
Abstract
This is a visual representation of the abstract.
Introduction
By scanning the surface of materials, hyperspectral imaging (HSI) can simultaneously provide abundant and valuable spatial–spectral information about external and internal chemical properties. This technique is rapid, noninvasive, nondestructive, and requires minimal sample preparation. Therefore, HSI has been widely applied for the quality evaluation of various food and agriculture products, such as discrimination of sesame oils, 1 determination of chia seed (Salvia hispanica) geographical origins, 2 differentiation of pine nuts, 3 and detection of foreign materials in cocoa beans. 4
The spatial–spectral hyperspectral images contain hundreds of spectral channels and thousands, even millions of spatial pixels. The different chemical characteristics and physical structures of the scanned materials reflect, absorb, and emit electromagnetic signals with distinctive patterns at different wavelengths. 5 Therefore, the quality of HSI can be affected by various factors, such as the sensors chosen, the experimental settings, or the environmental conditions.
The electromagnetic energy source might be unstable due to a variety of elements, such as cloud cover for remote sensing, power fluctuation of halogen lamps for laboratory hyperspectral equipment, temperature changes caused by heat from the energy source, or the brightness level variations produced by lamp ageing.6,7 Furthermore, the sensors that are used to capture the electromagnetic signals are also subject to dead pixels, dark currents, or abnormal spikes, which might be caused by dysfunction of focal plane array or electronic circuit noise.6,8,9 The obtained images might also contain useless information, such as background or specular reflection regions. 10 Therefore, it is essential to preprocess hyperspectral images to reduce the adverse effects of irrelevant and noisy information for subsequent tasks, such as classification, object detection, or regression analysis.
Different approaches have already been investigated to address the aforementioned issues. For instance, some inconsistent spectral profiles might still be captured by carefully monitored bench-top HSI devices, which might be influenced by ageing components or heat from halogen lamps. Thus, appropriate calibration methods were developed to remove variations and to standardize the spectral data. The calibration process is essential to guarantee the reliability of system operating environment, evaluate the reproducibility of HSI of different acquisitions, and diagnose instrumental errors if necessary. 11 Moreover, the instrumental noise could be partially removed by smoothing techniques, such as moving average, median filter, Savitzky–Golay, and Gaussian filters.6,12 Other disturbances to the spectral curves, such as light scattering that can cause drift in the baseline or peak of the spectra data, 13 could be corrected by standard normalize variate (SNV), multiple scattering correction, first or second derivatives, and orthogonal signal correction.6,10,12
For conventional chemometric analysis tasks, the application of machine learning algorithms and preprocessing is a standard procedure to improve the task performance.14,15 The appropriate preprocessing procedures are normally determined by trial and error.13,15,16 With the advancement of deep learning techniques, which can extract both linear and nonlinear features from high dimensional data, an increasing number of HSI classification or regression tasks have been applied to deep learning algorithms. For example, blueberry firmness could be classified by hyperspectral microscopic imaging and fusion-nets using one-dimensional convolutional neural networks (1D-CNN), 17 the total volatile basic nitrogen content in Pacific white shrimp (Litopenaeus vannamei) was predicted using features extracted by stacked auto-encoders, 18 hyperspectral satellite imagery was utilized for crop mapping with convolutional neural networks (CNN), 19 rapid quality assessment of nuts was conducted using HSI and CNN, 20 and pests have been identified from body fragments and larvae skins using CNN and a capsule network coupled with visible–near-infrared (Vis-NIR) hyperspectral imaging. 21
Usually, the HSI preprocessing techniques for deep learning are similar to those of machine learning, 15 and deep learning can also benefit from conventional preprocessing methods.22–25 There was also research that demonstrated that the appropriate CNN model could transform the input data to a suitable form for prediction and extract sufficient abstract features from raw spectrum so that the performance of quantitative analyzing tasks of spectroscopic data could be improved without data preprocessing.26–32 The potential of an end-to-end analysis system based on raw spectral data without preprocessing is attractive because inappropriate preprocessing methods might remove useful information and computational resources could be saved by avoiding redundant optimization. However, most research on deep learning with HSI has been dependent on the stability of neural networks due to the lack of transparency and interpretability for neural networks,15,33 so it might be beneficial to analyze the effects of normalization HSI data on the trained neural networks directly to have a better understanding of deep learning mechanism.
In the present study, different machine learning and deep learning classifiers, including random forest (RF), multilayer perceptron (MLP), and CNN with varying numbers of batch normalization (BatchNorm) layers, 34 were applied to categorize the botanic origins of different honey based on normalized and unnormalized hyperspectral imaging data without calibration. The classification performances of different classifiers combined with various spectral normalization techniques, including no normalization (“none”), MinMax normalization (MinMax), SNV normalization, centering power normalization (CP), and Pareto scaling normalization (Pareto), were compared. According to previous work, 35 these normalization methods were selected because CP, SNV, and Pareto had the top three separability powers based on evaluation using a silhouette coefficient (SC). 36 MinMax was simple and not commonly applied for spectral preprocessing. In addition, most studies about chemometrics only investigated the different normalization methods by comparing the performance of quantitative analysis tasks. This study was designed to analyze the effects of normalization methods directly on the trained neural networks. Specifically, the effects of BatchNorm on different CNN models combined with various normalizations were explored by comparing classification results and analyzing the distributions of the kernel weights of the convolutional layers. The distributions of neural network weights were visualized and briefly analyzed to demonstrate that BatchNorm did not address the “internal covariate shift” issue. 37 The present study proposed to investigate the kernel weight distributions of neural networks not only by briefly visualizing, but also by statistical description. The objectives of this study are: (i) to evaluate the classification performance of different algorithms based on hyperspectral imaging data of honey; (ii) to compare the categorization performance of RF, MLP, and different CNN models coupled with various normalization methods; (iii) to analyze the effects of normalization methods and BatchNorm layers on the kernel weights of the convolutional layers.
Materials and Methods
Hyperspectral Images of Honey Samples
The dataset contains honey products of 23 different botanic origins purchased from a local market in New Zealand.7,38 This dataset includes multiple monofloral honey types: clover, honeydew, blue borage, Rata, Rewarewa, Tawari, borage field, Kamahi, Pohutukawa, field + Tawari, and various Mānuka honeys. Mānuka honey is graded by the Unique Mānuka Factor (UMF) system and contains UMF5+, 10+, 12+, 13+, 15+, 18+, 20+, and 22+ types. There is also ungraded Mānuka, Mānuka Blend, Wildland, Wildflower, and Multifloral honey. The honey samples were heated in an oven to dissolve crystals at 40 °C in closed containers overnight. Each honey sample acquisition contained 7 g of honey, with the number of acquisitions for each honey type shown in Table I. The total number of honey acquisitions was 335.
Numbers of honey sample acquisitions in dataset.

The hyperspectral imaging system used in this study includes a SOC710-VP hyperspectral camera (Surface Optic Corporation, USA) equipped with a Schneider–Kreuznach Xenoplan 35 mm lens with a ring-light configuration with a dome (Figure 1). Each hyperspectral image data cube was acquired using a line-scanning method (pushbroom), 11 which contained 128 spectral bands from 399.40 to 1063.79 nm (i.e., Vis-NIR) under reflection mode with an approximately 4.9 nm spectral resolution and 520 × 696 pixel spatial resolution with 12-bit of data per pixel (0–4095 intensity value). 7 A randomly selected spectral band (895.86 nm) from a sample hyperspectral image and the three-dimensional (3D) illustration of this band of image is illustrated in Figure 2.

Reflection mode and transmission mode using the ring-light configuration with a dome. 7

(a) An example hyperspectral image on the 895.86 nm band; (b) the three-dimensional illustration for this hyperspectral image on band 895.86 nm.
Hyperspectral Imaging Data Sampling
As shown in Figure 2b, the edge of the container and the honey sample inside the container have distinct spectral characters. Therefore, all data points were sampled from a manually selected region of interest, as shown in Figure 3. In order to increase the number of samples in the dataset, 25 different groups of data points were randomly selected from each hyperspectral image acquisition within the region of interest. Each group contains 30 randomly sampled data points without repetition. Although the normalization techniques were chosen according to another work, 35 the simplified preprocessing steps with different strategies were implemented in this study. The calibration step was ignored, and only the outlier detection was conducted before normalization in the present work so that the interactions between normalization techniques and classifiers could be analyzed without interference.

Illustration for region of interest of an example image on the 895.86 nm band. (a) Region of interest in reflection mode. (b) the three-dimensional plot of spectral values inside the region of interest.
Because of the possibility of abnormal areas within the region of interest (as demonstrated in Figure 3b), the outliers of the 30 randomly sampled data points for each group were removed using clustering algorithms. After removing the outliers, each group's data points were averaged, meaning that there were 25 sampled data for each acquisition. Thus, the total number of data samples in the hyperspectral imaging dataset is 8375 (335 × 25). These data points were processed with four different normalization methods, including MinMax normalization (MinMax), SNV normalization, CP normalization, and Pareto normalization (Pareto). Together with the unnormalized data (“none”), these five different types of normalized hyperspectral imaging data were implemented to differentiate 23 botanical origins with various classifiers.
Image Cleaning and Normalization
Image Cleaning
The outlier points were detected using two different clustering algorithms, k-means, and hierarchical clustering. Each group of 30 randomly selected data points was separated into different numbers of clusters. Because the number of clusters is a hyperparameter for these two clustering algorithms, the effects of separability and fitness for the cluster numbers were evaluated using SCs.
36
The SC measure the separability of data clustered by considering cohesion (intraclass similarity) and separation (intraclass dissimilarity).
36
A SC sc(i) of a data point i is calculated as:
Both k-means and hierarchical clustering were experimented with each data points group with cluster numbers from 2 to 5. Then the combination of clustering algorithm and number of clusters with the highest SC was used to separate the data group. The cluster with the most data points was kept and these data points were averaged. Because both of these clustering algorithms should be configured with cluster number ≥ 2, so the data points of a specific group were considered as one cluster if the highest SC was lower than 0.8. In this case, all the 30 data points in this group would be kept and averaged to become one data point.
Normalization
After removing outliers and averaging each group of data points, the 8375 data points in the dataset were preprocessed with 5 different methods: unnormalized (“none”), MinMax normalization (MinMax), SNV normalization, CP normalization, and Pareto scaling normalization (Pareto). The four different normalization techniques are briefly introduced below.
MinMax normalization scales the spectral values concerning the minimum and maximum values. The transformation of spectrum S is defined as:
Standard normal variate shifts and scales the spectrum using mean and standard deviation at each wavelength:
40
CP normalization reduce variations in spectral values with nonlinear transformation functions and shifting factor:
41


Classification Methods
The normalized and unnormalized spectral data were classified using machine learning algorithms (random forest) with Scikit-Learn toolbox,
42
and deep learning models, i.e., MLP and CNN, using the PyTorch library.
Random forest ensembles multiple decision tree predictors. RF contains numerous decision trees and trains these independent trees with different bootstrapped sample subsets of the training dataset. The input features (columns of data points) are also split into different subsets at each split point while constructing trees.
43
Therefore, each decision tree in the forest is less correlated because each tree might be trained with a different subset of features. The hyperparameter configuration of RF in this study was the default setting from the package used.
42
Multilayer perceptron
44
is a feed-forward neural network (without connections to the previous layers) and can solve nonlinear problems with multiple hidden layers.
45
The output of each hidden layer before the nonlinear activation function is a dot product between the input of this hidden layer and layer weight, which is randomly initialized and can be updated during training. The MLP in this study has 6 layers; following the input layer, the first hidden layer has 256 neurons, the second has 512 neurons, the third has 256 neurons, and the fourth has 128 neurons. All these hidden layers use LeakyRelu as activation functions. The output layer has 23 neurons, corresponding to 23 botanical origins. Each MLP classifier was trained for 300 epochs with Adam
46
optimizer and cross-entropy loss. The CNN is a widely applied deep learning architecture introduced by Le Cun et al.
47
and improved by combining backpropagation
48
using a gradient descent optimization algorithm.
49
The convolutional layer preserves spatial and channel dimensions of the images rather than flattening the image into a 1D vector, which then implements kernels (filters or sliding window) in order to slide through each image channel spatially and updates the kernel weights using the backpropagated gradients. The final prediction results of CNN are a series of dot products of the trained kernel weights and corresponding image areas. A 1D-CNN was designed to extract features from the spectral value of honey hyperspectral imaging data. In addition, four different types of 1D-CNN classifiers, which contain eight convolutional layers, were developed in this study: a “vanilla” CNN without batch normalization (BatchNorm) layers,
34
a CNN with only one BatchNorm layer after the last convolutional layer (CNN BN 1), a CNN with one BatchNorm layer after each of the last two convolutional layers (CNN BN 2), and a CNN with one BatchNorm layer after each of the eight convolutional layers (CNN BN).
The BatchNorm was introduced to tackle the “internal covariate shift” issue, which was defined as the changing distribution of network activation during training due to the updating of parameters.
34
BatchNorm addresses this issue by normalizing the training mini-batch: It transforms layer input to zero mean and unit variances, and scales and shifts the normalized input according to trainable parameters,
37
The neural networks with BatchNorm can converge faster, be robust to weight initialization and hyperparameter setting, avoid explosion or vanishing gradients, and achieve better training performance.
34
However, later research demonstrated that the effectiveness of BatchNorm should be ascribed to smoothing the optimization landscape, which allowed for a faster training process by inducing more predictive and stable behavior of the gradients rather than by stabilizing the distribution of layer inputs. 37 BatchNorm reparametrized the optimization to be more stable and smooth so that the training process could converge to more flat minima. 37 Moreover, BatchNorm might not even reduce the internal covariate shift from an optimization viewpoint. 37 The effects of BatchNorm on different CNN classifiers with various normalization preprocessing methods is analyzed in this work from the perspective of both the classification performance and the distribution of the kernel weights of the convolutional layers. The details of the vanilla CNN of parameter configuration (kernel size, stride step, and padding) and output tensor size are shown in Table II. Figure 4 is an illustration of the neural network architecture. All four different CNN models were also trained for 100 epochs with Adam 46 optimizer and cross-entropy loss at each round of experiments.

Vanilla convolutional neural networks architecture.
Vanilla CNN model architectures, the parameter column show kernel size, stride step, and padding, respectively.

Results and Discussion
Each model was developed to classify 23 botanical origins with 128 spectral bands. All the classification tasks were repeated ten times to examine the stability of classification models. All classifiers used the same randomly split training (5862 ≈ 8375 × 70%) and testing (2513 ≈ 8375 × 30%) datasets for each round of experiments. The average values and the standard deviation of classification results are presented in Table III. In this table, without normalization is denoted as “none,” MinMax for MinMax normalization, SNV for standard normal variate normalization, CP for centering power normalization, and Pareto for Pareto normalization. In addition, RF is short for random forest classifier, MLP for multilayer perceptron, CNN for vanilla CNN without a BatchNorm layer, CNN BN 1 for CNN with a BatchNorm layer after the last convolutional layer, CNN BN 2 for CNN with BatchNorm layers after the last two convolutional layers, and CNN BN for CNN with BatchNorm layers after each convolutional layer.
Comparison of test classification results (macro-average F1 score).

All classification tasks were repeated 10 times to examine the stability of classification models. The mean values and the standard deviation of the classification results for each task are presented.
The normalization methods with the highest classification scores for each task are in bold.
Model Performance Evaluation
The macro-average F1 score was used to evaluate the performance of different models in this study. The macro-average F1 score calculates the unweighted mean of F1 scores for different classes so that the label imbalance does not affect the metrics. The F1 score computes the harmonic mean of the precision and recall scores. The relative contribution of precision and recall to the F1 score are equal. The F1 score was calculated with the following equation: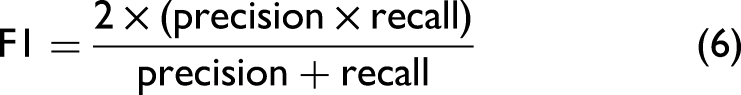
Normalization Evaluation
Previously, the separation effects of different normalization methods were compared using SCs based on the calculation results of three different honey types (i.e., clover, Mānuka blend, Mānuka UMF 10+). 35 After removing noisy bands and calibration, the best three normalization methods were centering power, Pareto scaling, and SNV (with SCs ≥ 0.75). In the present study, after removing outliers without calibration, the SCs of all 23 honey types with different normalization methods are shown in Table IV. It can be observed that the SCs of all normalization options are negative. The SC has a range between 1 and −1. Positive SCs mean that the intracluster distance is smaller than the intercluster distance, and samples in a cluster are separable from neighboring clusters. In contrast, negative SCs might indicate that the intracluster distance is larger than the intercluster distance or the Euclidean distance might not be a good measurement for a certain dataset.
Silhouette coefficients of different normalization methods.

In Table IV, the raw spectral data points had a SC of −0.2875. However, MinMax normalization worsened the separability to −0.3024 according to the measurement of SC. By comparison, SNV and Pareto scaling improved the separability to −0.2582 and −0.2638, respectively, and centering power only slightly increased the SC from −0.2575 for “none” normalization to −0.2855. These negative SCs show that the clusters were unresolved for all the normalization methods. The present study's results were inconsistent with the previous evaluation, 35 where the SC of only three heuristically selected honey classes were chosen to determine the normalization methods.
Classification Results
The comparison of the test classification results for different combinations of normalization methods and classifiers is shown in Table III.
Random forest: Various normalization techniques present diversified effects. RF achieved 89.62 ± 0.25% macro-average F1 score with “none” normalization, which was lower than those with any four normalization methods. The result of RF with MinMax normalization was slightly better than that without normalization. RF classifier obtained similar scores with SNV and Pareto normalization (≥94.90 ± 0.10%), which were best among all the five normalization experiments. Multilayer perceptron: Similarly, MLP without normalization had the lowest classification score. However, MLP with CP normalization acquired the best F1 score (96.16 ± 0.37%) among the five normalization methods. Unlike the experiment results of RF, MLP with MinMax and Pareto normalization achieved ≥94% F1 scores, while MLP with SNV normalization only obtained ≥93% F1 score, nearly 3% lower than MLP with CP. Vanilla CNN (without BatchNorm layer): The vanilla CNN model displays distinct experiment results compared to RF and MLP. Although vanilla CNN with SNV achieved 97.82 ± 0.77% F1 scores, which was the best among all normalization methods, the CNN classifier without normalization earned better classification results (90.47 ± 2.08%) than the classifiers with the other three normalization techniques, whose average F1 scores were only ≥ 87% with nearly 5% standard deviation. This phenomenon revealed that the vanilla CNN classifier used in this work was critical of normalization methods: inappropriate normalization steps might deteriorate classification results, and SNV can significantly improve the performance of vanilla CNN model. CNN BN 1: By adding one BatchNorm layer to the last convolutional layer, the CNN model realized improvements in all experiments with different normalization methods. The BatchNormed CNN with MinMax, SNV, and CP normalization achieved ≥98% scores, while it could also acquire ≥96% F1 score without normalization and ≥97% F1 scores with Pareto normalization. In addition, the standard deviation of the macro-average F1 scores for all normalization methods decreased compared to vanilla CNN. CNN BN 2: By attaching BatchNorm layers to each of the last two convolutional layers, the CNN classifier obtained higher average F1 scores with all four normalization algorithms (MinMax, SNV, CP, and Pareto). However, the result of this classifier declined slightly for the experiments without normalization methods compared to the CNN with only one BatchNorm layer: the average F1 score dropped from 96.45% to 95.97% with a higher standard deviation, which was from 0.38% to 0.80%. CNN BN: Compared with other classifiers, the CNN model with BatchNorm layer on each convolutional layer acquired the best classification scores for all normalization methods. After being preprocessed by the four different normalization methods, this all BatchNormed CNN achieved ≥99% with around 0.2% standard deviation. The classification scores were higher and more stable, with a slightly lower standard deviation. This CNN model can still obtain 97.32 ± 0.39% average F1 score without any normalization step.
It can be observed from Table III that the CNN BN obtained significantly better results than other classifiers regardless of normalization algorithms, and the effects of various normalization methods diminish as adding BatchNorm layers. The apparent differences among normalization techniques could be observed for RF, MLP, and vanilla CNN classifiers, and different classification algorithms have different compatible normalization methods. Furthermore, although the differences in classification results among normalization techniques were almost neglectable, all BatchNormed CNN (CNN BN 1, CNN BN 2, CNN BN) had the same preferences for normalization methods according to the average F1 scores (SNV > CP > MinMax > Pareto > “none”).
Although the classification performance was enhanced by normalization for most classifiers, vanilla CNN revealed a different pattern. According to the evaluation of separability in Table IV, the improvement of separability with SNV and Pareto were presented in most classifiers. The decrease of SC with MinMax was reflected on the classification results of vanilla CNN: the average macro F1 score of MinMax was lower than that of “none” normalization. However, the vanilla CNN with CP and Pareto also had lower average F1 scores with higher standard deviation with improved separability based on SC. This disparity indicates that the Euclidean distance used by SC is not appropriate to measure the separability of data in this study.
Analysis of Kernel Weights Distribution of Convolutional Layers
The statistical descriptions for the last convolutional layer's kernel weights of the four different CNN classifiers are displayed in Tables V, VI, and VII. For each of these four CNN classifiers, only one randomly selected model from the 10 rounds of experiments was analyzed. We also only chose the last convolutional layer to investigate because this layer had more impact on the prediction output of CNN classifiers than previous layers. For the final convolutional layer of these four classifiers, the kernel weights from all the channels were concatenated into one vector. The statistical descriptions were calculated based on the elements in these vectors. In Table VII, the skewness measures the asymmetry of a distribution: the skewness with a value of zero indicates that the distribution is perfectly symmetrical; the positive skewness means that the tail is on the right side of the distribution; in contrast, negative skewness suggests that the tail is on the left side of the distribution. 50 The kurtosis measures the “tailedness” of a distribution, where the tailedness indicates the frequency of outliers in a distribution. 51 A kurtosis greater than three means that the distribution has thicker tails (more frequent outliers) than normal distribution. In contrast, a kurtosis less than three means that the distribution has thinner tails (less frequent outliers) than normal distribution.
Mean and standard deviation of last convolutional layer kernel weights.

Maximum and minimum values and range of last convolutional layer kernel weights.

Skewness and kurtosis of last convolutional layer kernel weights.

Figure 5 illustrates the kernel density estimate (KDE) graphs for all channels in the eight convolutional layers of vanilla CNN and CNN BN (each convolutional layer with BatchNorm layer). From Figures 5a and 5b, it can be observed that the first convolutional layers kernel weights distributions for both vanilla CNN and CNN BN varied among different normalization methods: they have distant peaks that skewed from zero, and some of them have multiple peaks such as the vanilla CNN with “none” normalization as shown in Figure 5a. In addition, the first convolutional layers’ kernel weights of vanilla CNN have a broader range than CNN BN. As going deeper through the hidden convolutional layers, the vanilla CNN and CNN BN's kernel weights distributions became more concentrated toward zero. The last three convolutional layers of vanilla CNN had wider ranges between the maximum and minimum values and heavier densities around zero than those of CNN BN, and the kurtosis of kernel weights from the last three convolutional layers of vanilla CNN increased more sharply compared to CNN BN as shown in Figure 5k to 5p. The kurtosis of the last convolutional layer's kernel distribution of CNN BN was much closer to three, which was the kurtosis of normal distribution, than that of the final layer of vanilla CNN. The effects of BatchNorm on the last convolutional layers’ kernel weights distribution of different CNN classifiers will be analyzed in this section.

Convolutional layer kernel weight distribution density estimate graphs. The kurtosis of the kernel weights for each normalization methods were presented in the figure legends. (a) All channels of vanilla CNN convolutional layer 1. (b) All channels of BatchNorm CNN convolutional layer 1. (c) All channels of vanilla CNN convolutional layer 2. (d) All channels of BatchNorm CNN convolutional layer 2. (e) All channels of vanilla CNN convolutional layer 3. (f) All channels of BatchNorm CNN convolutional layer 3. (g) All channels of vanilla CNN convolutional layer 4. (h) All channels of BatchNorm CNN convolutional Layer 4. (i) All channels of vanilla CNN convolutional layer 5. (j) All channels of BatchNorm CNN convolutional layer 5; (k) All channels of vanilla CNN convolutional layer 6. (l) All channels of BatchNorm CNN convolutional layer 6. (m) All channels of vanilla CNN convolutional layer 7. (n) All channels of BatchNorm CNN convolutional layer 7. (o) All channels of vanilla CNN convolutional layer 8. (p) All channels of BatchNorm CNN convolutional layer 8. CNN: convolutional neural networks.
Mean and Standard Deviation
In Table V, it is obvious that the kernel weights of the last convolutional layer from all the three BatchNormed CNN classifiers had means closer to 0 than that of the vanilla CNN in general, except for CNN BN 2 without normalization, whose kernel weight mean (–0.000330) was relatively further from 0 than that of vanilla CNN (–0.000295). Furthermore, the means of the last convolutional layer for the kernel weights of the vanilla CNN were similar for the four normalization algorithms, which were around 0.002. However, the vanilla CNN without normalization had kernel weights mean closer to 0, which was −0.000295, and the lowest F1 score among all normalization methods. The kernel weight means of CNN BN with “none” (0.000019) and MinMax normalization (–0.000042) were much closer to 0 than those of CNN BN with SNV (–0.000119), CP (–0.000338), and Pareto (–0.000171), while CNN BN with MinMax, SNV, CP, and Pareto had similar classification results and the score of CNN BN with “none” was 2% lower than others. In addition, the mean of the last convolutional layer's kernel weights for CNN BN with SNV was −0.00119, which was further from 0 than that of CNN BN 2 with SNV (–0.000073), and with CP was −0.000338, which was also further from 0 compared to those of both CNN BN 1 (0.000030) and CNN BN 2 (–0.000169). In this case, the better classification results did not correspond to kernel weight means closer to 0.
The standard deviation of the kernel weights for these classifiers does not show a significant correlation with classification scores while comparing different normalization methods. The vanilla CNN without normalization had the lowest kernel weights standard deviation, and the one with SNV had the highest, while these two classifiers obtained the top two accuracies during experiments. Furthermore, the CNN BN with “none” normalization presents the standard deviation of the higher kernel weights (0.0220) than vanilla CNN and CNN BN 1 without normalization (0.0124 and 0.0204, respectively), while CNN BN with “none” normalization obtained higher F1 scores than vanilla CNN and CNN BN 1 with “none” normalization. In contrast, the kernel weights of CNN BN with SNV had the lowest standard deviation among other CNN models with SNV normalization, while CNN BN with SNV obtained the highest average classification scores.
Minimum and Maximum Values
In Table VI, the minimum, maximum, and range of the kernel weights from the last convolutional layers for various CNN classifiers were demonstrated. In general, the kernel weights of vanilla CNN have a more extensive range than those of CNN with BatchNorm layers regardless of normalization methods. For experiments using the “none” normalization step, the minimum and maximum values of vanilla CNN were −0.58 and 0.39 (range 0.9776), CNN BN 1 were −0.41 and 0.41 (range 0.82), CNN BN 2 were −0.54 and 0.37 (range 0.9137), and CNN BN were −0.26 and 0.28 (range 0.5307). Obviously, the range between the minimum and maximum values of kernel weights gradually decreased as BatchNorm layers were added to convolutional layers, except for CNN BN 1 and CNN BN 2, whose range values slightly increased as one more BatchNorm layer was added. This difference is consistent with the slightly decreased classification results shown in Table III. The same trend could also be observed in experiments with CP: the range of kernel weights declined from −0.60 and 0.50 (range 1.0136) for vanilla CNN to −0.23 and 0.25 (range 0.4725) for CNN BN, while slightly inclined from −0.33 and 0.35 (range 0.6818) for CNN BN 1, to −0.35 and 0.37 (range 0.7234) for CNN BN 2. However, the average F1 scores with CP for CNN BN 2 were still higher than those for CNN BN 1. In contrast, the range between minimum and maximum values of the last convolutional layers’ kernel weights decreased as more BatchNorm layers were added for CNN models using MinMax, SNV, and Pareto normalization, while their classification performance gradually improved.
The relationship between the range and classification performance while comparing different normalization algorithms is complicated, according to Table VI. CNN BN and CNN BN 2 achieved the highest average F1 scores with SNV and had the lowest range (0.56 and 0.41, respectively) among all normalization methods. However, CNN BN 1 also obtained the best classification results with SNV, but the range of kernel weights was higher (1.02) than other normalization techniques. For vanilla CNN, the range of the kernel weights from the last convolutional layer for the best-performing classifier (with SNV) was neither higher nor lower than those of vanilla CNN using other normalization methods.
Skewness and Kurtosis
In Table VII, it is clear that the last convolutional layer kernel weights’ skewness of all the three BatchNormed CNN classifiers is closer to zero in comparison with those of vanilla CNN regardless of normalization methods. However, the kernel weight skewness values of CNN BN 1 and CNN BN 2 with MinMax, SNV, and Pareto normalization were closer to zero than those of CNN BN. In contrast, the last convolutional layer kernel weight distributions of CNN BN with “none” and CP were less skewed than those of CNN BN 1 and CNN BN 2. This pattern cannot be used to explain the classification performance because CNN BN achieved the highest F1 scores among all the four CNN classifiers despite of normalization methods.
In addition, these last convolutional layers of the kernel weight skewness are even less correlated with classification results among different normalization methods. For instance, the kernel weights skewness of vanilla CNN with “none” (≥90% F1 score, skewness of −0.28) was less skewed than that of vanilla CNN with SNV (≥97% F1 score, skewness of −0.80), while that of vanilla CNN with MinMax (≥87% F1 score) had the lowest F1 scores and was most skewed (skewness of–1.48). In addition, according to Table III, although the CNN BN with MinMax, SNV, CP, and Pareto normalization have similar average F1 scores (≥99%), the kernel weights of CNN BN with Pareto were much more skewed (0.31) than all the other normalization methods. The CNN BN without normalization was least skewed (–0.03) and had lowest F1 score (≥97%). This phenomenon could also be observed in all CNN classifiers with different normalization techniques: the skewness did not change according to the classification results.
While analyzing the kurtosis from Table VII, it is evident that, in general, the kurtosis of last convolutional layers’ kernel weights decreased as more BatchNorm layers were added to the different CNN classifiers. With “none” normalization, the kernel weight kurtosis gradually declined from 17.95 (vanilla CNN), 8.43 (CNN BN 1), 5.69 (CNN BN 2), to 2.10 (CNN BN). The same pattern could also be observed in experiments with MinMax (17.55 for vanilla CNN, 6.41 for CNN BN 1, 4.22 for CNN BN 2, and 1.92 for CNN BN) and CP (20.40 for vanilla CNN, 9.96 for CNN BN 1, 5.06 for CNN BN 2, and 2.94 for CNN BN) normalization. However, the kurtosis of kernel weight distributions for experiments with SNV and Pareto normalization displayed a different trend: After adding more BatchNorm layers, the kurtosis of the last convolutional layer kernel weight for CNN with SNV increased from 6.82 for vanilla CNN to 9.15 for CNN BN 1 and then decreased to 3.81 for CNN BN 2 and 2.55 for CNN BN. Moreover, the kurtosis for CNN with Pareto grew slightly from 4.43 for CNN BN 2 to 4.66 for CNN BN as more BatchNorm layers were added.
Whereas the performance differences among normalization methods for the same classifier could not be strongly associated with the kurtosis of the last convolutional layer's kernel weights. For example, the vanilla CNN with SNV achieved the highest average F1 score (≥97%) and lowest kurtosis (6.82) among all normalization methods, while the vanilla CNN with MinMax and CP had similar classification results (≥87%) but different kurtosis (17.55 for MinMax and 20.40 for CP). In addition, the vanilla CNN with “none” and MinMax normalization had similar kurtosis (17.95 and 17.55, respectively) but significantly different average F1 scores (90.47 ± 2.08% and 87.85 ± 5.77%, respectively). Furthermore, CNN BN 1 and CNN BN with MinMax normalization had the lowest kurtosis (6.41 and 1.92, respectively) among all normalization methods. However, their classification performance was neither better nor worst.
Further Discussion
According to the previous analysis, it is evident that different classification algorithms had different preferred normalization methods. RF could obtain similar scores with SNV and Pareto, whose results were better than other methods. MLP achieved the best performance with CP, rather than the commonly applied SNV, and the F1 scores of MLP with MinMax and Pareto were higher than that of MLP with SNV. In contrast, CNN had a strong preference for SNV, whose results were nearly 10% higher than MinMax, CP, and Pareto, with a significantly lower standard deviation of F1 scores. These variations among different combinations of classifiers and normalization methods might be mainly due to the feature extractions of classification algorithms. In this study, the SNV and Pareto both set the means of the features in the dataset equal to zero and scaled with standard deviation (SNV) or the square root of standard deviation (Pareto). The CP scaling method only set the square root of means for the feature values to zero and does not scale the deviation. The MLP's preference for CP might be due to this character: the MLP simply conducts matrix multiplication and activation within each layer. The importance of features was determined entirely by the weight of each layer. And the scaling for features’ deviations might diminish their significance. In contrast, both RF and CNN specifically select the features: RF randomly chooses features and then evaluates their significance by entropy while CNN extracts features by convolutions. These feature selection mechanisms might require the features values’ standard deviation to be unit.
In addition, the CNN classifiers with batch normalization layers demonstrated superior performance compared to other classifiers. With only one BatchNorm layer to the last convolutional layer, CNN BN 1 improved performance for experiments with MinMax, CP, and Pareto by nearly 10%. The score with “none” also increased by around 6%. Among all the six different classifiers, CNN BN, which attached BatchNorm layer after each convolutional layer, achieved the highest macro-average scores regardless of normalization methods. In addition, the performance variances among different normalization techniques became almost neglectable (≤0.5%) for CNN BN, whereas those for other classifiers (RF, MLP, and vanilla CNN) were more remarkable.
By analyzing the statistical description of the last convolutional layer's kernel weights, the BatchNorm did not seem to address the issue of internal covariate shift because the kernel weights’ distributions still changed among CNN BN's 8 convolutional layers. This result is consistent with the statement of previous work on BatchNorm. 37 However, the BatchNorm improves prediction performance by increasing the stability and predictiveness of the gradients, 37 and this improvement might reflect in the distribution of kernel weights. In summary, the kernel weights of the convolutional layers for CNN with a BatchNorm layer have a smaller range between the maximum and minimum values and lower kurtosis (less frequent outliers) than vanilla CNN. By visually analyzing the KDE graphs of vanilla CNN and CNN BN in Figure 5, the kernel weights of CNN BN were less concentrated around 0 than those of vanilla CNN. Intuitively, less frequent outliers in kernel weights might indicate that the gradients are less likely to experience abrupt changes. A lower density of kernel weights around zero means that the gradients are less likely to be 0, thus avoiding vanishing gradients.
Generally speaking, while comparing the performances among different normalization methods, the kurtosis, density around zero, and range of last convolutional layers’ kernel weight distributions were essential to explain the variations of the models’ classification results, especially for vanilla CNN. The vanilla CNN with SNV had much better classification results and lower kurtosis than other normalization methods, and the vanilla CNN with MinMax had lowest classification performance and highest range. However, while comparing vanilla CNN with Pareto and “none,” the vanilla CNN with Pareto had lower kurtosis, lower density around 0 value, and similar range with vanilla CNN with “none,” but the vanilla CNN with Pareto also had a lower average F1 score with more significant variances than the one with “none.” For the three CNN classifiers with BatchNorm layers, the variations of statistical description among different normalization methods were much larger than those of classification results. The CNN BN 2 and CNN BN with SNV had highest classification scores and lowest range, and CNN BN 2 with SNV also had lowest kurtosis, whereas other CNN models with varying normalization methods might achieve similar classification scores but have distinct kernel weight distributions, and the CNN models with similar statistical measurement values of kernel weight distribution might have significantly different classification results. It is necessary to conduct further research so that the influences of different normalization techniques on the kernel weights of CNN classifiers can be better understood.
Conclusion
In conclusion, our study highlights the importance of appropriate data preprocessing and normalization techniques for accurately classifying honey hyperspectral images using neural networks. Our results demonstrate that misuse of normalization methods can lead to performance deterioration and highlights the need for careful consideration when selecting the appropriate normalization technique. Our findings also show that the BatchNormed CNN model is superior to other classifiers in terms of categorization ability and diminishes the risks of inappropriate preprocessing methods. We also observed that the selection of normalization methods had a more significant impact on vanilla CNN's performance than BatchNormed CNN, which can be attributed to the statistical description of the kernel weight distributions of convolutional layers. Overall, our study provides insights into the importance of data preprocessing and normalization for accurately classifying hyperspectral images using neural networks and emphasizes the need for further research in this area.
Footnotes
CRediT Authorship Contribution Statement
GZ contributed to conceptualization, methodology, software, investigation, writing: original draft, visualization, and writing: reviewing and editing. WA contributed to conceptualization, project administration, resources, supervision, and writing: reviewing and editing.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.