
Abstract
The rapid development of welding fabrication demands guidance data to support expert decision-making, retroactive process, and production pattern upgrades. Yet, the data is lacking. This paper developed the guidance corpus for welding manufacturing. The unstructured document guiding actual production was collected, and the data were segmented into words employing a conditional random field model. In addition, we organized an annotation team and developed the tool to accomplish data annotation using a Begin-Inside-Outside method. Machine learning and deep learning models were trained for the named entity recognition task under supervised learning to accomplish the challenge of corpus scalability. The corpus contained 19,410 labeled pairs of samples and involved multiple entity categories, that is, “standard,”“technology,”“design,”“department,”“manufacturing,” and “quality.” The baseline of the model on Precision, Recall, and F1-score metrics were listed to provide a reference for welding production research. Furthermore, we also gave some examples of task assignments and knowledge retrieval in conjunction with real production problems. The long-term goal was continually to enhance the corpus through more researchers, suggesting that a robust corpus would support more research and engineering applications in the welding domain.
Introduction
As a critical manufacturing method, the welding technique has gradually developed in the past decades, especially in smart manufacturing. Some intelligent methods based on essential domain data have been applied for process selection, 1 fault diagnosis, 2 and expert decision-making. 3 Most of the data are stored in structured databases, requiring strict form and correspondence. This makes data access difficult, and the application scope is limited due to the missing amount of data. Extracting data from unstructured text to support domain operations can effectively compensate for the shortage of structured data. However, the data from unstructured files are lacking in the manufacturing domain, 4 and even no relevant research has been performed in the field of welding. The main content of our research is how to automatically extract data from critical unstructured files to form the supporting data.
Meaningful data have a positive impact on engineering applications. In the welding process, domain experts must design the product, develop the strategy, guide the production, inspect the quality, and guarantee maintenance according to the guiding documents, such as standards, regulations, and requirements. The welding instruction documents cover the whole life cycle of welding and are characterized by multiple types, specialized content, and complex knowledge. Therefore, the guidance document was chosen as the data source due to its great engineering value. A large amount of knowledge in unstructured guidance documents requires domain experts to acquire proper knowledge through extensive searching and thinking. In addition, different areas and types of work involve different document contents, making the manual acquisition of practical knowledge more complex. These challenges make us focus on Natural Language Processing (NLP) technology. Building a corpus and extracting information with Named Entity Recognition (NER) 5 is essential for research and applications in welding engineering. Entity-based data weaken the limitations of content and format in different schemas. The corpus gathers discrete data in a standard form and can be used as a data driver for knowledge acquisition, decision-making, etc.
Corpus plays a vital role in knowledge extraction and application as the database of NLP technology. In recent years, many corpus pieces of research have focused on corpus types,6,7 construction methods, 8 and applications.9,10 Some of the studies are listed in Table 1. Yet, the corpus already contains monolingual corpus, 11 bilingual corpus, 12 and even multilingual corpus.13,14 NER is always an effective method for construction to develop and improve the corpus. Model learning methods are used as entity recognition to automate data collection. Cho et al. 15 proposed extracting different character-level representations from CNN and bi-LSTM based on bi-LSTM with conditional random field (CRF) and introducing an attention mechanism to improve the performance of the recognition model. Moreover, long-short dependencies 16 and transfer learning 17 were also used to refine and improve the NER technology. The NER approach is also used to define multiclass entities, which are essential components of the corpus. Typically, multi-entity classification focuses on the classification of the open domain18,19 (e.g. time, organization, position, etc.) and domain-specific entities 20 (e.g. disease, drugs, diet, etc.). These classified entities have been applied in biomedical, 21 linguistics, 22 etc. Based on these methods, more and more corpora are being built and used to analyze and solve practical problems. eHealth-KD corpus, 23 NCBI Disease Corpus, 24 Classical Music Corpus, 25 and Spanish AzBio Sentence Corpus 26 were developed to support research and applications in related domains. However, despite recent advances, the corpus is lacking in industries, especially the welding field, and little relevant research has focused on the welding corpus and the classification of welding entities. Perhaps there are several reasons for this: (i) the specialization and complexity of knowledge make it challenging to identify and tag the knowledge; (ii) the missing open web data or APIs make metadata challenging to obtain in the welding process; and (iii) weak connection between traditional welding domain and novel intelligent technology also make it challenging.
Corpus-related studies.

Combined with the characteristics of the corpus, we found that it has positive effects on the rapid acquisition and application of welding guidance knowledge. A Chinese welding corpus was created based on the actual production domain of welding. In corpus building, original data were gathered from many unstructured guidance documents for high-speed train fabrication. The CRF model is used as a Chinese word separation 27 and Begin-Inside-Outside (BIO) annotation method as an entity definition. Furthermore, we have organized teams and developed the tag tool to make the markup process more accurate and efficient. On this basis, the tagged data are trained via Hidden Markov Model (HMM), CRF, 28 Bidirectional Long Short-Term Memory (BILSTM), and Bidirectional Long Short-Term Memory and CRF (BILSTM + CRF). Furthermore, Precision, Recall, and F1-score (PRF) metrics are employed to evaluate models which provide a baseline on the corpus. We describe two use cases based on the corpus to improve knowledge acquisition efficiency and assist welding production. The research contribution can be described as follows:
(i) Collecting unstructured guidance data to form a corpus positively impacts the welding manufacturing domain. Original data were collected from unstructured welding instruction documents, and we manually annotated these words to construct the corpus. This work provides data support for knowledge engineering research in the welding domain.
(ii) Machine learning and deep learning methods are used as corpus data training, and baselines are listed via training results. The scalability of the corpus is achieved while providing a reference for subsequent research.
(iii) To express the importance of the corpus more visually, novel cases on welding task assignment and rapid welding knowledge acquisition are described based on the corpus. The work is significant for practical productivity improvement, knowledge reasoning, process decision-making, etc.
Our primary purpose is to supplement the lack of a welding corpus, so we build a corpus of welding process guidance documents, which provides supporting data for the research and application of knowledge during the welding process. The further aim is to enhance and improve the corpus. Thus, a complete and accurate corpus will benefit the research and application of welding knowledge. Furthermore, machine learning and deep learning methods were used for entity extraction, and the model baseline was released as a reference for subsequent research.
Material and methods
Data and annotations
The purpose of knowledge acquisition, efficient expert decision-making, and production model upgrade push us to focus our attention on guidance documents. Hence, we collected a large number of unstructured documents such as requirements, regulations, and standards. These documents have the characteristics of high standardization, guidance, and recognition. In addition, a data structure covering all sub-processes of the welding process might help establish a complete corpus, so the application of the data was also considered a fundamental principle for selection information. According to the actual welding production process, we selected guiding documents on product design, process development, assembly production, quality inspection, and others and changed these data to the initial form we needed.
For building an efficient corpus, a uniform annotation specification was used as a convention document. We organized the annotation team, which consisted of two annotators and a decision-maker. The annotators and the decision-maker have at least 3 or 4 years of welding learning experience. In addition, annotators can determine the content of the marker with an argument. In case of disagreement, the text will be marked according to the decision-maker. The welding data annotation task is the process of assigning a corresponding label to each word. Therefore, the BIO annotation method was used as data annotation. The beginning of an entity can be labeled by “B” (Begin) and belongs to the entity category; the rest of the entity can be labeled as “I” (Inside) and its relevant type. For inter-entity, connectives can be tagged with “O” (Outside).
Word segmentation
Currently, there are no apparent separator features in a sentence for the Chinese corpus, so probabilistic statistical models are often considered as an approach to separate words. 29 The primary purpose of this statistical analysis is to determine the most appropriate way of segmenting words from the multiple word combinations in a sentence. The most significant probability of distribution accompanies the optimal situation.
The CRF was proposed to describe the corresponding distribution probability relationship between two sequence sets. Chinese word segmentation based on the CRF iteratively calculates the maximum conditional distribution probability through observation and state sequences. The calculation principle is shown in Figure 1.
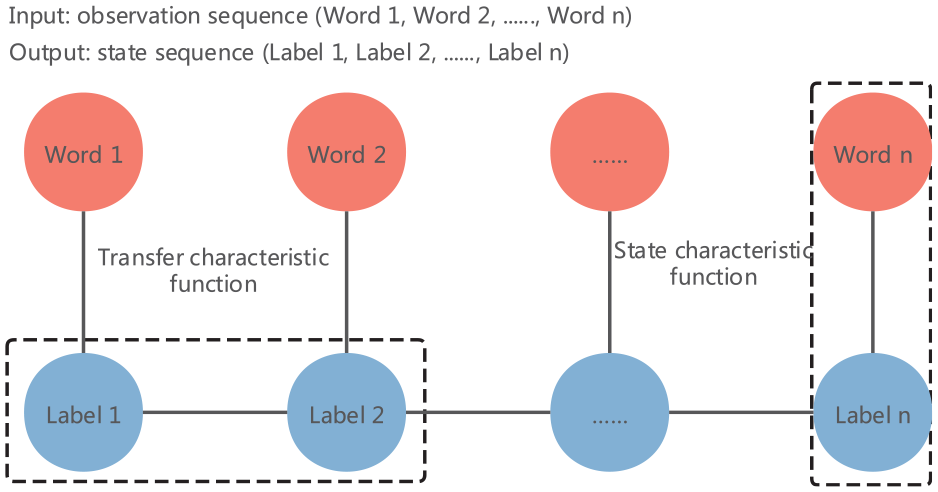
CRF word segmentation principle.
Calculating the distribution probability is the key to obtain the optimal separator words. Here, two random variables, X and Y were defined. Where X takes the value x, and the conditional probability Y takes the value y [P(y|x)]. The calculation formula is shown in equations (1) and (2).
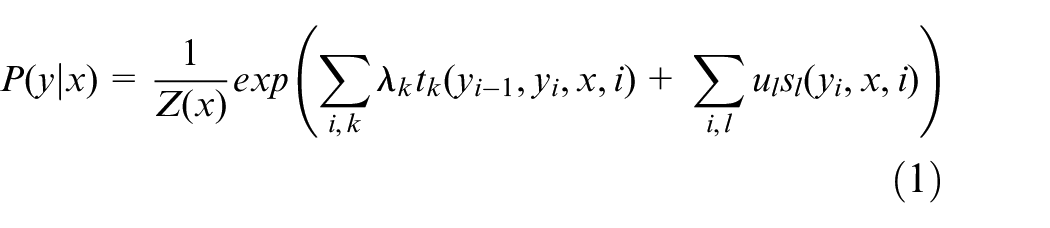
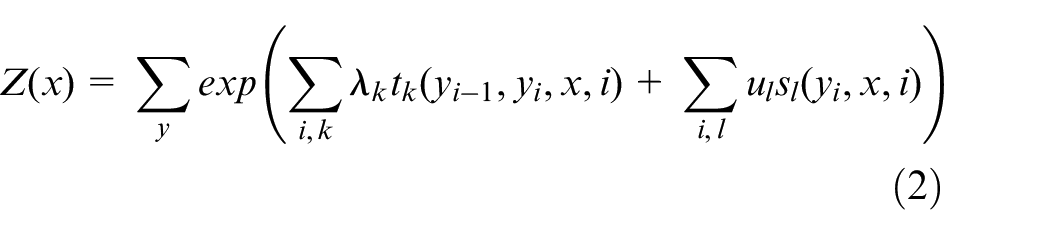
Where tk and sl are characteristic functions; λk and ul are corresponding weights; and Z(x) is the normalization factor.
Named entity recognition
Named entity recognition as a corpus subtask enables the automatic recognition and extraction of entity information. Rule-based, machine learning and deep learning are the frequently used methods to achieve entity recognition. The rule-based approach is a process of entity matching according to dictionary entity-specific rules based on a data dictionary. Machine learning-based methods mainly rely on probabilistic statistical methods such as HMM and CRF. The deep learning approach focuses on the data as a whole, with powerful vector representation and computational power. During the welding guidance corpus research, several classical machine learning (HMM and CRF) and deep learning (BILSTM and BILSTM + CRF) models were chosen to perform entity recognition tasks.
HMM is a statistically based learning model, and its labeled sequences are calculated according to five elements, that is, (N, M, A, B, and π). Where N denotes the word labels, M refers to the pronoun itself, A represents as the transfer probability matrix, B refers to the observation probability matrix, and π denotes the initial probability matrix. Defining the input sequence x = {x1, …, x N }, the status sequence y = {y1, …, y N }, and the joint distribution probability can be expressed under an equation (3). Where t represents any node state, p(y1) can be calculated according to π because of no precursor node, and p(y1|yt−1) and p(xt|yt) can be calculated separately based on A and B matrices.
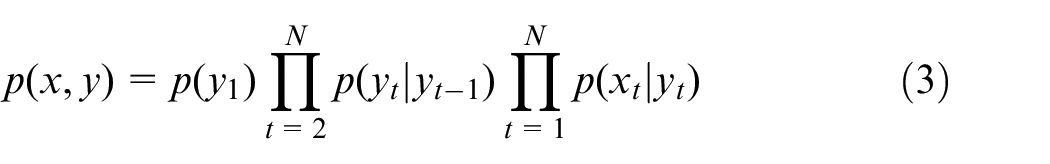
CRF is also a commonly used statistical model in the NER task. Defining the conditional probability model P(Y|X), X is the state sequence, and Y is the observation sequence. The model can be obtained based on the maximum likelihood estimates and data samples. We can predict the labels based on the training model and the given input sequence. The calculation formula is shown in equations (1) and (2).
Long Short-Term Memory Network (LSTM) 30 involves three unique structures (forget gate, input gate, and output gate), which are used to refine the long-range dependence problem based on the Recurrent Neural Network (RNN). Inter-gate action can help to obtain the desired state and achieve long-distance dependence. In the NER task, inter-semantic dependencies as non-negligible features cannot be adequately expressed via a single LSTM model. Therefore, BILSTM models are proposed to obtain bidirectional semantic features to improve model performance. In addition, BILSTM + CRF is employed as a synergistic BILSTM and CRF model for enhancing model outcome prediction, also widely used in NER tasks. The schematic of BILSTM + CRF is expressed in Figure 2, which includes the BILSTM model action process and the principle of LSTM.
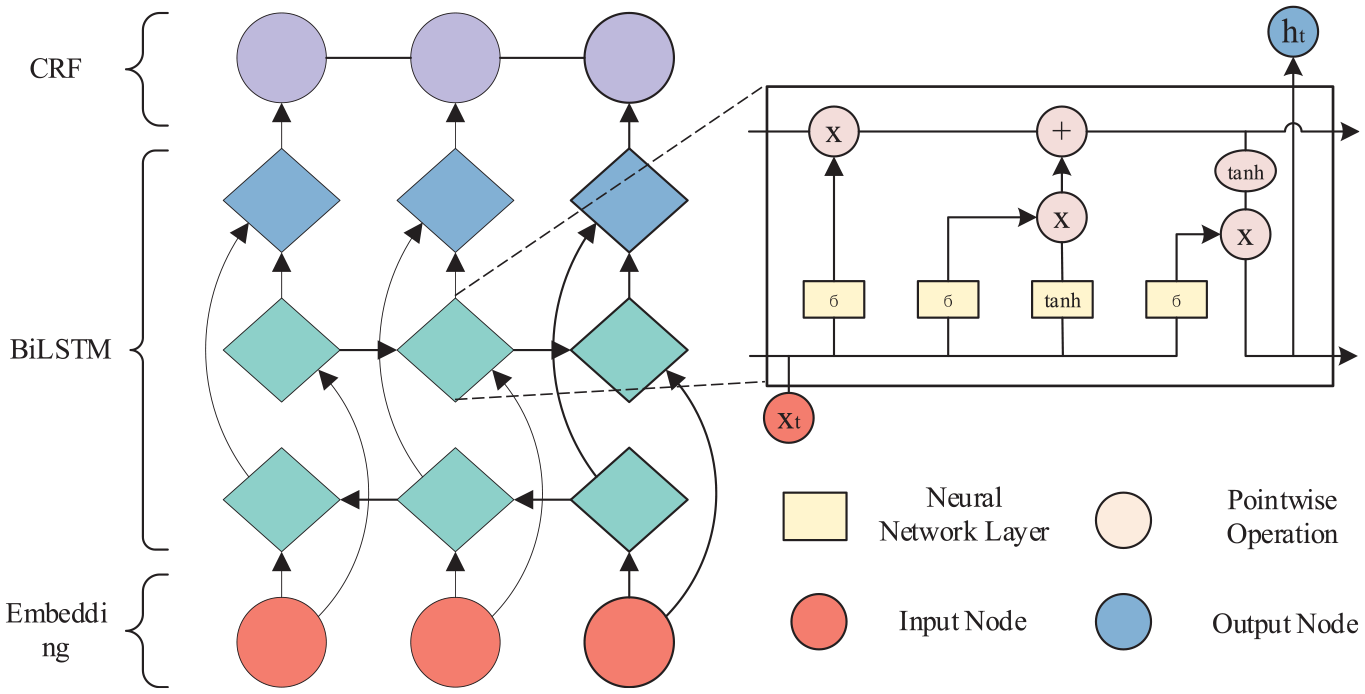
The schematic of BILSTM + CRF.
Method process
Corpus building and entity identification can be subdivided into several steps: data collection, sentence-level data collation, word segmentation, data annotation, model training, etc. The documents from welding production are collected and processed as sentence-level data. The CRF model is employed to segment sentences into multiple words. We also manually annotated these words by the BIO method. In addition, multiple NER models were trained to extract information and evaluate the corpus. The technical route of the task is illustrated in Figure 3.
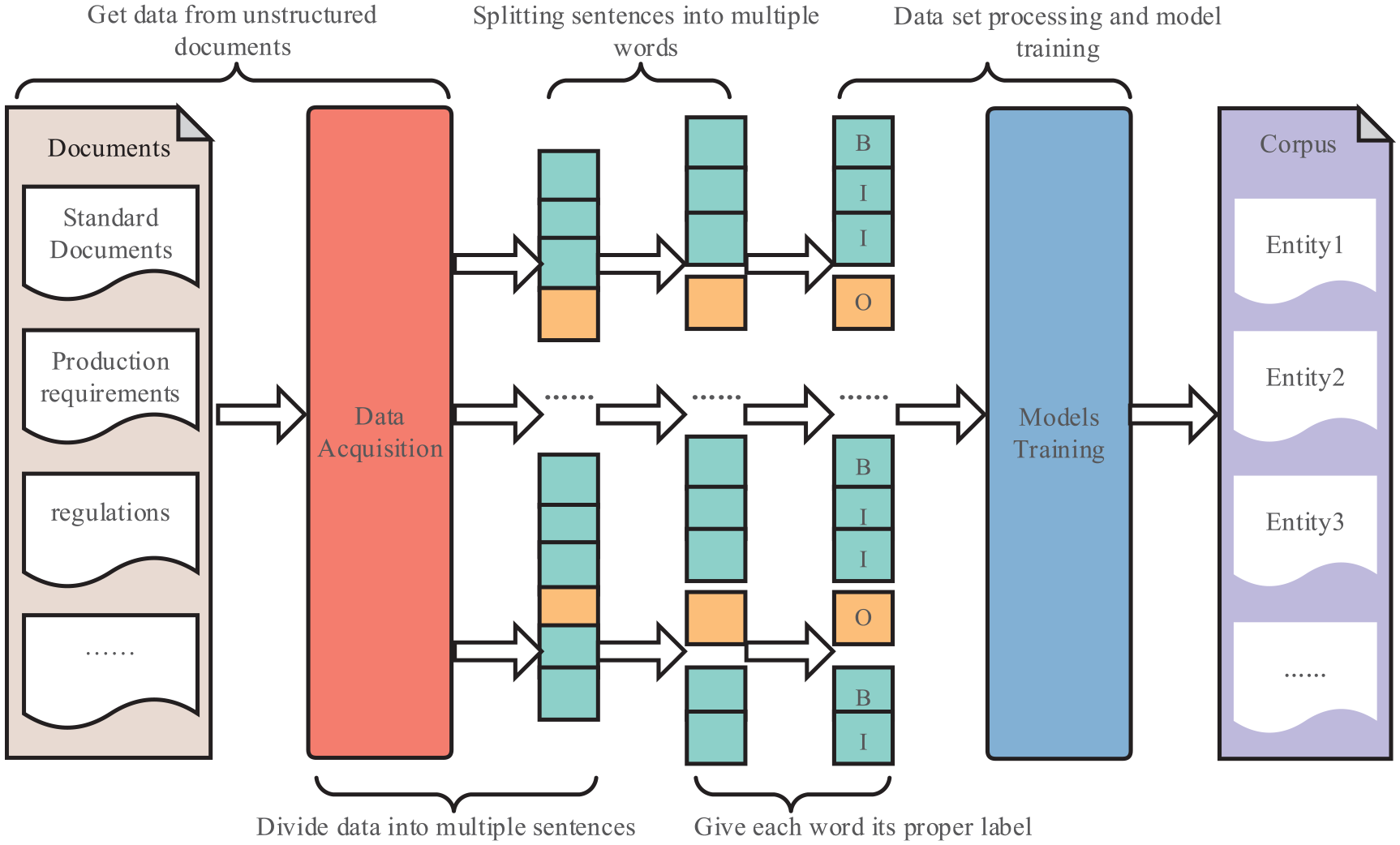
Overall research program.
Experiments
Data categories
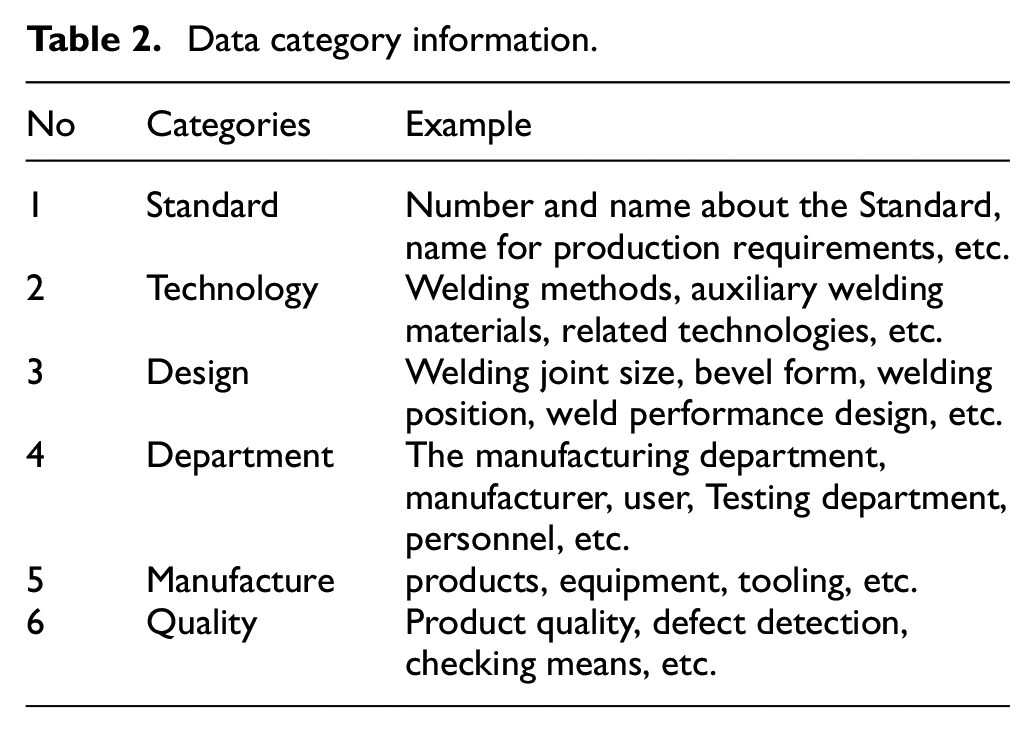
According to the actual production application, we divided our data into six categories, namely “standard,”“technology,”“design,”“department,”“manufacturing,” and “quality.”“Standard” includes production standards, requirements, and other guidance documents. “Technology” covers the production process and technical means. “Design” contains product geometry information and performance design. “Department” includes related personnel and institutions. “Manufacturing” covers production materials and the production process. “Quality” provides quality and testing requirements. Detailed information is described in Table 2.
Data category information.
Data processing
To quickly complete the annotation task, the simple model is trained through small batches of data samples, used for initial data annotation, and then artificially perfected. We developed a corresponding entity annotation tool containing essential functions, annotation fields, label editing, etc. Considering that the datasets contain Chinese characters, the basic function module developed the word separation function. The word segmentation module was constructed based on the trained CRF model. The specialized nature of welding data motivated us to introduce a dictionary of welding terms to avoid invalid segmentation. Therefore, we defined some labels in the label editing module according to the text category requirements and marked datasets in the annotation area via clicking defined tags. The tool function interface is shown in Figure 4.
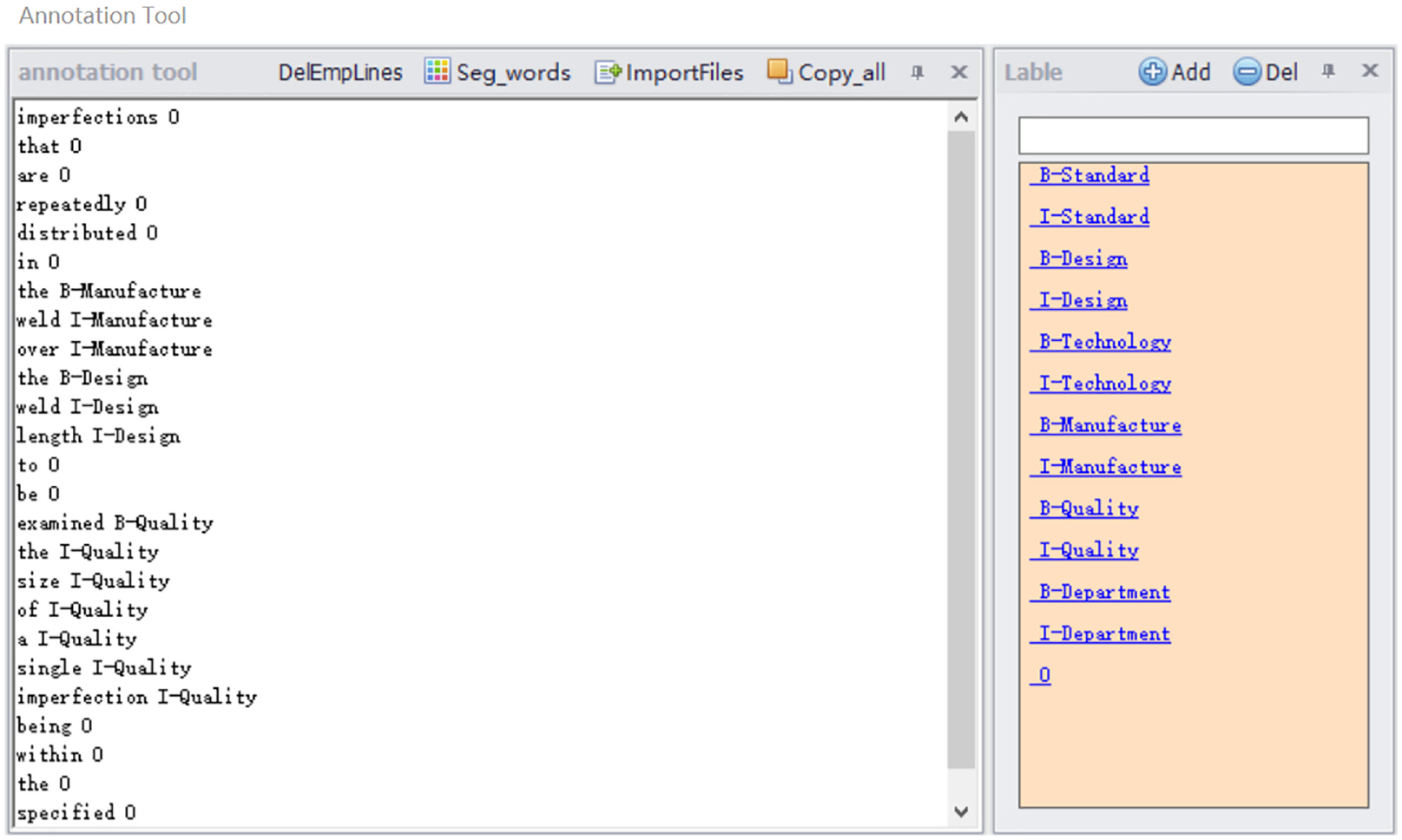
Annotation tool interface.
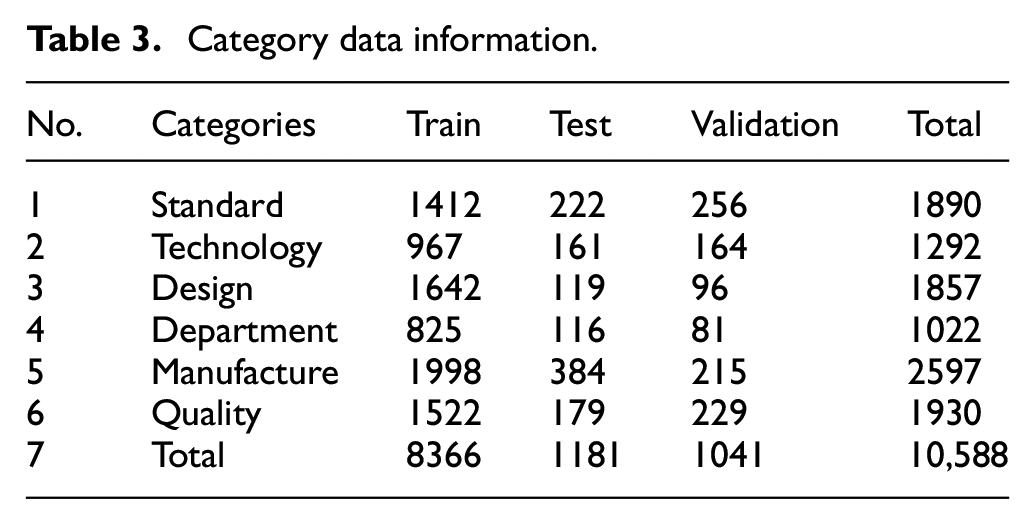
Dataset segmentation divides data according to the sample size to support model training, validation, and evaluation. For data volume, a total of 19,410 sample pairs of data were obtained in the labeling task. We initially divided the training set, test set, and validation set according to the ratio of 8:1:1. We manually checked and adjusted some of the data to ensure that each category was evenly distributed among the division data. The training set contained 15,113 pairs of samples for the modified data set, the test set involved 2350 pairs of samples, and the validation set had 1947 pairs of samples. The detailed data without the label “O” are shown in Table 3.
Category data information.
Model training
Statistical model-based methods (HMM and CRF) and deep learning-based methods (BILSTM and BILSTM + CRF) were trained under supervised conditions. Furthermore, we run the model program via the Python programing language (version: 3.7) in the Scikit-Learn framework (version: 0.24.2). Moreover, the parameters of BILSTM were set to batch size of 64, the learning rate of 0.001, epochs size of 100, while the parameters of BILSTM + CRF only differed in epochs size of 200. For other model parameters, the default value was adopted.
Evaluations
The prediction samples were classified as true positive (TP), true negative (TN), false positive (FP), and false-negative (FN) according to the model prediction results. Precision, Recall, and F1-score were used as model evaluation metrics. Here, Precision is the proportion of all true samples to the total sample, and Recall represents the proportion of true values in all positive samples. The overall performance of models was evaluated with the F1-score metric, based on Precision and Recall. These evaluation indicators are expressed as follows:
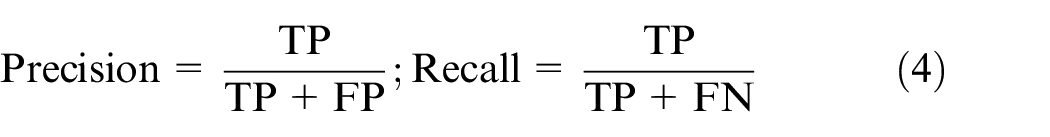

Results and discussion
Results and baseline
Based on a manually annotated corpus, four models were trained. The training process was analyzed, and the confusion matrix is plotted in Figure 5. In which the horizontal and vertical coordinates indicate the target category and output category, where the numbers 1–13 stand for “B-Technology,”“B-Manufacture,”“I-Manufacture,”“B-Design,”“B-Department,”“O,”“B-Standard,”“I-Design,”“I-Standard,”“I-Quality,”“B-Quality,”“I-Department,” and “I-Technology,” respectively, whereas (a), (b), (c), and (d) denote the confusion matrix of HMM, CRF, BILSTM, and BILSTM-CRF models, respectively. Any cell in the confusion matrix can be interpreted as the count of output categories predicted to be the target category.
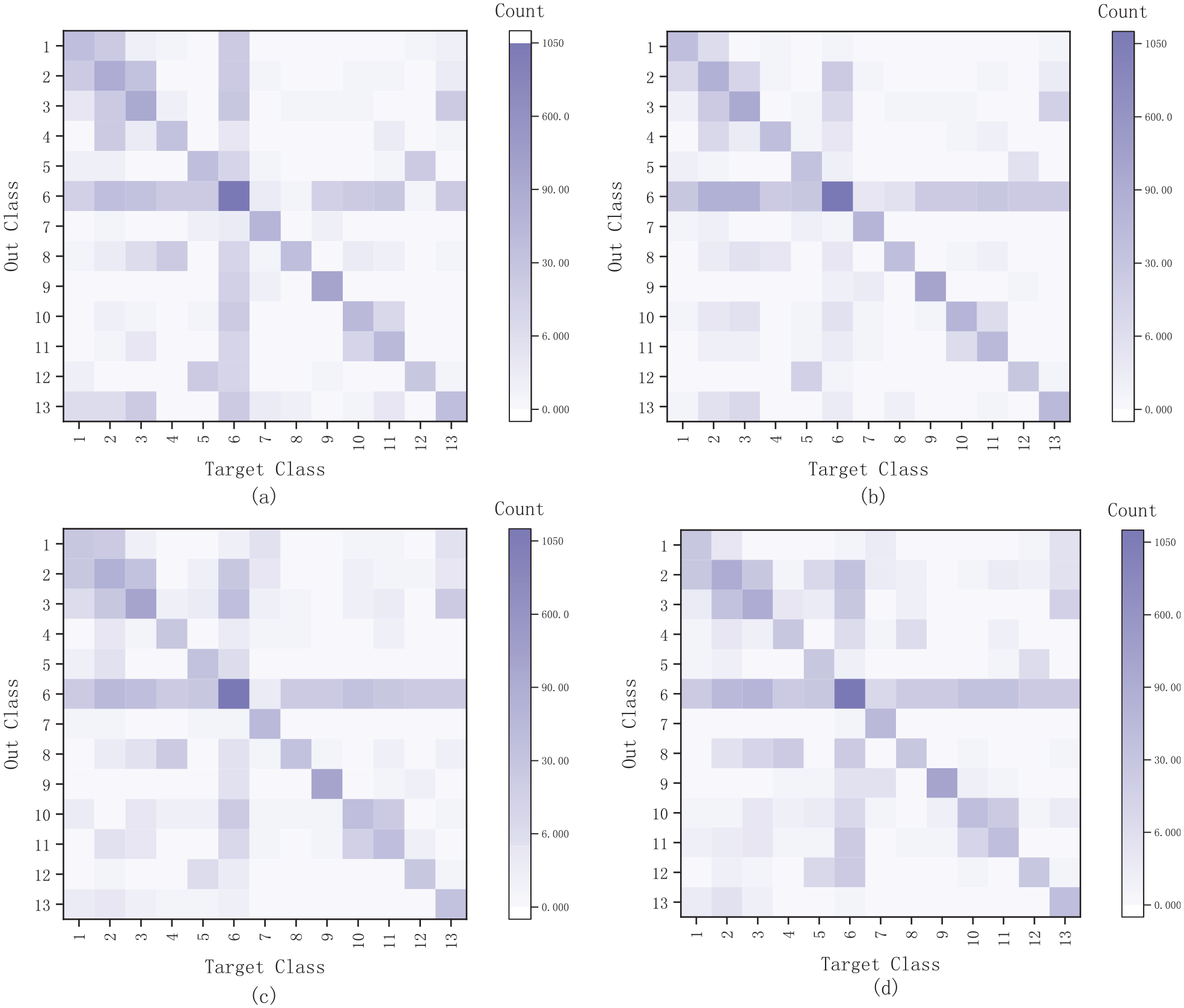
Confusion matrix. (a), (b), (c), and (d) denote the confusion matrices for the HMM, CRF, BILSTM, and BILSTM-CRF models, respectively.
As described in Figure 5, the darker-colored cells formed the diagonal of the matrix, and the values of the diagonal cells indicated the number of predicted and actual results as similar outcomes, therefore indicating that the four models have some degree of accuracy. In addition, we found that category “O” had different degrees of influence on the other categories. Furthermore, 1 and 2, 2 and 3, and 10 and 11 occurred in a more significant confusion than the other categories. The main reason for these results could be considered under the following points: (i) The characteristics of welding professional vocabulary lead to unclear category characteristics. For example, both “size of weld” and “sanding the weld” contained the keyword “weld,” but their categories were different and related to the different contexts. (ii) Confusion among the constituent entity units is also considered one of the factors affecting the model metrics.
The training process was analyzed, and the optimization process of the loss functions on BILSTM and BILSTM + CRF was obtained as described in Figure 6. We found that the model optimization process had a good convergence and no overfitting, making the training and parameter settings of our model reasonable.
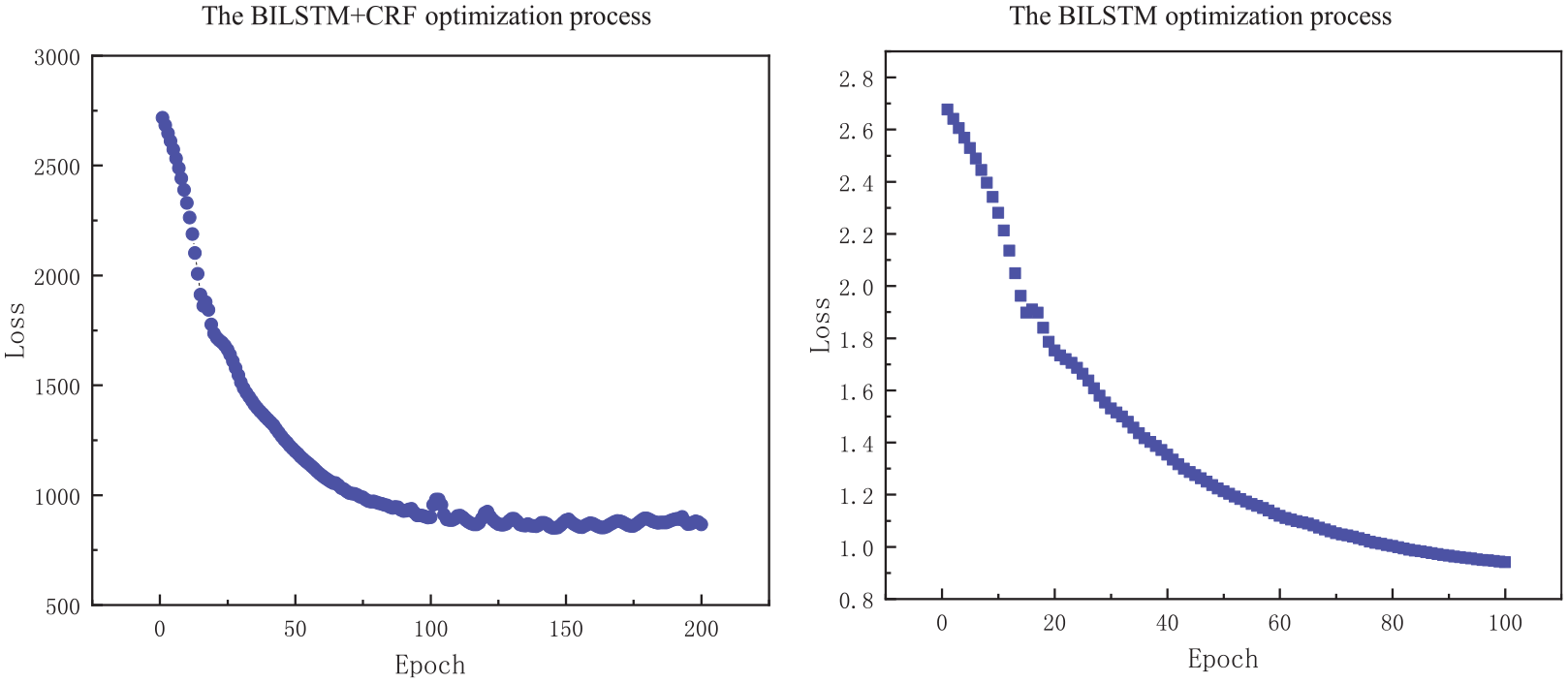
Models optimization process.
As a result, 19,410 pairs of annotated data sets contained six entity categories in the corpus. The NER method was used as an entity collection to improve the corpus scalability further, and the baseline was listed based on the Precision, Recall, and F1-score as described in Table 4.
Model results and baseline.
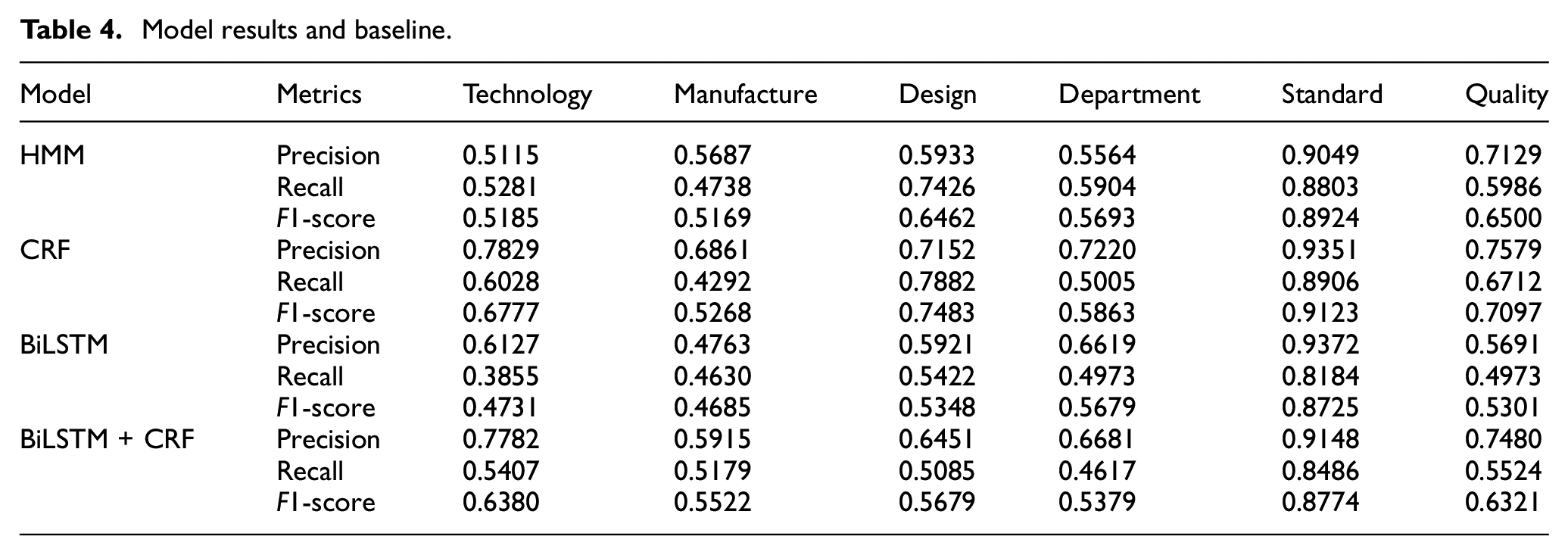
As shown in Table 4, the metrics of the other five categories were lower compared to the standard. The reason is that the standard categories showed evident characteristics, including keywords like standard, requirement, and document. In addition, the annotation quality and feature acquisition methods in five other categories were considered important factors in enhancing the metrics.
Corpus-based task allocation
A welding project or task often requires multiple departments to work together, so a reasonable task allocation is vital for efficient production. Latent Dirichlet allocation (LDA) 31 model is often used for topic determination. The basic process is to select a topic with a certain probability and choose words from the topic with a certain probability. However, the identification of invalid terms causes a waste of resources. Therefore, we combined the NER focus on significant entities to avoid retrieving irrelevant words.
In the NER task, we divided the entities into six categories, where design, technology, manufacturing, and quality corresponded to several important departments in actual production. However, the constraints of production conditions and product requirements make the assignment of tasks a matter of thematic correspondence. They are considered the unique performance requirements of the workpiece, and the tasks that initially belong to the process need to be assigned to the design department for completion. In addition, production equipment and conditions also influence the distribution of welding tasks. To address the issue of task assignment in actual fabrication, we collected a dictionary of terms that is important in the description of tasks in different sectors from the corpus. Task topics can be defined based on dictionaries and thresholds. For example, the keywords “design,”“structure,”“performance,” and “size” are important task characteristics for the design department, and we can assign task texts to design departments when the number of these words exceeds a certain empirical threshold. The task assignment process is shown in Figure 7.
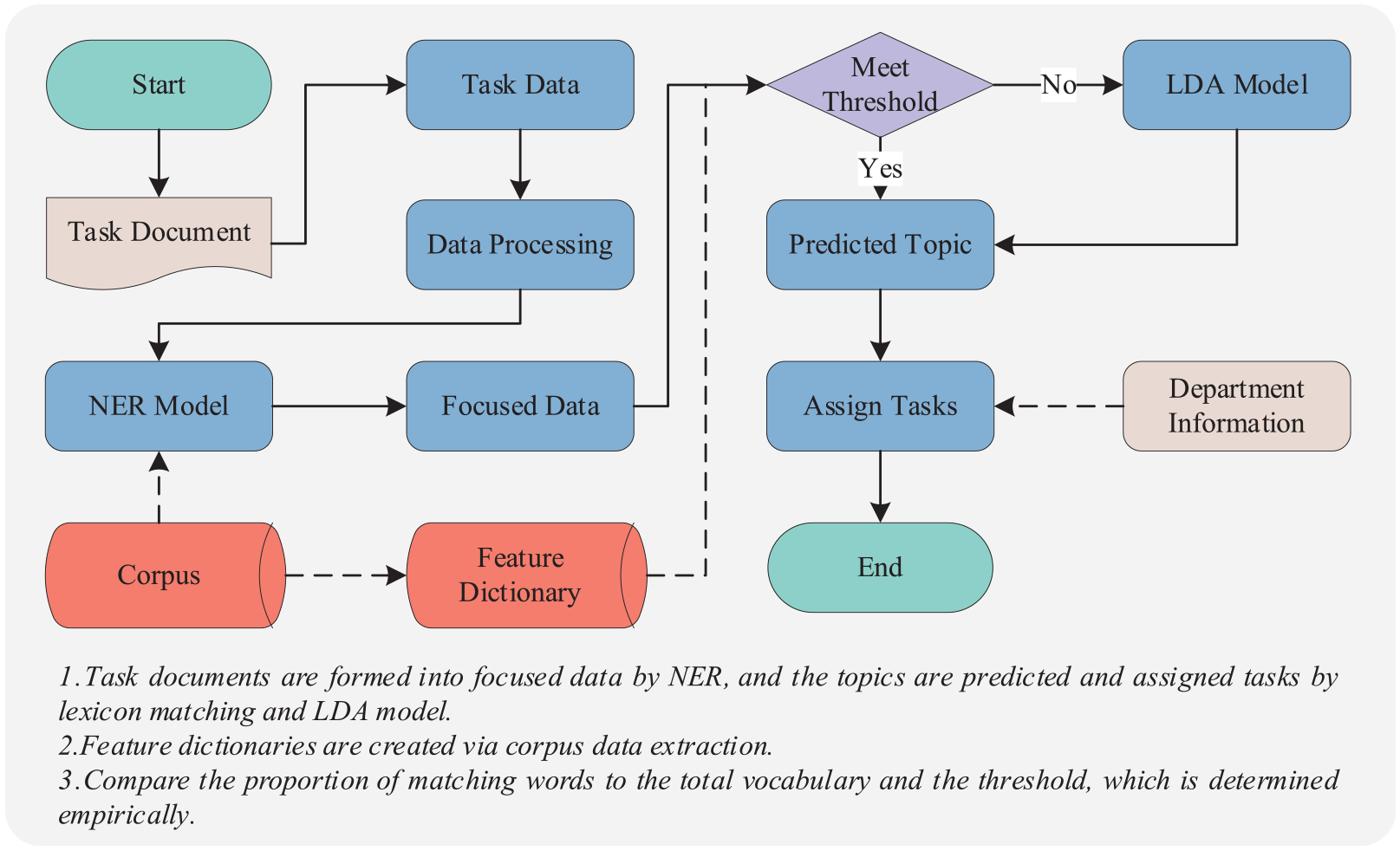
Corpus-based task allocation process.
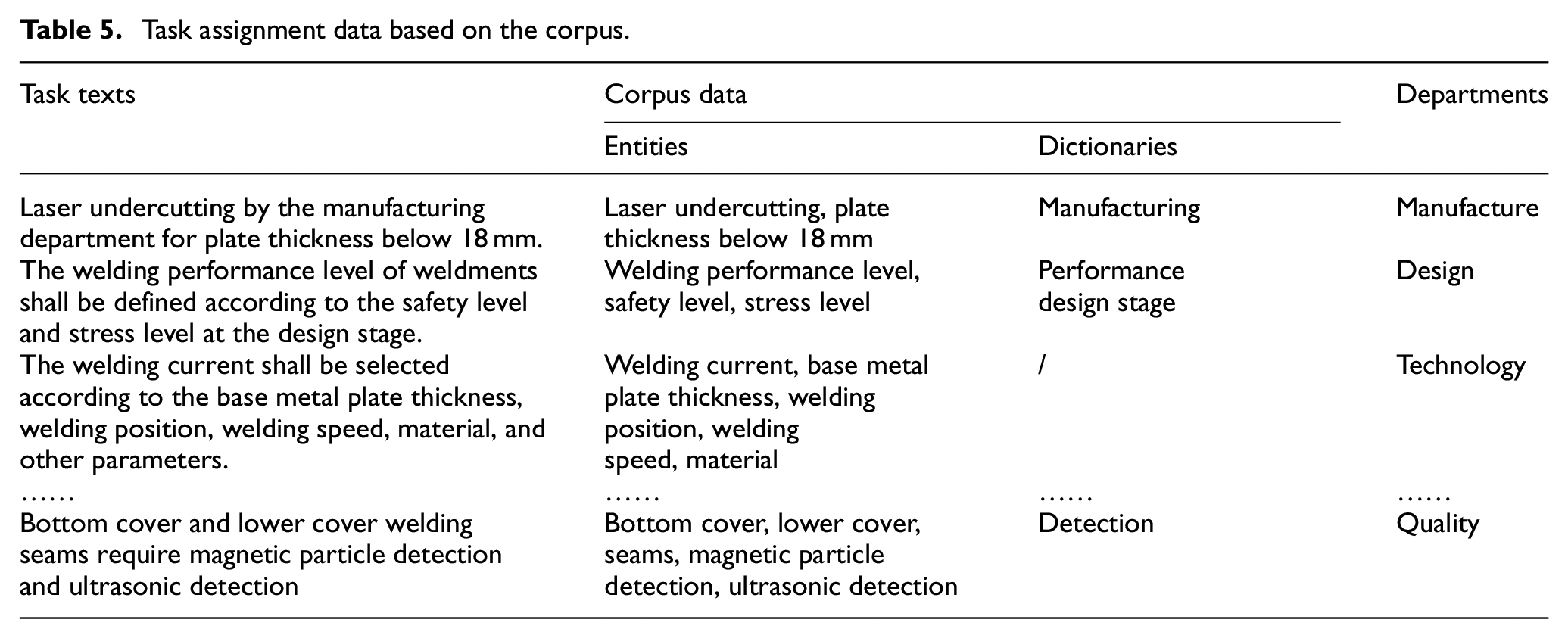
Corpus data are divided into entity data and dictionary data, which can provide data support for task allocation. For unstructured texts, important entity information is selected through the corpus and used as the definition of task categories. Some task descriptions in actual production are exemplified, and the corresponding data used to support classification are also listed in Table 5.
Task assignment data based on the corpus.
Corpus-based knowledge graph
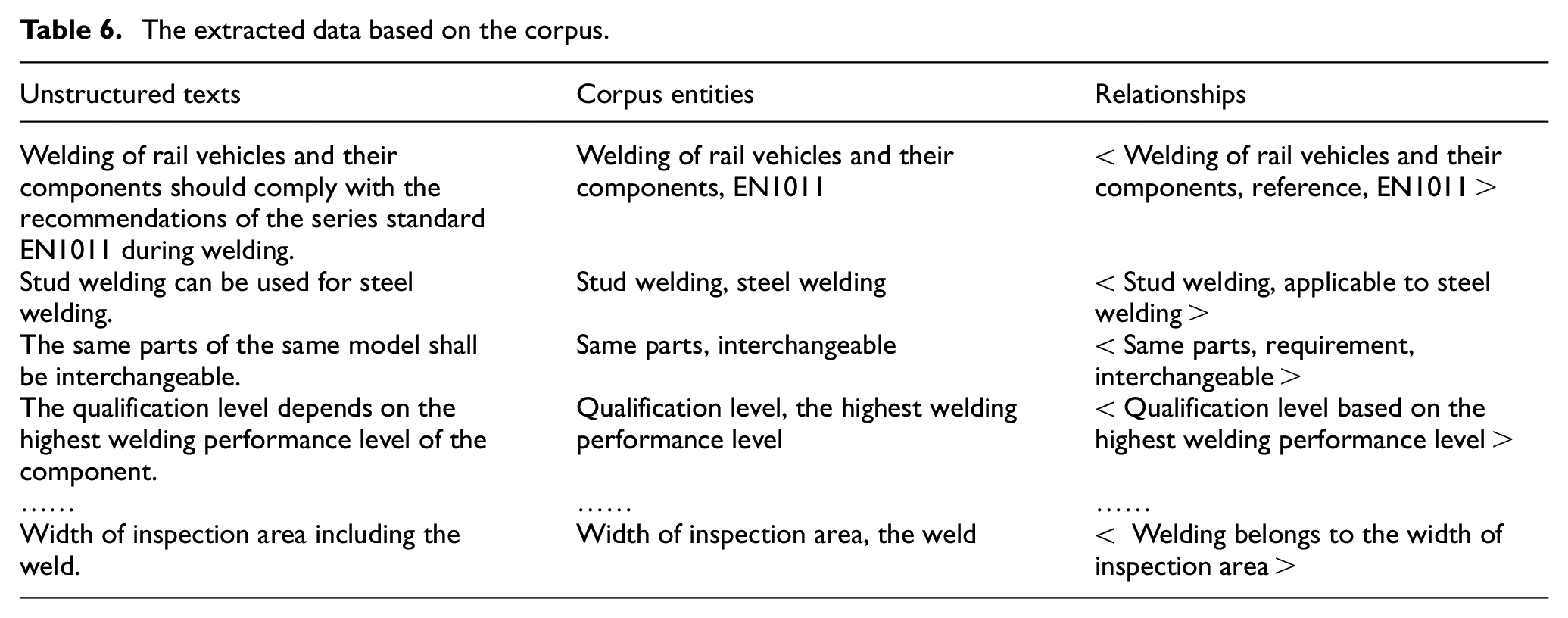
There has always been a knowledge discontinuity in actual fabrication because of staff turnover. Application changes can also limit the utilization of knowledge by domain experts. In addition, small and medium-sized enterprises have weak knowledge systems due to the lack of resources. Thus, it is crucial to achieving fast queries and access to knowledge systematically. The rapid retrieval and application of knowledge based on knowledge graphs 32 have gradually drawn attention. The construction of knowledge graphs based on corpus positively affects realizing the rapid acquisition of knowledge of welding guidance documents. Critical entities in unstructured texts are defined based on corpus data and form relational triples to support knowledge graph construction. Some specific data are shown in Table 6.
The extracted data based on the corpus.
In the corpus research, we manually annotated the entity information and achieved automatic entity recognition. The research considered relational extraction (RE) methods to verify the corpus’s scalability and build a knowledge acquisition system. We summarized six relationships (“belong to,”“reference,”“requirement,”“based on,”“applicable to” and “unknown”) based on corpus data. Welding process document data containing the entire life cycle of welding were selected in this research. The corpus identified significant entities, and entity verification and relationship annotation were done manually. In addition, entities and relationships were characterized by “<entity, relationship, entity>” and are embedded in the knowledge graph, as shown in Figure 8.
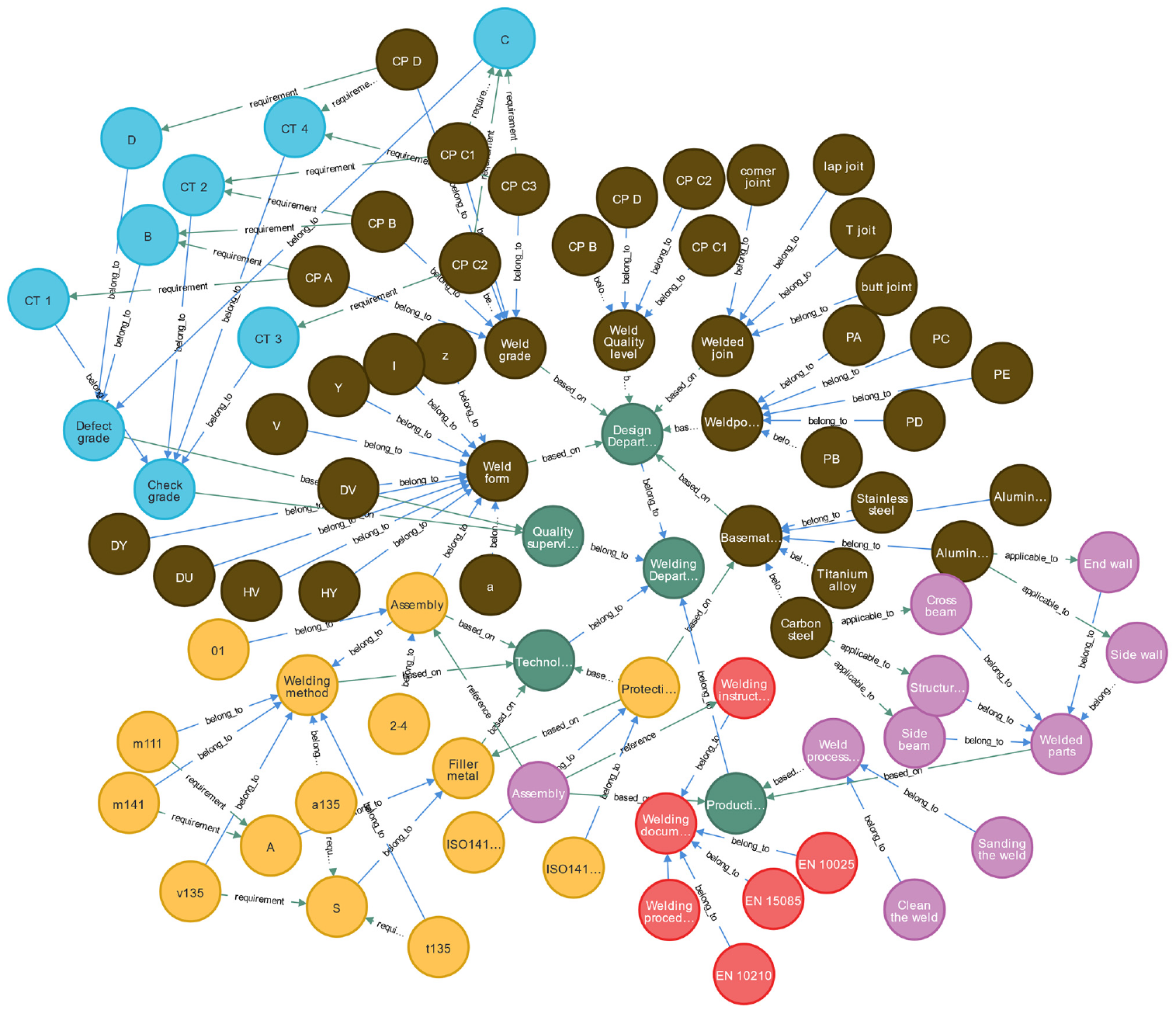
Corpus-based knowledge graph.
Consequently, as shown in Figure 8, we searched for information about check grades, then the basics and associated knowledge were quickly displayed in the form of a knowledge relationship diagram. Therefore, we obtained several meaningful details such as: (i) check grade containing CT 1, CT 2, CT 3, and CT 4; (ii) check grade was determined according to the quality level of the weld, and the quality control department completes; and (iii) check grade-related tasks.
Conclusion
The main objective of the proposed work is to extract data from significant unstructured documents and build a corpus to support engineering applications. The major conclusion remarks are summarized as follows: (i) Unstructured welding instruction information is automatically extracted to form the corpus, which can effectively compensate for the limitations of the structured data. (ii) To automatically acquire entity data, we trained four classical models for the named entity recognition task and published baselines with Precision, Recall, and F1-score metrics. (iii) We provide two use cases for task assignment and knowledge acquisition based on the corpus for actual fabrication.
This essential work can provide data support for engineering and manufacturing, especially for data-driven production operations. The main limitations of this study are its small sample from small-scale practice and the inherent limitations of qualitative research. Therefore, more research is needed to expand the data volume, refine the classification granularity, and design a more reasonable corpus structure. We predict that the research and data will support and contribute to welding knowledge acquisition, expert decision-making, and production pattern upgrade. Thus, improving and enriching the corpus, optimizing the entity recognition methods, and expanding the practical application scenarios of the corpus as new concerns.
Footnotes
Author statement
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant numbers: 51875072 and 52005071) and the Foundation for Overseas Talents Training Project in Liaoning Colleges and Universities (Grant number: 2018LNGXGJWPY-YB012).
Availability of data and material
The datasets used or analyzed during the current study are available from the corresponding author upon reasonable request.
Code availability
The codes involved in the paper are available upon reasonable request to the corresponding author.
Ethics approval
Not applicable.
Consent to participate
All authors listed have reviewed and approved the attached manuscript.
Consent for publication
The manuscript is approved by all authors for publication.