
Abstract
Court congestion is among society’s oldest legal problems; protections from it are enshrined in constitutions around the world. This paper uses publicly available data on the duration of millions of criminal court cases over the course of two decades across Canadian provinces to analyze the performance of the criminal justice system using queueing theory. Our new approach to estimating the delay of criminal trials appropriately includes the time from the point the charges are laid to first appearance, which is not available in raw data. We find that the queue sizes and wait times are growing in many provinces, suggesting that the criminal justice system is approaching, or perhaps beyond, capacity. Using several different time series specifications, we find that the utilization rate and model-implied queue size co-move positively with the population in pretrial custody. The results suggest that court congestion, as measured by statistics from queueing theory, has explanatory power for the rising population in pretrial custody.
And cases like this can last a long time, especially the ones that have been coming up lately. —Franz Kafka, The Trial
1. Introduction
Court congestion is among society’s oldest legal problems. We are told that in 42 A.D. the Emperor Claudius exhorted the Roman Senate to pass a law introducing a summer session into the congested Roman courts; 1 in 1215, King John promised in the famous and enduring clause 40 of the Magna Carta “[t]o no one will we sell, to no one deny or delay, right or justice” [emphasis added]; 2 Shakespeare’s Hamlet lists ‘law’s delay’ (3.1.82) fifth in his seven burdens of man; 3 Kafka’s early 20th century critique of Austro-Hungarian criminal procedure makes immediate mention of the phenomenon. The list goes on.
While the problem is an old one, it remains among the most the important legal problems today, proving its stubbornness. As of late, court delay has given rise to constitutional concerns in Canada, notably in R v. Jordan, 4 making the subject particularly relevant to the present moment. The framework in Jordan attempts to address what the Supreme Court of Canada called a “culture of complacency within the system towards delay” (at para. 4) by clearly defining the total duration of a case and how to calculate delay and then establishing presumptive ceilings on the duration of trials. Our theoretical approach allows us to infer the time from the point charges are laid to first appearance to fully account for what has become known as the “Jordan clock,” improving on existing measurements using raw data. 5 Moreover, central measures from queueing theory, such as the server-level utilization rate, queue size, and wait time co-move positively with the population in pretrial custody. 6 This suggests that court congestion, as measured by statistics from queueing theory, has predictive power for the secular rise in the population in pretrial custody across Canadian provinces.
Indeed, the right to trial within reasonable time is enshrined in the Sixth Amendment of the United States Constitution under the Speedy Trial Clause and in Section 11(b) of the Canadian Charter of Rights and Freedoms. 7 Constitutional protections from unreasonable delay are well-founded. Canada’s Charter protects the accused’s security, liberty, and fair trial interests, which keeps the accused from a trial or bail being held over their head for unreasonable lengths and ensures a trial in which witnesses and evidence are available. These guarantees mitigate the undue costs of prolonged detention in pretrial custody, such as failure to meet employment and housing obligations, deterioration of personal relationships, as well as the ability to prepare a defence. Prolonged delay may also be the product of inadequate administrative resources provided by the State, making constitutional protections necessary to ensure swift justice.
This paper uses publicly available data on millions of criminal court cases over the last two and a half decades in Canada to study the criminal justice system through the lens of a branch of mathematics known as queueing theory, the study of waiting times. We use data on the time lapse of criminal trials from first appearance to final disposition to estimate the service time distribution in days and the total number of charges laid in a given year compute the system’s arrival rate. 8 The service time distribution fits the exponential distribution well, suggesting that a standard memoryless queueing model could be appropriate. 9 Using our measure of the average number of cases that arrive per day, the total number of charges laid, and the rate of the service time distribution, we are able to compute the utilization rate, a key performance metric in queueing theory, of each provincial court system. With these estimates and data on the court’s open caseload, we are able to compute measures of the provincial criminal court system’s performance, such as queue size and wait time, using the multiple server queueing model with minimal assumptions. Data on measures such as the time from arrest to first appearance are currently unavailable in existing raw data, making our paper the first to properly estimate the full duration of a criminal proceeding according to the “Jordan clock” established by the Supreme Court of Canada in 2016. We find that the implied measures of queue size and wait time are non-stationary and increasing over our series, suggesting that the court’s backlog is growing and that the criminal justice system may not be able to handle all of the cases before it without substantial delay.
We then use our results from the queueing analysis to examine the extent to which queueing theory’s measures of court congestion can explain the rise of the population in pretrial custody. Several time series regressions detect positive co-movement between queueing theory’s measure of the total number being served, the server-level utilization rate λ t /μ t , and the average count of the population in pretrial custody. The model’s measure of queue size L q is also predictive of the population in pretrial custody, suggesting that our model’s measures perform better than raw data on open caseload. The results indicate that the statistics suggested by queueing theory have predictive content and that court congestion has explanatory power for the rising population in pretrial custody. Indeed, court congestion can help explain the paradox of falling crime with an ascending population in pretrial custody.
1.1. Queueing Theory
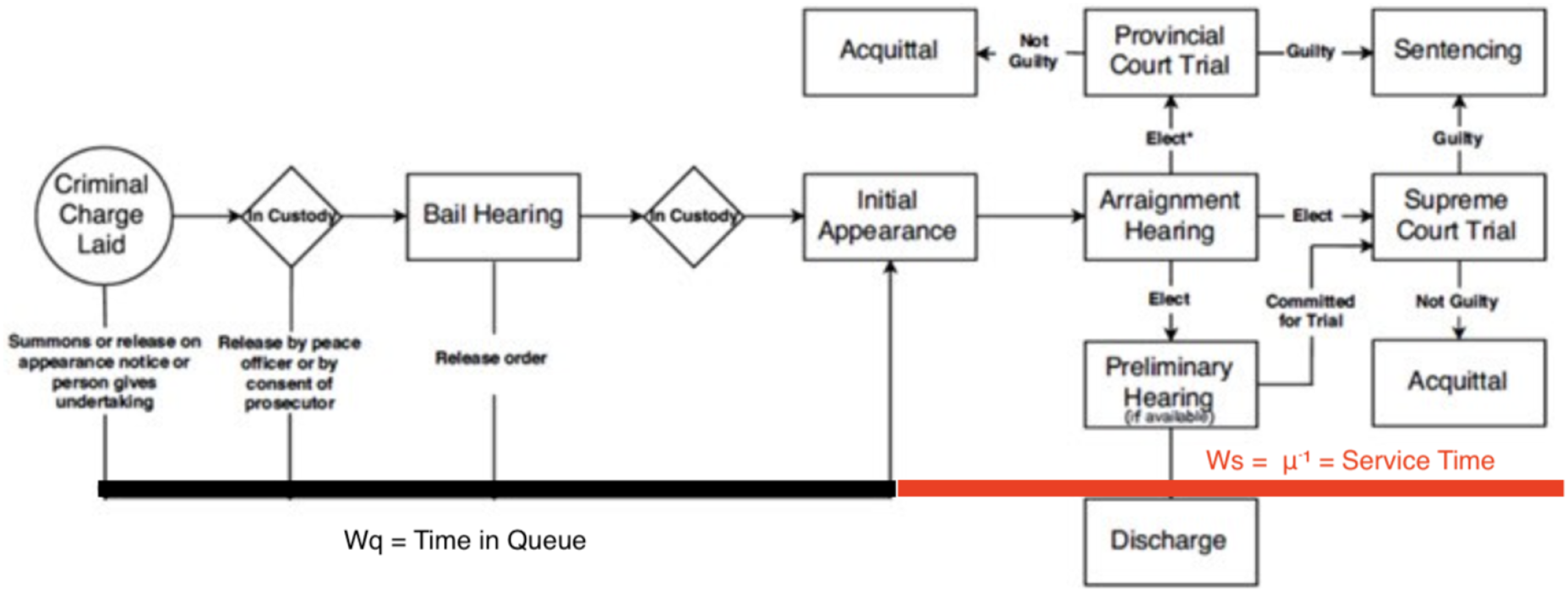
Originally developed to study telephone networks by A.K. Erlang, a Danish engineer who worked for the Copenhagen Telephone Exchange, queueing theory models the arrival and service of customers to provide a mathematical model through which to analyze the performance and equilibrium of a service system, like courts, such as the length of a waiting line, or queue, and average waiting times (Hlynka, 2017). Loosely speaking, queueing theory is the mathematical theory of lineups. Ross (2010) describes a queueing model as a model “in which customers arrive in some random manner at a service facility. Upon arrival they are made to wait in queue until it is their turn to be served. Once served they are generally assumed to leave the system.” Queueing theory has been widely successful at modeling congestion in a number of areas. Green (2006) writes that “[m]any organizations, including banks, airlines, telecommunications companies, and police departments, routinely use queueing models to help determine capacity levels needed to respond to experienced demands in a timely fashion.” In the most basic framework,“customers” arrive to a service center according to a homogeneous Poisson process with rate λ and are served first-come first-serve (FCFS) at a time distributed according to the exponential with rate μ. To immediately connect the theory with law and our data, the reader should think of charges being laid as an arrival of a case to the court system, any time leading up to the first appearance as the waiting time, and the service time as the duration of the trial from first appearance to final disposition, where service is the issue of a judgment by the court. A diagram of a multiple-server queuing system with two servers (c = 2) is below in Figure 1. The full criminal trial procedure in Canada can be seen below in Figure 2. Multiple-server queuing system with two servers (c = 2). Stages in a criminal case. Note. Figure displays criminal trial procedure in Canada. Source: https://www.court.nl.ca/supreme/rules-practice-notes-and-forms/criminal-proceedings/general/.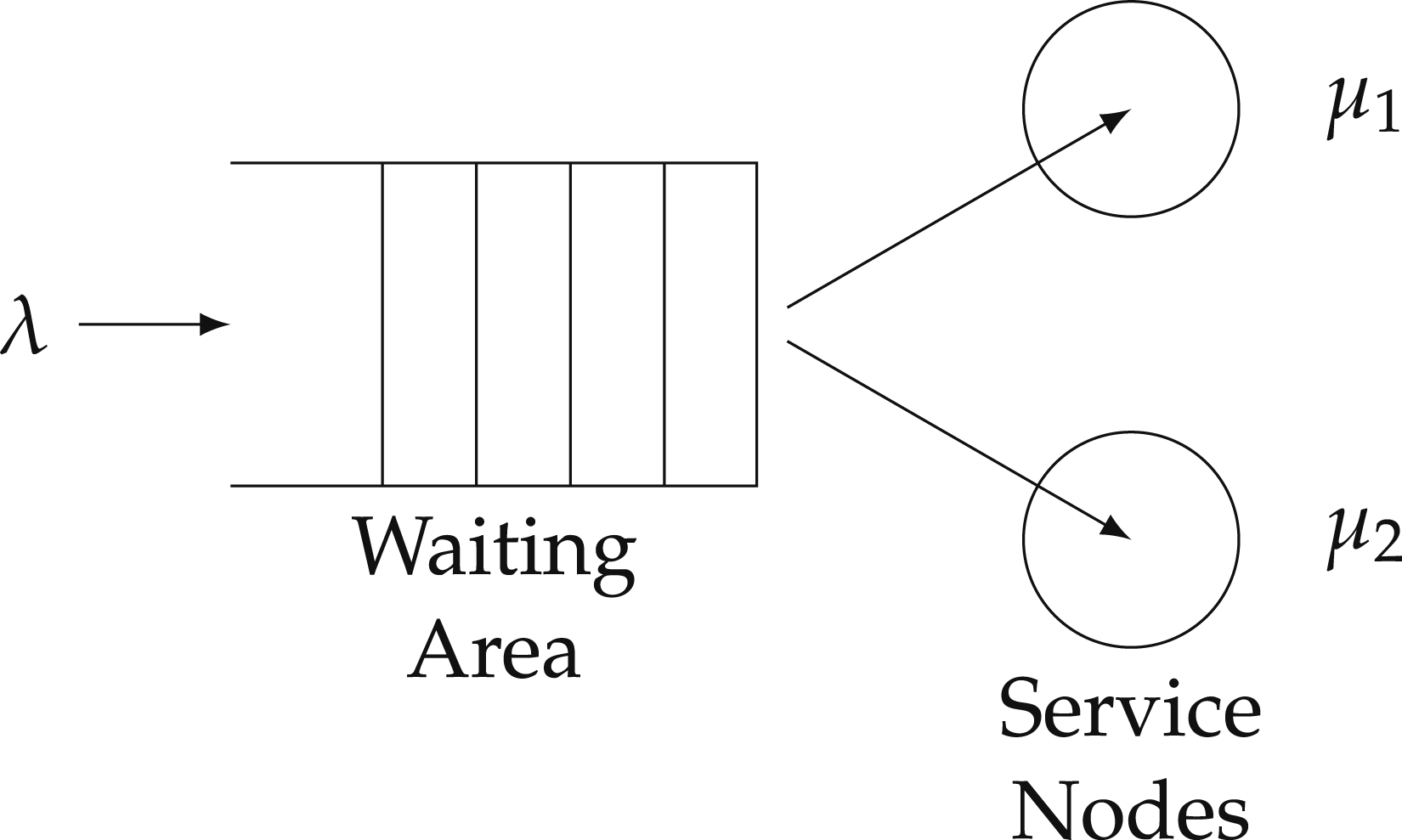
The important inputs to specifying a queueing model are as follows. (1) (2) (3) (4)
The important outputs of the queueing model are the utilization rate, total time in the system, average wait time, and queue size, which are currently not available in conventional data sources, such as the Canadian data that we use. We use queueing theory, in particular, Little’s Law, which holds under extremely general assumptions on the arrival process, the service discipline, and the number of servers, to back out measures of congestion using queueing theory. Little’s Law states that the total number in the system L is equal to the product of the arrival rate λ and the total time in the system W in expectation
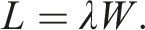
We use data on the open caseload to measure the total number in the system L and the arrival rate λ to back out total time in the system W. To compute the expected or implied wait time we can subtract mean service time μ−1 from total time in the system W. We find that measures of congestion from queueing theory, such as wait time and queue size, are, in many provinces, non-stationary and increasing.
A key performance measure in any queueing model is the utilization rate ρ = λ/μ, which is the arrival rate times the mean service time. 10 Using time series analysis on de-trended and differenced processes, we find strong co-movement between the utilization rate, queueing theory’s measure of traffic, and the population in pretrial custody (remand). The outputs from our model, such as server-level utilization and queue size, outperform conventional measures in the data, such as open caseload, in predicting the rising population in pretrial custody. This suggests that queueing theory has some predictive content for explaining the paradox of a falling crime rate, that is, the arrival rate, and rising population in pretrial custody.
1.2. Related Literature
Relative to other applications of queueing theory, such as healthcare and telephone networks, there has been little academic work using formal queueing theory to study the legal system, even despite the relatively obvious connection between court delays and queueing theory and the deep reliance in constitutional law, at least in Canada, on estimating the time from arrest to first appearance. We combine our estimates of the service time distribution with data on the court’s open caseload to compute conventional measures of performance from queueing theory, such as queue size and time in the queue. We are the first, to our knowledge, to then relate these measures back to the population in pretrial custody. Across several time series specifications, we find that the system’s server-level utilization rate is robustly related to the average count of individuals in pretrial custody, suggesting that court congestion can explain the recent rise in the population in pretrial custody across Canadian provinces. Indeed, the model’s measures of congestion outperform those measures readily available in the data, such as open caseload.
McAllister et al. (1991) first used queueing theory to simulate a five-stage model of the pretrial case processing system from arraignment to trial assignment. Their multi-stage queueing approach is particularly appropriate given the realities of court procedures, but is greedy in terms of the granularity of the data required to perform their exercise. Our approach relies on widely published, aggregate metrics and one basic theorem in queueing theory, that is, Little’s Law (Little, 1961), which does not depend on the arrival process, the number of servers, or the service discipline (Jewell, 1967; Eilon, 1969), to provide a diagnostic of the overall court system in long-run equilibrium by producing measures of performance that are predictive in terms of the population in pretrial custody. Examining behaviour of the queue and the model-implied time to first appearance, we find that wait time and queue size are increasing and non-stationary across provinces.
For the country we analyze, Canada, there has been a troubling rise of the population in pretrial custody, displayed in Figure 3, that one must reconcile with falling crime rates. A novel contribution of our approach is that we find that the measures it produces co-move with the rising population in pretrial custody, resolving this paradox. Thus, our approach has important ties to the focal concerns literature in criminology, and social science more broadly, studying the deleterious effects of court delay for those in pretrial custody, such as faster time to guilty pleas (Petersen, 2020). Average population in pretrial custody and mean daily arrivals. Note. Figure plots average annual population in pretrial custody (Source: Canadian Centre for Justice and Safety (CCJS) Correction Key Indicator Report (CKIR)) and mean number of charges per day in a given year (excluding administration of justice offences) (Source: Integrated Criminal Court Survey (ICCS)).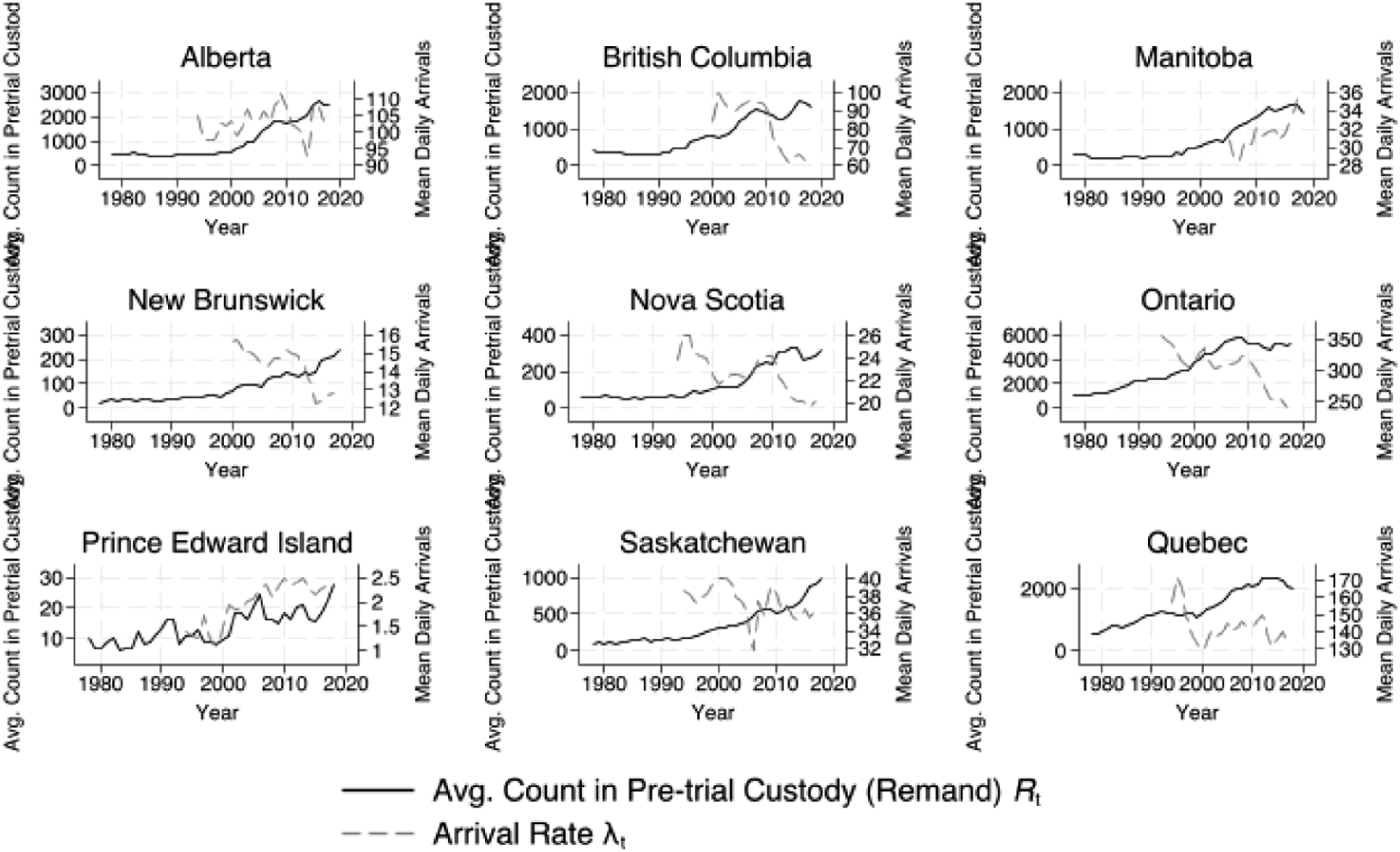
The literature on the link between sentencing, such as guilty pleas, and caseload has found little success. For instance, Yang (2016) finds no relationship between judicial vacancies and delay in the US, but a causal impact of vacancies on guilty pleas. Our approach can help create new measures that outperform measures currently available to researchers, such as open caseload and the arrival rate, in predicting the population in pretrial custody. This contributes to a larger literature on the causes and consequences of pretrial custody. For example, Dobbie et al. (2018), find that pretrial detention significantly increases the probability of conviction, primarily through an increase in guilty pleas, has no net effect on future crime, but decreases formal sector employment and the receipt of employment- and tax-related government benefits. Court congestion can resolve the paradox between rising pretrial populations and falling crime rates.
Mukherjee and Whalen (2018) examine the time lapse between when a case enters a court’s docket and when it is ultimately disposed of using data from the Supreme courts of the United States, Massachusetts, and Canada. The authors find that the underlying distribution of case resolution timing features a slow decay with a decreasing tail, demonstrating that, in each of the courts examined, the vast majority of cases are resolved relatively quickly, while there remains a small number of outlier cases that take an extremely long time to resolve. This paper uses queueing theory to compute statistics on the criminal justice system for nine Canadian provinces (excluding Newfoundland and Labrador). We use the estimate of the service time distribution using the time lapse from first appearance to final disposition with a maximum likelihood procedure. While this approach is consistent with Mukherjee and Whalen (2018), we explicitly interpret this quantity as the distribution of service time.
We find that the distribution of the duration criminal trials is well-fit by the exponential distribution, perhaps lending itself to a workhorse memoryless queueing model. We then use queueing theory to then back out the time from arrest to first appearance, which is of interest to the constitutional framework set out in Jordan. We find that both model-implied queues and wait times are increasing and non-stationary in many provinces. In pooled time series analysis, we find that these quantities of interest are related to the rising population in pre-trial custody.
Our novel approach to estimating the total time for trial comports with the framework as laid out in Jordan. For instance, a study by Karam et al. (2020) attempts to examine prima facie section 11(b) violations under the framework set out in Jordan using the same data publicly available data we use on the time lapse from first appearance to final disposition. However, this ignores the very clear fact set out in the framework established under Jordan that the time under consideration for s. 11(b) violations begins at the time the charges are laid, not the first appearance. Thus, the time from the point charges are laid to first appearance is a quantity of substantial interest, but is only available using data sources that are unavailable to researchers. We use queueing theory to estimate the time from the point the charges are laid to the first appearance. Thus, our new approach to estimating the delay of criminal trials should be incorporated into calculations of the share of cases at risk of violating s. 11(b) per the framework in Jordan.
The paper proceeds in five sections. Section 2 describes the data. Section 3 describes the estimation of the service rate. Section 4 computes the main measures of system performance from the multiple server queueing model. Section 5 uses time series analysis to examine the relationship between the queueing model outputs and the population in pretrial custody (remand). Section 6 concludes.
2. Data
The data used to construct estimates of service time and arrival rates are from Statistics Canada’s Integrated Criminal Court Survey (ICCS). The survey provides data from a dozen administrative databases across Canada from provinces from 1994 to 2019 for most provinces. The data draws on administrative records from provincial-territorial and superior courts in Canada. We focus our analysis the provinces in Canada: Alberta, British Columbia, Manitoba, Nova Scotia, New Brunswick, Ontario, Prince Edward Island, Quebec, and Saskatchewan. In particular, the ICCS case counts are broken down by geography, year, single or multiple charge(s), defendant age group (18+) and sex, and 23 offences, as well as by time lapse from first appearance to final disposition. 11 A case that has more than one charge is represented by the charge with the “most serious offence” (MSO). 12
2.1. Remand
The data on the population in pretrial custody come from the Canadian Centre for Justice and Safety (CCJS) Correction Key Indicator Report (CKIR). The CKIR is an annual administrative data survey. It collects aggregate data on average daily custody counts and month-end supervised community corrections counts in the youth and adult correctional systems. The information provides an overview of adult and youth corrections populations and serves as a basis for calculating incarceration rates. We use the average annual count in pretrial custody (on remand) from 1978 to 2019.
2.2. Caseload
The data on open caseload come from Statistics Canada’s Court Workload Indicators (CWI) which are derived from the ICCS. Caseload refers to the average number of open cases on any given day in the year excluding administration of justice offences. 13 The total number of open cases provides a measure of the total number in the system at any given point in time for 2008 to 2019. The CWI also provides data on the number of cases initiated and completed in a given year. We use the data on the cases initiated in a given year to validate our measure of the arrival rate from the ICCS, which is available over a longer time series, described below.
2.3. Service Time
The main variable of interest that allows us to estimate the service time distribution is the time lapse in days from first court appearance to final disposition. The ICCS data provides the number of charges within each of six bins for the time from first appearance at court to final disposition: 1 day, 2–60 days, 61–120 days, 121–240 days, 241–365 days, and
2.4. Arrivals
We also use the number of charges per year from the ICCS data to construct an arrival rate of cases to the system. To construct a variable which measures the arrival rate of cases to the court system we count of the total number of charges made in year t and divide by the number of days in a year, giving
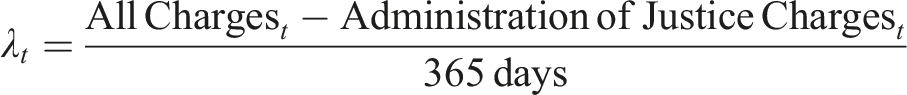
We exclude administration of justice offences from the number of charges to match the data on open caseload. The exclusion of these charges ensures that administration of justice offences, which are often related to other offences, are not double-counted in the data. For cases disposed of in year t with duration longer than a year, it is assumed that the case began, or “arrived”, in the previous year and is thus accounted for in the previous year’s count of all charges arriving in year t − 1. This assumption is made for simplicity. In practice, our estimates do not vary much when we change the arrival date of cases exceeding one year and our data are censored at cases exceeding one year in length. For that reason, data from the final year in the sample, 2018/2019, is omitted from calculations involving the arrival rate λ
t
in the paper, as charges that were laid, or “arrived”, in 2019 and lasted longer than one year are unreported in the data, as they are completed in 2019/2020. Values of the estimated yearly arrival rate λ
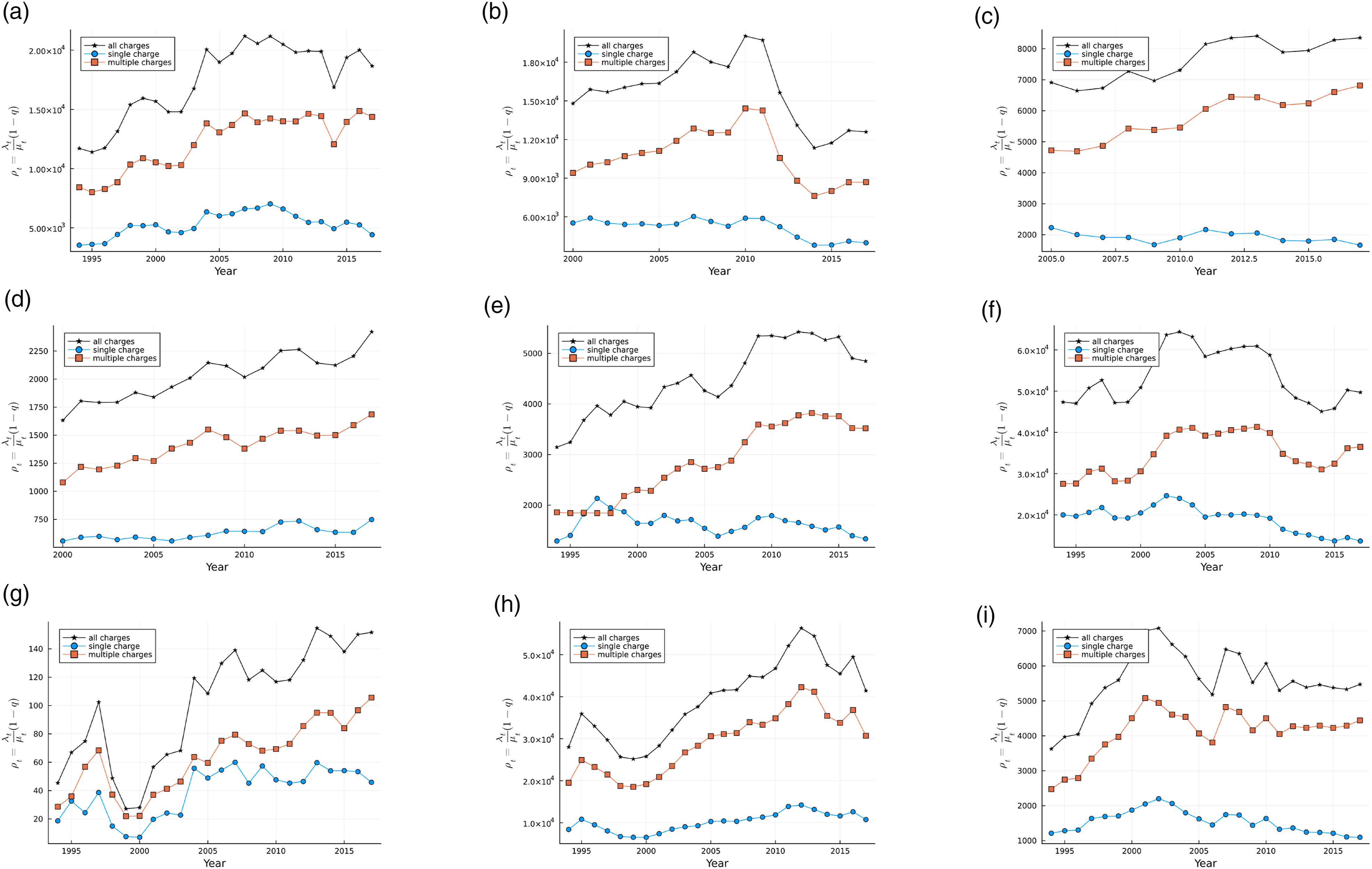
t
are plotted separately for single and multiple charges are plotted in Figure 4. It can be seen quite easily from Figure 4 that the arrival rate for 2018–2019 criminal charges are plausibly underestimated due to charges that were carried into the following year. Mean arrivals per day λ
t
. (a) Alberta, (b) British Columbia, (c) Manitoba, (d) New Brunswick, (e) Nova Scotia, (f) Ontario, (g) Prince Edward Island, (h) Quebec, (i) Saskatchewan.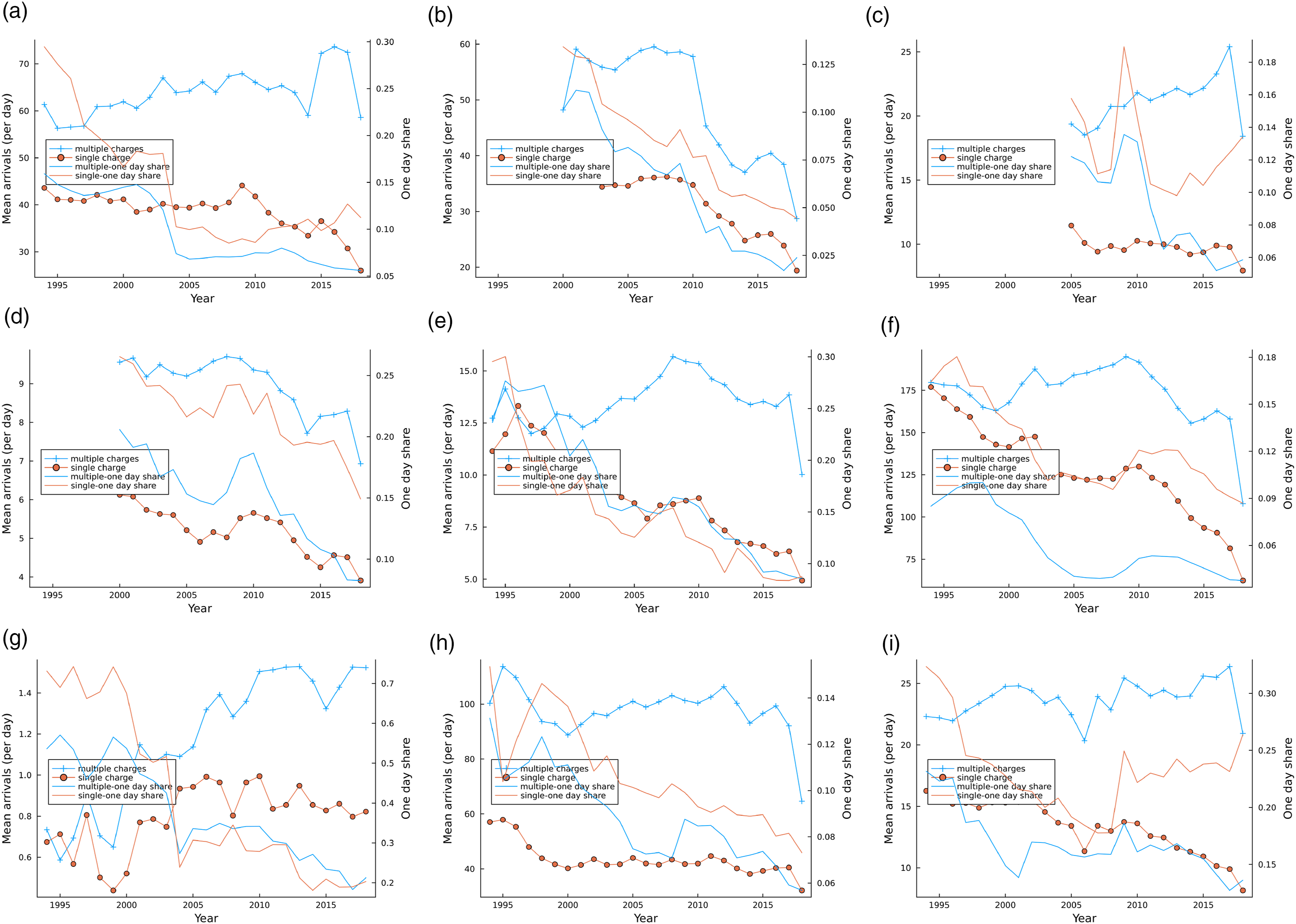
Figure 4 also plots the share of cases that have a service time of one day. The fraction of cases for which the court is able to produce a verdict in one day is extremely large relative to the theoretical probability implied by the duration of the case – one day – under most continuous probability distributions. Appendix A reports the fraction of cases with a duration of one day by offence and year for Alberta, Ontario, and Quebec. At one point in time, the one day case was most likely to be a prostitution or drug possession charge, but increasingly it has become used for crimes related to the administration of justice, such as failure to comply or failure to appear. Guilty pleas or dismissal or withdrawal of charges likely explain these quick, one-day cases. Indeed, in Canada around ninety percent of cases are resolved through the acceptance of guilty pleas (Statistics Canada, 2004).
2.5. Validating the Charge-Level Arrival Rate
The central reason we prefer our construction of the arrival rate from ICSS data is because it is available over a longer time series, going back to 1994 for most provinces. The two data, the ICCS and the CWI, are constructed differently in important ways: in the CWI, a case that is initiated is defined in terms of the information, which contains all charges per information, while the ICCS data, though more readily available over a longer series, provide data on the total number of charges with no information on the number of charges per information. However, we can validate our measure of the arrival rate by comparing it with the workload measure of cases initiated in a given year.
Figure 5 plots the relationship between our measure of arrivals and the cases initiated in a given year for the sub-sample for which we have both measures of arrivals. We find a robust positive relationship both in from regressions in logs and levels of the number of charges laid in a given year according to our measure on the number of cases initiated in that same year. Indeed, the correlation coefficient between the two measures of arrivals is 0.99. However, the coefficient estimate on the levels regression indicates that the arrival rate we construct under-estimates the total number of cases arriving in a given year, as the coefficient is below one, contrary to what one might expect if there were double-counting of charges per information in the ICCS data. This suggests the double-counting problem with cases of multiple-charges per information is not as severe as one might expect. Nevertheless, the high Pearson’s correlation and log coefficient of approximately one suggest that the ICCS measure of arrivals is appropriate to extrapolate the mean daily arrivals back in time with ICCS data, which we have beginning in 1994 for most provinces. Relationship between cases initiated and mean daily arrivals. Note. Figure plots number of charges in a given year (excluding administration of justice offences) (Source: Integrated Criminal Court Survey (ICCS)). Against the total number of cases initiated in a given year (Source: Court Workload Indicators). Coefficients are from regressions, both in levels and in logs, of the number of arrivals on the number of cases initiated. Correlation is Pearson’s correlation coefficient.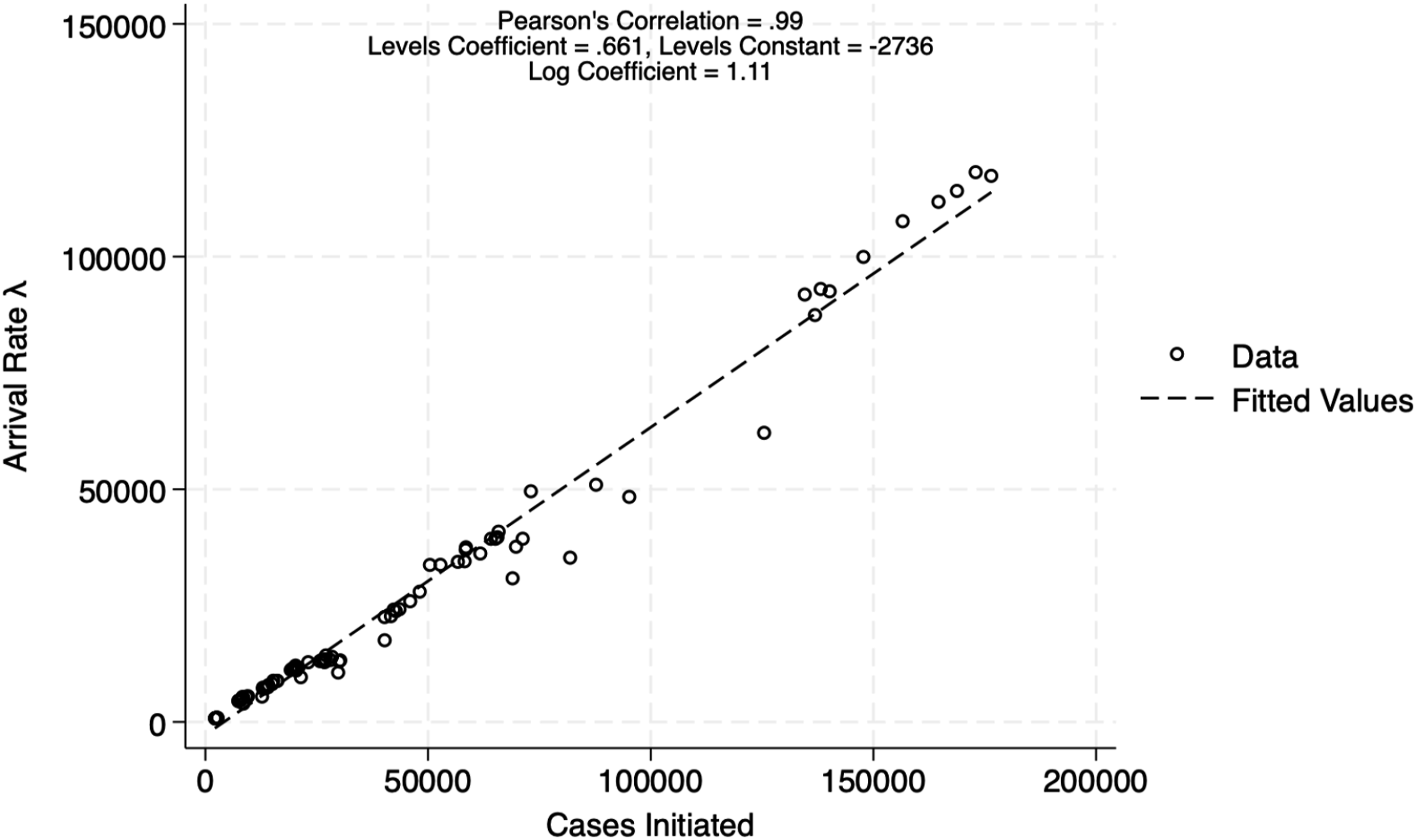
3. Estimation of Service Rate
Our goal in this section is to identify probability distributions that are consistent with our trial duration data, and use those distributions to obtain parametric estimates of mean trial duration. The service rate is defined as the time from first appearance to final disposition, or the end of trial, were there to be one. These estimates are, in turn, critical inputs into our estimates of pre-trial waiting times, as discussed later in Section 4.
It is important to note that our data is zero-inflated in the sense that far more trials are resolved extremely quickly (i.e., in less than one day) than would be implied by any of the most familiar probability distributions. To illustrate we consider the province of Ontario in 2010, in which case 11% of all single-charge cases required more than one year to resolve. If we were to assume that trial durations (as measured in days) followed an exponential distribution with rate β, then in order to match this observed frequency we would require 0.11 = e−365β or β ≈ 0.006. Now, if trial durations were exponentially distributed with rate β = 0.006 then the probability an individual trial is resolved within one day is 1 − e−0.006 ≈ 0.006 and we should expect to see 0.6% of all trials resolved within one day. In fact, for Ontario in 2010, 12% of all single-charge cases were resolved within one day, twenty times the rate implied by the exponential distribution as fit to the year-long trials. The point here is simple: the exponential distribution is unable to account for the substantial number of trials that are resolved extremely quickly, while simultaneously providing a good fit to the remaining data (i.e. durations of trials that are not resolved extremely quickly). One finds the same issue with virtually any of the most common probability distributions.
In order to formally describe our approach, let the random variable S denote the duration of an arbitrary trial in a given jurisdiction and year. We assume there is a positive probability that S = 0 and that if S > 0, then S behaves as a continuous random variable. In other words, we assume that trial durations are non-negative and continuous random variables, with a point mass at zero (the point mass being necessary to account for the substantial proportion of cases that are resolved extremely quickly). Formally, we assume that there exists a number q ∈ [0, 1] and probability density function f, supported on [0, ∞), such that
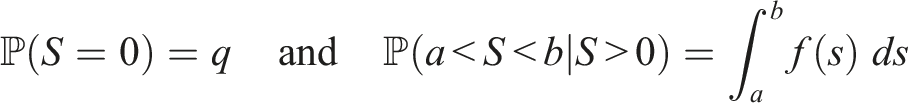
For later use, we note that for any 0 < a < b we have
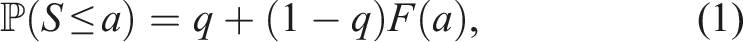
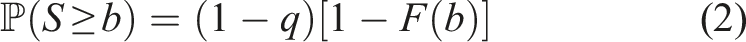
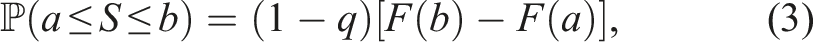
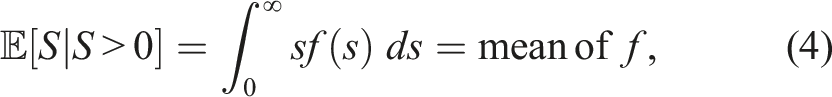
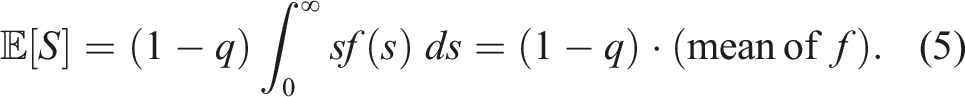
3.1. Parametric Estimates
It is tempting to assume that trial durations are exponentially distributed; queueing models with memoryless
14
service times tend to be the most mathematically tractable. That being said it is important to consider potential departures from memorylessness, and to this end we consider two different parametric families. A random variable is said to have a Weibull (Extreme Value Type III) distribution with scale parameter β > 0 and shape parameter α > 0 if it has a probability density function (pdf) of the form
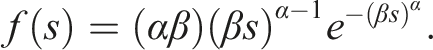
The Weibull mean is βΓ(1 + α−1), where Γ(⋅) denotes the gamma function, and the Weibull hazard fuction is
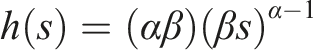
Note that if α = 1 then the Weibull distribution reduces to the exponential. If α > 1 then the hazard function is increasing and there is a negative relationship between a trial’s current age (number of days since it began) and remaining lifetime (expected time until resolution); the opposite is true if α < 1. If α = 1 then the hazard function is constant and the memoryless property prevails. Presumably the case α > 1 is more desirable in the present context, although that is admittedly a judgment call. An estimated value of α that is close to one would suggest that the memoryless property is a reasonable assumption for trial durations; an estimate that deviates substantially would indicate that the memoryless assumption is questionable.
It is also important to assess whether or not trial durations have so-called “heavy tails”, in which case excessively long trials would occur with concerning frequently. To this end we also consider the lognormal family, and recall that the random variable S is said to have a lognormal distribution with location parameter
In what follows we let θ denote the vector of unknown parameters in a given family, that is θ = β for the exponential, θ = (α, β) for the Weibull and θ = (m, v) for the lognormal. We write f(s; θ) and F(s; θ) instead of f(s) and F(s) in order to emphasize that the pdf and cdf do depend on the specific values of the parameters parameters (i.e., different parameter values produce different pdfs and cdfs).
We assume that within a given year, province and class (single- or multiple-charge), trial durations are independent and identically distributed. Unfortunately, we do not have access to exact trial durations, rather we have access to binned count data. In particular, for each year and province we have access to the number of trials whose ultimate durations were (i) less than one day, (ii) between 1 and 61 days, (iii) between 61 and 121 days, (iv) between 121 and 241 days, (v) between 241 and 365 days and (vi) in excess of one year. In other words our observed data is a vector of counts (n1, n2, n3, n4, n5, n6) where n i is the number of observations in the ith bin (e.g., n2 is the number of trials whose ultimate durations were between 1 and 61 days).
3.2. Parameter Estimation
The log-likelihood function that we are faced with is demonstrably given by
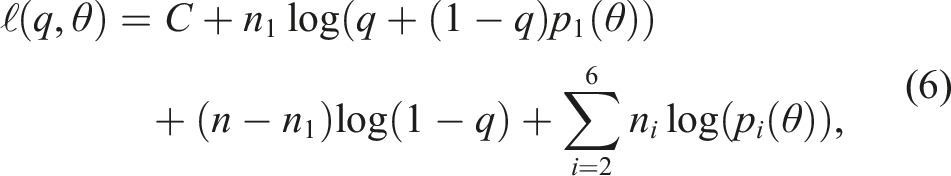
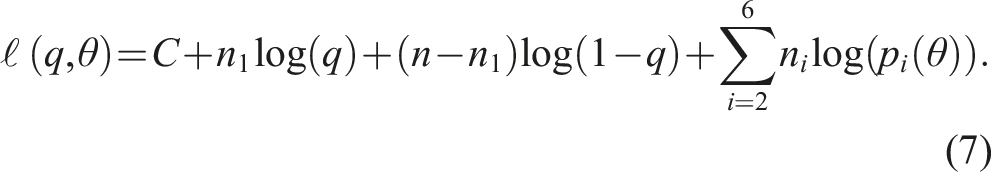
The advantage of (7) is that q and θ can be estimated separately. Indeed
3.3. Model Selection
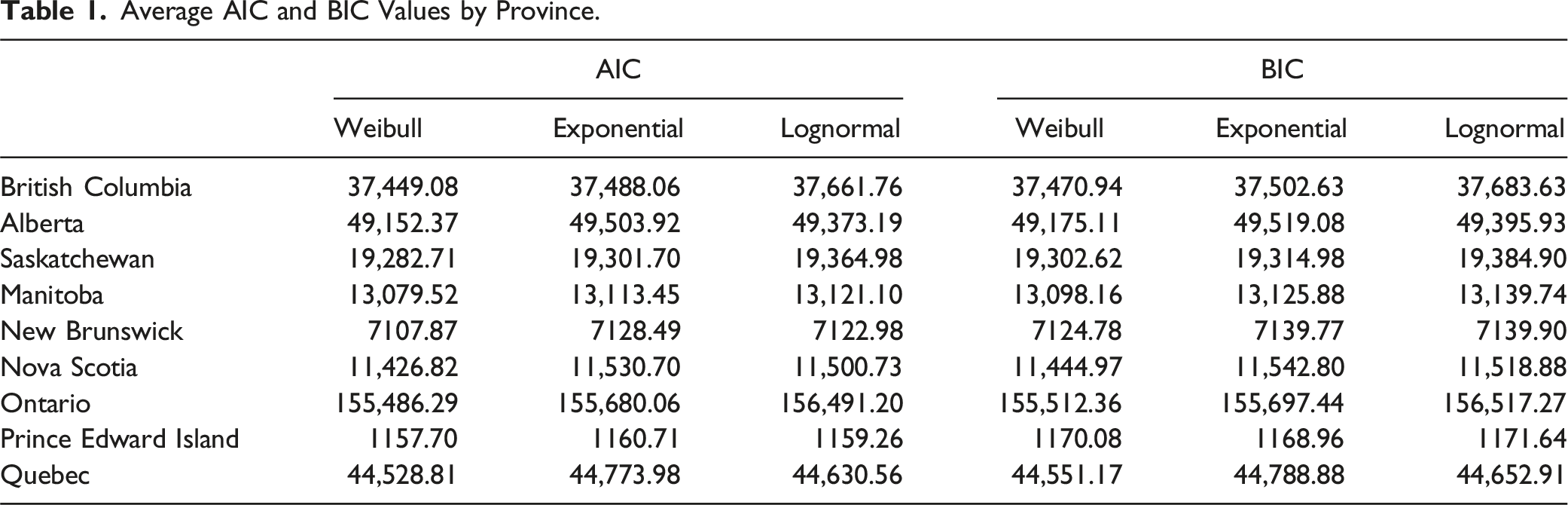
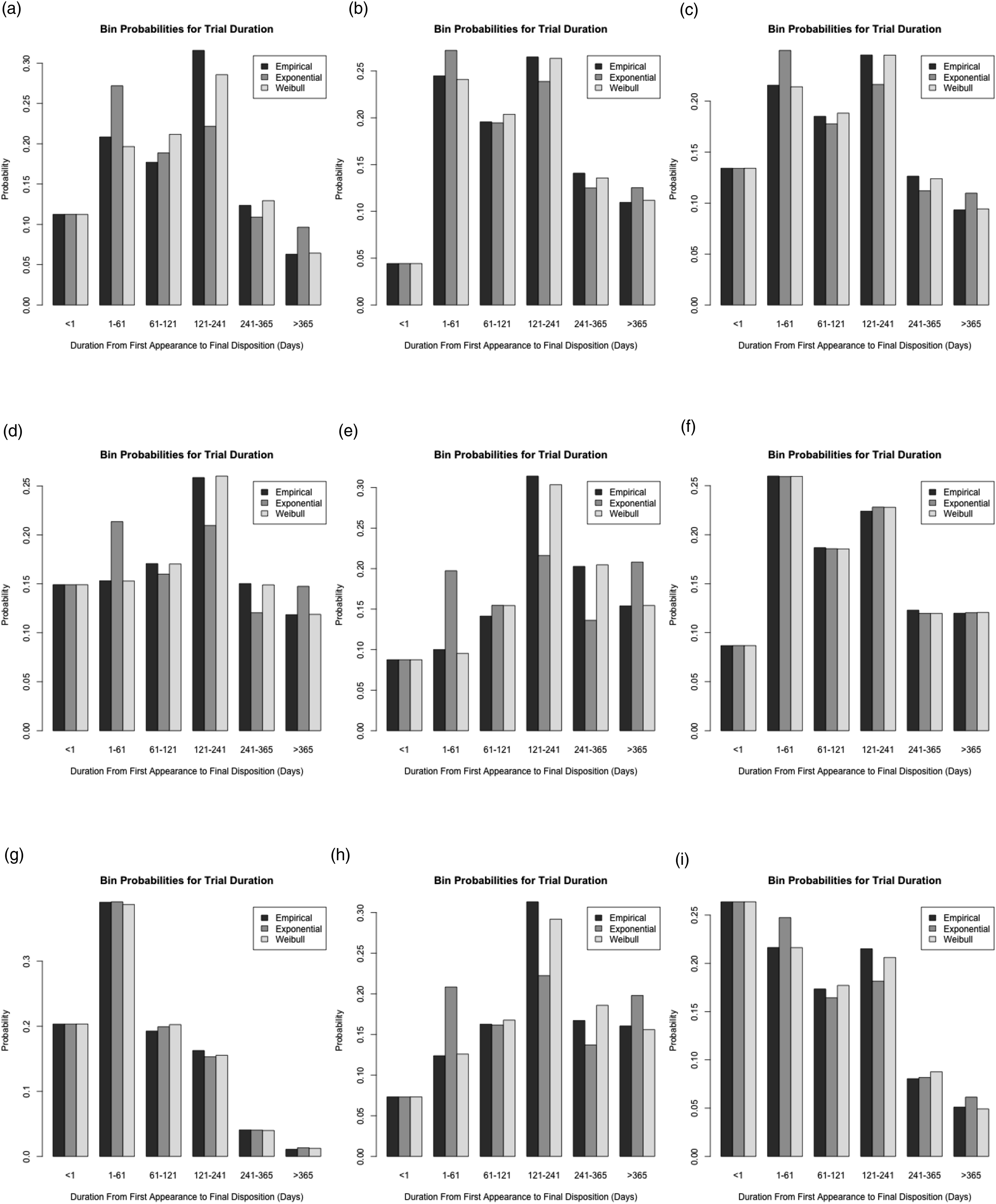
In this section we attempt to determine which of our three parametric models best fits the trial duration data. We begin by computing, for each year and province, the Akaike information criterion (AIC) and Bayesian information criterion (BIC) for each model. Recall that the AIC value for a particular model (in a particular year and province) is
Average AIC and BIC Values by Province.
Average p Values by Province.
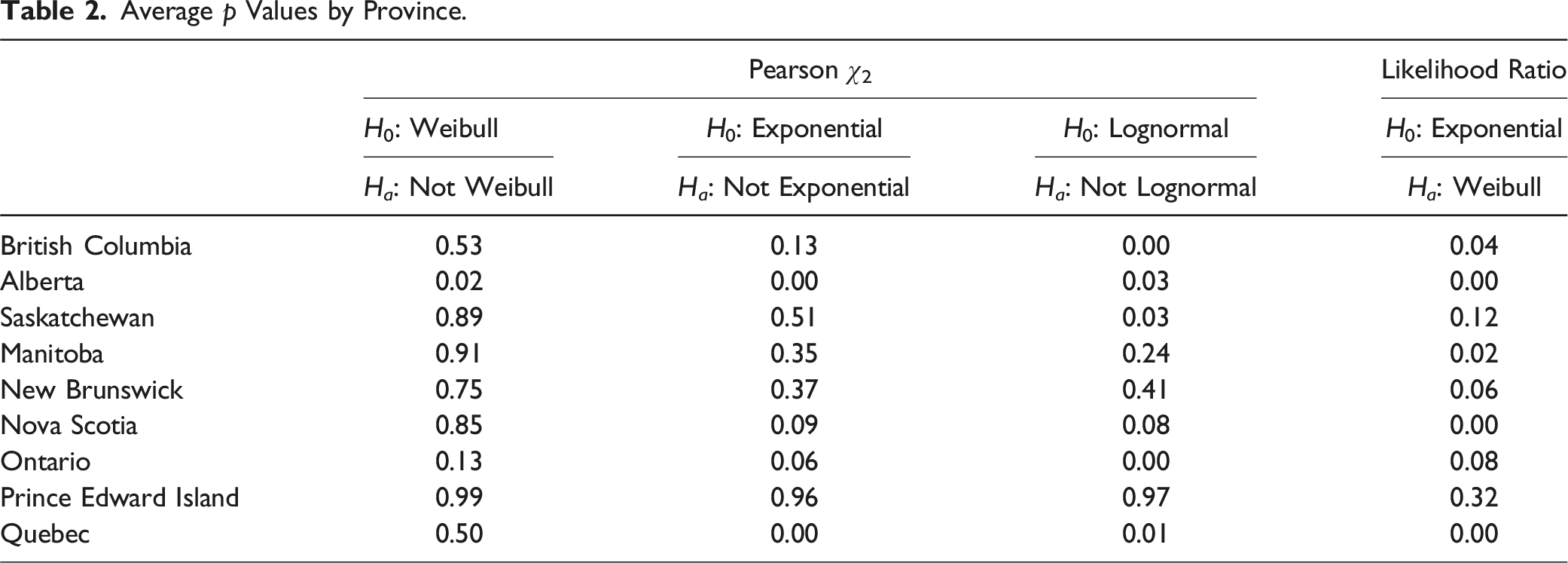
Because the Weibull contains the exponential as a special case, it is possible to directly test the hypothesis that trial durations are memoryless. To this end we assume the data is drawn from a Weibull distribution and employ a likelihood ratio test to test the null hypothesis that α = 1 (memoryless) against the alternative that α ≠ 1 (not memoryless). The last column of Table 2 reports average p values for each province. The data does cast some doubt on the validity of the memoryless assumption, but the evidence is certainly not overwhelming across all provinces.
3.4. Results
Weibull Mean Service Time Estimates.
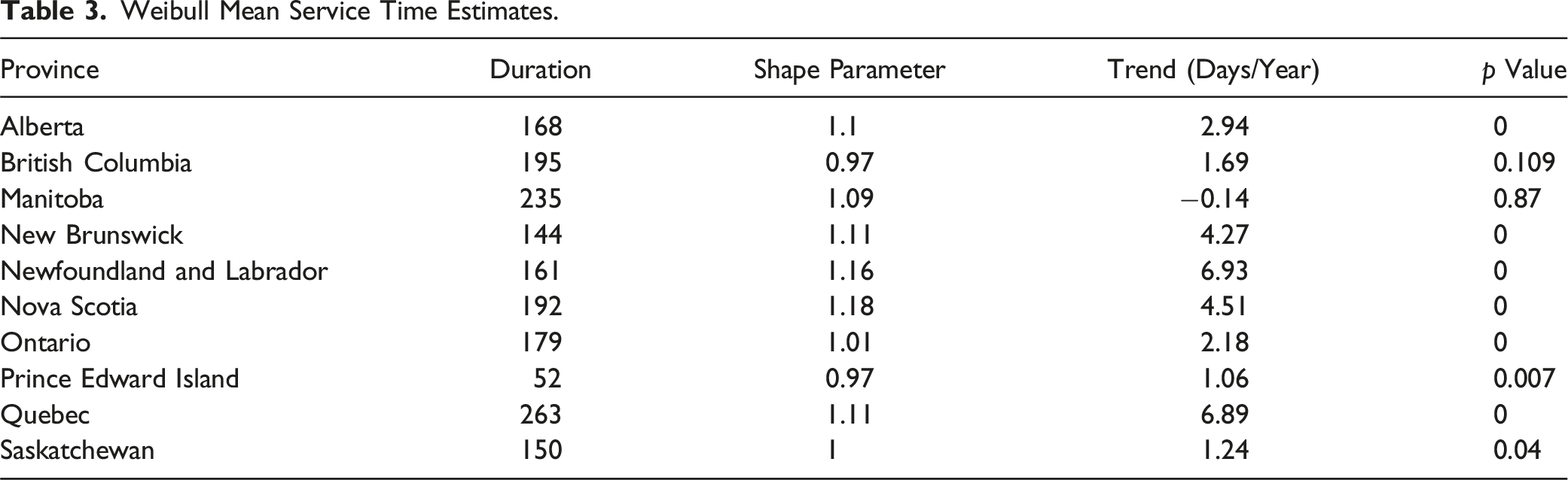
The second column of Table 3 displays the average estimated Weibull shape parameter across provinces. For each province we estimate a separate value of Weibull Shape Parameters α from CDF 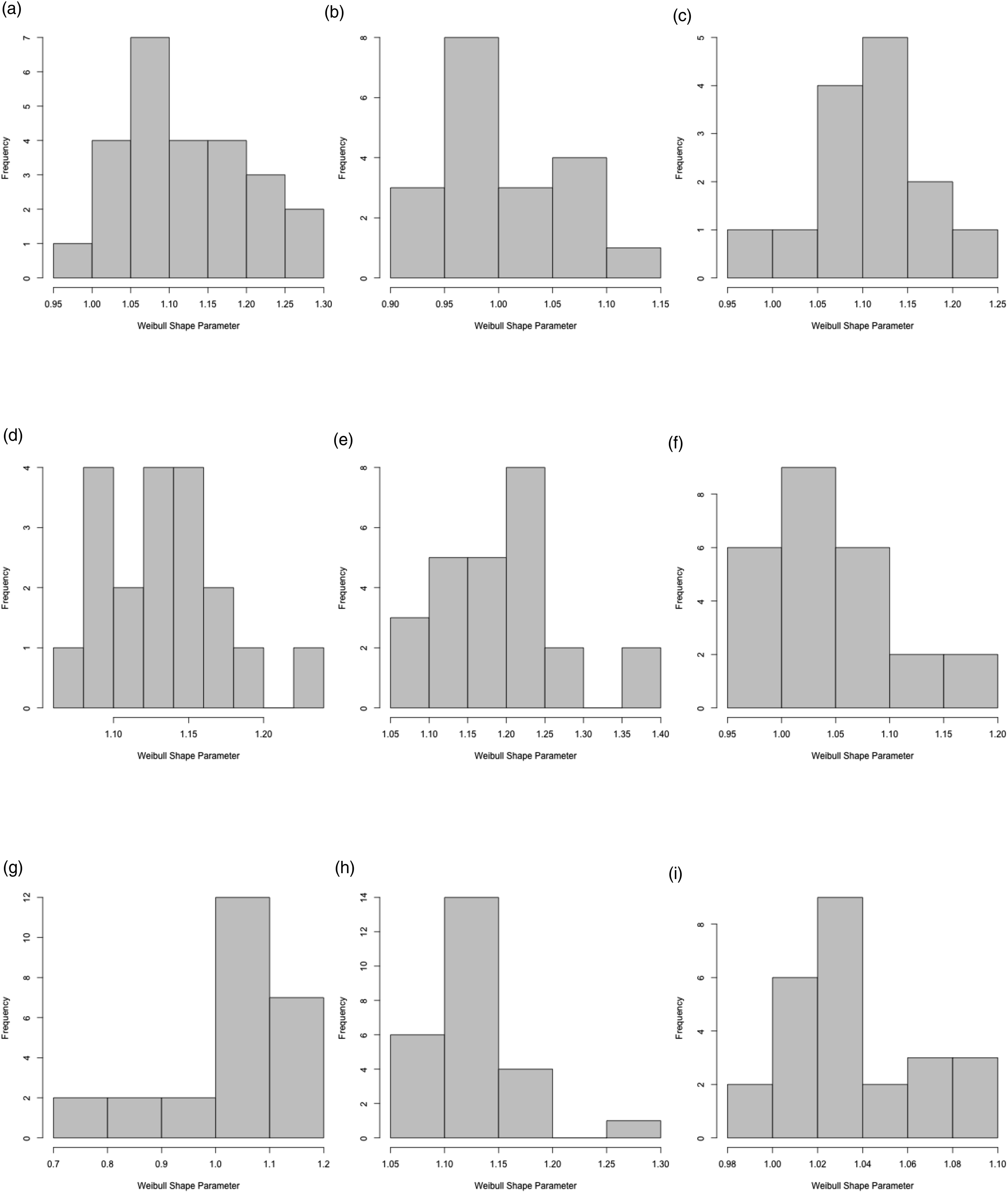
The last two columns of Table 3 consider time trends in mean trial durations. Specifically, for each province we regress our estimated mean durations against a time variable. The third row of the table reports estimated coefficients and the fourth row reports the p value associated with the test of the null hypothesis that the coefficient is equal to zero. In all but one or two provinces the estimated time trend coefficient is positive and statistically significant.
The results from the maximum likelihood procedure estimating the rate of the empirical service time distribution are displayed in Figure 7. It is important to remember that for the exponential distribution the mean is always greater than the median since ln(2) < 1, meaning that over half of cases will be served below the mean service time. The figure plots the mean of the Weibull distribution Mean service time: Inverse of maximum likelihood estimates Empirical versus Theoretical Service Time Distributions: 2018–2019. (a) Alberta, (b) British Columbia, (c) Manitoba, (d) New Brunswick, (e) Nova Scotia, (f) Ontario, (g) Prince Edward Island, (h) Quebec, (i) Saskatchewan.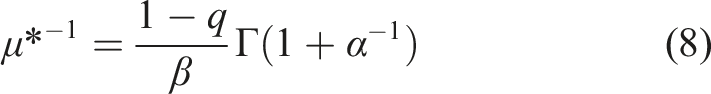
3.5. Grouped Charges
For the multiple charge data we can no longer consider the n i as “true” bin counts. Indeed the duration of a trial considering, say, three charges would be triple-counted in (6). The implication is that estimates based on (6) could potentially be skewed by the realized durations of larger trials (larger trials meaning those that consider more charges). In this section we argue that if there is no statistical relationship between trial size (number of charges being considered in that trial) and trial duration, then parameter estimates based on (6) should be reasonably accurate. While it is conceivable that there is a relationship between duration and number of charges, we do not have access to any information on trial size so it is not possible for us to assess whether such a relationship exists. 16 That being said, and as we discuss in this section, if duration and size are statistically independent then our estimation procedure for the single-charge data continues to be valid upon the inclusion of multiple-charge cases.
To begin suppose that the n charges are grouped into m cases. For 1 ≤ j ≤ m let S
j
denote the realized duration of the j
th
case, and for 1 ≤ i ≤ 6 let m
i
denote the number of cases for which S
j
falls in bin i. Further suppose we have access to the true bin counts (m1, m2, m3, m4, m5, m6). Then, under the assumption that trial size and duration are statistically independent, the log-likelihood function associated with the true counts is demonstrably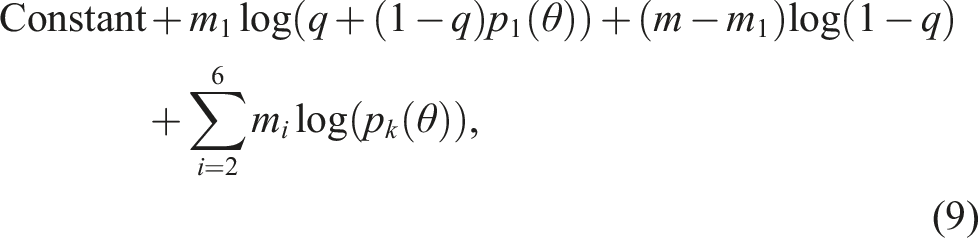
In order to compare the likelihood functions (9) and (6) we proceed as follows. For 1 ≤ i ≤ 6 and 1 ≤ ℓ ≤ m
i
let cℓ,i denote the number of charges associated with the ℓth case, among those cases for which the realized trial duration fell in bin i. Finally, let 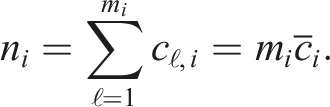
Now, if trial size and duration are independent, and we have a large number of observations, we would expect that the 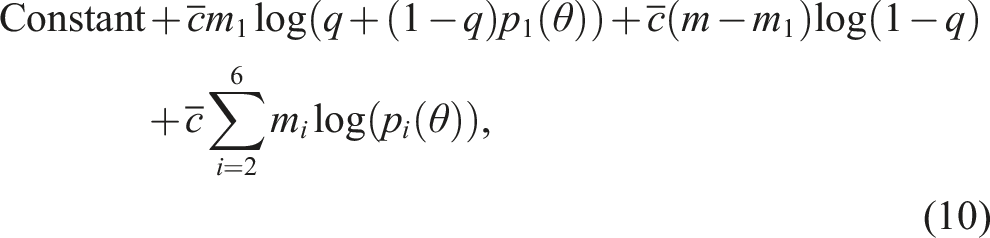
4. Queueing Theory
We now use our data and estimates to construct a model of the criminal justice system in each year for each province. Throughout our analysis, we are using long-run, equilibrium relationships assuming that one year is long enough for those relationships to materialize, as queueing theory uses expectations to model the average behaviour of a system over time. To measure the total number of cases in the system, L t , we use data on the provincial court system’s open caseload. With our arrival rate λ t , we can use Little’s Law (Little, 1961) to calculate total time in the system, and then subtract average service time 1/μ* to obtain the average implied wait time. Finally, we construct an estimate of the queue size L q by subtracting our estimate of the system’s server-level utilization rate ρ t = λ t /μ t from the total number in the system L t . 17
We exploit Little’s Law, an important queueing identity that applies to an extremely wide class of queueing models. Under extremely mild assumptions, Little’s Law states that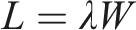
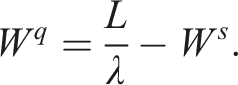
Armed with estimates of the arrival λ
t
and service rates μ
t
, as well as estimate of the average number of open cases during a given year L
t
, we can extract estimates of average waiting times in a particular year: Implied time in system W. (a) Implied time in system Implied time in Queue W
q
. (a) Implied time in Queue 
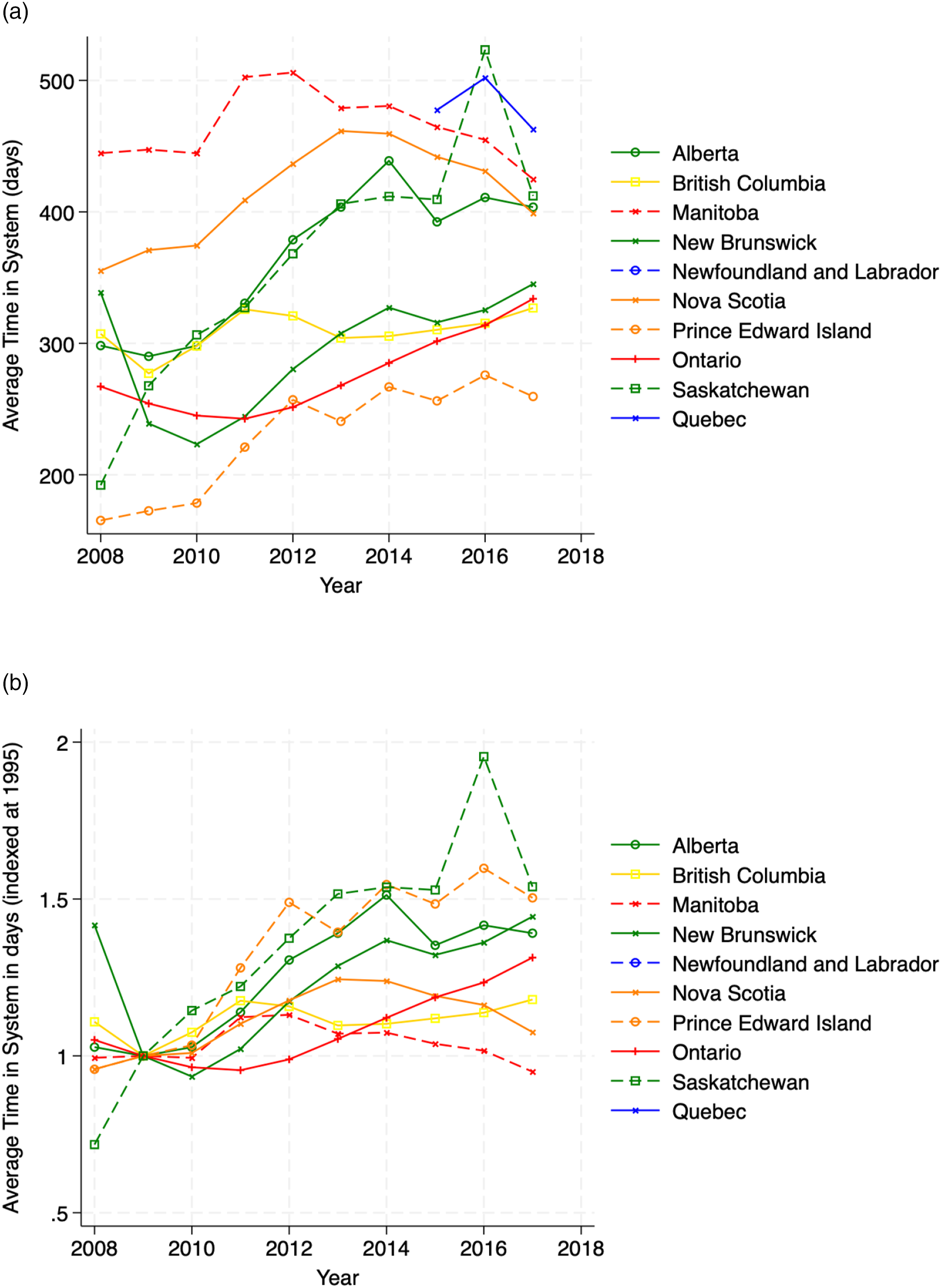
Regardless of the exact specification, many important measures of congestion, such as average time in system, average time in line, number of customers waiting for service, depend, in an increasing way, on the utilization rate – the ratio of the arrival rate λ
t
to the service rate μ
t
. In our notation, the utilization rate ρ
t
in year t would be Utilization rates 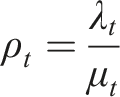
We use data on the open caseload at any given point in time to measure the total number in the system, both in the queue and being served, which we denote as L
t
. The total number in the system L
t
and the number being served ρ
t
are plotted in Figure 12. Indeed, we find that queueing theory’s measure of the number being served ρ
t
is highly correlated with open caseload, the total number in the system L
t
, suggesting that queueing theory has explanatory power. However, as we shall see, with a finite number of servers, the difference between these two quantities is the size of the queue. Open caseload L
t
and Utilization ρ
t
. Note. Figure plots open caseload L
t
and the server-level utilization rate ρ
t
. (a) Alberta, (b) British Columbia, (c) Manitoba, (d) New Brunswick, (e) Nova Scotia, (f) Ontario, (g) Prince Edward Island, (h) Quebec, (i) Saskatchewan.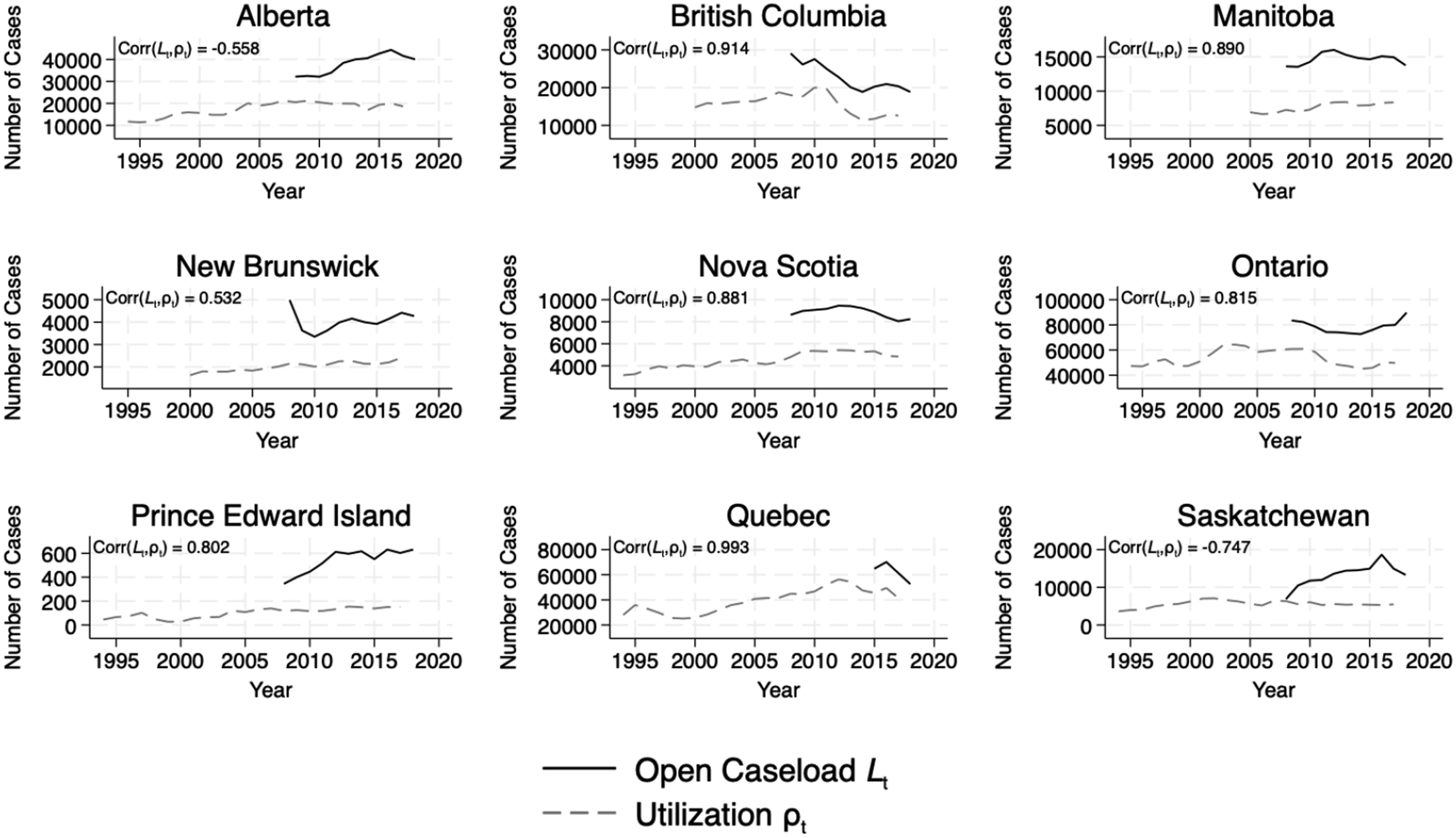
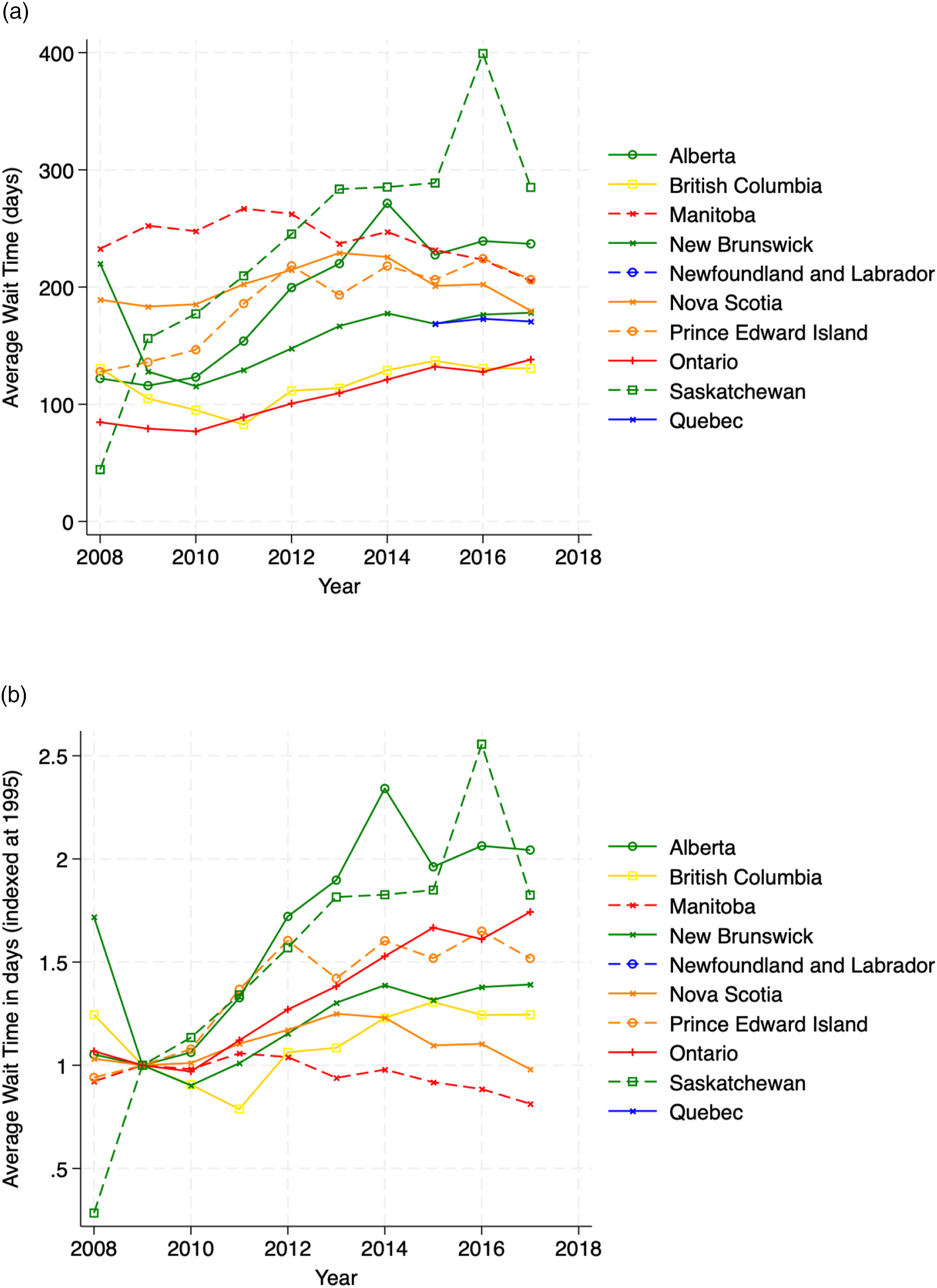
The queue size L
q
can be backed out again using Little’s Law for queues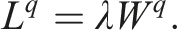
Inserting the equation for W
q
yields Implied number in Queue L
q
. (a) Implied number in Queue 
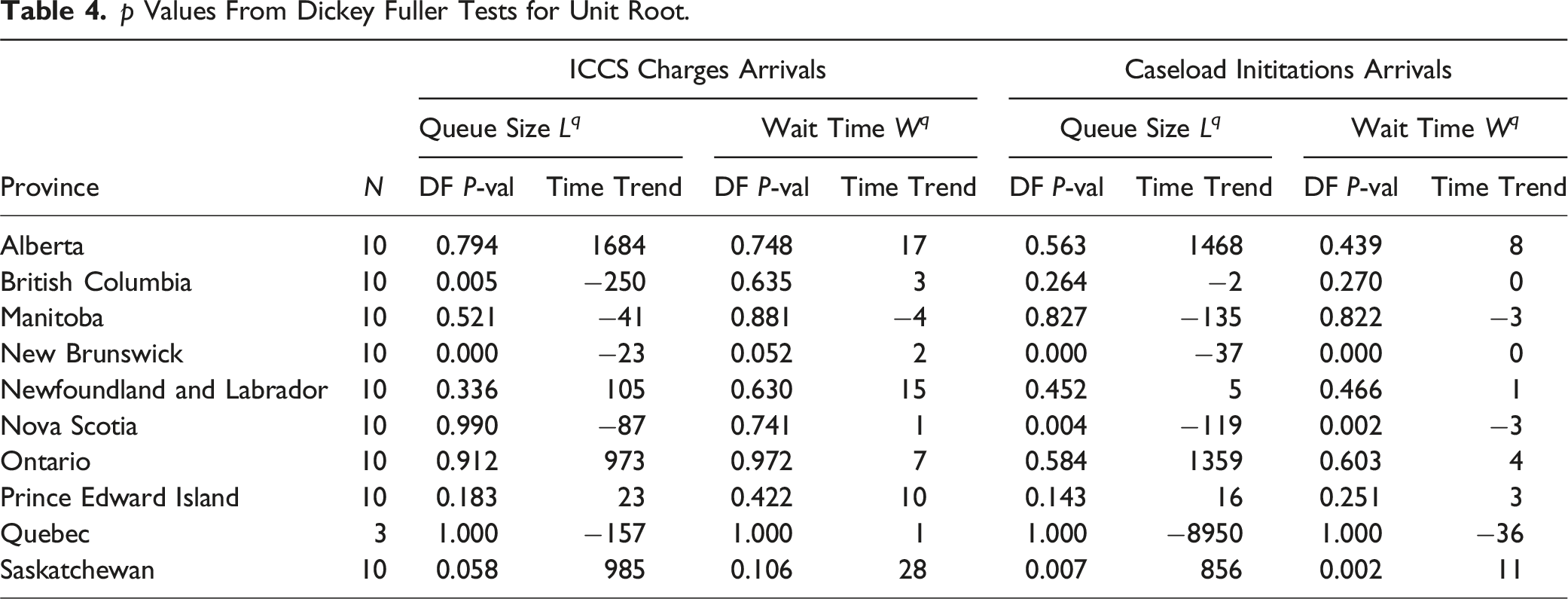
4.1. Stationarity
p Values From Dickey Fuller Tests for Unit Root.
4.2. Robustness Check: Singe-Charge Cases
An inconvenient feature of our arrivals data is that we only have data on the number of charges with no knowledge of the number of charges per information. One may rightly contend that changes in the composition of charges per information may bias our results, if not merely contribute to measurement error. Moreover, it may be of interest whether congestion in the system is driven by multiple-charge offences, which we have already seen have longer trials, but may also be more likely to opt for a preliminary hearing or a jury trial. To overcome these challenges, we thin out the full queueing system to study only single-charge cases to test if they follow a similar trend in wait times. To calculate the single-charge open caseload, we multiply the total open caseload by the fraction of arrivals that contain only a single-charge.
All model inputs and queueing results are re-produced in Figure 14. The wait times implied from the multiple-server queueing framework are, again, non-stationary and increasing. This allows us to conclude that our main results are not driven by changes in the number of charges per information, as the same phenomena are present in the thinned single-charge system. The fraction of open caseload attributable to single-charge cases is growing relative to the single-charge system server-level utilization. Thinned single-charge system. (a) Alberta, (b) British Columbia, (c) Manitoba, (d) New Brunswick, (e) Nova Scotia, (f) Ontario, (g) Prince Edward Island, (h) Quebec, (i) Saskatchewan.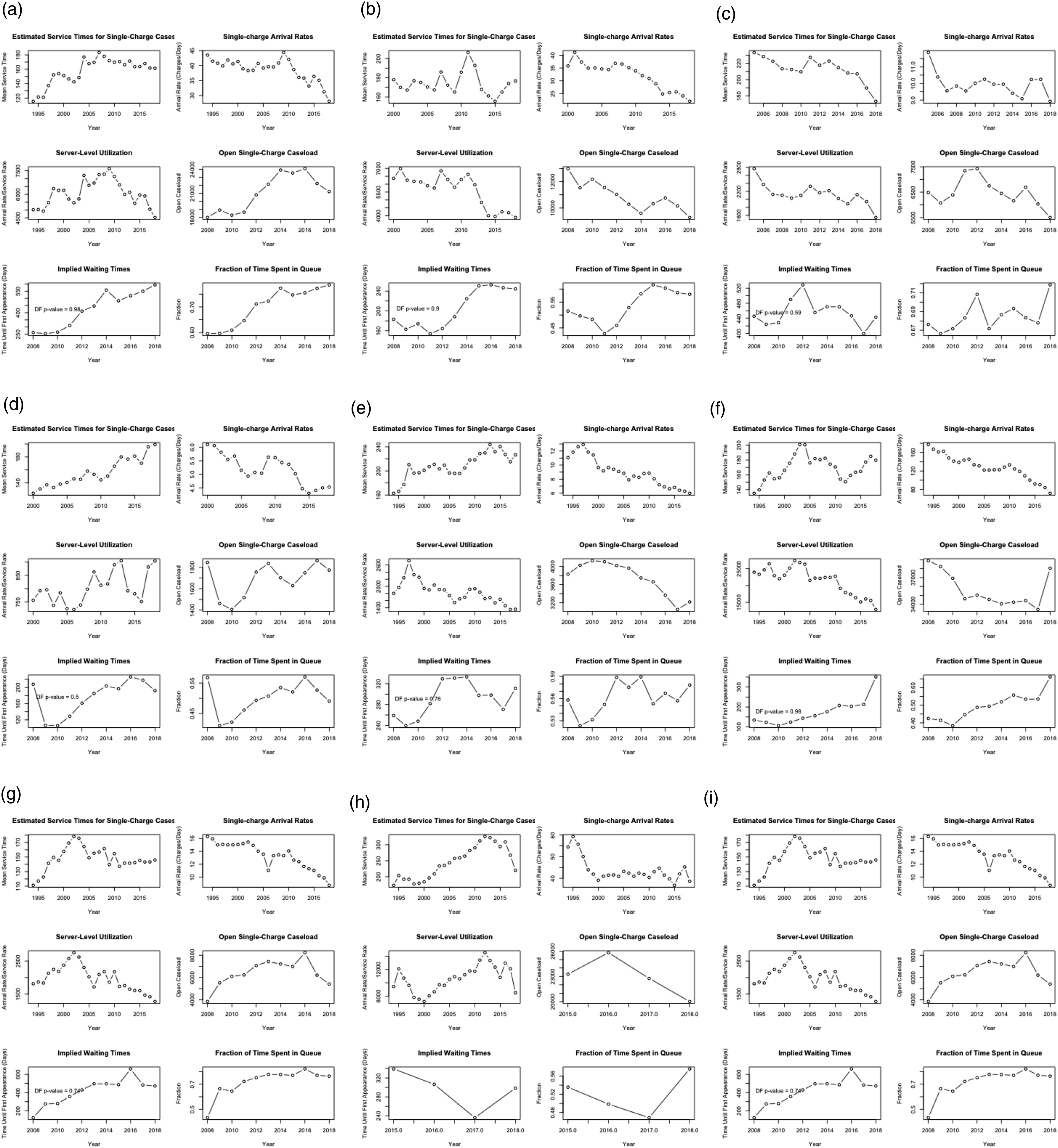
5. Remand
Up to and during trial, individuals not granted bail are held in remanded custody, sometimes referred to as pretrial custody. While a bail hearings are typically provided within three days, adjournments are possible if requested by either side or if administrative resources are inadequate. However, if bail is not granted, the accused is kept in custody leading up to trial, imposing an enormous limit on the liberty of the accused. The setting we examine is one where the population in pretrial custody is rapidly increasing across all jurisdictions. To what extent can our measures of the system explain the rise of the population in remand?
The central measure from queueing theory that we look to use is the utilization rate given that this is the measure we have the longest time series on. The server-level utilization rate is a key measure from queueing theory which all other measures, such as wait time and queue size, are increasing in. The key hypothesis from queueing theory is that the utilization rate will co-move positively with the population in pretrial custody if queueing theory can explain the secular rise in the population in pretrial custody. While we have a shorter time series on wait times and queue size, these might also co-move positively with the population in pretrial custody.
From a queueing perspective, the population in remand serves as a lower bound count of individuals in the system at any given point in time, with the caveat that some count of individuals in the system are not in remand, as they have been granted bail. Figure 15 plots the average count of individuals remanded in custody on the left axis and the utilization rate on the right axis over the 1994–2018 period. Movements in the system’s utilization rate are highly correlated with the average count remanded in custody. However, since the series are non-stationary, we must take care to ensure those correlations are not spurious. The Granger causality test is a statistical hypothesis test for determining whether one time series is useful in forecasting another. Average count in remand and utilization rate. Note. The figure plots the average count of the population in remanded custody on the right axis and the system’s utilization rate ρ
t
= λ
t
/μ
t
on the left axis. (a) Alberta, (b) British Columbia, (c) Manitoba, (d) New Brunswick, (e) Nova Scotia, (f) Ontario, (g) Prince Edward Island, (h) Saskatchewan, (i) Quebec.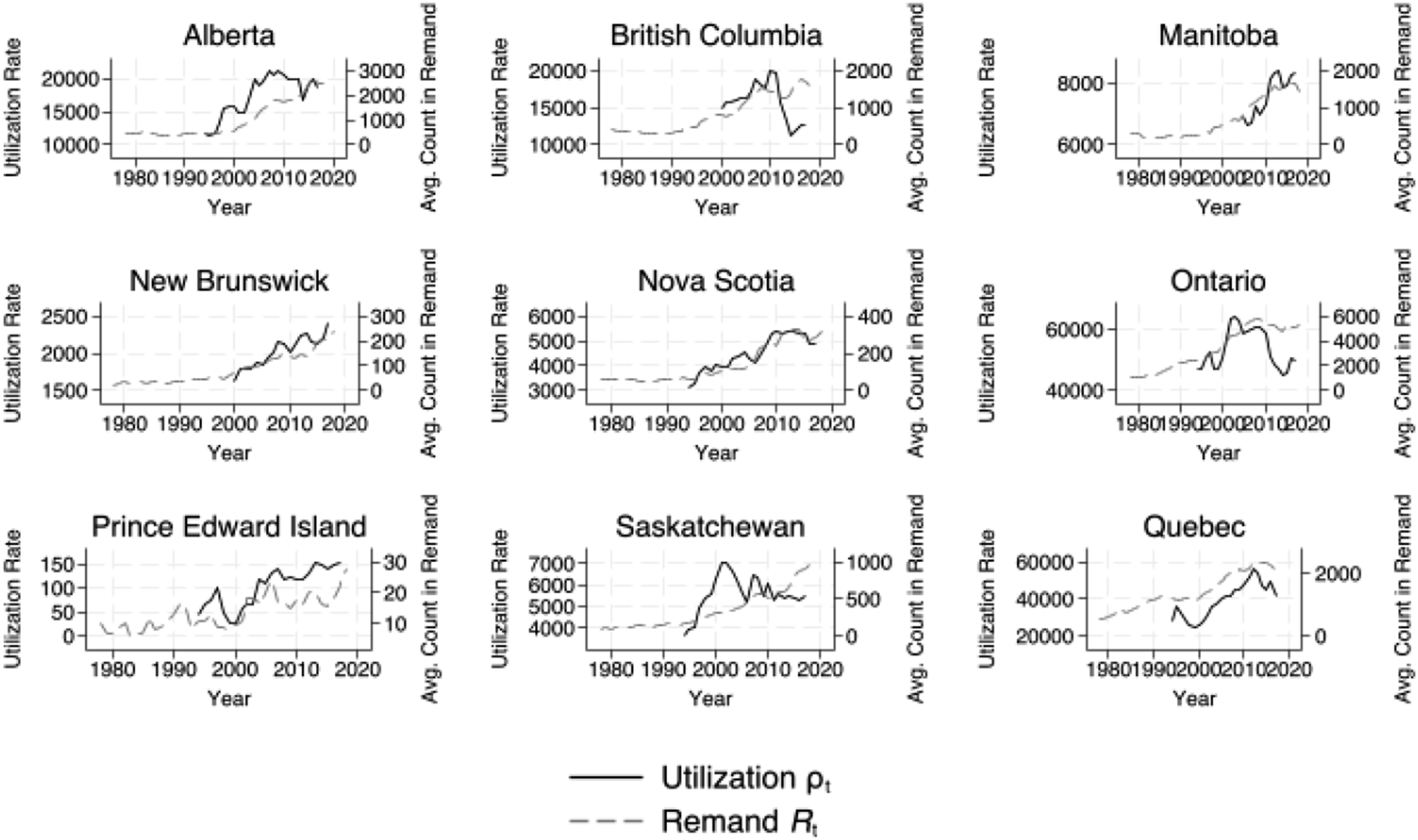
It can be seen immediately that both series are highly non-stationary, suggesting possible spurious correlation in their co-movement. In order to protect against the potential for spurious correlations, the series we compare must be stationary. Figure 16 plots series that have been adjusted in various ways to produce a stationary series. Figure 16(a) shows the remand and utilization series adjusted for a quadratic trend. Figure 16(b) shows the de-trended first differenced remand and utilization series. Figure 16(c) shows the remand and utilization residuals after adjusting for two independent AR(2) processes. Figure 16(d) shows the remand and utilization residuals from an AR(2) process after adjusting for a quadratic trend. Dickey-Fuller p values from a test for a unit root (non-stationarity) are shown. In general, all transformations produce stationary processes. Figure 17 plots the auto-correlation functions for four lags of each series by province. While the de-trended series appears to retain an AR(1) structure, the other adjustments, first differencing and AR(2) residuals, produce series that are approximately white noise. Remand and utilization adjusted time series. (a) Raw series adjusted for quadratic trend, (b) first difference series adjusted for linear trend, (c) residuals from AR(2) process, (d) residuals from AR(2) detrended process. Remand and utilization auto-correlation functions. (a) raw series adjusted for quadratic trend, (b) first difference series adjusted for linear trend, (c) residuals from AR(2) process, (d) residuals from AR(2) detrended process.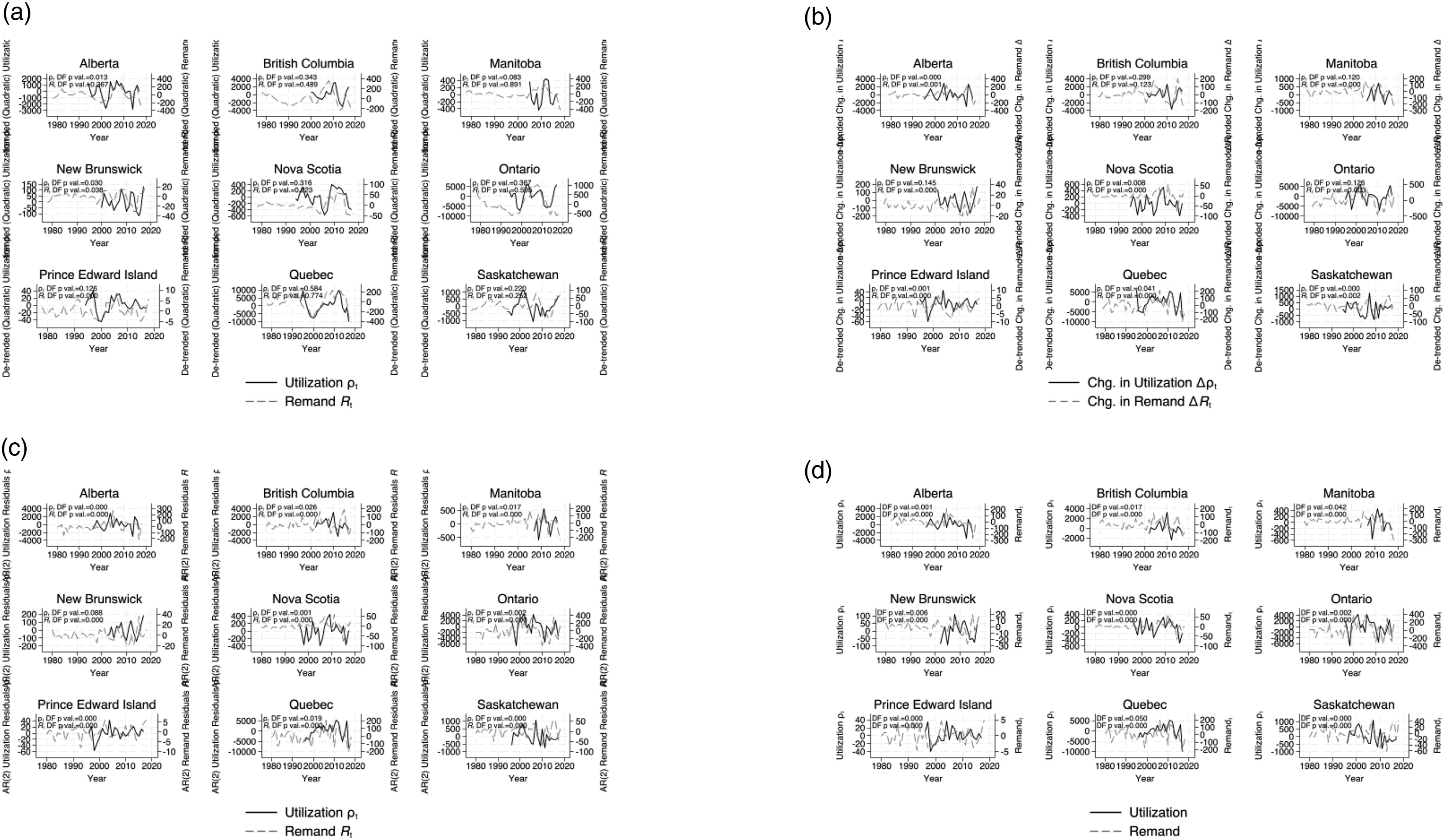

To detect co-movement between the utilization rate, the model’s measure of those being served, and the population remanded in custody, we run pooled time series regressions on adjusted series. Let R
pt
denote the average population in remand and ρ
pt
= λ
pt
/μ
pt
denote the utilization rate in province p in year t. Both utilization ρ
pt
and remand R
pt
are de-trended according to the following procedure. First, we estimate the following equation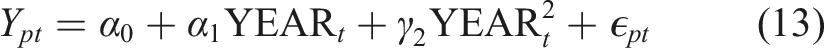
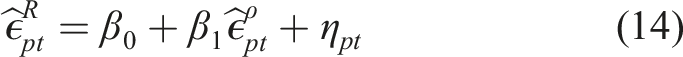
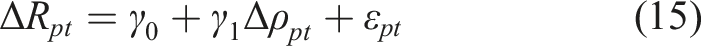
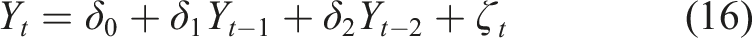
Pooled Time Series Regressions.
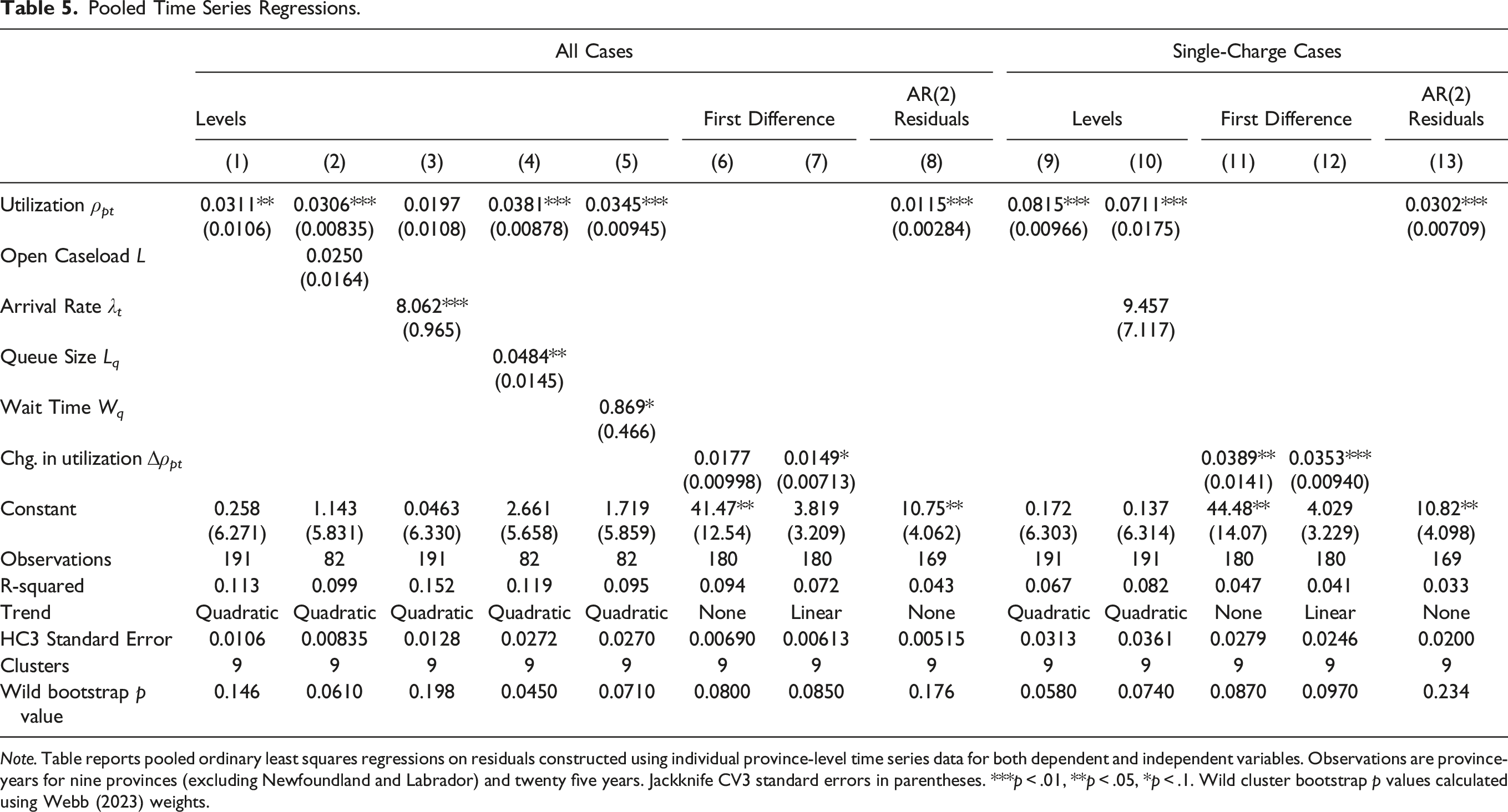
Note. Table reports pooled ordinary least squares regressions on residuals constructed using individual province-level time series data for both dependent and independent variables. Observations are province-years for nine provinces (excluding Newfoundland and Labrador) and twenty five years. Jackknife CV3 standard errors in parentheses. ***p
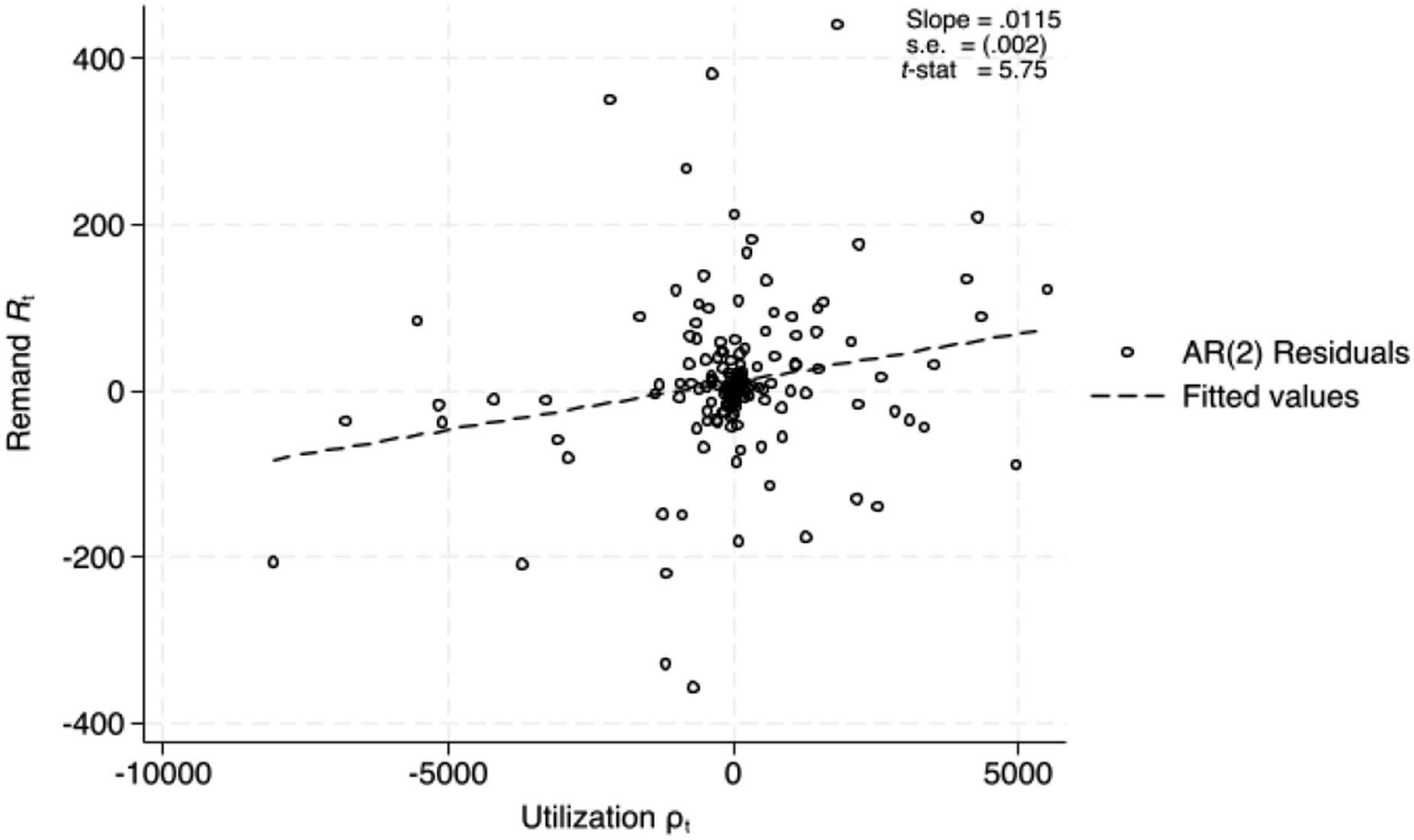
Partial relationship between AR(2) remand and utilization residuals. Note. The figure plots AR(2) residuals from independent regressions according to equation (16) for remand and utilization series.
5.1. Robustness Check: Single-charge Cases
The court system manages many types of cases. One way of distinguishing between types of cases is by single- and multiple-charges. The queueing system can be “thinned” by simply analyzing the service time and arrival rate for single-charge cases only. This serves as a robustness check, as we are unable to observe the number of charges per information for multiple-charge cases, but also allows us to test the mechanisms which underly the relationship between our measure of congestion and the population in pretrial custody. Indeed, one might expect no relationship between measures of single-charge congestion and the population in pretrial custody, as these accused in these cases are much less likely to be detained in custody due to the fact that they face less serious charges.
Table 5 also displays the results testing for co-movement between the thinned single-charge queueing theory measures, such as utilization ρ t and the arrival rate λ t , and the total population in pretrial custody. Again, we detect strong co-movement between queueing theory’s measure of traffic congestion, the thinned utilization rate, and find that this measure outperforms conventional measures such as the thinned arrival rate. The inclusion of the arrival rate does not result in a statistically insignificant coefficient estimate on the utilization rate in single-charge cases. The coefficient estimate in column 12 of Table 5 implies that an increase of one hundred cases being served in the system per year leads to an increase of three in remanded custody. In general, the thinned utilization measure produces coefficient estimates that are larger than when analyzing the total system, both single- and multiple-charge cases. The increase in coefficient estimates suggests either that the results from the total utilization regressions suffered from measurement error which led to attenuation bias.
The results are remarkable in yet another way. That is, one would not expect that congestion of single-charge cases would be related to remand since they will be more likely to be granted low or no bail, as their charges are less serious. However, the robustness of the results bolster the conclusion that court congestion is the mechanism that is driving the troubling trends in the population in pretrial custody. Single-charge cases clog up the court system, leaving those in pretrial custody waiting longer for their date in court.
6. Conclusion
The right to be tried within a reasonable time is widely recognized as a pillar of criminal justice systems around the world. However, criticisms of the court system’s efficiency are abound. In 1971, William Landes noted in The Journal of Law and Economics that “[i]t is widely recognized that the courts are burdened with a larger volume of cases than they can efficiently handle” (p. 74). This is particularly important in the criminal procedure context where it has been argued that the long delays “blunt the deterrent effect of the criminal law” (Meador, 1972). The problem of court congestion is documented throughout history and remains just as relevant today as it was then, in particular in Canada, where the population in pretrial custody has exploded.
Our paper resolves the paradox of rising pretrial populations and falling crime rates by exploiting a basic framework from the field of operations research widely known as queueing theory. We use data on millions of criminal cases to estimate the service time distributions of provincial criminal justice systems over two decades. We find that the duration of criminal trials fit an exponential distribution well, suggesting that a memoryless queueing model might be appropriate. We then used queueing theory to construct a measure of court congestion, the utilization rate, which is a measure of the court’s traffic flow. In the infinite-server, memoryless model (i.e., M/M/∞), with no delay, this number reflects the total number in the system, an idealized measure of open caseload were there to be no delay or capacity in the system. We then use data on the court’s actual open caseload to back out measures of implied queue size and wait time until first appearance by exploiting a fundamental idea in queueing theory, which is that a system’s queue grows as utilization ρ and open caseload L diverge. Both measures, queue size and wait time, are, in general, increasing and non-stationary for the nine provinces we examine, suggesting that some criminal courts are at or near capacity and may be spiralling out of control. Overall, our data validates the widely-held impression that the court system, in particular, the criminal justice system, is over-burdened.
Using time series analysis, we also found positive co-movement between the model’s measures of congestion, the utilization rate, the queue size, and wait time, and the average count of the population in pretrial custody, suggesting that court congestion has explanatory power for the rise of the population in remanded custody. Measures from our multiple-server queueing model, such wait time and queue size, outperform the measures currently available to researchers in the raw data, such as open caseload, in predicting the population in pretrial custody. Building on the seminal contribution of McAllister et al. (1991), our research further validates the use of queueing theory for analyzing the criminal justice system.
These basic relationships validate the use of our measures for the study of other lines of inquiry. Future research may also wish to exploit the COVID-19 shock to examine the impact on court delay and its effect on other outcomes (see, e.g., Paciocco, 2021). Given the robustness of the relationship between the model’s measure of court congestion and the population in pretrial custody, future research may also wish to use our approach to estimating the delay of criminal trials to study other outcomes of interest in the criminal justice system, such as guilty pleas.
There are many policy conclusions to be gained from this exercise. First, we believe our measures of court performance constructed from publicly available data can be used going forward as a real-time performance measure of the court system that can be used in s. 11(b) constitutional litigation. Second, our results suggest that the duration and number of trials co-move positively with the population in pretrial custody. The measures recovered from our queueing model help resolve the paradox of falling crime with a rising population in pretrial custody.
Future research should attempt to use finer geographic data to focus in on where congestion is being generated. This may involve changing the unit of analysis from the province down to the courthouse. Future research may also take advantage of higher frequency data in order to obtain more precise estimates of the relationship between court congestion and remand, such as day-of-week and month effects, as well as seasonality. Because of the annual periodicity of our data, we are unable to validate that the arrival process is indeed Poisson. We simply take annual averages of cases. Higher frequency data would be required to know if the Poisson process is appropriate, such as, for instance, if inter-arrival times are exponentially distributed. We have documented how the maximum likelihood estimation procedure would need to be augmented in order to account for data on the number of charges per information.
One aspect of queueing theory that we are unable to speak to is the service discipline. We have combined multiple data sources and exploited Little’s Law to avoid specifying the underlying structure of the system, such as the service discipline or number of servers. In many places, our invocation of memorylessness was for the benefit of its utility. In reality, criminal court systems often employ service disciplines that look more like priority queueing or processor sharing than first-come first-serve. Future research should attempt to examine the effect of these service discplines have on the estimated delay of criminal trials. Rather, we have exploited Little’s Law, which does not depend on assumptions about the arrival process, the number of servers in the system, or the service discipline (Eilon, 1969; Jewell, 1967) and invoked memorylessness to study the behaviour of the model-implied queue.
A host of recent policies in Canada have been directed at reducing congestion in the criminal justice system: the hybridization of offences as either summary or indictable; the restriction on the use of the preliminary inquiry; and the framework set out by the nation’s highest court in Jordan. We leave future research to debate the relative merits of jury trials, preliminary hearings, and the court’s screening function against the costs of court congestion. While we leave these thorny normative questions about how best to perform legal triage for the subject of future research, we do arm researchers with reliable statistics from which they can develop designs that measure the effects of these policies on court congestion and case outcomes.
Supplemental Material
Supplemental Material - Estimating the Delay of Criminal Trials: Evidence From Canada
Supplemental Material for Estimating the Delay of Criminal Trials: Evidence From Canada by Dylan R. Clarke and Adam Metzler in Journal of Law & Empirical Analysis
Footnotes
Acknowledgments
We are grateful for very helpful comments from Steve Coughlan and Palma Paciocco, and Sam Kaufman and Diana Grech at the Ministry of the Attorney General for guidance on the data.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.