
Abstract
Algorithms often outperform humans in making decisions, in large part because they are more consistent. Despite this, there remains widespread demand to keep a “human in the loop” to address concerns about fairness and transparency. Although evidence suggests that most human overrides are errors, we argue these errors can provide value: they generate new data from which algorithms can learn. To remain accurate, algorithms must be updated over time, but data generated solely from algorithmic decisions is biased, including only cases selected by the algorithm (e.g., individuals released on parole). Training on this algorithmically selected data can significantly reduce predictive accuracy. When a human overrides an algorithmic denial, it generates valuable training data for updating the algorithm. On the other hand, overriding a grant removes potentially useful data. Fortunately, demand for human oversight is strongest for algorithmic denials of benefits, where overrides add the most value. This alignment suggests a politically feasible and accuracy-enhancing reform: limiting human overrides to algorithmic denials. The article illustrates the accuracy-sustaining benefits of strategically keeping “error in the loop” with datasets on parole, credit, and law school admissions. In all three contexts, we demonstrate that simulated human overrides of algorithmic denials significantly improve the predictive value of newly generated data.
Keywords
1. Introduction
In an increasing number of contexts, algorithms have been shown to be more accurate than humans. Recent research suggests that they outperform humans in granting bail (Kleinberg et al., 2018), releasing inmates on parole (Laqueur & Copus, 2024), making credit decisions (Munkhdalai et al., 2019), and diagnosing medical conditions (Richens et al., 2020; Goh et al., 2024). The potential for algorithms to increase efficiency and reduce error has led to their widespread use in these and other high-stakes decision domains.
As algorithmic risk assessments proliferate, so does demand to identify the proper role of human judgment in these systems (Dawes et al., 1989; Vaccare & Waldo, 2019; De-Arteaga et al., 2020). One common proposal is to maintain human oversight by allowing overrides of algorithmic decisions—keeping a “human in the loop” (Abdul et al., 2018; Lynch, 2022). Human overrides have the potential to address several algorithmic limitations. They can help protect against gaming, whereby individuals learn and exploit algorithmic rules to their advantage (Karpus et al., 2021); better update to rapidly changing conditions (Grønsund & Aanestad, 2020); address failure in “long tail” or unusual cases that did not appear or were infrequent in the training data such that the algorithm could not learn applicable patterns (Agarwal et al., 2024); and increase perceptions of fairness (Mosqueira-Rey et al., 2023). There are also hopes that allowing humans to override algorithmic decisions, because of our ability to consider more factors and observe information not available to the algorithm, will increase general accuracy (Ostheimer et al., 2021; Wang et al., 2022).
In practice, however, human overrides often decrease accuracy. A recent study of discretionary overrides of algorithmic recommendations in bail decisions found the overrides decreased accuracy in 90% of decisions, and 69% of judges made worse decisions than if they had simply flipped a coin (Angelova et al., 2023). Another study found hiring managers who frequently overrode algorithmic recommendations chose employees whose tenures were on average 15% shorter and who produced about 11% less work per hour than employees hired by managers who rarely overrode (Hoffman et al., 2018). In medical diagnoses, academic performance prediction, lending, and many more arenas, human overrides of algorithmic determinations have been shown to significantly decrease decision-making accuracy (Rezazade Mehrizi et al., 2023; Sele & Chugunova, 2024; Green & Chen, 2019).
The reasons human overrides fail to improve accuracy are likely the same reasons algorithms often outperform human judgment. Though human decision-makers can consider more factors than algorithms, they have limited capacity to understand how those factors relate to outcomes (Meehl, 1954; Tversky & Kahneman, 1974; Dawes et al., 1989). People are subject to cognitive biases such as salience bias, recency bias, and subadditivity bias (Hilbert, 2012; Sunstein, 2019). Humans tend to over-index to feedback and to neglect base rates (Lin et al., 2020). They inconsistently apply heuristics and are susceptible to overweighing irrelevant variables, producing noisy decisions (Kahneman et al., 2021; Hilbert, 2012). People also often fail to recognize that their own judgments and the algorithms are correlated, leading to unwarranted confidence in their decisions (Agarwal et al., 2023).
Despite mounting evidence that human overrides decrease accuracy, algorithmic decisions are frequently overridden, and many people continue to prefer human control over automated systems. Recent research on risk assessment algorithms for sentencing and bail found judges overrode algorithmic recommendations in 18% of cases (Angelova et al., 2023, 2024), reaching inappropriate decisions for between 27% and 54% of high-risk defendants and 12% to 57% of low-risk defendants (Stevenson & Doleac, 2024). Survey data suggests that roughly 80% of people would rather have a human decisionmaker than an algorithm for high-stakes decisions, and 56% still prefer humans even when shown an algorithm performs better (Bansak & Paulson, 2024). Algorithmic errors are often judged more harshly than human ones (Renier et al., 2021): in one study, 40% of respondents penalized algorithms more than humans for equivalent levels of bias (Bansak & Paulson, 2024). Emotional reactions to unfavorable decisions are also stronger when they come from algorithms: between 17 and 26% more negative compared to a human decision (Lee et al., 2018).
This mistrust of algorithmic decision-making is increasingly reflected in legal and policy frameworks that restrict or oversee the use of automated systems. The EU’s Artificial Intelligence Act broadly classifies as high risk any algorithm that processes personal data to assess aspects of a person’s life, requiring human oversight (European Union, 2024). In 2020, the Hague District Court ordered the Dutch government to shut down its welfare program risk assessment tool, citing lack of safeguards and transparency (Rachovitsa & Johann, 2022). A suit against the French government for a similar algorithm is currently pending ( La Quadrature du Net et al. v. Caisse Nationale des Allocations Familiales (CNAF), 2024). Californian voters rejected a proposition for a pretrial risk assessment tool to replace the cash bail system, despite evidence that its implementation would reduce racial disparities in detention (Office of Secretary of State Padilla, 2020; Skog et al., 2020). Together, these examples illustrate a persistent reluctance to fully delegate decision-making authority to algorithms, despite evidence of superior performance.
In this article, we propose and explore an alternative paradigm for human-algorithm interaction: keeping humans in the loop to override only algorithmic denials. We use the term “denial” to refer decisions that both refuse a benefit (e.g., denying parole or credit) and prevent the observation of outcomes. The benefits of restricting overrides to denials are two-fold. First, human distrust of algorithms is disproportionately a distrust of algorithmic denials, particularly in high-stakes decisions like hiring, finance, and criminal justice (Kern et al., 2022; Treyger et al., 2023; Filiz et al., 2023). People subject to algorithmic denials report 15 to 21% less trust in and 17 to 26% less acceptance of the decision-maker than an identical decision by a human (Wesche et al., 2024) and are more likely to take legal action against the decision than denials by humans (Treyger et al., 2023). Thus, restricting human oversight to denials, rather than all decisions, may reduce the societal pressure to trade accuracy for perceived fairness or legitimacy. Second, and the focus of our analysis, human overrides of algorithmic denials can help keep algorithms updated by producing future training data that is more fully representative of the population onto which algorithms are applied.
Algorithms need to be updated. If they are not updated, accuracy will deteriorate as relationships between predictors and outcomes change with time (Zhu et al., 2016). For example, in the criminal justice setting, new legal classifications of offenses, such as reclassifying certain felonies as misdemeanors, will alter the meaning of felony arrest, conviction, and incarceration records. Similarly, changes in prosecutorial policies and practices, such as declining to prosecute certain low-level offenses or adjusting charging behavior, mean that historical patterns of arrests and convictions may no longer accurately reflect risk. Without updates to account for societal and policy changes, risk predictions will be less accurate when making predictions for new cohorts (Kelly et al., 1999; Montana et al., 2023). Furthermore, data collection practices improve over time, resulting in richer datasets with more predictive variables and combinations of variables. Failing to update an algorithm fails to take advantage of the improvements made possible by better data collection.
Despite the need to update algorithms, algorithmic decision-making can make updating difficult. One of the core strengths of algorithms is that they are, as coined by Cass Sunstein, “silent.” Much of their accuracy relative to humans comes from the fact that they are consistent, eliminating error due to noise (Sunstein, 2021). However, this algorithmic silence is also a weakness that has been underappreciated. The consistency of algorithms means that they fail to explore new patterns in high-risk populations.
More specifically, decisions based on algorithmic recommendations produce data that suffer from a magnified version of a problem already known to affect data generated by human decisions—selective labels (Lakkaraju et al., 2017). Selective labeling occurs when outcomes (i.e., labels) of interest (e.g., arrest, credit default, poor academic performance) are observed only for those people whom human decision-makers selected for treatment (e.g., bail, credit extension, offer of admission) (Ben-Baruch et al., 2022; Wei, 2021). The crux of the classic problem is that a model’s utility as a decision tool depends on its ability to predict outcomes for the full population on which it is deployed, but it can only be trained and evaluated on the subset of the population with observed outcomes (labels) (Lakkaraju et al., 2017). Because prior human decisions often determine who receives an outcome label, there may be significant differences between the training data (the data used to build the model) and full population (the group to which the model is applied) (De-Arteaga et al., 2018). If decision-makers selected the low-risk individuals and rejected the high-risk, models will be built on low-risk observations and are unlikely to accurately predict outcomes for a full population that includes high-risk individuals. Thus, the accuracy of an algorithm on the training population may significantly overstate accuracy in the full population.
Economic literature has generally characterized the selective labels problem as arising from unobservable features influencing the occurrence of missing labels (Lakkaraju et al., 2017). That is, some sets of variables are observed and used by the decision-maker (X, Z) and are relevant to the outcome (risk), but only a subset of those features (X) are in the administrative data used by the algorithm. However, even if there are no unobserved variables involved in the decision, only having labels for a subset of observations that were determined to be low risk may make it such that there is insufficient or absent representation of certain subsets in the training data relative to the full population. For example, even if age and crime of conviction are observed, various combinations of them may not be observed (or observed rarely) in the paroled population. This censoring may also cause an algorithm to perform poorly when applied to the full population of interest.
Though the selective labels problem represents a significant theoretical concern, empirical research suggests selective labeling can be surprisingly minor when humans make decisions. For example, Kleinberg et al. (2018) leveraged quasi-random judge assignment and differing judicial bail rates to find that the marginally released are not substantially different than the others released on bail. A recent study by Laqueur and Copus (2024) examined arrest patterns among those denied parole but released after expiration of their sentence, finding that selective labeling was minimal.
One likely reason for the empirical finding that selective labeling is minor in practice is the high level of inconsistency or noise in human decision-making. Because human decisions are noisy, the line between those selected and unselected is frequently blurred (Summerfield & Tsetsos, 2015). Selection into the training population (e.g., selection for bail) can depend substantially on inter-judge and intra-judge inconsistencies, such as how harsh one’s assigned judge is (Kahneman, et al., 2021), if the judge is up for reelection (Angelova et al., 2024), whether the judge’s football team won the night before (Eren & Mocan, 2018), or the temperature outside (Heyes & Saberian, 2019). As the amount of noise grows, the training population begins to represent a random sample of the full population, mitigating the selective labels problem.
While selective labeling following human decisions may be minor, once an algorithm is implemented to make decisions, it intensifies the selective labeling problem. Algorithms, unlike humans, are not noisy—they are, as described above, silent (Sunstein, 2021). The dividing line between selected and unselected is sharp: outcomes are observed for all cases with a predicted probability on one side of a threshold and unobserved for all cases with a predicted probability on the other (Ludwig & Mullainathan, 2021). Thus, there is an acute post-implementation split between labeled and unlabeled data. In this context, there is little reason to think that a model built on post-implementation labeled data would provide accurate updates on the full population.
The challenge reflects a version of the well-known exploration-exploitation dilemma in decision theory, wherein a decision-maker must choose between leveraging current knowledge to maximize immediate outcomes (exploitation) or making potentially suboptimal short term choices to gather possibly valuable new information (exploration) (Ensign et al., 2018; Berger-Tal et al., 2014; Chien et al., 2023; Harris et al., 2023). If an algorithm only selects individuals predicted to be the lowest risk, it jeopardizes exploration of changes in the population that might mean previously high-risk individuals are now low risk (Kelly et al., 1999; Montana et al., 2023). This absence of exploration in algorithmic decision-making leads to a magnified selective labeling problem, where algorithms systematically overlook a portion of the population, resulting in a limited and biased dataset that does not allow accurate updating (Chien et al., 2023).
We show that lack of exploration can generate datasets that degrade model performance when used for updating. Incorporating selectively labeled data into training sets can significantly reduce predictive accuracy while simultaneously showing false signs of improvement. The deleterious effects of feeding algorithmically influenced data back into an algorithm have been noted in other contexts. Researchers have documented the phenomenon of “model collapse,” whereby large language models degrade in quality when trained on text and images that they generate (Shumailov et al., 2023, 2024). Critics of predictive policing have also described a related phenomenon whereby police will tend to find more crime where they look for it, leading them back to the same locations and missing other high crime areas (Harcourt, 2019). In this paper, we demonstrate that these negative feedback loops can apply to standard algorithmic decision-making contexts.
To mitigate this problem and support algorithmic learning over time, we propose allowing human overrides of algorithmic denials. This approach reflects both practical and political considerations. Overrides often reduce short-term accuracy, but, when applied to denials, they can generate valuable data that would otherwise remain unobserved. Thus, overrides of denials may at least partially offset the cost to short-term accuracy by contributing to the long-term accuracy of algorithms. In contrast, overrides of algorithmic grants will tend to reduce short-term and long-term accuracy, as overrides will destroy a data point that could be used to update an algorithm. Additionally, in many domains, public and institutional scrutiny is focused on algorithmic denials, making oversight in these cases more politically important.
To be clear, our proposal is a pragmatic one: limiting human overrides to denials is not necessarily the optimal way to maximize decision-making accuracy across all settings. Depending on the context, the benefits to long-term accuracy provided by overrides might be outweighed by the costs to short-term accuracy. Additionally, if the goal is exploration, algorithms could be programmed to make exploratory “mistakes,” likely in a more efficient manner than humans. However, given the widespread human oversight of algorithms, and minimal appetite to remove it, our proposal is a compromise that maintains oversight where it is demanded most.
To formalize the tradeoffs between short-term accuracy and long-term learning, we introduce a simple two-period model of algorithmic decision-making with human intervention. This framework helps clarify the conditions under which human overrides can improve or degrade overall performance.
We then empirically demonstrate the potential benefits to long-term accuracy using partially simulated datasets from three contexts where the use of algorithms has been the subject of debate among legal scholars and social scientists: parole, credit extension, and law school admissions. We produce three main findings under realistic parameters. First, data collected subsequent to purely algorithmic decision-making is likely to have negative updating value. Second, a common method of evaluating algorithmic accuracy can misleadingly indicate positive updating value. Third, under conservative assumptions about their distribution, human overrides of denials would substantially restore the predictive value of data.
2. A Formal Model of Accuracy Tradeoffs
We present a simple two-period model to examine how human overrides affect both immediate accuracy and algorithmic learning over time.
2.1. Model Parameters and Structure
Consider a decision environment where: • • • • • • •
To isolate the effects of interest, we make the following assumptions: (1) The distribution of individual characteristics remains constant across periods. (2) The algorithmic grant rate is constant across periods. (3) The algorithmic selection rate is calibrated such that, without overrides, the algorithm updated on purely algorithmically selected data maintains its original accuracy A1 when applied to similar cases. This means that for cases with characteristics similar to those that were selected, the algorithm can fully adapt to environmental changes when trained on the outcomes of selected cases. (4) Additional training data has diminishing returns to accuracy.
2.2. The Significance of Override Randomness (β)
The parameter β captures a critical dimension of human override quality. At its extremes: • When β = 0, overrides follow a systematic pattern reflecting decision-maker biases. For example, a credit officer might override denials for all applicants from certain neighborhoods. Such systematically biased overrides provide information about only a narrow subset of the algorithmically denied population. • When β = 1, overrides approximate random sampling from the denied population. This might occur due to inconsistencies between decision-makers, variations in individual decision-maker behavior over time, or other sources of “noise” in human judgment. While seemingly inefficient, these noise-driven overrides provide representative information about the entire algorithmically denied population.
The value of β substantially affects how much information human overrides contribute to algorithm learning. Noise in human decision-making—often considered a weakness compared to algorithmic consistency—actually provides an exploration benefit critical to long-term algorithmic performance.
2.3. Period 1: Immediate Accuracy Effects
When humans override algorithmic decisions, immediate accuracy decreases according to:
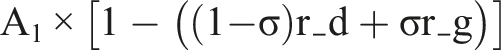
This reflects our assumption that the algorithm initially outperforms human judgment. Each override reduces accuracy proportionally, with (1 - σ)r_d representing overrides of denials and σr_g representing overrides of grants.
2.4. Period 2: Data Generation and Algorithmic Learning
Without updating, Period 2 accuracy would deteriorate to (1 − α)A1. With updating, accuracy depends on the data generated in Period 1.
The proportion of cases with observed outcomes is:
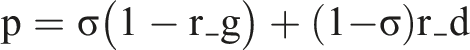
For analytical clarity, we separate Period 2 accuracy into two components:
2.5. Accuracy for the Observed Subpopulation (A_O)
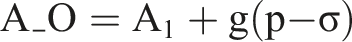
Where g(·) has the following properties: • g(0) = 0, ensuring that when p = σ (no net change in labeled data), A_O = A1 • g(x) > 0 for x > 0 (overriding denials increases accuracy for this subpopulation) • g(x) < 0 for x < 0 (overriding grants decreases accuracy for this subpopulation)
This formulation directly ties accuracy changes to the net change in observed data, highlighting that overriding denials provides additional information by expanding the labeled dataset, while overriding grants contracts the labeled dataset, reducing information.
2.6. Accuracy for the Unobserved Subpopulation (A_U)
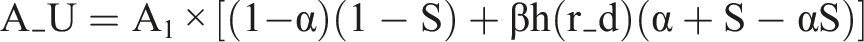
Where h(·) has the following properties: • h(0) = 0 • h is monotonically increasing • h’(r_d) is decreasing (diminishing returns)
This formula decomposes the accuracy for individuals similar to those without observed outcomes in Period 1: • (1 − α)(1 − S) represents accuracy maintained despite environmental changes and selective labeling • βh(r_d)(α + S − αS) represents accuracy recovered through human overrides
The term β critically modulates how much the overrides contribute to learning. When β is low (highly biased overrides), even a high override rate r_d provides limited value for learning about the general population. When β is high (more random overrides), each override contributes valuable information about different segments of the denied population.
To illustrate this distinction with a concrete example: Consider a parole system where 15% of inmates are granted parole algorithmically. If human overrides of denials only target white inmates with non-violent offenses (low β), the updated algorithm will improve accuracy for that specific subgroup but remain unable to accurately assess risk for other denied inmates. In contrast, if human overrides stem from inconsistencies between different parole board members or day-to-day variations in individual decision-making (high β), they will generate data across diverse subgroups of denied inmates, enabling broader algorithmic learning.
2.7. Overall Period 2 Accuracy
The overall accuracy would be a weighted average of A_O and A_U, with weights corresponding to the proportions of cases with characteristics similar to observed and unobserved cases from Period 1:
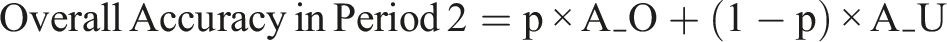
2.8. Global Accuracy
With expressions for accuracy in period 1 and period 2 and assuming equally sized total populations in both periods, global accuracy can be represented as:
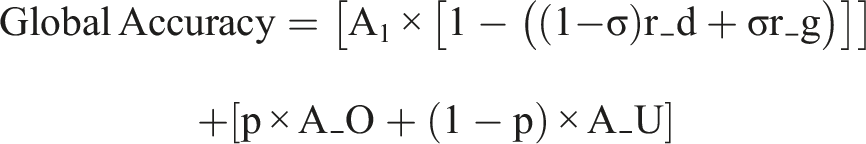
This formula quantifies the fundamental tradeoff between short-term accuracy losses and long-term learning gains from human overrides of denials.
2.9. Key Insights and Implications
This model captures several important insights: • Asymmetric effects of overrides: Our model mathematically demonstrates why overriding grants (r_g) is doubly harmful - it reduces immediate accuracy and eliminates valuable training data. In contrast, overriding denials (r_d) creates a productive tension between short-term costs and long-term benefits. • Selective labels problem and algorithmic feedback loops: As the selective labels problem (S) becomes more severe, algorithmic decisions create problematic feedback loops. When S is high, patterns learned from algorithmically selected cases poorly generalize to denied cases. This is captured in our A_U formula where increasing S reduces the (1−S) term while simultaneously increasing the potential benefit of overrides through the (α + S − αS) term. Without intervention, algorithms trained exclusively on their own selections become increasingly biased toward certain segments of the population, similar to the “model collapse” phenomenon observed in other AI contexts. • Environmental change amplifies benefits of exploration: When the environment changes significantly (high α), algorithms must be updated to maintain accuracy. However, the data needed for effective updating is precisely what algorithmic consistency eliminates. This creates a fundamental tension: the more consistent the implementation of an algorithm (less noise), the less changing patterns are explored, and the more rapidly its accuracy deteriorates over time without intervention. • The importance of noise: The very inconsistency in human decision-making that algorithms eliminate becomes valuable for maintaining long-term algorithmic performance. The parameter β quantifies this effect - when human overrides represent diverse, noise-driven decisions rather than systematic biases, they generate more representative data about the full population. • Diminishing returns to overrides: The monotonically increasing but concave function h(r_d) indicates that the first few overrides provide disproportionate learning value. This suggests that even a modest override rate can substantially improve long-term performance if those overrides are sufficiently random (high β). • Selection rate implications: The model reveals that the algorithmic selection rate (σ) affects the potential benefits of human overrides. When σ is very low, as in highly selective contexts like elite college admissions or restrictive parole systems, the selective labels problem becomes particularly acute, making the benefits of overriding denials more significant. This mathematical framework guides our empirical investigation. We test how algorithmically selected data and human overrides can plausibly improve the predictive value of training data in parole, credit extension, and law school admission contexts.
3. Methods
3.1. Simulation Strategy
To illustrate the challenge of updating an algorithm after it has been implemented and the benefit of introducing a small amount error in such contexts, we conduct simulations for each of our datasets (criminal justice, credit, law school admission). We divide each dataset into samples to simulate a world in which an initial model is trained and then applied such that it generates new data in a second, post-implementation period. Our main goal is to test the predictive value of data that is generated in the post-implementation period. Figure 1 displays our process. We first subset our datasets into three exclusive subsets: Simulation strategy.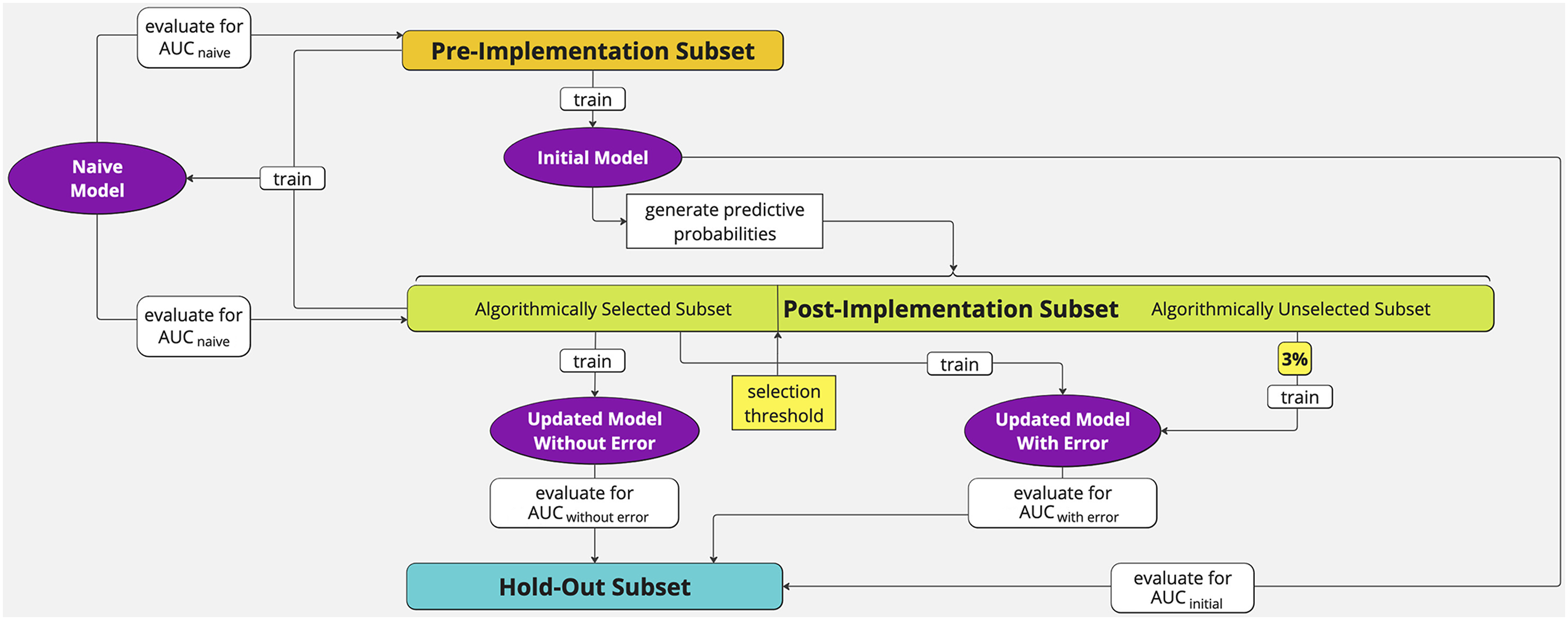
Post-Implementation Subset (green): A random sample of size n/σ. The main purpose of this dataset is to test how algorithmically selected data can alter predictive performance and metrics. The sample size is constructed to keep the size of the algorithmically selected data equal to the size of the pre-implementation data so that differences in model performance are not due to different training-set sizes.
We imagine that the initial model was implemented to generate predicted probabilities for a new cohort of cases in the post-implementation data. We then further divide the post-implementation data into two subsets, based on a chosen selection rate (σ).
Algorithmically Selected Subset: σ fraction of the lowest risk cases, as predicted by the initial model. These are the cases that would be selected (and thus labeled) if an algorithm were making decisions. It is a sample of size n.
Algorithmically Unselected Subset: the 1 − σ fraction of the highest risk cases, as predicted by the initial model. These are the cases that would not be selected (and thus not labeled) if an algorithm were making decisions.
We ultimately produce and compare four core models: an initial model, a model trained with post-implementation data, a model trained with post-implementation data that introduces a small amount of error, and a model trained on pre-implementation data plus algorithmically selected post-implementation data. We describe these models in greater detail below.
Note that our datasets are static. That is, there is no change in the environment (α) embedded in our datasets. Our intention is to test the predictive value of post-implementation data while holding α constant. In practice, α may be low such that there is little need to update the initial model. But policy makers would have little knowledge of α if data were algorithmically selected, as one could not observe changes in the statistical relationships between outcomes and predictors among the denied group (whose outcomes are unobserved). The choice of whether it is worth updating is thus largely a guess. Our goal here is to test the updating value of post-implementation data should the decision to update be made.
3.1.1. Initial Model
This is an initial model trained on the pre-implementation data and evaluated on the hold-out set. The evaluation metrics show how an algorithm would perform upon its initial deployment.
3.1.2. Model Without Error
This is an updated model trained on algorithmically selected data and evaluated on the hold-out set. This model tests the predictive value of data generated after the implementation of an algorithm in a context where human overrides are not allowed. The size of this training set is the same as the size of the training set for the initial model. If the performance of the model without error is significantly lower than the performance of the initial model, this suggests that using algorithmically selected data for training can undermine accuracy.
An additional note on the “without error” model is warranted. Why do we not simply add the algorithmically selected data back into the pre-implementation data, train a model on the combination, and then evaluate the model’s performance on the hold-out set? Would this not be a more realistic simulation? There are two reasons. First, our main point is that once an algorithm is implemented to make decisions, it may select data that prevents it from updating to changing social patterns. For assessing the value to updating, the new data is what matters. Second, even if patterns have not changed since the initial model, the predictive value of the algorithmically selected data is of special importance. This is because a responsible modeler, in anticipation of possible changing patterns (even if they do not happen), might include time predictors. For example, if one has training data for the years 2020–2024 and seeks to predict outcomes in 2025, one might include year terms when training the model and set the year equal to 2024 when generating predictions, under the assumption that the most recent patterns are the most informative. If such a model allows for interactions between predictors, the data from 2024 will have outsized influence on predictions for 2025. The predictive value of the most recent training data—here, the algorithmically selected data—is thus of particular interest. For these reasons, we isolate the predictive value of the selected data by training a model on it alone.
3.1.3. Model with Error
This is an updated model trained on algorithmically selected data plus a random sample of 3% of cases that were not algorithmically selected. Its purpose is to assess the predictive value of data generated after the implementation of an algorithm in a context where human overrides of denials are permitted.
Our choice to draw a random sample of 3% can be explained by reference to our formal model. Recall that βh(r_d)(α + S − αS) represents accuracy recovered through human overrides, showing that the combination of β (the amount of randomness in overrides) and r_d (the rate of overrides) is critical to the updating value of overrides. We effectively set β = 1 and r_d = .03. The choice to set β = 1 is a pragmatic choice. It is much easier to model random overrides than systematic overrides, as modeling systematic overrides would require that we choose the systematic nature of those overrides. Of course, an assumption that human overrides would be completely random is unrealistic. To counter that assumption, we set r_d at a very low rate of .03.
Taken together, we think the assumptions allow for a realistic and even conservative test of human overrides’ updating value: in practice, β is likely to be moderately lower than 1, while r_d is likely to be much higher than .03, such that the total amount of noise-driven exploration (β*r_d) is likely to be higher than our simulated assumption of 3%. We cannot predict exactly how much noise there would be in human overrides, but research suggests it would be substantial. For example, 65% of sentencing variability in criminal cases was attributable to which judge a defendant happened to draw (Clancy et al., 1981) and more than 20% of asylum officers deviated from regional grant rate norms by over 50% (Ramji-Nogales et al., 2007). Nor can we predict exactly what the override rate would be, but evidence suggests it would be much higher than 3%. For example, Angelova et al. (2023) found judges overrode algorithmic recommendations in 18% of cases.
We further explore the impact of noise v. bias in human overrides (β) by taking 1,000 draws of a random 3% override rate. Though each individual draw is random, some will inevitably reflect biased samples (e.g., overrides will be concentrated in particular subsets of the denied population). For each of the 1,000 samples, we construct and evaluate a new model. We present the distribution as well as the low and modal values of the AUC (or AUC-PR).
To ensure that any changes are not due to increasing the sample size from adding the 3%, we hold sample size constant by randomly dropping algorithmically selected cases.
As supplemental analyses, we (1) assess the effects of systematic (rather than purely random) overrides by conducting simulations in which human overrides were drawn exclusively from a specific subgroup (e.g., White individuals or male applicants) and (2) vary the override rate from .5% to 4%. Results are presented in the Appendix.
3.1.4. Naive Model
This is a model trained on a random 25% of the algorithmically selected data plus the full pre-implementation data. It is evaluated via cross-validation on its own training data. This is designed to reflect a common, real-world practice, whereby new training data is added to existing training data and is evaluated by how well the model predicts its total training data (via cross-validation). We sampled only 25% of the algorithmically selected data to reflect a more realistic scenario in which new training data from a new period constitutes only a fraction of the total training dataset.
3.2. Evaluation Metrics
For each model, our primary evaluation metric is the Area Under the Receiver Operating Curve (AUC). AUC is a common performance metric for classification algorithms that describes the model’s ability to distinguish between positive and negative instances. A classifier that can perfectly discriminate between positive and negative cases would have an AUC of 1, whereas an AUC score of 0.5 indicates that the model performs no better than random chance.
As a secondary metric, we also calculate AUC-PR, which measures the relationship between precision (positive predictive value) and recall (sensitivity, or the true positive rate) across different thresholds. While AUC describes the tradeoff between the true positive rate and the false positive rate, the Precision-Recall curve does not incorporate true negatives into the metric. Thus, AUC-PR is often used as a measure of performance when dealing with imbalanced data in which many true negatives can dominate the effects of changes in other metrics like false positives. A random classifier would have an AUC-PR equivalent to the base rate in the data (e.g., if there are 20% positive cases, a random classifier would be expected to have an AUC-PR of .20).
Finally, we compare outcomes (arrest rates, default rates, and bar passage rates) for the initial model, the model without error, and a model with error, across a range of thresholds from .10 to .90. Specifically, at each threshold, we select the subset of individuals based on their predicted probability of the outcome as provided by the model. For credit card default and risk of arrest, this means selecting the individuals predicted to have the lowest risk (e.g., the bottom 10%, 20%, etc., based on predicted probabilities). For bar passage, this means selecting the individuals predicted to have the highest probability of passing (e.g., the top 10%, 20%, etc.). We then compute the actual observed outcome rate for each group. This allows us to assess each model’s ability to identify individuals who are more or less likely to experience the outcome of interest. For the model with error, since predictions vary across the 1,000 simulations, we select predictions from a single model with an AUC equal to the modal value identified in the simulations.
3.3. Algorithm Selection Rate
To test whether algorithmically selected data realistically poses a threat to model updating, for our primary analysis, we chose simulated algorithmic selection rates that align with real-world systems, albeit on the lower end. For example, in our criminal justice dataset, in which we are simulating parole decisions, we selected a simulated parole release rate of 15%. While this is lower than most states, Alabama’s release rate was 15% in 2021 and 10% in 2022 (Willis, 2023). We chose relatively low but still realistic selection rates because, as our formal model indicates, higher selection rates will tend to diminish the updating problem we are investigating. To illustrate how results vary across the full range of selection rates, we also conduct simulations calculating AUCinitial and AUCno error for selection rates ranging from .05 to .95 for each of the three datasets. Detailed methods and results for the selection rate simulations are reported in the Appendix.
3.4. Algorithms
All models are created with Automatic Machine Learning (AutoML) Stacked Ensembles in the open-source H2O environment in R. H2O’s Stacked Ensembles employ a loss-based supervised learning approach that uses k-fold cross-validation to identify the optimal combination of a diverse set of base learning algorithms. Specifically, for each base learner algorithm in the ensemble (e.g., a generalized linear model, a random forest, a neural network, etc.), k-fold cross-validated predictions are generated. In this process, the dataset is divided into k subsets or folds. The learners are trained on k−1 of these folds and predictions are generated from the left-out fold. This process is repeated k times, with each fold used exactly once as the validation data. The predictions are then regressed on the true outcomes to assign each base algorithm a weight. The weighted combination of the algorithms is then used to generate an ensemble prediction function, which is subsequently applied to the full dataset. This Super Learning approach has been shown to be an asymptotically optimal system for learning (Polley & van der Laan, 2010).
AutoML automates the selection and tuning of base learning algorithms, eliminating the need for users to manually select which models and algorithms to include. The AutoML base learners in H2O encompass a range of algorithms including generalized linear models (GLMs), random forests, gradient boosting machines (GBMs), and deep neural networks (DNNs).
For each of our AutoML models, we specified a 10-fold cross-validation process and allowed for 10 base learning algorithms to be included in the ensemble. All tests for statistically significant differences between AUCs were conducted using the DeLong nonparametric test, implemented via the roc.test function in the pROC package in R.
3.5. Parole, Credit Extension, and Law School Admissions Datasets
3.5.1. Parole
The first dataset was from the Georgia Department of Community Supervision, made publicly available as part of the National Institute of Justice (NIJ) Recidivism Challenge. The data included individuals released from Georgia prisons to the custody of the Georgia Department of Community Supervision for the purpose of post-incarceration supervision between January 1, 2013, and December 31, 2015. We included all available predictors provided prior to release from prison. These included age (binned), race, place of residence, supervision risk score, education history, and prior arrests, convictions, and parole revocations. There were 18,300 observations after removing rows with missing data. Our outcome was any arrest within three years of release (59% of individuals were arrested within 3 years).
As noted above, we chose a simulated selection rate of 15% for release on parole. There were thus 2000 individuals in the pre-implementation data, 2,000 in the hold-out data, and 13,333 in the post-implementation data. The post-implementation data was further divided into the 15% who we simulated to have been algorithmically selected (n = 2,000) and those who were not selected (n = 11,333). When simulating human overrides, we randomly included 3% of those who were not selected by the algorithm. To hold sample size constant at 2,000, we randomly dropped 340 individuals selected by the algorithm.
3.5.2. Credit Extension
Our second example came from the Default of Credit Card Clients dataset from the UCI Machine Learning Repository. This dataset included 30,000 credit card holders from Taiwan in 2005. It contained 23 predictors including demographic variables (age, sex, marital stats), credit card usage, and payment history. It also included individuals’ default payment status in the next month, our target outcome. 22% of individuals defaulted on payment.
We chose a simulated selection rate of 60% for credit extension. There were thus 8,160 individuals in the pre-implementation data, 8160 in the hold-out data, and 13,600 in the post-implementation data. The post-implementation data was further divided into the 60% who we simulated were algorithmically selected (n = 8160) and those who were not selected (n = 5,540). When simulating human overrides, we randomly included 3% of those who were not selected by the algorithm. To hold sample size constant at 8,160, we randomly dropped 163 individuals selected by the algorithm.
3.5.3. Law School Admissions
The final dataset was the Bar Passage dataset from the Law School Admissions Council (LSAC), which followed law students from 1991 through 1997. It included 22,407 observations and seven pre-law school predictors including race, sex, grades, and LSAT scores. Our outcome was first attempt bar exam passage. 89% of students passed the bar on the first attempt.
We chose a simulated selection rate of 10% for law school admissions. There were thus 1,860 individuals in the pre-implementation data, 1860 in the hold-out data, and 18,600 in the post-implementation data. The post-implementation data was further divided into the 10% who we simulated were algorithmically selected (n = 1,860) and those who were not selected (n = 16,740). When simulating human overrides, we randomly included 3% of those who were not selected by the algorithm. To hold sample size constant at 1800, we randomly dropped 502 individuals selected by the algorithm.
4. Results
The Impact of Algorithmic Selection and Simulated Human Error on Model Accuracy.

AUCinitial is the initial algorithm’s performance on hold-out data. AUCwithout error is the hold-out performance of an algorithm updated with data that was selected for labeling by the initial model. Low AUCwith error is the lowest hold-out AUC of the 1,000 models updated on a training set that includes simulated human overrides of an initial model. Modal AUCwith error is the most common AUC of those 1,000 models. AUCnaive is the performance of an updated algorithm if data selected by the initial model were added to the initial training set and evaluated via cross-validation.
Figure 2 presents the full set of results for the simulations in graphical form, showing the distribution of AUC values across the 1,000 simulated models with 3% human error for each domain. Figure 2(a) displays the results for the parole simulation. AUCinitial was .71. An updated model trained on only algorithmically selected data performed worse on the hold-out set, with AUCwithout error = .65. The difference was statistically significant (p-value <.001). Adding simulated human error improved the performance in all 1,000 draws, with AUCwith error ranging from .68 to .72. In all 1,000 draws, the addition of just 3% of simulated human overrides yielded substantial improvements in accuracy, though the simulated error was sometimes insufficient to bring accuracy within range of AUCinitial. Although the algorithmically selected data were of low value for updating the algorithm, an AUCnaive of .76, as compared to a AUCwith error of .65, demonstrates that cross validating a model that is trained on both algorithmically selected and pre-implementation data could mask the selective labeling problem. The impact of algorithmic selection and simulated error on the accuracy of updated algorithms in parole, Credit extension, and law school admission: AUCinitial shows the initial algorithm’s performance on hold-out data. AUCwithout error shows how an algorithm trained with data that was selected for labeling by the initial model performs on hold-out data. The density curve shows the distribution of the 1,000 AUCs on the hold-out set when an algorithm is updated on a training set that includes simulated human overrides of an initial model (AUCwith error). AUCnaive displays the performance of an updated algorithm if data selected by the initial model were added to the initial training set and evaluated via cross-validation.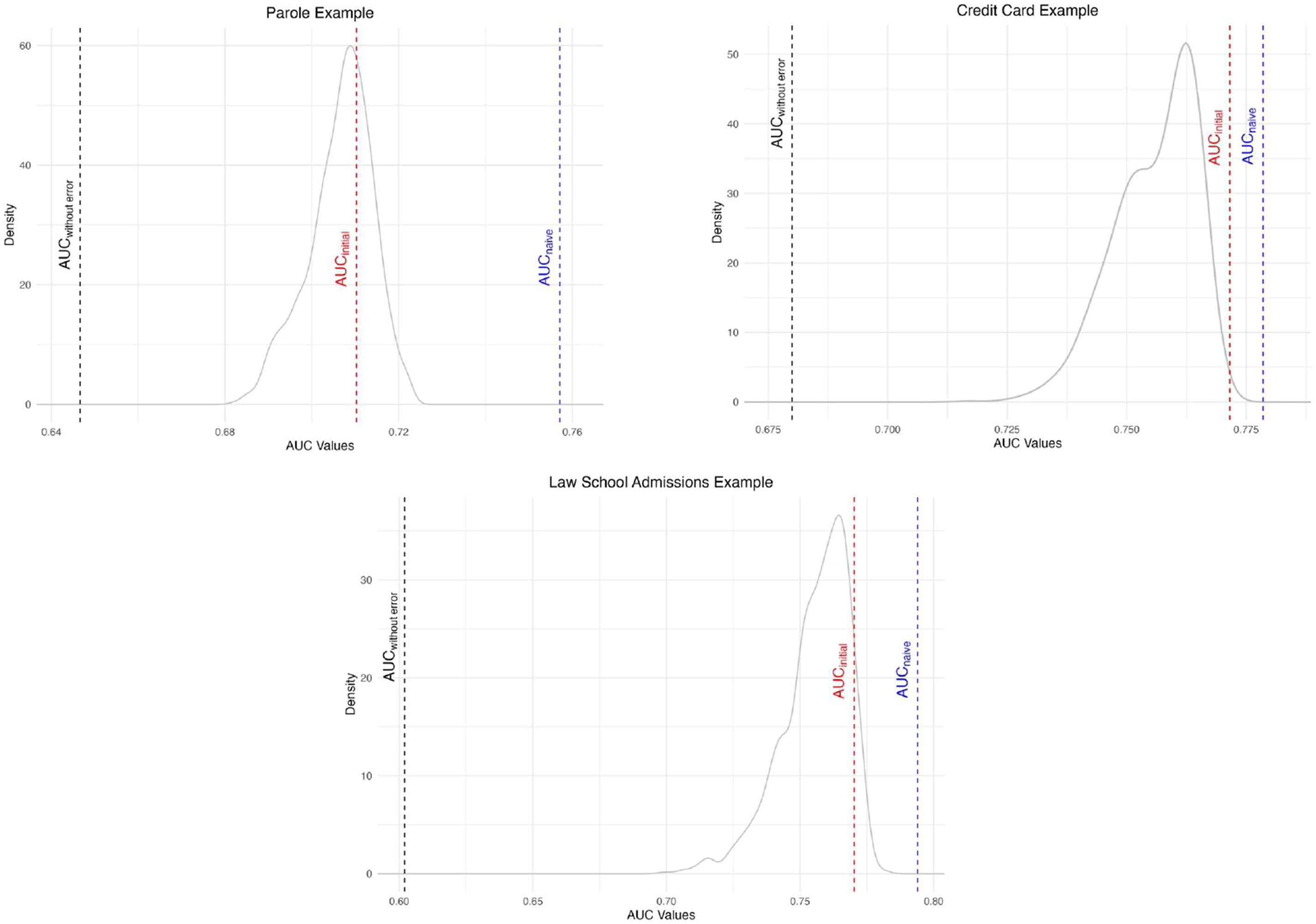
Figure 2(b) displays the results for the credit extension simulation. AUCinitial was .77. An updated model trained on only algorithmically selected data performed worse on the hold-out set, with AUCwithout error = .68. The difference was statistically significant (p-value < .001). Adding simulated human error improved the performance in all 1,000 draws, with AUCwith error ranging from .72 to .77. While simulated human error was, on average, sufficient to recover most of the initial model’s predictive accuracy, some simulated human overrides resulted in model performance that was well short of the initial model. AUCnaive was substantially higher than AUCwithout error, showing that adding algorithmically selected data to the original training set and evaluating via cross-validation would fail to reveal the intensified selective labeling problem.
Figure 2(c) displays the results for the law school admission simulation. AUCinitial was .77. An updated model trained on only algorithmically selected data performed substantially worse on the hold-out set, with AUCwithout error = .60. The difference was statistically significant (p-value <.001). Adding simulated human error improved the performance in all 1,000 draws, with AUCwith error ranging from .71 to .78. But for many of the draws, human overrides were insufficient to achieve the accuracy of the initial model. AUCnaive was 0.79, again showing that incorporating algorithmically selected data and evaluating model performance via cross-validation can mask the problem of intensified selective labeling.
We note that all three distributions of AUCwith error have a leftward skew and clear mode near the AUCinitial. Though each iteration involved random sampling of unselected cases, by chance, some samples will poorly represent the underlying population. The typical random draw should yield a representative sample of the population that would have gone unlabeled by an algorithm. That draw can be viewed as a noisy decision (i.e., random error). Thus, the modes of the AUCwith error distributions best reflect the expected impact from noise-driven overrides. The modes all approach AUCinitial, demonstrating that random error provides large improvements in algorithmic accuracy as compared to algorithmically selected data. The left tails of the AUC distribution reflect results from less representative draws. For example, one draw might, by chance, reflect a much higher rate of overrides for white individuals compared to black individuals. The lower AUCs associated with these non-representative draws illustrate that biased errors will tend to yield smaller accuracy gains than noise-driven overrides.
Results from biased override simulations—where overrides were restricted to specific subgroups—are summarized in in the Appendix (Table 2). Despite the systematic bias in who was selected, performance remained comparable to the random override simulations and substantially better than the no-override condition.
Also presented in the Appendix (Table 3) are the effects of varying override rates. In all three contexts, there are diminishing returns to increasing the override rate, with most improvements gained at a 1.5% to 2.5% override rate.
To assess the robustness of our findings across different algorithmic selection rates, we also estimated model performance (as measured by AUC) across decision thresholds ranging from 5% to 95%. These simulations, presented in the Appendix (Figure 2), show that the difference in AUCinitial and AUCno_error is largest at lower selection thresholds—i.e., contexts where the selective labels problem is most severe—and narrows as the selection threshold increases. This narrowing occurs because higher thresholds reduce the severity of the selective labels problem by producing training data that more closely resembles the full population.
Finally, Figure 3 displays the observed outcomes among individuals selected by each model across a range of predicted risk selection thresholds (e.g., the lowest 10%, 20%, etc.). In all cases, the model without error performs consistently worse than both the initial model and a modal model with error. For the parole and credit card examples, individuals identified as lowest risk (ranging from 10% to 90%) have higher actual recidivism and default rates. Similarly, in the bar passage example, among individuals predicted most likely to pass, the model without error yields lower actual passage rates than either the initial model or the model with error, again indicating that it is less effective at identifying high-likelihood candidates. The model with error generally performs similarly to the initial model, though it underperforms at some thresholds. Outcome rates by selection percentage for models with and without simulated error: At each selection percentage (10%–90%), individuals are selected based on predicted probabilities from each model. For arrest and default, we select the lowest-risk individuals; for bar passage, we select the highest scores. The figure shows observed outcome rates for three models: the initial model, a model retrained on data selected without error, and a model retrained on data including simulated human overrides (using predictions from a model with a modal AUC value).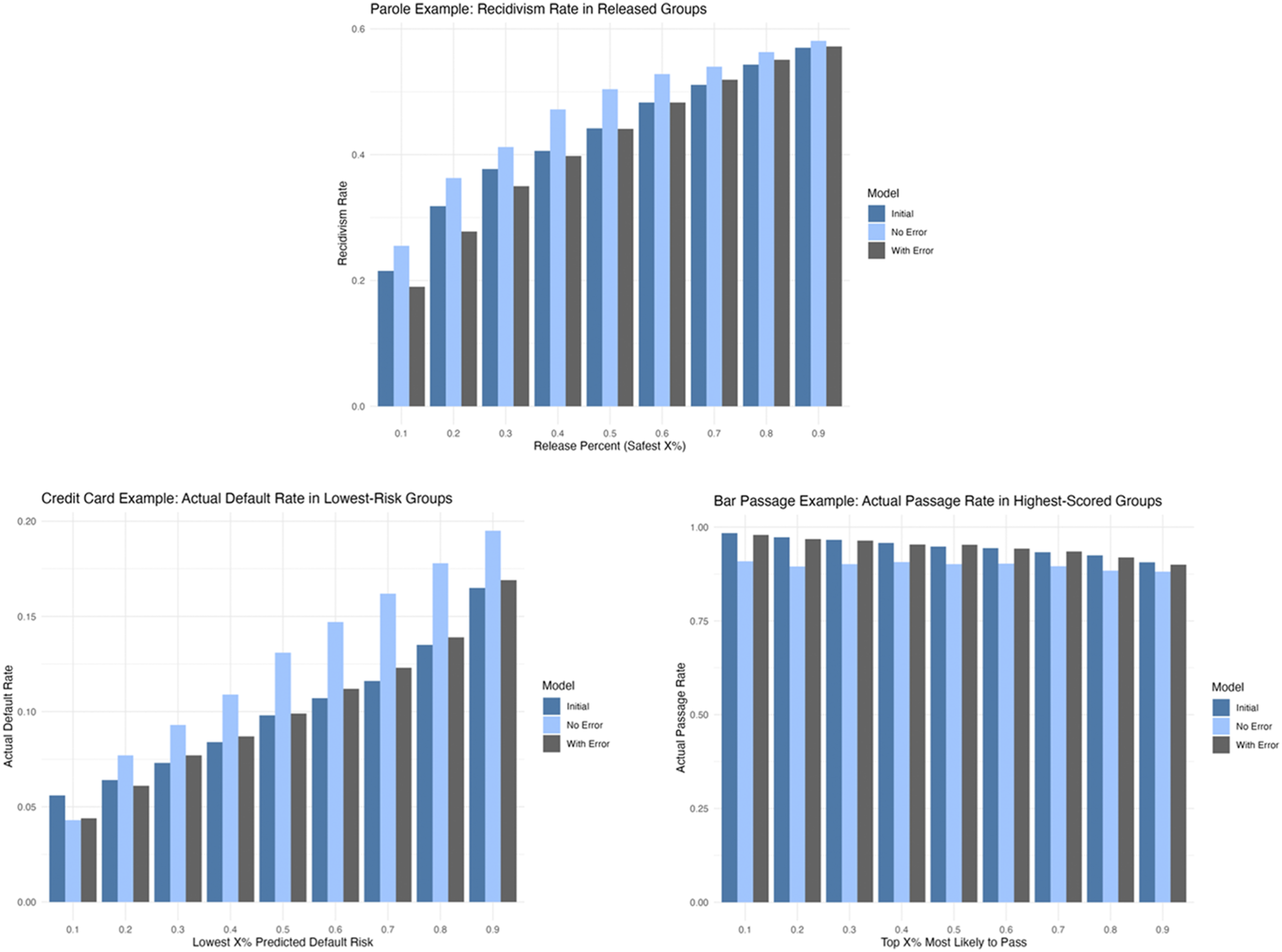
5. Discussion
Despite evidence that human overrides often reduce immediate decision accuracy, our findings suggest that these same errors can play a critical role in sustaining long-term algorithmic performance. The very consistency that gives algorithms an advantage over humans in the short term also suppresses the variation necessary for long-term learning. When algorithms make decisions, they repeatedly select the same types of individuals, intensifying the selective labels problem and leaving large parts of the population unobserved. Our simulations demonstrate that when data downstream of algorithmic decisions are used to update the model, accuracy can degrade substantially. Across all three domains—parole, credit, and law school admissions—the predictive value of post-algorithm data was significantly lower than that of the original training data. We also show that naïve evaluations, such as cross-validation on pooled training sets, can obscure this degradation.
These findings underscore the risks of fully automating high-stakes decisions without a mechanism for exploration. While algorithms can maximize short-term accuracy, complete deference to their recommendations may sacrifice long-term performance. Rather than focusing solely on short-term performance, we should evaluate algorithmic systems with the understanding that maintaining their long-term efficacy requires the strategic introduction of short-term error. This means periodically selecting individuals an algorithm would otherwise reject (e.g., higher risk individuals) so that they are represented in future training data.
We explore the accuracy-enhancing potential of a restricted human-in-the-loop approach: allowing overrides of algorithmic denials. This strategy responds to public outcry for oversight where it is most demanded—denials of benefits—while simultaneously generating the kind of data needed to update and improve algorithms. It may also improve short-term accuracy by eliminating human overrides of algorithmic grants, which likely introduce error and do not provide useful data for future learning.
Our simulations suggest that even a small number of noise-driven overrides can significantly improve algorithmic updating. We simulated a low override rate of 3%. In many real-world settings, overall override rates are substantially higher. Thus, if only a portion of overrides are noisy (as compared to biased), the conditions for long-term improvement are likely to be met. For example, at a 10% override rate, fewer than one in three overrides would need to be noise-driven to match our assumed 3% exploratory rate.
Our 1,000 draws of 3% produced a range of override samples, some of which will be less representative of the denied population due to chance. The distribution of AUC values illustrates that the effectiveness of overrides depends on the nature of the override error. The lower tail of the distribution —simulations where overrides were, by chance, less representative of the full denied population — can be interpreted as reflecting models generated from bias-driven overrides (low β). Yet even in those simulations, overrides still yielded improvements relative to the no-error model. These simulation results align with the theoretical expectations that bias-driven overrides are less valuable for updating algorithms.
Human overrides are likely to be most valuable in settings where selection rates are low and/or where relevant factors or conditions frequently change (high α). At low selection rates, post-implementation reflects only a narrow, non-representative subset of the population, exacerbating the selective labels problem. In dynamic settings, the very consistency that makes algorithms attractive becomes a liability, as they are unable to adapt to shifting relationships between predictors and outcomes.
The benefits of overrides also depend on the decision-making context and outcomes of interest. We focused on settings in which the outcome of interest is observed only for selected individuals (e.g., those granted parole, granted law school admission), but this one-sided structure does not apply universally. In some domains, neither decision arm fully reveals the counterfactual outcome of interest. For instance, if a doctor prescribes antibiotics, you observe recovery but not whether it would have occurred without treatment; if antibiotics are withheld, we can’t observe whether the patient would have suffered adverse side effects had they been treated or whether being treated would have prevented complications. Or when law enforcement employs forcible techniques, compliance is achieved but we don’t know if it could have been achieved without force; if force is not used there is no way to know whether it would have prevented harm or escalated the situation. Our framework is most applicable to settings where exploration directly expands the labeled outcome space.
Taken together, our results highlight a broader need to understand how algorithmic decision-making intensifies the selective labels problem, and the trade-offs between short-term and long-term algorithmic accuracy. While the bias- and noise-reducing benefits of using algorithms have been widely studied, the costs to continued learning have recieved little attention. Yet insofar as algorithms help us make better decisions in the short-term, they also change the data on which future algorithms can be trained. In the absence of mechanisms for exploration, short-term optimization may degrade the long-term data environment, undermining future performance. Understanding and addressing these tradeoffs is essential for building decision systems that remain accurate and adaptive over time.
Footnotes
Author Contributions
The authors contributed equally to the research, authorship, and publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
All data is publicly available. The Georgia Department of Community Supervision data is available as part of the National Institute of Justice (NIJ) Recidivism Challenge. The Default of Credit Card Clients dataset is available at Kaggle. The Bar Passage dataset from the Law School Admissions Council (LSAC) is available at Kaggle.