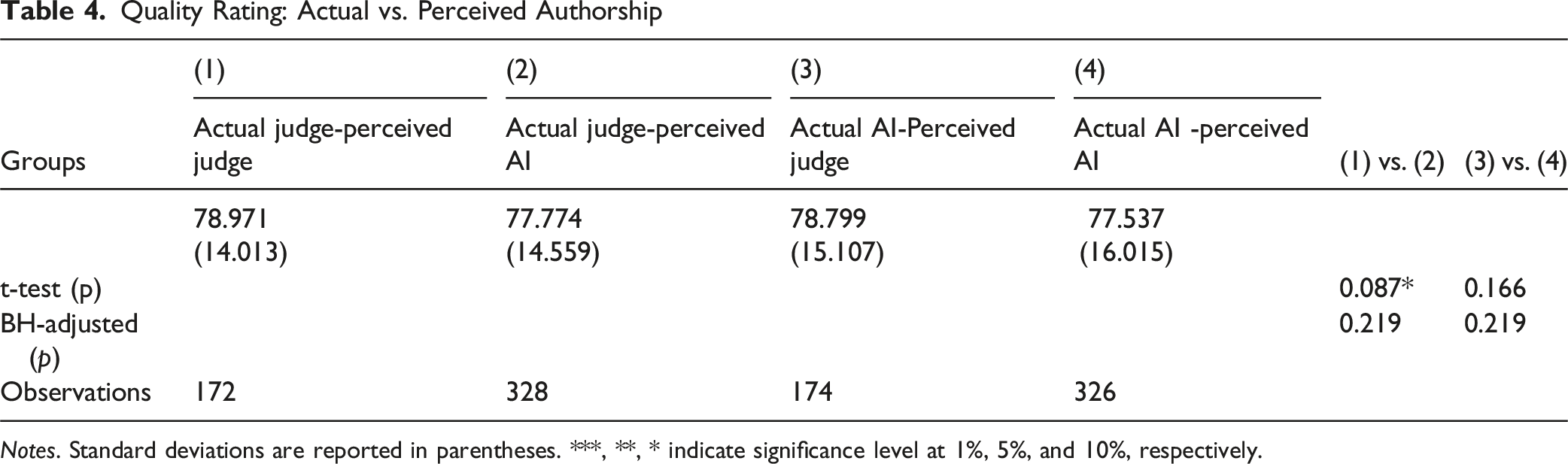
Notes. Standard deviations are reported in parentheses. ***, **, * indicate significance level at 1%, 5%, and 10%, respectively.
Given these findings, we adopt a conservative interpretation: our results provide mixed evidence of a contamination effect.
4.1.4. Effect Size
It is important to note that the effect sizes we found are modest. For example, compared to the control branch, the AI and AI-or-human branches show only about a 2-percentage-point drop in perceived quality. One likely reason is that participants’ baseline ratings of judicial opinions were already quite high. This may reflect the nature of our experimental materials: the cases were routine and relatively uncontroversial, and thus unlikely to provoke strong disagreement or emotional reactions. Laypeople tend to focus more on the perceived correctness of the outcome than on the finer points of the reasoning; when they view the outcome as appropriate, they are inclined to rate the accompanying reasoning favorably. In our survey setting, moreover, participants had no personal stake in the cases. Even under these relatively benign conditions—low personal involvement and ordinary cases—disclosure of AI involvement still depressed evaluations of the reasoning.
For these reasons, our findings should be understood as a conservative proof of concept. If AI disclosure already reduces perceived reasoning quality in low-stakes survey vignettes, it is reasonable to expect that the effects could be larger in real-world disputes, especially in high-salience or morally contested cases, and for the parties directly affected by judicial decisions. Our results thus provide a starting point, or reference point, for understanding how AI involvement in judicial reasoning may shape public perceptions in more consequential settings.
4.2. Exploring the Reasons
Typically, experimenters are faced with a decision: should they aim to test an effect, or should they seek to identify the mechanism that leads to a previously documented effect? The primary focus of this paper is on the former approach. However, we also carried out exploratory analysis to shed light on the underlying reasons for the aforementioned phenomena.
We tested whether knowledge of AI can potentially predict one’s ability to accurately identify AI-generated judicial decisions. In the experiment, participants were asked a series of questions designed to measure their self-reported knowledge of AI (refer to Appendix C for the questionnaire). 7 We consolidated their responses to these questions into a cumulative “knowledge of AI” indicator by summing the answers. The results, as shown in Table A.2, suggest that knowledge of AI had no predictive power of whether one can accurately identify the origin of a judicial opinion.
We also explored the factors contributing to the lesser trust people place in judicial opinions produced by AI. After participants had evaluated the adequacy and quality of reasoning they were presented with, they were asked to express their level of agreement with a set of statements concerning AI’s role in the judicial process. These included: (1) Generally speaking, machines (artificial intelligence) are more impartial than judges. (2) Letting machines make judgments is not serious and is disrespectful to the judicial process and the parties involved. (3) Machines have not yet developed to the intelligence level capable of making judgments. (4) Letting machines make judgments entails ethical issues and risks. (5) Machines can assist judges, allowing them to better complete judgments and reasoning tasks.
In these questions, questions 1, 3, 4, and 5 assess participants’ beliefs about AI’s capability to make or assist in judicial decisions, while question 2 examines participants’ beliefs regarding AI’s impact on procedural fairness. Each of these five aspects showed a statistically significant correlation with the perceived quality of the judicial opinions (using the sample from the AI treatment branch and the AI-or-human treatment branch), as indicated in Table A.5. These findings suggest that people’s skepticism towards AI’s participation in the judicial process may stem from concerns about procedural fairness as well as doubts about AI’s capability in aiding judicial decision-making.
5. Conclusion
Through a survey experiment with lay participants in China, this study demonstrates AI penalty in judicial reasoning. The public cannot reliably distinguish between AI-generated and human-authored judicial opinions. However, they tend to be skeptical about judicial opinions written by AI. This skepticism also appears to extend to human-written judicial decisions once participants are aware that AI could potentially be involved in formulating such opinions. Exploratory analysis suggests that people’s skepticism towards AI’s participation in the judicial process may stem from concerns about procedural fairness as well as doubts about AI’s capability.
As courts worldwide increasingly integrate AI into their workflows, public skepticism of AI poses significant challenges to its broader adoption in the judicial process. This skepticism is unlikely to be a temporary phenomenon. There are many areas where machines are trusted more than humans (for example, comparing Google Maps to asking for directions) (Volokh, 2019). The reliance is often driven by perceptions of accuracy, consistency, and convenience. However, the stakes involved in legal decision-making are considerably higher. When it comes to judicial processes, the acceptance of AI hinges on its ability to produce decisions that are not only accurate but also perceived as fair, unbiased, and justifiable. Currently, AI systems can generate reasoning that resembles judicial logic (as shown by the findings in this paper). Nonetheless, they often fall short when it comes to core judicial functions such as evaluating evidence, assessing credibility, and determining facts – tasks that require nuanced human judgment and contextual understanding. These tasks involve complex interpretative and decision-making processes that are difficult to codify into or learned by algorithms, especially given the variability and ambiguity inherent in legal cases. In the foreseeable future, it is unlikely that machines will fully master these fundamental decision-making skills. This limitation will fuel ongoing skepticism, as stakeholders question whether machines can truly understand and fairly evaluate the subtleties involved in justice. As a result, the skepticism toward AI’s role in legal tasks is expected to persist. This doubt may extend beyond decision-making to encompass AI-generated legal reasoning itself. Future research should explore strategies to mitigate this distrust.
Supplemental Material
Supplemental Material - AI Penalty in Judicial Reasoning: Indistinguishable From Human, Devalued when Revealed
Supplemental Material for AI Penalty in Judicial Reasoning: Indistinguishable From Human, Devalued when Revealed by John Zhuang Liu and Huijun Jia in Journal of Law & Empirical Analysis
Footnotes
Acknowledgements
We are grateful to the editor, Christoph Engel, and three anonymous reviewers for their insightful comments and constructive suggestions. We thank participants at the ALEA 2025 Meeting and the AsLEA 2025 Meeting for helpful discussions. We also thank Xinyi Ma and Shuhan Peng for research assistance. All remaining errors are our own.
Funding
This work was supported by the General Research Fund of Hong Kong (grant number: 17607423).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.